
Abstract
A growing demand is witnessed in both industry and academia for employing Deep Learning (DL) in various domains to solve real-world problems. Deep reinforcement learning (DRL) is the application of DL in the domain of Reinforcement Learning. Like any software system, DRL applications can fail because of faults in their programs. In this paper, we present the first attempt to categorize faults occurring in DRL programs. We manually analyzed 761 artifacts of DRL programs (from Stack Overflow posts and GitHub issues) developed using well-known DRL frameworks (OpenAI Gym, Dopamine, Keras-rl, Tensorforce) and identified faults reported by developers/users. We labeled and taxonomized the identified faults through several rounds of discussions. The resulting taxonomy is validated using an online survey with 19 developers/researchers. To allow for the automatic detection of faults in DRL programs, we have defined a meta-model of DRL programs and developed DRLinter, a model-based fault detection approach that leverages static analysis and graph transformations. The execution flow of DRLinter consists in parsing a DRL program to generate a model conforming to our meta-model and applying detection rules on the model to identify faults occurrences. The effectiveness of DRLinter is evaluated using 21 synthetic and real faulty DRL programs. For synthetic samples, we injected faults observed in the analyzed artifacts from Stack Overflow and GitHub. The results show that DRLinter can successfully detect faults in both synthesized and real-world examples with a recall of 75% and a precision of 100%.







Similar content being viewed by others
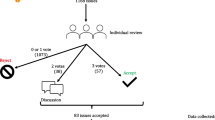


Notes
Openai gym. https://github.com/openai/gym (2016).
Taxonomy of real faults in deep reinforcement learning: Replication package. https://github.com/deepRLtaxonomy/drl-taxonomy (2020).
Github official website. (2020) https://github.com/about. Accessed: 2020-8-25.
Google forms. https://www.google.ca/forms/about/ (2020).
The source code of DRLinter. https://github.com/drlinter/drlinter (2020).
The source code of DRLinter. https://github.com/drlinter/drlinter (2020).
Train a deep q network with tf-agents. (2020) https://www.tensorflow.org/agents/tutorials/1_dqn_tutorial. Accessed: 2020-10-12.
Reinforcement learning (DQN) tutorial. (2020) https://pytorch.org/tutorials/intermediate/reinforcement_q_learning.html. Accessed: 2020-10-12.
Train a deep q network with tf-agents. (2020) https://www.tensorflow.org/agents/tutorials/1_dqn_tutorial. Accessed: 2020-10-12.
The source code of DRLinter. https://github.com/drlinter/drlinter (2020).
References
Agostinelli, F., Hocquet, G., Singh, S., Baldi, P.: From reinforcement learning to deep reinforcement learning: An overview. In: Braverman Readings in Machine Learning. Key Ideas From Inception to Current State, pp. 298–328. Springer (2018)
Akkaya, I., Andrychowicz, M., Chociej, M., Litwin, M., McGrew, B., Petron, A., Paino, A., Plappert, M., Powell, G., Ribas, R., et al.: Solving rubik’s cube with a robot hand. arXiv preprint arXiv:1910.07113 (2019)
Bagherzadeh, M., Khatchadourian, R.: Going big: a large-scale study on what big data developers ask. In: Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pp. 432–442 (2019)
Bellemare, M.G., Candido, S., Castro, P.S., Gong, J., Machado, M.C., Moitra, S., Ponda, S.S., Wang, Z.: Autonomous navigation of stratospheric balloons using reinforcement learning. Nature 588(7836), 77–82 (2020)
Borges, H., Hora, A., Valente, M.T.: Understanding the factors that impact the popularity of github repositories. In: 2016 IEEE International Conference on Software Maintenance and Evolution (ICSME), pp. 334–344. IEEE (2016)
Castro, P.S., Moitra, S., Gelada, C., Kumar, S., Bellemare, M.G.: Dopamine: A Research Framework for Deep Reinforcement Learning. arXiv:1812.06110 (2018)
Fischer, T.G.: Reinforcement learning in financial markets-a survey. Tech. rep., FAU Discussion Papers in Economics (2018)
François-Lavet, V., Henderson, P., Islam, R., Bellemare, M.G., Pineau, J.: An Introduction to Deep Reinforcement Learning, vol. 11 (2018)
Gandhi, D., Pinto, L., Gupta, A.: Learning to fly by crashing. In: 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 3948–3955. IEEE (2017)
Ghamarian, A.H., de Mol, M., Rensink, A., Zambon, E., Zimakova, M.: Modelling and analysis using groove. Int. J. Softw. Tools Technol. Transf. 14(1), 15–40 (2012)
Goodfellow, I., Bengio, Y., Courville, A.: Deep Learning. MIT Press, Cambridge (2016) http://www.deeplearningbook.org
Hartmann, T., Moawad, A., Schockaert, C., Fouquet, F., Le Traon, Y.: Meta-modelling meta-learning. In: 2019 ACM/IEEE 22nd International Conference on Model Driven Engineering Languages and Systems (MODELS), pp. 300–305. IEEE (2019)
Heckel, R.: Graph transformation in a nutshell. Electron. Notes Theor. Comput. Sci. 148(1), 187–198 (2006)
Humbatova, N., Jahangirova, G., Bavota, G., Riccio, V., Stocco, A., Tonella, P.: Taxonomy of real faults in deep learning systems. In: The 42nd International Conference on Software Engineering (ICSE 2020). ACM (2020)
Islam, M.J., Nguyen, G., Pan, R., Rajan, H.: A comprehensive study on deep learning bug characteristics. In: Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pp. 510–520 (2019)
Islam, M.J., Pan, R., Nguyen, G., Rajan, H.: Repairing deep neural networks: Fix patterns and challenges. In: 2020 IEEE/ACM 42nd International Conference on Software Engineering (ICSE), pp. 1135–1146. IEEE (2020)
Kuhnle, A., Schaarschmidt, M., Fricke, K.: Tensorforce: a tensorflow library for applied reinforcement learning. https://github.com/tensorforce/tensorforce (2017)
Lapan, M.: Deep Reinforcement Learning Hands-On: Apply modern RL methods, with deep Q-networks, value iteration, policy gradients, TRPO. Packt Publishing Ltd, AlphaGo Zero and more (2018)
Levine, S., Finn, C., Darrell, T., Abbeel, P.: End-to-end training of deep visuomotor policies. J. Mach. Learn. Res. 17(1), 1334–1373 (2016)
Lillicrap, T.P., Hunt, J.J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., Wierstra, D.: Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971 (2015)
Meldrum, S., Licorish, S.A., Savarimuthu, B.T.R.: Crowdsourced knowledge on stack overflow: A systematic mapping study. In: Proceedings of the 21st International Conference on Evaluation and Assessment in Software Engineering, pp. 180–185 (2017)
Mnih, V., Badia, A.P., Mirza, M., Graves, A., Lillicrap, T., Harley, T., Silver, D., Kavukcuoglu, K.: Asynchronous methods for deep reinforcement learning. In: International Conference on Machine Learning, pp. 1928–1937 (2016)
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A.A., Veness, J., Bellemare, M.G., Graves, A., Riedmiller, M., Fidjeland, A.K., Ostrovski, G., et al.: Human-level control through deep reinforcement learning. Nature 518(7540), 529–533 (2015)
Morales, M.: Grokking Deep Reinforcement Learning. Manning Publications, New York (2019)
Moravčík, M., Schmid, M., Burch, N., Lisỳ, V., Morrill, D., Bard, N., Davis, T., Waugh, K., Johanson, M., Bowling, M.: Deepstack: Eepert-level artificial intelligence in heads-up no-limit poker. Science 356(6337), 508–513 (2017)
Plappert, M.: keras-rl. https://github.com/keras-rl/keras-rl (2016)
Rensink, A.: The GROOVE simulator: A tool for state space generation. In: International Workshop on Applications of Graph Transformations with Industrial Relevance, pp. 479–485. Springer, Berlin (2003)
Sallab, A.E., Abdou, M., Perot, E., Yogamani, S.: Deep reinforcement learning framework for autonomous driving. Electron. Imag. 2017(19), 70–76 (2017)
Schrittwieser, J., Antonoglou, I., Hubert, T., Simonyan, K., Sifre, L., Schmitt, S., Guez, A., Lockhart, E., Hassabis, D., Graepel, T., et al.: Mastering atari, go, chess and shogi by planning with a learned model. Nature 588(7839), 604–609 (2020)
Seaman, C.B.: Qualitative methods in empirical studies of software engineering. IEEE Trans. Softw. Eng. 25(4), 557–572 (1999)
Silver, D., Huang, A., Maddison, C.J., Guez, A., Sifre, L., Van Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., et al.: Mastering the game of go with deep neural networks and tree search. Nature 529(7587), 484–489 (2016)
Sutton, R.S., Barto, A.G.: Reinforcement Learning: An Introduction. MIT Press, Cambridge (2018)
Trujillo, M., Linares-Vásquez, M., Escobar-Velásquez, C., Dusparic, I., Cardozo, N.: Does neuron coverage matter for deep reinforcement learning? a preliminary study. In: DeepTest Workshop, ICSE 2020 (2020)
Vijayaraghavan, G., Kaner, C.: Bug taxonomies: use them to generate better tests. Star East 2003, 1–40 (2003)
Watkins, C.J., Dayan, P.: Q-learning. Mach. Learn. 8(3–4), 279–292 (1992)
Yu, C., Liu, J., Nemati, S.: Reinforcement learning in healthcare: a survey. arXiv preprint arXiv:1908.08796 (2019)
Zhang, Y., Chen, Y., Cheung, S.C., Xiong, Y., Zhang, L.: An empirical study on tensorflow program bugs. In: Proceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis, pp. 129–140 (2018)
Zhang, T., Gao, C., Ma, L., Lyu, M.R., Kim, M.: An empirical study of common challenges in developing deep learning applications. In: The 30th IEEE International Symposium on Software Reliability Engineering (ISSRE) (2019)
Zhang, B., Rajan, R., Pineda, L., Lambert, N., Biedenkapp, A., Chua, K., Hutter, F., Calandra, R.: On the importance of hyperparameter optimization for model-based reinforcement learning. In: International Conference on Artificial Intelligence and Statistics, pp. 4015–4023. PMLR (2021)
Funding
This work is partly funded by the Natural Sciences and Engineering Research Council of Canada (NSERC) and the Fonds de Recherche du Québec (FRQ).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Nikanjam, A., Morovati, M.M., Khomh, F. et al. Faults in deep reinforcement learning programs: a taxonomy and a detection approach. Autom Softw Eng 29, 8 (2022). https://doi.org/10.1007/s10515-021-00313-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10515-021-00313-x