
Abstract
Current movie captioning architectures are not capable of mentioning characters with their proper name, replacing them with a generic “someone” tag. The lack of movie description datasets with characters’ visual annotations surely plays a relevant role in this shortage. Recently, we proposed to extend the M-VAD dataset by introducing such information. In this paper, we present an improved version of the dataset, namely M-VAD Names, and its semi-automatic annotation procedure. The resulting dataset contains 63 k visual tracks and 34 k textual mentions, all associated with character identities. To showcase the features of the dataset and quantify the complexity of the naming task, we investigate multimodal architectures to replace the “someone” tags with proper character names in existing video captions. The evaluation is further extended by testing this application on videos outside of the M-VAD Names dataset.






Similar content being viewed by others


Notes
The proposed dataset is publicly available at https://github.com/aimagelab/mvad-names-dataset.
References
Babenko B, Yang MH, Belongie S (2009) Visual tracking with online multiple instance learning. In: IEEE international conference on computer vision and pattern recognition
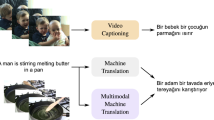
Baraldi L, Grana C, Cucchiara R (2017) Hierarchical boundary-aware neural encoder for video captioning. In: IEEE international conference on computer vision and pattern recognition
Bojanowski P, Bach F, Laptev I, Ponce J, Schmid C, Sivic J (2013) Finding actors and actions in movies. In: IEEE international conference on computer vision
Ding L, Yilmaz A (2010) Learning relations among movie characters: a social network perspective. In: European conference on computer vision
Donahue J, Anne Hendricks L, Guadarrama S, Rohrbach M, Venugopalan S, Saenko K, Darrell T (2015) Long-term recurrent convolutional networks for visual recognition and description. In: IEEE international conference on computer vision and pattern recognition
Everingham M, Sivic J, Zisserman A (2006) Hello! my name is... Buffy–automatic naming of characters in TV video. In: British machine vision conference
Guo Y, Zhang L, Hu Y, He X, Gao J (2016) MS-Celeb-1m: a dataset and benchmark for large-scale face recognition. In: European conference on computer vision
Hendricks LA, Venugopalan S, Rohrbach M, Mooney R, Saenko K, Darrell T (2016) Deep compositional captioning: describing novel object categories without paired training data. In: IEEE international conference on computer vision and pattern recognition
Jin S, Su H, Stauffer C, Learned-Miller E (2017) End-to-end face detection and cast grouping in movies using Erdos-renyí clustering. In: IEEE international conference on computer vision
Karpathy A, Fei-Fei L (2015) Deep visual-semantic alignments for generating image descriptions. In: IEEE international conference on computer vision and pattern recognition
Karpathy A, Toderici G, Shetty S, Leung T, Sukthankar R, Fei-Fei L (2014) Large-scale video classification with convolutional neural networks. In: IEEE international conference on computer vision and pattern recognition
Kiros R, Salakhutdinov R, Zemel R (2014) Unifying visual-semantic embeddings with multimodal neural language models. arXiv:1411.2539
Krishna R, Hata K, Ren F, Fei-Fei L, Niebles JC (2017) Dense-captioning events in videos. In: IEEE international conference on computer vision
Kuhn HW (1955) The hungarian method for the assignment problem. Naval Research Logistics Quarterly 2(1-2):83–97
Maaten LVD, Hinton G (2008) Visualizing data using t-SNE. J Mach Learn Res 9:2579–2605
Marín-Jiménez MJ, Zisserman A, Eichner M, Ferrari V (2014) Detecting people looking at each other in videos. Int J Comput Vis 106(3):282–296
Miech A, Alayrac JB, Bojanowski P, Laptev I, Sivic J (2017) Learning from video and text via large-scale discriminative clustering. In: IEEE international conference on computer vision
Pan P, Xu Z, Yang Y, Wu F, Zhuang Y (2016) Hierarchical recurrent neural encoder for video representation with application to captioning. In: IEEE international conference on computer vision and pattern recognition
Pan Y, Mei T, Yao T, Li H, Rui Y (2016) Jointly modeling embedding and translation to bridge video and language. In: IEEE international conference on computer vision and pattern recognition
Patron-Perez A, Marszalek M, Reid I, Zisserman A (2012) Structured learning of human interactions in TV shows. IEEE Trans Pattern Anal Mach Intell 34 (12):2441–2453
Pennington J, Socher R, Manning CD (2014) Glove: global vectors for word representation. In: Conference on empirical methods in natural language processing
Pini S, Cornia M, Baraldi L, Cucchiara R (2017) Towards video captioning with naming: a novel dataset and a multi-modal approach. In: International conference on image analysis and processing
Ramanathan V, Joulin A, Liang P, Fei-Fei L (2014) Linking people in videos with “their” names using coreference resolution. In: European conference on computer vision
Rohrbach A, Rohrbach M, Schiele B (2015) The long-short story of movie description. In: German conference on pattern recognition
Rohrbach A, Rohrbach M, Tandon N, Schiele B (2015) A dataset for movie description. In: IEEE international conference on computer vision and pattern recognition
Rohrbach A, Rohrbach M, Tang S, Oh SJ, Schiele B (2017) Generating descriptions with grounded and co-referenced people. In: IEEE international conference on computer vision and pattern recognition
Schroff F, Kalenichenko D, Philbin J (2015) Facenet: a unified embedding for face recognition and clustering. In: IEEE international conference on computer vision and pattern recognition
Shetty R, Rohrbach M, Hendricks LA, Fritz M, Schiele B (2017) Speaking the same language: matching machine to human captions by adversarial training. In: IEEE international conference on computer vision
Sivic J, Everingham M, Zisserman A (2009) Who are you? Learning person specific classifiers from video. In: IEEE international conference on computer vision and pattern recognition
Socher R, Karpathy A, Le QV, Manning CD, Ng AY (2014) Grounded compositional semantics for finding and describing images with sentences. Transactions of the Association of Computational Linguistics 2(1):207–218
Tapaswi M, Bäuml M, Stiefelhagen R (2012) Knock! Knock! Who is it? probabilistic person identification in TV-series. In: IEEE international conference on computer vision and pattern recognition
Torabi A, Pal C, Larochelle H, Courville A (2015)
Tran D, Bourdev L, Fergus R, Torresani L, Paluri M (2015) Learning spatiotemporal features with 3d convolutional networks. In: IEEE international conference on computer vision
Van Der Maaten L (2014) Accelerating t-SNE using tree-based algorithms. J Mach Learn Res 15(1):3221–3245
Venugopalan S, Xu H, Donahue J, Rohrbach M, Mooney R, Saenko K (2014) Translating videos to natural language using deep recurrent neural networks. North American Chapter of the Association for Computational Linguistics
Venugopalan S, Hendricks LA, Mooney R, Saenko K (2016) Improving lstm-based video description with linguistic knowledge mined from text. In: Conf. on empirical methods in natural language processing
Venugopalan S, Rohrbach M, Donahue J, Mooney R, Darrell T, Saenko K (2015) Sequence to sequence-video to text. In: IEEE international conference on computer vision
Vicol P, Tapaswi M, Castrejon L, Fidler S (2018) Moviegraphs: towards understanding human-centric situations from videos. In: IEEE international conference on computer vision and pattern recognition
Ward JHJ (1963) Hierarchical grouping to optimize an objective function. J Am Stat Assoc 58(301):236–244
Yao L, Torabi A, Cho K, Ballas N, Pal C, Larochelle H, Courville A (2015) Describing videos by exploiting temporal structure. In: IEEE international conference on computer vision
Yu H, Wang J, Huang Z, Yang Y, Xu W (2016) Video paragraph captioning using hierarchical recurrent neural networks. In: IEEE international conference on computer vision and pattern recognition
Zhang K, Zhang Z, Li Z, Qiao Y (2016) Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process Lett 23(10):1499–1503
Zhu Y, Kiros R, Zemel R, Salakhutdinov R, Urtasun R, Torralba A, Fidler S (2015) Aligning books and movies: towards story-like visual explanations by watching movies and reading books. In: IEEE international conference on computer vision and pattern recognition
Acknowledgements
We acknowledge Carmen Sabia and Luca Bergamini for supporting us during the annotation of the M-VAD Names dataset. We also gratefully acknowledge Facebook AI Research and Panasonic Corporation for the donation of the GPUs used in this work.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Pini, S., Cornia, M., Bolelli, F. et al. M-VAD names: a dataset for video captioning with naming. Multimed Tools Appl 78, 14007–14027 (2019). https://doi.org/10.1007/s11042-018-7040-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-018-7040-z