
Abstract
With the availability of low-cost depth-visual sensing devices, such as Microsoft Kinect, we are experiencing a growing interest in indoor environment understanding, at the core of which is semantic segmentation in RGB-D image. The latest research shows that the convolutional neural network (CNN) still dominates the image semantic segmentation field. However, down-sampling operated during the training process of CNNs leads to unclear segmentation boundaries and poor classification accuracy. To address this problem, in this paper, we propose a novel end-to-end deep architecture, termed FuseCRFNet, which seamlessly incorporates a fully-connected Conditional Random Fields (CRFs) model into a depth-based CNN framework. The proposed segmentation method uses the properties of pixel-to-pixel relationships to increase the accuracy of image semantic segmentation. More importantly, we formulate the CRF as one of the layers in FuseCRFNet to refine the coarse segmentation in the forward propagation, in meanwhile, it passes back the errors to facilitate the training. The performance of our FuseCRFNet is evaluated by experimenting with SUN RGB-D dataset, and the results show that the proposed algorithm is superior to existing semantic segmentation algorithms with an improvement in accuracy of at least 2%, further verifying the effectiveness of the algorithm.



Similar content being viewed by others

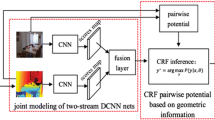
References
Alam FI, Zhou J, Liew WC et al (2017) Conditional random field and deep feature learning for hyperspectral image segmentation[J]. IEEE Trans Geosci Remote Sens PP:99
Badrinarayanan V, Handa A, Cipolla R (2015) Segnet: A deep convolutional encoder-decoder architecture for robust semantic pixel-wise labelling. arXiv preprint arXiv:1505.07293
Chen S, de Bruijne M (2018) An End-to-end Approach to Semantic Segmentation with 3D CNN and Posterior-CRF in Medical Images. arXiv preprint arXiv:1811.03549
Chen LC, Papandreou G, Kokkinos I et al (2016) DeepLab: semantic image segmentation with deep convolutional nets, Atrous convolution, and fully connected CRFs[J]. IEEE Trans Pattern Anal Mach Intell 40(4):834–848
Chen LC, Papandreou G, Schroff F, Adam H (2017) Rethinking Atrous convolution for semantic image segmentationar. Xiv preprint arXiv: 1706.05587
Chen LC, Zhu Y, Papandreou G, Schroff F, Adam H (2018) r-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), pp 801–818
Chen LC, Papandreou G, Kokkinos I, Murphy K, Yuille AL (2014) Semantic image segmentation with deep convolutional nets and fully connected CRFs. Computer Science (4):357–361
Chunfang ZH (2012) Image semantic segmentation based on conditional random field. Computer CD Software and Applications (9):21–23
Couprie C, Farabet C, Najman L, LeCun Y (2013) Indoor semantic segmentation using depth information. arXiv preprint arXiv: 1301.3572
Ding G, Guo Y, Chen K et al (2019) DECODE: deep confidence network for robust image classification[J]. IEEE Trans Image Process. https://doi.org/10.1109/TIP.2019.2902115
Han J, Pauwels EJ, Zeeuw PMD et al (2012) Employing a RGB-D sensor for real-time tracking of humans across multiple re-entries in a smart environment[J]. IEEE Trans Consum Electron 58(2):255–263
Han J, Shao L, Xu D, Shotton J (2013) Enhanced computer vision with microsoft kinect sensor: A review. IEEE Trans Cybern 43(5):1318–1334
Hazirbas C, Ma L, Domokos C et al (2016) FuseNet: incorporating depth into semantic segmentation via fusion-based CNN architecture[C]. In: Asian conference on computer vision. Springer, Cham
Janoch A, Karayev S, Jia Y, Barron JT, Fritz M, Saenko K, Darrell T (2013) A category-level 3d object dataset: Putting the kinect to work. In: Consumer depth cameras for computer vision. Springer, London, pp 141–165
Jiang J, Zhang Z, Huang Y, Zheng L (2017) Incorporating depth into both cnn and crf for indoor semantic segmentation. In 2017 8th IEEE International Conference on Software Engineering and Service Science (ICSESS), IEEE, pp 525–530
Kendall A, Badrinarayanan V, Cipolla R (2015) Bayesian segnet: Model uncertainty in deep convolutional encoder-decoder architectures for scene understanding. arXiv preprint arXiv: 1511.02680
Krähenbühl, Philipp, Koltun V (2012) Efficient inference in fully connected CRFs with Gaussian edge potentials[J]. In Advances in neural information processing systems, pp 109–117
Krizhevsky A, Sutskever I, Hinton G (2012) ImageNet classification with deep convolutional neural networks[C]. In: NIPS. Curran Associates Inc. In Advances in neural information processing systems, pp 1097–1105
Lafferty J, McCallum A, Pereira FCN (2001) Conditional random fields: probabilistic models for segmenting and labeling sequence data[J]
Li X, Belaroussi R (2016) Semi-dense 3D semantic mapping from monocular SLAM[J]. arXiv preprint arXiv:1611.04144
Li Z, Gan Y, Liang X et al (2016) LSTM-CF: unifying context modeling and fusion with LSTMs for RGB-D scene labeling[J]. In European conference on computer vision Springer, Cham, pp 541–557
Lin G, Shen C, Anton VDH et al (2017) Exploring context with deep structured models for semantic segmentation[J]. IEEE Trans Pattern Anal Mach Intell 40(6):1352–1366
Long J, Shelhamer E, Darrell T (2014) Fully convolutional networks for semantic segmentation[J]. IEEE Trans Pattern Anal Mach Intell 39(4):640–651
Luan S, Chen C, Zhang B et al (2018) Gabor convolutional networks[J]. IEEE Trans Image Process 27(9):4357–4366
Noh H, Hong S, Han B (2015) Learning deconvolution network for semantic segmentation[J]. In Proceedings of the IEEE international conference on computer vision, pp 1520–1528
Pang Y, Cao J, Li X (2015) Cascade learning by optimally partitioning[J]. IEEE transactions on cybernetics 47(12):4148–4161
Pang Y, Xie J, Nie F et al (2018) Spectral clustering by joint spectral embedding and spectral rotation[J]. IEEE Transactions on Cybernetics, pp 1–12
Pang Y, Zhou B, Nie F (2017) Simultaneously learning Neighborship and projection matrix for supervised dimensionality reduction[J]. IEEE Transactions on Neural Networks and Learning Systems
Paszke A, Chaurasia A, Kim S et al (2016) ENet: a deep neural network architecture for real-time semantic segmentation[J]. arXiv preprint arXiv:1606.02147.
Paszke A, Gross S, Chintala S et al (2017) Automatic differentiation in pytorch [J]
Ren X, Bo L, Fox D (2012) RGB-(D) scene labeling: features and algorithms[C]. In: Computer vision and pattern recognition (CVPR), 2012 IEEE conference on. IEEE
Ronneberger O, Fischer P, Brox T (2015) U-net: convolutional networks for biomedical image segmentation[J]. In International Conference on Medical image computing and computer-assisted intervention Springer, Cham, pp 234–241
Rumelhart DE (1986) Learning representations by back-propagating errors[J]. Nature 323:533–536
Russakovsky O, Deng J, Su H et al (2014) ImageNet large scale visual recognition challenge[J]. Int J Comput Vis 115(3):211–252
Sakkos D, Liu H, Han J et al (2018) End-to-end video background subtraction with 3d convolutional neural networks [J]. Multimedia Tools and Applications 77(17):23023–23041
Silberman N, Fergus R (2011) Indoor scene segmentation using a structured light sensor[C]. In: 2011 IEEE international conference on computer vision workshops (ICCV workshops). IEEE Computer Society, pp 601–608
Silberman N, Hoiem D, Kohli P et al (2012) Indoor segmentation and support inference from RGBD images[J]. In European Conference on Computer Vision. Springer, Berlin, Heidelberg, pp 746–760
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition[J]. Computer Science arXiv preprint arXiv:1409.1556
Song S, Lichtenberg SP, Xiao JSUN (2015) RGB-D: a RGB-D scene understanding benchmark suite[C]. In: 2015 IEEE conference on computer vision and pattern recognition (CVPR). IEEE
Sun H, Pang Y (2018) GlanceNets — efficient convolutional neural networks with adaptive hard example mining[J]. SCIENCE CHINA Inf Sci 61(10):109101
Teichmann MTT, Cipolla R (2018) Convolutional CRFs for semantic segmentation [J]. arXiv preprint arXiv:1805.04777
Teichmann M, Weber M, Zoellner M et al (2016) MultiNet: real-time joint semantic reasoning for autonomous driving[J]. In 2018 IEEE Intelligent Vehicles Symposium (IV). IEEE, pp 1013–1020
Wang CY, Chen JZ, Li W (2014) Review on superpixel segmentation algorithms. Application research of Computers 31(1):6–12
Wu G, Han J, Lin Z et al (2018) Joint image-text hashing for fast large-scale cross-media retrieval using self-supervised deep learning[J]. IEEE Transactions on Industrial Electronics
Wu G, Han J, Guo Y et al (2019) Unsupervised deep video hashing via balanced code for large-scale video retrieval[J]. IEEE Trans Image Process 28(4):1993–2007
Xiao J, Owens A, Torralba A (2013) SUN3D: a database of big spaces reconstructed using SfM and object labels[C]. In: 2013 IEEE international conference on computer vision (ICCV). IEEE Computer Society
Yan C, Xie H, Yang D et al (2017) Supervised hash coding with deep neural network for environment perception of intelligent vehicles[J]. IEEE Trans Intell Transp Syst 19(1):284–295
Yan C, Xie H, Chen J et al (2018) A fast Uyghur text detector for complex background images[J]. IEEE Transactions on Multimedia 20(12):3389–3398
Yu F, Koltun V (2015) Multi-scale context aggregation by dilated convolutions[J]. arXiv preprint arXiv:1511.07122
Zhao H, Shi J, Qi X et al (2016) Pyramid scene parsing network[J]. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2881–2890
Zhao B, Feng J, Wu X et al (2017) A survey on deep learning-based fine-grained object classification and semantic segmentation[J]. International Journal of Automation and Computing 14(2):119–135
Zheng S, Jayasumana S, Romera-Paredes B et al (2015) Conditional random fields as recurrent neural networks[J]
Acknowledgments
This work is supported in part by Science and Technology Program of Tianjin, China(14ZCDGSF00124), Basic Research Program of Tianjin, China (17JCTPJC55400) and in part by NSF of Hebei Province through the Key Program under Grant F2016202144.
I would like to acknowledge Professor Junhua GU for his support as scientific advisor and co-authoring the paper.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Li, W., Gu, J., Dong, Y. et al. Indoor scene understanding via RGB-D image segmentation employing depth-based CNN and CRFs. Multimed Tools Appl 79, 35475–35489 (2020). https://doi.org/10.1007/s11042-019-07882-w
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-019-07882-w