
Abstract
Things we can say, and the ways in which we can say them, compete with one another. And this has consequences: words we decide not to pronounce have critical effects on the messages we end up conveying. For instance, in saying Chris is a good teacher, we may convey that Chris is not an amazing teacher. How this happens is an unsolvable problem, unless a theory of alternatives indicates what counts, among all the things that have not been pronounced. It is sometimes assumed, explicitly or implicitly, that any word counts, as long as that word could have replaced one that was actually pronounced. We review arguments for going beyond this powerful idea. In doing so, we argue that the level of words is not the right (or at least not the only) level of analysis for alternatives. Instead, we capitalize on recent conceptual and associated methodological advances within the study of the so-called “language of thought” to reopen the problem from a new perspective. Specifically, we provide theoretical and experimental arguments that the relation between alternatives and words may be indirect, and that alternatives are not merely linguistic objects in the traditional sense. Rather, we propose that competition in language is significantly determined by general reasoning preferences, or thought preferences (preferences that may have forged the lexicons of modern languages in the first place, as argued elsewhere). We propose that such non-linguistic preferences can be measured and that these measures can be used to explain linguistic competition, non-linguistically, and more in depth.


Similar content being viewed by others



Notes
In principle, if both \(\beta \) and not \(\beta \) are alternatives of \(\alpha \), then one could imagine one of them, say not \(\beta \), being ‘ignored’ during implicature calculation, e.g. because context makes it less salient. In such a case, \(\alpha \) would implicate ‘not \(\beta \)’. However, in practice it has been argued that symmetry cannot be ‘broken’ in this way (by ignoring one of two symmetric alternatives) (Fox and Katzir 2011).
Thanks to an anonymous reviewer for raising this point about scales. The same reviewer also notes that, alternatively, we may assume that the implicature mechanism only excludes logically stronger alternatives, so that even if [3d] is an alternative of [3a], it won’t be negated since the two sentences are logically independent. While this assumption would indeed solve this challenge, there are empirical reasons to think that the implicature mechanism actually does exclude non-stronger (and non-weaker, i.e. logically independent) alternatives. (See Fox 2007 for arguments from free choice.) For instance, the example in the main text, I have red cards in my hand, may implicate the negation of the logically independent alternative I have black cards in my hand. Note that the logically stronger alternative I have red and black cards in my hand could play the same role, but this would require the potentially unnatural scale \(\langle red , red and black \rangle \).
Crucially, the alternative with and instead of or does not have the requisite wide-scope reading; that is to say, [i] below entails that there is one single rumor about both Mary and Bill being expelled; not two separate rumors, one about Mary and one about Bill.
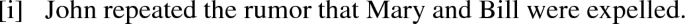
This may look like a technical trick, but the actual existence of a special pronoun of this form, capable of anaphorically referring to a piece of structure made available in the discourse, may actually be a sensible idea. For what it’s worth, it seems appealing to say that we can refer to thoughts, at least for ourselves (as in, “This and that are the reasons why...”). This may even happen in a rather visual manner, and the analogy with pointing pronouns in sign language may be of relevance (Schlenker 2017). Such considerations are not of central importance, but it’s useful to note that even if quite abstract, they could lead to actual predictions: under the view that a pronoun is responsible for picking up the piece of structure from the context, then no further replacement should be possible, even if we assume that replacements can occur recursively.
(Many thanks to Jacopo Romoli for raising the following issue clearly and forcefully.) In this experiment, we only address part of the problem, having to do with ‘some but not all’ not being an alternative, neither in the direct case, [11], nor in the indirect case, [12]. To be more complete, we would need to explain more, namely that:
-
(i)
Direct case: ‘all’ is an active alternative, while neither ‘some but not all’ nor ‘not all’ are.
-
(ii)
Indirect case: ‘none’ is an active alternative, while neither ‘some but not all’ nor ‘some’ are.
The direct case doesn’t seem to add much difficulty: the absence of ‘not all’ as an active alternative could simply be because ‘not all’ is intrinsically complex. This would need to be proven independently, but the ingredients seem to be there (on this view, ‘not all’ would not be an elementary primitive; it would have to be constructed from a negation and ‘all’). Note that this would not be so easy to test because of the logical relations between ‘all’ and ‘not all’ and the constraints on the task (there needs to be an overlap between the items to be compared). The indirect case may be more challenging, however, because ‘some’ is likely to be a good primitive (given, e.g., that it’s typically lexicalized), and so we need to explain why it does not play an active role in blocking the effect of the ‘none’ alternative. The experiment will not speak to this, but we mention here three possible solutions. First, even if both are primitives, it could be that ‘some’ is less primitive than ‘none’ (see Sect. 4.3). Second, if ‘some’ is a good primitive, then ‘not some’ is a very strong candidate in the context of ‘not all’; that is, if single word replacements are favored in the first place, then this in fact makes ‘not some’ \(=\) ‘none’ a more salient candidate for being an alternative than ‘some’ on its own. Finally, there may well be additional constraints on alternative building not considered here, which could solve this issue. See, for instance, the ‘Atomicity’ constraint proposed by Trinh and Haida (2015) and their discussion of its application to indirect implicatures. It would be interesting, in fact, to investigate whether such a constraint is rooted in cognitive constraints or preferences of the kind explored here and elsewhere.
-
(i)
We thank two anonymous reviewers who both pointed out this alternative interpretation of the results to us.
For example, one may try and reduce the number of objects in a box to just two, and the number of possible colors to just two (red and blue, say). In theory, then, a positive box that validates ‘all’ and one that validates ‘SBNA’ are equally constrained: both objects must be red in the former case, or one object must be red and the other blue in the latter. Thus, the likelihood of ‘all’ over ‘some’ is now equal to that of ‘SBNA’ over ‘some’. There are at least two problems with this approach. First, it’s unclear how one can ensure that the participants know that objects only come in pairs and can be only one of two possible colors. Even if they’re told this information at the outset, it’s difficult to determine whether they actually retain and use that information during the task. Second, even if that can be established or assumed, it’s no longer clear whether the rules/concepts being tested are still ‘some’, ‘all’, and ‘SBNA’, rather than, say, ‘some’, ‘both’, ‘exactly one’, ‘half’, and so on, which thus complicates matters in other ways.
In the upcoming implementation of this idea using logit models, the parameters will not directly represent rates of ‘yes’ responses, and they will not range between 0 and 1 but rather between \(-\infty \) and \(+\infty \). To convey the spirit of the analysis more simply, however, we ignore this technicality in this paragraph. To keep track of it, however, we mark the parameters in this informal description with a line above them, as in \(\overline{\alpha _p}\).
\(\alpha \) and \(\beta \) were always allowed to be distinct for the two pairs.
Models where parameter modifiers differed by subject and pair had this form:
$$\begin{aligned} Y_{spi} \sim \mathsf {bernoulli}(\mathsf {logit}^{-1}(\pi _{spi})) \end{aligned}$$$$\begin{aligned}&\text {with: } \pi _{spi} = (\alpha _p + u_{\alpha sp}) \cdot \textsc {no}_i + (\beta _q + u_{\beta sp}) \cdot \textsc {yes}_i\\&\qquad + (\alpha _p + u_{\alpha sp} + (\gamma _p + u_{\gamma sp})((\beta _p + u_{\beta sp}) - (\alpha _p + u_{\alpha sp}))) \cdot \textsc {target}_i + u_{0s}. \end{aligned}$$See Burnham and Anderson (2002, §2.6) for heuristics about differences on the deviance scale. Our \(\Delta _{elpd}\) values can be converted to that scale by multiplying them by \(-2\).
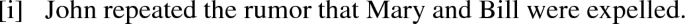
References
Bergen, L., Levy, R., & Goodman, N. D. (2016). Pragmatic reasoning through semantic inference. Semantics and Pragmatics, 9(20) https://doi.org/10.3765/sp.9.20.
Bourne, L. E. (1970). Knowing and using concepts. Psychological Review, 77(6), 546–556. https://doi.org/10.1037/h0030000.
Buccola, B., & Chemla, E. (2019). Alternatives of disjunctions: When a disjunct contains the antecedent of a pronoun. Snippets, 37, 16–18. https://doi.org/10.7358/snip-2019-037-buch.
Burnham, K. P., & Anderson, D. R. (2002). Model selection and multimodel inference: A practical information-theoretic approach. Second edition. New York: Springer.
Carcassi, F., & Szymanik, J. (2021). An alternatives account of ‘most’ and ‘more than half’. Ms., University of Amsterdam. https://semanticsarchive.net/Archive/TIxM2YzZ/.
Charlow, S. (2019). Scalar implicature and exceptional scope. Ms., Rutgers University. https://ling.auf.net/lingbuzz/003181.
Chemla, E. (2007). French both: A gap in the theory of antipresupposition. Snippets, 15, 4–5.
Chemla, E., Buccola, B., & Dautriche, I. (2019). Connecting content and logical words. Journal of Semantics 36(3), 531–547. https://doi.org/10.1093/jos/ffz001.
Chierchia, G. (2013). Logic in grammar: Polarity, free choice, and intervention. Oxford: Oxford University Press.
Chierchia, G., Fox, D., & Spector, B. (2012). Scalar implicature as a grammatical phenomenon. In C. Maienborn, K. von Heusinger, & P. Portner (Eds.), Semantics: An international handbook of natural language meaning (Vol. 3, pp. 2297–2331). Berlin: Mouton de Gruyter.
Fox, D. (2007). Free choice and the theory of scalar implicatures. In U. Sauerland & P. Stateva (Eds.), Presupposition and implicature in compositional semantics (pp. 71–120). New York: Palgrave Macmillan. https://doi.org/10.1057/9780230210752_4.
Fox, D., & Katzir, R. (2011). On the characterization of alternatives. Natural Language Semantics, 19(1), 87–107. https://doi.org/10.1007/s11050-010-9065-3.
Gamut, L. T. F. (1991). Logic, language, and meaning, Vol. 1: Introduction to logic. Chicago, IL: University of Chicago Press.
Gazdar, G. (1979). Pragmatics: Implicature, presupposition, and logical form. New York: Academic Press.
Geach, P. T. (1962). Reference and generality: An examination of some medieval and modern theories. Ithaca, NY: Cornell University Press.
Geurts, B., & van der Slik, F. (2005). Monotonicity and processing load. Journal of Semantics, 22(1), 97–117. https://doi.org/10.1093/jos/ffh018.
Grice, H. P. (1975). Logic and conversation. In P. Cole & J. L. Morgan (Eds.), Syntax and semantics 3: Speech acts (pp. 41–58). New York: Academic Press.
Gärdenfors, P. (2014). The geometry of meaning: Semantics based on conceptual spaces. Cambridge, MA: MIT Press.
Haygood, R. C., & Bourne, L. E. (1965). Attribute- and rule-learning aspects of conceptual behavior. Psychological Review, 72(3), 175–195. https://doi.org/10.1037/h0021802.
Horn, L. R. (1969). A presuppositional analysis of only and even. Chicago Linguistic Society (CLS), 5, 97–108.
Horn, L. R. (1972). On the semantics of logical operators in English. Ph.D. thesis, Yale University, New Haven, CT.
Horn, L. R. (1992). The said and the unsaid. Semantics and Linguistic Theory (SALT), 2, 163–192. https://doi.org/10.3765/salt.v2i0.3039.
Kadmon, N., & Landman, F. (1993). Any. Linguistics and Philosophy, 16(4), 353–422. https://doi.org/10.1007/BF00985272.
Karttunen, L. (1969). Pronouns and variables. Chicago Linguistic Society (CLS), 5, 108–116.
Karttunen, L., & Peters, S. (1979). Conventional implicature. In C.-K. Oh & D. Dineen (Eds.), Syntax and semantics 11: Presupposition (pp. 1–56). New York: Academic Press. https://doi.org/10.1163/9789004368880_002.
Katzir, R. (2007). Structurally-defined alternatives. Linguistics and Philosophy, 30(6), 669–690. https://doi.org/10.1007/s10988-008-9029-y.
Katzir, R., & Singh, R. (2013). Constraints on the lexicalization of logical operators. Linguistics and Philosophy, 36(1), 1–29. https://doi.org/10.1007/s10988-013-9130-8.
King, W. L. (1966). Learning and utilization of conjunctive and disjunctive classification rules: A developmental study. Journal of Experimental Child Psychology, 4(3), 217–231. https://doi.org/10.1016/0022-0965(66)90022-1.
Magri, G. (2009). A theory of individual-level predicates based on blind mandatory scalar implicatures. Natural Language Semantics, 17(3), 245–297. https://doi.org/10.1007/s11050-009-9042-x.
Matsumoto, Y. (1995). The conversational condition on Horn scales. Linguistics and Philosophy, 18(1), 21–60. https://doi.org/10.1007/BF00984960.
Norman, D. A., & Bobrow, D. G. (1975). On data-limited and resource-limited processes. Cognitive Psychology, 7(1), 44–64. https://doi.org/10.1016/0010-0285(75)90004-3.
Piantadosi, S. T., Tenenbaum, J. B., & Goodman, N. D. (2016). The logical primitives of thought: Empirical foundations for compositional cognitive models. Psychological Review, 123(4), 392–424. https://doi.org/10.1037/a0039980.
Rooth, M. (1985). Association with focus. Ph.D. thesis, University of Massachusetts Amherst, Amherst, MA.
Sauerland, U. (2004). Scalar implicatures in complex sentences. Linguistics and Philosophy, 27(3), 367–391. https://doi.org/10.1023/B:LING.0000023378.71748.db.
Schlenker, P. (2017). Sign language and the foundations of anaphora. Annual Review of Linguistics, 3, 149–177. https://doi.org/10.1146/annurev-linguistics-011415-040715.
Seuren, P. A. M., & Jaspers, D. (2014). Logico-cognitive structure in the lexicon. Language, 90(3), 607–643. https://doi.org/10.1353/lan.2014.0058.
Smith, R. W. (2020). Similative plurality and the nature of alternatives. Semantics and Pragmatics, 13(15). https://doi.org/10.3765/sp.13.15.
Spector, B. (2013). Bare numerals and scalar implicatures. Language and Linguistics Compass, 7(5), 273–294. https://doi.org/10.1111/lnc3.12018.
Strickland, B. (2017). Language reflects “core” cognition: A new theory about the origin of cross-linguistic regularities. Cognitive Science, 41(1), 70–101. https://doi.org/10.1111/cogs.12332.
Szabolcsi, A. (2020). Obviation in Hungarian: What is its shape, and is it due to competition? Colloquium talk given at Tel Aviv University.
Trinh, T., & Haida, A. (2015). Constraining the derivation of alternatives. Natural Language Semantics, 23(4), 249–270. https://doi.org/10.1007/s11050-015-9115-y.
Vehtari, A., Gelman, A., & Gabry, J. (2016). Practical Bayesian model evaluation using leave-one-out cross-validation and WAIC. Statistics and Computing, 27, 1413–1432. https://doi.org/10.1007/s11222-016-9696-4.
Xu, F., & Tenenbaum, J. B. (2007). Word learning as Bayesian inference. Psychological Review, 114(2), 245–272. https://doi.org/10.1037/0033-295X.114.2.245.
Acknowledgements
We would like to thank Denis Bonnay, Alexandre Cremers, Luka Crnič, Paul Egré, Danny Fox, Yosef Grodzinsky, Andreas Haida, Philippe Schlenker, Raj Singh, Paul Smolensky and Benjamin Spector, as well as three anonymous reviewers for Linguistics and Philosophy.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The research leading to this work was supported by the Israel Science Foundation (ISF 1926/14); the German-Israeli Foundation for Scientific Research (GIF 2353); the Austrian Science Fund (FWF), Project Number P 31422; the European Research Council under the European Union’s Seventh Framework Programme, ERC FP7 Grant 313610 (SemExp); and the Agence Nationale de la Recherche, ANR-17-EURE-0017 (FrontCog).
Appendix: Statistical analysis
Appendix: Statistical analysis
1.1 General description and notations
Semi-formally, our measure is based on three parameters for each quantifier pair p. First, \(\overline{\alpha _p}\) represents our best estimate of the true rate of ‘yes’ responses in the no cases, and \(\overline{\beta _p}\) represents our best estimate of the true rate of ‘yes’ responses in the yes cases. In an ideal world, we should find \(\overline{\alpha _p}=0\) and \(\overline{\beta _p}=1\).Footnote 8 Critically, \(\overline{\gamma _p}\) represents the preference between the weak and the strong quantifier, estimated as the position of the responses to the target types not as an absolute rate, but as a proportion with \(\overline{\alpha _p}\) and \(\overline{\beta _p}\) as extreme points. In pseudo-formula, this means that the actual response in the target type is predicted by \(\overline{\alpha _p} + \overline{\gamma _p} \cdot (\overline{\beta _p} - \overline{\alpha _p})\). Concretely, a maximal preference for the weaker quantifier in p would correspond to \(\overline{\gamma _p} = 100\%\), i.e. an expected response rate in the target case as high as in the yes cases: \(\overline{\alpha _p} + 100\% \cdot (\overline{\beta _p} - \overline{\alpha _p}) = \overline{\beta _p}\). Conversely, an extreme preference for the stronger quantifier would correspond to \(\overline{\gamma _p} = 0\%\), i.e. an expected response rate in the target case as low as in the no cases: \(\overline{\alpha _p} + 0\% \cdot (\overline{\beta _p} - \overline{\alpha _p}) = \overline{\alpha _p}\). Finally, a neutral preference corresponds to \(\overline{\gamma _p} = 50\%\) and an expected response rate exactly in between \(\overline{\alpha _p}\) and \(\overline{\beta _p}\): \(\overline{\alpha _p} + 50\% \cdot (\overline{\beta _p} - \overline{\alpha _p}) = (\overline{\alpha _p} + \overline{\beta _p})/2\).
To explain, imagine an ideal world in which participants always infer one of the two rules based on the quantifiers in the pair, and never any other rule. Then the yes items (where both rules are satisfied) and no items (where neither rule is satisfied) should be at ceiling and floor, respectively. In this ideal world, the responses to target items give us a direct measure of preference between the two rules. In actual fact, various biases, errors, and additional rules can play into the task, and hence yes and no items are not at ceiling/bottom. Still, the positioning of target items within the range between the two extremes provided by yes and no items provides a measure of preference: the closer target is to yes, the more the weaker quantifier is preferred to the stronger. This rescaling of the range for target items to the span between yes and no eliminates noise created by general yes/no biases and rules that are weaker or stronger than both quantifiers in the pair.
One source of simplification here is that we ignore the possibility that participants might infer a rule that is ‘intermediate’ between the two members of the pair; for example, ‘at least 3’ and ‘more than half’ are intermediate between ‘some’ and ‘all’. Depending on the specific rule participants infer and the particular test box showing, this could alter the rate of ‘yes’ responses, but not because participants opt for quantifiers from our pair. We thus work on the assumption that the two rules we compare are the most salient in their range. However, we also note that our main interpretations are based not only on pairs, but on the comparison between two pairs of quantifiers. We submit that the intermediate rules relevant for these two pairs are similar across the pairs we use, so that their role should be cancelled out in our analysis. For instance, when we compare ‘all’ and ‘SBNA’ through the pairs (some, all) and (some, SBNA), we assume that the relevant intermediate rules, which are compatible with the positive and negative examples being what they are, and which could make the test box true, are of the form ‘at least x’ in both cases.
1.2 Models and analyses
The logit models we fit thus had a slightly different structure from the generalized linear models commonly used in the analysis of binary response data. Their basic form was as follows:
Given a pair of quantifiers \(p=(x,y)\), the parameter \(\gamma _{(x,\,y)}\) thus represents the preference for the weaker member over the stronger member. Given two pairs of quantifiers \((x,\,y_1)\) and \((x,\,y_2)\) that share a common member x, we can then compare \(y_1\) and \(y_2\) by fitting a model to the data from both pairs and seeing whether there is evidence for a difference between \(\gamma _{(x,\,y_1)}\) and \(\gamma _{(x,\,y_2)}\). If there is one, then one of the y’s is preferred to the other, in that it is more distinct from x than the other is.
We partitioned our data into three sets based on the quantifier pairs that shared a member: (i) a set comprising data from (some, all) and (some, SBNA); (ii) a set comprising data from (not all, no) and (not all, SBNA); and (iii) a set comprising data from (at least n, exactly n) and (at most n, exactly n). On each of these three data sets, we fitted models that included either one or two \(\gamma \) parameters (allowing, or not allowing, for a relative preference between the two non-shared quantifiers in the two pairs, as discussed in the main text),Footnote 9 and different varying-effects structures: there was (or was not) a subject intercept \(u_{0s}\), and either no modification of the parameters, parameter modifiers differing by subject, or parameter modifiers differing by both subject and pair. All models were fitted with MCMC methods using STAN through the rstan package in R, with STAN’s default uniform (improper) prior over \(\alpha \), \(\beta \), and \(\gamma \) (in the latter case restricted to [0, 1]) as well as the standard deviation hyperparameters for the varying subject effects (which themselves were assumed to be normally distributed around 0). Models were evaluated by leave-one-out cross-validation, approximated by Pareto-smoothed importance sampling with the loo package (Vehtari et al. 2016) on the basis of 5000 samples of the likelihood for each data point, drawn after 5000 burn-in iterations.
1.3 Results
For all three data sets, the best model turned out to be the two-\(\gamma \) model with a subject intercept and parameter modifiers varying by subject, but not by pair:Footnote 10
In order to see whether the preference for two \(\gamma \)-parameters was meaningful, we compared the optimal models to the variants with identical varying effects structure, but only one (pair-independent) \(\gamma \)-parameter. Differences in estimated log pointwise predictive likelihood and their standard errors for models with one and two \(\gamma \)-parameters are given in Table 2.
In addition, posterior means and 95% credible intervals for the difference between \(\gamma \)-parameters are shown in Table 3.
With a \(\Delta _{elpd}\) of \(-32.0\), there is strong evidence for a preference for ‘all’ over ‘SBNA’.Footnote 11 The direction of this preference is given by the negative difference in \(\gamma \) parameters. If x is stronger than y in a pair (x, y), then a low \(\gamma _{(x,y)}\) indicates a stronger preference for x, and since \(\gamma _{(\text {some,all})}\) is smaller than \(\gamma _{(\text {some,SBNA})}\), we know that ‘all’ is preferred to ‘some’ more strongly than ‘SBNA’ is preferred to ‘some’, hence that ‘all’ is preferred to ‘SBNA’.
The same reasoning applies to the comparison of ‘no’ with ‘SBNA’ via comparison of each with ‘not all’. In this instance, however, the effect is smaller and the strength of the evidence, with a \(\Delta _{elpd}\) of \(-3.8\), much more modest.
For ‘at least’ and ‘at most’, a greater \(\gamma \) value indicates a stronger preference over ‘exactly’, because now the quantifiers of interest are the weaker members of the pair. Since \(\gamma _{(\text {at least,exactly})}\) is greater than \(\gamma _{(\text {at most,exactly})}\), we can infer a preference for ‘at least’ over ‘at most’. The effect size here is in the same ballpark as with ‘all’ versus ‘SBNA’, and the evidence quite strong.
Rights and permissions
About this article

Cite this article
Buccola, B., Križ, M. & Chemla, E. Conceptual alternatives. Linguist and Philos 45, 265–291 (2022). https://doi.org/10.1007/s10988-021-09327-w
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10988-021-09327-w