
Abstract
Laughter is a ubiquitous and important social signal, but its nature is yet to be fully explored. One of the open empirical questions is about the role of context in the interpretation of laughter. Can laughs presented on their own convey specific feelings and social motives? How influential is social context when a person tries to understand the meaning of a laugh? Here we test the extent to which the classification of laughs produced in different situations is guided by knowing the context within which these laughs were produced. In the current study, stimuli were spontaneous laughs recorded in social situations engineered to elicit amusement, embarrassment, and schadenfreude. In a between-subjects design, participants classified these laughs being assigned to one of the four experimental conditions: audio only, audio-visual, side-by-side videos of two interactants, and side-by-side videos accompanied by a brief vignette. Participants’ task was to label each laugh as an instance of amusement, embarrassment, or schadenfreude laugh, or “other.” Laughs produced in situations inducing embarrassment were classified more accurately than laughs produced in other situations. Most importantly, eliminating information about the social settings in which laughs were produced decreased participants’ classification accuracy such that accuracy was no better than chance in the experimental conditions providing minimal contextual information. Our findings demonstrate the importance of context in the interpretation of laughter and highlight the complexity of experimental investigations of schadenfreude displays.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Laughter is not only a signal of joy, pleasure, or amusement, but also a complex social behavior observed among humans and other mammalian species (Kret et al., 2021; Panksepp & Burgdorf, 2003; Provine, 2000; Winkler & Bryant, 2021). Humans laugh as many as 5 times during every 10 min of conversation (Vettin & Todt, 2004), and systematically underestimate the number of times they laugh during the day (e.g., Mannell & McMahon, 1982; Martin & Kuiper, 1999). Laughter is also inherently social: it is 30 times more likely to occur in social rather than solitary settings (Provine & Fischer, 1989) and is produced in a puzzling variety of social situations—not only when people feel playful or amused, but also to show superiority, signal sexual interest, be polite, mask embarrassment or tension, or even in reaction to another person’s misfortunes (e.g., Bachorowski & Owren, 2003; Charles Darwin, 1872; Hall & Alliń, 1897; Provine, 2004; Ragan, 1990). Although laughter is often linked with humor or interpreted as an expression of amusement (e.g., McKeown & Curran, 2015), signaling amusement is only one of the many functions of laughter. Research shows that laughs are only occasionally caused by conventionally funny external stimuli: People may laugh after saying something (Vettin & Todt, 2004) or following events that would not be amusing outside of a specific context (Provine, 1992). The absence of laughter is also a strong signal—a message of rejection (Jefferson, 1979).
The wide range of situations in which laughter is deployed attests to its flexibility as an interactional tool. If we also consider the staggering variety of what makes people laugh, and the sophistication of many humorous stimuli (e.g., McKeown, 2016), laughter appears to be a complex response to a wide range of events and situations, solving a number of sometimes contradictory social tasks, such as showing compassion or contempt. How exactly laughter serves these tasks and how people correctly understand its multiple meanings is yet to be explained. One of the outstanding questions concerns the extent to which the nuanced messages that laughter conveys are communicated by its intrinsic properties versus the context in which laughter occurs. This question has parallels with wider emotion literature debates between the essentialist views (e.g., Basic Emotion Theory; BET; Ekman & Cordaro, 2011, but see also Cowen et al., 2019; Keltner et al., 2019; Scarantino, 2015) and the accounts that emphasize the fundamental role of context in interpreting the meaning of social signals. The theories that give a primacy to context include constructionist accounts of emotional phenomena (e.g., the Theory of Constructed Emotion, Feldman Barrett, 2017; Feldman Barrett & Westlin, 2021) or the social signaling accounts of the Behavioural Ecology View (BECV) of facial displays (Fridlund, 2017a). The constructionist and BECV views emphasize the variation that is present in social signals—the same signals that are often purported by versions of BET to be of a natural kind—and that the same signals can be interpreted in many different ways depending on the contextual information available to the receiver of a signal. In these views, the signals in isolation would be ambiguous but become more meaningful with increased contextual information. There have been attempts to reconcile these views using analogies between nonverbal signals and linguistic pragmatics (e.g., Mazzocconi et al., 2020; Scarantino, 2017, 2018; but see also Crivelli & Fridlund, 2017b, 2019). While the debate continues, the extent to which context influences the meaning of social signals remains an open question, and this is certainly true of laughter.
There is evidence that people can accurately interpret the meaning of laughs using only auditory information (e.g., Szameitat et al., 2009a, 2022) and that laughs produced in distinct social situations have different acoustic properties (Wood, 2020; Wood et al., 2017). However, research on facial expressions increasingly shows that contextual information strongly affects how a given signal is perceived. Such contextual information can include the face of the expresser, their gender and age, their bodily posture, or the situation in which a given expression was produced (e.g., Aviezer et al., 2012; Hess & Hareli, 2017; Kalokerinos et al., 2014; Le Mau et al., 2021; Rychlowska et al., 2021). To our knowledge, existing research on how context affects the perception of social signals focuses on facial expressions. Studies on laughter, a social behavior whose functions may be as complex as those of facial expressions (e.gParkinson, 2005; Russell et al., 2003), is still scarce. Many studies focus on the distinction between spontaneous and volitional laughs (e.g., Bryant & Aktipis, 2014; Gervais & Wilson, 2005; Kamiloğlu et al., 2021; Lavan et al., 2016; McKeown et al., 2015; Ruch & Ekman, 2001) or their valence (e.g., Bachorowski & Owren, 2001; Owren & Riede, 2010), and relatively little is known about how the availability of contextual information affects judgments of laughter in interaction.
Empirical evidence examining the extent to which laughter acoustics can communicate distinct social motives and felt states is also inconclusive. Some research shows that laughter is a variable and flexible social signal. For example, the classic study by Bachorowski et al. (2001) revealed that laughs produced in the same, positive context—watching amusing video sequences from “Monty Python and the Holy Grail” and “When Harry Met Sally”—were extremely variable in their acoustics, including differences in production modes, fundamental frequency, and formant characteristics. Later, Curran et al. (2018) used recordings of male dyads during a storytelling task (McKeown et al., 2012) to extract a set of laughter stimuli, including unaltered occurrences of laughter as well as sequences in which original laughter episodes were replaced by other laughs taken from a different point in the same conversation. These substituted sequences were either matched in intensity to the original laughter or had a different subjectively perceived intensity (previously rated by another group of participants). Subjects watched the stimuli and judged the extent to which they perceived each situation as genuine and realistic. Results consistently showed that replacing the original laughter sequences with other laughs did not have a negative impact on perceived genuineness of the situation, as long as the substituted recording was matched for subjective intensity. The fact that the same laughs could be used across different contexts suggests that laughter is a flexible, ambiguous interaction signal serving to express or accentuate emotions and motives induced by the context or to coordinate interactions. This could make laughter functionally similar to indirect speech, a seemingly superfluous social signal that gives a person “the benefit of the doubt”, thus allowing them to successfully negotiate complex relationships and hierarchies or engage in risky communication acts (Pinker et al., 2008; Wood et al., 2017). Such an interpretation is supported by studies exploring contextual influences on laughter. For instance, in a study by Otten et al. (2017), participants read complimenting or insulting sentences, half of which were accompanied by sound recordings of a laughing group. An analysis of participants’ electroencephalographic (EEG) activity revealed that people reacted differently to insults and compliments, as reflected by the N400 and LPP event-related potentials, and that the presence of laughter made these early brain reactions more extreme. In other words, the same laughs had different effects when accompanied by complimenting versus insulting sentences, suggesting that the meaning of laughter is influenced by the situation in which it occurs. These findings dovetail with a growing body of literature showing that the interpretation of nonverbal behaviors largely depends on the social context, and that the same signals can have opposite effects depending on the behaviors that they accompany (e.g., Aviezer et al., 2012; de Melo et al., 2014; van der Schalk et al., 2015). If the meaning of laughter lies in the situation, it is also in the ear of the beholder: A study of Papousek et al. (2014) revealed that individuals high in gelotophobia, or fear of being derided by others (Ruch et al., 2014), reacted to laughs with cardiac responses previously linked with the experience of social rejection. No such response was observed in control participants low in gelotophobia when exposed to the same laughter stimuli.
Although some studies suggest that the meaning of laughter is largely determined by context, other research shows that laughter acoustics can vary across social situations, pointing to the possible existence of laughter ‘types.’ Notably, Szameitat et al. (2009a) explored listeners’ judgments of audio recordings of laughs associated with joy, tickling, schadenfreude, and taunting. Not only did a group of naïve listeners classify the laughs with accuracy levels significantly higher than chance, but, furthermore, the four laugh ‘types’ differed in their acoustic profiles and evaluations. Other, more recent evidence that expressers’ feelings and social motives are communicated by laughter acoustics comes from the research by Wood et al. (2017) who analyzed listeners’ ratings of 400 laughs from a public sound library. Specific acoustic features of laughter systematically predicted the extent to which laughs were perceived as spontaneous, communicating positive emotion, maintaining social bonds, and displaying superiority or dominance. Finally, a study by Oveis et al. (2016) used video recordings of interactions between low and high-status American fraternity brothers, and revealed that high status was communicated by specific acoustic features of laughter. Not only were the high-status laughs correctly distinguished in audio recordings, but the use of high-status laughter by low-status brothers increased their status, supporting the existence of a “special” kind of laughter conveying status. Such studies suggest that people produce different laughter sounds in different social situations or to convey distinct felt states or motives. One potential limitation of these findings is the limited ecological validity of stimuli used. For example, Wood et al. (2017) examined laughs from a public sound library and Szameitat et al. (2009a, 2009b) employed instances of laughter recorded by professional actors asked to imagine experiencing joy, tickling, schadenfreude, and taunting. Although this methodological choice is justified by the pioneering nature of these studies, one might argue that such stimuli reflect cultural concepts or norms about laughter, but not necessarily how people laugh in real life. The study by Oveis et al. (2016) overcomes this limitation as the stimuli were spontaneous conversations between young men. However, these stimuli are also bound to the specific context of taunting and power struggles. Similar validity concerns apply to recordings of canned laughter (Otten et al., 2017), prerecorded laughs (Papousek et al., 2014), or laughs extracted from conversational databases (Bryant et al., 2016; Curran et al., 2018). Such conversational laughs may be largely polite or volitional and thus not fully representative of the wide variety of situations in which people laugh.
Here we propose to investigate judgments of spontaneous laughs produced in social situations that were deliberately engineered to induce laughs and to be associated with experiences of amusement, embarrassment, and schadenfreude. Rather than asking people to create laughs of a certain type, we seek to create laughter production contexts with inherent socio-emotional characteristics and observe the laughter that is produced. The present research tests how accurately listeners can discriminate between different contexts of laughter production and how much these judgments are guided by contextual cues. We examine the classification of laughs produced in three types of social situations: amusement, embarrassment, and schadenfreude (see Niedenthal et al., 2010 and Wood, 2020 for a related classification of smiles and laughs). To generate these stimuli, we recorded groups of competing participants during three laughter-inducing tasks: reading tongue-twisters, which forces the reader to unintentionally utter swear words; a game of Pictionary, in which one person draws the meaning of a given word and other players are asked to guess the word; and Bop-It, a simple audio game in which players gain points by following verbal instructions from the game device. We then used specific criteria to extract 30 experimental stimuli from this corpus of recordings.
In the first category of “amusement laughs”, we captured participants’ laughter in reaction to a teammate reading a tongue twister and accidentally saying a swear word. For the second category of “embarrassment laughs”, we extracted videos of partipants realizing that, during a game of Pictionary, they had to draw a term describing a bodily function in front of the entire group. Finally, for the category of “schadenfreude laughs”, we captured laughs produced when a person saw a member of a competing team losing a round of the Bop It game. Using as stimuli natural and spontaneous laughs produced in these three contexts, we examined how accurately listeners could recognize the original laughter production context, when provided with varying levels of contextual information.
In the main experiment, participants rated 30 laughter recordings (10 laughs for each production context) and were asked to label each recording as an amusement laugh, an embarrassment laugh, schadenfreude laugh, or as “other”. In a between-subjects design, we manipulated the availability of contextual information. Figure 1 provides an overview of the four experimental conditions. The first, “vignette”, condition involved the maximal number of contextual cues. Here, participants were provided with a brief description of the social situation in which each laugh occurred, and watched side-by-side videos displaying the laughing person and the events that originally elicited each laugh (another person mispronouncing a tongue-twister in the amusement context, the Pictionary card with the embarrassing word in the embarrassment context, and another person losing the round of the Bop It game in the schadenfreude context). In the second, “side-by-side” condition, participants watched the side-by-side videos of each laugh and the eliciting events without any descriptions. In the third, “audio-visual” condition, subjects only saw the videos of the laughing person. The final, “audio-only” condition involved listening to the audio versions of each laugh. Our analysis examined how accurately participants could label the production context for each laugh across the four conditions. We predicted that reducing the amount of contextual information available would substantially reduce participants’ labeling accuracy.

Overview of the Four Experimental Conditions. In the vignette condition (A), participants watched side-by-side videos presenting the laughing person and the event that triggered the laugh. Videos were preceded by a brief description of the social context. In the side-by-side condition (B), participants watched the same videos but without the vignette. The audio-visual condition (C) involved watching a video recording of the laughing person. In the audio-only condition (D) participants heard audio recordings of laughs
Method
Participants and Design
Below we report all measures, manipulations, and exclusions. Two hundred and twenty six participants (135 women, 68 men, 23 did not provide gender information; age M = 18.81, SD = 0.80) were recruited via Prolific Academic and paid for their time. We aimed to ensure a minimum of 50 participants in each of the four experimental conditions (Simmons et al., 2018). The study was only available to UK nationals and people who spoke English as their first language. Among the 226 participants, 8 did not express consent, 6 did not pass the sound test, and 8 provided incomplete data, for a final sample of 204 participants. The experiment followed a mixed design with the experimental condition (vignette, side-by-side, audio-visual, audio-only) as a between-subject variable and the context of laughter production (amusement, embarrassment, schadenfreude) as a within-subjects variable.
Stimuli
Stimuli were recordings of laughs spontaneously produced in social contexts engineered to elicit amusement, embarrassment, and schadenfreude. We recorded 58 people (22 men, 36 women, age M = 30.17, SD = 9.78) playing three different games in 3- or 4-person groups. Participants played Pictionary, Bop It (a simple audio game using a device calling instructions to be followed by players), and read tongue twisters tricking the speaker into uttering swear words against their intention (McKeown et al., 2015). Three-person groups played against each other and four-person groups were divided into two-person teams competing for a small prize. Recordings were annotated using ELAN (Version 6.2), yielding more than 6000 laugh episodes. From these sequences, we selected laughs to be used as experimental stimuli. In order to be included in the “amusement context” category, laughs had to be produced by people in reaction to a member of their own team misarticulating tongue-twisters. In order to be included in the “embarrassment context” category, laughs had to be produced by people realizing that their task was to draw the word “defecation” in a Pictionary game (embarrassment context). Finally, in order to be included in the “schadenfreude context” category, laughs had to be produced by people observing a member of the competing team obtaining a low score in a Bop It game. These contexts were examined in a pilot study showing that another sample of participants associated the contexts with emotional experiences of amusement, embarrassment, and pleasure at seeing another person failing (see Supplemental Materials and Figures S1, S2, S3 for an overview of results and https://osf.io/x4kgv/ for the study questionnaire and data). To be included in the experimental stimuli, videos also needed to meet specific technical criteria, in particular show the laughing person’s face and have good sound quality. We thus excluded sequences where the face was moving out of camera range or where the participant turned their head away from full frontal view. We also excluded laughs overlapping with speech or with other background noises. We aimed to use equal numbers of laughs per category. The final stimulus set included 30 sequences produced by 23 persons (16 women, 7 men), with 10 videos for each of the three contexts. Stimuli are available at https://osf.io/x4kgv/.Footnote 1
Procedure
The study was an online questionnaire implemented in Qualtrics (version 1.869 s, Provo, UT, see https://osf.io/x4kgv/ for the survey and study data). Initial screening questions tested whether participants were able to correctly hear a voice pronouncing the words airport and republic; only participants who could hear these stimuli and correctly match them with response suggestions could proceed with the questionnaire. After providing consent, participants were told that their task would be to classify different laughs into one of the four categories: amusement, embarrassment, schadenfreude, or other. They then read definitions of the three categories. Amusement laughter was defined as communicating that a person is feeling amused or happy. Embarrassment laughter was described as a laugh communicating that someone is feeling uneasy or embarrassed. Finally, schadenfreude laughter was proposed to communicate that a person is feeling superior or pleased about someone else’s misfortunes. To reduce the biases inherent to the choice-from-array task (Barrett et al., 2019; Hoemann et al., 2019), participants were also informed that if a given laugh did not fit any of these categories, they could select the option “other” (Frank & Stennett, 2001). After reading these instructions, participants were randomly assigned to one of four experimental conditions. In each condition, participants saw 30 videos or listened to 30 audio recordings (10 laughs produced in the amusement context, 10 laughs produced in the embarrassment context, and 10 laughs produced in the schadenfreude context). Laughs were presented in a random order. In the vignette condition, providing maximum contextual cues, participants watched a side-by-side video presenting the laughing person as well as the event that triggered the laugh (the second interactant in the amusement and the schadenfreude contexts; the embarrassing Pictionary card in the embarrassment context). Side-by-side videos were preceded by a brief description of the social context. Laughs produced in the context of amusement were accompanied by the following vignette: [Laughing person] is listening to his/her teammate, [context person], reading a tongue-twister. [Context person] starts off well, but soon his/her tongue slips… In the embarrassment context, the vignette read: It’s [laughing person] turn to be the ‘Picturist,’ and he/she just saw the card that he/she needs to sketch. The word on the card is ‘defecation,’ which means having a bowel movement. The schadenfreude context was described as follows: [Context person] and [laughing person] are playing a competitive game against each other. It’s [context person’s] turn to play but soon he/she loses the round and needs to pass the device to [laughing person]. In the second, side-by-side condition, participants watched the side-by-side videos presenting the laughing person as well as the event that triggered the laugh (the second interactant in the amusement and the schadenfreude contexts; the embarrassing Pictionary card in the embarrassment context). This time, videos were presented without the vignette. The third, audio-visual condition involved watching a video recording of the laughing person. Finally, in the audio-only condition, participants heard audio recordings of each laugh, identical in duration to the one used in the audio-visual condition. Participants were instructed to listen to the recording/watch the video as many times as needed and to classify the laugh as an amusement laugh, an embarrassment laugh, a schadenfreude laugh, or as other. After classifying and rating the 30 laughs, participants provided demographic information, were debriefed, thanked, and paid for their time.Footnote 2
Results
Analytic Strategy
We predicted that participants’ decisions whether each laugh was produced in the contexts of amusement, embarrassment, schadenfreude, or other, would be determined by the amount of contextual information available to participants when making the judgment. We, therefore, predicted a main effect of the experimental condition, such that participants’ accuracy in classifying laughs would increase as a function of contextual information available. In other words, we expected highest classification accuracy in the condition where side-by-side videos were presented with an accompanying vignette, intermediate accuracy in the audio-visual and side-by-side conditions, and lowest accuracy in the audio-only condition. We were also interested in the interaction between the experimental condition and the laughter production context, that is, if potential effects of the experimental condition would vary as a function of the context in which laughter was produced.
As the dependent variable, we analyzed the signal detection sensitivity measure \(d^{\prime}\) (Abdi, 2007; Green & Swets, 1966). \(d^{\prime}\) is calculated based on the standardized proportions of hits (H) and false alarms (FA) such that \(d^{\prime}=Z\left(H\right)-Z\left(FA\right)\). Higher \(d^{\prime}\) values signal more accuracy and a value of 0 corresponds to a chance level. Here we calculated \(d^{\prime}\) values using the dprime function in the R package psycho (Makowski, 2018) with the adjustments for extreme values suggested by Hautus (1995). These adjustments to the basic calculation of \(d^{\prime}\) account for the occurrences of F or H being equal to 1 or zero in which case the standard \(d^{\prime}\) equation does not give sensible answers. The Hautus (1995) adjustment borrows a technique from log-linear analysis that adds 0.5 to each cell in the two-by-two contingency table, such that the new equation for \(d^{\prime}\) is: z(H + 0.5)/(H + M + 1)—z(F + 0.5)/F + CR + 1). In our multi-class design, the two-by-two contingency table was calculated using “Hits” as the number of correct responses when the laugh of a target category was present (e.g., laughter produced in the embarrassment context classified as an embarrassment laugh). “False alarms” were instances when participants incorrectly classified a non-target laugh as an exemplar of the target category (e.g., laughter produced in an amusing context classified as an embarrassment laugh). Proportion of false alarms was computed as the number of erroneous classifications of non-target laughs as the target category divided by the total number of non-target laughs presented. “Misses” were instances when participants incorrectly classified a laugh as an exemplar of the target category (e.g., laughter produced in an embarrassment context classified as an amusement laugh). “Correct rejections” represent all other possibilities (e.g., laughs produced in amusement or schadenfreude-inducing contexts classified as amusement or schadenfreude laughs).
The individual \(d^{\prime}\) scores computed for each participant and laughter production context were examined as a function of experimental condition as a between-subjects variable and laughter production context as a within-subjects variable. After testing these effects with a mixed-effects model, we used confusion matrices to further examine how participants classified the 30 stimuli (10 laughs produced in the amusement context, 10 laughs produced in the embarrassment context, 10 laughs produced in the schadenfreude context).
Effects of Experimental Condition and Laughter Production Context
Participants’ classification accuracy was indexed by the \(d^{\prime}\) sensitivity scores. We used a random-intercepts mixed-effects model, similar to a 4 (experimental condition: audio, audio-visual, side-by-side, vignette) × 3 (laughter production context: amusement, embarrassment, schadenfreude) mixed ANOVA, but more robust to violations of sphericity and other assumptions (Barr et al., 2013; Bates et al., 2015; Magezi, 2015).Footnote 3 Both predictors were coded using deviation coding (condition: 0.75, -0.25, -0.25, -0.25; laughter context: 0.66, -0.33, -0.33) and we used the maximal random effects structure for this design. The analysis showed a significant main effect of the experimental condition, \(F\left(3, 200\right)=64.41,p<.001,{\eta }_{p}^{2}=0.49\), such that accuracy was highest for the vignette conditions \(\left(M=0.94,SE=0.06\right)\) and the side-by-side condition \(\left(M=0.81,SE=0.05\right)\), lower for the audio-visual condition \(\left(M=0.24,SE=0.05\right)\), and lowest for the audio condition \(\left(M=0.02,SE=0.05\right)\). Detection sensitivity also varied significantly across the three laughter production contexts, \(F\left(2, 400\right)=95.31,p<.001,{\eta }_{p}^{2}=0.32\), with \(d^{\prime}\) values being highest for laughs produced in the embarrassment context \(\left(M=0.92,SE=0.04\right)\) than for the amusement context \(\left(M=0.28,SE=0.04\right)\) and the schadenfreude context \(\left(M=0.32,SE=0.04\right)\). Most importantly, there was a significant interaction between experimental condition and context, \(F\left(6, 400\right)=27.91,p<.001,{\eta }_{p}^{2}=0.30\). We, therefore, examined the effects of experimental condition separately for each laughter production context. Figure 2 shows the estimated marginal means of \(d^{\prime}\) values as a function of experimental condition and laughter production context for the model.

Estimated marginal means of \(d^{\prime}\) values for each condition and laugh production context
The classification of laughs produced in the amusement context was significantly affected by the experimental condition, \(F\left(3, 200\right)=13.18,p<.001,{\eta }^{2}=0.17\) such that \(d^{\prime}\) values were highest in the vignette condition \(\left(M=0.60,SE=0.07\right)\), intermediate in the side-by-side \(\left(M=0.38,SE=0.07\right)\) and audio-visual \(\left(M=0.11,SE=0.07\right)\) conditions, and lowest in the audio condition \(\left(M=0.03,SE=0.07\right)\). The differences between audio and side-by-side and audio and vignette conditions were significant, t(200) = -3.47, p = 0.004, and t(200) = -5.60, p < 0.001, respectively. The differences between the audio-visual and side-by-side conditions and audio-visual and vignette conditions were significant, t(200) = -2.70, p = 0.037 and t(200) = -4.85, p < 0.001, respectively. Table 1 shows all pairwise comparisons using Tukey adjustments across experimental conditions for the amusement context.
A similar trend was observed for laughs produced in the embarrassment context, F(3, 200) = 80.74, p < `0.001, \({\eta }^{2}=0.55\) with more marked differences between experimental conditions. Again, accuracy was highest in the vignette condition \(\left(M=1.84,SE=0.10\right)\), followed by the side-by-side condition \(\left(M=1.45,SE=0.10\right)\), and the audio-visual condition \(\left(M=0.34,SE=0.10\right)\), and lowest in the audio condition \(\left(M=0.03,SE=0.10\right)\). The differences between audio and side-by-side conditions and audio and vignette conditions were significant, t(200) = -10.45, p < 0.001, and t(200) = -13.23, p < 0.001, respectively. The same was true for the differences between audio-visual and side-by-side and vignette conditions, t(200) = -8.19, p < 0.001, and t(200) = -10.99, p < 0.001, respectively. This time the difference between side-by-side and vignette was also significant, t(200) = -2.83, p = 0.026. Table 2 shows all pairwise comparisons using Tukey adjustments across experimental conditions for the embarrassment context.
In the schadenfreude context, there was also a significant main effect of experimental condition, \(F\left(3, 200\right)=11.53,p<.001,{\eta }^{2}=0.15\). This time, the side-by-side condition showed the highest level of accuracy \(\left(M=0.61,SE=0.07\right)\), with the vignette condition \(\left(M=0.37,SE=0.07\right)\) having lower accuracy than side-by-side. Accuracy was lowest in the audio-visual condition \(\left(M=0.28,SE=0.07\right)\), and in the audio condition \(\left(M=0.01,SE=0.07\right)\). The differences between audio and audio-visual, side-by-side, and vignette conditions were significant, t(200) = -2.69, p = 0.039, t(200) = -5.82, p < 0.001, and t(200) = -3.49, p = 0.003, respectively. Also, the differences between audio-visual and side-by-side conditions were significant, t(200) = -3.16, p = 0.010. Table 3 shows all pairwise comparisons using Tukey adjustments across experimental conditions for the schadenfreude context.
Classification of Laughs Across Conditions
To examine all of the participants’ classification decisions as a whole, we computed confusion matrices for each of the four experimental conditions (see Fig. 3). The horizontal axes represent the context in which each laughter was produced (amusement, embarrassment, schadenfreude). Vertical axes represent participants’ decisions (amusement, embarrassment, schadenfreude, and other). High accuracy is indicated by each instance of a target category (e.g., laughter produced in the embarrassment context) being correctly labeled by observers (i.e., as an embarrassment laugh in our example). This is represented by the light blue squares. As before, we predicted that the audio-only experimental condition would yield classification levels closer to chance (represented by darker squares in the confusion matrices).

Confusion Matrices for the Audio-Only Condition (A), the Audio-visual Condition (B), the Side-by-Side Condition (C), and the Vignette Condition (D). Horizontal Axes Represent the Original Laughter Production Contexts and the Vertical Axes—Participants’ Responses. Numbers in Each Square Represent Percentages of Responses (With Chance Levels at 25%)
Figure 3 shows that the overall low accuracy in the audio-only condition (panel A) is in part due to participants’ tendency to classify most stimuli as amusement laughs (bottom row in the confusion matrix). It is worth noting that, in this condition, classification accuracy was no higher than chance for any of the three production contexts, t(50) = 0.44, p = 0.66 for the amusement context, t(50) = 0.30, p = 0.76 for the embarrassment context, and t(50) = 0.14, p = 0.89 for the schadenfreude context. The presence of visual information in the audio-visual condition (panel B) improved classification accuracy for laughs produced in the context of embarrassment. In the side-by-side condition (panel C), classification accuracy improved for the amusement and embarrassment laugh production contexts, but remained low for the schadenfreude context. The same pattern was observed in the vignette condition (panel D), where classification accuracy again improved for the amusement and embarrassment laugh production contexts, but remained low for schadenfreude.
Discussion
The present research examined the role of contextual information in classifying spontaneous laughs produced in social contexts associated with amusement, embarrassment, and schadenfreude. In four experimental conditions, we manipulated the amount of context available to participants from audio (no contextual information) to side-by-side videos of the two interactants accompanied by a vignette describing the social situation in which the laughter occurred (maximal contextual information). We then analyzed participants’.
d′ sensitivity index as a function of laughter production context and amount of contextual information available. In line with our predictions, participants’ classification accuracy was highest in the condition of the maximal contextual information and lowest in the audio-only condition, when no contextual information was available.
The effects of experimental condition interacted with the original laughter production context. Specifically, the availability of contextual information increased classification accuracy for each production context; but these effects were most marked for laughs produced in the situation associated with embarrassment, especially when comparing the side-by-side and the vignette conditions (see Fig. 2). This might be due to the high salience of the embarrassment task, which involved drawing a taboo word in front of other people. Another potential reason could be that laughs produced in embarrassment-inducing situations looked different than others. An inspection of these laughs reveals that 5 out of 10 videos involved touching the face and 8—looking down (see https://osf.io/x4kgv/ for stimuli), and both gestures have been described as nonverbal signs of embarrassment (Keltner, 1995). More importantly, however, the boost in participants’ classification accuracy in the side-by-side and the vignette conditions might be due to the nature of the context video accompanying the recording of the laughing person. Unlike the amusement and the schadenfreude laughs accompanied by the original events that elicited these laughs, the 10 embarrassment laughs were accompanied by the same side-by-side video. This video presented a series of images of a card dealing shoe, one card being removed, and then turned to reveal the word defecation. As such, this context could be much more explicit and prototypical than the context videos used with the laughs produced in situations inducing amusement or schadenfreude. In the side-by-side and the vignette conditions, laughs produced in the amusement- and schadenfreude-inducing contexts- were accompanied by audio-visual recordings of the other interactant in the situation. In the amusement-inducing contexts, this other person was a teammate who read a tongue twister and accidentally uttered a swear word. In the schadenfreude-inducing contexts, the other person was a competitor who played an audio game Bop It and lost a round, this made the competitor less likely to win and the laugher more likely to win. Although these contexts were associated with experiences of amusement and schadenfreude by another sample of participants (see Supplemental Materials and https://osf.io/x4kgv/), they could be less prototypical than the embarrassment-inducing context. Another plausible explanation is that, despite reading the definition of schadenfreude laughs, participants were relatively unfamiliar with this category and thus less likely to use it as an explanation. Such an interpretation is supported by the inspection of the confusion matrices (Fig. 3), where it can be seen that, among the four possible classification decisions (amusement, embarrassment, schadenfreude, other), participants were least likely to classify laughs as schadenfreude. Although participants were native English speakers provided with a definition of this emotion, and there is evidence that the concept of schadenfreude can be properly translated to English (e.g., Smith, 2013; Smith et al., 2009), future studies could be improved by including attention checks that would specifically probe participants’ understanding of schadenfreude. Finally, there might be an overlap between the categories of amusement and schadenfreude, the latter being defined as pleasure at someone else’s misfortune (Smith et al., 2009). This problem of potentially overlapping production contexts might extend to all three laughter production contexts, since a person can simultaneously experience amusement and embarrassment. Although we examined the three production contexts in a pilot study showing that similar situations are associated with amusement, embarrassment, and pleasure at seeing another person making a mistake (see https://osf.io/x4kgv/ for data and summary), engineering such contexts in a research laboratory and, more importantly, assessing participants’ emotional experience during the production of spontaneous laughs, remains a challenge. We sought to create ecologically valid spontaneous laughter in this study and we encourage others to do so; natural laughter is the phenomenon we wish to study. However, studying spontaneous laughs results in a loss of control and requires recording and discarding many stimuli to find experimentally suitable versions. This problem is greater for audio-visual stimuli than those that are audio-only.
One important finding of the present research is that the overwhelming majority of laughs were classified as amusement (see the confusion matrices, Fig. 3, bottom rows). This result is in line with the strong cultural tendency to interpret laughter as a sign of amusement (Laughing, n.d., 2021) and with the results of the study by Wood (2020), in which laughs produced in reward, affiliation, and dominance contexts were most likely to be categorized as reward—a category involving happiness, amusement, or joy, and thus overlapping with the class of amusement laughs used in the present study. A similar tendency was observed in a recent study by Szameitat et al. (2022), where fun and joy were the main affective states associated with laughter.
Overall, our results suggest that social context is an important determinant of the perceived meaning of laughs produced in different situations. Importantly, when participants did not have access to contextual information in the audio-only condition, their classification accuracy was no better than chance. Figure 1 shows that, apart from the side-by-side and vignette conditions for laughs produced in embarrassment-inducing contexts, values of d′ sensitivity index did not exceed 1, reflecting relatively poor performance in a multi-category classification task (Macmillan & Creelman, 2005). At first sight, our findings may seem at odds with other studies suggesting that specific acoustics of laughter convey different emotional states or social motives (e.g., Bryant et al., 2016; Szameitat et al., 2009a, 2022; Vouloumanos & Bryant, 2019; Wood, 2020). Discrepancies with these previous findings can be due to differences in stimuli and to the fact that our study focused on natural laughs produced during social situations. As such, our stimuli could be less emblematic than laughs produced by professional actors with the intention to convey specific meanings (Szameitat et al., 2009a, 2009b). This interpretation is in line with a growing body of literature showing that spontaneous real-life emotion expressions are highly variable and only occasionally correspond to expressive prototypes (Barrett et al., 2019). Moreover, recent research by Le Mau et al. (2021) reveals that, even when facial expressions are produced by professional actors, their interpretation remains largely driven by contextual information. It is important to mention that a novel paradigm used by Wood (2020) allowed generating spontaneous social laughs of reward, affiliation, and dominance during a video rating task (see also Szameitat et al., 2022, for a similar approach). An analysis of these laughs revealed that each of these three production contexts was associated with specific laughter acoustics. However, such effects can only be detected with very large samples of more than 3000 laughs. Here we adopted a different approach, focusing on 30 high-quality audio-visual laughs produced during face-to-face interactions, and we examined how accurately listeners could identify the contexts in which the laughs were produced. We also engineered three types of laughter-inducing social situations, building on previous research using unstructured conversations (Bryant et al., 2016; Curran et al., 2018), teasing (Oveis et al., 2016), and video rating tasks (Wood, 2020).
Although the use of spontaneous social laughs produced in three types of situations designed to elicit distinct emotional states is the strength of the present study, it also comes with limitations. One of them is the small number of stimuli used, where the initial sample of more than 6000 laughter episodes was reduced to 30 laughs occurring in highly specific situations, selected a priori to elicit states of amusement, embarrassment, and schadenfreude. Despite the strict selection of such situations and the corresponding laughs, we have only limited and mostly anecdotal access to laughers’ subjective experience in these situations. Although collecting participants’ reports during the study would be beneficial for the internal validity of the present research, it could have disrupted the group dynamic and prevented participants from laughing. Future studies will aim to find effective strategies for real-time measurement of participants’ subjective experience during laughter-inducing tasks. Finally, given that the form and the functions of laughter are likely subject to cultural variation (e.g., Bryant, 2021; Kamiloğlu et al., 2021), it is also important for future research to include participants from non-Western countries (Henrich, 2020).
The present findings examine spontaneous social laughs produced in contexts associated with amusement, embarrassment, and schadenfreude. We show that even a small sample of strictly defined laughs, carefully selected from a large database to be most representative of amusement, embarrassment, and schadenfreude, is not classified better than chance when presented without contextual information. Our results document the variability of spontaneously produced laughter and suggest that naturally occurring conversational laughs might be distinct from emblematic expressions deliberately produced to convey specific meanings or social motives. The findings also highlight the role of context in interpreting nonverbal interaction signals such as laughter.
Notes
The OSF repository includes all stimuli except one recording of laughter in the amusement-inducing context, as the participant did not provide consent for the videos to be used in future publications.
Participants also rated the intensity of each laugh. This measure was included for exploratory purposes and will not be discussed further.
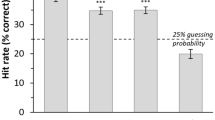
An additional analysis using Unbiased Hit Rates (Wagner, 1993) as an alternative measure of participants’ accuracy revealed an identical pattern of results with significant main effects of experimental condition and laughter production context, as well as a significant interaction effect (see Supplemental Materials).
References
Abdi, H. (2007). Signal detection theory (SDT) (pp. 886–889). Sage.
Aviezer, H., Trope, Y., & Todorov, A. (2012). Body cues, not facial expressions, discriminate between intense positive and negative emotions. Science, 338(6111), 1225–1229. https://doi.org/10.1126/science.1224313
Bachorowski, J.-A., & Owren, M. J. (2001). Not all laughs are alike: Voiced but not unvoiced laughter readily elicits positive affect. Psychological Science, 12(3), 252–257. https://doi.org/10.1111/1467-9280.00346
Bachorowski, J.-A., & Owren, M. J. (2003). Sounds of emotion: Production and perception of affect-related vocal acoustics. Annals of the New York Academy of Sciences, 1000(1), 244–265. https://doi.org/10.1196/annals.1280.012
Bachorowski, J.-A., Smoski, M. J., & Owren, M. J. (2001). The acoustic features of human laughter. Journal of the Acoustical Society of America, 110(3), 17.
Barr, D. J., Levy, R., Scheepers, C., & Tily, H. J. (2013). Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language, 68, 255–278.
Barrett, L. F., Adolphs, R., Marsella, S., Martinez, A. M., & Pollak, S. D. (2019). Emotional expressions reconsidered: Challenges to inferring emotion from human facial movements. Psychological Science in the Public Interest, 20(1), 1–68. https://doi.org/10.1177/1529100619832930
Bates, D., Mächler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67(1), 1–48. https://doi.org/10.18637/jss.v067.i01
Bryant, G. (2021). Vocal communication across cultures: Theoretical and methodological issues. Philosophical Transactions of the Royal Society b: Biological Sciences, 377, 1841. https://doi.org/10.1098/rstb.2020.0387
Bryant, G. A., & Aktipis, C. A. (2014). The animal nature of spontaneous human laughter. Evolution and Human Behavior, 35(4), 327–335. https://doi.org/10.1016/j.evolhumbehav.2014.03.003
Bryant, G. A., Fessler, D. M. T., Fusaroli, R., Clint, E., Aarøe, L., Apicella, C. L., Bang Petersen, M., Bickham, S. T., Bolyanatz, A., Chavez, B., De Smet, D., Díaz, C., Fančovičová, J., Fux, M., Giraldo-Perez, P., Hu, A., Kamble, S. V., Kameda, T., Li, N. P., … Zhou, Y. (2016). Detecting affiliation in colaughter across 24 societies. Proceedings of the National Academy of Sciences, 113(17), 4682–4687. https://doi.org/10.1073/pnas.1524993113
Cowen, A., Sauter, D., Tracy, J., & Keltner, D. (2019). Mapping the passions: Toward a high-dimensional taxonomy of emotional experience and expression. Psychological Science in the Public Interest, 20(1), 69–90. https://doi.org/10.1177/1529100619850176
Crivelli, C., & Fridlund, A. J. (2019). Inside-out: From basic emotions theory to the behavioral ecology view. Journal of Nonverbal Behavior, 43, 161–194. https://doi.org/10.1007/s10919-019-00294-2
Curran, W., McKeown, G. J., Rychlowska, M., André, E., Wagner, J., & Lingenfelser, F. (2018). Social context disambiguates the interpretation of laughter. Frontiers in Psychology, 8, 2342. https://doi.org/10.3389/fpsyg.2017.02342
Darwin, C. (1872). The expression of the emotions in man and animals. (First). London: John Murray. Retrieved from http://darwin-online.org.uk/content/frameset?itemID=F1142&viewtype=text&pageseq=1
de Melo, C. M., Carnevale, P. J., Read, S. J., & Gratch, J. (2014). Reading people’s minds from emotion expressions in interdependent decision making. Journal of Personality and Social Psychology, 106(1), 73–88. https://doi.org/10.1037/a0034251
Ekman, P., & Cordaro, D. (2011). What is meant by calling emotions basic. Emotion Review, 3(4), 364–370. https://doi.org/10.1177/1754073911410740
Feldman Barrett, L. (2017). How emotions are made: The secret life of the brain. Houghton Mifflin Harcourt.
Feldman Barrett, L., & Westlin, C. (2021). Navigating the science of emotion. In H. L. Meiselman (Ed.), Emotion measurement (pp. 38–84). Woodhead Publishing.
Frank, M. G., & Stennett, J. (2001). The forced-choice paradigm and the perception of facial expressions of emotion. Journal of Personality and Social Psychology, 80(1), 75–85. https://doi.org/10.1037/0022-3514.80.1.75
Fridlund, A. J. (2017a). The behavioral ecology view of facial displays, 25 years later. In J.-M. Fernández-Dols & J. A. Russell (Eds.), The science of facial expression (pp. 77–92). Oxford University Press.
Fridlund, A. J. (2017b). On scorched earths and bad births: Scarantino’s misbegotten Theory of Affective Pragmatics. Psychological Inquiry, 28(2–3), 197–205. https://doi.org/10.1080/1047840X.2017.1338093
Gervais, M., & Wilson, D. S. (2005). The evolution and functions of laughter and humor: A synthetic approach. The Quarterly Review of Biology, 80(4), 395–430. https://doi.org/10.1086/498281
Green, D. M., & Swets, J. A. (1966). Signal detection theory and psychophysics. Wiley. https://doi.org/10.1086/405615
Hall, G. S., & Alliń, A. (1897). The psychology of tickling, laughing, and the comic. The American Journal of Psychology, 9(1), 1–41. https://doi.org/10.2307/1411471
Hautus, M. (1995). Corrections for extreme proportions and their biasing effects on estimated values of d′. Behavior Research Methods, Instruments, & Computers, 27(1), 46–51. https://doi.org/10.3758/bf03203619
Henrich, J. (2020). The weirdest people in the world. Farrar, Straus and Giroux.
Hess, U., & Hareli, S. (2017). The social signal value of emotions: The role of contextual factors in social inferences drawn from emotion displays. In J. Russell & J.-M. Fernandez-Dols (Eds.), The science of facial expression (pp. 375–392). Oxford University Press.
Hoemann, K., Crittenden, A. N., Msafiri, S., Liu, Q., Li, C., Roberson, D., Ruark, G. A., Gendron, M., & Feldman Barrett, L. (2019). Context facilitates performance on a classic cross-cultural emotion perception task. Emotion (washington, d.c.), 19(7), 1292–1313. https://doi.org/10.1037/emo0000501
Jefferson, G. (1979). A technique for inviting laughter and its subsequent acceptance/declination (pp. 79–96). Irvington.
Kalokerinos, E., Greenaway, K., Pedder, D., & Margetts, E. (2014). Don’t grin when you win: The social costs of positive emotion expression in performance situations. Emotion, 14(1), 180–186. https://doi.org/10.1037/a0034442
Kamiloğlu, R., Tanaka, A., Scott, S., & Sauter, D. (2021). Perception of group membership from spontaneous and volitional laughter. Philosophical Transactions of the Royal Society B: Biological Sciences, 377, 1841. https://doi.org/10.1098/rstb.2020.0404
Keltner, D. (1995). Signs of appeasement: Evidence for the distinct displays of embarrassment, amusement, and shame. Journal of Personality and Social Psychology, 68(3), 441–454. https://doi.org/10.1037/0022-3514.68.3.441
Keltner, D., Sauter, D., Tracy, J., & Cowen, A. (2019). Emotional expression: Advances in basic emotion theory. Journal of Nonverbal Behavior, 43(2), 133–160. https://doi.org/10.1007/s10919-019-00293-3
Kret, M. E., Venneker, D., Evans, B., Samara, I., & Sauter, D. (2021). The ontogeny of human laughter. Biology Letters, 17(9), 20210319. https://doi.org/10.1098/rsbl.2021.0319
Lavan, N., Scott, S., & McGettigan, C. (2016). Laugh like you mean it: Authenticity modulates acoustic, physiological and perceptual properties of laughter. Journal of Nonverbal Behavior, 40(2), 133–149. https://doi.org/10.1007/s10919-015-0222-8
Le Mau, T., Hoemann, K., Lyons, S., Fugate, J., Brown, E., Gendron, M., & Barrett, L. (2021). Professional actors demonstrate variability, not stereotypical expressions, when portraying emotional states in photographs. Nature Communications. https://doi.org/10.1038/s41467-021-25352-6
Macmillan, N., & Creelman, C. (2005). Detection theory. Lawrence Erlbaum Associates.
Magezi, D. A. (2015). Linear mixed-effects models for within-participant psychology experiments: An introductory tutorial and free, graphical user interface (LMMgui). Frontiers in Psychology, 6, 2. https://doi.org/10.3389/fpsyg.2015.00002
Makowski, D. (2018). The Psycho Package: An efficient and publishing-oriented workflow for psychological science. Journal of Open Source Software, 3(22), 470. https://doi.org/10.21105/joss.00470
Mannell, R. C., & McMahon, L. (1982). Humor as play: Its relationship to psychological well-being during the course of a day. Leisure Sciences, 5(2), 143–155. https://doi.org/10.1080/01490408209512998
Martin, R. A., & Kuiper, N. A. (1999). Daily occurrence of laughter: Relationships with age, gender, and Type A personality. Humor, 12(4), 355–384. https://doi.org/10.1515/humr.1999.12.4.355
Mazzocconi, C., Tian, Y., & Ginzburg, J. (2020). Whats your laughter doing there?; a taxonomy of the pragmatic functions of laughter. IEEE Transactions on Affective Computing, 3045, 1–19.
McKeown, G., & Curran, W. (2015). The relationship between laughter intensity and perceived humour. In K. Truong, D. Heylen, J. Trouvain, & N. Campbell (Eds.), Proceedings of the 4th international workshop on laughter and other non-verbal vocalisations in speech (pp. 27–29). Queen’s University Belfast.
McKeown, G. (2016). Laughter and humour as conversational mind-reading displays. In N. Streitz & P. Markopoulos (Eds.) (Vol. 9749, pp. 317–328). Springer International Publishing. https://doi.org/10.1007/978-3-319-39862-4_29
McKeown, G., Cowie, R., Curran, W., Ruch, W., & Douglas-Cowie, E. (2012). 8th international conference on Language Resources and Evaluation (LREC) (p. 4). Istanbul, Turkey.
McKeown, G., Sneddon, I., & Curran, W. (2015). Gender differences in the perceptions of genuine and simulated laughter and amused facial expressions. Emotion Review, 7(1), 30–38. https://doi.org/10.1177/1754073914544475
Niedenthal, P., Mermillod, M., Maringer, M., & Hess, U. (2010). The Simulation of Smiles (SIMS) model: Embodied simulation and the meaning of facial expression. Behavioral and Brain Sciences, 33(6), 417–433. https://doi.org/10.1017/s0140525x10000865
Otten, M., Mann, L., van Berkum, J. J. A., & Jonas, K. J. (2017). No laughing matter: How the presence of laughing witnesses changes the perception of insults. Social Neuroscience, 12(2), 182–193. https://doi.org/10.1080/17470919.2016.1162194
Oveis, C., Spectre, A., Smith, P. K., Liu, M. Y., & Keltner, D. (2016). Laughter conveys status. Journal of Experimental Social Psychology, 65, 109–115. https://doi.org/10.1016/j.jesp.2016.04.005
Owren, M. J., & Riede, T. (2010). Voiced laughter elicits more positive emotion in listeners when produced with the mouth open than closed. The Journal of the Acoustical Society of America, 128(4), 2475–2475. https://doi.org/10.1121/1.3508873
Panksepp, J., & Burgdorf, J. (2003). “Laughing” rats and the evolutionary antecedents of human joy? Physiology & Behavior, 79(3), 533–547. https://doi.org/10.1016/S0031-9384(03)00159-8
Papousek, I., Aydin, N., Lackner, H. K., Weiss, E. M., Bühner, M., Schulter, G., Charlesworth, C., & Freudenthaler, H. H. (2014). Laughter as a social rejection cue: Gelotophobia and transient cardiac responses to other persons’ laughter and insult: Laughter as a social rejection cue. Psychophysiology, 51(11), 1112–1121. https://doi.org/10.1111/psyp.12259
Parkinson, B. (2005). Do facial movements express emotions or communicate motives? Personality and Social Psychology Review, 9(4), 278–311. https://doi.org/10.1207/s15327957pspr0904_1
Pinker, S., Nowak, M. A., & Lee, J. J. (2008). The logic of indirect speech. Proceedings of the National Academy of Sciences, 105(3), 833–838.
Provine, R. R. (1992). Contagious laughter: Laughter is a sufficient stimulus for laughs and smiles. Bulletin of the Psychonomic Society, 30(1), 1–4. https://doi.org/10.3758/BF03330380
Provine, R. R. (2000). Laughter. Viking.
Provine, R. R. (2004). Laughing, tickling, and the evolution of speech and self. Current Directions in Psychological Science, 13(6), 215–218. https://doi.org/10.1111/j.0963-7214.2004.00311.x
Provine, R. R., & Fischer, K. R. (1989). Laughing, smiling, and talking: Relation to sleeping and social context in humans. Ethology, 83(4), 295–305. https://doi.org/10.1111/j.1439-0310.1989.tb00536.x
Ragan, S. L. (1990). Verbal play and multiple goals in the gynaecological exam interaction’. Journal of Language and Social Psychology, 9(1–2), 67–84. https://doi.org/10.1177/0261927X9091004
Ruch, W., & Ekman, P. (2001). The expressive pattern of laughter. In A. W. Kaszniak (Ed.), Emotion, qualia, and consciousness (pp. 426–443). Word Scientific Publisher.
Ruch, W., Hofmann, J., Platt, T., & Proyer, R. (2014). The state-of-the art in gelotophobia research: A review and some theoretical extensions. Humor. https://doi.org/10.1515/humor-2013-0046
Russell, J. A., Bachorowski, J.-A., & Fernández-Dols, J.-M. (2003). Facial and vocal expressions of emotion. Annual Review of Psychology, 54(1), 329–349. https://doi.org/10.1146/annurev.psych.54.101601.145102
Rychlowska, M., van der Schalk, J., Niedenthal, P., Martin, J., Carpenter, S. M., & Manstead, A. S. (2021). Dominance, reward, and affiliation smiles modulate the meaning of uncooperative or untrustworthy behaviour. Cognition and Emotion, 35(7), 1281–1301.
Scarantino, A. (2015). Basic emotions, psychological construction, and the problem of variability. In L. F. Barrett & J. A. Russell (Eds.), The psychological construction of emotion (pp. 334–376). The Guilford Press.
Scarantino, A. (2017). How to do things with emotional expressions: The theory of affective pragmatics. Psychological Inquiry, 28(2–3), 165–185. https://doi.org/10.1080/1047840X.2017.1328951
Scarantino, A. (2018). Emotional expressions as speech act analogs. Philosophy of Science, 85(5), 1038–1053. https://doi.org/10.1086/699667
Simmons, J., Nelson, L., & Simonsohn, U. (2018). False-positive citations. Perspectives on Psychological Science, 13(2), 255–259. https://doi.org/10.1177/1745691617698146
Smith, R. (2013). The joy of pain. Oxford University Press.
Smith, R., Powell, C., Combs, D., & Schurtz, D. (2009). Exploring the when and why of Schadenfreude. Social and Personality Psychology Compass, 3(4), 530–546. https://doi.org/10.1111/j.1751-9004.2009.00181.x
Szameitat, D. P., Alter, K., Szameitat, A. J., Darwin, C. J., Wildgruber, D., Dietrich, S., & Sterr, A. (2009a). Differentiation of emotions in laughter at the behavioral level. Emotion, 9(3), 397–405. https://doi.org/10.1037/a0015692
Szameitat, D. P., Alter, K., Szameitat, A. J., Wildgruber, D., Sterr, A., & Darwin, C. J. (2009b). Acoustic profiles of distinct emotional expressions in laughter. The Journal of the Acoustical Society of America, 126(1), 354–366. https://doi.org/10.1121/1.3139899
Szameitat, D., Szameitat, A., & Wildgruber, D. (2022). Vocal expression of affective states in spontaneous laughter reveals the bright and the dark side of laughter. Scientific Reports. https://doi.org/10.1038/s41598-022-09416-1
van der Schalk, J., Kuppens, T., Bruder, M., & Manstead, A. S. R. (2015). The social power of regret: The effect of social appraisal and anticipated emotions on fair and unfair allocations in resource dilemmas. Journal of Experimental Psychology: General, 144(1), 151–157. https://doi.org/10.1037/xge0000036
Vettin, J., & Todt, D. (2004). Laughter in conversation: Features of occurrence and acoustic structure. Journal of Nonverbal Behavior, 28(2), 93–115. https://doi.org/10.1023/B:JONB.0000023654.73558.72
Vouloumanos, A., & Bryant, G. (2019). Five-month-old infants detect affiliation in colaughter. Scientific Reports. https://doi.org/10.1038/s41598-019-38954-4
Wagner, H. (1993). On measuring performance in category judgment studies of nonverbal behavior. Journal of Nonverbal Behavior, 17(1), 3–28. https://doi.org/10.1007/bf00987006
Winkler, S., & Bryant, G. (2021). Play vocalisations and human laughter: A comparative review. Bioacoustics, 30(5), 499–526. https://doi.org/10.1080/09524622.2021.1905065
Wood, A. (2020). Social context influences the acoustic properties of laughter. Affective Science, 1(4), 247–256. https://doi.org/10.1007/s42761-020-00022-w
Wood, A., Martin, J., & Niedenthal, P. (2017). Towards a social functional account of laughter: Acoustic features convey reward, affiliation, and dominance. PLoS ONE, 12(8), e0183811. https://doi.org/10.1371/journal.pone.0183811
Author information
Authors and Affiliations
Contributions
The authors made the following contributions. Magdalena Rychlowska: Conceptualization, Writing—Original Draft Preparation, Writing—Review & Editing; Gary J McKeown: Conceptualization, Writing—Original Draft Preparation, Writing—Review & Editing; Ian Sneddon: Conceptualization, Writing—Review & Editing; Will Curran: Conceptualization, Writing—Review & Editing.
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Rychlowska, M., McKeown, G.J., Sneddon, I. et al. The Role of Contextual Information in Classifying Spontaneous Social Laughter. J Nonverbal Behav 46, 449–466 (2022). https://doi.org/10.1007/s10919-022-00412-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10919-022-00412-7