
Abstract
In this paper we analyse spatial and temporal variation in the risk of intensive care unit (ICU) admission for COVID-19 in Sweden. The analysis is based on geocoded and time-stamped data from the Swedish Intensive Care Registry (SIR). We merge this data with a classification of Swedish neighbourhood cluster types constructed from multi-scalar measures of socio-economic and country of birth segregation (Kawalerowicz and Malmberg in Multiscalar typology of residential areas in Sweden, 2021 available from https://doi.org/10.17045/sthlmuni.14753826.v1). We examine 1) if residence in more socio-economically deprived or diverse neighbourhood cluster types was associated with a higher risk of ICU admission for COVID-19, 2) if residence in more affluent neighbourhoods was associated with a lower risk of ICU admission for COVID-19, and 3) how these patterns changed over time during the three first waves of the pandemic. While the highest overall risk was associated with residence in urban disadvantage coupled with diversity, models where neighbourhood cluster types were interacted with waves reveal that the highest risk was associated with living in a neighbourhood cluster type characterised by rural town disadvantage coupled with diversity under the 3rd wave (February 2021–June 2021). Residence in such a neighbourhood cluster type was associated with a four times higher risk of ICU admission, compared to the reference category of living in a homogeneous rural neighbourhood cluster type with average levels of deprivation under wave 1. Looking at disparities within each wave we found that residence in most affluent urban areas was at first associated with a slightly higher risk of ICU admission for COVID-19 as compared with the reference category of living in a homogeneous rural neighbourhood cluster type, but under waves 2 and 3 this risk was no longer statistically significant. The largest inequalities between different neighbourhood cluster types could be seen during the 1st wave. Over time, the risks converged between different neighbourhood cluster types.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
From the outbreak of the COVID-19 pandemic in Sweden in February 2020 until the end of 2022, the Swedish Health Agency confirmed over 21,000 fatal cases of the disease. The pandemic left its mark on life expectancy in Sweden, which declined by more than half a year due to the excess mortality related to COVID-19 (Aburto et al., 2022). After its outbreak, the extent and severity of the pandemic was not evenly spread, with urban, socio-economically deprived, and ethnic minority neighbourhoods hit particularly hard (Adhikari et al., 2020; Clouston et al., 2021; Kamis et al., 2021). In this paper we focus on geographic variation in the extent and severity with which different types of communities have been affected by COVID-19 in Sweden (Brandén et al., 2020; Rostila et al., 2021; Florida & Mellander, 2022; Fonseca-Rodríguez et al., 2021). Some researchers have suggested, in line with the “stages of disease” model, that with the emergence of new transmittable diseases, spatial inequalities increase since more affluent areas have more resources to apply mitigation strategies. Then, as mitigation strategies and treatments become accessible, incidence rates converge and inequalities decline between different communities (Clouston et al., 2016). The “stages of disease” model has been tested with respect to COVID-19, but to our knowledge this is the first study which looks at community level disparities over time, while controlling for known individual level epidemiological factors (Clouston et al., 2021). Another inspiration is Cliff et al. (1981) study of historical measles epidemics in Iceland which uses a spatial diffusion framework. In this study, the authors emphasise the importance of points of importation, hierarchical diffusion from the largest cities to smaller settlements, as well as local contagion (see Griffith & Li, (2021, for an application to COVID-19 of this framework). By using geo-coded individual level data on intensive care admissions for three waves of the pandemic in Sweden, we examine whether disparities related to neighbourhood context have grown, if outcomes have become more spatially polarised over time, and potential patterns of spatial diffusion.
This study adds to our knowledge of how the COVID-19 pandemic progressed in Sweden. Taking advantage of the availability of geo-coded register data we construct measures of neighborhood context using individualized (or bespoke) multi-scalar neighborhoods that allow precise measurements of the socio-demographic residential context of individuals (Johnston et al., 2000; Östh et al., 2014). By using individualized neighbourhoods it is possible to circumvent some of the problems that have been associated with using fixed geographical subdivisions (Fotheringham & Wong, 1991), it also allows us to trace the influence of local context on the spread of COVID-19. Earlier studies have used large-scale administrative units such as municipalities (Florida & Mellander, 2022; Fonseca-Rodríguez et al., 2021), or have focused on one or more metropolitan areas (Brandén et al., 2020; Calderón-Larrañaga et al., 2020). In our study, we combine a national perspective with a focus on local context, allowing us to study the geographical selectivity of the COVID-19 pandemic.
We use this neighbourhood cluster type classification to model COVID-19 hospitalisations, distinguishing between poor and affluent or diverse and homogeneous neighbourhoods in urban and rural settings.
Literature review
Researchers have established several factors associated with hospitalisation risk and mortality from COVID-19. Characteristics related to adverse outcomes for other diseases, for instance cardiovascular diseases, have been identified as risk factors for severe COVID-19 infection. These include older age, being male, ethnic minority background, and lower socio-economic status (Aradhya et al., 2020; de Lusignan et al., 2020; Drefahl et al., 2020). What is known about community level factors associated with COVID-19? Early studies reported higher incidence rates of COVID-19 in areas with a high population density, diverse population and overcrowded housing (Abedi et al., 2021; Chen & Krieger, 2021; Arbel et al., 2022). One emerging pattern is that COVID-19 exacerbated existing inequalities by hitting socio-economically disadvantaged communities particularly hard (Adhikari et al., 2020; Clouston et al., 2021; Meurisse et al., 2022). There is also evidence of an interaction between ethnic minority background and socio-economic deprivation, where communities that were both poor and diverse had higher incidence rates of COVID-19 (Adhikari et al., 2020).
As data became available, researchers started to look at how community and neighbourhood level factors influenced COVID-19 transmission. Population register studies from Scandinavian countries offered an insight into factors associated with the COVID-19 disease. In a study of COVID-19 mortality among those aged 70 and older in the Stockholm Region, Brandén et al. (2020) reported that during the first wave both household and neighbourhood level characteristics were associated with a risk of dying from COVID-19. The authors showed that mortality in the initial stages of the pandemic was higher in districts with a higher number of confirmed cases as well as more densely populated neighbourhoods. Similarly, Drefahl and colleagues observed that COVID-19 mortality in many respects mirrors overall mortality except for its spatial character, where higher mortality is observed in more urban areas (2020). There are good reasons why urban areas may be more affected by the pandemic – this can be due to higher population density and the presence of transportation hubs, both of which are related to more interaction and spreading of contagious diseases, but also due to the higher concentration of groups with poor health and living in overcrowded housing. At the same time rural areas could also become seriously affected by the pandemic and factors which made them susceptible include the higher concentration of older people or worse access to health care. The changing association of COVID-19 severity across the urban/rural spectrum was well documented in the US. While mortality in US was initially concentrated in metropolitan areas, non-metropolitan areas had caught up with metropolitan ones by August 2020, with mortality rates two-times higher for non-metropolitan areas in the autumn of 2021 (Cuadros et al., 2021; Matthews et al., 2021).
This brings us to the question of how COVID-19 affected distinct types of communities at different points in time. Clouston and colleagues examine mortality trends for historical epidemics and propose the “stages of disease” model to analyse how novel disease spreads in the population (2016). In the early days of the outbreak the disease is in the natural mortality stage, a period when little is known about it. With scarce information about the disease the applicability of mitigation strategies is limited. The second stage is producing inequalities; it is characterised by unequal diffusion of preventive innovations. As more knowledge about the disease becomes available, groups with more resources (economic, educational, political, or social) are better equipped to avoid exposure and access preventive strategies or treatments. What follows is the reducing inequalities stage. As advantaged groups reach a point of saturation in their uptake of preventive innovations, these innovations become more evenly distributed and widely accessible. Finally, novel diseases enter the disease reduction/elimination stage, when transmissions are low, and we observe limited differences in mortality by socio-economic status. How well does this model explain the dynamics of COVID-19 in distinct types of communities? Kamis et al. (2021) examined COVID-19 mortality rates across US counties and reported results in line with the stages of diseases framework. The authors found that spatial disparities in mortality from COVID-19 were lower in the initial period (April–May 2020). During the second period of the pandemic (June–July 2020), the county-level percentage of overcrowded households, a marker of deprivation that they adopted, was a stronger predictor of mortality compared to the first and third periods (August–October 2020). Similar results were reported by Clouston et al. (2021) who used survival analysis to show that in the initial stages of the pandemic, US county-level incidences and mortality were associated with higher SES, while later they were associated with lower SES. The authors argued that this shift started when states started implementing lockdowns. In another study Meurisse and colleagues (2022) examined the association between area level deprivation and COVID-19 incidence during three pandemic waves in Belgium. The authors found that the effect of deprivation differed significantly between periods. The largest differences between deprivation quintiles were observed in wave 2, between August 2020 and December 2020, while in the other periods differences were less pronounced. Griffith and Li (2021), in contrast, study only the very earliest phase of the COVID-19 epidemic in China (the first 19 days) and in the USA (first 33 days). Their conclusion is the hierarchical diffusion from large to smaller urban areas played a central role.
The Swedish context
In Sweden, the initial outbreak of COVID-19 coincided with winter break at the beginning of March 2020. Dyrdak and Albert showed that early strains of the virus came from Italy and Austria and were most likely introduced by holidaymakers returning home from ski holidays. Once in Sweden, the disease started to spread quickly through community transmission (2021). Another channel of transmission, which quickly reached groups that were most susceptible to the virus, was nursing homes employees, whose exposure in their own social networks was correlated with mortality in the nursing homes where they worked (Nilsson, 2021). After the initial weeks, the pandemic entered the inequality producing stage in the “stages of disease” model. This started with the introduction of mitigation strategies, some of which, such as a recommendation to work from home, were less inclusive of lower SES groups. One proposed explanation as to why low SES groups had a higher mortality rate from COVID-19 is the frontline workers hypothesis. According to this hypothesis, service and care workers (taxi drivers, transportation personnel and retail workers) who are overrepresented in more disadvantaged neighbourhoods were less able to follow the recommendations issued by the authorities. These workers tend to live in multigenerational and overcrowded households in low socio-economic status areas, hence once the virus was introduced to their communities and social networks, it spread quickly (Andersson et al., 2021; Billingsley et al., 2022; Brandén et al., 2020). Furthermore, Karimi (2021) suggests that health literacy and knowledge about available treatments and interventions offers some explanation for differences in COVID-19 outcomes between different socio-economic groups.
The question of how COVID-19 affected different communities was examined using Swedish register data. Researchers reported that excess mortality at the peak of the first wave in April 2020 in the Stockholm Region was higher in municipalities with lower education levels and income, and a higher proportion of foreign-born residents (Calderón-Larrañaga et al., 2020). Other studies have shown that municipalities with higher proportions of first- and second-generation migrants experienced more hospitalisations and higher mortality in 2020 (Florida & Mellander, 2022; Fonseca-Rodríguez et al., 2021). One study which explicitly looked at geographical variation for all of Sweden, albeit at the municipality level, is Florida and Mellander (2022). The authors analysed weekly infection rates in 290 municipalities during the first wave (until August 2020) and found that in comparison to spatial diffusion factors, geographic variation was only modestly associated with factors such as population density, population size and socio-economic characteristics. This led Florida and Mellander to conclude that “when it comes to place-based characteristics, there appears to be a high degree of randomness in the geographic variation of COVID-19 across Sweden”. In another study of urban areas and neighbourhoods in the Stockholm Region, Calderón-Larrañaga et al. (2020) took a closer look at a lower geographic resolution (DeSO) which, arguably, may be a better operationalisation of a neighbourhood. The authors analysed excess mortality and its variation by income, education, proportion of foreign-born and unemployment. They found that throughout the first wave there was a clear pattern where neighbourhoods with the lowest income, lowest educational attainment, and higher proportions of foreign-born and unemployed had increased excess mortality. Although they looked at the period from March 2020 until mid-May 2020, the plots of excess mortality according to neighbourhood characteristics suggest that the gap between affluent neighbourhoods and neighbourhoods with a higher proportion of foreign-born residents widened over time. The authors conclude that “rather than being socially neutral as claimed in the early days of the pandemic, COVID-19 exacerbates existing social inequalities in health and disease.” Commenting on the shifts over time, Sigurjónsdóttir et al. (2021) noted that districts of Stockholm with a higher proportion of residents with foreign background experienced a rapid increase in the number of confirmed cases during the first wave but not during the second wave: “by early November […] of 2020, the cumulative incidence of Covid-19 was for the first time lower in Rinkeby-Kista than in Stockholm Region as a whole, and the district, together with Spånga-Tensta, remained one of the least affected districts in Stockholm municipality for the remainder of 2020”. In contrast to Stockholm, districts with a higher proportion of population with a foreign background in Malmö (Rosengård) continued to be heavily affected during the second wave.
The aim of this paper is to examine disparities in COVID-19 hospitalisations between different types of neighbourhoods and at different periods of the pandemic. We applied the “stages of disease” model and expected that most disparities would be observed during the second wave of the disease, while the first and the third waves would show less pronounced inequalities. Socio-economic deprivation in the neighbourhood was expected to be associated with worse outcomes in regard to COVID-19. Additionally, we expected to see that disadvantaged neighbourhoods would be more exposed to the disease and that in the subgroup of disadvantaged communities those that are more diverse would be especially vulnerable. In our analysis we could distinguish between socio-economically disadvantaged neighbourhood types and neighbourhoods with high and low levels of population diversity, and examine differences in COVID-19 hospitalisations risks for residents living in them. But we also expect that spatial diffusion processes can play a role. In this analysis we studied differences in risk of ICU admission according to the different neighbourhood cluster types that are characteristic of urban or rural settings.
Data and method
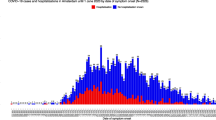
We used data on COVID-19 intensive care unit (ICU) admissions. Arguably, this type of data provides a better insight into the scale and spread of the disease than data such as mortality or cases (Green et al., 2021; Karimi, 2021; Leung, 2020). Individual level data on ICU admission come from the Swedish Health Agency and was linked with data, including detailed residential coordinates, from Swedish population registers using personal identification numbers. In this way we arrived at a population with 10,310,465 individuals where 7,397 individuals were admitted to the ICU between March 2020 and the first week of June 2021. Data on ICU admissions was time-stamped by month and date and by merging it with registers we could establish places of residence for individuals in the study population. Admission to ICU could be classified into waves as follows: first wave (March 2020-August 2020), second wave (September 2020-January 2021) and third wave (February 2021- first week of June 2021). Figure 1 shows the distribution of ICU admissions in the period under study.

COVID-19 ICU admissions by wave
Geographical classification of local contexts
In order to study geographical patterns in the risk of ICU-admissions, the residential location of each individual in the sample has been classified using information about the socio-demographic composition of the nearest 200, 400, 800, 1600, 3200, 6400, 12,800, 25,600, and 51,200 neighbours. Seven indicators, presented in Table 1, measuring country of birth, education, income, and employment were used. The resulting classification identified ten different neighbourhood types, presented in Table 2. For details on how the classification was carried out see Kawalerowicz and Malmberg (2021).
Social status and spatial process
In earlier studies, multi-scalar representations of geographical context are thought to have provided a better way for capturing neighbourhood effects because multi-scalar measures can capture differences between micro and macro level segregation (Lee et al., 2008; Östh et al., 2015; Andersson & Malmberg, 2015; Petrović et al., 2022). Additionally, a multi-scalar approach is useful for epidemiological studies where proximity to contrasting types of neighbourhoods (a situation where a neighbourhood is rather affluent but borders another type of neighbourhood with very different characteristics) or the scale of segregation (our typology distinguished between diverse, small and larger scale, deprived neighbourhood types) could be an additional factor affecting the spread of COVID-19.
The benefits of using a multi-scalar approach rather than predefined areas/aggregates when constructing such neighbourhood typologies is that the latter are susceptible to the MAUP problem (Openshaw, 1984). The multi-scalar neighbourhood cluster typology allows differentiation between neighbourhoods with similar characteristics, not according to administrative units but according to the characteristics of the residents (Kawalerowicz & Malmberg, 2021). Moreover, in earlier studies, multi-scalar representations of geographical context are thought to have provided a better way for capturing neighbourhood effects because multi-scalar measures can capture differences between micro and macro level segregation (Lee et al., 2008; Östh, Clark, Malmberg, 2015; Andersson & Malmberg, 2015; Petrović et al., 2022). Additionally, a multi-scalar approach is useful for epidemiological studies where proximity to contrasting types of neighbourhoods (a situation where a neighbourhood is rather affluent but borders another type of neighbourhood with very different characteristics) or the scale of segregation (our typology distinguished between diverse, small and larger scale, deprived neighbourhood types) could be an additional factor affecting the spread of COVID-19.
For modelling of individual level risk of ICU admission, we also controlled for individual level variables known to affect risk of severe COVID-19 infection and exposure. These income sex, age groups, country of birth groups based on World Bank classification of Gross National Incomes per capita where we distinguish between Sweden, other high-income countries (HIC), low-middle-income countries from Northern Africa and the Middle East (LMIC MENA), and other low-middle-income countries (LMIC other), the number of people per square meter living in the household (a measure of overcrowding), household composition, education level, and neighbourhood population density measured at the neighbourhood level (Swedish DeSO geography). Table 3 provides information about the descriptive statistics on the variables we use. To show how neighbourhood cluster type contributed to risk of ICU admission we fitted Poisson models with robust standard errors. We first fitted a model where risk was modelled by neighbourhood cluster type and then we examined the interaction of neighbourhood cluster type and wave. The results for how individual risk of ICU admission varied by residence in neighbourhood cluster types are shown in Figs. 2, 3 and 4. Regression tables can be found in the Appendix.

Predicted relative risk by neighbourhood cluster type. Poisson model with controls for sex, age group, country of birth group, the number of people per square meter living in the household, household type, education level, neighbourhood population density measured at DeSo level
Results
Figure 2 shows the incidence rate ratio (RR) for ICU admission with COVID-19 for all three waves together. Figures 3 shows RR of an interaction model with the reference category set as one of the neighbourhood cluster types (R_HOM) in wave 1 while Fig. 4 shows the results from a model when the reference category was set to be the same as the neighbourhood cluster types (R_HOM) in each wave. We present both models, since Fig. 3 is better for interpreting the overall relative risks and to establish which form of neighbourhood cluster type residence and at which time were associated with the highest RR of ICU admission, while Fig. 4 is more suitable for showing what differences in relative risk looked like for subsequent waves.

Predicted relative risk by neighbourhood cluster type and wave. Poisson model with controls. Reference category set as R_HOM in wave 1. Note that the bar for R_BOR was omitted due to wide confidence intervals in waves 2 and 3

Predicted relative risk by neighbourhood cluster type and wave. Poisson model with controls. Reference category set as R_HOM in each wave. Note that the bar for R_BOR was omitted due to wide confidence intervals in waves 2 and 3
ICU admissions for COVID-19 by neighbourhood cluster type
Figure 2 shows differences in how residence in different neighbourhood cluster types was associated with the risks of ICU admission for COVID-19. Residence in the Urban diverse core (U_DIV) neighbourhood cluster type was associated with nearly double (RR 1.74, 95% CI 1.54–1.95) the risk of ICU admission with COVID-19, as compared to residence in the rural homogeneous (R_HOM) neighbourhood cluster type. Importantly, this is not an artefact of higher population density in the Urban diverse area (which would entail greater transmissibility of the disease) because the model controls for population density at the neighbourhood level. The relative risk for ICU admission was also high for the Rural town diverse (RT_DIV) neighbourhood cluster type (RR 1.48, 95% CI 1.35–1.61) and Urban diverse buffer (U_DIV) which is a residual category for the Urban diverse neighbourhood cluster type (RR 1.45, 95% CI 1.31–1.61). Somewhat surprisingly, the fourth highest relative risk was observed for the Urban homogeneous (U_HOM) neighbourhood cluster type (RR 1.41, 95% CI 1.25–1.58). This neighbourhood cluster type refers to places where high labour market attachment and relative affluence are not coupled with educational attainment, and it is also, as for the urban context, relatively isolated from diversity. The neighbourhood cluster type associated with lowest relative risks are Rural Border (R_BOR). Although we do see some overall urban–rural gradient, the high relative risk associated with living in Rural town diverse (RT_DIV), a neighbourhood cluster type commonly observed in centres of small and middle-sized towns, does not allow us to form strong conclusions in this regard.
ICU admissions for COVID-19 by neighbourhood cluster type and wave
Figures 3 and 4 further divide relative risks for neighbourhood cluster types by waves. To make these figures clearer we omitted Rural Border (R_BOR), a neighbourhood cluster type which had wide CI in waves 2 and 3. Looking at Fig. 3, the highest relative risk for ICU admission for COVID-19 was associated with residence in Rural town diverse (RT_DIV) a neighbourhood cluster type under wave 3 (RR 3.64, 95% CI 2.71–4.88). This cluster refers to smaller scale diversity and disadvantage and it is often observed in smaller cities and towns. For the majority of neighbourhood cluster types, we observed that the relative risk increases with time. A clear example is Rural homogeneous (R_HOM), a neighbourhood cluster type where the 95% CI does not overlap between consecutive waves, but we also see a similar trend for Rural town diverse (RT_DIV) and Rural town working-class (RT_WC). This means that with time, residence in these neighbourhood cluster types became associated with increasing risk of ICU admission for COVID-19, relative to wave 1. In contrast, the pattern for decreasing relative risk is can be observed for Urban diverse (U_DIV) core neighbourhood cluster type was associated with a lower relative risk during wave 2 and wave 3, compared to wave 1. Next, we look at Fig. 4 to see how differences between neighbourhood cluster types evolved within waves. Here, differences between neighbourhood cluster types became less pronounced over time. During wave 1 we see the largest differences, driven by an elevated relative risk for residence in the Urban diverse (U_DIV) core neighbourhood cluster type. Additionally, with the exception of the Urban adjacent (U_ADJ) neighbourhoods cluster type, living in urban clusters was associated with a higher risk for ICU admission, compared to the reference category of residence in the Rural homogeneous (R_HOM) neighbourhood cluster type. During wave 2 we see that residence in some of the urban neighbourhood cluster types that was associated with increased risk of ICU admissions earlier, was no longer a significant factor. Such neighbourhood cluster types are: Urban elites (U_ELI), Urban homogeneous (U_HOM) and Urban academic (U_ACA). By wave 3 the differences between relative risks associated with residence in different neighbourhood cluster types were not significant. There in one exception. Residence in the Rural town diverse (RT_DIV) neighbourhood cluster type was associated with a higher risk of ICU admissions (RR 1.31, 95% CI 1.14–1.51). This is interesting, especially given that by wave 3 we see that living in the Urban diverse core (U_DIV) neighbourhood cluster type is no longer associated with increased risk of ICU admission. Instead, there is another neighbourhood cluster type which replaced this neighbourhood cluster type as a place with the highest risk of ICU admissions – Rural town diverse (RT_DIV).
Discussion
In this study we investigated individual level risk of ICU admissions for COVID-19 in different types of neighbourhoods in Sweden. The study contributes to a broad body of literature looking at spatial inequalities in health. We used high quality data on ICU admissions for COVID-19 from the Swedish Intensive Care Registry which cover a period of 15 months divided into three waves. Our study is unique in this regard, as many previous studies of COVID-19 focused on shorter time periods or looked at the initial wave. As suggested by the “stages of disease” model, the stage at which data is collected and analysed is likely to affect what conclusions can be drawn. For example, Abedi et al., (2021) who looked at cases in seven US states until April 2020 reported a higher incidence of COVID-19 in areas with higher median income in the US while for instance Madhav et al., 2020, who included a longer period and focused on Louisiana, reported that area deprivation was associated with a higher risk of COVID-19. Hence, in future studies of how context affects COVID-19 it is important to look at how these associations develop with time.
Another novelty of this approach was that we used grid cell data to create a neighbourhood classification which allowed to distinguish between different types of neighbourhoods in a more precise way. Neighbourhood clusters were constructed by using both characteristics of immediate and more remote neighbours and we use clustering algorithms to arrive at a classification distinguishing 10 predominant neighbourhood cluster types in Sweden. Our analysis revealed stark differences in the risk of ICU admissions for residents of different types of neighbourhoods. Overall, the highest risk was associated with residence in Urban diverse cluster type (U_DIV). When looking at the interaction between neighbouhrood types and waves, we found that the highest risk was associated with residence in the Rural town diverse (RT_DIV) neighbourhood cluster type during the third wave. In consecutive waves the inequalities in risk between different neighbourhood cluster types declined, mostly due to the decline in relative risk for the Urban diverse (U_DIV) cluster. One hypothesis is that these areas are home to more mobile international populations and are hence more exposed to a global pandemic (Andersson, 2021). Another line of inquiry which deserves further examination is the occupational structure of such neighbourhoods and their lower ability to self-isolate or for residents to work remotely. Both would put these areas at risk of being exposed early to the virus. Why do we see the most pronounced decline over time in the Urban diverse neighbourhood cluster type? It could be because of behavioural adaptation, because large sections of susceptible populations developing immunity, or because of better interventions from local authorities. As demonstrated in Kwon et al. (2021) higher rates of COVID-19 infections are associated with weaker social distancing at the community level and differences in individual protective behaviour (in the Kwon et al. study, measured by self-reported wearing of face masks). Thus, it could be that such factors have played a role in determining relative differences in ICU admissions for COVID-19 across neighbourhood types. If this is the case, convergence in admittance rates could be due to a convergence in behaviour.
Our study corroborates earlier findings on regional differences in Sweden. The convergence that is present in the Swedish data can also be observed in the data on the weekly subnational 14-day notification rate of new COVID-19 cases that was released by European Centre for Disease Prevention and Control (ECDC, 2021, 19 August) or in the study of Covid cases in different parts of Stockholm and Malmö by Sigurjónsdóttir et al. (2021). The ECDC study showed that during the first eight months of the epidemic the coefficient of variation in the cumulative rate of infection across NUTS regions was at 100% or above but then declined to below 40%. The pattern of convergence that we observed for neighbourhood types has previously been reported by other researchers for individual level factors. For instance, Andersson et al., (2021) observed a decline in the coefficient size for country of birth in COVID-19 mortality over time. In our study we also saw that residence in urban neighbourhoods with the highest diversity was associated with increased risk during the first wave, but this risk became insignificant by the third wave. Importantly, there may be a different dynamic for diversity and disadvantage in urban and rural areas, since we observe that living in rural town diversity (RT_DIV) neighbourhood cluster types is a risk factor for COVID-19 ICU admission during all waves.
The convergence over time in relative risk is in line with prediction of the “stages of disease” model; however, here we observe that the inequalities in risks are greatest during the first wave, and not in the second wave as some researchers report for other countries (Meurisse et al., 2022). This may be due to different criteria being used for constructing waves (especially for Kamis et al., 2021). However, the periods used in the study by Meurisse and colleagues more closely correspond to the periods used for the current study and the authors find that in Belgium inequalities were at a peak during the second wave. It seems that in Sweden the inequalities stage, when different degree of access to resources produces inequalities in exposure to disease and risk of transmission, might have been reached earlier. These results indicate that there is a need to consider explanations that can be related to the spatial diffusion of epidemics. High rates of ICU admissions in most metropolitan cluster types during the first wave correspond to the important role of hierarchical diffusion emphasises by Cliff et al. (1981) and Griffith and Li (2021), as does the low levels of relative risks in this period for R_HOM, the most peripheral cluster type. The increase in relative risk for the rural clusters in later waves also fit the hierarchical diffusion model. With respect to the U_DIV cluster it could be that high levels of relative risks in the early phase reflect an introduction of the infection before it was known that there was an ongoing spread of COVID-19. It should be noted that the level of education in U_DIV is higher than in most other cluster types (especially in comparison to rural clusters), and this could explain why the relative risk in this neighborhood type was strongly reduced during later phases when there was mitigation. Sweden is an interesting outlier with respect to the level of restrictions that were put in place during the pandemic (Born et al., 2021), and it is possible that these policies, together with spatial inequalities in access to healthcare, contributed to the production of spatially unequal outcomes.
Lastly, we would like to discuss the possible impact of self-sorting which should be consider when assessing the causality of the association. This mechanism would refer to a health-based selection in and out of different types of areas. For example, healthier and economically successful individuals would likely move out of certain types of neighbourhoods, since their characteristics would likely make them attracted to areas where residents have characteristics more in line with their own (Arcaya et al., 2014). In our study, this means that there would be higher levels of comorbidities of residents in more deprived areas making them more vulnerable to sever outcomes associated with COVID-19.
References
Abedi, V., Olulana, O., Avula, V., Chaudhary, D., Khan, A., Shahjouei, S., Li, J., & Zand, R. (2021). Racial, economic, and health inequality and COVID-19 infection in the United States. Journal of Racial and Ethnic Health Disparities, 8(3), 732–742.
Aburto, J. M., Schöley, J., Kashnitsky, I., Zhang, L., Rahal, C., Missov, T. I., Mills, M., & Kashyap, R. (2022). Quantifying impacts of the COVID-19 pandemic through life-expectancy losses: A population-level study of 29 countries. International Journal of Epidemiology, 51(1), 63–74.
Adhikari, S., Pantaleo, N. P., Feldman, J. M., Ogedegbe, O., Thorpe, L., & Troxel, A. B. (2020). Assessment of community-level disparities in coronavirus disease 2019 (COVID-19) infections and deaths in large US metropolitan areas. JAMA Network Open, 3(7), e2016938–e2016938.
Andersson, E. (2020). Boendesegregation och covid-19 i Sverige. Externa perspektiv: Segregation och COVID-19. Delegationen mot segregation, Delmos, available from https://www.humangeo.su.se/polopoly_fs/1.529154.1606476455!/menu/standard/file/eva_andersson_segregation_och_covid_19.pdf
Andersson, G., Drefahl, S., Mussino, E., Modig, K., & Mayer, A. (2021). Dödlighet och sjuklighet i covid-19 i Sverige under mars 2020-februari 2021. Underlagsrapport till SOU 2021:89 Sverige under pandemin Stockholm 2021. Submission to Swedish Coronakommissionen, Available from https://coronakommissionen.com/wp-content/uploads/2021/10/underlagsrapport-andersson-m-fl-dodlighet-och-sjuklighet-i-covid-19-i-sverige.pdf
Andersson, E. K., & Malmberg, B. (2015). Contextual effects on educational attainment in individualised, scalable neighbourhoods: Differences across gender and social class. Urban Studies, 52(12), 2117–2133.
Aradhya, S., Brandén, M., Drefahl, S., Obućina, O., Andersson, G., Rostila, M., Mussino, E., & Juárez, S. P. (2020). Lack of acculturation does not explain excess COVID-19 mortality among immigrants. A population-based cohort study. Stockholm Research Reports in Demography. Preprint. https://doi.org/10.17045/sthlmuni.13110365.v2
Arbel, Y., Fialkoff, C., Kerner, A., & Kerner, M. (2022). Do population density, socio-economic ranking and Gini Index of cities influence infection rates from coronavirus? Israel as a case study. The Annals of Regional Science, 68(1), 181–206.
Arcaya, M. C., Subramanian, S. V., Rhodes, J. E., & Waters, M. C. (2014). Role of health in predicting moves to poor neighborhoods among Hurricane Katrina survivors. Proceedings of the National Academy of Sciences, 111(46), 16246–16253.
Billingsley, S., Brandén, M., Aradhya, S., Drefahl, S., Andersson, G., & Mussino, E. (2022). COVID-19 mortality across occupations and secondary risks for elderly individuals in the household: A population register-based study. Scandinavian Journal of Work, Environment & Health, 48(1), 52.
Born, B., Dietrich, A. M., & Müller, G. J. (2021). The lockdown effect: A counterfactual for Sweden. PLoS ONE, 16(4), e0249732.
Brandén, M., Aradhya, S., Kolk, M., Härkönen, J., Drefahl, S., Malmberg, B., & Mussino, E. (2020). Residential context and COVID-19 mortality among adults aged 70 years and older in Stockholm: A population-based, observational study using individual-level data. The Lancet Healthy Longevity, 1(2), e80–e88.
Calderón-Larrañaga, A., Vetrano, D. L., Rizzuto, D., Bellander, T., Fratiglioni, L., & Dekhtyar, S. (2020). High excess mortality in areas with young and socially vulnerable populations during the COVID-19 outbreak in Stockholm Region, Sweden. BMJ Global Health, 5(10), e003595.
Chen, J. T., & Krieger, N. (2021). Revealing the unequal burden of COVID-19 by income, race/ethnicity, and household crowding: US county versus zip code analyses. Journal of Public Health Management and Practice, 27(1), S43–S56.
Cliff, AD, Ord, JK, Haggett, P, & Versey, GR. (1981). Spatial diffusion: an historical geography of epidemics in an island community (Vol. 14): CUP Archive.
Clouston, S. A., Natale, G., & Link, B. G. (2021). Socioeconomic inequalities in the spread of coronavirus-19 in the United States: A examination of the emergence of social inequalities. Social Science & Medicine, 268, 113554. https://www.sciencedirect.com/science/article/pii/S0277953620307735
Clouston, S. A., Rubin, M. S., Phelan, J. C., & Link, B. G. (2016). A social history of disease: Contextualizing the rise and fall of social inequalities in cause-specific mortality. Demography, 53(5), 1631–1656.
Cuadros, D. F., Branscum, A. J., Mukandavire, Z., Miller, F. D., & MacKinnon, N. (2021). Dynamics of the COVID-19 epidemic in urban and rural areas in the United States. Annals of Epidemiology, 59, 16–20. https://www.sciencedirect.com/science/article/pii/S1047279721000636
De Lusignan, S., Dorward, J., Correa, A., Jones, N., Akinyemi, O., Amirthalingam, G., Andrews, N., Byford, R., Dabrera, G., Elliot, A., Ellis, J., Ferreira, F., Bernal, J. L., Okusi, C., Ramsay, M., Sherlock, J., Smith, G., Williams, J., Howsam, G., … Hobbs, R. (2020). Risk factors for sars-cov-2 among patients in the oxford royal college of general practitioners research and surveillance centre primary care network: a cross- sectional study. The Lancet Infectious Diseases, 20(9), 1034–1042.
Drefahl, S., Wallace, M., Mussino, E., Aradhya, S., Kolk, M., Brandén, M., Malmberg, B., & Andersson, G. (2020). A population-based cohort study of socio-demographic risk factors for COVID-19 deaths in Sweden. Nature Communications, 11(1), 1–7.
Dyrdak, R., & Albert, J. (2021). Utredning av den initiala smittspridningen av SARS-CoV-2 till och inom Sverige. Underlagsrapport till SOU 2021:89 Sverige under pandemin available from https://coronakommissionen.com/wp-content/uploads/2021/10/underlagsrapport-dyrdak-albert-utredning-av-den-initiala-smittspridningen-av-sars-cov-2-till-och-inom-sverige.pdf
Florida, R., & Mellander, C. (2022). The geography of COVID-19 in Sweden. The Annals of Regional Science, 68(1), 125–150.
Fonseca-Rodríguez, O., Gustafsson, P. E., San Sebastián, M., & Connolly, A. M. F. (2021). Spatial clustering and contextual factors associated with hospitalisation and deaths due to COVID-19 in Sweden: A geospatial nationwide ecological study. BMJ Global Health, 6(7), e006247.
Fotheringham, A. S., & Wong, D. W. S. (1991). The modifiable areal unit problem in multivariate statistical analysis. Environment and Planning A, 23(7), 1025–1044.
Green, M. A., García-Fiñana, M., Barr, B., Burnside, G., Cheyne, C. P., Hughes, D., Ashton, M., Sheard, S., & Buchan, I. E. (2021). Evaluating social and spatial inequalities of large scale rapid lateral flow SARS-CoV-2 antigen testing in COVID-19 management: An observational study of Liverpool, UK (November 2020 to January 2021). The Lancet Regional Health-Europe, 6, 100107. https://www.thelancet.com/journals/lanepe/article/PIIS2666-7762(21)00084-3/fulltext
Griffith, D., & Li, B. (2021). Spatial-temporal modeling of initial COVID-19 diffusion: The cases of the Chinese Mainland and Conterminous United States. Geo-Spatial Information Science, 24(3), 340–362.
Johnston, R., Pattie, Ch., Dorling, D., MacAllister, I., Tunstall, J., & Rossiter, D. (2000). Local context, retrospective economic evaluations, and voting: The 1997 general election in England and Wales. Political Behavior, 22, 121–143.
Kamis, C., Stolte, A., West, J. S., Fishman, S. H., Brown, T., Brown, T., & Farmer, H. R. (2021). Overcrowding and COVID-19 mortality across US counties: Are disparities growing over time? SSM-Population Health, 15, 100845.
Karimi, A. (2021). Heterogeneity in mortality, morbidity, and health behaviors: Covid-19 and beyond. Underlagsrapport till SOU 2021:89 Sverige under pandemin Stockholm 2021. Submission to Swedish Coronakommissionen, available from https://coronakommissionen.com/wp-content/uploads/2021/10/underlagsrapport-karimi-heterogeneity-in-mortality-morbidity-and-health-behaviors.pdf
Kawalerowicz, J., & Malmberg, B. (2021). Multiscalar typology of residential areas in Sweden. Retrieved from Stockholm University. Online resource. https://doi.org/10.17045/sthlmuni.14753826.v1
Kwon, S., Joshi, A. D., Lo, C. H., Drew, D. A., Nguyen, L. H., Guo, C. G., Ma, W., Mehta, R. S., Shebl, F. M., Warner, E. T., & Astley, C. M. (2021). Association of social distancing and face mask use with risk of COVID-19. Nature Communications, 12(1), 1–10.
Lee, B. A., Reardon, S. F., Firebaugh, G., Farrell, C. R., Matthews, S. A., & O’Sullivan, D. (2008). Beyond the census tract: Patterns and determinants of racial segregation at multiple geographic scales. American Sociological Review, 73(5), 766–791.
Leung, C. (2020). Risk factors for predicting mortality in elderly patients with COVID-19: A review of clinical data in China. Mechanisms of Ageing and Development, 188, 111255. https://www.sciencedirect.com/science/article/pii/S0047637420300518?via%3Dihub
Madhav, K. C., Oral, E., Straif-Bourgeois, S., Rung, A. L., & Peters, E. S. (2020). The effect of area deprivation on COVID-19 risk in Louisiana. PLoS ONE, 15(12), e0243028.
Matthews, K. A., Ullrich, F., Gaglioti, A. H., Dugan, S., Chen, M. S., & Hall, D. M. (2021). Nonmetropolitan COVID-19 incidence and mortality rates surpassed metropolitan rates within the first 24 weeks of the pandemic declaration: United States, March 1–October 18, 2020. The Journal of Rural Health, 37(2), 272–277.
Meurisse, M., Lajot, A., Devleesschauwer, B., Van Cauteren, D., Van Oyen, H., Van den Borre, L., & Brondeel, R. (2022). The association between area deprivation and COVID-19 incidence: A municipality-level spatio-temporal study in Belgium, 2020–2021. Archives of Public Health, 80(1), 1–10.
Nilsson, P. (2021). Betydelsen av anställda och anhörigas sociala nätverk för smittspridning av COVID-19 på äldreboenden under 2020. Underlagsrapport till SOU 2021:89 Sverige under pandemin Stockholm 2021.
Openshaw, S. (1984). The modifiable areal unit problem, CATMOG 38. Geo Abstracts, Norwich, UK.
Östh, J., Clark, W. A., & Malmberg, B. (2015). Measuring the scale of segregation using k-nearest neighbor aggregates. Geographical Analysis, 47(1), 34–49.
Östh, J., Malmberg, B., & Andersson, E. K. (2014). Analysing segregation using individualised neighbourhoods. Social-spatial segregation: Concepts, processes, and outcomes (pp. 135–162). Policy Press.
Petrović, A., van Ham, M., & Manley, D. (2022). Where do neighborhood effects end? Moving to multiscale spatial contextual effects. Annals of the American Association of Geographers, 112(2), 581–601.
Rostila, M., Cederström, A., Wallace, M., Brandén, M., Malmberg, B., & Andersson, G. (2021). Disparities in COVID-19 deaths by country of birth in Stockholm, Sweden: A total population-based cohort study. American Journal of Epidemiology, 190(8), 1510–1518.
Sigurjónsdóttir, H. R., Sigvardsson, D., & Oliveira e Costa, S. (2021). Who is left behind? The impact of place on the possibility to follow Covid-19 restrictions. Nordic Council of Ministers.
Funding
Open access funding provided by Stockholm University. These authors were funded by the Swedish Foundation for Humanities and Social Sciences (grant number M18-0214:1). Agneta Cederström was funded by the Swedish Research Council for Health, Working Life and Welfare (grant number 2016-07128) and The Swedish Public Health Agency.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethical approval
The authors comply with ethical standard outlined by the journal. The authors have no relevant financial or non-financial interests to disclose. The authors have no competing interests to declare that are relevant to the content of this article. All authors certify that they have no affiliations with or involvement in any organization or entity with any financial interest or non-financial interest in the subject matter or materials discussed in this manuscript. This article does not contain any studies with human participants performed by any of the authors. The authors have no financial or proprietary interests in any material discussed in this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A
Regression tables
See Tables
4 and
5.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kawalerowicz, J., Cederström, A., Andersson, E. et al. COVID-19 in the neighbourhood: the socio-spatial selectivity of severe COVID-19 cases in Sweden, March 2020–June 2021. GeoJournal 88, 5757–5773 (2023). https://doi.org/10.1007/s10708-023-10939-x
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10708-023-10939-x