
Abstract
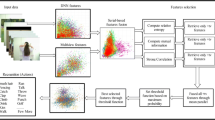
Visual recognition has been gradually played important roles in many fields. An effective feature descriptor, with higher discrimination and higher descriptiveness for the different visual recognition tasks, is a challenging issue. In this paper, we propose a novel feature, called mesh motion scale invariant feature description, to facilitate the different visual task description and balance discrimination and efficiency. Then, a hierarchical collaborative feature learning model for multi-visual tasks in complex scenes is presented for obtaining the recognition results. Four large databases, FRGC, CASIA, BU-3DFE and 3D Online Action, are introduced to the performance comparison and the experimental results show a better performance for face recognition, expression recognition and activity recognition based on our proposed method.







Similar content being viewed by others


References
Ahonen T, Hadid A, Pietikainen M (2006) Face description with local binary patterns: application to face recognition. IEEE Trans Pattern Anal Mach Intell 28 (12):2037–2041
Alain G, Bengio Y, Rifai S (2012) Universit de Montral, regularized auto-encoders estimate local statistics. arXiv:1211.4246
Andrew G, Arora R, Bilmes J, Livescu K (2013) Deep canonical correlation analysis. Int Conf Mach Learn:1247–1255
Batrinca L, Mana N, Lepri B, Sebe N, Pianesi F (2016) Multimodal personality recognition in collaborative goal-oriented tasks. IEEE Trans Multimed 18 (4):659–672
Bay H, Ess A, Tuytelaars T, Gool LJV (2008) Speeded up robust features. Comput Vis Image Underst 110(3):346–359
Bellotto N, Benfold B, Harland H, Nagal H-H, Pirla N, Reid L, Sommerlade E, Zhao C (2012) Cognitive visual tracking and camera control. Compter Vision and Image Understanding 116(2):457–471
Bengio Y, Courville A, Vincent P (2012) Representation learning: a review and new perspectives. IEEE Trans Pattern Anal Mach Intell 35(8):1798–1828
Bengio Y, Courville A, Vincent P (2012) Representation learning: A Review and New Perspectives, Arxiv
Chen M, Hauptmann A (2009) MoSIFT: Recognizing human actions in surveillance videos. Technical Report
Cheung W, Hamarneh G (2009) n-SIFT: n-dimensional scale invariant feature transform. IEEE Trans Image Process 18(1):2012–2021
Chiu L-C, Chang T-S, Chen J-Y, Chang NY-C (2013) Fast SIFT design for real-time visual feature extraction. IEEE Trans Image Process 22(8):3158–3167
Dardas NH, Georganas ND (2011) Real-time hand gesture detection and recognition using bag-of-features and support vector machine techniques. IEEE Trans Instrum Meas 60(11):3592–3607
Di Huang M, Ardabilian Y, Chen L (2012) 3D face recognition using eLBP based facial description and feature hybrid matching. IEEE Trans Inf Forensics Secur 7(5):1551–1565
Drom T, Keller Y (2012) Scale-invariant Features for 3D mesh model. IEEE Trans Image Process 21(5):2758–2769
Duan L, Xu D, Tsang IW-H, Luo J (2012) Visual event recognition in videos by learning from web data. IEEE Trans Pattern Anal Mach Intell 34(9):1667–1680
Evangelopoulos G, Zlantintsi A, Alexandros P, Maragos P, Rapantzikos K, Skoumas G, Avrithis Y (2013) Multimodal saliency and fusion for movie summarization based on aural, visual and texual attention. IEEE Trans Multimed 15 (7):1553–1568
Gao Z, Li S, Zhu Y et al (2017) Collaborative sparse representation learning model for RGBD action recognition. J Vis Commun Image Represent. https://doi.org/10.1016/j.jvcir.2017.03.014
Gao Z, Zhang H, Xu GP, Xue YB, Hauptmannc AG (2015) Multi-view discriminative and structured dictionary learning with group sparsity for human action recognition. Signal Process 112:83–97
Gao Z, Zhang L-F, Chen M-Y, Hauptmann A, Zhang H, Cai A (2014) Enhanced and hierarchical structure algorithm for data imbalance problem in semantic extraction under massive video dataset. Multimed Tool Appl 68(3):641–657
Goodfellow I, Courville A, Bengio Y (2012) Large-scale feature learning with spike-and-slab sparse coding. In: ICML
Goodfellow I, Courville A, Bengio Y (2012) Large-scale feature learning with spike-and-slab sparse coding. In: ICML
Huang L, Ma B, Shen J, He H, Shao L, Porikli F (2017) Visual tracking by sampling in part space. IEEE Trans Image Process 26(12):5800–5810
Hussain SU, Napoleon T, Jurie F (2012) Face recognition using local quantized patterns. In: British machive vision conference, pp 11–26
Kakadiaris IA, Passalis G, Toderici G, Murtuza N, Lu Y, Karampatziakis N, Theoharis T (2007) 3D face recognition in the presence of facial expressions: an annotated deformable model approach. IEEE Trans Pattern Anal Mach Intell 6 (4):640–664
Kavukcuoglu K, Ranzato M, LeCun Y (2010) Fast inference in sparse coding algorithms with applications to object recognition. arXiv:1010.3467
Kim D, Kim K, Kim JY, Lee S, Lee SJ, Yoo HJ (2009) GOPS Object recognition processor based on a memory-centric NoC. IEEE Trans Very Large Scale Integr Syst 17(3):370–382
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks NIPS
Lei Z, Pietikainen M, Li SZ (2014) Learning discriminant face descriptor. IEEE Trans Pattern Anal Mach Intell 36(2):289–302
Li X, Ruan Q, Ming Y (2012) A remarkable standard for estimating the performance of 3D facial expression features. Neurocomputing 82(1):99–108
Liu A-A, Su Y-T, Nie W-Z, Kankanhalli M (2017) Hierarchical clustering multi-task learning for joint human action grouping and recognition. IEEE Trans Pattern Anal Mach Intell 39(1):102–114
Lo TWR, Siebert JP (2009) Local feature extraction and matching on range images: 2.5D SIFT. Comput Vis Image Underst 113(12):1235–1250. Special issue on 3D Representation for Object and Scene Recognition
Lowe DG (2004) Distinctive image features from scale-invariant keypoints. Int J Comput Vis 60(2):91–110
Lu J, Liong VE, Zhou X, Zhou J (2015) Learning compact binary face descriptor for face recognition. IEEE Trans Pattern Anal Mach Intell 37(10):2041–2056
Maugey T, Frossard P (2016) Interactive multiview video system with low complexity 2D look around at decoder. IEEE Trans Multimedia 15(5):1070–1082
Mian AS, Bennamoun M, Owens R (2007) An efficient multimodal 2D-3D hybrid approach to automatic face recognition. IEEE Trans Pattern Anal Mach Intell 36(11):1927–1943
Ming Y (2015) Robust regional bounding spherical descriptor for 3D face recognition and emotion analysis. Image Vision Comput 35(3):14–22
Ming Y, Ruan Q, Hauptmann AG (2012) Activity recognition from RGB-d camera with 3D local spatio-temporal features. In: Proceedings of IEEE International Conference on Multimedia and Expo, pp 344–349
Ngiam J, Khosla A, Kim M, Nam J, Lee H, Ng AY (2011) Multimodal deep learning. In: International Conference on Machine Learning, pp 689–696
Osada K, Furuya T, Ohbuchi R (2008) Shrec08 entry: local volumetric features for 3d model retrieval. In: SMI08: International Conference on Shape Modeling and Applications. IEEE Computer Society, pp 245–246
Panagakis Y, Nicolaou MA, Zafeiriou S, Pantic M (2016) Robust correlated and individual component analysis. IEEE Trans Pattern Anal Mach Intell 38(8):1665–1678
Peng Y, Huang X, Qi J Cross-media Shared Representation by Hierarchical Learning with Multiple Deep Networks, 2016, International Joint Conference on Artificial Intelligence, pp 3846–3853
Phillips P, Flynn P, Scruggs T, Bowyer K, Chang J, Hoffman K, Marques J, Min J, Worek W (2005) Overview of the face recognition grand challenge. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp 947–954
Phillips PJ, Moon H, Rizvi S, Rauss PJ et al (2000) The feret evaluation methodology for face recognition algorithms. IEEE Trans Pattern Anal Mach Intell 22 (10):1090–1104
Song X, Jiang S, Herranz L (2017) Multi-scale multi-feature context modeling for scene recognition in the semantic manifold. IEEE Trans Image Process 26(6):2721–2735
Srivastava N, Salakhutdinov R (2012) Multimodal learning with deep boltzmann machines. Advan Neural Inform Process Syst:2222–2230
Tariq U, Huang TS Feature and fusion for expression recognition - A comparative analysis, 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, pp 146–152
Terriberry T, French L, Helmsen J (2008) GPU accelerating speeded-up robust features. In: 4th International Symposium on 3D Data Processing, Visualization, Transmission, pp 1–8
Wan J, Ruan Q, Li W, Deng S (2013) One-shot learning gesture recognition from RGB-d data using bag of features. J Mach Learn Res 14(1):2549–2582
Wu K Study on co-evolutionary method for image understanding, Hefei University of Technology PhD Thesis
Yang Y, Ma Z, Nie F, Chang X, Hauptmann AG (2015) Multi-class active learning by uncertainty sampling with diversity maximization. Int J Comput Vis 113(2):113–127
Yu G, Liu Z, Yuan J, Cremers D, Reid I, Saito H, Yang MH (2014) Discriminative orderlet mining for real-time recognition of human-object interaction. In: Computer vision, 12th springer international asian conference, ACCV14, Taiwan, pp 50–65
Zhang B, Gao Y, Zhao S, Liu J (2010) Local derivative pattern versus local binary pattern: face recognition with high-order local pattern descriptor. IEEE Trans Image Process 19(2):533–544
Zhang B, Yang Y, Chen C, Yang L, Han J, Shao L (2017) Action reocgnition using 3D histograms of texture and a multi-class boosting classifier. IEEE Trans Image Process 26(10):4648–4660
Zhang H, Shang X, Luan H, Wang M, Chua T-S (2016) Learning from collective intelligence: Feature learning using social images and tags. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), vol 13
Zhang H, Yang Y, Luan H, Yan S, Chua T-S Start from Scratch: towards Automatically Identifying, Modeling, and Naming Visual Attributes, 2014, ACM International Conference on Multimedia, pp 187–196
Zhang Q, Chen Y, Zhang Y, Xu Y (2008) SIFT Implementation and optimization for multi-core systems. In: IEEE International Symposium on Parallel Distributed Processing, pp 1–8
Acknowledgements
The work presented in this paper was supported by the National Natural Science Foundation of China (Grants No. NSFC-61402046), Fund for the Doctoral Program of Higher Education of China (Grants No. 20120005110002), National Great Science Specific Project (Grants No. 2011ZX0300200301, 2012ZX03005008) and Beijing Municipal Commission of Education Build Together Project.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Ming, Y., Shi, J. Mesh motion scale invariant feature and collaborative learning for visual recognition. Multimed Tools Appl 77, 22367–22384 (2018). https://doi.org/10.1007/s11042-018-5969-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-018-5969-6