
Abstract
UAVs rounding up is a game between UAV swarm and targets. The main challenge lies in achieving efficient collaboration between UAVs and the setting of rounding-up points. This paper extends our work in three aspects, including establishing an information interaction strategy model, dynamic rounding-up points, and detailed reward function settings. Inspired by the intelligence of the biological swarm, this paper constructs a communication multi-agent depth deterministic policy gradient (COM-MADDPG) framework, based on the communication topology during the rounding-up process, which proposes an information interaction strategy as action policy in reinforcement learning. When carrying out rounding up, it is no longer limited to a fixed threshold, and a dynamic rounding-up points is proposed to judge the success of the mission, each UAV has own area of rounding-up and cooperate to complete the swarm mission. In view of the situation where the target is at the corner or edge, the reward function of reinforcement learning is redefined, which effectively avoids the problem of rounding-up failure under special circumstances. Furthermore, the simulation results verify the COM-MADDPG framework perform better than DDPG and MADDPG in rounding-up tasks, and can be help for improving the success rate, which confirms the effectiveness of decision-making in those special situations. Those all have shown promise due to their robustness.














Similar content being viewed by others

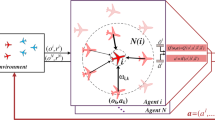
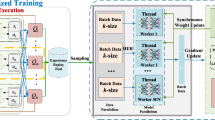
References
Hespanha JP, Prandini M, Sastry S (2000) Probabilistic pursuit-evasion games: a one-step nash approach. In: Proceedings of the 39th IEEE conference on decision and control (Cat. No. 00CH37187). IEEE, vol 3, pp 2272–2277. https://doi.org/10.1109/CDC.2000.914136
Weintraub IE, Pachter M, Garcia E (2020) An introduction to pursuit-evasion differential games. In: 2020 American control conference (ACC). IEEE, pp 1049–1066. https://doi.org/10.23919/ACC45564.2020.9147205
Li D, Cruz JB, Chen G, Kwan C, Chang M-H (2005) A hierarchical approach to multi-player pursuit-evasion differential games. In: Proceedings of the 44th IEEE conference on decision and control. IEEE, pp 5674–5679. https://doi.org/10.1109/CDC.2005.1583067
Bhattacharya S, Hutchinson S (2009) On the existence of nash equilibrium for a two player pursuit-evasion game with visibility constraints. In: Algorithmic foundation of robotics VIII. Springer, pp 251–265. https://doi.org/10.1007/978-3-642-00312-7_16
Jaleel H, Shamma JS (2020) Distributed optimization for robot networks: from real-time convex optimization to game-theoretic self-organization. Proc IEEE 108(11):1953–1967. https://doi.org/10.1109/JPROC.2020.3028295
El Ferik S (2017) Behavioral control of uavs with multi-threat evasion strategy inspired by biological systems. In: 2017 14th International multi-conference on systems, signals & devices (SSD). IEEE, pp 181–186. https://doi.org/10.1109/SSD.2017.8167018
Fu X, Chen Z (2021) Cooperative capture control method for multi-UAV based on consensus protocol. Syst Eng Electr 43(9):2501–2507. https://doi.org/10.12305/j.issn.1001-506X.2021.09.17
Huang S (2019) Research on applying deep reinforcement learning in pursuit-evasion problem, Huazhong University of Science & Technology. https://doi.org/10.27157/d.cnki.ghzku.2019.002980
Huang S-Y, Hu B, Liao R-Q, Xiao J-W, He D-X, Guan Z-H (2019) Multi-agent cooperative-competitive environment with reinforcement learning. In: 2019 IEEE 8th data driven control and learning systems conference (DDCLS). IEEE, pp 1382–1386. https://doi.org/10.1109/DDCLS.2019.8909048
Zhang Y, Xu J, Yao K, Liu J (2020) Pursuit missions for UAV swarms based on DDPG algorithm. Acta Aeronautica et As-tronautica Sinica 41(10):324000–324000. https://doi.org/10.7527/S1000-6893.2020.24000
Lowe R, Wu Y, Tamar A, Harb J, Abbeel P, Mordatch I (2017) Multi-agent actor-critic for mixed cooperative-competitive environments. In: Proceedings of the 31st international conference on neural information processing systems, pp 6382–6393. https://doi.org/10.48550/arXiv.1706.02275
Fu X, Wang H, Xu Zh (2022) Cooperative pursuit strategy for multi-UAVs based on DE-MADDPG algorithm. Acta Aeronautica et Astronautica Sinica 43(5):325311–325311. https://doi.org/10.7527/S1000-6893.2021.25311
Zou Ch, Zhen J, Zhang Zh (2020) Research on collaborative strategy based on gaed-maddpg multi-agent reinforcement learning. Appl Res Comput 37(12):142–147. https://doi.org/10.19734/j.issn.1001-3695.2019.09.0546
Bilgin AT, Kadioglu-Urtis E (2015) An approach to multi-agent pursuit evasion games using reinforcement learning. In: 2015 International conference on advanced robotics (ICAR). IEEE, pp 164–169. https://doi.org/10.1109/ICAR.2015.7251450
Su J, Adams S, Beling PA (2021) Value-decomposition multi-agent actor-critics. In: Proceedings of the AAAI conference on artificial intelligence, vol 35, pp 11352–11360. https://doi.org/10.48550/arXiv.2007.12306
Jiang J, Lu Z (2018) Learning attentional communication for multi-agent cooperation. Adv Neural Inf Process Syst 31(13):7254–7264. https://doi.org/10.48550/arXiv.1805.07733
Wang Y, Dong L, Sun C (2020) Cooperative control for multi-player pursuit-evasion games with reinforcement learning. Neurocomputing 412:101–114. https://doi.org/10.1016/j.neucom.2020.06.031
Das A, Gervet T, Romoff J, Batra D, Parikh D, Rabbat M, Pineau J (2019) Tarmac: targeted multi-agent communication. In: International conference on machine learning. PMLR, pp 1538–1546. https://doi.org/10.48550/arXiv.1810.11187
Su J, Adams S, Beling PA (2020) Counterfactual multi-agent reinforcement learning with graph convolution communication, vol 2004. https://doi.org/10.48550/arXiv.2004.00470
Rangwala M, Williams R (2020) Learning multi-agent communication through structured attentive reasoning. Adv Neural Inf Process Syst 33:10088–10098
Zhang W, Li X, Ma H, Luo Z, Li X (2021) Federated learning for machinery fault diagnosis with dynamic validation and self-supervision. Knowl-Based Syst 213:106679. https://doi.org/10.1016/j.knosys.2020.106679
Zhang W, Li X, Ma H, Luo Z, Li X (2021) Universal domain adaptation in fault diagnostics with hybrid weighted deep adversarial learning. IEEE Trans Industr Inform 17(12):7957–7967. https://doi.org/10.1109/TII.2021.3064377
Kong X, Xin B, Liu F, Wang Y (2017) Effective master-slave communication on a multiagent deep reinforcement learning system. In: Hierarchical reinforcement learning workshop at the 31st conference on NIPS, Long Beach, USA
Kong X, Xin B, Liu F, Wang Y (2017) Revisiting the master-slave architecture in multi-agent deep reinforcement learning. arXiv:1712.07305, https://doi.org/10.48550/arXiv.1712.07305
Mao H, Zhang Z, Xiao Z, Gong Z (2018) Modelling the dynamic joint policy of teammates with attention multi-agent ddpg. arXiv:1811.07029, https://doi.org/10.48550/arXiv.1811.07029
Yang Q, Zhu Y, Zhang J, Qiao S, Liu J (2019) Uav air combat autonomous maneuver decision based on ddpg algorithm. In: 2019 IEEE 15th international conference on control and automation (ICCA). IEEE, pp 37–42. https://doi.org/10.1109/ICCA.2019.8899703
Hou Y, Liu L, Wei Q, Xu X, Chen C (2017) A novel ddpg method with prioritized experience replay. In: 2017 IEEE international conference on systems, man, and cybernetics (SMC). IEEE, pp 316–321. https://doi.org/10.1109/SMC.2017.8122622
Wagner C, Back A (2008) Group wisdom support systems: aggregating the insights of many trough information technology. Issues Inf Syst (IIS) 9(2):343–350. https://doi.org/10.48009/2_iis_2008_343-350
Wei R, Zhang Q, Xu Z (2020) Peers’ experience learning for developmental robots. Int J Social Robot 12(1):35–45. https://doi.org/10.1007/s12369-019-00531-0
Zhou K, Wei K, Zhang Q, Ding C (2020) Learning method for autonomousair combat based on experience transfer. Acta Aeronautica et Astronautica Sinica 42((S2)):724285. https://doi.org/10.7527/S1000-6893.2020.24285
Bai X (2020) Research and application of reinforcement learning in multi-agent collaboration. University of Electr Sci Technol China. https://doi.org/10.27005/d.cnki.gdzku.2020.000375
Markova VD, Shopov VK (2019) Knowledge transfer in reinforcement learning agent. In: 2019 International conference on information technologies (InfoTech). IEEE, pp 1–4. https://doi.org/10.1109/InfoTech.2019.8860881
Patricia N, Caputo B (2014) Learning to learn, from transfer learning to domain adaptation: a unifying perspective. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1442–1449. https://doi.org/10.1109/CVPR.2014.187
Duan Y, Huang X, Yu X (2016) Multi-robot dynamic virtual potential point hunting strategy based on fis. In: 2016 IEEE Chinese guidance, navigation and control conference (CGNCC). IEEE, pp 332–335. https://doi.org/10.1109/CGNCC.2016.7828806
Li R, Yang H, Xiao C (2019) Cooperative hunting strategy for multi-mobile robot systems based on dynamic hunting points. Control Eng China 26(03):173–196. https://doi.org/10.14107/j.cnki.kzgc.161174
Lillicrap TP, Hunt JJ, Pritzel A, Heess N, Erez T, Tassa Y, Silver D, Wierstra D (2015) Continuous control with deep reinforcement learning. arXiv:1509.02971, https://doi.org/10.48550/arXiv.1509.02971
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper. This work is funded by the Science and Technology Innovation 2030-Key Project of “New Generation Artificial Intelligence”, China (No. 2018AAA0102403).
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Wei Ruixuan and Wang Dong are contributed equally to this work.
Rights and permissions
About this article

Cite this article
Jiang, L., Wei, R. & Wang, D. UAVs rounding up inspired by communication multi-agent depth deterministic policy gradient. Appl Intell 53, 11474–11489 (2023). https://doi.org/10.1007/s10489-022-03986-3
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-022-03986-3