
Abstract
In clinical practice, sleep stage classification (SSC) is a crucial step for physicians in sleep assessment and sleep disorder diagnosis. However, traditional sleep stage classification relies on manual work by sleep experts, which is time-consuming and labor-intensive. Faced with this obstacle, computer-aided diagnosis (CAD) has the potential to become an intelligent assistant tool for sleep experts, aiding doctors in the assessment and decision-making process. In fact, in recent years, CAD supported by artificial intelligence, especially deep learning (DL) techniques, has been widely applied in SSC. DL offers higher accuracy and lower costs, making a significant impact. In this paper, we will systematically review SSC research based on DL methods (DL-SSC). We explores DL-SSC from several important perspectives, including signal and data representation, data preprocessing, deep learning models, and performance evaluation. Specifically, this paper addresses three main questions: (1) What signals can DL-SSC use? (2) What are the various methods to represent these signals? (3) What are the effective DL models? Through addressing on these questions, this paper will provide a comprehensive overview of DL-SSC.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Sleep is the most fundamental biological process, occupying approximately one-third of human life and playing a vital role in human existence (Siegel 2009). Unfortunately, sleep disorders are prevalent in modern society. A global study involving nearly 500,000 people in 2022 indicated that the insomnia rate among the public reached as high as 40.5% during the COVID-19 pandemic (Jahrami et al. 2022). Sleep disorders are closely associated with various neurologic and psychiatric disorders (Van Someren 2021). For instance, research by Zhang et al. demonstrated a correlation between reduced deep sleep proportion in Alzheimer’s disease patients and the severity of dementia (Zhang et al. 2022b). Additionally, insomnia was found to double the risk of depression in people without depressive symptoms, as stated in Baglioni et al. (2011). Timely and effective treatment of insomnia was able to serve as a primary preventive measure for depression (Clarke and Harvey 2012). In summary, sleep issues have a significant impact on both physiological and psychological well-being, necessitating timely diagnosis. The essential step in clinical sleep disorder diagnosis and assessment is referred to as sleep stage classification (SSC) (Wulff et al. 2010), also known as sleep staging or sleep scoring.
In clinical practice, the gold standard for classifying sleep stages is the polysomnogram (PSG), which includes a set of nocturnal sleep signals such as electroencephalogram (EEG), electrooculogram (EOG), and electromyogram (EMG). The PSG signals are segmented into 30-second units, and the continuous segments obtained are referred to as sleep stages, with each segment belonging to a specific stage category. The criteria for determining the stage category of each epoch are known as R&K (Rechtschaffen 1968) and AASM (Iber 2007), with the former established in 1968 and the latter being the most recent and commonly used. R&K divides sleep into three basic stages: wakefulness (W), rapid eye movement (REM), and non-rapid eye movement (NREM). NREM can be subdivided into S1, S2, S3, and S4. AASM merging S3 and S4 into a single stage, resulting in five sleep stages: W, N1 (S1), N2 (S2), N3 (S3-S4), and REM. Based on these standards, researchers sometimes describe sleep stages differently. We have listed the various descriptions used in the studies included in this paper in Table 1. Different stages exhibit distinct characteristics during sleep. The N2 stage is typically marked by significant waves such as sleep spindles and K complexes (Parekh et al. 2019). Moreover, sleep is a continuous and dynamic process, and there exists contextual information between consecutive epochs (forming sequences) (Rechtschaffen 1968; Iber 2007). For instance, if isolated N3 occur between several consecutive N2, doctors still classify them as N2 (Wu et al. 2020).
Manual classification is time-intensive and laborious (Malhotra et al. 2013). In response to the immense demand in healthcare, numerous methods for automatically analyzing EEG for sleep staging have been proposed. These automatic sleep stage classification (ASSC) methods are developed using machine learning (ML) algorithms. Early ASSC was a combination of manual feature extraction and traditional ML. Researchers manually extract features from the time-domain, frequency-domain of signals and use traditional ML methods, such as support vector machines (SVM), for feature classification to achieve automation (Li et al. 2017; Sharma et al. 2017). However, manual feature engineering is very tedious and requires additional prior knowledge (Jia et al. 2021; Eldele et al. 2021). Moreover, due to the significant variability in EEG among different individuals (Subha et al. 2010), it is challenging to extract well-generalized features. Therefore, self-learning methods based on deep learning have begun to be used for sleep staging.
In recent years, deep learning (DL) has become a popular approach for automatic sleep stage classification. This may be because DL methods can automatically extract sleep features and complete classification in an end-to-end manner (Zhang et al. 2022a), avoiding the cumbersome feature extraction and explicit classification steps. In the current context of automatic sleep stage classification based on deep learning (DL-ASSC), there are three key points worth noting. On one hand, signals form the basis of ASSC. Various studies have extensively explored multiple types of signals, which can be broadly categorized into three classes: the first category is PSG, including EEG, EOG, and EMG (Guillot et al. 2020; Seo et al. 2020; Supratak et al. 2017); the second category is cardiorespiratory signals, including electrocardiogram (ECG), photoplethysmography (PPG), respiratory effort, etc. (Goldammer et al. 2022; Kotzen et al. 2022; Olsen et al. 2022); the third category is contactless signals, mainly radar, Wi-Fi and audio signals (Zhai et al. 2022; Yu et al. 2021a; Tran et al. 2023). On the other hand, the same signal can be represented in various forms, and different input representation into a DL model might yield different performance (Biswal et al. 2018). Popular data representations fall into three categories: the first category involves directly inputting raw one-dimensional (1D) signals into the network (Seo et al. 2020; Supratak et al. 2017); the second category uses transformed domain data of the signal as model input, commonly seen in two-dimensional (2D) time-frequency spectrograms [usually obtained from the original signal through continuous wavelet transform (Kuo et al. 2022) or short-time Fourier transform (Guillot et al. 2020)]; the third category combines both, typically employing a dual-stream structure where different input forms are processed separately in each branch (Phan et al. 2021; Jia et al. 2020a). Last but not least, the ASSC methods employing various DL models continue to emerge. Convolutional neural networks (CNNs), initially designed for the field of image processing, are commonly used by researchers for feature extraction. As a widely recognized foundational model, CNNs are widely applied in sleep stage classification, either directly using one-dimensional CNNs on raw signals or employing more common 2D CNNs on transformed domain representations of the signals. Another type of classical models takes the spotlight: recurrent neural networks (RNNs) and its two variants, long short-term memory (LSTM) and gated recurrent unit (GRU). RNNs are adept at handling time series data and can capture temporal information in sleep data. Moreover, in 2017, Google introduced the Transformer (Vaswani et al. 2017), which utilizes the multi-head self-attention (MHSA) mechanism and quickly became an indispensable technique in time-series data modeling. Compared with RNNs, MHSA can also effectively capture the time dependence of sleep data when applied to sleep stage classification. In practical applications, researchers often choose to customize (design) a deep neural network (DNN) to adapt to different needs and tasks. In the ASSC based on deep learning methods, the most commonly used architecture in existing research is feature extraction + sequence encoding. The feature extractor first maps the input signal to an embedding space, and then models the temporal information (context-dependent information) through the sequence encoder. CNN is a common choice for the feature extractor, and the sequence encoder is often implemented by RNN-like models or attention mechanisms.
DL-SSC research has achieved significant progress, and some studies have achieved clinically acceptable performance (Phan and Mikkelsen 2022). This topic has been addressed in several review articles. However, earlier publications such as those by Fiorillo et al. (2019) and Faust et al. (2019) do not encompass the developments of recent years. More comprehensive review papers have recently emerged, but they still have some limitations. For instance, the work by Alsolai et al. (2022) focuses more on feature extraction techniques and machine learning methods, with less emphasis on the latest end-to-end deep learning approaches. Sri et al. (2022) and Loh et al. (2020) reviewed the performance of different deep learning models using PSG signals but did not cover aspects such as signal representation and preprocessing. The studies by Phan and Mikkelsen (2022) and Sun et al. (2022) only considered EEG and ECG signals, excluding other types of signals. We have summarized these works in Table 2. Therefore, this paper provides a comprehensive review of recent years’ sleep stage classification based on deep learning. We have examined all the elements required for DL-SSC, including signals, datasets, data preprocessing, data representations, deep learning models, evaluation methods, etc. Specifically, the main topices discussed in this paper include: (1) signals that can be used in DL-SSC; (2) methods to represent data, i.e., how signals can be input into DL models for further processing; (3) effective DL models and their performance.
This paper is organized as follows. Section 2 describes the sources of literature and the search process. Section 3 discusses available signals and summarizes some public datasets. Section 4 discusses PSG-based research, including preprocessing, different data representations, and DL models. Sections 5 and 6 will cover research based on cardiorespiratory signals and non-contact signals, respectively. Finally, Sect. 7 and Sect. 8 will discuss and summarize the findings.
2 Review methodology
We conduct a literature search and screening through the following process, Fig. 1 is a visual representation of this process. We searched well-known literature databases, namely Google Scholar, Web of Science, and PubMed. The relevant studies on sleep stage classification using three different types of signals were identified using the following common keywords and their combinations: (“Deep Learning” OR “Deep Machine Learning” OR “Neural Network”) AND (“Sleep Stage Classification” OR “Sleep Staging” OR “Sleep Scoring”). The keywords specific to each signal type were: (“Polysomnography” OR “Electroencephalogram” OR “Electrooculogram” OR “Electromyogram”), (“Electrocardiogram” OR “Photoplethysmography”), (“Radar” OR “Wi-Fi” OR “Microphone”). For deep neural network models, no specific keywords were set, and the publication or release year of the literature was restricted to 2016 or later. After excluding some irrelevant or duplicate studies, the literature was assessed based on the following criteria, which define the inclusion and exclusion standards of the relevant studies:
-
(1)
Task—only studies that performed sleep stage classification tasks were included.
-
(2)
Signal—studies that used one or a combination of the signals mentioned in the text for sleep staging were included. Studies using other signals, such as functional near-infrared spectroscopy (fNIRS), were excluded due to their scarcity (Huang et al. 2021; Arif et al. 2021).
-
(3)
Method—only studies employing deep learning-based methods were included, i.e., those using neural networks with at least two hidden layers. Traditional machine learning methods were generally not reviewed, but a few studies that used a combination of deep neural networks and machine learning classifiers for feature extraction and classification (Phan et al. 2018) were included.
-
(4)
Time—the focus was on studies conducted after 2016 (the earliest relevant study included in this paper was published in 2016).
Finally, the publicly available datasets reviewed in this paper were found through three approaches: mentioned in the articles included in this review, using the Google search engine with the keywords “Sleep stage Dataset” and corresponding signal types, and the PhysionetFootnote 1 and NSRRFootnote 2 websites.

Schematic diagram of the literature selection process. It is divided into five steps: database paper search, duplicate removal, relevance screening, determination of topic compliance, and final inclusion in the review. In the diagram, n represents the number of papers, and the subscripts indicate different types of signals: 1 represents PSG, etc., 2 represents ECG, etc., and 3 represents non-contact signals. The paper search also includes additional database identifiers. This process ensures that the final included papers can summarize the main research content of recent years
3 Signals, datasets and performance metrics
3.1 Signals
The standard signal for sleep studies is PSG. In addition to this, signals containing cardiorespiratory information such as ECG, PPG, respiratory effort, etc., are commonly used. In recent years, signals like radar and Wi-Fi have also been explored due to their simplicity and comfort (Hong et al. 2019). Commonly used signals are listed in Table 3.
3.1.1 PSG signals
PSG signal refer to the signals obtained from polysomnogram recordings, which are used to monitor sleep stages. It records a set of signals during sleep using multiple electrodes, including various physiological parameters such as brain activity, eye movements, and muscle activity (Kayabekir 2019). Electrodes on the scalp are responsible for recording electrical signals related to brain neuron activity, known as EEG. Electrodes near the eyes record electrical signals associated with eye movements, known as EOG. Electromyogram or EMG typically requires needle electrodes inserted into muscles to obtain electrical signals related to muscle activity, and during sleep monitoring, EMG is usually recorded near the chin. These three signals together are referred to as PSG. PSG serves as the standard signal for quantifying sleep stages and sleep quality (Yildirim et al. 2019; Tăutan et al. 2020).
EEG contains information necessary for ML or DL analysis in various domains such as time domain, frequency domain, and time-frequency domain. In the time domain, EEG features are mainly reflected in the changes in amplitude over time. Event-related potentials (ERPs) and statistical features can be obtained through time-domain averaging (Aboalayon et al. 2016). The frequency domain mainly describes the distribution characteristics of EEG power across different frequencies. The fast Fourier transform (FFT) can be used to obtain five basic frequency bands as shown in Table 4, each with different implications (Aboalayon et al. 2016). EEG is a non-stationary signal generated by the superposition of electrical activities of numerous neurons (Li et al. 2022d). It possesses variability and time-varying characteristics, meaning it has different statistical properties at different times and frequency bands, and it undergoes rapid changes within short periods (Wang et al. 2021; Stokes and Prerau 2020). Time-frequency analysis is particularly suitable for such non-stationary signals. Common methods include short-time Fourier transform (STFT), continuous wavelet transform (CWT), and Hilbert-Huang transform (HHT), among others. Time-frequency analysis can simultaneously reveal changes in signals over time and frequency (Jeon et al. 2020; Tyagi and Nehra 2017). Figure 2 shows the time waveforms and time-frequency spectrogram of N1 and N2 stages. Due to its rich information features from multiple perspectives, EEG can be used in sleep stage classification tasks in various forms. For example, Biswal et al. (2018) constructed neural networks using raw EEG or time-frequency spectra as inputs. They also compared machine learning methods with expert handcrafted features as inputs, and the results showed that deep learning methods outperformed machine learning methods. EOG and EMG signals exhibit different characteristics in different sleep stages and can provide information for identifying sleep stages. For instance, during the REM stage, eye movements are more intense, whereas during the NREM stage, eye movements are relatively stable (Iber 2007). The amplitude of EMG near the chin during the W stage is variable but typically higher than that in other sleep stages (Iber 2007). However, EOG and EMG are usually used as supplements to EEG. Combining EEG, EOG, and EMG in multimodal sleep stage classification is a popular approach (Phan et al. 2021; Jia et al. 2020a). Multimodal approaches can generally improve performance, but continuous attachment of multiple electrodes might affect the natural sleep state of the subjects. Therefore, single-channel EEG is currently the most popular choice in research (Fan et al. 2021).

Single-channel EEG time waveform and STFT time-frequency spectrogram in N1 and N2 stages. a, b N1 and N2 stage (time waveform); c, d N1 and N2 stage (STFT time-frequency spectrogram)
3.1.2 Cardiorespiratory signals
PSG often needs to be conducted in specialized laboratories and is challenging for long-term monitoring. In contrast, cardiac and respiratory activities are easier to monitor. Many studies have also confirmed the correlation between sleep and cardiac activity (Bonnet and Arand 1997; Tobaldini et al. 2013). This has led people to explore an alternative approach to sleep monitoring apart from PSG.
Research indicates a strong connection between sleep and the activity of the autonomic nervous system (ANS) (Bonnet and Arand 1997; Tobaldini et al. 2013). When the human body is sleeping, it will be repeatedly controlled by the sympathetic and vagus nerves. When sleep changes from wakefulness to the N3 stage, the blood pressure and heart rate controlled by the ANS will also change accordingly (Shinar et al. 2006; Papadakis and Retortillo 2022). This manifests as different features in cardiac and respiratory activities corresponding to changes in sleep stages. For example, one of the features during REM is highly recognizable breathing frequency and potentially more irregular and rapid heart rate (HR). HR during NREM might be more stable, and during the W stage, there is low-frequency heart rate variability (HRV) and significant body movement (Sun et al. 2020). These discriminative features determine the applicability of cardiorespiratory signals in SSC. Cardiorespiratory signals encompass signals containing information about both heart and respiratory activities, primarily including ECG, PPG, and respiratory effort. ECG is a technique used to record cardiac electrical activity, which can directly reflect a person’s respiratory and circulatory systems (Sun et al. 2022). In SSC, raw ECG signals are not directly used; instead, derived signals are employed, such as HR (Sridhar et al. 2020), HRV (Fonseca et al. 2020), ECG-derived respiration (EDR) (Li et al. 2018), RR intervals (RRIs) (Goldammer et al. 2022), RR peak sequences (Sun et al. 2020), and others. An example of an ECG is shown in Fig. 3: the instantaneous heart rate sequence derived from the ECG and the corresponding overnight sleep stage changes (Sridhar et al. 2020). PPG is a low-cost technique measuring changes in blood volume, commonly used to monitor heart rate, blood oxygen saturation, and other information. PPG is simple to implement and can be collected at the hand using photodetectors embedded in watches or rings (Kotzen et al. 2022; Radha et al. 2021; Walch et al. 2019). HR and HRV can be derived from PPG, indirectly reflecting sleep stages. A small portion of research also uses raw PPG for classification (Kotzen et al. 2022; Korkalainen et al. 2020). Figure 4 shows examples of PPG signal waveforms corresponding to the five sleep stages (Korkalainen et al. 2020). Similar to EEG, ECG and PPG also have their auxiliary signals. Common choices include combining signals from chest or abdominal respiratory efforts with accelerometer signals (Olsen et al. 2022; Sun et al. 2020). For instance, in Goldammer et al. (2022), the authors derived RR intervals from ECG and combined them with breath-by-breath intervals (BBIs) derived from chest respiratory efforts for W/N1/N2/N3/REM classification. In Walch et al. (2019), the authors used PPG and accelerometer signals collected from the “Apple Watch” to classify W/NREM/REM sleep stages. It’s worth noting that most studies in cardiac and respiratory signal research focus on four-stage (W/L/D/REM, L: light sleep, D: deep sleep) or three-stage (W/NREM/REM) classification.

The instantaneous heart rate time series derived from the ECG signal throughout the night, and the corresponding changes in sleep stages throughout the night (Sridhar et al. 2020)

The waveforms of the original PPG signals corresponding to the five different sleep stages (Korkalainen et al. 2020)
3.1.3 Contactless signals
The use of cardiorespiratory signals can effectively reduce the inconvenience caused to patients during sleep monitoring (compared to PSG). However, it still involves physical contact with the subjects. The development of non-contact sensors (such as biometric radar, Wi-Fi, microphones, etc.) has changed this situation.
In recent years, radar technology has been used for vital sign and activity monitoring (Fioranelli et al. 2019; Hanifi and Karsligil 2021; Khan et al. 2022). In these systems, radar sensors emit low-power radio frequency (RF) signals and extract vital signs, including heart rate, respiration rate, movement, and falls, from reflected signals. Wi-Fi technology has subsequently been developed, utilizing Wi-Fi channel state information (CSI) to monitor vital signs more cost-effectively (Soto et al. 2022; Khan et al. 2021). For example, research by Diraco et al. (2017) used ultra-wideband (UWB) radar and DL methods to monitor vital signs and falls, and Adib (2019) achieved HR measurement and emotion recognition using Wi-Fi. Previous studies have demonstrated that HR, respiration, and movement information can be extracted from RF signals reflected off the human body, which fundamentally still falls under the category of cardiorespiratory signals, and they are also related to sleep stages. Therefore, in principle, we can perform contactless SSC using technologies such as radar or Wi-Fi (Zhao et al. 2017). Subsequent research has proven the feasibility of wireless signals for SSC (Zhai et al. 2022; Zhao et al. 2017; Yu et al. 2021a). Additionally, some research has achieved good results in sleep stage classification by recording nighttime breathing and snoring information through acoustic sensors (Hong et al. 2022; Tran et al. 2023). However, compared to other methods, audio signals might raise concerns about privacy.
3.2 Public datasets
Data is one of the most crucial components in DL. In recent years, the field of sleep stage classification has seen the emergence of several public databases, with the two most prominent ones being PhysioNet (Goldberger et al. 2000) and NSRR (Zhang et al. 2018). Widely used datasets such as Sleep-EDF2013 (SEFD13), Sleep-EDF2018 (SEDF18), and CAP-Sleep are all derived from the open-access PhysioNet database. The Sleep-EDF (SEDF) series is perhaps the most extensively utilized dataset. SEDF18 comprises data from each subject with 2 EEG channels, 1 EOG channel, and 1 chin EMG channel. The data is divided into two parts: SC (without medication) and ST (with medication). SC includes 153 (nighttime) recordings from 78 subjects who did not take medication. ST comprises 44 recordings from 22 subjects who took medication. The data is annotated using R&K rules, and EEG and EOG have a sampling rate of 100 Hz. Another notable database is NSRR, from which datasets like SHHS (Quan et al. 1997) and MESA (Chen et al. 2015) are derived. Table 5 summarizes some the public datasets.
Public datasets have significantly propelled the development of DL-SSC research, and their existence is highly beneficial. For instance, they can serve as common references and benchmarks, as well as be directly utilized for data augmentation or transfer learning to enhance model performance. However, existing datasets also present certain challenges. On one hand, different datasets vary in sampling rates and channels. Automated (DL) methods are often designed based on specific datasets, causing these methods to handle only particular input shapes (Guillot et al. 2021). A common solution is to perform operations like resampling and channel selection on different datasets to standardize the input shape (Lee et al. 2024). On the other hand, class imbalance issues are prevalent in sleep data. Class imbalance refers to a situation where certain categories in the dataset have significantly fewer samples than others. Due to the inherent nature of sleep, the duration of each stage in sleep recordings is not equal (Fan et al. 2020). We have compiled the sample distribution of several datasets in Table 6. The results indicate that the N2 constitutes around 40% of the total samples, while N1 have substantially fewer samples. This sample imbalance might introduce biases in model training. In current research, N1 stage recognition generally performs the worst. For example, in the study by Eldele et al. (2021), the macro F1-score for the N1 class was only around 40.0, while other categories scored around 85. This class imbalance is intrinsic to sleep and cannot be eliminated. However, its impact can be mitigated through certain methods, which we will discuss in Sect. 4.1.2.
3.3 Performance metrics
The essence of sleep staging is a multi-classification problem, commonly evaluated using performance metrics such as accuracy (ACC), macro F1-score (F1), and Cohen’s Kappa coefficient. Accuracy refers to the ratio between the number of correctly classified samples by the model and the total number of samples. The calculation formula is as follows:
where true positive (TP) is the number of samples correctly predicted as positive class by the model, and true negative (TN) is the number of samples correctly predicted as negative class by the model. TP and TN both represent instances where the model’s prediction matches the actual class, indicating correct predictions. False positive (FP) is the number of negative class samples incorrectly predicted as positive class by the model, and false negative (FN) is the number of positive class samples incorrectly predicted as negative class by the model. FP and FN represent instances where the model’s prediction does not match the actual class, indicating incorrect predictions.
ACC is a commonly used evaluation metric in classification problems, but it may show a “pseudo-high” characteristic when dealing with imbalanced datasets (Thölke et al. 2023). In contrast, the F1-score takes into account both precision (PR) and recall (RE) of the model. PR is the proportion of truly positive samples among all samples predicted as positive by the model (Yacouby and Axman 2020). RE is the proportion of truly positive samples among all actual positive samples, as predicted by the model. In classification problems, each class has its own F1-score, known as per-class F1-score. Taking the average of F1-scores for all classes yields the more commonly used macro F1-score (MF1). The calculation formula is as follows:
Cohen’s Kappa coefficient (abbreviated as Kappa) measures the agreement between observers and is used to quantify the consistency between the model’s predicted results and the actual observed results (Hsu and Field 2003). The calculation formula is as follows:
where \({P_{ec}}\) is the observed agreement (the proportion of samples with consistent actual and predicted labels), and \({P_{ei}}\) is the chance agreement (the expected probability of agreement between predicted and actual labels, calculated based on the distribution of actual and predicted labels). Kappa ranges from -1 to +1, with higher values indicating better agreement.
Among these three commonly used performance metrics, accuracy corresponds to the ratio of correctly classified samples to the total number of samples, ranging from 0 (all misclassified) to 1 (perfect classification). ACC represents the overall measure of a model’s correct predictions across the entire dataset. The basic element of calculation is an individual sample, with each sample having equal weight, contributing the same to ACC. Once the concept of class is considered, there are majority and minority classes, with the majority class obviously having higher weight than the minority class. Therefore, in the face of class-imbalanced datasets, the high recognition rate and high weight of the majority class can obscure the misclassification of the minority class (Grandini et al. 2020). This means that high accuracy does not necessarily indicate good performance across all classes.
MF1 is the macro-average of the F1-scores of each class. MF1 evaluates the algorithm from the perspective of the classes, treating all classes as the basic elements of calculation, with equal weight in the average, thus eliminating the distinction between majority and minority classes (the effect of large and small classes is equally important) (Grandini et al. 2020). This means that high MF1 indicates good performance across all classes, while low MF1 indicates poor performance in at least some classes.
The Cohen’s Kappa coefficient is used to measure the consistency between the classification results of the algorithm and the ground truth (human expert classification), ranging from -1 to 1, but typically falling between 0 and 1. From formula 7, it can be seen that the Kappa considers both correct and incorrect classifications across all classes. In the case of class imbalance, even if the classifier performs well on the majority class, misclassifications on the minority class can significantly reduce the Kappa (Ferri et al. 2009). To illustrate this with a simple binary classification problem, assume there are 100 samples in total for classes 0 and 1, with a ratio of 9 : 1. If a poorly performing model always predicts class 0, even if it is entirely wrong on class 1, the ACC would still be as high as 90%. Calculating the F1-score, it is found that class 0 has a score of 1.0 and class 1 has a score of 0, resulting in an MF1 of only 0.5. MF1 equally considers the majority and minority classes, fairly reflecting the poor classification performance. The Kappa value would be 0, indicating no correlation between the model’s predictions and the ground truth. Even though the overall accuracy is high, it does not indicate real classification ability. In summary, this confirms that in the face of class-imbalanced datasets, MF1 and the Kappa can provide more reliable and comprehensive evaluations than accuracy.
4 ASSC based on PSG signals
The essence of automatic sleep stage classification lies in the analysis of sleep data and the extraction of relevant information. In the process of data analysis, appropriate preprocessing and data representation methods can help the model learn and interpret these signals more effectively. This section will provide detailed explanations regarding the preprocessing of PSG signals, method of data representation, and deep learning models.
4.1 Preprocessing methods and class imbalance problems
Preprocessing plays a crucial role in the classification of sleep stages. Appropriate preprocessing methods have a positive impact on subsequent feature extraction, whether it is manual feature extraction in traditional machine learning or high-dimensional feature extraction in deep learning (Wang and Yao 2023). Class imbalance is a persistent problem in sleep stage classification, as shown in Table 6. In this section, we will discuss preprocessing methods and approaches to handling class imbalance problems (CIPs).
4.1.1 Preprocessing methods
In PSG studies, most research is actually based on single-channel EEG, while a small portion uses combinations of EEG and other signals. The original EEG signal is a typical low signal-to-noise ratio signal, usually weak in amplitude and contains a lot of undesirable background noise that needs to be eliminated before actual analysis (Al-Saegh et al. 2021). Additionally, there is sometimes a need to enhance the original EEG to better meet the requirements. Based on these needs and reasons, the following preprocessing methods have appeared in existing studies.
Notch filtering: Used to eliminate 50 Hz or 60 Hz power line interference noise (power frequency interference) (Zhu et al. 2023).
Bandpass filtering: Used to remove noise and artifacts. The cutoff frequencies for filtering are inconsistent across different studies, even for the same signal from the same dataset. For example, Phyo et al. (2022) and Jadhav et al. (2020) applied bandpass filtering with cutoff frequencies of 0.5–49.9 Hz and 0.5–32 Hz for the EEG Fpz-Cz channel of the SEDF dataset, respectively.
Downsampling: Signals from different datasets have varying sampling rates. When utilizing multiple datasets, downsampling is often performed to standardize the rates. Downsampling also reduces computational complexity (Fan et al. 2021).
Data scaling and clipping: Scaling adjusts the signal values proportionally to facilitate subsequent processing by adjusting the amplitude range. Clipping is done to prevent large disturbances caused by outliers during model training. Guillot et al. (2021) first scaled the data to have a unit-interquartile range (IQR) and zero-median and then clipped values greater than 20 times the IQR.
Normalization: Normalization should also belong to the large category of data scaling, and is listed here separately for convenience. The most common preprocessing step, normalization plays a significant role in deep learning. It scales the data proportionally to fit within a specific range or distribution. Normalization unifies the data of different features into the same range, ensuring that each feature has an equal impact on the results during model training, thereby improving the training effectiveness. Z-score normalization (standardization) is the most commonly used method, where data is transformed into a normal distribution with a mean of 0 and a standard deviation of 1 after Z-score normalization. Olesen et al. (2021) applied Z-score normalization to each signal during preprocessing to adapt to differences in devices and baselines while evaluating the generalization ability of the model across five datasets. Additionally, it is important to note that data scaling and data normalization should not be confused, despite their similarities and occasional interchangeability. It is crucial to understand that both methods transform the values of numerical variables, endowing the transformed data points with specific useful properties. In simple terms: scaling changes the range of the data, while normalization changes the shape of the data distribution. Specifically, data scaling focuses more on adjusting the amplitude range of the data, such as between 0 to 100 or 0 to 1. Data normalization, on the other hand, is a relatively more aggressive transformation that focuses on changing the shape of the data distribution, adjusting the data to a common distribution, typically a Gaussian (normal) distribution (Ali et al. 2014). These two techniques are usually not used simultaneously; in practice, the choice is generally made based on the specific characteristics of the data and the needs of the model. The characteristics of the data can be examined for the presence of outliers, the numerical range of features, and their distribution. For example, when data contains a small number of outliers, scaling is often more appropriate than normalization. In particular, the median and IQR-based scaling method used by Guillot et al. (2021) (often referred to as robust scaling) is especially suitable for data with outliers because it uses the median and interquartile range to scale the data, preventing extreme values from having an impact. However, outliers can significantly affect the mean and standard deviation of the data, thus impacting the effectiveness of normalization based on the mean and standard deviation. Different models also have different requirements. For instance, distance-based algorithms (such as SVM) typically require data scaling, while algorithms that assume data is normally distributed commonly use normalization.
4.1.2 Class imbalance problems
In the preceding text, we have discussed the problem of class imbalance in sleep data (Table 6). Deep learning heavily relies on data, and when learning from such imbalanced data, the majority class tends to dominate, leading to a rapid decrease in its error rate (Fan et al. 2020). The result of training might be a model biased towards learning the majority class, performing poorly on minority classes. Moreover, when the number of samples in the minority class is very low, the model might overfit to these samples’ features, achieving high performance on the training set but poor generalization to unseen data (Spelmen and Porkodi 2018). The class imbalance problem in sleep cannot be eradicated but can only be suppressed through certain measures. The most common approach in existing research is data augmentation (DA), which falls within the preprocessing domain, while another category manifests during the training process.
DA is a method to expand the number of samples without significantly increasing existing data (Zhang et al. 2022a). Typically, it generates new samples for minority classes to match the sample counts in each class, constructing a new dataset (Fan et al. 2020). Three methods are generally used in existing research to generate new augmented data.
Oversampling: Aims to increase the number of samples in minority classes. Different class distributions are balanced through oversampling, enhancing the recognition ability of classification algorithms for minority classes. To prevent the model from favoring the majority class excessively, Supratak et al. (2017) used “oversampling with replication” during training. By replicating minority stages from the original dataset, all stages had the same number of samples, avoiding overfitting. Mousavi et al. (2019) used “oversampling with SMOTE (synthetic minority over-sampling technique)” (Chawla et al. 2002). SMOTE synthesizes similar new samples by considering the similarity between existing minority samples.
Morphological transformation: A common image enhancement method in image processing is geometric transformation, including rotation, flipping, random scaling, etc. Similar transformations can be performed on physiological signals. Common operations include translation (along the time axis), horizontal or vertical flipping, etc. Noise can also be added, further introducing variability (Fan et al. 2021). Zhao et al. (2022) applied random morphological transformations, deciding whether to perform cyclic horizontal shifting and horizontal flipping on each EEG epoch with a 50% probability.
Generative adversarial networks (GANs): GAN itself is a deep learning model proposed by Ian Goodfellow and colleagues in 2014 (Goodfellow et al. 2014). The core of GAN is the competition between two neural networks (generator and discriminator), with the ultimate goal of generating realistic data. GAN are widely used in image generation in the field of images and have similar applications in physiological signals. For instance, Zhang and Liu (2018) proposed a conditional deep convolutional generative adversarial network (cDCGAN) based on GAN to augment EEG training data in the brain-computer interface field. This network can automatically generate artificial EEG signals, effectively improving the classification accuracy of the model in scenarios with limited training data. In Kuo’s study (Kuo et al. 2022), another variant of GAN, self-attention GAN (SAGAN) (Zhang et al. 2019), was used. SAGAN is a variant of GAN for image generation tasks. The authors applied continuous wavelet transform to the original EEG signal and used SAGAN to augment the obtained spectrograms. A detailed introduction to the GAN model can be found in Sect. 4.3.
Another category of methods does not belong to preprocessing but is manifested during model training. Firstly, there is class weight adjustment, usually performed in the loss function. The basic idea is to introduce class weights into the loss function, giving more weight to minority classes, thus focusing more on the classification performance of minority classes during training. Commonly used methods include weighted cross-entropy loss function (Zhao et al. 2022) and focal loss function (Lin et al. 2017; Neng et al. 2021). Secondly, there are ensemble learning strategies, which balance the model’s attention to different classes by combining predictions from multiple base models, thus improving performance. Neng et al. (2021) trained 13 basic CNN models, selected the top 3 best-performing ones to form an ensemble model, achieving an average accuracy of 93.78%. Research focusing on addressing data imbalance problems is summarized in Table 7.
We reviewed current methods for mitigating class imbalance in sleep stage classification. Various methods can achieve performance improvements, but their applicability needs further discussion. For DA, the key is to introduce additional information while minimizing changes to the physiological or medical significance of the signals, thereby increasing data diversity (Rommel et al. 2022). Oversampling typically involves replicating existing samples or synthesizing similar samples based on existing ones. GAN, through adversarial training, can implicitly learn the mapping from latent space to the overall distribution of sleep data, generating samples that better fit the original data distribution and are more diverse (Fan et al. 2020). However, in morphological transformation methods, the essence is to obtain new samples by flipping, translating, etc., the original samples. For weak signals like EEG, simple waveform fluctuations can lead to different medical interpretations. Morphological transformations may not bring about sample diversity and could introduce erroneously annotated new samples, severely disrupting model learning. These were demonstrated by Fan et al. (2020). They compared EEG data augmentation methods such as repeating the minority classes (DAR), morphological change (DAMC), and GAN (DAGAN) on the MASS dataset. The results showed that DAMC performed the worst among all methods, only improving accuracy by 0.9%, while DAGAN improved performance by 3.8%. However, DAGAN introduced additional model training and resource costs. In Fan et al.’s experiments, GAN required 71.69 h of training and 19.63 min to generate synthetic signals, whereas morphological transformations only needed 201 min.
Class weight adjustment is typically done in the loss function, introducing minimal additional computation but usually bringing in new hyperparameters. For instance, the weighted cross-entropy loss function is calculated as follows:
where \(\textit{y}_i^k\) is the actual label value of the \(\textit{i}\)th sample, \(\hat{y}_i^k\) is the predicted probability for class \(\textit{k}\) of the \(\textit{i}\)-th sample, \(\textit{M}\) is the total number of samples, and \(\textit{K}\) is the total number of classes. \(\textit{w}_k\) represents the weight of class \(\textit{k}\), which is typically provided as a hyperparameter by the researchers. Other functions, such as focal loss, introduce two hyperparameters: the modulation factor and class weight. Ensemble learning requires training multiple base models for combined predictions, which adds extra overhead.
In summary, each existing method has its pros and cons. In terms of low cost and ease of application, oversampling and morphological transformation have more advantages. Although weighted loss functions also have low costs, they come with hyperparameter issues. GAN have performance advantages. When researchers can accommodate the additional overhead brought by GAN or pursue higher performance, GAN are worth trying. Additionally, Fan et al. (2020) and Rommel et al. (2022) conducted in-depth comparisons and analyses of different data augmentation methods, and interested readers can refer to their works.
4.2 Data representation
When using DL methods to process sleep data, a crucial issue is transforming sleep signals into suitable representations for subsequent learning by DL models. The choice of representation largely depends on the model’s requirements and the nature of the signal (Altaheri et al. 2023). Appropriate input forms enable the model to effectively learn and interpret sleep information. Signals can be directly represented as raw values, in which case they are in the time domain. Through signal processing methods such as wavelet transforms, Fourier transforms, etc., transformed domain representations of the signal can be obtained. Moreover, a combination of these two approaches is also commonly used. Figure 5 displays the representation methods and their proportions used in the reviewed articles. Figure 6a categorizes the representation methods applicable to PSG data, while Fig. 6b provides examples of these different representations.

The proportional representation of each data representation in this review paper (*Spatial-frequency images)

Classification of PSG data representation methods, and examples of each representation method. a Classification of representations; b Raw multi-channel signal, [TP\(\times\)C]; c STFT gets [T\(\times\)F] time-frequency spectrogram; d STFT gets [T\(\times\)F\(\times\)C] time-frequency spectrogram; e FFT gets [F\(\times\)C] spatial-frequency spectrum. TP Time Point (sampling point), C Channel (electrode), T Time window (time segment), F Frequency
4.2.1 Raw signal
In the time domain, the raw signal represents the main information as variations in signal amplitude over time. When signals come from multiple channels (electrodes), they can be represented as a 2D matrix of [TP (time point)\(\times\)C (channel)] (for a single-channel, it would be [TP\(\times\)1]). This can be visualized as shown in Fig. 6b. Traditionally, specific manually designed time-domain features are extracted from raw signals for input, such as power spectral density features (Xu and Plataniotis 2016). However, DL methods can automatically learn complex features from extensive data. This allows researchers to bypass the manual feature extraction step, directly inputting 1D raw signals with limited or no preprocessing into neural networks. In recent years, this straightforward and effective approach has become increasingly mainstream (as indicated in Fig. 5). Existing studies have directly input raw signals into various DL models, achieving good performance. This includes classic CNN architectures like ResNet (He et al. 2016; Seo et al. 2020) and U-Net (Ronneberger et al. 2015; Perslev et al. 2019), as well as CNN models proposed by researchers (Tsinalis et al. 2016; Goshtasbi et al. 2022; Sors et al. 2018). It also encompasses models such as RNNs (long short-term memory or gated recurrent unit) and Transformer (Phyo et al. 2022; Olesen et al. 2021; Lee et al. 2024; Pradeepkumar et al. 2022). In these works, minimal or no preprocessing has been applied. For example, Seo et al. (2020) utilized an improved ResNet to extract representative features from raw single-channel EEG epochs and explicitly emphasized that their method was an “end-to-end model trained in one step”, requiring no additional data preprocessing methods.
4.2.2 Transform domain
Transformed domain data are typically obtained from the raw signals through methods such as short-time Fourier transform, continuous wavelet transform, Hilbert-Huang transform, fast Fourier transform, and others. STFT, CWT and HHT fall under time-frequency analysis methods, providing time-frequency spectrograms that encompass both time and frequency information. The spectrogram can be regarded as a specific type of image, offering better understanding of the signal’s time-frequency features and patterns of change. As depicted in Fig. 6c and d, spectrograms can be represented as [T (time window)\(\times\) F (frequency)] or in the case of multiple channels, [T\(\times\)F\(\times\)C]. Different time-frequency analysis methods have variances between them. For instance, STFT utilizes a fixed-length window for signal analysis, thus can be considered a static method concerning time and frequency resolution. In contrast, CWT employs multiple resolution windows, providing dynamic features (Herff et al. 2020; Elsayed et al. 2016). To our knowledge, there is a lack of comprehensive research comparing the performance of different time-frequency analysis methods. For EEG, the energy across different sleep stages not only varies in frequency but also in spatial distribution (Jia et al. 2020a). This spatial information can be introduced through the “spatial-frequency spectrum”, typically implemented using FFT (Cai et al. 2021), as shown in Fig. 6e.
Phan et al. (2019) transformed 30-second epochs of EEG, EOG, and EMG signals into power spectra using STFT (window size of 2 s, 50% overlap, Hamming window, and 256-point FFT). This resulted in a multi-channel image of [T\(\times\)F\(\times\)C], where C = 3. The authors input these spectrogram data into a bidirectional hierarchical RNN model with attention mechanisms for sleep stage classification. The spatial-frequency spectrum introduced EEG electrode spatial information to enhance classification accuracy. Jia et al. (2020a) first conducted frequency domain feature analysis on power spectral density using FFT for five EEG frequency bands (delta, theta, alpha, beta, gamma) closely related to sleep. They placed the frequency domain features of different electrodes in the same frequency band on a 16\(\times\)16 2D map, resulting in five 2D maps representing different frequency bands. Each 2D map was treated as a channel of the image, producing a 5-channel image for each sample representing the spatial distribution of frequency domain features from different frequency bands.
In addition to using a single type of input form, some studies simultaneously use both. In these studies, it is often considered that individual time-domain, frequency-domain, or spatial-domain features alone are insufficient to completely differentiate sleep stages. Their combination offers complementarity, supplementing classification information (Jia et al. 2020a; Cai et al. 2021; Phan et al. 2021; Fang et al. 2023). Researchers usually construct a multi-branch network to process different forms of data separately. Features from multiple branches are fused using specific strategies to achieve better classification results. For example, Jia et al. (2020a) established a multi-branch model, simultaneously inputting spatial-frequency spectrum from 20 EEG channels and raw signals (EEG, EOG, EMG) into the model.
4.3 Deep learning models
In automatic sleep stage classification, DL has become the mainstream method in recent years compared to traditional ML techniques. Figure 7a and b provide a comparative overview of the workflows between the two methods. DL methods automate the feature extraction and classification steps present in ML, enabling an end-to-end approach. In this section, different deep learning models used in relevant studies will be introduced. DL models can be categorized into two subclasses based on their functionality: discriminative models and generative models, as well as hybrid models formed by combinations of these, as depicted in Fig. 8.

a General workflow of machine learning; b General workflow of deep learning

Classification of deep learning models
4.3.1 Discriminative models
Discriminative models refer to DL architectures that can learn different features from input signals through nonlinear transformations and classify them into predefined categories using probability predictions (Altaheri et al. 2023). Discriminative models are commonly utilized in supervised learning tasks and serve both feature extraction and classification purposes. In the context of sleep stage classification, the two major types of discriminative models widely used are CNN and RNN.
4.3.1.1 CNN
CNN, one of the most common DL models, is primarily used for tasks such as image classification in computer vision, and in recent years, it has been applied to biological signal classification tasks like ECG and EEG (Yang et al. 2015; Morabito et al. 2016). CNN is composed of a series of neural network layers arranged in a specific order, typically including five layers: input layer, convolutional layer, pooling layer, fully connected layer, and output layer (Yang et al. 2015; Morabito et al. 2016), as illustrated in Fig. 9. Starting from the input layer, the initial few layers learn low-level features, while later layers learn high-level features (Altaheri et al. 2023). The convolutional layer is the core building block of a CNN, where feature extraction from the input data is achieved through convolutional kernels. For example, in a 2D convolution, if the input data is a 224\(\times\)224 matrix and the convolutional kernel is a 3\(\times\)3 matrix (which can be adjusted), the values within this matrix are referred to as weight parameters. The convolutional kernel is applied to a specific region of the input data, computing the dot product between the data in that region and the kernel. The result of this dot product is provided to the output array. After this computation, the kernel moves by one unit length, known as the “stride,” and the process is repeated. This procedure continues until the convolutional kernel has scanned the entire input matrix. The dot product results from a series of scans constitute the final output, known as the feature map, representing the features extracted by the convolution. Note that the kernel remains unchanged during its sliding process, meaning all regions of the input share the same set of weight parameters, which is referred to as “weight sharing” and is one of the critical reasons for CNN’s success. Pooling layer performs a similar but distinct operation by scanning the input with a pooling kernel. For instance, in the commonly used max pooling, if the pooling kernel size is 3\(\times\)3, the result of each pooling operation is the maximum value from a 3\(\times\)3 region of the input matrix. The essence of pooling is downsampling, aimed at reducing network complexity or computational load. Typically, a series of consecutive convolution-pooling operations are used to extract data features. The feature maps obtained from convolution and pooling are usually flattened and then fed into one or more fully connected layers. As shown in Fig. 9, in the fully connected layers, each node in the input feature map is fully connected to each node in the output feature map, whereas convolutional layers have partial connections. The fully connected layers often use the softmax function to classify the input appropriately, generating probability values between 0 and 1. CNN is one of the most important models in sleep stage classification, with 76% of the studies reviewed in this paper utilizing CNN, as shown in Fig. 10. The CNN variants used in existing research include both standard CNN architectures, as well as various modified versions of CNN. For example, the residual CNN (He et al. 2016), inception-CNN (Szegedy et al. 2015), dense-convolutional (DenseNet) (Huang et al. 2017), 3D-CNN (Ji et al. 2023), and multi-branch CNN (used in ensemble learning) (Kuo et al. 2021), among others, are listed in Table 8, and their structures are shown in Fig. 11.

Basic principles of CNN

The proportional representation of each DL model in this review paper

a The upper part is a single residual connection block, and the lower part is a cascade of multiple residual blocks; b Replacing conv-layer with attention module; c Inception structure proposed in GoogLeNet (Szegedy et al. 2015; d Using an ensemble learning approach, the outputs of three basic CNNs are fed into a neural network with a hidden fully connected layer for further learning; e A novel CNN variant: DenseNet (Huang et al. 2017) is a convolutional neural network architecture that directly connects each layer to all subsequent layers to enhance feature reuse, facilitate gradient flow, and reduce the number of parameters
Zhou et al. (2021) proposed a lightweight CNN model that utilized the inception structure (as shown in Fig. 11c) to increase network width while reducing the number of parameters. This model took EEG’s STFT spectrogram as input. In a multimodal deep neural network model proposed in Zhao et al. (2021a), which included two parallel 13-layer 1D-CNNs, residual connections (as shown in Fig. 11a) were used to address potential gradient vanishing problems. EEG and ECG features were extracted separately in their respective convolutional branches and were later merged through simple concatenation for input into the classification module. Jia et al. (2020a) proposed a CNN model using EEG, EOG, and EMG. The model had multiple convolutional branches, each extracting different features from raw signals, and features from images generated by FFT from EEG. Features from different data representations were concatenated and input into the classification module. Kanwal et al. (2019) combined EEG and EOG to create RGB images, which were then transformed into high bit depth FFT features using 2D-FFT and classified using DenseNet (as shown in Fig. 11e). Conversely, in Liu et al. (2023b), an end-to-end deep learning model for automatic sleep staging based on DenseNet was designed and built. This model took raw EEG as input and employed two convolutional branches to extract features at different frequency levels. Significant waveform features were extracted using DenseNet modules and enhanced with coordinate attention mechanisms, achieving an overall accuracy of 90% on SEDF. Kuo et al. (2021) designed a CNN model that utilized CWT time-frequency spectrograms as input and combined Inception and residual connections. They also trained other classic CNN models and selected the top 3 models with the highest accuracy as base CNNs. These outputs were further learned using a fully connected network with a hidden layer, implementing ensemble learning (as shown in Fig. 11d). In Fang et al. (2023), authors used an ensemble strategy based on Boosting to combine multiple weak classifiers. Additionally, various CNN variants have been introduced in other studies, such as architectures incorporating different attention modules, as seen in Liu et al. (2023a) and Liu et al. (2022b) (as shown in Fig. 11b).
4.3.1.2 RNN
In many real-world scenarios, the input elements exhibit a certain degree of contextual dependency (temporal dependency) rather than being independent of each other. For instance, the variation of stock prices over time and sleep stage signals both reflect this dependency. To capture such relationships, models need to possess a memory capability, enabling them to make predictive outputs based on both current elements and features of previously input elements. This requirement has led to the widespread use of RNN in sleep stage classification tasks. A typical RNN architecture is illustrated in Fig. 12a, which includes an input layer, an output layer, and a hidden layer. Define \(\textit{x}_t\) as the input at time \(\textit{t}\), \(\textit{o}_t\) as the output, \(\textit{s}_t\) as the memory, \(\textit{U}\), \(\textit{V}\), and \(\textit{W}\) as the weight parameter. As shown on the right side of Fig. 12a, when unfolded along the time axis, the RNN repetitively uses the same unit structure at different time steps, incorporating the memory from the previous time step into the hidden layer during each iteration. \(\textit{U}\), \(\textit{V}\), and \(\textit{W}\) are shared across all time steps, enabling all previous inputs to influence future outputs through this recurrence. RNN possess memory capabilities, making them suitable for the demands of sleep stage classification tasks. However, the memory capacity of RNN is limited: it is generally assumed that inputs closer to the current time have a greater impact, while earlier inputs have a lesser impact, restricting RNN to short-term memory. Additionally, RNN face challenges such as high training costs (due to the inability to perform parallel computations in their recurrent structure) and the problem of vanishing gradients (Yifan et al. 2020). To address these issues, two widely used variants of RNN were proposed: LSTM and GRU. The basic unit composition of LSTM is depicted in Fig. 12b. Unlike RNN, which have a single hidden state s representing short-term memory, LSTM introduce \(\textit{h}\) as the hidden state (short-term memory). Moreover, LSTM add a cell state \(\textit{c}\) capable of storing long-term memory. The basic unit is controlled by three gates: the input gate, the forget gate, and the output gate. These “gates” are implemented using the sigmoid function, which outputs a probability value between 0 and 1, indicating the amount of information allowed to pass through. Among the three gates in LSTM, the forget gate determines how much of the previous cell state \(\textit{c}_{t-1}\) is retained in the current cell state \(\textit{c}_t\), based on the current input \(\textit{x}_t\) and the previous output \(\textit{h}_{t-1}\). After forgetting the irrelevant information, new memories need to be supplemented based on the current input. The input gate determines how much of \(\textit{x}_t\) updates the cell state \(\textit{c}_t\) based on \(\textit{x}_t\), \(\textit{h}_{t-1}\), and the output of the forget gate. The output gate controls how much of the cell state ct is output based on \(\textit{x}_t\) and \(\textit{h}_{t-1}\). By introducing the cell state \(\textit{c}\) and gate structures, LSTM can maintain longer memories and overcome issues such as vanishing gradients. However, LSTM are still essentially recurrent structures and thus cannot perform parallel computations (Yifan et al. 2020). GRU, another common variant of RNN, simplifies the architecture by having only two gate structures, reducing the number of parameters and increasing computational efficiency, though it still lacks the capability for parallel computation (Chung et al. 2014).

a Typical basic structure of RNN; b Basic unit of LSTM
Phan et al. (2018) designed a bidirectional RNN with an attention mechanism to learn features from single-channel EEG signal’s STFT transformation. The authors first divided the EEG epoch into multiple small frames. Using STFT, they transformed these into continuous frame-by-frame feature vectors, which were then input into the model shown in Fig. 13 for training. The training objective was to enable the model to encode the information of the input sequence into high-level feature vectors. Note that this is not an end-to-end process; the RNN was used as a feature extractor, while the classification was performed by a linear SVM classifier. The final classification is done through SVM. As an improvement, they later proposed a bidirectional hierarchical LSTM model combined with attention. The model takes STFT transformations of signals (EEG, EOG, EMG) as input. Based on attention, bidirectional LSTM encodes epochs into attention feature vectors, which are further modeled by bidirectional GRU (Phan et al. 2019). Inspired by their work, Guillot et al. (2020) enhanced a model based on GRU and positional embedding, reducing the number of parameters. In the study by Xu et al. (2020), four LSTM models were constructed, each with different input signal lengths (1, 2, 3, and 4 epochs). It was found that each model exhibited varying sensitivity to different sleep stages. The authors combined models with distinct stage sensitivities, resulting in improved classification accuracy.

Attention-based bidirectional RNN (Phan et al. 2018)
4.3.1.3 Hybrid
There exists rich temporal contextual information between consecutive sleep stages, which should not be ignored whether in expert manual staging or computer-assisted staging. For instance, if one or more sleep spindles or K-complexes are observed in the second half of the preceding epoch or the first half of the current epoch, the current epoch is classified as N2 stage. Moreover, sleep exhibits continuous stage transition patterns like N1-N2-N1-N2, N2-N2-N3-N2 (Iber 2007; Tsinalis et al. 2016). Both intra-epoch features and inter-epoch dependencies within the epoch sequence should be considered simultaneously (Seo et al. 2020). This is a challenge that individual CNN or RNN models cannot effectively address. Hence, the most common type of model in sleep stage classification is actually the hybrid of CNN and RNN (CRNN), which is designed to simultaneously handle feature extraction and model long-term dependencies. As shown in Fig. 14, hybrid models can be generalized into two main components: feature extractor (FE) and sequence encoder (SE). CNN is commonly used as FE, responsible for extracting epoch features and encoding invariant information over time; RNN is typically used as SE, focusing on representing relationships between epochs and encoding temporal relationships within the epoch sequence (Supratak et al. 2017; Phyo et al. 2022; Phan and Mikkelsen 2022).

A hybrid model consisting of Feature Extractor (FE) and Sequence Encoder (SE). \(x_1\)-\(x_L\) constitute an epoch sequence, FE extracts features at the intra-epoch level, and SE captures contextual information at the inter-epoch level. L \(\ge\) 1 (integer)
Such hybrid structure is implemented in DeepSleepNet, proposed by Supratak et al. (2017). The model extracts invariant features from raw single-channel EEG using a dual-branch CNN with different kernel sizes and encodes temporal information into the model with bidirectional LSTM featuring residual connections. DeepSleepNet achieved an accuracy of 82.0% on SEDF. In subsequent improvements, the authors significantly reduced the parameter count of the CRNN structure (approximately 6% of DeepSleepNet) and improved the performance to 85.4% (Supratak and Guo 2020). Seo et al. (2020) utilized the epoch sequence of raw single-channel EEG as input, employed an improved ResNet-50 network to extract representative features at the sub-epoch level, and captured intra- and inter-epoch temporal context from the obtained feature sequence with bidirectional LSTM. Performance comparisons were made with input sequences of different lengths (L) ranging from 1 to 10, with the model achieving the best accuracy of 83.9% on SEDF and 86.7% on SHHS datasets when L=10. Neng et al. divided sleep data into three levels: frame, epoch, and sequence, where frame is a finer division of epoch, and sequence represents epoch sequences (Neng et al. 2021). Based on this, they designed models with frame-level CNN, epoch-level CRNN, and sequence-level RNN, essentially aiming at modeling long-term dependencies. The input sequence length of the model was 25 epochs, and it achieved an accuracy of 84.29% on SEDF.
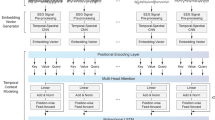
CRNN is the most widely used approach, but RNN suffers from long training times and challenges in parallel training. Hence, researchers have explored attention mechanisms and Transformer architectures based on self-attention (Vaswani et al. 2017), which have shown excellent performance in sequential tasks. The self-attention mechanism excels at capturing the inherent relationships and dependencies within input sequences. As depicted in Fig. 15, the basic structure of self-attention involves computing the relationship between each position in the input sequence and every other position, yielding a weight distribution. By performing a weighted summation of the input sequence based on this distribution, an output sequence encapsulating internal dependencies is produced (Guo et al. 2022). The core of the Transformer is the self-attention mechanism, which is divided into two main parts: the encoder and the decoder. In existing research, the encoder part is typically used. The Transformer encoder comprises several key components: positional encoding, multi-head self-attention, feed-forward neural network, layer normalization, and residual connections, as illustrated in Fig. 16a. The first operation of the encoder is to encode the position of the input sequence. MHSA can model the relationships within the input time series, but it cannot perceive the local positional information of the input sequence (Foumani et al. 2024). Therefore, positional information is first added to the input using fixed positional encoding based on sine and cosine functions of different frequencies (Vaswani et al. 2017):
where \(\textit{t}\) represents the input sequence data, \(\textit{p}\) represents the matrix calculated by the positional encoding function PE, \(\textit{p}os\) is the position index in the input sequence, d is the dimension of the input embeddings, and \(\textit{i}\) is the index of the dimension in the positional encoding vector. Next, MHSA modeling is performed. MHSA is an extension of self-attention that divides the input sequence into H sub-sequences, utilizing H parallel self-attention heads to capture different interactive information in various projection spaces (each head has different parameters). These H heads can capture different features and relationships of the input elements, and their fusion results in a richer global representation. As shown in Fig. 16b, taking the \(\textit{h}\)-th head and sub-sequence input \(\textit{x}\) as an example, three linear projections are first obtained for \(\textit{x}\), resulting in three copies of \(\textit{x}\) (query (\(\textit{q}\)), key (\(\textit{k}\)), and value (\(\textit{v}\)) matrices). This can be represented as:
where \(\textit{x}_q^h\), \(\textit{x}_k^h\), and \(\textit{x}_v^h\) represent the \(\textit{q}\), \(\textit{k}\), and \(\textit{v}\) copies, respectively, and \(\textit{W}_q^h\), \(\textit{W}_k^h\), and \(\textit{W}_v^h\) represent the learnable projection matrices. The self-attention output of the \(\textit{h}\)-th head is:
where \(\textit{d}_k\) is the dimension of the h-th head. Assuming there are H heads, each head’s output can be represented as \(O^i\) (\(1 \le i \le H\)). Concatenating the outputs of all heads and applying another linear projection \(W_o\) yields the final output of MHSA. This can be represented as:
After the multi-head self-attention mechanism, each encoder layer also includes a feed-forward neural network. This network typically consists of two fully connected layers and a nonlinear activation function, such as ReLU. It operates on the inputs at each position to generate new representations for each element. Layer normalization follows the multi-head self-attention and feed-forward neural network, helping to stabilize the training process and accelerate convergence. It normalizes the inputs of each layer so that the output has a mean of 0 and a standard deviation of 1. Residual connections, which appear alongside layer normalization, add the input of a sub-layer directly to its output. This connection helps to address the problem of vanishing gradients in deep networks and speeds up the training process. These components together form a standard Transformer encoder layer, and the encoder typically stacks multiple such layers. Each layer produces higher-level abstract representations, with the output of one layer serving as the input to the next, thereby extracting deeper features step by step. Compared to the recursive computations of RNN, the self-attention mechanism can parallelize the entire sequence, making it easily accelerated by GPU, similar to CNN (Guo et al. 2022). Furthermore, the self-attention mechanism can effortlessly obtain global information. These factors contribute to its widespread application in sequence data tasks, including sleep stage classification problems.

The basic structure of the self-attention mechanism

a Transformer encoder: It is composed of N standard encoder layers stacked together. The encoder layer consists of positional encoding, multi-head self-attention, feed-forward neural network, layer normalization, and residual connections; b The self-attention calculation process of the \(\textit{h}\)-th head
Attention and Transformer encoders (as shown in Fig. 16a) are often combined with CNNs to form hybrid models, where they also play the role of SE. For example, in the CNN-Attention model constructed by Zhu et al. (2020), CNN is used to encode epoch features, and self-attention is employed to learn temporal dependencies. AttnSleep, proposed by Eldele, uses CNN for feature extraction and employs a Transformer-encoder module combined with causal convolutions for encoding temporal context (Eldele et al. 2021). A CNN-Transformer model for real-time sleep stage classification on energy-constrained wireless devices was proposed in Yao and Liu (2023). The model, applied to single-channel input data of size (3000, 1) (signal length 30 s, sampling rate 100 Hz), extracts features of size (19, 128) through 4 consecutive convolutional layers. The Transformer-encoder is then used to learn temporal information from these features. The downsized model was tested on an Arduino development board, achieving an accuracy of 80% on the SEDF dataset. Lee et al. (2024) and Pradeepkumar et al. (2022) also introduced their CNN-Transformer approaches. Additionally, Phan et al. (2022b) proposed a model called SleepTransformer, which entirely eliminates the need for convolutional and recurrent operations. SleepTransformer no longer relies on CNN for epoch feature extraction but instead relies entirely on Transformer’s encoder to serve as FE and SE.
4.3.2 Generative models
In sleep stage classification, one popular generative DL model is GAN. It is important to note that the task reviewed in this paper is a classification task. GAN itself is used for data generation, and although it has a discriminator that performs binary classification, its sole purpose is to distinguish between real data and data synthesized by the generator, ultimately aiding the generator in producing realistic data. In the current context, GAN is typically used in the data augmentation phase to mitigate issues such as insufficient EEG training data or class imbalance, as described in Sect. 4.1.2. The data augmented by GAN still requires a classification model to achieve classification. Several studies have compared the effects of GAN with traditional data augmentation methods (such as SMOTE, morphological transformations, etc.) (Fan et al. 2020; Yu et al. 2023). The results of these studies indicate that sleep data augmentation based on GAN significantly improves classification performance. Fan et al. (2020) compared five data augmentation methods: repeating minority class samples, signal morphological transformations, signal segmentation and recombination, dataset-to-dataset transfer, and GAN. The results showed that GAN increased accuracy by 3.79% and 4.51% on MASS and SEDF, respectively, achieving the most remarkable performance improvement. Cheng et al. (2023a) designed a new GAN model (SleepEGAN), using the model from Supratak and Guo (2020) as the generator and discriminator of GAN, combined with a CRNN classifier to perform the classification task. After SleepEGAN augmentation on the SHHS dataset, the number of samples in the N1 stage increased from 10,304 to 46,272, and the overall classification accuracy improved to 88.0% (the second-best method achieved 84.2%). In Cheng’s study, original signals were augmented, while in Kuo et al. (2022), self-attention GAN was used to augment spectrogram images, and ResNet was employed for classification. On their private dataset, the combination of spectrogram, self-attention GAN and ResNet achieved an accuracy of 95.70%, whereas the direct classification approach was only 87.50%. Moreover, Yu et al. (2023); Zhou et al. (2022); Ling et al. (2022), and other studies also utilized GAN for data augmentation. In Yu et al. (2023), the generator and discriminator of the GAN model were both based on Transformer-encoder. Figure 8 displays the proportion of deep learning methods included in the reviewed studies, and Tables 9, 10 and 11 summarizes key information extracted from the papers. In these tables, we have compiled information on various types of input data, datasets, preprocessing methods, deep learning models, and their reported performance in recent papers.
5 ASSC based on cardiorespiratory signals
Currently, PSG remains the “gold standard” signal in sleep research. However, the time-consuming and labor-intensive nature of PSG data collection can disrupt a subject’s natural sleep patterns. Due to these limitations, sleep monitoring based on PSG struggles to transition from sleep labs to everyday life. Recent studies have demonstrated the correlation between sleep and respiratory or circulatory systems (Sun et al. 2020). In contrast, signals reflecting such activities, such as ECG, PPG, etc., offer unique advantages in terms of signal acquisition, cost, and subject comfort. For example, PPG can be collected using smartwatches. Hence, researchers have started exploring how to perform sleep stage classification using signals from the heart and lungs.
In studies based on heart and lung signals, various preprocessing methods and input formats are employed. However, unlike PSG, most studies do not directly use raw ECG or PPG signals but instead use derived time series (derived signals) such as HR, HRV, RRIs, etc. (Goldammer et al. 2022; Sun et al. 2020; Sridhar et al. 2020; Fonseca et al. 2020). These studies typically involve four steps: signal collection, extraction of derived time series, preprocessing, and neural network classification. Firstly, most studies still use public datasets, with only a few using their own data. For instance, in Fonseca et al. (2020), data from 11 sleep labs in five European countries and the United States were used for training, while data from another lab in the Netherlands served as a reserved validation set. The study involved 389 subjects, which is relatively small compared to some public datasets. The second step involves extracting derived time series. This often involves different algorithms aimed at extracting the required derived signals from the raw signal. Commonly derived signals include HR, HRV, RRIs, EDR, RR peak sequences, etc. Goldammer et al. (2022) used ECG and chest respiratory effort data from SHHS. RRIs were extracted from the raw ECG using a filter band algorithm, while breath-to-breath intervals were extracted from chest respiratory effort data using another algorithm. These algorithms can be found in Afonso et al. (1999) and Baillet et al. (2011). Sridhar et al. (2020) used ECG data provided by SHHS, MESA, etc. To extract heart rate information, they first normalized the raw ECG and then detected R-waves using the Pan-Tompkins algorithm, a common algorithm for automatic R-wave detection (Pan and Tompkins 1985). The time differences between consecutive R-waves form the interbeat interval (IBI) time series. Taking the reciprocal of IBI yields the required heart rate information (Sridhar et al. 2020). Sun et al. (2020) also used the Pan-Tompkins algorithm for ECG R-peak detection. However, after obtaining the time points of R-peaks, they converted the ECG into a binary sequence (1 at R-peaks, 0 elsewhere). The third step is preprocessing. In fact, this step is not consistent across studies; different studies preprocess either the raw signal or both the raw and derived signals. Common preprocessing methods include interpolation resampling, normalization, and outlier removal. In Goldammer et al. (2022), both RRIs and BBIs were linearly interpolated, resampled at a frequency of 4 Hz, and z-score normalized. The first and last five minutes of each signal were considered outliers (poor signal quality) and were truncated. Sridhar et al. (2020) simultaneously processed the raw ECG and derived signals. The raw ECG was normalized before extracting HR, and after obtaining HR, each night was independently z-score normalized and linearly interpolated and resampled to a sampling rate of 2Hz. Padding with zeros was performed to fix the size at 10 h. Sun et al. (2020) also identified potential non-physiological artifact segments based on voltage values. The final step involves using neural networks for classification. In heart and lung signals, CRNN remains popular. For example, Sun et al. (2020) constructed multiple neural networks, each comprising CNN and LSTM components. The former learned features related to each epoch, while the latter learned temporal patterns between consecutive epochs.
Apart from using derived time series as input, some studies have chosen raw signals or images as input. In Kotzen et al. (2022) and Korkalainen et al. (2020), preprocessed PPG was directly input into neural network models for classification. Olsen et al. (2022) used both PPG and accelerometer data, with PPG coming from clinical collection and wearable devices. All accelerometer and PPG data were resampled to 32 Hz, and outlier removal was performed after cropping the data. After STFT, time-frequency representations of both data types were obtained. The authors used a CNN model similar to U-Net to receive these time-frequency data as input, achieving an accuracy of 69.0% on the reserved validation set. Key information extracted from the heart and lung related research is summarized in Table 12.
6 ASSC based on contactless signals
In recent years, monitoring physiological signals through non-contact methods has emerged as a promising field in e-health. These methods aim to provide a viable alternative to contact-based signal acquisition. Contact-based methods, such as those involving EEG, EOG, and ECG mentioned in Sect. 4 and Sect. 5, require direct skin contact via sensors or electrodes. These methods are often impractical for subjects with severe burns, skin diseases, sensitive skin (as in elderly patients or infants), and they typically necessitate the involvement of healthcare personnel, as the correct placement of electrodes can be challenging for laypersons. Non-contact methods, which eliminate physical contact during data collection, include technologies like radar, Wi-Fi, and microphones. These signals can be seamlessly integrated into the environment, having minimal impact on the subject, and enabling remote and unobtrusive data collection (Nocera et al. 2021). This characteristic is particularly advantageous for long-term tasks such as sleep monitoring. Consequently, many researchers have recently begun exploring the combination of non-contact signals and deep learning techniques in this domain. Table 13 presents a summary of recent studies in this area. Figure 17 shows a flow chart of contactless sleep stage classification using radar or Wi-Fi. Signal acquisition is usually implemented by a pair of transmitters and receivers. After preprocessing, features such as motion and breathing are extracted and fed into the DL model for classification.

Flowchart of sleep stage classification using radar or Wi-Fi. From top to bottom: signal acquisition, feature extraction and deep learning model classification. The transmitter transmits wireless signals, interacts with human activities in the middle, and the receiver receives signals containing physiological information. After preprocessing, features such as movement, breathing, and heartbeat are extracted and finally sent to the DL model for classification
6.1 Radar
Radar and Wi-Fi both fall under the category of radio frequency (RF) signals and are currently widely applied in remote vital signs monitoring and activity recognition. RF-based non-contact transmission can capture reflections caused by physiological activities such as thoracic respiration and heartbeats. These reflection signals are often complex due to the presence of large-scale body movements, resulting in a non-linear combination of vital sign information and other motion data (Chen et al. 2021). Since the vital sign information is subtle but persistent, powerful tools like deep learning are required to extract and map this data to sleep stages for classification. Radar is an excellent non-contact sensor that can directly measure relevant information about a target, such as distance, speed, and angle, through the emission, reflection, and reception of electromagnetic waves. In Table 13, we review eight papers that classify sleep stages using radar. These studies exhibit distinct characteristics, which we detail below:
6.1.1 Radar equipment
Among the eight reviewed studies, various types of radar equipment were used (two studies did not specify the type). These included impulse-radio ultra-wideband (IR-UWB) radar (Park et al. 2024; Kwon et al. 2021; Toften et al. 2020), continuous wave (CW) Doppler radar (Chung et al. 2018; Favia 2021), and microwave radar (Wang and Matsushita 2023). CW Doppler radar appeared twice, IR-UWB three times, and microwave radar once. Although these numbers lack statistical significance, another review on radar in healthcare reported similar findings, showing that UWB and CW radars have usage rates of 26% and 29% respectively in healthcare applications (Nocera et al. 2021). This suggests that these radar types may be more suited for sleep monitoring tasks, though fair comparative experiments are needed to confirm this. Notably, Zhai et al. (2022) compared radar working frequencies, collecting nighttime sleep radar signals at 6 GHz and 60 GHz, respectively, for W/L/D/REM classification. They found that the lower frequency 6 GHz signals achieved an accuracy of 79.2%, whereas the 60 GHz signals achieved only 75.2%.
6.1.2 Datasets
There are no publicly available datasets in the existing research. Among the eight studies, only the data collected by Zhao et al. (2017) is available upon simple request.
6.1.3 Preprocessing
The preprocessing methods show no consistency, with techniques including downsampling to reduce computational complexity, normalization to constrain data distribution, and high-pass or band-pass filtering to remove noise. Unique to this review is the “moving average method” used to remove clutter (Park et al. 2024), appearing exclusively in this context.
6.1.4 Data representation
Regarding the use of radar signals, Wang and Matsushita (2023), Kwon et al. (2021), Toften et al. (2020), and Chung et al. (2018) all chose to input hand-crafted features into their models. These features included motion characteristics, respiratory features, and heart rate features, likely due to the weaker nature of radar signals compared to direct signals like EEG and ECG. Additionally, Park et al. (2024) and Zhao et al. (2017) used spectral forms of the signals. Zhai et al. (2022) and Favia (2021) used raw one-dimensional signals, preprocessed with filtering and normalization, as model inputs. Favia also compared raw signal inputs with STFT spectral inputs, finding that models using raw data outperformed those using spectral inputs. They noted that it would be simplistic to conclude that raw data is inherently better suited for the task, suggesting that multiple factors, such as non-optimal windowing or FFT points in STFT, or the model’s suitability for the task, could be influencing the results.
6.1.5 Deep learning models
Similar to Sect. 4, hybrid models like CNN-RNN (Toften et al. 2020) and CNN-Transformer (Park et al. 2024) dominate the landscape for radar signals, appearing five times, whereas RNNs alone appear only once. Additionally, multilayer perceptron (MLP) models, which are rarely used alone in PSG studies, appear twice in this context (Wang and Matsushita 2023; Chung et al. 2018). Although we reviewed the models and their performance, it is important to note that these are not fair comparisons, highlighting the potential value of a comparative study in this field.
6.1.6 Number of sleep stage categories
Almost all studies in Table 13 performed classification into the four sleep stages W/L/D/REM (or just W/Sleep), likely because non-contact signals struggle to distinguish between N1 and N2 stages. In fact, even when using PSG signals, N1 and N2 stages are often confused in existing research (Supratak and Guo 2020).
6.2 Wi-Fi
In recent years, Wi-Fi signals have been utilized for tasks such as activity recognition, respiratory detection, and sleep monitoring. Compared to radar equipment, Wi-Fi is undoubtedly a cheaper and more embedded technology within real-life environments. As a mature technology already prevalent in households, Wi-Fi has been explored for sleep monitoring. As early as 2014, Liu et al. (2014) proposed Wi-sleep, which uses off-the-shelf Wi-Fi devices to continuously collect fine-grained channel state information (CSI) during sleep. Wi-sleep extracts rhythm patterns associated with breathing and sudden changes due to body movements from the CSI data. Their tests showed that Wi-sleep can track human breathing and posture changes during sleep. In recent years, researchers have begun exploring the use of Wi-Fi signals to identify sleep stages. Although related studies are few (as shown in Table 13), we believe this technology holds great potential because it is inexpensive, requires no specialized equipment, and is entirely unobtrusive. Table 13 includes three Wi-Fi related studies: Yu et al. (2021b), Liu et al. (2022a), and Maheshwari and Tiwari (2019).
6.2.1 Datasets
All studies used private datasets, making direct performance comparison challenging.
6.2.2 Signal types
The authors of the three studies chose to use amplitude and phase information of fine-grained CSI for subsequent operations. Another channel information type in Wi-Fi sensing is received signal strength (RSS), which provides coarse-grained channel data and can be used for indoor localization, object tracking, and monitoring heart and respiratory rates (Liu et al. 2022a). However, RSS is more susceptible to obstruction and electromagnetic environment changes, which might explain the common choice of CSI.
6.2.3 Preprocessing
Due to the influence of surrounding environments and hardware noise, raw CSI data is often very noisy (Maheshwari and Tiwari 2019). Furthermore, Wi-Fi devices receive signals from different subcarriers with various spatial paths, each interacting differently with human body parts (Yu et al. 2021b). This introduces high-dimensional data issues in Wi-Fi sensing. To improve the signal-to-noise ratio and extract the main information from each path (dimensionality reduction), Maheshwari and Tiwari (2019) used principal component analysis (PCA), while Yu et al. (2021b) combined maximum ratio combining (MRC) with PCA to integrate signals from all subcarriers.
6.2.4 Data representation and deep learning models
Liu et al. (2022a) designed a CNN-based model for W/L/D/REM sleep stage classification, using one-dimensional amplitude and phase signals as input, achieving 95.925% accuracy on private data. Maheshwari and Tiwari (2019) and Yu et al. (2021b) used manually extracted features related to respiratory rate and movement. Maheshwari and Tiwari (2019) implemented a simple Bi-LSTM model for sleep motion classification to compute sleep stage information, while Yu et al. (2021b) used a hybrid CNN and Bi-LSTM model, incorporating conditional random fields for transition constraints between sleep stages, achieving 81.8% classification accuracy, close to results obtained with PSG signals.
6.3 Sound (Microphones)
During sleep, although the human body is unconscious, different physiological events spontaneously generate different audio signals, such as snoring and respiratory obstructions. Indeed, recent studies have explored detecting snoring (Xie et al. 2021a) and sleep apnea (Wang et al. 2022) events using sleep sound signals recorded by microphones. Nighttime sounds are easy to obtain and have a mapping relationship with sleep stages. For example, respiratory frequency decreases and becomes more regular during NREM stages, while it increases and varies more during REM stages. Additionally, unconscious body movements during the night produce friction sounds with bedding, capturing movement characteristics that can further supplement sleep stage classification (Dafna et al. 2018). Despite the rich sleep-related information contained in sound signals, they also include a significant amount of redundant information (Zhang et al. 2017). Therefore, extracting these features and mapping them to sleep stages has become a focus of research in recent years, with deep learning methods gaining significant attention. Table 13 lists five studies included in this review.
6.3.1 Microphone equipment
Various types of microphones appeared in the reviewed papers. Early studies, such as Zhang et al. (2017) and Dafna et al. (2018), used a recording pen microphone and a professional microphone, respectively. More recent studies by Hong et al. (2022) and Tran et al. (2023) used more common and cost-effective smartphone microphones, exploring how existing devices can facilitate sleep research outside laboratory or hospital settings. Han et al. (2024) used in-ear microphones embedded in sleep earplugs.
6.3.2 Datasets
All studies used private datasets, but Hong et al. (2022) and Tran et al. (2023), considering the limited data volume, also utilized a large public dataset, PSG Audio (Korompili et al. 2021), which contains synchronized recordings of PSG signals and audio.
6.3.3 Preprocessing
Sound signals usually have high sampling frequencies, so downsampling was applied in Han et al. (2024), Zhang et al. (2017), and Hong et al. (2022). Sound signals in real environments are typically noisy, including background noise and noise from recording devices. To suppress noise and outliers, Hampel filtering (Han et al. 2024), adaptive noise reduction (Tran et al 2023), and Wiener filter-based adaptive noise reduction (Dafna et al. 2018) were applied. Additionally, Tran and Hong achieved data augmentation through pitch shifting.
6.3.4 Data representation and deep learning models
Recognizing sleep stages through sound still involves capturing cardiopulmonary activities and body movement information. Therefore, Dafna et al. (2018) extracted 67 features in five groups, including respiratory and body movement features, and used an artificial neural network (ANN) to classify W/NREM/REM and W/Sleep with accuracies of 86.9% and 91.7%, respectively. Han et al. (2024) extracted body activity features, snoring and sleep talking features, and physiological features such as heart and respiratory rates, using a CNN-RNN hybrid model with attention mechanisms for W/L/D/REM classification, achieving an MF1 score of 69.51. In other studies, Zhang et al. (2017), Hong et al. (2022), and Tran et al. (2023) used spectral representations of audio signals. Zhang et al. extracted STFT spectra and Mel-frequency cepstral coefficients (MFCC), using CNNs for classification. Hong and Tran used the Mel spectrogram, the most common audio analysis tool, and implemented hybrid models of CNNs, RNNs, and multi-head attention for classification, achieving accuracies of 70.3% and 59.4%, respectively, in four-class classification. Although the performance was lower, their research showed that combining deep learning with smartphones could achieve sleep stage classification in uncontrolled home environments. Among the five studies, hybrid models were predominant.
In summary, we have reviewed studies on automatic sleep stage classification using non-contact signals and deep learning, focusing on radar, Wi-Fi, and microphone audio signals. This field also includes other forms of research, such as sleep stage monitoring through near-infrared cameras (Carter et al. 2023) or home surveillance cameras (Choe et al. 2019). We have organized relevant information in Table 13 for readers to explore further.
7 Discussions and challenges
7.1 Discussions
This section discusses and summarizes research on deep learning for sleep stage classification, focusing on three main aspects, available signals, data representations, and deep learning models, as well as their performance.
7.1.1 Signals (sleep physiological data)
Deep learning is a data-driven approach that relies on large amounts of data and uses deep neural networks to address real-world problems. The first crucial step in solving sleep stage classification problems is collecting signals (data) containing information about sleep physiological activities. However, in current research, this step is often overlooked due to the availability of public datasets. Researchers typically improve models or algorithms using existing data. The existing data includes not only traditional PSG signals but also “new signals” such as cardiac and non-contact signals.
Among the signal types reviewed in this paper, PSG, as the “gold standard,” dominates in terms of both the number of related studies and performance, as shown in Tables 9, 10, 11, 12, and 13. In PSG systems, single-channel EEG is currently the most popular modality. On the one hand, single-channel EEG alone can achieve good performance(Supratak et al. 2017; Phyo et al. 2022); on the other hand, it simplifies signal acquisition. However, there are still issues, as EEG is collected through electrodes distributed at different positions on the head, resulting in variations in the information and quality of signals obtained from different electrodes, which can lead to different model performance. Supratak et al. (2017) tested two EEG channels, Fpz-Cz (frontal) and Pz-Oz (occipital), from the Sleep-EDF-2013 dataset, achieving an overall accuracy of 82.0% on the Fpz-Cz channel, but only 79.8% on the Pz-Oz channel. Additionally, model performance can be improved by increasing the number of EEG channels or by supplementing with EOG and EMG signals (Cui et al. 2018; Jia et al. 2021; Olesen et al. 2021). However, when using EEG, EOG, or EMG simultaneously to form multimodal inputs, extra attention must be paid to the differences and fusion between modalities. To fairly compare these scenarios, we refer to the study by Zhu et al. (2023), in which the authors compared single-channel EEG (Fpz-Cz channel), EEG+EOG, and EEG+EOG+EMG on the Sleep-EDF-2018 dataset. Table 14 shows their results, with model performance increasing as the number of channels increases, especially with a significant improvement brought by the addition of EOG. In the study by Fan et al. (2021), the authors performed sleep stage classification using only a single-channel EOG, but the accuracy was only around 76%.
Cardiac and non-contact signals essentially fall into the same category of data, as the information contained in non-contact signals also pertains to cardiac activity. The main advantage of these signals over PSG lies in the comfortable and convenient signal acquisition methods. For example, PPG signals can be collected using a simple photoplethysmographic sensor integrated into smartwatches, while non-contact signals like Wi-Fi are ubiquitous in daily life. Although the association between cardiac signals and sleep conditions has long been recognized, these signals have only recently been utilized for sleep stage classification, thanks to advancements in deep learning techniques. Compared to EEG, research on these types of signals is still limited. In these studies, derived time series such as HR (Sridhar et al. 2020), HRV (Fonseca et al. 2020), and EDR (Li et al. 2018) extracted from raw signals are commonly used for classification. Therefore, they involve an additional step of “derived time series extraction” compared to PSG. Moreover, studies based on cardiac or non-contact signals mostly perform well in the W/L/D/REM four-stage classification but struggle with the more detailed AASM 5-stage classification. This limitation may stem from the inherent characteristics of these signals, which contain less sleep information compared to EEG.
7.1.2 Data representation
Automated sleep stage classification essentially involves extracting sleep physiological information from physiological signals using deep learning tools. Physiological signals, whether PSG or cardiac signals, can be represented in various forms, including raw one-dimensional signals, spectrogram images, derived time series, or combinations thereof. For PSG systems, inputting raw signal values directly into deep learning models is a popular choice, as demonstrated in Fig. 5. This straightforward approach has proven to be effective, driving the widespread adoption of this method. Additionally, spectral representations obtained through signal analysis methods such as STFT, CWT, and HHT are commonly used. Some researchers have noticed the benefits of combining these two representations. In cardiac and non-contact signals, most studies use derived signals extracted from raw data as inputs. Some also explore using raw signals or transformed domain data (Korkalainen et al. 2020; Olsen et al. 2022). PSG-related research is more abundant, so using raw signals is a popular choice. However, for cardiac and non-contact signals, due to the limited number of studies and lack of uniform methods, it is challenging to determine the most popular data representation method. It is essential to note that in terms of data representation, raw signals seem to be more straightforward and avoid information loss during the transformation process.
It is actually difficult to draw this conclusion. Because different studies vary greatly in terms of data preprocessing, data volume, validation methods, and network structures, simply comparing the reported performance in various studies is insufficient to support this conclusion. We believe this could be a direction for future work, that is, conducting a fair and comprehensive comparison including models, signal types, input forms, etc. Additionally, in Phan and Mikkelsen (2022) and Phan et al. (2021), the authors argue that different input forms should not be compared and should be seen as different mappings of underlying data distributions.
7.1.3 Deep learning models
In the studies we reviewed, about 35% adopted a fully CNN-based deep learning structure, while approximately 41% proposed combining CNN with other deep learning models, such as recurrent (RNN, LSTM, etc.), Transformer, and generative (GAN) models. Research involving CNN accounts for around 76% of the total studies. The widespread use of CNN can be justified by the following points. Firstly, the CNN structure can extract deep discriminative features and spatial patterns from sleep signals, thus CNN is used for direct classification or as a feature extractor. Secondly, CNN resources are abundant and have achieved success in many fields, such as image and video processing, with numerous accessible CNN-related resources (open code). Therefore, researchers have more opportunities to learn and use CNN, and can even transfer CNNs from other fields to the current subject, as Seo et al. (2020) used the well-known ResNet (He et al. 2016) from the image domain. Thirdly, various representations of sleep physiological signals, including raw one-dimensional signals, two-dimensional spectral representations obtained from various transformations, and extracted feature sequences, can all be accepted and processed by different forms of CNNs. Some studies have demonstrated that CNNs outperform other deep learning methods. In Stuburić et al. (2020), the authors tested the performance of CNN and LSTM networks on a combination of heartbeat, respiration, and motion signals (one-dimensional time series data). The CNN consisted of three convolutional layers and two fully connected layers, while the LSTM had only one LSTM hidden layer and two fully connected layers. The authors conducted five-class (W/N1/N2/N3/REM) and four-class (W/L/D/REM) tests, with the CNN and LSTM achieving overall accuracies of 40% and 32% in the five-class test, and 55% and 51% in the four-class test, respectively, proving that CNN outperformed LSTM. Despite the simplicity of the LSTM used, the authors claimed that its computational cost was still much higher than that of the CNN, a significant drawback of RNN-type models. Parekh et al. (2021) tested various well-known visual CNN models on the Sleep-EDF-2018 dataset, including AlexNet (Krizhevsky et al. 2012), VGG (Simonyan and Zisserman 2014), ResNet, DenseNet, SqueezeNet (Iandola et al. 2016), and MobileNet (Howard et al. 2017), with input being grayscale images visualizing single-channel EEG waveforms. All models were pre-trained on the large image vision dataset ImageNet (Deng et al. 2009). The experimental results showed that almost every model achieved around 95% accuracy, which is impressive. Another study (Phan et al. 2022a) compared the CRNN hybrid model (DeepSleepNet (Supratak et al. 2017)), pure RNN model (SeqSleepNet (Phan et al. 2019)), pure Transformer model (SleepTransformer (Phan et al. 2022b)), FCNN-RNN model (fully convolutional neural network hybrid RNN), and a time-frequency combined input model (XSleepNet (Phan et al. 2021), essentially a combination of FCNN-RNN and SeqSleepNet, receiving raw input and time-frequency transformed input to leverage their complementarity). The experiments were conducted on a pediatric sleep dataset, and the results showed that the time-frequency combined input model performed best (ACC = 88.9), while the pure Transformer model performed the worst (ACC = 86.9), possibly due to the limited data. In another study, Yeckle and Manian (2023) compared the performance of LeNet (LeCun et al. 1998), ResNet, MLP, LSTM, and CNN-LSTM hybrid models under the same conditions using single-channel one-dimensional EEG signals on the Sleep-EDF dataset. The results showed that LeNet performed best, achieving an accuracy of 85%. This may be due to the small amount of data used, only 20 subjects’ data. Overall, there is a relative lack of sufficient comparison of CNN structures in existing studies, such as the impact of different numbers of convolutional layers and fully connected layers, different activation functions, and different pooling methods on sleep staging.
A very small portion of studies entirely use RNN (including LSTM and GRU variants), which is much fewer than expected, given that RNN has always shown good performance in learning time series features. One explanation for this phenomenon is that RNN-type models consume a lot of training time and memory, especially for longer sequences. Although there is no fully relevant comparison in existing studies, Eldele et al. (2021) recorded the training times of their proposed model AttnSleep and DeepSleepNet (Supratak et al. 2017). Both models use similar multi-scale convolution to extract single-channel EEG features, but the former uses multi-head attention to model temporal dependencies, while the latter uses two-layer bidirectional LSTM. On Sleep-EDF-2018, AttnSleep required only 1.7 h of training time, while DeepSleepNet required 7.2 h, nearly four times the difference. Furthermore, although the number is small, almost all RNN-based studies included in this paper used LSTM, except for one study that used GRU (Guillot et al. 2020). There is currently a lack of sufficient comparison between the two, and it is recommended to test both to determine which method performs better. Another reason for the rare occurrence of RNN is the emergence of more promising alternatives, namely Transformer models based on multi-head attention. In recent studies, such as Maiti et al. (2023), Zhu et al. (2023), Yubo et al. (2022), Pradeepkumar et al. (2022), Eldele et al. (2021), Phan et al. (2022b), and Dai et al. (2023), it has appeared frequently. Siddhad et al. (2024) compared the effectiveness of Transformer, CNN, and LSTM in EEG classification. Their test results on a private age and gender EEG dataset showed that Transformer outperformed the other two methods. In the binary classification problem of gender, the Transformer achieved 94.53% accuracy, while the other two only had around 86%; in the six-class age task, the Transformer still had 87.79% accuracy, while the other two had only around 67%. However, in the current subject (ASSC), there is a lack of fair comparison between Transformer and RNN-type models.
Hybrid models, which are the most numerous type, usually combine CNN with other model structures. These models have shown strong spatial feature extraction and temporal feature modeling capabilities in many studies, with the former typically achieved by CNN and the latter by RNN or Transformer, especially the CNN-Transformer hybrid, which is gradually becoming a trend. Additionally, a small number of studies in the review used representative generative models: GANs, aimed at alleviating issues of insufficient training data or imbalanced sample classes through GANs.
In recent years, deep learning-based automatic sleep stage classification has achieved significant progress. The overall accuracy on PSG signals typically exceeds 80%. Although it’s difficult to deem this result entirely satisfactory, it seems that deep learning methods have reached a plateau in terms of performance. Given this situation, it may be challenging to achieve better performance simply by designing new model architectures. Instead, we should focus on the practical application of these models. In real-world applications, sleep data originate from various institutions, devices, demographic characteristics, and collection conditions, leading to substantial differences in data distribution. For instance, individuals of different ages, genders, races, or those with different medical conditions exhibit variations in sleep structure. Moreover, different PSG equipment and acquisition settings may result in differences in resolution, channel numbers, and signal-to-noise ratios, further increasing data heterogeneity. This diversity makes it difficult for existing DL models to generalize their performance beyond their local testing environments.
A promising solution emerging in current research to address this issue is transfer learning and domain adaptation. The core idea is to transfer pre-trained models (usually trained on large source domains) across different data domains, enabling them to adapt to the target data domain. This includes supervised, semi-supervised, and unsupervised methods. Supervised domain adaptation typically involves fine-tuning pre-trained models using annotated samples available from the target domain (Phan et al. 2020). The target domain could be a small clinical sleep dataset or the sleep records of an individual. A representative work in this area is the study by Phan et al. (2020), who extensively explored the transferability of features learned by sleep stage classification networks. However, it is evident that supervised domain adaptation requires a sufficient number of labeled samples from the target domain to be effective, which is not always feasible. Therefore, semi-supervised or unsupervised domain adaptation is employed. Banluesombatkul et al. (2020) proposed a transfer learning framework based on model-agnostic meta-learning (MAML), a typical semi-supervised framework that can quickly adjust models to new domains with only a few labeled samples. In the works of Yoo et al. (2021), Zhao et al. (2021b), and Nasiri and Clifford (2020), adversarial training-based frameworks for unsupervised domain adaptation are introduced. These methods achieve domain adaptation by matching the feature distributions of the source and target domains through domain classifiers and specifically designed models. While these studies seem promising, they still rely on specially designed networks rather than a universal framework.
7.1.4 The computational cost of models
In current research, three basic models-CNN, RNN, and Transformer-are widely used, but their computational costs and performance vary, necessitating reasonable selection based on requirements. Stuburić et al. (2020) tested a three-layer CNN model and a one-layer LSTM model on one-dimensional cardiopulmonary data, achieving 40% and 32% accuracy in the W/N1/N2/N3/REM five-class classification and 55% and 51% in the W/L/D/REM four-class classification, respectively, with CNN outperforming LSTM. Despite the simplicity of the LSTM used, the authors claimed its computational cost was much higher than that of the CNN. Eldele et al. (2021) proposed the CNN-Transformer hybrid model AttnSleep with 0.51 M parameters; Supratak et al. (2017) proposed the CNN-LSTM model DeepSleepNet with 21 M parameters. These are two very similar models with significant differences only in the LSTM and Transformer parts. In addition to the parameter count, on Sleep-EDF-2018, AttnSleep required only 1.7 h of training, whereas DeepSleepNet needed 7.2 h-nearly a fourfold difference-with AttnSleep achieving better performance. These studies in fact demonstrate that RNN models neither provide a performance advantage nor are resource-efficient.
Liu et al. (2023a) proposed the CNN model MicroSleepNet, which can run on smartphones. MicroSleepNet has only 48.2 K parameters but outperforms the 21 M parameter DeepSleepNet (82.8% vs. 82.0%). Compared to the SleepTransformer model built entirely on the Transformer architecture, there is a performance gap (79.5% vs. 81.4%), but the high parameter count of 3.7 M limits SleepTransformer’s deployment and real-time inference on mobile devices (Phan et al. 2022b). Pradeepkumar et al. (2022) and Yao and Liu (2023) optimized the CNN-Transformer hybrid models for light weight, but their parameter counts still reached 320 K and 300 K, with performance lower than MicroSleepNet (79.3% accuracy for Pardeepkumar et al. and 77.5% for Yao et al.). Zhou et al. (2023) also proposed a fully CNN-based lightweight model with only about 42 K parameters, outperforming other models that include LSTM or multi-head attention mechanisms.
The above indicates that RNNs result in higher parameter counts and computational resource consumption without performance advantages. Without considering computational cost and pursuing high performance, CNN and Transformer models are suitable. In scenarios requiring low parameter and computational cost, introducing Transformer structures does not significantly improve CNN model performance, and simple CNN structures can achieve competitive results in sleep stage classification tasks.
7.1.5 Other learning methods (self-supervised, semi-supervised learning)
Above, we provided a detailed discussion of sleep stage classification based on deep learning methods. Our investigation covered popular practices in signal processing, data representation, and modeling in the context of sleep stage classification. Additionally, during the survey, we identified some relatively niche research methods, mainly focusing on self-supervised or semi-supervised learning approaches. Unsupervised, self-supervised and semi-supervised learning is considered in contrast to supervised learning methods. In supervised learning, which is a primary paradigm in machine learning, the algorithm or model’s objective is to learn the mapping relationship between inputs and outputs from labeled training data (Qi and Luo 2020). However, in the real world, a significant portion of data is unlabeled, especially in medical fields. This limitation results in the waste of a large amount of unlabeled data, and emerging unsupervised, self-supervised, or semi-supervised methods aim to address this issue. Unsupervised learning, as the name suggests, involves training algorithms or models entirely on unlabeled data, allowing the model to autonomously learn the intrinsic structure of the data. Self-supervised learning is a subset of unsupervised learning, where the model learns from data by creating a “pretext task” to generate useful representations for subsequent tasks. Self-supervised learning doesn’t require data labels; instead, it uses some form of information inherent in the data as “pseudo-labels” for training. Pretext tasks need to be designed based on the application; for example, in computer vision, a pretext task might involve predicting the color of a certain part of an image (Misra and Maaten 2020). If the network can successfully accomplish this task, it indicates that it has learned general features in the data (Yun et al. 2022). Self-supervised learning is often categorized into three types: generative-based methods, contrastive-based methods, and adversarial-based methods (Zhang et al. 2023). Among these, contrastive-based methods, commonly known as contrastive learning, is most frequently used in sleep stage classification and is one of the widely adopted strategies in self-supervised learning. Contrastive learning aims to learn data representations by contrasting positive and negative samples (Chen et al. 2020). Most methods use two data augmentation techniques to generate different views of input samples x and y, denoted as \(\textit{x}_1\), \(\textit{y}_1\), and \(\textit{x}_2\), \(\textit{y}_2\). The model’s learning objective is to maximize the similarity between views from the same sample (\(\textit{x}_1\)-\(\textit{x}_2\), \(\textit{y}_1\)-\(\textit{y}_2\)) and minimize the similarity between views from different samples (\(\textit{x}_1\)-\(\textit{y}_2\), \(\textit{x}_2\)-\(\textit{y}_1\)) (Jaiswal et al. 2020). Through this contrastive training, the model’s representation learning capability is enhanced, making it better suited for subsequent tasks. Semi-supervised learning is a “middle-ground” approach that utilizes both labeled and unlabeled data, bridging the gap between supervised and unsupervised (self-supervised) learning (Chen et al. 2020). Semi-supervised learning typically handles unlabeled data with unsupervised or self-supervised methods, while labeled data is learned using traditional supervised methods (Li et al. 2022c). Although novel learning methods such as semi-supervised, self-supervised, and even unsupervised methods are widely used in fields like computer vision, their entry into the field of sleep analysis has been much slower, with relatively limited research at present.
Jiang et al. (2021) designed a contrastive learning-based backbone network for EEG, employing seven data transformation methods, including adding Gaussian noise and flipping, with the pretext task of matching transformation pairs from the same sample. Through contrastive training, a robust EEG feature extractor was obtained, and a classifier head (a fully connected output layer) was added to the backbone for subsequent sleep stage classification tasks (backbone network parameter freezing). Li et al. (2022c) designed a semi-supervised learning model for pediatric sleep staging. For unlabeled data, they used contrastive learning based on data augmentation for self-supervised learning, with the pretext task of predicting the data augmentation method used. For labeled data, the authors employed a supervised contrastive learning strategy (Khosla et al. 2020), incorporating label information into contrastive learning. This supervised contrastive learning strategy proposed by Khosla et al. (2020) aligns well with sleep stage classification problems, as evidenced in Lee et al. (2024) and Huang et al. (2023). In fact, existing labeled sleep data is relatively abundant Lee et al. (2024), and mining information from sleep data itself is challenging, making the performance of self-supervised algorithms less satisfactory. In such circumstances, not utilizing existing data is likely a waste. In Table 15, we extracted and summarized the information from these studies based on self-supervised or semi-supervised learning. The table extracts information from recent papers on self-supervised, semi-supervised, or supervised learning based on methods such as contrastive learning. In these papers, there are primarily two methods for creating pairs of samples required for contrastive learning. The first method involves creating sample pairs based on data augmentation, while the second method utilizes contrastive predictive coding (CPC) (Oord et al. 2018). Data augmentation methods are as described above, and the core of CPC lies in the model predicting future samples based on existing samples for learning (Brüsch et al. 2023). Additionally, we have compiled pretext tasks set in various studies and provided brief descriptions of their main content.
7.2 Challenges
In existing research, most work can be summarized as following the pattern of “proposing a model-applying public data-performance improvement.” This approach is undoubtedly meaningful; however, as of now, the problem of automatic sleep stage classification seems to be largely addressed (Phan and Mikkelsen 2022). Although various new models continue to push the performance metrics, it is challenging to ascertain whether such improvements have practical significance. Researchers, besides focusing on designing or building new models to achieve performance enhancement, should also address other challenges and explore innovative opportunities. In our investigation, we have identified three main areas for potential improvement: sleep data, deep learning models, and future scalable research.
-
(1)
Sleep data
-
The use of large and diverse datasets is lacking in relevant research: Existing studies often focus on several commonly used datasets, such as Sleep-EDF-2018, SHHS, and MASS. However, in fact, large database websites such as PhysioNet and NSRR have already openly released many large datasets. These data can be accessed with simple applications (some without), covering various populations including the elderly, children, and individuals with cardiovascular and pulmonary diseases. However, existing research tends to concentrate on classic benchmark datasets like Sleep-EDF-2018. Although this facilitates the comparison of algorithm or model performance, it fails to validate the generalization of models on heterogeneous data. We believe this is worth exploring; an excellent deep learning model should not only perform well on Sleep-EDF but should also be applicable to other datasets with minimal adjustments. This can be achieved through methods such as unsupervised domain adaptation (Yoo et al. 2021) and knowledge distillation (Duan et al. 2023), which can compensate for differences in data distributions.
-
Class imbalance in sleep data: Sleep data suffer from severe class imbalance issues, particularly in the N1 stage. Existing research often struggles with accurately identifying the N1 stage. For instance, in Jia et al. (2021), the F1-score for the N1 stage was only 56.2 (using the SEDF dataset), while other stages scored 87.2 or higher. Class imbalance is an inherent issue in sleep data. In fact, this paper statistically analyzes research focusing on class imbalance, with major mitigation methods including oversampling, morphological transformation, GAN synthetic samples, and adjusting loss functions and ensemble learning. We believe GAN synthetic samples are a more promising direction. This is because physiological signals are highly sensitive, and slight variations can lead to different medical interpretations. Oversampling or morphological transformation may have difficulty controlling whether the generated new samples are reasonable. However, GANs, through adversarial training between the generator and discriminator, have the potential to guide the generator to produce distributions extremely similar to real samples. Meanwhile, issues exist with loss functions and ensemble learning as well. The former typically brings about hyperparameter selection problems, while the latter entails high training costs.
-
The impact of noise and denoising processes on sleep stage classification systems: Noise is a pervasive issue during the acquisition of signals, whether they come from EEG, radar, Wi-Fi, or other sources, potentially leading to inaccuracies in sleep stage classification. In our review, we found that many studies incorporate denoising steps during data preprocessing. However, as far as we know, only Zhu et al. (2022) have investigated the impact of removing internal artifacts (noise) from EEG on deep learning-based sleep stage classification systems. They developed a novel method for removing internal EOG or EMG artifacts from sleep EEG and fed the denoised and original signals into deep neural networks in both time-domain one-dimensional and transformed domain (STFT) forms for classification. Their comparative results showed that when using the original time-domain signals, the presence of artifacts improved the accuracy of the W stage but reduced the accuracy for N1, N2, N3, and REM stages. Conversely, when using the signals in their time-frequency domain form, the artifacts had minimal impact. They concluded that appropriate artifact removal from EEG signals is advisable. Similar studies on other types of signals are currently lacking, and future research could benefit from exploring these findings to apply them to other signals.
-
Potential issues with noisy labels: The development of ASSC aims to bypass the labor-intensive process of manually annotating sleep data. However, until this field reaches full maturity, researchers must rely on expert manual annotations to train deep learning models. This reliance introduces a potential problem: the accuracy of these dataset annotations is uncertain. The uncertainty stems from various factors, including the quality of the data and the expertise of the annotators. For example, in the open-source dataset ISRUC released by Khalighi et al. (2016), the annotation labels were provided by two experts. They reported a Cohen’s Kappa coefficient of 0.9 in the healthy population (subgroup-3) and a lower value of 0.82 in the sleep disorder population (subgroup-2). This indicates that even expert annotations can result in misclassifications or disagreements, raising concerns about label reliability, commonly referred to as the issue of noisy labels. When labels are noisy, deep neural networks with a large number of parameters can overfit these erroneous labels. Zhang et al. (2021) conducted experiments on datasets with noisy labels and demonstrated that deep neural networks could easily fit training data with any proportion of corrupted labels, leading to poor generalization on test data. Moreover, they showed that popular regularization methods do not mitigate the impact of noisy labels, making them more detrimental than other types of noise, such as input data noise. Several methods have been proposed to train models robust to noisy labels, but most focus on image classification (Karimi et al. 2020). Unlike images, time series data, such as EEG and ECG, present additional challenges. These data types are harder to interpret and may have more ambiguities. Our survey found relatively little focus on addressing noisy labels in the context of ASSC. Fiorillo et al. (2023b) analyzed discrepancies among multiple annotators’ labels within the SSC. They used annotations from multiple annotators to train two lightweight models on three multi-annotator datasets. During training, they incorporated label smoothing and a soft-consensus distribution to calibrate the classification framework. Their approach, where models learn to align with the consensus among multiple annotators, suggests robustness to label noise even with annotator disagreements. In other domains, such as emotion recognition, Li et al. (2022a) addressed the issue of noisy labels in EEG data. They employed capsule networks combined with a joint optimization strategy for classification in the presence of noisy labels. Similarly, in the ECG domain, Liu et al. (2021) used a CNN model with a specially designed data cleaning method and a new loss function to effectively suppress the impact of noisy labels on arrhythmia classification. Furthermore, Song et al. (2022) provided a comprehensive review of methods for handling noisy labels in deep learning, including non-deep learning, machine learning, and deep learning approaches. Although their survey focuses on the image domain, these methods could potentially be adapted for ASSC. For instance, in the work of Vázquez et al. (2022), a state-of-the-art self-learning label correction method (Han et al. 2019) used for image classification was adapted for ECG tasks.
-
Impact of diseases on sleep stage classification: Current research typically uses sleep data from healthy individuals to validate algorithm performance. However, sleep disorders (Boostani et al. 2017; Malafeev et al. 2018b) and other neurological diseases (Patanaik et al. 2018b; Stephansen et al. 2018) can alter sleep structures, making accurate sleep stage identification in such patients highly challenging. Timplalexis et al. (2019) examined the differences in sleep stage classification using machine learning methods across healthy individuals, untreated sleep disorder patients, and medicated sleep disorder patients: EEG patterns in healthy individuals are easier to distinguish, while sleep disorders and medication seem to distort EEG, reducing classification accuracy by approximately 3%. They attempted to apply algorithms trained on healthy data to sleep disorder patients, resulting in a significant drop in accuracy. Korkalainen et al. (2019) observed that with increasing severity of obstructive sleep apnea, the classification accuracy based on single-channel EEG decreased. This confirms that diseases can cause potential changes in sleep structures and signal patterns. However, current studies lack exploration of the underlying reasons: How exactly do diseases like obstructive sleep apnea affect sleep stages? Can models circumvent or correct these impacts? Additionally, other studies have explored predicting the occurrence of sleep disorders [e.g., sleep apnea (Wang et al. 2023)] using deep learning during sleep. Cheng et al. (2023b) developed a multitask model capable of predicting both sleep stages and sleep disorders, but there was no interaction between the two tasks. We believe that increasing interaction and feedback between multitask branches might help the model more accurately identify sleep stages in diseased populations.
-
-
(2)
Deep learning models
-
Interpretability of deep learning models: One of the primary obstacles to the clinical application of automatic sleep staging based on deep learning is the black box suspicion. Deep learning algorithms are often perceived as “black boxes,” making it challenging to understand why they make specific decisions. To address this issue, using models with stronger interpretability is a good approach, such as the self-attention mechanism model Transformer. In the study proposed by Phan et al. (2022b), the SleepTransformer achieved high interpretability. They input a sequence of continuous sleep epochs into the model, first extracting sleep-related features within each epoch. Subsequently, they visualize attention scores between epochs, representing the influence of different adjacent epochs (i.e., context) in the input sequence on the identification of the target epoch. This approach closely mimics the process of manual classification by human experts. Additionally, feature visualization techniques, such as t-distributed Stochastic Neighbor Embedding (t-SNE) (Van der Maaten and Hinton 2008) and Gradient-weighted Class Activation Mapping (Grad-CAM) (Selvaraju et al. 2017), are also options to enhance model interpretability by observing the model features.
-
Performance challenges of non-invasive, non-contact methods: Non-invasive and non-contact methods have the advantage of being comfortable and non-intrusive, unlike PSG systems, which are invasive and uncomfortable. However, their association with sleep stages is relatively weak, making it challenging to explore and resulting in poor performance in existing research. Additionally, signals like Wi-Fi or radar face challenges in multi-person environments. We envision that this can be addressed by designing more effective models or algorithms and extracting more efficient and richer features.
-
-
(3)
Future scalable research
-
Acceptability of results from new methods to experts: The acceptability of sleep stage classification results obtained through contactless signals by doctors or experts remains an open question. As a novel approach that has emerged in recent years alongside advancements in wireless communication and electronic technologies, the reliability and acceptance of these methods are not well-established. In existing research, PSG remains the universally recognized gold standard for sleep stage classification. Experts can trust PSG results and base their diagnoses on them. However, when it comes to contactless signals, such as those obtained through radar or Wi-Fi, the acceptance and reliability of these methods by medical professionals are unknown and pose significant challenges. Future efforts may involve large-scale data collection and expert surveys to address this issue.
-
Extending from sleep stages to other diseases: The accurate classification of sleep stages aims to assist in diagnosing and preventing other diseases, such as sleep disorders and neurological diseases. When sleep stage classification is linked to the prediction and diagnosis of specific diseases, ASSC may become more practically significant. In fact, some datasets are designed to explore the relationship between sleep and certain diseases. For example, the SHHS dataset aims to investigate the potential relationship between sleep-disordered breathing and cardiovascular diseases. Xie et al. demonstrated that using overnight polysomnography and machine learning methods to predict ischemic stroke is feasible (Xie et al. 2018, 2021b). They extracted sleep stages, EEG-related features, and relevant clinical feature information from the data of SHHS participants who had experienced a stroke, and successfully predicted stroke in 17 out of 20 patients using their proposed prediction model. Although this is excellent work, their predictions rely on manually annotated sleep stage information by experts. Future research might combine automatic sleep stage classification models with prediction models to create an end-to-end integrated model, achieving fully automated monitoring, and potentially expanding to other diseases. This would be a significant advancement.
-
8 Conclusions
This paper studies and reviews deep learning methods for automatic sleep stage classification. Unlike traditional approaches, deep learning methods can automatically learn advanced and latent complex features from sleep data, eliminating the need for additional feature extraction steps. The paper comprehensively analyzes the signals, datasets, data representation methods, preprocessing techniques, deep learning models, and performance evaluations in sleep stage classification. We provide an overview of traditional PSG studies, and our survey reveals researchers’ focus on extracting different features from PSG data using various new models or methods. Most of these studies are based on large publicly available PSG datasets, and some of them have shown promising performance. Additionally, we discuss research involving less invasive and non-contact signals, namely cardiorespiratory signals and contactless signals. Compared to PSG, cardiorespiratory and contactless signals offer the advantages of convenient and comfortable signal acquisition, although their performance currently lags behind. Our review indicates that by combining deep learning with different types of signals, ASSC can be flexibly implemented without being confined to specialized PSG equipment, which is crucial for bringing sleep stage classification out of the laboratory. We believe that future research should focus on three key areas: firstly, the accuracy of cardiorespiratory and contactless signal classification; secondly, the robustness of the models in various real-world environments (e.g., home settings); and thirdly, the generalization capability of the models when faced with new data. These are not the only research directions that need attention, but they play a significant role in the practical application of ASSC.
Data Availability
No datasets were generated or analysed during the current study.
References
Aboalayon KAI, Faezipour M, Almuhammadi WS et al (2016) Sleep stage classification using EEG signal analysis: a comprehensive survey and new investigation. Entropy 18(9):272. https://doi.org/10.3390/e18090272
Adib F (2019) Seeing with radio wi-fi-like equipment can see people through walls, measure their heart rates, and gauge emotions. IEEE Spectr 56(6):34–39. https://doi.org/10.1109/MSPEC.2019.8727144
Afonso VX, Tompkins WJ, Nguyen TQ et al (1999) Ecg beat detection using filter banks. IEEE Trans Biomed Eng 46(2):192–202. https://doi.org/10.1109/10.740882
Ali PJM, Faraj RH, Koya E et al (2014) Data normalization and standardization: a technical report. Mach Learn Tech Rep 1(1):1–6
Al-Saegh A, Dawwd SA, Abdul-Jabbar JM (2021) Deep learning for motor imagery EEG-based classification: a review. Biomed Signal Process Control 63:102172. https://doi.org/10.1016/j.bspc.2020.102172
Alsolai H, Qureshi S, Iqbal SMZ et al (2022) A systematic review of literature on automated sleep scoring. IEEE Access 10:79419–79443
Altaheri H, Muhammad G, Alsulaiman M et al (2023) Deep learning techniques for classification of electroencephalogram (EEG) motor imagery (MI) signals: a review. Neural Comput Appl 35(20):14681–14722. https://doi.org/10.1007/s00521-021-06352-5
Arif S, Khan MJ, Naseer N et al (2021) Vector phase analysis approach for sleep stage classification: a functional near-infrared spectroscopy-based passive brain-computer interface. Front Hum Neurosci 15:658444
Baek J, Lee C, Yu H et al (2022) Automatic sleep scoring using intrinsic mode based on interpretable deep neural networks. IEEE Access 10:36895–36906. https://doi.org/10.1109/ACCESS.2022.3163250
Baglioni C, Battagliese G, Feige B et al (2011) Insomnia as a predictor of depression: a meta-analytic evaluation of longitudinal epidemiological studies. J Affect Disord 135(1–3):10–19. https://doi.org/10.1016/j.jad.2011.01.011
Baillet S, Friston K, Oostenveld R (2011) Academic software applications for electromagnetic brain mapping using MEG and EEG. Comput Intell Neurosci 2011:12–12. https://doi.org/10.1155/2011/972050
Banluesombatkul N, Ouppaphan P, Leelaarporn P et al (2020) Metasleeplearner: a pilot study on fast adaptation of bio-signals-based sleep stage classifier to new individual subject using meta-learning. IEEE J Biomed Health Inform 25(6):1949–1963
Banville H, Chehab O, Hyvärinen A et al (2021) Uncovering the structure of clinical EEG signals with self-supervised learning. J Neural Eng 18(4):046020. https://doi.org/10.1088/1741-2552/abca18
Biswal S, Sun H, Goparaju B et al (2018) Expert-level sleep scoring with deep neural networks. J Am Med Inform Assoc 25(12):1643–1650. https://doi.org/10.1093/jamia/ocy131
Biswal S, Kulas J, Sun H, et al (2017) Sleepnet: automated sleep staging system via deep learning. arXiv preprint arXiv:1707.08262https://doi.org/10.48550/arXiv.1707.08262
Bonnet M, Arand D (1997) Heart rate variability: sleep stage, time of night, and arousal influences. Electroencephalogr Clin Neurophysiol 102(5):390–396. https://doi.org/10.1016/S0921-884X(96)96070-1
Boostani R, Karimzadeh F, Nami M (2017) A comparative review on sleep stage classification methods in patients and healthy individuals. Comput Methods Programs Biomed 140:77–91
Brüsch T, Schmidt MN, Alstrøm TS (2023) Multi-view self-supervised learning for multivariate variable-channel time series. In: 2023 IEEE 33rd International Workshop on Machine Learning for Signal Processing (MLSP), IEEE, pp 1–6, https://doi.org/10.1109/MLSP55844.2023.10285993
Cai X, Jia Z, Jiao Z (2021) Two-stream squeeze-and-excitation network for multi-modal sleep staging. In: 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), IEEE, pp 1262–1265, https://doi.org/10.1109/BIBM52615.2021.9669375
Carter J, Jorge J, Venugopal B, et al (2023) Deep learning-enabled sleep staging from vital signs and activity measured using a near-infrared video camera. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 5940–5949
Casal R, Di Persia LE, Schlotthauer G (2021) Classifying sleep-wake stages through recurrent neural networks using pulse oximetry signals. Biomed Signal Process Control 63:102195. https://doi.org/10.1016/j.bspc.2020.102195
Chawla NV, Bowyer KW, Hall LO et al (2002) Smote: synthetic minority over-sampling technique. J Artif Intell Res 16:321–357. https://doi.org/10.1613/jair.953
Chen X, Wang R, Zee P et al (2015) Racial/ethnic differences in sleep disturbances: the multi-ethnic study of atherosclerosis (mesa). Sleep 38(6):877–888. https://doi.org/10.5665/sleep.4732
Cheng YH, Lech M, Wilkinson RH (2023) Simultaneous sleep stage and sleep disorder detection from multimodal sensors using deep learning. Sensors 23(7):3468
Cheng X, Huang K, Zou Y, et al (2023a) Sleepegan: A gan-enhanced ensemble deep learning model for imbalanced classification of sleep stages. arXiv preprint arXiv:2307.05362https://doi.org/10.48550/arXiv.2307.05362
Chen T, Kornblith S, Norouzi M, et al (2020) A simple framework for contrastive learning of visual representations. In: International conference on machine learning, PMLR, pp 1597–1607
Chen Z, Zheng T, Cai C, et al (2021) Movi-fi: Motion-robust vital signs waveform recovery via deep interpreted rf sensing. In: Proceedings of the 27th Annual International Conference on Mobile Computing and Networking, pp 392–405, https://doi.org/10.1145/3447993.3483251
Choe J, Schwichtenberg AJ, Delp EJ (2019) Classification of sleep videos using deep learning. In: 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), IEEE, pp 115–120
Chung KY, Song K, Cho SH et al (2018) Noncontact sleep study based on an ensemble of deep neural network and random forests. IEEE Sens J 18(17):7315–7324
Chung J, Gulcehre C, Cho K, et al (2014) Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555https://doi.org/10.48550/arXiv.1412.3555
Clarke G, Harvey AG (2012) The complex role of sleep in adolescent depression. Child Adolesc Psychiatr Clin 21(2):385–400. https://doi.org/10.1016/j.chc.2012.01.006
Cui Z, Zheng X, Shao X et al (2018) Automatic sleep stage classification based on convolutional neural network and fine-grained segments. Complexity. https://doi.org/10.1155/2018/9248410
Dafna E, Tarasiuk A, Zigel Y (2018) Sleep staging using nocturnal sound analysis. Sci Rep 8(1):13474
Dai Y, Li X, Liang S et al (2023) Multichannelsleepnet: a transformer-based model for automatic sleep stage classification with psg. IEEE J Biomed Health Inform. https://doi.org/10.1109/JBHI.2023.3284160
Deng J, Dong W, Socher R, et al (2009) Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition, Ieee, pp 248–255
Devuyst S, Dutoit T, Kerkhofs M (2005) The dreams databases and assessment algorithm. Zenodo: Geneva, Switzerland Zenodo https://zenodo.org/records/2650142#.ZG1w6XZBw2w
Diraco G, Leone A, Siciliano P (2017) Detecting falls and vital signs via radar sensing. In: 2017 IEEE SENSORS, IEEE, pp 1–3, https://doi.org/10.1109/ICSENS.2017.8234405
Duan L, Zhang Y, Huang Z, et al (2023) Dual-teacher feature distillation: A transfer learning method for insomniac psg staging. IEEE Journal of Biomedical and Health Informatics
Efe E, Ozsen S (2023) Cosleepnet: automated sleep staging using a hybrid CNN-LSTM network on imbalanced EEG-EOG datasets. Biomed Signal Process Control 80:104299
Eldele E, Chen Z, Liu C et al (2021) An attention-based deep learning approach for sleep stage classification with single-channel EEG. IEEE Trans Neural Syst Rehabil Eng 29:809–818. https://doi.org/10.1109/TNSRE.2021.3076234
Elsayed M, Badawy A, Mahmuddin M, et al (2016) Fpga implementation of dwt eeg data compression for wireless body sensor networks. In: 2016 IEEE Conference on Wireless Sensors (ICWiSE), IEEE, pp 21–25, https://doi.org/10.1109/ICWISE.2016.8187756
Fan J, Sun C, Chen C et al (2020) Eeg data augmentation: towards class imbalance problem in sleep staging tasks. J Neural Eng 17(5):056017. https://doi.org/10.1088/1741-2552/abb5be
Fan J, Sun C, Long M et al (2021) Eognet: a novel deep learning model for sleep stage classification based on single-channel EOG signal. Front Neurosci 15:573194. https://doi.org/10.3389/fnins.2021.573194
Fang Y, Xia Y, Chen P et al (2023) A dual-stream deep neural network integrated with adaptive boosting for sleep staging. Biomed Signal Process Control 79:104150. https://doi.org/10.1016/j.bspc.2022.104150
Faust O, Razaghi H, Barika R et al (2019) A review of automated sleep stage scoring based on physiological signals for the new millennia. Comput Methods Programs Biomed 176:81–91. https://doi.org/10.1016/j.cmpb.2019.04.032
Favia A (2021) Deep learning for sleep state detection using cw doppler radar technology. Master’s thesis, Aalto University
Ferri C, Hernández-Orallo J, Modroiu R (2009) An experimental comparison of performance measures for classification. Pattern Recogn Lett 30(1):27–38
Fioranelli F, Le Kernec J, Shah SA (2019) Radar for health care: recognizing human activities and monitoring vital signs. IEEE Potentials 38(4):16–23. https://doi.org/10.1109/MPOT.2019.2906977
Fiorillo L, Puiatti A, Papandrea M et al (2019) Automated sleep scoring: a review of the latest approaches. Sleep Med Rev 48:101204. https://doi.org/10.1016/j.smrv.2019.07.007
Fiorillo L, Favaro P, Faraci FD (2021) Deepsleepnet-lite: a simplified automatic sleep stage scoring model with uncertainty estimates. IEEE Trans Neural Syst Rehabil Eng 29:2076–2085. https://doi.org/10.1109/TNSRE.2021.3117970
Fiorillo L, Monachino G, van der Meer J et al (2023) U-sleep’s resilience to aasm guidelines. NPJ Digit Med 6(1):33
Fiorillo L, Pedroncelli D, Agostini V et al (2023) Multi-scored sleep databases: how to exploit the multiple-labels in automated sleep scoring. Sleep 46(5):zsad028
Fonseca P, van Gilst MM, Radha M et al (2020) Automatic sleep staging using heart rate variability, body movements, and recurrent neural networks in a sleep disordered population. Sleep 43(9):zass048. https://doi.org/10.1093/sleep/zsaa048
Foumani NM, Tan CW, Webb GI et al (2024) Improving position encoding of transformers for multivariate time series classification. Data Min Knowl Disc 38(1):22–48
Goldammer M, Zaunseder S, Brandt MD et al (2022) Investigation of automated sleep staging from cardiorespiratory signals regarding clinical applicability and robustness. Biomed Signal Process Control 71:103047. https://doi.org/10.1016/j.bspc.2021.103047
Goldberger AL, Amaral LA, Glass L et al (2000) Physiobank, physiotoolkit, and physionet: components of a new research resource for complex physiologic signals. Circulation 101(23):e215–e220. https://doi.org/10.1161/01.CIR.101.23.e215
Goodfellow I, Pouget-Abadie J, Mirza M, et al (2014) Generative adversarial nets. Adv Neural Inf Process Syst 27
Goshtasbi N, Boostani R, Sanei S (2022) Sleepfcn: a fully convolutional deep learning framework for sleep stage classification using single-channel electroencephalograms. IEEE Trans Neural Syst Rehabil Eng 30:2088–2096. https://doi.org/10.1109/TNSRE.2022.3192988
Grandini M, Bagli E, Visani G (2020) Metrics for multi-class classification: an overview. arXiv preprint arXiv:2008.05756
Guillot A, Sauvet F, During EH et al (2020) Dreem open datasets: multi-scored sleep datasets to compare human and automated sleep staging. IEEE Trans Neural Syst Rehabil Eng 28(9):1955–1965. https://doi.org/10.1109/TNSRE.2020.3011181
Guillot A, Sauvet F, During EH et al (2021) Robustsleepnet: transfer learning for automated sleep staging at scale. IEEE Trans Neural Syst Rehabil Eng 29:1441–1451. https://doi.org/10.1109/TNSRE.2021.3098968
Guo MH, Xu TX, Liu JJ et al (2022) Attention mechanisms in computer vision: a survey. Computational Visual Media 8(3):331–368. https://doi.org/10.1007/s41095-022-0271-y
Han F, Yang P, Feng Y et al (2024) Earsleep: In-ear acoustic-based physical and physiological activity recognition for sleep stage detection. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies 8(2):1–31
Hanifi K, Karsligil ME (2021) Elderly fall detection with vital signs monitoring using cw doppler radar. IEEE Sens J 21(15):16969–16978. https://doi.org/10.1109/JSEN.2021.3079835
Han J, Luo P, Wang X (2019) Deep self-learning from noisy labels. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 5138–5147
Herff C, Krusienski DJ, Kubben P (2020) The potential of stereotactic-EEG for brain-computer interfaces: current progress and future directions. Front Neurosci 14:123. https://doi.org/10.3389/fnins.2020.00123
He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 770–778
Hong H, Zhang L, Zhao H et al (2019) Microwave sensing and sleep: noncontact sleep-monitoring technology with microwave biomedical radar. IEEE Microwave Mag 20(8):18–29. https://doi.org/10.1109/MMM.2019.2915469
Hong J, Tran HH, Jung J et al (2022) End-to-end sleep staging using nocturnal sounds from microphone chips for mobile devices. Nat Sci Sleep. https://doi.org/10.2147/NSS.S361270
Howard AG, Zhu M, Chen B, et al (2017) Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861
Hsu LM, Field R (2003) Interrater agreement measures: comments on Kappan, Cohen’s kappa, Scott’s π, and Aickin’s α. Underst Stat 2(3):205–219. https://doi.org/10.1207/S15328031US0203_03
Huang J, Ren L, Zhou X et al (2022) An improved neural network based on senet for sleep stage classification. IEEE J Biomed Health Inform 26(10):4948–4956. https://doi.org/10.1109/JBHI.2022.3157262
Huang X, Schmelter F, Irshad MT et al (2023) Optimizing sleep staging on multimodal time series: Leveraging borderline synthetic minority oversampling technique and supervised convolutional contrastive learning. Comput Biol Med 166:107501. https://doi.org/10.1016/j.compbiomed.2023.107501
Huang M, Jiao X, Jiang J, et al (2021) An overview on sleep research based on functional near infrared spectroscopy. Sheng wu yi xue Gong Cheng xue za zhi= Journal of Biomedical Engineering= Shengwu Yixue Gongchengxue Zazhi 38(6):1211–1218
Huang G, Liu Z, Van Der Maaten L, et al (2017) Densely connected convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 4700–4708
Iandola FN, Han S, Moskewicz MW, et al (2016) Squeezenet: Alexnet-level accuracy with 50x fewer parameters and\(<\) 0.5 mb model size. arXiv preprint arXiv:1602.07360
Iber C (2007) The aasm manual for the scoring of sleep and associated events: rules, terminology, and technical specification. (No Title)
Jadhav P, Rajguru G, Datta D et al (2020) Automatic sleep stage classification using time-frequency images of cwt and transfer learning using convolution neural network. Biocybern Biomed Eng 40(1):494–504. https://doi.org/10.1016/j.bbe.2020.01.010
Jahrami HA, Alhaj OA, Humood AM et al (2022) Sleep disturbances during the covid-19 pandemic: a systematic review, meta-analysis, and meta-regression. Sleep Med Rev 62:101591. https://doi.org/10.1016/j.smrv.2022.101591
Jaiswal A, Babu AR, Zadeh MZ et al (2020) A survey on contrastive self-supervised learning. Technologies 9(1):2. https://doi.org/10.3390/technologies9010002
Jeon H, Jung Y, Lee S et al (2020) Area-efficient short-time fourier transform processor for time-frequency analysis of non-stationary signals. Appl Sci 10(20):7208. https://doi.org/10.3390/app10207208
Ji X, Li Y, Wen P (2023) 3dsleepnet: a multi-channel bio-signal based sleep stages classification method using deep learning. IEEE Trans Neural Syst Rehabil Eng. https://doi.org/10.1109/TNSRE.2023.3309542
Jia Z, Cai X, Zheng G et al (2020) Sleepprintnet: a multivariate multimodal neural network based on physiological time-series for automatic sleep staging. IEEE Trans Artif Intell 1(3):248–257. https://doi.org/10.1109/TAI.2021.3060350
Jia Z, Lin Y, Wang J, et al (2020b) Graphsleepnet: adaptive spatial-temporal graph convolutional networks for sleep stage classification. In: IJCAI, pp 1324–1330
Jia Z, Lin Y, Wang J, et al (2021) Salientsleepnet: Multimodal salient wave detection network for sleep staging. arXiv preprint arXiv:2105.13864https://doi.org/10.48550/arXiv.2105.13864
Jiang X, Zhao J, Du B, et al (2021) Self-supervised contrastive learning for eeg-based sleep staging. In: 2021 International Joint Conference on Neural Networks (IJCNN), IEEE, pp 1–8, https://doi.org/10.1109/IJCNN52387.2021.9533305
Kanwal S, Uzair M, Ullah H, et al (2019) An image based prediction model for sleep stage identification. In: 2019 IEEE International Conference on Image Processing (ICIP), IEEE, pp 1366–1370, https://doi.org/10.1109/ICIP.2019.8803026
Karimi D, Dou H, Warfield SK et al (2020) Deep learning with noisy labels: exploring techniques and remedies in medical image analysis. Med Image Anal 65:101759
Kayabekir M (2019) Sleep physiology and polysomnogram, physiopathology and symptomatology in sleep medicine. In: Updates in Sleep Neurology and Obstructive Sleep Apnea. IntechOpen
Khalighi S, Sousa T, Santos JM et al (2016) Isruc-sleep: a comprehensive public dataset for sleep researchers. Comput Methods Programs Biomed 124:180–192. https://doi.org/10.1016/j.cmpb.2015.10.013
Khan MI, Jan MA, Muhammad Y et al (2021) Tracking vital signs of a patient using channel state information and machine learning for a smart healthcare system. Neural Comput Appl. https://doi.org/10.1007/s00521-020-05631-x
Khan F, Azou S, Youssef R et al (2022) IR-UWB radar-based robust heart rate detection using a deep learning technique intended for vehicular applications. Electronics 11(16):2505. https://doi.org/10.3390/electronics11162505
Khosla P, Teterwak P, Wang C et al (2020) Supervised contrastive learning. Adv Neural Inf Process Syst 33:18661–18673
Korkalainen H, Aakko J, Nikkonen S et al (2019) Accurate deep learning-based sleep staging in a clinical population with suspected obstructive sleep apnea. IEEE J Biomed Health Inform 24(7):2073–2081
Korkalainen H, Aakko J, Duce B et al (2020) Deep learning enables sleep staging from photoplethysmogram for patients with suspected sleep apnea. Sleep 43(11):zsaa098. https://doi.org/10.1093/sleep/zsaa098
Korompili G, Amfilochiou A, Kokkalas L et al (2021) Psg-audio, a scored polysomnography dataset with simultaneous audio recordings for sleep apnea studies. Scientific Data 8(1):197
Kotzen K, Charlton PH, Salabi S et al (2022) Sleepppg-net: a deep learning algorithm for robust sleep staging from continuous photoplethysmography. IEEE J Biomed Health Inform 27(2):924–932. https://doi.org/10.1109/JBHI.2022.3225363
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. Adv Neural Inf Process Syst 25
Kuo CE, Chen GT, Liao PY (2021) An EEG spectrogram-based automatic sleep stage scoring method via data augmentation, ensemble convolution neural network, and expert knowledge. Biomed Signal Process Control 70:102981. https://doi.org/10.1016/j.bspc.2021.102981
Kuo CE, Lu TH, Chen GT et al (2022) Towards precision sleep medicine: self-attention gan as an innovative data augmentation technique for developing personalized automatic sleep scoring classification. Comput Biol Med 148:105828. https://doi.org/10.1016/j.compbiomed.2022.105828
Kwon HB, Choi SH, Lee D et al (2021) Attention-based lSTM for non-contact sleep stage classification using IR-UWB radar. IEEE J Biomed Health Inform 25(10):3844–3853. https://doi.org/10.1109/JBHI.2021.3072644
LeCun Y, Bottou L, Bengio Y et al (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324
Lee S, Yu Y, Back S et al (2024) Sleepyco: automatic sleep scoring with feature pyramid and contrastive learning. Expert Syst Appl 240:122551. https://doi.org/10.1016/j.eswa.2023.122551
Li X, Cui L, Tao S et al (2017) Hyclasss: a hybrid classifier for automatic sleep stage scoring. IEEE J Biomed Health Inform 22(2):375–385. https://doi.org/10.1109/JBHI.2017.2668993
Li Q, Li Q, Liu C et al (2018) Deep learning in the cross-time frequency domain for sleep staging from a single-lead electrocardiogram. Physiol Meas 39(12):124005. https://doi.org/10.1088/1361-6579/aaf339
Li C, Hou Y, Song R et al (2022) Multi-channel EEG-based emotion recognition in the presence of noisy labels. Sci China Inf Sci 65(4):140405
Li C, Qi Y, Ding X et al (2022) A deep learning method approach for sleep stage classification with EEG spectrogram. Int J Environ Res Public Health 19(10):6322. https://doi.org/10.3390/ijerph19106322
Li Y, Luo S, Zhang H et al (2022) Mtclss: multi-task contrastive learning for semi-supervised pediatric sleep staging. IEEE J Biomed Health Inform. https://doi.org/10.1109/JBHI.2022.3213171
Li T, Gong Y, Lv Y et al (2023) Gac-sleepnet: a dual-structured sleep staging method based on graph structure and Euclidean structure. Comput Biol Med 165:107477
Lin TY, Goyal P, Girshick R, et al (2017) Focal loss for dense object detection. In: Proceedings of the IEEE international conference on computer vision, pp 2980–2988
Ling H, Luyuan Y, Xinxin L et al (2022) Staging study of single-channel sleep EEG signals based on data augmentation. Front Public Health 10:1038742. https://doi.org/10.3389/fpubh.2022.1038742
Li Z, Sun S, Wang Y, et al (2022d) Time-frequency analysis of non-stationary signal based on sliding mode singular spectrum analysis and wigner-ville distribution. In: 2022 3rd International Conference on Information Science and Education (ICISE-IE), IEEE, pp 218–222, https://doi.org/10.1109/ICISE-IE58127.2022.00051
Liu Z, Luo S, Lu Y et al (2022) Extracting multi-scale and salient features by MSE based u-structure and CBAM for sleep staging. IEEE Trans Neural Syst Rehabil Eng 31:31–38. https://doi.org/10.1109/TNSRE.2022.3216111
Liu G, Wei G, Sun S et al (2023) Micro sleepnet: efficient deep learning model for mobile terminal real-time sleep staging. Front Neurosci. https://doi.org/10.3389/fnins.2023.1218072
Liu Z, Qin M, Lu Y et al (2023) Densleepnet: densenet based model for sleep staging with two-frequency feature fusion and coordinate attention. Biomed Eng Lett. https://doi.org/10.1007/s13534-023-00301-y
Liu X, Cao J, Tang S, et al (2014) Wi-sleep: Contactless sleep monitoring via wifi signals. In: 2014 IEEE Real-Time Systems Symposium, IEEE, pp 346–355
Liu M, Lin Z, Xiao P, et al (2022a) Human biometric signals monitoring based on wifi channel state information using deep learning. arXiv preprint arXiv:2203.03980https://doi.org/10.48550/arXiv.2203.03980
Liu X, Wang H, Li Z (2021) An approach for deep learning in ecg classification tasks in the presence of noisy labels. In: 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), IEEE, pp 369–372
Loh HW, Ooi CP, Vicnesh J et al (2020) Automated detection of sleep stages using deep learning techniques: a systematic review of the last decade (2010–2020). Appl Sci 10(24):8963
Maheshwari S, Tiwari AK (2019) Ai-enabled wi-fi network to estimate human sleep quality based on intensity of movements. In: 2019 IEEE International Conference on Advanced Networks and Telecommunications Systems (ANTS), IEEE, pp 1–6
Maiti S, Sharma SK, Bapi RS (2023) Enhancing healthcare with eog: a novel approach to sleep stage classification. arXiv preprint arXiv:2310.03757https://doi.org/10.48550/arXiv.2310.03757
Malafeev A, Laptev D, Bauer S et al (2018) Automatic human sleep stage scoring using deep neural networks. Front Neurosci 12:781
Malhotra A, Younes M, Kuna ST et al (2013) Performance of an automated polysomnography scoring system versus computer-assisted manual scoring. Sleep 36(4):573–582. https://doi.org/10.5665/sleep.2548
Malik J, Lo YL, Ht Wu (2018) Sleep-wake classification via quantifying heart rate variability by convolutional neural network. Physiol Meas 39(8):085004. https://doi.org/10.1088/1361-6579/aad5a9
Misra I, Maaten Lvd (2020) Self-supervised learning of pretext-invariant representations. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 6707–6717
Morabito FC, Campolo M, Ieracitano C, et al (2016) Deep convolutional neural networks for classification of mild cognitive impaired and alzheimer’s disease patients from scalp eeg recordings. In: 2016 IEEE 2nd International Forum on Research and Technologies for Society and Industry Leveraging a better tomorrow (RTSI), IEEE, pp 1–6, https://doi.org/10.1109/RTSI.2016.7740576
Mousavi S, Afghah F, Acharya UR (2019) Sleepeegnet: automated sleep stage scoring with sequence to sequence deep learning approach. PLoS ONE 14(5):e0216456. https://doi.org/10.1371/journal.pone.0216456
Nasiri S, Clifford GD (2020) Attentive adversarial network for large-scale sleep staging. In: Machine Learning for Healthcare Conference, PMLR, pp 457–478
Neng W, Lu J, Xu L (2021) Ccrrsleepnet: a hybrid relational inductive biases network for automatic sleep stage classification on raw single-channel eeg. Brain Sci 11(4):456. https://doi.org/10.3390/brainsci11040456
Nocera A, Senigagliesi L, Raimondi M et al (2021) Machine learning in radar-based physiological signals sensing: a scoping review of the models, datasets and metrics. Mach Learn 19:1
Olesen AN, Jørgen Jennum P, Mignot E et al (2021) Automatic sleep stage classification with deep residual networks in a mixed-cohort setting. Sleep 44(1):zsaa161. https://doi.org/10.1093/sleep/zsaa161
Olsen M, Zeitzer JM, Richardson RN et al (2022) A flexible deep learning architecture for temporal sleep stage classification using accelerometry and photoplethysmography. IEEE Trans Biomed Eng 70(1):228–237. https://doi.org/10.1109/TBME.2022.3187945
Oord Avd, Li Y, Vinyals O (2018) Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748https://doi.org/10.48550/arXiv.1807.03748
O’reilly C, Gosselin N, Carrier J et al (2014) Montreal archive of sleep studies: an open-access resource for instrument benchmarking and exploratory research. J Sleep Res 23(6):628–635. https://doi.org/10.1111/jsr.12169
Pan J, Tompkins WJ (1985) A real-time QRS detection algorithm. IEEE Trans Biomed Eng 3:230–236. https://doi.org/10.1109/TBME.1985.325532
Papadakis Z, Retortillo SG (2022) Acute partial sleep deprivation and high-intensity exercise effects on cardiovascular autonomic regulation and lipemia network. In: International Journal of Exercise Science: Conference Proceedings, p 12
Parekh A, Mullins AE, Kam K et al (2019) Slow-wave activity surrounding stage n2 k-complexes and daytime function measured by psychomotor vigilance test in obstructive sleep apnea. Sleep 42(3):zsy256. https://doi.org/10.1093/sleep/zsy256
Parekh N, Dave B, Shah R et al (2021) Automatic sleep stage scoring on raw single-channel eeg: A comparative analysis of cnn architectures. 2021 Fourth International Conference on Electrical. Computer and Communication Technologies (ICECCT), IEEE, pp 1–8
Park J, Yang S, Chung G, et al (2024) Ultra-wideband radar-based sleep stage classification in smartphone using an end-to-end deep learning. IEEE Access
Patanaik A, Ong JL, Gooley JJ et al (2018) An end-to-end framework for real-time automatic sleep stage classification. Sleep 41(5):zsy041
Perslev M, Darkner S, Kempfner L et al (2021) U-sleep: resilient high-frequency sleep staging. NPJ Digi Med 4(1):72. https://doi.org/10.1038/s41746-021-00440-5
Perslev M, Jensen M, Darkner S, et al (2019) U-time: a fully convolutional network for time series segmentation applied to sleep staging. Adv Neural Inf Process Syst 32
Phan H, Mikkelsen K (2022) Automatic sleep staging of EEG signals: recent development, challenges, and future directions. Physiol Measurement 43(4):04TR01. https://doi.org/10.1088/1361-6579/ac6049
Phan H, Andreotti F, Cooray N et al (2019) Seqsleepnet: end-to-end hierarchical recurrent neural network for sequence-to-sequence automatic sleep staging. IEEE Trans Neural Syst Rehabil Eng 27(3):400–410. https://doi.org/10.1109/TNSRE.2019.2896659
Phan H, Chén OY, Koch P et al (2020) Towards more accurate automatic sleep staging via deep transfer learning. IEEE Trans Biomed Eng 68(6):1787–1798
Phan H, Chén OY, Tran MC et al (2021) Xsleepnet: multi-view sequential model for automatic sleep staging. IEEE Trans Pattern Anal Mach Intell 44(9):5903–5915. https://doi.org/10.1109/TPAMI.2021.3070057
Phan H, Mertins A, Baumert M (2022) Pediatric automatic sleep staging: a comparative study of state-of-the-art deep learning methods. IEEE Trans Biomed Eng 69(12):3612–3622
Phan H, Mikkelsen K, Chén OY et al (2022) Sleeptransformer: automatic sleep staging with interpretability and uncertainty quantification. IEEE Trans Biomed Eng 69(8):2456–2467. https://doi.org/10.1109/TBME.2022.3147187
Phan H, Andreotti F, Cooray N, et al (2018) Automatic sleep stage classification using single-channel eeg: learning sequential features with attention-based recurrent neural networks. In: 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), IEEE, pp 1452–1455, https://doi.org/10.1109/EMBC.2018.8512480
Phyo J, Ko W, Jeon E et al (2022) Transsleep: transitioning-aware attention-based deep neural network for sleep staging. IEEE Trans Cybern. https://doi.org/10.1109/TCYB.2022.3198997
Pradeepkumar J, Anandakumar M, Kugathasan V, et al (2022) Towards interpretable sleep stage classification using cross-modal transformers. arXiv preprint arXiv:2208.06991https://doi.org/10.48550/arXiv.2208.06991
Qi GJ, Luo J (2020) Small data challenges in big data era: a survey of recent progress on unsupervised and semi-supervised methods. IEEE Trans Pattern Anal Mach Intell 44(4):2168–2187. https://doi.org/10.1109/TPAMI.2020.3031898
Quan SF, Howard BV, Iber C et al (1997) The sleep heart health study: design, rationale, and methods. Sleep 20(12):1077–1085. https://doi.org/10.1093/sleep/20.12.1077
Radha M, Fonseca P, Moreau A et al (2021) A deep transfer learning approach for wearable sleep stage classification with photoplethysmography. NPJ Digi Med 4(1):135. https://doi.org/10.1038/s41746-021-00510-8
Rechtschaffen A (1968) A manual of standardized terminology, techniques and scoring system for sleep stage of human subject. (No Title)
Rommel C, Paillard J, Moreau T et al (2022) Data augmentation for learning predictive models on EEG: a systematic comparison. J Neural Eng 19(6):066020
Ronneberger O, Fischer P, Brox T (2015) U-net: convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, Springer, pp 234–241, https://doi.org/10.1007/978-3-319-24574-4_28
Selvaraju RR, Cogswell M, Das A, et al (2017) Grad-cam: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE international conference on computer vision, pp 618–626
Seo H, Back S, Lee S et al (2020) Intra-and inter-epoch temporal context network (iitnet) using sub-epoch features for automatic sleep scoring on raw single-channel eeg. Biomed Signal Process Control 61:102037. https://doi.org/10.1016/j.bspc.2020.102037
Sharma R, Pachori RB, Upadhyay A (2017) Automatic sleep stages classification based on iterative filtering of electroencephalogram signals. Neural Comput Appl 28:2959–2978. https://doi.org/10.1007/s00521-017-2919-6
Shen Q, Xin J, Liu X, et al (2023) Lgsleepnet: an automatic sleep staging model based on local and global representation learning. IEEE Transactions on Instrumentation and Measurement
Shinar Z, Akselrod S, Dagan Y et al (2006) Autonomic changes during wake-sleep transition: a heart rate variability based approach. Auton Neurosci 130(1–2):17–27. https://doi.org/10.1016/j.autneu.2006.04.006
Siddhad G, Gupta A, Dogra DP et al (2024) Efficacy of transformer networks for classification of EEG data. Biomed Signal Process Control 87:105488
Siegel JM (2009) Sleep viewed as a state of adaptive inactivity. Nat Rev Neurosci 10(10):747–753. https://doi.org/10.1038/nrn2697
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556
Song H, Kim M, Park D, et al (2022) Learning from noisy labels with deep neural networks: a survey. IEEE transactions on neural networks and learning systems
Sors A, Bonnet S, Mirek S et al (2018) A convolutional neural network for sleep stage scoring from raw single-channel EEG. Biomed Signal Process Control 42:107–114. https://doi.org/10.1016/j.bspc.2017.12.001
Soto JC, Galdino I, Caballero E et al (2022) A survey on vital signs monitoring based on wi-fi CSI data. Comput Commun 195:99–110. https://doi.org/10.1016/j.comcom.2022.08.004
Spelmen VS, Porkodi R (2018) A review on handling imbalanced data. In: 2018 international conference on current trends towards converging technologies (ICCTCT), IEEE, pp 1–11, https://doi.org/10.1109/ICCTCT.2018.8551020
Sri TR, Madala J, Duddukuru SL, et al (2022) A systematic review on deep learning models for sleep stage classification. In: 2022 6th International Conference on Trends in Electronics and Informatics (ICOEI), IEEE, pp 1505–1511
Sridhar N, Shoeb A, Stephens P et al (2020) Deep learning for automated sleep staging using instantaneous heart rate. NPJ Digi Med 3(1):106. https://doi.org/10.1038/s41746-020-0291-x
Stephansen JB, Olesen AN, Olsen M et al (2018) Neural network analysis of sleep stages enables efficient diagnosis of narcolepsy. Nat Commun 9(1):5229
Stokes PA, Prerau MJ (2020) Estimation of time-varying spectral peaks and decomposition of EEG spectrograms. IEEE Access 8:218257–218278. https://doi.org/10.1109/ACCESS.2020.3042737
Stuburić K, Gaiduk M, Seepold R (2020) A deep learning approach to detect sleep stages. Procedia Computer Sci 176:2764–2772
Subha DP, Joseph PK, Acharya UR et al (2010) EEG signal analysis: a survey. J Med Syst 34:195–212
Sun H, Ganglberger W, Panneerselvam E et al (2020) Sleep staging from electrocardiography and respiration with deep learning. Sleep 43(7):zsz306. https://doi.org/10.1093/sleep/zsz306
Sun C, Hong S, Wang J et al (2022) A systematic review of deep learning methods for modeling electrocardiograms during sleep. Physiol Meas. https://doi.org/10.1088/1361-6579/ac826e
Supratak A, Dong H, Wu C et al (2017) Deepsleepnet: a model for automatic sleep stage scoring based on raw single-channel EEG. IEEE Trans Neural Syst Rehabil Eng 25(11):1998–2008. https://doi.org/10.1109/TNSRE.2017.2721116
Supratak A, Guo Y (2020) Tinysleepnet: an efficient deep learning model for sleep stage scoring based on raw single-channel eeg. In: 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), IEEE, pp 641–644, https://doi.org/10.1109/EMBC44109.2020.9176741
Szegedy C, Liu W, Jia Y, et al (2015) Going deeper with convolutions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 1–9
Tăutan AM, Rossi AC, De Francisco R, et al (2020) Automatic sleep stage detection: a study on the influence of various psg input signals. In: 2020 42nd Annual International Conference of the Ieee Engineering in Medicine & Biology Society (EMBC), IEEE, pp 5330–5334, https://doi.org/10.1109/EMBC44109.2020.9175628
Thölke P, Mantilla-Ramos YJ, Abdelhedi H et al (2023) Class imbalance should not throw you off balance: choosing the right classifiers and performance metrics for brain decoding with imbalanced data. Neuroimage 277:120253. https://doi.org/10.1016/j.neuroimage.2023.120253
Timplalexis C, Diamantaras K, Chouvarda I (2019) Classification of sleep stages for healthy subjects and patients with minor sleep disorders. In: 2019 IEEE 19th International Conference on Bioinformatics and Bioengineering (BIBE), IEEE, pp 344–351
Tobaldini E, Nobili L, Strada S et al (2013) Heart rate variability in normal and pathological sleep. Front Physiol 4:294. https://doi.org/10.3389/fphys.2013.00294
Toften S, Pallesen S, Hrozanova M et al (2020) Validation of sleep stage classification using non-contact radar technology and machine learning (somnofy®). Sleep Med 75:54–61
Tran HH, Hong JK, Jang H et al (2023) Prediction of sleep stages via deep learning using smartphone audio recordings in home environments: model development and validation. J Med Internet Res 25:e46216. https://doi.org/10.2196/46216
Tsinalis O, Matthews PM, Guo Y, et al (2016) Automatic sleep stage scoring with single-channel eeg using convolutional neural networks. arXiv preprint arXiv:1610.01683https://doi.org/10.48550/arXiv.1610.01683
Tyagi A, Nehra V (2017) Time frequency analysis of non-stationary motor imagery eeg signals. In: 2017 International Conference on Computing and Communication Technologies for Smart Nation (IC3TSN), IEEE, pp 44–50, https://doi.org/10.1109/IC3TSN.2017.8284448
Van der Maaten L, Hinton G (2008) Visualizing data using t-sne. J Mach Learn Res 9(11):2579–2605
Van Someren EJ (2021) Brain mechanisms of insomnia: new perspectives on causes and consequences. Physiol Rev 101(3):995–1046. https://doi.org/10.1152/physrev.00046.2019
Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Adv Neural Inf Process Syst 30
Vázquez CG, Breuss A, Gnarra O et al (2022) Label noise and self-learning label correction in cardiac abnormalities classification. Physiol Meas 43(9):094001
Vilamala A, Madsen KH, Hansen LK (2017) Deep convolutional neural networks for interpretable analysis of eeg sleep stage scoring. In: 2017 IEEE 27th international workshop on machine learning for signal processing (MLSP), IEEE, pp 1–6
Walch O, Huang Y, Forger D et al (2019) Sleep stage prediction with raw acceleration and photoplethysmography heart rate data derived from a consumer wearable device. Sleep 42(12):zsz180. https://doi.org/10.1093/sleep/zsz180
Wang X, Matsushita D (2023) Non-contact determination of sleep/wake state in residential environments by neural network learning of microwave radar and electroencephalogram-electrooculogram measurements. Build Environ 233:110095
Wang Y, Yao Y (2023) Application of artificial intelligence methods in carotid artery segmentation: a review. IEEE Access. https://doi.org/10.1109/ACCESS.2023.3243162
Wang Q, Wei HL, Wang L et al (2021) A novel time-varying modeling and signal processing approach for epileptic seizure detection and classification. Neural Comput Appl 33:5525–5541. https://doi.org/10.1007/s00521-020-05330-7
Wang B, Tang X, Ai H et al (2022) Obstructive sleep apnea detection based on sleep sounds via deep learning. Nat Sci Sleep 31:2033–2045
Wang E, Koprinska I, Jeffries B (2023) Sleep apnea prediction using deep learning. IEEE Journal of Biomedical and Health Informatics
Wulff K, Gatti S, Wettstein JG et al (2010) Sleep and circadian rhythm disruption in psychiatric and neurodegenerative disease. Nat Rev Neurosci 11(8):589–599. https://doi.org/10.1038/nrn2868
Wu Y, Lo Y, Yang Y (2020) Stcn: A lightweight sleep staging model with multiple channels. In: 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), IEEE, pp 1180–1183, https://doi.org/10.1109/BIBM49941.2020.9313371
Xie J, Aubert X, Long X et al (2021) Audio-based snore detection using deep neural networks. Comput Methods Programs Biomed 200:105917
Xie J, Wang Z, Yu Z et al (2021) Ischemic stroke prediction by exploring sleep related features. Appl Sci 11(5):2083
Xie J, Wang Z, Yu Z et al (2018) Enabling efficient stroke prediction by exploring sleep related features. 2018 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications. Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), IEEE, pp 452–461
Xu Z, Yang X, Sun J et al (2020) Sleep stage classification using time-frequency spectra from consecutive multi-time points. Front Neurosci 14:14. https://doi.org/10.3389/fnins.2020.00014
Xu H, Plataniotis KN (2016) Affective states classification using eeg and semi-supervised deep learning approaches. In: 2016 IEEE 18th International Workshop on Multimedia Signal Processing (MMSP), IEEE, pp 1–6, https://doi.org/10.1109/MMSP.2016.7813351
Yacouby R, Axman D (2020) Probabilistic extension of precision, recall, and f1 score for more thorough evaluation of classification models. In: Proceedings of the first workshop on evaluation and comparison of NLP systems, pp 79–91, https://doi.org/10.18653/v1/2020.eval4nlp-1.9
Yang C, Li B, Li Y et al (2023) Lwsleepnet: a lightweight attention-based deep learning model for sleep staging with singlechannel EEG. Digital Health 9:20552076231188210. https://doi.org/10.1177/20552076231188206
Yang H, Sakhavi S, Ang KK, et al (2015) On the use of convolutional neural networks and augmented csp features for multi-class motor imagery of eeg signals classification. In: 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), IEEE, pp 2620–2623, https://doi.org/10.1109/EMBC.2015.7318929
Yao Z, Liu X (2023) A cnn-transformer deep learning model for real-time sleep stage classification in an energy-constrained wireless device. In: 2023 11th International IEEE/EMBS Conference on Neural Engineering (NER), IEEE, pp 1–4, https://doi.org/10.1109/NER52421.2023.10123825
Ye J, Xiao Q, Wang J et al (2021) Cosleep: a multi-view representation learning framework for self-supervised learning of sleep stage classification. IEEE Signal Process Lett 29:189–193. https://doi.org/10.1109/LSP.2021.3130826
Yeckle J, Manian V (2023) Automated sleep stage classification in home environments: an evaluation of seven deep neural network architectures. Sensors 23(21):8942
Yifan Z, Fengchen Q, Fei X (2020) Gs-rnn: a novel rnn optimization method based on vanishing gradient mitigation for hrrp sequence estimation and recognition. In: 2020 IEEE 3rd International Conference on Electronics Technology (ICET), IEEE, pp 840–844, https://doi.org/10.1109/ICET49382.2020.9119513
Yildirim O, Baloglu UB, Acharya UR (2019) A deep learning model for automated sleep stages classification using PSG signals. Int J Environ Res Public Health 16(4):599. https://doi.org/10.3390/ijerph16040599
Yoo C, Lee HW, Kang JW (2021) Transferring structured knowledge in unsupervised domain adaptation of a sleep staging network. IEEE J Biomed Health Inform 26(3):1273–1284
Young T, Palta M, Dempsey J et al (2009) Burden of sleep apnea: rationale, design, and major findings of the Wisconsin sleep cohort study. WMJ: Off Publ State Med Soc Wisconsin 108(5):246
Yu B, Wang Y, Niu K et al (2021) Wifi-sleep: sleep stage monitoring using commodity wi-fi devices. IEEE Internet Things J 8(18):13900–13913. https://doi.org/10.1109/JIOT.2021.3068798
Yubo Z, Yingying L, Bing Z et al (2022) Mmasleepnet: a multimodal attention network based on electrophysiological signals for automatic sleep staging. Front Neurosci 16:973761. https://doi.org/10.3389/fnins.2022.973761
Yun S, Lee H, Kim J, et al (2022) Patch-level representation learning for self-supervised vision transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 8354–8363
Yu L, Tang P, Jiang Z, et al (2023) Denoise enhanced neural network with efficient data generation for automatic sleep stage classification of class imbalance. In: 2023 International Joint Conference on Neural Networks (IJCNN), IEEE, pp 1–8, https://doi.org/10.1109/IJCNN54540.2023.10191282
Zhai Q, Tang T, Lu X et al (2022) Machine learning-enabled noncontact sleep structure prediction. Adv Intell Syst 4(5):2100227. https://doi.org/10.1002/aisy.202100227
Zhang GQ, Cui L, Mueller R et al (2018) The national sleep research resource: towards a sleep data commons. J Am Med Inform Assoc 25(10):1351–1358. https://doi.org/10.1093/jamia/ocy064
Zhang J, Yao R, Ge W et al (2020) Orthogonal convolutional neural networks for automatic sleep stage classification based on single-channel EEG. Comput Methods Programs Biomed 183:105089. https://doi.org/10.1016/j.cmpb.2019.105089
Zhang C, Bengio S, Hardt M et al (2021) Understanding deep learning (still) requires rethinking generalization. Commun ACM 64(3):107–115
Zhang R, Tian D, Xu D et al (2022) A survey of wound image analysis using deep learning: classification, detection, and segmentation. IEEE Access 10:79502–79515. https://doi.org/10.1109/ACCESS.2022.3194529
Zhang Y, Ren R, Yang L et al (2022) Sleep in alzheimer’s disease: a systematic review and meta-analysis of polysomnographic findings. Transl Psychiatry 12(1):136. https://doi.org/10.1038/s41398-022-01897-y
Zhang Y, Chen Y, Hu L, et al (2017) An effective deep learning approach for unobtrusive sleep stage detection using microphone sensor. In: 2017 IEEE 29th International Conference on Tools with Artificial Intelligence (ICTAI), IEEE, pp 37–44
Zhang H, Goodfellow I, Metaxas D, et al (2019) Self-attention generative adversarial networks. In: International Conference on Machine Learning, PMLR, pp 7354–7363
Zhang Q, Liu Y (2018) Improving brain computer interface performance by data augmentation with conditional deep convolutional generative adversarial networks. arXiv preprint arXiv:1806.07108https://doi.org/10.48550/arXiv.1806.07108
Zhang K, Wen Q, Zhang C, et al (2023) Self-supervised learning for time series analysis: taxonomy, progress, and prospects. arXiv preprint arXiv:2306.10125https://doi.org/10.48550/arXiv.2306.10125
Zhao R, Xia Y, Wang Q (2021) Dual-modal and multi-scale deep neural networks for sleep staging using EEG and ECG signals. Biomed Signal Process Control 66:102455. https://doi.org/10.1016/j.bspc.2021.102455
Zhao R, Xia Y, Zhang Y (2021) Unsupervised sleep staging system based on domain adaptation. Biomed Signal Process Control 69:102937
Zhao C, Li J, Guo Y (2022) Sleepcontextnet: a temporal context network for automatic sleep staging based single-channel eeg. Comput Methods Programs Biomed 220:106806. https://doi.org/10.1016/j.cmpb.2022.106806
Zhao M, Yue S, Katabi D, et al (2017) Learning sleep stages from radio signals: a conditional adversarial architecture. In: International Conference on Machine Learning, PMLR, pp 4100–4109
Zhou D, Xu Q, Wang J et al (2022) Alleviating class imbalance problem in automatic sleep stage classification. IEEE Trans Instrum Meas 71:1–12. https://doi.org/10.1109/TIM.2022.3191710
Zhou H, Liu A, Cui H et al (2023) Sleepnet-lite: a novel lightweight convolutional neural network for single-channel EEG-based sleep staging. IEEE Sensors Lett 7(2):1–4
Zhou D, Xu Q, Wang J, et al (2021) Lightsleepnet: a lightweight deep model for rapid sleep stage classification with spectrograms. In: 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), IEEE, pp 43–46, https://doi.org/10.1109/EMBC46164.2021.9629878
Zhu T, Luo W, Yu F (2020) Convolution-and attention-based neural network for automated sleep stage classification. Int J Environ Res Public Health 17(11):4152. https://doi.org/10.3390/ijerph17114152
Zhu H, Wu Y, Shen N et al (2022) The masking impact of intra-artifacts in EEG on deep learning-based sleep staging systems: a comparative study. IEEE Trans Neural Syst Rehabil Eng 30:1452–1463
Zhu H, Zhou W, Fu C et al (2023) Masksleepnet: a cross-modality adaptation neural network for heterogeneous signals processing in sleep staging. IEEE J Biomed Health Inform. https://doi.org/10.1109/JBHI.2023.3253728
Author information
Authors and Affiliations
Contributions
PL conducted literature survey and wrote the main manuscript text. WQ guided literature survey. HZ guided literature survey. YZ guided the literature survey. G.X. guided the literature survey. QH guided the literature survey. QL guided the literature survey. YY guided the literature survey and the writing of the main manuscript text. All authors reviewed the manuscript
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, P., Qian, W., Zhang, H. et al. Automatic sleep stage classification using deep learning: signals, data representation, and neural networks. Artif Intell Rev 57, 301 (2024). https://doi.org/10.1007/s10462-024-10926-9
Accepted:
Published:
DOI: https://doi.org/10.1007/s10462-024-10926-9