
Abstract
How do learners make sense of what they are learning? In this article, I present a new framework of sense-making based on research investigating the benefits and boundaries of generative learning activities (GLAs). The generative sense-making framework distinguishes among three primary sense-making modes—explaining, visualizing, and enacting—that each serve unique and complementary cognitive functions. Specifically, the framework assumes learners mentally organize and simulate the learning material (via the visualizing and enacting modes) to facilitate their ability to generalize the learning material (via the explaining mode). I present evidence from research on GLAs illustrating how visualizations and enactments (instructor-provided and/or learner-generated) can facilitate higher quality learner explanations and subsequent learning outcomes. I also discuss several barriers to sense-making that help explain when GLAs are not effective and describe possible ways to overcome these barriers by appropriately guiding and timing GLAs. Finally, I discuss implications of the generative sense-making framework for theory and practice and provide recommendations for future research.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Generative learning involves “making sense” of provided learning material by actively organizing and integrating it with one’s existing knowledge (Wittrock, 1989). The intended outcome of generative learning is to construct coherent mental representations that enable learners to apply their knowledge to new situations. Unfortunately, many learners do not spontaneously engage in sense-making, such as when learning from text (e.g., Fiorella & Mayer, 2017), visualizations (e.g., Hannus & Hyönä, 1999), or examples (e.g., Renkl, 1997). Consequently, learners may fail to achieve meaningful and durable learning outcomes. One potential remedy is to explicitly prompt learners to engage in generative learning activities (GLAs): overt behavioral activities intended to support and/or reveal one’s understanding of the learning material (Fiorella & Mayer, 2015). Put simply, a GLA is something a learner does to try to make sense of what they are learning.
In prior reviews, Fiorella and Mayer (2015, 2016) identified and analyzed the evidence for eight GLAs: summarizing, mapping, drawing, imagining, self-testing, self-explaining, teaching, and enacting. Several subsequent reviews and meta-analyses have further examined the benefits and boundary conditions of various individual GLAs (Bisra et al., 2018; Brod, 2021a; Dargue et al., 2019; Fiorella & Zhang, 2018; Lachner et al., 2021a; Schroeder et al., 2018). The evidence suggests each GLA can support learning, but each is also susceptible to potential boundary conditions associated with specific learner characteristics, characteristics of the learning materials, and the level of GLA support learners receive. For example, some learners may struggle to generate high-quality representations without extensive guidance (Fiorella & Zhang, 2018); some learning contexts may be less appropriate than others for specific types of GLAs (Bobek & Tversky, 2016; Fiorella et al., 2020); and some GLAs may not be suitable for younger learners (Brod, 2021a). Taken together, GLAs have promise, but it is important to understand how and when they work most effectively.
In this article, I attempt to “make sense” of generative learning. First, I review prior frameworks related to generative learning and discuss their limitations. Then I propose a new framework of sense-making that distinguishes among three sense-making modes—explaining, visualizing, and enacting—that serve unique and complementary cognitive functions. I present evidence from research on GLAs illustrating the primary assumption of the framework: the visualizing and enacting modes serve to facilitate the explaining mode. Then I discuss potential barriers to sense-making that help explain when GLAs are not effective and describe possible ways to overcome some of these barriers by appropriately guiding and timing GLAs. Finally, I discuss implications of the framework for theory and practice and provide recommendations for future research.
Prior Frameworks of Generative Learning
Researchers commonly use one of two existing frameworks to explain how different types of learning activities affect learning processes and outcomes: (a) the select-organize-integrate (SOI) framework (Fiorella & Mayer, 2015) and (b) the interactive-constructive-active–passive (ICAP) framework (Chi & Wylie, 2014). Both frameworks focus on learning activities that foster “sense-making” and “understanding,” where sense-making refers to the set of (meta)cognitive processes that support construction of coherent mental representations of the learning material, and understanding refers to a type of learning outcome that allows learners to generate inferences and solve new problems, often assessed via measures of comprehension and transfer. Thus, these frameworks and their corresponding learning activities are most applicable to conceptual learning materials, such as learning about scientific phenomena (e.g., how the human circulatory system works) and mathematical principles (e.g., mathematical equivalence).
SOI Framework
According to the SOI framework (Fiorella & Mayer, 2015), learning for understanding involves selecting key information from the provided learning material, organizing it into a coherent structure in working memory, and integrating it with existing knowledge from long-term memory. Organizing and integrating are considered generative processes because they involve generating appropriate structural or conceptual relationships among the selected ideas (e.g., cause-effect, compare-and-contrast) and one’s existing knowledge structures. The intended result of these sense-making processes is the construction of coherent mental representations, such as a mental model of how a tire pump works or schemas for solving different types of problems in statistics.
Like other cognitive theories of learning and instruction (e.g., Sweller et al., 2019), the SOI framework assumes a very limited working memory capacity in which learners actively engage in sense-making processes. It also assumes prior knowledge activated from long-term memory guides sense-making processes in working memory. Finally, the framework assumes sense-making depends on motivational and metacognitive processes: learners must be motivated to invest the necessary effort to engage in sense-making, and students need to continually monitor and regulate their thinking processes during sense-making.
The primary strength of the SOI framework is that it provides a simple explanation for the key cognitive processes involved in sense-making. As documented in prior reviews (e.g., Bisra et al., 2018; Fiorella & Mayer, 2016; Fiorella & Zhang, 2018; Schroeder et al., 2018), the framework accounts for a broad range of empirical research demonstrating that GLAs, such as self-explaining, drawing, or gesturing, are often (but not always) more effective than non-generative activities, such as rereading, highlighting, or verbatim notetaking. Furthermore, the framework posits that the effectiveness of GLAs depends on whether learners are successful at generating appropriate relationships among the ideas presented in the learning material and one’s existing knowledge. Indeed, the quality of students’ explanations, visualizations, and enactments is predictive of performance on subsequent measures of understanding, such as comprehension and transfer tests (e.g., Chi et al., 1989; Renkl, 1997; Schwamborn et al., 2010). Accordingly, the model sets basic boundary conditions for GLAs, most notably the role of prior knowledge and level of GLA guidance in affecting the quality of what learners generate during learning.
ICAP Framework
The ICAP framework (Chi & Wylie, 2014) distinguishes among four modes of cognitive engagement reflected by learners’ overt behavioral activity during learning. Passive engagement involves no overt behavior, such as simply viewing an instructional video. Active engagement involves overt behavior that reflects selectively attending to a subset of the learning material, such as when paraphrasing, summarizing, or using pointing gestures. Constructive engagement involves overt behavior that reflects an attempt to construct meaning from the learning material by generating inferences, such as generating a self-explanation or a concept map. The constructive level of engagement most closely resembles generative processing in the SOI framework. Finally, interactive engagement involves overt behaviors that reflect an attempt to co-construct meaning across multiple learners, such as within peer tutoring or collaborative learning environments.
ICAP predicts higher levels of engagement will correspond to higher quality learning outcomes (i.e., Interactive > Constructive > Active > Passive). For example, constructive learning activities should generally be more effective at supporting comprehension and transfer than merely active or passive learning activities. The primary strength of the ICAP framework is its emphasis on analyzing the outputs of learners’ overt behavioral activities during learning as an indicator of their level of internal cognitive engagement. This is important because an activity intended to support a higher level of engagement may actually support a lower level of engagement. For example, learners prompted to generate a self-explanation (intended: constructive mode) may instead only restate what was presented in the lesson without generating inferences (actual: active mode). Thus, it is important for instructors to analyze the external products of what learners generate to determine the actual level of learners’ engagement, and if necessary, adapt the implementation of the learning activity to foster higher levels of engagement. In this way, the SOI and ICAP frameworks both recognize the importance of the quality of what learners generate and the importance of explicitly guiding constructive or generative learning activities.
Summary and Limitations of Prior Frameworks
In summary, both the SOI and ICAP frameworks posit that GLAs support understanding by fostering key sense-making processes. In the SOI framework, the key sense-making processes consist of organizing and integrating the learning material with one’s existing knowledge; similarly, in the ICAP framework, sense-making depends on using one’s existing knowledge to generate inferences that go beyond the learning material. Accordingly, both frameworks predict that GLAs should be more effective than non-generative activities or activities that involve ostensibly “active” or “passive” engagement. The primary caveat in both frameworks is that learners must demonstrate evidence of actually engaging in generative or constructive processing, reflected by producing high-quality representations (e.g., explanations, visualizations, and enactments) that involve inference generation. Among other factors, generating high-quality representations will depend on learners having sufficient background knowledge and GLA support.
One key limitation acknowledged by both frameworks is that they emphasize differences across categories of learning activities (generative vs. non-generative or constructive vs. active) rather than differences within categories. Consequently, the frameworks are unable to specify how different types of GLAs uniquely and collectively contribute to sense-making. For example, generating an explanation, generating a drawing, and using hand gestures are qualitatively distinct activities (e.g., Kang et al., 2015), yet both frameworks explain their benefits (compared to more superficial activities) in terms of the same general mechanisms (e.g., organizing, integrating, inference generation). A closely related limitation is that the existing frameworks are unable to specify how GLAs interact with qualitatively distinct types of instructor-provided representations, such as text, visualizations, or examples. This is important because different types of GLAs may be more appropriate for generating inferences from different types of learning materials. At present, we do not have a coherent framework for understanding how instructor-provided and learner-generated representations interact to support specific internal sense-making processes.
The Generative Sense-Making Framework
The purpose of the generative sense-making framework is to describe how learners make sense of conceptual learning materials, such as scientific phenomena and mathematics principles. It maintains many of the basic assumptions, predictions, and boundary conditions of the SOI and ICAP frameworks, including the limited capacity of working memory, the importance of using one’s existing knowledge to actively construct meaning, and the effectiveness of GLAs over non-generative learning activities (assuming learners have sufficient background knowledge and guidance). However, it also addresses critical limitations of prior frameworks by specifying how different types of internal and external representations, including those supported by GLAs, interact to support sense-making.
The framework is derived from three basic assumptions rooted in the GLA, multimedia learning, and grounded cognition literatures, as well as complementary literatures within math and science education:
-
1.
Distinct modes: Sense-making involves three qualitatively distinct modes: explaining (generating coherent verbal representations), visualizing (generating coherent visual representations), and enacting (generating coherent motor representations). The three modes of sense-making are primarily derived from the GLA literature (Fiorella & Mayer, 2016, 2022): GLAs require learners to generate explanations (such as for oneself or others), visualizations (such as maps or drawings), or enactments (such as gestures or object manipulations). Explaining, visualizing, and enacting activities are also commonly explored and distinguished within the math and science education literatures (e.g., Nathan & Walkington, 2017; Quillin & Thomas, 2015; Tyler et al., 2020) .
-
2.
Unique functions: Each sense-making mode serves unique and complementary functions: explaining generalizes one’s knowledge, visualizing organizes one’s knowledge, and enacting simulates one’s knowledge. This principle is derived from the GLA, multimedia learning, cognitive science, and embodied cognition literatures (e.g., Ainsworth, 2006, 2022; Hostetter & Alibali, 2019; Lombrozo, 2006; Mayer & Fiorella, 2022; McCrudden & Rapp, 2017), which indicate that qualitatively different representations (verbal, visual, and motor) provide unique affordances: verbal representations afford abstract descriptions of knowledge, visual representations afford explicit organization of knowledge, and motor representations afford dynamic simulations of knowledge. Leveraging the unique functions of different types of representations is particularly critical when learning, communicating, and problem solving within math and science (e.g., Alibali & Nathan, 2012; Rau, 2017; Treagust Tsui, 2013).
-
3.
Grounded sense-making: The explaining mode is grounded in the visualizing and enacting modes. That is, the visualizing and enacting modes function to facilitate the explaining mode. This principle is primarily derived from the embodied and grounded cognition literatures (e.g., Barsalou, 2008; Glenberg et al., 2013; Hostetter & Alibali, 2019; Lindgren & Johnson-Glenberg, 2013; Reed, 2010; Tversky, 2019), which posit that conceptual understanding is grounded in sensorimotor experiences interacting in the world. It is also consistent with research demonstrating the importance of one’s ability to internally visualize and enact complex concepts for understanding abstract scientific phenomenon and mathematical principles (e.g., Wai et al., 2009), as well as the reliance on visual and motor representations for teaching, communicating, and problem solving within math and science (e.g., Cromley, 2020; Stylianou et al., 2020).
Overview of Framework
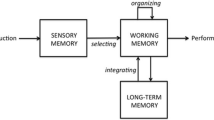
Figure 1 depicts the key components of the generative sense-making framework, including how instruction, learner characteristics, and GLAs interact with internal sense-making processes to support comprehension and transfer.

Generative sense-making framework
Internal Sense-Making Modes
As shown in Fig. 1, the framework posits learners use their prior knowledge and beliefs from long-term memory to internally explain, visualize, and enact the provided learning materials in working memory. The grounded sense-making assumption posits learners mentally organize and simulate the learning material (via the visualizing and enacting modes) to facilitate their ability to generalize knowledge of the learning material (via the explaining mode). Specifically, the visualizing mode generates a coherent visual representation that explicitly conveys how the learning material is organized, such as the spatial proximity of physical structures or more abstract visual representations of conceptual relationships (e.g., comparison, hierarchy). The enacting mode generates a coherent motor representation that simulates dynamic elements of the learning material, such as how a physical system changes over time or how to perform a problem-solving strategy or procedure. The explaining mode uses representations generated from the visualizing and enacting modes as a scaffold from which to generate inferences and induce underlying mechanisms or principles that generalize one’s knowledge of the learning material. Constructing a coherent internal explanation of underlying conceptual mechanisms or principles supports performance on subsequent learning outcome measures that require learners to generate new inferences, make predictions, and solve novel problems, such as comprehension and transfer tests.
External GLA Products
The framework assumes many learners will not spontaneously attempt to explain, visualize, and/or enact the provided learning materials on their own (e.g., Fiorella & Mayer, 2017; Renkl, 1997; Stull et al., 2012). Thus, learners will often benefit from explicit prompting and guidance to engage in corresponding GLAs, indicated by the arrow from “Instruction” to “Internal Sense-Making Modes” in Fig. 1. GLAs often require learners to externalize their knowledge, such as by overtly producing explanations (e.g., orally or on paper), visualizations (e.g., on paper or on a computer), or body movements (e.g., hand gestures or object manipulations), indicated by the arrow from “Internal Sense-Making Modes” to “External GLA Products” in Fig. 1. Externalizing knowledge can reduce working memory load and enhance one’s capacity to engage in internal sense-making processes (e.g., Cox, 1999; Goldin-Meadow et al., 2001; Stull et al., 2018), indicated by the doubled-sided arrow from “External GLA Products to “Internal Sense-Making” in Fig. 1. However, while some external GLA products are relatively permanent and inspectable (e.g., written explanations or drawings on paper), other products are fleeting (e.g., oral explanations or hand gestures) and thus need to be encoded in working memory. Furthermore, some GLAs are only performed internally, such as prompts to generate a mental image (e.g., Leopold & Mayer, 2015). Thus, a drawback of purely covert GLAs is that they are not directly inspectable to learners or instructors (or researchers), and therefore it is not possible to analyze the quality of the GLA product.
GLAs that yield external products are valuable because they provide instructors with diagnostic information regarding the quality of learners’ thinking and knowledge (e.g., van de Pol et al., 2020). Instructors can use GLA products as formative assessments and adapt instruction and GLA guidance as necessary, indicated by the arrows from “External GLA Products” to “Instruction” to “Internal Sense-Making Modes.” For example, when learners’ external GLA products reveal knowledge gaps or misconceptions, instructors can provide targeted feedback to support subsequent internal sense-making processes, GLA products, and learning outcomes. Thus, while GLAs can directly support sense-making and learning outcomes, they also can reveal a learner’s level of understanding and inform subsequent instruction.
Overall, the primary contribution of the framework is in specifying the unique and complementary functions of the three sense-making modes and how GLAs and the provided learning materials interact to (directly or indirectly) support each mode. In the following section, I elaborate on specific types of GLAs and the rationale for their corresponding functions. Then I use prior research on GLAs to illustrate the interdependent relationships among the three sense-making modes—namely, how the visualizing and enacting modes serve to facilitate the explaining mode.
As shown in Fig. 1, the framework also incorporates how learner characteristics and GLAs affect sense-making. Later in the article, I summarize prior research on how learner characteristics such as students’ age, prior knowledge, and beliefs might serve as “barriers” to sense-making and thus moderate the effectiveness of GLAs (see “Barriers to Sense-Making” section). I also discuss ways to alleviate some of these barriers with appropriate GLA guidance (see “Guiding GLAs” section).
Generative Learning Activities
Based on the proposed framework, I reconceptualize the original GLAs in terms of their primary sense-making mode (explaining, visualizing, or enacting)Footnote 1 and corresponding functions (generalizing, visualizing, and enacting), as summarized in Table 1.
Explaining GLAs
Description
Explaining GLAs prompt learners to generate coherent verbal statements (orally or in writing) to clarify, interpret, or justify a phenomenon or problem. The most common explaining GLA is self-explaining, in which learners generate clarifying and elaborative statements to themselves (for recent reviews, see Chi, 2022; Renkl & Eitel, 2019). For example, learners might self-explain the solution steps of a worked example in statistics (e.g., Renkl et al., 1998). Another common explaining GLA is learning by teaching, in which learners generate explanations intended for others (for recent reviews, see Kobayashi, 2019; Lachner et al., 2021a; Ribosa & Duran, 2022). For example, learners might record a video lecture explaining how the Doppler effect works as if they were teaching a fictitious peer (Fiorella & Mayer, 2013, 2014). Other common variations of explaining GLAs include comparing (explaining similarities, e.g., Gentner et al., 2003) and predicting (testing explanations, Brod, 2021b).
Function
According to Lombrozo (2006, 2012), the primary function of explanations is to integrate new information with prior knowledge in a way that supports knowledge generalization. For example, one might learn that a knife is sharp because it is for cutting and then infer other things used for cutting are probably sharp. Reviews of the learning by explaining literature also highlight knowledge integration and knowledge generalization as key mechanisms underlying learner-generated explanations (Chi, 2022; Renkl, 2014; Rittle-Johnson & Loehr, 2017). For example, Renkl’s (2014) theory of example-based learning posits transfer from examples to new problems depends on generating inferences in one’s self-explanations that relate the provided solutions steps to underlying principles. Similarly, Chi’s work on self-explaining science texts (e.g., Chi et al., 1994; see Chi, 2022 for a review) reveals the importance of inference generation for constructing a coherent mental model of how complex systems function, such as the human circulatory system, which allow learners to apply their knowledge to new situations. These and other prior frameworks emphasize that learners need to use their existing knowledge to transform the provided learning materials into explanations that are relevant, coherent, complete, and accurate (e.g., see Leinhardt, 2001), rather than simply relying on or reproducing provided explanations (e.g., Ryoo & Linn, 2014; Schworm & Renkl, 2006). In short, the generalizing function of explaining—in which learners generate inferences beyond the provided learning material—is fundamental to sense-making.
Visualizing GLAs
Description
Visualizing GLAs involve generating coherent external or internal visual representations to convey the physical and/or conceptual organization of the learning material. There are three broad classes of visualizing GLAs: drawing, mapping, and imagining. Drawing (or sketching) involves generating external visuals that depict physical structures and their relationships (for recent reviews, see Ainsworth & Scheiter, 2021; Fiorella & Zhang, 2018; Leutner & Schmeck, 2022; Wu & Rau, 2019), such as the structure of the human circulatory system (Zhang & Fiorella, 2019), the mechanics of a bicycle tire pump (Bobek & Tversky, 2016), or the structures underlying invisible molecular processes (Cooper et al., 2017). Mapping involves generating external visuals that spatially arrange text (using lines and shapes) to convey abstract conceptual relationships (for recent reviews, see Adesope et al., 2022; Schroeder et al., 2018), such as creating a graphic organizer to compare eastern and western steamboats (Ponce & Mayer, 2014) or creating concept maps to spatially arrange key relationships described in science texts (Chang et al., 2002). Other common mapping variations include generating sequence diagrams, hierarchies, and matrices. Imagining involves generating an internal visual representation of physical structures or conceptual relationships (for a recent review, see Leopold, 2022), such as forming mental images of the structure of the human respiratory system (Leopold & Mayer, 2015).
Function
Early research in cognitive science suggests that visualizations are more computationally efficient than purely linguistic representations because they explicitly organize information in conceptually meaningful ways (Cox, 1999; Larkin & Simon, 1987; Stenning & Oberlander, 1995). For example, a visualization of a tire pump explicitly displays how the different components of the system—the handle, piston, inlet valve, and outlet valve—are spatially organized. This provides learners a scaffold for generating appropriate inferences about the cause-effect mechanisms of the system, such as inferring that when someone pushes down on the handle, the inlet valve will close, and the outlet valve will open (Bobek & Tversky, 2016; Mayer & Anderson, 1992). According to McCrudden and Rapp’s (2017) framework of learning from visual displays, different types of visualizations afford different types of organizational inferences. For example, pictorial visuals like a diagram of the tire pump support inferences about the cause-effect mechanisms of the system, whereas semantic visuals like sequence diagrams or matrices afford temporal and compare-contrast inferences, respectively. Of course, visualizations often afford multiple types of inferences, such as a knowledge map that conveys hierarchical and temporal relationships (e.g., Kuhlmann & Fiorella, 2022).
Theories of learner-generated visualizations similarly emphasize the importance of externally organizing the learning material (Fan, 2015; Van Meter & Firetto, 2013; Wu and Rau, 2019). According to the cognitive theory of drawing construction (Van Meter & Firetto, 2013), drawing benefits learning from text because it forces learners to use their existing knowledge to translate a linguistic representation into an explicitly organized visual representation. Wu and Rau’s (2019) model applies the organizing function of drawings through a socio-cultural lens, such that visualizations convey the structure of complex concepts in STEM to facilitate communication among learners and practitioners in STEM. Finally, Schroeder et al. (2018) posit that the explicit organization of semantic relationships is a key mechanism underlying the benefits of concept mapping. Importantly, like explanations, creating visualizations should require learners to use their prior knowledge to explicitly organize the learning material, such as when learning from science text (Leutner & Schmeck, 2022), mathematics words problems (Schukajlow et al., 2022), or when translating across different types of visual representations (Gagnier et al., 2017). Simply relying on and reproducing provided visuals is less likely to facilitate inference generation that supports knowledge generalization (e.g., see Fiorella et al., 2020; Zhang & Fiorella, 2019). In short, the key function of visualizations is to organize information around a coherent conceptual structure to facilitate communication, learning, and problem-solving.
Enacting GLAs
Description
Enacting GLAs involve generating coherent external or internal movements to simulate actions, translate across representations, or convey dynamic physical and/or conceptual relationships (for a recent review, see Fiorella, 2022a). There are two main forms of enacting in the literature: gesturing and manipulating. Gesturing involves using one’s hands to map concepts or strategies onto one’s body (Novack and Goldin-Meadow, 2015), such as when learning problem-solving strategies in mathematics (Wakefield & Goldin-Meadow, 2019), or when enacting dynamic elements described in science texts (Cutica et al., 2014). A related activity is finger tracing, in which learners trace key elements of provided learning materials (examples, visualizations) with their finger during learning (e.g., Ginns et al., 2016). Manipulating involves moving physical or virtual objects to represent concepts or strategies, such as using concrete manipulatives to represent mathematical operations (e.g., Bustamante et al., 2022; Carbonneau & Marley, 2015; Carbonneau et al., 2013), translate across representations in chemistry (Stull et al., 2018), directly experience physics principles (Kontra et al., 2015), or enact events described in a story (Glenberg et al., 2004).
Enacting activities may also include more dynamic forms of imagining, such as imagining changes in provided static visuals (Hegarty et al., 2003), imagining performing the steps in a procedure (Cooper et al., 2001), or imagining the learning material from one’s own perspective (Leopold et al., 2019). Thus, imagining can function as a visualizing and/or enacting activity depending on what learners are prompted to generate (e.g., Blunt & VanArsdall, 2021). As mentioned above, a downside of imagining activities is that they do not produce external GLA products, and thus learners, instructors, and researchers do not have direct access to the quality of what learners generated. Finally, recent studies have also explored the benefits of asking learners to physically or mentally manipulate the design of provided learning materials, such as spatially integrating text with corresponding visualizations (for a recent review, see Zhang et al., 2022).
Function
According to embodied theories of cognition, thinking is grounded in sensorimotor processing that functions to simulate knowledge (Barsalou, 2008; Glenberg et al., 2013; Lindgren & Johnson-Glenberg, 2013). Indeed, research suggests the human motor system is involved in a wide range of cognitive tasks, including language production and comprehension (Glenberg & Kaschak, 2002; Goldin-Meadow & Alibali, 2013), mathematics (Alibali & Nathan, 2012), and social cognition (Sommerville et al., 2005). According to Hostetter and Alibali’s (2008, 2019) Gesture as Simulated Action framework, gestures reflect embodied sensorimotor simulations that occur automatically when people think and speak to support inference generation. For example, gestures can be used to simulate the events described in a story (Dargue et al., 2019) , the directions for navigating a route (So et al., 2014), or strategies for solving abstract mathematics problems (Wakefield & Goldin-Meadow, 2019).
Other frameworks of embodied learning similarly highlight the role of gestures, object manipulations, and other body movements in dynamically simulating knowledge. Lindgren and Johnson-Glenberg’s (2013) framework focuses on the potential of various enacting activities within virtual and mixed reality environments. A key component of their framework is in establishing congruency between the actions learners enact (e.g., gestures or other body movements) and the targeted concept, or what they refer to as “action-concept congruency.” For example, when learning about pendulum motion, a congruent gesture might be to swing one’s forearm while keeping one’s elbow fixed, whereas a non-congruent action would be tapping a touch screen to set a pendulum in motion. Thus, actions should be structurally analogous to the targeted concept; otherwise, learners will not generate the appropriate inferences to generalize one’s knowledge (e.g., Laski & Seigler, 2014; Samara & Clements, 2009). In short, enacting serves to dynamically simulate the conceptually relevant spatial and motor elements of the learning material.
Grounded Sense-Making with GLAs
The core assumption of the generative sense-making framework is that the visualizing and enacting modes serve to facilitate the explaining mode (i.e., grounded sense-making). This suggests the effectiveness of GLAs—and instruction more broadly—depends on all three sense-making modes, either directly or indirectly. For example, explaining GLAs directly activate the explaining mode but still depend on the visualizing and enacting modes. That is, the framework assumes learners rely on their ability to visualize and enact the material to produce quality explanations. This suggests the effectiveness of explaining (GLAs) depends on whether learners have appropriate visualizing and enacting support. In some situations, learners may have sufficient background knowledge and motivation to spontaneously visualize and enact the learning material without needing external support. For example, a sentence like, “The dog jumped over the fence,” is relatively easy for most readers to spontaneously visualize and enact. In contrast, a complex text describing the human circulatory system (“The right side receives relatively oxygen-poor blood from the body through the large superior and inferior venae cavae and pumps it out through the pulmonary trunk”) will be much more challenging for a novice to mentally visualize and enact (Zhang & Fiorella, 2019). Thus, when learning complex and unfamiliar conceptual material, most learners will benefit from explicit visualizing and enacting support, either via (a) instructor-provided visuals, examples, or enactments (“Learning Materials” in Fig. 1), or (b) explicit prompts to engage in visualizing and enacting GLAs (“GLA Products” in Fig. 1).
Conversely, prompting learners to engage in visualizing and enacting GLAs directly activates their respective modes but ultimately depends on the explaining mode. That is, learners must internally self-explain what they visualized or enacted, regardless of whether they were explicitly prompted to explain. This suggests the effectiveness of visualizing and enacting GLAs depends on the extent to which they support high-quality internal explanations. It also suggests visualizing and enacting GLAs are most appropriate when the provided learning materials do not already provide this type of support, such as when learning from expository text, mathematics word problems, or equations. Ideally, prompting learners to visualize or enact would cause learners to spontaneously generate internal self-explanations. However, learners may still need explicit prompting to engage the explaining mode. Thus, the framework posits learners may benefit from prompting to engage in explaining GLAs across a wide range of learning contexts, and a major instructional goal should be to provide appropriate visualizing and enacting support (either via provided materials or GLAs) to facilitate high-quality explanations.
In the following sub-sections, I use prior research on GLAs to demonstrate evidence for the facilitative functions of visualizing and enacting for explaining. Thus, I specifically focus on studies that (a) manipulate some aspect of visualizing and enacting support (either via provided representations or visualizing and enacting GLAs) and (b) measure their effects on learners’ explanations during learning and subsequent learning outcomes (comprehension or transfer).Footnote 2 In subsequent sections of the article, I address several general and GLA-specific factors that may moderate the effectiveness of GLAs, including learner characteristics and level of GLA support.
Visualizing Facilitates Explaining
One implication of the framework is that explaining GLAs should be most effective when learners receive explicit visualizing support. In a study by Ainsworth and Loizou (2003), college students studied a lesson on the human circulatory system that consisted of provided text or provided diagrams. All students were prompted to generate self-explanations during learning. Students who self-explained diagrams generated more inferences in their explanations and performed better on a subsequent comprehension test than students who explained text only. In terms of the framework, these findings suggest the provided diagrams served to explicitly display the structural organization of the circulatory system, which facilitated inferences about the system’s causal mechanisms and allowed learners to generalize their knowledge to new situations. In contrast, learners who only self-explained text were forced to internally visualize and enact what they were reading without the availability of an external visualization as a scaffold.
A study by Butcher (2006) replicated and extended the findings from Ainsworth and Loizou (2003) to different forms of visualizing support. First, the study replicated the finding that students generated more inferences about the human circulatory system when they learned from provided text and diagrams compared to text alone. Furthermore, the study found that students generated more accurate inferences when they self-explained diagrams that emphasized the conceptual structure of the system (i.e., blood flow through the four chambers of the heart) compared to diagrams that included specific details that were not directly relevant to the heart’s function. In line with the framework, high-quality visualizing support that emphasized the conceptual organization of the learning material facilitated higher quality self-explanations, which resulted in better learning outcomes.
Another form of visualizing support is to prompt learners to generate their own visualizations. A study by Bobek and Tversky (2016) compared the effectiveness of asking college students to generate written self-explanations or create drawings on paper while learning from texts on how a tire pump works and the differences between ionic and covalent bonds. Because the provided materials consisted of text only, learners were not provided explicit visualizing support. Thus, according to the framework, students prompted to write explanations were forced to internally visualize and enact the learning materials on their own. On the other hand, creating drawings on paper allowed learners to create an external visual representation on paper, which may facilitate internal self-explanations (Cox, 1999). Learners who created drawings exhibited higher comprehension test performance than learners who wrote verbal summaries (see also Scheiter et al., 2017). This suggests explicit support to visualize from text was more effective at fostering inference generation than explaining without provided visualizing support. This effect applied to materials organized around the mechanics of a physical system (a tire pump) as well as materials organized around a more abstract comparison structure (ionic vs. covalent bonds).
The framework suggests visualizing activities like drawing are effective insofar as they support higher quality explanations. However, like many GLA studies, the study by Bobek and Tversky (2016) tested explaining and drawing separately and thus it could not directly assess how drawing affected the quality of students’ explanations. A recent study by Fiorella and Kuhlmann (2020) addressed this issue. College students studied a text about the human respiratory system and then were asked to “teach” what they learned on video to a fictitious peer. Students were taught by either orally explaining, creating drawings on paper, or creating drawings while orally explaining. One week after teaching, all students completed comprehension and transfer tests. Students who created drawings while explaining generated more elaborative inferences in their oral explanations than students who only orally explained, and this resulted in better subsequent comprehension and transfer test performance. Interestingly, the drawing-only and explaining-only groups did not significantly differ, suggesting (as the framework assumes) learners may need explicit prompting to explain what they visualize or enact.
Taken together, the studies described above support the basic assumption of the framework that provided and learner-generated visualizations function to facilitate explanations, which results in better understanding. Other studies report a complementary pattern of results (Cromley et al., 2010, 2013; Eitel et al., 2013), including research on self-explaining dynamic visualizations (e.g., de Koning et al., 2011) and multiple visual representations (Berthold & Renkl, 2009; Rau et al., 2015). One question raised by this prior work is whether learners benefit more from provided or generated visuals, an issue that has yielded mixed results in the literature (see Fiorella & Zhang, 2018; Guo et al., 2020). Provided visuals ensure learners receive an accurate representation, but recent work suggests they can at times serve as a crutch rather than a scaffold. In a study by Fiorella (2022b), college students wrote explanations after each part of a video on the human kidney. Students who explained with provided visuals from the lesson generated higher quality explanations than students who explained without provided visuals; however, there was no difference in performance between the two explanation groups on a subsequent transfer test. This suggests students likely relied on the provided external visual rather than internalizing the visual.
There are also downsides of learner-generated visuals. While generating visuals can force learners to attempt to internally visualize the material, visualizing GLAs like drawing can be cognitively demanding and time consuming, particularly when learners have insufficient background knowledge or receive insufficient guidance. Consequently, many learners may struggle to generate high-quality drawings. Recent work by Zhang and Fiorella (2019, 2021) and related early work by Van Meter (2001) suggest learners may benefit most from a combination of generated and provided visuals. Specifically, Zhang and Fiorella (2019) found college students learned performed best on a transfer test when they created drawings of a text on the human circulatory system before (rather than after) viewing an instructor-provided visual. This suggests learners benefit most from viewing a provided visual as feedback rather than prior to creating their own. When provided visuals are available first, drawing may tempt learners to merely copy the provided visual rather than use it as a scaffold for sense-making (e.g., see also Fiorella et al., 2020).
Enacting Facilitates Explaining
According to the framework, explicit enacting support is also expected to facilitate explanation quality and meaningful learning outcomes. Research by Goldin-Meadow and colleagues (Cook et al., 2008; Goldin-Meadow et al., 2009) has examined the role of gestures—enacted by the instructor or by the learner—in supporting children’s explanations and understanding of mathematical equivalence problems. For example, learners might receive the following problem: 4 + 9 + 3 = 4 + ___, with the provided verbal instructions of “I want to make one side equal to the other side.” Without additional explicit support, learners must spontaneously visualize and enact the appropriate solution strategy on their own to support an internal self-explanation of the underlying principle of equivalence. Gestures can serve as a form of enacting support by using one’s body movements to explicitly simulate the solution procedure. For example, instructors can make a sweeping gesture under each side of the equation to represent the “equalizer” strategy. Many studies have shown that children benefit from both observing and enacting appropriate gestures compared to only receiving verbal instruction (or engaging in irrelevant gestures), reflected by superior performance on subsequent tests that require children to transfer their knowledge of mathematical equivalence to new problems (Novack and Goldin-Meadow, 2015).
In line with the framework, this research also reveals that a key benefit of gesturing is that it adds appropriate problem-solving strategies to children’s verbal explanations. In a study by Goldin-Meadow et al. (2009), children learned to solve mathematical equivalence problems by generating correct gestures, partially correct gestures, or no gestures. Specifically, students were taught the correct or partially correct version of the “V” strategy, which involves using two fingers to show how two numbers on one side of the equation can be grouped and moved to the other side of the equation. All children received the same verbal instruction to “make one side of the equal to the other.” After the instruction phase, children were asked to solve new problems and explain their solution methods. As predicted, generating correct gestures led to better problem-solving performance than generating partial gestures, which was more effective than generating no gestures. Critically, this effect was mediated by whether children verbalized the “grouping” strategy in their explanations. That is, viewing the correct “V” strategy helped learners spontaneously self-explain the principle of “grouping,” which resulted in better problem-solving performance. The facilitative effects of gesturing for mathematics problem-solving have been observed in many other studies (see Wakefield & Goldin-Meadow, 2019) and align with the basic assumptions of the generative sense-making framework.
A study by Nathan and Martinez (2015) demonstrated the facilitative effects of gesturing for explaining when learning from science text. In three experiments, college students were interviewed after reading a lesson on the human circulatory system. Experiment 1 showed that students generated more gestures when they responded to inference questions compared to general knowledge questions that did not require inference generation. This supports the assumption that gestures are used to facilitate knowledge integration and generalization (i.e., the explaining mode). Experiment 2 showed that students gestured more frequently when they learned from a text without illustrations compared to a text with illustrations. In both cases, students generated a similar number of inferences, suggesting that students learning from text only used their gestures to make up for the lack of a provided visual. Finally, Experiment 3 showed that when learners were prevented from making gestures while explaining, they generated fewer inferences. Taken together, this pattern provides strong evidence for the role of gestures in facilitating inference generation and knowledge generalization (see also Cutica et al., 2014; Nathan et al., 2021; Pilegard & Fiorella, 2021).
Finally, there is evidence that manipulating task-relevant objects supports learners’ explanations during learning. In a recent study by Lafay et al. (2021), third and fifth graders used concrete manipulatives (e.g., colored plastic chips) or paper-and-pencil to solve “part-whole” or “compare” word problems (e.g., “Aurelie picked 13 bananas, which is 9 more than Jeremy. How many bananas did Jeremy pick?”). After solving the problems, all learners were asked to explain how they got their answer. Among the third graders, students who used manipulatives used more accurate problem-solving strategies and produced higher quality verbal justifications of their solutions than students who learned with pencil and paper. In contrast, fifth graders did not benefit from using manipulatives, perhaps because they were able to represent the structure of the word problems on their own without additional enacting support. Overall, this study demonstrates that appropriate enacting support facilitates explanation-based reasoning, including the ability to generate inferences about the general structure of mathematics word problems (see also Glenberg et al., 2007; Manches & O’Malley, 2016; Martin & Schwartz, 2005; Wall et al., 2022).
Examples Facilitate Explaining
There is also strong evidence that the effectiveness of learning from examples ultimately depends on the explaining mode (Renkl, 2014, 2022). In terms of the generative sense-making framework, examples provide learners explicit visualizing and enacting support by grounding abstract principles within more specific situations. There are two primary ways to support learning from examples examined in the literature (Renkl, 2014): self-explaining worked examples and comparing across multiple examples.
First, there is substantial literature on the benefits of learning from worked examples, particularly for novice learners (Renkl, 2014, 2022). Worked examples explicitly provide learners with the problem, each solution step, and the solution. Additionally, worked examples may provide explanations of the solution steps, but these explanations can sometimes interfere with learner-generated self-explanations (Schworm & Renkl, 2006). Worked examples are a strong form of visualizing and enacting support because they explicitly display the sequential organization of the solution steps in a way that demonstrates (or simulates) how to solve the problem. Worked examples can also include provided visuals in addition to text and equations.
Research suggests the effectiveness of worked examples depends on whether learners generate “principle-based explanations”—explanations of the general principle underlying the problem (Renkl, 2014). Learners may not spontaneously generate principle-based explanations when studying worked examples (Chi et al., 1989; Renkl, 1997), and so they often need explicit prompting and support to engage in self-explaining. For example, Atkinson et al. (2003) found that prompting high school learners to self-explain probability worked examples by identifying the underlying principle (e.g., principle of complementarity, multiplication principle, addition principle) led to greater transfer to new problems then learners who did not receive prompting to self-explain. Other studies show a similar result (Hilbert & Renkl, 2009; Hilbert et al., 2008; Renkl et al., 1998). There is also evidence that improving the design of worked examples (i.e., improving the quality of visualizing and enacting support) helps learners generate higher quality explanations. For example, research by Catrambone (1996) shows that visually grouping solution steps by their underlying sub-goals helps learners better organize these steps around general solution procedures (as indicated by the quality of their self-explanations), and results in better transfer performance. Thus, in line with the assumptions of the generative sense-making framework, enhanced visualizing and enacting support facilitates higher quality learner explanations and better subsequent transfer performance.
Second, there is also substantial research on the benefits of comparing across multiple examples or cases (Holyoak, 2012; Rittle-Johnson & Star, 2011), in which learners explain the similarities across examples that share the same underlying principle. Like worked examples, providing multiple examples supports the visualizing and enacting modes, but particularly when the examples are explicitly juxtaposed side-by-side (i.e., organized) to facilitate comparison. Still, many learners do not generate comparisons spontaneously (Catrambone & Holyoak, 1989) and thus need explicit prompting and support. For example, in a study by Gentner et al. (2003), college students learned from multiple cases describing negotiation strategies, such as the trade-off strategy and the contingent-contract strategy. Learners who received explicit prompting to compare two cases involving the same underlying strategy were much more likely to use that corresponding strategy in a subsequent transfer scenario than those who studied the cases separately. Furthermore, the extent to which learners identified the underlying principle across the cases was strongly associated with their transfer performance. Many other studies show that explicitly prompting and guiding learners to compare examples or cases results in better transfer performance by helping learners induce underlying principles (Alfieri et al., 2013; Gerjets et al., 2008; Richland & Sims, 2015). Overall, the pattern is aligned with the core assumption of the generative sense-making framework: the explaining mode is grounded in the visualizing and enacting modes.
Barriers to Sense-Making
Prompting learners to engage in GLAs by no means guarantees that sense-making will be successful. GLAs are general strategies or heuristics intended to encourage and guide each sense-making mode: explanations should ideally convey appropriate inferences about underlying mechanisms and principles, visualizations should ideally convey appropriately organized conceptual structures, and enactments should ideally convey task-relevant movements to appropriately simulate knowledge. Yet for myriad reasons, learners may struggle to actually generate high-quality representations and thus may not benefit from GLAs (Renkl, 1997; Van Meter, 2001). Indeed, there are several examples of studies that do not show a benefit of engaging in GLAs (e.g., Colliot & Jamet, 2019; Cooper et al., 2001; Grobe & Renkl, 2006; McNeil et al., 2009; Schwamborn et al., 2010; Van Meter et al., 2006). Prior reviews have identified potential boundary conditions of individual GLAs associated with learner characteristics like age, prior knowledge, cognitive abilities, and beliefs, and instructional characteristics like the design of the provided learning materials and the level of GLA support provided (Bisra et al., 2018; Brod, 2021a; Fiorella & Zhang, 2018; Lachner et al., 2021a). Here I aim to synthesize these factors into the learner characteristics that serve as potential “barriers” to sense-making, and later I describe how to modify instruction in ways that might overcome some of these barriers. Table 2 summarizes three types of barriers that might impede one’s ability to productively engage in GLAs.
Cognitive Barriers
Cognitive barriers include insufficient background knowledge or available working memory capacity to engage in GLAs effectively (Castro-Alonso et al., 2021). Learners must have sufficient background knowledge to generate the inferences required for sense-making (Simonsmeier et al., 2022; Willingham, 2007). Without sufficient background knowledge, the learning material simply will not make sense regardless of which GLA is used. That said, assuming learners have sufficient background knowledge, there is evidence that learners with relatively low knowledge often benefit more from GLAs than learners with relatively high knowledge (see Fiorella & Mayer, 2015). One likely explanation is that higher-knowledge learners are more likely to spontaneously engage in sense-making without the need for support. Indeed, people are more likely to spontaneously explain information or situations that are highly familiar (Lombrozo, 2006).
A related barrier concerns whether learners have sufficient available working memory capacity to engage in GLAs effectively (Breitweister & Brod, 2021a, 2021b). As Brod (2021a) argues, some GLAs are more cognitively demanding than others, which may explain potential age-related differences in GLA effectiveness. For example, drawing and generating questions are likely more cognitively demanding than predicting or generating answers to questions. Indeed, there is evidence that drawing is not effective for elementary school students (van Essen & Hamaker, 1999; Van Meter et al., 2006), and middle schoolers benefit from drawing only if they receive extensive guidance (Van Meter, 2001; Van Meter et al., 2006). In contrast, a meta-analysis by Bisra et al. (2018) suggests that prompting learners to self-explain is effective for learners across elementary school, high school, and at the undergraduate level, though the effect size appears slightly higher for undergraduates.
Other research indicates individual differences in cognitive abilities may contribute to the effectiveness of some GLAs. For example, Zhang and Fiorella (2019) found learners with higher spatial ability generated higher quality drawings, which led to better transfer test performance. Thus, spatial ability likely influences one’s capacity to engage in the visualizing mode. The role of cognitive abilities and prior knowledge may also interact to influence the effectiveness of GLAs. For instance, according to the circumvention-of-limits hypothesis (Hambrick et al., 2012), learners rely on general cognitive abilities, such as spatial ability, when they have relatively low prior knowledge, but cognitive abilities may play less of a role as learners gain expertise.
Instructional design also influences learners’ capacity to engage in GLAs. If the design of the learning materials imposes extraneous cognitive load, such as by including seductive details or requiring excessive visual search across multiple sources of information, then this may interfere with learners’ ability to productively explain, visualize, and enact (see Mayer & Fiorella, 2022; Sweller et al., 2019).
Metacognitive Barriers
Metacognitive barriers include insufficient strategic knowledge of what GLAs are, how to select appropriate GLAs, and how to implement them effectively. As mentioned above, many learners do not use GLAs spontaneously, such as when studying texts (Fiorella & Mayer, 2017), visualizations (Renkl & Scheiter, 2017), or worked examples (Chi et al., 1989; Renkl, 1997), or when solving problems (Rellensmann et al., 2022), discussing material with peers (Roscoe & Chi, 2007), or writing essays (Scardamalia & Bereiter, 1987). For example, Fiorella and Mayer (2017) found that most students simply reproduce the contents of science texts when taking notes, but the small proportion of students who spontaneously attempted to create images or diagrams tended to perform better on a subsequent comprehension test.
Even with explicit prompting, GLAs still require learners to effectively plan, monitor, and regulate their GLA performance to produce high-quality explanations, visualizations, and enactments. Many learners struggle to generate high-quality representations without explicit instructional support. For example, generic prompts to explain, visualize, or enact are generally not as effective as providing specific prompting or scaffolding (e.g., Berthold et al., 2009; Schmeck et al., 2014). Supporting quality representations is important because, not surprisingly, the quality of what learners generate during learning generally predicts performance on subsequent comprehension and transfer tests (e.g., Chi et al., 1989; Fiorella & Kuhlmann, 2020; Goldin-Meadow et al., 2009; Renkl, 1997; Schwamborn et al., 2010). Furthermore, as Cromley (2020) notes, effectively coordinating across multiple (provided or generated) representations is cognitively and metacognitively challenging, and learners often need explicit support to ensure they are generating appropriate inferences.
Informing learners about how to use GLAs and why they are effective also does not guarantee learners will spontaneously transfer them to new learning situations on their own (Manalo Uesaka Chinn, 2018). Recent research suggests many learners may be aware of effective learning strategies, but they do not necessarily apply this knowledge to their actual studying (Rea et al., 2022). One likely contributing factor is that learners may have suboptimal existing learning habits, such as passively rereading, underlining, or highlighting (Bjork et al., 2013; Dunlosky et al., 2013), which can serve as a metacognitive barrier for spontaneous use of GLAs (Fiorella, 2020).
Motivational Barriers
Motivational barriers include beliefs about one’s ability to use GLAs successfully, the perceived value of GLAs for achieving one’s goals, or the perceived cost of GLAs (e.g., Schukajlow et al., 2022). There is substantial research indicating that various aspects of academic motivation are associated with self-regulated learning strategies and academic achievement (Winne & Marzouk, 2019; Rosenzweig et al., 2019; Schunk and Greene, 2017) . For example, learners who believe they are capable of success, perceive the learning material as valuable, and attribute their learning more to their effort than ability tend to engage in more effortful learning strategies and persist during challenges than learners with a less productive motivational profile (see Renninger Hidi, 2019; Wentzel & Miele, 2016).
Despite the vast literature on achievement motivation, there is limited direct evidence examining learners’ motivation to use specific learning strategies (Karabenick et al., 2021), or what Schukajlow et al. (2022) refer to as strategy-based motivation. Recent research found that students’ motivational beliefs about drawing, including their expectancies for success, were associated with their spontaneous use of drawing during mathematics problem-solving, the quality of their drawings, and their subsequent problem-solving performance (Rellensmann et al., 2022; Schukajlow et al., 2022). Yet most learners do not use visualizing activities spontaneously (Fiorella & Mayer, 2017) and may be more comfortable with verbal activities like self-explaining (Miller-Cotto et al., 2022). Furthermore, learners may tend to gravitate toward learning activities that they perceive as requiring less effort, such as restudying the learning material (e.g., Hui et al., 2022). Overall, GLAs that are less familiar, perceived as more cognitively demanding, or perceived as less useful impose stronger motivational barriers.
Guiding GLAs
Fortunately, instructors can overcome at least some of the barriers described above by appropriately guiding GLAs. As depicted in Fig. 1, appropriate guidance depends on adapting the provided learning materials and GLA support based on learners’ existing knowledge and beliefs to support the quality of learners’ internal sense-making processes and external GLA products. Importantly, instructors can then use the quality of learners external GLA products as formative assessments, which can inform subsequent modifications to the learning materials or GLA support (indicated by the arrow from “External GLA Products” to “Instruction” in Fig. 1).
Provided Learning Materials
Effective GLA guidance begins with well-designed learning materials. First and foremost, the learning materials should be knowledge appropriate: the materials do not assume knowledge that learners do not already have, nor do they provide knowledge that is excessively redundant with what learners already know (Kalyuga, 2022). A potential misconception of GLAs is that they depend on “high” prior knowledge, or relatedly, that they are a less-guided alternative to providing explicit instruction to novices. However, the critical criterion is whether learners have sufficient prior knowledge relative to the learning materials, rather than “low” or “high” prior knowledge relative to each other (e.g., see knowledge threshold hypothesis, Simonsmeier et al., 2022). Once this threshold is met, learners that have relatively high levels of prior knowledge are more likely to spontaneously engage in sense-making and thus less likely to benefit from explicit prompting to use GLAs. Learners with relatively low prior knowledge may be more likely to benefit from GLAs but also likely need more explicit GLA support.
The provided learning materials also need to be designed to reduce or manage other sources of extraneous cognitive load (Sweller et al., 2019). Cognitive load theory and multimedia learning researchers have identified several design principles for reducing or managing cognitive load, such as removing seductive details, spatially or temporally integrated related sources of information, offloading printed text to speech, and breaking down complex materials into more manageable parts (see Mayer & Fiorella, 2022; Sweller et al., 2019). Following these design principles frees up working memory resources to devote toward GLAs.
GLA Support
Even with well-designed materials, many learners will need explicit GLA support to generate high-quality GLA products.Footnote 3 As summarized in Table 3, there are three broad levels of GLA support: explicit instruction, scaffolded practice, and independent practice. These levels align with prior research on individual GLAs (e.g., Fiorella & Zhang, 2018; McNamara, 2017) and are analogous to guidance recommendations derived by cognitive load theory (Sweller et al., 2019) : progressing from explicit instruction (worked examples) to scaffolded practice (partial problems) to independent practice (problem-solving practice). In general, instructors should anticipate progressing sequentially through the three GLA guidance levels, though learners who present more barriers, such as younger learners, learners with relatively lower domain knowledge, or learners with limited experience using (specific types of) GLAs will likely need more explicit support. Again, instructors should use learners’ external GLA products as a guide for selecting appropriate levels of guidance and when to progress to the next level.
Explicit Instruction
Explicit instruction involves explanations and demonstrations of how to select and perform GLAs in the context of domain-specific examples. This can be in the form of provided examples or peer or instructor demonstrations. For example, instructors can model the (meta)cognitive processes involved in explaining texts or worked examples, creating visualizations from text, or using hand gestures to represent problem-solving strategies (e.g., Cook et al., 2008; Leopold & Leutner, 2015; McNamara, 2017). Learners may be unfamiliar with GLAs or how to use them, such as not knowing what constitutes a quality explanation or drawing, or not knowing how to perform activities like concept mapping or task-relevant gestures. Modeling aims to reduce cognitive load, provide strategic knowledge, and increase learner self-efficacy prior to learners engaging in GLAs on their own.
Scaffolded Practice
Scaffolded practice involves providing specific prompts or hints (e.g., Berthold et al., 2009; Roelle et al., 2017) , or partial representations for learners to complete (e.g., Fiorella et al., 2021; Ponce et al., 2020; Schwamborn et al., 2010). For example, self-explaining is generally more effective when learners receive focused prompts targeting specific relationships or principles than when they receive open or generic prompts (Berthold et al., 2009). Learners may also benefit from receiving scaffolded prompts in which learners fill in key components of an explanation rather than generating a complete explanation themselves (Bai et al., 2022) . Similarly, drawing and mapping activities are typically more effective when learners are provided partial drawings, graphic organizers, or concept maps to complete (e.g., Chang et al., 2002; Schmeck et al., 2014; Wang et al., 2021). The use of manipulatives can be scaffolded by using “concreteness fading” (Fyfe et al., 2014): progressing from concrete representations that are more familiar learners to more abstract representations that support transfer. Another way to scaffold manipulatives is to constrain what learners can manipulate, such as by using virtual rather than physical objects (Barrett et al., 2015). Overall, scaffolding methods primarily serve to reduce the cognitive demands of GLAs and focus learners’ attention on critical conceptual relationships.
Independent Practice
Independent practice involves repeated opportunities to use GLAs in specific learning contexts. Practicing appropriate use of GLAs is important for learners to continue to use GLAs spontaneously (Manalo Uesaka Chinn, 2018). Simply knowing about effective strategies and even intending to use them does not guarantee learners will use them (e.g., Blasiman et al., 2017), likely because the intention to use GLAs competes with learners’ existing habits to use alternative strategies (Fiorella, 2020; Wood & Runger, 2016). To create a new habit, learners need repeated practice using GLAs successfully in appropriate learning contexts. Instructors can support good habits by frequently modeling, scaffolding, and providing feedback for GLAs in class. Learners may also benefit from forming if–then plans, or “implementation intentions,” to specify the contexts in which they will use GLAs (e.g., Duckworth et al., 2011)—for example, “when I see a diagram in a textbook, I will attempt to explain what it means to myself,” or “after I read a section in the textbook, I will try to create my own visualization to represent the key ideas.” With repeated practice in stable and supportive contexts, the decision to use GLAs should become more automatic over time (Lally et al., 2009).
Feedback and Learning from Errors
Scaffolded and independent practice is most effective when it is followed by appropriate feedback: information designed to help learners evaluate and correct their performance (see Johnson & Marraffino, 2022; Marsh & Eliseev, 2019). In the GLA literature, feedback is often presented in the form of provided explanations, visualizations, or enactments, so that learners can compare what they generated to an “expert” representation (e.g., Roelle & Renkl, 2020; van Meter, 2001; Zhang & Fiorella, 2021). However, as with other forms of provided representations, learners may not spontaneously attempt to make sense of provided feedback without explicit prompting and guidance. First, learners may have difficulty detecting their errors, such as critical differences between their own drawings and instructor-provided illustrations (van Meter, 2001). Second, learners may need support generating internal feedback—self-explaining why their response was inaccurate and revising their knowledge accordingly (Zhang & Fiorella, 2023). Instructors can facilitate learning from feedback by explicitly highlighting students’ errors, using visualizations to scaffold the presentation of feedback, explicitly prompting learners to reflect on the feedback, and providing opportunities to discuss feedback with the instructor and/or one’s peers (e.g., Burkhart et al., 2021; Eshuis et al., 2022; Lachner & Neuburg, 2019). Overall, learning from errors is itself a generative activity that ultimately relies on supporting the explaining mode with explicit guidance (see Zhang & Fiorella, 2023).
Timing GLAs
Another important consideration is the timing at which GLAs are implemented in the learning process. GLAs have traditionally been studied as sense-making activities during instruction—that is, when the provided learning materials are available to learners (e.g., Doctorow et al., 1978). In this case, learners use their existing knowledge to construct a new representation, such as an explanation, visualization, or enactment. They may additionally receive modeling, scaffolding, and/or feedback to support high-quality representations. However, recent research has explored the potential unique benefits of implementing GLAs before or after instruction.
GLAs as Preparatory Activities
Pre-instruction GLAs serve to activate prior knowledge and thereby prepare learners to benefit from subsequent instruction. Consistent with the framework, pre-instruction activities should be most effective for supporting understanding when they encourage learners to generate inferences and focus on underlying mechanisms rather than on remembering specific information. Research on productive failure and generating predictions represents two variations of potentially effective pre-instruction explaining GLAs.
Productive failure research suggests that learners who attempt to generate solutions to problems prior to receiving explicit instruction generally exhibit better understanding than learners who receive explicit instruction prior to problem-solving (Kapur, 2016; Loibl et al., 2017; Sinha & Kapur, 2021). The benefits of problem-solving-first approaches appear strongest when learners attempt to solve rich problems that afford generating multiple potential solutions (Kapur, 2016; Sinha & Kapur, 2021). Similarly, generating predictions before instruction requires learners to specify an expectation based on their existing (perhaps naïve) explanation of a phenomenon. Consequently, learners are primed to compare their prediction with subsequent instruction, perhaps provoking a surprise response that motivates learners to update their existing explanation (e.g., Brod et al., 2018).
Other research has found support for enacting pre-instruction GLAs. In a study by Brooks and Goldin-Meadow (2016), children who performed relevant gestures before learning about mathematical equivalence benefited more from subsequent instruction than learners who generated irrelevant gestures, even though the relevant gestures group showed no better understanding prior to instruction. Apparently, performing relevant gestures helped learners activate relevant motor representations that they could map onto unfamiliar symbolic representations.
In line with the framework, pre-instruction activities may be relatively less effective for understanding when they involve responding to specific questions rather than actively generating inferences. For example, pre-testing research indicates learners can benefit from taking pre-tests before instruction, even when most of their solutions are incorrect (Carpenter & Toftness, 2017; Richland et al., 2009); however, effects on subsequent post-tests may be limited to the specific information from the pre-test (Toftness et al., 2018).
GLAs as Retrieval Activities
After instruction, GLAs require learners to actively retrieve the learning material from memory without access to the provided materials. Retrieval practice serves to strengthen and consolidate one’s memory, making it more accessible in the future (Karpicke, 2012). There is a vast literature demonstrating the benefits of retrieval practice, particularly for supporting long-term retention (Adesope et al., 2017; Agarwal et al., 2021). Consistent with the framework, retrieval activities should be most effective when they encourage learners to actively generate inferences rather than when they only require learners to recognize or reproduce the learning material. For example, some studies have found that prompts to explain or elaborate during retrieval are more effective than taking free recall tests (Jacob et al., 2020; Lachner et al., 2021b). Retrieval-based activities also depend on whether learners can successfully retrieve high-quality explanations, visualizations, and enactments. When retrieval is unsuccessful, learners need feedback or opportunities to restudy the learning material, after which they can benefit from additional retrieval practice opportunities.
One effective approach is to interpolate retrieval-based GLAs throughout instruction. Several studies have found benefits of integrating explaining GLAs between segments of a lesson (such as an instructional video or text) rather than only at the end of a lesson (Fiorella et al., 2020; Fiorella, 2022b; Lachner et al., 2020; Lawson & Mayer, 2021). For example, Lachner et al. (2020) found college students who generated oral explanations on video in between parts of a text about combustion engines outperformed those students who explained at the end of the lesson. In this case, the GLA serves as a retrieval practice opportunity for the preceding part of the lesson and as a potential preparatory activity for the subsequent parts of the lesson.
Other studies have directly compared implementing GLAs during instruction (“open-book” or with the materials accessible) to implementing GLAs after instruction (“closed-book” or without the materials accessible). The results of such comparisons have been predictably mixed (Hiller et al., 2020; Roelle & Berthold, 2017; Sibley et al., 2022; Waldeyer et al., 2020), given that sense-making and retrieval activities serve distinct instructional goals and have different strengths and weaknesses. GLAs during instruction should generally support more productive encoding of the provided materials, but as discussed, the provided learning materials need to be appropriately designed and learners likely need explicit guidance to ensure high-quality representations. On the other hand, retrieval practice should support long-term retention, yet it depends on whether learners are successful at retrieving the information.
Another important factor is whether the specific characteristics of the learning materials are more conducive to encouraging elaborative encoding (during instruction) or retrieval processes (after instruction). For example, Roelle and Nückles (2019) found that a during-instruction explaining GLA was more effective learning from an expository text low in cohesion and elaboration, presumably because the GLA encouraged learners to use their prior knowledge to improve cohesion and elaborate on the learning material. In contrast, a retrieval-based explaining GLA was more effective when the text was high in cohesion and elaboration, presumably because these characteristics facilitate retrieval. Additional research is needed to further specify the precise conditions under which GLAs are most effective at different time points.
Table 4 summarizes how the timing of GLAs serves distinct functions. Under the right conditions, there is value in implementing GLAs throughout the learning process: before instruction as a preparatory activity, during instruction as a sense-making activity, and after instruction as a retrieval activity.
Implications for Theory and Practice
In earlier reviews (Fiorella & Mayer, 2015, 2016), the original eight GLAs were examined individually and explained in terms of the select-organize-integrate (SOI) framework. That is, GLAs improve understanding because they encourage learners to select key ideas, organize those ideas in working memory, and integrate those ideas with existing knowledge from long-term memory. Similarly, GLAs fit under the constructive mode of the ICAP framework (Chi & Wylie, 2014) because they support inference generation and integration of the learning material with one’s existing knowledge. The SOI and ICAP frameworks are valuable because they allow researchers and educators to distinguish between GLAs and non-generative activities: Learners who demonstrate evidence of generative or constructive processing during learning should generally perform better on measures of comprehension and transfer than learners who only show evidence of “active” or “passive” engagement. However, the SOI and ICAP frameworks are unable to explain how different types of GLAs interact with provided learning materials to uniquely contribute to specific internal sense-making processes.
Specifying Unique and Complementary Sense-Making Modes
The generative sense-making framework advances prior work by specifying how three interdependent sense-making modes interact to support learner understanding. First, the framework uses prior research on GLAs to distinguish among three qualitative distinct sense-making modes: explaining (generating coherent verbal representations), visualizing (generating coherent visual representations), and enacting (generating coherent motor representations). Second, the framework uses prior research in cognitive science and multimedia learning to specify the primary cognitive function of each mode: explaining generalizes knowledge, visualizing organizes knowledge, and enacting simulates knowledge. Third, the framework uses prior research on embodied and grounded cognition to specify the relationships among the three modes: the visualizing and enacting modes serve to facilitate the explaining mode, and the explaining mode (by generalizing knowledge) is the proximate cause of understanding.
A few key implications follow from this new framework. First, it suggests the explaining mode is fundamental to sense-making and thus a primary goal of instruction is to help students generate high-quality internal (self-)explanations. Because many learners may not spontaneously attempt to make sense of what they are learning, they will often benefit from explicit prompting and support to engage in explaining GLAs. However, a second key implication of the framework is that the ability to productively self-explain depends on one’s ability to appropriately ground the learning material in high-quality sensorimotor representations (i.e., visualizing and enacting). One way to support the visualizing and enacting modes is through instructor-provided representations, such as well-designed visualizations, examples, and enactments. A second way to support the visualizing and enacting modes is to prompt learners to engage in visualizing and enacting GLAs, such as by creating drawings or concept maps, or by gesturing or manipulating objects. In line with the framework, the research evidence described in this article suggests high-quality visualizing and enacting support (instructor-provided or learner-generated) can facilitate higher quality explanations (often reflected by a higher number of accurate inferences), which results in better subsequent comprehension and transfer test performance. The evidence also suggests a combination of instructor-provided and learner-generated visualizing and enacting supports may help maximize the unique benefits of both approaches.
Overall, the effectiveness of different types of GLAs depends on all three modes: explaining GLAs will be most effective when learners receive sufficient visualizing and enacting support to appropriately organize and simulate the learning material, and visualizing and enacting GLAs will be effective insofar as they appropriately organize and simulate the learning material to facilitate the explaining mode. Thus, all GLAs (and instructional methods more broadly) can be seen as tools intended to support the generalizing function of the explaining mode by grounding the learning material in the visualizing and enacting modes.
Specifying Barriers to Sense-Making and Potential Ways to Overcome Them
Critically, the framework emphasizes that GLAs will not work as intended unless the learning environment avoids potential cognitive, metacognitive, and motivational barriers to sense-making. Identifying these barriers provides theoretical implications for understanding how and when GLAs support understanding and practical implications for how instructors might overcome these barriers. At the cognitive level, learners need sufficient background knowledge and available working memory capacity to make sense of the learning material; at the metacognitive level, learners need sufficient strategic knowledge of how and when to use GLAs effectively, efficiently, and spontaneously; and at the motivational level, learners need productive beliefs about their ability to use GLAs effectively and about the value of GLAs to support their learning goals.
The framework also specifies how instructors might overcome at least some of these potential barriers by appropriately guiding and timing GLAs. GLA guidance consists of designing knowledge-appropriate learning materials and progressing through the three primary levels of GLA support: explicit GLA instruction, scaffolded GLA practice, and independent GLA practice. Importantly, instructors should use the external GLA products learners produce as formative assessments to identify knowledge gaps or misconceptions and adapt instruction and the level of GLA support as necessary. Instructors can also leverage the unique effects of implementing GLAs at different time points, such as using GLAs as preparatory activities before instruction (to activate knowledge) and retrieval activities after instruction (to consolidate knowledge).
Future Research Directions
The generative sense-making framework provides a blueprint for addressing many remaining gaps in our understanding of how GLAs work. Much of prior work has tested individual GLAs against relatively weak control conditions, such as non-generative activities like rereading. Furthermore, some studies have directly compared individual GLAs, such as self-explaining and drawing. However, testing individual GLAs with a given set of learning materials does not fully capture the interdependent nature of the three sense-making modes outlined in the proposed framework.
To test the implications of the framework more directly, future research should systematically investigate how different forms of visualizing and enacting support affect the quality of learners’ explanations and subsequent performance on comprehension or transfer tests. One approach is to systematically manipulate the design of the provided learning materials—such as provided visualizations, examples, or enactments. Another approach is to systematically manipulate the implementation of visualizing and enacting GLAs—such as with different types of instructions or levels of guidance. Research should also explore differences and interactions among instructor-provided and learner-generated visualizing and enacting support. The framework posits that the effectiveness of visualizing and enacting support on subsequent comprehension and transfer tests will be mediated by the explaining mode—that is, the extent to which learners generate appropriate inferences about the underlying mechanisms or principles of the learning material.
The framework also posits GLAs will only be successful if instructors account for potential cognitive, metacognitive, and motivational barriers to sense-making. Further research is needed to provide more direct evidence of how these barriers moderate the effectiveness of specific GLAs in different situations. For example, learning materials need to be knowledge appropriate, but learners will still vary in their level of background knowledge for a given set of learning materials. These individual differences may affect the quality of representations learners are able to generate and thus the types of guidance they will need to optimize the use of GLAs. Moreover, research is needed to understand the unique contributions of domain knowledge, general cognitive abilities, and age-related developmental differences on specific types of GLAs. For example, although the bulk of prior research on GLAs involves learners at the high school or college level, there is evidence that activities like drawing and questioning may not be effective for elementary school students even when they receive extensive guidance (Brod, 2021a), thereby highlighting an area where a barrier of GLAs might in fact be a boundary. In these cases, students may need alternative forms of support, such as explicit prompting to explain provided visuals. Similarly, some GLAs might differ in effectiveness for learners with lower versus higher general cognitive abilities, such as working memory capacity or spatial ability. However, at present, we do not know the precise conditions under which specific GLAs are most beneficial for learners with different cognitive abilities.
Relatively little research has directly examined the metacognitive and motivational barriers of GLAs. Most studies explicitly prompt learners to use specific GLAs, and therefore, little is known about how individual differences in strategic knowledge and different types of beliefs about GLAs are associated with the types of strategies chosen to use spontaneously. Studies also rarely test whether learners spontaneously transfer explicit instruction on GLAs into their own studying. Long-term GLA training studies are needed to provide learners sufficient guidance and practice on how to apply GLAs most effectively in different learning contexts.
On a related note, many learners may have had little prior experience or explicit training using explaining, visualizing, and enacting activities. We know learners generally need GLA guidance, but we do not precisely which forms or levels of guidance are most effective for different learners. Similarly, we do not know how different forms of guidance might interact with the different time points at which specific GLAs are implemented throughout the learning process. For example, it is unclear the extent to which learners should receive guidance during preparatory activities and how to strike the appropriate balance between retrieval effort and success when designing GLAs as retrieval activities. Moreover, relatively few studies have implemented visualizing and enacting activities as preparatory or retrieval activities, and so we do not know the conditions in which different types of activities might be most effective at different time points.
Another important direction for future research is to more systematically test the assumptions of the proposed framework in collaborative settings. The ICAP framework posits that learning activities will be even more effective when learners actively co-construct knowledge, such as by generating explanations for each other. Similarly, Wu and Rau's (2019) model of learning with visualizations highlights the important socio-cultural role of creating visuals for communicating and problem-solving in STEM. Future research should test how visualizations and enactments among learners can be leveraged to support higher quality explanations and learning outcomes.
This review focused on the benefits of GLAs for supporting understanding, yet there is growing evidence that GLAs can provide metacognitive benefits by revealing learners’ level of understanding to themselves and to instructors (see Griffin et al., 2019; Prinz et al., 2020; van de Pol et al., 2020). Research is needed to clarify the conditions under which specific GLAs uniquely support the accuracy of learners’ and instructors’ judgments of learning, and how these judgments affect subsequent self-regulation behaviors. For example, like their effects on comprehension, the unique functions of explaining, visualizing, and enacting likely yield unique metacognitive cues to instructors and learners that individually or collectively support metacomprehension in different situations, such as with different types of provided learning materials or at different time points throughout instruction. Thus, in addition to supporting understanding, GLAs can serve as valuable self- and formative assessments to reveal learners’ level of understanding to learners and instructors.
Conclusion
In conclusion, the generative sense-making framework distinguishes among three sense-making modes that serve unique and complementary functions: explaining (to generalize knowledge), visualizing (to organize knowledge), and enacting (to simulate knowledge). A key assumption of the framework is that the visualizing and enacting modes serve to facilitate the explaining mode. This suggests a primary goal of instruction is to provide visualizing and enacting support via instructor-provided representations (e.g., visuals, examples, or enactments and/or visualizing and enacting GLAs (e.g., drawing, mapping, gesturing) to facilitate high-quality self-explanations in learners.
To implement GLAs effectively, instructors need to be cognizant of potential barriers to sense-making, such as insufficient background knowledge, insufficient strategic knowledge, or unproductive beliefs about GLAs. Instructors may overcome many of these barriers by designing knowledge-appropriate materials that minimize extraneous load, and by providing explicit GLA guidance to foster high-quality explanations, visualizations, and enactments. Instructors should use learners’ external GLA products as formative assessments to inform subsequent modifications to instruction and GLA guidance. Instructors can also strategically implement GLAs throughout the learning process to support specific instructional goals.
Several open questions remain for future research, including precisely how many of the variables outlined in this review interact with each other—interactions among different types of GLAs, the design of the provided learning materials, learner characteristics, and methods of guiding and timing GLAs. Future research is also needed to implement the principles from this review within authentic educational settings and assess the long-term impact of GLAs on achievement. Overall, my hope is that this article provides researchers a useful framework for continued progress at “making sense” of GLAs and provides instructors some practical guidelines for implementing GLAs to support learner understanding.
Notes
Summarizing is excluded here because, as Dunlosky and colleagues (2013) note, it has relatively low utility when compared to explaining activities (e.g., see Coleman et al., 1997). Similarly, Chi and Wylie’s (2014) ICAP framework designates summarizing as supporting only the “active” mode of engagement, whereas self-explaining supports the “constructive” (or what I would call “generative”) mode. Self-testing is excluded here because it represents one way of timing GLAs (i.e., after instruction) to serve a specific function (i.e., retrieval practice). As I describe in the “Timing GLAs” section, any GLA could be implemented as a self-testing opportunity.
Most prior studies on GLAs test the effectiveness of individual GLAs on learning outcomes without (a) systematically manipulating the provided learning materials and/or (b) measuring the quality of learners’ explanations during learning. Thus, such studies cannot provide direct insight into the interdependent nature of the three sense-making modes, as described in the proposed framework. I discuss this issue in the “Future Research Directions” section.
There may be some situations in which specific GLAs are not effective, even with extensive guidance. As mentioned, Brod (2021a) reviews evidence that elementary school learners may not benefit from drawing or questioning activities despite scaffolding and practice. These activities may impose unique cognitive and metacognitive demands on younger learners, and thus, alternative methods or GLAs may be more appropriate. For instance, learners may benefit more from receiving provided visuals (rather than drawing) and being prompted to explain and/or from generating responses to provided questions (rather than being asked to generate questions on their own).
References
Adesope, O. O., Trevisan, D. A., & Sundararajan, N. (2017). Rethinking the use of tests: A meta-analysis of practice testing. Review of Educational Research, 87(3), 659–701.
Adesope, O. O., Nesbit, J. C., & Sundararajan, N. (2022). The mapping principle in multimedia learning. In R. E. Mayer & L. Fiorella (Eds.), The Cambridge handbook of multimedia learning (3rd ed., pp. 351–359). Cambridge University Press.
Agarwal, P. K., Nunes, L. D., & Blunt, J. R. (2021). Retrieval practice consistently benefits student learning: A systematic review of applied research in schools and classrooms. Educational Psychology Review, 33(4), 1409–1453.
Ainsworth, S. (2006). DeFT: A conceptual framework for considering learning with multiple representations. Learning and Instruction, 16(3), 183–198.
Ainsworth, S. (2022). The multiple representations principle in multimedia learning. In R. E. Mayer & L. Fiorella (Eds.), The Cambridge handbook of multimedia learning (3rd ed., pp. 158–170). Cambridge University Press.
Ainsworth, S., & Loizou, A. (2003). The effects of self-explaining when learning with text or diagrams. Cognitive Science, 27, 669–681.
Ainsworth, S. E., & Scheiter, K. (2021). Learning by drawing visual representations: Potential, purposes, and practical implications. Current Directions in Psychological Science, 30(1), 61–67.
Alfieri, L., Nokes-Malach, T. J., & Schunn, C. D. (2013). Learning through case comparisons: A meta-analytic review. Educational Psychologist, 48(2), 87–113.
Alibali, M. W., & Nathan, M. J. (2012). Embodiment in mathematics teaching and learning: Evidence from learners’ and teachers’ gestures. Journal of the Learning Sciences, 21(2), 247–286.
Atkinson, R. K., Renkl, A., & Merill, M. M. (2003). Transition from studying examples to solving problems: Combining fading with prompting fosters learning. Journal of Educational Psychology, 95, 774–783.
Bai, C., Yang, J., & Tang, Y. (2022). Embedding self-explanation prompts to support learning via instructional video. Instructional Science, 50, 681–701.
Barrett, T. J., Stull, A. T., Hsu, T. M., & Hegarty, M. (2015). Constrained interactivity for relating multiple representations in science: When virtual is better than real. Computers & Education, 81, 69–81.
Barsalou, L. W. (2008). Grounded cognition. Annual Reviews of Psychology, 59, 617–645.
Berthold, K., & Renkl, A. (2009). Instructional aids to support conceptual understanding of multiple representations. Journal of Educational Psychology, 101(1), 70–87.
Berthold, K., Eysink, T. H., & Renkl, A. (2009). Assisting self-explanation prompts are more effective than open prompts when learning from multiple representations. Instructional Science, 37(4), 345–363.
Bisra, K., Liu, Q., Nesbit, J. C., Salimi, F., & Winne, P. H. (2018). Inducing self-explanation: A meta-analysis. Educational Psychology Review, 30(3), 703–725.
Bjork, R. A., Dunlosky, J., & Kornell, N. (2013). Self-regulated learning: Beliefs, techniques, and illusions. Annual Review of Psychology, 64, 417–444.
Blasiman, R. N., Dunlosky, J., & Rawson, K. A. (2017). The what, how much, and when of study strategies: Comparing intended versus actual study behavior. Memory, 25(6), 784–792.
Blunt, J. R., & VanArsdall, J. E. (2021). Animacy and animate imagery improve retention in the method of loci among novice users. Memory & Cognition, 49(7), 1360–1369.
Bobek, E., & Tversky, B. (2016). Creating visual explanations improves learning. Cognitive Research: Principles and Implications, 1, 1–14.
Breitwieser, J., & Brod, G. (2021). Cognitive prerequisites for generative learning: Why some learning strategies are more effective than others. Child Development, 92(1), 258–272.
Brod, G. (2021a). Generative learning: Which strategies for what age? Educational Psychology Review, 33(4), 1295–1318.
Brod, G., Hasselhorn, M., & Bunge, S. A. (2018). When generating a prediction boosts learning: The element of surprise. Learning and Instruction, 55, 22–31.
Brod, G. (2021b). Predicting as a learning strategy. Psychonomic Bulletin & Review, 1–9
Brooks, N., & Goldin-Meadow, S. (2016). Moving to learn: How guiding the hands can set the stage for learning. Cognitive Science, 40(7), 1831–1849.
Burkhart, C., Lachner, A., & Nückles, M. (2021). Using spatial contiguity and signaling to optimize visual feedback on students’ written explanations. Journal of Educational Psychology, 113(5), 998–1023.
Bustamante, A. S., Begolli, K. N., Alvarez-Vargas, D., Bailey, D. H., & Richland, L. E. (2022). Fraction ball: Playful and physically active fraction and decimal learning. Journal of Educational Psychology, 114(6), 1307–1320.
Butcher, K. R. (2006). Learning from text with diagrams: Promoting mental model development and inference generation. Journal of Educational Psychology, 98, 182–197.
Carbonneau, K. J., & Marley, S. C. (2015). Instructional guidance and realism of manipulatives influence preschool children’s mathematics learning. Journal of Experimental Education, 83(4), 495–513.
Carbonneau, K. J., Marley, S. C., & Selig, J. P. (2013). A meta-analysis of the efficacy of teaching mathematics with concrete manipulatives. Journal of Educational Psychology, 105(2), 380–400.
Carpenter, S. K., & Toftness, A. R. (2017). The effect of prequestions on learning from video presentations. Journal of Applied Research in Memory and Cognition, 6(1), 104–109.
Castro-Alonso, J. C., de Koning, B. B., Fiorella, L., & Paas, F. (2021). Five strategies for optimizing instructional materials: Instructor-and learner-managed cognitive load. Educational Psychology Review, 33(4), 1379–1407.
Catrambone, R. (1996). Generalizing solution procedures learned from examples. Journal of Experimental Psychology: Learning, Memory, and Cognition, 22, 1022–1031.
Catrambone, R., & Holyoak, K. J. (1989). Overcoming contextual limitations on problem-solving transfer. Journal of Experimental Psychology: Learning, Memory, and Cognition, 15, 1147–1156.
Chang, K., Sung, Y., & Chen, I. (2002). The effect of concept mapping to enhance text comprehension and summarization. Journal of Experimental Education, 71(1), 5–23.
Chi, M. T. H. (2022). The self-explanation principle in multimedia learning. In R. E. Mayer & L. Fiorella (Eds.), The Cambridge handbook of multimedia learning (3rd ed., pp. 381–393). Cambridge University Press.
Chi, M. T., & Wylie, R. (2014). The ICAP framework: Linking cognitive engagement to active learning outcomes. Educational Psychologist, 49(4), 219–243.
Chi, M. T., Bassok, M., Lewis, M. W., Reimann, P., & Glaser, R. (1989). Self-explanations: How students study and use examples in learning to solve problems. Cognitive Science, 13(2), 145–182.
Chi, M. T. H., De Leeuw, N., Chiu, M., & Lavancher, C. (1994). Eliciting self-explanations improves understanding. Cognitive Science, 18(3), 439–477.
Coleman, E. B., Brown, A. L., & Rivkin, I. D. (1997). The effect of instructional explanations on learning from scientific texts. The Journal of the Learning Sciences, 6(4), 347–365.
Colliot, T., & Jamet, É. (2019). Asking students to be active learners: The effects of totally or partially self-generating a graphic organizer on students’ learning performances. Instructional Science, 47(4), 463–480.
Cook, S. W., Mitchell, Z., & Goldin-Meadow, S. (2008). Gesturing makes learning last. Cognition, 106(2), 1047–1058.
Cooper, G., Tindall-Ford, S., Chandler, P., & Sweller, J. (2001). Learning by imagining. Journal of Experimental Psychology: Applied, 7(1), 68–82.
Cooper, M. M., Stieff, M., & DeSutter, D. (2017). Sketching the invisible to predict the visible: From drawing to modeling in chemistry. Topics in Cognitive Science, 9(4), 902–920.
Cox, R. (1999). Representation construction, externalized cognition and individual differences. Learning and Instruction, 9, 343–363.
Cromley, J. G., Snyder-Hogan, L. E., & Luciw-Dubas, U. A. (2010). Cognitive activities in complex science text and diagrams. Contemporary Educational Psychology, 35(1), 59–74.
Cromley, J. G., Bergey, B. W., Fitzhugh, S., Newcombe, N., Wills, T. W., Shipley, T. F., & Tanaka, J. C. (2013). Effects of three diagram instruction methods on transfer of diagram comprehension skills: The critical role of inference while learning. Learning and Instruction, 26, 45–58.
Cromley, J. G. (2020). Learning from multiple representations: Roles of task interventions and individual differences. In Handbook of learning from multiple representations and perspectives (pp. 62–75). Routledge
Cutica, I., Iani, F., & Bucciarelli, M. (2014). Learning from text benefits from enactment. Memory & Cognition, 42(7), 1026–1037.
Dargue, N., Sweller, N., & Jones, M. P. (2019). When our hands help us understand: A meta-analysis into the effects of gesture on comprehension. Psychological Bulletin, 145(8), 765–784.
de Koning, B. B., Tabbers, H. K., Rikers, R. M., & Paas, F. (2011). Improved effectiveness of cueing by self-explanations when learning from a complex animation. Applied Cognitive Psychology, 25(2), 183–194.
Doctorow, M., Wittrock, M. C., & Marks, C. (1978). Generative processes in reading comprehension. Journal of Educational Psychology, 70(2), 109–118.
Duckworth, A. L., Grant, H., Loew, B., Oettingen, G., & Gollwitzer, P. M. (2011). Self-regulation strategies improve self-discipline in adolescents: Benefits of mental contrasting and implementation intentions. Educational Psychology, 31(1), 17–26.
Dunlosky, J., Rawson, K. A., Marsh, E. J., Nathan, M. J., & Willingham, D. T. (2013). Improving students’ learning with effective learning techniques: Promising directions from cognitive and educational psychology. Psychological Science in the Public Interest, 14(1), 4–58.
Eitel, A., Scheiter, K., Schuler, A., Nystrom, M., & Holmqvist, K. (2013). How a picture facilitates the process of learning from text: Evidence for scaffolding. Learning and Instruction, 28, 48–63.
Eshuis, E. H., ter Vrugte, J., & de Jong, T. (2022). Supporting reflection to improve learning from self-generated concept maps. Advance online publication.
Fan, J. E. (2015). Drawing to learn: How producing graphical representations enhance scientific thinking. Translational Issues in Psychological Science, 1(2), 170–181.
Fiorella, L. (2020). The science of habit and its implications for student learning and well-being. Educational Psychology Review, 32(3), 603–625.
Fiorella, L. (2022a). The embodiment principle in multimedia learning. In R. E. Mayer & L. Fiorella (Eds.), The Cambridge handbook of multimedia learning (3rd ed., pp. 286–295). Cambridge University Press.
Fiorella, L. (2022b). Learning by explaining after pauses in video lectures: Are provided visuals a scaffold or a crutch? Applied Cognitive Psychology, 36(5), 1142–1149.
Fiorella, L., & Kuhlmann, S. (2020). Creating drawings enhances learning by teaching. Journal of Educational Psychology, 112(4), 811–822.
Fiorella, L., & Mayer, R. E. (2013). The relative benefits of learning by teaching and teaching expectancy. Contemporary Educational Psychology, 38(4), 281–288.
Fiorella, L., & Mayer, R. E. (2014). Role of expectations and explanations in learning by teaching. Contemporary Educational Psychology, 39(2), 75–85.
Fiorella, L., & Mayer, R. E. (2015). Learning as a generative activity: Eight learning strategies that promote understanding. Cambridge University Press.
Fiorella, L., & Mayer, R. E. (2016). Eight ways to promote generative learning. Educational Psychology Review, 28(4), 717–741.
Fiorella, L., & Mayer, R. E. (2017). Spontaneous spatial strategy use in learning from scientific text. Contemporary Educational Psychology, 49, 66–79.
Fiorella, L., & Mayer, R. E. (2022). The generative activity principle in multimedia learning. In R. E. Mayer & L. Fiorella (Eds.), The Cambridge handbook of multimedia learning (3rd ed., pp. 339–350). Cambridge University Press.
Fiorella, L., & Zhang, Q. (2018). Drawing boundary conditions for learning by drawing. Educational Psychology Review, 30(3), 1115–1137.
Fiorella, L., Stull, A. T., Kuhlmann, S., & Mayer, R. E. (2020). Fostering generative learning from video lessons: Benefits of instructor-generated drawings and learner-generated explanations. Journal of Educational Psychology, 112(5), 895.
Fiorella, L., Pyres, M., & Hebert, R. (2021). Explaining and drawing activities for learning from multimedia: The role of sequencing and scaffolding. Applied Cognitive Psychology, 35(6), 1574–1584.
Fyfe, E. R., McNeil, N. M., Son, J. Y., & Goldstone, R. L. (2014). Concreteness fading in mathematics and science instruction: A systematic review. Educational Psychology Review, 26(1), 9–25.
Gagnier, K. M., Atit, K., Ormand, C. J., & Shipley, T. F. (2017). Comprehending 3D diagrams: Sketching to support spatial reasoning. Topics in Cognitive Science, 9(4), 883–901.
Gentner, D., Loewenstein, J., & Thompson, L. (2003). Learning and transfer: A general role for analogical encoding. Journal of Educational Psychology, 95(2), 393–408.
Gerjets, P., Scheiter, K., & Schuh, J. (2008). Information comparisons in example-based hypermedia environments: Supporting learners with processing prompts and an interactive comparison tool. Educational Technology Research and Development, 56, 73-92.
Ginns, P., Hu, F. T., Byrne, E., & Bobis, J. (2016). Learning by tracing worked examples. Applied Cognitive Psychology, 30(2), 169–169.
Glenberg, A. M., & Kaschak, M. P. (2002). Grounding language in action. Psychonomic Bulletin & Review, 9(3), 558–565.
Glenberg, A. M., Gutierrez, T., Levin, J. R., Japuntich, S., & Kaschak, M. P. (2004). Activity and imagined activity can enhance young children’s reading comprehension. Journal of Educational Psychology, 96(3), 424–436.
Glenberg, A. M., Jaworski, B., Rischal, M., & Levin, J. R. (2007). What brains are for: Action, meaning, and reading comprehension. In D. McNamara (Ed.), Reading comprehension strategies:Theories, interventions, and technologies (pp. 221–240). Erlbaum.
Glenberg, A. M., Witt, J. K., & Metcalfe, J. (2013). From the revolution to embodiment: 25 years of cognitive psychology. Perspectives on Psychological Science, 8(5), 573–585.
Goldin-Meadow, S., & Alibali, M. W. (2013). Gesture’s role in speaking, learning, and creating language. Annual Review of Psychology, 64, 257–283.
Goldin-Meadow, S., Nusbaum, H., Kelly, S. D., & Wagner, S. (2001). Explaining math: Gesturing lightens the load. Psychological Science, 12, 516–522.
Goldin-Meadow, S., Cook, S. W., & Mitchell, Z. A. (2009). Gesturing gives children new ideas about math. Psychological Science, 20(3), 516–522.
GriffinMielicki, T. D. M. K., & Wiley, J. (2019). Improving students’ metacomprehension accuracy. In J. Dunlosky & K. A. Rawson (Eds.), The Cambridge handbook of cognition and education (pp. 619–646). Cambridge University Press.
Grobe, C. S., & Renkl, A. (2006). Effects of multiple solution methods in mathematics learning. Learning and Instruction, 17, 612–634.
Guo, D., McTigue, E. M., Matthews, S. D., & Zimmer, W. (2020). The impact of visual displays on learning across the disciplines: A systematic review. Educational Psychology Review, 32(3), 627–656.
Hambrick, D. Z., Libarkin, J. C., Petcovic, H. L., Baker, K. M., Elkins, J., Callahan, C. N., & Ladue, N. D. (2012). A test of the circumvention-of-limits hypothesis in scientific problem solving: The case of geological bedrock mapping. Journal of Experimental Psychology: General, 141(3), 397–403.
Hannus, M., & Hyönä, J. (1999). Utilization of illustrations during learning of science textbook passages among low- and high-ability children. Contemporary Educational Psychology, 24(2), 95–123.
Hegarty, M., Kriz, S., & Cate, C. (2003). The roles of mental animations and external animations in understanding mechanical systems. Cognition and Instruction, 4, 209–249.
Hilbert, T. S., & Renkl, A. (2009). Learning how to use a computer-based concept mapping tool: Self-explaining examples helps. Computers in Human Behavior, 25, 267–274.
Hilbert, T. S., Renkl, A., Kessler, S., & Reiss, K. (2008). Learning to prove in geometry: Learning form heuristic example and how it can be supported. Learning and Instruction, 18, 54–65.
Hiller, S., Rumann, S., Berhold, K., & Roelle, J. (2020). Example-based learning: Should learners receive closed-book or open-book self-explanation prompts? Instructional Science, 48, 623–649.
Holyoak, K. J. (2012). Analogy and relational reasoning. In K. J. Holyoak & R. G. Morrison (Eds.), The Oxford handbook of thinking and reasoning (pp. 234–259). Oxford University Press.
Hostetter, A. B., & Alibali, M. W. (2008). Visible embodiment: Gestures as simulated action. Psychonomic Bulletin & Review, 15, 495–514.
Hostetter, A. B., & Alibali, M. W. (2019). Gesture as simulated action: Revisiting the framework. Psychonomic Bulletin & Review, 26, 721–752.
Hoyos, C., & Gentner, D. (2017). Generating explanations via analogical comparison. Psychonomic Bulletin & Review, 24(5), 1364–1374.
Hui, L., de Bruin, A. B. H., Donkers, J., & van Merrienboer, J. J. G. (2022). Why students do (or do not) choose retrieval practice: Their perceptions of mental effort during task performance matter. Applied Cognitive Psychology, 36(2), 433–444.
JacobLachner, L., & Scheiter, K. (2020). Learning by explaining orally or in written form? Text Complexity Matters. Learning and Instruction, 68, 101344.
Johnson, C. I., & Marraffino, M. D. (2022). The feedback principle in multimedia learning. In R. E. Mayer & L. Fiorella (Eds.), The Cambridge handbook of multimedia learning (3rd ed., pp. 286–295). Cambridge University Press.
Kalyuga, S. (2022). The expertise reversal principle in multimedia learning. In R. E. Mayer & L. Fiorella (Eds.), The Cambridge handbook of multimedia learning (3rd ed., pp. 171–181). Cambridge University Press.
Kang, S., Tversky, B., & Black, J. B. (2015). Coordinating gesture, word, and diagram: Explanations for experts and novices. Spatial Cognition and Computation, 15(1), 1–26.
Kapur, M. (2016). Examining productive failure, productive success, unproductive failure, and unproductive success in learning. Educational Psychologist, 51(2), 289–299.
Karabenick, S. A., Berger, J., & Ruzek, K. (2021). Strategy motivation and strategy use: Role of student appraisal of utility and cost. Metacognition and Learning, 16, 345–366.
Karpicke, J. (2012). Retrieval-based learning: Active retrieval promotes meaningful learning. Current Directions in Psychological Science, 21(3), 157–163.
Kobayashi, K. (2019). Learning by preparing-to-teach and teaching: A meta-analysis. Japanese Psychological Research, 61(3), 192–203.
Kontra, C., Lyons, D. J., Fischer, S. M., & Beilock, S. L. (2015). Physical experience enhances science learning. Psychological Science, 26(6), 737–749.
Kuhlmann, S., & Fiorella, L. (2022). Effects of instructor-provided visuals on learner-generated explanations. Advance online publication.
Lachner, A., & Neuburg, C. (2019). Learning by writing explanations: Computer-based feedback about the explanatory cohesion enhances students’ transfer. Instructional Science, 47(1), 19–37.
Lachner, A., Blackfisch, I., van Gog, T., & Renkl, A. (2020). Timing matters! Explaining between study phases enhances students’ learning. Journal of Educational Psychology, 112(4), 841–853.
Lachner, A., Jacob, L., & Hoogerheide, V. (2021b). Learning by writing explanations: Is explaining to a fictitious student more effective than self-explaining? Learning and Instruction, 74, 101483.
Lachner, A., Hoogerheide, V., van Gog, T., & Renkl, A. (2021a). Learning-by-teaching without audience presence or interaction: When and why does it work? Educational Psychology Review, 1–33.
Lafay, A., Osana, H. P., & Guillan, J. (2021). Can manipulatives help students in the third and fifth grades understand the structure of word problems? Educational Psychology, 41(9), 1180–1198.
Lally, P., van Jaarsveld, C. H. M., Potts, H. W. W., & Wardle, J. (2009). How are habits formed: Modelling habit formation in the real world. European Journal of Social Psychology, 40(6), 998–1009.
Larkin, J. H., & Simon, H. A. (1987). Why a diagram is (sometimes) worth ten thousand words. Cognitive Science, 11, 65–100.
Laski, E. V., & Seigler, R. S. (2014). Learning from number board games: You learn what you encode. Developmental Psychology, 50(3), 853–864.
Lawson, A. P., & Mayer, R. E. (2021). Benefits of writing an explanation during pauses in multimedia lessons. Educational Psychology Review, 33(4), 1859–1885.
Leinhardt, G. (2001). Instructional explanations: A commonplace for teaching and location for contrast. In Richardson (Ed.), Handbook of research on teaching (pp. 333–357). American Educational Research Association.
Leopold, C. (2022). The imagination principle in multimedia learning. In R. E. Mayer & L. Fiorella (Eds.), The Cambridge handbook of multimedia learning (3rd ed., pp. 370–380). Cambridge University Press.
Leopold, C., & Leutner, D. (2015). Improving students’ science text comprehension through metacognitive self-regulation when applying learning strategies. Metacognition & Learning, 10, 313–346.
Leopold, C., & Mayer, R. E. (2015). An imagination effect in learning from scientific text. Journal of Educational Psychology, 107(1), 47–63.
Leopold, C., Mayer, R. E., & Dutke, S. (2019). The power of imagination and perspective in learning from science texts. Journal of Educational Psychology, 111(5), 793–808.
Leutner, D., & Schmeck, A. (2022). The drawing principle of multimedia learning. In R. E. Mayer & L. Fiorella (Eds.), The Cambridge handbook of multimedia learning (3rd ed., pp. 360–369). Cambridge University Press.
Lindgren, R., & Johnson-Glenberg, M. (2013). Emboldened by embodiment: Six precepts for research on embodied learning and mixed reality. Educational Researcher, 42(8), 445–452.
Loibl, K., Roll, I., & Rummel, N. (2017). Towards a theory of when and how problem solving followed by instruction supports learning. Educational Psychology Review, 29(4), 693–715.
Lombrozo, T. (2006). The structure and function of explanations. Trends in Cognitive Sciences, 10(10), 464–470.
Lombrozo, T. (2012). Explanation and abductive inference. In K. J. Holyoak & R. G. Morrison (Eds.), The Oxford handbook of thinking and reasoning (pp. 260–276). Oxford University Press.
Manalo, E., Uesaka, Y., & Chinn, C. A. (Eds.). (2018). Promoting spontaneous use of learning and reasoning strategies: Theory, research, and practice for effective transfer. Routledge.
Manches, A., & O’Malley, C. (2016). The effects of physical manipulatives on children’s numerical strategies. Cognition & Instruction, 34(1), 27–50.
Marsh, E. J., & Eliseev, E. D. (2019). Correcting student errors and misconceptions. In J. Dunlosky & K. A. Rawson (Eds.), The Cambridge handbook of cognition and education (pp. 437–459). Cambridge University Press.
Martin, T., & Schwartz, D. L. (2005). Physically distributed learning: Adapting and reinterpreting physical environments in the development of fraction concepts. Cognitive Science, 29(4), 587–625.
Mayer, R. E. (2022). The cognitive theory of multimedia learning. In R. E. Mayer & L. Fiorella (Eds.), The Cambridge handbook of multimedia learning (3rd ed., pp. 57–72). Cambridge University Press.
Mayer, R. E., & Fiorella, L. (Eds.). (2022). The Cambridge handbook of multimedia learning (3rd ed.). Cambridge University Press.
Mayer, R. E., & Anderson, R. B. (1992). The instructive animation: Helping students build connections between words and pictures in multimedia learning. Journal of Educational Psychology, 84(4), 444–452.
McCrudden, M. T., & Rapp, D. N. (2017). How visual displays affect cognitive processing. Educational Psychology Review, 29(3), 623–639.
McNamara, D. S. (2017). Self-explanation and reading strategy training (SERT) improves low-knowledge students’ science course performance. Discourse Processes, 54(7), 479–492.
McNeil, N. M., Uttal, D. H., Jarvin, L., & Sternberg, R. J. (2009). Should you show me the money? Concrete objects both hurt and help performance on mathematics problems. Learning and Instruction, 19, 171–184.
Miller-Cotto, D., Booth, J. L., & Newcombe, N. S. (2022). Sketching and verbal explanation: Do they help middle school children solve science problems. Applied Cognitive Psychology, 36(4), 919–935.
Nathan, M. J., & Martinez, C. V. (2015). Gesture as model enactment: The role of gesture in mental model construction and inference making when learning from text. Learning: Research and Practice, 1(1), 4–37.
Nathan, M. J., & Walkington, C. (2017). Grounded and embodied mathematical cognition: Promoting mathematical insight and proof using action and language. Cognitive Research: Principles and Implications, 2, 1–20.
Nathan, M. J., Schenck, K. E., Vinsonhaler, R., Michaelis, J. E., Swart, M. I., & Walkington, C. (2021). Embodied geometric reasoning: Dynamic gestures during intuition, insight, and proof. Journal of Educational Psychology, 113(5), 929–948.
Novack, M., & Goldin-Meadow, S. (2015). Learning from gesture: How our hands change our minds. Educational Psychology Review, 27(3), 405–412.
Pilegard, C., & Fiorella, L. (2021). Using gestures to signal lesson structure and foster meaningful learning. Applied Cognitive Psychology, 35(5), 1362–1369.
Ponce, H. R., & Mayer, R. E. (2014). An eye movement analysis of highlighting and graphic organizer study aids for learning from expository text. Computers in Human Behavior, 41, 21–32.
Ponce, H. R., Loyola, M. S., & Lopez, M. J. (2020). Study activities that foster generative learning: Notetaking, graphic organizer, and questioning. Journal of Educational Computing Research, 58(2), 275–296.
Prinz, A., Golke, S., & Wittwer, J. (2020). To what extent do situation-model-approach interventions improve relative comprehension accuracy? Meta-analytic insights. Educational Psychology Review, 32, 917–949.
Quillin, K., & Thomas, S. (2015). Drawing to learn: A framework for using drawings to promote model-based reasoning in biology. CBE Life Sciences, 14(1), 1–16.
Rau, M. A. (2017). Conditions for the effectiveness of multiple visual representations in enhancing STEM learning. Educational Psychology Review, 29, 717–761.
Rau, M. A., Aleven, V., & Rummel, N. (2015). Successful learning with multiple graphical representations and self-explanation prompts. Journal of Educational Psychology, 107(1), 30–46.
Rea, S. D., Wang, L., Muenks, K., & Yan, V. X. (2022). Students can (mostly) recognize effective learning, so why do they not do it? Intelligence, 10, 127.
Reed, S. K. (2010). Thinking visually. Psychology Press.
Rellensmann, J., Schukajlow, S., Blomberg, J., & Leopold, C. (2022). Effects of drawing instructions and strategic knowledge on mathematical modeling performance: Mediated by the use of the drawing strategy. Applied Cognitive Psychology, 36(2), 402–417.
Renkl, A. (1997). Learning from worked-out examples: A study on individual differences. Cognitive Science, 21(1), 1–29.
Renkl, A. (2014). Toward an instructionally oriented theory of example-based learning. Cognitive Science, 38(1), 1–37.
Renkl, A. (2022). The worked example principle in multimedia learning. In R. E. Mayer & L. Fiorella (Eds.), The Cambridge handbook of multimedia learning (3rd ed., pp. 231–240). Cambridge University Press.
Renkl, A., & Scheiter, K. (2017). Studying visual displays: How to instructionally support learning. Educational Psychology Review, 29(3), 599–621.
Renkl, A., & Eitel, A. (2019). Self-explaining: Learning about principles and their application. In J. Dunlosky & K. A. Rawson (Eds.), The Cambridge handbook of cognition and education (pp. 528–549). Cambridge University Press.
Renkl, A., Stark, R., Gruber, H., & Mandl, H. (1998). Learning from worked-out examples: The effects of example variability and elicited self-explanations. Contemporary Educational Psychology, 23, 90–108.
Renninger, K. A., & Hidi, S. (Eds.). (2019). The Cambridge handbook of motivation and learning. Cambridge University Press.
Ribosa, J., & Duran, D. (2022). Do students learn what they teach when generating teaching materials for others? A meta-analysis through the lens of learning by teaching. Educational Research Review, 100475
Richland, L. E., & Sims, N. (2015). Analogy, higher order thinking, and education. Wire’s Cognitive Science, 6(2), 177–192.
Richland, L. E., Kornell, N., & Kao, L. S. (2009). The pretesting effect: Do unsuccessful retrieval attempts enhance learning? Journal of Experimental Psychology: Applied, 15(3), 243–257.
Rittle-Johnson, B., & Loehr, A. M. (2017). Eliciting explanations: Constraints on when self-explanation aids learning. Psychonomic Bulletin & Review, 24(5), 1501–1510.
Rittle-Johnson, B., & Star, J. R. (2011). The power of comparison in learning and instruction: Learning outcomes supported by different types of comparisons. Psychology of Learning and Motivation, 55, 199–225.
Roelle, J., & Berthold, K. (2017). Effects of incorporating retrieval into learning tasks: The complexity of the task matters. Learning and Instruction, 49, 142–156.
Roelle, J., & Nückles, M. (2019). Generative learning versus retrieval practice in learning from text: The cohesion and elaboration of the text matters. Journal of Educational Psychology, 111(8), 1341.
Roelle, J., & Renkl, A. (2020). Does an option to review instructional explanations enhance example-based learning? It depends on learners’ academic self-concept. Journal of Educational Psychology, 112(1), 131–147.
Roelle, J., Hiller, S., Berthold, K., & Rumann, S. (2017). Example-based learning: The benefits of prompting organization before providing examples. Learning and Instruction, 49, 1–12.
Roscoe, R. D., & Chi, M. T. H. (2007). Understanding tutor learning: Knowledge-building and knowledge-telling in peer tutors’ explanations and questions. Review of Educational Research, 77, 534–574.
Rosenzweig, E. Q., Wigfield, A., & Eccles, J. (2019). Expectancies, values, and its relevance for student motivation and learning. In K. A. Renninger & S. Hidi (Eds.), The Cambridge handbook of student motivation and learning (pp. 617–644). Cambridge University Press.
Ryoo, K., & Linn, M. C. (2014). Designing guidance for interpreting dynamic visualizations: Generating versus reading explanations. Journal of Research in Science Teaching, 51(2), 147–174.
Samara, J., & Clements, D. (2009). Concrete computer manipulatives in mathematics education. Child Development Perspectives, 3, 145–150.
Scardamalia, M., & Bereiter, C. (1987). Knowledge telling and knowledge transforming in written composition. Advances in Applied Psycholinguistics, 2, 142–175.
Scheiter, K., Schleinschok, K., & Ainsworth, S. (2017). Why sketching may aid learning from science texts: Contrasting sketching with written explanations. Topics in Cognitive Science, 9(4), 866–882.
Schmeck, A., Mayer, R. E., Opfermann, M., Pfeiffer, V., & Leutner, D. (2014). Drawing pictures during learning from scientific text: Testing the generative drawing effect and the prognostic drawing effect. Contemporary Educational Psychology, 39, 275–286.
Schroeder, N. L., Nesbit, J. C., Anguiano, C. J., & Adesope, O. O. (2018). Studying and constructing concept maps: A meta-analysis. Educational Psychology Review, 30(2), 431–455.
Schukajlow, S., Blomberg, J., Rellensmann, J., & Leopold, C. (2022). The role of strategy-based motivation in mathematical problem solving: The case of learner-generated drawings. Learning and Instruction, 80, 101561.
Schunk, D. H., & Greene, J. A. (2017). Handbook of self-regulation and performance (2nd ed.). Routledge.
Schwamborn, A., Mayer, R. E., Thillmann, H., Leopold, C., & Leutner, D. (2010). Drawing as a generative activity and drawing as a prognostic activity. Journal of Educational Psychology, 102, 872–879.
Schwartz, D. L., Chase, C. C., Oppezzo, M. A., & Chin, D. B. (2011). Practicing versus inventing with contrasting cases: The effects of telling first on learning and transfer. Journal of Educational Psychology, 103(4), 759–775.
Schworm, S., & Renkl, A. (2006). Computer-supported example-based learning: When instructional explanations reduce self-explanations. Computers & Education, 46, 426–445.
Sibley, L., Fiorella, L., & Lachner, A. (2022). It’s better when I see it: Students benefit more from open-book than closed-book teaching. Advance online publication.
Simonsmeier, B. A., Flaig, M., Deiglmayr, A., Schalk, L., & Schneider, M. (2022). Domain-specific prior knowledge and learning: A meta-analysis. Educational Psychologist, 57(1), 31–54.
Sinha, T., & Kapur, M. (2021). When problem solving followed by instruction works: Evidence for productive failure. Review of Educational Research, 91(5), 761–798.
So, W. C., Ching, T.H.-W., Lim, P. E., Cheng, X., & Ip, K. Y. (2014). Producing gestures facilitates route learning. PLoS ONE, 9, 1–21.
Sommerville, J. A., Woodward, A. L., & Needham, A. (2005). Action experience alters 3-month-old infants’ perception of others’ actions. Cognition, 96(1), B1–B11.
Stenning, K., & Oberlander, J. (1995). A cognitive theory of graphical and linguistic reasoning: Logic and implementation. Cognitive Science, 19(1), 97–140.
Stull, A. T., Hegarty, M., Dixon, B., & Stieff, M. (2012). Representational translation with concrete models in organic chemistry. Cognition and Instruction, 4, 404–434.
Stull, A. T., Gainer, M. J., & Hegarty, M. (2018). Learning by enacting: The role of embodiment in chemistry education. Learning and Instruction, 55, 80–92.
Stylianou, D. A., et al. (2020). Problem solving in mathematics with multiple representations. In P. Van Meter (Ed.), Handbook of learning from multiple representations and perspectives (pp. 107–120). Routledge.
Sweller, J., van Merrienboer, J. J., & Paas,. (2019). Cognitive architecture and instructional design: 20 years later. Educational Psychology Review, 31(2), 261–292.
Toftness, A. R., Carpenter, S. K., Lauber, S., & Mickes, L. (2018). The limited effects of prequestions on learning from authentic video lectures. Journal of Applied Research in Memory and Cognition, 7(3), 370–378.
Treagust, D. F., & Tsui, C. (Eds.). (2013). Multiple representations in biological education. Springer.
Tversky, B. (2019). Mind in motion: How action shapes thought. Basic Books.
Tytler, R., Prain, V., Aranda, G., Ferguson, J., & Gorur, R. (2020). Drawing to reason and learn in science. Journal of Research in Science Teaching, 57(2), 209–231.
van de Pol, J., van Loon, M., van Gog, T., Braumann, S., & de Bruin, A. (2020). Mapping and drawing to improve students’ and teachers’ monitoring and regulation of students’ learning from text: Current findings and future directions. Educational Psychology Review, 32(4), 951–977.
van Essen, G., & Hamaker, C. (1990). Using self-generated drawings to solve arithmetic word problems. The Journal of Educational Research, 83(6), 301–312.
Van Meter, P. (2001). Drawing construction as a strategy for learning from text. Journal of Educational Psychology, 69, 129–140.
Van Meter, P., & Firetto, C. M. (2013). Cognitive model of drawing construction: Learning through the construction of drawings. In G. Schraw (Ed.), Learning through visual displays (pp. 247–280). Information Age Publishing.
Van Meter, P., Aleksic, M., Schwartz, A., & Garner, J. (2006). Learner-generated drawing as a strategy for learning from content area text. Contemporary Educational Psychology, 31(2), 142–166.
Wai, J., Lubinski, D., & Benbow, C. P. (2009). Spatial ability for STEM domains: Aligning over 50 years of cumulative psychological knowledge solidifies its importance. Journal of Educational Psychology, 101(4), 817–835.
Wakefield, E. M., & Goldin-Meadow, S. (2019). Harnessing our hands to teach mathematics: How gesture can be used as a teaching tool in the classroom. In J. Dunlosky & K. A. Rawson (Eds.), The Cambridge handbook of cognition and education (pp. 209–233). Cambridge University Press.
Waldeyer, J., Heitmann, S., Moning, J., & Roelle, J. (2020). Can generative learning tasks be optimized by incorporation of retrieval practice? Journal of Applied Research in Memory and Cognition, 9, 355–369.
Wall, D., Foltz, S., Kupfer, A., & Glenberg, G. (2022). Embodied action scaffolds dialogic reading. Educational Psychology Review, 34, 401–419.
Wang, X., Mayer, R. E., Zhou, P., & Lin, L. (2021). Benefits of interactive graphic organizers in online learning: Evidence for generative learning theory. Journal of Educational Psychology, 113(5), 1024–1037.
Wentzel, K. R., & Miele, D. B. (2016). Handbook of motivation at school (2nd ed.). Routledge.
Willingham, D. T. (2007). Critical thinking: Why is it so hard to teach? American Educator, Summer, 2007, 8–19.
Winne, P. H., & Marzouk, K. (2019). Learning strategies and self-regulated learning. In J. Dunlosky & K. A. Rawson (Eds.), The Cambridge handbook of cognition and education (pp. 696–715). Cambridge University Press.
Wittrock, M. C. (1989). Generative processes of comprehension. Educational Psychologist, 24(4), 345–376.
Wood, W., & Runger, D. (2016). Psychology of habit. Annual Reviews of Psychology, 67, 289–314.
Wu, S. P., & Rau, M. A. (2019). How students learn content in science, technology, engineering, and mathematics (STEM) through drawing activities. Educational Psychology Review, 31(1), 87–120.
Zhang, Q., & Fiorella, L. (2019). Role of generated and provided visuals in supporting learning from scientific text. Contemporary Educational Psychology, 59, 101808.
Zhang, Q., & Fiorella, L. (2021). Learning by drawing: When is it worth the time and effort? Contemporary Educational Psychology, 66, 101990.
Zhang, Q., & Fiorella, L. (2023). An integrated model of learning from errors. Educational Psychologist., 58(1), 18–34.
Zhang, S., de Koning, B., Agostinho, S., Tindall-Ford, S., Chandler, P., & Paas, F. (2022). The cognitive load self-management principle in multimedia learning. In R. E. Mayer & L. Fiorella (Eds.), The Cambridge handbook of multimedia learning (3rd ed., pp. 430–436). Cambridge University Press.
Acknowledgements
I thank Deborah Barany, Paula Lemons, and Meg Mittelstadt for their helpful comments on earlier drafts of this article.
Funding
This research was supported by grants from the National Science Foundation (1955349 and 2055117) and a National Academy of Education/Spencer Postdoctoral Fellowship.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Fiorella, L. Making Sense of Generative Learning. Educ Psychol Rev 35, 50 (2023). https://doi.org/10.1007/s10648-023-09769-7
Accepted:
Published:
DOI: https://doi.org/10.1007/s10648-023-09769-7