
Abstract
Aim
The present study has designed, implemented, and evaluated a machine learning model that can predict fall risk and fall occurrence in community-dwelling elderly based on their home care usage.
Subjects and methods
A dataset consisting of 2542 weekly home care records for 1499 citizens (59% female, 41% male) with a mean age of 77 years (SD 10 years) was collected from a large municipality in Denmark. The data were recorded between January 1, 2021, and December 31, 2021. The dataset was divided into two cohorts. Subsequently, five machine learning-based survival analysis models were trained and evaluated using cross-validation.
Results
The CoxBoost model showed the best discriminative performance with a mean 0.64 (95% CI 0.57–0.72) Harrell’s concordance index, indicating better ranking than chance-level by 14% on average. However, the model could not accurately predict when the next fall would take place.
Conclusions
The proposed method enables professionals to assess individual fall risk by using home care records from an Electronic Health Record (EHR) system. This facilitates the initiation of targeted fall-prevention programs for those at highest risk. Additionally, it is expected that a risk-based approach can lead to a lower number needed to treat (NNT), indicating greater effectiveness of health interventions.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Falls among elderly citizens constitute a significant and widespread problem in society (Franse et al. 2017). Studies have shown that simple strength training exercises and daily outdoor activities can reduce the incidence rate of falls (Salminen et al. 2009; Klaperski-van Der Wal et al. 2023), however, the current efforts of Danish municipalities have traditionally focused on reactive approaches. To adopt a proactive approach and narrow down the search criteria for eligible adults, machine learning has been adopted to identify people at risk of falling. This is done primarily in hospitalized adults with good results (Lindberg et al. 2020; Patterson et al. 2019; Nakatani et al. 2020), but few studies have focused on community-dwelling elderly. In this setting, most proposed methods are invasive, where researchers, for example, place cameras around participants in their homes, which can be seen as intrusive and a violation of privacy (Dubois et al. 2019; Yang et al. 2019; Wilmink et al. 2020). The few noninvasive studies that exist have only studied binary classification methods (Chelli and Patzold 2019; Dormosh et al. 2022), which cannot distinguish individuals at risk beyond a few classes. They also rely on fall reports to determine if someone has fallen or not, but falls in older adults are often underreported or incorrectly reported (Hoffman et al. 2018).
In this observational study, we propose a noninvasive method to predict individual fall risk using survival analysis. Survival analysis is a form of regression modeling that supports censored data, i.e., where the event of interest is partially observed. Conventional machine learning methods do not support censoring and can thus produce biased predictions if censored observations are ignored (Stepanova and Thomas 2002a). We use personal alarm subscriptions as our event of interest (Hoffman et al. 2018). Our method is based on data from a large Danish municipality, where personal alarms are given to citizens who have been evaluated as being at risk of falling. The municipality participated in a signature project funded by the Danish government on fall prevention with the corresponding university from 2020 to 2022. The data consist of 2542 weekly home care observations for 1499 citizens over a period of one year, which we divide into two cohorts with a 6-month follow-up period. We train five different survival models and establish an evaluation pipeline using cross-validation to access model performance. The goal is to offer a noninvasive decision support tool that can help healthcare professionals select the right candidates for fall prevention programs. In summary, our contributions are the following:
-
We propose a novel and noninvasive predictive model to assess fall risk in home care clients using survival analysis.
-
We use personal alarm subscriptions as the event of interest to avoid the bias and noise that surround fall reports.
-
We demonstrate the effectiveness of our approach using different models and feature selection algorithms.
Related work
Work in fall-risk assessment and prevention using machine learning can generally be split into two categories: sensor data studies, where sensors or motion trackers are placed on or in the vicinity of the individual, and electronic health record (EHR) studies, where stored data about an individual’s historical traits are used. We denote the former as invasive methods, since they require active involvement of the individual to operate, whereas the latter is noninvasive, since a model trained on EHR data can be used unobtrusively and without involving the individual. In this section, we provide a brief overview of the latest research in noninvasive methods and motivate our approach.
Noninvasive methods do not require ubiquitous or pervasive monitoring to work, and rely solely on historical information about the individual. Kuspinar et al. (2019) developed a predictive algorithm to predict fall risk based on home care data from a cohort of more than 80,000 adults between 2002 and 2014; however, the authors only report odds ratios for different groups of fallers without any assessment of predictive performance. In addition, the follow-up period is only 90 days (3 months) and all observed falls are self-reported, which may lead to underreporting or recall bias. The fall assessment is based on data from a Resident Assessment Instrument-Home Care (RAI-HC) evaluation, a standardized assessment scheme, which would have to be performed in person with the patient, making their method not entirely noninvasive. Lo et al. (2019) used a random forests algorithm on home care data extracted from the Outcomes and Assessment Information Set (OASIS) database to predict fall risk, which showed initial promise (ROC scores between 0.66 and 0.68), however, their model can only classify people into two categories (faller or not a faller) and thus cannot predict neither the time to fall nor individual risk scores. Other data sources in addition to home care have also been explored for noninvasive fall assessment, such as clinical notes (Santos et al. 2020; Fu et al. 2022) and fall reports (Dos Santos et al. 2019).
Recently, Dormosh et al. (2022) developed a fall-prediction model using logistic regression based on hospital registration data. The authors found significant correlations between a range of health record features and the risk of falling, but had to rely on cumbersome manual labeling to identify fallers from clinical notes. The main limitation of their work is that older people tend not to report falls, unless medical attention is required (Stevens et al. 2012), which is consistent with the observation that many falls go unreported (Hoffman et al. 2018). Furthermore, reported falls may lack detail or may not be caused by a lack of strength or mobility, but by other factors (e.g., alcoholism). Another limitation of Dormosh et al. (2022) is the use of binary logistic regression, which does not provide information about the time to the next fall, cannot rank individuals by risk, nor exploit any temporal information in the data. Logistic regression also struggles with bad expressiveness (e.g., interactions must be added manually).
We propose a novel, noninvasive method that can predict fall risk within 6 months based solely on home care data and without involving the individual of interest. Our method has the following novelties: (a) it is based on survival analysis, which can handle the problem of incomplete observations, something not addressed in previous approaches based on machine learning (Patterson et al. 2019; Ye et al. 2020). (b) Our model captures the time-to-event information not used in previous works (Chelli and Patzold 2019; Fu et al. 2022; Dormosh et al. 2022), which rely on binary classification. (c) Instead of falls, we use personal alarm subscriptions as the event of interest, which addresses the issue of biases in fall reports (Stevens et al. 2012; Hoffman et al. 2018).
Materials and methods
Survival analysis
Survival analysis is a form of regression that models the time until some event takes place, which can be partially observed (i.e., censored). It has found important use in many domains, such as healthcare informatics (Zhu et al. 2016; Kim et al. 2019), econometrics (Stepanova and Thomas 2002b), and predictive maintenance (Lillelund et al. 2023). We define a survival problem by a sequence of observations represented as triplets, (\(\varvec{x}_{i}\), \(t_{i}\), \(\delta _{i}\)), where \(\varvec{x}_{i} \in \mathbb {R}^{d}\) is a feature/covariate vector for some observation i, \(t_{i} \in \mathbb {R}\) is the time of censoring or the time of event depending on which occurred first, and \(\delta _{i} \in \{0, 1\}\) is the binary event indicator. If \(\delta _{i} = 0\), then \(t_{i} = c_{i}\), where \(c_{i}\) is the time of censoring, otherwise, if \(\delta _{i} = 1\), then \(t_{i} = e_{i}\), where \(e_{i}\) is the time of event. A survival model can predict the probability that some event occurs at time T later than t, i.e., the survival probability, \(S({t}) = \text {Pr}({T>t}) = 1-\text {Pr}({t\le T})\). To estimate S(t), we use the so-called hazard function:
which corresponds to the event rate at a point after t, assuming the individual survived past that time (Gareth et al. 2021, Ch. 11). The hazard function is related to the survival function through \(h({t}) = f({t})/S({t})\), where f(t) is the probability density associated with T, \(f({t}) := \lim _{\Delta t \rightarrow 0} \text {Pr}({t<T\le t+\Delta t})/\Delta t \), that is, the instantaneous rate of event at time t. In this regard, h(t) is the probability density of T conditional on \(T>t\), and the functions S(t), h(t), f(t), all correspond to equivalent ways of describing the distribution of T, formalizing, e.g., the intuition that higher values for h(t) correspond to higher event probabilities.
The Cox proportional hazards (CoxPH) model is a popular regression model for survival analysis. It assumes a conditional individual hazard function of the form \(h({t\vert \varvec{x}_i}) = h_0({t}) \exp ({f({\varvec{\theta },\varvec{x}_i})})\). The risk score is denoted as \(f({\varvec{\theta },\varvec{x}_i})\). In Cox (1972), f is set to a linear function of the covariates, that is, \(f({\varvec{\theta },\varvec{x}_i}) = \varvec{x}_i\varvec{\theta }\), and the maximum likelihood estimator \(\hat{\varvec{\theta }}\) is derived by numerically maximizing the partial Cox log-likelihood.
The dataset
A large Danish municipality has provided the two datasets used in this study from their EHR system. The first dataset consists of 229,850 home care observations over 52 weeks (2021) divided into two cohorts (6 months) and covers home care for 6398 citizens in total. Each observation contains the amount of care delivered in minutes, the type of care and the number of social or health workers who provided the service. The type of care follows a standardized naming scheme across all Danish municipalities, FSIII (English: Common Language III. Danish: Faellessprog III). The second dataset contains a list of citizens who have subscribed to a personal alarm system in 2021. First, we merged the two datasets and removed individuals who had already subscribed to a personal alarm prior. Second, we created a window that spanned 26 weeks (6 months, from \(t=1\) to \(t=26\)) and fixed a starting time for citizens at \(t=1\) in that window. For each observation, we assigned the time of event or censoring given the event indicator \(\delta \in \{0,1\}\); \(\delta =0\) if the citizen had dropped out or not subscribed yet, \(\delta =1\) if the citizen had subscribed. We included only citizens who received at least 100 min of home care per week and were born between 1930 and 1970. The final dataset has 2542 observations for 1499 citizens, a censoring rate of 95% (2416/126) and 49 nonzero covariates. No outlier detection or feature scaling was done. There was no missing values. Columns with only zero values were removed (Tables 1, 2 and 3).
Results
Setup
We implement the plain vanilla Cox model (CoxPH) (Cox 1972), the Cox model with LASSO regularization (CoxPH \(\ell _{1}\)) (Simon et al. 2011), the Cox model with Ridge regularization (CoxPH \(\ell _{2}\)) (Simon et al. 2011), Random Survival Forests (RSF) (Ishwaran et al. 2008) and the Cox model using boosting (CoxBoost) (Hothorn et al. 2005). To evaluate our approach, we report Harrell’s concordance-index (CIH) (Harrell et al. 1996), Uno’s concordance-index (CIU) (Uno et al. 2011), the integrated Brier score (IBS) (Graf et al. 1999), the mean absolute error (MAE) (Qi et al. 2024) using hinge loss, and D-calibration (Haider et al. 2020). See Appendix A for more details on the performance metrics. We train the models using either all covariates or only those selected by a feature selector, e.g., low-variance thresholding (LowVar), SelectKBest (SKB) or Recursive Feature Elimination (RFE). We set \(K=10\), i.e., the desired number of covariates will be 10.
To estimate the generalization error of each model and feature selector, we run stratified nested cross-validation with five outer loops and five inner loops. Stratification ensures that the event times and censoring rates are consistent across the training and test sets. Using nested cross-validation, feature selection and hyperparameter optimization are performed together within each fold. Appendix B reports the best obtained hyperparameters by highest CIH.
Model performance
Table 4 shows the predictive and calibration performance from cross-validation, averaged over five folds. The CI (CIH and CIU) measures how well a model can predict risk scores that match the order of events, i.e., people with higher risk should experience the event before people with lower risk. The plain vanilla CoxPH model obtained a CIH of 0.53, which means that it has ranked 53 out of 100 pairs correctly. A CI of 0.5 indicates chance-level ranking. A CoxPH model with a LASSO penalty term obtained a CIH of 0.61, thus reducing the number of covariates leads to better discriminative performance in this case. CoxBoost provided the most concordant risk predictions with a mean CIH of 0.64 (95% CI 0.57–0.72) using low-variance thresholding. We note that multiple types of home care are provided only on a sporadic basis. This means that the dataset has many covariates with predominant zero values, which in turn can make it difficult for the model to identify which covariates are important and which are not. This phenomenon can lead to poor performance on new data. We see that restricting the feature space using LASSO or a feature selection algorithm gives better CI results on average.
On the surface, the results of the integrated Brier score look promising, as a lower number indicates a better estimate of the survival curve. However, the high censoring in this dataset means that for many cases, the predicted survival curve only has a slight decline over the follow-up period. This reflects the cumulative incidence function for the event, but does not offer much valuable application, since the discrepancies in the survival probabilities between the two groups (citizens that receive an alarm and citizens that do not) are few. RSF was best at predicting the survival curve with a mean integrated Brier score of 0.033 (95% CI 0.031–0.035). RSF was also best at predicting the time to event with a mean MAE of 83.5 (95% CI 79.1–87.9) using RFE to select the best covariates. The MAE is the absolute difference between the actual and predicted survival times (e.g., the median of the curve) using a Hinge loss function; if the prediction is higher than the censored time, the loss is not penalized. This means that the error comes from censored samples with an overly pessimistic prediction (less than the censoring time) and uncensored samples with an overly optimistic prediction (more than the event time). With a 95% average censoring rate, the model overshoots the true event time for the few individuals who experience the event; thus, our model is poor at predicting when the event occurs in the sample population. We used Pearson’s \(\chi ^2\) goodness-of-fit test to assess D-calibration, and find that, on average, CoxPH with LASSO, RSF and CoxBoost gave predicted survival curves that were calibrated with respect to the actual survival distribution.

Mean predicted survival functions by the CoxPH, RSF and CoxBoost models, versus the unbiased Kaplan–Meier estimator on the test set. The survival functions are predicted over the entire event horizon from \(t=1\) to \(t=26\)

SHAP summary plot. The covariates are on the y-axis and the SHAP-value is on the x-axis. Covariates are ranked based on their importance, which is given by the mean of their absolute SHAP values (higher positioning means more important). For each covariate, one point corresponds to a single citizen. Its position on the x-axis represents the impact that covariate had on the model’s output, which corresponds to the risk across citizens. The color indicates whether the citizen had a low (blue) or high (red) value of that covariate
Model explainability
After cross-validation, we adopt a 70–30% train-test split, configure the models with sensible default parameters and retrain them for plotting purposes. Figure 1 shows the mean predicted survival function for all samples in the test set by the CoxPH using LASSO, RSF and CoxBoost models. As a reference, we have included the Kaplan–Meier (KM) (Kaplan and Meier 1958) estimator with a 95% confidence interval. In the present study, we assume censoring to be noninformative: consider two citizens with the same risk factors, both yet to experience the event of interest by time t. One individual is lost to follow-up at that time, i.e., their event time at t is right-censored, and the other continues in the study. Under the assumption of noninformative censoring, we assume these two individuals have the same subsequent risk of experiencing the event, and knowing that one of them is censored does not add additional information. Under this assumption, the KM is unbiased, regardless of the proportion of censoring. Similarly, the hazard ratios of a Cox’s proportional hazards model represent a good estimate of relative risk and are unbiased regardless of the amount of censoring. The predicted survival probabilities and the KM align well in this plot. All models fall within the KM’s confidence interval after \(t=8\), however, a slight overestimation of risk is seen between \(t=0\) and \(t=7\).

Left: SHAP dependence plots of the respective covariate. The color indicates whether the covariate has a low (blue) or high (red) value. Right: Partial dependence plot of the same covariate
Figure 2 shows the most important covariates and covariate values according to SHAP (Lundberg and Lee 2017). These values were obtained from a Random Survival Forests model. The covariates are on the y-axis and the SHAP value on the x-axis. The color indicates if the covariate value is low (blue) or high (red) for a particular observation. According to the SHAP values, the most important covariates are: “Personal hygiene”, “SUL §138”, “Excretions”, “RH Nutrition” and “Medication administration”. The SHAP values exhibit a slight positive correlation between risk and the number of minutes received in the category “Personal hygiene”, but a strictly positive correlation for “Excretions” and “SUL §138”. In this context, “SUL §138” refers to a section of the Danish health legislation that requires the municipality to provide an individual with a community nurse by referral from their general practitioner. We see that some covariates have both positive and negative correlations (e.g., “Cleaning”, “Medication administration” and “RH Personal hygiene”). These may seem counterintuitive at first, as we would usually associate increased reliance on home care with an increased risk of falling, but we study purely the correlations between care and the risk of getting a personal alarm. Elderly people who depend on a lot of home care have fewer falls, as they are attended to very often and many have daily check-ins by a nurse or a care practitioner; hence, they have less need for a personal alarm.

Predicted individual survival (left) and hazard (right) functions for 20 randomly selected citizens from the test set using the RSF model. Solid lines represent citizens who do not receive an alarm within 6 months. Dotted lines represent citizens that do
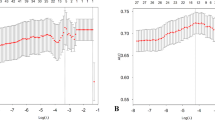
Figure 3 is a SHAP feature dependence plot and partial dependence plot for three of the most important covariates (“Personal hygiene”, “Excretions” and “Cleaning”). These provide more detail on the exact correlations between risk and received care. A partial dependence plot is created by marginalizing the model output over the distribution of the covariates in a set of irrelevant covariates, C, and returning a function that depends only on covariates in a relevant covariate set, S, interactions included. This tells us, for given values of covariates S, what the average marginal effect on the prediction is, i.e., how the outcome changes when a specific independent variable changes. In Fig. 3a on the left, we see a vague, but positive correlation between minutes and SHAP value for the “Personal hygiene” covariate, which is also explained by the partial dependence plot on the right. The vertical gray bars in the plot show the data distribution. In Fig. 3b, we plot the “Excretions” covariate and see a much steeper increase in both SHAP value and estimated risk from 0 to 200 minutes, but it increases only slightly after that. Lastly, Fig. 3c shows that “Cleaning” has a negative trend between 0 and 100 minutes, but rises suddenly from 100 and onward.
Figure 4 shows predicted individual survival and hazard functions for 20 randomly selected citizens using a random survival forests model. Solid lines represent citizens who did not subscribe to a personal alarm within 6 months. The dotted lines represent the citizens who subscribed to one. We see in the upper row that most citizens reach a survival probability (probability of no alarm) at \(t=26\) between 0.98 and 0.90 and a cumulative hazard between 0.01 and 0.10, but some citizens have a significantly lower survival probability and associated cumulative hazard. In this figure, only one citizen in this random draw subscribed to a personal alarm during the study, but the individual has similar predicted survival probabilities over the event horizon as the remaining cohort. This tells us that predicting the time to event from these curves alone is difficult.
Discussion
Applicability
The proposed method represents a change from a reactive mindset to a proactive mindset and is applicable in a municipality setting, where efficient management of resources and healthcare personnel is crucial. By accurately identifying those citizens who are at the highest risk of falling, the municipality can allocate its resources more effectively by providing personalized home care, physical therapy, and other healthcare services. This is important, as the consequences of falls can often be more severe for the elderly due to existing health problems and reduced mobility (Franse et al. 2017). Wang et al. (2023) find that exercise appears to be particularly effective for people with higher fall rates. In their study, exercise was more effective in trials with a higher prospective fall rate (32% reduction in falls and 442 prevented falls in 1000 people over one year). However, trials with a lower prospective fall rate showed a comparatively reduced effectiveness, resulting in a mere 12% reduction in the number of falls and preventing only 64 falls in 1000 people in the same period. At first glance, it appears to be a sound strategy to offer exercise and physical therapy to any older adult over 65 years of age, but a broad preventive approach is very expensive if training is to be supervised, which multiple studies advocate for (Donat and Özcan 2007; Youssef and Shanb 2016). Moreover, we expect that the number needed to treat (NNT), as a measure of the effectiveness of a health intervention, will likely be lower (better) with a more targeted and risk-based approach. When prevention and intervention are focused on the most relevant citizens, the number of people who need to be trained to prevent a single fall is reduced.
Model performance
Concerning the predictive performances, all models obtained concordance index scores between 0.51 and 0.64, indicating that the proposed method can rank individuals by risk statistically better than chance-level ranking (0.5). This was validated by Harrell’s and Uno’s concordance index using cross-validation across five folds. However, the proposed method cannot accurately predict when the next fall would occur for the few citizens who experienced the event within the 6-month cohort given the current dataset and event horizon. This was confirmed by observing a relative high mean absolute error between the actual event time and the predicted event time. We attribute this to the high censoring rate and the lack of qualitative covariates for this specific task. Regarding the calibration performance, the CoxPH model predicted D-calibrated survival curves in all five cross-validation folds when using the LASSO regularization technique, i.e., zeroing out coefficients and thus preventing overfitting. The two ensemble-based and gradient-boosting models predicted D-calibrated survival curves in all folds as well.
Limitations
Our method is trained only on EHR data from a single municipality. Although being one of the largest in Denmark, the correlations we have found between home care usage and personal alarm subscriptions may not translate to other municipalities or government institutions, let alone in Denmark. Although personal alarms are an objective arrangement to avoid future falls, not all personal alarms in Denmark are given to people at risk of falling or who have had falls. They can be subscribed to a person in need of a secure environment or individuals suffering from anxiety. When adopting a machine learning model for fall prediction, it should be trained and evaluated in the population that it is used in. Another limitation is the high censoring rate. Ninety-five percent of the people in this study did not receive a personal alarm during either cohort. We regard this kind of censoring as noninformative, i.e., the presence of censoring contains no information about the actual time to event. Under this assumption, the proposed Cox proportional hazards models are not biased (Leung et al. 1997). However, the high censoring rate means that using the median of the survival function as the predicted time to event often requires a great deal of extrapolation outside the event horizon, and these estimates hereby carry a lot of uncertainty. Without more predictive features (e.g., physical strength tests, previous falls) or a longer study period, our method is not able to predict the time to the next fall accurately.
Ethical concerns
The present study did not include human trials and all data were completely anonymized before any data processing or machine learning took place. A contract was signed between the data owner and Aarhus University to help ensure privacy and confidentiality in the handling, processing, and dissemination stages. The proposed tool is intended as a whitelisting tool that can highlight potential candidates for fall prevention programs. There are no side effects if more people are selected for fall prevention, as strength training for elderly people is always beneficial if it is done correctly and properly supervised (Donat and Özcan 2007; Youssef and Shanb 2016). Today, most of the elderly often experience multiple falls at home before being offered fall prevention, and the socioeconomically advantaged elderly have easier access to health care resources than the disadvantaged elderly (McMaughan et al. 2020). A data-driven model can ensure that risk assessment and eligibility for a fall prevention program are independent of socioeconomic status. In this way, it will contribute to reducing health inequality, as all citizens, regardless of background, will have access to relevant and timely prevention offers.
Conclusions
Based on 2542 home care observations for 1499 citizens (59% female, 41% male) with a mean age of 77 years (SD 10 years), we have trained a selection of machine learning-based survival analysis models to predict the per-individual risk of falling over 6 months. Using 5-fold cross-validation, the best model in terms of ranking performance was CoxBoost with a mean Harrell’s concordance index of 0.64 (95% CI 0.57–0.72). This concordance index indicates better ranking performance than chance-level by 14% on average. The CoxBoost model also produced survival curves that were D-calibrated across all five folds according to a Pearson’s \(\chi ^2\) test. Our method can be used as a decision support tool to choose the right candidates for a fall prevention program and can provide a cost-effective and timely way to assess fall risk among community-dwelling elderly, which can potentially improve their quality of life and reduce the burden on the healthcare system.
Data availability
The data supporting the findings of this study come from a large Danish municipality. Restrictions apply to the availability of the data, which were used under license for the current study and are therefore not publicly available.
Code availability
All data processing, machine learning, and evaluation were done in Python 3.8. The source code is available from the corresponding author upon request.
References
Breslow NE (1975) Analysis of survival data under the proportional hazards model. International Statistical Review pp 45–57
Chelli A, Patzold M (2019) A machine learning approach for fall detection and daily living activity recognition. IEEE Access 7:38670–38687. https://doi.org/10.1109/ACCESS.2019.2906693
Cox DR (1972) Regression models and life-tables. J Roy Stat Soc: Ser B (Methodol) 34(2):187–202
Klaperski-van Der Wal S, Bruton A, Felton L, Turner S (2023) A mixed-method exploration of the effects and feasibility of an intergenerational fall-prevention gardening programme in older adults at risk of falling: a clinical trial. J Public Health. https://doi.org/10.1007/s10389-023-02154-2
Donat H, Özcan A (2007) Comparison of the effectiveness of two programmes on older adults at risk of falling: unsupervised home exercise and supervised group exercise. Clin Rehabil 21(3):273–283. https://doi.org/10.1177/0269215506069486
Dormosh N, Schut MC, Heymans MW, Van Der Velde N, Abu-Hanna A (2022) Development and internal validation of a risk prediction model for falls among older people using primary care electronic health records. The Journals of Gerontology: Series A 77(7):1438–1445. https://doi.org/10.1093/gerona/glab311
Dos Santos HD, Silva AP, Maciel MCO, Burin HMV, Urbanetto JS, Vieira R (2019) Fall detection in EHR using word embeddings and deep learning. In: 2019 IEEE 19th International Conference on Bioinformatics and Bioengineering (BIBE), IEEE, pp 265–268, https://doi.org/10.1109/BIBE.2019.00054
Dubois A, Mouthon A, Sivagnanaselvam RS, Bresciani JP (2019) Fast and automatic assessment of fall risk by coupling machine learning algorithms with a depth camera to monitor simple balance tasks. J Neuroeng Rehabil 16(1):71. https://doi.org/10.1186/s12984-019-0532-x
Franse CB, Rietjens JA, Burdorf A, van Grieken A, Korfage IJ, van der Heide A, Raso FM, van Beeck E, Raat H (2017) A prospective study on the variation in falling and fall risk among community-dwelling older citizens in 12 european countries. BMJ Open 7(6), https://doi.org/10.1136/bmjopen-2017-015827
Fu S, Thorsteinsdottir B, Zhang X, Lopes GS, Pagali SR, LeBrasseur NK, Wen A, Liu H, Rocca WA, Olson JE, Sauver JS, Sohn S (2022) A hybrid model to identify fall occurrence from electronic health records. Int J Med Informatics 162:104736. https://doi.org/10.1016/j.ijmedinf.2022.104736
Gareth J, Daniela W, Trevor H, Robert T (2021) An introduction to statistical learning: with applications in R, 2nd edn. Springer
Graf E, Schmoor C, Sauerbrei W, Schumacher M (1999) Assessment and comparison of prognostic classification schemes for survival data. Stat Med 18(17–18):2529–2545. https://doi.org/10.1002/(SICI)1097-0258(19990915/30)18:17/18<2529::AID-SIM274>3.0.CO;2-5
Haider H, Hoehn B, Davis S, Greiner R (2020) Effective ways to build and evaluate individual survival distributions. J Mach Learn Res 21(1):1–63
Harrell FE, Lee KL, Mark DB (1996) Multivariable prognostic models: issues in developing models, evaluating assumptions and adequacy, and measuring and reducing errors. Stat Med 15:361–87. https://doi.org/10.1002/(SICI)1097-0258(19960229)15:4<361::AID-SIM168>3.0.CO;2-4
Hoffman GJ, Ha J, Alexander NB, Langa KM, Tinetti M, Min LC (2018) Underreporting of Fall Injuries of Older Adults: Implications for Wellness Visit Fall Risk Screening: Accuracy of Self-Reported Fall Injuries. J Am Geriatr Soc 66(6):1195–1200. https://doi.org/10.1111/jgs.15360
Hothorn T, Bühlmann P, Dudoit S, Molinaro A, Van Der Laan MJ (2005) Survival Ensembles. Biostatistics 7(3):355–373
Ishwaran H, Kogalur UB, Blackstone EH, Lauer MS (2008) Random Survival Forests. The Annals of Applied Statistics 2(3):841–860. https://doi.org/10.1214/08-AOAS169
Kaplan EL, Meier P (1958) Nonparametric Estimation from Incomplete Observations. J Am Stat Assoc 53(282):457–481. https://doi.org/10.2307/2281868
Kim DW, Lee S, Kwon S, Nam W, Cha IH, Kim HJ (2019) Deep learning-based survival prediction of oral cancer patients. Sci Rep 9(1):6994. https://doi.org/10.1038/s41598-019-43372-7
Kuspinar A, Hirdes JP, Berg K, McArthur C, Morris JN (2019) Development and validation of an algorithm to assess risk of first-time falling among home care clients. BMC Geriatr 19(1):264. https://doi.org/10.1186/s12877-019-1300-2
Leung KM, Elashoff RM, Afifi AA (1997) Censoring issues in survival analysis. Annu Rev Public Health 18(1):83–104. https://doi.org/10.1146/annurev.publhealth.18.1.83
Lillelund CM, Pannullo F, Jakobsen MO, Pedersen CF (2023) Predicting survival time of ball bearings in the presence of censoring. Accepted at AAAI Fall Symposium 2023 on Survival Prediction, 2309.07188
Lindberg DS, Prosperi M, Bjarnadottir RI, Thomas J, Crane M, Chen Z, Shear K, Solberg LM, Snigurska UA, Wu Y, Xia Y, Lucero RJ (2020) Identification of important factors in an inpatient fall risk prediction model to improve the quality of care using EHR and electronic administrative data: A machine-learning approach. Int J Med Informatics 143:104272. https://doi.org/10.1016/j.ijmedinf.2020.104272
Lo Y, Lynch SF, Urbanowicz RJ, Olson RS, Ritter AZ, O’Connor M, Keim SK, McDonald M, Moore JH, Bowles H (2019) Using machine learning on home health care assessments to predict fall risk. Studies in Health Technology and Informatics 264:684–688. https://doi.org/10.3233/SHTI190310
Lundberg SM, Lee SI (2017) A unified approach to interpreting model predictions. In: Proceedings of the 31st International Conference on Neural Information Processing Systems, p 4768–4777
McMaughan DJ, Oloruntoba O, Smith ML (2020) Socioeconomic Status and Access to Healthcare: Interrelated Drivers for Healthy Aging. Front Public Health 8:231. https://doi.org/10.3389/fpubh.2020.00231
Nakatani H, Nakao M, Uchiyama H, Toyoshiba H, Ochiai C (2020) Predicting Inpatient Falls Using Natural Language Processing of Nursing Records Obtained From Japanese Electronic Medical Records: Case-Control Study. JMIR Med Inform 8(4):e16970. https://doi.org/10.2196/16970
Patterson BW, Engstrom CJ, Sah V, Smith MA, Mendonça EA, Pulia MS, Repplinger MD, Hamedani AG, Page D, Shah MN (2019) Training and Interpreting Machine Learning Algorithms to Evaluate Fall Risk After Emergency Department Visits. Med Care 57(7):560–566. https://doi.org/10.1097/MLR.0000000000001140
Sa Qi, Sun W, Greiner R (2024) SurvivalEVAL: A comprehensive open-source python package for evaluating individual survival distributions. Proceedings of the AAAI Symposium Series 2:453–457. https://doi.org/10.1609/aaaiss.v2i1.27713
Salminen M, Vahlberg T, Kivelä SL (2009) The long-term effect of a multifactorial fall prevention programme on the incidence of falls requiring medical treatment. Public Health 123(12):809–813. https://doi.org/10.1016/j.puhe.2009.10.018
Santos J, D P Dos Santos H, Vieira R (2020) Fall detection in clinical notes using language models and token classifier. In: 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), IEEE, pp 283–288, https://doi.org/10.1109/CBMS49503.2020.00060
Simon N, Friedman J, Hastie T, Tibshirani R (2011) Regularization Paths for Cox’s Proportional Hazards Model via Coordinate Descent. Journal of Statistical Software 39(5), https://doi.org/10.18637/jss.v039.i05
Stepanova M, Thomas L (2002) Censoring issues in survival analysis. Oper Res 50(2):277–289. https://doi.org/10.1146/annurev.publhealth.18.1.83
Stepanova M, Thomas L (2002) Survival Analysis Methods for Personal Loan Data. Oper Res 50(2):277–289. https://doi.org/10.1287/opre.50.2.277.426
Stevens JA, Ballesteros MF, Mack KA, Rudd RA, DeCaro E, Adler G (2012) Gender differences in seeking care for falls in the aged medicare population. Am J Prev Med 43(1):59–62. https://doi.org/10.1016/j.amepre.2012.03.008
Uno H, Cai T, Pencina MJ, D’Agostino RB, Wei LJ (2011) On the C-statistics for evaluating overall adequacy of risk prediction procedures with censored survival data. Stat Med 30(10):1105–1117. https://doi.org/10.1002/sim.4154
Wang BY, Sherrington C, Fairhall N, Kwok WS, Michaleff ZA, Tiedemann A, Wallbank G, Pinheiro MB (2023) Exercise for fall prevention in community-dwelling people aged 60+: more effective in trials with higher fall rates in control groups. J Clin Epidemiol 159:116–127. https://doi.org/10.1016/j.jclinepi.2023.05.003
Wilmink G, Dupey K, Alkire S, Grote J, Zobel G, Fillit HM, Movva S (2020) Artificial intelligence-powered digital health platform and wearable devices improve outcomes for older adults in assisted living communities: Pilot intervention study. JMIR Aging 3(2):e19554. https://doi.org/10.2196/19554
Yang Y, Hirdes JP, Dubin JA, Lee J (2019) Fall risk classification in community-dwelling older adults using a smart wrist-worn device and the resident assessment instrument-home care: Prospective observational study. JMIR Aging 2(1):e12153. https://doi.org/10.2196/12153
Ye C, Li J, Hao S, Liu M, Jin H, Zheng L, Xia M, Jin B, Zhu C, Alfreds ST, Stearns F, Kanov L, Sylvester KG, Widen E, McElhinney D, Ling XB (2020) Identification of elders at higher risk for fall with statewide electronic health records and a machine learning algorithm. Int J Med Informatics 137:104105. https://doi.org/10.1016/j.ijmedinf.2020.104105
Youssef EF, Shanb AAE (2016) Supervised versus home exercise training programs on functional balance in older subjects. Malays J Med Sci 23(6):83–93
Zhu X, Yao J, Huang J (2016) Deep convolutional neural network for survival analysis with pathological images. In: 2016 IEEE International Conference on Bioinformatics and Biomedicine, pp 544–547, https://doi.org/10.1109/BIBM.2016.7822579
Acknowledgements
This work was done in connection with DigiRehab A/S, Denmark. DigiRehab A/S is a privately-held Danish company.
Funding
Open access funding provided by Aarhus Universitet. This research was funded by the PRECISE project (http://www.aal-europe.eu/projects/precise/) under Grant Agreement No. AAL-2021-8-90-CP by the European AAL Association.
Author information
Authors and Affiliations
Contributions
C. M. Lillelund and M. Harbo conceived the present idea. C. M. Lillelund developed the theory, gathered the data, performed the experiments, and took the lead in writing the manuscript. M. Harbo encouraged C. M. Lillelund to investigate falls and home care usage, provided valuable domain knowledge, and helped interpret the results. C. F. Pedersen provided valuable feedback on the study design and implementation, and supervised the writing process. All authors discussed the results and contributed to the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
C. M. Lillelund and C. F. Pedersen declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper. M. Harbo is the head of development at DigiRehab A/S, which have a business relationship with the Danish municipality that provided the dataset for the present study. Neither DigiRehab A/S nor the municipality in question have influenced the reported work.
Ethics approval
Ethics approval is not applicable. The study did no human trials and all data were completely anonymized.
Appendices
Appendix A: Performance metrics
CI\(_{{\textbf {H}}}:\) Harrell’s concordance index measures a model’s ability to rank individuals by risk. It is defined as the ratio of all comparable pairs in which the predictions and outcomes are concordant. A pair is considered comparable if we can determine who has the event first. It is defined as (Harrell et al. 1996):
where \(\eta _i\) represents the risk score of individual i.
CI\(_{{\textbf {U}}:}\) Uno’s concordance index measures an estimator’s ranking ability by comparing relative risk scores across all comparable pairs like Harrell’s, however, it does not depend on the distribution of censoring times in the test data. Instead, it introduces censoring weights based on the estimated censoring cumulative distribution computed from the survival times in the training data. This has been shown to be preferable to Harrell’s in presence of high censoring (Uno et al. 2011).
BS/IBS: The Brier score is the mean squared error between the actual binary outcome and the probability of the outcome at some time point t, i.e., the accuracy of the survival prediction. The metric has a probabilistic outcome between 0 and 1, and all outcomes for a single individual must sum up to one. Consider a sample of N observations, \(\varvec{y}_{i} \; (i=1, 2, ..., N)\), the predicted binary outcome is \(\hat{y_{i}}(t_{k})\), where \(t_{k}\) is some measurement time on the event horizon of K discretized times, \([t_0, t_1, t_2, \ldots , t_K]\), and the actual outcome is \(y_{i}(t_{k})\), then the Brier score is Graf et al. (1999):
where the actual outcome \(y_{i}(t_{k})\) for each observation can only be 1 or 0. The integrated Brier score is then the accuracy of the predicted survival curve at all available times \(t_{0} \le t_{k} \le t_{K}\) over the interval [\(t_{0}\);\(t_{K}\)], i.e., \(IBS = \int _{t_{0}}^{t_{K}} BS(t) \,dw(t)\), where \(w(t) = t_{k}/t_{K}\) is used as a weighting function (Graf et al. 1999).
MAE: The mean absolute error is the absolute difference between the actual and predicted survival times (e.g., median of the survival function). Given some individual survival distribution, \(S({t\;|\;\varvec{x}_{i}}) = \text {Pr}({T>t\;|\;\varvec{X} = \varvec{x}_{i}})\), we compute the predicted survival time \(\hat{t}_i\) as the median survival time as in Qi et al. (2024):
where \(\tau \in [0,1]\) denotes the quantile probability level. To calculate the MAE, we use hinge loss function that supports censored observations; if the predicted survival time is smaller than the censored time, the loss is the time of censoring minus the predicted time. If the predicted survival time is equal to or greater than the censored time, the loss is zero. Thus, the MAE and MAE-Hinge are, respectively:
D-calibration: Distribution calibration is a statistical test to evaluate the calibration performance of the survival curve S(t) (Haider et al. 2020), i.e., should we trust the probability predictions suggested by S(t)? For each uncensored citizen \(\varvec{x}_{i}\), we can observe the time of the event \(t_{i}\), and also determine the probability \(P(S(t\text {|}\varvec{x}_{i}(t)))\) for that time based on S(t). By example of Haider et al. (2020), if S(t) is D-calibrated, we expect 10% of the citizens to fall in the [100%, 90%] interval and subsequently another 10% to fall in the [90%, 80%] interval. For all individual distributions \(d_{i}\), the set \(\{S_{i}(d_{i})\}\) should therefore be uniformly distributed between 0 and 1, so that each 10% interval covers 10% of D. We adopt Pearson’s \(\chi ^2\) goodness-of-fit test to examine if the proportion of citizens in each interval is uniformly distributed given mutually exclusive and equal-sized intervals, as in Haider et al. (2020).
Appendix B: Hyperparameter optimization
Table 5 shows the best obtained hyperparameters from cross-validation on average. The following hyperparameters were evaluated:
-
CoxPH: The maximum number of iterations and the tolerance for the optimizer.
-
CoxPH (\(\ell _{1}\)): The maximum number of iterations, the tolerance for the optimizer and the number of alphas.
-
CoxPH (\(\ell _{2}\)): The maximum number of iterations and the tolerance for the optimizer.
-
RSF: The maximum depth, the number of estimators, and the minimum number of samples required for splitting internally and at a leaf node.
-
CoxBoost: The maximum depth, the number of estimators, the learning rate, the dropout rate, the subsampling ratio, the feature selection strategy and the minimum number of samples required for splitting internally and at a leaf node.
Appendix C: Baseline survival function
We used the Breslow estimator to estimate the baseline survival function \(\hat{S_0}({t})\) on the 70% training dataset (1779 observations, 95% censoring) over the entire event horizon (see Fig. 5) (Breslow 1975). Setting the coefficients \(\beta _{i}=0\), the baseline can be estimated without estimating the parameters of the model, and vice versa in a proportional hazards model.

Baseline survival function \(\hat{S_0}({t})\) (Breslow 1975)
Appendix D: Cox regression coefficients
We train a plain vanilla Cox proportional hazards model on the 70% training dataset (1779 observations, 95% censoring) to estimate hazard ratios, \(\exp (\beta _{i})\), with a small ridge penalty applied to ensure convergence (see Table 6). All covariates are included in the model. A \(\beta _{i}\)-value exceeding zero, or alternatively, a hazard ratio surpassing one, suggests that with an increase in the ith covariate’s value, there is an associated rise in the event hazard, leading to a decrease in survival time.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lillelund, C.M., Harbo, M. & Pedersen, C.F. Prognosis of fall risk in home care clients: A noninvasive approach using survival analysis. J Public Health (Berl.) (2024). https://doi.org/10.1007/s10389-024-02317-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10389-024-02317-9