
Abstract
Cloud computing has revolutionized the way a variety of ubiquitous computing resources are provided to users with ease and on a pay-per-usage basis. Task scheduling problem is an important challenge, which involves assigning resources to users’ Bag-of-Tasks applications in a way that maximizes either system provider or user performance or both. With the increase in system size and the number of applications, the Bag-of-Tasks scheduling (BoTS) problem becomes more complex due to the expansion of search space. Such a problem falls in the category of NP-hard optimization challenges, which are often effectively tackled by metaheuristics. However, standalone metaheuristics generally suffer from certain deficiencies which affect their searching efficiency resulting in deteriorated final performance. This paper aims to introduce an optimal hybrid metaheuristic algorithm by leveraging the strengths of both the Artificial Gorilla Troops Optimizer (GTO) and the Honey Badger Algorithm (HBA) to find an approximate scheduling solution for the BoTS problem. While the original GTO has demonstrated effectiveness since its inception, it possesses limitations, particularly in addressing composite and high-dimensional problems. To address these limitations, this paper proposes a novel approach by introducing a new updating equation inspired by the HBA, specifically designed to enhance the exploitation phase of the algorithm. Through this integration, the goal is to overcome the drawbacks of the GTO and improve its performance in solving complex optimization problems. The initial performance of the GTOHBA algorithm tested on standard CEC2017 and CEC2022 benchmarks shows significant performance improvement over the baseline metaheuristics. Later on, we applied the proposed GTOHBA on the BoTS problem using standard parallel workloads (CEA-Curie and HPC2N) to optimize makespan and energy objectives. The obtained outcomes of the proposed GTOHBA are compared to the scheduling techniques based on well-known metaheuristics under the same experimental conditions using standard statistical measures and box plots. In the case of CEA-Curie workloads, the GTOHBA produced makespan and energy consumption reduction in the range of 8.12–22.76% and 6.2–18.00%, respectively over the compared metaheuristics. Whereas for the HPC2N workloads, GTOHBA achieved 8.46–30.97% makespan reduction and 8.51–33.41% energy consumption reduction against the tested metaheuristics. In conclusion, the proposed hybrid metaheuristic algorithm provides a promising solution to the BoTS problem, that can enhance the performance and efficiency of cloud computing systems.
Similar content being viewed by others
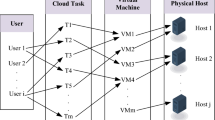

Avoid common mistakes on your manuscript.
1 Introduction
Cloud computing (CC) represents the latest computing paradigm, which provides seamless, ubiquitous, and cost-effective resources to bag-of-Tasks (BTA) applications of users as per their demand through Infrastructure as a service (IaaS) model [1, 2]. Different resources can be leased to users, which include CPU, memory, storage etc. Collectively, these resources are offered in the form of leasing various types of virtual machines. Empowered with robust computing capabilities, CC infrastructures have been extensively used to tackle scheduling problems related to BTA and workflow applications belonging to real-life areas such as engineering, chemistry, transportation, physics, astronomy, and biology to name a few [3].
Task scheduling (TS) or assignment problem in cloud computing systems is the process of assigning suitable resources such as virtual machines (VMs) to competing users’ applications so that scheduler performance is maximized in terms of any of the objectives such as makespan, energy efficiency, execution cost, and resource utilization [4] [5]. Therefore, the TS is the most important process in CC systems as it affects the systems’ load and performance. Due to the heterogeneity of cloud resources, the rising scale and size of the cloud, and the dynamic demand of cloud users, the complexity of the TS problem increases. Hence, cloud TS falls into the category of NP-hard problems [6, 7]. Ideally, there are \(R^{T}\) ways of allocating T tasks over R computing resources, and the problem of obtaining an optimal feasible schedule fulfilling physical and timing constraints is known to be NP-hard [8].
Cloud computing systems offer anytime, anywhere remote access to run various cloud-subscriber applications belonging to IoT, Big Data analytics, HPC engineering, biomedical, etc. The reliance on the cloud is growing daily as a result of its adaptability, scalability, and affordability. For instance, in just five years, the total amount of cloud traffic surged from 6 ZB in 2016 to almost 20 ZB in 2021 [9, 10]. Due to the recent COVID-19 pandemic and the everyday online access to several critical services in the sectors of employment, food, healthcare, and education, dependence on the cloud has increased [11]. As a result, cloud infrastructures are growing in size and scope to meet the rising demands of cloud subscribers, which has led to a sharp increase in the amount of electricity (energy) needed to run cloud services. As a result, harmful carbon emissions into the atmosphere and cloud service providers’ (CSPs) energy expenses rise. According to reports, cloud infrastructures consume 4.5% of the world’s total energy, and by 2025, it is predicted that these cloud data centres will produce around 100 million metric tonnes of carbon pollution annually. Consequently, it is crucial to tackle the ever-growing issue of energy consumption in cloud computing.
Moreover, in addition to the energy-saving angle of CSPs, cloud users are always interested in executing their applications as fast as possible since their focus is always on maximizing performance or cost [2, 12]. The above−mentioned performance and energy-saving requirements of CSPs and cloud users inspired the authors of this paper to propose an energy-efficient scheduling solution for executing BTA applications on IaaS clouds without compromising makespan performance.
The task scheduling problem (TSP) being an NP-hard problem is one of the core issues that pose a great challenge and motivation to researchers to develop efficient schedulers [13]. Solutions to TSP are categorized into Deterministic algorithms (DA) and Approximation algorithms (AA) [14]. DAs are easily stuck in local optima and are found suitable for only small-scale TSP problems. With the increase in problem size, it becomes infeasible to find DA-based scheduling solutions in a reasonable time. Examples of DAs are mathematical programming, exact solutions, etc. On the contrary, AA methods such as metaheuristic algorithms (MAs) are widely utilized for finding acceptable solutions to complex TSP problems in a reasonable time while optimizing more than one objective at a time. Other reasons for the wide use of AAs are their search efficiency, easy implementation, problem independence, and gradient-free mechanism.
Population-based MAs are capable of optimizing multiple solutions simultaneously and finding the best solution out of obtained solutions during each iteration. This is the main reason for their better searching efficiency over single−solution-based MAs [15]. Population-based MAs are further categorized based on the source of inspiration; evolutionary algorithms (inspired by human evolution), swarm-intelligence algorithms (representing the behaviour of a flock of birds or animals), physics-related algorithms (representing physics-based activities), and human-related algorithms (inspired by the human activities). Famous examples of these categories of MAs are as follows:
-
Evolutionary algorithms – Differential Evolution (DE) [16], Genetic Algorithm (GA) [17] and Biogeography-based Optimization (BBO) [18]).
-
Swarm-intelligence Algorithms – Ant Colony Optimization (ACO) [19], Particle Swarm Optimization (PSO) [20], Grey Wolf Optimization (GWO) [21], Whale Optimization Algorithm (WOA) [22, 23], Dragonfly algorithm (DA) [24], Cuckoo Search (CS) [25], Snake Optimizer (SO) [26], Slime Mould Algorithm (SMA) [27], Salp Swarm Algorithm (SSA) [28], Moth-flame optimization (MFO) [29], etc.
-
Physics-based algorithms – Simulated Annealing (SA) [30], Henry Gas Solubility Optimizer (HGSO) [31].
-
Human-related Algorithms – Teaching-Learning Based Optimization (TLBO) [32], Neural Network Algorithm (NNA) [33], and Sine Cosine Algorithm (SCA) [34].
GTO and HBA are the recent algorithms that have been efficiently applied over a wide range of applications such as parameter tuning in photovoltaic models [35,36,37], image segmentation [38], fault diagnosis [39], biomedical engineering, wireless sensor networks [40], structural modeling, global optimization [41], engineering design and feature selection [42], energy efficiency [43, 44], etc. However, according to the best of the authors’ knowledge, these algorithms are still not applied to the Bag-of-Tasks scheduling problem in cloud computing systems. Therefore, we are motivated to select GTO and HBA algorithms to explore the potential of these latest algorithms in solving task scheduling problems.
The research presented in this paper aims to propose a hybrid metaheuristic GTOHBA for solving the task scheduling problem over the cloud to optimize performance and energy by improving the original GTO algorithm. Our contributions to this research are summarized as follows:
-
1.
Firstly, we highlighted the motivations for solving the challenging task scheduling problem using metaheuristics to optimize performance and energy objectives.
-
2.
Next, we identify the deficiencies of the original GTO algorithm by examining the related literature.
-
3.
Thereafter, we develop a hybrid algorithm GTOHBA by combining the features of HBA with the GTO method to remove deficiencies of the traditional GTO method and adapted it for the task scheduling problem.
-
4.
Next, to test the efficacy of GTOHBA, we have tested its performance against well-known metaheuristics using CEC2017 & CEC2022 global optimization benchmarks.
-
5.
Lastly, the performance of the GTOHBA approach is validated on the practical cloud task scheduling problem and results are compared with classical metaheuristic-based solutions.
The rest of the paper is structured as follows: Sect. 2 presents the background of the GTO and HBA algorithms that are used in the proposed GTOHBA approach. Section 3 deals with presenting the hybrid GTOHBA approach by fusion of the GTO and HBA algorithms. In Sect. 4, the application of the proposed GTOHBA over global optimization benchmarks is discussed. Simulation results for real-life task scheduling problem are presented in Sect. 5. Lastly, Sect. 6 provides the final remarks on the research work and presents future directions.
2 Related work
Current literature witnesses the availability of many swarm-intelligence (SI) algorithms, which have been efficiently applied for solving single or multi-objective cloud TS problems. These solutions include the standard version of metaheuristics (MH) algorithms, improved versions by modifications of their original operators, and hybrid solutions by hybridizing these with other MH algorithms. Al-maamari et al. in [45] combined the CS and PSO algorithms for solving the cloud TS problem for minimizing the makespan and energy consumption. However, the resulting algorithm PSOCS suffered from low resource utilization. In [46], an improved single−objective task scheduling solution was suggested by enhancing the Harris Hawks optimizer with an intent to minimize the makespan. Liang et al. (2018) proposed a self-adaptive learning particle swarm optimization to schedule tasks over resources of a hybrid IaaS cloud environment to reduce energy consumption [47]. Ni et al. (2021) introduced a task scheduling solution named GCWOAS2 by integrating the Gaussian model and the Opportunistic Load Balancing (OBL) method with the standard WOA resulting in significant performance improvement over the compared algorithms [48]. Recently, in [12], authors proposed a hybrid metaheuristic OWPSO by hybridizing the standard WOA, OBL, and PSO algorithms to save energy and reduce makespan. In [49], authors incorporated mutation operators of a Bee optimization algorithm in the standard WOA for generating an efficient mapping of VMs to cloud tasks to minimize execution time and cost.
Abdullahi et al. (2019) introduced a multiobjective TS approach by combining symbiotic organisms search and chaotic optimization method resulting in an optimal task-resource pair schedule [50]. Mapetu et al. (2019) introduced a binary PSO technique with the intent to balance the task loads in cloud computing [51]. In [52], the authors proposed two workflow scheduling techniques by hybridizing heterogeneous earliest finish time (HEFT) based heuristics with an ACO algorithm for minimizing makespan and cost. In addition, Elaziz et al. 2021 introduced an enhanced salp swarm algorithm (SSA) to assign IoT requests to resources of a hybrid cloud-fog computing system [53]. The resultant solution has achieved significant performance improvement over the compared approaches when tested with variable−size datasets. In [54], an improved Dragonfly was suggested to tackle the intelligent workflow scheduling problem. Rana et al. 2021 suggested a modified Whale optimization algorithm using the differential evolution for VM scheduling in cloud computing [55].
Authors in [56] suggested an adaptive PSO-based scheduling solution by incorporating an adaptive inertia weight scheme in the standard PSO to ensure balance among exploration and exploitation phases. In another work, authors combined PSO and ACO algorithms to maintain population diversity and enhance solution quality [57]. In [58], the authors proposed a multi-objective PSO scheduler for maximizing the system performance and minimising the execution cost. Similarly, authors in [59, 60] proposed two task scheduling solutions using multi-objective PSO to improve QoS under deadline constraints. In [61], the authors introduced a multi-objective PSO for cutting down the makespan time.
In [4], the exploration ability of the Manta ray foraging optimization (MRFO) approach is hybridized with the local search power of SSA resulting in improved balance among exploration-exploitation phases, which produced an optimal solution of allocating IOT tasks to cloud resources under some priority constraints to minimize the makespan. In another study, Elaziz et al. 2021 have provided an improved scheduling method by merging the DE’s efficient exploitation power with the MS algorithm [62]. In [63] introduced the BFO-based scheduling approach for improving certain QoS metrics by mimicking the foraging behaviour of bacteria. In yet another promising work, the WPCO algorithm resulted in efficient task-resource pairs [64]. In [7], authors enhanced the moth search algorithm by incorporating the local pollination strategy of the flower pollination algorithm to schedule tasks in such as way that minimizes makespan and energy consumption. The resultant multi-objective scheduling algorithm produced better performance than the baseline algorithms.
In [65], authors utilized the SGO algorithm to minimize makespan and maximize throughput of the task scheduling problem. More recently, a GA-based improved scheduling solution was suggested, where the initial population is optimized by the Modified Worst Fit Decreasing heuristic [66]. Authors in [13], proposed an improved whale optimization algorithm based on elite strategy for solving engineering design and cloud scheduling problems. Further, in [67], a hybrid of the multi-verse optimizer and GA was suggested to reduce total execution time while scheduling independent tasks over cloud resources. Similarly, more recent task scheduling solutions have been found in the literature using improved ACO for executing BTA application in [5], multiobjective workflow scheduling solution using hybrid HEFT-ACO algorithm [68], and deep-reinforcement learning (DRL) scheduler [69] to optimize different QoS parameters (Table 1).
Current related literature witnesses the availability of many MA-based scheduling solutions. However, continuous research in this domain is still underway to provide better solutions by developing new, improved or hybrid metaheuristics. This research is supported by two facts; first the “No Free Launch (NFL) theorem” [70], which asserts that no unique MA is suitable for solving all optimization problems. Secondly, most standalone MAs suffer from inherent deficiencies leading to sub-optimal or deteriorated solutions. These facts motivated us to propose a hybrid metaheuristic by fusing the good qualities of the two latest metaheuristics, the GTO [71] and the HBA [72] methods.
3 Background
3.1 Gorilla Troops Optimizer
Gorilla Troops Optimizer (GTO) [71] is a swarm-inspired metaheuristic optimizer that simulates the social gorilla intelligent behavior in nature. In this section the mathematical mechanisms of the exploration and exploitation of the search space are presented.
During the exploration phase, GTO utilizes three operators to increase the spread of solutions across the search space and maintain a balance between the intensification and divergence of the search. The update rule for the exploration phase is given by the following equation 1:
GX refers to the solutions of the population at the next iteration (t+1), X denotes the current positions for individuals at iteration t, p takes a value that ranges between 0 and 1, while Lb and Ub denote the lower and upper bounds of the solutions. \(X_r\) and \(GX_r\) refer to randomly chosen solution candidates and randomly selected gorilla candidate solutions, respectively. Additionally, \(r_1\) - \(r_3\), and rand are random numbers within the range [0, 1]. The values of parameters C, L, and H are estimated using the following equations 2, 4, and 5.
where It and MaxIt refer to the current and maximum number of iterations, r4 and l are randomly generated numbers in the range (0, 1) and (-1, 1) respectively.
From Eq. 1, the variable p is handled as a control parameter for determining the solution’s updating probability to a generated random position if the condition \(rand \ge p\) is true. Otherwise, the \(2^{nd}\) operator will be performed only if \((rand >= 0.5)\) which will update the individual positions with respect to the locations of other individuals in order to have a good balance between exploration and exploitation. Otherwise, the individuals’ locations will be updated to unknown positions which will help them in avoiding local optimal areas.
To simulate the exploitation phase, 2 different techniques are used to mimic the habits of gorillas either moving towards the best individual (silverback) or fighting for adult females. This will be determined based on the value of C calculated from Eq. 2. If C is greater than W, Eq. 7 is selected, otherwise, Eq. 10 will be used. where W denotes a parameter that is already configured before the optimization process.
Following the best agent (Silverback)
where \((X_{silverback})\) represents the location of the best gorilla, L can be calculated from Eq. 4, M can be calculated from the following the equations:
Competing/Fighting for Females
where GX(i) refers to the i-th candidate individual’s vector location, Q and E can be calculated by the following 2 equations:
where \(\beta\) is a fixed value chosen by the user, \(r_{5}\) is a random number in the interval [0, 1], and E can be calculated by the following equation
where \(N_{1}\) refers to the normal distribution’s random values with respect to the dimensions of the problem whereas \(N_{2}\) refers to the normal distribution’s random values only.
3.2 Honey Badger Algorithm
HBA is a metaheuristic algorithm introduced by Hashim et al. [72] which belongs to the swarm-inspired category. It mimics the foraging behavior of honey badgers in nature when searching for food. Honey badgers use two techniques to locate food sources. The first one is to rely on their sense of smell to roughly locate the food source, and then they start digging to catch the prey whereas the second technique is following honey-guide birds to directly detect the beehive. HBA optimizer consists of two main stages, namely the digging stage and the honey stage. To mathematically simulate HBA, the first step is to generate a random population with N candidates as described in Eq. 16.
In the \(2^{nd}\) step, the smell intensity of the honey badger towards the prey is defined as I. Inverse Square Law can be used to determine the intensity of the honey badger’s smell towards the prey. intensity can be treated as a function of prey concentration & the distance between the prey and honey badger as shown in equations 17, 18, and 20.
In the \(3^{rd}\) step, the density parameter \(\alpha\) is updated to control the randomness rate and ensure a smooth transition from the exploration phase to the exploitation phase and its value can be calculated from the next equation.
where t and \(t_{max}\) refer the current and maximum iterations number.
The developed algorithm includes a flag F to prevent being trapped in local optima by changing the search direction. This helps agents to cover the search area more accurately and is mathematically defined in the following equation:
Next, one needs to update individuals positions X new. As earlier- mentioned, the update process is achieved through the digging and honey activities which can be formulated as in the next 2 equations:
4 Proposed GTOHBA approach
4.1 Shortcomings of GTO
Despite the effectiveness of the original GTO since its first appearance, it still has some drawbacks especially when solving composite & high-dimensional problems. These drawbacks are falling into local optimal, unbalancing between exploration and exploitation, weak exploitative abilities and premature convergence.
4.2 Architecture of GTOHBA
In this subsection, the architecture of the developed algorithm called GTOHBA is described in detail. To overcome the weakness of exploitation abilities observed in the original GTO, new equations have been proposed for the two gorilla behaviors: “Following the best agent (Silverback)” and “Competing/Fighting for Females.”
The new updating equation for following the best agent (Silverback) has more randomization on it. It is presented as follows:
where \(rand_1\) denotes a random number in the interval [0,1] and \(\delta\) refers to a new control parameter that can be computed from the next equation:
In the “Competing/Fighting for Females” behavior, the equation has been modified using a novel equation inspired by HBA. HBA was selected for hybridization with GTO due to its robust exploitative capabilities. Notably, its equation features a flag operator that alters the search direction and incorporates multiple randomized parameters for control. The new equation is presented as follows:
where F refers to a flag operator that will either 1 or -1, \(rand_2\) denotes a random number in the interval [0, 1], and \(\alpha\) is an operator that can be easily calculated as follows:
where \(t \text { and } T\) refers to current iteration and max iteration number.
Moreover, the exploration phase of the original GTO optimizer is modified as follows: the third operator has been hybridized with HBA to add more randomness to allow it to escape from local optimal regions. The new GTOHBA equation is as follows:
where \(\gamma\) is a parameter in the range [-1, 1] and can be given as follows \(\gamma = 2 \times rand - 1\)
The pseudo code of the developed algorithm is given in Alg. 1 and the flowchart is shown in Fig. 1.

GTOHBA flowchart

Algorithm 1: GTOHBA
5 Application of the GTOHBA on CEC Benchmarks
The performance of the suggested GTOHBA optimizer is evaluated on the CEC2017 & CEC2022 benchmark problems before applying it to the cloud scheduling problem.
The results of the proposed GTOHBA are compared with standard GTO, standard HBA and various existing optimization methods, namely: Snake Optimizer (SO), Moth-flame Optimization (MFO), Butterfly Optimization Algorithm (BOA), Whale Optimization Algorithm (WOA), Cuckoo Search (CS), and Particle Swarm Optimization (PSO). The parameter setting to each of the previously mentioned algorithms can be found in Table 2. The simulations were carried out on a computer with a 2.0 GHz processor and 16 GB RAM using MATLAB R2022b.
5.1 Experimentation on CEC’17 Benchmarks
5.1.1 Statistical analysis on CEC’17 test suite
To achieve and ensure a fair and objective comparison, we conducted 30 runs of the GTOHBA algorithm and its competitors on the same set of problems. For all the problems, the maximum number of iterations was set to 1000 and the population size was set to 50 for all algorithms.
The performance of the algorithm is evaluated by comparing the results obtained on the CEC2017 functions. The average, minimum, maximum, and standard deviation of the best solutions obtained at each run are used to measure the efficiency of each algorithm. Table 3 displays the values of the metrics for each algorithm when applied to functions with a dimension of 30, denoted as Dim = 30.
From this table, it is notable that GTOHBA has a very good outcome results compared to other algorithms. GTOHBA ranked first in 14 functions out of 29 namely: F5-F11, F16-F17, F20-F21, F23, f25, and F28. On the other hand it achieve the seond-best in other five functions namely: F1, F15, F18-F19, and F29.
5.1.2 Convergence performance analysis
Convergence analysis stands as a critical metric for evaluating optimizer stability, with Fig. 2 depicting convergence rates of the GTOHBA against other compared algorithm. The previous mentioned figure illustrates that the proposed algorithm has the swiftest convergence rate across the CEC’17 benchmark test functions when compared to other algorithms. It can be easily seen that GTOHBA reaches its optimal solution rapidly with a minimum iterations number, proving its efficiency in solving real-time optimization issues and tasks requiring swift computation.

Convergence curve of CEC2017 functions from F1–F30 for all algorithms
5.1.3 Boxplot behavior analysis
The distribution characteristics of data can be analyzed through boxplot visualization. As functions in this benchmark have many local solutions, a boxplot is included for each function to provide more information about the distribution of results. In Fig. 3, the boxplots show the distribution of results for twenty-nine functions. Boxplots use quartiles to represent data distribution, where the whiskers represent the lowest and highest data points of the algorithm, and the ends of the rectangles delimit the upper and lower quartiles. Narrow boxplots indicate high agreement among the data. From the above mentioned figures, it is clear that the boxplots for the suggested GTOHBA algorithm are generally narrow compared to other algorithm distributions, and it achieves the lowest values for most functions.

Box Plot of CEC2017 functions from F1–F30 for all algorithms
5.1.4 Wilcoxon rank sum test results
To assess the significance of the obtained results, Wilcoxon’s rank-sum test is conducted, indicating that the behavior of the algorithm is not arbitrary. Although MAs are stochastic, their performance is expected to be accurate [73]. In this study, Wilcoxon’s rank sum test based on the average values is utilized to investigate the difference between GTOHBA and other optimization techniques. Table 4, presents a comparison of the outcomes obtained by GTOHBA and other algorithms. The “p-value” is a measure of significance in a statistical test that determines whether the null hypothesis should be rejected. The significance level of the test is typically set to less than 5%, which means that if the calculated p-value is less than 0.05, then the null hypothesis is rejected and the results are considered statistically significant.
5.2 Experimentation on on CEC’22 Benchmarks
5.2.1 Statistical analysis on CEC’22 test suite
The performance of the developed optimizer GTOHBA is evaluated by comparing the results obtained on the CEC2022 functions. The average, minimum, maximum, and standard deviation of the best solutions obtained at each run are used to measure the efficiency of each algorithm. Table 5 displays the values of the metrics for each algorithm when applied to functions with a dimension of 10.
From this table, it is notable that GTOHBA has a very good outcome results compared to other algorithms. GTOHBA ranked first in 5 functions out of 12 namely: F1-F4, and F7. On the other hand it achieve the seond-best in other five functions namely: F5, F8-F9, and F11-F12.
5.2.2 Convergence performance analysis
Convergence analysis serves as a crucial benchmark for gauging algorithm stability. Illustrated in Fig. 4, our proposed algorithm exhibits notably superior convergence rates compared to competing algorithms across the CEC2022 benchmark test functions. It demonstrates a remarkable ability to reach the optimal solution in significantly fewer iterations, showcasing its potential for tackling real-time optimization tasks and scenarios necessitating rapid computational performance.

Convergence curve of CEC2022 functions from F1–F12 for all algorithms
5.2.3 Boxplot behavior analysis
Boxplot visualizations offer valuable insights into the distribution characteristics of data. Given the presence of numerous local solutions within the benchmark functions, each function is accompanied by a boxplot to offer a comprehensive view of result distribution.
In Fig. 5, twelve functions are depicted, showcasing the distribution of results. Boxplots utilize quartiles to illustrate data distribution, with the whiskers denoting the lowest and highest data points of the algorithm, while the ends of the rectangles delineate the upper and lower quartiles. Narrow boxplots signify strong agreement among the data points.
Upon analysis of the aforementioned figure, it becomes evident that the boxplots associated with the proposed GTOHBA algorithm generally exhibit narrow widths compared to distributions of other algorithms. Moreover, the GTOHBA algorithm consistently achieves lower values across most functions.

Box Plot of CEC2022 functions from F1–F12 for all algorithms
5.2.4 Comparing with advanced algorithms
In this subsection, GTOHBA is compared with four enhanced algorithms namely mRSA [74], mCapSA [75], mFDA [76], mBWO [77] using 12 functions from CEC2022. The results are given in Table 6.
6 Application of GTOHBA to the cloud scheduling problem
6.1 System model and problem definition
In this section, the BTA application, cloud data center, problem objectives, and fitness function of the undertaken BTASP problem are modeled and explained. Table 7 presents various mathematical notations used throughout this section.
6.1.1 Cloud data center (CDC) model
The IaaS cloud analyzed in this paper consists of two configurations; first cloud configuration has a single data center with Nvtm virtual machines paired with Nphm physical machines for assignment to the submitted BTA applications using the proposed GTOHBA scheduling algorithm. On the other hand, second cloud configuration contains two CDCs.
The cloud data center (CDC) is represented as follows:
Each \(PHM_i\) is defined as a distinct group of \(VTM_{m}\) and mathematically described as follows:
Each \(VTM_{m}\) is denoted using three attributes:
Each \(C_{mk}\) of \(VTM_{m}\) is represented using four tuples:
6.1.2 BTA application and scheduling model
Bag-of-Tasks (BTA) applications, which comprise a collection of non-coordinating tasks, are examined in this study. Processing each task of a BTA application requires a single CPU core. Typically, several BTAs are simultaneously submitted to the cloud (or CDC broker) by different cloud users. These BTAs are collected in a group, called BAG and submitted to the CDC broker using a static scheduling mode. CDC broker utilizes GTOHBA scheduler to schedule these BTAs on cloud resources. Task manager and task scheduler are the components of the proposed GTOHBA scheduling approach, which are responsible for managing concurrent BTAs and determining the execution order of submitted BTAs and to allocate the necessary number of virtual machines (VTMs) to these applications. As depicted in Fig. 6, this allocation is predicated on the fitness function being satisfied.

Scheduling model
BAG, represents a set of concurrent BTAs, which are presented to the CDC broker for scheduling. BAG is denoted as follows:
Every BTA application \(BTA_j\) is defined as follows:
BTA application execution time BTAET is calculated as follows:
6.1.3 Problem objectives and fitness function
Here, we will first describe the makespan and energy consumption models, which are the objectives of the undertaken BTASP (BTA scheduling problem). Next, we will define the fitness function combining both objectives of the BTASP problem.
-
Makespan model The term Makespan refers to the total time taken to complete all tasks of a submitted BTA application, where the completion time of task is calculated by adding its wait time to the execution time. Makespan of each individual BTA is calculated and maximum makespan among the calculated makespan of all BTAs is recorded. Mathematically, the total makespan (TMS) can be expressed as follows:
$$\begin{aligned} TMS= max_{j\in BAG} (CompletionTime_j ) \end{aligned}$$(33) -
Energy model The energy consumption (EC) of each CPU core is represented as follows:
$$\begin{aligned} EC(C_k) =\int _0^{MS} EComp(C_k,t)+ ECompI(C_k,t) dt, \end{aligned}$$(34)where \(EComp(C_k,t)\) and \(ECompI(C_k,t)\) indicate the energy consumption of each CPU core \(EC(C_k)\) during computation and during idle time, respectively. The total energy consumption (TEC) of the CDC is calculated as follows:
$$\begin{aligned} TEC=\sum _{C_k}^{Nvm} EC(C_k ) \end{aligned}$$(35) -
Fitness Function. In this research paper, the BTASP problem is modelded as a constrained combinatorial optimization problem with an objective to cut-down both total makespan and total energy consumption objectives. The fitness function FF(X) is modeled with the help of the Weighted-sum-method by assigning weights to TMS and TEC objectives as follows:
$$\begin{aligned} Fitness function, FF(X) = min (TMS_{weight} \times TMS + TEC_{weight} \times TEC) \end{aligned}$$(36)where \(TMS_{weight}\text { and }TEC_{weight}\) are weights of TMS and TEC objectives, respectively. The optimal values of these weights are determined by conducting a few independent pilot experiments with varying weights.
In this research, we assume some constraints on the BTASP problem, which are presented as follows:
-
Execution requirements of each BTA application in terms of the number of VTMs are fixed.
-
BTAs are executed using a space−sharing mechanism with each VTM performing a single task at a time.
-
There is a fixed number of BTAs and VTMs in the CDC.
-
There are no execution deadlines for BTA applications.
6.1.4 Solution encoding
To successfully implement the proposed GTOHBA on the task scheduling problem, the initial and most crucial step is to encode the solution. This scheduling problem relies heavily on two key decisions: determining the order in which tasks are executed in the waiting queue and assigning computational resources to tasks. The effectiveness of the solution largely depends on these decisions. Our study has focused on optimizing both of these subproblems in task scheduling. Figure 7 demonstrates that an individual X, representing a task scheduling solution, comprises two decision variables: the task-order component (O) and the allocation component (A).

Solution encoding and optimization example
We denote a continuous task scheduling vector as \(X^{O+A}\), designed to address both the sequencing and allocation of tasks. Since task scheduling is a discrete−value problem, therefore, a conversion mechanism between discrete−valued task scheduling solutions and real-value meta-heuristic solutions is essential.
To convert the task vector part of the solution into a discrete−valued job execution order, the Smallest Position Value (SPV) approach [78] is utilized. This approach is applied to the continuous solution vector \(X^O\), which contains six tasks with values generated randomly within the problem space. By sorting the continuous values of \(X^O\) using the SPV method, the discrete indices of the tasks are obtained and stored in the new vector \(X^{*O}\), which represents the discrete job execution order.
The VM Availability Matrix (AM) scheme, influenced by the blacklist allocation mechanism [79], is employed to manage the allocation of tasks within the scheduling solution. Each cell in the AM corresponds to a task-VM class combination and includes a value indicating the availability or unavailability level of a VM class linked to a physical machine. This scheme strategically reserves specific virtual machines in each VM class for queued tasks. It allows a predetermined percentage of VMs from each class of physical machines to be allocated to parallel applications. The resource allocation heuristic, based on the discrete task-order vector \(X^{*O}\) and the availability matrix, generates the scheduling solution’s discrete−value allocation portion \(X^{*A}\). This final allocation represents the actual assignment of virtual machines to tasks and the distribution of processing elements or CPU cores among the tasks, as outlined by the dotted rectangles in the \(X^{*A}\) vector. The DeRA allocation heuristic proposed in [2] has been adapted to allocate resources to tasks in this framework efficiently.
6.2 Experimentation and results with single data centre
The standard CloudSim 3.0.3 simulator and JMetal 5.4 meta-heuristic framework are used to implement the considered scheduling metaheuristic algorithms. CloudSim is recognised world-widely as a standard simulation platform due to its ability to reproduce results and ease of conducting experimentation with different cloud configurations. Twenty workloads as shown in Table 8 are used in the current research work for performing the experiments. These workloads are extracted from the CEA-Curie and HPC2N workload logs obtained from the supercomputing sites (refer http://www.cs.huji.ac.il/labs/parallel/workload). The cloud computing infrastructure with a single CDC consists of pre−configured virtual machines belonging to five different categories, as outlined in Table 9.
6.2.1 Statistical results
This sub-section aims to assess the efficiency of the GTOHBA algorithm over the popular baseline scheduling approaches. The evaluation is based on the Best, Average, and Worst metrics, which respectively represent the minimum, average, and maximum values obtained from 30 repeated executions of the scheduling experiment. The experimental results of the proposed GTOHBA are compared against popular metaheuristics viz. original GTO [71], original HBA [72], SO [26], MFO, BOA, WOA, CS, and PSO algorithms.
Results in Tables 10 and 11 demonstrate that the GTOHBA algorithm outperforms other tested metaheuristics in terms of the minimum best, average, and worst values for both makespan and energy consumption, respectively for the majority of the CEA-Curie workloads. This superior performance of GTOHBA is also observed for HPC2N workloads, as shown in Tables 12 and 13.
6.2.2 Boxplot analysis
In order to clearly and concisely present the results of the scheduling experiments, box plot diagrams are used to illustrate the makespan and energy consumption outcomes. The lowest whisker i.e. the first quartile (Q1) in the box plot represents the aggregate minimum, and the highest whisker represents the maximum. The median (second quartile (Q2)) is depicted by the bold horizontal line within the box or frame in the interquartile range, while the average or mean is represented by a plus sign. The makespan and energy consumption results of an entire series of scheduling experiments can be effectively communicated using box plot tools. The least values of these parameters are desired. It is evident from Figs. 8 and 9 that the GTOHBA has shown significant improvements in the makespan and energy consumption in terms of minimum, maximum, mean, and median metrics over the tested metaheuristics. The results of these plots indicate that the GTOHBA has the least makespan dispersion among all scheduling algorithms, demonstrating its superiority and stability.
6.2.3 Summarizing the overall results with single data centre
Finally, Table 14 provides the summary of the experimental results of the undertaken BTASP problem in terms of the mean, median, and standard deviation of the makespan and energy consumption objectives. The results clearly express that the proposed GTOHBA method generates superior schedules, resulting in optimal makespan and energy savings when compared to classical metaheuristics.
Next, we calculate the percentage of relative performance improvement (RPI%) as per Eq. 38 to understand the percentage improvement of the GTOHBA over other tested scheduling algorithms.
Table 15 demonstrates that the GTOHBA algorithm outperforms other algorithms as indicated by RPI% results, resulting in a significant reduction in makespan and energy consumption over compared algorithms for both CEA-Curie and HPC2N workloads. The GTOHBA algorithm shows a significant reduction in both objectives for CEA-Curie workloads, with reductions ranging from 8.12 to 22.76% for makespan and 6.21 to 18.00% for energy consumption. Whereas for HPC2N workloads, GTOHBA achieved 8.46–30.97 % makespan reduction and 8.51–33.41 % energy consumption reduction over the compared metaheuristics.

Box plots for CEA-Curie Workloads a Makespan b Energy consumption

Box plot for HPC2N Workloads a Makespan b Energy consumption
6.3 Experimentation and results with two cloud data centres
For executing the parallel BoT application on geographically distributed cloud data centres, we have followed the BoT execution time model adopted by many related research works [80,81,82]. Bag-of-Tasks Application j can be coallocated on multiple cloud data centres. BoT application execution time is influenced by the presence of processing slowdown (\(SP_j\)) due to heterogeneous computing resources and communication slowdown (\(SP_j\)) because of contention present on inter-CDC communication link in a multi-data centre Cloud. The processing slowdown (\(SP_j\)) component of BoT job j’s execution time is calculated on the basis of slowest CPU core to which job j is assigned, which is calculated as follows:
where \(RCSPE_{nm}\) is the relative computing speed of each CPU core, which is assigned to the job j and is calculated with respect to the computing speed of the slowest CPU core of the Cloud computing system as follows:
The processing slowdown will be less when powerful CPU cores are allocated to the job whereas it will be more as the slower CPU cores are assigned to the job.
The second component of BoT job execution time is the communication slowdown, which mainly depends upon the congestion on the network links when a job is coallocated on the multiple cloud data centres. It is assumed that CPU cores within a computing site is connected using fastest communication channel or link. Therefore, communication slowdown due to intra-data centre site communication is less or negligible as compared to congestion on the inter-data centre communication link. In calculating the communication slowdown, we have not considered the negligible intra-CDC communication delay following the best practices used in the previous research works [80,81,82]. The cross-data centre allocation of a parallel BoT job j consumes a certain amount of bandwidth in each inter-data centre site communication link Lm, which is calculated as as follows using Eq. 41:
where \(PTBW_j\) is the required per-task bandwidth in computing site m, \(size_j\) is the number of tasks in BoT job j, and \(asize_j^m\) is the number of tasks of job j, which are assigned to the data centre site \(DC_m\).
The first term in the equation expresses the total bandwidth consumed by tasks of job j in the computing site \(DC_m\), and the second term expresses the percentage of communication with other computing sites on which the job is coallocated.
When co-allocated applications consume a lot of bandwidth exceeding the available communication channel capacity, then congestion occurs and link is considered to be saturated. This saturation has an adverse effect on applications because it can significantly increase their time communication, thereby affecting its total execution time due to higher slowdown communication (SC). The saturation degree (\(DS^m\)) of a communication channel \(L_m\) relates the maximum bandwidth of this channel with bandwidth requirements of coallocated parallel applications, and is expressed as follows.
When \(DS^m < 1\) the link Lm is saturated, and the execution time of jobs using the link are delayed; otherwise, it is not. Then, the communication slowdown (SC) for job \(J_j\) and link Lm, which depends on the saturation, is represented using following Eq. 43.
The communication slowdown for job \(J_j\) denotes the \(SC_j^m\) from the most saturated link used, expressed by Eq. 44.
For a parallel BoT job j, Cumulative slowdown \(SD_j\) due to processing slowdown, \(SP_j\) and communication slowdown, \(SC_j\), is calculated using Eq. 45. \(\sigma _j\) is the communication to computation (CCR) time ratio in overall execution time.
The actual job execution time \(T_{aej}\) with processing and communication slowdown is calculated in Eq. 46.
where \(T_{eej}\) is the estimated execution time of job j, which is obtained from the input workload and provided to the scheduler before the start of scheduling process. The cloud system configuration with 2 CDCs is presented in Table 16.
6.3.1 Boxplot analysis
It is evident from Figs. 10 and 11 that the GTOHBA has shown significant improvements in the makespan and energy consumption in terms of minimum, maximum, mean, and median metrics over the other baseline metaheuristics. These results in the case of 2 CDCs are in synchronization with results of single CDC, with GTOHBA yielding the least makespan dispersion among all scheduling algorithms, demonstrating its superiority and stability.

Box plots for CEA-Curie Workloads for 2 CDCs a Makespan b Energy consumption

Box plot for HPC2N Workloads for 2 CDCs a Makespan b Energy consumption
6.3.2 Summarizing the overall results with two data centres
The overall makespan and energy consumption produced by GTOHBA as per Table 17 is minimum among all tested metaheuristics in both CEA-Curie and HPC2N workloads. These results in the case of 2 CDCs are higher than those obatined with single CDC. This is because of penalty imposed by the communication slowdown on the overall execution time of the BoT applications, which increases both makespan and energy consumption thereafter.
Table 18 demonstrates that the proposed GTOHBA approach outperforms other tested algorithms with a quite good margin as indicated by RPI% results, resulting in a significant reduction in makespan and energy consumption for both CEA-Curie and HPC2N workloads. The GTOHBA algorithm shows a significant reduction for CEA-Curie workloads, with reductions ranging from 7.86 to 22.92% for makespan and 5.88 to 12.46% for energy consumption. Whereas for HPC2N workloads, GTOHBA achieved 8.05–30.41 % makespan reduction and 7.91–32.65 % energy consumption reduction over the compared metaheuristics.
7 Conclusions and future work
Task scheduling in cloud computing infrastructures is a challenging NP-Hard problem having a direct impact on the overall performance. This paper proposed the GTOHBA approach to resolve the cloud task scheduling problem with the intent to minimize two important scheduling objectives; makespan and energy consumption. GTOHBA hybridizes the good searching qualities of GTO and HBA algorithms in order to remove deficiencies of individual GTO method. Proposed GTOHBA was first tested on standard 29 CEC2017 as well as 12 CEC2022 benchmarks and obtained results were found to be superior to classical metaheuristics. Further, for evaluating the performance of the proposed approach for the task scheduling problem, multiple simulation experiments were performed on the CloudSim simulator by executing standard parallel workload traces viz. CEA-Curie and HPC2N. Similar to the performance evaluation strategy with standard benchmark instances, a comparative analysis was performed with other modern algorithms and the proposed GTOHBA managed to achieve better makespan and energy consumption reduction. While GTOHBA exhibits promising results in the cloud task scheduling model, it is important to acknowledge its limitations. As noted by the No Free Lunch (NFL) theory, while the algorithm may excel in certain domains, it may yield suboptimal outcomes when applied to diverse problem sets such as feature selection or image processing. Therefore, while GTOHBA demonstrates effectiveness in specific contexts, its performance may vary across different problem domains. In future, we plan to test our proposed approach by incorporating more objectives in the cloud task scheduling model using workflows workloads in addition to Bag-of-Tasks applications. In addition, we also plan to develop more hybrid metaheuristics by hybridizing GTO with other swarm intelligence algorithms for tackling the cloud scheduling problem and other NP-Hard problems as well.
Data availability
No datasets were generated or analysed during the current study.
References
Moghaddam, S.K., Buyya, R., Ramamohanarao, K.: Performance−aware management of cloud resources: a taxonomy and future directions. ACM Comput. Surv. 52(4), 1–37 (2019)
Chhabra, A., Singh, G., Kahlon, K.S.: Multi-criteria hpc task scheduling on iaas cloud infrastructures using meta-heuristics. Clust. Comput. 24(2), 885–918 (2021)
Brochard, L., Kamath, V., Corbalán, J., Holland, S., Mittelbach, W., Ott, M.: Energy-Efficient Computing and Data Centers. Wiley, New York (2019)
Attiya, I., Abd Elaziz, M., Abualigah, L., Nguyen, T.N., Abd El-Latif, A.A.: An improved hybrid swarm intelligence for scheduling iot application tasks in the cloud. IEEE Trans. Ind. Inform. 18, 1 (2022)
Natarajan, Y., Kannan, S., Dhiman, G.: Task scheduling in cloud using ACO. Recent Adv. Comput. Sci. Commun. 15(3), 348–353 (2022)
Ajagekar, A., Humble, T., You, F.: Quantum computing based hybrid solution strategies for large−scale discrete−continuous optimization problems. Comput. Chem. Eng. 132, 106630 (2020)
Gokuldhev, M., Singaravel, G.: Local pollination-based moth search algorithm for task-scheduling heterogeneous cloud environment. Comput. J. 65(2), 382–395 (2022)
Tindell, K.W., Burns, A., Wellings, A.J.: Allocating hard real-time tasks: an np-hard problem made easy. Real-Time Syst. 4(2), 145–165 (1992)
Maurya, A.K., Meena, A., Singh, D., Kumar, V.: An energy-efficient scheduling approach for memory-intensive tasks in multi-core systems. Int. J. Inf. Technol. 14(6), 2793–2801 (2022)
Kumar, N., Vidyarthi, D.P.: A novel energy-efficient scheduling model for multi-core systems. Clust. Comput. 24(2), 643–666 (2021)
Kak, S.M., Agarwal, P., Alam, M.A.: Task scheduling techniques for energy efficiency in the cloud. EAI Endorsed Trans. Energy Web 9(39), e6–e6 (2022)
Chhabra, A., Huang, K.-C., Bacanin, N., Rashid, T.A.: Optimizing bag-of-tasks scheduling on cloud data centers using hybrid swarm-intelligence meta-heuristic. J. Supercomput. 78(7), 9121–9183 (2022)
Chakraborty, S., Saha, A.K., Chhabra, A.: Improving whale optimization algorithm with elite strategy and its application to engineering-design and cloud task scheduling problems. Cogn. Comput. 1, 1–29 (2023)
Singh, R.M., Awasthi, L.K., Sikka, G.: Towards metaheuristic scheduling techniques in cloud and fog: an extensive taxonomic review. ACM Comput. Surv. 55(3), 1–43 (2022)
Gharehchopogh, F.S.: Quantum-inspired metaheuristic algorithms: comprehensive survey and classification. Artif. Intell. Rev. 1, 1–65 (2022)
Mohamed, A.W.: A novel differential evolution algorithm for solving constrained engineering optimization problems. J. Intell. Manuf. 29(3), 659–692 (2018)
Raspudic, V.: Optimal design of laterally unrestrained i-beams using genetic algorithm. In: Proceedings of the 31st DAAAM International Symposium, pp. 0683–0691 (2020)
Yujun, Lu, X., Zhang, M., Chen, S.: Hybrid biogeography-based optimization algorithms. In: Biogeography-Based Optimization: Algorithms and Applications, pp. 89–115. Springer, Berlin (2019)
Dorigo, M., Stützle, T.: Ant colony optimization: overview and recent advances. Handbook of Metaheuristics, pp. 311–351 (2019)
Kennedy, J., Eberhart, R.: Particle swarm optimization. In: Proceedings of ICNN’95-International Conference on Neural Networks, vol. 4, pp. 1942–1948. IEEE (1995)
Mirjalili, S., Aljarah, I., Mafarja, M., Heidari, A.A., Faris, H.: Grey wolf optimizer: theory, literature review, and application in computational fluid dynamics problems. Nature−Inspired Optimizers, pp. 87–105 (2020)
Mirjalili, S., Lewis, A.: The whale optimization algorithm. Adv. Eng. Softw. 95, 51–67 (2016)
Hussien, A.G., Hassanien, A.E., Houssein, E.H., Bhattacharyya, S., Amin, M.: S-shaped binary whale optimization algorithm for feature selection. In: Recent Trends in Signal and Image Processing, pp. 79–87. Springer, Berlin (2019)
Mirjalili, S.: Dragonfly algorithm: a new meta-heuristic optimization technique for solving single−objective, discrete, and multi-objective problems. Neural Comput. Appl. 27(4), 1053–1073 (2016)
Yang, X.-S., Deb, S.Cuckoo search via lévy flights. In: 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC), pp. 210–214. IEEE (2009)
Hashim, F.A., Hussien, A.G.: Snake optimizer: a novel meta-heuristic optimization algorithm. Knowl.-Based Syst. 242, 108320 (2022)
Li, S., Chen, H., Wang, M., Heidari, A.A., Mirjalili, S.: Slime mould algorithm: a new method for stochastic optimization. Futur. Gen. Comput. Syst. 111, 300–323 (2020)
Hussien, A.G., Hassanien, A.E., Houssein, E.H.: Swarming behaviour of salps algorithm for predicting chemical compound activities. In: 2017 Eighth International Conference on Intelligent Computing and Information Systems (ICICIS), pp. 315–320. IEEE (2017)
Hussien, A.G., Amin, M., Abd El Aziz, M.: A comprehensive review of moth-flame optimisation: variants, hybrids, and applications. J. Exp. Theoret. Artif. Intell. 32(4), 705–725 (2020)
Assad, A., Deep, K.: A hybrid harmony search and simulated annealing algorithm for continuous optimization. Inf. Sci. 450, 246–266 (2018)
Hashim, F.A., Houssein, E.H., Mabrouk, M.S., Al-Atabany, W., Mirjalili, S.: Henry gas solubility optimization: a novel physics-based algorithm. Futur. Gen. Comput. Syst. 101, 646–667 (2019)
Rao, R.V., Savsani, V.J., Vakharia, D.P.: Teaching-learning-based optimization: a novel method for constrained mechanical design optimization problems. Comput. Aided Des. 43(3), 303–315 (2011)
Sadollah, A., Sayyaadi, H., Yadav, A.: A dynamic metaheuristic optimization model inspired by biological nervous systems: neural network algorithm. Appl. Soft Comput. 71, 747–782 (2018)
Mirjalili, S.: Sca: a sine cosine algorithm for solving optimization problems. Knowl.-Based Syst. 96, 120–133 (2016)
Ashraf, H., Abdellatif, S.O., Elkholy, M.M., El-Fergany, A.A.: Honey badger optimizer for extracting the ungiven parameters of pemfc model: steady-state assessment. Energy Convers. Manag. 258, 115521 (2022)
Abd Elaziz, M., Abualigah, L., Issa, M., Abd El-Latif, A.A.: Optimal parameters extracting of fuel cell based on gorilla troops optimizer. Fuel 32, 126162 (2023)
Han, E., Ghadimi, N.: Model identification of proton-exchange membrane fuel cells based on a hybrid convolutional neural network and extreme learning machine optimized by improved honey badger algorithm. Sustain. Energy Technol. Assess. 52, 102005 (2022)
Sayed, G.I., Soliman, M.M., Hassanien, A.E.: A novel melanoma prediction model for imbalanced data using optimized squeezenet by bald eagle search optimization. Comput. Biol. Med. 136, 104712 (2021)
Chen, Y., Gou, L., Li, H., Wang, J.: Sensor fault diagnosis of aero engine control system based on honey badger optimizer. IFAC-PapersOnLine 55(3), 228–233 (2022)
Houssein, E.H., Saad, M.R., Ali, A.A., Shaban, H.: An efficient multi-objective gorilla troops optimizer for minimizing energy consumption of large−scale wireless sensor networks. Expert Syst. Appl. 212, 118827 (2023)
Gomaa, I., Zaher, H., Ragaa Saeid, N., Sayed, H.: A novel enhanced gorilla troops optimizer algorithm for global optimization problems. Int. J. Ind.Eng. Prod. Res. 34(1), 1–9 (2023)
Mostafa, R.R., Gaheen, M.A., Abd ElAziz, M., Al-Betar, Azmi, M., Ewees, A.A.: An improved gorilla troops optimizer for global optimization problems and feature selection. In: Knowledge−Based Systems, p. 110462 (2023)
Can, Ö., Eroğlu, H., Öztürk, A.: Metaheuristic-based automatic generation controller in interconnected power systems with renewable energy sources. In: Comprehensive Metaheuristics, pp. 293–311. Elsevier (2023)
Elkholy, M.H., Elymany, M., Yona, A., Senjyu, T., Takahashi, H., Lotfy, M.E.: Experimental validation of an ai-embedded fpga-based real-time smart energy management system using multi-objective reptile search algorithm and gorilla troops optimizer. Energy Convers. Manag. 282, 116860 (2023)
Al-maamari, A., Omara, F.A.: Task scheduling using hybrid algorithm in cloud computing environments. J. Comput. Eng. 17(3), 96–106 (2015)
Attiya, I., Abd Elaziz, M., Xiong, S.: Job scheduling in cloud computing using a modified harris hawks optimization and simulated annealing algorithm. In: Computational Intelligence and Neuroscience (2020)
Liang, H., Yanhua, D., Li, F.: Business value−aware task scheduling for hybrid iaas cloud. Decis. Support Syst. 112, 1–14 (2018)
Ni, L., Sun, X., Li, X., Zhang, J.: Gcwoas2: multiobjective task scheduling strategy based on gaussian cloud-whale optimization in cloud computing. In: Computational Intelligence and Neuroscience (2021)
Manikandan, N., Gobalakrishnan, N., Pradeep, K.: Bee optimization based random double adaptive whale optimization model for task scheduling in cloud computing environment. Comput. Commun. 187, 35–44 (2022)
Abdullahi, M., Ngadi, M.A., Dishing, S.I., Ahmad, B.I., et al.: An efficient symbiotic organisms search algorithm with chaotic optimization strategy for multi-objective task scheduling problems in cloud computing environment. J. Netw. Comput. Appl. 133, 60–74 (2019)
Mapetu, J.P.B., Chen, Z., Kong, L.: Low-time complexity and low-cost binary particle swarm optimization algorithm for task scheduling and load balancing in cloud computing. Appl. Intell. 49(9), 3308–3330 (2019)
Kaur, A., Kaur, B.: Load balancing optimization based on hybrid heuristic-metaheuristic techniques in cloud environment. J. King Saud Univ. 1, 1 (2019)
Abd Elaziz, M., Abualigah, L., Attiya, I.: Advanced optimization technique for scheduling iot tasks in cloud-fog computing environments. Futur. Gener. Comput. Syst. 124, 142–154 (2021)
Abualigah, L., Diabat, A., Elaziz, M.A.: Intelligent workflow scheduling for big data applications in iot cloud computing environments. Clust. Comput. 24(4), 2957–2976 (2021)
Rana, N., Abd Latiff, M.S., et al.: A hybrid whale optimization algorithm with differential evolution optimization for multi-objective virtual machine scheduling in cloud computing. In: Engineering Optimization, pp. 1–18 (2021)
Nabi, S., Ahmad, M., Ibrahim, M., Hamam, H.: Adpso: adaptive pso-based task scheduling approach for cloud computing. Sensors 22(3), 920 (2022)
Chen, X., Long, D.: Task scheduling of cloud computing using integrated particle swarm algorithm and ant colony algorithm. Clust. Comput. 22(2), 2761–2769 (2019)
Sun, Y., Li, J., Xueliang, F., Wang, H., Li, H.: Application research based on improved genetic algorithm in cloud task scheduling. J. Intell. Fuzzy Syst. 38(1), 239–246 (2020)
Kumar, M., Sharma, S.C.: Pso-cogent: Cost and energy efficient scheduling in cloud environment with deadline constraint. Sustain. Comput. 19, 147–164 (2018)
Kumar, M., Sharma, S.C.: Pso-based novel resource scheduling technique to improve qos parameters in cloud computing. Neural Comput. Appl. 32(16), 12103–12126 (2020)
Zhou, Z., Li, F., Abawajy, J.H., Gao, C.: Improved pso algorithm integrated with opposition-based learning and tentative perception in networked data centres. IEEE Access 8, 55872–55880 (2020)
Abd Elaziz, M., Xiong, S., Jayasena, K.P.N., Li, L.: Task scheduling in cloud computing based on hybrid moth search algorithm and differential evolution. Knowl.-Based Syst. 169, 39–52 (2019)
Srichandan, S., Kumar, T.A., Bibhudatta, S.: Task scheduling for cloud computing using multi-objective hybrid bacteria foraging algorithm. Fut. Comput. Inf. J. 3(2), 210–230 (2018)
Nasr, A.A., Chronopoulos, A.T., El-Bahnasawy, N.A., Attiya, G., El-Sayed, A.: A novel water pressure change optimization technique for solving scheduling problem in cloud computing. Clust. Comput. 22(2), 601–617 (2019)
Praveen, S.P., Thirupathi Rao, K., Janakiramaiah, B.: Effective allocation of resources and task scheduling in cloud environment using social group optimization. Arab. J. Sci. Eng. 43(8), 4265–4272 (2018)
Materwala, H., Ismail, L.: Performance and energy-aware bi-objective tasks scheduling for cloud data centers. Proc. Comput. Sci. 197, 238–246 (2022)
Abualigah, L., Alkhrabsheh, M.: Amended hybrid multi-verse optimizer with genetic algorithm for solving task scheduling problem in cloud computing. J. Supercomput. 78(1), 740–765 (2022)
Belgacem, A., Beghdad-Bey, K.: Multi-objective workflow scheduling in cloud computing: trade−off between makespan and cost. Clust. Comput. 25(1), 579–595 (2022)
Cheng, F., Huang, Y., Tanpure, B., Sawalani, P., Cheng, L., Liu, C.: Cost-aware job scheduling for cloud instances using deep reinforcement learning. Clust. Comput. 25(1), 619–631 (2022)
Wolpert, D.H., Macready, W.G.: No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1(1), 67–82 (1997)
Abdollahzadeh, B., Gharehchopogh, F.S., Mirjalili, S.: Artificial gorilla troops optimizer: a new nature−inspired metaheuristic algorithm for global optimization problems. Int. J. Intell. Syst. 36(10), 5887–5958 (2021)
Hashim, F.A., Houssein, E.H., et al.: New metaheuristic algorithm for solving optimization problems. Honey badger algorithm. Math. Comput. Simul. 192, 84–110 (2022)
Wilcoxon, F.: Individual comparisons by ranking methods. Springer, Berlin (1992)
Kamel, S., Abdel-Mawgoud, H., Hashim, F.A., Bouaouda, A., Domínguez-García, J.L.: Achieving optimal pv allocation in distribution networks using a modified reptile search algorithm. IEEE Access 1, 1 (2024)
Tolba, M.A., Houssein, E.H., Ali, M.H., Hashim, F.A.: A new robust modified capuchin search algorithm for the optimum amalgamation of dstatcom in power distribution networks. Neural Comput. Appl. 36(2), 843–881 (2024)
Elfatah, A.A., Hashim, F.A., Mostafa, R.R., Abd El-Sattar, H., Kamel, S.: Energy management of hybrid pv/diesel/battery systems: a modified flow direction algorithm for optimal sizing design-a case study in Luxor. Egypt. Renew. Energy 218, 119333 (2023)
Hussien, A.G., Khurma, R.A., Alzaqebah, A., Amin, M., Hashim, F.A.: Novel memetic of beluga whale optimization with self-adaptive exploration-exploitation balance for global optimization and engineering problems. Soft. Comput. 27(19), 13951–13989 (2023)
Tasgetiren, M.F., Liang, Y., Sevkli, M., Gencyilmaz, G.: Particle swarm optimization and differential evolution algorithms for single machine total weighted tardiness problem. Ann. Oper. Res. 1, 1 (2004)
Gabaldon, E., Lerida, J.L., Guirado, F., Planes, J.: Blacklist muti-objective genetic algorithm for energy saving in heterogeneous environments. J. Supercomput. 73(1), 354–369 (2017)
Blanco, H., Llados, J., Guirado, F., Lérida, J.L.: Ordering and allocating parallel jobs on multi-cluster systems. In: 12th International Conference Computational and Mathematical Methods in Science and Engineering (CMMSE’12), vol. 1, pp. 196–206, 2012
Gabaldon, E., Lerida, J.L., Guirado, F., Planes, J.: Multi-criteria genetic algorithm applied to scheduling in multi-cluster environments. J. Simul. 9, 287–295 (2015)
Chhabra, A., Singh, G., Kahlon, K.S.: Performance−aware energy-efficient parallel job scheduling in hpc grid using nature−inspired hybrid meta-heuristics. J. Ambient Intell. Hum. Comput. 12(2), 1801–1835 (2021)
Funding
Open access funding provided by Linköping University. This work was funded by ELLIIT – Excellence Center at Linköping-Lund on Information Technology.
Author information
Authors and Affiliations
Contributions
All authors contributed equally to the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hussien, A.G., Chhabra, A., Hashim, F.A. et al. A novel hybrid Artificial Gorilla Troops Optimizer with Honey Badger Algorithm for solving cloud scheduling problem. Cluster Comput (2024). https://doi.org/10.1007/s10586-024-04605-1
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10586-024-04605-1