
Abstract
Almost 35 years after its introduction, coronary artery calcium score (CACS) not only survived technological advances but became one of the cornerstones of contemporary cardiovascular imaging. Its simplicity and quantitative nature established it as one of the most robust approaches for atherosclerotic cardiovascular disease risk stratification in primary prevention and a powerful tool to guide therapeutic choices. Groundbreaking advances in computational models and computer power translated into a surge of artificial intelligence (AI)-based approaches directly or indirectly linked to CACS analysis. This review aims to provide essential knowledge on the AI-based techniques currently applied to CACS, setting the stage for a holistic analysis of the use of these techniques in coronary artery calcium imaging. While the focus of the review will be detailing the evidence, strengths, and limitations of end-to-end CACS algorithms in electrocardiography-gated and non-gated scans, the current role of deep-learning image reconstructions, segmentation techniques, and combined applications such as simultaneous coronary artery calcium and pulmonary nodule segmentation, will also be discussed.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Atherosclerosis, a multifactorial, dynamic, heterogeneous disease, profoundly impacts morbidity and mortality, imposing a substantial economic burden on the healthcare system [1, 2]. This complex, inflammatory-based disease affects the elastic and muscular arteries leading to the formation of atherosclerotic plaques [3, 4]. Atherosclerotic plaques involve arteries’ intima and consist of a mixture of lipid, foam cells, debris, connective-tissue elements, and immune cells, inducing asymmetric focal thickenings of the affected vessels [3, 4]. There is a desire for simple, non-invasive biomarkers to quantify and characterize this disease, particularly in the cardiovascular field [5]. Calcium deposition and plaque calcification is a well-known process involving the lipid core of atherosclerotic plaques [5]. In patients with unknown atherosclerotic cardiovascular disease (ASCVD), coronary artery calcium (CAC) quantification, measured on computed tomography (CT) images (also named CAC score, CACS, or Agatston score), proved to be a robust, reliable and reproducible marker of subclinical coronary atherosclerosis [6,7,8,9]. CACS is a well-grounded approach for primary ASCVD risk stratification and a predictor for cause-specific cardiovascular mortality [6,7,8,9].
The groundbreaking advances of artificial intelligence (AI) in recent years and those foreseen in the future are expected to drastically change medicine, improving patient diagnosis, tailoring therapeutic strategies to patient needs, and relieving the medical community of tedious, error-prone tasks [10,11,12]. Imaging is one of the medical specialties at the forefront of the AI revolution. The ubiquitous presence of CT scanners [13], their short scan time, superiority (over other imaging techniques) in detecting vascular calcification [14], and the high clinical relevance of CAC detection [15], paved the way for CACS to embody the perfect task to benefit from the development and progress of AI. In fact, while plane chest X-ray, coronary angiography, ultrasound, and magnetic resonance, have the potential to image calcium deposition in the vessels, only CT can accurately quantify it [16].
In this critical review, we aim to describe the current state of research on this topic. Also, by introducing basic concepts of AI, we will unveil their potential, fully exploring the expected advances for healthcare and setting the ground for a thorough understanding of their use in CACS.
Coronary artery calcium score (CACS)
In 1990, Agatston et al. provided pivotal evidence on the capability of (electron-beam) CT to quantify CAC, theorizing the CACS [17]. Since then, technological improvements in CT scanners have been tremendous, but the elegance and simplicity of the proposed method ensured CACS’s longevity. The Agatston score is a radiological construct based on 3 mm, electrocardiogram-gated (ECG-gated), non-contrast images, which relies on a semiautomatic quantification of calcified plaques, adopting 130 Hounsfield Units (HU) and 1 mm2 as the minimal cutoffs to differentiate calcified plaques from random noise [17]. Agatston score is the product of the weighted sum score of the peak density multiplied by the plaque’s area, summed across all eligible lesions (defined by n in the formula underneath) [18].
Since its introduction, minimal changes have been made to the technical parameters for acquiring the CACS images. However, the introduction of multidetector CT, the most prominent change since CACS theorization [19], forced the standardization of the scanning protocol, which was achieved in 2007 owing to the work of McCollough et al. [20] (Table 1). Since then, imaging societies have discouraged any possible modification to these parameters [21].
The CACS can be expressed in absolute or relative values. The latter weighs the CACS according to the age-, sex-, and race-specific percentile [8]. Absolute values stratify the near-to-midterm ASCVD risk (5 to 10 years), whereas the relative score compares the ASCVD risk of the patient with that of peers [22]. While both methods can predict coronary events, absolute values had better performances and a more robust correlation with event risk [22]. In asymptomatic patients, CACS risk scores are grouped into the following categories: very low (CACS 0), mildly increased (CACS 1-99), moderately increased (CACS 100-299), moderately-to-severely increased (CACS 300-999), and severely increased (CACS ≥ 1000) [23, 24]. Since 2018 CACS reporting has been standardized according to the CAC data and reporting system (CAC-DRS) issued by the Society of Cardiovascular Computed Tomography (SCCT) [24].
Although the Agatston score is the most widely adopted method, it is not the only score to evaluate CAC. The calcium volume and calcium mass represent the total volume of calcified voxels and the “true mass” of calcium in the coronary tree, respectively [19, 25]. Both calcium volume and calcium mass had higher interscan reproducibility compared to the Agatston score [19, 26, 27]. Additionally, the results of a sub-study of the Multi-Ethnic Study of Atherosclerosis (MESA) on 3,398 participants with CACS > 0 showed the benefits of adding calcium volume and calcium density to coronary artery disease (CAD) and ASCVD risk evaluation. Interestingly, calcium volume was associated with a stepwise increase in CAD and ASCVD risk, while calcium density scores showed a stepwise decrease in the risks [19, 27]. These results helped disentangle the inverse relation existing between calcium density and ASCVD risk [6]. Indeed, highly dense plaques are more stable and inversely associated with ASCVD risk factors, begetting a lower ASCVD risk [19, 28, 29]. Therefore, calcium density improved CACS score based ASCVD risk quantification, solving some of the Agatston score’s intrinsic imperfections.
Clinical value of CACS
Recently, several clinical guidelines endorsed the use of CACS to up or down-stratify asymptomatic, middle-aged patients at intermediate risk of ASCVD [15] and to guide therapeutic decisions (Table 2). Nonetheless, the benefits of CACS have not been fully exploited yet. Recent evidence showed that CACS-weighted pre-test probability models better stratified the risk of obstructive CAD compared to those based on conventional risk factors in patients with typical and atypical chest pain [30]. Additionally, by reclassifying 54% of patients to a lower CAD pre-test probability based on their CACS, it reduced downstream diagnostic testing [30].
Of note, while the “power of 0” is still debated [31], the 10-year risk of all-cause mortality of CACS 0 is < 1% [19]. Conversely, minimal increases (CACS 1-10) are associated with a two-fold increase in the overall mortality rates [32]. Moreover, individuals with a CACS ≥ 1000 have five times the risk of ASCVD and roughly three times the risk for all-cause mortality of those with a CACS 0 after adjusting for conventional risk factors [33]. Even more alarming is the absence, of a disease-specific and all-cause mortality plateau effect in this patient population [33].
CACS in non-ECG-gated images
Although CACS was developed on ECG-gated images, a meta-analysis of 661 adults showed a high correlation between scores derived from ECG-gated and non-gated, non-contrast images [34]. This may improve ASCVD risk assessment in specific cohorts of patients, namely candidates for lung cancer (LC) screening and oncologic patients sharing risk factors with patients with ASCVD. Former or active smokers enrolled in the control arm of an LC screening randomized controlled trial had equivalent 10-year mortality rates of LC and ASCVD (24% and 21%, respectively) [35]. Indeed, older age and a heavier smoking history increased the likelihood of undergoing LC screening in a population-based study involving more than 14,500 adults, of whom 67% were overweight or obese and 22% had diabetes [36]. Further, 62% of patients enrolled in a cross-sectional LC screening study were CACS positive, 7% had values > 1000, and 57% of those qualifying for primary prevention statin therapy were not actively treated [37]. Tailor et al. corroborated this evidence, confirming that a minority of LC screening patients carried a diagnosis of ASCVD (31%), while most (74%) were eligible for statin therapy but not under active treatment [38].
However, performing CACS on non-gated images may underestimate the Agatston score. Xie et al. showed that 9% of CACS-positive and 19% of CACS ≥ 400 patients on ECG-gated images were downgraded to CACS 0 or < 400 on non-gated images, respectively [34]. A possible solution to the problem of accurate CACS quantification in non-gated images could be qualitative analysis. CAC-DRS also supports the qualitative evaluation of the presence and extent of coronary tree calcification on non-gated images [24, 39]. Qualitative CAC-DRS are divided into the following categories: very low (CAC-DRS 0), mildly increased (CAC-DRS 1), moderately increased (CAC-DRS 2), and moderate to severely increased (CAC-DRS 3), mirroring their quantitative counterpart, and providing similar ASCVD risk stratification and treatment recommendations [24].
Limits and future directions of CACS
Neither the Agatston score nor CAC-DRS considers plaque location. However, involvement of the left main trunk and left anterior descending artery (LAD) is associated with a worse outcome [40,41,42]. Additionally, the higher the number of affected vessels, the higher the risk of CAD [43]. Hence, the SCCT suggested reporting CAC location, irrespective of the evaluation method applied [24]. Scan-rescan studies showed the complexity of measuring a modifiable parameter. Those with a short interscan period (23 ± 27 days) demonstrated low measurement variations [44]. Conversely, a sub-study of the MESA with an interscan period between 1 and 5 years showed that baseline CACS values, body mass index, and scanner factors must be considered when quantifying CACS variations in longitudinal studies [45]. Of the 2,832 patients with CACS > 0 at baseline, 85% showed an increase in CACS at follow-up scans [45]. However, 52% of the variation was attributable to the previous factors, and factor-adjusted analysis demonstrated that only 32% of the initial patients had increased CACS values [45]. An additional point not yet taken into consideration is the difference in CAC profiles between sexes. Women have fewer calcified plaques and less calcified vessels, ultimately generating a lower CAC volume [46]. Additionally, the proportion of women with detectable CAC typically rises at the age of 46, nearly a decade after that observed in men [46]. Nonetheless, CACS-positive women have an overall 1,3-fold higher relative risk of ASCVD-related death compared to men. This relationship increases with CACS values, being ~ 1,8-fold higher in women with CACS > 100 [46]. Interestingly, a sub-study of the MESA involving 2,456 postmenopausal women showed that those with early menopause had a lower prevalence of CACS 0 (55%) than those without early menopause (60%) [47]. Further, in the coronary artery risk development in young adults study, the prevalence of women with CACS > 0 was 18%, 21%, and 13% for premature menopause, menopause ≥ 40 years, and premenopausal, respectively [48]. Of note, the results of these studies did not reach statistical significance, leaving the association between CACS and menopausal status unanswered. Finally, it is worth noting that, irrespective of sex, ~ 10% of CACS-negative individuals have non-calcified plaques, 1% have obstructive non-calcified plaques, and ~ 0.5% develop cardiac events at long-term follow-up (≥ 42 months) [49].
Installation and availability of dual-energy and photon-counting CT (PCCT) brought exciting perspectives into CACS [39, 50]. These techniques allow the reconstruction of virtual non-contrast (VNC) images from contrast-enhanced exams [18]. Therefore, CACS could be quantified from contrast-enhanced scans. However, VNC images proportionally underestimated CACS values derived from non-contrast images primarily because of an underestimation of plaque volume and density, requiring ad-hoc conversion factors to yield accurate results [51, 52]. Additionally, ultra-low dose non-enhanced CACS images acquired using a dual-energy scanner underestimated CACS-based risk categories in 17% of patients compared to their standard-dose counterparts [39]. PCCT, a pioneering technique directly converting the energy of X-ray photons into an electric pulse, can increase the contrast-to-noise ratio (CNR) and detect smaller and less calcified objects [50, 53]. PCCT scanners implemented in clinical routine have detectors of 2 mm thickness and a ~ 200 μm pixel dimension at the isocenter [54], lower than the ~ 1000 μm of energy integrating detectors [55]. While the foreseeable benefits of PCCT adoption are huge, studies comparing CACS between normal (energy integrating) scanners and PCCT showed a systematic reduction in CACS values in PCCT, leading to the reclassification of 5% of patients [56].
Artificial intelligence
AI can be defined as the creation and development of hardware and software capable of performing tasks usually confined to human intelligence or broadly as intelligence exhibited by machines [57, 58]. The implementation of AI is expected to improve medicine thanks to its ability to learn and adapt to a huge amount of data and handle onerous tasks requiring great cognitive dexterity [58,59,60]. Furthermore, it is expected to free clinicians from tedious and repetitive tasks still demanding undistracted attention [58,59,60]. At its core, AI encompasses a broad range of concepts, including but not limited to machine learning (ML), deep learning (DL), and convolutional neural networks (CNNs) (Fig. 1). Each of these concepts has a characteristic range of applications, is associated with distinct algorithm architectures, and has various layers of complexity.

Deep-learning and convolutional neural network algorithm architecture. A Deep learning (DL) relies on multiple hidden layers of artificial neural networks (ANN), hence the name "deep". These layers are usually defined as "hidden" because they do not belong either to the input or output layer. The number of hidden layers determines the depth of a model. Their role is to capture patterns and features, transforming input data into other data forms usable by the subsequent layer of neurons. Indeed, each neuron contained in these layers relates to the formers. Information flows from layer to layer, moving from input to output, progressively increasing its complexity and abstractedness. B Convolutional neural networks (CNN) are the most common DL architecture used in image analysis. This architecture has two major components: convolutional and pooling layers. The former is the core building of a CNN and works by applying filters to the input data, generating an activation map. Pooling layers combine the outputs of the convolutional step, reducing the number of features extracted. These steps can be repeated multiple times. Usually, the last step is allocated to layers of artificial neural networks, which in turn generates the output. ANN artificial neural network, CNN Convolutional neural network, DL deep learning
ML learns patterns directly from data/examples [57, 59]. This overcomes the traditional rule-based approach that sees computers accurately reproducing the programmer’s instructions [59]. Several different components need to be considered when building an ML algorithm. Although a detailed description is beyond the scope of this review, we will briefly guide the readers through some ML approaches [61]. ML usually relies upon one of the following approaches: supervised learning, semi-supervised learning, reinforcement learning, or unsupervised learning. Supervised learning uses labeled datasets with a known output or outcome variable [57]. The model learns patterns and relationships existing between inputs (in our case images) and outputs by minimizing the difference between its predictions and the real outputs throughout an iterative, optimized process [57]. Semi-supervised learning overcomes the challenges often caused by the scarce availability of high-quality datasets curated by experts [57, 59]. This approach trains the algorithms using both labeled and unlabeled output data. Unsupervised learning opts for using the ML algorithm against unlabeled output datasets, mainly aiming to discover hidden patterns or structures within the data. This strategy relies on a naïve approach to data, exempting the algorithm from previous evidence and empowering it to unveil otherwise hidden connections and associations. Finally, reinforcement learning, infrequently used in medicine, finds a balance between exploration and exploitation in a specific environment by yielding different grades of rewards.
DL represents a subset of ML that uses stacks of artificial neural networks (ANNs) processing layers to perform representation learning on structured and unstructured raw data (Fig. 1) [62,63,64]. ANNs are inspired by the human brain, particularly the primary visual cortex, and are composed of interconnected linear units called neurons [62, 63]. As their biological counterpart, artificial neurons receive and process signals (using a non-linear activation function, mostly ReLU), activating (i.e., passing the information to subsequent units) based on the weighted sum of their inputs [65]. Artificial neurons have full pairwise connections with the following layers [65, 66]. Conversely, they are not connected to neurons of the same layer [65, 66]. Passing through multiple, hidden ANN layers extracting and transforming lower-level features into higher-level features, the input information is interpreted [57, 63]. Therefore, ANNs can learn different intricate representations at different levels of abstraction [62].
CNNs are a specialized type of ANN architecture, working best on grid-like topology data, such as images and videos. Therefore, they are commonly used to analyze medical images [62, 63]. Three layers form the CNN: convolutional, pooling, and fully connected layers (Fig. 1) [67]. The convolutional layer plays a vital role in CNNs by processing small regions of space of the input images using learnable filters, extracting local patterns and spatial relationships, and generating feature maps [67, 68]. Pooling layers down sample feature maps, preserving important information [68]. The output of the pooling layer is finally fed to fully connected layers of ANNs. A significant upgrade in CNNs came with the development of the so-called U-net and ResNet/VGGNet, which currently represent two of the most used algorithms for image analysis [65, 66]. U-net consists of a symmetric architecture, including a contracting and an expansive path, yielding a U-shaped appearance, and is largely employed for image segmentation [66, 69]. This architecture, devoid of any fully connected layers, relies only on convolutions [69], improving the spatial localization of image features and maintaining high performances in image classification. ResNet and VGGNet are classically adopted in image classification tasks. VGGNet was developed to increase the CNN depth by applying small-size filters [66], while ResNet overcame the degradation problem encountered as the depth increased [70, 71]. A detailed description of these networks’ architecture is beyond the scope of this review. However, further details can be found in the review from Alzubaidi et al. [66].
AI performance assessment
Datasets, model fitting, and model performances are crucial notions to understand the complexities and nuances of ML, DL, and CNNs. The training dataset is used to build the model/algorithm, whereas the validation dataset serves to tune and improve the learning performance of the algorithm and the testing dataset to evaluate the model’s performance (Fig. 2, i.e., accuracy, precision, recall, etc.), respectively [61, 62]. It is not surprising that the size of the training dataset should be tailored to the underlying task, with more complex tasks requiring larger datasets. Larger training datasets also obviate false pattern recognition due to imbalances in variables (i.e., sex, age, smoking status, etc.) used to build the algorithm [58]. Training, validation, and testing datasets need to be independent, with no overlap. Further, to increase the algorithm’s generalizability, the testing dataset should, ideally, be external [61]. These steps help reduce overfitting, which refers to an algorithm working exceptionally well on the data (images) it was trained on (training dataset) but then fails to generalize adequately to new, unseen data (testing dataset) [61].

Steps required to create, validate, and commercialize an AI algorithm. AI algorithm/model creation always starts by identifying a research/clinical question, which dictates the starting dataset. Similarly, the algorithm’s architecture is selected among those performing best according to the data type. Subsequently, the starting dataset is subdivided into separate datasets of different dimensions, naming training dataset, validation dataset, and test dataset. The latter does not need to be generated from the starting dataset. Indeed, it is preferable to have an external test dataset. During the training step, the model analyzes the training dataset, deriving features that are tested against the ground truth. The identical process is performed on a separate dataset, the validation dataset. This validates the performances of the algorithm and fine-tunes it. Subsequently, the algorithm is tested on an additional separate dataset (the test dataset), and its final performances are evaluated. Valuable AI models are finally commercialized. After commercialization, the algorithms learn continuously from real-world data. Also, the model can be re-trained to overcome some flaws encountered when dealing with a real-world scenario. AI artificial intelligence
Several performance metrics can be used to interpret the quality and accuracy of the results of AI algorithms. Accuracy evaluates the number of correct predictions within the whole dataset. Although useful, accuracy is generic and unable to disentangle the performance in different classes (i.e., sensitivity and specificity) [72]. The confusion matrix and the area under the receiver-operating curve improve the understanding of the performance of the classifier [72], while the F1-score evaluates the harmonic average between recall and precision rates [66]. Jaccard index and DICE similarity index are commonly used to grade image segmentation, measuring the degree of proximity between two segmentations on a pixel-wise analysis [72, 73]. Their values always lie between 0 and 1, with the two extremes representing the lack of or the exact correspondence between the segmentation generated by the algorithm and the ground truth [73]. Finally, signal-to-noise ratio (SNR), CNR, modulation transfer function, and noise power spectrum are commonly used to quantify the image quality. The mathematical formulas used to calculate these metrics are reported in Table 3.
Translating AI concepts into CACS
CAC detection and segmentation
CAC detection and segmentation strategies rely either on the intrinsic high density of calcified plaques or on the anatomic location of coronary arteries (Fig. 3) [74]. While these approaches seem robust, the presence of high-density cardiac (i.e., aortic and valvular calcification) and non-cardiac (i.e., lymph nodes, metal structures, noise, etc.) mediastinal structures, as well as the low coronary arteries-to-myocardium contrast difference on non-contrast images, are inherent difficulties encountered in automatic CAC segmentation algorithms creation [75, 76]. To date, the following approaches have been used in ECG-gated images:
-
Calcified plaque detection based on the localization of large structures (i.e., cardiac profile and the aortic root). This approach allowed either image co-registration with previously built atlases, deriving the expected location of coronary arteries [77], or isolating the heart by applying various subsequent segmentation steps. Subsequently, calcifications were identified on the segmented images by image thresholding or geometrical constraints locating coronary arteries’ origin [78, 79].
-
ML-based selection of imaging features correctly classifying the presence of CAC [75, 76]. In this scenario, different approaches were explored, ranging from those necessitating user inputs [75, 80] to fully automatized ones [76]. At their core, these approaches rely on letting software grow regions of interest from which different features were derived. Features were further subdivided into intensity-based features (i.e., mean or maximum density), spatial features (i.e., the cartesian coordinates of the plaque), or geometrical features (i.e., the shape and size of the plaque) [81]. The best feature combination, enabling accurate CAC detection, was calculated by combining and testing various models [75, 76, 80]. Interestingly, lesion location and plaque highest density always led to the best model performances, whereas shape- and dimension-related features were consistently discharged [75, 76]. The results of these approaches varied considerably, with a study reporting a calcification detection of ~ 74% [76], while others had sensitivity and specificity values of 92–93% and 98–99%, respectively [75].
-
ML-based derivation of imaging features obtained using coronary arteries-based atlases, created upon CT-angiography images [74, 81, 82]. This method summed up the advantages of the formers using both lesion features and atlases and yielded CAC detection sensitivity between 81 and 87%, while specificity varied between 97% and 100% [82].
In non-gated CT images, the cardiac motion artifacts preclude the possibility of applying segmentation-based approaches [74]. Lessemann et al. overcame this shortcoming by proposing a two-stage CNN approach [74]. The first CNN’s large receptive field applied image thresholding, categorizing all voxels exceeding 130 HU and subdividing them according to the presumed coronary artery they belonged to, while the second CNN’s smaller receptive field refined the results of the previous subdividing authentic calcification from other high-density structures (false positive voxels) [74].

Coronary artery calcium segmentation. Automatic detection, segmentation, and classification of coronary artery calcium in the left main (light green) and left anterior descending artery (purple blue) in an 80-year-old man with severe coronary artery calcification (i.e., Agatston score: 2187).
CACS quantification
Fully automated CACS algorithms offered high performances on both ECG-gated and non-gated scans. In ECG-gated images, the mean difference between manually and AI-calculated Agatston scores was − 2.86 to 3.24 [83] in older algorithms and 0.0 to 1.3 in more recent ones [84]. Additionally, experts-to-AI intraclass correlation coefficient (ICC) values ranging from 0.84 to 0.99 were reported by several authors [84,85,86,87,88], while the expert-to-expert ones were 0.84, 0.85, and 0.77 [84]. Interestingly, the availability of additional datasets rather than adopting multiple models (in the same dataset) improved the AI-based accuracy [89]. While these results already proved the potential of AI, the adoption of U-net++, an ameliorated version of U-net [90], reduced the CACS error from 5.5 to 0.48, indicating a bright future for this application [91]. On non-gated images, ICC values of 0.99 and 0.90 were reported using chest CT scans [92] and low-dose chest CT scans acquired for LC screening [93], respectively. Similarly, AI and expert CACS evaluation had a good correlation on Bland-Altmann plots using non-gated chest scans [94]. However, the agreement of risk categorization between AI and expert evaluation varied according to the test dataset used, being between k = 0.58 and k = 0.80 on routine chest CT using external datasets [83] and between k = 0.85 [93] and k = 0.91 [74] on low-dose chest CT using internal ones. Similarly, the agreement between risk categories based on ECG-gated and non-gated images ranked from k = 0.52 to 0.82, with lower values obtained with external datasets [83, 95]. This proves the important connection between the algorithm’s performance and the dataset-specific characteristics (i.e., scanner, field-of-view, reconstruction filter, slice thickness, etc.) in non-gated images, resulting in a rapid performance degradation varying the input data [96]. In the study by Lessmann et al., the overall sensitivity of the algorithm, trained on soft reconstruction kernels only, decreased from 91 to 54% when applied to images reconstructed with a sharp kernel [74]. To overcome these issues, van Velzen et al. retrained their algorithm with a small additional set of representative data-specific examinations [96]. Supplementing the network with data-specific scans generated narrower confidence intervals (CIs) on Bland-Altman plots, indicating an improved correlation between the Agatston values calculated by the software and the reference standard [96]. Further, the combined reliability of risk category assignment improved from k = 0.90 to 0.91 [96]. However, the amount of supplementary data-specific scans needed to ensure optimal performance is unknown. Besides these drawbacks, a recent study on 5,678 adults without known ASCVD transitioned AI usage from research into a clinical scenario by utilizing a DL-based algorithm to analyze CACS on non-gated images, showing that adults with DL-CACS ≥ 100 had an increased risk of death (adjusted hazard ratio: 1.51; 95% CI: 1.28 to 1.79) compared to those with DL-CACS 0 [97]. A fascinating, additional perspective was provided by a cloud-based DL CACS evaluator showing high ICC value (0.88; 95% CI: 0.83 to 0.92) between ECG-gated and non-gated images derived from 18 F-fluorodeoxyglucose positron emission tomography (PET) [95]. Although these results were not replicated in a similar setting [98], cloud-based tools have the potential to broaden the users of AI-based CACS evaluation beyond university and tertiary hospitals, helping to reach its full potential.
Total CACS is currently used by international guidelines to guide therapeutic decisions; however, it is worth noting that CAC is unevenly distributed, mostly located in the LAD or the right coronary artery [41]. However, as previously discussed, heavily calcified left main trunk or LAD correlates with a higher mortality risk [41, 42]. Therefore, detailing algorithm performances on a vessel-based level is of uttermost importance but often overlooked or done by using dissimilar metrics, as described in Table 4.
Computational time
Algorithm architecture, use of graphic processing unit, and the number of cores of the computer processing unit strongly impacted the computational time taken to quantify CACS, generating heterogeneous results (mean computational time: 3 min, range: 2 s to 10 min, Fig. 4) [74, 81, 83,84,85,86, 96, 98,99,100]. Irrespective of the computational time, these results show that automatizing CACS calculation may reduce its costs and streamline the workflow of imaging departments.

Computational time taken to quantify CACS according to different technical set-ups. The computational time taken to analyze the images was extremely heterogeneous between studies, varying from a few seconds (invisible cones) to approximately ten minutes. This heterogeneity was highly dependent on the computational approach used. However, most studies reported computational times lower than that taken by experts (red ring). The latter was based on the results by Eng et al. [83] CPU central processing unit, GPU graphics processing unit, min minutes, sec seconds
Deep learning image reconstruction
The growing awareness of the potential risks associated with ionizing radiation usage forced CT manufacturers and the medical community to adopt low-dose protocols [101]. Low-dose images inherently exhibit higher image noise and artifacts than standard-dose images. Hence, in the last five years, vendors have introduced deep learning reconstruction (DLR) to address these problems [102, 103]. To date, three DLR methods have been developed: TrueFidelity, AiCE, and Precise Image. These algorithms differ based on the input data used in the training phase, the framework they were built on, and the ground truths adopted to compare their performances [102]. Inputs included raw data (sinograms), filtered back projections (FBP), or iterative reconstruction IR images (specifically model-based iterative reconstruction), while frameworks distinguished between direct and indirect. Direct frameworks generated DLR-optimized images in a single step by applying DL algorithms to sinograms (TrueFidelity and Precise Image). Indirect frameworks either generate DL-optimized sinograms before reconstructing images or optimize reconstructed images using DL algorithms (AiCE) [102]. A more comprehensive and detailed description of the strategies used to create DLR can be found in Koetzier et al. [102].
The use of DLR led to a reduction in image noise and a concomitant increase in SNR and CNR compared to FBP [104,105,106]. However, a phantom study using standard acquisition parameters showed that, compared with other image reconstruction techniques, DLR failed to detect calcifications ≤ 1.2 mm [107]. While most studies showed Agatston scores being comparable throughout different reconstruction techniques, its values were reduced with increasing DLR strengths compared to FBP [104,105,106]. This translated into a downward reclassification of risk scores in 2 to 8% of patients [104,105,106,107]. The sole study comparing 3 mm FBP-reconstructed ECG-gated images to 1 mm, low-dose, non-gated DLR-reconstructed images showed that the latter underestimated the CACS (94 ± 249 vs. 105 ± 249) and had 90% accuracy in classifying different risk classes (Fig. 5) [108]. These results prove that DLRs are a promising tool. However, their intrinsic tendency to down-quantify the Agatston score may profoundly impact treatment strategies. Hence, their implementation in CACS evaluation needs additional studies or correction factors.

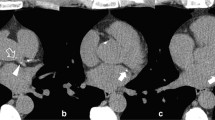
CAC detectability according to different image reconstruction algorithms. Coronary artery calcium detectability according to different image reconstruction algorithms in a 78-year-old hypertensive male. Two small calcifications were detectable on the filtered back projection image (dotted white arrowhead) along the course of the right coronary artery. However, the same calcifications (dotted white arrowhead) on the corresponding images, reconstructed using various deep-learning strengths, were less evident. Specifically, using the highest deep-learning reconstruction strength (DLIR-H), the margins of the bigger calcification were more blurred, while the smaller classification became barely evident. The Agatston score reduced from 691 to 688, 674, and 667, with FBP, DLIR-L, DLIR-M, and DLIR-H, respectively. CAC coronary artery calcium, DLIR deep-learning image reconstruction, FBP filtered back projections
Extracardiac findings
Although CACS images rely on a limited field-of-view, a holistic AI algorithm aiming to automatize CACS reporting should not overlook possible extracardiac findings. A systematic review including more than 11,000 patients undergoing cardiac CT showed that 41% of them had extracardiac findings (ECFs) with an average prevalence of clinically significant ECFs of 16% [109]. Although these results may not be entirely transferable to patients undergoing CACS, they highlight the need for additional automated AI-based evaluation of ECFs. Suspicious lung nodules, hiatal hernia, emphysema, enlarged lymph nodes, and pleural effusion accounted for 63% of clinically significant ECFs [109] and are readily diagnosable on non-enhanced CT images. The sole study exploring the automated detection of CAC and solid lung nodules on low-dose CT images had ambiguous results [110]. The AI-to-expert agreement was excellent in discriminating between patients with CACS 0 and those with CACS > 0 (k = 0.85), whereas the performance of nodule detection was suboptimal (k = 0.42) [110]. These results prove that further research is needed to improve the performance of AI algorithms in handling multiple inputs.
Conclusions
The discrepancies between the number of chest CT (~ 12,7 million), PET/CT (~ 1,8 million), and ECG-gated CACS scans (~ 57,500) acquired in the United States [111] highlight the potential to diagnose/refine the ASCVD risk in a wider population [112]. However, it also confirms the future additional diagnostic burden expected to impact the medical imagers community. In this context, AI may be a valuable tool to alleviate the workload, supporting everyday routine. While this process is expected to transform medical imaging, it will likely not put imagers out of their job nor alter their professional identity or autonomy [11, 113, 114]. Instead, it will enable them to profit from the human-to-AI relationship, benefiting from complementary strengths, ultimately fortifying the central role that imaging plays in modern medicine. Before this becomes a reality, additional steps must be taken into consideration. Automated CACS quantification needs to be a reliable, error-free, and easily implementable tool, irrespective of the computational power. An interesting perspective to further improve algorithms’ performances would be gathering a highly curates, analyzed CACS dataset, including scans acquired from different vendors, serving as the global benchmark to test algorithms. Additionally, testing fully trained algorithms on different datasets would ensure the reproducibility of the results. The effects of image filters and reconstruction on the algorithm’s performances should be clarified in detail. DLR could be retrained using ECG-gated, normal-dose scans, enabling the quantification of the performance changes compared with non-dedicated training. Finally, a holistic approach to image analysis should be regarded as the ultimate goal, including the evaluation of extracardiac findings, bone density, and anemia detection, quantifying blood density [115], ensuring to derive the most from a single scan.
Data availability
No datasets were generated or analysed during the current study.
References
Libby P (2021) The changing landscape of atherosclerosis. Nature 592(7855):524–533. https://doi.org/10.1038/s41586-021-03392-8
Khera R, Valero-Elizondo J, Nasir K (2020) Financial toxicity in atherosclerotic cardiovascular disease in the United States: current state and future directions. J Am Heart Assoc. https://doi.org/10.1161/JAHA.120.017793
Hansson GK (2005) Inflammation, atherosclerosis, and coronary artery disease. N Engl J Med 352(16):1685–1695. https://doi.org/10.1056/NEJMra043430
Ross R (1999) Atherosclerosis—an inflammatory disease. N Engl J Med 340(2):115–126. https://doi.org/10.1056/NEJM199901143400207
Alexopoulos N, Raggi P (2009) Calcification in atherosclerosis. Nat Rev Cardiol 6(11):681–688. https://doi.org/10.1038/nrcardio.2009.165
Nasir K, Razavi AC, Dzaye O (2023) Coronary artery calcium density in clinical risk prediction: ready for primetime? Circ Cardiovasc Imaging 16(2):e015150. https://doi.org/10.1161/CIRCIMAGING.123.015150
Cheong BYC, Wilson JM, Spann SJ, Pettigrew RI, Preventza OA, Muthupillai R (2021) Coronary artery calcium scoring: an evidence-based guide for primary care physicians. J Intern Med 289(3):309–324. https://doi.org/10.1111/joim.13176
Obisesan OH, Osei AD, Uddin SMI, Dzaye O, Blaha MJ (2021) An update on coronary artery calcium interpretation at chest and cardiac CT. Radiol Cardiothorac Imaging 3(1):e200484. https://doi.org/10.1148/ryct.2021200484
Peng AW et al (2021) Very high coronary artery calcium (>/=1000) and association with cardiovascular disease events, non-cardiovascular disease outcomes, and mortality: results from MESA. Circulation 143(16):1571–1583. https://doi.org/10.1161/CIRCULATIONAHA.120.050545
Sahni NR, Carrus B (2023) Artificial intelligence in U.S. health care delivery. N Engl J Med 389(4):348–358. https://doi.org/10.1056/NEJMra2204673
Haug CJ, Drazen JM (2023) Artificial intelligence and machine learning in clinical medicine. N Engl J Med 388:1201–1208. https://doi.org/10.1056/NEJMra2302038
Allen B, Agarwal S, Coombs L, Wald C, Dreyer K (2021) 2020 ACR data science institute artificial intelligence survey. J Am Coll Radiol 18(8):1153–1159. https://doi.org/10.1016/j.jacr.2021.04.002
Healthcare resource statistics—technical resources and medical technology. https://ec.europa.eu/eurostat/statistics-explained/index.php?title=Healthcare_resource_statistics_-_technical_resources_and_medical_technology#Availability_of_technical_resources_in_hospitals
Mujaj B et al (2017) Comparison of CT and CMR for detection and quantification of carotid artery calcification: the rotterdam study. J Cardiovasc Magn Reson 19(1):28. https://doi.org/10.1186/s12968-017-0340-z
Golub IS et al (2023) Major global coronary artery calcium guidelines. JACC Cardiovasc Imaging 16(1):98–117. https://doi.org/10.1016/j.jcmg.2022.06.018
Fayad ZA, Fuster V, Nikolaou K, Becker C (2002) Computed tomography and magnetic resonance imaging for noninvasive coronary angiography and plaque imaging: current and potential future concepts. Circulation 106(15):2026–2034. https://doi.org/10.1161/01.cir.0000034392.34211.fc
Agatston AS, Janowitz WR, Hildner FJ, Zusmer NR, Viamonte M, Detrano R (1990) Quantification of coronary artery calcium using ultrafast computed tomography. J Am Coll Cardiol. https://doi.org/10.1016/0735-1097(90)90282-t
Gupta A et al (2022) Coronary artery calcium scoring: current status and future directions. Radiographics 42(4):947–967. https://doi.org/10.1148/rg.210122
Blaha MJ, Mortensen MB, Kianoush S, Tota-Maharaj R, Cainzos-Achirica M (2017) Coronary artery calcium scoring: is it time for a change in methodology? JACC Cardiovasc Imaging 10(8):923–937. https://doi.org/10.1016/j.jcmg.2017.05.007
McCollough CH, Ulzheimer S, Halliburton SS, Shanneik K, White RD, Kalender WA (2007) Coronary artery calcium: a multi-institutional, multimanufacturer international. Radiology 243(2):527–538. https://doi.org/10.1148/radiol.2432050808
Pontone G et al (2022) Clinical applications of cardiac computed tomography: a consensus paper of the European association of cardiovascular imaging-part I. Eur Heart J Cardiovasc Imaging 23(3):299–314. https://doi.org/10.1093/ehjci/jeab293
Budoff MJ et al (2009) Coronary calcium predicts events better with absolute calcium scores than age-sex-race/ethnicity percentiles: MESA (multi-ethnic study of atherosclerosis). J Am Coll Cardiol 53(4):345–352. https://doi.org/10.1016/j.jacc.2008.07.072
Hecht H et al (2017) Clinical indications for coronary artery calcium scoring in asymptomatic patients: expert consensus statement from the society of cardiovascular computed tomography. J Cardiovasc Comput Tomogr 11(2):157–168. https://doi.org/10.1016/j.jcct.2017.02.010
Hecht HS et al (2018) CAC-DRS: coronary artery calcium data and reporting system. an expert consensus document of the society of cardiovascular computed tomography (SCCT). J Cardiovasc Comput Tomogr 12(3):185–191. https://doi.org/10.1016/j.jcct.2018.03.008
Kumar P, Bhatia M (2023) Coronary artery calcium data and reporting system (CAC-DRS): a primer. J Cardiovasc Imaging 31(1):1–17. https://doi.org/10.4250/jcvi.2022.0029
Alluri K, Joshi PH, Henry TS, Blumenthal RS, Nasir K, Blaha MJ (2015) Scoring of coronary artery calcium scans: history, assumptions, current limitations, and future directions. Atherosclerosis 239(1):109–117. https://doi.org/10.1016/j.atherosclerosis.2014.12.040
Criqui MH et al (2014) Calcium density of coronary artery plaque and risk of incident cardiovascular events. JAMA 311(3):271–278. https://doi.org/10.1001/jama.2013.282535
Razavi AC et al (2022) Discordance between coronary artery calcium area and density predicts long-term atherosclerotic cardiovascular disease risk. JACC Cardiovasc Imaging 15(11):1929–1940. https://doi.org/10.1016/j.jcmg.2022.06.007
Razavi AC et al (2022) Evolving role of calcium density in coronary artery calcium scoring and atherosclerotic cardiovascular disease risk. JACC Cardiovasc Imaging 15(9):1648–1662. https://doi.org/10.1016/j.jcmg.2022.02.026
Winther S et al (2020) Incorporating coronary calcification into pre-test assessment of the likelihood of coronary artery disease. J Am Coll Cardiol 76:2421–2432. https://doi.org/10.1016/j.jacc.2020.09.585
Hussain A, Ballantyne CM, Nambi V (2020) Zero coronary artery calcium score: desirable, but enough? Circulation 142(10):917–919. https://doi.org/10.1161/CIRCULATIONAHA.119.045026
Blaha M et al (2009) Absence of coronary artery calcification and all-cause mortality. JACC Cardiovasc Imaging 2(6):692–700. https://doi.org/10.1016/j.jcmg.2009.03.009
Peng AW et al (2020) Long-term all-cause and cause-specific mortality in asymptomatic patients with CAC >/=1,000: results from the CAC consortium. JACC Cardiovasc Imaging 13(1 Pt 1):83–93. https://doi.org/10.1016/j.jcmg.2019.02.005
Xie X et al (2013) Validation and prognosis of coronary artery calcium scoring in nontriggered thoracic computed tomography: systematic review and meta-analysis. Circ Cardiovasc Imaging 6(4):514–521. https://doi.org/10.1161/CIRCIMAGING.113.000092
de Koning HJ et al (2020) Reduced lung-cancer mortality with volume CT screening in a randomized trial. N Engl J Med 382:503–513. https://doi.org/10.1056/NEJMoa1911793
Rustagi AS, Byers AL, Keyhani S (2022) Likelihood of lung cancer screening by poor health status and race and ethnicity in US adults, 2017 to 2020. JAMA Netw Open. https://doi.org/10.1001/jamanetworkopen.2022.5318
Ruparel M et al (2019) Evaluation of cardiovascular risk in a lung cancer screening cohort. Thorax 74(12):1140–1146. https://doi.org/10.1136/thoraxjnl-2018-212812
Tailor TD et al (2021) Cardiovascular risk in the lung cancer screening population: a multicenter study evaluating the association between coronary artery calcification and preventive statin prescription. J Am Coll Radiol 18(9):1258–1266. https://doi.org/10.1016/j.jacr.2021.01.015
Messerli M, Hechelhammer L, Leschka S, Warschkow R, Wildermuth S, Bauer RW (2018) Coronary risk assessment at X-ray dose equivalent ungated chest CT: results of a multi-reader study. Clin Imaging 49:73–79. https://doi.org/10.1016/j.clinimag.2017.10.014
Blaha MJ et al (2016) Improving the CAC score by addition of regional measures of calcium distribution: multi-ethnic study of atherosclerosis. JACC Cardiovasc Imaging 9(12):1407–1416. https://doi.org/10.1016/j.jcmg.2016.03.001
Tota-Maharaj R et al (2015) Usefulness of regional distribution of coronary artery calcium to improve the prediction of all-cause mortality. Am J Cardiol 115(9):1229–34. https://doi.org/10.1016/j.amjcard.2015.01.555
Williams M et al (2008) Prognostic value of number and site of calcified coronary lesions compared with the total score. JACC Cardiovasc Imaging 1(1):61–9. https://doi.org/10.1016/j.jcmg.2007.09.001
Ferencik M et al (2017) Coronary artery calcium distribution is an independent predictor of incident major coronary heart disease events: results from the framingham heart study. Circ Cardiovasc Imaging. https://doi.org/10.1161/CIRCIMAGING.117.006592
Ghadri JR et al (2011) Inter-scan variability of coronary artery calcium scoring assessed on 64-multidetector computed tomography vs. dual-source computed tomography: a head-to-head comparison. Eur Heart J 32(15):1865–1874. https://doi.org/10.1093/eurheartj/ehr157
Chung H, McClelland RL, Katz R, Carr JJ, Budoff MJ (2008) Repeatability limits for measurement of coronary artery calcified plaque with cardiac CT in the multi-ethnic study of atherosclerosis. AJR Am J Roentgenol 190(2):W87–W92. https://doi.org/10.2214/AJR.07.2726
Shaw LJ et al (2018) Sex differences in calcified plaque and long-term cardiovascular mortality: observations from the CAC consortium. Eur Heart J 39:3727–3735. https://doi.org/10.1093/eurheartj/ehy534
Chu JH et al (2022) Coronary artery calcium and atherosclerotic cardiovascular disease risk in women with early menopause: the multi-ethnic study of atherosclerosis (MESA). Am J Prev Cardiol 11:100362. https://doi.org/10.1016/j.ajpc.2022.100362
Freaney PM et al (2021) Association of premature menopause with coronary artery calcium: the CARDIA study. Circ Cardiovasc Imaging 14(11):e012959. https://doi.org/10.1161/CIRCIMAGING.121.012959
Sama C et al (2023) Non-calcified plaque in asymptomatic patients with zero coronary artery calcium score: a systematic review and meta-analysis. J Cardiovasc Comput Tomogr. https://doi.org/10.1016/j.jcct.2023.10.002
van der Werf NR et al (2022) Improved coronary calcium detection and quantification with low-dose full field-of-view photon-counting CT: a phantom study. Eur Radiol 32(5):3447–3457. https://doi.org/10.1007/s00330-021-08421-8
Nadjiri J et al (2018) Accuracy of calcium scoring calculated from contrast-enhanced coronary computed tomography angiography using a dual-layer spectral CT: a comparison of calcium scoring from real and virtual non-contrast data. PLoS ONE 13(12):e0208588. https://doi.org/10.1371/journal.pone.0208588
Mahoney R et al (2014) Clinical validation of dual-source dual-energy computed tomography (DECT) for coronary and valve imaging in patients undergoing trans-catheter aortic valve implantation (TAVI). Clin Radiol 69(8):786–794. https://doi.org/10.1016/j.crad.2014.03.010
Douek PC et al (2023) Clinical applications of photon-counting CT: a review of pioneer studies and a glimpse into the future. Radiology. https://doi.org/10.1148/radiol.222432
Boccalini S et al (2022) First in-human results of computed tomography angiography for coronary stent assessment with a spectral photon counting computed tomography. Invest Radiol 57(4):212–221. https://doi.org/10.1097/RLI.0000000000000835
Butler PH et al (2019) MARS pre-clinical imaging: the benefits of small pixels and good energy data, presented at the developments in X-ray Tomography XII
Wolf EV et al (2023) Intra-individual comparison of coronary calcium scoring between photon counting detector- and energy integrating detector-CT: effects on risk reclassification. Front Cardiovasc Med. https://doi.org/10.3389/fcvm.2022.1053398
Ongsulee P (2017) Artificial intelligence, machine learning and deep learning, presented at the 2017 15th International Conference on ICT and Knowledge Engineering (ICT&KE)
Solomonides AE et al (2022) Defining AMIA’s artificial intelligence principles. J Am Med Inf Assoc 29(4):585–591. https://doi.org/10.1093/jamia/ocac006
Rajkomar A, Dean J, Kohane I (2019) Machine learning in medicine. N Engl J Med 380:1347–1358. https://doi.org/10.1056/NEJMra1814259
Erickson BJ, Korfiatis P, Akkus Z, Kline TL (2017) Machine learning for medical imaging. Radiographics 37(2):505–515. https://doi.org/10.1148/rg.2017160130
Bluemke DA et al (2020) Assessing radiology research on artificial intelligence: a brief guide for authors, reviewers, and readers-from the radiology editorial board. Radiology 294(3):487–489. https://doi.org/10.1148/radiol.2019192515
Castiglioni I et al (2021) AI applications to medical images: from machine learning to deep learning. Phys Med 83:9–24. https://doi.org/10.1016/j.ejmp.2021.02.006
LeCun Y, Bengio Y, Hinton G (2015) Deep learning. Nature 521(7553):436–444. https://doi.org/10.1038/nature14539
Muscogiuri G et al (2022) Application of AI in cardiovascular multimodality imaging. Heliyon. https://doi.org/10.1016/j.heliyon.2022.e10872
Soffer S, Ben-Cohen A, Shimon O, Amitai MM, Greenspan H, Klang E (2019) Convolutional neural networks for radiologic images: a radiologist’s guide. Radiology 290(3):590–606. https://doi.org/10.1148/radiol.2018180547
Alzubaidi L et al (2021) Review of deep learning: concepts, CNN architectures, challenges, applications, future directions. J Big Data 8(1):53. https://doi.org/10.1186/s40537-021-00444-8
Yamashita R, Nishio M, Do RKG, Togashi K (2018) Convolutional neural networks: an overview and application in radiology. Insights Imaging 9(4):611–629. https://doi.org/10.1007/s13244-018-0639-9
O’Shea K, Nash R An introduction to convolutional neural networks, arXiv:1511.0845810.48550/arXiv.1511.08458
Ronneberger O, Fischer P, Brox T U-Net: convolutional networks for biomedical image segmentation, arXiv:1505.0459710.48550/arXiv.1505.04597
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition, arXiv preprint arXiv:1409.1556
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778
Singh G et al (2018) Machine learning in cardiac CT: basic concepts and contemporary data. J Cardiovasc Comput Tomogr 12(3):192–201. https://doi.org/10.1016/j.jcct.2018.04.010
Banchhor SK et al (2018) Calcium detection, its quantification, and grayscale morphology-based risk stratification using machine learning in multimodality big data coronary and carotid scans: a review. Comput Biol Med 101:184–198. https://doi.org/10.1016/j.compbiomed.2018.08.017
Lessmann N et al (2018) Automatic calcium scoring in low-dose chest CT using deep neural networks with dilated convolutions. IEEE Trans Med Imaging 37(2):615–625. https://doi.org/10.1109/TMI.2017.2769839
Kurkure U, Chittajallu DR, Brunner G, Le YH, Kakadiaris IA (2010) A supervised classification-based method for coronary calcium detection in non-contrast CT. Int J Cardiovasc Imaging 26(7):817–828. https://doi.org/10.1007/s10554-010-9607-2
Isgum I, Rutten A, Prokop M, van Ginneken B (2007) Detection of coronary calcifications from computed tomography scans for automated risk assessment of coronary artery disease. Med Phys 34(4):1450–1461. https://doi.org/10.1118/1.2710548
Ourselin S et al (2015) Automated coronary artery calcium scoring from non-contrast CT using a patient-specific algorithm, presented at the medical imaging 2015: image processing
van Ginneken B, Wu J, Ferns G, Giles J, Lewis E, Novak CL (2012) A fully automated multi-modal computer aided diagnosis approach to coronary calcium scoring of MSCT images, presented at the medical imaging 2012: computer-aided diagnosis
Dawant BM, Wu J, Haynor DR, Ferns G, Giles J, Lewis E (2011) A framework for automated coronary artery tracking of low axial resolution multi slice CT images, presented at the medical imaging 2011: image processing
Brunner G, Chittajallu DR, Kurkure U, Kakadiaris IA (2010) Toward the automatic detection of coronary artery calcification in non-contrast computed tomography data. Int J Cardiovasc Imaging 26:829–838. https://doi.org/10.1007/s10554-010-9608-1
Yang G, Chen Y, Ning X, Sun Q, Shu H, Coatrieux JL (2016) Automatic coronary calcium scoring using noncontrast and contrast CT images. Med Phys 43(5):2174. https://doi.org/10.1118/1.4945045
Shahzad R et al (2013) Vessel specific coronary artery calcium scoring: an automatic system. Acad Radiol 20(1):1–9. https://doi.org/10.1016/j.acra.2012.07.018
Eng D et al (2021) Automated coronary calcium scoring using deep learning with multicenter external validation. NPJ Digit Med 4(1):88. https://doi.org/10.1038/s41746-021-00460-1
Winkel DJ et al (2022) Deep learning for vessel-specific coronary artery calcium scoring: validation on a multi-centre dataset. Eur Heart J Cardiovasc Imaging 23(6):846–854. https://doi.org/10.1093/ehjci/jeab119
Sartoretti T et al (2023) Fully automated deep learning powered calcium scoring in patients undergoing myocardial perfusion imaging. J Nucl Cardiol 30(1):313–320. https://doi.org/10.1007/s12350-022-02940-7
Zhang N et al (2021) Fully automatic framework for comprehensive coronary artery calcium scores analysis on non-contrast cardiac-gated CT scan: total and vessel-specific quantifications. Eur J Radiol 134:109420. https://doi.org/10.1016/j.ejrad.2020.109420
Sandstedt M et al (2020) Evaluation of an AI-based, automatic coronary artery calcium scoring software. Eur Radiol 30(3):1671–1678. https://doi.org/10.1007/s00330-019-06489-x
Wang W et al (2020) Coronary artery calcium score quantification using a deep-learning algorithm. Clin Radiol. https://doi.org/10.1016/j.crad.2019.10.012
Gogin N et al (2021) Automatic coronary artery calcium scoring from unenhanced-ECG-gated CT using deep learning. Diagn Interv Imaging 102(11):683–690. https://doi.org/10.1016/j.diii.2021.05.004
Zhou Z, Mahfuzur RSM, Tajbakhsh N, Liang J, UNet++: a nested U-Net architecture for medical image segmentation, arXiv:1807.1016510.48550/arXiv.1807.10165
Hong JS et al (2022) Automated coronary artery calcium scoring using nested U-Net and focal loss. Comput Struct Biotechnol J 20:1681–1690. https://doi.org/10.1016/j.csbj.2022.03.025
Choi JH et al (2022) Validation of deep learning-based fully automated coronary artery calcium scoring using non-ECG-gated chest CT in patients with cancer. Front Oncol 12:989250. https://doi.org/10.3389/fonc.2022.989250
Takx RA et al (2014) Automated coronary artery calcification scoring in non-gated chest CT: agreement and reliability. PLoS ONE 9(3):e91239. https://doi.org/10.1371/journal.pone.0091239
van Assen M et al (2021) Automatic coronary calcium scoring in chest CT using a deep neural network in direct comparison with non-contrast cardiac CT: a validation study. Eur J Radiol 134:109428. https://doi.org/10.1016/j.ejrad.2020.109428
Morf C et al (2022) Diagnostic value of fully automated artificial intelligence powered coronary artery calcium scoring from 18F-FDG PET/CT. Diagnostics (Basel). https://doi.org/10.3390/diagnostics12081876
van Velzen SGM et al (2020) Deep learning for automatic calcium scoring in CT: validation using multiple cardiac CT and chest CT protocols. Radiology 295(1):66–79. https://doi.org/10.1148/radiol.2020191621
Peng AW et al (2023) Association of coronary artery calcium detected by routine ungated CT imaging with cardiovascular outcomes. J Am Coll Cardiol 82(12):1192–1202. https://doi.org/10.1016/j.jacc.2023.06.040
Sartoretti E et al (2022) Opportunistic deep learning powered calcium scoring in oncologic patients with very high coronary artery calcium (>/= 1000) undergoing 18F-FDG PET/CT. Sci Rep 12(1):19191. https://doi.org/10.1038/s41598-022-20005-0
Ihdayhid AR et al (2023) Evaluation of an artificial intelligence coronary artery calcium scoring model from computed tomography. Eur Radiol 33(1):321–329. https://doi.org/10.1007/s00330-022-09028-3
Shahzad R, Vliet L, Niessen W, van Walsum T (2014) Automatic classification of calcification in the coronary vessel tree Proceedings of the MICCAI Challenge on Automatic Coronary Calcium Scoring: ISI
Andreassi MG, Picano E (2014) Reduction of radiation to children: our responsibility to change. Circulation 130(2):135–137. https://doi.org/10.1161/CIRCULATIONAHA.114.010699
Koetzier LR et al (2023) Deep learning image reconstruction for CT: technical principles and clinical prospects. Radiology. https://doi.org/10.1148/radiol.221257
Willemink MJ, Noel PB (2019) The evolution of image reconstruction for CT-from filtered back projection to artificial intelligence. Eur Radiol 29(5):2185–2195. https://doi.org/10.1007/s00330-018-5810-7
Otgonbaatar C et al (2023) Coronary artery calcium quantification: comparison between filtered-back projection, hybrid iterative reconstruction, and deep learning reconstruction techniques. Acta Radiol. https://doi.org/10.1177/02841851231174463
Rossi A et al (2023) Impact of deep learning image reconstructions (DLIR) on coronary artery calcium quantification. Eur Radiol 33(6):3832–3838. https://doi.org/10.1007/s00330-022-09287-0
Wang Y et al (2021) Influence of deep learning image reconstruction and adaptive statistical iterative reconstruction-V on coronary artery calcium quantification. Ann Transl Med 9(23):1726. https://doi.org/10.21037/atm-21-5548
Dobrolinska MM et al (2023) Systematic assessment of coronary calcium detectability and quantification on four generations of CT reconstruction techniques: a patient and phantom study. Int J Cardiovasc Imaging 39(1):221–231. https://doi.org/10.1007/s10554-022-02703-y
Choi H, Park EA, Ahn C, Kim JH, Lee W, Jeong B (2023) Performance of 1-mm non-gated low-dose chest computed tomography using deep learning-based noise reduction for coronary artery calcium scoring. Eur Radiol 33(6):3839–3847. https://doi.org/10.1007/s00330-022-09300-6
Karius P, Schuetz GM, Schlattmann P, Dewey M (2014) Extracardiac findings on coronary CT angiography: a systematic review. J Cardiovasc Comput Tomogr. https://doi.org/10.1016/j.jcct.2014.04.002
Chamberlin J et al (2021) Automated detection of lung nodules and coronary artery calcium using artificial intelligence on low-dose CT scans for lung cancer screening: accuracy and prognostic value. BMC Med 19(1):55. https://doi.org/10.1186/s12916-021-01928-3
Mahesh M, Ansari AJ, Mettler FA (2023) Patient exposure from radiologic and nuclear medicine procedures in the United States and worldwide: 2009–2018. Radiology. https://doi.org/10.1148/radiol.221263
Blumenthal RS, Grant J, Whelton SP (2023) Incidental coronary artery calcium: nothing is more expensive than a missed opportunity. J Am Coll Cardiol 82(12):1203–1205. https://doi.org/10.1016/j.jacc.2023.06.039
Yang L, Ene IC, Arabi Belaghi R, Koff D, Stein N, Santaguida PL (2022) Stakeholders’ perspectives on the future of artificial intelligence in radiology: a scoping review. Eur Radiol 32(3):1477–1495. https://doi.org/10.1007/s00330-021-08214-z
Rajpurkar P, Lungren MP (2023) The current and future state of AI interpretation of medical images. N Engl J Med 388:1981–1990. https://doi.org/10.1056/NEJMra2301725
Gennari AG et al (2022) Low-dose CT from myocardial perfusion SPECT/CT allows the detection of anemia in preoperative patients. J Nucl Cardiol 29(6):3236–3247. https://doi.org/10.1007/s12350-021-02899-x
Arnett DK et al (2019) 2019 ACC/AHA guideline on the primary prevention of cardiovascular disease: executive summary: a report of the american college of cardiology/American heart association task force on clinical practice guidelines. J Am Coll Cardiol 74(10):1376–1414. https://doi.org/10.1016/j.jacc.2019.03.009
Pearson GJ et al (2021) 2021 Canadian cardiovascular society guidelines for the management of dyslipidemia for the prevention of cardiovascular disease in adults. Can J Cardiol 37(8):1129–1150. https://doi.org/10.1016/j.cjca.2021.03.016
M . Authors/Task Force, E. S. C. C. f. P. Guidelines, and E. S. C. N. C. Societies (2019) ESC/EAS guidelines for the management of dyslipidaemias: lipid modification to reduce cardiovascular risk. Atherosclerosis 290:140–205. https://doi.org/10.1016/j.atherosclerosis.2019.08.014
Liew G et al (2017) Cardiac society of Australia and New Zealand position statement: coronary artery calcium scoring. Heart Lung Circ 26(12):1239–1251. https://doi.org/10.1016/j.hlc.2017.05.130
Kinoshita M et al (2018) Japan atherosclerosis society (JAS) guidelines for prevention of atherosclerotic cardiovascular diseases 2017. J Atheroscler Thromb 25(9):846–984. https://doi.org/10.5551/jat.GL2017
(2021) Chinese Guideline on the primary prevention of cardiovascular diseases, Cardiol Discov 1(2):70–104. https://doi.org/10.1097/cd9.0000000000000025
Orringer CE et al (2021) The national lipid association scientific statement on coronary artery calcium scoring to guide preventive strategies for ASCVD risk reduction. J Clin Lipidol 15(1):33–60. https://doi.org/10.1016/j.jacl.2020.12.005
Takahashi D et al (2023) Fully automated coronary artery calcium quantification on electrocardiogram-gated non-contrast cardiac computed tomography using deep-learning with novel heart-labelling method. Eur Heart J Open 3(6):oead113. https://doi.org/10.1093/ehjopen/oead113
Aknowledgement
M.M., M.S., and T.S. are supported by a research grant from the Palatin Foundation, Switzerland. A.G.G. would like to thank the Swiss Government Excellence Scholarship, Switzerland, and the Premio Nino ed Hansi Cominotti, Italy, for funding. A.A.G. is supported by research funding grants from the Promedica Foundation and Max and Sophielene Iten-Kohaut Foundation. M.W.H. received grants and speaker honoraria from GE Healthcare and a fund by the Alfred and Annemarie von Sick legacy. Further A.G.G., M.S., M.M. and M.W.H. are supported by a grant from the clinical research priority program (CRPP) Artificial Intelligence in Oncological Imaging Network of the University of Zurich. M.vA is supported by research funding from Siemens Healthineers. C.N.DC received institutional research support and / or personal speaker/consulting fees from Bayer, Siemens, and Xeos. These were originally contained in the competing interest section which has not been included in the manuscript. However, we want to thank the founders for supporting our work.
Funding
Open access funding provided by University of Zurich. Neither the funders nor GE had any role in the study.
Author information
Authors and Affiliations
Contributions
Conceptualization: A.G.G., A.R., C.N.DC, M.vA, T.S., A.A.G, M.S., M.H., and M.M; Writing-original draft preparation: A.G.G.; Writing-review and editing: A.G.G., A.R., C.N.DC, M.vA, T.S., A.A.G, M.S., M.H., and M.M. All authors read and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Ethical approval
Not applicable.
Consent to participant
Not applicable.
Consent for publication
Not applicable.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gennari, A.G., Rossi, A., De Cecco, C.N. et al. Artificial intelligence in coronary artery calcium score: rationale, different approaches, and outcomes. Int J Cardiovasc Imaging 40, 951–966 (2024). https://doi.org/10.1007/s10554-024-03080-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10554-024-03080-4