
Abstract
The \(\ell _1\)-ball is a nicely structured feasible set that is widely used in many fields (e.g., machine learning, statistics and signal analysis) to enforce some sparsity in the model solutions. In this paper, we devise an active-set strategy for efficiently dealing with minimization problems over the \(\ell _1\)-ball and embed it into a tailored algorithmic scheme that makes use of a non-monotone first-order approach to explore the given subspace at each iteration. We prove global convergence to stationary points. Finally, we report numerical experiments, on two different classes of instances, showing the effectiveness of the algorithm.
Similar content being viewed by others

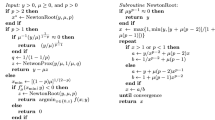

Avoid common mistakes on your manuscript.
1 Introduction
In this paper, we focus on the following problem:
where \(\varphi :\mathbb {R}^n \rightarrow \mathbb {R}\) is a function whose gradient is Lipschitz continuous with constant \(L>0\), \(\Vert x \Vert _1\) denotes the \(\ell _1\)-norm of the vector x and \(\tau\) is a suitably chosen positive parameter.
Problem (1) includes, as a special case, the so called LASSO problem, obtained when
with A and b being a \(m \times n\) matrix and a m-dimensional vector, respectively. Here and in the following, \(\Vert \cdot \Vert\) denotes the Euclidean norm. Loosely speaking, in LASSO problems the \(\ell _1\)-norm constraint is able to induce sparsity in the final solution, and then these problems are widely used in statistics to build regression models with a small number of non-zero coefficients [17, 32].
Standard optimization algorithms (like, e.g., interior-point methods), besides being very expensive when the number of variables increases, do no properly exploit the main features and structure of the considered problem. This is the reason why, in the last decade, a number of first-order methods have been considered in the literature to deal with problem (1). Those methods can be divided into two main classes: projection-based approaches, like, e.g., gradient-projection methods [15, 31] and limited-memory projected quasi-Newton methods [30], which efficiently handle the problem by making use of tailored projection strategies [8, 16], and projection-free methods, like, e.g., Frank–Wolfe variants [5, 6, 25, 26], that embed a cheap linear minimization oracle.
As highlighted before, the main goal when using the \(\ell _1\) ball is to get very sparse solutions (i.e., solutions with many zero components). In this context, it hence makes sense to devise strategies that allow to quickly identify the set of zero components in the optimal solution. This would indeed guarantee a significant speed-up of the optimization process. A number of active-set strategies for structured feasible sets is available in the literature (see, e.g., [3, 4, 7, 9, 10, 13, 18, 19, 22,23,24, 28] and references therein), but none of those directly handles the \(\ell _1\) ball.
In this paper, inspired by the work carried out in [10], we propose a tailored active-set strategy for problem (1) and embed it into a first-order projection-based algorithm. At each iteration, the method first sets to zero the variables that are guessed to be zero at the final solution. This is done by means of the tailored active-set estimate, which aims at identifying the manifold where the solutions of problem (1) lie, while guaranteeing, thanks to a descent property, a reduction of the objective function at each iteration. Then, the remaining variables, i.e., those variables estimated to be non-zero at the final solution, are suitably modified by means of a non-monotone gradient-projection step.
The paper is organized as follows. In Sect. 2, we describe the active-set strategy and analyze the descent property connected to it. We then devise, in Sect. 3, our first-order optimization algorithm and carry out a global convergence analysis. We further report a numerical comparison with some well-known first order methods using two different classes of \(\ell _1\)-constrained problems (that is, LASSO and constrained sparse logistic regression) in Sect. 4. Finally, we draw some conclusions in Sect. 5.
2 The active-set estimate
Since the feasible set of problem (1) is convex and can be written as convex combination of the vectors \(\pm \tau e_i\), \(i=1,\ldots ,n\), we can characterize the stationary points as follows.
Definition 1
A feasible point \(x^*\) of problem (1) is stationary if and only if
In the next proposition, we state some “complementarity-type” conditions for stationary points of problem (1).
Proposition 1
Let \(x^*\) be a stationary point of problem (1). Then
-
(i)
\(x_i^*>0 \, \Rightarrow \, \nabla \varphi (x^*)^T (\tau e_i - x^*)=0\),
-
(ii)
\(x_i^*<0 \, \Rightarrow \, \nabla \varphi (x^*)^T (-\tau e_i - x^*)=0\).
Proof
If \(|x_i^*| = \tau\), then \(x^* = \tau \, {{\,\mathrm{sgn}\,}}(x^*_i) \, e_i\) and the result trivially holds. To prove point (i), now let \(0< x_i^* <\tau\). Taking into account (2), by contradiction we assume that
Let \(d^+\in \mathbb {R}^n\) be defined as follows:
We have
so that \(d^+\) is a feasible direction in \(x^*\). Therefore, (3) and (4) imply that \(d^+\) is a feasible descent direction for \(\varphi (\cdot )\) in \(x^*\). This contradicts the fact that \(x^*\) is a stationary point of problem (1) and point (i) is proved. To prove point (ii), we can use the same arguments as above, considering \(-\tau< x_i^* < 0\) and, assuming by contradiction that \(\nabla \varphi (x^*)^T (-\tau e_i - x^*)>0\), we obtain that
is such that \(\Vert x^*+d^-\Vert _1 \le \tau\), that is, \(d^-\) is a feasible and descent direction for \(\varphi (\cdot )\) in \(x^*\), leading to a contradiction. \(\square\)
With little abuse of standard terminology, given a stationary point \(x^*\) we say that a variable \(x^*_i\) is active if \(x^*_i=0\), whereas a variable \(x^*_i\) is said to be non-active if \(x^*_i \ne 0\). We can thus define the active set \({\bar{A}}_{\ell _1}(x^*)\) and the non-active set \({\bar{N}}_{\ell _1}(x^*)\) as follows:
Now, we show how we estimate these sets starting from any feasible point x of problem (1). In order to obtain such an estimate we first need to suitably reformulate our problem (1) by introducing a dummy variable z. Let \({\bar{\varphi }}(x,z) :\mathbb {R}^{n+1} \rightarrow \mathbb {R}\) be the function defined as \({\bar{\varphi }}(x,z) = \varphi (x)\) for all (x, z). Problem (1) can then be rewritten as
Every feasible point of problem (5) can be expressed as convex combination of \(\{\pm \tau e_1,\ldots , \pm \tau e_n, \tau e_{n+1}\} \subset \mathbb {R}^{n+1}\). Therefore, we can define the following matrix, where I denotes the \(n \times n\) identity matrix:
and we obtain the following reformulation of (1) as a minimization problem over the unit simplex:
Note that, given any feasible point x of problem (1), we can compute a feasible point y of problem (6) such that
The rationale behind our approach is sketched in the three following points:
-
(i)
For any feasible point x of problem (1), by (7) we can compute a feasible point y of problem (6) such that
$$\begin{aligned} y_i = 0 \, \Leftrightarrow \, x_i \le 0 \quad \text {and} \quad y_{n+i} = 0 \, \Leftrightarrow \, x_i \ge 0, \qquad i = 1,\ldots ,n. \end{aligned}$$(8) -
(ii)
According to (8), for every feasible point x of problem (1) we have that
$$\begin{aligned} x_i = 0 \, \Leftrightarrow \, y_i = y_{n+i} = 0, \quad i = 1,\ldots ,n. \end{aligned}$$(9)Thus, it is natural to estimate a variable \(x_i\) as active at \(x^*\) if both \(y_i\) and \(y_{n+i}\) are estimated to be zero at the point corresponding to \(x^*\) in the y space. To estimate the zero variables among \(y_1,\ldots ,y_{2n+1}\) we use the active-set estimate described in [10], specifically devised for minimization problems over the unit simplex.
-
(iii)
Then, we are able to go back in the original x space to obtain an active-set estimate of problem (1) without explicitly considering the variables \(y_1,\ldots ,y_{2n+1}\) of the reformulated problem.
Remark 1
The introduction of the dummy variable z is needed in order to get a reformulation of problem (1) as a minimization problem over the unit simplex satisfying (8). Since every feasible point x of problem (1) can be expressed as a convex combination of the vertices of the polyhedron \(\{x\in \mathbb {R}^n:\; \Vert x\Vert _1 \le {\tau }\}\), a straightforward reformulation of problem (1) would then be the following:
with \(M = \tau \,\begin{bmatrix}&I&\vline&{-I}&\end{bmatrix}\). However, this reformulation does not work for our purposes, as there exist feasible points x of problem (1) for which no y feasible for problem (10) satisfying (8) can be found. In particular, if x is in the interior of the \(\ell _1\)-ball (e.g., the origin), we cannot find any y feasible for problem (10) such that (8) holds.
Considering problem (6) and using the active-set estimate proposed in [10] for minimization problems over the unit simplex, given any feasible point y of problem (6) we define:
where \(\epsilon\) is a positive parameter. A(y) contains the indices of the variables that are estimated to be zero at a certain stationary point and N(y) contains the indices of the variables that are estimated to be positive at the same stationary point (see [10] for details of how these formulas are obtained). As mentioned above, taking into account (9), we estimate a variable \(x_i\) as active for problem (1) if both \(y_i\) and \(y_{n+1}\) are estimated to be zero. Namely,
Now we show how \(A_{\ell _1}(x)\) and \(N_{\ell _1}(x)\) can be expressed without explicitly considering the variables y and the objective function f(y) of the reformulated problem. This allows us to work in the original x space, avoiding to double the number of variables in practice.
To obtain the desired relations, first observe that
and
Let us distinguish two cases:
-
(i)
\(x_i \ge 0\). Recalling (11)–(12), we have that \(i \in A(y)\) if and only if
$$\begin{aligned} \begin{aligned} 0 \le \frac{1}{\tau }x_i =y_i&\le \epsilon \nabla f(y)^T(e_i - y) = \epsilon (\nabla _i f(y) - \nabla f(y)^T y) \\&= \epsilon (\tau \nabla _i \varphi (x) - \nabla \varphi (x)^Tx) = \epsilon \nabla \varphi (x)^T (\tau e_i - x) \end{aligned} \end{aligned}$$(15)and \((n+i) \in A(y)\) if and only if
$$\begin{aligned} \begin{aligned} -\frac{1}{\tau } x_i \le 0 = y_{n+i}&\le \epsilon \nabla f(y)^T(e_{n+i} - y) = \epsilon (\nabla _{n+i} f(y) - \nabla f(y)^T y)\\&= \epsilon (-\tau \nabla _i \varphi (x) - \nabla \varphi (x)^Tx) = -\epsilon \nabla \varphi (x)^T (\tau e_i + x). \end{aligned} \end{aligned}$$(16) -
(ii)
\(x_i < 0\). Similarly to the previous case, we have that \(i \in A(y)\) if and only if
$$\begin{aligned} \begin{aligned} \frac{1}{\tau } x_i < 0 = y_i&\le \epsilon \nabla f(y)^T(e_i - y) = \epsilon (\nabla _i f(y) - \nabla f(y)^T y) \\&= \epsilon (\tau \nabla _i \varphi (x) - \nabla \varphi (x)^Tx) = \epsilon \nabla \varphi (x)^T (\tau e_i - x) \end{aligned} \end{aligned}$$(17)and \((n+i) \in A(y)\) if and only if
$$\begin{aligned} \begin{aligned} 0 < -\frac{1}{\tau }x_i = y_{n+i}&\le \epsilon \nabla f(y)^T(e_{n+i} - y) = \epsilon (\nabla _{n+i} f(y) - \nabla f(y)^T y)\\&= \epsilon (-\tau \nabla _i \varphi (x) - \nabla \varphi (x)^Tx) = -\epsilon \nabla \varphi (x)^T (\tau e_i + x). \end{aligned} \end{aligned}$$(18)
From (15), (16), (17) and (18), we thus obtain
Let us highlight again that \(A_{\ell _1}(x)\) and \(N_{\ell _1}(x)\) do not depend on the variables y and on the objective function f(y) of the reformulated problem, so no variable transformation is needed in practice to estimate the active set of problem (1). In the following, we prove that under specific assumptions, \({\bar{A}}_{\ell _1}(x^*)\) is detected by our active-set estimate, when evaluated in points sufficiently close to a stationary point \(x^*\).
Proposition 2
If \(x^*\) is a stationary point of problem (1), then there exists an open ball \({\mathcal {B}}(x^*,\rho )\) with center \(x^*\) and radius \(\rho > 0\) such that, for all \(x \in {\mathcal {B}} (x^*,\rho )\), we have
Furthermore, if the following “strict-complementarity-type” assumption holds:
then, for all \(x \in {\mathcal {B}} (x^*,\rho )\), we have
Proof
Let \(i\in N_{\ell _1} (x^*)\), then \(|x_i^*|>0\). Proposition 1 implies that either
or
Then, the continuity of \(\nabla \varphi\) and the definition of \(N_{\ell _1} (x)\) imply that there exists an open ball \({\mathcal {B}}(x^*,\rho )\) with center \(x^*\) and radius \(\rho > 0\) such that, for all \(x\in {\mathcal {B}}(x^*,\rho )\), we have that \(i \in N_{\ell _1} (x)\). This proves (22) and, consequently, also (21). If (23) holds, the definition of \(N_{\ell _1} (x)\) and the continuity of \(\nabla \varphi\) ensures that \({\bar{A}}_{\ell _1} (x^*) \subseteq A_{\ell _1}(x)\) for all \(x\in {\mathcal {B}}(x^*,\rho )\), implying that (24) and (25) hold. \(\square\)
2.1 Descent property
So far, we have obtained the active and non-active set estimates (19)–(20) passing through a variable transformation which allowed us to adapt the active and non-active set estimates proposed in [10] to our problem (1).
In [10], the active and non-active set estimates, designed for minimization problems over the unit simplex, guarantee a decrease in the objective function when setting (some of) the estimated active variables to zero and moving a suitable estimated non-active variable (in order to maintain feasibility).
In the following, we show that the same property holds for problem (1) using the active and non-active set estimates (19)–(20). To this aim, in the next proposition we first introduce the index set \(J_{\ell _1}(x)\) and relate it with \(N_{\ell _1}(x)\).
Proposition 3
Let \(x \in \mathbb {R}^n\) be a feasible non-stationary point of problem (1) and define
Then, \(J_{\ell _1}(x) \subseteq N_{\ell _1}(x)\).
Proof
Let y be the point given by (7) and consider the reformulated problem (6). Let A(y) and N(y) be the index sets given in (11)–(12), that is, the active and non-active set estimates for problem (6), respectively.
From the expression of \(\nabla f(y)\) given in (14), and exploiting the hypothesis that x is non-stationary (implying that \(\nabla \varphi (x) \ne 0)\), it follows that
Since \(\nabla _{2n+1} f(y) = 0\) (again from (14)), it follows that
From Proposition 1 in [10], there exists \(\nu \in \{1,\ldots ,2n\}\) such that
In particular, we can rewrite (27) as
Taking into account (26), we obtain
Now, let \(j \in \{1,\ldots ,n\}\) be the following index:
Using again (14), we get \(|\nabla _{\nu } f(y) | = |\nabla _j f(y) | = \tau |{\nabla _j \varphi (x)} |\). This, combined with (29), implies that
Finally, using (28) and (30), it follows that at least one index between j and \((n+j)\) belongs to N(y). Therefore, from (13b) we have that \(j \in N_{\ell _1}(x)\) and the assertion is proved. \(\square\)
Now, we need an assumption on the parameter \(\epsilon\) appearing in (19)–(20). It will allow us to prove the subsequent proposition, stating that \(\varphi (x)\) decreases if we set the variables in \(A_{\ell _1}(x)\) to zero and suitably move a variable in \(J_{\ell _1}(x)\).
Assumption 1
Assume that the parameter \(\epsilon\) appearing in the estimates (19)–(20) satisfies the following conditions:
where \(C>0\) is a given constant.
Proposition 4
Let Assumption 1hold. Given a feasible non-stationary point x of problem (1), let \(j \in J_{\ell _1}(x)\) and \(I = \{1,\ldots ,n\} \setminus \{j\}\). Let \({\hat{A}}_{\ell _1}(x)\) be a set of indices such that \({\hat{A}}_{\ell _1}(x) \subseteq A_{\ell _1}(x)\). Let \({\tilde{x}}\) be the feasible point defined as follows:
Then,
where \(C > 0\) is the constant appearing in Assumption 1.
Proof
Define
Since \(\nabla \varphi\) is Lipschitz continuous with constant L, from known results (see, e.g., [29]) we can write
and then, in order to prove the proposition, what we have to show is that
From the definition of \({\tilde{x}}\), we have that
Furthermore,
Since \(j \in J_{\ell _1}(x)\), from the definition of \(J_{\ell _1}(x)\) it follows that \(-|\nabla _i \varphi (x) | \ge -|\nabla _j \varphi (x) |\) for all \(i \in \{1,\ldots ,n\}\). Therefore, we can write
Using (19) and (35), for all \(i\in {\hat{A}}^+\) we have that
and then,
Combining this inequality with (33), we obtain
From (34) and (36), it follows that the left-hand side term of (32) is less than or equal to
The desired result is hence obtained, since inequality (32) follows from the assumption we made on \(\epsilon\), using the fact that \(|{\hat{A}}^+ | \le n - 1\) (as a consequence of Proposition 3) and \(\sum _{i \in {\hat{A}}^+} |x_i| (\nabla _i \varphi (x) \, {{\,\mathrm{sgn}\,}}(x_i) + |\nabla _j \varphi (x) |) \ge 0\) (as a consequence of (36)). \(\square\)
We would like to highlight that the parameter \(\epsilon\) depends on n by Assumption 1. However, from the proof of the above proposition, it is clear that n could be replaced by \(|{\hat{A}}^+|+1\), with \({\hat{A}}^+\) defined as in (31). Note that \(|{\hat{A}}^+|\) might be much smaller than n.
3 The algorithm
Based on the active and non-active set estimates described above, we design a suitable active-set algorithm for solving problem (1), exploiting the property of our estimates and using an appropriate projected-gradient direction. At the beginning of each iteration k, we have a feasible point \(x^k\) and we compute \(A_{\ell _1}(x^k)\) and \(N_{\ell _1}(x^k)\), which, for ease of notation, we will refer to as \(A_{\ell _1}^k\) and \(N_{\ell _1}^k\), respectively. Then, we perform two main steps:
-
First, we produce the point \({\tilde{x}}^k\) as explained in Proposition 4, obtaining a decrease in the objective function (if \(x^k \ne {\tilde{x}}^k\));
-
Afterward, we move all the variables in \(N^k_{\ell _1}\) by computing a projected-gradient direction \(d^k\) over the given non-active manifold and using a non-monotone Armijo line search. In particular, the reference value \({\bar{\varphi }}\) for the line search is defined as the maximum among the last \(n_m\) function evaluations, with \(n_m\) being a positive parameter.
In Algorithm 1, we report the scheme of the proposed algorithm, named Active-Set algorithm for minimization over the \(\ell _1\)-ball (AS- \(\ell _1\)).


The search direction \(d^k\) at \({\tilde{x}}^k\) (see line 7 of Algorithm 1) is made of two subvectors: \(d^k_{A_{\ell _1}^k}\) and \(d^k_{N_{\ell _1}^k}\). Since we do not want to move the variables in \(A_{\ell _1}^k\), we simply set \(d^k_{A_{\ell _1}^k}=0\). For \(d^k_{N_{\ell _1}^k}\), we compute a projected gradient direction in a properly defined manifold. In particular, let \({\mathcal {B}}_{N_{\ell _1}^k}\) be the set defined as
and let \(P(\cdot )_{{\mathcal {B}}_{N_{\ell _1}^k}}\) denote the projection onto the \({\mathcal {B}}_{N_{\ell _1}^k}\). We also define
where \(0< {\underline{m}} \le m^k \le {\overline{m}} < \infty\) and with \({\underline{m}}\), \({\overline{m}}\) being two constants. Then, \(d^k_{N_{\ell _1}^k}\) is defined as
In the practical implementation of AS- \(\ell _1\), we compute the coefficient \(m^k\) so that the resulting search direction is a spectral (or Barzilai–Borwein) gradient direction. This choice will be described in Sect. 4.
3.1 Global convergence analysis
In order to prove global convergence of AS- \(\ell _1\) to stationary points, we need some intermediate results. We first point out a property of our search directions, using standard results on projected directions.
Lemma 1
Let Assumption 1hold and let \(\{x^k\}\) be the sequence of points produced by AS- \(\ell _1\). At every iteration k, we have that
and \(\{d^k\}\) is a bounded sequence.
Proof
Using the properties of the projection, at very iteration k we have
with \(B_{N_{\ell _1}^k}\) and \({\hat{x}}^k\) being defined as in (37) and (38), respectively. Choosing \(x={\tilde{x}}^k\) in the above inequality and recalling the definition of \(d^k\) given in (39), we get
Since \(m^k \le {\overline{m}}\), for all k we obtain (40).
Furthermore, from the property of the projection we have that
Since \(m^k \le {\overline{m}}\) and \(\{\nabla \varphi ({\tilde{x}}^k)\}\) is bounded, it follows that \(\{d^k\}\) is bounded. \(\square\)
We now prove that the sequence \(\{{\bar{\varphi }}^k\}\) converges.
Lemma 2
Let Assumption 1hold and let \(\{x^k\}\) be the sequence of points produced by AS- \(\ell _1\). Then, the sequence \(\{ {\bar{\varphi }}^k\}\) is non-increasing and converges to a value \({\bar{\varphi }}\).
Proof
First note that the definition of \({\bar{\varphi }}^k\) ensures \(\bar{\varphi }^k\le \varphi ({\tilde{x}}^0)\) and hence \(\varphi ({\tilde{x}}^k)\le \varphi ({\tilde{x}}^0)\) for all k. Moreover, we have that
Since \(\varphi ({\tilde{x}}^{k+1}) \le {\bar{\varphi }}^k\) by the definition of the line search, we derive \({\bar{\varphi }}^{k+1} \le {\bar{\varphi }}^k\), which proves that the sequence \(\{ {\bar{\varphi }}^k\}\) is non-increasing. This sequence is bounded from below by the minimum of \(\varphi\) over the unit simplex and hence converges. \(\square\)
The next intermediate result shows that the distance between \(\{x^k\}\) and \(\{{\tilde{x}}^k\}\) converges to zero and that the sequences \(\{\varphi (x^k)\}\) and \(\{\varphi ({\tilde{x}}^k)\}\) converge to the same point, using similar arguments as in [20].
Proposition 5
Let Assumption 1hold and let \(\{x^k\}\) be the sequence of points produced by AS- \(\ell _1\). Then,
Proof
For each \(k\in \mathbb {N}\), choose \(l(k)\in \{k - \min (k,n_m),\dots ,k\}\) such that \({\bar{\varphi }}^k = \varphi ({\tilde{x}}^{l(k)})\). From Proposition 4 we can write
Furthermore, from the instructions of the line search and the fact that the sequence \(\{\varphi ({\tilde{x}}^{l(k)})\}\) is non-increasing, for all \(k \ge 1\)we have
and then,
Since \(\{\varphi ({\tilde{x}}^{l(k)})\}\) converges to \({\bar{\varphi }}\), we have that (43) and (44) imply
Furthermore, from Lemma 1 we have
and then the following limit holds:
Considering that \(x^{l(k)} = {\tilde{x}}^{l(k)-1} + \alpha ^{l(k) -1} d^{l(k) -1}\), (46) implies
Furthermore, from the triangle inequality, we can write
Then,
and in particular, from the uniform continuity of \(\varphi\) over \(\{x\in \mathbb {R}^n : \Vert x\Vert _1 \le \tau \}\), we have
Let
We show by induction that, for any given \(j\ge 1\),
If \(j=1\), since \(\{{\hat{l}}(k)\}\subset \{l(k)\}\) we have that (49), (50) and (51) follow from (45), (47) and (48), respectively.
Assume now that (49), (50) and (51) hold for a given j. Then, reasoning as in the beginning of the proof, from the instructions of the line search and considering that \(\{\varphi ({\tilde{x}}^{l(k)})\}\) is non-increasing, we can write
and
Therefore we get
so that
The limit in (53) implies (49) for \(j+1\). The properties of the direction stated in Lemma 1, combined with (52), ensure that
Furthermore, since \(x^{{\hat{l}}(k)-j} = {\tilde{x}}^{{\hat{l}}(k)-(j+1)} + \alpha ^{{\hat{l}}(k) -(j+1)} d^{{\hat{l}}(k) -(j+1)}\), we have that (54) implies
Using the triangle inequality, we can write
Then,
and in particular, from the uniform continuity of \(\varphi\) over \(\{x\in \mathbb {R}^n : \Vert x\Vert _1 \le \tau \}\), we can write
Thus we conclude that (50) and (51) hold for any given \(j\ge 1\).
Recalling that
we have that (50) implies
Furthermore, since
Since \(\{\varphi ({\tilde{x}}^{{\hat{l}}(k)})\}\) has a limit, from the uniform continuity of \(\varphi\) over \(\{x\in \mathbb {R}^n : \Vert x\Vert _1 \le \tau \}\), (56) and (55) it follows that
and
proving (42). From the instructions of the algorithm and Proposition 4, we can write
and then from (42) we have that (41) holds. \(\square\)
The following proposition states that the directional derivative \(\nabla \varphi ({\tilde{x}}^k)^Td^k\) tends to zero.
Proposition 6
Let Assumption 1hold and let \(\{x^k\}\) be the sequence of points produced by AS- \(\ell _1\). Then,
Proof
To prove (57), assume by contradiction that it does not hold. Lemma 1 implies that the sequence \(\{\nabla \varphi ({\tilde{x}}^k)^Td^k\}\) is bounded, so that there must exist an infinite set \(K\subseteq {\mathbb {N}}\) such that
for some real number \(\eta >0\). Taking into account (41) and the fact that the feasible set is compact, without loss of generality we can assume that both \(\{x^k\}_K\) and \(\{{\tilde{x}}^k\}_K\) converge to a feasible point \(x^*\) (passing into a further subsequence if necessary). Namely,
Moreover, since the number of possible different choices of \(A^k\) and \(N^k\) is finite, without loss of generality we can also assume that
and, using the fact that \(\{d^k\}\) is a bounded sequence, that
(passing again into a further subsequence if necessary). From (59), (60), (61) and the continuity of \(\nabla \varphi\), we can write
Taking into account (58), from the instructions of AS- \(\ell _1\) we have that, at every iteration \(k \in K\), a non-monotone Armijo line search is carried out (see line 2 in Algorithm 2) and a value \(\alpha ^k \in (0,1]\) is computed such that
or equivalently,
From
(42), the left-hand side of the above inequality converges to zero for \(k \rightarrow \infty\), hence
Using (59), we obtain that \(\displaystyle {\lim _{k \rightarrow \infty , \, k \in K} \alpha ^k = 0}\). It follows that there exists \({\bar{k}} \in K\) such that
From the instructions of the line search procedure, this means that \(\forall k \ge {\bar{k}}, \, k \in K\)
Using the mean value theorem, \(\xi ^k\in (0,1)\) exists such that
In view of (63) and (64), we can write
From (60), and exploiting the fact that \(\{\xi ^k\}_K\), \(\{\alpha ^k\}_K\) and \(\{d^k\}_K\) are bounded sequences, we get
Therefore, taking the limits in (65) we obtain that \(\nabla \varphi (x^*)^T {\bar{d}} \ge \gamma \, \nabla \varphi (x^*)^T {\bar{d}}\), or equivalently, \((1-\gamma ) \nabla \varphi (x^*)^T {\bar{d}} \ge 0\). Since \(\gamma \in (0,1)\), we get a contradiction with (62). \(\square\)
We are finally able to state the main convergence result.
Theorem 1
Let Assumption 1hold and let \(\{x^k\}\) be the sequence of points produced by AS- \(\ell _1\). Then, every limit point \(x^*\) of \(\{x^k\}\) is a stationary point of problem (1).
Proof
From Definition 1, we can characterize stationarity using condition (2). In particular, we can define the following continuous functions \(\Psi _i(x)\) to measure the stationarity violation at a feasible point x:
so that a feasible point x is stationary if and only if \(\Psi _i(x) = 0\), \(i = 1,\ldots ,n\).
Now, let \(x^*\) be a limit point of \(\{x^k\}\) and let \(\{x^k\}_K\), \(K \subseteq {\mathbb {N}}\), be a subsequence converging to \(x^*\). Namely,
Note that \(x^*\) exists, as \(\{x^k\}\) remains in the compact set \(\{x\in \mathbb {R}^n | \Vert x \Vert _1 \le \tau \}\). Since the number of possible different choices of \(A^k\) and \(N^k\) is finite, without loss of generality we can assume that
(passing into a further subsequence if necessary).
By contradiction, assume that \(x^*\) is non-stationary, that is, an index \(\nu \in \{1,\ldots ,n\}\) exists such that
First, suppose that \(\nu \in {\hat{A}}\). Then, from the expressions (19), we can write
so that \(\Psi _\nu (x^k) = 0\), for all \(k \in {\bar{K}}\). Therefore, from (66), the continuity of \(\nabla \varphi\) and the continuity of the functions \(\Psi _i\), we get \(\Psi _\nu (x^*) = 0\), contradicting (67).
Then, \(\nu\) necessarily belongs to \({\hat{N}}\). Namely, \(x^*\) is non-stationary over \({\mathcal {B}}_{N_{\ell _1}^k}\), with \({\mathcal {B}}_{N_{\ell _1}^k}\) defined as in (37). This means that
Using Proposition 6 and Lemma 1, we have that \(\lim _{k\rightarrow \infty , \, k\in K} \Vert d^k\Vert = 0\), that is, recalling the definition of \(d^k\) given in (38)–(39),
From the properties of the projection we have that
so that the following holds
Using (66), the continuity of the projection and taking into account (41) in Proposition 6, we obtain
This contradicts (68), leading to the desired result. \(\square\)
4 Numerical results
In this section, we show the practical performances of AS- \(\ell _1\) on two classes of problems frequently arising in data science and machine learning that can be formulated as problem (1):
-
LASSO problems [32], where
$$\begin{aligned} \varphi (x) = \Vert Ax-b\Vert ^2, \end{aligned}$$(69)for given matrix \(A\in \mathbb {R}^{m\times n}\) and vector \(b\in \mathbb {R}^m\);
-
\(\ell _1\)-constrained logistic regression problems, where
$$\begin{aligned} \varphi (x) = \sum _{i=1}^l \log (1 + \exp (-y_i x^T a_i)), \end{aligned}$$(70)with given vectors \(a_i\) and scalars \(y_i \in \{1,-1\}\), \(i=1,\ldots ,l\).
In our implementation of AS- \(\ell _1\), we used a non-monotone line search with memory length \(n_m = 10\) (see Algorithm 2) and a spectral (or Barzilai–Borwein) gradient direction for the variables in \(N_{\ell _1}^k\). In particular, the coefficient \(m^k\) appearing in (38) was set to 1 for \(k=0\) and, for \(k \ge 1\), we employed the following formula, adapting the strategy used in [2, 4, 11]:
where \({\underline{m}} = 10^{-10}\), \({\overline{m}} = 10^{10}\), \(m^k_a = \dfrac{(s^{k-1})^T y^{k-1}}{\Vert s^{k-1} \Vert ^2}\), \(m^k_b = \dfrac{\Vert y^{k-1} \Vert ^2}{(s^{k-1})^T y^{k-1}}\), \(s^{k-1} = {\tilde{x}}^k_{N_{\ell _1}^k}-{\tilde{x}}^{k-1}_{N_{\ell _1}^k}\) and \(y^{k-1} = \nabla _{N_{\ell _1}^k} \varphi ({\tilde{x}}^k) - \nabla _{N_{\ell _1}^k} \varphi ({\tilde{x}}^{k-1})\).
The \(\epsilon\) parameter appearing in the active-set estimate (19) should satisfy Assumption 1 to guarantee the descent property established in Proposition 4 and the convergence of the algorithm. Since the Lipschitz constant L is in general unknown, we approximate \(\epsilon\) following the same strategy as in [9, 10, 12], where similar estimates are used. Starting from \(\epsilon = 10^{-6}\), we update its value along the iterations, reducing it whenever the expected decrease in the objective, stated in Proposition 4, is not obtained.
In our experiments, we implemented AS- \(\ell _1\) in Matlab and compared AS- \(\ell _1\) with the two following first-order methods, implemented in Matlab as well:
-
A spectral projected gradient method with non-monotone line search, which will be referred to as NM-SPG, downloaded from Mark Schmidt’s webpage https://www.cs.ubc.ca/~schmidtm/Software/minConf.html;
-
The away-step Frank–Wolfe method with Armijo line search [5, 6], which will be referred to as AFWFootnote 1.
Finally, we report a comparison between AS- \(\ell _1\) and AS-PG, an active-set algorithm devised in [10], showing the benefit of explicitly handling the \(\ell _1\)-ball.
For every considered problem, we set the starting point equal to the origin and we first run AS- \(\ell _1\), stopping when
where \(P(\cdot )_{\ell _1}\) denotes the projection onto the \(\ell _1\)-ball. Then, the other methods were run with the same starting point and were stopped at the first iteration k such that
with \(f^*\) being the objective value found by AS- \(\ell _1\). A time limit of 3600 s was also included in all the considered methods.
In NM-SPG, we used the default parameters (except for those concerning the stopping condition). Moreover, in AS- \(\ell _1\) and NM-SPG we employed the same projection algorithm [8], downloaded from Laurent Condat’s webpage https://lcondat.github.io/software.html.
In all codes, we made use of the Matlab sparse operator to compute \(\varphi (x)\) and \(\nabla \varphi (x)\), in order to exploit the problem structure and save computational time. The experiments were run on an Intel Xeon(R) CPU E5-1650 v2 @ 3.50GHz with 12 cores and 64 Gb RAM.
The AS- \(\ell _1\) software is available at https://github.com/acristofari/as-l1.
4.1 Comparison on LASSO instances
We considered 10 artificial instances of LASSO problems, where the objective function \(\varphi (x)\) takes the form of (69). Each instance was created by first generating a matrix \(A \in \mathbb {R}^{m \times n}\) with elements randomly drawn from a uniform distribution on the interval (0, 1), using \(n=2^{15}\) and \(m = n/2\). Then, a vector \(x^*\) was generated with all zeros, except for \(\text {round}(0.05m)\) components, which were randomly set to 1 or \(-1\). Finally, we set \(b = Ax^* + 0.001 v\), where v is a vector with elements randomly drawn from the standard normal distribution, and the \(\ell _1\)-sphere radius \(\tau\) was set to \(0.99\Vert x^*\Vert _1\).
The detailed comparison on the LASSO instances is reported in Table 1. For each instance and each algorithm, we report the final objective function value found, the CPU time needed to satisfy the stopping criterion and the percentage of zeros in the final solution, with a tolerance of \(10^{-5}\). In case an algorithm reached the time limit on an instance, we consider as final solution and final objective value those related to the last iteration performed. NM-SPG reached the time limit on all instances, being very far from \(f^*\) on 6 instances out of 10, with a difference of even two order of magnitude. AFW gets the same solutions as those obtained by AS- \(\ell _1\), being however an order of magnitude slower than AS- \(\ell _1\).
The same picture is given by Fig. 1, where we report the average optimization error \(f(x^k)-f_{\text {best}}\) over the 10 instances, with \(f_{\text {best}}\) being the minimum objective value found by the algorithms. We can notice that AS- \(\ell _1\) clearly outperforms the other two methods.

Average optimization error over LASSO instances (y axis) vs CPU time in seconds (x axis). The y axis is in logarithmic scale
4.2 Comparison on logistic regression instances
For the comparison among AS- \(\ell _1\), NM-SPG and AFW on \(\ell _1\)-constrained logistic regression problems, where the objective function \(\varphi (x)\) takes the form of (70), we considered 11 datasets for binary classification from the literature, with a number of samples l between 100 and 25,000, and a number of attributes n between 500 and 100,000. We report the complete list of datasets in Table 2.
For each dataset, we considered different values of the \(\ell _1\)-sphere radius \(\tau\), that is, 0.01n, 0.03n and 0.05n. The final results are shown in Table 3. As before, for each instance and each algorithm, we report the final objective function value found, the CPU time needed to satisfy the stopping criterion and the percentage of zeros in the final solution, with a tolerance of \(10^{-5}\). In case an algorithm reached the time limit on an instance, we consider as final solution and final objective value those related to the last iteration performed. Excluding the instance obtained from the Rev1_train.binary dataset with \(\tau = 0.05n\), the three solvers get very similar solutions on all instances, with a difference of 0.02 at most in the final objective values. When considering \(\tau = 0.01n\), AS- \(\ell _1\) is the fastest solver on 4 instances out of 11. Note that on the instance from the Farm-ads-vect dataset, AS- \(\ell _1\) is able to get the solution in a third of the CPU time needed by the other two solvers. On the other instances, the CPU time needed by AS- \(\ell _1\) is always comparable with the one needed by the fastest solver. Looking at the results for larger values of \(\tau\), we can notice that the instances get more difficult and in general less sparse. For \(\tau = 0.03n\) and \(\tau = 0.05n\), AS- \(\ell _1\) is the fastest solver on all the instances but two, those obtained from the Arcene and the Dorothea datasets, which are however addressed within 2 s. On other instances, such as those built from the Real-sim and the Rev1_train.binary datasets, AS- \(\ell _1\) is one or even two orders of magnitude faster with respect to NM-SPG and AFW.
In Fig. 2 we report the average optimization error \(f(x^k)-f_{\text {best}}\) over the 11 instances, for each value of \(\tau\), with \(f_{\text {best}}\) being the minimum objective value found by the algorithms. We can notice that AFW is outperformed by the other two algorithms, which have similar performance when considering the average optimization error above \(10^{-2}\). When considering the average optimization error below \(10^{-2}\), we see that AS- \(\ell _1\) outperforms NM-SPG too.

Average optimization error over \(\ell _1\)-constrained logistic regression instances (y axis) vs CPU time in seconds (x axis). The y axis is in logarithmic scale
4.3 Comparison with AS-PG
We now compare AS- \(\ell _1\) with AS-PG, an active set algorithm that uses a projected gradient direction, presented in [10]. As for AFW, AS-PG was run by reformulating (1) as an optimization problem over the unit simplex. In Figs. 3 and 4, we report the comparison over LASSO and logistic regression instances, respectively. The considered LASSO instances are obtained as before with \(n=2^{12}\) and \(m = n/2\). As we can easily see by taking a look at the plots, the proposed approach guarantees better performances.

Average optimization error over LASSO instances (y axis) vs CPU time in seconds (x axis). The y axis is in logarithmic scale

Average optimization error over \(\ell _1\)-constrained logistic regression instances (y axis) vs CPU time in seconds (x axis). The y axis is in logarithmic scale
5 Conclusions
In this paper, we focused on minimization problems over the \(\ell _1\)-ball and described a tailored active-set algorithm. We developed a strategy to guess, along the iterations of the algorithm, which variables should be zero at a solution. A reduction in terms of objective function value is guaranteed by simply fixing to zero those variables estimated to be active. The active-set estimate is used in combination with a projected spectral gradient direction and a non-monotone Armijo line search. We analyzed in depth the global convergence of the proposed algorithm. The numerical results show the efficiency of the method on LASSO and sparse logistic regression instances, in comparison with two widely-used first-order methods.
Data availability
The data analysed during the current study are available from the corresponding author on reasonable request.
Notes
AFW was run by reformulating (1) as an optimization problem over the unit simplex, exploiting the fact that the feasible set is a convex combination of the vectors \(\pm \tau e_i\), \(i=1,\ldots ,n\).
References
LIBSVM data: classification, regression, and multi-label. https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/
Andreani, R., Birgin, E.G., Martínez, J.M., Schuverdt, M.L.: Second-order negative-curvature methods for box-constrained and general constrained optimization. Comput. Optim. Appl. 45(2), 209–236 (2010)
Bertsekas, D.P.: Projected Newton methods for optimization problems with simple constraints. SIAM J. Control. Optim. 20(2), 221–246 (1982)
Birgin, E.G., Martínez, J.M.: Large-scale active-set box-constrained optimization method with spectral projected gradients. Comput. Optim. Appl. 23(1), 101–125 (2002)
Bomze, I.M., Rinaldi, F., Bulo, S.R.: First-order methods for the impatient: support identification in finite time with convergent Frank–Wolfe variants. SIAM J. Optim. 29(3), 2211–2226 (2019)
Bomze, I.M., Rinaldi, F., Zeffiro, D.: Active set complexity of the Away-step Frank–Wolfe Algorithm. arXiv preprint arXiv:1912.11492 (2019)
Brás, C.P., Fischer, A., Júdice, J.J., Schönefeld, K., Seifert, S.: A block active set algorithm with spectral choice line search for the symmetric eigenvalue complementarity problem. Appl. Math. Comput. 294, 36–48 (2017)
Condat, L.: Fast projection onto the simplex and the \(\ell _1\) ball. Math. Program. 158(1), 575–585 (2016)
Cristofari, A., De Santis, M., Lucidi, S., Rinaldi, F.: A two-stage active-set algorithm for bound-constrained optimization. J. Optim. Theory Appl. 172(2), 369–401 (2017)
Cristofari, A., De Santis, M., Lucidi, S., Rinaldi, F.: An active-set algorithmic framework for non-convex optimization problems over the simplex. Comput. Optim. Appl. 77(1), 57–89 (2020)
Cristofari, A., Rinaldi, F., Tudisco, F.: Total variation based community detection using a nonlinear optimization approach. SIAM J. Appl. Math. 80(3), 1392–1419 (2020)
De Santis, M., Lucidi, S., Rinaldi, F.: A fast active set block coordinate descent algorithm for \(\ell _1\)-regularized least squares. SIAM J. Optim. 26(1), 781–809 (2016)
Di Serafino, D., Toraldo, G., Viola, M., Barlow, J.: A two-phase gradient method for quadratic programming problems with a single linear constraint and bounds on the variables. SIAM J. Optim. 28(4), 2809–2838 (2018)
Dua, D., Graff, C.: UCI machine learning repository (2017). http://archive.ics.uci.edu/ml
Duchi, J., Gould, S., Koller, D.: Projected subgradient methods for learning sparse gaussians. arXiv preprint arXiv:1206.3249 (2012)
Duchi, J., Shalev-Shwartz, S., Singer, Y., Chandra, T.: Efficient projections onto the l 1-ball for learning in high dimensions. In: Proceedings of the 25th International Conference on Machine learning, pp. 272–279 (2008)
Efron, B., Hastie, T., Johnstone, I., Tibshirani, R.: Least angle regression. Ann. Stat. 32(2), 407–499 (2004)
Facchinei, F., Fischer, A., Kanzow, C.: On the accurate identification of active constraints. SIAM J. Optim. 9(1), 14–32 (1998)
Facchinei, F., Júdice, J., Soares, J.: An active set Newton algorithm for large-scale nonlinear programs with box constraints. SIAM J. Optim. 8(1), 158–186 (1998)
Grippo, L., Lampariello, F., Lucidi, S.: A nonmonotone line search technique for Newton’s method. SIAM J. Numer. Anal. 23(4), 707–716 (1986)
Guyon, I., Gunn, S.R., Ben-Hur, A., Dror, G.: Result analysis of the NIPS 2003 feature selection challenge. In: NIPS, vol. 4, pp. 545–552 (2004)
Hager, W.W., Zhang, H.: A new active set algorithm for box constrained optimization. SIAM J. Optim. 17(2), 526–557 (2006)
Hager, W.W., Zhang, H.: An active set algorithm for nonlinear optimization with polyhedral constraints. Sci. China Math. 59(8), 1525–1542 (2016)
Hager, W.W., Zhang, H.: Projection onto a polyhedron that exploits sparsity. SIAM J. Optim. 26(3), 1773–1798 (2016)
Jaggi, M.: Revisiting Frank–Wolfe: projection-free sparse convex optimization. In: International Conference on Machine Learning, pp. 427–435. PMLR (2013)
Lacoste-Julien, S., Jaggi, M.: On the global linear convergence of Frank–Wolfe optimization variants. In: NIPS 2015—Advances in Neural Information Processing Systems (2015)
Lewis, D.D., Yang, Y., Russell-Rose, T., Li, F.: Rcv1: a new benchmark collection for text categorization research. J. Mach Learn. Res. 5, 361–397 (2004)
Moré, J.J., Toraldo, G.: Algorithms for bound constrained quadratic programming problems. Numer. Math. 55(4), 377–400 (1989)
Nesterov, Y.: Introductory lectures on convex optimization: a basic course, vol. 87. Springer, Berlin (2013)
Schmidt, M., Berg, E., Friedlander, M., Murphy, K.: Optimizing costly functions with simple constraints: a limited-memory projected quasi-newton algorithm. In: Artificial Intelligence and Statistics, pp. 456–463. PMLR (2009)
Schmidt, M., Murphy, K., Fung, G., Rosales, R.: Structure learning in random fields for heart motion abnormality detection. In: 2008 IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–8. IEEE (2008)
Tibshirani, R.: Regression shrinkage and selection via the lasso. J. R. Stat. Soc.: Ser. B (Methodol.) 58(1), 267–288 (1996)
Funding
Open access funding provided by Università degli Studi di Roma La Sapienza within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cristofari, A., De Santis, M., Lucidi, S. et al. Minimization over the \(\ell _1\)-ball using an active-set non-monotone projected gradient. Comput Optim Appl 83, 693–721 (2022). https://doi.org/10.1007/s10589-022-00407-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-022-00407-6