
Abstract
We study the asymptotic behavior of second-order algorithms mixing Newton’s method and inertial gradient descent in non-convex landscapes. We show that, despite the Newtonian behavior of these methods, they almost always escape strict saddle points. We also evidence the role played by the hyper-parameters of these methods in their qualitative behavior near critical points. The theoretical results are supported by numerical illustrations.



Similar content being viewed by others

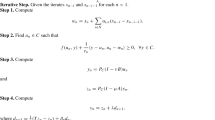

Data Availability Statement
No additional data are needed to reproduce the experiments, and the code is publicly available (see above).
Notes
This requires more assumptions on \(\mathcal {J}\), e.g., the Kurdyka-Łojasiewicz property, see [38].
The main algorithmic result of this paper, Theorem 4.1 holds beyond Morse functions.
The distribution of \((\theta _0,\psi _0)\) must be absolutely continuous w.r.t. the Lebesgue measure, that is: for any set \(\textsf{I}\subset \mathbb {R}^P\times \mathbb {R}^P\) with zero Lebesgue measure, \(\mathbb {P}((\theta _0,\psi _0)\in \textsf{I})=0\).
Additionally H preserves the parametrization by time (i.e., the orientation of oriented curves is preserved see [36, Chapter 2.8, Definition 1]).
We could consider non-autonomous ODEs [33], but we do not for the sake of simplicity.
References
Alecsa, Cristian Daniel, László, Szilárd Csaba., Viorel, Adrian: A gradient-type algorithm with backward inertial steps associated to a nonconvex minimization problem. Numer. Algor. 84(2), 485–512 (2020)
Alecsa, Cristian Daniel, László, Szilárd Csaba., Pinţa, Titus: An extension of the second order dynamical system that models Nesterov’s convex gradient method. Appl. Math. Optim. 84(2), 1687–1716 (2021)
Alvarez, Felipe, Attouch, Hedy, Bolte, Jérôme., Redont, Patrick: A second-order gradient-like dissipative dynamical system with Hessian-driven damping: application to optimization and mechanics. Journal de Mathématiques Pures et Appliquées 81(8), 747–779 (2002)
Ašić, M.D., Adamović, D.D.: Limit points of sequences in metric spaces. Am. Math. Monthly 77(6), 613–616 (1970). https://www.tandfonline.com/doi/abs/10.1080/00029890.1970.11992549
Attouch, H., László, S.C.: Newton-like inertial dynamics and proximal algorithms governed by maximally monotone operators. SIAM J. Optim. 30(4), 3252–3283 (2020)
Attouch, H., László, S.C.: Continuous Newton-like inertial dynamics for monotone inclusions. Set-Valued Variat. Anal 29(3), 555–581 (2021)
Attouch, Hedy, Redont, Patrick: The second-order in time continuous Newton method. In: Lassonde, M. (ed.) Approximation, Optimization and Mathematical Economics, pp. 25–36. Springer, NewYork (2001)
Attouch, H.: Bolte, Jérôme, Svaiter, Benar Fux: Convergence of descent methods for semi-algebraic and tame problems: proximal algorithms, forward-backward splitting, and regularized Gauss-Seidel methods. Math. Program. 137(1), 91–129 (2013)
Attouch, Hedy, Peypouquet, Juan, Redont, Patrick: A dynamical approach to an inertial forward-backward algorithm for convex minimization. SIAM J. Optim. 24(1), 232–256 (2014)
Attouch, Hedy, Peypouquet, Juan, Redont, Patrick: Fast convex optimization via inertial dynamics with Hessian driven damping. J. Differ. Eq. 261(10), 5734–5783 (2016)
Attouch, Hedy, Chbani, Zaki, Peypouquet, Juan, Redont, Patrick: Fast convergence of inertial dynamics and algorithms with asymptotic vanishing viscosity. Math. Program. 168(1), 123–175 (2018)
Attouch, Hedy: Chbani, Zaki, Riahi, Hassan: rate of convergence of the Nesterov accelerated gradient method in the subcritical case \(\alpha \le 3\). ESAIM Control Optim. Calc. Var. 25(2), 1–34 (2019)
Attouch, Hedy, Chbani, Zaki, Fadili, Jalal, Riahi, Hassan: First-order optimization algorithms via inertial systems with Hessian driven damping. Math. Program. 194(4), 1–43 (2020)
Attouch, H., Boţ, R.I., Csetnek, E.R.: Fast optimization via inertial dynamics with closed-loop damping. J. Eur. Math. Soc. 25(5), 1985–2056 (2022)
Aujol, Jean-Francois., Dossal, Charles, Rondepierre, Aude: Optimal convergence rates for Nesterov acceleration. SIAM J. Optim. 29(4), 3131–3153 (2019)
Bertsekas, Dimitri P.: Nonlinear Programming. Athena Scientific, (1998)
Boţ, R.I., Csetnek, E.R., László, S.C.: An inertial forward-backward algorithm for the minimization of the sum of two nonconvex functions. EURO J. Comput. Optim. 4(1), 3–25 (2016)
Boţ, R.I., Csetnek, E.R., László, S.C.: Tikhonov regularization of a second order dynamical system with Hessian driven damping. Math. Program. 189(1), 151–186 (2021)
Castera, Camille, Pauwels, Edouard: An inertial Newton algorithm for deep learning. J. Mach. Learn. Res. 22(134), 1–31 (2021)
Chen, Long, Luo, Hao: First order optimization methods based on Hessian-driven Nesterov accelerated gradient flow. arXiv:1912.09276, (2019)
Dauphin, Y.N., Pascanu, Razvan, Gulcehre, Caglar, Cho, Kyunghyun, Ganguli, Surya, Bengio, Yoshua: Identifying and attacking the saddle point problem in high-dimensional non-convex optimization. In: Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K.Q. Weinberger (ed) Advances in Neural Information Processing Systems (NeurIPS), vol. 27, pp. 2933-2941. (2014)
Goudou, Xavier, Munier, Julien: The gradient and heavy ball with friction dynamical systems: the quasiconvex case. Math. Program. 116(1), 173–191 (2009)
Grobman, David M.: Homeomorphism of systems of differential equations. Doklady Akademii Nauk SSSR 128(5), 880–881 (1959)
Hartman, Philip: A lemma in the theory of structural stability of differential equations. Proc. Am. Math. Soc. 11(4), 610–620 (1960)
Hunter, John D.: Matplotlib: a 2D graphics environment. Comput. Sci. Eng. 9(3), 90–95 (2007)
Kelley, Al.: The stable, center-stable, center, center-unstable, unstable manifolds. J. Differ. Eq. (1966). https://doi.org/10.1016/0022-0396(67)90016-2
Kelley, John L.: General Topology. Springer, NewYork (1975)
Lee, Jason D., Simchowitz, Max, Jordan, Michael I., Recht, Benjamin: Gradient descent only converges to minimizers. In V. Feldman, A. Rakhlin, and O. Shamir, editors, Conference on Learning Theory (COLT), volume 49, pages 1246–1257, (2016)
Mertikopoulos, P., Hallak, N., Kavis, A., Cevher, V.: On the almost sure convergence of stochastic gradient descent in non-convex problems. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, (ed), Advances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 1117–1128, (2020)
Milnor, John: Morse Theory. Princeton University Press, New Jersey (2016)
Nesterov, Yurii: A method for unconstrained convex minimization problem with the rate of convergence \({O}(1/k^2)\). In Doklady USSR 269, 543–547 (1983)
Nocedal, Jorge: Wright, Stephen: Numerical Optimization. Springer, Newyork (2006)
Ochs, Peter: Local convergence of the heavy-ball method and ipiano for non-convex optimization. J. Optim. Theory Appl. 177(1), 153–180 (2018)
O’Neill, Michael, Wright, Stephen J.: Behavior of accelerated gradient methods near critical points of nonconvex functions. Math. Program. 176(1), 403–427 (2019)
Palmer, Kenneth J.: A generalization of Hartman’s linearization theorem. J. Math. Anal. Appl. 41(3), 753–758 (1973)
Panageas, Ioannis, Piliouras, Georgios: Gradient descent only converges to minimizers: Non-isolated critical points and invariant regions. In: C.H. Papadimitriou, (ed), Theoretical Computer Science Conference (ITCS), vol. 67, pp. 1–12, (2017)
Panageas, Ioannis, Piliouras, Georgios, Wang, Xiao: First-order methods almost always avoid saddle points: The case of vanishing step-sizes. In: H. Wallach, H. Larochelle, A. Beygelzimer, F. d’ Alché-Buc, E. Fox, and R. Garnett, (ed), Advances in Neural Information Processing Systems (NeurIPS), vol. 32, pp. 1–12, (2019)
Perko, Lawrence: Differential Equations and Dynamical Systems. Springer, NewYork (2013)
Polyak, Boris T.: Some methods of speeding up the convergence of iteration methods. USSR Comput. Math. Math. Phys. 4(5), 1–17 (1964)
Rossum, Guido: Python reference manual. CWI (Centre for Mathematics and Computer Science), (1995)
Shi, B., Du, S.S., Jordan, M.I., Su, W.J.: Understanding the acceleration phenomenon via high-resolution differential equations. Math. Program. 195(1), 79–148 (2022)
Shub, Michael: Global Stability of Dynamical Systems. Springer, NewYork (2013)
Su, W., Boyd, S., Candes, E.: A differential equation for modeling Nesterov’s accelerated gradient method: theory and insights. In: Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K.Q. Weinberger, (ed), Advances in Neural Information Processing Systems (NeurIPS), vol. 27, pp. 2510–2518, (2014)
Szilárd Csaba László: Convergence rates for an inertial algorithm of gradient type associated to a smooth non-convex minimization. Math. Program. 190(1), 285–329 (2021)
Truong, Tuyen Trung: Convergence to minima for the continuous version of backtracking gradient descent. arXiv preprint arXiv:1911.04221, (2019)
Truong, Tuyen Trung, Nguyen, Tuan Hang: Backtracking gradient descent method for general \({C}^{1}\) functions, with applications to deep learning. arXiv preprint arXiv:1808.05160, 2018
Vassilis, Apidopoulos, Jean-François, Aujol, Charles, Dossal: The differential inclusion modeling FISTA algorithm and optimality of convergence rate in the case \(b \le 3\). SIAM J. Optim. 28(1), 551–574 (2018)
van der Walt, Stéfan., Colbert, Chris, Varoquaux, Gael: The NumPy array: a structure for efficient numerical computation. Comput. Sci. Eng 13(2), 22–30 (2011)
Viktor Aleksandrovich Pliss: A reduction principle in the theory of stability of motion. Izvestiya Akademii Nauk SSSR. Seriya Matematicheskaya 28(6), 1297–1324 (1964)
Acknowledgements
The author acknowledges the support of the European Research Council (ERC FACTORY-CoG-6681839) and the Air Force Office of Scientific Research (FA9550-18-1-0226). The author deeply thanks Jérôme Bolte, Cédric Févotte, and Edouard Pauwels for their valuable comments and the anonymous reviewers for their suggestions which led to significant improvements, such as tackling non-isolated critical points. The numerical experiments were made with the following libraries: [25, 47, 48].
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Olivier Fercoq.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
A Permutation Matrices
We specify the permutations matrices used to obtain the block diagonalization in (7). Denote by \(\textrm{mod}\) the modulo operator. We can choose the permutation matrix \(U\in \mathbb {R}^{2P\times 2P}\) as the matrix whose coefficients are all zero except the following, for all \(p\in \{1,\ldots ,P\}\),
B Proof of Theorem 4.1
We consider functions with possibly uncountably many critical points, this yields additional difficulties, which we overcome using the following result as done in [34].
Lemma B.1
(Lindelõf [27]) For every open cover there is a countable sub-cover.
The proof of Theorem 4.1 follows similar steps as that of Theorem 3.2, so we omit some details and use the notations of Sect. 3.1. First, for any \((\theta ,\psi )\in \mathbb {R}^P\times \mathbb {R}^P\), we redefine G:
so that iterations \(k\in \mathbb {N}\) of INNA read \((\theta _{k+1},\psi _{k+1}) = G(\theta _{k},\psi _{k})\). Remark that the set of fixed points of G is \(\textsf{S}\), the stationary points of (3), indeed, for any \((\theta ,\psi )\in \mathbb {R}^P\times \mathbb {R}^P\),
Since G is \(C^1\) on \(\mathbb {R}^{P}\times \mathbb {R}^P\), the Jacobian matrix of G (displayed by block) reads,
We can again block-diagonalize \(DG(\theta ,\psi )\) (see (7)), in blocks of the form (up to symmetric permutations): \(M_p = \begin{pmatrix} 1 - \gamma (\alpha -\frac{1}{\beta }) -\gamma \beta \lambda _p &{} &{} -\frac{\gamma }{\beta } \\ -\gamma (\alpha -\frac{1}{\beta }) &{} &{} 1-\frac{\gamma }{\beta } \end{pmatrix}\), where \(\lambda _p\) is an eigenvalue of \(\nabla ^2\mathcal {J}(\theta )\). To use the Theorem 4.2, we need G to be a local diffeomorphism.
Theorem B.1
Under the same assumptions as that of Theorem 4.1, the mapping G defined in (17) is a local diffeomorphism from \(\mathbb {R}^P\times \mathbb {R}^P\) to \(\mathbb {R}^P\times \mathbb {R}^P\).
This result is proved later in Section B.1. We can now prove Theorem 4.1.
Proof of Theorem 4.1
Let \(\alpha \), \(\beta \) and \(\gamma \) such that the assumptions of the theorem hold and let G defined in (17) with these parameters. By Theorem B.1, G is a local diffeomorphism. Let \((\theta ^\star ,\psi ^\star )\in \textsf{S}_{<0}\), to use Theorem 4.2 we study the magnitude of the eigenvalues of \(DG(\theta ^\star ,\psi ^\star )\). Let \(\lambda _p<0\) be a negative eigenvalue of \(\nabla ^2\mathcal {J}(\theta ^\star )\), using the notations and elements stated in the beginning of this section, the eigenvalues of \(M_p\) are the roots of
The discriminant of \(\chi _{M_p}\) is:
Remark that Lemma 3.1 gives again the sign of \(\Delta _{M_p}\). Thus since \(\lambda _p<0\), we necessarily have \(\Delta _{M_p}\ge 0\), and can ignore the case \(\Delta _{M_p}<0\). So \(M_p\) has two real eigenvalues,
Since \(\lambda _p<0\), then \(\vert \alpha +\beta \lambda _p\vert < \sqrt{(\alpha +\beta \lambda _p)^2 - 4\lambda _p}\), so observe that \(\sigma _{p,+}>1\) and \(\sigma _{p,-}<1\), so \(DG(\theta ^\star ,\psi ^\star )\) has at least one eigenvalue with magnitude larger than one.
We can now use the stable manifold theorem and we omit some details since the arguments are the same as for the proof of Theorem 3.1. By Theorem 4.2, around each \((\theta ^\star ,\psi ^\star )\in \textsf{S}_{<0}\), there exists a neighborhood \(\mathsf {\Omega }_{(\theta ^\star ,\psi ^\star )}\) on which the stable manifold theorem holds. Denote by \(\textsf{A}\) the possibly uncountable union of all these neighborhoods: \(\textsf{A} = \bigcup _{(\theta ^\star ,\psi ^\star )\in \textsf{S}_{<0}} \mathsf {\Omega }_{(\theta ^\star ,\psi ^\star )}\). By Lemma B.1, there exists a countable sub-cover of this set, i.e., there exists a sequence \((\theta _i^\star ,\psi _i^\star )_{i\in \mathbb {N}}\) in \(\textsf{S}_{<0}\) such that
Let \((\theta ^\star ,\psi ^\star )\in \textsf{S}_{<0}\), it need not be an element of \((\theta _i^\star ,\psi _i^\star )_{i\in \mathbb {N}}\), but according to (18), there exists \(i\in \mathbb {N}\) such that \((\theta ^\star ,\psi ^\star )\in \mathsf {\Omega }_{(\theta _i^\star ,\psi _i^\star )}\). Let an initialization \((\theta _0,\psi _0)\) such that the associated realization \((\theta _k,\psi _k)_{k\in \mathbb {N}}\) of INNA converges to \((\theta ^\star ,\psi ^\star )\). This means that there exists \(k_0\in \mathbb {N}\) such that \(\forall k\ge k_0\), \(G^k(\theta _0,\psi _0)\in \mathsf {\Omega }_{(\theta _i^\star ,\psi _i^\star )}\) and thus \(G^k(\theta _0,\psi _0)\in \textsf{W}^{sc}_{(\theta _i^\star ,\psi _i^\star )}\), where \(\textsf{W}^{sc}_{(\theta _i^\star ,\psi _i^\star )}\) is the stable manifold around \((\theta _i^\star ,\psi _i^\star )\) as defined in Theorem 4.2. By Theorem B.1, G is a local diffeomorphism, so we can reverse the iterations and obtain, \( (\theta _0,\psi _0) \in \bigcup _{j\in \mathbb {N}}G^{-j}\left( \mathsf {\Omega }_{(\theta _i^\star ,\psi _i^\star )}\cap \textsf{W}^{sc}_{(\theta _i^\star ,\psi _i^\star )}\right) \). Since \((\theta _i^\star ,\psi _i^\star )\in \textsf{S}_{<0}\), we showed that \(DG(\theta _i^\star ,\psi _i^\star )\) has at least one eigenvalue with magnitude strictly larger than 1, so by Theorem 4.2, \(W^{sc}_{(\theta _i^\star ,\psi _i^\star )}\) has zero measure. Then, by Theorem B.1 for all \(j\in \mathbb {N}\), \(G^{-j}\) is a local diffeomorphism, so the union above has zero measure. Using (18), the rest of the proof is then similar to the end of that of Theorem 3.1 since \( \bigcup _{i\in \mathbb {N}}\left[ \bigcup _{j\in \mathbb {N}}G^{-j}\left( \mathsf {\Omega }_{(\theta _i^\star ,\psi _i^\star )}\cap \textsf{W}^{sc}_{(\theta _i^\star ,\psi _i^\star )}\right) \right] \) is a countable union of zero-measure sets, so it has again measure zero. \(\square \)
1.1 B.1 Missing Proofs
We begin by proving the lemmas stated in Sect. 3.2.
Proof of Lemma 3.1
Let \(\alpha \ge 0\), and \(\beta >0\), the function \(h(\lambda )=(\alpha +\beta \lambda )^2-4\lambda = \beta ^2\lambda ^2 + 2(\alpha \beta -2)\lambda +\alpha ^2\) is a second-order polynomial in \(\lambda \) whose discriminant is \(16(1-\alpha \beta )\). If \(\alpha \beta >1\) this discriminant is negative so h is always positive. If \(\alpha \beta \le 1\), then h has two real roots: \(\frac{(2-\alpha \beta )}{\beta ^2} \pm \frac{2\sqrt{1-\alpha \beta }}{\beta ^2}\), which are equal to \(l_{\textrm{min}}\) and \(l_{\textrm{max}}\) since \(X^2\pm 2X+1 = (X\pm 1)^2\). \(\square \)
Proof of Lemma 3.2
Assume that \(\lambda _p>0\), if \(\Delta _{M_p}<0\), then \( 2\Re (\sigma _{p,-}) = 2\Re (\sigma _{p,+}) = -(\alpha +\beta \lambda _p)<0\). If \(\Delta _{M_p}\ge 0\) then \(\sigma _{p,-}\) and \(\sigma _{p,+}\) are real. Remark that \(\sigma _{p,-}\sigma _{p,+}=\lambda _p\) so the eigenvalues have the same sign, and \(\sigma _{p,-}+\sigma _{p,+}= -(\alpha +\beta \lambda _p)<0,\) so they are negative. \(\square \)
Proof of Theorem B.1
Let \((\theta ,\psi )\in \mathbb {R}^P\times \mathbb {R}^P\), to prove that G is a local diffeomorphism we prove that \(DG(\theta ,\psi )\) is invertible and then use the local inversion theorem. Using again the block transformation of \(DG(\theta ,\psi )\), \(\det (DG(\theta ,\psi )) = \prod _{p=1}^P \det (M_p)\), where
We want \(\gamma \) such that \(\det (M_p)\ne 0\) for any \((\theta ,\psi )\in \mathbb {R}^P\times \mathbb {R}^P\), hence for any \(\lambda _p\in [-L,L]\) (using Assumption 1). First, if \(\lambda _p=0\), from (19), we must take \(\gamma \ne 1/\alpha \). Now let \(\lambda _p\ne 0\), then (19) is a second-order polynomial in \(\gamma \) with discriminant \( (\alpha +\beta \lambda _p)^2 - 4\lambda _p= \Delta _{M_p}\) already studied Sect. 3.1 and Lemma 3.1. If \(\Delta _{M_p}<0\), then \(\det (M_p)\) has no real roots and the choice of \(\gamma \) is free. Assume now that \(\Delta _{M_p}\ge 0\), there exists two real roots to (19):
Remark that when \(\lambda _p<0\), \(\gamma ^+<0\) and when \(\lambda _p>0\), \(0<\gamma ^-<\gamma ^+\), so in every case we only need to ensure \(0<\gamma <\gamma ^-\), for every \(\lambda _p\in [-L,L]\). So, for every \(\lambda \in \mathbb {R}\) for which it is well defined, consider the function \(\gamma ^{-}(\lambda )=\frac{(\alpha +\beta \lambda )}{2\lambda } - \frac{\sqrt{(\alpha + \beta \lambda )^2 - 4\lambda }}{2 \lambda }\). When defined, its derivative is \( -\frac{\alpha \sqrt{\left( \alpha +\beta \lambda \right) ^2-4\lambda }+\left( 2-\alpha \beta \right) \lambda -\alpha ^2}{2\lambda ^2\sqrt{\left( \alpha +\beta \lambda \right) ^2-4\lambda }}\). The denominator is always positive so we study the numerator: \(h(\lambda )=-\alpha \sqrt{(\alpha +\beta \lambda )^2-4\lambda }-(2-\alpha \beta )\lambda +\alpha ^2 \), and we differentiate it:
This allows deducing the minimal value of \(\gamma ^-(\lambda )\) in each setting by constructing the tables of variations displayed in Fig. 4. There, it follows from standard computations that \(h'(0)=h(0)=0\), \(h(l_{\textrm{max}})\le 0\) and \(\lim _{\lambda \rightarrow +\infty } h'(\lambda )=-2\) (when \(\alpha \beta \le 1\)), and via L’Hôpital’s rule we obtained \(\lim _{\lambda \rightarrow 0}\gamma ^-(\lambda )=1/\alpha \). We deduce from the tables that G is a local diffeomorphism if \(\gamma <\gamma ^-(L)\) when \(\alpha \beta >1\) and if \(\gamma <\min (\gamma ^-(L),\gamma ^-(-L))\) when \(\alpha \beta \le 1\) and \(L\notin [l_{\textrm{min}},l_{\textrm{max}}]\). Remark that the condition \(\gamma \ne \frac{1}{\alpha }\) is implied in both cases. This proves the theorem. \(\square \)

Tables of variations for the proof of Theorem B.1. The sign of \(h''\) allows deducing the variations and signs of \(h'\) and h which themselves allow deducing the minima of \(\gamma ^-\)
C Proof of Convergence of INNA
To prove Theorem 4.3, we will use the following lemma.
Lemma C.1
( [4]) If a bounded sequence \((u_k)_{k\in \mathbb {N}}\) in \(\mathbb {R}^P\) satisfies, \( \lim \limits _{k\rightarrow +\infty } \Vert u_{k+1} - u_k\Vert =0, \) then the set of accumulation points of \((u_k)_{k\in \mathbb {N}}\) is connected. If this set is finite, then it reduces to a singleton and \((u_k)_{k\in \mathbb {N}}\) converges.
Proof of Theorem 4.1
Assume that Assumption 1 holds and \(\alpha >0\). Let \((\theta _0,\psi _0)\in \mathbb {R}^P\times \mathbb {R}^P\), and let \(\gamma >0\) such that (15) holds. Let \((\theta _k,\psi _k)_{k\in \mathbb {N}}\) be the sequence generated by INNA initialized at \((\theta _0,\psi _0)\). We first show that the sequence \((\mathcal {E}_k)_{k\in \mathbb {N}}\) defined \(\forall k\in \mathbb {N}\) by
converges. The sequence \((\mathcal {E}_k)_{k\in \mathbb {N}}\) represents an “energy” that decreases along the iterations, where the first and second terms in (21) represent “potential” and “kinetic” energies, respectively. This sequence resembles the Lyapunov function of DIN [3, 19] but is more involved to derive, as often for algorithms compared to ODEs. We use the notations \(a=\alpha -1/\beta \), \(b=1/\beta \), \(\Delta \theta _k =\theta _{k+1}-\theta _k\) and \(\Delta \psi _k =\psi _{k+1}-\psi _k\), for \(k\in \mathbb {N}\), so that INNA is rewritten as:
Also denote \(\mu = 1+\alpha \beta -\gamma \alpha \), where \(\mu >0\) since \(\gamma < 1/\alpha + \beta \). Let \(k\in \mathbb {N}\), we will prove \(\mathcal {E}_{k+1}-\mathcal {E}_{k}\le 0\). From Assumption 1 follows a descent lemma (see [16, Proposition A.24]):
which according to (22), can equivalently be rewritten as,
We save this for later and now turn our attention to the other term in \(\mathcal {E}_{k+1}-\mathcal {E}_k\),
Expanding this and using the fact that \( a\theta _{k} + b\psi _{k} = -\Delta \psi _k/\gamma \), we can show that,
We then use \(\Vert \Delta \psi _k\Vert ^2 = \Vert \Delta \theta _k - \Delta \psi _k\Vert ^2 + \Vert \Delta \theta _k\Vert ^2 -2\langle \Delta \theta _k,\Delta \theta _k-\Delta \psi _k\rangle \) and \(\langle \Delta \theta _k,\Delta \psi _k\rangle = \Vert \Delta \theta _k\Vert ^2 -\langle \Delta \theta _k,\Delta \theta _k-\Delta \psi _k\rangle \) in (24) to obtain:
We then simplify the factors using the identity \(a+b=\alpha \), as well as \(\frac{a^2}{2}+\frac{b^2}{2}+ ab = \frac{1}{2}(a+b)^2 = \frac{\alpha ^2}{2}\), and \(-b^2-ab = -\alpha /\beta \) to deduce that (25) is equal to
We can finally combine (23) and (26),
Notice that \(\mu = 1+\alpha \beta -\gamma \alpha \) is specifically chosen so that the last term in (27) vanishes, so,
To prove the decrease of \((\mathcal {E}_k)_{k\in \mathbb {N}}\), it remains to justify that both terms in (28) are negative. First, the condition \(\gamma <2\beta \) in (15) makes the second term negative. Then,
A simpler sufficient condition for this to hold is \(\left( \alpha ^2+ (1+\alpha \beta )L\right) \gamma - 2\alpha <0\) or equivalently \(\gamma < 2\alpha /\left( \alpha ^2+ (1+\alpha \beta )L\right) \), which holds from (15). So the sequence \((\mathcal {E}_k)_{k\in \mathbb {N}}\) is a decreasing. It is also lower-bounded since \(\mathcal {J}\) is lower-bounded, so it converges.
The rest of the proof then relies on exploiting (28). Let \(K\in \mathbb {N}\), we sum (28):
The left-hand side is a telescopic series, and it follows from (22) that \(\forall k\in \mathbb {N}\), \(\Delta \theta _k-\Delta \psi _k = -\gamma \beta \nabla \mathcal {J}(\theta _k)\), so denoting \(C_1 = -(\gamma \mu L+\gamma \alpha ^2 -2\alpha )/2\gamma >0\) and \(C_2 = -(\gamma ^2-2\gamma \beta )/2>0\),
Then, \(\mathcal {E}_{0} - \mathcal {E}_{K+1}\) is upper bounded since \((\mathcal {E}_k)_{k\in \mathbb {N}}\) converges, so \(\sum _{k=0}^{K} \Vert \nabla \mathcal {J}(\theta _k)\Vert ^2<+\infty \). This implies that \(\lim _{k\rightarrow +\infty }\Vert \nabla \mathcal {J}(\theta _k)\Vert ^2 =0\) and we deduce similarly that \(\lim _{k\rightarrow +\infty }\Vert \theta _{k+1}-\theta _{k}\Vert ^2 =0\). Using (14), we also have,
The convergence of \((\mathcal {E}_k)_{k\in \mathbb {N}}\) and (29) imply that \((\mathcal {J}(\theta _k))_{k\in \mathbb {N}}\) converges, which proves the first part of the theorem. Assume that the critical points are isolated and that the sequence \((\theta _k)_{k\in \mathbb {N}}\) is uniformly bounded on \(\mathbb {R}^P\). According to Lemma C.1, since \((\theta _k)_{k\in \mathbb {N}}\) is bounded and \(\lim _{k\rightarrow +\infty }\Vert \theta _{k+1}-\theta _{k}\Vert =0\), the set of accumulation points of \((\theta _k)_{k\in \mathbb {N}}\) is connected. By continuity of \(\nabla \mathcal {J}\), accumulation points of \((\theta _k)_{k\in \mathbb {N}}\) are critical points of \(\mathcal {J}\), which are assumed to be isolated. So the set of accumulation points is a singleton and \((\theta _k)_{k\in \mathbb {N}}\) converges to it. \(\square \)
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Castera, C. Inertial Newton Algorithms Avoiding Strict Saddle Points. J Optim Theory Appl 199, 881–903 (2023). https://doi.org/10.1007/s10957-023-02330-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10957-023-02330-0