
Abstract
Depth estimation is an essential component of computer vision applications for environment perception, 3D reconstruction and scene understanding. Among the available methods, self-supervised monocular depth estimation is noteworthy for its cost-effectiveness, ease of installation and data accessibility. However, there are two challenges with current methods. Firstly, the scale factor of self-supervised monocular depth estimation is uncertain, which poses significant difficulties for practical applications. Secondly, the depth prediction accuracy for high-resolution images is still unsatisfactory, resulting in low utilization of computational resources. We propose a novel solution to address these challenges with three specific contributions. Firstly, an interleaved depth network skip-connection structure and a new depth network decoder are proposed to improve the depth prediction accuracy for high-resolution images. Secondly, a data vertical splicing module is suggested as a data enhancement method to obtain more non-vertical features and improve model generalization. Lastly, a scale recovery module is proposed to recover the accurate absolute depth without additional sensors, which solves the issue of uncertainty in the scale factor. The experimental results demonstrate that the proposed framework significantly improves the prediction accuracy of high-resolution images. In particular, the novel network structure and data vertical splicing module contribute significantly to this improvement. Moreover, in a scenario where the camera height is fixed and the ground is flat, the effect of scale recovery module is comparable to that achieved by using ground truth. Overall, the RSANet framework offers a promising solution to solve the existing challenges in self-supervised monocular depth estimation.








Similar content being viewed by others

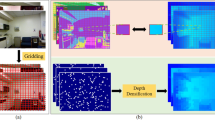

Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to privacy.
References
Dokhanchi SH, Mysore BS, Mishra KV et al (2021) Enhanced automotive target detection through radar and communications sensor fusion. In: ICASSP 2021-2021 IEEE International conference on acoustics, speech and signal processing, IEEE, pp 8403–8407
Qi CR, Su H, Mo K et al (2017) Pointnet: Deep learning on point sets for 3d classification and segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 652–660
Mohapatra S, Yogamani S, Gotzig H et al (2021) Bevdetnet: bird’s eye view lidar point cloud based real-time 3d object detection for autonomous driving. In: 2021 IEEE International intelligent transportation systems conference, IEEE, pp 2809–2815
Pillai S, Ambruş R, Gaidon A (2019) Superdepth: Self-supervised, super-resolved monocular depth estimation. In: 2019 International conference on robotics and automation, IEEE, pp 9250–9256
Goldman M, Hassner T, Avidan S (2019) Learn stereo, infer mono: Siamese networks for self-supervised, monocular, depth estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 2886–2895
Poggi M, Tosi F, Mattoccia S (2018) Learning monocular depth estimation with unsupervised trinocular assumptions. In: 2018 International conference on 3d vision, IEEE, pp 324–333
Casser V, Pirk S, Mahjourian R et al (2019) Depth prediction without the sensors: Leveraging structure for unsupervised learning from monocular videos. In: Proceedings of the AAAI conference on artificial intelligence, pp 8001–8008
Godard C, Mac Aodha O, Brostow GJ (2017) Unsupervised monocular depth estimation with left-right consistency. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 270–279
Pillai S, Ambruş R, Gaidon A (2019) Superdepth: Self-supervised, super-resolved monocular depth estimation. In: 2019 International conference on robotics and automation, IEEE, pp 9250–9256
Godard C, Mac Aodha O, Firman M et al (2019) Digging into self-supervised monocular depth estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 3828–3838
Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: International conference on medical image computing and computer-assisted intervention, Springer, pp 234–241
Palou G, Salembier P (2012) From local occlusion cues to global monocular depth estimation. 2012 IEEE International Conference on Acoustics. Speech and Signal Processing, IEEE, pp 793–796
Liu M, Salzmann M, He X (2014) Discrete-continuous depth estimation from a single image. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 716–723
Eigen D, Puhrsch C, Fergus R (2014) Depth map prediction from a single image using a multi-scale deep network. Advances in neural information processing systems pp 2366–2374
Li Y, He K, Sun J et al (2016) R-fcn: Object detection via region-based fully convolutional networks. Advances in neural information processing systems pp 379–387
Fu H, Gong M, Wang C et al (2018) Deep ordinal regression network for monocular depth estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 2002–2011
Vaswani A, Shazeer N, Parmar N et al (2017) Attention is all you need. Advances in neural information processing systems pp 6000–6010
Ranftl R, Bochkovskiy A, Koltun V (2021) Vision transformers for dense prediction. In: Proceedings of the IEEE/CVF International conference on computer vision, pp 12,179–12,188
Garg R, Bg VK, Carneiro G et al (2016) Unsupervised cnn for single view depth estimation: Geometry to the rescue. In: European conference on computer vision, Springer, pp 740–756
Patil V, Van Gansbeke W, Dai D et al (2020) Don’t forget the past: Recurrent depth estimation from monocular video. IEEE Robotics and Automation Lett pp 6813–6820
Zhou T, Brown M, Snavely N et al (2017) Unsupervised learning of depth and ego-motion from video. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 1851–1858
Guizilini V, Ambrus R, Pillai S et al (2020) 3d packing for self-supervised monocular depth estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 2485–2494
Guizilini V, Hou R, Li J et al (2020) Semantically-guided representation learning for self-supervised monocular depth. International conference on learning representations pp 658–667
Zhou D, Dai Y, Li H (2019) Ground-plane-based absolute scale estimation for monocular visual odometry. IEEE Trans Intell Transportation Syst pp 791–802
Jianrong Wang ZWXLGe Zhang, Liu L (2020) Self-supervised joint learning framework of depth estimation via implicit cues. In: 2020 IEEE International conference on robotics and automation, IEEE, pp 988–995
Xue F, Zhuo G, Huang Z et al (2020) Toward hierarchical self-supervised monocular absolute depth estimation for autonomous driving applications. In: 2020 IEEE/RSJ International conference on intelligent robots and systems, IEEE, pp 2330–2337
Zhang H, Cisse M, Dauphin YN et al (2018) mixup: Beyond empirical risk minimization. In: International conference on learning representations, pp 167–176
Yun S, Han D, Oh SJ et al (2019) Cutmix: Regularization strategy to train strong classifiers with localizable features. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 6023–6032
Zhong Z, Zheng L, Kang G et al (2020) Random erasing data augmentation. In: Proceedings of the AAAI conference on artificial intelligence, pp 13,001–13,008
Gurram A, Tuna AF, Shen F et al (2021) Monocular depth estimation through virtual-world supervision and real-world sfm self-supervision. IEEE Transactions on intelligent transportation systems pp 12,738–12,751
Hui TW (2022) Rm-depth: Unsupervised learning of recurrent monocular depth in dynamic scenes. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 1675–1684
Zhao YZMPFTXGZZGHYTChaoqiang, Mattoccia S (2022) Monovit: Self-supervised monocular depth estimation with a vision transformer. In: In 2022 International conference on 3D vision (3DV), pp 668–678
Qiao NNXYGZFWYJZShanbao, Jiang X (2023) Self-supervised learning of depth and ego-motion for 3d perception in human computer interaction. In: ACM Transactions on multimedia computing, communications, and applications, pp 1–21
Zhang FNGVNing, Kerle N (2023) Lite-mono: A lightweight cnn and transformer architecture for self-supervised monocular depth estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 18,537–18,546
Bae SMJinwoo, Im S (2023) Deep digging into the generalization of self-supervised monocular depth estimation. In: In Proceedings of the AAAI conference on artificial intelligence, pp 187–196
Peng R, Wang R, Lai Y et al (2021) Excavating the potential capacity of self-supervised monocular depth estimation. In: Proceedings of the IEEE/cvf international conference on computer vision, pp 15,560–15,569
Pillai S, Ambruş R, Gaidon A (2019) Superdepth: Self-supervised, super-resolved monocular depth estimation. In: 2019 International conference on robotics and automation, IEEE, pp 9250–9256
Lyu X, Liu L, Wang M et al (2021) Hr-depth: High resolution self-supervised monocular depth estimation. In: Proceedings of the AAAI conference on artificial intelligence, pp 2294–2301
He K, Zhang X, Ren S et al (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 770–778
Eigen D, Fergus R (2015) Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In: Proceedings of the IEEE international conference on computer vision, pp 2650–2658
Mahjourian R, Wicke M, Angelova A (2018) Unsupervised learning of depth and ego-motion from monocular video using 3d geometric constraints. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 5667–5675
Gordon A, Li H, Jonschkowski R et al (2019) Depth from videos in the wild: Unsupervised monocular depth learning from unknown cameras. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 8977–8986
Zhongkai Zhou PSXinnan Fan, Xin Y (2021) R-msfm: Recurrent multi-scale feature modulation for monocular depth estimating. In: Proceedings of the IEEE international conference on computer vision, pp 187–196
Petrovai A, Nedevschi S (2022) Exploiting pseudo labels in a self-supervised learning framework for improved monocular depth estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 1568–1578
Han eaWencheng (2022) Brnet: Exploring comprehensive features for monocular depth estimation. In: European conference on computer vision, pp 586–602
Shu C, Yu K, Duan Z et al (2020) Feature-metric loss for self-supervised learning of depth and egomotion. In: European conference on computer vision, Springer, pp 572–588
Watson J, Firman M, Brostow GJ et al (2019) Self-supervised monocular depth hints. In: Proceedings of the IEEE/CVF International conference on computer vision, pp 2162–2171
Acknowledgements
The project was supported by the Natural Science Foundation of Fujian Province of China under Grant No. 2023J01047 and the Natural Science Foundation of Xiamen City under Grant No.3502Z20227185.
Author information
Authors and Affiliations
Contributions
Yuquan Zhou: Writing - Original Draft, Conceptualization, Methodology, Software, Investigation, Validation. Chentao Zhang: Writing - Review & Editing, Supervision, Project administration, Funding acquisition. Lianjun Deng: Resources, Data Curation, Software, Formal analysis. Jianji Fu: Visualization, Validation, Resources. Hongyi Li: Formal analysis, Software. Zhouyi Xu: Data Curation, Supervision. Jianhuan Zhang: Supervision, Resources.
Corresponding author
Ethics declarations
Conflict of interests
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhou, Y., Zhang, C., Deng, L. et al. Resolution-sensitive self-supervised monocular absolute depth estimation. Appl Intell 54, 4781–4793 (2024). https://doi.org/10.1007/s10489-024-05414-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-024-05414-0