
Abstract
Previous studies suggest an individual’s risk of depression following adversity may be moderated by their genetic liability. No study, however, has examined peer victimisation, an experience repeatedly associated with mental illness. We explore whether the negative mental health outcomes following victimisation can be partly attributed to genetic factors using polygenic scores for depression and wellbeing. Among participants from the Avon Longitudinal Study of Parents and Children (ALSPAC), we show that polygenic scores and peer victimisation are significant independent predictors of depressive symptoms (n=2268) and wellbeing (n=2299) in early adulthood. When testing for interaction effects, our results lead us to conclude that low mental health and wellbeing following peer victimisation is unlikely to be explained by a moderating effect of genetic factors, as indexed by current polygenic scores. Genetic profiling is therefore unlikely to be effective in identifying those more vulnerable to the effects of victimisation at present. The reasons why some go on to experience mental health problems following victimisation, while others remain resilient, requires further exploration, but our results rule out a major influence of current polygenic scores.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Depression is a debilitating disorder and leading cause of worldwide disability (World Health Organization 2018). Heritability estimates for depression are around 30%–40% (Sullivan, Neale and Kendler 2000), highlighting a significant role for genetic factors. Genome-wide association studies (GWAS) into the genetic architecture of depression have revealed it is highly polygenic (Howard et al. 2019), meaning effects are driven by numerous genetic variants, each of small effect. These can be indexed by polygenic risk scores and used to estimate an individual’s genetic risk of depression (Lewis and Vassos 2020).
Polygenic scores are calculated using the weighted sum of independent risk alleles from a discovery GWAS (Dudbridge 2013). By summarising the combined effects of multiple genetic variants, polygenic scores provide a more accurate representation of the genetic risk of complex traits like depression compared to single candidate genes. Their utility is highlighted by research that has demonstrated an ability to predict disease status within both case-control studies (Howard et al. 2019) and population-based cohorts (Musliner et al. 2019). Current polygenic scores account for approximately 3% of the variance in depression (Howard et al. 2019), suggesting their main effects alone may have a negligible impact on the risk of depression. Researchers have therefore urged that studies consider interactions between genetic and environmental factors when investigating the etiology of psychiatric disorders (Assary et al. 2017).
Although genetic liability to a trait or disorder is fixed from birth, the risk is dynamic, meaning it may be altered by certain exposures (Haworth and Davis 2014). Diathesis-stress models propose that stress activates a predisposed vulnerability, or diathesis, which eventually transpires into sufficient conditions for disorder onset (Monroe and Simons 1991). Thus, the genetic risk of psychiatric disorders may be heightened by stressful environments. This genetically driven sensitivity towards environments can be empirically tested through gene-by-environment studies.
Gene-environment interaction (G×E) studies assess the extent to which psychiatric risk is influenced by genetic predispositions and environmental exposures. The presence of a G×E indicates that the influence of an environment is different for individuals with different genotypes (Ottman 1996). A G×E can also refer to the different outcomes of a genotype among individuals with differing environmental exposures (Ottman 1996). Studies using the G×E framework to test the diathesis-stress model of depression have shown that interactions between polygenic scores and negative life events predict an increased risk of depression (Colodro-Conde et al. 2018). Such findings imply a heightened risk for individuals with both genetic vulnerability to depression and negative life experiences.
Similar findings have been reported when exploring the specific impact of childhood trauma (Peyrot et al. 2014), although findings are conflicted. One study provided evidence of an inverse association and found that individuals subjected to childhood trauma are at greatest risk if they also have a low polygenic score for depression (Mullins et al. 2016). These findings were contrary to what was predicted, which was that polygenic scores would correlate with an increased risk. Such a finding is yet to repeated, with others reporting no interactions between polygenic risk and childhood trauma in predicting depression (Peyrot et al. 2018). A recent phenome-wide association study which investigated the association between depression polygenic scores and many environments, revealed varying interactive results depending on the age at which the trauma took place, with interactions identified using childhood trauma but not trauma that took place in adulthood (Shen et al. 2020a). No study to date has used the polygenic approach to consider experiences in adolescence, a critical period for the onset of mental health problems (Kessler et al. 2005), or the role of peer victimisation.
Peer victimisation refers to the experience in which an individual is repeatedly exposed to discomfort at the expense of another peer’s actions (Olweus 1994). It is a common occurrence in schools worldwide, with prevalence rates ranging from 8.6%–45.2% (Craig et al. 2009). Peer victimisation is deemed a major public health concern (Srabstein and Merrick 2013), associated with adverse outcomes across the lifespan, including depression (Arsenault 2017) and low wellbeing (Armitage et al. 2021). Not all individuals exposed to peer victimisation however, go on to develop problems with their mental health. Around 15% of individuals who report frequent victimisation during adolescence have a clinical diagnosis of depression by early adulthood (Bowes et al. 2015), suggesting many display resilience to its effects.
It is possible that some individuals are especially vulnerable to the effects of victimisation due to their heightened genetic risk. Heritability estimates for peer victimisation range from 65%–77% (Johansson et al. 2020; Veldkamp et al. 2019). Research has revealed that this genetic susceptibility may be explained by an increased genetic risk towards other traits and disorders, such as depression (Schoeler et al. 2019). This finding of a shared genetic liability has led some to propose that the negative outcomes of peer victimisation may largely reflect pre-existing vulnerabilities (Singham et al. 2017). This gene-environment correlation (rGE), whereby the risk of an individual experiencing an event is partly attributed to their genotype (Plomin et al. 1977), could account for both the increased risk of peer victimisation and the subsequent susceptibility to depression. Individuals more capable of displaying resilience after peer victimisation may therefore be those at a lower genetic risk to mental health problems.
One study investigating this theory attempted to predict outcomes of individuals following the death of a spouse using polygenic scores (Domingue et al. 2017). It was found that individuals with higher wellbeing polygenic scores showed significantly smaller increases in depressive symptoms than those with lower polygenic scores following the loss of a loved one. This study, however, did not investigate whether the polygenic scores moderated levels of wellbeing, but focused solely on buffering effects on depression. Wellbeing refers to feelings of satisfaction and happiness (Diener 2000) and is therefore more than the absence of a mental illness (Westerhof and Keyes 2010). Studies have shown overlapping but also distinct genetic and environmental factors associated with depression and wellbeing (Haworth et al. 2017), highlighting the need to consider both to attain a more complete understanding of resilient functioning.
Current Study
The aim of the current study was to test the hypothesis that the relationship between peer victimisation in adolescence and mental health in early adulthood is moderated by an individual’s polygenic risk. We explore both depression and wellbeing outcomes to provide the first insight into whether genetic information can be used to target those more vulnerable to the effects of victimisation to help foster resilience.
Methods
Participants
Phenotypic and genotype data were taken from the Avon Longitudinal Study of Parents and Children (ALSPAC; Boyd et al. 2013), a prospective cohort based in the United Kingdom. Pregnant women residing in the former Avon area, with an expected delivery date between April 1991 and December 1992 were enrolled for the study (Fraser et al. 2013). The initial cohort consisted of 14,062 live births but has since increased to 14,901 children who were alive after one year with further recruitment (Northstone et al. 2019). Data gathered from 22 years and onwards were collected and managed using REDCap electronic data capture tools hosted at the University of Bristol (Harris et al. 2009). Please note that the study website contains details of all the data that is available through a fully searchable data dictionary and variable search tool (http://www.bristol.ac.uk/alspac/researchers/our-data/). Further information relating to genotyping can be found in the supplementary material.
Our study involved individuals who completed the victimisation assessment at 13 years (n=6527) and provided genotype data (n=4829). Of these, we used data from 2268 individuals who also completed the assessment for depressive symptoms at 23 years, and from 2299 individuals who completed the wellbeing questionnaire at 23 years. Individuals with genotype data were more likely to be female and less likely to be of a non-white ethnicity, consistent with previous genetic studies (Mullins et al. 2016). However, victimisation scores did not significantly differ between those with and without genotype information, or between those with missing data on the mental health outcomes (Supplementary Table S1). Ethical approval for our study was obtained from the ALSPAC Ethics and Law Committee and the Local Research Ethics Committees. Informed consent for the use of data collected via questionnaires and clinics was obtained from participants following the recommendations of the ALSPAC Ethics and Law Committee at the time.
Measures
Peer Victimisation
Peer victimisation was measured at 13 years using the previously validated Bullying and Friendship Interview Schedule (Wolke et al. 2001). Participants responded to nine statements relating to direct and indirect experiences of victimisation within the last six months. Direct victimisation is characterised by physical or verbal acts of aggression, while indirect relates to experiences of social exclusion. Adolescents responded based on the frequency of these experiences (0=Never, 1=Seldom, 2=Frequently, 3=Very Frequently). Correlations between the direct and indirect items were moderate (r=0.52), therefore scores from all items were summed. Scores ranged from 0–25 (M= 1.81, SD=2.75), with 0 representing those who had never been bullied. Owing to high amounts of positive skew (skew=2.4), victimisation scores were log transformed. This reduced the skew to 0.72. Main analyses were carried out using the log-transformed scores and repeated using the untransformed scores. Results using the untransformed scores are presented in the supplementary materials (see Table S2).
Mental Health
At 23 years, depressive symptoms were assessed using the Short Mood and Feelings Questionnaire (SMFQ) (Angold et al. 1995). The MFQ has proven a reliable and valid measure of depression in both clinical and non-clinical samples (Daviss et al. 2006). The shortened version represents a 13-item scale derived from the 33-item Moods and Feelings Questionnaire (MFQ) which aims to capture the presence of depression symptoms within the last two weeks (Costello and Angold 1988). Overall scores on the sMFQ range from 0 to 26, with a score of 12 or above indicative of depression. Scores in the current sample had a mean of 6.64 (SD=5.82) and a skew greater than 1 (skew=1.15). This was adjusted for in the regression analyses using a negative binomial model, as described below.
Wellbeing was assessed for the first time at 23 years using the Warwick-Edinburgh Mental Well-Being Scale (WEMWBS) (Tennant et al. 2007). Although other wellbeing measures were available, we chose this scale because of its ability to capture affective and cognitive aspects, as well as overall psychological functioning (Tennant et al. 2007). WEMWBS is also widely used within public health and policy and has proven reliability across populations in Europe (López et al. 2013). The scale comprises of 14 items relating to experiences over the last two weeks. Individuals choose from a 5-point Likert scale that best describes their experience. Items are scored positively and summed to produce a minimum score of 14 and a maximum score of 70. Scores in the current sample had a mean average of 49.17 (SD=8.74) and a slight positive skew (skew=− 0.41). However, because this skew value was below 1, analyses were conducting using a standard linear regression.
Polygenic Scores
Polygenic scores for depression were created in PRSice (http://prsice.info, Euesden, Lewis, and O'Reilly 2015) using publicly available summary statistics from the largest GWAS to date of major depression (Howard et al. 2019). This GWAS meta-analysed data from the three largest GWASs of depression (Howard et al. 2018; Hyde et al 2016; Wray et al. 2018). The studies each used a different diagnostic instrument to assess depression, with one based on self-reported help-seeking behaviour, another on self-declared clinical depression, and the third used clinically obtained reports. Despite this, strong genetic correlations (>0.85) were identified between the three, suggesting an overlap in the underlying genetic architecture.
For comparative purposes, polygenic scores associated with wellbeing were also investigated. These were also created in PRSice using summary data from the multivariate genome-wide-association meta-analysis (GWAMA) of wellbeing (Baselmans et al. 2019). We used data from the N-weighted multivariate GWAMA (N-GWAMA) to generate overall wellbeing-polygenic scores. The N-GWAMA is a novel method that was introduced by the authors to test for a unitary effect of SNPs on four related traits: life satisfaction, positive affect, neuroticism, and depressive symptoms. The authors collectively refer to these as the well-being spectrum (Baselmans et al. 2019).
Both the depression-polygenic scores and wellbeing-polygenic scores were generated by combining the number of risk alleles present for each SNP (0, 1, or 2), weighted by their effect estimates as reported in the original discovery GWAS. ALSPAC is an independent sample and was not included in either of the discovery GWASs. Each SNP was used to construct a polygenic score in the ALSPAC cohort using best guess imputation genotypes. SNPs with a minor allele frequency (MAF) <1% and an imputation quality score <0.8 have been removed. Clumping was carried out to remove SNPs in linkage disequilibrium (LD) based on an r-squared threshold of 0.10 within a 500kb window. This was to align with previous procedures using both the depression (Howard et al. 2019) and the wellbeing GWAS (Baselmans et al. 2019). Polygenic scores were initially calculated using p-value thresholds of 5×10−8, 1×10−6, 1×10−4, 0.001, 0.01, 0.1, 0.2, 0.3, 0.4, 0.5 and 1. The number of SNPs included were 70, 159, 1000, 2197, 12924, 62678, 99128, 127673, 150781, 169733 and 192822 respectively for the depression-polygenic scores and 198, 418, 1628, 4009, 12381, 38939, 55626, 68192, 78160, 86119 and 107155 for the wellbeing-polygenic scores. All polygenic scores were z-standardised to a mean of 0 and standard deviation of 1 to facilitate interpretability (Lewis and Vassos 2017). Correlations between the depression and wellbeing polygenic scores, as well as with peer victimisation and the mental health measures can be found in Table 1.
Statistical Analyses
The main effects of the polygenic scores on depression and wellbeing were first examined using linear regressions. These models controlled for sex and the first two genetic principal components (PCs) to reduce possible subtle confounding by population stratification, as per previous studies (Mullins et al. 2016). The number of PCs to include depends largely on the variation within the sample (Anderson et al. 2019). Given that our cohort comprised of individuals of white European ancestry who were from a single region, 2 PCs were deemed sufficient to control for population stratification. We ran models exploring all SNP-association thresholds to inform the polygenic scores that had the highest incremental R2 value. This was calculated by separately regressing the depressive symptom and wellbeing outcomes onto sex and the two PCs, and then comparing models to those that included the polygenic scores. This is common practice for selecting which scores to use for subsequent analyses (Anderson et al. 2019). We then re-test the main effects of the polygenic-scores with the highest variance while also adjusting for the log-transformed victimisation scores. This allowed us to determine the main and independent effects of both victimisation and polygenic risk. We subsequently test for a potential gene-environment correlation (rGE) by exploring associations between the polygenic scores and victimisation. Studying both forms of gene-environment interplay (rGE and G×E) is vital as omission of either could lead to an overestimation of environmental effects (Eaves et al. 2003).
To investigate whether the polygenic scores moderate the wellbeing and depressive symptoms of individuals exposed to victimisation, we subsequently ran regression models that included an interaction term (victimisation by the polygenic scores). These initially used the genome-wide significant polygenic scores (p < 5×10-8) and then further analyses explored other significance thresholds. These thresholds were chosen to reflect the largest main effects for each polygenic score (see Supplementary Figure S1). All analyses controlled for the main effects of the polygenic scores and victimisation, as recommended when modelling interaction terms (Greenland and Pearce 2015), as well as sex and the first two PCs to correct for population stratification. To adjust for the potential effects of covariates on the interaction, we included adjustments for all covariate x polygenic score and covariate x victimisation interactions, as previously recommended (Keller 2014).
All analyses predicting wellbeing were run using standard linear regression, while analyses predicting depressive symptoms used negative binomial regression to address the negative skew. Negative binomial regression models were chosen over the standard Poisson model as the Poisson regression assumes identical parameters for the mean and variance, this was not the case for our depressive symptoms measure (M=6.64, σ²=34.8). We used the ‘MASS’ package (Venables and Ripley 2002) in R Studio version 4.5.0 (R Core Team 2021) to carry out the negative binomial regression models and the ‘rsq’ package (Zhang 2018) to generate R-squared estimates. To control for the probability of making a Type I error on multiple comparisons, Benjamini-Hochberg False Discovery Rate (FDR; Benjamini and Hochberg 1995) was used. This approach allows for the non-independence of repeated tests and works by controlling for the expected proportion of incorrect rejections at a designated value. This was set as α = 0.05 for the current study.
Results
Participant Characteristics
Of the individuals who completed the wellbeing and depressive symptom assessments, 54% scored above 0 on the victimisation scale, indicating some experience of victimisation in adolescence. Of these, 12.4% experienced frequent victimisation, defined as scoring 1 SD above the mean, as per previous research (Stadler et al. 2010). Among individuals who provided complete data and who reported some experience of victimisation, 18.7% had clinically relevant symptoms of depression compared to 12% of individuals who did not experience victimisation. Wellbeing scores averaged 48.53 (range 14–70) among those who experienced some victimisation, with scores averaging 50.04 (range 17-70) among those never victimised. Depressive symptoms and wellbeing were both predicted by sex, with females more likely to report increased depressive symptoms (ß=.172, SE=.04, p<0.001) and reduced wellbeing (ß=− 1.08, SE=.38, p<0.001).
Main Effect Analyses
When exploring associations between our outcome variables and the depression-polygenic scores, we find that the direction of effects was as predicted; all scores were positively associated with depressive symptoms, and negatively associated with wellbeing, with estimates typically stronger using more liberal thresholds (see Table S3). The depression-polygenic scores with a p-value threshold of 0.1 explained the most variance in depressive symptoms (incremental R2 = 1.43%), while the p-value threshold of 0.2 explained the most variance in wellbeing (incremental R2 = 1.21%). When investigating the wellbeing-polygenic scores, associations were also in the expected direction, with positive associations found with wellbeing, and negative associations with depressive symptoms (Table S4). The p-value threshold of 0.001 explained the most variance in both wellbeing (incremental R2 = 2.09%) and depressive symptoms (incremental R2 = 2.11%).
When investigating the main effects of the polygenic scores after accounting for victimisation, findings revealed highly similar results for both the depression- and wellbeing-polygenic scores (see Table S5). The main effects of victimisation on our outcome variables also remained largely the same after accounting for polygenic risk (Table S5). Such findings suggest that both victimisation and the polygenic scores are independent predictors of depressive symptoms and wellbeing. To explore a possible rGE between victimisation and the polygenic scores, we subsequently explored associations between the two. Findings revealed that some of the polygenic scores were associated with victimisation (Table 2). However, the depression-polygenic scores explained just 0.42% of the variance in victimisation, while the wellbeing-polygenic scores accounted for up to 0.45% of the variance. Correlations between the polygenic scores and victimisation were also low, reaching r=0.06 between victimisation and the depression-polygenic scores, and r=− 0.07 with the wellbeing-polygenic scores. We therefore believe it unlikely that any G×E findings will be largely attributable to a rGE.
Interaction Analyses to Test for G×E Effects
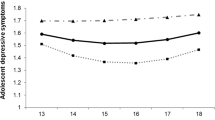
No interactions were found between either the depression- or wellbeing-polygenic scores and victimisation in predicting either depressive symptoms or wellbeing (Table 3). When using depression-polygenic scores based on the genome-wide significant threshold, findings revealed a borderline interaction effect (p= 0.056) when predicting wellbeing (Fig. 1). While plots of these findings suggest that having a lower polygenic risk to depression could prove protective to wellbeing for those exposed to more victimisation, the difference in wellbeing scores between individuals at a high polygenic risk was not significantly different. This was also the case for individuals exposed to no victimisation whose wellbeing scores were largely similar among those at a low or high genetic risk to depression. It is interesting to note that when entered as an interaction term, victimisation remained associated with an increased risk of depressive symptoms but was no longer predictive of wellbeing. This is likely due to the significant negative interactions that were observed between victimisation and sex in all models predicting wellbeing but not depressive symptoms. This suggests that associations between victimisation and wellbeing are heavily driven by sex; with female victims more likely to experience reductions in their wellbeing compared to males. Such findings demonstrate the importance of appropriate control over confounding variables as such effects can lead to misinterpretations of interactive effects (Keller 2014).
Analyses using the untransformed victimisation scores revealed similar results, with confidence intervals that overlapped with those using the transformed scores. (Table S2). These analyses revealed a significant interaction term between the depression-polygenic scores and victimisation in predicting wellbeing, however such findings were not robust after correction for multiple testing. For completeness, results from the other polygenic score thresholds can be found in the supplementary (see Table S6). Findings were highly consistent across different polygenic thresholds.

Interactive effects of log-transformed victimisation scores and the depression-polygenic scores (PGS) (P-value thereshold=5×108) on depressive symptoms and wellbeing. A demonstrates no differences in depressive symptoms at α= 0.05 among victims with varying polygenic scores. B provides some evidence of an effect of polygenic risk towards depression on wellbeing scores, with those reporting higher victimisation scores and a PGS 1 SD above the mean more likely to report lower wellbeing. This difference in wellbeing scores corresponded to p=0.056
Discussion
We consider for the first time whether the increased risk of mental illness and low wellbeing following victimisation can be partly attributed to genetic factors using polygenic scores for depression and wellbeing. Polygenic scores derived from the depression GWAS of adult samples explained up to 1.60% of the variance in depressive symptoms in our emerging adulthood sample, while wellbeing-polygenic scores explained up to 2.56% of the variance in wellbeing. These estimates are slightly higher than previous reports for both depression (Mullins et al. 2016) and wellbeing (Okbay et al. 2016), reflecting the increase in power gained from using larger and more recent meta-analyses of GWAS data. Overall, we report significant independent effects of the polygenic scores and peer victimisation in predicting the risk of depressive symptoms and wellbeing, but no clear interaction effects.
Few studies have considered the underlying paths driving resilience to the effects of peer victimisation. Those that have explored possible pathways have focused on estimating the role of genes and environments in influencing protective factors (Bowes, Maughan, Caspi, Moffitt and Arseneault 2010). By expanding this research to explore the impact of genetic liabilities to specific traits, our study offers novel insight into the potential moderating role of genetic risk. Findings suggest that the risk for poorer mental health among victims is not significantly different for those with varying polygenic risk to depression and wellbeing. Such findings are not consistent with diathesis-stress models of depression (Colodre et al. 2018) which would hypothesise that the mental health of victims varies according to their polygenic risk.
Our findings are also not consistent with the presence of a strong gene-environment correlation. To investigate gene-environment correlations, we explored associations between the polygenic scores and victimisation. Findings revealed that while some of the polygenic scores predicted the risk of peer victimisation (Table 2), the variance explained was small. This suggests that the risk of experiencing peer victimisation cannot be largely accounted for by an increased genetic risk to depression or wellbeing, as encapsulated by the current polygenic scores. Such findings may explain the absence of strong moderating effects of the polygenic scores. It is possible that the relationship between victimisation and mental health might be one in which genetic factors have a negligible effect. Similar conclusions were drawn from a twin study which reported that although pre-existing vulnerabilities may increase the likelihood of victimisation, they do not solely explain the increased risk of psychopathology among victims (Schaefer et al. 2018). This was based on the finding that victims experienced increased mental health problems independent of their early-life emotional problems, family background, and genetic risk (Schafer et al. 2018). The authors interpreted this as suggestive of a direct impact of victimisation on mental illness.
Our results lead us to a similar conclusion and allow us to also conclude that having a low polygenic risk to depression, or a high polygenic score for wellbeing, does not clearly reduce the risk of peer victimisation, or significantly buffer against mental illness to predict resilience to victimisation. Equally, findings suggest that having a higher genetic risk towards depression and low wellbeing does not heighten the risk of poor mental following peer victimisation. These weak moderating effects of genetic risk factors reflect previous findings from a meta-analysis of G×E studies (Peyrot et al. 2018). This revealed that the risk of depression among individuals exposed to childhood trauma is unlikely to be attributable to a moderation of genome-wide genetic effects. While our study results do not completely rule out the presence of a G×E, they suggest that using the current polygenic scores, there are no meaningful moderating effects on the mental health of individuals exposed to peer victimisation. Our study had 80% power to detect the current interactive effects at a = 0.05 (see Supplementary), therefore it is likely that larger discovery GWASs will be necessary to detect more subtle interactive effects.
It is important that when interpreting the absence of main and moderating effects of the polygenic scores that researchers are mindful of what the polygenic scores represent. Polygenic scores only include additive genetic effects and therefore do not represent the full genetic loading for a trait or disorder. In addition to this, while polygenic scores do capture information from the environment (Lewis et al. 2020), such as through environmentally mediated parental genetic effects, it is unclear from the current design to what degree this occurred. While the goal of the present study was not to study the aetiology of depression or wellbeing but possible pathways from peer victimisation to resilience, future research using polygenic scores within a family-based design could provide further insight into potential gene-by-environment correlations (Selzam et al. 2019).
Our study has both strengths and limitations. We are the first to explore predictors of both depression and wellbeing, and represent the only study to use polygenic scores for both depression and wellbeing. While our polygenic scores for wellbeing were derived from a GWAS that included measures of depression, we still identify moderate but not identical (rG~0.62) correlations between our depression- and wellbeing-polygenic scores. This suggests that they each capture independent genetic effects, reinforcing the need to expand current research focused solely on depression. Our findings also encourage more careful consideration of the thresholds used to derive the polygenic scores. Previous studies have tended to use arbitrary SNP p-value thresholds, which is a likely contribution to the lack of consistency within the literature. We present findings using the genome-wide significance cut-off to ensure polygenic scores were specific to the trait of interest and less likely to reflect noise. It is important to note however, that these scores did not have main effects at a = 0.05 on our outcome variables. We therefore supplement analyses using polygenic scores that captured the most variance in our outcome variables. All analyses were adjusted for multiple testing, as previously advised when exploring possible SNP-thresholds for analyses (Anderson et al. 2019).
One potential limitation of our methods for creating the polygenic scores is that we selected SNPs based on their main effects. These may not be the same variants that are involved in G×E. The generalisability of our findings must also be considered in relation to the discovery GWASs used to construct our polygenic scores. The extent to which participants from the original GWASs were victimised is unknown. It is therefore not possible to make deductions about the relative impact on our results. Both GWASs also included large samples from the UKBiobank. Participants from the UKBiobank are on average healthier than the general population, are more likely to be of white European decent, and are less likely to come from socioeconomically deprived areas (Fry et al. 2017). Assessments of mental health in these groups may therefore have less variation than the general population. Findings have shown, however, that prevalence rates for mental health disorders are largely similar across members from the UKBiobank and the general population (Davis et al. 2018). Recent research has also revealed that polygenic scores derived from these studies can be used to predict psychiatric disorders among individuals from different ancestral and cultural backgrounds (Shen et al. 2020b). It was noted, however, that the predictive ability of these polygenic scores is reduced compared to predictions among European samples. Nevertheless, these findings offer promising scope for the future of polygenic scores. Further research should now seek to include larger and more diverse samples in GWASs. This will be crucial to reducing the potential for health disparities that may arise from further polygenic research (Martin et al. 2019), and will prove key to ensuring any potential benefits offer improvements for both European and non-European populations (Lewis and Vassos 2020).
Overall, our study provides a unique approach to the study of resilience following peer victimisation. While we find no strong evidence that the mental health of victims is moderated by their polygenic risk to depression or wellbeing, further research using larger and more highly powered GWAS samples is necessary to rule it out. This will help detect more subtle G×E effects to clarify whether genetic profiling could be used to identify those more vulnerable to the effects of victimisation. Such findings could have clinical relevance and allow us to understand more about the reasons some go on to experience mental health problems, while others remain resilient following peer victimisation.
Data Availability
The data analysed in the current study is not publicly available. This is because the informed consent obtained from participants in ALSPAC does not allow data to be made freely available through any third party maintained public repository. Data used for this submission, however, can be made available on request to the ALSPAC Executive. Please refer to the ALSPAC data management plan which describes the policy regarding data sharing. This is through a system of managed open access. Full instructions for applying for data access can be found here: http://www.bristol.ac.uk/alspac/researchers/access/. The ALSPAC study website contains details of all the data that are available (http://www.bristol.ac.uk/alspac/researchers/our-data/).
References
Anderson JS, Shade J, DiBlasi E, Shabalin AA, Docherty AR (2019) Polygenic risk scoring and prediction of mental health outcomes. Curr Opin Psychol 27:77–81
Angold A, Costello EJ, Messer SC, Pickels A, Winder F, Silver D (1995) Development of a short questionnaire for use in epidemiological studies of depression in children and adolescents. Int J Methods Psychiatr Res 5(4):237–249
Armitage JM, Wang RAH, Davis OSP, Bowes L, Haworth CMA (2021) Peer victimisation during adolescence and its impact on wellbeing in adulthood: A prospective cohort study. BMC Public Health 21(148):1–13
Arsenault L (2017) The long-term impact of bullying victimization on mental health. World Psychiatry 16(1):27–28
Assary E, Vincent JP, Keers R, Pluess M (2017) Gene-environment interaction and psychiatric disorders: Review and future directions. Semin Cell Dev Biol 77:133–143
Baselmans BML, Jansen R, Ip HF, van Dongen J, Abdellaoui A, van de Weijer MP et al (2019) Multivariate genome-wide analyses of the well-being spectrum. Nat Genet 51(3):445–451
Benjamini Y, Hochberg Y (1995) Controlling the false discovery rate: a practical and powerful approach to multiple testing. J R Stat Soc B 57(1):289–300
Bowes L, Joinson C, Wolke D, Lewis G (2015) Peer victimisation during adolescence and its impact on depression in early adulthood: prospective cohort study in the United Kingdom. BMJ 350:h2469
Bowes L, Maughan B, Caspi A, Moffitt TE, Arseneault L (2010) Families promote emotional and behavioural resilience to bullying: evidence of an environmental effect. J Child Psychol Psychiatry 51(7):809–817
Boyd A, Golding J, Macleod J, Lawlor DA, Fraser A, Henderson J et al (2013) Cohort Profile: the 'children of the 90s'--the index offspring of the Avon Longitudinal Study of Parents and Children. Int J Epidemiol 42(1):111–127
Colodro-Conde L, Couvy-Duchesne B, Zhu G, Coventry WL, Byrne EM, Gordon S et al (2018) A direct test of the diathesis-stress model for depression. Mol Psychiatry 23(7):1590–1596
Costello EJ, Angold A (1988) Scales to assess child and adolescent depression: checklists, screens, and nets. J Am Acad Child Adolesc Psychiatry 27(6):726–737
Craig W, Harel-Fisch Y, Fogel-Grinvald H, Dostaler S, Hetland J, Simons-Morton B et al (2009) A cross-national profile of bullying and victimization among adolescents in 40 countries. Int J Public Health 54(Suppl 2(Suppl 2):216–224
Davis KAS, Coleman JRI, Adams M, Allen N, Breen G, Cullen B et al (2018) Mental health in UK Biobank: development, implementation and results from an online questionnaire completed by 157 366 participants. BJPsych Open 4(3):83–90
Daviss WB, Birmaher B, Melhem NA, Axelson DA, Michaels SM, Brent DA (2006) Criterion validity of the mood and feelings questionnaire for depressive episodes in clinic and non-clinic subjects. J Child Psychol Psychiatry 47(9):927–934
Diener E (2000) Subjective well-being. The science of happiness and a proposal for a national index. Am Psychol 55(1):34–43
Domingue BW, Liu H, Okbay A, Belsky DW (2017) Genetic heterogeneity in depressive symptoms following the death of a spouse: polygenic score analysis of the U.S. health and retirement study. Am J Psychiatry 174(10):963–970
Dudbridge F (2013) Power and predictive accuracy of polygenic risk scores. PLoS Genet 9(3):e1003348
Eaves L, Silberg J, Erkanli A (2003) Resolving multiple epigenetic pathways to adolescent depression. J Child Psychol Psychiatry 44(7):1006–1014
Euesden J, Lewis CM, O’Reilly PF (2015) PRSice: polygenic risk score software. Bioinformatics 31(9):1466–1468
Fraser A, Macdonald-Wallis C, Tilling K, Boyd A, Golding J, Davey Smith G et al (2013) Cohort profile: the Avon longitudinal study of parents and children: ALSPAC mothers cohort. Int J Epidemiol 42(1):97–110
Fry A, Littlejohns TJ, Sudlow C, Doherty N, Adamska L, Sprosen T et al (2017) Comparison of sociodemographic and health-related characteristics of UK biobank participants with those of the general population. Am J Epidemiol 186(9):1026–1034
Greenland S, Pearce N (2015) Statistical foundations for model-based adjustments. Annu Rev Public Health 18(36):89–108
Harris PA, Taylor R, Thielke R, Payne J, Gonzalez N, Conde JG (2009) Research electronic data capture (REDCap)--a metadata-driven methodology and workflow process for providing translational research informatics support. J Biomed Inform 42(2):377–381
Haworth CM, Davis OS (2014) From observational to dynamic genetics. Front Genet 21:5:6
Haworth CM, Carter K, Eley TC, Plomin R (2017) Understanding the genetic and environmental specificity and overlap between well-being and internalizing symptoms in adolescence. Dev Sci 20(2):e12376
Howard DM, Adams MJ, Shirali M, Clarke TK, Marioni RE, Davies G et al (2018) Genome-wide association study of depression phenotypes in UK Biobank identifies variants in excitatory synaptic pathways. Nat Commun 9(1):1470
Howard DM, Adams MJ, Clarke TK, Hafferty JD, Gibson J, Shirali M et al (2019) Genome-wide meta-analysis of depression identifies 102 independent variants and highlights the importance of the prefrontal brain regions. Nat Neurosci 22(3):343–352
Hyde CL, Nagle MW, Tian C, Chen X, Paciga SA, Wendland JR et al (2016) Identification of 15 genetic loci associated with risk of major depression in individuals of European descent. Nat Genet 48(9):1031–1036
Johansson A, Huhtamäki A, Sainio M, Kaljonen A, Boivin M, Salmivalli C (2020) Heritability of bullying and victimization in children and adolescents: moderation by the KiVa antibullying program. J Clin Child Adolesc Psychol 16:1–10
Keller MC (2014) Gene × environment interaction studies have not properly controlled for potential confounders: the problem and the (simple) solution. Biol Psychiatry 75(1):18–24
Kessler RC, Berglund P, Demler O, Jin R, Merikangas KR, Walters EE (2005) Lifetime prevalence and age-of-onset distributions of DSM-IV disorders in the National Comorbidity Survey Replication. Arch Gen Psychiatry 62(6):593–602
Lewis CM, Vassos E (2017) Prospects for using risk scores in polygenic medicine. Genome Med 9(1):96
Lewis CM, Vassos E (2020) Polygenic risk scores: from research tools to clinical instruments. Genome Med 12(44):1–11
López MA, Gabilondo A, Codony M, García-Forero C, Vilagut G, Castellví P et al (2013) Adaptation into Spanish of the Warwick-Edinburgh mental well-being scale (WEMWBS) and preliminary validation in a student sample. Qual Life Res 22(5):1099–1104
Martin AR, Kanai M, Kamatani Y, Okada Y, Neale BM, Daly MJ (2019) Clinical use of current polygenic risk scores may exacerbate health disparities. Nat Genet 51:584–591
Monroe SM, Simons AD (1991) Diathesis-stress theories in the context of life stress research: implications for the depressive disorders. Psychol Bull 110(3):406–425
Mullins N, Power RA, Fisher HL, Hanscombe KB, Euesden J, Iniesta R et al (2016) Polygenic interactions with environmental adversity in the aetiology of major depressive disorder. Psychol Med 46(4):759–770
Musliner KL, Mortensen PB, McGrath JJ, Suppli NP, Hougaard DM, Bybjerg-Grauholm J et al (2019) Association of polygenic liabilities for major depression, bipolar disorder, and schizophrenia with risk for depression in the Danish population. JAMA Psychiatry 76(5):516–525
Northstone K, Lewcock M, Groom A, Boyd A, Macleod J, Timpson N et al (2019) The Avon Longitudinal Study of Parents and Children (ALSPAC): an update on the enrolled sample of index children in 2019. Wellcome Open Res 14(4):51
Okbay A, Baselmans B, De Neve J, Turley P, Nivard MG, Fontana MA et al (2016) Genetic variants associated with subjective well-being, depressive symptoms, and neuroticism identified through genome-wide analyses. Nat Genet 48:624–633
Olweus D (1994) Bullying at school: basic facts and effects of a school based intervention program. J Child Psychol Psychiatry 35(7):1171–1190
Ottman R (1996) Gene-environment interaction: definitions and study designs. Prev Med 25(6):764–770
Peyrot WJ, Milaneschi Y, Abdellaoui A, Sullivan PF, Hottenga JJ, Boomsma DI et al (2014) Effect of polygenic risk scores on depression in childhood trauma. Br J Psychiatry 205(2):113–119
Peyrot WJ, Van der Auwera S, Milaneschi Y, Dolan CV, Madden PAF, Sullivan PF et al (2018) Does childhood trauma moderate polygenic risk for depression? A meta-analysis of 5765 subjects from the psychiatric genomics consortium. Biol Psychiatry 84(2):138–147
Plomin R, DeFries JC, Loehlin JC (1977) Genotype-environment interaction and correlation in the analysis of human behavior. Psychol Bull 84(2):309–322
R Core Team (2021) R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/
Schaefer JD, Moffitt TE, Arseneault L, Danese A, Fisher HL, Houts R et al (2018) Adolescent victimization and early-adult psychopathology: Approaching causal inference using a longitudinal twin study to rule out noncausal explanations. Clin Psychol Sci 6(3):352–371
Schoeler T, Choi SW, Dudbridge F, Baldwin J, Duncan L, Cecil CM, Walton E, Viding E, McCrory E, Pingault JB (2019) Multi-polygenic score approach to identifying individual vulnerabilities associated with the risk of exposure to bullying. JAMA Psychiatry 76(7):730–738. https://doi.org/10.1001/jamapsychiatry.2019.0310
Selzam S, Ritchie SJ, Pingault JB, Reynolds CA, O'Reilly PF, Plomin R (2019) Comparing within- and between-family polygenic score prediction. Am J Hum Genet 105(2):351–363. https://doi.org/10.1016/j.ajhg.2019.06.006
Shen X, Howard DM, Adams MJ, Hill WD, Clarke TK; Major Depressive Disorder Working Group of the Psychiatric Genomics Consortium (2020a) A phenome-wide association and Mendelian Randomisation study of polygenic risk for depression in UK Biobank. Nat Commun 11(1):2301
Shen H, Gelaye B, Huang H, Rondon MB, Sanchez S, Duncan LE (2020b) Polygenic prediction and GWAS of depression, PTSD, and suicidal ideation/self-harm in a Peruvian cohort. Neuropsychopharmacology 45(10):1595–1602
Singham T, Viding E, Schoeler T, Arseneault L, Ronald A, Cecil CM, McCrory E, Rijsdijk F, Pingault JB (2017) Concurrent and longitudinal contribution of exposure to bullying in childhood to mental health: the role of vulnerability and resilience. JAMA Psychiatry 74(11):1112–1119
Srabstein JC, Merrick J (2013) Bullying: A public health concern. Nova Science Publishing, Hauppauge
Stadler C, Feifel J, Rohrmann S, Vermeiren R, Poustka F (2010) Peer-victimization and mental health problems in adolescents: are parental and school support protective? Child Psychiatry Hum Dev 41(4):371–386
Sullivan PF, Neale MC, Kendler KS (2000) Genetic epidemiology of major depression: review and meta-analysis. Am J Psychiatry 157(10):1552–1562
Tennant R, Hiller L, Fishwick R, Platt S, Joseph S, Weich S et al (2007) The Warwick-Edinburgh Mental Well-being Scale (WEMWBS): development and UK validation. Health Qual Life Outcomes 27(5):63
Veldkamp SAM, Boomsma DI, de Zeeuw EL, van Beijsterveldt CEM, Bartels M, Dolan CV, van Bergen E (2019) Genetic and environmental influences on different forms of bullying perpetration, bullying victimization, and their co-occurrence. Behav Genet 49:432–443
Venables WN, Ripley BD (2002) Modern Applied Statistics with S, 4th edn,. Springer, New York
Westerhof GJ, Keyes CL (2010) Mental illness and mental health: the two continua model across the lifespan. J Adult Dev 17(2):110–119
World Health Organization (2018) Global Health Estimates 2016: Disease burden by cause, ages Sex, by Country and by Region, 2000-2016. World Health Organization, Geneva
Wolke D, Woods S, Stanford K, Schulz H (2001) Bullying and victimization of primary school children in England and Germany: prevalence and school factors. Br J Psychol 92(Pt 4):673–696
Wray NR, Ripke S, Mattheisen M, Trzaskowski M, Byrne EM, Abdellaoui A et al (2018) Genome-wide association analyses identify 44 risk variants and refine the genetic architecture of major depression. Nat Genet 50(5):668–681
Zhang D (2018) rsq: R-Squared and Related Measures. R package version 1.1. https://CRAN.R-project.org/package=rsq
Acknowledgments
We are extremely grateful to all the families who took part in this study, the midwives for their help in recruiting them, and the whole ALSPAC team, which includes interviewers, computer and laboratory technicians, clerical workers, research scientists, volunteers, managers, receptionists and nurses.
Funding
The UK Medical Research Council and Wellcome (Grant ref: 217065/Z/19/Z) and the University of Bristol provide core support for ALSPAC. This publication is the work of the authors and JMA will serve as guarantor for the contents of this paper. A comprehensive list of grants funding is available on the ALSPAC website (http://www.bristol.ac.uk/alspac/external/documents/grant-acknowledgements.pdf). GWAS data was generated by Sample Logistics and Genotyping Facilities at Wellcome Sanger Institute and LabCorp (Laboratory Corporation of America) using support from 23andMe. The wellbeing measures in the ALSPAC Me@23 questionnaire were specifically funded by a grant to CMAH from the Elizabeth Blackwell Institute for Health Research, University of Bristol, and the Wellcome Trust Institutional Strategic Support Fund (105612/Z/14/Z). CMAH’s research is supported by a Philip Leverhulme Prize. OSPD and CMAH are funded by the Alan Turing Institute under the EPSRC grant EP/N510129/1. JMA was supported by a studentship from the Economic and Social Research Council (ESRC). RAW was supported by an ESRC Postdoctoral Fellowship (ES/T007370/1). JMA and OSPD are members of the MRC Integrative Epidemiology Unit at the University of Bristol [MC_UU_00011/7]. This study was also supported by the National Institute for Health Research (NIHR) Biomedical Research Centre at the University Hospitals Bristol NHS Foundation Trust and the University of Bristol (BRC-1215-2011). The views expressed in this publication are those of the authors and not necessarily those of the UK National Health Service, National Institute for Health Research, or Department of Health and Social Care. The funders had no role in the study design, data collection and analysis, decision to publish or preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
JMA defined the research question with CMAH. Funding acquisition and data collection for the wellbeing material in ALSPAC were performed by CMAH. Data preparation, analysis, and investigation were performed by JMA. Interpretations of the data were made by JMA, CMAH, R.AHW and OSPD. The original draft of the manuscript was written by JMA. CMAH, R.AHW and OSPD read and approved the final manuscript.
Corresponding author
Ethics declarations
Statement of Human and Animal rights
This article does not contain any studies with human participants or animals performed by any of the authors.
Conflict of interest
Jessica M. Armitage, R. Adele H. Wang, Oliver S. P. Davis and Claire M. A. Haworth declare that they have no conflict of interest.
Ethical Approval
Ethical approval for the study was obtained from the ALSPAC Law and Ethics Committee. Full details of ethics committee approval references for ALSPAC can be found online (http://www.bristol.ac.uk/alspac/researchers/research-ethics/).
Consent to Participate
Informed consent for the use of data collected via questionnaires and clinics was obtained from participants following the recommendations of the ALSPAC Law and Ethics Committee. Consent was implied via the written completion and return of questionnaires. Study participants have the right to withdraw their consent for specific elements of the study, or from the study as a whole at any time.
Consent for Publication
Not applicable.
Additional information
Handling Editor: Meike Bartels
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Armitage, J.M., Wang, R.A.H., Davis, O.S.P. et al. A Polygenic Approach to Understanding Resilience to Peer Victimisation. Behav Genet 52, 1–12 (2022). https://doi.org/10.1007/s10519-021-10085-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10519-021-10085-5