
Abstract
Day by day, human-agent negotiation becomes more and more vital to reach a socially beneficial agreement when stakeholders need to make a joint decision together. Developing agents who understand not only human preferences but also attitudes is a significant prerequisite for this kind of interaction. Studies on opponent modeling are predominantly based on automated negotiation and may yield good predictions after exchanging hundreds of offers. However, this is not the case in human-agent negotiation in which the total number of rounds does not usually exceed tens. For this reason, an opponent model technique is needed to extract the maximum information gained with limited interaction. This study presents a conflict-based opponent modeling technique and compares its prediction performance with the well-known approaches in human-agent and automated negotiation experimental settings. According to the results of human-agent studies, the proposed model outpr erforms them despite the diversity of participants’ negotiation behaviors. Besides, the conflict-based opponent model estimates the entire bid space much more successfully than its competitors in automated negotiation sessions when a small portion of the outcome space was explored. This study may contribute to developing agents that can perceive their human counterparts’ preferences and behaviors more accurately, acting cooperatively and reaching an admissible settlement for joint interests.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
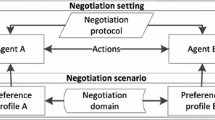
Negotiation is an interaction among self-interested parties that have a conflict of interests and aim to achieve a joint agreement. It can occur daily basis when parties need to make decisions collectively on any matters such as personal activities (e.g., arranging holiday plans), professional procedures (e.g., job interviews, task or resource allocations), or societal matters(e.g., effective energy distribution). Depending on the complexity of the decisions, this process can be time-consuming and cumbersome for human stakeholders. Therefore, researchers in the field of Artificial Intelligence have put their effort into automating this process over the last decades [1, 8, 14]. Recently, there has been a high interest in human-agent negotiations in which intelligent agents negotiate with their human counterparts [4, 28]. Creating large-scale social impact by such intelligent systems requires understanding how human decisions are made and their preferences and interests [26]. That is, agents should be capable of understanding why their opponent made such offers and what is acceptable to their opponent so that it can adapt its bidding strategy accordingly to increase the chance of reaching mutually beneficial agreements. That shows the importance of the opponent modeling during the negotiation.
There are a variety of opponent modeling techniques proposed in automated negotiation literature [6]. As far as the existing opponent models to predict the opponent’s preferences are concerned, it is observed that they attempt to learn a model from bid exchanges and mostly have some particular assumptions about both opponent’s bidding behavior and preference model (e.g., having an additive utility function and employing time-based concession strategy). Even simple heuristic models such as the frequentist approach [19, 31] perform well in negotiation. Although there are relatively much fewer offer exchanges in human-agent negotiation in contrast to automated one (i.e., the number of offers typically does not exceed 20-30 offers in human-agent negotiation [22]), some studies adopt their variants in human-agent negotiation [25].
This study pursues an alternative way of modeling human opponents’ preferences by searching for cause-effect relationships in human negotiators’ bidding patterns. Here, the main challenge is to learn meaningful preference relations that enable our agents to generate offers that are more likely to be acceptable by their opponents despite the small number of offer exchanges. Accordingly, this study proposes a novel conflict search-based opponent modeling strategy mainly designed to learn human opponents’ preferences in multi-issue negotiations to generate well-targeted offers leading to mutually beneficial agreements (i.e., high social welfare). The proposed opponent modeling approach has been evaluated experimentally concerning different performance metrics, such as the model’s accuracy and the model’s effect on the negotiation and negotiation outcome. To show the performance of the proposed approach, we conducted two human-agent negotiation experiments involving 70 participants in total and compared our agent performance with those of the aforementioned well-known frequentist approaches [19, 31]. Our results showed that the proposed conflict-based opponent model outperformed them dramatically in terms of their prediction accuracy. Furthermore, we studied the effect of the model on the negotiation outcome in automated negotiation by involving 15 state-of-the-art negotiation agents from the International Automated Negotiating Agents Competition (ANAC) [15] on six different negotiation scenarios. Our results showed that our agent gained the highest average individual utility and social welfare (i.e., both product of utilities and the sum of utilities) on average.
The rest of the paper is organized as follows. Section 2 reviews the related work on opponent modeling. The proposed opponent model is explained in Section 3, and the negotiation strategy of the agent utilizing the model is defined in Section 4. Section 5 presents our experimental setup and analysis of the results. Finally, we conclude our work with a discussion involving future work directions in Section 6.
2 Related work
Automated negotiation has been widely studied for several decades, and a variety of negotiation frameworks have been proposed so far [2, 8]. By their nature, automated agents try to find the most beneficial agreement for both parties by making many consecutive offers up to a particular deadline (time or round). As Hindriks, Jonker, and Tykhonov point out that agents can benefit from learning about their opponent during negotiation [12], a variety of opponent modeling approaches have been proposed in the negotiation community, such as opponent’s preferences (e.g., [12, 19, 21, 25, 31, 32]), the acceptability of an offer (e.g., [20, 26, 29]) and negotiation strategy/attitude (e.g., [16, 23, 27]). The main opponent strategy is identifying the opponent’s preferences by analyzing offer exchanges between parties. Afterward, the agent examines the opponent’s negotiation offers with estimated opponent preferences to get an idea about its strategy/attitude. Various modeling techniques have been used in these strategies, such as kernel density, Bayesian learning, and frequentist models. While building up their model, those opponent modeling approaches rely on some assumptions such as having a predetermined deadline, capturing their preferences in the form of an additive utility function, and following a turn-taking negotiation protocols such as (Stacked) Alternating Offers Protocol [2] and conceding over time (e.g., time-based concession strategies). In the following part, we mention the most relevant works. A more detailed explanation about opponent modeling can be found in the survey [6].
Another common preference model technique in the literature is based on Bayesian learning [12, 32]. Hindriks et al. use Bayesian learning to predict the shape of the opponent’s utility function, the corresponding rank of issue values, and issue weights [12]. As an extension of Hindrik’s work, Yu et al. incorporate regression analysis into Bayesian learning by comparing the predicted future bids and actual incoming bids. Accordingly, they update the Bayesian belief model by considering both current and expected coming bids.
Recent studies’ most common preference modeling strategies are variations of the frequentist models. The winner of the Second Automated Negotiating Agents Competition [15] called Hardheaded agent [19] uses a simple counting mechanism for each issue value and analyzes the contents of the opponent’s consequent offers. The main heuristic is that the opponent would concede less on the essential issues while using the preferred values in its offers. Therefore, while analyzing the opponent’s current and previous offer, if the value of an issue is changed, that issue’s weight is decreased by a certain amount. While such a simple approach is initially intuitive, information loss seems inevitable. Due to the nature of the negotiation, the opponent may need to concede even on important issues. Those moves may mislead the model. In addition, the concession amount may vary during the negotiation, which the frequentist approach needs to capture.
Moreover, suppose the opponent repeats the same bid multiple times. In that case, the model may overvalue those repeated issue values while underestimating the unobserved values (e.g., converging a zero utility since it is not seen). Tunalı, Aydoǧan, and Sanchez [31] aims to resolve those problems by comparing the windows of offers instead of consecutive pairs of offers and offering a more robust estimation of the opponent’s behavior. It adopts a decayed weight update to avoid incorrect updates when opponents concede on the most critical issues. Furthermore, it smoothly increases the importance of issue values to avoid unbalanced issue value distributions when the opponent offers the same offer repeatedly. Although their approach outperforms the classical frequency approach, it still suffers from only counting the issue value appearance because it ignores the varying utility patterns of the opponent’s offers.
Apart from the opponent modeling in automated negotiation, we review the opponent modeling approaches particularly designed for human-agent negotiations. Lin et al. introduce the QOAgent using kernel density estimation (KDE) for modeling opponent’s preferences [21]. According to their results, the QOAgent can reach more agreements. In most cases, it achieves better agreements than the human counterpart playing the same role in individual utility. As an extension of QOAgent, Oshrat et al. present an agent unlike most other negotiating agents in the automated negotiation, the KBAgent attempts to utilize previous negotiations with other human opponents having the same preferences to learn the current human opponent [26]. This approach requires an essential assumption that human participants will behave similarly to each other. Thus, KBAgent builds a broad knowledge base from its previous opponents and accordingly offers based on a probabilistic model constructed from the knowledge base utilizing kernel density estimation. In their experimental comparison, the KBAgent outperformed the QOAgent. In these studies, the authors focus on the overall negotiation performance rather than the performance of the proposed opponent modeling approach. However, we examine the accuracy of the opponent modeling and the performance of the whole negotiation strategy.
Furthermore, Nazari, Lucas, and Gratch follow a similar intuition with frequentist models for human-agent negotiation [25]. However, they take into account only the preference ranking of the negotiation issues instead of estimating the overall utility of each outcome. For issue values, they consider a predefined ordering. However, those assumptions may not hold in negotiations where a human participant may have a different evaluation of issue values. In their negotiation, their agent considers the importance of the issues and the expected ordering of the issue values while generating their offers. A similar heuristic with the frequentist approach holds here. That is, an issue is more important if the opponent consistently asks for more on that issue. It leads to the same intrinsic problem of the frequentist approach.
Instead of learning an explicit preference model, some studies focus on understanding what offers would be acceptable for their opponent. Sanchez et al. use Bayesian classifiers to learn the acceptability of partial offers for each team member in a negotiation team [29]. They present a model for negotiation teams that guarantees unanimous decisions consisting of predictable, compatible, and unforeseen issues. The model maximizes the probability of being accepted by both sides. While their model relies on predictable issues such as price, our model is designed to handle unpredictable discrete issues. Lastly, it is good to mention the reinforcement learning approach proposed for human-agent negotiation [20]. Lewis et al. collect a large dataset consisting of offers represented in natural language from 5808 sessions on Amazon’s Mechanical Turk. They present a reinforcement learning model to maximize the agent’s reward against human opponents. Accordingly, they aim to estimate the negotiation states acceptable for their human counterparts.
More recently, researchers have been trying to incorporate deep learning models in opponent modeling. For instance, Sengupta et al. has implemented a reinforcement learning-based agent that can adapt to unknown agents per experiences with other agents. In order to model the opponent, they have applied the Recurrent Neural Networks model, specifically LSTM, since they use time series data from the negotiation steps. However, they switched their implementation to a 1D-CNN classifier instead due to data limitations. They observe an opponent agent’s bidding strategy according to the agent’s self-utility and try to cast it into a class of known behaviors. According to this classification, the agent swaps negotiation strategy within the runtime [30].
Meanwhile, Hosokowa and Fujita expand upon the classical frequentist approach through the addition of the ratio of offers within specified slices of the negotiation timeline, and they implement a weighting function to stabilize the ratios as time passes to capture the change of an opponent’s concession toward the end of negotiation [13].
3 Proposed conflict-based opponent modelling (CBOM)
Our opponent modeling called Conflict-Based Opponent Modeling (CBOM) aims to estimate the opponent’s preferences represented utilizing an additive utility function shown in (1) where \(w_{i}\) represents the importance of the negotiation issue \(I_i\) (i.e., issue weight), \(o_{i}\) represents the value for issue i in offer o, and \(V_{i}\) is the valuation function for issue i, which returns the desirability of the issue value. Without losing generality, it is assumed that \(\sum _{i\in n} w_{i} = 1\) and the domain of \(V_{i}\) is (0,1) for any i. The higher the \(V_{i}\) is, the more preferred an issue value is.
Regarding the issue valuation/weight functions (i.e., preferences on issue values), targeting to learn these functions directly from the opponent’s offer history may not be a reliable approach since the opponent’s negotiation strategy may mislead us. Although the contents of the opponent’s offers give insight into which values are more preferred over others, depending on the employed strategy, we may end up with a different model estimation. For instance, the frequency of the issue value appearance might be a good indicator for understanding the ranking of issue values. However, it is not sufficient to deduce to what extent each issue value is preferred. Fluctuations in the opponent’s offers or repeating the exact offers often mislead the agent into accurately estimating the additive utility function. Therefore, we aim first to detect the preference ordering pattern rather than quantifying an evaluation function directly and then interpolate it.
As most of the existing opponent models in the literature do, our model assumes the opponent concedes over time. Initially, the agent does not know anything about its opponent’s preferences; therefore, it creates a template estimation model according to the given domain configuration. In other words, the agent starts with an initial belief in ranking the issue values (\(V_i\)) and issues (\(W_i\)). The agent may assume that the opponent’s value function is the opposite of its value function. For instance, If the agent prefers \(V_1>\) to \(V_2\), it may consider that its opponent prefers \(V_2\) to \(V_1\). Alternatively, it may consider an arbitrary ordering for the opponent. Consider that we have n issues and for each issue i there are possible issue values denoted by \({D_{i}}=\{v_{1}^{i},\dots ,v_{m}^{i}\}\). Assuming an arbitrary preference ordering for the opponent, (2) and (3) shows how the initial valuation values and issue weight are initiated. The agent keeps the issues and issue values in order in line with the estimated opponent preferences. Meaning that \(v_{k}^{i}\) is preferred over \(v_{j}^{i}\) by the opponent where where \(k>j\). Accordingly, (2) assigns compatible evaluation values via max normalization. Similarly, the issue weights are initialized by sum normalization, where each issue weight is in the [0, 1] range, and their sum is equal to 1. Equation (3) ensures that their sum equals one.
As the agent receives the opponent’s offers during the negotiation, it updates its belief incrementally based on the inconsistency between the current model and the opponent’s offers. To achieve this, it stores all bids made by the opponent so far, and when a new offer arrives, the current offer is compared with the previous bids with respect to any conflicting ordering. In particular, common and different values in the offer contents are detected. For different values, the system checks whether there is any conflicting situation with the current model. Recall that the current offer is expected to have the less preferred values since the model assumes that the opponent concedes over time. However, according to the learned model, the ordering may not match the expectation. In such a case, the model is updated.
Two types of conflict in the estimated model could be detected: issue value conflict and issue conflict. To illustrate those conflicts, let us examine some examples where agents negotiate over three issues (i.e., A, B, and C) in Fig. 1. As current belief indicates \(b_1 \succ b_2 \succ b_3\) where \(b_i\) denotes a possible issue value for the issue B, \(b_1\) is preferred \(b_2\). In the given negotiation dialogue in Fig. 1a, it can be seen that the opponent’s previous offer and current offers are \(O_{t}=<a_1, b_2, c_1>\) and \(O_{t+1}=<a_1, b_1, c_1>\), respectively. Agents can examine the contents of the offers and find unique value changes to make some inferences on the preferences. For our case, the only difference in the offers is the value of the issue B. Relying on the assumption that the human negotiator leans towards concession over time, the agent could infer \(b_2 \succ b_1\). Recall that the most preferred values would appear early. As seen clearly, this preference ordering conflicts with that of the agent’s belief. We call this type of conflict “issue value conflict” in our study.

Preference conflict extraction example
The latter conflict type is about the importance of the issues. In the given an example in Fig. 1b, the consecutive offers involve more than one issue value difference, particularly on issues B and C. Then, the agent can deduce \((c_1,b_2) > (c_2, b_1)\) by relying on the concession assumption mentioned above. Individually, ordering in issue C is consistent with the belief (i.e., \(c_1 \succ c_2\)); however, the ordering on issue B is conflicting (i.e., \(b_2 > b_1\)). Therefore, in order to have \((c_1,b_2) \succ (c_2, b_1)\), the importance of the issue C should be higher than that of B (i.e., \(C \succ B\)). This inference conflicts with the current belief of the agent, which says B is more important than C.

Conflict-based Opponent Model (CBOM).
Algorithm 1 shows how the ranking of the issue values is extracted. When the opponent makes an offer (\(O_c\)), the agent compares the content of the current offer with that of each offer in the opponent’s offer history to find the unique values and consequently extract some preferential comparisons (Lines 1–4). Afterward, the agent keeps all those comparisons in a dictionary called CM (Line 3). By reasoning on each comparison in this set by considering the current belief set, each conflict is extracted and stored in AC (Line 5-7). It is worth noting that the method can find issue value conflicts consisting of multiple issues. After keeping track of all possible conflicts, the agent must determine how to update its beliefs. Counting the number of conflicts on each issue value pair, it considers the issue value orderings having the least conflicts and updates its belief accordingly (Lines 8-16). The agent detects issue value pairs in the conflict set for each issue and compares their occurrences to determine which one to stick on. For instance, if the agent observes conflicting information, the more frequent ordering becomes more dominant, and the agent adapts its beliefs accordingly. After updating the beliefs about issue value orderings, it does the same kind of updates for the issue ordering (Lines 18-25). After finalizing the updates on the rankings, it estimates the utility space of the opponent by utilizing the update operations in (2) & (3).

Example process of the conflict-based opponent model (CBOM)
To illustrate this, we trace the negotiation in Fig. 2, where we can observe how this opponent model works. Following the same domain, we first arbitrarily set our initial beliefs about preference ordering (e.g., \(a_3 \succ a_2 \succ a_1\) for the values of issue A). The agent keeps track of offers made by the opponent so far. In our example, you can see the offer history at time \(t+2\). Following, the agent compares all previous offers with each other (i.e., pairwise comparison) and tries to extract an ordering relation. Here, \(O_{t}\) and \(O_{t+1}\) denote the first and second offer made by the opponent. Since the agent believes that the opponent’s earlier offers are more preferred over the later offers, it extract that \(a_1\), \(b_2\) \(\succ \) \(a_2\), \(b_1\). This knowledge does not give any novel insight to update our beliefs, but we store this ordering for future analysis in the following rounds. When the opponent makes the offer \(O_{t+2}\), the model compares it with all the previous offers pairwisely as well as the previously extracted information (e.g., the \(a_1\), \(b_2\) \(\succ \) \(a_2\), \(b_1\) relation). Starting from the first offer in the offer history (\(O_{t}\)-\(O_{t+2}\)), the model acquires the information of \(a_1 \succ a_2\), since there is only one issue with a different value. When it compares \(O_{t+1}\) with \(O_{t+2}\), it extracts (\(b_1 \succ b_2\)) and updates its beliefs accordingly. Similarly, the extracted information could be utilized to reason about the ordering of the negotiation issues (e.g., \(A \succ B\)) based on the contradiction between (\(a_1\), \(b_2 \succ a_2, b_1\)) and (\(b_1 \succ b_2\)). Consequently, the agent deduces that the importance of issue A is more than issue B considering the assumption that one-issue comparisons are more reliable than multi-issue comparisons, which conflicts with the current belief and updates its belief accordingly.
4 Proposed conflict-based negotiation strategy
This section presents our negotiation strategy employing the opponent model mentioned above. This strategy incorporates the estimated opponent modeling into the Hybrid strategy [16], which estimates the target utility of the current offer based on time and behavior-based concession strategies.
The Algorithm 2 elaborates how the agent makes its decisions during the negotiation. In each round, it calculates a target utility by employing the hybrid bidding strategy. Consequently, it generates candidate offers that were not offered by the agent (i.e., CBOM Agent). Its utility is in the range of lower and upper target utility (i.e., \(TU_{cbom}\) - \(\epsilon \) and \(TU_{cbom}\) + \(\epsilon \)) (Lines 1–9). If there is no such an offer, the boundary is enlarged with a dynamically generated small number according to the domain size (Line 8). We define a round count n where we believe the agent has enough offers from its opponent to estimate their preferences. The value of n may vary depending on whether the agent negotiates with a human or agent negotiator. If the number of received offers from the opponent is less than n, the agent picks the offer maximizing its utility among potential offers (Lines 10–12). Shortly, the system does not engage the opponent model until there are enough offers accumulated in the history of opponent offers. Otherwise, the agent selects the offer whose estimated utility product is the maximum (Line 14). If the opponent made an offer with a utility higher than our lowest utility bid and the utility of the current candidate’s offer (Line 16), the agent accepted its opponent’s offer instead of making the offer. This acceptance condition is slightly more cooperative than the \(AC_{next}\) acceptance strategy. Otherwise, it makes the chosen offer (Line 19).

Conflict-based negotiation strategy.
Equation (4) outlines how the agent computes the target utility for its upcoming offer, according to [16]. The concession function (\(TU_{Times}\)), represented by (5), incorporates t, the scaled time (\(t \in [0, 1]\)), and \(P_0\), \(P_1\), \(P_2\), which correspond to the curve’s maximum value, curvature, and minimum value, respectively. Note that the values of \(P_0\), \(P_1\), and \(P_2\) in our experiment are 0.9, 0.7, and 0.4, respectively. The behavioral aspect of the "Hybrid" strategy involves scaling the overall utility change by a time-varying parameter, \(\mu \), to estimate the target utility, as demonstrated in (4). \(U(O_a^{t-1})\) signifies the agent’s utility for its preceding offer. Positive changes imply that the opponent has made concessions; hence, the agent should also make concessions. In (6), \(U(O_a^{t-1})\) again represents the agent’s utility for its prior offer. Positive changes indicate that the opponent has conceded, prompting the agent to make concessions. Considering the opponent’s previous n bids, where \(W_i\) represents the weights of each utility difference, the behavior-based approach determines overall utility changes, as demonstrated in (7). Equation (8) reveals that the value of the coefficient \(\mu \) is determined by the current time and \(P_3\), which controls the degree of mimicry. Initially, the agent decreases or increases the target utility less than its opponent; subsequently, the degree of mimicry rises over time. Therefore, the “HybridAgent” strategy can smoothly conform with domains of varying sizes and harmonize with distinctive opponents utilizing behavior-based components of the HybridAgent. As an extension of the bidding strategy, CBOM agent also generates a target utility value by combining different p-values for various domain sizes. It cares about the social welfare score for both parties, choosing the most agreeable offer from the list of offers that the opponent model creates. Thus, it is expected that CBOM agent can achieve higher utility while maximizing social welfare and finding quicker mutual agreement.

Offer selection example of the CBOM Agent according to \(\epsilon \) boundary
In accordance, Fig. 3 illustrates an example of the selected offer of the CBOM Agent according to its boundaries. The figure is structured with the y-axis representing the agent’s utility and the x-axis representing the opponent’s utility for the potential outcomes in the domain. Each outcome is depicted by blue dots on the graph. The red dot represents the target utility offer at a given time, indicating the preferred outcome for the agent. The red circle is drawn by adding the target utility to an epsilon value. Within this boundary, the agent selects the offer closest to the Nash offer (\(d_N\)), depicted in green. When the domain size is limited, only a few bids may remain within a specific utility range. Without enlarging the epsilon, the agent might end up repeating certain offers. The number of offers within the offer window should be increased in such situations. Expanding this boundary allows the agent to explore more offers, which helps avoid sending repetitive final offers to the opponent while still adhering to the target window. Examining other offers within the same window allows the agent to identify a more appropriate choice while upholding its target utility.
5 Experimental analysis
We first examine the performance of the proposed Conflict-based Opponent Model (CBOM) by conducting two different human experiments (Section 5.1) and extend this evaluation by considering the performance of the proposed strategy using this opponent model through agent-based negotiation simulations (Section 5.2).
5.1 Evaluation of opponent modeling via human-agent experiments
To show how well the proposed opponent modeling approach predicts the human opponent’s preferences, we conducted experiments where participants negotiated with our agent on a given scenario to find a consensus within limited rounds by following the Alternating Offers Protocol (Section 3).

RMSE & Spearman Correlations for the experiment in Island Scenario (\(\star \) represents p < 0.001)
We consider the performance metrics to assess the quality of the predictions: Spearman’s correlation and root-mean-square error (RMSE). The former metric indicates the accuracy of the predicted order of the outcomes according to the learned utility function, whereas the latter measures how accurate estimated utilities are. For correlation estimation, possible outcomes are sorted concerning the learned opponent model, and this ranking is compared with the actual ordering. Consequently, the Spearman correlation is calculated between the actual outcome ranking and the estimated one. The correlation would be high when both orderings are similar to each other. The correlation coefficient r ranges between -1 and 1, where the sign of the coefficient shows the direction, and the magnitude is the strength of the relationship. For RMSE, the utility of each outcome is estimated according to the learned model, and the error in the prediction is calculated (See (9)). When the estimated utility values are close to the actual utility values, the RSME values would be low. In summary, low RSME and high correlation values are desired in our case.
Baarslag et al. compare the performance of the existing opponent models in automated negotiation [5]. Their results show that frequentist-based opponent modeling approaches are the most effective among the existing ones despite the approach’s simplicity. Therefore, we use a benchmark involving two different state-of-the-art frequentist opponent modeling approaches widely used in automated negotiation employed in HardHeaded [19] and Scientist [31] agents to evaluate the performance of the proposed opponent model. Frequentist opponent modeling techniques mostly rely on heuristics, assuming that the opponent would concede less on the essential issues and the preferred values appear more often than less preferred ones. Consequently, they check the frequency of each issue value’s appearance in the offers. Furthermore, they compare the content of the consecutive offers and find out the issues with changed values. In other words, if the value of an issue is changed in the opponent’s consecutive offers, the weights of those issues are decreased by a certain amount (i.e., becoming less critical). In the Scientist Agent, Tunalı et al. aims to resolve some update problems and enhance the model by comparing a group of offer exchanges instead of only consecutive pairs of offers and adopting a decayed weight update mechanism. Each opponent model is fed and updated in each round by simulating the negotiation data obtained from human-agent negotiation experiments. At the end of each negotiation, the estimated models are evaluated according to the RMSE and Spearman correlation metrics explained above.

RMSE & Spearman Correlations for the experiment in Grocery Scenario (\(\star \) represents p < 0.001)
5.1.1 Study 1: human-agent negotiation in deserted Island scenario
We analyzed and utilized the negotiation log data collected during the human-agent negotiation experiments in [4], where the participants negotiated on a particular scenario called “Deserted Island”. They negotiated resource allocation based on the division of eight survival products by two partners who fell on the deserted island. Each participant attended two negotiation sessions where the utility distributions of the issues were the same, but the orderings differed. Table 1 shows the preference profiles for both sessions. During the experiments, participants only know their preferences, and so does the agent. In this study, 42 participants (21 men, 21 women, median age: 23) were included and asked to negotiate with our agent on a face-to-face basis, and the agent made counteroffers. Offer exchanges in both sessions were recorded separately for each session. At the end of this data collection process, 46 sessions using the time-based stochastic bidding tactic (TSBT) and 38 sessions using the behavior-based adaptive bidding tactic (BABT) were obtained. The average negotiation rounds to reach an agreement was 14.84, with a standard deviation of 5.2.
Figure 4 shows box plots for each opponent modeling technique’s RMSE and Spearman correlation values. As far as the correlation values are concerned, it can be said that CBOM’s ranking predictions are better than Scientist and Frequentist (See Fig. 4b). To apply the appropriate statistical significance test, we first check the normality of the data distribution via the Kolmogorov-Smirnov normality test and then the homogeneity of variance via Levene’s Test. We applied the dependent sample t-test or the Wilcoxon Signed Rank test, depending on the results. If the data distribution passes these tests, the paired t-test is applied; otherwise, a non-parametric statistics test, namely the Wilcoxon-Signed Rank test. All statistical test results are given at the 99\(\%\) confidence interval (i.e., \(\alpha \) = 0.01). When we apply the statistical tests, it is seen that CBOM’s ranking performance is statistically significantly better than others (p < 0.01). Similarly, the errors on the estimated utilities via CBOM are lower than the errors via other approaches (see Fig. 4a). Furthermore, it is seen that Scientist statistically significantly performed better than Frequentist for both metrics except when the agent employs the TSBT strategy.
5.1.2 Study 2: human-agent negotiation in grocery scenario
In this part, we analyzed and utilized the negotiation log data collected during another human-agent negotiation experiment in [16] where the participants negotiated on a particular scenario called “Grocery”. Different from the first study, the negotiation domain does not consist of binary resource items (i.e., allocate or not allocate). Instead, the negotiation parties negotiate on the number of items to be allocated (i.e., how many items will be allocated). In this scenario, there are four types of fruits, where each participant can have up to four of each, and the opponent gets the rest. The participants aim to find an adequate division of the fruits. Table 2 shows the agent and participant’s preference profiles for both sessions. It is worth noting that each party only knows its scores. In this experiment, the participants negotiated against an agent employing the hybrid strategy where TSBT and BABT strategies are used together for bidding. 28 participants attended two negotiation sessions where all negotiation sessions ended with an agreement, thus, totaling up to 56 negotiation sessions against the agent. The average negotiation rounds to reach an agreement was 19.39, with a standard deviation of 11.82.
Similar to the previous study, we update each opponent modeling by using the offer exchanges by the human participants and calculate the error and correlation values with the final model at the end of each negotiation. Figure 5 shows box plots for RMSE and Spearman correlation values per each opponent modeling technique in this scenario. We can conclude that CBOM statistically significantly outperformed others, whereas Frequentist performs better than Scientist when we analyze the statistical test results. Those results are in line with the first study and strongly show the success of the proposed opponent modeling in human-agent negotiations. It is worth noting that the prediction error in the grocery scenario is lower than in the island scenario. Although the number of possible outcomes in these scenarios is the same (256), the number of issues in grocery scenarios is lower than in the island scenario. Therefore, one can intuitively think it is easier to predict the evaluation values in the grocery scenario compared to island scenarios. In addition, this study’s average number of rounds is higher (19.39 versus 14.84). When we receive more offers, the model’s accuracy may increase depending on the model.
5.2 Evaluation of the CBOM agent via automated negotiation experiments
In this section, we evaluate the performance of our agent employing the proposed CBOM opponent modeling by comparing its performance with that of the state-of-the-art negotiating agents available in automated negotiation literature. We built a rich benchmark of 15 successful negotiating agents who competed in the International Automated Negotiating Agents Competition ANAC [15] between 2011 and 2017. We ran negotiation tournaments in Genius, where each agent bilaterally negotiated on various negotiation scenarios. Six negotiation scenarios were used during the tournament, and the details of those scenarios are given in Table 3. As can be seen, the size and opposition degree of preference profiles in the given scenario is different. The size of the scenarios determines the search space. The larger the search space is, the more difficult it might be to estimate an accurate model based on the opponent’s offers exchanges. Next, the opposition is valuable information regarding understanding the domain’s capacity to satisfy both parties [5]. That is, it indicates how difficult it is to find a consensus. Taking the opposition of the preference profiles into account while analyzing the negotiation results may help us get an insight into how well the proposed negotiation strategy is in terms of social welfare with varying difficulties in finding an agreement.
We formed a pool of agents involving our Conflict-based agent and the ANAC finalists in different categories. We ran a tournament in Genius where each agent bilaterally negotiated with each other on scenarios described in Table 3. The ANAC agents used in this evaluation are listed as follows:

Agreement rates of agents
-
Boulware and Conceder are baseline agents available in Genius framework.
-
Hardheaded [19] was the winner of individual utility category in ANAC 2011.
-
NiceTitForTat [7] was the finalist of individual utility category in ANAC 2011.
-
CUHKAgent [11] was the winner of individual utility category in ANAC 2012.
-
IAmHaggler2012 [15] was the winner of the Nash category in ANAC 2012.
-
Atlas3 [24] was the winner of individual utility category in ANAC2015, .
-
ParsAgent2 [17] was the winner of the Nash category in ANAC 2015.
-
AgentX [9] was fourth of the Nash category in ANAC 2015.
-
Caudeceus [10] was the winner of individual utility category in ANAC 2016.
-
YXAgent [3] was the second of individual utility category in ANAC 2016.
-
PonPoko Agent [3] was winner of individual utility category in ANAC 2017.
-
AgentKN [3] was the second of the Nash category in ANAC 2017.
In order to study how well our opponent model performs when it negotiates with automated negotiating agents, we compare the performance of opponent models used in Conflict-based (CBOM), Scientist, and HardHeaded by integrating those opponent models into our negotiation strategy. We calculated the Spearman correlation between the actual and estimated ranks of the outcomes per each scenario and reported their averages. Note that the higher correlation is, the better the prediction is. Table 4 shows those Spearman correlations and RMSE in the utility calculations where the best scores are boldfaced. It is seen that CBOM is more successful than others in terms of Spearman correlation, except for the results obtained in the grocery and politics domains. Furthermore, RMSE results show that the CBOM is more successful in all domains.
Next, we analyze the performance of the proposed negotiation strategy relying on the CBOM opponent modeling against the ANAC finalists. The most widely used performance metric in negotiation is the final received utility, which is intuitive and in line with Kiruthika’s approach to Multi-Agent Negotiation systems [18]. There are other metrics, such as nearness to Pareto optimal solutions/Kalai point/the Nash point, the sum of both agents’ agreement utility (i.e., social welfare), and the product of those agreement utilities. Accordingly, we evaluate the performances regarding average individual received utility, Nash distance, and social welfare.

Best six agents in all automated negotiation results
First, we analyze the average individual utilities received by each agent. Table 5 shows those utilities per each agent in each negotiation scenario where the highest scores are boldfaced. The last column shows the average scores of each agent in all domains. Our agent took in the first top three agents. We noticed that the worst performance of our agent was in the supermarket domain, where the outcome space is too large to search. Moreover, our agent performed well in the smart energy grid and grocery scenarios, whose opposition levels are high.
Table 6 shows the average Nash distance for each agent in all scenarios separately, and the final column indicates the average of all scenarios. Here, the lower the Nash distance is, the fairer the agent’s outcomes are. Our conflict-based agent outperformed the ANAC finalist agents except for Nice TitForTat, which is known for maximizing social welfare in the Politics scenario (See Table 8 in Appendix). Similar results were obtained when we analyzed the social welfare in terms of summation of both agents’ agreement utilities (See Appendix). Overall results support the success of our agent, and the reason may stem from the fact that our agent aims to learn its opponent’s preferences over time and aims to find win-win solutions for both sides.
When we investigate the overall agreement rate, it can be seen that most of the agents have a high acceptance rate, and the leading ones, like ours and Atlas3, found agreements in all negotiations, as seen in Fig. 6. The final metric that we investigated is the average rounds to reach an agreement. In our experiments, the deadline is set to 5000 rounds per negotiation scenario. Table 7 shows the average rounds that the agent reached their agreement. It can be observed that the the size of the outcome space and the opposition level may influence the agreement round. In large and competitive scenarios, agents needed more rounds to reach an agreement. Among all agents, Agent X tended to reach a consensus sooner than all other agents. Furthermore, IAMHaggler2012 and ParsCat agents tend to explore the offered space as much as they can in the given time. Therefore, these are the agents least affected by the size of the outcome space and its competitiveness. Our conflict-based agent could reached an agreement sooner than more than half of the agents but it is worth noting that it took more time in terms of seconds due to its computational complexity similar to AgentKN (See Table 9 in Appendix).
As a result of all the automated negotiations, we determined the six most successful agents in both the individual and fairness category. Figure 7 shows clearly that our agent gains the highest individual gain while having a fairer win-win solution (i.e., minimum distance to Nash solution). It is worth noting that while having high utility, our agent lets its opponent gains relatively high utility in contrast to other top agents.
6 Conclusion and future work
In conclusion, this work presents a conflict-based opponent modeling approach and a bidding strategy employing this model for bilateral negotiations. Apart from evaluating the performance of the proposed opponent model in two different human-negotiation experiment settings, the proposed strategy was also tested against the finalist of the ANAC agents considering various performance metrics such as individual utility and distance to the Nash solution. Our results show that the proposed approach outperformed the state of the negotiating agents, and the proposed opponent model performed better than other frequency-based models. The contribution of this study is twofold: (1) introducing a novel opponent modeling approach to learn human negotiators’ preferences from limited bid exchanges and (2) presenting a suitable bidding strategy relying on the proposed opponent model for both collaborative and competitive negotiation settings.
Due to the algorithm’s complexity, the agent’s performance decreases when the outcome space becomes more extensive or the number of generated offers made by the opponent increases in automated negotiation. We are planning to reduce the computational complexity of the opponent modeling by adopting dynamic programming properties and local search. The upcoming study will focus on opponent model strategies that decrease the human-agent negotiation duration with the optimal number of rounds. It would be interesting to create stereotype profiles by mining the previous negotiation history and matching the current opponent’s profile based on their recent offer exchanges.
Understanding and discovering the opponent’s preferences over negotiation may play a key role in adopting strategic bidding strategies to find mutually beneficial agreements. However, as stated before, it is challenging to create a mental model for the opponent’s preferences based on a few bid exchanges. In contrast to automated negotiation, the number of exchanged bids is limited in human-agent negotiation. That requires a bidding strategy smartly exploring the potential bids and building upon an opponent model, capturing the critical components of the opponent’s preferences. While creating such modeling is not trivial with limited bid exchanges, the agent can exploit its previous negotiation experiences and take advantage of repeated patterns. As future work, it would be interesting to create different mental models from previous negotiation experiences by applying our model and trying to detect which mental model fits better for the current human negotiators. Consequently, instead of starting to learn from scratch, our model can enhance the chosen model by analyzing the current bid exchanges. Furthermore, the agent can exploit different types of inputs, such as the opponent’s arguments and facial expressions, to enhance opponent modeling.
References
Amini M, Fathian M, Ghazanfari M (2020) A boa-based adaptive strategy with multi-party perspective for automated multilateral negotiations. Appl Intell 50. https://doi.org/10.1007/s10489-020-01646-y
Aydoğan R, Festen D., Hindriks K, Jonker C (2017) Alternating Offers Protocols for Multilateral Negotiation, pp 153–167. Studies Comput Intell Springer Sci. https://doi.org/10.1007/978-3-319-51563-2_10
Aydoğan R, Fujita K, Baarslag T, Jonker CM, Ito T (2021) ANAC 2017: Repeated multilateral negotiation league. Advances in automated negotiations. Springer Singapore, Singapore, pp 101-115
Aydoğan R, Keskin MO, Çakan U (2022) Would you imagine yourself negotiating with a robot, jennifer? why not? IEEE Trans Hum Mach Syst 52(1):41–51. https://doi.org/10.1109/THMS.2021.3121664
Baarslag T, Hendrikx M, Hindriks K, Jonker C (2013) Predicting the performance of opponent models in automated negotiation. In: 2013 IEEE/WIC/ACM International joint conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT), vol 2, pp 59–66. https://doi.org/10.1109/WI-IAT.2013.91
Baarslag T, Hendrikx MJC, Hindriks K, Jonker C (2016) A survey of opponent modeling techniques in automated negotiation. In: AAMAS
Baarslag T, Hindriks K, Jonker C (2013) A tit for tat negotiation strategy for real-time bilateral negotiations. In: Complex automated negotiations: theories, models, and software competitions. Springer Berlin Heidelberg, Berlin, Heidelberg, pp 229–233. https://doi.org/10.1007/978-3-642-30737-9_18
Fatima S, Kraus S, Wooldridge M (2014) Principles of automated negotiation. Cambridge University Press. https://doi.org/10.1017/CBO9780511751691
Fujita K, Aydoğan R, Baarslag T, Hindriks K, Ito T, Jonker C (2017) The Sixth automated negotiating agents competition (ANAC 2015). Springer International Publishing, Cham, pp 139–151 (2017). https://doi.org/10.1007/978-3-319-51563-2_9
Güneş TD, Arditi E, Aydoğan R (2017) Collective voice of experts in multilateral negotiation. PRIMA 2017: Principles and practice of multi-agent systems. Springer International Publishing, Cham, pp 450–458
Hao J, Leung Hf (2014) CUHKAgent: An Adaptive negotiation strategy for bilateral negotiations over multiple items. Springer Japan, Tokyo, pp 171–179. https://doi.org/10.1007/978-4-431-54758-7_11
Hindriks K, Jonker C, Tykhonov D (2009) The benefits of opponent models in negotiation. In: 2009 IEEE/WIC/ACM International joint conference on Web Intelligence and Intelligent Agent Technology (WI-IAT). pp 439–444. https://doi.org/10.1109/WI-IAT.2009.192
Hosokawa Y, Fujita K (2020) Opponent’s preference estimation considering their offer transition in multi-issue closed negotiations. IEICE Trans Inf Syst E103.D, 2531–2539 (2020). https://doi.org/10.1587/transinf.2020SAP0001
Jonge Dd, Sierra C (2015) NB3: a multilateral negotiation algorithm for large, non-linear agreement spaces with limited time. Auton Agents Multi-Agent Syst 29(5):896–942. https://doi.org/10.1007/s10458-014-9271-3
Jonker C, Aydogan R, Baarslag T, Fujita K, Ito T, Hindriks K (2017) Automated negotiating agents competition (ANAC). Proceedings of the AAAI Conference on Artificial Intelligence 31(1). https://ojs.aaai.org/index.php/AAAI/article/view/10637
Keskin MO, Çakan U, Aydoğan R (2021) Solver agent: Towards emotional and opponent-aware agent for human-robot negotiation. In: Proceedings of the 20th international conference on Autonomous Agents and MultiAgent Systems, AAMAS 21. International Foundation for Autonomous Agents and Multiagent Systems, Richland, SC, pp 1557–1559
Khosravimehr Z, Nassiri-Mofakham F (2017) Pars agent: hybrid time-dependent, random and frequency-based bidding and acceptance strategies in multilateral negotiations. Springer International Publishing, Cham, pp 175–183. https://doi.org/10.1007/978-3-319-51563-2_12
Kiruthika U, Somasundaram TS, Subramanian KS (2020) Lifecycle model of a negotiation agent: A survey of automated negotiation techniques. Group Decision and Negotiation 29:1–24. https://doi.org/10.1007/s10726-020-09704-z
van Krimpen T, Looije D, Hajizadeh S (2013) HardHeaded. Springer Berlin Heidelberg, Berlin, Heidelberg, pp 223–227. https://doi.org/10.1007/978-3-642-30737-9_17
Lewis M, Yarats D, Dauphin Y, Parikh D, Batra D (2017) Deal or no deal? end-to-end learning of negotiation dialogues. In: Proceedings of the 2017 conference on empirical methods in natural language processing. Assoc Comput Ling, Copenhagen, Denmark, pp 2443–2453. https://doi.org/10.18653/v1/D17-1259
Lin R, Kraus S, Wilkenfeld J, Barry J (2008) Negotiating with bounded rational agents in environments with incomplete information using an automated agent. Artif Intell 172(6–7):823–851
Mell J, Gratch J, Aydoğan R, Baarslag T, Jonker CM (2019) The likeability-success tradeoff: Results of the 2nd annual human-agent automated negotiating agents competition. In: 2019 8th international conference on affective computing and intelligent interaction (ACII). pp 1–7. https://doi.org/10.1109/ACII.2019.8925437
Mell J, Lucas GM, Mozgai S, Gratch J (2020) The effects of experience on deception in human-agent negotiation. J Artif Intell Res 68:633–660
Mori A, Ito T (2017) Atlas3: A negotiating agent based on expecting lower limit of concession function. Springer International Publishing, Cham, pp 169–173. https://doi.org/10.1007/978-3-319-51563-2_11
Nazari Z, Lucas G, Gratch J (2015) Opponent modeling for virtual human negotiators. In: International conference on intelligent virtual agents. pp 39–49. https://doi.org/10.1007/978-3-319-21996-7_4
Oshrat Y, Lin R, Kraus S (2009) Facing the challenge of human-agent negotiations via effective general opponent modeling. Proceedings of the International Joint Conference on Autonomous Agents and Multiagent Systems, AAMAS 2:377–384. https://doi.org/10.1145/1558013.1558064
Peled N, Gal YK, Kraus S (2015) A study of computational and human strategies in revelation games. Auto Agents Multi-Agent Syst 29(1):73–97
Rosenfeld A, Zuckerman I, Segal E, Drein O, Kraus S (2014) Negochat: a chat-based negotiation agent. In: AAMAS. pp 525–532
Sanchez-Anguix V, Aydoğan R, Julian V, Jonker C (2014) Unanimously acceptable agreements for negotiation teams in unpredictable domains. Elec Comm Res Appl 13(4):243–265
Sengupta A, Mohammad Y, Nakadai S (2021) An autonomous negotiating agent framework with reinforcement learning based strategies and adaptive strategy switching mechanism. In: Proceedings of the 20th international conference on autonomous agents and multiAgent systems, AAMAS ’21. pp 1163–1172
Tunalı O, Aydoğan R, Sanchez-Anguix V: Rethinking frequency opponent modeling in automated negotiation. In: International. pp 263–279 (2017). https://doi.org/10.1007/978-3-319-69131-2_16
Yu C, Ren F, Zhang M (2013) An adaptive bilateral negotiation model based on bayesian learning. Springer, vol 435, pp 75–93. https://doi.org/10.1007/978-3-642-30737-9_5
Funding
This work has been supported by a grant of The Scientific and Research Council of Turkey (TÜBİTAK) with grant number 118E197 and partially supported by the Chist-Era grant CHIST-ERA-19-XAI-005, the Scientific and Research Council of Turkey (TÜBİTAK, G.A. 120N680).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Keskin, M.O., Buzcu, B. & Aydoğan, R. Conflict-based negotiation strategy for human-agent negotiation. Appl Intell 53, 29741–29757 (2023). https://doi.org/10.1007/s10489-023-05001-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-023-05001-9