
Abstract
In this paper, we propose an algorithmic framework, dubbed inertial alternating direction methods of multipliers (iADMM), for solving a class of nonconvex nonsmooth multiblock composite optimization problems with linear constraints. Our framework employs the general minimization-majorization (MM) principle to update each block of variables so as to not only unify the convergence analysis of previous ADMM that use specific surrogate functions in the MM step, but also lead to new efficient ADMM schemes. To the best of our knowledge, in the nonconvex nonsmooth setting, ADMM used in combination with the MM principle to update each block of variables, and ADMM combined with inertial terms for the primal variables have not been studied in the literature. Under standard assumptions, we prove the subsequential convergence and global convergence for the generated sequence of iterates. We illustrate the effectiveness of iADMM on a class of nonconvex low-rank representation problems.

Similar content being viewed by others

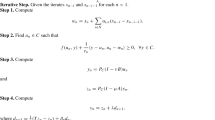
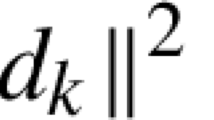
Availability of data and material, and Code availability
The data and code are available from https://github.com/nhatpd/iADMM.
Notes
We use in this paper the terminology “inertial" to mean that an inertial term that involves the current iterate and the previous iterates is added to the objective of the subproblem to update each block, see [21].
Specifically, the second equality of [51, Expression (51)] is not correct.
It is important noting that it is possible to embed the general inertial term \({\mathcal {G}}_i^k\) to the surrogate of \(x_i\mapsto {\mathcal {L}}(x_i,x^{k,i}_{\ne i},y^k,\omega ^k)\) as in [21]. This inertial term may also lead to the extrapolation for the block surrogate function of f(x) or for both the two block surrogates. However, to simplify our analysis, we only consider here the effect of the inertial term for the block surrogate of \(\varphi ^k(x)\).
References
Attouch, H., Bolte, J.: On the convergence of the proximal algorithm for nonsmooth functions involving analytic features. Math. Program. 116(1), 5–16 (2009)
Attouch, H., Bolte, J., Redont, P., Soubeyran, A.: Proximal alternating minimization and projection methods for nonconvex problems: an approach based on the Kurdyka-Łojasiewicz inequality. Math. Oper. Res. 35(2), 438–457 (2010)
Attouch, H., Bolte, J., Svaiter, B.F.: Convergence of descent methods for semi-algebraic and tame problems: proximal algorithms, forward-backward splitting, and regularized gauss-seidel methods. Math. Program. 137(1), 91–129 (2013)
Bach, F., Jenatton, R., Mairal, J., Obozinski, G.: Optimization with sparsity-inducing penalties. Found. Trends Mach. Learn. (2011). https://doi.org/10.1561/2200000015
Beck, A., Tetruashvili, L.: On the convergence of block coordinate descent type methods. SIAM J. Optim. 23, 2037–2060 (2013)
Bochnak, J., Coste, M., Roy, M.F.: Real Algebraic Geometry. Springer (1998)
Bolte, J., Sabach, S., Teboulle, M.: Proximal alternating linearized minimization for nonconvex and nonsmooth problems. Math. Program. 146(1), 459–494 (2014)
Bot, R.I., Nguyen, D.K.: The proximal alternating direction method of multipliers in the nonconvex setting: convergence analysis and rates. Math. Oper. Res. 45(2), 682–712 (2020)
Boyd, S., Parikh, N., Chu, E., Peleato, B., Eckstein, J.: Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 3(1), 1–122 (2011)
Bradley, P.S., Mangasarian, O.L.: Feature selection via concave minimization and support vector machines. In: Proceeding of International Conference on Machine Learning ICML’98 (1998)
Buccini, A., Dell’Acqua, P., Donatelli, M.: A general framework for admm acceleration. Numer. Algorithms (2020). https://doi.org/10.1007/s11075-019-00839-y
Candès, E.J., Li, X., Ma, Y., Wright, J.: Robust principal component analysis? J. ACM 58(3), 1–37 (2011)
Canyi, L., Feng, J., Yan, S., Lin, Z.: A unified alternating direction method of multipliers by majorization minimization. IEEE Trans. Pattern Anal. Mach. Intell. 40, 527–541 (2018). https://doi.org/10.1109/TPAMI.2017.2689021
Chouzenoux, E., Pesquet, J.C., Repetti, A.: A block coordinate variable metric forward-backward algorithm. J. Glob. Optim. 66, 457–485 (2016)
Deng, W., Yin, W.: On the global and linear convergence of the generalized alternating direction method of multipliers. Rice CAAM tech report TR12-14 66 (2012)
Fazel, M., Pong, T.K., Sun, D., Tseng, P.: Hankel matrix rank minimization with applications to system identification and realization. SIAM J. Matrix Anal. Appl. 34(3), 946–977 (2013)
Gabay, D., Mercier, B.: A dual algorithm for the solution of nonlinear variational problems via finite element approximation. Comput. Math. Appl. 2(1), 17–40 (1976)
Glowinski, R., Marroco, A.: Sur l’approximation, par éléments finis d’ordre un, et la résolution, par pénalisation-dualité d’une classe de problèmes de dirichlet non linéaires. ESAIM Math. Model. Numer. Anal. Modélisation Mathématique et Analyse Numérique 9(R2), 41–76 (1975)
Grippo, L., Sciandrone, M.: On the convergence of the block nonlinear gauss-seidel method under convex constraints. Oper. Res. Lett. 26(3), 127–136 (2000)
Hien, L.T.K., Gillis, N., Patrinos, P.: Inertial block proximal method for non-convex non-smooth optimization. In: Thirty-Seventh International Conference on Machine Learning ICML 2020 (2020)
Hien, L.T.K., Phan, D.N., Gillis, N.: Inertial block majorization minimization framework for nonconvex nonsmooth optimization (2020). arXiv:2010.12133
Hildreth, C.: A quadratic programming procedure. Naval Res. Logist. Q. 4(1), 79–85 (1957)
Hong, M., Chang, T.H., Wang, X., Razaviyayn, M., Ma, S., Luo, Z.Q.: A block successive upper-bound minimization method of multipliers for linearly constrained convex optimization. Math. Oper. Res. 45(3), 833–861 (2020)
Huang, F., Chen, S., Huang, H.: Faster stochastic alternating direction method of multipliers for nonconvex optimization. In: Chaudhuri, K., Salakhutdinov, R. (eds.) Proceedings of the 36th International Conference on Machine Learning, Proceedings of Machine Learning Research, vol. 97, pp. 2839–2848. PMLR (2019). http://proceedings.mlr.press/v97/huang19a.html
Huang, F., Chen, S., Lu, Z.: Stochastic alternating direction method of multipliers with variance reduction for nonconvex optimization (2016). arXiv:1610.02758
Koren, Y., Bell, R., Volinsky, C.: Matrix factorization techniques for recommender systems. Computer 42(8), 30–37 (2009)
Lai, R., Osher, S.: A splitting method for orthogonality constrained problems. J. Sci. Comput. (2014). https://doi.org/10.1007/s10915-013-9740-x
Lee, D.D., Seung, H.S.: Learning the parts of objects by non-negative matrix factorization. Nature 401(6755), 788–791 (1999)
Li, G., Pong, T.K.: Global convergence of splitting methods for nonconvex composite optimization. SIAM J. Optim. 25(4), 2434–2460 (2015). https://doi.org/10.1137/140998135
Li, H., Lin, Z.: Accelerated alternating direction method of multipliers: an optimal o(1 / k) nonergodic analysis. J. Sci. Comput. 79, 671–699 (2019)
Lin, Z., Liu, R., Su, Z.: Linearized alternating direction method with adaptive penalty for low-rank representation. In: Shawe-Taylor, J., Zemel, R., Bartlett, P., Pereira, F., Weinberger, K.Q. (eds.) Advances in Neural Information Processing Systems, vol. 24, pp. 612–620. Curran Associates Inc. (2011)
Liu, G., Lin, Z., Yan, S., Sun, J., Yu, Y., Ma, Y.: Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 35(1), 171–184 (2013)
Liu, G., Yan, S.: Latent low-rank representation for subspace segmentation and feature extraction. In: 2011 International Conference on Computer Vision, pp. 1615–1622 (2011)
Liu, Q., Shen, X., Gu, Y.: Linearized admm for nonconvex nonsmooth optimization with convergence analysis. IEEE Access 7, 76131–76144 (2019)
Lu, C., Tang, J., Yan, S., Lin, Z.: Nonconvex nonsmooth low rank minimization via iteratively reweighted nuclear norm. IEEE Trans. Image Process. 25(2), 829–839 (2016)
Mairal, J.: Optimization with first-order surrogate functions. In: Proceedings of the 30th International Conference on International Conference on Machine Learning, vol. 28, ICML’13, pp. 783–791. JMLR.org (2013)
Markovsky, I.: Low Rank Approximation: Algorithms, Implementation, Applications. vol. 906. Springer (2012)
Melo, J.G., Monteiro, R.D.C.: Iteration-complexity of a jacobi-type non-euclidean admm for multi-block linearly constrained nonconvex programs (2017)
Nesterov, Y.: Introductory Lectures on Convex Optimization: A Basic Course. Kluwer Academic Publ. (2004)
Ochs, P.: Unifying abstract inexact convergence theorems and block coordinate variable metric ipiano. SIAM J. Optim. 29(1), 541–570 (2019)
Ouyang, Y., Chen, Y., Lan, G., Pasiliao, E.: An accelerated linearized alternating direction method of multipliers. SIAM J. Imag. Sci. 8(1), 644–681 (2015)
Parikh, N., Boyd, S.: Proximal algorithms. Found. Trends Optim. 1(3), 127–239 (2014)
Pock, T., Sabach, S.: Inertial proximal alternating linearized minimization (iPALM) for nonconvex and nonsmooth problems. SIAM J. Imag. Sci. 9(4), 1756–1787 (2016)
Powell, M.J.D.: On search directions for minimization algorithms. Math. Program. 4(1), 193–201 (1973)
Razaviyayn, M., Hong, M., Luo, Z.: A unified convergence analysis of block successive minimization methods for nonsmooth optimization. SIAM J. Optim. 23(2), 1126–1153 (2013)
Recht, B., Fazel, M., Parrilo, P.A.: Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization. SIAM Rev. 52(3), 471–501 (2010)
Rockafellar, R.T.: The Theory Of Subgradients And Its Applications To Problems Of Optimization - Convex And Nonconvex Functions. Heldermann, Heidelberg (1981)
Rockafellar, R.T., Wets, R.J.B.: Variational Analysis. Springer, Heidelberg (1998)
Scheinberg, K., Ma, S., Goldfarb, D.: Sparse inverse covariance selection via alternating linearization methods. In: Lafferty, J.D., Williams, C.K.I., Shawe-Taylor, J., Zemel, R.S., Culotta, A. (eds.) Advances in Neural Information Processing Systems 23, pp. 2101–2109. Curran Associates Inc. (2010)
Shi, J., Malik, J.: Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 22(8), 888–905 (2000)
Sun, T., Barrio, R., Rodríguez, M., Jiang, H.: Inertial nonconvex alternating minimizations for the image deblurring. IEEE Trans. Image Process. 28(12), 6211–6224 (2019)
Sun, Y., Babu, P., Palomar, D.P.: Majorization-minimization algorithms in signal processing, communications, and machine learning. IEEE Trans. Signal Process. 65(3), 794–816 (2017). https://doi.org/10.1109/TSP.2016.2601299
Tseng, P.: Convergence of a block coordinate descent method for nondifferentiable minimization. J. Optim. Theory Appl. 109(3), 475–494 (2001)
Tseng, P., Yun, S.: A coordinate gradient descent method for nonsmooth separable minimization. Math. Program. 117(1), 387–423 (2009)
Udell, M., Horn, C., Zadeh, R., Boyd, S.: Generalized low rank models. Found. Trends Mach. Learn. 9(1), 1–118 (2016)
Udell, M., Townsend, A.: Why are big data matrices approximately low rank? SIAM J. Math. Data Sci. 1(1), 144–160 (2019)
Von Luxburg, U.: A tutorial on spectral clustering. Stat. Comput. 17(4), 395–416 (2007)
Wang, Y., Yin, W., Zeng, J.: Global convergence of admm in nonconvex nonsmooth optimization. J. Sci. Comput. 78, 29–63 (2019). https://doi.org/10.1007/s10915-018-0757-z
Wang, Y., Zeng, J., Peng, Z., Chang, X., Xu, Z.: Linear convergence of adaptively iterative thresholding algorithms for compressed sensing. IEEE Trans. Signal Process. 63(11), 2957–2971 (2015)
Wen, Z., Yin, W.: A feasible method for optimization with orthogonality constraints. Math. Program. 142, 397–434 (2010)
Xu, M., Wu, T.: A class of linearized proximal alternating direction methods. J. Optim. Theory Appl. 151, 321–337 (2011). https://doi.org/10.1007/s10957-011-9876-5
Xu, Y., Yin, W.: A block coordinate descent method for regularized multiconvex optimization with applications to nonnegative tensor factorization and completion. SIAM J. Imag. Sci. 6(3), 1758–1789 (2013). https://doi.org/10.1137/120887795
Xu, Y., Yin, W.: A globally convergent algorithm for nonconvex optimization based on block coordinate update. J. Sci. Comput. 72(2), 700–734 (2017)
Yang, J., Zhang, Y., Yin, W.: An efficient TVL1 algorithm for deblurring multichannel images corrupted by impulsive noise. SIAM J. Sci. Comput. 31(4), 2842–2865 (2009)
Yang, L., Pong, T.K., Chen, X.: Alternating direction method of multipliers for a class of nonconvex and nonsmooth problems with applications to background/foreground extraction. SIAM J. Imag. Sci. 10(1), 74–110 (2017). https://doi.org/10.1137/15M1027528
Yin, W., Osher, S., Goldfarb, D., Darbon, J.: Bregman iterative algorithms for l(1)-minimization with applications to compressed sensing. SIAM J. Imag. Sci. 1, 143–168 (2008)
Funding
LTKH and NG acknowledge the support by the European Research Council (ERC starting grant no 679515), and by the Fonds de la Recherche Scientifique - FNRS and the Fonds Wetenschappelijk Onderzoek - Vlaanderen (FWO) under EOS Project no O005318F-RG47. NG also acknowledges the Francqui Foundation.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Le Thi Khanh Hien finished this work when she was at the University of Mons, Belgium.
Appendices
Appendix 1: Preliminaries of non-convex non-smooth optimization
In this appendix, we recall some basic definitions and results, namely directional derivative and subdifferentials in Definition 3, critical point in Definition 4, the subdifferential of a sum of function in Proposition 6, and KŁ functions in Definition 6.
Let \(g: {\mathbb {E}}\rightarrow {\mathbb {R}}\cup \{+\infty \}\) be a proper lower semicontinuous function.
Definition 3
[48, Definition 8.3]
-
(i)
For any \(x\in \mathrm{dom}\,g,\) and \(d\in {\mathbb {E}}\), we denote the directional derivative of g at x in the direction d by
$$\begin{aligned}g'\left( x;d\right) =\liminf _{\tau \downarrow 0}\frac{g(x+\tau d)-g(x)}{\tau }. \end{aligned}$$ -
(ii)
For each \(x\in \mathrm{dom}\,g,\) we denote \({\hat{\partial }}g(x)\) as the Frechet subdifferential of g at x which contains vectors \(v\in \mathbb {E}\) satisfying
$$\begin{aligned} \liminf _{y\ne x,y\rightarrow x}\frac{1}{\left\| y-x\right\| }\left( g(y)-g(x)-\left\langle v,y-x\right\rangle \right) \ge 0. \end{aligned}$$If \(x\not \in \mathrm{dom}\,g,\) then we set \({\hat{\partial }}g(x)=\emptyset .\)
-
(iii)
The limiting-subdifferential \(\partial g(x)\) of g at \(x\in \mathrm{dom}\,g\) is defined as follows:
$$\begin{aligned} \partial g(x) := \left\{ v\in \mathbb {E}:\exists x^{(k)}\rightarrow x,\,g\left( x^{(k)}\right) \rightarrow g(x),\,v^{(k)}\in {\hat{\partial }}g\left( x^{(k)}\right) ,\,v^{(k)}\rightarrow v\right\} . \end{aligned}$$ -
(iv)
The horizon subdifferential \(\partial ^{\infty } g(x)\) of g at x is defined as follows:
$$\begin{aligned} \partial ^{\infty } g(x)&:= \Big \{ v\in \mathbb {E}:\exists \lambda ^{(k)}\rightarrow 0, \lambda ^{(k)}\ge 0, \lambda ^{(k)} x^{(k)}\rightarrow x,\,g(x^{(k)})\rightarrow g(x),\\&\qquad \,v^{(k)}\in {\hat{\partial }}g(x^{(k)}),\,v^{(k)}\rightarrow v\Big \} . \end{aligned}$$
Definition 4
We call \(x^{*}\in \mathrm {dom}\,F\) a critical point of F if \(0\in \partial F\left( x^{*}\right) .\)
Definition 5
[48, Definition 7.5] A function \(f:{\mathbb {R}}^{{\mathbf {n}}} \rightarrow {\mathbb {R}} \cup \{+\infty \}\) is called subdifferentially regular at \({{\bar{x}}}\) if \(f({{\bar{x}}})\) is finite and the epigraph of f is Clarke regular at \(({{\bar{x}}}, f({{\bar{x}}}))\) as a subset of \({\mathbb {R}}^{{\mathbf {n}}} \times {\mathbb {R}}\) (see [48, Definition 6.4] for the definition of Clarke regularity of a set at a point).
Proposition 6
[48, Corollary 10.9] Suppose \(f=f_1 +\cdot + f_m\) for proper lower semi-continuous function \(f_i:{\mathbb {R}}^{{\mathbf {n}}}\rightarrow {\mathbb {R}}\cup \{+\infty \}\) and let \({{\bar{x}}} \in \mathrm{dom} f\). Suppose each function \(f_i\) is subdifferential regular at \({{\bar{x}}}\), and the condition that the only combination of vector \(\nu _i \in \partial ^{\infty } f_i({{\bar{x}}})\) with \(\nu _1 + \ldots \nu _m=0\) is \(\nu _i=0\) for \(i\in [m]\). Then we have
To obtain a global convergence, we need the following Kurdyka-Łojasiewicz (KŁ) property for \(F(x) + h(y)\).
Definition 6
A function \(\phi (\cdot )\) is said to have the KŁ property at \(\bar{{\mathbf {x}}}\in \mathrm{dom}\,\partial \, \phi\) if there exists \(\varsigma \in (0,+\infty ]\), a neighborhood U of \(\bar{{\mathbf {x}}}\) and a concave function \(\varUpsilon :[0,\varsigma )\rightarrow \mathbb {R}_{+}\) that is continuously differentiable on \((0,\varsigma )\), continuous at 0, \(\varUpsilon (0)=0\), and \(\varUpsilon '(t)>0\) for all \(t\in (0,\eta ),\) such that for all \({\mathbf {x}}\in U\cap [\phi (\bar{{\mathbf {x}}})<\phi ({\mathbf {x}})<\phi (\bar{{\mathbf {x}}})+\varsigma ],\) we have
where \({{\,\mathrm{dist}\,}}\left( 0,\partial \phi ({\mathbf {x}})\right) =\min \left\{ \Vert {\mathbf {z}}\Vert :{\mathbf {z}}\in \partial \phi ({\mathbf {x}})\right\}\). If \(\phi ({\mathbf {x}})\) has the KŁ property at each point of \(\mathrm{dom}\, \partial \phi\) then \(\phi\) is a KŁ function.
When \(\varUpsilon (t) = c t^{1-{\mathbf {a}}}\), where c is a constant, we call \({\mathbf {a}}\) the KŁ coefficient.
Many non-convex non-smooth functions in practical applications belong to the class of KŁ functions, for examples, real analytic functions, semi-algebraic functions, and locally strongly convex functions, see for example [6, 7].
Appendix 2: Proofs
In this appendix, we provide the proofs of all propositions and theorems of our paper. Before that, let us give some preliminary results. We use x, z to denote vectors in \({\mathbb {R}}^n\).
Lemma 1
[21, Lemma 2.8] If the function \(x_i\mapsto \varTheta (x_i,z)\) is \(\rho\)-strongly convex, differentiable at \(z_i\), and \(\nabla _{x_i} \varTheta (z_i,z)=0\) then we have
We recall the notation \((x_i,z_{\ne i}) = (z_1,\ldots ,z_{i-1},x_i,z_{i+1},\ldots ,z_s)\). Suppose we are trying to solve
Proposition 7
[21, Theorem 2.7] Suppose \({\mathcal {G}}^k_i: {\mathbb {R}}^{{\mathbf {n}}_i} \times {\mathbb {R}}^{{\mathbf {n}}_i} \rightarrow {\mathbb {R}}^{{\mathbf {n}}_i}\) be some extrapolation operator that satisfies \({\mathcal {G}}^k_i(x^{k}_i, x^{k-1}_i)\le a_i^k\Vert x^{k}_i - x^{k-1}_i\Vert\). Let \(u_i(x_i,z)\) is a block surrogate function of \(\varPhi (x)\). We assume one of the following conditions holds:
-
\(x_i\mapsto u_i(x_i,z) + g_i(x_i)\) is \(\rho _i\)-strongly convex,
-
the approximation error \(\varTheta (x_i,z):=u_i(x_i,z)-\varPhi (x_i,z_{\ne i})\) satisfying \(\varTheta (x_i,z)\ge \frac{\rho _i}{2} \Vert x_i-z_i\Vert ^2\) for all \(x_i\).
Note that \(\rho _i\) may depend on z. Let
Then we have
where
and \(0<\nu <1\) is a constant. If we do not apply extrapolation, that is \(a_i^k=0\), then (26) is satisfied with \(\gamma _i^k=0\) and \(\eta _i^k = \rho _i/2\).
The following proposition is derived from [20, Remark 3] and [62, Lemma 2.1].
Proposition 8
Suppose \(x_i\mapsto \varPhi (x)\) is a \(L_i\)-smooth convex function and \(g_i(x_i)\) is convex. Define \({{\bar{x}}}^{k,i-1}=(x^{k+1}_1,\ldots ,x^{k+1}_{i-1},{{\bar{x}}}^{k}_i, x^{k}_{i+1},\ldots ,x^k_s)\), \({\hat{x}}_i^k=x_i^k + \alpha _i^k (x_i^k-x_i^{k-1})\) and \({{\bar{x}}}_i^k=x_i^k + \beta _i^k (x_i^k-x_i^{k-1})\). Let \(x_i^{k+1}={{\,\mathrm{argmin}\,}}_{x_i} \langle \nabla \varPhi ({{\bar{x}}}^{k,i-1}),x_i\rangle + g_i(x_i)+ \frac{L_i}{2}\Vert x_i -{\hat{x}}_i^k\Vert ^2.\) Then we have Inequality (26) is satisfied with
If \(\alpha _i^k=\beta _i^k\) then we have Inequality (26) is satisfied with
1.1 Proof of Proposition 1
(i) Suppose we are updating \(x_i^k\). Let us recall that
where
Denote \({\mathbf {u}}_i(x_i,z,y,\omega )= u_i(x_i,z)+ h(y) + {{\hat{\varphi }}}_i(x_i,z,y,\omega ),\) where
We see that \({{\hat{\varphi }}}_i(x_i,z,y,\omega )\) is a block surrogate function of \(x\mapsto \varphi (x, y, \omega )\) with respect to block \(x_i\), and \({\mathbf {u}}_i(x_i,z,y,\omega )\) is a block surrogate function of \(x\mapsto f(x) + h(y) + \varphi (x, y, \omega )\) with respect to block \(x_i\). The update in (8) can be rewritten as follows.
where
The block approximation error function between \({\mathbf {u}}_i(x_i,z,y,\omega )\) and \(x\mapsto f(x) + h(y) + \varphi (x, y, \omega )\) is defined as
We have \(\nabla _{x_i}\theta _i(x_i,z,y,\omega )=\kappa _i\beta (x_i - z_i) +\nabla _{x_i} \varphi (z, y, \omega ) - \nabla _{x_i} \varphi ((x_i,z_{\ne i}), y, \omega )\). So \(\nabla _{x_i}\theta _i(z_i,z,y,w)=0\). On the other hand, note that \(x_i \mapsto \varphi ((x_i,z_{\ne i}), y^k, \omega ^k)\) is \(\beta \Vert {\mathcal {A}}_i^* {\mathcal {A}}_i\Vert\) - smooth. So, \(x_i\mapsto \theta _i(x_i,z,y,\omega )\) is a \(\beta (\kappa _i - \Vert {\mathcal {A}}_i^* {\mathcal {A}}_i\Vert )\) - strongly convex function. From Lemma 1 we have \(\theta _i(x_i,z,y,w)\ge \frac{ \beta (\kappa _i - \Vert {\mathcal {A}}_i^* {\mathcal {A}}_i\Vert ) }{2} \Vert x_i-z_i\Vert ^2\). The result follows from (28), (30) and Proposition (7).
(ii) When \(x_i\mapsto u_i(x_i,z)+g_i(x_i)\) is convex and we apply the update as in (8), it follows from Proposition 8 (see also [21, Remark 4.1]) that
On the other hand, note that \(u_i(x_i^{k},x^{k,i-1}) = f(x^{k,i-1})\) and \(u_i(x_i^{k+1},x^{k,i-1})\ge f(x^{k,i})\). The result follows then.
1.2 Proof of Proposition 2
Denote
Then we have \({\hat{h}}(y,y') +\frac{\beta }{2}\Vert {\mathcal {A}} x +\mathcal By -b \Vert ^2\) is a surrogate function of \(y\mapsto h(y) + \varphi (x,y,\omega )\). Note that the function \(y\mapsto {\hat{h}}(y,y') +\frac{\beta }{2}\Vert {\mathcal {A}} x +\mathcal By -b \Vert ^2\) is \((L_h + \beta \lambda _{\min }({\mathcal {B}}^*{\mathcal {B}}))\)-strongly convex. The result follows from Proposition 7 (see also [21, Section 4.2.1]).
Suppose h(y) is convex. We note that \(y\mapsto \frac{\beta }{2}\Vert {\mathcal {A}} x + \mathcal By -b \Vert ^2\) is also convex and plays the role of \(g_i\) in Proposition 8. The result follows from Proposition 8.
1.3 Proof of Proposition 3
Note that
From the optimality condition of (9) we have
Together with (10) we obtain
Hence,
which implies that
where \(\varDelta z^{k+1} = z^{k+1} - z^k\) and \(z^{k+1}= \nabla h({\hat{y}}^k) + L_h (\varDelta y^{k+1} -\delta _k \varDelta y^{k} )\). We now consider 2 cases.
Case 1: \(0<\alpha \le 1\). From the convexity of \(\Vert \cdot \Vert\) we have
Case 2: \(1<\alpha < 2\). We rewrite (35) as \({\mathcal {B}}^*\varDelta w^{k+1} = - (\alpha -1) {\mathcal {B}}^* \varDelta w^{k} - \frac{\alpha }{2-\alpha } (2-\alpha )\varDelta z^{k+1}.\) Hence
Combine (36) and (37) we obtain
which implies
On the other hand, when we use extrapolation for the update of y we have
If we do not use extrapolation for y then we have
Furthermore, note that \(\sigma _{{\mathcal {B}}}\Vert \varDelta w^{k+1}\Vert ^2 \le \Vert {\mathcal {B}}^* \varDelta w^{k+1}\Vert ^2\). Therefore, it follows from (39) that
The result is obtained from (42), (32) and Proposition 1.
1.4 Proof of Proposition 4
(i) From Inequality (17) and the conditions in (18),
By summing from \(k=1\) to K Inequality (43) and noting that \(C_1+C_2=C_y\) we obtain (20).
(ii) Let us prove \(\{\varDelta y^k\}\) and \(\{\varDelta x_i^k \}\) converge to 0. Let us first prove the second situation, that is we use extrapolation for the update of y and Inequality (19) is satisfied. From (34) we have \(\alpha {\mathcal {B}}^*w^{k+1}=-(1-\alpha ) {\mathcal {B}}^* \varDelta \omega ^{k+1}- \alpha z^{k+1} ,\) where \(z^{k+1}= \nabla h({\hat{y}}^k) + L_h (\varDelta y^{k+1} -\delta _k \varDelta y^{k} )\). Using the same technique that derives Inequality (38), we obtain the following
On the other hand, we have
Together with (44) and
we obtain
Since h(y) is \(L_h\)-smooth, for all \(y\in {\mathbb {R}}^q\) and \(\alpha _L>0\) we have, (see [39])
Let us choose \(\alpha _L\) such that \(\alpha _L(1-\frac{L_h \alpha _L}{2})=\frac{4\alpha }{2\beta \sigma _{{\mathcal {B}}}(1-|1-\alpha |)}\). Note that this equation always has a positive solution when \(\beta \ge \frac{4L_h \alpha }{\sigma _{\mathcal { B}} (1-|1-\alpha | )}\). Then we have
Together with (45) we get
So from \(\frac{\alpha _1}{\beta }\ge \frac{|1-\alpha |}{2\alpha \beta \sigma _{{\mathcal {B}}}}\), \(\mu \ge \frac{\alpha 12L_h^2}{2\beta \sigma _{{\mathcal {B}}}(1-|1-\alpha |)}\), \((1-C_1)\mu \ge \frac{\alpha 12L_h^2 12\delta _{k}^2}{2\beta \sigma _{{\mathcal {B}}}(1-|1-\alpha |)}\) we have
Hence \({\mathcal {L}}^{K+1} + \mu \Vert \varDelta y^{K+1} \Vert ^2 + \frac{\alpha _1}{ \beta } \Vert B^* \varDelta w^{K+1}\Vert ^2 + (1-C_1)\mu \Vert \varDelta y^{K}\Vert ^2\) is lower bounded.
Furthermore, since \(\eta _i\) and \(\mu\) are positive numbers we derive from Inequality (20) that \(\sum _{k=1}^\infty \Vert \varDelta y^k \Vert ^2<+\infty\) and \(\sum _{k=1}^\infty \Vert \varDelta x_i^k\Vert ^2 <+\infty\). Therefore, \(\{\varDelta y^k\}\) and \(\{\varDelta x_i^k \}\) converge to 0.
Let us now consider the first situation when \(\delta _k=0\) for all k.
From Inequality (17) and the conditions in (18) we have
By summing Inequality (48) from \(k=1\) to K we obtain
Denote the value of the right side of Inequality (48) by \({{\hat{{\mathcal {L}}}}}^k\). Note that \(0<C_x,C_y<1\), then from (48) we have the sequence \(\{{{\hat{{\mathcal {L}}}}}^{k}\}\) is non-increasing. It follows from [38, Lemma 2.9] that \({{\hat{{\mathcal {L}}}}}^k\ge \vartheta\) for all k, where \(\vartheta\) is is the lower bound of \(F(x^{k}) +h(y^{k})\). For completeness, let us provide the proof in the following. We have
Assume that there exists \(k_0\) such that \({{\hat{{\mathcal {L}}}}}^k < \vartheta\) for all \(k\ge k_0\). As \({{\hat{{\mathcal {L}}}}}^k\) is non-increasing we have
Hence \(\sum _{k=1}^\infty ({{\hat{{\mathcal {L}}}}}^k - \vartheta )= -\infty\). However, from (50) we have
which gives a contradiction.
Since \({{\hat{{\mathcal {L}}}}}^K\ge \vartheta\) and \(\eta _i\) and \(\mu\) are positive numbers we derive from Inequality (20) that \(\sum _{k=1}^\infty \Vert \varDelta y^k \Vert ^2<+\infty\) and \(\sum _{k=1}^\infty \Vert \varDelta x_i^k\Vert ^2 <+\infty\). Therefore, \(\{\varDelta y^k\}\) and \(\{\varDelta x_i^k \}\) converge to 0.
Now we prove \(\{\varDelta \omega ^k\}\) goes to 0. Since \(\sum _{k=1}^\infty \Vert \varDelta y^k \Vert ^2<+\infty\), we derive from (40) that \(\sum _{k=1}^\infty \Vert \varDelta z^k \Vert ^2<+\infty\). Summing up Equality (38) from \(k=1\) to K we have
which implies that \(\sum _{k=1}^\infty \Vert {\mathcal {B}}^*\varDelta \omega ^k \Vert ^2 <+\infty\). Hence, \(\Vert {\mathcal {B}}^*\varDelta \omega ^k \Vert ^2\rightarrow 0\). Since \(\sigma _{{\mathcal {B}}}>0\) we have \(\{\varDelta \omega ^k\}\) goes to 0.
1.5 Proof of Proposition 5
We remark that we use the idea in the proof of [58, Lemma 6] to prove the proposition. However, our proof is more complicated since in our framework \(\alpha \in (0,2)\), the function h is linearized and we use extrapolation for y.
Note that as \(\sigma _{{\mathcal {B}}}>0\) we have \({\mathcal {B}}\) is a surjective. Together with the assumption \(b+ Im({\mathcal {A}}) \subseteq Im({\mathcal {B}})\) we have there exist \({{\bar{y}}}^k\) such that \(\mathcal Ax^k+{\mathcal {B}}{{\bar{y}}}^k-b =0\).
Now we have
From (33) we have
Therefore, it follows from (51) and \(L_h\)-smooth property of h that
On the other hand, we have
We have proved in Proposition 4 that \(\Vert \varDelta \omega ^k\Vert\), \(\Vert \varDelta x^k\Vert\) and \(\Vert \varDelta y^k\Vert\) converge to 0. Furthermore, from Proposition 4 we have \({\mathcal {L}}^k\) is upper bounded. Therefore, from (52), (53) and (20) we have \(F(x^{k}) + h({{\bar{y}}}^k)\) is upper bounded. So \(\{x^k\}\) is bounded. Consequently, \(\mathcal Ax^k\) is bounded.
Furthermore, we have
Therefore, \(\{y^k\}\) is bounded, which implies that \(\Vert \nabla h({\hat{y}}^k)\Vert\) is also bounded. Finally, from (33) and the assumption \(\lambda _{\min }({\mathcal {B}}{\mathcal {B}}^*)>0\) we also have \(\{\omega ^k\}\) is bounded.
1.6 Proof of Theorem 1
Suppose \((x^{k_n},y^{k_n},\omega ^{k_n})\) converges to \((x^*,y^*,\omega ^*)\). Since \(\varDelta x_i^k\) goes to 0, we have \(x_i^{k_n+1}\) and \(x_i^{k_n-1}\) also converge to \(x_i^*\) for all \(i\in [s]\). From (28), for all \(x_i\),
Choosing \(x_i=x_i^*\) and \(k=k_n-1\) in (54) and noting that \({\mathbf {u}}_i(x_i,z)\) is continuous by Assumption 2 (i), we have \(\limsup _{n\rightarrow \infty } {\mathbf {u}}_i(x_i^*,x^*,y^*,\omega ^*) + g_i(x_i^{k_n}) \le {\mathbf {u}}_i(x_i^*,x^*,y^*,\omega ^*)+ g_i(x_i^*).\) On the other hand, as \(g_i(x_i)\) is lower semi-continuous. Hence, \(g_i(x_i^{k_n})\) converges to \(g_i(x_i^*)\). Now we choose \(k=k_n\rightarrow \infty\) in (54) for all \(x_i\) we obtain
where \(L_0(x,y,\omega )=f(x) + h(y) + \varphi (x, y, \omega )\) and \({\mathbf {e}}_i\) is the approximation error defined in (30). We have
Note that \({{\bar{e}}}_i(x^*_i,x^*)=0\) by Assumption 2. From (55) we have \(x_i^*\) is a solution of
Writing the optimality condition for this problem we obtain \(0 \in \partial _{x_i} {\mathcal {L}}(x^*,y^*,\omega ^*)\). Totally similarly we can prove that \(0 \in \partial _{y} {\mathcal {L}}(x^*,y^*,\omega ^*)\). On the other hand, we have
Hence, \(\partial _\omega {\mathcal {L}}(x^*,y^*,\omega ^*) = {\mathcal {A}} x^* + {\mathcal {B}} y^* -b=0.\)
As we assume \(\partial F(x)=\partial _{x_1} F(x) \times \cdots \times \partial _{x_s} F(x)\), we have
So \(0\in \partial {\mathcal {L}}(x^*,y^*,\omega ^*)\).
1.7 Proof of Theorem 2
Note that we assume the generated sequence of Algorithm 1 is bounded. The following analysis is considered in the bounded set that contains the generated sequence of Algorithm 1. We first prove some preliminary results.
(A) The optimality condition of (28) gives us
As (22) holds, there exists \({\mathbf {s}}_i^{k+1}\in \partial u_i(x_i^{k+1},x^{k,i-1})\) and \({\mathbf {t}}_i^{k+1}\in \partial g_i(x_i^{k+1})\) such that
As (23) holds, there exists \(\xi _i^{k+1}\in \partial _{x_i} f(x^{k+1})\) such that
Denote \(\tau ^{k+1}_i:= \xi _i^{k+1} + {\mathbf {t}}_i^{k+1} \in \partial _{x_i} F(x^{k+1})\) (as (22) holds). Then, from (57) we have
On the other hand, we note that
Let \(d_i^{k+1}:= \tau _i^{k+1}+ {\mathcal {A}}_i^*\big (\omega ^{k+1} + \beta ({\mathcal {A}} x^{k+1} + \mathcal By^{k+1}-b) \big ) \in \partial _{x_i} {\mathcal {L}}(x^{k+1},y^{k+1},\omega ^{k+1})\). From (59),
Together with (58) we obtain
It follows from (9) that
Let \(d_y^{k+1}:=\nabla h(y^{k+1}) +{\mathcal {B}}^*\big (\omega ^{k+1} +\beta ({\mathcal {A}} x^{k+1} + {\mathcal {B}} y^{k+1} -b )\big ).\) Then \(d_y^{k+1}\in \partial _y {\mathcal {L}}(x^{k+1},y^{k+1},\omega ^{k+1})\) and
Let \(d_\omega ^{k+1}:={\mathcal {A}} x^{k+1} + {\mathcal {B}}^{k+1} -b\). We have \(d_\omega ^{k+1}\in \partial _\omega {\mathcal {L}}(x^{k+1},y^{k+1},\omega ^{k+1})\) and
(B) Let us now prove \(F(x^{k_n})\) converges to \(F(x^*)\). This implies \({\mathcal {L}}(x^{k_n},y^{k_n},\omega ^{k_n})\) converges to \({\mathcal {L}}(x^*,y^*,\omega ^*)\) since \({\mathcal {L}}\) is differentiable in y and \(\omega\). We have
So \(F(x^{k_n})\) converges to \(u_s(x_i^*,x^*) +\sum _{i=1}^s g_i(x_i^*)=F(x^*)\).
We now proceed to prove the global convergence. Denote \({\mathbf {z}}= (x,y,\omega )\), \(\tilde{\mathbf {z}}= ({{\tilde{x}}}, {{\tilde{y}}}, {{\tilde{\omega }}})\), and \({\mathbf {z}}^k= (x^k,y^k,\omega ^k)\). We consider the following auxiliary function
The auxiliary sequence \({\bar{{\mathcal {L}}}} ({\mathbf {z}}^k, {\mathbf {z}}^{k-1})\) has the following properties.
-
1.
Sufficient decreasing property From (48) we have
$$\begin{aligned}&{\bar{{\mathcal {L}}}} ({\mathbf {z}}^{k+1}, {\mathbf {z}}^{k}) + \sum _{i=1}^s \frac{\eta _i- C_x \eta _i}{2}\big ( \Vert x_i^{k+1} -x_i^k \Vert ^2 + \Vert x_i^{k} -x_i^{k-1} \Vert ^2\big ) \\&\quad + \frac{(1-C_y)\mu }{2} \big ( \Vert y^{k+1} -y^k \Vert ^2 + \Vert y^{k} -y^{k-1} \Vert ^2\big )\le {\bar{{\mathcal {L}}}} ({\mathbf {z}}^k, {\mathbf {z}}^{k-1}). \end{aligned}$$ -
2.
Boundedness of subgradient In the proof (A) above, we have proved that
$$\begin{aligned} \Vert d^{k+1}\Vert \le a_1 (\Vert x^{k+1}-x^k\Vert +\Vert x^k-x^{k-1}\Vert + \Vert y^{k+1}-y^k\Vert + \Vert \omega ^{k+1}-\omega ^k\Vert ) \end{aligned}$$for some constant \(a_1\) and \(d^{k+1} \in \partial {\mathcal {L}}({\mathbf {z}}^{k+1})\). On the other hand, as we use \(\alpha =1\), from (35) we obtain
$$\begin{aligned} \begin{aligned}&\sqrt{\sigma _{{\mathcal {B}}}}\Vert \omega ^{k+1}-\omega ^k\Vert \le \Vert B^*(\omega ^{k+1}-\omega ^k)\Vert = \Vert \varDelta z^{k+1}\Vert \\&\quad =\Vert \nabla h(y^{k}) - \nabla h(y^{k-1}) + L_h(\varDelta y^{k+1} - \varDelta y^k) \Vert \le 2L_h\Vert y^{k}-y^{k-1}\Vert + L_h\Vert y^{k+1}-y^{k}\Vert . \end{aligned} \end{aligned}$$(63)Hence,
$$\begin{aligned} \Vert d^{k+1}\Vert \le a_2 (\Vert x^{k+1}-x^k\Vert +\Vert x^k-x^{k-1}\Vert + \Vert y^{k+1}-y^k\Vert + \Vert y^{k}-y^{k-1}\Vert ) \end{aligned}$$for some constant \(a_2\). Note that
$$\begin{aligned} \partial {\bar{{\mathcal {L}}}}({\mathbf {z}}, \tilde{\mathbf {z}})=\partial {\mathcal {L}}({\mathbf {z}}, \tilde{\mathbf {z}}) + \partial \Big (\sum _{i=1}^s \frac{\eta _i + C_x \eta _i}{2}\Vert x_i - {{\tilde{x}}}_i \Vert ^2 + \frac{(1+C_y) \mu }{2} \Vert y-{{\tilde{y}}}\Vert ^2 + \frac{\alpha _1}{\beta } \Vert B^* (\omega - {{\tilde{\omega }}})\Vert ^2 \Big ). \end{aligned}$$Hence, it is not difficult to show that
$$\begin{aligned} \Vert {\mathbf {d}}^{k+1}\Vert \le a_3 (\Vert x^{k+1}-x^k\Vert +\Vert x^k-x^{k-1}\Vert + \Vert y^{k+1}-y^k\Vert + \Vert y^{k}-y^{k-1}\Vert ) \end{aligned}$$for some constant \(a_3\) and \({\mathbf {d}}^{k+1} \in \partial {\bar{{\mathcal {L}}}}({\mathbf {z}}^{k+1},{\mathbf {z}}^{k})\).
-
3.
KL property Since \(F(x) + h(y)\) has KL property, then \({\bar{{\mathcal {L}}}}({\mathbf {z}}, \tilde{\mathbf {z}})\) also has KŁ property.
-
4.
A continuity condition Suppose \({\mathbf {z}}^{k_n}\) converges to \((x^*,y^*,\omega ^*)\). In the proof (B) above, we have proved that \({\mathcal {L}}({\mathbf {z}}^{k_n})\) converges to \({\mathcal {L}}(x^*,y^*,\omega ^*)\). Furthermore, from Proposition 4 we proved that \(\Vert {\mathbf {z}}^{k+1}-{\mathbf {z}}^{k} \Vert\) goes to 0. Hence we have \({\mathbf {z}}^{k_n-1}\) converges to \((x^*,y^*,\omega ^*)\). So, \({\bar{{\mathcal {L}}}} ({\mathbf {z}}^{k+1}, {\mathbf {z}}^{k})\) converges to \({\bar{{\mathcal {L}}}} ({\mathbf {z}}^*, {\mathbf {z}}^*)\).
Using the same technique as in [7, Theorem 1], see also [20, 40], we can prove that
which implies \(\{(x^k,y^k)\}\) converges to \((x^*,y^*)\). From (63) we obtain
Hence, \(\{\omega ^k\}\) also converges to \(\omega ^*\).
Appendix 3: Additional experiment for different values of \(\alpha\)
In this experiment, we rerun the experiments from Sect. 3 with other values for \(\alpha\), namely 0.5, 1.4 and 1.8; see Figs. 2, 3 and 4 (on pages 31-33). The penalty parameter \(\beta\) is computed by \(\beta = 2(2 + C_y)\alpha _2/C_y\), where \(C_y = 1 - 10^{-6}\) and \(\alpha _2=\frac{3\alpha }{(1-|1-\alpha |)^2}\). Although the segmentation errors and objective function values differ for different values of \(\alpha\), we observe that, in all cases, iADMM-mm outperforms ADMM-mm which outperforms linearizedADMM. This confirms our observations from Sect. 3. On the other hand, we observe that the performances of ADMM-mm and linearizedADMM are similar for different values of \(\alpha\); however, the performances of iADMM-mm (that is, ADMM-mm with inertial terms) for \(\alpha = 0.5\) and \(\alpha = 1.4\) are slightly worse than for \(\alpha =1\), and the value \(\alpha = 1.8\) leads to significantly worse performances for iADMM-mm. It is known that, in the convex setting, the ADMM variants often perform better for \(\alpha > 1\). However, in our experiments, \(\alpha =1\) provides the best performance for iADMM-mm. A possible reason is that the global convergence of iADMM-mm has been established only for the case \(\alpha =1\) (see Theorem 2) while \(\alpha \in (0,2)\) only guarantees a subsequential convergence (see Theorem 1).
Appendix 4: Additional experiments for a regularized nonnegative matrix factorization problem
In the previous example, the function \(f(X,Y) = \lambda _1 \Vert X\Vert _* + r_2(Y )\) was separable while our framework allows non-separable functions; see (1) and the discussion that follows. To illustrate the use and effectiveness of iADMM on a non-separable case, let us consider the following regularized nonnegative matrix factorization (NMF) problem
where \(X\in {\mathbb {R}}^{n\times m}\) is a given nonnegative matrix, and \(c_1>0\) and \(c_2>0\) are regularized parameters. Problem (64) can be rewritten in the form of (1) as follows:
In this case, \(x_1=W\), \(x_2=H\), \(y=Y\), \(f(W,H)=\frac{1}{2} \Vert X-W H\Vert ^2 + \beta \Vert W\Vert _F^2\), \(g_1(W)\) and \(g_2(H)\) are indicator functions of \({\mathbb {R}}^{n\times r}_+\) and \({\mathbb {R}}^{r\times m}_+\) respectively, \(h(Y)=c_2 \Vert Y\Vert _F^2\), \({\mathcal {A}}_1=0\), \({\mathcal {A}}_2={\mathcal {I}}\), \(\mathcal {B}= -{\mathcal {I}}\) (where \({\mathcal {I}}\) is identity operator), and \(b=0\). As \(W\mapsto f(W,H)\) is \(L_W\)-Lipschitz smooth and \(H\mapsto f(W,H)\) is \(L_H\)-Lipschitz smooth, where \(L_W=\Vert H H^\top \Vert +2 c_1\) and \(L_H=\Vert W^\top W\Vert\), we use the Lipschitz gradient surrogate for block W and H as in (12), and apply the inertial term as in the footnote 3 (that is, we apply inertial terms that also lead to the extrapolation for the block surrogate of f). The augmented Lagrangian for (65) is
Applying iADMM for solving (65), the update of W is
where \({{\bar{W}}}^k=W^k + \zeta _1^k (W^k-W^{k-1})\). Note that we have used extrapolation for the surrogate of \(W\mapsto f(W,H)\). The update of H is
where \({{\bar{H}}}^k=H^k + \zeta _2^k (H^k-H^{k-1})\). We do not use extrapolation for Y (that is, \(\delta _k=0\)), and simply choose \(\alpha =1\). The update of Y is
while the update of \(\omega\) is
Choosing parameters By Proposition 8, the update of W in (66) implies that Inequality (14) is satisfied:
where
Note that we use \(\eta ^k_1\) instead of \(\eta _1\) as this value varies along with the update of H (because we used the extrapolation for the surrogate of \(W\mapsto f(W,H)\)). Similarly, the update of H in (67) implies that Inequality (14) is satisfied:
where
Because of the update of Y in (68), the inequality in Proposition (2) is satisfied:
where \(\eta _y=c_2\) and \(\gamma _y^k=0\). Following the same rationale that leads to Theorem 1, we obtain, as in (18),
where \(\alpha _2=\frac{3\alpha }{\sigma _{{\mathcal {B}}}(1-|1-\alpha |)^2}=3\) and \(0<C_x, C_y<1\). In our experiments, we choose
where \(a_0=1\), \(a_k=\frac{1}{2}(1+\sqrt{1+4a_{k-1}^2})\), and \(\beta \ge 4 c_2 \frac{(6+3C_y)}{C_y}\).
Experiments We will compare iADMM with (i) ADMM (that is iADMM without using the inertial terms: \(\zeta _1^k=\zeta _2^k=0\)), and (ii) TITAN - the inertial block majorization minimization proposed in [21] that directly solves Problem (64) and competes favorably with the state of the art on the NMF problem (see [20] which is a special case of TITAN). In our implementation, we use Lipschitz gradient surrogate for W and H and use default parameter setting for TITAN.
In the following experiments, we set the parameters \(c_1\) and \(c_2\) of Problem (64) to be \(c_1=0.001\) and \(c_2=0.01\).
In the first experiment, we generate 2 synthetic low-rank data sets X with \((n,m,r)=(500,200,20)\) and \((n,m,r)=(500,500,20)\): we generate U and V by using the MATLAB command rand(n,r) and rand(r,m) respectively, and then let X=U*V. For each data set, we run each algorithm with the same 30 random initial points \(W_0\)=rand(n,r), \(H_0\)=rand(r,m) (for iADMM and ADMM we let \(Y_0\)=\(H_0\) and \(\omega _0\)=zeros(r,m)), and for each initial point we run each algorithm for 15 s. We report the evolution of the average objective function values of Problem (64) with respect to time in Fig. 5 and the mean ± std of the final objective function values in Table 2. We observe that iADMM outperforms ADMM which illustrates the acceleration effect. Among the algorithms, TITAN converges the fastest, but only slightly faster than iADMM. However, iADMM provides the best final objective function values on average.
In the second experiment, we test the algorithms on 4 image data sets CBCLFootnote 4 (2429 images of dimension \(19 \times 19\)), ORLFootnote 5 (400 images of dimension \(92 \times 112\)), FreyFootnote 6(1965 images of dimension \(28 \times 20\)), and UmistFootnote 7 (565 images of dimension \(92 \times 112\)). For each data set, we run each algorithm with the same 20 random initial points. We run each algorithm 100 s for the data sets Umist and ORL and 30 s for the data sets CBCL and Frey. We draw the evolution of the average objective functions values with respect to time in Fig. 6 and the mean ± std of the final objective function values in Table 3.
Once again we observe that although iADMM converges slighly slower than TITAN, iADMM always produces the best objective function values among the three algorithms. On the other hand, ADMM also outperforms TITAN in term of the final objective function values. This means that, for some reason, ADMM and iADMM are able to avoid spurious local minima more effectively than TITAN.

Evolution of the average value of the segmentation error rate and the objective function value with respect to time on Hopkins155

Evolution of the segmentation error rate and the objective function value with respect to time on Umist10

Evolution of the segmentation error rate and the objective function value with respect to time on Yaleb10

Evolution of the average value of the objective function value of Problem (64) with respect to time on synthetic data sets with \((n,m,r)= (500,200,20)\) (left) and \((n,m,r)= (500,500,20)\) (right)

Evolution of the average value of the objective function value of Problem (64) with respect to time on the image data sets CBCL (top left), ORL (top right), Frey (bottom left) and Umist (bottom right)
Rights and permissions
About this article

Cite this article
Hien, L.T.K., Phan, D.N. & Gillis, N. Inertial alternating direction method of multipliers for non-convex non-smooth optimization. Comput Optim Appl 83, 247–285 (2022). https://doi.org/10.1007/s10589-022-00394-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-022-00394-8