
Abstract
Aim
The health of the Hungarian population is not as good as it could be according to the socioeconomic development of the country. Since unhealthy behavior is widespread in the population, behavior change seems to be an appropriate tool to improve health in Hungary. To develop effective interventions, it is first necessary to identify homogeneous groups of people from the point of view of behavior change, i.e., healthstyles. Our aim was to develop a suitable survey methodology and segmentation procedure for identifying healthstyles in Hungary. In this article we present the results of our methodological developments.
Subjects and methods
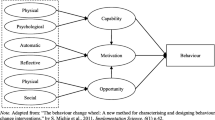
Several blocks of questions were developed based on the COM-B model, which synthesizes the most recognized behavior change models. The questions cover knowledge about and attitude to health, somatic and mental health status, subjective well-being, psychological characteristics, health behaviors, social support, media consumption, health-related information seeking and socio-demographic characteristics. Nationally representative two-stage samples of schoolchildren and adults were drawn. Iterative weighting was applied, which was supplemented with a design weight correcting the design effects. For segmentation, latent cluster analysis was used.
Results
Questionnaires based on the COM-B model were developed and administered to schoolchildren and adults. Several numerical and graphical methods were developed to explore the statistical characteristics of the segmentation models obtained by latent cluster analysis.
Conclusions
The developed survey methodology and segmentation methods were successfully applied to produce statistically stable clusters in both schoolchildren and adults. The statistical methods chosen for segmentation and validation of clusters seem suitable to identify healthstyles.






Similar content being viewed by others

Notes
The database contains data about 4438 schools in the 2014–2015 school year. Based on the database the number of fifth classes was 4556, the number of seventh classes was 4680, and the number of ninth classes was 4755.
Social Renewal Operational Program 6.1.3./B/12/1 “Developing public health communication”
For a more comprehensive description of the statistical viewpoint of the model-based framework, see Sterba (2009).
Due to the high number of variables involved (more than 100), application of imputation methods was excluded for theoretical reasons.
The software version is R 3.2.1., and the computations were performed on a 64-bit Windows 2012 R2 server.
The ‘poLCA’ package (version 1.4.1) was built under R version 3.2.2.
In the sense of interpretation, this nature of the LCA method makes the results similar to those that come from a factor model.
Technically, the model selection in LCA aims to specify the number of clusters.
Identification of many separate clusters would be counterproductive, and technically it would be too difficult to overview and interpret all of them.
To describe the axes, a table containing the most important variables defining the axes belongs to each plot, which is not described in this article.
The adjusted standardized residual is the Pearson residual divided by the standard deviation of all residuals.
The positive values indicate that the given attribute is typical of a cluster, and in contrast the negative values characterize the cluster by the lack of a given attribute. If the absolute value exceeds two, then we can reasonably say that the given attributes are statistically significant. The higher the absolute value is, the more significant the attributes are. It is important to note that significant values do not mean exclusivity; they denote just the relative differences from the expected values.
As it can validate the model externally.
Of course, the identification of the different health-style clusters is not always so obvious as in the example above. (A detailed discussion of these models is not part of this article. We would like to present them in a different publication in the future.)
Symmetric and asymmetric Goodman-Kruskall λ, Theil’s uncertainty coefficient and Cramer’s V (Liebetrau 1983).
We have also displayed some of these values on the plots above.
The disadvantage of the applied simulation method is its time consumption as it was a function of the amount of the input elements. In general, the requested amount of time was more than 1 h per iteration, and 25 iterations were made for each parameter set.
For the purpose of comparability of the different models, the deviation was normalized to the expected value of the deviation given by the complete random reclassification. For example, the fifth-grade children’s model consists of three clusters with approximately the same size; therefore, the rate of misclassification in a completely random reclassification is approximately 66%—but depends on the sizes of each cluster. (Generally speaking, the expected value of the deviation is a function of the number of clusters and the distribution of the cluster sizes. Without the normalization, the comparison of the different stability models may lead to an erroneous conclusion.)
As the two examined attributes (rate of omitted variables or observations) interact with each other, the dots are partial values, as is the displayed non-linear model fitted on these partial values.
For the purpose of evaluating the results, investigating the transition function of the deviations is necessary as it can be interpreted as an indicator of the sensibility.
Approximately 0.75 is the expected value of the relative deviation from the simple random model omitting 75% of the cases in contrast to omitting 75% of variables—the corresponding values do not exceed 0.4 in either case.
The final model for the seventh-grade children is incomparably less stable than the others. One possible assumption is that the confusion of responses was related to the stage of personality development (Candida 2013), but to declare it with certainty we need more investigations.
References
Abbott RA, Macdonald D, Stubbs CO, Lee AJ, Harper C, Davies PS (2008) Healthy kids Queensland survey 2006- Full report. https://www.health.qld.gov.au/ph/documents/hpu/healthykidsqld2006.pdf. Accessed 08 Dec 2016
Ahlquist JS, Breunig C (2012) Model-based clustering and typologies in the social sciences. Polit Anal 20:92–112. doi:10.1093/pan/mpr039
Balku E, Berki J, Csizmadia P, Varsányi P, Vitrai J, Csohán Á, Horváth G, Kurucz A, Melles M, Bakacs M, Boros J, Györke J, Pásztorné ES, Szabó Zs K (2015) Health report. National Institute for Health Development. http://www.egeszseg.hu/szakmai_oldalak/assets/files/news/egeszsegjelentes-2015.pdf. Accessed 08 Dec 2016
Bandura A (1999) Social cognitive theory of personality. Handb Personal:154–196. doi: 10.1016/0749-5978(91)90022-L
Bock HH (1987) On the interface between cluster analysis, principal component analysis, and multidimensional scaling. In: Bozdogan and Gupta (eds) Multivariate statistical modeling and data analysis. Springer Netherlands, p 17–34. doi:10.1007/978-94-009-3977-6_2
Buhi ER, Daley EM, Fuhrmann HJ, Smith S (2009) An observational study of how young people search for online sexual health information. J Am Coll Heal 58:101–111. doi:10.1080/07448480903221236
Bush K, Kivlahan DR, McDonell MB, Fihn SD, Bradley KA (1998) The AUDIT alcohol consumption questions (AUDIT-C): an effective brief screening test for problem drinking. Arch Intern Med 158:1789–1795. doi:10.1001/archinte.158.16.1789
Candida CP (2013) Looking forward through the lifespan: developmental psychology. Pearson Higher Education, Melbourne
Cantril H (1965) The pattern of human concerns. Rutgers Un, New Brunswick
Centers for Disease Control and Prevention-Healthstyles Survey (1999) https://www.cdc.gov/healthcommunication/toolstemplates/entertainmented/healthstylessurvey.html Accessed 08 Dec 2016
Community and Environment Committee; East Cambridgeshire (2013) Littleport health action plan. http://www.eastcambs.gov.uk/sites/default/files/Littleport%20Action%20Plan.pdf. Accessed 08 Dec 2016
Costa FM, Jessor R, Turbin MS, Dong Q, Zhang H, Whang C (2005) The role of social contexts in adolescence: context protection and context risk in the United States and China. Appl Dev Sci 9:67–85. doi:10.1207/s1532480xads0902_3
Craig R, Shelton N (2008) Health survey for England 2007, healthy lifestyles: knowledge, attitudes and behaviour. London. http://content.digital.nhs.uk/catalogue/PUB00415/heal-surv-life-know-atti-beha-eng-2007-rep-v2.pdf. Accessed 08 Dec 2016
Dziak JJ, Coffman DL, Lanza ST, Li R (2012) Sensitivity and specificity of information criteria. PeerJ Inc., Pennsylvania
ESPAD (2011) European school survey project on alcohol and other drugs. http://www.can.se/contentassets/8d8cb78bbd28493b9030c65c598e3301/the_2011_espad_report_full.pdf. Accessed 08 Dec 2016
EU (2014) Sport and physical activity-Special Eurobarometer. http://ec.europa.eu/health//sites/health/files/nutrition_physical_activity/docs/ebs_412_en.pdf. Accessed 08 Dec 2016
European Commission (1999) A pan-EU survey on consumer attitudes to physical activity. Body-weight and Health, Luxembourg
Eurostat (2013) European health interview survey (EHIS wave 2). http://ec.europa.eu/eurostat/documents/3859598/5926729/KS-RA-13-018-EN.PDF/26c7ea80-01d8-420e-bdc6-e9d5f6578e7c. Accessed 08 Dec 2016
Eurostat (2015) SILC. http://ec.europa.eu/eurostat/web/microdata/european-union-statistics-on-income-and-living-conditions. Accessed 08 Dec 2016
Gebauer F (2008) Applicability of the Mérei’s “multidimensional sociometry” today. Budapesti Nevelő 2:67–72 [in Hungarian]
Genge E (2013) A latent class analysis of the public attitude towards the euro adoption in Poland. Adv Data Anal Classif 8:427–442. doi:10.1007/s11634-013-0156-0
Glanz K, Rimer BK (2005) Theory at a glance: a guide for health promotion practice. Heal San Fr 83:52. doi:10.1128/MCB.25.21.9532
Goldberg DP, Hillier VF (1979) A scaled version of the general health questionnaire. Psychol Med 9:139–145. doi:10.1017/S0033291700021644
Gordon W, Langmaid R (1988) Qualitative market research: a practitioner’ and buyer’s guide. Gower, London
Gosling SD, Rentfrow PJ, Swann WB (2003) A very brief measure of the big-five personality domains. J Res Pers 37:504–528. doi:10.1016/S0092-6566(03)00046-1
Haughton D, Legrand P, Woolford S (2009) Review of three latent class cluster analysis packages: latent gold, poLCA, and MCLUST. Am Stat 63:81–91. doi:10.1198/tast.2009.0016
HBSC (2014) Health behaviour in school-aged children. http://www.hbsc.org/about/HBSC%20ToR.pdf. Accessed 08 Dec 2016
Hibell B, Guttormsson U, Ahlström S, Balakireva O, Bjarnason T, Kokkevi A, Kraus L (2012) The 2011 ESPAD report: substance use among students in 36 European countries. http://www.echosurvey.hu/_user/browser/File/espad/The_2011_ESPAD_Report.pdf. Accessed 08 Dec 2016
Hoyle RH, Stephenson MT, Palmgreen P, Lorch PE, Donohew L (2002) Reliability and validity of a brief measure of sensation seeking. Pers Individ Dif 32:401–414. doi:10.1016/S0191-8869(01)00032-0
Huebner E, Laughlin JE, Ash C, Gilman R (1998) Further validation of the multidimensional students’ life satisfaction scale. J Psychoeduc Assess 16:118–134. doi:10.1177/073428299801600202
Hungarian Central Statistical Office (2014) European health interview survey http://www.ksh.hu/docs/hun/xftp/stattukor/elef14.pdf Accessed 08 Dec 2016
Institute for Health Metrics and Evaluation (IHME) (2015) GBD compare. http://www.healthdata.org/data-visualization/gbd-compare. Accessed 08 Dec 2016
Ipsos M (2012) Alcohol: public knowledge, attitudes and behaviours. http://www.drugs.ie/resourcesfiles/reports/Alcohol_Public_Knowledge_Attitudes_and_Behaviours_Report.pdf. Accessed 08 Dec 2016
Israel AC, Roderick HA, Ivanova MY (2002) A measure of the stability of activities in a family environment. J Psychopathol Behav Assess 24:85–95. doi:10.1023/A:1015336707701
Jessor R, In Bonino S, Cattelino E, Ciairano S (2005) Adolescents and risk: behaviors, functions, and protective factors. New York
Kasser T, Ryan RM (1996) Further examining the American dream: differential correlates of intrinsic and extrinsic goals. Personal Soc Psychol Bull 22:280–287. doi:10.1177/0146167296223006
Lazarsfeld P (1950a) The logical and mathematical foundations of latent structure analysis. In: Stouffer SA (ed) Measurement and prediction, the American soldier: studies in social psychology in World war II. Princton University Press, Princeton, pp 362–412
Lazarsfeld P (1950b) The interpretation and computation of some latent structures. In: Stouffer SA (ed) Measurement and prediction, the American soldier: studies in social psychology in world war II. Princton University Press, Princeton, pp 413–472
Liebetrau AM (1983) Measures of association. Quantitative applications in the social sciences series no. 32. Sage Publications, Newbury Park
Linzer DA, Lewis JB (2011) poLCA: an R package for polytomous variable latent class analysis. J Stat Softw 42:1–29. doi:10.18637/jss.v042.i10
Macías YF, Glasauer P (2014) Guidelines for assessing nutrition-related Knowladge, attitudes and practices. Food and Agriculture Organization of the United Nations, Rome
Maibach EW, Maxfield A, Ladin K, Slater MD (1996) Translating health psychology into effective health communication: the American healthstyles audience segmentation project. J Health Psychol 1:261–277. doi:10.1177/135910539600100302
Majerszki N (2014) The Z generation of the twenty first century. Verpelét
Michie S, Abraham C (2004) Interventions to change health behaviours: evidence-based or evidence-inspired? Psychol Health 19:29–49. doi:10.1080/0887044031000141199
Michie S, Johnston M, Abraham C, Lawton R, Parker D, Walker A (2005) Making psychological theory useful for implementing evidence based practice: a consensus approach. Qual Saf Health Care 14:26–33. doi:10.1136/qshc.2004.011155
Morris J, Marzano M, Dandy N, O’Brien L (2012) Theories and models of behaviour and behaviour change. For Sustain Behav Behav Chang Theor :1–27
Nárai E (2009) Healthstyle segmentation, attitudes to health. Eötvös Loránd University
Networks C (2013) E-communications household survey. http://ec.europa.eu/public_opinion/archives/ebs/ebs_381_en.pdf Accessed 08 Dec 2016
Ngai EWT, Xiu L, Chau DCK (2009) Application of data mining techniques in customer relationship management: a literature review and classification. Expert Syst Appl 36:2592–2602
OECD (2009) PISA 2006 technical report. https://www.oecd.org/pisa/pisaproducts/42025182.pdf. Accessed 08 Dec 2016
Olson DH, Sprenkle DH, Russell CS (1979) Circumplex model of marital and family system: I. Cohesion and adaptability dimensions, family types, and clinical applications. Fam Process 18:3–28. doi:10.1111/j.1545-5300.1979.00003.x
Oreg S (2003) Resistance to change: developing an individual differences measure. J Appl Psychol 88:680–693. doi:10.1037/0021-9010.88.4.680
Pikó B (2008) Value orientation and health behavior in adolescents. Iskolakultúra :62–86
Politis D, Romano J, Wolf M (1999) Subsampling. Springer, New York
Rokeach M (1973) The nature of human values. Free Press, Michingan
Schwarzer R, Jerusalem M (1995) General self-efficacy scale. Meas Heal Psychol A user’s portfolio Causal Control beliefs. :35–37. doi: 10.1037/t00393-000
Semmelweis University Budapest (2013) Hungarostudy. http://www.hungarostudy.hu/index.php/2014-04-07-17-21-12/hungarostudy-2013. Acesses 08 Dec 2016
Sillars A, Koerner A, Fitzpatrick MA (2005) Communication and understanding in parent-adolescent relationships. Hum Commun Res 31:102–128. doi:10.1093/hcr/31.1.102
Smolak L, Levine MP (1994) Toward an empirical basis for primary Prevention of eating problems with elementary school children. Eat Disord J Treat Prev 2:293–307. doi:10.1080/10640269408249128
Sterba SK (2009) Alternative model-based and design-based frameworks for inference from samples to populations: from polarization to integration. Multivar Behav Res 44:711–740. doi:10.1080/00273170903333574
The Behaviour Change Wheel. http://www.behaviourchangewheel.com/. Accessed 08 Dec 2016
UK Department of Health (2010) Healthy Foundations Life-stage Segmentation Model Toolkit. http://www.cancerresearchuk.org/prod_consump/groups/cr_common/@nre/@hea/documents/generalcontent/cr_045215.pdf. Accessed 08 Dec 2016
Utility C, Properties P (2003) AUDIT-C questionnaire. Intern Med 163:2–3
Vermunt JK (2003) Applications of latent class analysis in social science research. In: Nielsen TD, Nevin Lianwen Z (eds) Symbolic and quantitative approaches to reasoning with uncertainty. Springer, Berlin Heidelberg, pp 22–36
Vermunt J, Magidson J (2002) Latent class cluster analysis. In: Hagenaars J, McCutcheon A (eds) Applied latent class analysis. Cambridge University Press, Cambridge, pp 89–106
Wardle AJ, Steptoe A, Wardle J (2003) Socioeconomic differences in attitudes and beliefs about healthy lifestyles. Epidemiol Commun Health 57:440–443
Weber EU, Blais A-R, Betz NE (2002) A domain-specific risk-attitude scale: measuring risk perceptions and risk behaviors. J Behav Decis Mak 15:263–290. doi:10.1002/bdm.414
World Health Organization (2007) Global adult tobacco survey (GATS). http://www.who.int/tobacco/surveillance/survey/gats/en/. Accessed 08 Dec 2016
World Health Organization (2013) Global physical activity questionnaire ( GPAQ ). 1–3. http://www.who.int/chp/steps/resources/GPAQ_Analysis_Guide.pdf. Accessed 08 Dec 2016
World Health Organization, Centers for Disease Control and Prevention (2013) Global youth tobacco survey. http://www.who.int/tobacco/surveillance/gyts/en/. Accessed 08 Dec 2016
World Health Organization Regional Office for Europe (2014) European “Health for All” Database (HFA-DB). World Heal Organ Reg Off Eur. http://www.euro.who.int/en/data-and-evidence/databases/european-health-for-all-database-hfa-db. Accessed 08 Dec 2016
Zabriskie RB, McCormick BP (2001) The influences of family leisure patterns on perceptions of family functioning. Fam Relat 50:281–289. doi:10.1111/j.1741-3729.2001.00281.x
Zanotti CCC, Currie AMD, Roberts MDLC, Barnekow OSRFSV (2010) Social determinants of health and well-being among young people. Health Policy Child Adolesc 272
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Funding
The Healthstyle Survey was implemented within the Social Renewal Operational Program “Development of public health communication” project (grant no. 6.1.3.B-12/1-2013-0001) funded by the European Social Fund.
Ethical approval
All procedures performed in studies involving human participants were conducted in accordance with the ethical standards of the institutional research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards.
Informed consent
Informed consent was obtained from all individual participants included in the study.
Rights and permissions
About this article

Cite this article
Balku, E., Tóth, G., Nárai, E. et al. Methodology for identification of healthstyles for developing effective behavior change interventions. J Public Health 25, 387–400 (2017). https://doi.org/10.1007/s10389-017-0799-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10389-017-0799-y