
Abstract
This paper presents a race-free cascaded dynamic current mode logic (DyCML) derived from NORA-based CMOS dynamic circuits. Cascading two stages of DyCML gates poses the challenge of erroneous evaluation between stages. To address this, two traditional cascading mechanisms, one using a clock delay scheme and the other employing a self-timing scheme, both require intermediary circuits, such as inverters or buffers, between stages. This paper proposes a new complementary DyCML for the NORA-based cascaded technique, which is completely race-free, regardless of the overlap period of the two complementary clock signals. The proposed technique eliminates the need for intermediary circuitry, thereby resolving the issue of erroneous evaluation. The new NORA-based technique enhances performance, including reductions in delay, power consumption, and area. The proposed NORA-based DyCML circuit was optimized using a combination of Taguchi and ANOVA statistical techniques. Following this optimization process, the circuit achieved a delay of 121.8 ps, a power consumption of 6.11 µW, and a power-delay product (PDP) of 0.744 fJ. Simulations conducted in Cadence Virtuoso using GPDK 45 nm CMOS technology at a 1 V supply voltage demonstrate improvements of 69.55%, 17.85%, 74.97%, and 27.90% in delay, power consumption, power-delay product, and area, respectively, compared to the existing design. Post-layout simulations further validate the performance parameters, while Monte Carlo simulations and process, voltage, and temperature (PVT) variations confirm the robustness of the proposed circuit. Overall, the proposed NORA-based DyCML technique offers significant advantages in performance and area efficiency, making it a viable solution for low-power, high-performance logic circuits.
Similar content being viewed by others


1 Introduction
In mixed-signal applications, low-power and high-performance circuits are crucial. However, traditional CMOS logic is not well-suited for these applications due to the significant switching noise it generates [1]. To address issues related to switching and transient noise, various logic families have been developed over time, specifically designed for low-voltage, low-power mixed-mode circuit designs. Among these, MOS-Current Mode Logic (MCML) and Positive Feedback Source-Coupled Logic (PFSCL), which operate on the current-steering principle, are widely employed in high-speed circuit designs [2,3,4,5,6,7,8,9,10,11,12,13,14,15,16]. Recent literature [17,18,19,20,21,22,23,24,25] has reported significant advancements in the analysis, design, and optimization of MCML and PFSCL. These developments underscore the potential of MCML as a promising alternative to conventional logic design techniques, particularly for low-power applications in mixed-signal integrated circuits. MCML is also critical in RF and microwave systems such as 5G networks, radar, and satellite communications, where it facilitates high-frequency signal processing. In high-performance computing, MCML plays a vital role in supporting clock distribution networks and high-speed interconnects. In the aerospace and defense sectors, it is widely employed in satellite communication systems and radar signal processing. Its inherent power efficiency and ability to operate at high speeds also make it well-suited for emerging technologies such as quantum computing and cryogenic electronics [26,27,28,29].
Among differential logic families, MCML is a popular choice due to its low-noise characteristics, reduced power consumption, and improved power-delay product at high frequencies. In MCML, transient currents are minimized or controlled by utilizing reduced voltage swings during switching events. However, despite its advantages in high-performance digital systems, MCML has the drawback of significant static power consumption. The speed of static MCML logic primarily depends on charging and discharging parasitic capacitances during switching, but at lower supply voltages and smaller voltage swings, gate and interconnect power dissipation becomes more dominant, affecting overall performance. The dynamic version of current mode logic (DyCML) [30,31,32,33,34,35,36,37,38,39] offers an enhanced alternative based on charge distribution logic, delivering high performance at lower supply voltages with reduced power consumption. Unlike static CML circuits, DyCML eliminates static current sources, making it suitable for portable and battery-operated devices. As a result, DyCML avoids static power dissipation, and its dynamic power consumption is independent of input combinations, being lower than other differential logic families due to a smaller output voltage swing. In DyCML circuits, parasitic capacitances play a key role in the circuit’s functionality, enabling a pre-charge and evaluation process within a specified clock cycle. Recent research emphasizes the significance of DyCML in achieving low power and high-speed circuit performance, especially in nanometer CMOS technologies [40]– [41].
Although DyCML gates are efficient in terms of delay and power consumption at lower supply voltages, yet they suffer from an erroneous evaluation problem in multistage operations when evaluating any logic function [37]. In the direct cascading of two DyCML gates, unwanted bleeding of charges from pre-charged nodes can occur, leading to incorrect evaluation between two directly cascaded stages within the limited clock evaluation cycle. To address this issue, two cascading mechanisms are suggested in the literature [31, 36,37,38], which use an intermediary circuit in the form of either an inverter or a self-timed buffer. While these techniques prevent erroneous evaluation, they do so at the cost of increased power dissipation and delay due to the use of buffers and inverters. Now, an improved technique in cascading of DyCML gates is proposed in which alternative nMOS and pMOS logic stages are used, which is called the NORA technique [42,43,44]. The NORA technique effectively solves the erroneous evaluation problem, offering greater logic flexibility with fewer transistors required for the same function realization.
The structure of the paper is divided into seven sections. The cascading mechanism in DyCML gate is briefly reviewed in Sect. 2, and the issues in multistage operation of DyCML gate are also discussed. The proposed complementary Dynamic CML inverter along with race-free NORA based technique for cascading in DyCML gate, is presented in Sects. 3 and 4. Section 5 provides a detailed explanation of the design optimization process, employing both Taguchi and ANOVA statistical methods. The functionality, simulation, and performance of the proposed technique, compared with the existing techniques, are presented in Sect. 6. Lastly, the conclusions are presented in Sect. 7.
2 Cascaded dynamic CML
Dynamic Current Mode Logic (DyCML) is a high-speed, high-performance logic style that operates at lower supply voltages and with reduced voltage swings compared to static MOS Current Mode Logic (MCML). Unlike static CML, which uses a static current source, a DyCML gate incorporates a dynamic current source. The fundamental structure of a DyCML gate is illustrated in Fig. 1. In this design, the transistor pair (M1-M2) along with capacitor CS form the dynamic current source Sects [31,32,33,34,35,36,37,38]. The transistor pair (M3-M4) serves as the pull-down network (PDN), while transistors M5 and M6 make up the pre-charge circuit. The operation of the DyCML gate is controlled by the clock (CLK) signal, alternating between pre-charge and evaluation phases.
When the CLK signal is low, the pre-charge phase begins. In this phase, transistors M2, M5, and M6 are activated, while M1 is deactivated. The differential output nodes, Q and Q̅, are pre-charged to a high voltage level (VOH = VDD) via transistors M5 and M6. At the same time, capacitor CS discharges to ground through transistor M2. During this pre-charge phase output is independent of applied differential input A, because transistors M5 and M6 are on and transistor M1 is off. Once the CLK signal goes high, the circuit moves into the evaluation phase, deactivating M5 and M6 and activating M1. During this phase, the differential outputs are evaluated based on the applied differential inputs. Thus, the DyCML gate operates using a pre-charge-evaluate logic, where the output node capacitances are first pre-charged and then evaluated depending on the inputs.

In multistage applications of DyCML gates, cascading two gates presents certain challenges. To illustrate this issue, consider the cascaded DyCML gate depicted in Fig. 2(a) [37]. During the pre-charge phase, both the outputs (Q1 and Q2) are high, regardless of the differential input stage (A). When the evaluation phase begins, Q1 and Q2 initially remain high. If the input A to the first stage of the DyCML gate is high, the output (Q1) decreases to a low level during evaluation. Since both DyCML gates evaluate simultaneously, the second stage output (Q2) also incorrectly drops to a low level, as shown in Fig. 2(b) [37]. This issue arises because the two stages evaluate at the same time in direct cascading, leading to erroneous evaluation.

(a) Cascading of two DyCML gates (b) Outputs of the two stages of DyCML gate with respect to the common clock (CLK)
The problem of erroneous evaluation can be resolved by either delaying the second stage’s evaluation until the first stage output is achieved or by ensuring low to high transition at the output. The literature suggests two techniques for implementing multi-stage DyCML gates, which are detailed here:
2.1 Insertion of MCML inverter
Inserting an MCML inverter between two cascaded DyCML stages can prevent erroneous evaluations by ensuring a low-to-high transition at the output [37]. While this technique enables the use of DyCML gates in multi-stage applications, it incurs the drawback of static power consumption by the MCML inverter, limiting its overall suitability.
2.2 Insertion of Self-timed buffer
The second method employs a self-timed buffer [37] placed between consecutive stages of DyCML gates. This buffer translates the voltage stored on capacitor CS,1 in the dynamic current source of the first stage into a full-swing output signal (CLK2), which then triggers the evaluation of the next stage, as illustrated in Fig. 3.

Cascaded DyCML gates with self-timed buffer [37]
During the pre-charge phase of the first stage, when the CLK signal is low, the output load capacitances (CL,1) are pre-charged to a high voltage level (VDD). At the same time, the capacitor CS,1 discharges to ground potential. This ensures the self-timed buffer output remains low, keeping the second stage in its pre-charge phase. During the evaluation phase, when the CLK signal goes high, the capacitor CS,1 in the first stage charges to a high voltage level (VDD-VSWING), resulting in a high voltage output from the self-timed buffer. As a result, the second stage enters its evaluation phase only after the first stage completes its evaluation.
It is clear that in the multistage application of DyCML gate there is an intermittent circuitry is required to realize any logic function correctly which leads to the requirement of large implementation area. Other than this complementary clock operation also puts constraints on the overlap period of CLK and \(\:\stackrel{-}{\text{C}\text{L}\text{K}}\) signal for race-free operation [42,43,44]. Thus these limitations in cascaded DyCML gates restrict its use for any logic function realization. To eliminate this intermittent circuitry a new complementary dynamic CML inverter gate is proposed which can be directly cascaded to the existing N-type dynamic CML inverter gate i.e. a new NORA based cascaded DyCML technique is proposed which possess higher logic flexibility with less number of transistors.
In the next section, a new complementary dynamic CML inverter is proposed to alleviate the problems of above techniques by eliminating the use of intermittent circuitry.
3 Proposed complementary dynamic CML inverter
The basic architecture of an existing DyCML inverter gate is illustrated in Fig. 1. In the existing DyCML inverter gate pull down network consists of NMOS transistor pair (M3-M4), so it can be called as N-type inverter, where input signal is applied which is evaluated according to CLK signal operation. Using the same CLK signal, a new complementary (P-type) dynamic CML inverter gate can be proposed. In the new proposal of the complementary dynamic CML inverter as illustrated in Fig. 4, the PMOS transistor pair (M1-M2) along with capacitor Cs form the dynamic current source section, the PMOS transistor pair (M3-M4) make up the pull down network (PDN) and the PMOS transistor pair (M5-M6) constitute the pre-discharge circuit respectively.

Proposed complementary Dynamic CML inverter gate
The fundamental operation of complementary DyCML inverter gate is similar to that of existing DyCML inverter. The circuit operates based on pre-discharge and evaluate logic. Both operations are performed in the same phase of the CLK signal, as in the existing design [37]. When applied CLK signal is low, pre-discharge phase occurs, where PMOS transistors M1, M5, and M6 are activated, while M2 is deactivated. During this phase the differential output nodes are pre-discharged to the low voltage level and pulled down to a potential equal to the threshold value of the PMOS transistor (VOL=|Vt, p|). This pre-discharge operation of the output nodes is done through the PMOS transistor pair M5 and M6. Additionally, the capacitor Cs is charged to the high potential (VDD) via transistor M1 during this pre-discharge phase. During this phase any changes at input in pull down network do not alter the output voltage level as the pre-discharge transistors M5, M6 are ON, while transistor M2 remains OFF. Conversely, during the evaluation phase, when the CLK signal goes high, transistors M1, M5 and M6 are turned OFF, and M2 is turned ON. This may result in a direct current path been created between the output nodes and intermediate capacitors (CL and CS). Now during this evaluation phase differential outputs are determined based on the applied differential inputs. For this gate, one of the output nodes may get charged to high voltage (VOH = |Vt, p| + VSWING) through the transistor M2 while the other remains at the voltage level of |Vt, p|.
Thus the operation of the complementary DyCML inverter gate follows a pre-discharge and evaluate logic where the output nodes capacitances are first pre-discharged to low voltage (|Vt, p|) and then evaluated according to the applied differential inputs. The inverted output waveforms with the applied differential inputs and CLK signal operation for the existing DyCML inverter [31, 37] and the proposed complementary DyCML inverter is illustrated in the Fig. 5.

(a) Output waveforms of the existing DyCML inverter and (b) Output waveforms of the proposed complementary DyCML inverter
3.1 Determining the value of capacitor CS to accomplish desired voltage swing
During the evaluation phase, charge is shifted from capacitor CS of the dynamic current source to the load capacitor CL. This charge transfer follows the charge conservation principle to accomplish the desired voltage swing at the output.
Where COUT represents the overall load capacitance at the output node, which includes both parasitic capacitances and the external load capacitance CL. Therefore, the value of capacitor CS required to accomplish the desired voltage swing at the output node can be calculated as follows:
In practice, capacitor CS is designed using MOSFET, for this source and drain terminals of MOSFET are tied together. Thus, CS is replaced by \(\:{\text{W}}_{{\text{C}}_{\text{S}}}\times\:\) \(\:{\text{L}}_{{\text{C}}_{\text{S}}}\times\:\) COX. For the given value of length \(\:{\text{L}}_{{\text{C}}_{\text{S}}}\) and the width \(\:{\text{W}}_{{\text{C}}_{\text{S}}}\) of the MOSFET is computed as follows:
Where \(\:{\text{W}}_{{\text{C}}_{\text{S}}}\) and \(\:{\text{L}}_{{\text{C}}_{\text{S}}}\) represent the width and length of the MOS transistor for CS, respectively, and COX is the gate oxide capacitance per unit area.
3.2 Power dissipation of the complementary DyCML inverter gate
In the complementary dynamic CML circuit, there is no direct connection between the power supply and ground. A clock signal is employed to ensure that transistors M1 and M2 are not activated simultaneously, thereby minimizing static power consumption. However, because of the load capacitor, the circuit still consumes dynamic power. Consequently, the dynamic power consumption can be described by:
Where fCLK denotes the frequency of the CLK signal and α represents the circuit’s switching activity.
4 Proposed NORA based cascaded dynamic CML
A new NORA logic based technique for cascading of DyCML gates is proposed which includes two complementary dynamic logic blocks (N-type and P-type) as depicted in Fig. 6. In this technique self-timed buffer (STB) is not required. The figure shows two dynamic CML gates: the first gate uses pull down network (PDN) for the implementation of logic function and the second gate uses pull up network (PUN) for the same logic function realization.

Proposed NORA based Cascaded DyCML gates
In this design, the pre-charge and evaluation timing for N-type DyCML stage is controlled by the clock signal (CLK), while the pre-discharge and evaluation timing for P-type DyCML (Complementary DyCML) stage is also managed by the clock signal (CLK). The NORA based cascaded dynamic CML circuit functions as follows: When the clock signal is low, the output nodes of N-type DyCML stages are pre-charged to VDD through PMOS pre-charge transistors, and the output nodes of P-type DyCML stages are pre-discharged to VOL (|Vt, p|) via PMOS discharge transistors controlled by CLK. Upon transitioning from low to high, the clock signal initiates the sequential evaluation of all cascaded N-type and P-type logic stages.
In this NORA based cascaded circuit the differential inputs are applied to transistors M3,1 and M4,1 of first dynamic CML gate. When the clock signal (CLK) is low, the pre-charge transistors M5,1 and M6,1 of the first gate turn on and pre-charges the node Q1 and \(\:\stackrel{-}{\text{Q}1}\) to supply voltage (VDD), whereas the evaluate transistor M1,1 turns off, avoiding any charge flow through capacitor CS,1. At the same time the pre-discharge PMOS transistors M5,2 and M6,2 of the second gate turn on by discharging any charge present on outputs node Q2 and \(\:\stackrel{-}{\text{Q}2}\) to VOL (|Vt, p|) while transistor M1,2 turns on and charges capacitor CS,2 to supply voltage (VDD).
Conversely, when the clock signal (CLK) is high, the evaluate transistor M1,1 of the first gate is activated while transistor M2,1 is deactivated. Considering the input signal A to be high, at this time transistor M3,1 turns on, bringing output node Q1 to low voltage(VDD - VSWING) and transistor M4,1 remains in off stage keeping node \(\:\stackrel{-}{\text{Q}1}\) at high voltage (VDD). These two outputs are applied as inputs to the second stage of dynamic CML gate. During high phase of clock, PMOS transistor M2,2 turns on and according to the input conditions on transistors M3,2 and M4,2, charging of the node Q2 or \(\:\stackrel{-}{\text{Q}2}\) is done. Here in this case as Q1 is at low voltage, the PMOS transistor M3,2 turn on by charging output node Q2 to a high potential (VOH=|Vt, p| + VSWING) and the other output node \(\:\stackrel{-}{\text{Q}2}\) remains at the low voltage level of |Vt, p|.
5 Optimization of the proposed NORA based technique using Taguchi design of experiments and analysis of variance (ANOVA) statistical techniques
Taguchi Design of Experiments (DoE) and Analysis of Variance (ANOVA) are two powerful statistical techniques widely used for optimization in engineering, manufacturing, and research processes. Taguchi DoE, developed by Genichi Taguchi, focuses on improving product quality and performance by minimizing the impact of uncontrollable factors, often referred to as noise factors. It uses a systematic and structured approach to design experiments with a reduced number of trials while still capturing essential information about the process or system under study. Taguchi’s method uses orthogonal arrays (OA) to plan experiments strategically and efficiently vary multiple factors at different levels. This not only facilitates a clear understanding of how each parameter affects the desired output response but also helps conserve time and resources by means of a more efficient experimental process.
The Analysis of Variance (ANOVA) technique is commonly used in conjunction with the Taguchi DoE method. It provides a quantitative measure, known as the F-ratio, to determine whether changes in input factor levels have a statistically significant effect on the output variable. ANOVA also allows for the calculation of the percentage contribution of each input factor and their interactions to the overall variation in the results. This information helps researchers prioritize control factors for process optimization. Input factors with higher contribution percentages are considered more influential and are therefore critical for achieving optimal system performance.
The combination of Taguchi DoE for experimental planning and ANOVA for result analysis provides a robust framework for identifying the most favorable process parameters, understanding their impact, and determining the optimal levels to improve product quality and performance while minimizing variability.
In this research, three important independent variables were chosen for study: the width of the NMOS transistors (Wn), the width of the PMOS transistors (Wp), and the supply voltage (VDD). To thoroughly assess their impact on the circuit’s performance, each control parameter was evaluated at three distinct levels. The details of these parameters and their corresponding levels are summarized in Table 1. To efficiently design the experiments, an L9 orthogonal array was used, resulting in a total of nine experimental runs, as presented in Table 2. This structured approach not only simplifies the experimental process but also helps in determining the optimal combination of design parameters for improving circuit performance.
The Taguchi Design of Experiments (DoE) approach assesses system performance using the Signal-to-Noise Ratio (SNR) as a key evaluation metric. It is essential to highlight that the concept of SNR applied in this context differs from the conventional SNR commonly used in analog circuit design. In this study, the SNR values were computed for each experimental trial and for each output parameter under consideration. The selection of the appropriate SNR formula depends on the desired output characteristic, whether it is aimed at minimization or maximization. Specifically, the formulas for calculating SNR under the “smaller-the-better” and “larger-the-better” conditions are provided in Eqs. (5) and (6), respectively.
Where, Qi denotes the output value for the i-th experiment, while n represents the total number of experimental trials conducted. The corresponding Signal-to-Noise Ratio (SNR) values for every output have been graphically illustrated in Fig. 7(a-c).
In this study, the response with the highest Signal-to-Noise Ratio (SNR) is considered to have the most significant influence, while a lower SNR indicates a lesser impact. Three critical output parameters have been selected to determine the optimal design configuration: power dissipation, delay, and power-delay product (PDP). To achieve a balanced and efficient design, the objective is to minimize power consumption, delay, and PDP. Statistical analysis and SNR calculations have been performed using Minitab software. A summary of the output results, along with their corresponding SNR values, is presented in Table 2. Among all trials, Experiment 9 recorded the lowest delay, highest power consumption, and the lowest PDP value. This experiment exhibited a relatively low signal-to-noise ratio (SNR) for delay, but a high SNR for both power dissipation and power-delay product (PDP).

Plots for SNR ratio of different parameters for the proposed NORA based Technique (a) Delay (b) Power Dissipation (c) PDP. (a) Delay, (b) Power dissipation, (c) PDP
In Table 3, ‘Delta’ represents the change in each performance metric resulting from variations in the corresponding control parameter. A higher Delta value signifies a greater impact on circuit behaviour. By analyzing the results shown in Fig. 7(a-c) alongside the data in Table 3, it is evident that VDD has a stronger influence on delay and power consumption while Wn has a more significant impact on the PDP in the NORA-based cascaded dynamic CML circuit.
Table 3 presents the average Signal-to-Noise Ratio (SNR) values for each of the output parameters delay, power consumption, and PDP calculated across three levels for each control variable: VDD, Wp, and Wn. For each control factor, the level that yields the highest average SNR is considered the most optimal. Based on this analysis, the optimal levels identified are level 3 for VDD, level 2 for Wp, and level 1 for Wn. These correspond to specific values of 1 V for VDD, 0.9 μm for Wp, and 1.8 μm for Wn, indicating the combination most favourable for enhancing overall circuit performance.
To identify which independent variable or control factor most significantly affects a particular output parameter of the proposed NORA based circuit, an Analysis of Variance (ANOVA) is conducted. The resulting P-value from this statistical test serves as an indicator of the factor’s influence. Among the control variables, the one with the lowest P-value is considered to have the most substantial effect on the corresponding output parameter.
Table 4 presents the models derived through ANOVA for each of the output performance metrics. The results of the analysis reveal that VDD exhibits the lowest P-value among the control factors for delay and power dissipation, while Wn shows the lowest P-value for PDP. Furthermore, Eqs. (7)–(9), developed based on the ANOVA results, describe the mathematical relationship between the input factors and their corresponding output parameters, providing a predictive framework for design optimization.
To achieve optimal performance with respect to power consumption, delay, and PDP, the proposed NORA based design was refined using the ANOVA-based optimization approach. The predicted outcomes generated through this method are mentioned in Table 5. The optimized values of VDD = 1 V, Wp = 0.9 μm, Wn = 1.8 μm obtained through the Taguchi DoE, were implemented in the design and simulation of the proposed NORA circuit to evaluate the effectiveness and reliability of the Taguchi DoE and ANOVA techniques. Simulation results demonstrate that the proposed design achieves a delay of 121.8 ps, power consumption of 6.11 µW, and a PDP of 0.744 fJ.
Table 5 presents a comparison between the simulated outputs of the proposed circuit and the predicted results derived using the Taguchi DoE and ANOVA optimization techniques. The close alignment between the simulated and predicted results confirms the accuracy and reliability of the statistical approach.
6 Simulation results
In this simulation section, both the existing technique and the proposed NORA-based technique for cascaded DyCML gates are analyzed using 45 nm CMOS technology node with a supply voltage of 1 V. The existing and proposed NORA-based technique for cascaded DyCML gates are evaluated with respect to various performance parameters including delay, power dissipation, and power-delay product. To ensure a fair and consistent comparison, all DyCML gates are configured to operate with a 500mV voltage swing. The output waveforms for the existing cascaded DyCML gates with a self-timed buffer (STB) [31, 37] and the proposed NORA-based technique are illustrated in Fig. 8.

6.1 PVT analysis
A PVT (Process, Voltage, and Temperature) analysis of the proposed NORA-based technique for cascaded DyCML gates has been conducted to determine variations in transient characteristics. The supply voltage is adjusted from 1 V to 1.4 V, and the temperature ranged from 0 °C to 80 °C. Measurements are taken for various output parameters, including propagation delay, power dissipation, and power-delay product. A summary of the PVT analysis for the existing cascaded DyCML gates with self-timed buffer (STB) [31] and proposed NORA-based technique is presented in Table 6. In the process variation for the proposed NORA-based technique, the best-case propagation delay of 97.31ps occurs at the FF corner with a peak power consumption of 6.467µW. In contrast, the worst-case propagation delay of 156.2ps is observed at the SS corner, where the power consumption is at its lowest, 5.703µW.
Figure 9 depicts the process corner analysis of cascaded DyCML gate designs under FF, FS, SF, TT, and SS conditions. The results confirm that the proposed NORA-based technique ensures reliable operation across all corners. Figure 10 shows the effect of supply voltage variation: delay increases as voltage decreases (Fig. 10a), while dynamic power decreases (Fig. 10b). The corresponding change in power-delay product is shown in Fig. 10c. Figure 11a and c depict the effects of temperature on delay, power dissipation, and power-delay product, respectively.

Process Corners results of Cascaded DyCML gates (a) Propagation Delay (b) Power Dissipation
(c) Power-delay product.

Performance variation in parameters with respect to supply voltage (a) Propagation Delay (b) Power Dissipation (c) Power-delay product

Performance variation in parameters with respect to temperature (a) Propagation Delay (b) Power Dissipation (c) Power-delay product
6.2 Monte Carlo analysis
A Monte Carlo simulation with 500 number of samples has been performed to assess the variation of our proposed NORA-based technique for cascaded DyCML gates under a 3σ process. The propagation delay ranges from 108.717ps to 135.597ps, power consumption varies from 6.07278µW to 6.15184µW, and power-delay product extends from 664.1aJ to 829.234aJ. The deviations from the mean values for propagation delay, power consumption, and power-delay product are 3.6%, 0.21%, and 3.6%, respectively, indicating the robustness of the proposed NORA-based technique. The proposed circuit achieves optimal values compared to existing technique as depicted in Table 7. Figure 12a and b, and 12c illustrate the histograms for propagation delay, power consumption, and power-delay product, respectively.

Monte Carlo Analysis for the proposed NORA technique (a) Propagation delay (b) Power dissipation (c) Power-delay product
6.3 Post layout simulations
To examine the impact of parasitics on the proposed circuit, its layout has been designed. Figure 13 illustrates the layout of the proposed circuit, covering an area of 35.76 μm². These simulations enable a direct comparison between the post-layout and schematic-level results, ensuring that parasitic effects are accurately accounted for. As summarized in Table 8, the post-layout results show that key performance metrics such as propagation delay, power dissipation, and power-delay product remain almost unchanged compared to the pre-layout simulations. This consistency between pre-layout and post-layout results highlights the robustness of the proposed NORA-based cascaded dynamic DyCML gates, demonstrating minimal impact from parasitics on circuit performance.

Layout of proposed NORA-based technique
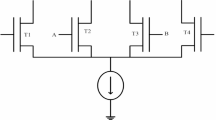
6.4 Application example: realization of 4 × 1 multiplexer using NORA based technique
To illustrate the effectiveness of the proposed NORA-based technique in multistage applications, a 4 × 1 multiplexer has been implemented as a benchmark example. Figure 14 depicts an example of cascading in realisation of a 4 × 1 MUX utilizing a self-timed buffer (STB) [45], where the self-timed buffer connects the first-stage 2 × 1 MUX to the second-stage 2 × 1 MUX [46]. In dynamic CML designs, direct cascading of gates is not possible, necessitating the insertion of self-timed buffers between stages [31, 37]– [38]. However, Fig. 15 shows the implementation of the 4 × 1 MUX using the proposed NORA-based style, which eliminates the need for self-timed buffer. These results in reduced delay, power consumption, and area associated with the self-timed buffer. In the proposed 4 × 1 MUX design, the first-stage 2 × 1 MUX is based on the DyPFSCL architecture as described in the literature [45]– [46], and the same design approach is applicable to its differential counterpart, DyCML. The second-stage 2 × 1 MUX, however, is implemented using the proposed complementary dynamic CML gate.


Block diagram of 4 × 1 MUX using proposed NORA based technique
All circuits are evaluated under the same simulation conditions as previously described, and the corresponding performance parameters are summarized in Sect. 6.5.2. These results clearly indicate that the 4 × 1 multiplexer implemented using the proposed scheme outperforms its counterparts designed with other logic styles. Table 9 presents the summary of the PVT analysis for the 4 × 1MUX designed using the proposed NORA-based technique. A Monte Carlo simulation with 500 samples was carried out to evaluate the performance variations of the 4 × 1 MUX under a 3σ process variation. Figure 16a and b, and 16c show the histograms for propagation delay, power consumption, and power-delay product, respectively. The deviations from the mean values for propagation delay, power consumption, and power-delay product are 10.9%, 0.85%, and 10.7%, respectively, indicating the robustness of the 4 × 1 MUX using proposed technique.

Monte Carlo Analysis (a) Propagation delay (b) Power dissipation (c) Power-delay product
6.5 Performance comparison summary
To comprehensively evaluate the effectiveness of the proposed NORA-based DyCML technique, a detailed performance comparison has been conducted with existing DyCML circuit implementation available in the literature. The comparison aims to demonstrate the improvements achieved in terms of key performance parameters such as propagation delay, power dissipation, power-delay product (PDP), and implementation area. Both the cascaded DyCML gate configurations and complex logic realizations (such as the 4 × 1 multiplexer) have been analyzed under identical simulation conditions using 45 nm CMOS technology.
The comparative analysis highlights the advantages of the proposed design, emphasizing its capability to achieve high-speed and low-power operation with a reduced number of transistors, thereby improving circuit compactness and energy efficiency. The following subsections summarize the results for the cascaded DyCML gates and the 4 × 1 MUX implementations, respectively.
6.5.1 Performance comparison: cascaded DyCML gates
The proposed NORA-based technique for cascaded DyCML gates has been compared to the existing cascaded DyCML technique with a self-timed buffer (STB) [31]. Table 10 shows that the proposed technique achieves reduced delay, power dissipation and power-delay product compared to the existing method. Table 10 also demonstrates that the proposed technique effectively reduces both transistor count and implementation area. The proposed NORA-based technique achieves reductions of 69.55% in delay, 17.84% in power consumption, 74.97% in power-delay product and 27.90% in area when compared to the existing technique.
6.5.2 Performance comparison: 4 × 1 multiplexers using various cascaded techniques
To further validate the scalability and performance of the proposed NORA-based DyCML technique, a 4 × 1 multiplexer (MUX) was implemented and analyzed alongside other established logic styles under identical simulation conditions. The comparative results, presented in Table 11, include parameters such as transistor count, propagation delay, power dissipation, and power-delay product (PDP).
The results clearly indicate that the proposed NORA-based 4 × 1 MUX outperforms all other counterparts, including static CMOS, dynamic CMOS, static MCML, and cascaded DyCML with a self-timed buffer. The proposed design achieves reductions of 39.61% in delay, 19.27% in power dissipation, and 51.52% in PDP compared to the self-timed buffer-based DyCML MUX. These improvements are attributed to the elimination of intermediate buffering, reduced transistor count and efficient complementary clocking inherent to the NORA-based DyCML structure.
Overall, the proposed design demonstrates superior energy efficiency and high-speed performance, establishing its suitability for low-power, high-performance mixed-signal applications.
7 Conclusion
The proposed race-free NORA-based DyCML technique provides significant improvements for multistage logic applications by eliminating the need for static MCML inverters or self-timed buffers between dynamic CML stages. Through the alternate use of N-type and P-type DyCML gates, the design enables direct cascading, leading to significant reductions in delay, power dissipation, power-delay product (PDP), and implementation area by 69.55%, 17.85%, 74.97%, and 27.90%, respectively, compared to existing techniques. Performance optimization using Taguchi Design of Experiments (DoE) and Analysis of Variance (ANOVA) ensures efficient transistor sizing and design tuning. To comprehensively validate robustness and real-world applicability, detailed post-layout simulations were conducted alongside process, voltage, and temperature (PVT) variation analysis and extensive Monte Carlo simulations. These analyses confirmed minimal performance deviations under varying conditions, demonstrating high reliability and resilience to mismatch and environmental fluctuations. Overall, the proposed NORA-based DyCML design, with its reduced hardware complexity and robust operation, offers a practical and efficient solution for low-power, high-speed pipelined circuit implementations in advanced CMOS technologies.
Data availability
Data will be made available on request.
References
Allstot, D. J., Chee, S. H., Kiaei, S., & Shrivastawa, M. (1993). Folded source-coupled logic vs. CMOS static logic for low-noise mixed-signal ICs. IEEE Transactions on Circuits and Systems I: Fundamental Theory and Applications, 40(9), 553–563.
Yamashina, M., & Yamada, H. (1995). An MOS current mode logic (MCML) circuit for low-power ghz processors. NEC Research & Development, 36(1), 54–63.
Ismail, A. H., & Elmasry, M. (2003). A low power design approach for MOS current mode logic. In IEEE International Systems-on-Chip (SoC) Conference, pp. 143–146.
Alioto, M., Pancioni, L., Rocchi, S., & Vignoli, V. (2004). Modeling and evaluation of positive feedback source-coupled logic. IEEE Transactions on Circuits and Systems I: Regular Papers, 51, 2345–2355.
Luong, H. C., & Leung, G. C. (2004). Low-voltage CMOS RF frequency synthesizers. Cambridge University Press.
Houlgate, M. P., Olszewski, D. J., Abdelhalim, K., & MacEachern, L. (2004). Adaptable MOS current mode logic for use in a multi-band RF prescaler. In IEEE International Symposium on Circuits and Systems (IEEE Cat. No. 04CH37512), 2004, IV-329.
Alioto, M., Fort, A., Pancioni, L., Rocchi, S., & Vignoli, V. (2004). Positive-Feedback Source-Coupled Logic: a Delay Model. In Proceedings of IEEE Symposium on Circuits and Systems, pp. II/641–644.
Hassan, H., Anis, M., & Elmasry, M. (2005). MOS current mode circuits: Analysis, design, and variability. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 13(8), 885–898.
Alioto, M., Fort, A., Pancioni, L., Rocchi, S., & Vignoli, V. (2005). An approach to the design of PFSCL gates. In Proceedings of the IEEE Symposium on Circuits and Systems, 2437–2440.
Liu, Y., & Yang, H. (Eds.). (2006). High-speed optical transceivers: Integrated circuits designs and optical devices techniques. World Scientific.
Alioto, M., & Palumbo, G. (2006). Feature-power-aware design techniques for nanometer MOS current-mode logic gates: A design framework. IEEE Circuits and Systems Magazine, 6(4), 42–61.
Alioto, M., Mita, R., & Palumbo, G. (2006). Design of high-speed power-efficient MOS current-mode logic frequency dividers. IEEE Transactions on Circuits and Systems II: Express Briefs, 53(11), 1165–1169.
Alioto, M., Pancioni, L., Rocchi, S., & Vignoli, V. (2007). Power–delay–area–noise margin trade-offs in positive-feedback MOS current-mode logic. IEEE Transactions on Circuits and Systems I: Regular Papers, 54(9), 1916–1928.
Musa, O., & Shams, M. (2010). An efficient delay model for MOS current-mode logic automated design and optimization. IEEE Transactions on Circuits and Systems I: Regular Papers, 57(8), 2041–2052.
Chia, Z. V., Ng, S. S., & Je, M. (2013). Current mode logic circuits for 10-bit 5 GHz high speed digital to analog converter. International Journal of Electrical, Computer, Energetic, Electronic and Communication Engineering, 7(9), 1211–1214.
Badel, S., Baltaci, C., Cevrero, A., & Leblebici, Y. (2019). Design automation for differential MOS current-mode logic circuits. Springer International Publishing.
Gupta, K., Pandey, N., & Gupta, M. (2013). Analysis and design of MOS current mode logic exclusive-OR gate using triple-tail cells. Microelectronics Journal, 44, 561–567.
Gupta, K., Pandey, N., & Gupta, M. (2013). Low-power tri-state buffer in MOS current mode logic. In Analog Integrated Circuits and Signal Processing, 75, 157–160.
Pandey, N., Gupta, K., & Gupta, M. (2014). An efficient triple-tail cell based PFSCL D latch. Microelectronics Journal, 45(8), 1001–1007.
Pandey, N., & Choudhary, B. (2015). Improved tri-state inverter/buffer in MOS current mode logic and its application. Analog Integrated Circuits and Signal Processing, 84, 333–340.
Pandey, N., Gupta, M., & Gupta, K. (2015). A PFSCL based configurable logic block. In: 2015 Annual IEEE India Conference (INDICON), 1–4.
Pandey, N., Choudhary, B., Gupta, K., & Mittal, A. (2016). Bus implementation using new low-power PFSCL tristate buffers. Active and passive electronic components journal. Article ID, 4517292, 8.
Pandey, N., Choudhary, B., Gupta, K., & Mittal, A. (2017). New sleep-based PFSCL tri-state inverter/buffer topologies. Journal of Circuits, Systems, and Computers, 26(12), 1750186–15pages.
Sivaram, R., Gupta, K., & Pandey, N. (2021). Impact of multi-threshold transistor in positive feedback source-coupled logic (PFSCL) fundamental cell. Analog Integrated Circuits and Signal Processing, 109, 173–185.
Shikha, P. N., & Gupta, K. (2023). Memristor-Based Architectures for PFSCL Circuit Realizations. Circuits, Systems, and Signal Processing, 1–28.
Malmir, R., & Ghaznavi-Ghoushchi, M. B. (2023). Design and analysis of an ultralow-voltage complementary fold-interleaved multiple-tail current mode logic. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 31(11), 1675–1685.
Sivasakthi, M., & Radhika, P. (2024). A high-speed MCML charge pump design at 10 ghz frequency in 45 Nm CMOS technology for PLL application. Analog Integrated Circuits and Signal Processing, 118, 49–66.
Madheswaran, S., & Panneerselvam, R. (2024). Design of a high-speed MCML D-latch at 0.6 V in 45 Nm CMOS technology. International Journal of Power Electronics and Drive Systems (IJPEDS), 15(2), 1052–1060.
Patnaik, A., & Yoon, D. (2025). A 24–64 ghz wideband static CML frequency divider in a 90-nm CMOS technology. IEEE Microwave and Wireless Components Letters, 35(1), 71–74.
Allam, M. W., & Elmasry, M. I. (2000). Dynamic current mode logic (DyCML), a new low-power high-performance logic family. In Proceedings of the IEEE 2000 Custom Integrated Circuits Conference (Cat. No. 00CH37044), 421–424.
Allam, M. W., & Elmasry, M. I. (2001). Dynamic current mode logic (DyCML): A new low-power high-performance logic style. IEEE Journal of Solid-State Circuits, 36(3), 550–558.
Hassoune, I., Macé, F., Flandre, D., & Legat, J. D. (2006). Low-swing current mode logic (LSCML): A new logic style for secure and robust smart cards against power analysis attacks. Microelectronics Journal, 37(9), 997–1006.
Ramakrishnan, S., & Lau, K. T. (2008). Improved dynamic current mode logic for low power applications. Journal of Circuits, Systems, and Computers, 17(02), 183–90.
Pandey, N., Garg, D., Gupta, K., & Choudhary, B. (2016). Hybrid dynamic MCML style: A high speed dynamic MCML style. Journal of Engineering. https://doi.org/10.1155/2016/8027150
Shen, J., Geng, L., & Zhang, F. (2017). Dynamic current mode logic based flip-flop design for robust and low‐power security integrated circuits. Electronics Letters, 53(18), 1236–1238.
Jain, R., Gupta, K., & Pandey, N. (2021). Hybrid dynamic CML with modified current source (H-MDyCML): A low-power dynamic MCML style. Advances in Electrical and Electronic Engineering, 19(1), 57–65.
Gupta, K., Pandey, N., & Gupta, M. (2020). Model and design of improved current mode logic gates. Springer Singapore.
Jain, R., Gupta, K., & Pandey, N. (2021). Dynamic Current Mode Logic: Concepts to Advancements. Lambert Academic Publishing.
Saw, S. K., Nanda, U., Laskar, N., & Majumder, A. (2022). A dynamic current mode design approach of 2/3 prescaler for phase locked loop application. Analog Integrated Circuits and Signal Processing. https://doi.org/10.1007/s10470-021-01966-0
Verma, G. K., Bansal, M., & Pandey, N. (2023). Realisation of 4: 2 Compressor using Dynamic MCML Variants. Second International Conference on Electrical, Electronics, Information and Communication Technologies (ICEEICT). IEEE.
Maiti, M., Bhattacharjee, P., Al-Shidaifat, A., Song, H., Bhattacharyya, B. K., & Majumder, A. (2025). Analysis of high speed dynamic current mode D-FlipFlop in nanometer CMOS. International Journal of Electronics Letters. https://doi.org/10.1080/21681724.2025.2456916
Goncalves, N. F., & De Man, H. (1983). NORA: A racefree dynamic CMOS technique for pipelined logic structures. IEEE Journal of Solid-State Circuits, 18(3), 261–266.
Kang, S. M., & Leblebici, Y. (2003). CMOS Digital Integrated Circuits. MacGraw-Hill.
Rabaey, J. M., Chandrakasan, A., & Nikolic, B. (2003). Digital Integrated Circuits: A Design Perspective (2nd edition). Pearson Education.
Sivaram, R., Gupta, K., & Pandey, N. (2020). A new realization scheme for dynamic PFSCL style. Integration, 75, 169–177.
Sivaram, R., Gupta, K., & Pandey, N. (2022). On improving the performance of dynamic positive-feedback source-coupled logic (D-PFSCL) through inclusion of transmission gates. Microprocessors and Microsystems, 90, 104521.
Gupta, K., Pandey, N., & Gupta, M. (2013). Low-voltage MOS current mode logic multiplexer. Radio Engineering Journal, 22, 259–268.
Anugraha, R. V., Durga, D. S., & Avudaiammam, R. (2017). Design and performance analysis of 2:1 multiplexer using multiple logic families at 180 nm technology. 2nd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, 1849–1853.
Acknowledgements
The authors would like to thank MNIT Jaipur for supporting this work.
Funding
Not Applicable.
Author information
Authors and Affiliations
Contributions
Conceptualization, Software, Review, Investigation, Validation, Visualization, Writing-original draft: Dheeraj Singh RajputReview, Investigation, Validation, Supervision, and Editing: Dr. Bharat ChoudharyInvestigation, Supervision, and Editing: Prof. Dharmendar BoolchandaniSoftware, Review, Validation and Visualization: Archana Singhal.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Consent to participate
Not Applicable.
Consent for publication
Not Applicable.
Ethics approval
Not Applicable.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Rajput, D.S., Choudhary, B., Boolchandani, D. et al. An efficient race-free dynamic MCML design for multistage applications. Analog Integr Circ Sig Process 126, 6 (2026). https://doi.org/10.1007/s10470-025-02536-4
Received:
Revised:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1007/s10470-025-02536-4