
Abstract
Multilevel ensemble-based data assimilation (DA) as an alternative to standard (single-level) ensemble-based DA for reservoir history matching problems is considered. Restricted computational resources currently limit the ensemble size to about 100 for field-scale cases, resulting in large sampling errors if no measures are taken to prevent it. With multilevel methods, the computational resources are spread over models with different accuracy and computational cost, enabling a substantially increased total ensemble size. Hence, reduced numerical accuracy is partially traded for increased statistical accuracy. A novel multilevel DA method, the multilevel hybrid ensemble Kalman filter (MLHEnKF) is proposed. Both the expected and the true efficiency of a previously published multilevel method, the multilevel ensemble Kalman filter (MLEnKF), and the MLHEnKF are assessed for a toy model and two reservoir models. A multilevel sequence of approximations is introduced for all models. This is achieved via spatial grid coarsening and simple upscaling for the reservoir models, and via a designed synthetic sequence for the toy model. For all models, the finest discretization level is assumed to correspond to the exact model. The results obtained show that, despite its good theoretical properties, MLEnKF does not perform well for the reservoir history matching problems considered. We also show that this is probably caused by the assumptions underlying its theoretical properties not being fulfilled for the multilevel reservoir models considered. The performance of MLHEnKF, which is designed to handle restricted computational resources well, is quite good. Furthermore, the toy model is utilized to set up a case where the assumptions underlying the theoretical properties of MLEnKF are fulfilled. On that case, MLEnKF performs very well and clearly better than MLHEnKF.
Article PDF
Similar content being viewed by others
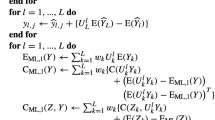


Avoid common mistakes on your manuscript.
Abbreviations
- \(\mathbb {B}\) :
-
Bias
- A:
-
Empirical forecast cross covariance
- \(\mathbb {C}\) :
-
Covariance
- Q :
-
Cost
- N :
-
Ensemble size
- K :
-
Kalman gain
- L :
-
Number of levels
- w :
-
Weights in MLEnKF
- ρ :
-
Mean squared error
- \(\mathbb {V}\) :
-
Variance
- Ω :
-
Scale matrix in Wishart distribution
- C:
-
Monte Carlo estimate of covariance
- V:
-
Empirical variance in toy model
- E:
-
Monte Carlo estimate of expectation
- Ξ 2 :
-
Matrix of element-wise squared bias
- x :
-
Position in space
- d :
-
Data vector
- H :
-
Measurement operator
- \(\mathbb {E}\) :
-
Expectation
- κ :
-
Fixed cost
- δ :
-
Fixed MSE error
- M :
-
Arbitrary deterministic forward model
- \(\mathcal {N}\) :
-
Gaussian distribution
- 𝜃 :
-
Realization from \(\mathcal {N}\)
- ∥⋅∥:
-
Matrix norm
- m :
-
Parameter
- p():
-
Probability density function
- k :
-
Permeability
- ω :
-
Arbitrary random variable
- \(\mathbb {X}\) :
-
Unspecified statistics
- Y, Z :
-
State vector
- 𝜖 :
-
Level-specific error for toy models
- Ψ :
-
Grid-coarsening factor
- σ :
-
Average value over elements of Σ
- Σ :
-
Matrix of element-wise variance
- R:
-
Total available computational resources
References
Aanonsen, S.I., Eydinov, D.: A multiscale method for distributed parameter estimation with application to reservoir history matching. Comput. Geosci. 10(1), 97–117 (2006). https://doi.org/10.1007/s10596-005-9012-4
Aanonsen, S.I., Nævdal, G., Oliver, D.S., Reynolds, A.C., Vallès, B.: The ensemble Kalman filter in reservoir engineering–a review. SPE J. 14(3), 393–412 (2009). https://doi.org/10.2118/117274-PA
Axelsson, O.: Iterative Solution Methods. Cambridge University Press, Cambridge (1994)
Chen, Y., Oliver, D.S.: Ensemble randomized maximum likelihood method as an iterative ensemble smoother. Math. Geosci. 44(1), 1–26 (2012). https://doi.org/10.1007/s11004-011-9376-z
Chen, Y., Oliver, D.S.: Levenberg-Marquardt forms of the iterative ensemble smoother for efficient history matching and uncertainty quantification. Comput. Geosci. https://doi.org/10.1007/s10596-013-9351-5 (2013)
Chernov, A., Hoel, H., Law, K.J.H., Nobile, F., Tempone, R.: Multilevel ensemble Kalman filtering for spatially extended models. arXiv:1608.08558 (2016)
Durlofsky, L.: Upscaling of geocellular models for reservoir flow simulation: a review of recent progress. 7th International Forum on Reservoir Simulation Bühl/Baden-Baden, Germany, 23–27 (2003)
Emerick, A.A., Reynolds, A.C.: History matching time-lapse seismic data using the ensemble Kalman filter with multiple data assimilations. Comput. Geosci. 16(3), 639–59 (2012). https://doi.org/10.1007/s10596-012-9275-5
Emerick, A.A., Reynolds, A.C.: Ensemble smoother with multiple data assimilation. Comput. Geosci. 55, 3–15 (2013). https://doi.org/10.1016/j.cageo.2012.03.011
Emerick, A.A., Reynolds, A.C.: Investigation of the sampling performance of ensemble-based methods with a simple reservoir model. Comput. Geosci. 17(2), 325–350 (2013). https://doi.org/10.1007/s10596-012-9333-z
Evensen, G.: Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics. J. Geophys. Res. 99(C5), 10,143 (1994). https://doi.org/10.1029/94JC00572
Farmer, C.L.: Upscaling: a review. Int. J. Numer. Methods Fluids 40(1-2), 63–78 (2002). https://doi.org/10.1002/fld.267
Flowerdew, J.: Towards a theory of optimal localisation. Tellus Series A: Dynamic Meteorology and Oceanography 67(1). https://doi.org/10.3402/tellusa.v67.25257 (2015)
Fossum, K., Mannseth, T.: Parameter sampling capabilities of sequential and simultaneous data assimilation: I. Analytical comparison. Inverse Problems 114(11), 002 (2014). https://doi.org/10.1088/0266-5611/30/11/114002
Fossum, K., Mannseth, T.: Parameter sampling capabilities of sequential and simultaneous data assimilation: II. Statistical analysis of numerical results. Inverse Problems 114(11), 003 (2014). https://doi.org/10.1088/0266-5611/30/11/114003
Fossum, K., Mannseth, T.: Assessment of ordered sequential data assimilation. Comput. Geosci. (1). https://doi.org/10.1007/s10596-015-9492-9 (2015)
Fossum, K., Mannseth, T.: Coarse-scale data assimilation as a generic alternative to localization. Comput. Geosci. 21(1), 167–186 (2017). https://doi.org/10.1007/s10596-016-9602-3
Gentilhomme, T., Oliver, D.S., Mannseth, T., Caumon, G., Moyen, R., Doyen, P.: Ensemble-based multi-scale history-matching using second-generation wavelet transform. Comput. Geosci. 19(5), 999–1025 (2015). https://doi.org/10.1007/s10596-015-9517-4
Giles, M.B.: Multi-level Monte Carlo path simulation. Oper. Res. 56(3), 607–617 (2008). https://doi.org/10.1287/opre.1070.0496
Giles, M.B.: Multilevel Monte Carlo methods. Acta Numerica 24(2015), 259–328 (2015). https://doi.org/10.1017/S096249291500001X
Grimstad, A.A., Mannseth, T.: Nonlinearity, scale, and sensitivity for parameter estimation problems. SIAM J. Sci. Comput. 21(6), 2096–2113 (2000). https://doi.org/10.1137/S1064827598339104
Grimstad, A.A., Mannseth, T., Nævdal, G., Urkedal, H.: Adaptive multiscale permeability estimation. Comput. Geosci. 7(1), 1–25 (2003)
Guo, Z., Reynolds, A.C.: INSIM-FT in three-dimensions with gravity. J. Comput. Phys. 380, 143–169 (2019). https://doi.org/10.1016/j.jcp.2018.12.016
Hamill, T.M., Snyder, C.: A hybrid ensemble Kalman filter–3D variational analysis scheme. Mon. Weather. Rev. 128(8), 2905–2919 (2000). https://doi.org/10.1175/1520-0493(2000)128<2905:AHEKFV>2.0.CO;2
He, J., Sarma, P., Durlofsky, L.J.: Reduced-order flow modeling and geological parameterization for ensemble-based data assimilation. Comput. Geosci. 55, 54–69 (2013). https://doi.org/10.1016/j.cageo.2012.03.027. http://linkinghub.elsevier.com/retrieve/pii/S0098300412001227
Hoel, H., Law, K.J.H., Tempone, R.: Multilevel ensemble Kalman filtering. SIAM J. Numer. Anal. 54 (3), 1813–1839 (2016). https://doi.org/10.1137/15M100955X
Houtekamer, P.L., Mitchell, H.L.: Data assimilation using an ensemble Kalman filter technique. Mon. Weather. Rev. 126(1969), 796–811 (1998). https://doi.org/10.1175/1520-0493(1998)126<0796:DAUAEK>2.0.CO;2
Iglesias, M.A.: Iterative regularization for ensemble data assimilation in reservoir models, vol. 19. https://doi.org/10.1007/s10596-014-9456-5 (2015)
Iglesias, M.A., Law, K.J.H., Stuart, A.M.: Ensemble Kalman methods for inverse problems. Inverse Problems 045(4), 001 (2013). https://doi.org/10.1088/0266-5611/29/4/045001
Iglesias, M.A., Law, K.J.H., Stuart, A.M.: Evaluation of Gaussian approximations for data assimilation in reservoir models. Comput. Geosci. 17(5), 851–85 (2013). https://doi.org/10.1007/s10596-013-9359-x
Jansen, J.D.: SimSim: a simple reservoir simulator (2011)
Lerlertpakdee, P., Jafarpour, B., Gildin, E.: Efficient production optimization with flow-network models. SPE J. 19(06), 1083–1095 (2014). https://doi.org/10.2118/170241-pa
Li, X., Tsai, F.T.: Bayesian model averaging for groundwater head prediction and uncertainty analysis using multimodel and multimethod. Water Resour. Res. 45(9), 1–14 (2009). https://doi.org/10.1029/2008WR007488
Lødøen, O.P., Omre, H.: Scale-corrected ensemble Kalman filtering applied to production-history conditioning in reservoir evaluation. SPE J. 13(02), 177–194 (2008). https://doi.org/10.2118/111374-PA
Mannseth, T.: Permeability identification from pressure observations: some foundations for multiscale regularization. Multiscale Mode Simul. 5(1), 21–44 (2006). https://doi.org/10.1137/050630167
Mannseth, T.: Comparison of five different ways to assimilate data for a simplistic weakly nonlinear parameter estimation problem. Comput. Geosci. (1). https://doi.org/10.1007/s10596-015-9490-y (2015)
Muirhead, R.J.: Aspects of Multivariate Statistical Theory. Wiley Series in Probability and Statistics. Wiley, Hoboken (2005). https://doi.org/10.1002/9780470316559. https://www.jstor.org/stable/2987858?origin=crossref http://doi.wiley.com/10.1002/9780470316559
Nævdal, G., Mannseth, T., Brusdal, K., Nordtvedt, J.E.: Multiscale estimation with spline wavelets, with application to two-phase porous-media flow. Inverse Problems 16(2), 315–332 (2000). https://doi.org/10.1088/0266-5611/16/2/304
Oliver, D.S., Chen, Y.: Recent progress on reservoir history matching: a review. Comput. Geosci. 15(1), 185–221 (2010). 10.1007/s10596-010-9194-2
Schlumberger Ltd: ECLIPSE Reservoir simulation software: technical description. Schlumberger Software, London, UK (2009)
Tarrahi, M., Elahi, S.H., Jafarpour, B.: Fast linearized forecasts for subsurface flow data assimilation with ensemble Kalman filter. Comput. Geosci., 929–952. https://doi.org/10.1007/s10596-016-9570-7. http://link.springer.com/10.1007/s10596-016-9570-7 (2016)
Trottenberg, U., Oosterlee, C.: Schuller a.: Multigrid (2001)
Wanderley de Holanda, R., Gildin, E., Jensen, J.L.: A generalized framework for capacitance resistance models and a comparison with streamline allocation factors. J Petrol Sci Eng 162(October 2017), 260–282 (2018). https://doi.org/10.1016/j.petrol.2017.10.020
Funding
The authors are grateful for the financial support provided by the NORCE research project Assimilating 4D Seismic Data: Big Data Into Big Models (4DSEIS) which is funded by industry partners Aker BP, Equinor, Lundin, Repsol, and Total EP NORGE, as well as the Research Council of Norway (PETROMAKS 2)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1. Bayesian model averaging
The expectation and covariance of Y is obtained from the laws of total expectation and total covariance, resulting in (see, e.g., [33])
Empirical estimates for \(\mathbb {E}[{}{Y}{]}\) and \(\mathbb {C}{[}{Y}{]}\) are obtained by replacing expectations and covariances on the right-hand sides of Eqs. 35 and 36 by their MC counterparts
where \(N_{\varSigma } = {\sum }_{s=1}^{S} N_{s}\).
Appendix 2. Multilevel Monte Carlo - theoretical efficiency
Since all elements in the sequence \({\{\omega _{l}\}}_{l=0}^{L}\) are independent, \(\mathbb {V}{[}\mathrm {E}_{ML}({Y}_{L}){]}\) can be expressed as a sum of contributions from the individual terms on the right-hand side of Eq. 13
The computational cost involved in evaluating EML(YL) is
Let δ denote a real number, and let Qδ denote the computational cost required to achieve \(\mathbb {V}{[}\mathrm {E}_{*}(Y_{L}){]} = \delta ^{2}\), where the subscript “*” can denote either MC or MLMC. Furthermore, let \({\{N_{l}^{o}\}}_{l=0}^{L}\) be the optimal sample sizes for MLMC, that is, those that minimize \(\mathbb {V}{[}\mathrm {E}_{ML}({Y}_{L}){]}\) under the constraint that Qδ(EML(YL)) = κ is fixed. One may then show (see, e.g., [20]) that the optimal ensemble sizes are given by
where the shorthand notation \(Q_{0}^{n}\) has been introduced to denote \(Q(Y_{0}^{n}(\omega _{0}))\), and so on. The corresponding cost and minimized variance my be expressed as
respectively. Let R denote the total available computational resources. Inserting Eqs. 42 into 41 and assuming that κ = R, the optimal ensemble size for level l can be given as
Giles [20] presents arguments for why
in the two extreme cases where either \(\sqrt {Q_{0}^{n} \mathbb {V}_{0}^{n}}\) or \(\sqrt {Q_{\varDelta L}^{n} \mathbb {V}_{\varDelta L}^{n}}\) dominates the other terms, such that either \(Q_{\delta }^{o}({\mathrm {E}_{ML}{}{({Y}_{L})}}) \approx \delta ^{-2} Q_{0}^{n} \mathbb {V}_{0}^{n}\) or \(Q_{\delta }^{o}({\mathrm {E}_{ML}{}{({Y}_{L})}}) \approx \delta ^{-2} Q_{\varDelta L}^{n} \mathbb {V}_{\varDelta L}^{n}\).
Appendix 3. Multilevel EnKF
With MLEnKF there will be L forecast ensembles, and two corresponding (but otherwise arbitrary) ensemble members in forecast ensembles number l − 1 and l are given by
Empirical estimates of the two first moments of the forecast distribution are obtained as EML(YL) and C)ML(YL), see, Eqs. 13 and 12. The corresponding ensemble members after assimilation of the data are given by
where the multilevel Kalman gain is given by
Empirical estimates of the two first moments of the analysis distribution are obtained as EML(ZL) and CML(ZL), respectively. It has been shown [26] that EML(ZL) and CML(ZL) converge to the KF analysis mean and covariance in the case where \(N_{l}\rightarrow \infty \) for all involved values of l. Hence, the MLEnKF is an unbiased estimator for the KF.
Appendix 4. Numerical models
1.1 4.1 Motivating example
A square 2D reservoir with slightly compressible two-phase flow of oil and water is modelled. ML is discretized on a 90 × 90 grid, while the approximate models are generated with L = 2 and Ψ = 3. Here Ψ denotes the number of grid cells that are merged in each coordinate direction during coarsening. The permeability field, k(x), on the 90 × 90 grid is considered as the unknown parameter function, while porosity is modelled as homogeneous and equal to 0.4.
The prior model for k(x) is Gaussian with mean 3.5 × 10− 13m2 and covariance generated from a spherical variogram model with standard deviation 3.7 × 10− 14m2 and range 10 grid cells. Furthermore, the anisotropy ratio is 0.5, and the main principal anisotropy axis is along the horizontal axis. A realization from the prior model is shown in Fig. 15a, while its representations on level 1 and level 0 are shown in Fig. 15 b and c, respectively.

a A realization from the prior model for k(x). b Its representation on level 1. c Its representation on level 0
The reservoir contains a five-spot well pattern with an injector in the center and producers in each corner. The water injection rate is set to 0.003m3/s and the production wells operate at a constant pressure of 25 × 106Pa.
The flow equations are solved by the SimSim [31] reservoir simulator. The four production rates and the BHP in the injector are measured every 30 days for 240 days, starting at day 10. Hence, there are 40 measurements available altogether. The level-specific computational cost, \({Q}_{l}^{n}\), is gauged by the wall-clock time for runs on the different levels. Normalization with respect to \({Q}_{2}^{n}\) results in
1.2 4.2 Toy model
To understand the behavior of the different multilevel DA methods, it is convenient to control the evolution of the level special-mean and variance. To this end, we design a multilevel family of bivariate toy models, \(\{M_{l}\}_{l=0}^{L}\). Let mT = (m1,m2), where m1 and m2 are independent, and define the outcome from ML by
Hence, m1 is weakly correlated to the data while m2 is strongly correlated to the data. We define the outcomes from Ml for l ∈ [0,L − 1] by
where 𝜖l is a level-specific error term. It is useful to define 𝜖l such that one can relate the level-specific mean and variance to the high-resolution mean and variance via two control variables. To achieve this we let
where 𝜃l denotes a realization from \(\mathcal {N} (0, \gamma _{l} \mathrm {V}(y_{L} (m)))\), \(\mathcal {N}\) denotes the Gaussian distribution and V denotes the empirical variance. The variables μl and γl are then defined as the fractions of the level-specific empirical mean and variance to the high-resolution empirical mean and variance, respectively;
The prior model for m is \(\mathcal {N}(\overline {m}, C_{m})\), where
and
Three different multilevel structures are defined; firstly, a case with low errors that decrease monotonically with l (low error), secondly, a case mimicking the structure of RM2 (reservoir error), and, finally, a case in between the low-error and the reservoir-error cases (medium error). The corresponding values of μl and γl are listed in Table 5.
The reservoir-error case is established by selecting Y as a single reservoir-simulation output, the well oil production rate from P after 45 timesteps. We estimate \({\{\mathrm {E}(y_{l})\}}_{l = 0}^{L}\) and \({\{\mathrm {V}(y_{l})\}}_{l = 0}^{L}\) from the level-specific forecasts of RM2 by bootstrapping, and calculate μl and γl using Eqs. 55 and 56, thereby ensuring that the level-specific errors in the toy model have the same relative sizes as those of RM2.
In Fig. 16a, we plot the kernel density estimates (KDEs), calculated from 2000 runs, of the level-specific forecasts of the selected simulation output from RM2. The KDEs of the level-specific forecasts from the toy model (Fig. 16) shows that, with the estimated values for μl and γl, the multilevel structure of the toy model is similar to that of RM2. (In Fig. 16, we plot KDEs only for l = 1, 3 and 5. However, KDEs for l = 0, 2 and 4 show similar behavior.)

Kernel density estimates of forecasts. Level 1: dotted curve, level 3: dashed curve, level 5: solid curve. a RM2. b Toy model.
For reasons given in the first paragraph of Section 3.3.2, the toy model is designed such the correlation between m1 and y is much smaller than between m2 and y. Hence, variance dominates for the m1 while bias dominate for m2.
1.3 4.3 Reservoir model 1
A square 2D reservoir with compressible two-phase flow of oil and water is modelled. ML is discretized on a 60 × 60 grid, while the approximate models are generated with L = 5 and Ψ = 2. The log permeability field, \(\log k (x)\), on the 60 × 60 grid is considered as the unknown parameter function, while porosity is modelled as homogeneous and equal to 0.2.
The prior model for \(\log k (x)\) is Gaussian with mean 5 and covariance generated from a spherical variogram model with standard deviation 1 and range 30 grid cells. Furthermore, the anisotropy ratio is 0.33, and the main principal anisotropy axis is rotated 45 degrees counterclockwise with respect to the positive horizontal axis.
The reservoir contains a producer (P) in the lower left corner, and an injector (I) in the upper right corner. Both wells are controlled by the bottom hole pressure (BHP), with a target of 27.5 × 106 Pa for the injector and 10.3 × 106 Pa for the producer. Figure 17 a shows a realization from the prior log permeability model, along with the positions of the wells.

Log-k(x) realizations with well locations. a RM1. b RM2 (with fault position indicated)
The flow equations are solved by the commercial reservoir simulator ECLIPSE [40]. There are 80 report steps, and at each step, the oil production rate from P and the water injection rate from I are reported. Hence, there are 160 measurements available altogether. The standard deviation is defined as 20% of the observed values.
1.4 4.4 Reservoir model 2
Reservoir model 2 (RM2) (Fig. 17b) is an exact copy of Reservoir model 1 (RM1), except that in RM2 an impermeable fault from the lower right corner to the upper left corner, ending five grid cells from the boundaries, is present in the reservoir. The fault makes the upscaling procedure more challenging, and is added to introduce more bias in \({\{M_{l}\}}_{l=0}^{L-1}\). The flow equations are solved by ECLIPSE and the data setup is as for RM1.
Appendix 5. Numerical results—toy model
1.1 5.1 MLMC potential
Figure 18 shows \(\log _{2} (\sigma _{0})\), and \(\log _{2} ({\sigma }_{{\varDelta }_{l}})\) for l ∈ [1, 5]. Table 6 lists values for \({\{N_{l}^{o}\}}_{l=0}^{5}\) obtained by inserting the estimated values for σ0, \(\{\sigma _{{\varDelta }_{l}}\}_{l=1}^{5}\), and the costs in Eqs. 29, into 44. Table 7 lists values for \(\mathbb {V}_{\kappa }^{o} ({\mathrm {E}_{ML}({Y}_{L})})/\mathbb {V}_{\kappa }^{o} ({\mathrm {E}({Y_{L}})})\) obtained by inserting the estimated values for σ0, \(\{\sigma _{{\varDelta }_{l}}\}_{l=1}^{5}\), and the costs in Eqs. 29, into 43, and the calculated value for σ5 into Eq. 4. Figure 18 shows that \(\log _{2} ({\sigma _{{\varDelta }_{l}}})\) decreases monotonically when l increases in the low-error case, while \(\sigma _{{\varDelta }_{l}}\) does not show systematic behavior in the two other cases. Table 6 shows that considerably more computational resources can be distributed to the lower levels in the low-error case than in the two other cases. Table 7 shows that the variance of MLEnKF is orders of magnitude lower than that of EnKF in the low-error case, while it is comparable to that of EnKF in the two other cases.

\(\log _{2} (\varsigma _{0})\), and \(\log _{2} (\varsigma _{{\Delta }_{l}})\) versus l for l ∈ [1,L] for Toy model. Solid curve: low error, dashed curve: medium error, dotted curve: reservoir error
1.2 5.2 Ensemble-based DA
Figure 19 shows KDEs for m1 obtained with 50 mean values from the analyzed ensemble.

KDEs of m1 from the analyzed ensemble. Solid curve: True posterior. Dashed curve: MLHEnKF. Dash-dotted curve: EnKF. Dotted curve: MLEnKF. a Low error. b Medium error. c Reservoir error.
Figure 19 a shows results obtained in the low-error case. MLEnKF approximates the true posterior very well, while MLHEnKF approximates the true posterior clearly better than EnKF, but clearly not as well as MLEnKF. Figure 19 b and c show results obtained in the medium-error and reservoir-error cases. Here, MLEnKF and EnKF both perform poorly. MLHEnKF is biased, particularly in the reservoir-error case, but the variance is small and closer to the true posterior when comparing with the other methods.
Figure 20 shows KDEs for m2 obtained with 50 mean values from the analyzed ensemble.
Figure 20 a shows results obtained in the low-error case. MLEnKF approximates the true posterior clearly better than EnKF, which does not perform well, while MLHEnKF performs worse than EnKF. Figure 20 b and c show results obtained in the medium-error and reservoir-error cases. EnKF approximates the true posterior slightly better than MLEnKF and MLHEnKF, which both perform poorly.

KDEs of m2 from the analyzed ensemble. Solid curve: True posterior. Dashed curve: MLHEnKF. Dash-dotted curve: EnKF. Dotted curve: MLEnKF. a Low error. b Medium error. c Reservoir error.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Fossum, K., Mannseth, T. & Stordal, A.S. Assessment of multilevel ensemble-based data assimilation for reservoir history matching. Comput Geosci 24, 217–239 (2020). https://doi.org/10.1007/s10596-019-09911-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10596-019-09911-x