
Abstract
The year 2020 and 2021 was the witness of Covid 19 and it was the leading cause of death throughout the world during this time period. It has an impact on a large geographic area, particularly in countries with a large population. Due to the fact that this novel coronavirus has been detected in all countries around the world, the World Health Organization (WHO) has declared Covid-19 to be a pandemic. This novel coronavirus spread quickly from person to person through the saliva droplets and direct or indirect contact with an infected person. The tests carried out to detect the Covid-19 are time-consuming and the primary cause of rapid growth in Covid19 cases. Early detection of Covid patient can play a significant role in controlling the Covid chain by isolation the patient and proper treatment at the right time. Recent research on Covid-19 claim that Chest CT and X-ray images can be used as the preliminary screening for Covid-19 detection. This paper suggested an Artificial Intelligence (AI) based approach for detecting Covid-19 by using X-ray and CT scan images. Due to the availability of the small Covid dataset, we are using a pre-trained model. In this paper, four pre-trained models named VGGNet-19, ResNet50, InceptionResNetV2 and MobileNet are trained to classify the X-ray images into the Covid and Normal classes. A model is tuned in such a way that a smaller percentage of Covid cases will be classified as Normal cases by employing normalization and regularization techniques. The updated binary cross entropy loss (BCEL) function imposes a large penalty for classifying any Covid class to Normal class. The experimental results reveal that the proposed InceptionResNetV2 model outperforms the other pre-trained model with training, validation and test accuracy of 99.2%, 98% and 97% respectively.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In December 2019, an epidemic of a new virus family, SARS-COV-2 (Severe Acute Respiratory Syndrome), established itself as the primary cause of human and animal mortality. The resulting damage to the global economy and public health has been catastrophic. Due to the virus intricate structure and zoonotic origin, it is challenging to diagnose this virus at an early stage. It has claimed over 21 million lives worldwide (till August 2021), including 18 lakh fatalities and 18.88 million recoveries, prompting the WHO to proclaim COVID-19 a pandemic in February 2020 [24]. The top ten coronavirus-affected countries in the globe are listed in Table 1.
Almost all countries have been infected by this virus, however certain countries have shown to be more resistant than others. The distribution of top 5 most effective counties depicted in Fig. 1.

Top 5 countries wise Covid cases distribution [https://www.worldometers.info/coronavirus/#countries]
COVID-19 or the COV family is highly infectious and is transmitted to others by droplets [17, 32]. Infection occurs when a person comes into direct touch with another person who has already been infected due to the spread of sneezes and coughs, or by coming into contact with contaminated surfaces. The infected person initially exhibits no symptoms but gradually develops a few symptoms such as high fever, a dry cough, a sore throat, and mild Pneumonia. However, in the later stages, the person suffers from the complete loss of sense of smell and taste and severe respiratory abnormalities escorted by multi-organ failures and death. The current situation is characterised by an insufficient supply of medical diagnosis services. According to a recent study, COVID patients in the early stages (middle COVID) can recover without ICU or ventilator care. These health facilities are primarily required for COVID patients with severe diseases. To diagnosis Covid, RT-PCR (Real-time-Polymerase Chain Reaction) is used as a standard solution [6, 17]. It was shown to be beneficial but not optimal due to low RT-PCR sensitivity (about 60%–70%), an expensive approach, a high rate of false-negative results, and the lack of a needed test for illness diagnosis [17, 24]. Only a few test kits and ventilators are accessible, and vaccines have yet to be developed, exacerbating the critical situation worldwide. Due to the limited test kits availability, high cost, and lengthy process, researchers changed their focus to investigating AI-based alternatives for diagnosing COVID utilizing X-ray and CT scan images. As a result, it motivates academicians and researchers to build rapid, convenient, accurate, and automate COVID-19 detection systems.
The disease prolonged incubation period and the time required to validate test results may spread the disease. Machine Learning (ML) and Artificial Intelligence (AI) are widely used in the medical field these days [25, 28]. Because of cloud computing [10], AI-based technology has matured to the point that it can be utilized to detect negative and positive COVID-19 cases. Asnaoui et al. [25] proposed AI-based approaches on radiologists images such as X-rays and CT scans, for the Covid identification and provided a promising and complete identification of COVID-19. Study done by Yue et al. [32], stated that CT-scan or X-ray images is used as a major evidence of Covid detection by doctors hence the researchers can use these images to trained a model for Covid detection in the early state. This approach opened the door to qualitative and quantitative analyses of COVID 19 patients by removing RT-PCR constraints. The various characteristics of chest X-ray images such as Ground glass opacities, Multiple lesions, Bilateral involvement, Posterior part, Cavitation etc., can be useful for Covid identification.
Due to the availability of Covid and Normal (healthy person) X-ray or CT-scan images, an AI model can be trained to identify the Covid and Normal X-ray images. These AI-based solutions can be utilised as a preliminary test prior to grinding. If an individual has been classified as a Covid patient, additional clinical trials can be conducted to establish that the individual is a Covid patient. It is possible to take preventive measures such as home isolation to break the Covid chain if the individual is diagnosed as a Covid patient in an early stage.
In this work, an AI-based system was developed to determine whether or not a person is a Covid patient. In order to compensate for the limited availability of Covid X-ray images, we employ a pre-trained model that has been customized to be suitable for Covid detection. Since the Covid and Normal dataset available in the public domain is highly imbalanced so we apply the under-sampling method to balance the dataset. A binary cross-entropy loss (BCEL) is modified so that it will impose a high penalty if any Covid image is classified as a Normal class image. In addition, regularization techniques also apply to reduce the possibility of overfitting.
The rest of the paper is structured as follows, Sect. 2 highlights on the relevant work and literature research. Section 3 explains the proposed model, Sect. 4 reveals the performance assessment of the proposed model and Sect. 5 ends the work as a whole and sets out guidelines for future work.
2 Related work
After the diagnosis of the first Covid case in 2019, several Deep Learning and Machine Learning based approaches like ChexNet [26], ChestNet [31], have been proposed to detect Covid-19. Image segmentation [9, 22] can also be used for identifying the location and severity of the Covid. Most of the AI-based approaches used for the Covid detection use the pre-trained model because the publicly available dataset for the research number is small in size. Gozes et al. [8], suggested ResNet-50 model for the detection of Covid-19. A binary classification model classifies the input image into the Normal and Covid class using the localization map of lung abnormalities.
Bhandary et al. [4] suggested two AI based model to identified lung abnormalities. Authors first proposed a framework combining Modified AlexNet and support vector machine to classify normal CT images from the pneumonia images. To improve the model’s accuracy, a threshold filter is used that removes the artifacts from the Lung CT images. Narin et al. [21], introduced deep CNN to identified the positive and negative Covid patients from the X-ray images. The authors claimed 98% accuracy of the model. Hemdan et al. [14] introduced COVIDX-Net framework for the identification of Covid and non-Covid classes. COVIDX-Net uses pre-trained model for the classification. The performance of the model is 89%–91%. Farooq et al. [7] suggested the COVID_ ResNet model for classifiying the input image into three classes named Covid, Normal and Pneumonia with 83.5% accuracy.
Zhang et al. [33] proposed Chest X-ray based Covid anomaly detection by using Deep CNN. They have collected 1531 X-ray images of 1078 Covid patients and. It is a binary classification model with two classes named Covid and Normal. The author claimed the model accuracy is 95%, where the model is 96% able to identify Covid patients while 70.65% can detect non-Covid cases. Gupta et al. [11], present the impact of Covid-19 on the environment and suggested a pre-trained model to detect and identified the Covid-19 patients. Due to the Covid large amount of medical wastages are generated that need proper handling. This paper has shown the comparative study of three pre-trained models named VGGNet, ResNet, and InceptionNet, claiming that InceptionResnetV2 outperforms the others. Hussain et al. [16] suggested two CNN-based models called COVID-RENet-1 and COVID-RENet-2 for the discrimination of Covid and Pneumonia patients from the X-ray images. To extract the useful features from the X-ray images, they applied some Region and Edge-based techniques over the image. Authors evaluate the model performance based on accuracy, sensitivity, F1 score, area under the curve. The accuracy of the model is 98%.
Abbas et al. [1] proposed a deep learning-based model called Decompose, Transfer, and Compose (DeTraC to diagnose Covid disease using chest X-ray images. First, they detect the boundaries to identify the X-ray images irregularities by using a class decomposition mechanism. Then applied the ImageNet pre-trained model for classifying the input image. The highest accuracy achieved by the model is 93.1% with 100% sensitivity. Ozturk et al. [23] suggested two AI-based models for diagnosing Covid and Pneumonia disease. First, they developed a binary classification model which will classify the input image into the Covid and Non-covid class while other is the multiclass model that classified the input image into the Covid, Pneumonia and Non-covid class. They modified DarkCovidNet model and added 17 convolution layers with different filters. The accuracy of binary and multiclass classification models is 98.08% and 87.02% respectively.
Togaçar et al. [30] proposed an ensemble model for Covid identification that incorporates a support vector machine (SVM), MobileNetV2 and SqueezeNet pre-trained models, and a support vector machine (SVM) and MobileNetV2 and SqueezeNet pre-trained models. The Social Mimic optimization strategy is used to improve the overall performance of the model. The overall accuracy of the model is 99.2%. Hassantabaret al. [12], proposed a segmentation based Covid detection and diagnosis method by using lungs X-ray images. deep CCN model is used on the fractal feature of images. The highest accuracy achieved by the trained model is 93.2%. Mahmud et al. [20], proposed a multi-dilation CNN model called CovXNet for the automatic detection of Covid and Pneumonia using chest X-ray images. This model works in two steps. In the first step, a model is trained for many healthy people and Pneumonia X-ray images. Once the model is sufficiently trained, the model is retrained for the X-ray images. The authors claim 96.2% accuracy of the model.
3 Proposed methodology
The major purpose of this study is to develop an artificial intelligence-based technique for diagnosing Covid-19 utilizing CT scan or chest X-ray images. To achieve this, a model is trained on two well-known publicly available datasets named chest X-ray & CT dataset [18] and Covid dataset [5]. The covid-19 dataset has a few images, so a pre-trained model is used to train a Covid detection model. The block diagram of the suggested Covid-19 detection model is depicted in Fig. 2.

Block diagram of the proposed model
The suggested model comprises of following steps.
-
Dataset Description and Data Pre-processing
-
Customization and Training of Pre-trained Model
-
Performance Evaluation of Suggested Model
3.1 Dataset preparation and data pre-processing
The dataset for being model is trained plays a significant role in the model performance and typically increases with increasing in quality and quantity of dataset. Accurate data availability is one of the major problem phased by researchers in the medical domain. In this work, we trained our model for two well-known publicly available dataset named chest X-ray & CT [18] and Covid19 Chest X-ray [5]. Chest X-ray & CT dataset contained Pneumonia and Normal X-ray images while Covid19 dataset contains X-ray images of Covid patients. The total number of X-ray or CT scan images in the chest X-ray & CT dataset is 5856, which is split into two classes named Pneumonia (4273 images) and Normal. (1583). The Covid dataset, on the other hand, has only 930 images. Because the dataset is highly skewed, we trained a model for it; nonetheless, the model will be biased and classify the majority of the images in the Normal category. In addition, imbalancing in the dataset may lead to the overfitting. To prevent the overfitting and bias nature of the dataset, we use under-sampling methods where 930 images of Normal class are selected randomly from the chest X-ray & CT dataset. So, after applying the under-sampling strategy, there are 930 images in both classes. As the Covid symptoms are very much similar to Pneumonia, MERS and SARS so Covid class dataset also includes some images of each class that will help minimize the possibility of Covid class being classified as Normal class. Table 2 shows the dataset description used for to trained model.
To increase the convergence during the training bath normalization (BN) approach is used to normalized the output of different layers by taking the mean and variance. Consider a mini-batch B of n size, which is represented by
Then corresponding normalized value is denoted by
The bath normalization of mini-batch is defined as a linear transformation of a batch which is denoted by \(\left\{{y}_{1}, {y}_{2}, {y}_{3}----{y}_{n}\right\}\) and shown by Eq. 1 is calculated as follow
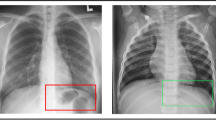
X-ray scans of a Covid patient and a normal person are shown in Fig. 3. It shows that normal X-ray scans exhibit both clear lungs with no areas of abnormal opacification. In contrast, Covid X-ray image shows a diffuse interstitial pattern in both lungs. Since we are using a pre-trained model and all pre-trained model have their own pre-processing function. So after rescaling and augmentation, X-ray image is pass to the pre-processing function of their corresponding pre-trained model.

X-ray images of Covid and Normal class
3.2 Pre-trained model training and customization
One of the essential prerequisites for any AI model is that it must be trained on a large dataset. According to the study, the models performance improves as the dataset size for which it was trained. Due to the tiny size of the publicly accessible Covid dataset, a simple Deep Learning-based model will not provide substantial accuracy. To address this issue, we modified some existing pre-trained models that had already been trained on vast amounts of data for Covid detection.
Several pre-trained models such as VGGNet-16, VGG-19, ResNet, Inceptionv3, ResNet Inception resnet V2, GoogleNet, MobileNet, EfficientNet etc. are available. The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) [27] was used to train these pre-trained models on a massive dataset. The ILSVRC dataset has 1000 classes and was trained on over 1.2 million images. This study mainly focuses on VGG-19, ResNet, Inception ResNet V2, and GoogleNet.
The main difference between the different pre-trained models is the number of fully connected layers, pooling layers, and convolution layers. Feature extraction occurs in the convolution layer, whereas the pooling layer reduces trainable parameters. If an input image I and kernel K is represented by I \(\left(n \times m\right)\) and K \(\left(a \times b\right)\) respectively then convolution operation (Cov) can be expressed by the Eqs. 2.
where \({Cov}_{ij}\) shows ith and jth pixel value of an image.
The activation function, loss function and optimizer play an important role in order to optimize model performance. It will assist the neural network in learning more quickly and efficiently by updating weights. In the recent few decades, a large variety of action functions have been proposed, including Stochastic Gradient Descent with Momentum (SGD), AdaGrad, RMSProp, Adam Optimizer, and others. A decision on which optimization function is better appropriate for a particular problem is typically made on the basis of how differentiable the objective functions are at a certain point in the optimization process. As an optimizer, we use SGD with mini batch that can be trained in less time and with higher efficiency than other optimizers.
In neural network, loss functions are used to know the difference between the actual error and the predicted output based on this optimizer updated the weights. The suggested model is a binary classification model, so the BCEL function can be used as a loss function. The equation for a BCEL function can be expressed by using Eq. 3.
where 0 and 1 represent Covid and Normal class respectively. (X,y) shows the input and their corresponding actual output and Y indicates the predicted output. Since, a Covid detection model is more effective if we have higher recall value for Covid class. Hence less number of Covid images are classified as Normal images. This has been accomplished by updating the binary cross entropy function and assigning more weights to the Covid class. The modified loss function is depicted in Eq. 4.
Additionally, the modified loss function performs well when the given dataset is unbalanced, meaning that there are more images in one class than others. Table 3 shows the mathematical equations for the various model optimization parameter.
Where \({o}_{i}\) shows the output of ith pooling layer, (a, b) is the size of the filter, \({Z}_{i}\) represent pre-activation output of layer i, \({y}_{i}\) and \({\widehat{y}}_{i}\) shows the actual and predicted output respectively. This study main aim is to classify the input image into the Covid and non-Covid images so the suggested model has two classes named Covid and Normal. Because none of the pre-trained models had been trained on the X-ray images, we adjusted the pre-trained model by adding and removing layers as needed, and then trained the customised model on the X-ray images once again. Each pre-trained model has a classification layer for classifying the input image into a specific class. So first, we removed this layer and add the Global Average Pooling Layer (GAPL) [19] which reduces the input dimension of \(h\times\) w \(\times D\) to \(1\times\) 1 \(\times D\). Then five FC layers are added to the model which takes the input from GAPL and send to the classification layer. Each FC layers has 2048 neurons, whereas classification has only one neuron. All hidden layers employ the LeakyReLu activation function, whereas the last classification layer uses the sigmoid activation function. Non-linearity was introduced into the model through the LeakyRelu activation function, which has some value in the negative slop whereas other activation functions have no value in the negative slop, which causes the model to stop learning. To increase model performance, we used binary cross-entropy as a loss function and the SGD optimizer as an optimization function. Our research primarily focuses on the VGG-19, ResNet, InceptionResNet V2, and MobileNet. All modified pre-trained model is only trained on the newly added layer (i.e., five layers) because all pre-trained models have been thoroughly trained on a large dataset. Pseudocode for the suggested model is given below.

3.2.1 VGGNet- 19
Simonyan and Zisserman [27] introduced VGGNet pre-trained model in 2014. The total number of layers in this model is 19, including 16 convolution layers, 2 fully connected (FC) layers, one classification layer, and 5 max-pooling layers. The number of neurons in each convolution layer is 4096, whereas last classification layers contain 1000 neurons and Softmax activation functions. Layers architecture of VGGNet-19 is shown in Fig. 4.

VGGNet-19 architecture [27]
After adding and removing layers in the existing pre-trained model, total number of layers in the updated model is 28 (22(layers from existing model), 5(newly added layers) and one classification layer) and updated model will be trained only for newly added layers.
3.2.2 ResNet-50
He et al. [13], proposed a ResNet-50 which is made-up of number of convolutions building blocks. This model includes 175 blocks and one classification layer (FC layers). This model is also trained on 1000 classes. ResNet architecture is shows in Fig. 5. The total number of layers in the updated model is 186 which includes 175 convolution block, 5FC layers and one classification layer Fig. 6.

Architecture of ResNet-50 [13]

InceptionResNetV2 architecture [29]
3.2.3 InceptionResNetV2
Szegedy et al. [29], proposed InceptionResNetV2 pre-trained model in 2015, which uses several inception blocks instead of simple convolution blocks. This model can also be used to for extracting the features from the segmented image [2, 3]. This model consists of 780 blocks and one classification layer. This model uses ReLu activation function in the activation layer and sigmoid activation function in the classification layer. The total number of layers in updated InceptionResNetV2 is 786, including 780 inception blocks, 5FC layers and one classification layer).
3.2.4 MobileNetV2
This model is introduced by the Google researcher A. G. Howard et al. [15]. The main aim of designing MobileNet model is to develop a light-weighted neural network. Because it uses a separate deep convolution block, it takes low power and can be employed with certain resource constraints in diverse situations. The total number of layers in the MobileNetV2 model is 30, including the convolutional layer, depthwise layer, pointwise layer, and classification layer. Figure 7 depicts the architecture of MobileNetV2. The updated model has 36 layers.

MobileNetV2 architecture [2]
Table 4 depicts the comparative analysis of all pre-trained model in terms of the number of layers, trainable parameters and training time for 25 iterations.
3.3 Model performance evaluation
As we perform the classification and all pre-trained models perform well on labelled data, precision, recall, specificity, and F1 score can be used to evaluate the model performance. Table 5 depicts the confusion matrix, a n × n matrix representing correct and incorrect predictions.
Table 6 shown the different evaluation used to measure the performance of the model.
4 Result discussion
This section discusses the performance of four different updated pre-trained models for Covid detection. To achieve this, all pre-trained models are implemented in the Google Colab that provide the clous based Jupyter notebook freely and support for Graphics processing unit (GPU) and Tensor Processing Unit (TPU). As each pre-trained model has a specific image size support, we must first resize the input image to ensure it is compatible with the model. For example, all input images in VGG-19, MobileNetV2, and ResNet-50 are resized to 224 × 224 pixels, whereas Inception ResNetV2 supports a 299 × 299 pixels image size. In order to save training time, the updated model is trained solely for the newly added layers. Figures 8 and 9 shows the training and validation loss and accuracy respectively.

Training and validation loss

Training and validation accuracy
It is clear from the Figs. 8 and 9 that the model gets the maximum accuracy in approx. 20 iterations. Hence, we trained each model for 20 iterations. The training environment used to evaluate model performance is depicts in Table 7.
4.1 Performance evaluation of VGGNet- 19
The modified VGGNet-19 has a total of 28 layers and the model is trained only for the newly added ten layers. Figure 10 depicts the confusion matrix for the updated VGGNet pre-trained model.

Confusion matrix for a training data, b validation data, c test data
The performance of the suggested VGG model can be summarised by using Fig. 7 and Tables 8, 9 and 10. In the above table 0 and 1 represents the Covid and Normal class respectively. The model accuracy in the test phase is 50%, indicating that the model is not learning anything and the trained model classifies all images as Normal images. The primary cause of this may be a smaller number of layers. As the model has a small number of layers, i.e. 28 and trained for a small number of iterations, the model is unable to learn the pattern to distinguish between Covid and normal X-ray images. Hence VGG model is not a suitable pre-trained model for the covid detection. Figures 11, 12 and 13 depicts the X- ray images classification for the training, validation and testing phase.

Chest X-ray image classification during training phase

Chest X-ray image classification during validation phase

Chest X-ray image classification during testing phase
4.2 Performance evaluation of ResNet-50
After the modification in the original ResNet the total number of layers in the updated model is 181 and the model is trained only for five newly added layers. The confusion matrix for the training, validation and testing phase for the updated ResNet-50 is shown in Fig. 14.

Confusion matrix for a training data, b validation data, c test data
The performance of the suggested trained model is depicted in Fig. 14 and Tables 11, 12, and 13. As shown in Tables 11, 12, and 13, the accuracy of the suggested model is 98%, 96% and 73% for the training, validation and testing phase respectively. The model performs well in training and validation but not in testing. Moreover, one of the main objectives of the Covid detection model is to minimize the false-positive rate. Hence, a model must have minimum probability to classify Covid patients as Normal (Healthy person). The trained model has a higher false positive rate, so the updated model is not suitable for the Covid detection.
4.3 Performance evaluation of InceptionResNetV2
The total number of layers in the updated InceptionResNetV2 is 786 and the model is trained only for the newly added ten layers. The confusion matrix of the updated InceptionResNetV2 for the training, validation and testing phase is shown in Fig. 15.

Confusion matrix for a training data, b validation data, c test data
Figure 15 and Tables 14, 15, and 16 shown the performance of the updated InceptionResNetV2 model. As shown in Tables 14, 15 and 16, the model training, validation and testing accuracy is 99%, 98% and 97% respectively. It is visible from Fig. 15, that suggested the model has a minimum false positive rate. Hence, the updated InceptionResNetV2 model can be used for the Covid detection task.
4.4 Performance evaluation of MobileNetV2
The total number of layers in the updated MobileNetV2 is 159. As the model is already trained, we trained the updated model only for the ten newly added layers. The confusion matrix of the updated MobileNetV2 for the training, validation and testing phase is shown in Fig. 16.

Confusion matrix for a training data, b validation data, c test data
The performance of the updated MobileNetV2 model is shown in Fig. 16 and Tables 17, 18 and 19. The training, validation and testing performance of the updated MobileNetV2 is 96%, 95% and 87% respectively. This seems to be overfitted because the updated model performs well in the training and validation phase, but the model performance decreases significantly in the testing phase.
This paper shown the comparative analysis of four different pre-trained model for Covid detection. Based on the result shown in Tables 8, 9, 10, 1, 12, 13, 14, 15, 16, 17, 18, and 19 and Figs. 10, 11, 12, 13, 14, 15 and 16, it can be concluded that the InceptionResnetV2 model performs well as compare to the other pre-trained model. The comparative analysis of four different pre-trained models for the training, validation and testing phase is shown in Fig. 17 and Table 20.

Comparative performance analysis of updated VGGNet-19, ResNet, InceptionResNetV2 and MobiuleNetV2
Figure 18 shown the comparative performance analysis of the proposed work with the existing Covid detection model.

Comparative analysis of proposed Covid detection model
As illustrated in the picture 18, the suggested model outperformed the existing Covid detection algorithms when compared to the baseline.
5 Conclusion
As the Covid-19 positive cases are increasing exponentially in many countries which create the medical emergency in the entire world. Early detection of the Covid patient is the only way to control this pandemic. Due to insufficient clinical diagnosis resources with limited test kits & ventilators, there is a need for a tool that can automatically detect Covid patients. This paper proposes an AI enable model for detecting and identifying Covid patients by using the chest X-ray and CT-scan images. Due to the availability of the small Covid dataset, pre-trained models are trained for Covid detection. In this paper four pre-trained model named VGGNet19, Resnet, InceptionResNetV2 and MobileNet are modified and trained on the Covid Dataset. Under-sampling and regularization methods is used to deal with Overfitting and underfitting. The cross-entropy loss function has been revised in order to inflict a greater penalty for the misclassification of Covid class into Normal class. The results of the experiments revealed that InceptionResnetV2 provides greater accuracy than VGGNet, ResNet and MobileNet.
The proposed model is trained using the Covid and Normal datasets that are publicly available. It can also be trained on real-time data and then used to evaluate the performance of the proposed model on real-world data sets. Responsible artificial intelligence (AI) can be utilised to improve the transparency of the model.
References
Abbas A et al (2020) Classification of COVID-19 in Chest X-ray images using DeTraC deep convolutional neural network. Appl Intell 51:854–864
Ashok M, Gupta A (2021) A systematic review of the techniques for the automatic segmentation of organs-at-risk in thoracic computed tomography images. Archiv Comput Methods Eng 28(4):3245–3267
Ashok M, Gupta A (2021) March. Deep learning-based techniques for the automatic segmentation of organs in thoracic computed tomography images: a comparative study. In 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS) (pp. 198–202). IEEE.
Bhandary A et al (2020) Deep-learning framework to detect lung abnormality: a study with chest X-Ray and lung CT scan images. Pattern Recogn Lett 129:271–278
Cohen et al. (2020) Covid chest X-ray dataset. Available at https://github.com/ieee8023/covid-chestxray-dataset
El-Asnaoui K, Chawki Y (2020) Using X-ray images and deep learning for automated detection of coronavirus disease. J Biomol Struct Dyn 39(10): 3605–3614.
Farooq M, Hafeez A (2020) COVID-ResNet: a deep learning framework for screening Of COVID19 from radiographs. arXiv Preprint. https://arxiv.org/abs/2003.14395
Gozes O et al. (2020) Rapid AI development cycle for the Coronavirus (COVID-19) pandemic: initial results for automated detection & patient monitoring using deep learning CT image analysis. arXiv Preprint. https://arxiv.org/abs/2003.05037
Gupta A (2019) Current research opportunities of image processing and computer vision. Comput Sci 20(4):1–11
Gupta RK, Pateriya RK (2017) Balance resource utilization (BRU) approach for the dynamic load balancing in cloud environment by using AR prediction model. J Organ End User Comput 29(4):2
Gupta RK et al. (2021) Novel deep neural network technique for detecting environmental effect of COVID-19. Energy Sources Part A pp. 1–18
Hassantabar S et al (2020) Diagnosis and detection of infected tissue of COVID-19 patients based on lung x-ray image using convolutional neural network approaches. Chaos Solitons Fractals 140:1–14
He K et al. (2016) Deep residual learning for image recognition. In: Proceeding of IEEE conference on computer vision and pattern recognition (CVPR), pp. 1–12.
Hemdan E et al. (2020) COVIDX-Net: a framework of deep learning classifiers to diagnose COVID-19 in X-ray images. arXiv Preprint. pp. 1–14. https://arxiv.org/abs/2003.11055
Howard AG et al (2017) MobileNets: efficient convolutional neural networks for mobile vision applications. Comput Vis Pattern Recognit 4:1–9
Hussain S, Khan A (2020) Coronavirus disease analysis using chest X-ray images and a novel deep convolutional neural network. Photodiagn Photodyn Therapy 30:1–11
Khan AI et al (2020) CoroNet: a deep neural network for detection and diagnosis of Covid-19 from chest X-ray images. Comput Methods Progr Biomed 196:1–9
Kermany et al. (2018) Chest X-ray & CT dataset. Available at https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia
Lin M, Chen Q, Yan S (2014) Network in network. Neural Evolut Comput 8:1–10
Mahmud T et al (2020) CovXNet: a multi-dilation convolutional neural network for automatic COVID-19 and other pneumonia detection from chest X-ray images with transferable multi-receptive feature optimization. Comput Biol Med 122:1–16
Narin A, Kaya C, Pamuk Z (2021) Automatic detection of Coronavirus disease (COVID-19) Using X-ray images and deep convolutional neural networks,. Pattern Analysis and Applications 24:1207–1220
Neelapu BC et al (2017) The reliability of different methods of manual volumetric segmentation of pharyngeal and sinonasal subregions. Oral Surg Oral Med Oral Pathol Oral Radiol 124(6):577–587
Ozturk T et al (2021) Automated detection of COVID-19 cases using deep neural networks with X-ray images. Comput Biol Med 121:1–11
Ozturka T et al (2020) Automated detection of COVID-19 cases using deep neural networks with X-ray images. Comput Biol Med 121:1–11
Poongodi M et al. (2021) Diagnosis and combating COVID-19 using wearable Oura smart ring with deep learning methods. Person Ubiquit Comput 1–11. https://doi.org/10.1007/s00779-021-01541-4
Rajpurkar P et al. (2017) Chexnet: radiologist-level pneumonia detection on chest x-rays with deep learning. arXiv. https://arxiv.org/abs/1711.05225
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. In: proceeding in the international Conference on Learning Representations (ICLR).
Sodhi GK et al (2021) COVID-19: role of robotics, artificial intelligence, and machine learning during pandemic. Curr Med Imaging 1–13. https://pubmed.ncbi.nlm.nih.gov/33655845/
Szegedy C et al. (2017) Inception-v4, inception-ResNet and the impact of residual connections on learning. In: proceedings of the thirty-first AAAI conference on artificial intelligence. pp. 4278–4284
Togaçar M et al (2020) COVID-19 detection using deep learning models to exploit Social Mimic Optimization and structured chest X-ray images using fuzzy color and stacking approaches. Comput Biol Med 121:1–12
Wang H, Xia Y (2018) Chestnet: a deep neural network for classification of Thoracic diseases on chest radiography. arXiv. pp. 1-8. https://arxiv.org/abs/1807.03058
Yue Z et al (2020) Coronavirus disease 2019 (COVID-19): a perspective from China. Radiology 295(3):1–29
Zhang J et al. (2020) COVID-19 screening on chest x-ray images using deep learning based anomaly detection. arXiv Preprint. pp. 1–6
Funding
Authors have not received research grants from any organization.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
We declare that we have no conflicts of interest to disclose.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Gupta, R.K., Kunhare, N., Pathik, N. et al. An AI-enabled pre-trained model-based Covid detection model using chest X-ray images. Multimed Tools Appl 81, 37351–37377 (2022). https://doi.org/10.1007/s11042-021-11580-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-021-11580-x