
Abstract
Human–computer interaction (HCI) improved via voice detection of emotions. Speech Emotion Recognition (SER) software typically detects the appearance of various feelings in the speaker. However, there are significant challenges in combining information from multidisciplinary domains, notably speech-emotion recognition and applied psychology. Some researchers have used handcrafted attributes to categorize emotions and obtained high classification accuracy. However, these attributes reduce the categorization accuracy for multi-lingual environments. Deep learning algorithms have been utilized to autonomously retrieve the local representation from supplied speech data. The given strategies can't extract the most valuable characteristics from challenging speech inputs. To address this constraint, we propose an innovative SER framework that employs data augmentation approaches before generating relevant feature sets from each utterance and selecting the most discriminative optimum features. And the chosen feature vector is sent into the Normalized 1D CNN for emotion recognition using multi-lingual databases. This study evaluates the effectiveness of an XGB classifier for multi-lingual emotion recognition by testing its performance on data from a corpus trained on a different corpus. The testing outcomes displayed that our proposed SER architecture functioned better than existing SER approaches.




Similar content being viewed by others
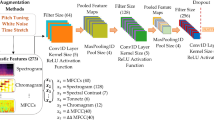
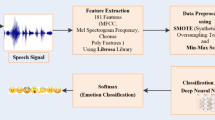

Data availability
Data sharing not applicable to this article, because it’s confidential.
References
Abdel-Hamid, O., Mohamed, A. R., Jiang, H., Deng, L., Penn, G., & Yu, D. (2014). Convolutional neural networks for speech recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 22(10), 1533–1545.
Ancilin, J., & Milton, A. (2021). Improved speech emotion recognition with Mel frequency magnitude coefficient. Applied Acoustics, 179, 108046.
Anvarjon, T., & Kwon, S. (2020). Deep-net: A lightweight CNN-based speech emotion recognition system using deep frequency features. Sensors, 20(18), 5212.
Bertero, D., & Fung, P. (2017). A first look into a convolutional neural network for speech emotion detection. In 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 5115–5119). IEEE.
Chakraborty, R., Pandharipande, M., & Kopparapu, S. K. (2016). Knowledge-based framework for intelligent emotion recognition in spontaneous speech. Procedia Computer Science, 96, 587–596.
Chalapathi, M. M., Kumar, M. R., Sharma, N., & Shitharth, S. (2022). Ensemble learning by high-dimensional acoustic features for emotion recognition from speech audio signal. Security and Communication Networks, 2022.
Chatterjee, J., Mukesh, V., Hsu, H. H., Vyas, G., & Liu, Z. (2018). Speech emotion recognition using cross-correlation and acoustic features. In 2018 IEEE 16th international conference on dependable, autonomic and secure computing, 16th international conference on pervasive intelligence and computing, 4th international conference on big data intelligence and computing and cyber science and technology congress. (DASC/PiCom/DataCom/CyberSciTech) 2018 (pp. 243–249). IEEE.
Choudhary, R. R., Meena, G., & Mohbey, K. K. (2022). Speech emotion based sentiment recognition using deep neural networks. Journal of Physics: Conference Series, 2236(1), 012003.
Cowie, R., Douglas-Cowie, E., Tsapatsoulis, N., Votsis, G., Kollias, S., Fellenz, W., & Taylor, J. G. (2001). Emotion recognition in human-computer interaction. IEEE Signal Processing Magazine, 18(1), 32–80.
Fayek, H. M., Lech, M., & Cavedon, L. (2017). Evaluating deep learning architectures for speech emotion recognition. Neural Networks, 92, 60–68.
Goel, S., & Beigi, H. (2020). Cross lingual cross corpus speech emotion recognition. arXiv preprint arXiv:2003.07996.
Issa, D., Demirci, M. F., & Yazici, A. (2020). Speech emotion recognition with deep convolutional neural networks. Biomedical Signal Processing and Control, 59, 101894.
Jahangir, R., Teh, Y. W., Mujtaba, G., Alroobaea, R., Shaikh, Z. H., & Ali, I. (2022). Convolutional neural network-based cross-corpus speech emotion recognition with data augmentation and features fusion. Machine Vision and Applications, 33(3), 41.
Kim, J., & Saurous, R. A. (2018). Emotion recognition from human speech using temporal information and deep learning. In Interspeech (pp. 937–940).
Kumaran, U., Radha Rammohan, S., Nagarajan, S. M., & Prathik, A. (2021). Fusion of Mel and gammatone frequency cepstral coefficients for speech emotion recognition using deep C-RNN. International Journal of Speech Technology, 24, 303–314.
Latif, S., Qayyum, A., Usman, M., & Qadir, J. (2018). Cross lingual speech emotion recognition: Urdu vs. Western languages. In 2018 international conference on frontiers of information technology (FIT) (pp. 88–93). IEEE.
Latif, S., Rana, R., Younis, S., Qadir, J. & Epps, J. (2018). Transfer learning for improving speech emotion classification accuracy. arXiv preprint arXiv:1801.06353.
McFee, B., Raffel, C., Liang, D., Ellis, D. P., McVicar, M., Battenberg, E., & Nieto, O. (2015). Librosa: Audio and music signal analysis in Python. In Proceedings of the 14th Python in science conference (Vol. 8, pp. 18–25).
Nantasri, P., Phaisangittisagul, E., Karnjana, J., Boonkla, S., Keerativittayanun, S., Rugchatjaroen, A., & Shinozaki, T. (2020). A light-weight artificial neural network for speech emotion recognition using average values of MFCCs and their derivatives. In 2020 17th international conference on electrical engineering/electronics, computer, telecommunications and information technology (ECTI-CON). IEEE.
Neumann, M., & Vu, N. T. (2017). Attentive convolutional neural network based speech emotion recognition: A study on the impact of input features, signal length, and acted speech. arXiv preprint arXiv:1706.00612
Parlak, C., Diri, B., & Gürgen, F. (2014). A cross-corpus experiment in speech emotion recognition. In SLAM@ INTERSPEECH (pp. 58–61).
Patel, N., Patel, S., & Mankad, S. H. (2022). Impact of autoencoder based compact representation on emotion detection from audio. Journal of Ambient Intelligence and Humanized Computing, 13, 867–885.
Pawar, M. D., & Kokate, R. D. (2021). Convolution neural network based automatic speech emotion recognition using Mel-frequency Cepstrum coefficients. Multimedia Tools and Applications, 80, 15563–15587.
Rabiner, L. R. (1978). Digital processing of speech signals. Pearson Education India.
Roberts, L. S. (2012). A forensic phonetic study of the vocal responses of individuals in distress. Doctoral dissertation, University of York.
Rothenberg, M. (1973). A new inverse-filtering technique for deriving the glottal air flow waveform during voicing. The Journal of the Acoustical Society of America, 53(6), 1632–1645.
Sasou, A. (2018). Glottal inverse filtering by combining a constrained LP and an HMM-based generative model of glottal flow derivative. Speech Communication, 104, 113–128.
Schuller, B., Zhang, Z., Weninger, F., & Rigoll, G. (2011). Using multiple databases for training in emotion recognition: To unite or to vote? In Twelfth annual conference of the international speech communication association (Interspeech).
Schuller, B., Vlasenko, B., Eyben, F., Wöllmer, M., Stuhlsatz, A., Wendemuth, A., & Rigoll, G. (2010). Cross-corpus acoustic emotion recognition: Variances and strategies. IEEE Transactions on Affective Computing, 1(2), 119–131.
Shilandari, A., Marvi, H., Khosravi, H., & Wang, W. (2022). Speech emotion recognition using data augmentation method by cycle-generative adversarial networks. Signal, Image and Video Processing, 16(7), 1955–1962.
Stuhlsatz, A., Meyer, C., Eyben, F., Zielke, T., Meier, G. & Schuller, B. (2011). Deep neural networks for acoustic emotion recognition: Raising the benchmarks. In 2011 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 5688–5691). IEEE.
Sultana, S., Iqbal, M. Z., Selim, M. R., Rashid, M. M., & Rahman, M. S. (2021). Bangla speech emotion recognition and cross-lingual study using deep CNN and BLSTM networks. IEEE Access, 10, 564–578.
TESS Dataset. (2022). Retrieved March 3, 2022, from https://tspace.library.utoronto.ca/handle/1807/24487.
Trigeorgis, G., Ringeval, F., Brueckner, R., Marchi, E., Nicolaou, M. A., Schuller, B., & Zafeiriou, S. (2016). Adieu features? End-to-end speech emotion recognition using a deep convolutional recurrent network. In 2016 IEEE international conference on acoustics, speech and signal processing (ICASSP 2016) (pp. 5200–5204). IEEE.
Vogt, T., & André, E. (2006). Improving automatic emotion recognition from speech via gender differentiation. In Proceedings of language resources and evaluation conference.
Vryzas, N., Matsiola, M., Kotsakis, R., Dimoulas, C., & Kalliris, G. (2018). Subjective evaluation of a speech emotion recognition interaction framework. In Proceedings of the audio mostly 2018 on sound in immersion and emotion (pp. 1–7).
Wang, L., Gao, Y., Li, J., & Wang, X. (2021). A feature selection method by using chaotic cuckoo search optimization algorithm with elitist preservation and uniform mutation for data classification. Discrete Dynamics in Nature and Society, 2021, 1–19.
Wei, S., Zou, S., & Liao, F. (2020). A comparison on data augmentation methods based on deep learning for audio classification. Journal of Physics Conference Series, 1453(1), 012085.
Xu, M., Zhang, F., & Zhang, W. (2021). Head fusion: Improving the accuracy and robustness of speech emotion recognition on the IEMOCAP and RAVDESS dataset. IEEE Access, 9, 74539–74549.
Zvarevashe, K., & Olugbara, O. (2020). Ensemble learning of hybrid acoustic features for speech emotion recognition. Algorithms, 13(3), 70.
Funding
The authors declare that no funds, grants, or other support were received during the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
NB—methodology, study conception and design. DKS—analysis and interpretation of results. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Ethical approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
All contributors agreed and given consent to Publish.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Barsainyan, N., Singh, D.K. Optimized cross-corpus speech emotion recognition framework based on normalized 1D convolutional neural network with data augmentation and feature selection. Int J Speech Technol 26, 947–961 (2023). https://doi.org/10.1007/s10772-023-10063-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-023-10063-8