
Abstract
Over the past few decades, Alberta has witnessed a remarkable expansion in its oil and gas sector. Unfortunately, this growth has come at a cost, as Alberta has become the fastest-growing source of pollutant emissions in greenhouse gases (GHGs), sulphur emissions, and water pollution in Canada. Among these GHGs, methane stands out as the second most prevalent GHG, possessing a global warming potential ~ 28 times higher than carbon dioxide over a span of 100 years, and ~ 80 times higher over a period of 20 years. Since 1986, the Alberta Energy Regulator (AER) has been diligently gathering data on methane concentrations. Although this data is publicly available, its analysis has not been thoroughly explored. Our study aims to investigate the impact of temperature, wind speed, and wind direction on the predictions of methane concentration time series data, utilizing a long short-term memory (LSTM) neural network model. Our findings indicate that the inclusion of climate variables enhances the predictive capabilities of the LSTM model. However, the results show that it is not obvious which variable has the most impact on the improvement although temperature appears to have a better effect on improving predictive performance compared to wind speed and direction. The results also suggest that the variance of the input data does not affect forecasting performance.
Similar content being viewed by others

Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
1 Introduction
Methane is a potent greenhouse gas (GHG), trapping more than 80 times more heat in the atmosphere than carbon dioxide after it reaches the atmosphere over the first 20 years [1, 2, 3]. According to the Canadian federal government’s official greenhouse gas inventory, methane accounts for 13% of Canada’s GHG emissions. About 43% of methane emissions in Canada are sourced from oil and gas operations and 29% from agricultural (e.g. cattle) activities [4, 5]. Just under 20% of global warming can be attributed to methane [6]. Despite COVID-19 pandemic shutdowns worldwide, methane concentration still grew in 2021 as shown in Fig. 1 [7].

Global monthly methane mean concentration from July 1983 to December 2021 [7]
There have been many policies and activities targeted at reducing methane emissions in recent years. For example, the Global Methane Pledge launched in November 2021 at COP26 aims to reduce global methane emissions 30% below 2020 levels by 2030 [8]. Canada has committed to this pledge. Alberta, as a proactive provincial government, has committed to a methane emission reduction objective for the oil and gas sector, positioning itself as a leader in emission reduction efforts [9, 10]. In September 2021, the Canadian government set a target to reduce methane emissions by 45% below 2012 levels by 2025. This reduction target is part of Canada’s efforts to address climate change aligning with its commitments under the Paris Agreement. To achieve the 45% target, the Canadian government has implemented various measures, including regulations and industry-specific initiatives in particular, focused on the oil and gas sector. Alberta [9] has reported that oil and gas methane emissions dropped by 44% between 2014 and 2021 although there are uncertainties that need to be addressed with respect to potential underestimates methane emission volumes [11]. Further to the 45% target, the Government of Canada has committed to reducing methane emissions from the upstream oil and gas industry by 75% from the 2012 levels by 2030 whereas the Government of Alberta is considering a 75–80% reduction from 2014 levels by 2030.
Given the trends for GHG emissions and concentrations in the atmosphere, it is important to have tools to predict the evolution of methane air concentrations through time as a basis for establishing a baseline to ensure reductions are occurring. Therefore, accurate methane prediction models are required for projecting how methane emissions link to industry activities as well as to provide informative and prompt analysis, allowing government and even people in affected areas to take timely actions to reduce emissions.
Methane concentration prediction is a time series problem. Traditional time series analysis and forecasting methods, for example, the autoregressive moving average (ARIMA) method uses univariate time series to make predictions without accounting for ambient climate variables [12, 13]. However, it is well known that methane concentration is affected by many factors, such as temperature and wind speed and directions. Wind speed and direction reflect the atmospheric pressure distribution. In recent years, machine learning–based models for predicting GHG emissions have been acknowledged as both efficient and reasonably accurate [14,15,16,17,18,19]. Numerous prediction models of methane emissions have been developed using data obtained from dairy cows [20], sheep and dietary factors [21, 22], rice paddies [23, 24], and other natural systems such as agricultural soil [14, 25], wetlands [26], and inland freshwater bodies, i.e. ponds, reservoirs, and lakes [15, 16]. Despite this work, there remains no consensus on the best method and type of additional data, e.g. temperature and wind conditions, that can be used to improve predictions of methane concentration time series data.
Several machine learning approaches have been used to model methane concentration [14, 19]. Among those studies, multiple variable linear regression has been used to analyze the percentage of the variance of emissions associated with production volume [27]. Support vector machines (SVMs) have been used for forecasting methane emissions from landfills [28]. Long short-term memory (LSTM) neural networks have been used to predict emissions from soil [14]. The Prophet model has been used for forecasting air pollution time series data [17]. There has been considerable progress in developing neural network methods for air pollution modelling [29, 30]. Athira et al. [31] applied recurrent neural networks (RNNs) to predict air quality and Ma et al. [21, 32] used long short-term memory (LSTM) neural networks to forecast particulate matter and carbon dioxide emissions. LSTMs, due to their ability to have “memory” and capture long-term dependencies, have been shown to provide strong performance for predicting data trends, but no studies so far have focused on their use to build models to predict methane emission using multivariate data.
Here, we examine the application of LSTM for analysis of the time series tied to multivariate climate data, in particular, temperature and wind speed and direction, to predict methane concentration in the air. Methane concentration, temperature, wind speed, and direction data in the Fort McMurray area, Alberta, are explored using LSTMs. The seven adjacent air quality monitoring station datasets in the Wood Buffalo area of Alberta, Canada, displayed in Fig. 2, were used for the analysis.

Wood Buffalo monitoring sites [33]. The data used here is from the following stations: Anzac, Bruderheim, Buffalo Viewpoint, Fort McMurray—Athabasca Valley, Fort McMurray—Patricia McInnes, Lower Camp, Mildred Lake
2 Materials and Methods
2.1 Data Description
The air quality data used to train and test the machine learning models is categorized as multivariate and discrete-time series data. Specifically, multivariate and discrete-time series are data points that contain sequential multiple variable records measured over contiguous time periods at discrete time points.
The quality of the observation data for training is one of the most critical factors for the successful performance of a machine learning prediction model. In the province of Alberta, air quality is monitored in airshed regions by industry, communities, and Alberta Environment and Parks Canada [9]. In 1992, Canada established the National Pollutant Release Inventory (NPRI), where industries, businesses, and facilities are required to report the release of substances and disposal to the NPRI [34]. This data helps the government monitor emissions and air quality and regulate environmental policies [35, 9]. This study has multivariate data from seven permanent monitoring stations, listed in Table 1, with data spanning dates ranging from 2010 to 2021. All seven stations are from the Wood Buffalo Environmental Association (WBEA) [36]. The WBEA operates the largest airshed in the largest municipality and is considered Canada’s most integrated and intensive air and terrestrial monitoring [36]. The WBEA monitors the air in the Regional Municipality of Wood Buffalo (RMWB) 24 h a day, 365 days a year.
The Continuous Emission Monitoring Systems (CEMS) Code of Alberta holds standards and requirements for installing, operating, maintaining, and certification continuous emission monitoring systems [37, 10, 35]. The code has been taken effect since 1998 and got recently revised in 2021, with the intention to ensure effective and standardized measurement, recording and reporting of specified emissions and other parameters [9]. All the quality assurance and quality control actions taken for each dataset collected in the Alberta Airsheds guarantee the quality of the time series data we are feeding for the machine learning models. In addition, the WBEA works closely with Alberta Environment and Parks (AEP) to ensure they have followed every standard, enhancing the overall quality of the monitoring data, both air and terrestrial.
Table 1 lists a detailed date range, number of data points, and statistical parameters for methane data from each station. The corresponding number of data points of temperature, wind speed, and wind direction are the same as the methane data points. In this study, we focus on examining the deep feature relationships between different combinations of climate variables among these seven monitoring stations.
We use hourly air quality data from the Alberta Air Data Warehouse for the seven stations shown in Fig. 2. The dataset contains several variables: methane concentration, outdoor air temperature, wind speed, and wind direction. Table 2 provides detailed information about the input variables, units, and measurement methods. The wind speed, \(U\), is preprocessed by converting it into latitudinal (x) and longitudinal (y) direction components:
where the wind direction \(\varnothing\) is expressed in radians. An example of the input variables profile for the Anzac monitoring station for 2020 is shown in Fig. 3 (the other six station’s data are displayed in the “Supplementary Information” section). In our analysis, all data points are used.

Time series plots of methane, temperature, and wind speed components (x and y) for the Anzac monitoring station in Northern Alberta [35]
In another example, Fig. 4 illustrates the methane concentration (in ppm) versus temperature through time, in 1-year increments, for the Bruderheim station. In some years, the data shows that there is a tendency for higher methane concentrations in winter (lower temperature) and lower in summer (higher temperature), although in some years, there are methane concentration peaks occurring in warmer weather (see 2010–2011 and 2012–2013 for example). A large fraction of the data is at a concentration of about 2 ppm with less data found above 3 ppm. The data shows that there are many peaks in some years with data above 3 ppm (e.g. 2014–2015 and 2015–2017), but after 2017, the data is mainly focused below 3 ppm with a tendency for flatter profiles.

Methane concentration (in ppm) versus temperature (in °C) for the Bruderheim station through time.
2.2 Long Short-Term Memory
Long short-term memory (LSTM) neural networks are an improvement of the recurrent neural networks (RNN) approach, which was designed to avoid the vanishing and exploding gradient problems [38, 39]. As a variant of RNN, LSTM consists of a chain of repeating modules. Each module contains exclusive “cell states” that preserve long-term dependencies throughout the model training progress [40]. Compared to the standard RNN, the LSTM neural network performs better in training with long-time sequences. Each LSTM storage unit consists of one memory cell \({C}_{{\text{t}}}\) and three gates, including the forget gate \({f}_{{\text{t}}}\), the input gate \({i}_{{\text{t}}}\), and the output gate \({o}_{{\text{t}}}\). The state of the memory cell \({C}_{{\text{t}}}\) is jointly controlled by the three gates [41, 42]. Formally, the LSTM network can be formulated as:
At the start, an input \({x}_{{\text{t}}}\) at time t is fed to the network. The forget gate \({f}_{{\text{t}}}\) then decides which information from the previous output \({h}_{{\text{t}}-1}\) is discarded or kept. Then, the input gate \({i}_{{\text{t}}}\) decides which state will be updated. With the outputs obtained from the forget gate and the input gate, in addition to a vector of new \(\widetilde{{C}_{{\text{t}}}}\) generated with a \({\text{tanh}}\) layer, an updated new cell state \({C}_{{\text{t}}}\) is determined. The result \({h}_{{\text{t}}}\) comprises a sigmoid neural network layer and a \({\text{tanh}}\) function with respect to the new cell state. The weights \({W}_{{\text{X}}}(X \in [f, i, C, o])\) are for the previous hidden state and current input, \({b}_{{\text{X}} }(X \in \left[f, i, C, o\right])\) are the bias vectors, and \(\sigma\) is the sigmoid function given by \(\sigma = \frac{{e}^{{\text{x}}}}{{e}^{{\text{x}}}+1}\). Here, “\(\odot\)” is the Hadamard product (an element-wise product). Also, “ + ” represents pointwise addition.
2.3 Rolling Window
The collected raw data are in a consecutive form that the model cannot take in as input data directly. To deal with this, the rolling window method for data preprocessing before feeding it into the model was used. To predict the time-series value at time t + 1, the model not only needs the value at time t but also the values at time t − 1, t − 2, …, t − ∆t. ∆t is defined as the lookback window size. A smaller lookback size might not give an equivalent prediction performance compared with a larger lookback size. However, the larger the lookback size, the greater the computational work, noise, and complexity [21, 32, 43]. In our approach, the lookback window size is optimized. For sequential data such as time-series data where subset samples of the data are not likely independent, we use a blocked time-series cross-validation. In this approach, two margins are used: first, we added a gap between the training data set and the validation data to make sure that there were no lag values or “history” to interfere the validation [44]. The second gap was between each iteration with size equal to the lookback window size (the data sets are organized in the rolling window structure) to help prevent the model memorizing the pattern from previous samples [44].
For each individual station, 80% of its data is used for training, 10% retained for testing, and the remaining 10% reserved for cross-validation. For training, testing, and validation, the data from the stations were kept separate. Detailed information about how the data was fed into the model is illustrated in Fig. 5. In each epoch, the model is trained on batches of data with the data object shape of [lookback window size, 1] until the model has traversed all the training data.

Rolling window data structure for ML algorithms
3 Experimental Design
3.1 Proposed Architecture
The objective is to select the hyperparameter combinations that yield the best forecasting model. Figure 6 presents the flowchart for the multivariate prediction of the air quality data. The proposed framework consists of three main parts: data preprocessing, neural network training, optimization, and multivariate prediction. The data preprocessing stage is responsible for extracting and validating the time series data and then formatting the data with the rolling window before feeding it into the neural network models. Next, in the second stage, the neural network will be trained again and again with different hyperparameter combinations to find the one with the best forecasting performance yielding a model ready for forecasting.

Flowchart of the proposed architecture
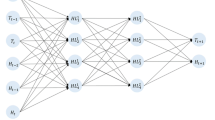
To take a closer look at each layer of the neural network, Fig. 7 shows the proposed topology of the proposed multivariate LSTM networks. First, the inputs of the climate variables are extracted and validated from the raw dataset after removing invalid data, which is indicated by abnormal or erroneous observations, such as sudden temperature spikes. In this research, two processes were used to evaluate invalid data. We use the Z-score method to detect how many standard deviations away a data point is from the mean. Although the Z-score is one of the most efficient ways to detect anomalies, the potential drawback of mean and standard deviation being highly affected by outliers should be validated. Here, to deal with this, the isolation forest, a binary tree–based unsupervised machine learning method, is used to verify and ensure that the mean and standard deviation are not affected by outliers. Second, the feature datasets are reformed with the rolling window structure with a given window size where the window size represents how much history is contained within each training step. Third, the datasets are normalized and fed to the LSTM layer; each input has its own LSTM layer. Last, the results from each input are concatenated and fed to the final dense layer to generate the prediction result.

Multivariate LSTM Architecture
3.2 Hyperparameters Optimization
A LSTM neural network contains parameterized functions that directly affect the performance of the algorithm for providing better predictions. A grid search of the hyperparameters was used for the optimization process; the points used are listed in Table 3. After hyperparameters are found that yield the best results, the model is trained for making predictions. The pseudo-code for the proposed multivariate LSTM structure is illustrated in Algorithm 1, which is divided into three parts to reflect the flowchart described above.

Pseudo-code for procedures of proposed prediction framework
3.3 Measures of Error
The root mean squared error (RMSE), one of the most common scoring rules to evaluate the accuracy of the model, is calculated from:
where \({Y}_{{\text{i}}}\) is the actual value of methane concentration, \({P}_{{\text{i}}}\) is the predicted value, and \(n\) is the number of data points. The RMSE measures the average magnitude of the error from the calculation, which gives high weight to large errors. It is evident that the smaller the RMSE value is, the more accurate the prediction is. The mean absolute error (MAE) is another criterion to evaluate model performance that shows the average offset compared with the actual observation, given by:
In the equation, \({Y}_{{\text{t}}}\) is the actual value while \({P}_{{\text{t}}}\) is the predicted value.
4 Results and Discussion
Figures 8 and 9 show the predicted values of each climate combination and observed (raw) methane concentration values for the Lower Camp and Mildred Lake stations, respectively (the other station results are displayed in the “Supplementary Information” section). The x-axis represents the time, and the y-axis is the methane concentration in parts per million (ppm). The blue line shows the raw data, whereas the red line shows the univariate model prediction value (prediction obtained from training with the methane data alone); this model is the Methane-only model. The green line showed the methane concentration prediction when the model was trained with both the methane and temperature data; this model is referred to as the Methane + Temp model. The purple line shows the predicted methane concentration when the model is trained with both the methane concentration and wind speed and direction data; this model is referred to as the Methane + Wind model. Finally, the orange line shows the methane concentration predictions when the model is trained with the methane concentration, temperature, and wind data; this model is referred to as the Methane + Temp + Wind model.

Lower Camp station predicted value versus the observed (raw) methane concentration

Mildred Lake station predicted value versus the observed (raw) methane concentration
Table 4 lists the MAE and RMSE evaluations between the different models and monitoring stations for the training and validation phase. In general, the Methane + Temp model outperforms the Methane + Wind model with respect to both MAE and RMSE, and in some cases, the Methane + Temp + Wind outperforms the Methane + Temp model. For example, in the training and validation phases, the MAE for the Anzac station was lowered from 0.00245 ppm for the Methane-only model to 0.00207 ppm with the Methane + Temp model and 0.00322 ppm for the Methane + Wind model and further lowered to 0.00168 for the Methane + Temp + Wind model. In the other cases, the Methane + Temp model performed better than the Methane + Temp + Wind model. The RMSE is also lowered for the Methane + Temp models in the training and validation phases. For example, the RMSE for methane prediction of the Fort McMurray-Athabasca Valley station data is 0.000410 for the Methane-only model, which rises to 0.000412 for the Methane + Wind model and 0.000439 for the Methane + Temp model.
Table 5 lists the MAE and RMSE values for forecasting data that the models had not seen before (the forecasting phase). The results exhibit similar trends to that of the training and validation phases. The MAE for the prediction of the Fort McMurray-Patricia McInnes station data is reduced from 0.0478 ppm for the Methane-only model to 0.0486 ppm for the Methane + Wind model and 0.0457 ppm for the Methane + Temp model. The Methane + Temp + Wind model achieves a RMSE of 0.0464 ppm. The RMSE for this station is 0.109 for the Methane-only model which declined to 0.107 for the Methane + Temp model. When the wind parameters are included in the training set (the Methane + Temp + Wind model), the RMSE is larger. Overall, the models trained with both methane concentration and temperature data in most cases achieve the best predictive performance.
When looking at the forecasting error versus the variance value of the methane concentration data for different monitoring stations listed in Table 1, it becomes clear that the data with a higher variance has lower training errors. For example, the Bruderheim station has a variance of 0.1217 but still has an RMSE (training and validation) of only 0.000277. On the other hand, Buffalo Viewpoint has a relatively low variance of 0.0357 but has a higher RMSE of 0.00122. This provides evidence that the variance of the input data does not affect the forecasting performance.
The results demonstrate that the addition of temperature data to the methane concentration training set provides a better predictive model than that when the wind parameters are included. One reason for this could be that as the temperature rises, a given number of moles of methane would have greater volume (as shown by the ideal gas law). Thus, the higher the temperature, the greater the amount of methane that would leak from a system containing methane. Also, the larger the temperature, the lower the solubility of methane in water and oil. In oil and gas operations where methane is dissolved in the produced water and oil (in the form of solution gas, for example), the higher the temperature, the larger the amount of methane released from this water and oil. Alberta is a large oil-producing province holding the third-largest reserves of oil globally (March 2022) which implies that there are industry sources for methane emissions. The wind parameters (speed and direction) do not provide an improvement of the predictive performance of the model when included in the training data. This is likely because the wind is somewhat random in nature and does not have a physical link between it and methane concentration. However, the greater the wind, due to dilution effects, the lower would be the methane concentration. However, the results do not demonstrate that when the wind is added to the training set that it helps the predictive capabilities of the model over that of training the model on the methane data alone.
5 Conclusions
A multivariate prediction LSTM-based machine learning model to forecast methane concentrations has been evaluated. The results suggest that adding temperature and wind speed and direction to the methane concentration training dataset may help or harm the prediction performance of the machine learning model. On the one hand, when the temperature is added to the training dataset, the ability of the model to predict methane concentration is improved over that of using the methane concentration data alone. On the other hand, the use of the wind speed and direction led to less accurate predictions. The results reveal that the models provide different degrees of performance depending on the station. This demonstrates that the machine learning model is not able to perform uniformly for the stations. Another observation is that the MAE for the forecasting phase is roughly an order of magnitude higher than that of the training and validation phase. The RMSE exhibits similar trends to that of the MAE results. The results also suggest that the variance of the data does not affect forecasting performance. Limitations of the study arise from the LSTM method itself: potential overfitting by the LSTM, non-optimal choice of hyperparameters, and detection of anomalous data. Although attention was paid to detect issues arising from these limitations, future work will expand on understanding why the model was not able to perform uniformly for all of the stations as well as examining other machine learning methods that can improve the ability to predict methane concentrations when integrated with temperature and wind speed data.
Data Availability
The raw data used is available at the Alberta Airshed Council at https://www.albertaairshedscouncil.ca/.
References
Nature. (2021). Control methane to slow global warming – fast. Nature, 596, 461. https://www.nature.com/articles/d41586-021-02287-y
Myhre, G., Shindell, D., Bréon, F.-M., Collins, W., Fuglestvedt, J., Huang, J., Koch, D., Lamarque, J.-F., Lee, D., Mendoza, B., Nakajima, T., Robock, A., Stephens, G., Takemura, T., & Zhang, H. (2013). Anthropogenic and natural radiative forcing. In Climate Change 2013: The Physical Science Basis. Contribution of Working Group I to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change. T.F. Stocker, D. Qin, G.-K. Plattner, M. Tignor, S.K. Allen, J. Doschung, A. Nauels, Y. Xia, V. Bex, and P.M. Midgley, Eds., Cambridge University Press, pp. 659–740. https://doi.org/10.1017/CBO9781107415324.018
US EPA https://www.epa.gov/ghgemissions/understanding-global-warming-potentials. Accessed on 15 Dec 2021.
Ciais, P., Sabine, C., Bala, G., Bopp, L., Brovkin, V., Canadell, J., Chhabra, A., DeFries, R., Galloway, J., Heimann, M., Jones, C., Le Quéré, C., Myneni, R. B., Piao, S., & Thornton, P. (2013). Carbon and other biogeochemical cycles supplementary material. In Climate Change 2013: The Physical Science Basis. Contribution of Working Group I to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change Stocker, T.F., D. Qin, G.-K. Plattner, M. Tignor, S.K. Allen, J. Boschung, A. Nauels, Y. Xia, V. Bex and P.M. Midgley (Eds.). Available from https://www.ipcc.ch/site/assets/uploads/2018/02/WG1AR5_Chapter06_FINAL.pdf
Government of Canada, Greenhouse gas sources and sinks: Executive summary. (2023). Available at https://www.canada.ca/en/environment-climate-change/services/climate-change/greenhouse-gas-emissions/sources-sinks-executive-summary-2023.html#
Borunda, A. (2021). Methane facts and information. Available at https://www.nationalgeographic.com/environment/article/methane
Dlugokencky, E. (2022). Trends in atmospheric methane. Available at https://gml.noaa.gov/ccgg/trends_ch4/NOAA/GML
CCAC. (2021). Global methane pledge. Climate & Clean Air Coalition Secretariat, United Nations Environment Programme. Available at https://www.globalmethanepledge.org
Government of Alberta. (2022). Air quality monitoring and management in Alberta. Available at https://www.alberta.ca/air-quality.aspx
Alberta Airsheds Council. (2017). Working together for cleaner air. https://www.albertaairshedscouncil.ca/
Bryant, A. (2023). Too soon to celebrate progress in reducing methane gas emissions. Policy Options. Available at: https://policyoptions.irpp.org/magazines/january-2023/methane-gas-emissions/
Malik, A., Khokhar, M., Hussain, E., & Baig, S. (2020). Forecasting CO2 emissions from energy consumption in Pakistan under different scenarios: The China-Pakistan economic corridor. Greenhouse Gases: Science and Technology, 10(2), 380–389. https://doi.org/10.1002/ghg.1968
Tudor, C., & Sova, R. (2021). Benchmarking GHG emissions forecasting models for global climate policy. Electronics, 10(24), 3149. https://doi.org/10.3390/electronics10243149
Hamrani, A., Akbarzadeh, A., & Madramootoo, C. (2020). Machine learning for predicting greenhouse gas emissions from agricultural soils. Science of The Total Environment, 741, 140338. https://doi.org/10.1016/j.scitotenv.2020.140338
Li, T., Hua, M., & Wu, X. (2020). A hybrid CNN-LSTM model for forecasting particulate matter (PM2.5). IEEE Access, 8, 26933-26940. https://doi.org/10.1109/access.2020.2971348
Li, G., Yang, M., Zhang, Y., Grace, J., Lu, C., Qing, Z., Jia, Y., Liu, Y., Lei, J., Geng, X., Wu, C., Lei, G., & Chen, Y. (2020). Comparison model learning methods for methane emission prediction of reservoirs on a regional field scale: Performance and adaptation of methods with different experimental datasets. Ecological Engineering, 157, 105990. https://doi.org/10.1016/j.ecoleng.2020.105990
Shen, J., Valagolam, D., & McCalla, S. (2020). Prophet forecasting model: A machine learning approach to predict the concentration of air pollutants (PM2.5, PM10, O3, NO2, SO2, CO) in Seoul, South Korea. PeerJ, 8, e9961. https://doi.org/10.7717/peerj.9961
Xayasouk, T., Lee, H., & Lee, G. (2020). Air pollution prediction using long short-term memory (LSTM) and deep autoencoder (DAE) models. Sustainability, 12(6), 2570. https://doi.org/10.3390/su12062570
Zhang, B., Zhang, H., Zhao, G., & Lian, J. (2019). Constructing a PM2.5 concentration prediction model by combining auto-encoder with Bi-LSTM neural networks. Environmental Modelling & Software, 124, 104600. https://doi.org/10.1016/j.envsoft.2019.104600
Niu, P., Schwarm, A., Bonesmo, H., Kidane, A., Aspeholen, A. B., Storlien, T. M., Kreuzer, M., Alvarez, C., Sommerseth, J. K., & Prestløkken, E. (2021). A basic model to predict enteric methane emission from dairy cows and its application to update operational models for the national inventory in Norway. Animals, 11(7), 1891. https://doi.org/10.3390/ani11071891
Ma, J., Li, Z., Cheng, J. C., Ding, Y., Lin, C., & Xu, Z. (2019a). Air quality prediction at new stations using spatially transferred bi-directional long short-term memory network. Science of The Total Environment, 705, 135771. https://doi.org/10.1016/j.scitotenv.2019.135771
Ma, J., Ding, Y., Cheng, J. C., Jiang, F., & Wan, Z. (2019b). A temporal-spatial interpolation and extrapolation method based on geographic long short-term memory neural network for PM2. 5. Journal of Cleaner Production, 237, 117729.
Shaukat, M., Muhammad, S., Maas, E., Khaliq, T., & Ahmad, A. (2022). Predicting methane emissions from paddy rice soils under biochar and nitrogen addition using DNDC model. Ecological Modelling, 466, 109896. https://doi.org/10.1016/j.ecolmodel.2022.109896
Tian, Z., Niu, Y., Fan, D., Sun, L., Ficsher, G., Zhong, H., Deng, J., & Tubiello, F. N. (2018). Maintaining rice production while mitigating methane and nitrous oxide emissions from paddy fields in China: Evaluating tradeoffs by using coupled agricultural systems models. Agricultural Systems, 159, 175–186. https://doi.org/10.1016/j.agsy.2017.04.006
Homaira, M., & Hassan, R. (2021). Prediction of agricultural emissions in Malaysia using the Arima, LSTM, and regression models. International Journal on Perceptive and Cognitive Computing, 7(1), 33–40.
Irvin, J., Zhou, S., McNicol, G., Lu, F., Liu, V., Fluet-Chouinard, E., Ouyang, Z., Knox, S., Lucas-Moffat, A., Trotta, C., Papale, C., Vitale, D., Mammarella, I. Alekseychik, P. Aurela, M., Avati, A., Baldocchi, D., Bansal, S., Bohrer, G., & Jackson, R. (2021). Gap-filling eddy covariance methane fluxes: Comparison of machine learning model predictions and uncertainties at FLUXNET-CH4 wetlands. Agricultural and Forest Meteorology, 308–309. https://doi.org/10.1016/j.agrformet.2021.108528
Wang, J., Nadarajah, S., Wang, J., & Ravikumar, A. (2020). A machine learning approach to methane emissions mitigation in the oil and gas industry. https://doi.org/10.31223/X57W29
Mehrdad, S.M., Abbasi, M., Yeganeh, B., & Kamalan, H. (2021). Prediction of methane emission from landfills using machine learning models. Environmental Progress & Sustainable Energy, 40(4), 13629. https://doi.org/10.1002/ep.13629
Ayturan, A., Ayturan, Z., & Altun, H. (2018). Air pollution modelling with deep learning: A review, 1, 58–62.
Cabaneros, S. M., Calautit, J.K., & Hughes, B. (2019). A review of artificial neural network models for ambient air pollution prediction. Environmental Modelling & Software, 119. https://doi.org/10.1016/j.envsoft.2019.06.014
Athira, V., Geetha, P., Vinayakumar, R., & Soman, K. P. (2018). DeepAirNet: Applying recurrent networks for air quality prediction. Procedia Computer Science, 132, 1394–1403. https://doi.org/10.1016/j.procs.2018.05.068
Ma, T., Deng, K., & Diao, Q. (2019). Prediction of methane emission from sheep based on data measured in vivo from open-circuit respiratory studies. Asian-Australasian Journal of Animal Sciences, 32(9), 1389–1396. https://doi.org/10.5713/ajas.18.0828.
Wood Buffalo Environmental Association. (2022). The WBEA monitors your air quality 24/7. https://wbea.org/
Government of Canada. (2021). Greenhouse gas sources and sinks: Executive Summary 2021. Available at https://www.canada.ca/en/environment-climate-change/services/climate-change/greenhouse-gas-emissions/sources-sinks-executive-summary-2021.html
Government of Alberta. (2022). Alberta Air Data Warehouse. https://www.alberta.ca/alberta-air-data-warehouse.aspx
Wood Buffalo Environmental Association Annual Report. (2015). https://wbea.org/wp-content/uploads/2018/02/wbea_2015_annual_report.pdf
Government of Canada, Continuous Emission Monitoring System (CEMS) Code. (2021). https://open.alberta.ca/publications/continuous-emission-monitoring-system-cems-code#summary
Nguyen, H.-P., Liu, J., & Zio, E. (2020). A long-term prediction approach based on long short-term memory neural networks with automatic parameter optimization by Tree-structured Parzen estimator and applied to time-series data of NPP steam generators. Applied Soft Computing, 89, 106116. https://doi.org/10.1016/j.asoc.2020.106116
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780.
Krishan, M., Jha, S., Das, J., Singh, A., Goyal, M. K., & Sekar, C. (2019). Air quality modelling using long short-term memory (LSTM) over NCT-Delhi, India. Air Quality, Atmosphere & Health, 12, 899–908.
Graves, A., & Schmidhuber, J. (2005). Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural networks, 18, 602–610.
Zhao, J., Deng, F., Cai, Y., & Chen, J. (2019). Long short-term memory - Fully connected (LSTM-FC) neural network for PM2.5 concentration prediction. Chemosphere, 220, 486–492.
Brockwell, P.J., Davis, R.A., & Calder, M.V. (2002). Introduction to time series and forecasting. Springer. ISBN: 978–0–387–21657–7.
Roberts, D. R., Bahn, V., Ciutu, S., Boyce, M. S., Elith, J., Guillera-Arroita, G., Houenstein, S., Lahoz-Monfort, J. J., Schöder, B., Thuiller, W., Wintle, B. A., Hartig, F., & Dormann, C. F. (2017). Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure. Ecography, 40(8), 913–929.
Acknowledgements
The authors acknowledge support from the University of Calgary’s Canada First Research Excellence Fund program, the Global Research Initiative (GRI) for Sustainable, Low-Carbon Unconventional Resources.
Author information
Authors and Affiliations
Contributions
Ran Luo: Conceptualization, Methodology, Investigation, Data curation, Validation, Visualization, Writing—Original Draft. Jingyi Wang: Investigation, Software, Writing – Reviewing and Editing. Ian D. Gates: Conceptualization, Methodology, Resources, Funding Acquisition, Project administration, Writing- Reviewing and Editing.
Corresponding author
Ethics declarations
Ethical Approval
Not applicable.
Competing Interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Luo, R., Wang, J. & Gates, I. Forecasting Methane Data Using Multivariate Long Short-Term Memory Neural Networks. Environ Model Assess 29, 441–454 (2024). https://doi.org/10.1007/s10666-024-09957-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10666-024-09957-x