
Abstract
This study analyzes Federal Open Market Committee (FOMC) minutes using state-of-the-art Natural Language Processing techniques. We sought to investigate the effect of the global COVID-19 crisis on the FOMC minutes’ pattern and the strength of the Federal Reserve to influence inflation expectations through its primary press releases. To this end, we first quantified minutes leveraging domain-specific pre-trained Bidirectional Encoder Representations from Transformers models (FinBERTs). Then, we applied dynamic time warping to measure temporal sequence proximity over time. In addition, we built multivariable autoregressive integrated moving average models to verify our findings by injecting exogenous variables as indicator functions into the time series. The results suggest that the Federal Reserve has abstained from adjusting its tone and the forward-lookingness settings of its statements for the global pandemic. Therefore, the longstanding association of the FED's tone and forward-lookingness with consumers’ inflation expectations index has weakened during the global health crisis.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The advent of inflation-targeting regimes among central banks in the 1990s has underscored the escalating significance of crafting adept communication policies and devising effective channels to accommodate such frameworks (Schmidt-Hebbel & Carrasco, 2016). The consensus in economic research is that sustainable long-term strategies are vital for maintaining price stability. Moreover, as a secondary mandate conferred by political entities, central banks strive to underpin persistent economic expansion and curtail unemployment levels. Following the financial turmoil of 2008, maintaining the orderly functioning of financial markets has become another ancillary role assumed by these monetary authorities. Nonetheless, a central bank that aims to achieve price stability needs to have a long-term perspective and be able to implement its policies independently of politics or other interest groups, which have a shorter-term perspective by nature. The independence of central banks in both policy and institutional practices brings with it the responsibility of accountability (Haan et al., 2018). To achieve this objective, it is necessary to implement an effective communication policy that will protect the transparency of the central banks (Freedman & Laxton, 2009).
Arguing the reasons for monetary policy practices and declaring them publicly provide a better understanding, internalization, and support for these practices, as well as contribute to forming expectations in line with the policy objectives to the extent of credibility. According to Muth, “Economic agents make optimum decisions by utilizing all of the information that is available to them.” which implies that they act on current information available to them as well as past experiences (Muth, 1961). Moreover, central banks make market responses to monetary policy more predictable by increasing their predictability to the markets, enabling better economic management (Goodfriend, 1990). Thus, a strong communication strategy and transparency will increase the predictability and, hence, the effectiveness of the monetary policy. Expectation management mainly shapes this relationship between communication policy, transparency, and the strength of the monetary policy (Blinder et al., 2008).
Financial markets are all eyes and ears when central bankers start to whisper. Nevertheless, it was a long journey for central banks to find the best practices to bring out their intentions appropriately (Issing, 2019). Today, a vast amount of information on monetary policy is available to those in the financial industry who obsess over every word they hear. That said, most central banks hold conferences, reveal meeting minutes, publish thorough inflation reports, make public statements, and give speeches before their legislative committees. Although they have recently been trying to appeal to the masses of people with relatively low levels of financial literacy through social media platforms such as Twitter and other communication means, almost all this effort is still for their traditional audience: financial markets and other expert groups. Fortunately, some central banks have initiated efforts to increase consumers' financial literacy by leveraging the availability of technological opportunities. For example, Economics for AllFootnote 1 is a stand-out initiative from the Central Bank of the Republic of Turkey.
One of the most considerable obstacles currently confronting central banks in transmitting their signals to consumers is the complexity level of their releases since they voice in market-coded words. Recent studies show that informal communication has more significant effects in general, particularly on the monetary policy posture (Su et al., 2020). Yet, central banks still maintain high-profile releases as their primary communication tool. It is not surprising that Alan Greenspan, a former chair of the FED, phrased in a business audience, “I guess I should warn you, if I turn out to be particularly clear, you have probably misunderstood what I said.” (Cornwell, 1996).
On the other hand, we have seen natural language processing (NLP) in many areas of our daily lives over the last decade (Rayward, 2016). Natural language processing has been increasing its functionality by incrementally giving more accurate and consistent results in direct proportion to the development of artificial intelligence technology. In parallel, Text Mining, an allied sub-field, helps us make sense of the subjective language elements in written content. While it is extensively applied in other disciplines, such as politics and marketing, text mining has historically been less frequent in economics (Bholat et al., 2015). However, text mining may be worthwhile in extracting policymakers' true intentions and look-outs hidden in the central bank announcements, as they greatly influence the financial market (Hansen & McMahon, 2015). That being said, sentiment analysis, often called opinion mining, is a text-mining approach that aims to identify and categorize subjective views in source materials (e.g., a document or sentence) using text analytics, computational linguistics, and natural language processing. Generally, sentiment analysis seeks to ascertain a writer's perspective on a subject or the overall contextual polarity of the communication (Luo et al., 2013).
Essentially, two conventional approaches for sentiment analysis exist, which are Dictionary-Footnote 2 and machine-learning-based methods. Dictionary-based approaches leverage dictionaries containing words labeled with pre-determined directions and scores. The main drawback of this method is that people wield the richness of languages, such as metaphors, idioms, and proverbs. It might be problematic to capture feelings by hard coding in such circumstances. Nevertheless, dictionary-based techniques are advantageous since they do not need large data sets. In contrast, depending on the algorithm used, machine learning methods require sufficient data and yield better results with more input data.
Supervised and unsupervised learning are two primary types of machine learning modeling techniques, which deviate in their training procedures and conditions of the required data. Each has different strengths, so the task or problem faced by a supervised versus unsupervised learning model usually differs. While supervised methods perform the learning process with labeled data, unsupervised algorithms assume that the input data is distributed according to some unknown underlying statistical distribution and try to learn the true nature of this distribution (Taboada, 2016). For this purpose, these algorithms lean on specific measures such as intra- and inter-cluster distances based on specific arguments (e.g., cluster size). In addition, novel derivations that work under less restrictive input-requirement environments via a supervised manner (e.g., semi-supervised) are also available. However, they then need strict assumptions on the data distribution to achieve performance gains. That is, some relationships to the underlying data distribution must hold (e.g., continuity/smoothness, cluster, or manifold). Sometimes, dictionary-based methods can be implemented as supervised since lexicons contain a ground truth for the data. Indeed, if the analysis relies on using fixed weights on a lexicon, then it is neither supervised nor unsupervised. In fact, there are no weight updates, hence no learning. Therefore, it is not machine learning at all.
In this study, we applied state-of-the-art text mining and semantic analysis techniques to extract quantitative information about monetary policy tendency and foresight from the FOMC minutes between February 1993 and May 2023. We initially conducted a Zipfian compliance inspection to see whether FOMC releases comply with Zipfian nature and/or show any significant deviation from its historical pattern.Footnote 3 Then, we glanced at the releases' readability characteristics briefly utilizing prevalent readability algorithms. In the last part of the exploratory analysis of the study, we brought out the topic intensity evolution of the documents to discover the general view of the FOMC agenda over time.
Subsequently, we analyzed the sentimental and forward-lookingness inclination of the communiqués. General-purpose dictionaries are one-size-fits-all solutions, and generally, central bank communiqués have a high formality level and incorporate technical expressions. Therefore, we embraced a machine-learning approach. Specifically, we exploited a financial domain-specific pre-trained NLP model, FinBERT, to unearth the semantic orientation of the minutes (Huang et al., 2022). Furthermore, we ran another investigation on the forward-lookingness of the meeting releases utilizing another pre-trained and financial domain-specific BERT model, FinBERT FLS (Forward-lookingness), which looks for soothsaying ingredients through the texts and returns both types of forward-lookingness and its severity (Yang, 2022). To assess the possible effects of the COVID-19 crisis on the relationship between the communication tone of the FED and Consumer Inflation Expectations (CIE), we implemented a well-known signal processing technique, namely Dynamic time warping (DTW) and measured the pairwise similarity of the time series as temporal sequences, i.e., Consumer Inflation Expectations (CIE) for one-year and three-year ahead horizon and time series derived from the minutes, exclusively. Finally, we modeled each time series using an autoregressive integrated moving average model with a COVID-19 indicator as an exogenous variable.
The rest of the paper is organized as follows. Section 2 reviews the literature of opinion mining and polarity exploration research on financial and economics-related texts, particularly central bank releases. Section 3 introduces the research methodology, a brief description of the data, and the discovery of abstract topics and Sect. 4 presents exploratory analysis. Section 5 presents the empirical path for semantic and forward-lookingness modeling. Section 6 reports the results. Finally, Sect. 7 concludes the results, draws some policy implications, and suggests future routes for further research.
2 Literature Review
A large part of NLP research that has been done in recent years focused on analyzing the direction and severity of users' thoughts and emotions on a particular topic on social media data. Though several superimposed mechanisms have been proposed to extend the functionality of general-purpose dictionaries for a given domain, these efforts still need the ability to correctly interpret the true meanings of the words in highly technical documents. One of the main reasons for this is that the standard gold dictionaries used in lexicon-based methods cannot produce successful results in domain-specific texts.
Lucca and Trebbi (2009) proposed an automated method to measure the polarity of the content of central bank disclosure documents and conducted an empirical analysis of the statements released by FOMC after its policy meetings. They exclusively employed Google’s and Factiva’s semantic orientation scoring systems to extract quantified meaning at both sentence- and document-level. Using vector autoregression (VAR) models, they found that it takes more than a year for a significant change in the policy documents to be accompanied by a policy interest rate change. Furthermore, short-term nominal treasury yields are more sensitive to changes in policy rates around policy announcements, while long-term treasuries spy on the changes in policy communication.
Szyszko et al. (2022) scrutinized six European economies and investigated the drifts of central banks’ tone on consumers' inflation expectations between 2010 and 2019. After deriving the relevant content from the releases leveraging the latent Dirichlet allocation (LDA) technique, they used a dictionary launched by Loughran and McDonald (LM) to quantify consumer review surveys, arguing that consumers’ knowledge is relatively low. That is, any lexicon well-tailored for the policy texts would be too specific, and the LM dictionary is a good option for that purpose (Loughran & Mcdonald, 2011).
Tumala and Omotosho (2019) applied opinion-mining techniques to analyze the efficiency of the Central Bank of Nigeria’s communication hand-outs by building a specific lexicon using their previous meeting communiqués for the last fifteen years. Besides readability and word occurrence frequency check, they used topic modeling methods for a detailed assessment of the subject density evolution of the documents throughout the years.
Kahveci and Odabas (2016) ran an investigation on a set of aspects as certainty and optimism of press releases of three specific central banks, namely FED, European Central Bank (ECB), and Central Bank of the Republic of Turkey (CBRT), exploiting Diction 7Footnote 4 to appraise the changes in communication transparency. They claimed that while there were no significant shifts in the tone of ECB and CBRT, an upward trend in certainty and a decline in the optimism of FED declarations were remarkable.
Park et al. (2019) quantified the Bank of Korea's meeting minutes to capture partial consequences of the Korean central bank's manner for the national macroeconomic variables. To this end, they applied contiguous sequences of the word (n-gram) approach to a field-specific Korean dictionary (eKoNLPy) since some words might mislead the results if they are left alone, e.g., recovery conveys an applauding meaning while sluggish recovery does not. They also built a machine learning-based model leveraging the Naïve Bayes Classifier and replicated the analysis for several well-known lexicons for comparison. Their study strongly suggested that the machine learning approach outperforms other dictionary-based models to explain current policy changes and provide insight into future movements.
Moniz and de Jong (2022) presented another automated framework that gauges the influence of central bank communications on investors' interest rate expectations in the United Kingdom. Using an automated summarization algorithm, TextRank, to detect word-level communities, they adopted the LDA (Latent Dirichlet allocation) technique with a naïve classifier to infer topic clusters from the documents for verification purposes. Finally, they mined the sentiment score with the help of the General Inquirer dictionary, a set of procedures for identifying recurrent patterns within text documents created by the Massachusetts Institute of Technology (MIT) (Stone et al., 1966).
Giuseppe Bruno from the Bank of Italy constructed a setup similar to Moniz et al.'s (Bruno, 2016). He took a close look at Bank of Italy's previous twenty Governor's Concluding Remarks documents released between 1996 and 2015 and analyzed the evolution of the documents for different aspects, such as formality, memorability, polarity, etc., over time. He concluded that the sentiment of these documents stayed relatively neutral during the period, whereas with different short-term economic conditions, it occasionally showed slight volatility.
Sohangir et al. (2018) assessed the performance of three famed lexicons in the opinion mining field using StockTwits, a financial social network data set. They also included a bunch of machine learning algorithms in their work. Their experiment showed that TextBlobFootnote 5 intends to classify too many words as neutral compared to other lexicons and machine learning models, seemingly making it inappropriate for texts that contain technical jargon. They also found that only the VADER dictionaryFootnote 6 outperforms baseline machine learning algorithms in terms of both accuracy and computational complexity.
Devlin et al. (2018) introduced a new language representation model called Bidirectional Encoder Representations from Transformers (BERT) in 2019. They designed BERT to pre-train deep bidirectional representations from an unlabeled text by joint conditioning on all layers' left and right contexts. Moreover, they inserted one additional output layer to create a model that struggles with various tasks, such as question answering and language inference, without substantial task-specific architecture modifications. They demonstrated the importance of bidirectional pre-training for language representations and its capability that allows the same pre-trained model to tackle a broad set of NLP tasks successfully.
Howard and Ruder (2018) claimed that pre-training of a language model on a target domain corpus enhances classification performance. They conducted further pre-training processes to discover whether such adaptation would be advantageous for the realm of finance and economics. To do this, they conducted several experiments exploiting the TRC2-financial corpus, a subset of Reuters’ TRC2 corpora, and Financial PhraseBank from the study of Malo et al. (2014). Sixteen professionals with backgrounds in business and finance annotated these sentences. Although Financial Phrasebank is relatively small, they concluded that using data from the direct target provides a better target domain adaptation.
Furthermore, Araci (2019) employed a transfer learning path and introduced a downstream language model based on BERT in 2019, called FinBERT, to deal with financial domain-specific texts for NLP tasks.
Yang et al. (2020) built another BERT model in 2020, addressing domain-specific precision issues in NLP. They collected a vast financial domain corpus comprising the three most representative corpora in finance and business communications, amounting to over 4.9 billion tokens. Based on their initial pre-training, they developed a model that classifies a sentence according to its forward-looking tendency. In other words, the model classifies a sentence into one of three categories: Specific FLS, non-specific FLS, and Not-FLS.Footnote 7 Labeling a sentence as Specific FLS implies that it is a definitive judgment about the future of a specific entity. In contrast, non-specific FLS spells its future-oriented structure without referring to matters pointedly. As the name suggests, the not-FLS tags indicate that the sentence has no forward-looking chemistry. Although it varies according to the model's fine-tuning parameters and data set, their experiment results showed a substantial improvement (between 4.3 and 29.2%) of FinBERT models over the generic BERT models.
This study will contribute to the literature since it is the first study that questions the effects of the recent pandemic on central banking communication by exploiting the state-of-the-art BERT models, off-domain tools, and further statistical analysis.
3 Methodology
This study intends to investigate the potential impacts of the COVID-19 crisis on the communication tone of the Federal Reserve (FED), as well as to examine the dynamics of the relationship between FED statements and consumer expectations during the periods before and after the crisis. We sought to provide a comprehensive analysis of how the COVID-19 crisis may have influenced the communication posture of the FED and their effectiveness in shaping consumer expectations in different periods, with the ultimate goal of answering the following questions:
-
How have FED statements evolved regarding readability level, Zipfian compatibility, and topic distribution over time? Is there any significant change in the trend during the pandemic?
-
What has occurred in the last decade years in the landscape of the co-movement between the semantic orientation and forward-lookingness intensity of FED statements and consumers' inflation expectations? Has there been a change in the appearance of this association along with the global health crisis?
-
Has the pandemic significantly impacted the polarity orientation and forward-looking strength of the FOMC communiqués?
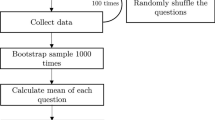
To answer these questions, we followed the workflow given in Fig. 1.

Research workflow
3.1 Data
3.1.1 Data Acquisition
We acquired the sampling data from the Federal Reserve Board's official page using web scraping techniques and then placed each meeting release in a separate text document. That way obtained a corpus comprising 214 FOMC meeting minutes releases from February 1992 to May 2023.Footnote 8 Additionally, we extracted monthly consumers' inflation expectation data for one- and three-year ahead time horizons from the Federal Reserve Bank of New York's online sources.Footnote 9
3.1.2 Data Preprocessing
Text preprocessing stands as a cornerstone in natural language processing (NLP), with a significant impact on the performance of downstream algorithms. Engaging in these foundational preparatory tasks requires careful consideration of several key issues. These encompass whether to strip away punctuation and stop words, how best to segment text into sentences, words, or even individual characters, whether to maintain the original form of words or reduce them to their roots, and the approach for addressing spelling inaccuracies. That said, meticulous tokenization can significantly improve the accuracy of part-of-speech tagging, and maintaining compound expressions can be critical for enhanced reasoning and machine translation. Conversely, reckless preprocessing may lead to an unfortunate erosion of valuable content. Trivially, it is also vital for managing the sheer volume of data in extensive corpora.
3.2 Stop-Word Removal
Stop words are available in abundance in any human language. These words are often considered a single collection of words, which may indicate diverse matters to various applications. Considering all candidate words from determiners (e.g., the, a) to prepositions (e.g., above, across) to some adjectives (e.g., good, excellent) may be an appropriate action in certain cases. Removing stop words discards low-level information from the text to give more focus to the relevant elements. Besides that, it reduces the data set size and thus cuts the training time due to the fewer tokens involved in the training phase. However, one should be careful while creating a stop word list and treat domain-specific wording assuredly.
Moreover, removing stop words may not be a good decision in some specific scenarios. That is, eliminating some words can be troublesome since these words might be decisive in contextualizing the intention. For instance, ignoring adjectives like “good” and “lovely” as well as negations like “not” may cause algorithms to malfunction in polarity research as it changes the valence of the passage and omits the context. Thus, stop words are retained when using contextual models like BERT.
3.3 Normalization and Tokenization
The normalization phase of preprocessing aims to reduce inflectional forms and occasionally derivatively related forms of a word to a single base form. Lemmatization and stemming are the two most common normalization techniques applied in NLP to lessen data irregularity and bring it closer to a predefined standard. However, the two differ in their flavor. Its straightforwardness and lesser computational complexity prompted us to use stemming in this study. Following cleaning redundant words from the corpora, we put the remaining part of the documents into the stemming process for normalization. We preferred Porter stemmer so as not to prune too tightly and, thus, avoid any possible costly data loss.
3.4 Word Embeddings
To do calculations on text data, one needs a way to represent the corpus that can be manipulated mathematically. We strive to convert words in a phrase to numbers so that the computer can read and comprehend them since computers can only speak the language of numbers. Extracting semantic and syntactic relationships demands more than mapping a word in a sentence or document to mere numbers. Consequently, only a large representation of those numbers can represent a corpus's semantic and syntactic properties. Thus, a convenient word embedding is compelling to capture the context of the paragraph or previous sentences and fetch their semantic and syntactic properties and similarities. One Hot Encoding, Bag-of-Words, TF-IDF, Word2Vec, and FastText are well-known word embedding methods. In addition to its simplicity, elasticity, and scalability, there was no need to preserve the order for the topic evaluation part. Thus, we preferred the Bag-of-Words technique to represent text data in the documents.
Note that we leveraged text preprocessing procedures only for the exploratory analysis part of this study since FinBERTs do not require such an effort to input data. Instead, FinBERTs have built-in contextual word embeddings. For a given token, its input representation is constructed by summing the corresponding token, segment, and position embeddings.
3.5 Transformations for Stationarity
Stationarity refers to the statistical properties of a time series remaining constant over time. In other words, a stationary time series is one where the mean, variance, and autocorrelation structure of the data do not change with time. Non-stationary time series may have trends, seasonality, or other patterns that change, making it challenging to model and forecast accurately. The lack of stationarity may lead to spurious correlations, where two variables appear to be correlated when, in fact, they are not due to the presence of common trends or other non-stationary patterns. Hence, to receive consistent and reliable results, the non-stationary data needs to be transformed into a stationary form (Nason, 2006). Several methods, including differencing, log transformation, sessional decomposition, detrending, and Box-Cox transformation, may be employed for the stationarity transformation, a common preprocessing step in time series analysis.
We ran Augmented Dickey–Fuller (ADF) and Kwiatkowski–Phillips–Schmidt–Shin test procedures to check the series' stationarity at the levels. Note that these tests have inherited limitations regarding detecting different types of non-stationarity, and they may offer complementary information. Moreover, they hold their assumptions. For example, the ADF test assumes that the residuals are normally distributed and that the autoregressive (AR) process is correctly specified. The KPSS test, on the other hand, assumes that the time series has a finite variance and that the errors are serially uncorrelated. Thus, we evaluated the results holistically, seeking a comprehensive and robust assessment. Table 1 provides the results.
Observe that there is no sufficient evidence to see the violation of the H0 hypothesis for the COVID-19 indicator. Therefore, we cannot reject it for the ADF test. However, we reject the null hypothesis for the COVID-19 series at all significance levels in the KPSS test. Note that both imply that the series has a unit root, indicating that the series has a random walk behavior and does not exhibit mean reversion since the unit root implies that the time series does not possess a stable, constant mean over time. So, the COVID-19 series is non-stationary. Furthermore, at the first difference of all series, we encounter a rejection of H0 for the ADF and non-rejection for the KPSS at a 1% significance level, which we exploited later for modeling purposes.
4 Exploratory Analysis
This section explores some insightful facts about the FOMC minutes press releases. We started by glancing at the paragraph and word volumes of the documents. Figure 2 denotes a visual presentation of the growth pattern that the meeting documents inferred over time. While the discussion volume of the committee meetings remained stagnant until 2007, the releases progressively increased in length from this year onward. In addition, there was a dramatic jump in the size of documents after 2010.

Word and paragraph volume
In the next subsections, we conducted a statistical analysis of the data according to normative features of computational linguistics based on word occurrence frequency, followed by an examination of the readability level of the minutes with respect to different measurement schemes.
4.1 Zipfian Compliance
Zipf's Law claims that given a corpus of natural language utterances, the frequency of any word is roughly inversely proportional to its rank in the frequency table. If the most common word occurs 1000 times, for example, it is expected that the second most common word will appear 500 times, the third will occur 333 times, and so on. Besides that, a relevant principle of information theory states that a text should follow Zipf's Law to boost its capacity to convey information with a limited set of words (Zhu et al., 2018).
After producing the Zipf's tables for aggregated corpus for each year, we appealed the Kolmogorov–Smirnov testFootnote 10 to see whether the data comes from a population with the Zipfian distribution. Test results failed to reject the null hypothesis that claims the corpus holds a Zipfian nature at the significance level of 5% for all years. That is, there is no sufficient evidence to gainsay the hypothesis that the sample data comes from a Zipfian distribution. Thus, we remain to assume that the minutes show Zipfian compliance and that the COVID-19 crisis has not caused any violation that would rule out the Zipfian nature of FOMC communiqués (see Table 2).
4.2 Readability Investigation
Readability measures how easily the audience of a text might understand it. Readability indices are scoring schemes measuring how contextually tricky it is to read a text based on its properties by using constructs known to reflect the complexity, such as average sentence length and the number of complex words. Indeed, this rating should be distinct from the intelligibility of a text because intelligibility varies according to the reader's knowledge regarding the subject and the qualitative and quantitative characteristics. We exclusively engaged three different readability scoring systems, namely the Flesch–Kincaid, Gunning–Fog index, and automated readability index (ARI). Figure 3 reveals fluctuations in the readability of FOMC communiqués in time.

FOMC minutes releases' readability indices
Flesch–Kincaid Grade Level reflects the US education system and shows the required education to understand a text. For example, a score of thirteen corresponds to the college student level. In the Gunning–Fog ranking, 17–20 and + 20 indicate post-graduate and post-graduate plus levels, respectively. Lastly, ARI outputs a number approximating the age needed to understand the text. As a rough guide, grade 12, the highest US secondary school grade before college, conforms to the reading level of a seventeen-year-old.
4.3 Topic Modeling
Topic modeling, also called topic extraction, is a form of statistical modeling trivially used to rate the main subheadings traced in a set of documents. Note that topic modeling is generally considered an unsupervised machine-learning approach in which algorithms identify topics based on patterns (such as word clusters and their frequencies). In contrast, topic classification is a supervised learning approach that uses rule-based systems (learning algorithms) that are manually trained using annotated data and predefined tags. The algorithm can only accurately classify unseen texts based on these labels after discovering the training data.
We put to use the Latent Dirichlet allocation (LDA) method, a generative probabilistic model introduced by Blei et al. (2001). That way, we delved into abstract topics with their weights in the documents and then questioned alteration points for these weights in the FOMC meetings in years. We clustered the words that passed through the preprocessing as discussed earlier and then labeled the groups by the most occurred terms in each. Figure 4 demonstrates the topic intensity evolution path of FOMC minutes for all periods.

Relative topic intensity of FOMC minutes
5 Polarity and Forward-Lookingness Analysis
Polarity or semantic analysis, commonly known as sentiment analysis, is a natural language processing (NLP) technique that determines the sentiment or emotional tone expressed in a text, such as a sentence, paragraph, or document. It involves automatically identifying and categorizing the sentiment conveyed in the text as positive, negative, or neutral. Polarity analysis aims to understand the subjective opinion, emotion, or sentiment expressed in text data, which can be valuable for various applications such as social media monitoring, customer feedback analysis, brand perception analysis, and market research. For polarity analysis by leveraging machine learning, practitioners train algorithms using data sets where experts manually annotate sentiments. This process allows the algorithms to identify and assimilate the relationships between words, phrases, and their corresponding sentiment labels.
On the other hand, forward-lookingness, also known as future or forward-looking information, refers to the aspect of information or data that pertains to the future or predicts future events, trends, or outcomes. Hence, the primary goal is to analyze and interpret data that provide insights or forecasts about what may happen in the future. Forward-lookingness is often used in various fields, such as economics, finance, business, and technology, to make informed decisions, develop strategies, and anticipate potential risks and opportunities. Forward-lookingness can encompass various data types, including economic indicators, market trends, predictive analytics, scenario modeling, and expert opinions. It allows stakeholders to proactively plan and adapt to changing circumstances, make strategic decisions, and stay ahead in a dynamic and uncertain environment.
The following subsections introduce the tools we exploited and the route pursued throughout this part of the analysis.
5.1 Bidirectional Encoder Representations from Transformers (BERT)
The development of deep learning models for sentiment analysis has significantly transitioned from the early use of LSTM-based models to the more recent emergence of BERT models. LSTM models have been initially used for sentiment analysis, and they were relatively successful in capturing temporal dependencies in sequential data. However, the emergence of transformer-based models, such as BERT, enabled more effective handling of contextual information by exploiting self-attention mechanisms. BERT's success in capturing rich contextual information from pre-trained language models led to the maturation of BERT-based sentiment analysis models, which have consistently outperformed LSTM-based models in recent years.
Bidirectional encoder representations from transformers (BERT) is a state-of-the-art natural language processing (NLP) model that has revolutionized the field of language understanding and representation (Devlin et al., 2018). It is a pre-trained deep learning model capable of capturing bidirectional contextualized representations of words and sentences, leading to significant advancements in various NLP tasks such as text classification, named entity recognition, question answering, and sentiment analysis. At the heart of BERT lies the transformer architecture, a neural network that enables efficient and parallel processing of input sequences. Unlike traditional NLP models that deal with words or sentences sequentially, BERT processes input text in parallel, allowing faster and more effective representations. During pre-training, BERT employs a masked language modeling (MLM) objective, randomly masking words in a sentence. The model is trained to predict the masked words based on the contextual information from the surrounding words. This aspect of BERT enables it to learn bidirectional contextual representations, as it must rely on both the left and right context to predict the masked words accurately. In contrast to traditional word embeddings that are static and do not change based on the context, bidirectional nature allows BERT to capture the meaning of a word within the context of the entire sentence, enabling it to grasp the intricate nuances of language, such as word sense disambiguation, syntactic structure, and semantic relationships. Leveraging a masked language model (MLM) training approach, BERT can predict missing words in a sentence, forcing it to understand the dependencies between words and the context in which they appear.
BERT has been widely adopted in the NLP community and has achieved state-of-the-art results on a wide range of benchmark data sets. It has also been used as a base model for fine-tuning specific NLP tasks. Researchers and practitioners can fine-tune BERT on task-specific data with minimal modifications to the model architecture. This transfer learning capability of BERT has significantly reduced the need for large amounts of task-specific labeled data, making it a powerful tool for many real-world NLP applications with limited data availability.
BERT has also inspired further research and advancements in the field of NLP, leading to the development of variants and extensions of the original BERT model, such as ALBERT,Footnote 11 ELECTRA,Footnote 12 and RoBERTa.Footnote 13 These variants have further pushed the boundaries of NLP performance and opened new research avenues in areas such as multilingual NLP, low-resource NLP, and domain adaptation. There are BERT adaptations for the finance- and economics-related domains as well. Two notable examples are FinBERT and FinBERT FLS (Huang et al., 2022; Yang, 2022). These models cater to the unique characteristics and requirements of financial text data, making them particularly well-suited for financial sentiment analysis, financial event prediction, and financial risk assessment tasks.
5.1.1 FinBERT
FinBERT is a domain-specific adaptation of BERT trained on a large corpus of financial documents, such as financial reports, earnings calls, and news articles related to finance and economics. By pre-training on such domain-specific data, FinBERT captures the nuances and domain-specific language used in financial texts, which can differ from general-purpose language. Hence, FinBERT perceives financial jargon, industry-specific terminology, and domain-specific contextual information, which is critical for analyzing financial text data accurately.
On the other hand, FinBERT FLS (forward-looking sentence) is a variant of FinBERT, fine-tuned to detect the forward-looking structure of the sentences in financial documents. These models can identify phrases or sentences that indicate future events, predictions, or expectations, which is crucial for the decision-making process in financial programming. For instance, FinBERT can recognize phrases that may contain a projection into the future to identify forward-looking information in financial text data. This feature enables analysts to understand better the prospects, risks, and opportunities associated with financial entities or events and make more informed decisions. FinBERT and FinBERT FLS have proven highly effective in various financial text analysis tasks. They have been used in applications such as sentiment analysis of financial news, predicting stock price movements based on financial sentiment, and identifying financial risks and opportunities. These domain-specific BERT models have demonstrated superior performance to general-purpose BERT models in financial text analysis tasks, showcasing the importance of domain-specific adaptations for specialized domains in economics and finance.
We extracted quantitative information from the documents using FinBERT and FinBERT FLS. FinBERT assigns labels to each sentence in the documents, classifying them as positive, negative, or neutral, whereas FinBERT FLS produces an outcome, categorizing sentences as either specific forward-looking-sentence, non-specific forward-looking-sentence, or not-forward-looking-sentence. Labeling a sentence as Specific FLS implies that it is a definitive judgment about the future of a specific entity. In contrast, non-specific FLS spells its future-oriented structure without referring to matters pointedly. As the name suggests, the Not-FLS tags indicate that the sentence has no forward-looking nature. We calculated the average scores for each class in a meeting-wise manner as follows:
\(non{ - }Specific\;FLS = \frac{{Total\;non{ - }Specific\;FLS\;Score}}{Total\;Sentence\;Count}\)
where total scores (e.g., Total Positive Score) are simply the sum of all scores produced at the sentence level for each class (e.g., Positive). Figures 5 and 6 illustrate the time series for each defined variable with a joined bar graph representing the word counts on the opposite axis.

Scores (line graph on the left-axis) and total sentence counts (bar graph on the right-axis) results for polarity search

Scores (line graph on the left-axis) and total sentence counts (bar graph on the right-axis) results for forward-lookingness search
Figures 5 and 6 demonstrate a substantial decrease in the magnitude of the volume of the minutes after 2004. Remarkably, the decline in the number of neutral sentences appears more pronounced than positive and negative ones. This trend suggests that the FED displayed a discernible inclination towards eschewing statements that lack a definitive direction in following the attitude change. However, a resurgence emerged in the volume of neutral expressions towards the culmination of a period spanning approximately three years. Subsequently, in the aftermath of the 2007–2008 financial crisis, the sentence volume in the minutes exhibits a state of relative stability.
The contraction in the minutes' length is mirrored in the specific and general volumes of forward-looking content. Nevertheless, the intensity of forward-looking sentiment in the FOMC statements shows greater variability than the shifts in sentiment polarity. Notably, the forward-lookingness scores exhibit significant volatility at times, as observed from 1999 to 2003 for targeted forward-looking statements and similarly in 2005, as well as from 2013 to 2015 for broad forward-looking statements. Additionally, following the aforementioned adjustment period, the volume of forward-looking references maintained a more erratic profile than the consistency of sentiment polarity.
5.2 Temporal Sequence Similarity
A temporal sequence is a series of data points or observations ordered chronologically. It represents the evolution of a variable or phenomenon over time, where each data point is associated with a specific time point or time interval.
Measuring the similarity between two temporal sequences with different frequencies can be challenging due to differences in the granularity or resolution of the data. One common approach is to resample or aggregate the data to a standard frequency before calculating proximity measures. Several other methods commonly employed for measuring the similarity between temporal sequences with different frequencies include dynamic time weaving (DTW), cross-correlation, Fourier-based methods, Pearson correlation, and wavelet-based methods.
Resampling or aggregating data to a standard frequency for measuring similarity between temporal sequences with different frequencies may have limitations. It may cause loss of information, potential misalignment, or distortion of temporal patterns and introduce biases. Careful consideration should be given to this approach's potential implications and limitations, such as the impact on the accuracy and validity of the measures and the potential loss of fine-grained temporal dynamics. Alternative methods that account for the inherent differences in frequency between the sequences may be employed to mitigate these limitations. Therefore, we chose the Dynamic Time Warping method for this analysis.
5.2.1 Dynamic Time Warping (DTW)
Dynamic time warping (DTW) is a widely used technique for measuring proximity between time series data with varying temporal dynamics, making it particularly useful for comparing sequences with different frequencies. DTW is a nonparametric approach that allows for local time shifts and scaling, making it robust to temporal misalignments in time series data.
The main advantage of DTW is its flexibility in capturing complex temporal patterns in time series data. It responds to linear and non-linear relationships between data points, making it suitable for various applications, such as speech recognition, gesture recognition, and financial time series analysis. Intuitively, Fig. 7 represents the logic behind DTW by comparing it with the Euclidian counterpart. DTW can handle time series data with different frequencies, allowing for local time shifts, making it particularly useful for comparing sequences with irregular or asynchronous time intervals. Additionally, DTW can handle sequences with different lengths, as it allows for partial alignments and does not require sequences to have the same number of data points.

Graphical representation of the comparison between Dynamic Time Warping and Euclidean distance (Tavenard, 2021)
DTW operates by aligning two temporal sequences in a dynamic programming framework. The basic idea is to find an optimal warping path that aligns the sequences in a way that minimizes the overall cost of warping. The cost of warping is typically defined as the dissimilarity or distance between corresponding data points in the sequences. The algorithm finds the path with the minimum cumulative cost, taking into account possible shifts in time and scaling of the sequences.
Given two time series, denoted as \(\mathrm{X }= \{{x}_{1},{x}_{2},...,{x}_{n}\}\) and \(\mathrm{Y }= \{{y}_{1},{y}_{2},...,{y}_{n}\}\), where n and m are the lengths of \({\text{X}}\) and \({\text{Y}}\), and \({x}_{i}\) and \({{\text{y}}}_{i}\) represent the values of the time series at the time i and j, respectively. DTW aims to find a mapping between the two-time series \({\text{X}}\) and \(Y\), which minimizes the cumulative distance between corresponding data points, subject to certain constraints (Ge & Chen, 2020).
Let \({{\text{y}}}_{j}\) as \({\text{d}}({{\text{x}}}_{{\text{i}}},{{\text{y}}}_{{\text{j}}})\) be the distance between two data points \({{\text{x}}}_{i}\), which could be any valid distance metric, such as Euclidean distance, Manhattan distance, or any other distance measure based on the problem domain. The DTW algorithm computes a similarity matrix, denoted as \(\mathrm{D }= \{{\text{d}}({\text{i}},{\text{j}})\}\), where \(d(i,j)\) represents the distance between \({{\text{x}}}_{i}\) and \({{\text{y}}}_{j}\). This similarity matrix has the exact dimensions as the time series data \({\text{X}}\) and \(Y\).
The DTW algorithm uses a dynamic programming approach to compute the similarity matrix \(D\) in an iterative manner. The key idea is to compute the minimum cumulative distance from the starting point \((\mathrm{0,0})\) to each point \((i,j)\) in the similarity matrix \(D\), by considering the minimum of the three possible previous points: \((i-1,j)\), \((i,j-1)\), and \((i-1,j-1)\).
The recurrence relation for computing the similarity matrix \(D\) is given by:
where \({\text{D}}({\text{i}},{\text{j}})\) represents the minimum cumulative distance from the starting point \((\mathrm{0,0})\) to the point \(({\text{i}},{\text{j}})\) in the similarity matrix, and \(d({x}_{i},{y}_{j})\) represents the distance between xi and yj. Once the similarity matrix D is computed, the DTW distance between two-time series X and Y is given by the value at the bottom-right corner of the similarity matrix, i.e., \({\text{D}}({\text{n}},{\text{m}})\), where n and m are the lengths of X and Y, respectively.
We attained the proximity between consumer inflation expectations and each series using the DTW method. Since the consumers' inflation expectations vary depending on the time horizon, we exclusively considered the short- and medium-term expectations for our analysis. Figures 8 and 9 show the distances between consumer inflation expectations and each scoring series over the course of time.

DTW Distances for one-year ahead consumer inflation expectations

DTW Distances for three-year ahead consumer inflation expectations
The distances between the sequences show extreme similarity for the one-year and three-year consumer inflation expectations for the pre-crisis period. However, the distances between the sequences have increased to 13–16 units for one-year expectations and 8–10 for three-year expectations with the pandemic. Indeed, this is not very striking since, as the literature suggests, consumers' inflation expectations tend to be more stable over longer time horizons. Short-term expectations can be more volatile and subject to sudden changes in economic conditions or perceptions of economic policy. On the other hand, while the distance between three-year inflation expectations and the FOMC scoring series for the post-crisis period shows the normalization tendency more clearly, we need to observe more data for one-year expectations.
The accumulated cost matrix represents the cumulative cost of aligning the pairwise series of sequences at each point in time. The cost at each position is computed based on a distance metric between the elements at that position and a set of neighboring positions in the accumulated cost matrix. The goal is to find the optimal warping path through the matrix with the minimum accumulated cost, representing the best alignment between the two sequences. Additionally, the warping path represents the optimal alignment or mapping between the two sequences, indicating that the corresponding data points in the two sequences are most similar. A shorter path or a lower accumulated cost indicates a higher similarity between the sequences, whereas a longer path or a higher accumulated cost indicates a lower similarity. The warping path can be interpreted as a sequence of pairs of indices from the two sequences that indicate which elements are matched or aligned. The warping paths can also provide information on the time lag or shift between the two sequences, indicating any temporal misalignment or time lag in the similarity patterns. Figures 10 and 11 visualize all possible warping paths (also called the accumulated cost matrix) for one- and three-year ahead produced by the DTW algorithm, respectively.

Accumulated cost matrices and warping paths for one-year ahead consumer inflation expectations. Specific FLS (left-top), non-Specific FLS (right, top), Positivity (left-middle), Negativity (right-middle), and Neutrality (bottom)

Accumulated cost matrices and warping paths for one-year ahead consumer inflation expectations. Specific FLS (left-top), non-Specific FLS (right, top), Positivity (left-middle), Negativity (right-middle), and Neutrality (bottom)
Note that a diagonal move is a match between the two sequences. In contrast, off-diagonal moves imply either duplication of one point of one sequence (expansion) or elimination of one of the points (contradiction). Observe that those pairwise warping paths for one- and three-year are almost identical except for the negativity series, whose three-year path flourishes a salient deviation from its one-year-ahead pattern. Thus, the patterns between the series obtained from the FED minutes and the one- and three-year ahead consumer inflation expectations are alike. Moreover, all pairwise series show a phase shift once or twice during the last decade. The accumulated similarity matrix and paths produced by the DTW algorithm display a non-monotonic pattern during these periods, suggesting that the scoring series (e.g., positivity) experienced a temporal distortion or phase shift compared to the other time series (e.g., consumer inflation expectation).
5.3 ARIMAX Modeling
ARIMAX (AutoRegressive Integrated Moving Average with eXogenous variables) extends the ARIMA model by incorporating exogenous variables and external factors that may affect the time series. In this expanded model, one introduces exogenous variables as additional predictors, together with the autoregressive, moving average, and integrated components. This proves essential for forecasting when one expects external factors to influence the time series data and must include them in the analysis (Anggraini et al., 2015). The below equation constructs an \(ARIMA(p,I,q)\):
where \({Y}_{t}\) is the value of the time series variable at time t, \({\phi }_{1},...,{\phi }_{p}\) are the parameters of the AR component, \({\theta }_{1},...,{\theta }_{q}\) are the parameters of the MA component.
Let \({\beta }_{1},...,{\beta }_{m}\) be the parameters of the exogenous variables \({X}_{1},...,{X}_{m}\). Then the general form of an \(ARIMAX(p,I,q)\) can be expressed correspondingly (Respondek et al., 2014):
To determine the appropriate model order, we went through the autocorrelation function (ACF) and partial autocorrelation function (PACF) plots and identified the autoregressive (AR) and moving average (MA) components. We also explored the possible model neighborhoods and evaluated the prospective models by their AIC (Akaike Information Criterion) values to find the best fit. And finally, we embedded a dummy variable into the equation as an indicator function. Tables 3 and 4 present the coefficients, standard errors, and p values. Moreover, Fig. 12. Residuals illustrates the residuals, i.e., unexplained variation between the observed values of a dependent variable and the values predicted by the model.

Residuals. Specific FLS (left-top), non-Specific FLS (right, top), Positivity (left-middle), Negativity (right-middle), and Neutrality (bottom)
Based on the results in Table 3 and 4, and Fig. 12. Residuals, coefficients associated with the COVID-19 indicator variable are not statistically significant for any time series, as indicated by p-values that are larger than any predefined significance level (e.g., \(\alpha =0.05\)). This implies that including the indicator function variable does not significantly contribute to the models' predictive performance for the respective time series. Besides, the residuals of the polarity models displayed more desirable characteristics than the forward-lookingness models, as they showed less prominent patterns and deviations from the expected behavior, suggesting a better fit to the data.
6 Results
This section presents the findings from our analytical review of Federal Reserve (FED) communications for the pre- and post-pandemic periods. These insights illuminate the stand-still dynamics of FED communication in response to the pandemic's challenges.
We first note a significant increase in the volume of words and paragraphs in FED releases, a trend that began in mid-2007 and continued to rise, with a notable spike in 2011. It is particularly evident that the communications from the first meetings of the new year tend to be lengthier, likely reflecting the necessity for a detailed annual economic review and the strategic formulation of monetary policies for the ensuing year. This pattern necessitates more detailed initial communications from the FOMC to articulate their assessments, projections, and policy directions adequately.
The complexity of the FED's releases experienced a decline post-1990s but saw an upsurge around the 2008 financial crisis, ultimately settling at college-level readability in later years. Although ARI and Gunning-Fog deviated from each other till the 2010s, the latter produced higher scores than the former in general. Nevertheless, they tended to overlap after that time. Notably, the readability levels of FED releases declined after the 1990s, whereas it showed a steep rise probably associated with the 2008 financial crisis. Eventually, all indexes remained stable around the college level for the last couple of years. However, the Gunning-Fog and ARI indexes have recently shown a mild downward trend. In addition, the adherence to Zipf's Law underscores a coherent text flow, prioritizing key concepts and ideas. Our analysis confirms that compliance with Zipf's Law in the minutes' structure has been consistent over time.
Aggregate Demand has formed the most substantial part of FOMC communiqués between 1995 and 2023. Its ranking has stayed above all other subheadings with a weight of over 20% in all years in question. Not surprisingly, the Credit Market has taken mostly the second largest slice of the cake for the meeting agendas, except for 1996. Specifically, the credit market, where agents trade their debts, comprises about one-fifth of the meeting agendas after the 2000s. We observe that the share of Inflation, which was 16.73% in 1995, decreased to around 11% towards the first years of the millennium, followed by an increase after 2005, and remained stable at around 15% in recent years. That is, there have been no substantial changes in the nominal ratio of the relative subject intensity of the Fed meetings, specifically after the 2010s. In other words, it has settled into a particular lane following the global financial crisis. Finally, the stake in matters linked to Outlook has shown a smooth enlargement from the beginning of the 2000s and stabilized after 2010 at about 18%.
Our analysis also indicates a reduction in the overall length of FED minutes post-2004, with a particular decline in neutrally toned sentences, suggesting a strategic shift by the FED towards more pointed communication. However, after three years, an increase in the use of neutral language is noticeable. Following the financial crisis of 2007–2008, the length of sentences leveled off. This contraction in minute length coincided with fluctuations in the use of specific and general forward-looking statements, showing greater variance in forward-looking intensity than in sentiment polarity. Notable fluctuations in the forward-looking statements were evident between 1999 and 2003 and between 2005 and 2015. Yet, post-adjustment, the volume of forward-looking references has continued to be more erratic when compared to sentiment polarity.
The study revealed that including a COVID-19 indicator variable did not significantly improve the forecast accuracy of our models, as the p-values exceeded the accepted significance level, implying that the COVID-19 variable is not a significant predictor in our time series models. Additionally, the residuals of the polarity models showed more favorable characteristics than those for forward-lookingness, suggesting a more robust fit to the data.
While imperfect residuals can raise questions about the estimated parameters' predictive accuracy and stability, our research contributes valuable insights into the FED's communicative tone and strategic focus. Nevertheless, it is essential to recognize the limitations presented by the residuals and to explore alternative explanations or methodological approaches. Future research could investigate different modeling techniques or include new variables to improve the precision and reliability of the findings.
7 Conclusions
The COVID-19 pandemic has had profound and far-reaching effects on countries' economies worldwide, resulting in widespread disruptions in supply chains, business closures, job losses, and fiscal challenges. The economic impacts of the pandemic have been diverse and complex and continue to evolve, posing significant challenges for policymakers and necessitating unprecedented measures to mitigate the economic fallout.
On the other hand, central banks' communication strategies play a pivotal role in shaping consumer and market expectations. It helps to guide decision-making, influence behavior, and manage perceptions about monetary policy and economic outlook. That said, transparent, timely, and effective communication is crucial in enhancing credibility and building trust, fostering stability in financial markets and the broader economy. A valid communication strategy and the invention of tools adequately aligned with these strategies are essential catalysts for shaping consumer perceptions and guiding economic behavior. Therefore, central banks must adapt their communication accordingly in the face of unexpected circumstances, considering their role in navigating through crises for their countries.
Unprecedented times demand unconventional remedies. Traditional approaches to monetary policy may not be enough to address the challenges during those periods, and financial authorities need to be open and adaptable in their communication to promote faster economic recovery before they leave sticky impairments. Particularly, central banks should adopt more transparent and long-sighted communication strategies to provide guidance to markets and the public about their policy stance while being flexible and responsive to sudden changing economic conditions.
Despite the limitations mentioned earlier, our study contributes to the literature on central bank communication and sets the stage for further investigation of the potential effects of the global pandemic. Further research could explore the long-term effects of central bank communication during the pandemic and extend this study to other countries employing different modeling approaches.
Notes
Despite the nuance between a lexicon and a dictionary by their linguistic definitions, we use them interchangeably.
Texts that follow Zipf's law are typically easier to read and understand because they prioritize the most important words and efficiently use language (Ferrer-i-Cancho & Sole, 2001).
A computer-assisted program for determining the tone of a verbal message using pre-defined dictionaries to process a passage, then compares the results to built-in norms.
TextBlob is a popular open-source Python library for NLP that provides a simple interface for common NLP tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, and translation, among others.
VADER (Valence Aware Dictionary and sEntiment Reasoner) is a pre-trained rule-based sentiment analysis tool developed by Hutto and Gilbert (2015).
FLS: Forward-looking sentence.
A non-parametric test of the equality of continuous (or discontinuous) and one-dimensional probability distributions that can be used to compare a sample with a reference probability distribution, or to compare two samples.
ALBERT (A Lite BERT) is an optimized version of the BERT (Bidirectional Encoder Representations from Transformers) model that reduces the number of parameters while maintaining the model's performance.
ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately) is a more computationally efficient pre-training method for language models that uses a discriminator to predict which tokens in a text have been replaced by fake tokens.
RoBERTa is a refined version of the BERT (Bidirectional Encoder Representations from Transformers) model, which uses longer training and larger batch sizes to improve language understanding performance.
References
Anggraini, W., Vinarti, R., & Kurniawati, Y. (2015). Performance comparisons between arima and arimax method in moslem kids clothes demand forecasting: Case study. Procedia Computer Science, 72, 630–637.
Araci, D. (2019). FinBERT: Financial sentiment analysis with pre-trained language models. arXiv:1908.10063
Bholat, D., Hans, S., Santos, P., & Schonhardt-Bailey, C. (2015). Text mining for central banks. In Centre for central banking studies, Bank of England (p. 33).
Blei, D., Ng, A., & Jordan, M. (2001). Latent Dirichlet allocation. In Advances in neural information processing systems.
Blinder, A., Haan, J., Ehrmann, M., Fratzscher, M., & Jansen, D. (2008). Central bank communication and monetary policy: A survey of theory and evidence. Journal of Economic Literature, 46, 910–945.
Bruno, G. (2016). Text mining and sentiment extraction in central bank documents. In IEEE international conference on big data.
Cornwell, R. (1996). Independent Co UK. Retrieved December 21, 2022, from https://www.independent.co.uk/news/business/if-i-ve-made-myself-too-clear-you-must-have-misunderstood-me-1328606.html
Devlin, J., Chang, M., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805
Ferrer-i-Cancho, R., & Sole, R. (2001). Two regimes in the frequency of words and the origins of complex lexicons: Zipf’s law revisited. Journal of Quantitative Linguistics, 8, 165–173.
Freedman, C., & Laxton, D. (2009). Inflation targeting pillars: Transparency and accountability. In International monetary fund, IMF working papers (p. 19).
Ge, L., & Chen, S. (2020). Exact dynamic time warping calculation for weak sparse time series. Applied Soft Computing, 96, 106631.
Goodfriend, M. (1990). Interest rates and the conduct of monetary policy. In: Federal Reserve Bank of Richmond—Working papers (p. 90-06).
Haan, J., Bodea, C., Hicks, R., & Eijffinger, S. (2018). Central bank independence before and after the crisis. Comparative Economic Studies, 60, 183–202.
Hansen, S., & McMahon, M. (2015). Shocking language: Understanding the macroeconomic effects of central bank communication. Journal of International Economics, 96, 114–133.
Howard, J., & Ruder, S. (2018). Universal language model fine-tuning for text classification. arXiv:1801.06146
Huang, A. H., Wang, H., & Yang, Y. (2022). FinBERT: A large language model for extracting information from financial text. Contemporary Accounting Research, 40, 806–841.
Hutto, C. J., & Gilbert, E. (2015). VADER: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the 8th international conference on weblogs and social media.
Issing, O. (2019). The long journey of central bank communication. MIT Press.
Kahveci, E., & Odabas, A. (2016). Central banks’ communication strategy and content analysis of monetary policy statements: The case of FED, ECB and CBRT. Procedia-Social and Behavioral Sciences, 235, 618–629.
Loughran, T., & Mcdonald, B. (2011). When is a liability not a liability? Textual analysis, dictionaries, and 10-Ks. Behavioral and Experimental Accounting eJournal, 66, 35–65.
Lucca, D., & Trebbi, F. (2009). Statements, measuring central bank communication: An automated approach with application to FOMC. In National Bureau of Economic Research, Inc, working papers (p. 15367).
Luo, T., Chen, S., Xu, G., & Zhou, J. (2013). Sentiment analysis. In Trust-based collective view prediction (pp. 53–68).
Malo, P., Sinha, A., Korhonen, P., Wallenius, J., & Takala, P. (2014). Good debt or bad debt: Detecting semantic orientations in economic texts. Journal of the Association for Information Science and Technology, 65, 782–796.
Moniz, A., & de Jong, F. (2022). Predicting the impact of central bank communications on financial market investors’ interest rate expectations (pp. 144–155). Springer.
Muth, J. F. (1961). Rational expectations and the theory of price movements. Econometrica, 29, 315–335.
Nason, G. P. (2006). Stationary and non-stationary time series. Geological Society of London.
Park, K. Y., Lee, Y. J., & Kim, S. (2019). Deciphering monetary policy board minutes through text mining approach: The case of Korea. SSRN Electronic Journal, 1.
Rayward, W. (2016). Michael D Gordin, Scientific babel: How science was done before and after global english. Isis, 107, 665–666.
Respondek, G., Gröger, J., Floeter, J., & Temming, A. (2014). Variability of fishing effort for the German brown shrimp (Crangon Crangon) fishing fleet: Influencing factors, and seasonal and spatial patterns. ICES Journal of Marine Science, 71, 1805–1817.
Schmidt-Hebbel, K., & Carrasco, M. (2016). The Past and future of inflation targeting: implications for emerging-market and developing economies. In Monetary policy in India: A modern macroeconomic perspective (pp. 583–622).
Sohangir, S., Petty, N., & Wang, D. (2018). Financial sentiment lexicon analysis In. IEEE 12th international conference on semantic computing (ICSC).
Stone, P., Dunphy, D., Smith, M., & Ogilvie, D. (1966). The general inquirer: A computer approach to content analysis. American Educational Research Journal, 4, 1.
Su, S., Ahmad, A. H., & Wood, J. (2020). How effective is central bank communication in emerging economies? An empirical analysis of the Chinese money markets responses to the People’s Bank of China’s policy communications. Review of Quantitative Finance and Accounting, 54, 1195–1219.
Szyszko, M., Rutkowska, A., & Kliber, A. (2022). Do words affect expectations? The effect of central banks communication on consumer inflation expectations. The Quarterly Review of Economics and Finance, 86, 221–229.
Taboada, M. (2016). Sentiment analysis: An overview from linguistics. Annual Review of Linguistics, 2, 325–347.
Tavenard, R. (2021). An introduction to dynamic time warping. Retrieved December 10, 2022, from https://rtavenar.github.io/blog/dtw.html
Tumala, M., & Omotosho, B. (2019). A text mining analysis of central bank monetary policy communication in Nigeria. Central Bank of Nigeria Journal of Applied Statistics, 10, 73–107.
Yang, Y. (2022). Hugging face. Retrieved January 13, 2023, from https://huggingface.co/yiyanghkust/finbert-fls
Yang, Y., Uy, M., & Huang, A. (2020). FinBERT: A pretrained language model for financial communications. arXiv:2006.08097
Zhu, Y., Zhang, B., Wang, Q., Li, W., & Cai, X. (2018). The principle of least effort and Zipf distribution. Journal of Physics, 1113, 012007.
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK). The authors have not disclosed any funding.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Taskin, B., Akal, F. Tales of Turbulence: BERT-based Multimodal Analysis of FED Communication Dynamics Amidst COVID-19 Through FOMC Minutes. Comput Econ (2024). https://doi.org/10.1007/s10614-023-10533-w
Accepted:
Published:
DOI: https://doi.org/10.1007/s10614-023-10533-w