
Abstract
Singer identification is one of the important aspects of music information retrieval (MIR). In this work, traditional feature-based and trending convolutional neural network (CNN) based approaches are considered and compared for identifying singers. Two different datasets, namely artist20 and the Indian popular singers’ database with 20 singers are used in this work to evaluate proposed approaches. Cepstral features such as Mel-frequency cepstral coefficients (MFCCs) and linear prediction cepstral coefficients (LPCCs) are considered to represent timbre information. Shifted delta cepstral (SDC) features are also computed beside the cepstral coefficients to capture temporal information. In addition, chroma features are computed from 12 semitones of a musical octave, overall forming a 46-dimensional feature vector. Experiments are conducted with different feature combinations, and suitable features are selected using the genetic algorithm-based feature selection (GAFS) approach. Two different classification techniques, namely artificial neural networks (ANNs) and random forest (RF), are considered on the features mentioned above. Further, spectrograms and chromagrams of audio clips are directly fed to CNN for classification. The singer identification results obtained using CNNs seem to be better than the traditional isolated and ensemble classifiers. Average accuracy of around 75% is observed with CNN in the case of Indian popular singers database. Whereas, on artist20 dataset, the proposed configuration of feature-based approach and CNN could not give better than 60% accuracy.





Similar content being viewed by others


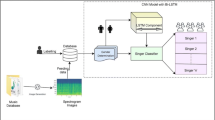
Notes
Pitch frequency for the starting note of a raga.
References
Attokaren, D. J., Fernandes, I. G., Sriram, A., Murthy, Y. V. S., & Koolagudi, S. G. (2017). Food classification from images using convolutional neural networks. In TENCON 2017-2017 IEEE Region 10 Conference, (pp. 2801–2806). IEEE.
Batta, K. B., Gurrala, V. R., & Srinivasa Murthy Yarlagadda, V. (2020). A node to node security for sensor nodes implanted in cross cover multi-layer architecture using mc-nie algorithm. Evolutionary Intelligence, (pp. 1–17).
Biswas, R., Murthy, Y. V., Srinivasa, K., Shashidhar G., & Vishnu, S. G. (2020). Objective assessment of pitch accuracy in equal-tempered vocal music using signal processing approaches. In Smart computing paradigms: New progresses and challenges, (pp. 161–168). Springer.
Boger, Z., & Guterman, H. (1997). Knowledge extraction from artificial neural network models. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Computational Cybernetics and Simulation, vol. 4, (pp. 3030–3035). IEEE.
Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5–32.
Cai, W., Li, Q., & Guan, X. (2011). Automatic singer identification based on auditory features. In Natural Computation (ICNC), 2011 Seventh International Conference on, (vol. 3, pp. 1624–1628). IEEE.
Chakradhar, M., Sri Charan, M., Umesh Sai, R., Kunal, M., Murthy, Y. V. S., & Shashidhar, G. K. (2019). Academic curriculum load balancing using ga. In 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), (pp. 1–5). IEEE.
Comon, P., & Jutten, C. (2010). Handbook of Blind Source Separation: Independent component analysis and applications. Academic press.
Eghbal Z., Hamid, S., Markus, & Widmer, G. (2015). Timbral modeling for music artist recognition using i-vectors. In Proceedings of the 23rd European Signal Processing Conference (EUSIPCO), (pp. 1286–1290). IEEE.
Ellis, D. P. W. (2007). Classifying music audio with timbral and chroma features. Proceedings of the Eighth International Symposium on Music Information Retrieval (ISMIR), 7, 339–340.
Feller, W. (2008). An introduction to probability theory and its applications. Hoboken: Wiley.
Fletcher, H. (1940). Auditory patterns. Reviews of Modern Physics, 12(1), 47.
Fujihara, H., Kitahara, T., Goto, M., Komatani, K., Ogata, T., & Okuno, H. G. (2005). Singer identification based on accompaniment sound reduction and reliable frame selection. In ISMIR, (pp. 329–336).
Fujihara, H., Goto, M., Kitahara, T., & Okuno, H. G. (2010). A modeling of singing voice robust to accompaniment sounds and its application to singer identification and vocal-timbre-similarity-based music information retrieval. IEEE Transactions on Audio, Speech, and Language Processing, 18(3), 638–648.
Güçlü, U., & van Gerven, M. (2017). Probing human brain function with artificial neural networks. Computational Models of Brain and Behavior, 17, 413.
Harte, C., & Sandler, M. (2005). Automatic chord identification using a quantised chromagram. In Audio Engineering Society Convention 118. Audio Engineering Society.
Helen, M., & Virtanen, T. (2005). Separation of drums from polyphonic music using non-negative matrix factorization and support vector machine. In Proceedings of the 13th European Signal Processing Conference (EUSIPCO), pages 1–4. IEEE.
Ho, Tin Kam. (1995). Random decision forests. In Proceedings of the Third International Conference on Document Analysis and Recognition, (vol. 1, pp. 278–282). IEEE.
Kalayar, K., Swe, Z., Nwe, T. L., & Li, H. (2008). Singing voice detection in pop songs using co-training algorithm. In Acoustics, Speech and Signal Processing, 2008. ICASSP 2008. IEEE International Conference on, (pp. 1629–1632). IEEE.
Karpathy, A, Toderici, G, Shetty, S, Leung, T, Sukthankar, R., & Fei-Fei, L. (2014). Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, (pp. 1725–1732)
Kim, Y. E., & Whitman, B. (2002). Singer identification in popular music recordings using voice coding features. In Proceedings of the 3rd international conference on music information retrieval, vol. 13, p. 17.
Koolagudi, S. G., Vishwanath, B. K., Akshatha, M., & Murthy, Y. V. S. (2017). Performance analysis of lpc and mfcc features in voice conversion using artificial neural networks. In Proceedings of the International Conference on Data Engineering and Communication Technology, (pp. 275–280). Springer.
Koolagudi, S. G., Bharadwaj, A., Murthy, Y. V. S., Reddy, N., & Rao, P. (2017). Dravidian language classification from speech signal using spectral and prosodic features. International Journal of Speech Technology (IJST), 20(4), 1005–1016.
Koolagudi, S. G., Murthy, Y. V. S., & Bhaskar, S. P. (2018). Choice of a classifier, based on properties of a dataset: Case study-speech emotion recognition. International Journal of Speech Technology, 21(1), 167–183.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, (pp. 1097–1105).
Kumar, K., Kim, C., & Stern, R. M. (2011). Delta-spectral cepstral coefficients for robust speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), (pp. 4784–4787). IEEE.
Lagrange, M., Ozerov, A., & Vincent, E. (2012). Robust singer identification in polyphonic music using melody enhancement and uncertainty-based learning. In 13th International Society for Music Information Retrieval Conference (ISMIR).
Langlois, T., & Marques, G. (2009). A music classification method based on timbral features. In ISMIR, (pp. 81–86).
LeCun, Y. (2015). LeNet-5, convolutional neural networks.
Liu, C.-C., & Huang, C.-S. (2002). A singer identification technique for content-based classification of mp3 music objects. In Proceedings of the eleventh international conference on Information and knowledge management, (pap. 438–445). ACM.
Liu, J., Pan, Y., Li, M., Ziyue Chen, L., Tang, C. L., & Wang, J. (2018). Applications of deep learning to MRI images: A survey. Big Data Mining and Analytics, 1(1), 1–18.
Loh, W.-Y. (2011). Classification and regression trees. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 1(1), 14–23.
Luitel, B., Murthy, Y. V. S., & Koolagudi, S. G. (2016). Sound event detection in urban soundscape using two-level classification. In 2016 IEEE Distributed Computing, VLSI, Electrical Circuits and Robotics (DISCOVER), (pp. 259–263). IEEE.
Maddage, N. C., Xu, Changsheng, & Wang, Y. (2004). Singer identification based on vocal and instrumental models. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR), volume 2, (pp. 375–378). IEEE.
Mammone, R. J., Zhang, X., & Ramachandran, R. P. (1996). Robust speaker recognition: A feature-based approach. IEEE Signal Processing Magazine, 13(5), 58–71.
Mesaros, A., Virtanen, T., & Klapuri, A. (2007). Singer identification in polyphonic music using vocal separation and pattern recognition methods. In ISMIR, (pp. 375–378).
Ming, J., Hazen, T. J., Glass, J. R., & Reynolds, D. A. (2007). Robust speaker recognition in noisy conditions. Audio, Speech, and Language Processing, IEEE Transactions on, 15(5), 1711–1723.
Murthy, Y. V. (2019). Content-based music information retrieval (CB-MIR) and its applications towards music recommender system. PhD thesis, National Institute of Technology Karnataka, Surathkal.
Murthy, Y. V. S., Jeshventh, T. K. R., Zoeb, M., Saumyadip, M., & Shashidhar, G. K. (2018). Singer identification from smaller snippets of audio clips using acoustic features and dnns. In 2018 eleventh international conference on contemporary computing (IC3), (pp. 1–6). IEEE.
Murthy, Y. V., Srinivasa, & Koolagudi, S. G. (2015). Classification of vocal and non-vocal regions from audio songs using spectral features and pitch variations. In Proceedings of the 28th IEEE Canadian conference on electrical and computer engineering (CCECE), (pp. 1271–1276). IEEE.
Murthy, Y. V. Srinivasa, Koolagudi, S. G., & Swaroop, V. G. (2017). Vocal and non-vocal segmentation based on the analysis of formant structure. In 2017 Ninth international conference on advances in pattern recognition (ICAPR), (pp. 1–6). IEEE.
Murthy, Y. V. S., Harish, K., Varma, D. K. V., Sriram, K., & Revanth, B. V. S. S. (2014). Hybrid intelligent intrusion detection system using Bayesian and genetic algorithm (baga): Comparative study. International Journal of Computer Applications, 99(2), 1–8.
Murthy, Y. V. S., Jagadish, G., Mrunalini, K., Siva, K., Satyanarayana, P. V. V., & Raj Kumar, V. N. (2011). A novel approach to troubleshoot security attacks in local area networks. IJCSNS International Journal of Computer Science and Network Security, 11(9), 116–123.
Murthy, Y. V. S., & Koolagudi, S. G. (2018). Classification of vocal and non-vocal segments in audio clips using genetic algorithm based feature selection (gafs). Expert Systems with Applications, 106, 77–91.
Murthy, Y. V. S., & Koolagudi, S. G. (2018). Content-based music information retrieval (cb-mir) and its applications toward the music industry: A review. ACM Computing Surveys (CSUR), 51(3), 1–46.
Murthy, Y. V. S., Satapathy, S. C., Srinivasu, P., & Saranya, A. A. S. (2011). Key generation for text encryption in cellular networks using multi-point crossover function. International Journal of Computer Applications, 975, 8887.
Noll, A. M. (1969). Pitch determination of human speech by the harmonic product spectrum, the harmonic sum spectrum, and a maximum likelihood estimate. In Proceedings of the symposium on computer processing communications, vol. 779.
Noll, P. (1997). Mpeg digital audio coding. Signal Processing Magazine, IEEE, 14(5), 59–81.
Pachet, F., & Aucouturier, J.-J. (2004). Improving timbre similarity: How high is the sky. Journal of negative results in speech and audio sciences, 1(1), 1–13.
Pan, D. (1995). A tutorial on mpeg/audio compression. IEEE Multimedia, 2(2), 60–74.
Patil, . A., Radadia, P. G., & Basu, T. K. (2012). Combining evidences from mel cepstral features and cepstral mean subtracted features for singer identification. In Proceedings of the International Conference on Asian Language Processing (IALP), (pp. 145–148). IEEE.
Pradeep, T., Srinivasu, P., Avadhani, P. S., & Murthy, Y. V. S. (2011). Comparison of variable learning rate and Levenberg–Marquardt back-propagation training algorithms for detecting attacks in intrusion detection systems. International Journal on Computer Science and Engineering, 3(11), 3572.
Prasad, K. S., Murthy, Y. V S., Rao, C. S., Nageswara Rao, D., & Jagadish, G. (2012). Unconstrained optimization for maximizing ultimate tensile strength of pulsed current micro plasma arc welded inconel 625 sheets. In Proceedings of the International Conference on Information Systems Design and Intelligent Applications 2012 (INDIA 2012) held in Visakhapatnam, India, January 2012, (pp. 345–352). Springer.
Prasad, K. S., Rao, C. S., Rao, D. N., & Vishnu Srinivasa Murthy, Y. (2011). Optimizing pulsed current micro plasma arc welding parameters to maximize ultimate tensile strength of ss304l sheets using hooke and jeeves algorithm. Journal for Manufacturing Science & Production, 11(1–3), 39–48.
Radadia, . G., & Patil, H. A. (2014). A cepstral mean subtraction based features for singer identification. In Proceedings of the International Conference on Asian Language Processing (IALP), (pp. 58–61). IEEE.
Rafii, Z., & Pardo, B. (2013). Repeating pattern extraction technique (repet): A simple method for music/voice separation. IEEE Transactions on Audio, Speech and Language Processing, 21(1), 73–84.
Ratanpara, T., & Patel, N. (2015). Singer identification using perceptual features and cepstral coefficients of an audio signal from Indian video songs. EURASIP Journal on Audio, Speech, and Music Processing, 2015(1), 16.
Regnier, L., & Peeters, G. (2012). Singer verification: singer model. vs. song model. In Acoustics, speech and signal processing (ICASSP), 2012 IEEE International Conference on, (pp. 437–440). IEEE.
Ross Quinlan, J. (2014). C4.5: Programs for machine learning. Elsevier.
Ryo, M., & Rillig, M. C. (2017). Statistically reinforced machine learning for nonlinear patterns and variable interactions. Ecosphere, 8, 11.
Sarkar, Rajib, & Saha, Sanjoy Kumar. (2015). Singer based classification of song dataset using vocal signature inherent in signal. In Proceedings of the Fifth National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG), pages 1–4. IEEE.
Scaringella, N., Zoia, G., & Mlynek, D. (2006). Automatic genre classification of music content: A survey. Signal Processing Magazine, IEEE, 23(2), 133–141.
Shen, J., Cui, B., Shepherd, J., & Tan, K.-L. (2006). Towards efficient automated singer identification in large music databases. In Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval, (pp. 59–66). ACM.
Sreenivasa Rao, K., & Sarkar, S. (2014). Robust speaker verification: A review. In Robust Speaker Recognition in Noisy Environments, (pp. 13–27). Springer.
Sridhar, R., & Geetha, T. V. (2009). Raga identification of Carnatic music for music information retrieval. International Journal of Recent Trends in Engineering, 1(1), 571–574.
Sturm, B. L. (2014). A survey of evaluation in music genre recognition. In Adaptive multimedia retrieval: Semantics, context, and adaptation, (pp. 29–66). Springer.
Su, L., & Yang, Y.-H. (2013). Sparse modeling for artist identification: Exploiting phase information and vocal separation. In ISMIR, (pp. 349–354)
Sundberg, J. (1977). The acoustics of the singing voice. Scientific American, 236(3), 82–91.
Sundberg, J., & Rossing, T. D. (1990). The science of singing voice. The Journal of Acoustical Society of America, 87(1), 462–463.
Thomas, M., Jothish, M., Thomas, N., Koolagudi, S. G., & Murthy, Y. V. S. (2016). Detection of similarity in music files using signal level analysis. In 2016 IEEE Region 10 Conference (TENCON), (pp. 1650–1654). IEEE.
Thomas, M., Murthy, Y. V. S., & Koolagudi, S. G. (2016). Detection of largest possible repeated patterns in indian audio songs using spectral features. In 2016 IEEE Canadian conference on electrical and computer engineering (CCECE), (pp. 1–5). IEEE.
Thomas, M., Murthy, Y. V. S., & Koolagudi, S. G. (2016). Detection of largest possible repeated patterns in indian audio songs using spectral features. In Proceedings of the IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), (pp. 1–5). IEEE.
Tsai, W.-H., Liao, S.-J., & Lai, C. (2008). Automatic identification of simultaneous singers in duet recordings. In Proceedings of the 9th International Symposium on Music Information Retrieval (ISMIR), (pp. 115–120). ISMIR.
Tsai, W.-H., Wang, H.-M., & Rodgers, D. (2003). Automatic singer identification of popular music recordings via estimation and modeling of solo vocal signal. In INTERSPEECH.
Tsai, W.-H., & Wang, H.-M. (2006). Automatic singer recognition of popular music recordings via estimation and modeling of solo vocal signals. IEEE Transactions on Audio, Speech, and Language Processing, 14(1), 330–341.
Vieira, A., & Ribeiro, B. (2018). Image processing. In Introduction to Deep Learning Business Applications for Developers, (pp. 77–109). Springer.
Wang, J., Yang, Y., Mao, J., Huang, Z., Huang, C., & Xu, W. (2016). CNN-RNN: a unified framework for multi-label image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (pp. 2285–2294).
Wang, H., Leung, C.-C., Lee, T., Ma, B., & Li, H. (2013). Shifted-delta mlp features for spoken language recognition. IEEE Signal Processing Letters, 20(1), 15–18.
Wei, J., Liu, C.-H., Zhu, Z., Cain, L. R., & Velten, V. J. (2018). Vehicle engine classification using normalized tone-pitch indexing and neural computing on short remote vibration sensing data. Expert Systems with Applications, 115, 276–286.
Wong, E., & Sridharan, S. (2001). Comparison of linear prediction cepstrum coefficients and mel-frequency cepstrum coefficients for language identification. In Intelligent Multimedia, Video and Speech Processing, 2001. Proceedings of 2001 International Symposium on, (pp. 95–98). IEEE.
Ying, H., & Liu, G. (2015). Separation of singing voice using non-negative matrix partial co-factorization for singer identification. IEEE Transactions on Audio, Speech and Language Processing, 23(4), 643–653.
Zhang, T. (2003). Automatic singer identification. In Proceedings of the International Conference on Multimedia and Expo. (ICME), volume 1, (pp. I–33). IEEE.
Zhang, T., & Packard, H. (2003). System and method for automatic singer identification. RESEARCH DISCLOSURE, pp. (756–756)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Srinivasa Murthy, Y.V., Koolagudi, S.G. & Jeshventh Raja, T.K. Singer identification for Indian singers using convolutional neural networks. Int J Speech Technol 24, 781–796 (2021). https://doi.org/10.1007/s10772-021-09849-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-021-09849-5