
Abstract
Additive manufacturing brings inspection issues for quality assurance of final parts because non-destructive testing methods are faced with shape complexity, size, and high surface roughness. Thus, to drive additive manufacturing forward, advanced non-destructive testing methods are required. Methods based on resonant ultrasound spectroscopy (RUS) can take on all the challenges that come with additive manufacturing. Indeed, these full body inspection methods are adapted to shape complexity, to nearly any size, and to high degrees of surface roughness. Furthermore, they are easy to implement, fast and low cost. In this paper, we present the benefit of a resonant ultrasound spectroscopy method, combined with a statistical analysis through Z score implementation, to classify supposedly identical parts, from a batch comprised of several individual builds. We also demonstrate that the inspection can be further accelerated and automated, to make the analysis operator independent, whether the analysis of the resonant ultrasound spectroscopy data is performed supervised or unsupervised with machine learning algorithms.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
To be able to rely on the integrity of parts additively manufactured (AM), their inspection is required prior to use. However, one of the main benefits of AM is to build very complex part geometries, such as cavities, internal channels, free forms, lattices, which do not facilitate ease of inspection. Besides being non-destructive, the quality method needs to be volumetric, and capable of complex shapes and rough surfaces. The challenge is high. X-ray computed tomography (XCT) meets these requirements, but is strongly limited by the size and density of the parts [1, 2]. Furthermore, it is a complex and expensive technique. Therefore, alternative methods are required. Among other investigated non-destructive methods on complex shape AM parts [3,4,5,6,7] only resonant ultrasound spectroscopy (RUS) methods have shown particularly promising [4,5,6,7,8,9,10,11,12,13]. Indeed, among the existing non-destructive methods, RUS are the only methods capable of handling both complex shapes and rough surfaces on parts of all sizes. Thus, a RUS method was chosen to be investigated. According to ASTM E2001 [14] standard, RUS includes two types of methods: swept sine and impulse excitation methods (IEM). Swept sine methods have already been deeply investigated [9, 10] and are standardized, but independent system usage, access, and availability is very limited [15]. In fact, the tests have to be performed by a service provider as the systems are not made available to customers. Thus, an IEM was investigated in this study, as these systems are readily available in the market. The principle of these full body RUS methods is based on the analysis of the positions, in frequency, of the resonant vibrational modes of the part under test as a result of an impulse excitation. Shifts in frequency of the positions of the resonant peaks (resonance with amplitude above the noise for a given frequency) compared to parts from the same family or simulations is synonymous of a difference in the integrity of the part. These full body methods have the advantage of being faster, easier to use, and cheaper than XCT, but also suitable for large and dense parts. Additionally, by implementing machine learning (ML) algorithms on the collected RUS data for clustering or classification, using unsupervised and supervised algorithms respectively, the data analysis can be automated. Indeed, ML algorithms can provide significant advantages for the automation of non-destructive evaluation (NDE) and test (NDT) in different condition monitoring applications for various materials and structures [16]. Harley and Sparkman, in 2019, showed that the use of ML to solve NDE problems could provide a potential revolution for future NDE challenges [17].
Typically, RUS enables the detection of parts as acceptable or unacceptable from a training set of known parts. We have already successfully demonstrated the inspection/sorting capability of RUS on a set of parts without any (acceptable parts) and with known internal features simulating typical AM defects, designed in the numerical model, on dense stainless steel AM parts containing different numbers of internal features [1, 2]. In this specific case, we have shown that RUS allowed the separation of the acceptable and unacceptable dense parts but could not sort the parts according to the number of features they contained. However, on cobalt-chromium AM lattice structures with various numbers of missing struts, not only the analysis of the RUS data enabled separating the parts with and without missing struts, but also nearly the entire set of parts, could be classified according to the number of missing struts [8].
In addition, RUS enables the classification of different sets of parts according to their manufactured process parameters. We have already demonstrated this capability of RUS on a set of parts additively manufactured with various machine parameters (wall thicknesses, laser powers, scanning speeds, and scanning strategies) [18]. The RUS data statistical analysis allowed the classification of all parts according to their process parameters.
In this paper, we present the statistical analysis, through Z-scores implementation, of the RUS data of a batch of parts, comprised of several individual builds, which are supposedly identical and go a step forward by implementing ML algorithms as a post-processing model to make the analysis operator independent to automate the whole analysis: 1) considering only the available RUS data, an unsupervised model was implemented. Then based on the clustering performed by the unsupervised model, a supervised model was initiated; 2) the available RUS data were considered as well as the results of the Z-score analysis to identify acceptable and unacceptable parts for labelling the data and generating virtual parts. Considering these data, several supervised models were implemented. Z-score analysis was selected over other statistical analysis for the clear interpretation of the results the method delivers, and ML methods were implemented in the aim to provide an alternative analysis operator-independent. This, to our knowledge, has never be done on non-basic shape parts.
This article is structured as follows. Section 2 describes the basic principle of RUS methods in general, and then focuses on the specificities of impulse excitation methods (IEM). Section 3 presents the AM parts which were investigated in this study and Sect. 4, their NDT with an IEM. Sections 5 and 6 address, respectively, the Z-score and ML IEM data analysis of the investigated parts. Finally, Sect. 6 draws conclusion.
2 Principle of the Experimental Method
In this study, a Resonant Ultrasound Spectroscopy (RUS) method was used to identify each part’s conformity in regard to its group of like parts. RUS takes advantage of the correlation between the resonance properties of the mechanical vibration modes of a part and its intrinsic properties, such as its geometry, density, elasticity, and internal and external structure, to detect defects and material variations in the part. The basic principle of this whole body non-destructive examination technique is to excite and record, in the acoustic and/or ultrasonic ranges, the spectrum of the natural resonant frequencies of the vibration modes of the part and to compare it to the spectra of an established acceptable resonant frequency pattern (reference parts or parts from the same group or simulations). Any shift in resonant frequency between the spectrum of the part under test and the spectra of the pattern will be the signature of a difference between the part and the pattern. Thus, the method enables classification of the parts as acceptable or unacceptable or according to their intrinsic properties.
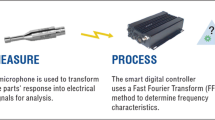
As already mentioned in the introduction, according to ASTM E2001 [19] standard, RUS includes two types of excitation methods: swept sine and impulse excitation methods (IEM). We will focus on IEM as an IEM type of method was used in the frame of this study. However, in a previous study, we successfully demonstrated that an IEM and a swept sine method, provided the same results on complex AM components [4]. In IEM (Fig. 1), the part is excited with a mechanical impact (hammer) to stimulate its natural resonant frequencies, then its vibration response is captured with a measurement transducer (microphone, piezo transducer, accelerometer, laser vibrometer), recorded, processed, and analysed with a data acquisition device and software. In the present study, the IEM system (Modal Shop NDT-RAM) was comprised of hardware including a modal instrumented hammer to induce vibration to the part, a microphone to collect the part response, a high-speed analog to digital converter (24 bits) to perform a Fast Fourier Transform (FFT) that provides frequency spectra. Finally, a software program is enabled to display the spectra and to define frequency ranges of acceptable variability around the established resonant frequency pattern peaks to sort the parts. This simple principle makes IEM particularly easy and fast to implement.

Various schematic representations of the Impulse Excitation Methods (IEM). “micro” stands for microphone, “piezo” for piezoelectric transducer, “accelero” for accelerometer and “laser vibro” for laser vibrometer
3 Description of the Tested Parts
The investigated parts (Fig. 2) were manufactured in the titanium alloy TA6V ELI (Ti-6Al-4 V), by Safran, using a laser powder bed fusion (PBF-LB) machine, Renishaw 500Q, Y48 implementing 3 lasers.

Photographs of the Safran parts on one of the platforms (a) and of an individual part as final (b)
In total, a group of 27 like parts were manufactured but only 24 were provided for RUS examination. The parts are labelled from 1 to 27 (parts 15, 16, and 21 were not provided). They were manufactured on three different platforms (Fig. 2a): parts 1 to 9 on platform 1, parts 10 to 18 on platform 2, and parts 19 to 27 on platform 3. After manufacturing, the part went through the following post-treatment: (1) powder removal, (2) first sandblasting, (3) second sandblasting, (4) heat treatment to release residual stress, (5) support removal, (6) visual inspection, and (7) hot isostatic pressing (HIP).
4 Experimental Examination of the Tested Parts
For repeatability assessment, thirty tests were performed on each part, positioned on foam, and impacted at approximately the same location. The influences of the impact's location (six different geometrical impact locations were tested, 30 tests per location), the environmental condition (30 tests were performed in five different rooms with and without air-conditioning), the type of foam used (five different foams were tested, 30 tests per foam), and the operator (four different operators performed 30 tests) on the frequencies of resonance peaks were examined. Both absolute frequency location and Z-score calculations were used for this prior to the actual tests and the results were considered to be negligible and have little to no influence in the Z-score [-2, 2] interval. However, the amplitude results of these peaks was not found to be as reproducible but this did not matter in this particular study. The acquisitions were performed in the range of 0–94 kHz with a resolution of 1.465 Hz corresponding to an acquisition time of 0.683 s. The first thirteen resonant mono-peaks, located in the range of 0–20 kHz (Fig. 3), turned out to contain all the required information to classify the parts. Thus, in the following statistical analyses, only this range of the spectra was considered.

Typical RUS spectrum of the tested part in the range 0–20 kHz corresponding to the first thirteen resonant peaks
5 Z-score Analysis of the Tested Parts
The objective of this analysis is to classify the parts into various risk categories computing Z-score statistical tool which, beyond its simplicity of execution, offers a physical interpretation. A Z-score is used to compare a sample’s location within a population of reference samples. It expresses the deviation of the sample from the mean value of the reference samples’ population in terms of standard deviation on the population taken as reference. For this study, any sample lying in between [-1, 1] Z-score is acceptable to the population, if it is between [-2, -1]U[1, 2] it is considered as low risk, if it is between [-2.5, -2]U[2, 2.5] it is considered as medium risk and outside these intervals as high risk. These are arbitrary grouping choices based on statistical separation.
The Z-scores were computed with the frequencies at maximum amplitude of the first thirteen peaks (< 20 kHz) using this relation:
where x represents the peak frequency of a sample, µ the mean of the peak frequencies of a reference samples’ population, and σ the standard deviation of the peak frequencies of the reference samples’ population.
Therefore, thirteen Z-scores were computed for each part and then the mean and standard deviation of those thirteen results were calculated. An individual part’s total calculated Z-score mean and standard deviation are representative of a total resonance responses for each.
Before undertaking the main statistical analysis to compare all the parts to each other independently of their original platform, the bias between the three platforms was examined to ensure that there was no platform effect. To do this, the Z-scores on the frequency resonant peaks, for each of the series of parts manufactured on the same platform, were computed considering first all the parts on each platform as reference (Fig. 4) and then considering the average of the parts of the three platforms as reference (Fig. 5).

Z-score graphs displaying the platform effect. Each platform was successively considered as reference

Z-scores’ graph to evaluate the platform effect. All platforms were considered as reference
From Fig. 4, it can be observed that all Z-scores, for all platforms, whatever the chosen reference, have some level of positional variation, but they all are concentrated within the interval [-2, 2] except for three parts: S18 from platform 2, S20, and S24 from platform 3. A similar phenomenon is observed when considering all platforms as reference (Fig. 5). In this case, all parts are concentrated in the interval [-1, 1] except the three previously listed parts as well as S8 from platform 1. These four parts were not manufactured on the same platform so one can conclude that it is truly a part effect and that this renders any minor platform effect as negligible. Thus, the parts do not need to be linked to their manufacturing platform in the main analysis.
As all the parts are supposed to be identical, in order to select reference parts for the Z-score analysis, first, all parts, from all platforms, were considered as reference. This step enables identification of the parts located in the interval [-1, 1] to be chosen as reference parts for the final Z-score analysis plotted in Fig. 6.

Z-score’ graph of the tested parts
Figure 6 highlights, with boundaries, the deviation of a part to the population of parts in the horizontal direction and the dispersion over the mean in the vertical direction. As observed in Fig. 6, most of the parts are located in the interval [-1, 1]. This signifies that these parts respond similarly across all the frequencies and that they should be similar in material properties and dimensions. However, there are five outliers: S8 (platform 1), S13 and S18 (platform 2), S20 and S24 (platform 3). S24 is the weakest part in the batch as the frequencies of its resonant peaks are shifted to lower frequencies (Fig. 7). Generally, lower frequencies are driven by a defect or low mechanical properties. S20 (Fig. 7) and S13 are in the same situation to a lesser degree. The deviation from S8 and particularly S18 could be rather attributed to grain size, stress, or dimensional variations as the shift of their resonant peaks goes toward higher frequencies [20]. These outliers were not manufactured at the same location on their respective platform so their difference cannot be linked to that cause. Only S24 is outside the interval [-2, 2], thus, for the ML analysis, S24 is the only outlier noted.

Shifts in frequencies between reference part group S14 and outliers S18, S20 and S24
6 Machine Learning Analysis of the Tested Parts
Machine learning (ML), on the RUS data, was computed for the purpose of automating the whole analysis, to make the RUS analysis operator-independent.
ML is divided into two categories: unsupervised and supervised. The use of one or the other depends on the initial available data [21]. In supervised learning, a set of data for which each input corresponds to an output (the data are said to be labelled or targeted) must be available to predict the output of new data. Whereas, in unsupervised learning, the analysis is based on un-labelled data that are simply grouped together for a better view and understanding of them. In both cases, models are trained to predict classes (supervised) or clusters (unsupervised) of the data. Then to evaluate which model is the more performing, each of them is compared to each other in terms of accuracy and sensitivity of the model to evaluate the number of false negatives that would correspond to a defective part reported as compliant.
In the current studies, two clearly separate ML studies were implemented to show two different possibilities. The first study implements an unsupervised model followed by a supervised study using the results from the unsupervised model as input, and do not consider the Z score analysis to remove this step. The second study, completely uncorrelated to the first one, used the Z score results to run a supervised analysis. In other words, first (Sect. 5.1), considering only the available RUS data, an unsupervised model was implemented on the frequencies at the maximum amplitude of the first thirteen peaks (< 20 kHz). Then based on the clustering performed by the unsupervised model, a supervised model was run; Second (Sect. 5.2), the available RUS data were considered as well as the results of the Z-score analysis to identify acceptable and unacceptable parts for labelling the data and generating virtual parts. Considering these real and virtual data, several supervised models were implemented on the frequencies at maximum amplitude of the first thirteen peaks (< 20 kHz) as well as on the whole spectra up to 20 kHz.
6.1 Automated Unsupervised Followed by Supervised Analysis to Label Parts
In this section, an attempt has been made to examine the RUS data using ML methods for further research in future and to show the possibilities of using ML as a complete methods for clustering and classification of RUS data. In this study, the number of available data is very limited compared to real production and manufacturing process cases concerning higher number of parts. It has been tried to pay attention to data clustering and data classification by using ML as a complete package independently to compare it with Z-score analysis. As we know, although statistical methods provide appropriate answers in many cases, they have limitations for predicting huge amount of data as well as analysing non-linear or complex data. In this section, it has been discussed using ML on the same data that has been analysed using statistical methods.
6.1.1 Unsupervised Analysis
For unsupervised methods, after running different methods, we chose the K-means method widely used for partitioning a dataset into distinct clusters based on similarity. It is an efficient method for various sizes of datasets. However, it is important to note that the choice of the number of clusters (k) can affect results. Currently, utilization of the K-means clustering method was driven by the need to uncover inherent patterns and relationships within a small dataset. By applying this method, we aimed to objectively identify natural groupings, and facilitating data exploration. The unsupervised nature of K-means ensured an unbiased approach, while visual representations of the resulting clusters aided in conveying insights. The method's scalability, speed, and potential for unexpected discoveries further underscored its suitability for this analysis. An unsupervised K-means analysis [22], a data clustering, and a recognition method enabling to distinguish data similarity and dissimilarity was implemented [22]. In this study, four clusters, using the Euclidian distance, were used to categorize the data with peaks as input (first 13 peaks at maximum frequency in the range < 20 kHz). After training with different number of clusters, the optimum results are obtained for 4 clustering groups shown in Fig. 8 by different colours, and their centroid points are indicated. As it shown, cluster number 4 is including two samples: S20 and S24, outliers which were also identified in the Z-score analysis.

Clustering using K-means with peaks as input. The clusters in 13 dimensions (13 peaks) are represented here in 2 dimensions with the help of principal component analysis. Axis correspond to the 2 directions with maximum standard deviation for better separation of clusters
In the next step, this research employs a dual-stage methodology to maximize data analysis efficacy. Leveraging these insights, the subsequent section harnesses neural network-supervised models for heightened accuracy. By integrating K-means results as features or labels, the neural networks capitalize on inherent clustering information, enhancing predictive capabilities. This synergistic approach optimizes evaluation and bolsters accuracy assessment, thereby contributing to a comprehensive and potent data-driven investigation.
6.1.2 Supervised Analysis
In the second step, we elucidate the utilization of neural networks (NN) as a supervised learning method. Neural networks, inspired by the human brain's interconnected structure, are trained on labelled datasets, enabling them to learn intricate patterns and relationships within the data to make accurate predictions or classifications [23, 24]. Neural networks are suitable for our study as they excel in capturing complex patterns and relationships within labelled data, thereby enabling accurate predictions through supervised learning. For this aim the cluster output, which was obtained by K-means, was used in order to see the model performance and prediction [25].
To simulate complex relationships in our data, we used a Feedforward Neural Network (FNN) with a single hidden layer with 10 neurons and Levenberg–Marquardt (LM) training. The data splitting is random, and based on the LM training, the performance is firmed by Mean Squared Error (MSE) [26, 27]. The Levenberg–Marquardt algorithm is advantageous for our application due to its effectiveness in optimizing the parameters of nonlinear models. Its ability to balance between the Gauss–Newton and gradient descent methods often leads to the robust, faster convergence, making it well-suited for refining complex models and achieving accurate results [28, 29].
In the pursuit of refining the predictive capacity and generalization of our neural network model, we also introduced principled regularization techniques and conducted a systematic hyper-parameter exploration. Incorporating L2 regularization (weight decay) mitigated overfitting tendencies, while meticulous tuning of hyper-parameters, encompassing learning rates and hidden layer sizes, honed model behavior. The outcome yielded a model characterized by exceptional validation and test performance, evidenced by minimal Mean Squared Error (MSE) and elevated coefficients of determination (R) across distinct datasets. This approach underscores the pivotal role of strategic regularization and tailored hyper-parameter selection in cultivating robust neural network models with heightened predictive capabilities. The data are split into three categories: Training (70%), validation (15%), and test (15%), (for more details see Table 1).
In summary, the results shown a robust and well-generalizing neural network model. The low MSE values, high R values, and consistency between different datasets indicate that the model has learned meaningful patterns from the data and can make accurate predictions on new, unseen instances. These results reflect a model that is likely to be reliable for making predictions in practical applications. In this study, 24 specimens were used. However, the L2 regularization and hyperparameter adjustment were used to reduce the overfitting problems. We should consider the inherent limitations that the small dataset size could present. Therefore, we intend to investigate methods by gathering more data and considering model topologies while performing sophisticated regularization models in order to overcome these limitations in future work. Furthermore, current results provide insightful information and show how the data set size and related restrictions may affect the results.
6.2 Supervised Analysis Based on Z-Score Results to Label Parts
In this section, the data are assumed to be labelled using the splitting from the Z-score analysis. Thus, a supervised analysis is performed on these data to evaluate automation capabilities on larger sets of labelled RUS data. The limitation in size of the available RUS data is partially overcome by data augmentation: initially the RUS data on the 24 real parts were considered and, to increase the amount of data, 9 virtual outliers and 68 inliers were generated in order to have a total of 100 parts to run the models. A rate of 10% was taken for outliers to be as representative as possible of industrial cases. The virtual outliers were generated in a random and uniform manner. Some of their peaks were shifted toward lower or higher frequencies based on the frequency shifts observed for all real part spectra compared to the mean reference part spectra. The virtual inliers were generated by concatenation of the twenty three spectra of the real inliers parts according to the Z-scores results. Then, to perform the analysis, the whole set of parts was distributed into three groups: 70% of the parts were considered for training, 15% for validation and 15% for testing. First, the training set was used to find the model’s parameters. Second, the validation set was injected in all models to find the best combination of model and hyper-parameters. Finally, the test set enabled to evaluate the capacity of prediction of the best model on new data. For a better estimation of the capacity of prediction, a stratified cross-validation was performed: different train and validation sets were selected in a loop (70% train and 15% validation) and the capacity of prediction was computed at each iteration. 15% of the data was kept for testing the model at the end of the cross-validation in order to estimate the generalizability of the model to previously unseen RUS data.
The supervised analysis was performed on different preprocessed data to choose the most suitable input: 1) on the frequencies at the maximum amplitude of the first thirteen resonant peaks (< 20 kHz); 2) on the whole spectra up to 20 kHz. Prior to analysis, noise reduction was applied on the spectra [30]: 1) a baseline correction was applied on the spectra, 2) if the amplitudes were positives, they were kept as they are and, if they were negatives, they were set to zero. For the ML analysis, several supervised algorithms had been executed but only the four showing the highest accuracy were selected at first: 1) SVM (Vector Machine Support) with four different "kernel" hyper-parameters (radial, polynomial, sigmoid, and linear), 2) the K-NN model (K Nearest Neighbours) with the hyper-parameter k taking three different values (k = 5, k = 10 and k = 15) then two models without hyper-parameter modifications: 3) the Naïve Bayes model and 4) the decision tree [31, 32]. Second, the three most efficient combinations “model and hyper-parameter” were selected to go further: 1) SVM with the radial kernel, 2) SVM with polynomial kernel and 3) Naïve Bayes.
The mean and the standard deviation (Std) on the accuracy, as well as the mean and Std on the sensitivity are given in Table 2 for the frequencies at the maximum amplitude of the first thirteen resonant peaks (< 20 kHz). These metrics were calculated by stratified cross-validation on the validation sets.
From Table 2, one can be observed, that during the validation, the three mean accuracies are close to each model. To differentiate them, one can compare their mean sensitivity which represents the rate of unacceptable parts compared to acceptable parts. From this point of view, the Naïve Bayes model stands out. A fivefold cross-validation, on the validation sets, was performed, from which five confusion matrices were extracted. In the best cases, the confusion matrices were the same for both models. However, in the worst cases, the Naive Bayes model has a false negative rate of 0% and a high false positive rate which is positive whereas it is the opposite for the SVM kernel radial model. As the best compromise between high accuracy and sensitivity is required, the Naïve Bayes model was selected and evaluated on the test set (Fig. 9). Its performance reached an accuracy and sensitivity of 100%. Therefore, the Naïve Bayes model is a good candidate for the analysis of the resonance peaks. Its performance could be explained by its capability to handle small datasets compared to SVM models, especially for high dimensional features, as is the case for the spectra as input. Furthermore, Naive Bayes is less prone to overfitting due to its low number of parameters.

Confusion matrices for Naïve Bayes model, on the test set, with peaks as input. The table located right explained how to understand the confusion matrices. The best is to have maximum percentage in the green boxes, to have a low percentage in the orange box. Having higher than “0” in the red box is problematic. The number “1” indicates that a part is acceptable and “0” that it is not acceptable
The mean precision, mean sensitivity, standard deviation on precision and of sensitivity, also calculated by stratified cross-validation on the validation sets, are given in Table 3 for the whole spectra up to 20 kHz.
Considering the analysis with the spectra as input, Table 3 shows that the Naïve Bayes model has the highest mean sensitivity and a mean accuracy above 90%. This model is therefore also the best candidate when considering all the data provided by the spectra instead of only the frequencies at maximum amplitude. However, the mean sensitivity of 53% is much lower in the present case. Five confusion matrices were calculated with five different combinations of the selected 15% validation sets as before. The confusion matrix for the Naïve Bayes model, on the test set, is presented in Fig. 10 left. The confusion matrices on validation sets, for peaks and spectra as input, are the same. However, the confusion matrices for the test set with spectra as input displays 6.7% of false negative. Furthermore, considering that the mean sensitivity is only 53% compared to 100% for the peaks (Table 2), one can conclude that the Naïve Bayes is more effective for peaks than for spectra as input.

Confusion matrices for Naïve Bayes model. Left: on the test set with peaks as input. Right: on the 24 real parts with spectra as input
In order to confirm that the Naïve Bayes model works properly, it was tested with the twenty-four real labelled parts. The results are displayed in Fig. 10 right. The matrix indicates that 1 part over the 24 was not predicted correctly. It was predicted false positive i.e. unacceptable instead of acceptable. Otherwise, the rest of the parts was predicted correctly, 22 parts are acceptable and 1 part over 24 is non-acceptable.
In summary, among the three ML models which were investigated, one of them stand out for its high mean accuracy and sensitivity: the probabilistic Naïve Bayes model. However, the mean sensitivity is not high when considering spectra as input rather than peaks. Moreover, the model applied on the spectra is more time-consuming. Thus, the ML Naïve Bayes model should be implemented on peaks rather than on spectra to automate the RUS data analysis.
7 Conclusion
The adoption of AM in the industry is going slowly because the qualification of parts is an issue regarding their possible complexity in geometry, their size and their high surface roughness. In addition to being adapted to complex geometries, nearly any size, and high roughness, the evaluation must be non-destructive, and ideally simple to implement, fast, and inexpensive. These require innovation in the NDT sector. The RUS method described here, combined with Z-score analysis and/or ML, is a solution from these perspectives. The method is suitable for any shape, size, and surface roughness. It is also easy to implement, fast and inexpensive. And combined with Z-score analysis and/or ML, it enables to be fully automated and thus expedites the part qualification process, which lowers the costs of validation quality control.
In the current paper, we have presented an application of RUS through IEM and addressed statistical methods such as Z-score, and supervised and unsupervised models to automate successfully the analysis of RUS data on a batch of supposedly identical parts.
The ML study should be pursued on a larger set of RUS data and implementing models that will lead to high accuracy and sensitivity.
Availability of Data and Material
All of the data and material are owned by the authors and/or no permissions are required.
References
Chiffre, L., Carmignato, S., Kruth, J.-P., Schmitt, R., Weckenmann, A.: Industrial applications of computed tomography. CIRP Ann. Manuf. Technol. 63, 655–677 (2014)
Carmignato, S., Dewulf, W., Leach, R.: Industrial X-Ray Computed Tomography. Springer, New York (2017)
Todorov, E., Spencer, R., Gleeson, S.P., Jamshidinia, M., Kelly, S.M.: America makes: National Additive Manufacturing Innovation Institute (NAMII) project 1: nondestructive evaluation (NDE) of complex metallic additive manufactured (AM) Structures. Doi: 10. 21236/ ada61 2775 (2014)
Obaton, A.-F., Butsch, B., McDonough, S., Carcreff, E., Laroche, N., Gaillard, Y., Tarr, J., Bouvet, P., Cruz, R., Donmez, A.: Evaluation of nondestructive volumetric testing methods for additively manufactured parts. In: Structural Integrity of Additive Manufactured Parts, N. Shamsaei, S. Daniewicz, N. Hrabe, S. Beretta, J. Waller, and M. Seifi: West Conshohocken, PA, pp 51–91 (2020). https://www.astm.org/stp162020180099.html
ASTM E3166.: 2020 Standard Guide for Nondestructive Examination of Metal Additively Manufactured Aerospace Parts After Build (West Conshohocken, PA. ASTM International, approved 2015), https://www.astm.org/Standards/E3166.htm
Segovia Ramíreza, I., García Márqueza, F.P., Papaeliasb, M.: Review on additive manufacturing and non-destructive testing. J. Manuf. Syst. 66, 260–286 (2023). https://doi.org/10.1016/j.jmsy.2022.12.005
ISO/ASTM TR 52905.: 2023 Additive Manufacturing of Metals—Non-destructive Testing and Evaluation-Defect Detection in Parts
Ibrahim, Y., Li, Z., Davies, C.M., Maharaj, C., Dear, J.P., Hooper, P.A.: Acoustic resonance testing of additive manufactured lattice structures. Addit. Manuf. 24, 566–576 (2018). https://doi.org/10.1016/j.addma.2018.10.034
Trolinger, J., Lal, A., Dioumaev, A.K., Dimas, D.: A non-destructive evaluation system for additive manufacturing based on acoustic signature analysis with laser Doppler vibrometry. In: Interferometry XIX, Vol. 10749, pp. 80–91. SPIE (2018)
Livings, R., Biedermann, E., Wang, C., Chung, T., James, S., Waller, J., Volk, S., Krishnan, A., Collins, S.: Nondestructive evaluation of additive manufactured parts using process compensated resonance testing. In: Symposium on Structural Integrity of Additive Manufactured Parts, pp. 165–205. ASTM International (2020)
Obaton, A.-F., Butsch, B., Carcreff, E., Laroche, N., Tarr, J., Donmez, A.: Efficient volumetric non-destructive testing methods for additively manufactured parts. Weld World 64(8), 1417–1425 (2020). https://doi.org/10.1007/s40194-020-00932-0
Obaton, A.F., Wang, Y., Butsch, B., Huang, Q.: A non-destructive resonant acoustic testing and defect classification of additively manufactured lattice structures. Weld. World 65(3), 361–371 (2021). https://doi.org/10.1007/s40194-020-01034-7
Taheri, H., Dababneh, F., Weaver, G., Butsch, B.: Assessment of material property variations with resonant ultrasound spectroscopy (RUS) when using additive manufacturing to print over existing parts. J. Adv. Join. 5, 100117 (2022)
ASTM E2001.: Guide for resonant ultrasound spectroscopy for defect detection in both metallic and non-metallic parts.
ASTM E3081-21.: Standard Practice for Outlier Screening Using process Compensated Resonance Testing via Swept Sine Input for Metallic and Non-Metallic Parts
Kazemi Majd, F., Fallahi, N., Gattulli, V.: Detection of Corrosion Defects in Steel Bridges by Machine Vision. In: International Conference of the European Association on Quality Control of Bridges and Structures August. 2021, pp. 830–834, Springer, Cham (2021)
Harley, J.B., Sparkman, D.: Machine learning and NDE: Past, present, and future. In: AIP Conference Proceedings 2102, 090001 (2019). https://doi.org/10.1063/1.5099819 (2019).
Obaton, A.-F., Weaver, G., Fournet Fayard, L., Montagner, F., Burnet, O., Van den Bossche, A.: Classification of metal L-PBF parts manufactured with different process parameters using resonant ultrasound spectroscopy. Accepted to Welding in the World (2022)
ASTM E2001: Guide for resonant ultrasound spectroscopy for defect detection in both metallic and non-metallic parts
Fallahi, N., Nardoni, G., Heidary, H., Palazzetti, R., Yan, X.T., Zucchelli, A.: Supervised and non-supervised AE data classification of nanomodified CFRP during DCB tests. FME Trans. 44(4), 415–421 (2016)
David, A., Vassilvitskii, S.: K-means++: the advantages of careful seeding. In: SODA ‘07: Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 1027–1035 (2007)
Fallahi, N.: Analysis and optimization of variable angle tow composites through unified formulation. Doctoral dissertation, Politecnico di Torino (2021)
Forooghi, A., Fallahi, N., Alibeigloo, A., Forooghi, H., Rezaey, S.: Static and thermal instability analysis of embedded functionally graded carbon nanotube-reinforced composite plates based on HSDT via GDQM and validated modeling by neural network. Mechanics Based Design of Structures and Machines 1–34 (2022). https://www.tandfonline.com/doi/abs/https://doi.org/10.1080/15397734.2022.2094407
Oskouei, A.R., Heidary, H., Ahmadi, M., Farajpur, M.: Unsupervised acoustic emission data clustering for the analysis of damage mechanisms in glass/polyester composites. Mater. Des. 37, 416–422 (2012)
Fallahi, N., Nardoni, G., Heidary, H., Palazzetti, R., Yan, X.T., Zucchelli, A.: Supervised and non-supervised AE data classification of nanomodified CFRP during DCB tests. FME Trans. 44, 415–421 (2016)
Fallahi, N., Nardoni, G., Palazzetti, R., Zucchelli, A.: Pattern Recognition of Acoustic Emission signal During the Mode I Fracture Mechanisms in Carbon- Epoxy Composite. In: 32nd European Conference on Acoustic Emission Testing (2016)
Gavin, H.P.: The Levenberg-Marquardt Algorithm for Nonlinear Least Squares Curve-Fitting Problems, p. 19. Duke University, Department of civil and environmental engineering, Durham (2019)
Marquardt, D.W.: An algorithm for least-squares estimation of nonlinear parameter. J. Soc. Ind. Appl. Math. 11(2), 431–441 (1963)
Hovde Liland, K., Almøy, T., Mevik, B.-H.: Optimal choice of baseline correction for ultivariate calibration of spectra. Appl. Spectrosc. 64(9), 1007–1016 (2010). https://doi.org/10.1366/000370210792434350
Meyer, D.: Support Vector Machines, The Interface to libsvm in package e1071, 1–8 (2022). https://rdrr.io/rforge/e1071/f/inst/doc/svmdoc.pdf
Meyer, D., Dimitriadou, E., Hornik, K., Weingessel, A., Leisch, F., Chang, C.-C., Lin.: Algorithm Library Package ‘e1071 52–53 (2022). https://cran.r-project.org/web/packages/e1071/index.html
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
A-FO wrote the main manuscript text and performed the RUS experiments (Sect. 3). GW and AT performed the Z-score analysis (Sect. 4). NF performed the automated unsupervised followed by supervised analysis to label parts (Sect. 5.1). AT and L-F performed the supervised analysis based on Z-score results to label parts (Sect. 5.2). All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
I declare that the authors have no competing interests as defined by Springer, or other interests that might be perceived to influence the results and/or discussion reported in this paper.
Ethical Approval
Not applicable.
Consent to Participate
Not applicable.
Consent for Publication
The authors give consent for publication.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Obaton, AF., Fallahi, N., Tanich, A. et al. Statistical Analysis and Automation Through Machine Learning of Resonant Ultrasound Spectroscopy Data from Tests Performed on Complex Additively Manufactured Parts. J Nondestruct Eval 43, 21 (2024). https://doi.org/10.1007/s10921-023-01035-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10921-023-01035-8