
Abstract
Relative smoothness—a notion introduced in Birnbaum et al. (Proceedings of the 12th ACM conference on electronic commerce, ACM, pp 127–136, 2011) and recently rediscovered in Bauschke et al. (Math Oper Res 330–348, 2016) and Lu et al. (Relatively-smooth convex optimization by first-order methods, and applications, arXiv:1610.05708, 2016)—generalizes the standard notion of smoothness typically used in the analysis of gradient type methods. In this work we are taking ideas from well studied field of stochastic convex optimization and using them in order to obtain faster algorithms for minimizing relatively smooth functions. We propose and analyze two new algorithms: Relative Randomized Coordinate Descent (relRCD) and Relative Stochastic Gradient Descent (relSGD), both generalizing famous algorithms in the standard smooth setting. The methods we propose can be in fact seen as particular instances of stochastic mirror descent algorithms, which has been usually analyzed under stronger assumptions: Lipschitzness of the objective and strong convexity of the reference function. As a consequence, one of the proposed methods, relRCD corresponds to the first stochastic variant of mirror descent algorithm with linear convergence rate.



Similar content being viewed by others
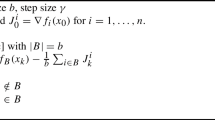


Notes
We assume that f is differentiable on some open set containing Q.
An equivalent characterization of L-smoothness is to require the inequality \(\Vert \nabla f(x)-\nabla f(y)\Vert \le L\Vert x-y\Vert\) to hold for all \(x,y\in Q\).
Minimization of a finite sum is a backbone of training machine learning models, for example.
A similar analysis in the standard smooth setting was done in [41].
References
Afkanpour A, György A, Szepesvári C, Bowling M: A randomized mirror descent algorithm for large scale multiple kernel learning. In: International Conference on Machine Learning, pp. 374–382 (2013)
Allen-Zhu, Z., Orecchia, L.: Linear coupling: an ultimate unification of gradient and mirror descent. arXiv:1407.1537 (2014)
Bauschke, H.H., Bolte, J., Teboulle, M.: A descent lemma beyond Lipschitz gradient continuity: first-order methods revisited and applications. Math. Oper. Res. 330–348 (2016)
Beck, A., Teboulle, M.: Mirror descent and nonlinear projected subgradient methods for convex optimization. Oper. Res. Lett. 31(3), 167–175 (2003)
Benning, M., Betcke, M., Ehrhardt, M., Schönlieb, C.-B.: Gradient descent in a generalised Bregman distance framework. arXiv:1612.02506 (2016)
Bertero, M., Boccacci, P., Desiderà, G., Vicidomini, G.: Image deblurring with poisson data: from cells to galaxies. Inverse Probl. 25(12), 123006 (2009)
Birnbaum, B., Devanur, N.R., Xiao, L.: Distributed algorithms via gradient descent for Fisher markets. In: Proceedings of the 12th ACM conference on Electronic commerce, pp. 127–136. ACM (2011)
Chang, C.-C., Lin, L.: A library for support vector machines. ACM transactions on intelligent systems and technology (TIST) 2(3), 1–27 (2011)
Csiszar, I., et al.: Why least squares and maximum entropy? An axiomatic approach to inference for linear inverse problems. Ann. Stat. 19(4), 2032–2066 (1991)
Dang, C.D.: Stochastic block mirror descent methods for nonsmooth and stochastic optimization. SIAM J. Optim. 25(2), 856–881 (2015)
Defazio, A., Bach, F., Lacoste-Julien, S.: Saga: a fast incremental gradient method with support for non-strongly convex composite objectives. arXiv:1407.0202 (2014)
Flammarion, N., Bach, F.: Stochastic composite least-squares regression with convergence rate \(\cal{O}(1/n)\). arXiv:1702.06429 (2017)
Ghadimi, S., Lan, G.: Optimal stochastic approximation algorithms for strongly convex stochastic composite optimization i: a generic algorithmic framework. SIAM J. Optim. 22(4), 1469–1492 (2012)
Hien, L.T.K., Lu, C., Xu, H., Feng, J.: Accelerated stochastic mirror descent algorithms for composite non-strongly convex optimization. arXiv preprint arXiv:1605.06892 (2016)
Johnson, R., Zhang, T.: Accelerating stochastic gradient descent using predictive variance reduction. Adv. Neural Inf. Process. Syst. 26, 315–323 (2013)
Kenneth, L.: MM Optimization Algorithms. SIAM (2016)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. In: Proceedings of the 3rd International Conference on Learning Representations (ICLR) (2014)
Krichene, W., Bayen, A., Bartlett, P.L.: Accelerated mirror descent in continuous and discrete time. Adv. Neural Inf. Process. Syst. 28, 2845–2853 (2015)
Lan, G., Lu, Z., Monteiro, R.D.: Primal-dual first-order methods with \({\cal{O}}(1/ \epsilon )\) iteration-complexity for cone programming. Math. Program. 126(1), 1–29 (2011)
Lu, H.: Relative-continuity for non-Lipschitz non-smooth convex optimization using stochastic (or deterministic) mirror descent. arXiv preprint arXiv:1710.04718 (2017)
Lu, H., Freud, R.M., Nesterov, Y.: Relatively-smooth convex optimization by first-order methods, and applications. arXiv preprint arXiv:1610.05708 (2016)
Nedic, A., Lee, S.: On stochastic subgradient mirror-descent algorithm with weighted averaging. SIAM J. Optim. 24(1), 84–107 (2014)
Nemirovski, A., Juditsky, A., Lan, G., Shapiro, A.: Robust stochastic approximation approach to stochastic programming. SIAM J. Optim. 19(4), 1574–1609 (2009)
Nemirovsky, A., Yudin, D.B.: Problem Complexity and Method Efficiency in Optimization. Wiley, New York (1983)
Nesterov, Y.: Efficiency of coordinate descent methods on huge-scale optimization problems. SIAM J. Optim. 22(2), 341–362 (2012)
Nesterov, Y.: A method of solving a convex programming problem with convergence rate \({O}(1/k^2)\). Soviet Math. Doklady 27(2), 372–376 (1983)
Nesterov, Yurii: Introductory Lectures on Convex Optimization: A Basic Course. Kluwer Academic Publishers, London (2004)
Nguyen, L., Liu, J., Scheinberg, K., Takáč, M.: Sarah: a novel method for machine learning problems using stochastic recursive gradient. arXiv preprint arXiv:1703.00102 (2017)
Polyak, B.T.: Introduction to Optimization. Optimization Software (1987)
Qu, Zheng, Richtárik, P.: Coordinate descent with arbitrary sampling I: algorithms and complexity. Optim. Methods Softw. 31(5), 829–857 (2016)
Qu, Zheng, Richtárik, Peter: Coordinate descent with arbitrary sampling II: expected separable overapproximation. Optim. Methods Softw. 31(5), 858–884 (2016)
Rakhlin, A., Shamir, O., Sridharan, K.: Making gradient descent optimal for strongly convex stochastic optimization. In: Proceedings of the 29th International Conference on Machine Learning, pp. 449–456 (2012)
Richtárik, Peter, Takáč, Martin: On optimal probabilities in stochastic coordinate descent methods. Optim. Lett. 10(6), 1233–1243 (2016)
Richtárik, P., Takáč, M.: Parallel coordinate descent methods for big data optimization. Math. Program. 156(1–2), 433–484 (2016)
Richtárik, P., Takáč, M.: Iteration complexity of randomized block-coordinate descent methods for minimizing a composite function. Math. Program. 144, 1–38 (2014)
Richtárik, P., Takáč, M.: Parallel coordinate descent methods for big data optimization. Math. Program. 156(1), 433–484 (2016)
Robbins, H., Monro, S.: A stochastic approximation method. Ann. Math. Stat. 22, 400–407 (1951)
Roux, N.L., Schmidt, M., Bach, F.: A stochastic gradient method with an exponential convergence rate for finite training sets. Adv. Neural Inf. Process. Syst. 2663–2671 (2012)
Shalev-Shwartz, S., Ben-David, S.: Understanding Machine Learning: from Theory to Algorithms. Cambridge University Press, Cambridge (2014)
Shalev-Shwartz, S., Zhang, T.: Stochastic dual coordinate ascent methods for regularized loss. J. Mach. Learn. Res. 14(1), 567–599 (2013)
Tappenden, R., Takáč, M., Richtárik, P.: On the complexity of parallel coordinate descent. arXiv preprint arXiv:1503.03033 (2015)
Tseng, P.: On accelerated proximal gradient methods for convex-concave optimization. Technical report, Department of Mathematics, University of Washington (2008)
Zhang, L.: Proportional response dynamics in the Fisher market. Theor. Comput. Sci. 412(24): 2691 – 2698 (2011). Selected Papers from 36th International Colloquium on Automata, Languages and Programming (ICALP 2009)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
All theoretical results of this paper were obtained by June 2017.
Appendices
Appendix 1: Relative randomized coordinate descent with short stepsizes
As promised, we provide a simplified version of relRCD along with a simplified analysis. We give two slightly different ways to analyze the convergence. However, neither of them provides a speedup comparing to Algorithm 1 . We mention this for educational purposes, to illustrate our techniques. This issue was be addressed in Section 3, providing us a potential speedup comparing to Algorithm 1.
Throughout this section, we assume that f is L-smooth and \(\mu\)-strongly convex relative to some separable function h.
1.1 Algorithm
We introduce here Algorithm 2 —Relative Randomized Coordinate descent with short stepsizes. From now, let us denote \(\mathbf{1}^i\) to be i-th column of \(n\times n\) identity matrix. The update is given by (7) with
Subset of coordinates \(M_t\) is chosen randomly such that \(\mathbf{P}(i\in M_t)=\mathbf{P}(j\in M_t)\) for all \(i,j\le n\) and \(|M_t|=\tau\).

1.2 Key lemma
It will be useful to introduce
as we will use this notation in the analysis.
The following lemma describes behavior of Algorithm 2 in each iteration, providing us on the expected upper bound on the value in the next iterate using the previous iterate.
Lemma 7.1
(Iteration decrease for Algorithm 2) Suppose that f is L-smooth and \(\mu\)-strongly convex relative to separable function h. Then, running Algorithm 2 we obtain for all \(x\in Q\):
Proof
The equality \((*)\) above holds due to the fact that \(x_{t+1}^{(i)}=x_{t}^{(i)}\) for \(i\not \in M_t\). Note that
Plugging it into (27), we get
Taking the expectation over the algorithm and using the tower property we obtain the desired result. \(\square\)
The lemma above provides us with the expected decrease in the objective every iteration. It holds for all \(x\in Q\), particularly for \(x=x_t\) we obtain that the sequence \(\{f(x_t)\}\) is nonincreasing in expectation.
1.3 Strongly convex case: \(\mu >0\)
The following theorem uses recursively Lemma 7.1 with \(x=x_*\), obtaining a convergence rate of Algorithm 2 .
Theorem 7.2
(Convergence rate for Algorithm 2) Suppose that f is L-smooth and \(\mu\)-strongly convex relative to separable function h for \(\mu >0\). Running Algorithm 2 for k iterations we obtain:
where \(c= (c_1,\ldots ,c_k)\in \mathbb {R}^k_+\) is a positive vector with entries summing up to 1.
Proof
The proof follows by applying Lemma 8.1 on Lemma 7.1 with \(x=x_*\) for \(f_t=\mathbf{E}\left[ f(x_t)\right] ,\,D_t=\mathbf{E}\left[ D_h(x_*,x_t)\right] ,\,f_*= f(x_*),\, \delta =\tfrac{\tau }{n},\,\ \varphi =L,\, \psi =\mu\). \(\square\)
Note that the term driving the convergence rate in Theorem 7.2 is \(\left( L/(L-\tfrac{\tau }{n}\mu )\right) ^{1-k} = \left( 1-\tfrac{\tau }{n}\tfrac{\mu }{L}\right) ^{k-1},\) where k is the number if iterations. In the special case when \(\tau =n\), using simple algebra one can verify that Theorem 7.2 matches the results from Theorem 2.5.
1.4 Non-strongly convex case: \(\mu =0\)
The following theorem provides us with the convergence rate of Algorithm 2 when f is convex but not necessarily relative strongly convex (i.e., \(\mu =0\)).
Theorem 7.3
(Convergence rate for Algorithm 2) Suppose that f is convex and L-smooth relative to separable function h. Running Algorithm 2 for k iterations we obtain:
where \(c=(c_1,\ldots ,c_k)\in \mathbb {R}^k\) is a positive vector proportional to \(\big (\frac{\tau }{n},\,\frac{\tau }{n},\,\ldots ,\,\frac{\tau }{n},\,1 \big )\).
Proof
For simplicity, denote \(r_t=\mathbf{E}\left[ f(x_t)\right] -f(x_*)\). We can follow the proof of Theorem 7.2 using Lemma 8.1 to get the equation (35), which can be rewritten for \(\mu =0\) as follows:
The inequality above can be easily rearranged as
\(\square\)
As previously, Theorem 7.3 captures known results of Relative Gradient Descent for \(\tau =n\) (Theorem 2.5).
1.5 Improvements using a symmetry measure
For completeness, we provide a different analysis of Algorithm 2 using a different power function which is a combination of \(f(x_{t})-f(x_*)\) and \(D_h(x_{*},x_t)\).Footnote 5 We will obtain a slight improvement in terms of the convergence rate thanks to exploiting a possiblesymmetry in Bregman distance, as proposed in [3]:
Definition 7.4
(Symmetry measure) Given a reference function h, the symmetry measure of \(D_h\) is defined by
Note that we clearly have \(0\le \alpha (h)\le 1\). A symmetry measure \(\alpha _h\) was also used in [3]. In our case, considering the symmetric measure for \(D_h\) would improve the result from the next theorem. However our results does not rely on it and hold even if there is no symmetry present, i.e. \(\alpha (h)=0\).
Theorem 7.5
(Convergence rate for Algorithm 2) Suppose that f is L-smooth and \(\mu\)-strongly convex relative to separable function h. Denote \(Z_t^{L}\overset{\text {def}}{=}LD_h(x_{*},x_t)+f(x_{t})-f(x_*)\). Running Algorithm 2 for k iterations we obtain:
when \(\mu =0\) and
when \(\mu > 0\).
Proof
From Lemma 7.1 we have
If \(\mu =0\), we can easily telescope the above and get the following inequality
which leads to
Let us look at the case when \(\mu \ne 0\). Firstly note that from relative strong convexity of f combining with definition of the symmetric measure \(\alpha (h)\) we have
Therefore, (29) can be rewritten as
Using recursively the inequality above, we get
\(\square\)
Note that as soon as \(\alpha (h)=0\), rate from the theorem above is up to the constant same as rate from Theorem 7.2 since \(\left( L/ (L-\frac{\tau }{n}\mu )\right) ^{-1} = 1-\frac{\tau }{n}\frac{\mu }{L}.\) However both theorems are measuring a convergence rate for a different quantity. On the other hand, in the best case if \(\alpha (h)=1\) we have
thus the convergence rate we obtained might be up to 2 times faster comparing to rate from Theorem 7.2. Thus the convergence rate is also up to 2 times faster comparing to Theorem 2.5 for the case \(\tau =n\) if \(\alpha (h)<0\). On the other hand, Theorem 7.5 provides us with convergence rate of \(\mathbf{E}\left[ D_h(x_*,x_k)\right]\), as the following inequality trivially holds:
Suppose that we have a fixed budget on the total work of the algorithm, i.e. we can make only \(k/\tau\) iterations. It is a simple exercise to notice that the bound on the suboptimality for Theorems 7.2, 7.3 and 7.5 after \(k/\tau\) iterations is not getting better when minibatch size \(\tau\) is decreasing. We address next section in order to solve this issue.
Appendix 2: Key technical lemmas
For completeness, we firstly give proof of Three point property.
1.1 Proof of the three point property
Note that \(\phi (x)+D_h(x,z)\) is differentiable and convex in x. Using the definition of \(z_+\) we have
Using definition of \(D_h(\cdot ,\cdot )\) we can see that
Putting the above together, we see that
The last inequality is due to convexity of \(\phi\).
1.2 Key lemma for analysis
The following lemma allows us to get a convergence rate for Algorithms
Lemma 8.1
Suppose that for positive sequences \(\{f_t\}, \{D_t\}\) we have
where \(\delta ,\,\varphi ,\,\psi \in \mathbb {R}\) satisfy \(1\ge \delta >0\) and \(\varphi \ge \psi >0\). Then, the following inequality holds
where \(c_t\overset{\text {def}}{=}C_t/\sum _{t=1}^kC_t\) for
Proof
Let us multiple the inequality (31) by \(\big (\frac{\varphi }{\varphi -\delta \psi }\big )^t\) for iterates \(t=0,1,\ldots ,k-1\) and sum them:
Rearranging the terms, we get
For simplicity, throughout this proof denote \(r_t=f_{t}-f_*\). Let us continue with the bound above:
Equality \((*)\) is obtained by the fact that the sum of terms corresponding to \(f(\cdot )\) is 0 (this can be easily seen as it is equal to (32)).
Recall that we have
and \(c_t\overset{\text {def}}{=}C_t/\sum _{t=1}^kC_t\). Since the sum of terms corresponding to \(f_t\) for some t or \(f_*\) in (34) is 0 (because it is equal to (32)), we have
Thus, we can rewrite (35) as follows
\(\square\)
Appendix 3: Proofs for Section 4
1.1 Proof of Corollary 4.6
Denote \(l_t=(L_t)^{-1}\) for simplicity. It is easy to see that
Denote
Minimizing RHS of (25) to obtain the best rate is equivalent to minimize
Notice that the expression above is minimized for constant \(l_t\), as if \(l_t\ne l_s\), setting \(l_t=l_s=\frac{l_t+l_s}{2}\) leads to strictly smaller value of the expression. Therefore, it suffices to minimize
in l. First order optimality condition yields
which is equivalent to
The quadratic equation above have a single solution
which finishes the proof.
1.2 Proof of Lemma 4.7
For simplicity, denote \(l_t=(L_t^{-1})\). Thus, \(\{l_t\}\) is nonincreasing sequence. Note that the rate from the Theorem 4.5 is O(1/k) if and only if both
are O(1/k).
Let us now consider that \(\{c_t\}\) is nonincreasing for \(t\ge T\). Suppose that
Then for all k there is \(K\ge k\) such that
Thus there is infinitely many t such that
Since \(\{c_t\}\) is nonincreasing for \(t\ge T\), we have that \(\{c_t\}\rightarrow 0\) which is a contradiction with the assumption that \(\tfrac{1}{C_t}=O(1/t)\). Thus we have
which implies that
The above means that \(L_t=\Theta (t)\). We have just proven the lemma for asymptotically nonincreasing \(\{c_t\}\).
Now, suppose that \(\{c_t\}\) is increasing sequence for \(t\ge T\). Then we have for all \(t\ge T\)
Thus \(L_t<L_{t-1}+\mu\), which implies that \(L_t=O(t)\) and \(l_t=\Omega (1/t)\).
On the other hand, looking at \(\sum _{t=0}^{k-1} \tfrac{c_tl_t}{C_k}\) as the weighted sum of \(l_t\), since \(l_{k-1}\) is the smallest from \(\{l_t \}\) we immediately have
which means that \(l_t=O(1/t)\). Thus, \(l_t=\Theta (1/t)\) and \(L_t=\Theta (t)\).
1.3 Proof of Lemma 4.8
First, we introduce two technical lemmas.
Lemma 9.1
Let us fix \(\alpha >0\). There exist a convex continuous function \(\gamma _\alpha (x)\) on \(\mathbb {R}_+\) such that for all \(x>0\) we have
Proof
We will construct function \(\gamma _{\alpha }\) in the following way - Let us set \(\gamma _{\alpha }(x)=0\) for \(x\in [1,1+\alpha )\). For \(x\ge 1+\alpha\) let us set recursively \(\gamma _{\alpha }(x+\alpha )=\log (x)+\gamma _{\alpha }(x)\) and for \(x<1\) let us set \(\gamma _{\alpha }(x)=-\log (x)\). Clearly, equality (37) holds.
We will firstly prove that \(\gamma _{\alpha }\) is continuous on \(\mathbb {R}_+\) and differentiable on \(R_+\backslash \{1\}\). Let us start with intervals \([1+k\alpha ,1+(k+1)\alpha )\) for all k.
Clearly, \(\gamma _{\alpha }\) it is continuous and differentiable on \([1,1+\alpha )\). Suppose now inductively that \(\gamma _{\alpha }\) is continuous and differentiable on \([1+k\alpha ,1+(k+1)\alpha )\) for some \(k\ge 0\). Then, for \(x\in [1+(k+1)\alpha ,1+(k+2)\alpha )\) we have
Since both \(\log (x-\alpha )\) and \(\gamma _{\alpha }(x-\alpha )\) are continuous and differentaible functions on \([1+(k+1)\alpha ,1+(k+2)\alpha )\), \(\gamma _{\alpha }(x)\) is also continuous and differentaible on \([1+(k+1)\alpha ,1+(k+2)\alpha )\).
Clearly, \(\gamma _{\alpha }\) it is continuous and differentiable on (0, 1).
It remains to show continuity and differentiability in the points \(\{1+k\alpha \}\) for \(k\ge 1\) and continuity in \(\{1\}\). It is a simple exercise to see the continuity and differentiability in \(\{1+\alpha \}\). For \(1+k\alpha\) where \(k\ge 2\) we can show it inductively—as \(\gamma _{\alpha }(x-\alpha )\) and \(\log (x-\alpha )\) are continuous and differentiable on \((1+(k-\tfrac{1}{2})\alpha ,1+(k+\tfrac{1}{2})\alpha )\), then \(\gamma _{\alpha }(x)\) is continuous and differentiable on \((1+(k-\tfrac{1}{2})\alpha ,1+(k+\tfrac{1}{2})\alpha )\) as well and thus it is continuous and differentiable in point \(\{1+k\alpha \}\). On top of that, \(\gamma _\alpha\) is clearly continuous in \(\{1\}\).
We have just proven that \(\gamma _\alpha\) is continuous on \(\mathbb {R}_+\) and differentiable on \(\mathbb {R}_+\backslash \{1\}\).
Now we can proceed with the proof of convexity. We will show that the (sub)derivative of \(\gamma _{\alpha }\) is nonegative for all \(x>0\). Clearly, \(\gamma _{\alpha }'(x)\ge 0\) for \(x\in (0,1)\) and subdifferential in \(\{1\}\) is nonegative as well. Let us write \(x=1+\{x\}_\alpha +k\alpha\), where \(0\le \{x\}_\alpha <\alpha\) and \(k\ge -1\). Then we have
Equality \((*)\) holds since for small enough \(\epsilon\) we have \(1+\{x\}_\alpha +\epsilon <2\alpha\) and inequality \((**)\) holds due to the fact that logarithm is an increasing function. \(\square\)
Denote
for \(\gamma _{\alpha }\) given from Lemma 9.1. Thus, \(\Gamma _{\alpha }\) is log-convex function satisfying
Note that when \(\alpha =1\), function \(\gamma\) can be chosen as log Gamma function and thus \(\Gamma _1\) can be chosen to be standard Gamma function.
The following lemma is crucial for our analysis, allowing us to bound the ratio of functions \(\Gamma _{\alpha }(\cdot )\) with nearby arguments.
Lemma 9.2
Consider a function \(\Gamma _{\alpha }\) defined above. Then, we have for all \(0\le s\le \alpha\) and \(x>0\):
Proof
Using convexity of \(\gamma _{\alpha }\) we have
Rearranging the above we obtain
On the other hand, using convexity of \(\gamma _{\alpha }\) again we obtain
By rearranging the above, we get
\(\square\)
We can now proceed with the proof of Lemma 4.8 itself.
Proof
Note that
Let us firstly consider the case when \(\alpha >\mu\). Choosing \(x= L-\mu +t\alpha\) and \(s=\mu\) in (40) we get
The inequality above allows us to get the following bound on \(c_t\)
Clearly, \(\{c_t\}\) is decreasing and thus using the bound above we obtain
Inequality \((*)\) holds since \((L-\mu +(t+1)\alpha )^{\mu /\alpha -1}\) is decreasing in t. On the other hand, we have
Inequality \((*)\) holds due to the fact that \((L+t\alpha )^{-1}\le (L-\mu +t\alpha )^{-1}\) and inequality \((**)\) holds since \((L-\mu +t\alpha )^{\mu /\alpha -2}\) is decreasing in t. Thus we have
and we have just proven the first part of the lemma.
Let us now look at the case when \(\alpha \le \mu\). It will be useful to denote \(\lfloor \mu \rfloor _\alpha\) as the largest integer such that \(\mu - \lfloor \mu \rfloor _\alpha \alpha\) is positive. Denote also
Using (39) we obtain
Upper and lower bounding the equality above we get
Using (40) we have
Now we are ready to get upper and lower bound on \(c_t\):
Recall that we have \(m_\mu =\max (\alpha ,\mu -\alpha )\). Then, we can get the following bound on \(C_k:\)
Inequality \((*)\) holds since \((L-m_\mu +t\alpha )^{\mu /\alpha -1}\) is increasing function. Note that in the case when \(\alpha =\mu\), all bounds above hold with equality and we have
To finish the proof of the second and third part of the Lemma, it remains to upper bound \(\sum _{t=0}^{k-1} c_tL_t^{-1}\). Firstly, note that
Inequality \((*)\) holds due to the fact that \(L-\{\mu \}_\alpha +(t -1)\alpha \le L+t\alpha\). We can continue bounding as follows
Inequality \((*)\) holds due to the fact that for \(\mu \ge 2\alpha\) we have
and for \(\mu < 2\alpha\) we have
Equality \((**)\) holds since
and
for \(\alpha <\mu\).
To finish the proof, let us now consider the special case when \(\alpha =\tfrac{\mu }{2}\) (in other words \(L_t=L+t\tfrac{\mu }{2}\)). Note that we have
Thus, according to (48) and (50) we have
Combining (51), (52) with Theorem 4.5 we obtain
which concludes the proof. \(\square\)
Appendix 4: Notation glossary
See Table 1.
Rights and permissions
About this article

Cite this article
Hanzely, F., Richtárik, P. Fastest rates for stochastic mirror descent methods. Comput Optim Appl 79, 717–766 (2021). https://doi.org/10.1007/s10589-021-00284-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-021-00284-5