
Abstract
Open source software projects often use issue repositories, where project contributors submit bug reports. Using these repositories, more bugs in software projects may be identified and fixed. However, the content and therefore quality of bug reports vary. In this study, we aim to understand the significance of different elements in bug reports. We interviewed 35 developers to gain insights into their perceptions on the importance of various contents in bug reports. To assess our findings, we surveyed 305 developers. The results show developers find it highly important that bug reports include crash description, reproducing steps or test cases, and stack traces. Software version, fix suggestions, code snippets, and attached contents have lower importance for software debugging. Furthermore, to evaluate the quality of currently available bug reports, we mined issue repositories of 250 most popular projects on Github. Statistical analysis on the mined issues shows that crash reproducing steps, stack traces, fix suggestions, and user contents, have statistically significant impact on bug resolution times, for ∼70%, ∼76%, ∼55%, and ∼33% of the projects. However, on avarage, over 70% of bug reports lack these elements.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Open source software projects often maintain issue repositories to manage feature requests and bug reports. There are potential advantages to using open issue repositories (Anvik et al. 2005). Contributors of software projects provide their inputs and maintain focused conversations over them. As a result, more bugs in software projects may be identified and fixed (Anvik et al. 2005).
Bug reports contain various types of information, including: software version, crash description, reproducing steps, reproducing test cases, crash stack traces, and fix suggestions. To make bug reports consistent, often default templates are provided in project repositories, where certain required or at least recommended fields are specified to be filled by the contributors. Yet, the content and therefore quality of bug reports vary (Zimmermann et al. 2010). Potential reasons for this issue include: data loss during a software crash, difficulty to find crash data in log files, and lack of sufficient technical experience (Zimmermann et al. 2010).
If too little data is provided in bug reports, then understanding the problem, and therefore reproducing it is nontrivial and time-consuming. On the other hand, reproducing software crashes is a vital step in software debugging. Developers need to know how to reproduce the crashes to be able to confirm the fixes they deliver. Furthermore, low quality bug reports may demotivate developers and therefore take longer to be processed.
The following are examples of bug reports from various popular projects on Github (2019a; b; c, d, e, f, g, h) . These examples illustrate when a crash stack trace or reproducing test case are missing, developers respond by first asking the bug reporter to provide these elements. Figure 1 shows a bug report (Github 2019a) as well as the responses to the bug report. As Fig. 1a shows, the bug report includes various elements such as actual behavior, reproducing steps, versions of various components, etc. However, the bug report misses a crash stack trace. As Fig. 1b shows, the developers explicitly ask for the crash stack trace. Since after one month, this information is not provided, the bug report is closed.

An snapshot of a bug report (Github 2019a) which is missing a crash stack trace, as well as the responses to it
We aim to understand the significance of various information in bug reports for software debugging. To gain an in-depth understanding of developers’ perceptions, we interviewed 35 developers. We used Grounded Theory Adolph et al. (2011) and Glaser and Holton (2004) techniques to analyse the interview results. To examine the findings from the interviews, we surveyed 305 developers. Our findings confirm that crash description, crash reproducing steps and test cases, and stack traces are of high importance for developers when debugging. On the other hand, developers find extra information that users may provide such as fix suggestions, code snippets, and links to user content, such as screenshots, of lower importance.
To gain insights on how often important elements are included in bug reports and their impact on bug resolution times, we developed the IMaChecker approach. IMaChecker receives Github repositories as input, then mines all issues posted in the input repository. Once the issues are downloaded, IMaChecker analyses the issues to check whether they are bug reports, and if they contain elements including: crash description, reproducing steps or test cases, stack traces, code snippets, links to user content, or fix suggestions.
To create a corpus of repositories for evaluation, we first selected five popular languages used in Github according to The State of the Octoverse (2017, 2018) , which are namely: Javascript, Python, Java, PHP, and Ruby. For each language, we selected 50 most popular repositories, resulting in 250 repositories in total, on Github.
To analyse the impact of various elements of bug reports on bug resolution times, we used the Wilcoxon-Mann Whitney test.
To study realistic projects and maintain statistical power, only those projects which provided at least 10 issues for both experimental and control groups, were analysed. Experimental groups contained issues which only included the element of interest in the bug report (e.g., the issue only included stack traces). Control groups contained issues which only included general description of the crash. The results confirm that reproducing steps, stack traces, fix suggestions, and user contents have statistically significant impact on bug resolution times, for ∼70%, ∼76%, ∼55%, and ∼33% of the projects, respectively. For code snippets, representative projects were not found.
Furthermore, we used descriptive statistics to report the average percentages of bug reports that include different bug report elements. Despite our findings on important bug report elements and their impact on bug resolution times, on average, over ∼70% of bug reports lack all important elements.
The above results help to raise awareness of the significance of various contents in bug reports for software debugging. Developers can use this information to prepare better templates for bug reports, in which all important elements are explicitly asked for. Furthermore, future work may investigate means to support and enable users to find and provide the information elements.
The contributions of the paperFootnote 1 are the following:
-
1.
an extensive report from developer interviews and surveys, in addition to the interview and survey questionnaires,
-
2.
IMaChecker as an open source tool, written in Python, which can be used to mine and analyse issues from Github repositories, and
-
3.
a reproducible package which contains the data set of all mined issues from 250 most popular Github repositories, together with the R scripts used to analyse the mined data.
The remainder of this paper is organized as following: Section 2 presents the research methodology. Section 3 presents the IMaChecker approach. Section 4 presents the results. Section 5 provides discussion on the findings of the paper. Section 6 provides related work. Finally, Section 7 concludes the paper.
2 Research Methodology
The overarching goal of this study is to identify the significance of elements of bug reports for software debugging. Therefore we define the following research questions:
-
RQ1: What types of information do developers perceive as important in bug reports?
Motivation: The quality of bug reports varies depending on the kinds of information which are included in them. The study by Zimmermann et al. (2010) shows developers and users of Apache, Eclipse, and Mozilla find reproduction steps and crash stack traces to be the most useful elements in bug reports. However, there is little knowledge about the other elements in bug reports and the extent to which they are perceived as important for software debugging. We raise RQ1 to broaden our perspective and gain a holistic understanding about the extent to which different bug report elements are of importance for software debugging in developers’ perception.
Data collection and analysis: To answer RQ1 we aim to combine interviewing developers with surveying them. By conducting interviews, we intend to gain a preliminary understanding of developers’ views on bug reports and the role that each bug report element plays in the process of software debugging. We use thematic analysis to analyse the interview data. Using the information from the interviews, we devise a survey study where we examine and quantify the results from the interviews. We use descriptive statistics to measure the percentages of participants who consider a bug report element as highly important, moderately important, slightly important, or not important for software debugging.
-
RQ2: Do the important elements in bug reports impact bug resolution times?
Motivation: While with RQ1 we identify the extent to which different bug report elements are important in developers’ perception, it would still be unclear in real-world practice, what impact these elements may have on bug resolution times. Therefore, we raise RQ2 to understand the effect of different bug report elements on the time it takes to resolve bug reports. By raising RQ2, we intend to evaluate and correspond the extent the bug report elements that software developers perceive important for software debugging, actually impact the time it takes to resolve bug reports.
Data collection and analysis: To answer RQ2, we use Github APIs to mine bug report repositories from Github. Once we obtain the bug reports from Github, we use the IMaChecker technique (presented in Section 3) to parse the bug reports statically. Once the static analysis is done, we then use statistical tests to measure the impact of various bug report elements on bug resolution times.
-
RQ3: How often do bug reports contain the important elements?
Motivation: With RQ1 and RQ2, we gain an understanding about the extent to which different bug report elements are important for bug resolution. However, it would still be unclear how often these important elements are actually provided in bug reports. For example, as the study by Zimmermann et al. (2010) shows, elements such as crash stack traces are difficult to provide.
Data collection and analysis: To answer RQ3, we use the results from the static analysis which is performed by IMaChecker on the mined bug reports. As a result of this analysis, different elements of bug reports are identified. Therefore, we use descriptive statistics to report how often various elements appear in bug reports.
By combining qualitative and quantitative research methods, we use a mixed-method research approach (Creswell and Creswell 2017) to answer the research questions. In what follows, we further present the research techniques we used.
2.1 Interviews
To answer RQ1, we followed a qualitative research method (Creswell and Creswell 2017). We interviewed 35 developers in order to gain an understanding of their debugging techniques and the kind of information they find important to receive in bug reports. In what follows, we present the interview protocol, the participants, and data analysis technique we used for the interviews.
2.1.1 Protocol
We conducted semi-structured interviews (Hove and Anda 2005), in which we combined broad and open-ended questionsFootnote 2 with specific questions. In this way, we let participants freely respond and explore relevant topics, while we made sure the intended topics were also explored by asking specific questions. As suggested by Barriball and While (1994) and Jacob and Furgerson (2012), we conducted four pilot interviews before we performed the main interviews. As a result, we received feedback on the general flow of the questions from two of the pilot interviews. According to this feedback, we should have noted the role the participants play in their organization. Therefore, we added two questions in the interview instrument where we specifically ask about the role of the participant and we ask if the participant can briefly explain what this role entails.
We let the participants know in advance that we intend to use the data anonymously. Prior to the interviews we got permission from the participants to record the interviews. Furthermore, 15 out of 35 interviews were conducted through online calls because the developers were not available in person. Each interview took between 20 minutes to 60 minutes.
2.1.2 Participants
We intended to form a diverse group of participants. Thus, using our social contacts, we reached out to developers who work in the following areas: e-commerce development, ERP application development, automotive industry, artificial intelligence, embedded programming, and database administrating. We sent personalized emails to 50 developers who worked in these industries. 40 people with background in e-commerce development, ERP application development, and automotive industry agreed to participate in this study. After 35 interviews we reached theoretical saturation (Glaser and Holton 2004). Figure 2 shows the years of professional experience of the interview participants. The participants had at least five and at most 25 years of professional experience as a developer.

The years of professional experience of the interview participants
2.1.3 Data Analysis
After the interviews, we manually transcribed the recorded interviews. To analyse the collected data, we used thematic analysis Gibbs (2007) and Braun and Clarke (2006) to identify emerging categories in the transcripts. Thematic analysis is a technique that is used when analysing textual data. Using this technique, the first author read the transcripts intensively. The first author then used open and axial coding techniques (Moghaddam 2006) to tag the pieces of text which would relate to RQ1. After identifying the tags, the first author reviewed them and grouped them together to form more generic themes. Ultimately, the identified themes addressed two main categories: the debugging techniques developers used, and the kind of information in bug reports they considered important for software debugging. Figure 3 is a visual representation of the main themes that were identified throughout this process.

The identified themes after analysing the interview transcripts
2.2 Surveying Developers
To generalize the findings from the interviews, and measure the prevalence of the debugging practices and developers’ perceptions on the importance of different bug report elements for software debugging, we surveyed 305 developers. In what follows, we describe the survey protocol, survey participants, and our data analysis approach.
2.2.1 Protocol
To construct the surveyFootnote 3, we used guidelines from Fink (2003), De Vaus and de Vaus (2013), Pfleeger and Kitchenham (2001, 2002). We used closed questions to make the survey more compelling for the participants to fill in. To avoid forcing the participants to choose an option, for each closed question, there was an option where the participants could write their responses. We provided a brief overview of the purpose of the survey in the introduction. We let participants know we would use the data anonymously.
Before sending out the survey, we used pilot studies with four participants who were professional developers. We asked the participants to fill in the survey, and provide us with their feedback about the structure and questions of the survey. One feedback we received was about the length of the introduction at the beginning of the survey. The participant mentioned that the introduction could be shortened for more readability. In addition, another feedback was about asking the participants if they wish to receive the results after the survey is done. This is why we added one last question at the end of survey where the participants can leave their contact information if they wish to receive the results. We discarded the results of the pilot studies from the main results in this paper.
2.2.2 Participants
To find participants for the survey, we searched for trending developersFootnote 4. Trending developers on Github are developers who maintain the most popular projects on Github. In addition, we searched for active developers from 85 popular software projects on Github. The main rationale behind this approach for selecting the participants is that we intended to involve participants who are selected from a pool of experienced developers. We considered experienced developers to be those who have been maintaining projects on Github. Typically, these developers have more than at least one year of experience in software development. Nevertheless, we did not consider a strict threshold for the minimum number of years of experience in software development by the respondents. From each project we selected three to four active developers. This way we reached out to 317 people. We sent personalized emails to these developers, and briefly explained the purpose of the study to them. We received 222 responses. In addition, we used the snowballing technique (Myers and Newman 2007) to collect more participants. After the participants responded to the survey, we asked them if they could introduce us to colleagues who would be interested to participate in the study. In our request, we mentioned that we intended to get in touch with experienced colleagues who know the project well and have been contributing to the project for at least the past year. We relied on the judgment of the respondents to connect us with the colleagues who would fulfill this criterion. We sent personalized emails to 105 developers, and we received 83 responses. In total, we received 305 responses for the survey. Figure 4 shows the years of professional experience of the survey participants.

The figure presents the years of professional experience of the survey participants
2.2.3 Data Analysis
To analyse the results of the survey, we used descriptive statistics to report the findings from the closed questions. Therefore, for each bug report element, we simply measure the percentages of participants who perceive the element as highly important, moderately important, slightly important, or not important. Furthermore, we count the number of participants who are project manager, software developer, software tester, software maintainer, scrum master, or those who indicate any other type of role they play. We also count the number of years of professional experience the participants indicate to have. For the questions which let the participants write an answer in text, we use thematic textual analysis to identify emerging categories from the written texts.
2.3 Mining Github Issues
To answer RQ2 and RQ3, we mined and analysed issues from 250 projects on Github. To do so, we developed the Issue Miner and Checker (IMaChecker) approach. IMaChecker mines the issues of the received repositories, and further checks them to detect whether stack traces, reproducing steps, fix suggestions, code snippets, and user content are provided in the issues. In Section 4 we will further describe the IMaChecker approach.
To select the projects, we first identified the five most popular programming languages used in Github. According to The State of the Octoverse (2017, 2018), the languages are: Javascript, Python, Java, PhP, and Ruby. Next, based on the measures of popularity that Borgens et al. identify (Borges et al. 2015), for each language, we selected 50 projects, 250 projects in total, that have the most number of stars and forks. Table 4 (in Appendix A ) presents an overview of the projects, the number of stars, forks, contributors, as well as the year in which the first commits were provided in the projectFootnote 5.
2.3.1 Analysis of the Mined Issues
To measure the impact of various elements of bug reports on bug resolution times, we use the Wilcoxon-Mann Whitney statistical test. This is a non-parametric test that is used to analyse the impact of an independent variable that is at least ordinal. When it is not possible to make assumptions about whether the data is normally distributed or not, Wilcoxon-Mann Whitney is an alternative approach that can be used instead of techniques such as the independent samples t-test. Since in this case the dependent variable is resolution time, we only consider closed issues where the reported bug is fixed. The null hypotheses in these experiments are the following:
-
H01: the time it takes to close a bug report which only includes a problem description and crash stack trace is the same as the time it takes to close a bug report that only includes a problem description.
-
H02: the time it takes to close a bug report which only includes a problem description and reproduction steps is the same as the time it takes to close a bug report that only includes a problem description.
-
H03: the time it takes to close a bug report which only includes a problem description and fix suggestion is the same as the time it takes to close a bug report that only includes a problem description.
-
H04: the time it takes to close a bug report which only includes a problem description and user content is the same as the time it takes to close a bug report that only includes a problem description.
-
H05: the time it takes to close a bug report which only includes a problem description and code snippet is the same as the time it takes to close a bug report that only includes a problem description.
We use experimental and control groups. In experimental groups, only those issues are present which only include one of the bug report elements e.g., stack traces, depending on the element under analysis. Control groups contain those issues in which none of the bug report elements are present. To analyse realistic projects and maintain statistical power, we make sure that the sample sizes are at least 10, i.e., at least 10 issues are analysed in each group. Furthermore, the test does not assume that the samples are normally distributed. We consider α= 0.05 for Type I errors to assess the significance of the results.
We use the Vargha-Delaney Â12 statistic (Vargha and Delaney 2000) to assess the effect sizes. Vargha-Delaney Â12 is also a non-parametric approach for comparing performances of two independent groups. The outcome of this test is a value between 0 and 1. Therefore, if the outcome of Vargha-Delaney Â12 is 0.5, the two groups perform the same. On the other hand, if the result of Vargha-Delaney Â12 is less than 0.5, the first group performs worse, while if the outcome is larger than 0.5, the first group perform better than the second group. The closer Â12 is to 0.5, the smaller the difference between the two groups is. Furthermore, when the first group performs better than the second group, Â12 is considered small when it is between 0.6 and 0.7, while it is considered medium, when it is between 0.7 and 0.8. If Â12 is larger than 0.8, then it is considered large. We note that these thresholds are arbitrary to some extent. Using Vargha-Delaney Â12, we report effect magnitudes which indicate the following effect sizes: negligible, small, medium, and large.
3 The IMaChecker Approach
To mine and analyse the issues, we developed the Issue Miner and Checker (IMaChecker) in Python 3. This approach has been tested on a Linux kernel version 4.15, as well as a MacOS 10.14 machine.
Figure 5 presents an overview of the approach. IMaChecker receives the list of Github Repositories as input. Next, IMaChecker downloads all issues posted to the repository, using the Github API (developer.github 2015). After the issues of all projects are downloaded, the user can use the APIs that IMaChecker provides to analyse the downloaded issues.

The figure presents an overview of the IMaChecker Approach
IMaChecker uses regular expressions to detect issues that are originally labeled as bugs. Often various terms (e.g. “crash”) are used to mark an issue as a bug in issue repositories. Therefore, it is possible to feed IMaChecker with specific terms of interest to detect originally labeled bugs.
IMaChecker uses specific strings and regular expressions to detect whether the issues include stack traces, reproducing steps, fix suggestions, code snippets, and links to user contents. To identify the strings and design the regular expressions, we studied 255 bug reports which were randomly selected from the projects presented in Table 4 (in Appendix A). After we reached the saturation point and did not find any new keys in the context of the bug reports, we collected a pool of strings which were commonly used to refer to different bug report elements. Table 2 shows these strings and regular expressions Table 1.
Since each programming language uses a specific format to generate stack traces, IMaChecker uses five different regular expressions that are adjusted to the five different stack trace formats in Javascript, Python, Java, PhP, and Ruby. Table 2 shows examples of stack traces for different languages as well as the regular expressions used to detect them.
If IMaChecker detects a stack trace in the issue, the exception type of the stack trace is recorded as well. This can be used when one wishes to report frequency of various exception types. In addition, if IMaChecker detects crash reproducing steps or stack traces, or fix suggestions, then it automatically marks the issue as a bug. This can be useful as not always the issues are labeled in a Github Repository.
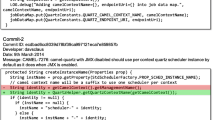
Furthermore, Fig. 6 shows an exampleFootnote 6 of a bug report from the AngularJS project. As the example shows, this bug report contains a description of a memory allocation problem together with a snapshot that is included as a .png file. When IMaChecker parses the bug report content, it detects the user content is provided through the .png file.

An example of a bug report from the AngularJS project
To evaluate the precision of the IMaChecker approach, we randomly selected 100 bug reports from the projects in Table 4 (in Appendix A). We manually analyzed the bug reports and made an account of the elements included in them. We then ran IMaChecker in order to detect the bug report elements automatically. The precision was around 92%. This was because there were bug reports in which reproduction steps or stack traces were provided through user contents (e.g., through links to external pages). Therefore, it was not possible for the IMaChecker approach to detect these elements by parsing the texts.
4 Results
We used a mixed-method research approach to discover the significance of bug report elements in software debugging. To answer the research questions, we combined interviewing developers with surveying them. In addition, we mined 250 issue repositories and used descriptive statistics as well as statistical tests on the mined issues. In this section, we present the results and thereby answer RQ1, RQ2, and RQ3.
4.1 RQ1. What Types of Information do Developers Perceive as Important in Bug Reports?
During the interviews, in order to get a broad understanding of the debugging process the developers have, we asked the participants to describe the debugging approach they take typically. In this regard, we gained the following insights. When picking up a bug report to process, developers first try to reproduce the problem on their side. This step is important because not only developers confirm there is a problem to fix, but also by being able to reproduce the problem, developers can evaluate the fixes they provide.
After reproducing the problem, developers need to assess the state of the programs at different stages of the executions. To do so, the interview participants often prefer using printf s for debugging. When a crash is complex, then 45% of the interview participants indicated they would use a debugger to further analyse the execution scenarios. In addition, all participants indicated that especially when they face a new error they have not seen before, they typically google the error message. Often it is the case that on platforms such as stackoverflowFootnote 7, someone else has posted a similar problem, which provides the participants an opportunity to get further insights. Otherwise, they may open a new issue on those platforms, share their problem, and ask the community to look into the questions.
To answer RQ1, we derived 7 categories from the interview results which indicate the information elements that developers perceive as important, which they prefer to be included in bug reports: crash description, software version, reproduction steps, stack traces, code snippets, user content and fix suggestions. To quantify these results and gain insights into the extent to which these elements are of importance for debugging, we surveyed more developers.
According to the survey results, 38% of the respondents mentioned that they use default templates for bug reports in their projects. As Fig. 7 presents, 96% of the participants find reproduction steps or test cases of high importance while 4% of them believe reproducing steps or tests are moderately important. 95% of the participants find crash stack traces of high importance while 5% of them find crash stack traces of moderate importance.

Developers’ perception on the importance of various data for bug resolution time
In addition, around 89% of the participants find crash description of high importance, while 11% of them believe crash descriptions are of average importance. Around 12% of the participants find software version of high importance, while 66% of them believe software versions are of average importance.
Around 14% of the participants find code snippets of high importance, while 68% of them believe code snippets are of average importance. 16% of the participants find code snippets of slight importance. 2% of the participants find code snippets of no importance for software debugging. In this regard, a participant mentioned: “I prefer to receive them in a pull request not in a bug report.”
13% of the participants find software versions of slight importance. 9% of the participants do not find software version important for software debugging. One of the participants indicated: “Often the version is understood from the context of the bug report. For example, certain features are only available in our latest release.”
Around 8% of the participants find fix suggestions of high importance, while around 81% of them believe fix sugestions are of average importance. 11% of the participants believe fix suggestions are of little importance.
Around 3% of the participants find user contents of high importance, while 74% of them believe user contents are of average importance. 19% of the participants find user contents of slight importance. 3% of the participants find user contents of no importance for software debugging. In this regard, a participant mentioned: “User content could be anything. They are supplementary.”
4.2 RQ2. Do the Important Elements in Bug Reports Impact Bug Resolution Times?
Table 3 presents the results of Wilcoxon-Mann Whitney and Vargha Delaney Â12 statistical analysis on four elements of bug reports, namely: stack traces, crash reproducing steps or test cases, fix suggestions, and user contents.
4.3 RQ3. How Often do Bug Reports Contain the Important Elements?
To identify how often various bug report elements are included in bug reports, we used IMaCheckerFootnote 8 to mine and analyse issue repositories from 250 Github projects. In total, 835381 issues were mined, out of which 89761 issues (∼11%) were open while 745620 issues (∼89%) were closed. 114053 bug reports (∼29.64%) were originally labeled as bugs in bug repositories while 219803 bug reports (∼70.36%) were automatically detected.
According to the results, for 228 projects, crash reproducing steps and stack traces were detected. For 244 projects fix suggestions were detected. For 226 projects user contents were detected. For 178 projects code snippets were identified. Finally, for 34 projects no bugs were originally labeled while IMaChecker detected bugs.
For kilimchoi/engineering-blogs, doctrine/inflector, and doctrine/lexer repositories no issues were originally or automatically marked as bugs. These repositories have 66, 27, and 2 issues, respectively. For these repositories, no reproducing steps, stack traces, fix suggestions, code snippets, or user contents were detected. For more detailed results, please see Table 5 in Appendix B.
In addition, Fig. 8 presents the average percentages of different bug report elements. According to Fig. 8, on average, ∼27.16% of the bug reports included stack traces, ∼27.07% of the bug reports included reproducing steps, and ∼20.59% of the bug reports included fix suggestions. In addition, on average, ∼14.23% of the bug reports included user contents, and ∼1.06% of the bug reports included code snippets.

Average percentages of various elements of bug reports
5 Discussion
In this paper, we aim to identify the contents in bug reports that are of importance for debugging. Therefore, we sought for developers’ perceptions in this regard, we analysed whether any of the bug report elements impact bug resolution times, and we measured how often various information elements are included in bug reports.
Our results show that certain elements, namely: crash description, reproducing steps, and stack traces are of high importance for debugging in developers’ perceptions. According to the statistical analysis, reproducing steps, stack traces, fix suggestions, and user contents have statistically significant impacts on bug resolution times. Despite the above findings, as Fig. 8 shows, on average, over ∼70% of the bug reports lack these elements. These findings indicate that in order to support developers for more efficient software debugging, it is important to include the aforementioned elements when reporting bugs. Furthermore, it is also important to understand why over ∼70% of the bug reports lack the important elements despite the impact they can have on efficient debugging. Understanding the underlying reasons in this regard may help seek approaches to ensure quality of bug reports is maintained high. In what follows we further discuss the findings.
5.1 Bug Report Templates and User Support
In order to keep the issues consistent, and make sure certain elements are provided in bug reports, repositories often provide templates for reporting issues. The specified elements in such templates vary. While these templates often specify reproducing steps, or fix suggestions as fields to be filled by the users, stack traces, user contents or code snippets are not mentioned in the templates. Therefore, it is up to the issue reporter to provide them.
Our results show each of those elements, particularly stack traces, impact the bug resolution times. Therefore, to help keep the structure of issues consistent, and make sure important elements of bug reports are asked for, it is important to provide complete and well-structured bug report templates. The results presented in this paper help increase awareness in this regard.
On the other hand, as Zimmermann et al. (2010) report, it may not be possible for users to provide certain information in their bug reports while at the same time it is important to do so. It is simply because important information are not always easy to be found. For example, stack traces are often hidden in log files, and therefore, it is not easy to find them, even if the issue templates ask for them. Therefore, future work may investigate means to support users and enable them to provide important information in bug reports.
5.2 Representative Samples
When analysing the impact of various bug report elements, many projects were excluded from the analysis because they did not offer representative samples for experiment and control groups. This is why it was not possible to analyse the impact of code snippets on bug resolution times.
The automated mechanism in IMaChecker helps increase the number of bug reports, thereby the sample sizes for experimental groups. IMaChecker detects whether an issue is a potential bug if a certain element such as stack trace or fix suggestion is included in the reported issue.
However, if an issue does not include any of the elements, the only way to identify whether it is a bug report would be to check the labels put on the issue. At the same time, many of the bug reports were not originally labeled as bugs. Therefore, they could not be used in the control groups. As a result, many projects were excluded from the analysis.
This observation highlights the importance of properly documenting the bug reports. The IMaChecker approach provides a more accurate overview of the issues if bug reports are properly marked by developers.
5.3 Internal Validity of the Experiments
Internal validity of a study refers to how well the findings of the study explain a claim about a cause and effect. In the context of our study, threats to internal validity refer to alternative reasons why a bug report is closed more quickly than others.
In some cases, bug reports are created, however they either have no content or very minimal amount of information. We have observed that these kinds of bug reports are typically very quickly closed because there is not much that can be done for them. When developers close such bug reports, often they ask the contributors who opened the bug reports to provide further information. Furthermore, sometimes bug reports are re-opened. One possible explanation is that the issue, which was addressed previously, resurfaces, either for the same contributor who previously opened the issue or someone else.
In our experiments, IMaChecker automatically checks the contents in experimental groups and control groups before they are included in the statistical tests. Therefore, the bug reports used in these experiments are never entirely empty. However, it could be that they are closed because they included too little information. In addition, in these experiments, we do not check whether an issue is re-opened later on. This is mainly due to the fact that the information that can be retrieved through the Github API does not include sufficient details with regards to whether the issue was re-opened or not.
5.4 Construct Validity
Before conducting the interviews and survey, we performed pilot studies with four professional developers. We received feedback from the pilot studies, incorporated the feedback before performing the main interviews and survey, and discarded the results of the pilot studies from the main results reported in this paper. We note that while we intended to discover which bug report elements are important specifically for efficient handling of the reported bugs, the questions we asked in the interviews and survey did not explicitly clarify what we mean by elements being important for software debugging. This can be a potential threat to the construct validity of the study in that the survey respondents may have had their own interpretation of what being important is, based on which they may have responded to the questions.
5.5 Generalizability of Results
As Basili et al. (1999) discuss, carrying out empirical work in software engineering is complex and time consuming. They argue that one reason for such complexity is that there are a large number of context variables. Therefore, creating a cohesive understanding of the experimental results requires effort.
We selected participants from three different industries, e-commerce, ERP, and automotive. In addition, the survey participants were either trending developers on Github or selected from over 85 distinct popular software projects. The professional experience of these participants ranged from one year to 27 years. While we intended to involve experienced developers in the survey, we did not ensure if the developers have experience in developing closed source projects or not.
To make a corpus of open-source projects, we selected 250 projects from Github. Github is a popular platform where over 2 million organizations and 96 million repositories are hosted to which over 31 million developers contribute, according to The State of the Octoverse (2019). To select the open source projects, first we chose five popular programming languages, and then we used common measures of popularity, i.e., number of stars and forks, to identify the projects. Furthermore, we used statistical tests to analyse the results.
However, we can not claim that the findings are transferable to closed-source projects. Communication with users and debugging practices differ in closed-source projects. Future work may investigate closed-source projects as well as expert developers in the field, and compare the results with the findings reported in this paper.
5.6 Automated Crash Reproduction
Depending on the available information and complexity of the reported crash, reproducing the crash may be a complex and time consuming task for developers. Researchers have proposed several approaches to automated crash reproduction. The state of the art techniques are: STAR (Chen and Kim 2015), EVOCRASH (Soltani et al. 2018), and JCHARMING (Nayrolles et al. 2015).
Each of the proposed approaches have certain advantages and limitations, which are to some extent reported in Soltani et al. (2018). Upon further advances in this direction, automated crash reproduction may compensate for lack of crash reproducing steps in bug reports.
5.7 What Do User Contents Provide?
The results show that user contents have statistically significant impact on bug resolution times for ∼33% of the projects. User contents are provided through a link in the bug reports. However, their contents vary. In our manual analysis, we found out that the links may refer to long stack traces that the users preferred to provide separately from the main bug report. It is also possible for user contents to address fix suggestions or UI features. Future work may investigate the kinds of data provided through user contents and their frequencies. Such investigation helps analyse the impact of user contents more accurately.
5.8 Ethics Approval
Typically, prior to conducting human research, researchers obtain ethics approval from the organization they are a member of. While in some countries and academic organizations, it is mandatory to obtain ethics approval, in the country where the authors conducted the reported research, obtaining ethics approval is an optional task.
Even though the authors did not obtain ethics approval, they did follow certain standard guidelines when interviewing and surveying participants which are reported in Section 2. In particular, the authors made sure to inform the participants about the goals and context of the studies prior to the interviews and surveys, and how the data will be used while keeping the data anonymous. In addition, prior to the interviews, the authors asked the participants for permission for recording the interviews.
6 Related Work
To understand what makes a good bug report, Zimmermann et el. (2010) conducted a survey among developers and users of Apache, Eclipse, and Mozilla. They found out that across all three projects, crash reproducing steps, and stack traces, are most useful. At the same time these types of information are most difficult for users to provide. Their results show, to a large extent, lack of tool support causes this mismatch. For example, while stack traces are hidden in log files, experienced users of Eclipse know that Error logs exists. Therefore, experienced users can provide stack traces while for other users it is difficult to do so (Zimmermann et al. 2010).
In addition, Zimmermann et al. (2010) asked developers to rate 289 bug reports, that were selected randomly, from very poor to very good, using a five-point Likert scale (Likert 1932). They use the rated bug reports to train the CUEZILLA approach they propose. CUEZILLA measures the quality of bug reports, and recommends which elements should be added to improve the quality of bug reports.
This paper builds on the work by Zimmermann et al. (2010) in that we interviewed and surveyed developers to understand their perceptions on the importance of different bug report elements. However, while Zimmermann et al. (2010) surveyed the developers and users of Apache, Eclipse, and Mozilla, our approach to finding interview and survey participants were different. We first found participants from ERP, E-commerce, and automotive industries to execute the interviews. We used the insights from the interviews to construct a survey study where we contacted active developers from 85 different trending projects on Github. Furthermore, while CUEZILLA uses developers’ ratings to measure the quality of bug reports, IMaChecker takes a different approach for analyzing the bug reports. IMaChecker statically parses the bug reports from 250 projects (developed in five different languages) to identify which elements are present in the bug reports, and using this information, IMaChecker applies statistical tests to identify the impact of the bug report elements on bug resolution times. Our findings with regards to the impact of bug report elements on bug resolution times are aligned with the findings reported by Zimmermann et al. (2010) in that the results from interviews, surveys, and statistical tests show crash reproduction steps and stack traces are most useful for processing bug reports. Furthermore, despite the indicated importance, our results show that the majority of times, these elements are not included in bug reports.
Schroter et al. (2010) conducted an empirical study with the Eclipse project to understand the extent to which stack traces are useful when debugging. Their findings show that the average lifetimes of bug reports which include stack traces are significantly lower than of other bugs. Furthermore, their findings show up to 60% of bug reports which included stack traces involved changes to one of the stack frames.
In this paper, we expand the findings reported by Schroter et al. (2010) in that we study bug reports from 250 projects to assess the impact of several different bug report elements, including crash stack traces. Our results on the importance of crash stack traces for bug resolution times are aligned with the findings reported by Schroter et al. (2010).
With regard to characterizing bug report quality, Hooimeijer and Weimer (2007) provide a descriptive model based on a statistical analysis of 27000 publicly available bug reports for the Mozilla Firefox project. The proposed model predicts whether a reported bug is fixed within a given amount of time.
With regards to estimating the time it take to fix a bug report, Zeng and Rine (2004) present a non-parametric approach based on using dissimilarity matrix and self-organizing neural networks. They used NASA’s KC1 data set to evaluate their approach. The results indicated that their clustering approach performs well when applied on a family of products such as software projects in product lines. However, the defect fix estimation performed poorly when applied on software projects from different environments. Moreover, Weiss et al. (2007) propose an approach that automatically predicts the time it takes to fix a bug. Given a new reported issue, their technique finds similar older issues and uses their resolution time for prediction. They evaluated their approach using effort data from JBoss project. For bug reports, their technique is off by one hour.
In this paper, rather than providing a prediction model for estimating the time it takes to fix a bug, we use statistical tests to show how different bug report elements impact the time it takes to close bug reports. Furthermore, rather than looking into a single case study, we studied bug reports from 250 open source projects from Github.
7 Conclusions
Software projects often have open issue repositories. Bug reports that are submitted to issue repositories have varying contents. Therefore it is important to gain understanding about the significance of different elements in bug reports.
To understand the extent to which developers percieve various types of information important, we interviewed 35 developers. To asses the findings, we further surveyed 305 developers. The results show crash description, reproducing steps, and stack traces are of high importance in developers’ perceptions.
To identify how often the important information elements are provided in bug reports, and what their impact is on bug resolution times, we developed IMaChecker to mine and analyse issues from Github repositories. Our statistical analysis, on issues from 250 projects on Github, confirms that crash reproducing steps, stack traces, fix suggestions and user contents have statistically significant impact on bug resolution times. However, on average, over ∼70% of the bug reports of a given repository lack these elements. Future work may investigate means to support users and developers for providing high quality bug reports.
Notes
The interview and survey questions, as well as the dataset package are available via the following DOI: https://doi.org/10.5281/zenodo.3666763
The interview questions are provided in the reproduction package, via DOI: https://doi.org/10.5281/zenodo.3666763
The survey questions are provided in the reproduction package, via DOI: https://doi.org/10.5281/zenodo.3666763
The results were collected on 2019-05-15.
This bug report can be found via: https://github.com/angular/angular.js/issues/16853
The mining was done on 2019-05-13.
References
Adolph S, Hall W, Kruchten P (2011) Using grounded theory to study the experience of software development. Empir Softw Eng 16(4):487–513
Anvik J, Hiew L, Murphy GC (2005) Coping with an open bug repository. In: Proceedings of the 2005 OOPSLA workshop on Eclipse technology eXchange, ACM, pp 35–39
Barriball KL, While A (1994) Collecting data using a semi-structured interview: a discussion paper. J Adv Nursing-Institut Subscript 19(2):328–335
Basili VR, Shull F, Lanubile F (1999) Building knowledge through families of experiments. IEEE Trans Softw Eng 25(4):456–473
Borges H, Valente MT, Hora A, Coelho J (2015) On the popularity of github applications: a preliminary note. arXiv:1507.00604
Braun V, Clarke V (2006) Using thematic analysis in psychology. Qual Res Psycho 3(2):77–101
Chen N, Kim S (2015) Star: stack trace based automatic crash reproduction via symbolic execution. IEEE Tr Sw Eng 41(2):198–220
Creswell JW, Creswell JD (2017) Research design: qualitative, quantitative, and mixed methods approaches. Sage Publications, California
De Vaus D, de Vaus D (2013) Surveys in social research. Routledge, Abingdon
Fink A (2003) The survey handbook. Sage, Newbury Park
Gibbs GR (2007) Thematic coding and categorizing. analyzing qualitative data. Sage, London, pp 38–56
developer.github (2015) https://developer.github.com/v3/issues/, accessed on 2015-05-01
Github (2019a) https://github.com/netty/netty/issues/8285, accessed on 2019-06-20
Github (2019b) https://github.com/axios/axios/issues/376, accessed on 2019-06-20
Github (2019c) https://github.com/axios/axios/issues/246, accessed on 2019-06-20
Github (2019d) https://github.com/apache/dubbo/issues/1500, accessed on 2019-06-20
Github (2019e) https://github.com/apache/dubbo/issues/3236, accessed on 2019-06-20
Github (2019f) https://github.com/activeadmin/activeadmin/issues/2623, accessed on 2019-06-20
Github (2019g) https://github.com/activeadmin/activeadmin/issues/3185, accessed on 2019-06-20
Github (2019h) https://github.com/activeadmin/activeadmin/issues/4650, accessed on 2019-06-20
Github (2019i) https://github.com/angular/angular.js/issues/16697, accessed on 2019-06-20
Github (2019j) https://github.com/ageitgey/face_recognition/issues/854, accessed on 2019-06-20
Github (2019k) https://github.com/airbnb/lottie-android/issues/1202, accessed on 2019-06-20
Github (2019l) https://github.com/barryvdh/laravel-debugbar/issues/237, accessed on 2019-06-20
Github (2019m) https://github.com/activeadmin/activeadmin/issues/4250, accessed on 2019-06-20
Glaser BG, Holton J (2004) Remodeling grounded theory. In: Forum qualitative sozialforschung/forum: qualitative social research, vol 5
Hooimeijer P, Weimer W (2007) Modeling bug report quality. In: Proceedings of the twenty-second IEEE/ACM international conference on automated software engineering, ACM, pp 34–43
Hove SE, Anda B (2005) Experiences from conducting semi-structured interviews in empirical software engineering research. In: 11Th IEEE international software metrics symposium (METRICS’05), IEEE, pp 10–pp
Jacob SA, Furgerson SP (2012) Writing interview protocols and conducting interviews: Tips for students new to the field of qualitative research. Qual Rep 17(42):1–10
Kitchenham BA, Pfleeger SL (2002) Principles of survey research: part 3: constructing a survey instrument. ACM SIGSOFT Softw Eng Notes 27 (2):20–24
Likert R (1932) A technique for the measurement of attitudes. Archives of psychology
Moghaddam A (2006) Coding issues in grounded theory. Issues Educ Res 16(1):52–66
Myers MD, Newman M (2007) The qualitative interview in is research: examining the craft. Inform Organ 17(1):2–26
Nayrolles M, Hamou-Lhadj A, Tahar S, Larsson A (2015) Jcharming: a bug reproduction approach using crash traces and directed model checking. In: 2015 IEEE 22nd international conference on software analysis, evolution, and reengineering (SANER), IEEE, pp 101–110
Pfleeger SL, Kitchenham BA (2001) Principles of survey research: part 1: turning lemons into lemonade. ACM SIGSOFT Softw Eng Notes 26(6):16–18
Schroter A, Schröter A., Bettenburg N, Premraj R (2010) Do stack traces help developers fix bugs?. In: 2010 7th IEEE working conference on mining software repositories (MSR 2010), IEEE, pp 118–121
Soltani M, Panichella A, Van Deursen A (2018) Search-based crash reproduction and its impact on debugging. IEEE Trans Softw Eng
The state of the octoverse (2017) https://octoverse.github.com/2017/, accessed on 2019-05-012019
The state of the octoverse (2018) Top programming languages of. https://github.blog/2018-11-15-state-of-the-octoverse-top-programming-languages/, accessed on 2019-05-01
The state of the octoverse (2019) https://octoverse.github.com/, accessed on 2019-05-01
Vargha A, Delaney HD (2000) A critique and improvement of the CL common language effect size statistics of McGraw and Wong. J Educ Behav Stat 25(2):101–132
Weiss C, Premraj R, Zimmermann T, Zeller A (2007) How long will it take to fix this bug?. In: Fourth international workshop on mining software repositories (MSR’07: ICSE workshops 2007), IEEE, pp 1–1
Zeng H, Rine D (2004) Estimation of software defects fix effort using neural networks. In: Proceedings of the 28th annual international computer software and applications conference, 2004. COMPSAC 2004. IEEE, vol 2, pp 20–21
Zimmermann T, Premraj R, Bettenburg N, Just S, Schroter A, Weiss C (2010) What makes a good bug report?. IEEE Trans Softw Eng 36(5):618–643
Acknowledgments
We cordially thank all interview and survey participants for their invaluable contributions.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by: Federica Sarro
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A
Table 4 shows the corpus of 250 open source projects we selected from Github.
Appendix: B
Table 5 presents the results of mining 250 issue repositories in detail.
Since we compare resolution times, we only consider closed issues where the reported bug is fixed. To maintain statistical power, we made sure that in each project, there are at least 10 issues which have none of the comparison elements in the description (control group), and there are at least 10 issues which have only the comparison factor (e.g., stack traces) in the description (experimental group). If a project does not provide such groups, we excluded it from the analysis.
To analyse the impact of stack traces, we found 139 projects, which provide the control and experimental groups. In 106 projects out of 139 projects (∼76%) statistically significant results show that including stack traces impacts the bug resolution times. For 33 projects (∼24%) no conclusion was drawn.
To analyse the impact of reproducing steps or test cases, we found 142 projects, which provide the control and experimental groups. In 100 projects out of 142 projects (∼70%) statistically significant results show that including reproducing steps impacts the bug resolution times. For 42 projects (∼30%) no conclusion was drawn.
To analyse the impact of fix suggestions, we found 148 projects, which provide the control and experimental groups. In 81 projects out of 148 projects (∼55%) statistically significant results show that including fix suggestions impacts the bug resolution times. For 67 projects (∼45%) no conclusion was drawn.
To analyse the impact of user contents, we found 33 projects, which provide the control and experimental groups. In 11 projects out of 33 projects (∼33%) statistically significant results show that including user contents impacts the bug resolution times. For 22 projects (∼67%) no conclusion was drawn.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Soltani, M., Hermans, F. & Bäck, T. The significance of bug report elements. Empir Software Eng 25, 5255–5294 (2020). https://doi.org/10.1007/s10664-020-09882-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10664-020-09882-z