
Abstract
Domain-specific languages allow engineers and domain experts to express problems and design solutions using domain-focused vocabularies and abstractions, by means of graphical or textual syntaxes. In the case of textual syntaxes, language engineers can opt for creating a language-specific syntax by defining and maintaining a BNF-style grammar, or use an existing general-purpose reflective syntax such as the XML Metadata Interchange (XMI) or the Human Usable Textual Notation (HUTN), which do not require any development and maintenance effort, but which are more verbose and cannot be customised. We present Flexmi: a new general-purpose textual syntax for defining models that conform to Eclipse Modelling Framework’s Ecore-based metamodels. Flexmi offers XML and YAML/JSON syntax flavours, it can be fuzzily parsed to reduce verbosity, and it includes a templating system to facilitate encapsulation of reusable composite model element structures, thus enabling more concise model specifications. We have evaluated Flexmi for verbosity and model loading performance against XMI, HUTN, and a bespoke (i.e. custom) textual syntax for Ecore (Emfatic). Our results indicate that the use of fuzzy parsing and templates allow Flexmi to achieve a significant reduction in the verbosity of models compared to XMI/HUTN and can become almost as concise as a bespoke textual syntax, with a moderate performance penalty.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Model-based software development processes commonly involve the development of domain-specific languages (DSLs) that provide domain-focused vocabularies and abstractions. A DSL consists of an abstract syntax describing the language’s concepts, features and permitted relationships; one or more concrete (e.g. graphical, textual) syntaxes that allow modellers to construct models conforming to the language; and artefacts specifying the language’s semantics (e.g. denotational/operational semantics specifications, translators, interpreters). A DSL is classified as internal, when it extends the syntax and semantics of an existing language, or external, when its abstract and concrete syntaxes are defined from scratch.
This paper is concerned with text-based editing of models conforming to external DSLs, defined using the metamodelling facilities of the widely used and open-source Eclipse Modelling Framework (EMF) [1]. In this technological space, developers of DSLs have two main options for textual model editing: they can either define a dedicated grammar for their textual syntax using tools such as Xtext [2], EMFText [3], or Monticore [4], from which language-specific parsers and editors can be generated; or they can use generic syntaxes such as HUTN [5], EMFJSON [6] or XMI [7].
The main benefits of language-specific textual syntaxes are customisability and conciseness. On the flip side, developing a bespoke textual syntax requires substantial expertise and upfront development effort, and incurs a maintenance cost over time as the abstract syntax of the language and the underlying framework/IDE evolve. General-purpose reflective syntaxes on the other hand are more verbose and lack in customisability, but they eliminate the cost and effort of developing, distributing and maintaining language-specific tooling. Intuitively, reflective syntaxes can be more desirable at the early stages of development of a DSL where the abstract syntax is fluid or for smaller-scale applications that do not justify the effort of implementing and maintaining custom tooling, while bespoke syntaxes can be more appropriate at more mature stages of development and in larger endeavours where the return of investment is clearer.
To address some of the weaknesses of existing reflective textual syntaxes, we present Flexmi: a new XML/YAML-based, general-purpose textual syntax for EMF-based DSLs, which (1) can be fuzzily parsed to reduce verbosity, and (2) includes a templating mechanism for encapsulating reusable composite model element structures to reduce repetition.
To assess Flexmi’s verbosity and repetition reduction capabilities, we replicated 503 Ecore models from a publicly available dataset [8] and we compared the resulting Flexmi files against equivalent models in XMI, HUTN and in a bespoke textual syntax for Ecore (Emfatic [9]). Our results indicate that Flexmi is able to reduce model size roughly by half with respect to XMI, with close results to those of Emfatic. These improvements in conciseness come at the cost of lower parsing speed, which depends on the Flexmi features that are used to specify a model (e.g. reusable templates and the YAML flavour take longer to parse).
Early versions of Flexmi’s fuzzy parsing algorithm and its mechanism for defining reusable templates were introduced in two (workshop) papers, [10, 11] respectively. This paper consolidates and updates those works, including the following novel contributions:
-
A more detailed commentary on the advantages and disadvantages of bespoke and generic modelling syntaxes in Sect. 2
-
A description-by-example of Flexmi’s syntax and features in Sect. 3 that complements the explanation of the parsing algorithm from [10] (adapted in Sect. 3.1)
-
A new YAML syntax flavour for Flexmi models with full feature parity with respect to the original XML flavour (Sect. 3.2)
-
Support for dynamic values via executable attributes, and for importing external EOL [12] operations (Sects. 3.5 and 3.8)
-
The ability to set attribute values with the contents of external files (Sect. 3.6)
-
An improved templating mechanism over the previous work [11] that allows filling elements generated from templates through internal slots (Sect. 3.7)
-
A systematic experimental evaluation of the impact of Flexmi’s fuzzy parsing and templating mechanism on verbosity and repetition (Sect. 4)
-
A systematic performance evaluation of Flexmi’s XML and YAML-based parsers
The rest of the paper is organised as follows: Section 2 introduces to domain-specific modelling and to bespoke and generic textual syntaxes. Section 3 presents the main features of Flexmi, and Sect. 4 describes the evaluation we carried out. Lastly, Sect. 5 concludes the article and outlines future work.
2 Background and motivation
2.1 Domain-specific modelling
This paper focuses on external domain-specific languages defined using object-oriented metamodelling techniques [13]. When defining a new modelling language using these techniques, there is a separation between the specification of the intrinsic concepts and relationships that define the language, denoted as the abstract syntax; and the graphical or textual constructs that can be used to create models in the language, known as the concrete syntax. The abstract syntax is specified with a metamodel, which is generally depicted in the form of a UML-like class diagram containing the main classes of the language, their attributes, and their references. Models that adhere to the structural rules defined in the abstract syntax of a language are said to conform to such abstract syntax.
The Eclipse Modelling Framework (EMF) [1] is the de-facto metamodelling standard in the Java ecosystem. EMF’s Ecore is an object-oriented meta-metamodelling language that allows defining the abstract syntax of domain-specific languages. As an example of an abstract syntax of a DSL, which is also used to demonstrate Flexmi throughout the paper, we present a contrived EMF-based project scheduling language (PSL), whose Ecore metamodel is depicted in Fig. 1. In PSL, projects contain tasks, which are allocated to one or more people in a team. Tasks have a start month and a duration (also in months), and people can specify a list of skills and allocate part of their time to a task (percentage in class Effort).

PSL metamodel in Ecore
Creating PSL models would require one or more concrete syntaxes, which allow users to specify models in some sort or graphical or textual manner that is later parsed into an in-memory model conforming to the abstract syntax of Fig. 1. We focus on textual concrete syntaxes in this work, which are introduced next.
2.2 Textual concrete syntaxes
An important component of an external domain-specific language is its concrete syntax, through which users of the language can create models that conform to it. The concrete syntax of a DSL can be graphical, textual, form-based, table-based or hybrid, integrating multiple styles for different parts of the language (e.g. a graphical syntax for the structural parts of the language and an embedded textual micro-syntax for capturing behaviour).
The concrete syntax of a DSL is driven by a range of factors, such as the nature and purpose of the DSL and the skills and preferences of its target audience. In this work, we are concerned with textual syntaxes for external DSLs, with a particular focus on the widely adopted open-source Eclipse modelling ecosystem [1]. Therefore, a discussion on other forms of concrete syntaxes and a comparison of their relative strengths and weaknesses is beyond the scope of this paper.
In the Eclipse modelling ecosystem, there are two main options for textual editing of models that conform to Ecore-based DSLs: defining a bespoke (i.e. custom, specific) textual syntax, or using a generic syntax. These options are discussed in detail as follows:

2.2.1 Bespoke textual syntaxes
Xtext [2, 14] is currently the most widely used and actively maintained framework for defining bespoke textual syntaxes for DSLs in the Eclipse modelling ecosystem. From an EBNF-like grammar, the Xtext tooling can produce an ANTLR-based parser for the syntax as well as Eclipse-based and web-based editors that support syntax highlighting, and advanced features such as context-aware code completion, reference navigation and refactoring. Xtext also provides a reusable expression language (Xbase [15]), support for defining custom scoping and name resolution rules, and a workspace indexer. The XSemantics [16] framework extends Xtext with support for defining complex type systems. Frameworks with similar aims and capabilities include EMFText [3], Spoofax [17] and Monticore [4].
The main benefits of developing a bespoke textual syntax using one of the available frameworks discussed above include the ability to fully customise the syntax of the language to meet the needs and accommodate the preferences of its target audience, and the ability to offer high-quality supporting tooling to users with features such as code writing assistance and reference navigation with minimal effort.
On the other hand, a bespoke textual syntax needs to be accompanied by supporting documentation and examples, it needs to co-evolve with the abstract syntax of the language, and mechanisms need to be provided to allow installing and updating its supporting parser and development tools as the abstract syntax, underlying framework (e.g. Xtext) and host IDE (e.g. Eclipse) evolve over time.
2.2.2 Generic textual syntaxes
If developing a bespoke textual syntax is not desirable or is deemed unlikely to provide an acceptable return of investment, another option is to use a generic textual syntax such as the Object Management Group’s Human Usable Textual Notation (HUTN) [5], EMFJSON [6] or XMI [7].
An excerpt of a HUTN model that conforms to the PSL metamodel is shown in Listing 1. When the HUTN parser processes this model, it interprets the Project token of line 1 as an instance of the Project type from the PSL metamodel, it populates the title and description attributes of the project from the string literals in lines 2 and 3; and it processes the rest of the document in a similar fashion to create, populate and link a task (line 4), an effort (line 8) and a person (line 12) instance.
The XMI and EMFJSON syntaxes are very similar to HUTN, with the main difference being that XMI is XML-based while EMFJSON is JSON-based. All three formats require exact matching between tokens in the textual model and names of classes and features in the metamodel; for example if “description” was changed to “desc” in line 3 of Listing 1, the HUTN parser would fail, as it would not be able to find a feature with that name in the Project class. This can make models rather verbose when longer class/feature names are used in the metamodel. Also, none of these syntaxes provides support for encapsulating and reusing (instead of repeating) recurring model element patterns, which are discussed later in Sect. 3.7 of the paper.
Based on the above, bespoke and existing generic syntaxes present some advantages and disadvantages, which we have summarised in Table 1. The following section introduces our flexible and generic syntax that aims to improve the current state of the art.
3 Flexmi

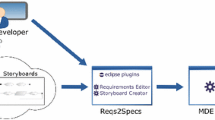
Overview of the main Flexmi components and parsing process
Flexmi is a generic textual syntax for EMF-based DSLs which attempts to address the weaknesses listed in Sect. 2.2.2 by providing the following novel features:
-
Intelligent and forgiving parsing that does not require exact lexical correspondence with type or feature names present in the metamodel (useful for conciseness)
-
A language-agnostic mechanism for defining and instantiating reusable model element templates (useful for conciseness and reuse)
Figure 2 shows an overview of the main components involved in writing and parsing a Flexmi model. As the following sections explain, Flexmi offers two syntax flavours: one is XML-based, while the other is based in YAML. Both flavours can be used from the same Flexmi editor. XML Flexmi models are translated with a standard parser into an XML DOM, while for YAML a custom parser is used to achieve the same task. Lastly, the Flexmi parser is able to convert the XML DOM into an in-memory EMF model by applying fuzzy parsing, among other features. Next section describes the Flexmi parsing process in detail.
3.1 Fuzzy parsing of elements
Listing 2 presents an XML document that Flexmi can parse into a valid instance of the PSL metamodel in Fig. 1. To start using Flexmi, the only requirement is the existence of an Ecore metamodel. On every Flexmi model, we must indicate the namespace URI of the metamodel being instantiated: this is achieved by means of a special nsuri XML processing instruction. In line 1 of Listing 2, a nsuri is used to specify that the model instantiates types from the PSL metamodel. Other XML processing instructions allow importing external Flexmi models, as well as operations defined in the Epsilon Object Language (EOL) [12] that can be invoked inside the expressions of executable model element attributes (described in Sect. 3.5).
The parsing of a Flexmi model takes place by transforming XML elements into elements of an in-memory EMF model in a depth-first fashion. An overview of how the XML syntax is used to represent EMF models in Flexmi is given in Fig. 3. In the following, we discuss how the Flexmi parser interprets the document of Listing 2. The parsing process is depicted in Fig. 4, and the complete algorithm that is applied over each XML element can be found in Listing 3.



XML syntax to EMF model in Flexmi

Parsing process over a simplified Listing 2
The parsing of XML elements takes place with the help of a stack. When Flexmi encounters the proj element in line 2 of the model, the parser stack is empty, which means that the name of this element is matched against the names of all classes in the PSL metamodel. This case is covered by lines 2–6 of the algorithm in Listing 3. By contrast to parsers of existing reflective textual formats, Flexmi’s fuzzy parser does not require exact lexical matching between the names of types/features in the metamodel and the XML tags it encounters in a model—the closest match by name similarity is selected instead. For the proj element, this match is the Project class, and therefore, Flexmi creates an instance of Project in the in-memory representation of the model. In addition, the project instance is pushed into the stack, to keep track of the context of the children of the proj element (Fig. 4a). A model element is maintained in the stack until all descendants of its associated XML element have been processed. For instance, element desc in line 3 is only matched against the possible features (i.e. attributes and references) of the Project class, and in this case, it is paired with the description attribute (Fig. 4b). The structure of this element is treated in a special way by the Flexmi algorithm (covered in lines 9–12 of Listing 3), because it has no XML attributes, and it only contains text (i.e. no extra children). When that is the case, the (trimmed) text of the XML element is set as the value of the selected feature, which in this example is the project’s description. This use of the text of an XML element is useful for multi-line string attribute values.
Line 4 presents the general case of finding an XML element that will eventually be parsed as a model element, while there are model elements in the stack (corresponds with lines 16–30 in Listing 3 and Fig. 4c). Again in the context of a project, the parser has two options for interpreting the person element: it can be either a Task belonging to the tasks containment (analogous to UML’s composition) reference of the project, or a Person belonging to its people reference. Based on string similarity, it opts for the latter. Things change in line 6, where the task element is a better match for a Task under the tasks reference. The rest of the XML elements are processed into model elements in the same fashion.
Fuzzy matching is also used to map XML attribute names to attributes and non-containment references of model elements. The algorithm that is used to set element feature values from XML attributes is defined in Listing 4. This algorithm is called in lines 5, 27 and 35 of Listing 3. For example, in line 8 of Listing 2, after a Task element is created, the Flexmi parser uses the Hungarian algorithm [18] to decide the optimal mapping between the title, start and dur XML attribute names and the possible features of elements of type Task (line 4 of Listing 4 and Fig. 4d). In this case, the XML attributes are allocated and hence used to populate the title, start and duration Task attributes, respectively (lines 12–18 of Listing 4).

3.2 YAML/JSON syntax flavours

Apart from XML, Flexmi also offers a YAML [19] flavour to specify models. The rationale behind this inclusion was providing an even more concise and human-readable syntax on top of what is already achieved by the fuzzy parsing of XML-based Flexmi models.
Listing 5 shows the Flexmi model of Listing 2 represented in YAML. In this format, content is organised as entries, composed of a key and a value separated by a colon (:). There are two main constructs to specify the nesting structure of these entries: block sequences and flow mappings. In YAML, block styles use space-based indentation to denote structure, while flow styles include explicit indicators to organise entries. Both types of styles can be mixed to define the elements of a model.
Block sequences are formed by placing a succession of entries at the same level of indentation and by having each entry key prefixed by a dash (-) and a space. For instance, lines (7–12) of Listing 5 define a block sequence that represents the attributes and references of the Analysis task, and line 12 (which is indented an extra level) represents a single-entry sequence containing a person reference that belongs to the effort element of line 11. Alternatively, flow mappings are specified by surrounding with braces a set of comma-separated entries. In the example, lines 13–18 show a specification of the Design task that uses a flow mapping to define the task features. This flow style basically allows defining models using the JSON [20] format, and this is possible due to YAML being a superset of JSON.
Implementation-wise, and to minimise duplication, YAML-based Flexmi models are parsed into an XML Document Object Model (DOM), and then, they are processed by the algorithms shown in Listings 3 and 4 as it happens with XML-based models. Figure 5 depicts model examples of how the main YAML constructs are translated into XML, and how the final XML is then parsed to obtain an EMF model. Examples a and b show two YAML specifications of the same PSL model, composed of a root element (a project), an attribute (the project’s name), and a nested element (a task). While example a uses block sequences for structuring elements, example b applies flow mappings. Nevertheless, the internal XML DOM generated during the parsing of both examples is the same, which is shown as example c. These examples also show an nsuri processing instruction being detected and translated: any key of a YAML entry starting with a question mark (?) symbol is translated into a processing instruction in the internal XML DOM. Lastly, examples d and e show a model fragment where an Alice person is defined having two skills: Java and XML. These examples present the last YAML constructs required when specifying Flexmi models: block sequences of scalars and flow sequences. Both constructs are used to specify lists of scalars (i.e. primitive values), which in EMF are needed to specify non-containment references (e.g. the skills of the person in the example) and multi-valued attributes. While block sequences imply placing each scalar into its own line (example d), flow sequences are delimited by brackets and separate the scalars by commas, like JSON arrays (example e). Example f shows the resulting translation to XML of d and e, where the scalar values are stored as the text of XML elements. These text elements are processed by Flexmi as described in Sect. 3.1 and in lines 0–12 of Listing 3.

Parsing of YAML representations using block and flow-based styles to XML DOMs
The Flexmi parser detects whether a file is XML- or YAML-based by checking the first non-whitespace character of the file contents: when it is a less-than symbol (<), Flexmi selects XML as the model flavour; it selects YAML otherwise. This detection also makes it possible for the Eclipse-based Flexmi editor to detect the flavour used and adapt its syntax highlighting capabilities accordingly.
Both the XML and YAML syntax flavours have full feature parity, so they can specify the same Flexmi models. Apart from personal preference, using a more human-readable and writeable syntax is the main reason for choosing the YAML flavour over the XML one. On the flip side, XML might be a better candidate when models have multi-line text attributes, as these can be specified as the text content between the tags of an XML element, such as the description of a PSL Project (line 3 of Listing 2). Other reasons for choosing XML over YAML are avoiding mandatory style requirements like the space indentation required in Fig. 5a, d, or the minor parsing performance penalty of having to first parse the YAML models into XML DOMs.
For simplicity, the examples found in the remainder of this article are presented using the XML flavour. The interested reader can find alternative model specifications in YAML as part of the external repository accompanying this work.Footnote 1
3.3 Containment slots
Depending on the modelling language, a model element could fit into more than one containment reference of its parent. For instance, let’s suppose that a PSL project has two containment references of type Task, namely regularTasks and disseminationTasks, instead of the tasks reference depicted in Fig. 1. Naming XML elements that represent tasks as task (e.g. as in Listing 2) would not explicitly indicate in which of the two references the element should be placed. The Flexmi parser would choose a reference based on name similarity,Footnote 2 which in this case would mean that tasks elements would always be placed into regularTasks. There are two ways to actually specify which containment reference to populate. First, instead of using task to name the task elements, we could use a name closer to the containment reference we wish to select, e.g. regtask or dissemtask, or the full reference name if preferred. Second, Flexmi offers an optional construct to include model elements (e.g. tasks) under the compatible containment reference of our choice: containment slots.

Listing 6 shows an example with two containment slots: regular-tasks and dissemination-tasks. A containment slot is detected by Flexmi because of having a name with the highest string similarity with a containment reference and having no XML attributes (lines 13–15 of Listing 3). When such a containment slot is detected, it is pushed to the parser’s stack, so any children of the slot are directly added to the associated containment reference of the parent model element (lines 31–37 of Listing 3). Containment slots might be preferred over the alternative of using the containment reference name when users want to be consistent with the naming of model elements, e.g., using task to denote all Task elements of the model.
3.4 Non-containment references
So far we have discussed how the Flexmi parser interprets XML element names and attributes to create model elements and populate their containment references and attributes. To support non-containment references such as the person reference of the PSL Effort type, target elements need to have a unique identifier. If a class has an attribute marked as identifier in the Ecore metamodel [1], Flexmi will use that to identify its instances. Otherwise, it will use the value of the name attribute, if present. Using this convention, the XML element of Listing 2, line 7, which is interpreted as an instance of the Effort type, refers to the Alice person defined in line 4 of the document via her name. Fully qualified ID paths separated by dots (.) are also supported. The path of an element is formed by combining the IDs of all its containers until the root of the model is reached (i.e. ACME.Alice to refer to the person in line 4). These paths can be useful to resolve ambiguities caused when two elements have the same local identifier. Independently of the ID that is finally used, non-containment references are collected during the parsing process (Listing 4, lines 19–27 and Fig. 4e), and they are resolved at the end of the document, so that all elements that can be referenced are already present in the in-memory model (Fig. 4f).
It could happen that a model element has neither an attribute defined as identifier in its associated class, nor a name attribute that could be used instead. In this case, it is still possible to reference this element through the use of Flexmi’s variables and executable attributes, which are introduced next.
3.5 Executable attributes and variables

Prepending a colon (:) to the name of an attribute instructs the Flexmi parser to interpret its value as an executable EOL [12] expression instead of a literal value. Also, Flexmi supports attaching a :var or a :global attribute to XML elements, to declare local/global variables that can be used in EOL expressions. The scope of local (:var) variables includes siblings of the element, and their descendants, while global variables can be accessed from anywhere in the model.
For example, in line 9 of the Flexmi model in Listing 7, the Design task is assigned to a local variable named design, which is then used in line 12 to compute the value of the start month of the implementation task.
Continuing with the ways of targeting elements from the previous section, line 3 of Listing 7 shows how the person instance can be made available through a :global attribute denoted alice (notice the lowercase name). That attribute creates a global variable, which is later used in line 14 to refer to the person element contained in such variable through an executable :person attribute. As in the case for non-containment references, variables and executable attributes are collected and resolved once the end of the document has been reached (lines 3 and 9 of Listing 4).
3.6 Setting attribute values from file contents
Apart from using executable attributes as defined above, it is also possible to set model element features with the contents of external files. To do this, the name of the XML attribute must have an underscore (_) suffix, and the value of the attribute should point to the file from which to load the contents. The loading of the contents of the referenced file as the value of the XML attribute takes place before calling to the start_element algorithm of Listing 3, which allows using fuzzy matching for the attribute name as if it were a regular one.
Listing 8 shows how the description of a project is loaded from an external file acmeDescription.txt, by using the desc_ attribute name and the relative path of the file, which indicates that the text file must be located in the same folder as the Flexmi model. In the different places where Flexmi can reference external resources, both absolute/relative filesystem paths and Eclipse-based platform URIs are supported.

3.7 Templates
Flexmi supports defining reusable templates through the reserved <:template> XML tag. For example, when designing one-person projects where all tasks take place in sequence, we can omit all the repetitive <effort> elements that refer to the same person, and we can automate the calculation of the start date of each task by using a template, as shown in Listing 9.
All Flexmi templates have two properties: the name that must be used as tag name to instantiate the template; and a content children, which provides the XML elements that will be processed by the Flexmi parser. In Listing 9, a template named simpletask is defined in lines 10–21. This template is used three times in lines 5–7. Based on its content (lines 11–20), each usage of this template generates a task element, which also contains an effort element. The start of the task and the person allocated to the effort are defined through executable attributes. The :start expression calculates the start time of a task by obtaining the task index in the list of all existing tasks, and then by accumulating the duration of all preceding tasks. The :person expression simply assigns the effort to the first Person element of the model (i.e. the only one available, Alice). As a side note, this is the first appearance of the <_\({>}{<}\)/_> special XML element, which is used to support Flexmi models that have more than one top-level elements (similarly to the <xmi:xmi> tag in XMI).

3.7.1 Parametric templates
Flexmi templates also support string parameters, which can be used to customise the generated content when instantiated. Listing 10 includes a template (solo) that can be used to define tasks carried out by a single person (lines 8–16). This template accepts a name and a person parameter (lines 9 and 10), which are used to name the task and to assign all the effort to the provided person, respectively. Parameters are provided as regular XML attributes when instantiating the template, as it happens in line 5 where Design and Alice are passed as name and person.

3.7.2 Dynamic templates and slots
It is possible to use embedded model-to-text transformations to further customise the content that templates produce. In Listing 11, an EGL [22] transformation is defined inside the <content> element of the longtask template (lines 10–19). This template can be used to create tasks using years as duration unit, by providing a years value through a parameter (lines 5 and 11), which is translated to months in the EGL code (line 14). Also, Flexmi supports including a <:slot> element in the content of templates, which specifies where any nested elements of the caller (e.g. the effort element of line 6) should be placed in the produced XML.

3.8 Importing other Flexmi Models and External Operations
Other Flexmi models can be imported through the use of the <?import other.flexmi?> and <?include other.flexmi?> processing instructions. The use of import creates a new EMF Resource for the other.flexmi file, which is useful for referencing elements and for having the same Flexmi model imported by several models. On the other hand, include parses the contents of other.flexmi as if they were embedded in the Flexmi model that contains the include processing instruction, just as the input command works for embedding LaTeX documents. This inclusion happens at the position where the processing instruction is placed, this means, we could include the contents of an external Flexmi file as children of a concrete XML element in the source file.
In the context of PSL, all Person elements working in different projects could be centralised in a model denoted people.flexmi, which is depicted in Listing 12. This model can be imported from Flexmi models containing project details to reference the people that will carry out that project tasks, as shown in Listing 13. While we could also use the include instruction here, using import is preferred because if any project model also references another project, then the people.flexmi will only be loaded once.


It is also possible to use processing instructions to import operations contained in an external EOL file, with the aim of using them as part of executable attributes (see Sect. 3.5). For instance, the expression of the :start attribute in the simpletask template of Listing 9 (lines 12–17) is a one-liner that could be made more readable if divided into several lines. Listing 14 shows a pslOperations.eol file doing just that in the getStartTime() operation, which is defined in a block of instructions and with the help of syntax highlighting. Then, Listing 15 shows how to use this EOL file from a Flexmi model: the eol processing instruction must be used (line 2), which allows changing the :start attribute to a simpler call to getStartTime() (line 7).


3.9 Tool support

The Flexmi editor and its integration with the Outline, Properties and Problems view from the Eclipse IDE
Flexmi is developed as part of the Eclipse Epsilon project,Footnote 3 and it is supported by a dedicated Eclipse editor that can be seen on Fig. 6. As mentioned in Sect. 3.2, this editor can detect whether the chosen flavour for the opened Flexmi model is XML or YAML, and then select the appropriate syntax highlighting. In addition, the editor offers comprehensive error reporting capabilities, including malformed XML/YAML mistakes, exceptions in executable attributes, unresolved references, missing imported/included files, or other errors detected by standard EMF validation (e.g. violation of minimum and maximum metamodel cardinalities, omission of mandatory features). In Fig. 6, the editor (top right) shows the Flexmi model depicted in Listing 2. This editor is integrated with other views of the Eclipse IDE. For instance, the top left of the figure shows the Outline view, which depicts the tree structure of the in-memory EMF model parsed from the Flexmi model. The elements of this EMF model can be inspected in the Properties view (bottom left), which in the figure shows the three attributes of the Analysis task selected in line 6 of the editor. Lastly, any warnings or errors in the model would be listed in the Problems view (bottom right), as well as marked in the editor. In the example, we have introduced a small mistake by assigning the string fifty to the percentage numerical attribute of the effort element in line 13. The Problems view shows this mistake as a warning, including its location in the acme.flexmi file.

Flexmi also provides an implementation of EMF’s Resource interface, which allows Flexmi models to be consumed by any EMF-compatible application or model management language (e.g. ATL, Acceleo). Listing 16 shows a Java snippet that loads a Flexmi model as a standard EMF Resource. Additionally, Flexmi offers a facility for transforming Flexmi models to XMI. Finally, apart from being installable as an Eclipse bundle, Flexmi is also available as a standalone Java library on Maven CentralFootnote 4 and is used as the modelling format of choice in Epsilon’s web-based Playground.Footnote 5
3.10 Limitations
Although Flexmi models can be seamlessly loaded and used by any EMF-compatible application, changes made to their in-memory representations cannot be serialised back to XML/YAML. While the shortened terms of the fuzzy matching could be stored and recovered for serialisation, the results of executable attributes and the application of templates (see Sects. 3.5 to 3.7) cannot be unrolled in the general case.
In Sect. 3.1, we introduced the nsuri processing instruction that allows specifying the namespace URIs of the metamodels that the Flexmi model is instantiating. Multiple nsuri instructions can appear in a Flexmi model if it contains instances of types from multiple metamodels. However, a caveat of Flexmi’s fuzzy matching mechanism is that it is not able to differentiate between two classes with the same name coming from different metamodels. While this issue could be solved by adopting namespace prefixes, this option was discarded in favour of simplicity and conciseness, as supporting such prefixes would bring back part of the undesirable complexity and verbosity of XMI.
Metamodel evolution could cause unexpected mappings of XML elements or attributes to model element types or features, respectively. For instance, if an Effort’s percentage attribute is renamed to cost in the PSL metamodel of Fig. 1, the Flexmi parser will automatically map the perc XML attributes in lines 13–14 of Listing 2 to the new cost attribute of an Effort, which might or might not be the desired behaviour. While setting a minimum similarity threshold below which no matching is accepted could help, this is an approach that needs to be further studied, as establishing a threshold that is too restrictive could also prevent valid matches from being accepted.
Lastly, as part of the tooling, Flexmi’s Eclipse-based editor does not currently offer syntax highlighting for inlined code from Epsilon languages, such as EOL expressions (e.g. see Sect. 3.5) or EGL-based dynamic templates (described in Sect. 3.7.2). We will aim to support these languages as future work.
4 Evaluation
To evaluate Flexmi, we measured the impact of fuzzy parsing and templates in terms of conciseness and performance. All code and artefacts involved in this evaluation can be found in an external repository.Footnote 6 In terms of testing, the Flexmi parser is backed by 57 automated unit and integration tests that assert that it behaves as expected against 76 test models, and protect future development from regressions.
4.1 Evaluation method
We compared Flexmi against three existing textual syntaxes for Ecore models: XMI and HUTN (generic syntaxes), and Emfatic (bespoke syntax). For the purposes of our evaluation, we treat Ecore as an EMF-based object-oriented DSL (i.e. a mini UML), overlooking its role as the metamodelling language of EMF. The reasons behind opting for Ecore are (1) the availability of many existing Ecore models in the public domain (to avoid bias), and (2) the availability of existing bespoke textual syntaxes for it such as Emfatic, Xcore [23] and OCLInEcore [24]. The selection of Emfatic over Xcore and OCLInEcore was a free choice given that all three syntaxes are very similar in terms of conciseness.
4.1.1 Ecore model dataset
We reused the dataset presented in [8], which consists of 2,420 XMI-based Ecore models mined from different open source software repositories. However, most of these Ecore models contain issues, such as syntactical errors or unresolvable proxies (i.e. references to external models). We limited the evaluation to self-contained models (i.e. no proxies), which did not suffer from errors during the evaluation procedure, and with at least 5KiB in size (to filter out toy examples), ending up with 503 models, whose XMI byte size ranges from 5KiB to 3.4 MiB.
4.1.2 Textual syntaxes generation
The Ecore models in the dataset were stored in XMI, from which we automatically generated replica models in the other syntaxes. For instance, for Emfatic and HUTN, we used the built-in transformations provided by their implementations to obtain, for each Ecore XMI model, an Emfatic and HUTN-based model, respectively.
We used a model-to-text transformation to generate Flexmi Ecore models out of the XMI ones. In particular, we generated two Flexmi model versions for each Ecore model: one that makes use of templates (see Sect. 3.7) and one that does not (denoted as plain in the following). The rationale behind this decision was so that we could independently measure the conciseness benefits and performance overhead of the templating mechanism on top of a plain version of Flexmi, where only fuzzy parsing was applied (described in Sect. 3.1). Additionally, we generated two Flexmi models for each variant: one using the XML flavour, and another using YAML (introduced in Sect. 3.2), with the objective to measure the overhead of the extra YAML-to-XML transformation that takes place when using the YAML flavour. Therefore, a total of four Flexmi models was generated for each Ecore XMI model.
The plain Flexmi versions only benefit from fuzzy matching mechanisms to allow a concise wording of Ecore terms for the model tags and attributes. Table 2 shows how these terms were shortened when generating Flexmi models. The shortened terms were not chosen focusing exclusively on reducing length, as this might make the model more difficult to understand (i.e. using u instead of upperBound for ETypedElements), but also in maintaining readability (so, upper was finally used in this case).
The templated versions are plain Flexmi models that also use a set of templates where possible. An excerpt of the templates file for XML Flexmi models can be seen in Listing 17. These templates are mostly parametric ones (see Sect. 3.7.1), and allow representing Ecore EAttributes (lines 3–9), EReferences (lines 10–24), and a special type of EAnnotations (GenModel documentation, in lines 25–32) more concisely. Applying templates allowed us to mimic the bespoke Emfatic syntax in some cases. For instance, there are two templates that use the val term to represent containment references, just as Emfatic does. The val term is used for single-valued containment references (lines 10–14), while vals is used for multi-valued ones (lines 15–19). There is also a dynamic template t_enum (see Sect. 3.7.2) that allows representing an Ecore’s EEnum in a single XML element that enumerates the list of literal names, instead of having to define a tag for the enum and then an additional nested element for each literal (EEnumLiteral). This is achieved by means of a model-to-text transformation (lines 36–45), which iterates over the list of literals to generate the EEnumLiteral elements in the background, assigning an incremental literal value to each one of them. Figure 7 contains an example of a Month EEnum expressed in all the compared syntaxes, which were extracted from one of the metamodels of the dataset .


An Ecore EEnum representing the months of the year in all the compared notations
4.1.3 Measuring method
For the conciseness, we measured the character counts of the models corresponding to each syntax, omitting whitespace. This size measure was preferred over a more conventional lines of code (LOC) one because of the different styles of the compared syntaxes, e.g. the tag-based format of the XMI and Flexmi XML models differs from the Java-like syntax of Emfatic. Nonetheless, given the popularity of the LOC measure we also included it in our analysis.
Related to performance, we compared model loading times of each textual syntax. Due to the small size of some models, individual model loading measurements turned impractical, as some load operations took less than one millisecond. Therefore, we instead measured the accumulated time it took each syntax to load the whole dataset of models, which was in the order of seconds.
Performance measurements were carried out in a MacBook Pro with a quad-core i5 CPU, 32 GiB of LPDDR4X RAM, and an NVME SSD. To increase reliability, measurements were taken 20 times, and unmeasured warm-up repetitions were included to mitigate any perturbation due to idle states of the operating system.
4.2 Results
4.2.1 Conciseness comparison
To compare measurements of heterogeneous models, character counts were normalised with respect to the ones of Emfatic. As this notation offers a tailored syntax for Ecore, it consistently achieved the lowest character counts across all measured models. Therefore, the closer the results of other syntaxes get to the ones of Emfatic, the better they score in terms of conciseness. Figure 8 shows character count box plots of XMI, HUTN, and the four Flexmi variants relative to the Emfatic results, which are represented by a green dashed line at the “1” value.

Character counts relative to Emfatic (dashed line)

Examples of how EAttributes and EReferences are represented in the compared notations
At a first glance, there is a higher dispersion in the XMI and HUTN results with respect of those of the Flexmi versions, whose boxes and distances between the exterior whiskers are smaller. This higher dispersion can be explained by these syntaxes having a much greater verbosity for certain syntax constructs with respect to Emfatic, and by the different proportion of these constructs in the models of the dataset. For instance, Ecore EAttributes and EReferences take way more characters to be expressed in XMI and HUTN than in Emfatic. An example of this can be seen in Fig. 9. We can see that the Emfatic syntax (e) is free of all the verbosity that is required for the XMI and HUTN serialisation (a and b, respectively). Therefore, models having a greater number of EReferences and EAttributes would have a greater relative size in XMI/HUTN with respect to Emfatic than those containing a lower proportion of these syntax constructs. Similar comparisons can be made with other Ecore syntax constructs, such as EAnnotations or EEnums (see Fig. 7).
While the same analogy can be made for the Flexmi versions, these are much more concise than XMI, making their results less sensitive to the input model contents and thus more consistent. Coming back to Fig. 9 example, in plain Flexmi (c) an attr or ref tag name is enough to start the element, and similar fuzzy names are used for tag attributes (see Table 2 for other fuzzy matching examples). When defining attribute types, Flexmi allows omitting the Ecore namespace URI, so just the type identifier needs to be specified, which in the case of Ecore is done through a name-based URI (e.g. //EString). Lastly, as depicted in Fig. 9d, the templated Flexmi version includes templates for data types and for representing containment references of different multiplicities. In the example, an EAttribute of type EString is represented simply with a string tag, and a multi-valued containment reference is defined by using the vals tag (these Flexmi templates are defined in Listing 17, among others). Although Fig. 9 only contains the Flexmi examples for the XML flavour due to space restrictions, the same rationale applies to the YAML one too, which in addition is a bit more concise because of the added verbosity of XML tags.
When considering numerical results, the XMI and HUTN median values sit at 3.70 and 3.74, respectively, which are considerably higher than the 2.01 and 1.81 results of the XML and YAML plain Flexmi versions, and than the 1.71 and 1.53 results of the templated versions, respectively. Focusing on the 75\(^{th}\) percentile (i.e. the rightest line of the box of each boxplot), XMI and HUTN sizes are 4.31 and 4.20 times those of Emfatic, while the Flexmi versions are only 2.21, 1.98, 1.88 and 1.68 times as big.

GenModel annotation representation
Lastly, related to LOC measurements, the effect of certain Ecore syntax constructs is even more pronounced than in the character counts, specially in the case of EAnnotations. We show an example of this in Fig. 10 depicting a GenModel annotation, which is used to include documentation in model elements. Such an annotation always has, at least, a nested doc detail element. As can be seen, this annotation takes a minimum of 3 LOC in XMI. In plain XML Flexmi, it takes the same number of lines, while there is a GenModel template that can be seen in lines 25–32 of Listing 17, so the templated version of Flexmi can make use of it to take only one LOC. Emfatic has a specific syntax construct for annotations that allows representing them in a single line as well. Moreover, this syntax construct can be also used with custom annotations, these are, those that were defined specifically for a concrete Ecore metamodel, in which case there is no generic Flexmi defined in our evaluation setup. Therefore, Emfatic can represent any EAnnotation in the metamodel as a one-liner.
In summary, Emfatic has a great advantage in the LOC measurements, and a model-by-model relative comparison as done in the character count analysis was not as fair in this case. Therefore, we performed a dataset-level LOC count, answering the following question: how many lines does it take each syntax to specify all Ecore models in the dataset? The results can be found in Table 3.
Starting with HUTN and the Flexmi YAML versions, these syntaxes require more LOC because of their greater usage of new lines when specifying model elements. When comparing the two, HUTN requires a greater number of lines, due to the extra curly brace that is required to close each element (e.g. see lines 10–11 or 14–15 of Listing 1). With respect to the XML-based syntaxes, we can see how \(\sim \) 10% of lines are skipped in plain XML Flexmi with respect to XMI, which goes up to \(\sim \) 28% when Flexmi templates are also applied. Lastly, and mainly due to the special EAnnotation syntax described above, Emfatic is able to use \( \sim \) 52% less lines than XMI.
4.2.2 Performance comparison

Accumulated time taken to load the whole dataset
Figure 11 shows the accumulated time it took the Emfatic, XMI and Flexmi parsers to load the whole models dataset, including 95% confidence intervals. We opted to leave HUTN out of these results, as the performance of its implementation [5] is not on par with the others (the full dataset load took more than 8 minutes, far from the seconds it takes the other approaches). We can see that the results for Emfatic and plain XML Flexmi are very close, at 2.39 and 2.49 times the results of XMI (i.e. the faster notation), respectively. As for the templated XML Flexmi version, its result is 3.96 times the one of XMI, and 1.5 times that of Emfatic. This is due to the overhead of processing of parametric and dynamic templates (see Sects. 3.7.1 and 3.7.2, respectively). The Flexmi YAML flavours are the slower ones, taking 3.57 times that of XMI for the plain version, and 4.46 times for the templated version. When comparing the flavours, the plain YAML version takes 30% more time than the XML one, while the templated YAML version takes 12% more time than the XML counterpart. This increase was expected, as the YAML models are first transformed to an XML DOM before being processed by the Flexmi parser.
4.3 Threats to validity
We comment here on any detected threat that might be influencing the outcome of our experiments.
With the aim of avoiding bias in the results for the specific case of Ecore, XMI, HUTN and Emfatic, we opted for a third-party dataset with a reasonable distribution in terms of the size and key characteristics of the models it contains, such as the number of classes, attributes and references in each, summarised in Table 4.
It could also be argued that using just an example language (Ecore) may not be enough to generalise the results. While this might be true, we prioritised quality over quantity of examples, this is, we avoided the creation of synthetic examples to prevent the potential inclusion of biases due to the performed experiments. In fact, the inherent simplicity of the Ecore language caused that only a handful of templates were worth considering, so some Flexmi features might prove even more useful when applied to models from other domains, which we will explore in the future.
The better results in conciseness provided by Flexmi might come at a cost of readability of the models. We tried to mitigate this risk by selecting terms that offered a good balance between conciseness and understandability (see Table 2 to check how terms were shortened). When in doubt, the complete, original terms were used. We will perform real readability and learnability experiments with end users as part of our future work.
For the comparison, the models of the two Flexmi versions and of the Emfatic notation were automatically generated. So, it could be argued that the conciseness results are tied to how good the generator that created the models is. After a manual inspection of the automatically generated models, apart from some whitespace (which is ignored in the character counts of the comparison), we did not detect any extra-verbose syntax construct that might be improved if manually defined. We consider that model contents would be very close to those of hand-crafted models if the transformation was performed manually instead (a much more error-prone task though), so we believe that the use of transformations to obtain the compared models of certain notations is not affecting the validity of the results.
The incurred performance overhead ranged from 2.5 to 4.5 slower parse times with respect to XMI, being in some configurations nearly as fast to parse as the bespoke Emfatic syntax. On the other hand, the performance of a bespoke parser can depend on a number of factors such as the sophistication of the underlying parser generator and the complexity of the BNF grammar, and therefore, the performance results against Emfatic cannot be safely generalised.
4.4 Discussion
While Flexmi is certain to be more concise than XMI and HUTN, and has been shown to be nearly as concise as Emfatic, bespoke textual syntaxes can be substantially more concise than Flexmi in some scenarios. For example, in the context of a DSL that allows defining arbitrarily complex Boolean expressions, a bespoke syntax could provide a very concise encoding such as (a and b) or c, while it would require a much more verbose encoding in Flexmi as shown in Listing 18.
In general, factors that can affect the compactness of a custom textual syntax include (1) the ability to reuse established concise notations that the target audience are already familiar with (e.g. single-character mathematical symbols with already well-understood semantics instead of longer keywords) and (2) the training effort one is prepared to invest since a more concise syntax might require more training for users to understand and remember.

Beyond conciseness, when deciding whether Flexmi or a custom syntax is more appropriate for the task at hand, the following concerns should be taken into account:
-
Stability of the metamodel: in early iteration cycles Flexmi can be preferable to a custom syntax as it can eliminate the need to co-evolve a grammar as the metamodel evolves;
-
Expected return of investment: a custom textual syntax can provide usability benefits but also involves developing, maintaining, testing and distributing dedicated software (e.g. a grammar, scoping rules). While for large-scale projects (e.g. long-lived, many developers) the usability benefits of dedicated tooling can justify this additional effort, for smaller-scale projects a generic textual syntax like Flexmi can be preferable.
5 Conclusions and future work
We have presented Flexmi, a generic textual syntax for EMF-based DSLs that provides greater conciseness, flexibility and customisability than existing generic syntaxes, while avoiding the upfront cost of developing a bespoke textual syntax. Flexmi achieves this by applying fuzzy parsing, by allowing the definition and instantiation of reusable templates, and by supporting dynamic functionality through executable expressions and embedded model-to-text transformations. It also provides two feature-equivalent syntax flavours to choose from, based in XML and YAML, respectively.
Our planned future work includes improving the Flexmi editor to better support syntax highlighting of inlined EOL/EGL languages, auto-completion and preview/navigation of references. We also wish to evaluate the performance implications of making the parsing algorithm smarter by e.g. also considering value types during attribute allocation, or by including look-ahead mechanisms that check deeper levels of the parsed DOM to decide e.g. whether an XML element represents a model element or a containment reference slot. Usability and learnability experiments involving end users trying out Flexmi are also part of our future goals.
Notes
Flexmi currently uses Levenshtein’s distance [21] to calculate string similarity, but other methods could also be applied.
References
Steinberg, D., Budinsky, F., Paternostro, M., Merks, E.: EMF: Eclipse Modeling Framework, 2nd edn. Addison-Wesley Professional (2009)
Eysholdt, M., Behrens, H.: Xtext: implement your language faster than the quick and dirty way. In: Proceedings of the ACM International Conference Companion on Object Oriented Programming Systems Languages and Applications Companion, pp. 307–309 (2010)
Heidenreich, F., Johannes, J., Karol, S., Seifert, M., Wende, C.: Model-based language engineering with emftext. In: International Summer School on Generative and Transformational Techniques in Software Engineering, pp. 322–345. Springer (2011)
Hölldobler, K., Rumpe, B.: MontiCore 5 Language Workbench Edition 2017. Aachener Informatik-Berichte, Software Engineering, Band 32. Shaker Verlag (2017). http://www.se-rwth.de/phdtheses/MontiCore-5-Language-Workbench-Edition-2017.pdf
Rose, L.M., Paige, R.F., Kolovos, D.S., Polack, F.: Constructing models with the human-usable textual notation. In: Model Driven Engineering Languages and Systems, 11th International Conference, MoDELS 2008, Toulouse, France, September 28–October 3, 2008. Proceedings, Lecture Notes in Computer Science, vol. 5301, pp. 249–263. Springer (2008). https://doi.org/10.1007/978-3-540-87875-9_18
Hillairet, G.: EMFJSON—EMF Binding for JSON. https://github.com/emfjson/emfjson-jackson
Group, O.M.: XML metadata interchange (XMI) specification. https://www.omg.org/spec/XMI/About-XMI/
Barriga, A., Di Ruscio, D., Iovino, L., Nguyen, P.T., Pierantonio, A.: An extensible tool-chain for analyzing datasets of metamodels. In: Proceedings of the 23rd ACM/IEEE International Conference on Model Driven Engineering Languages and Systems: Companion Proceedings, pp. 1–8. ACM, Virtual Event Canada (2020). https://doi.org/10.1145/3417990.3419626
Foundation, E.: Emfatic. https://www.eclipse.org/emfatic/
Kolovos, D.S., Matragkas, N., García-Domínguez, A.: Towards Flexible Parsing of Structured Textual Model Representations. In: Proceedings of the 2nd Workshop on Flexible Model Driven Engineering Co-located with ACM/IEEE 19th International Conference on Model Driven Engineering Languages & Systems (MoDELS 2016), Saint-Malo, France, October 2, 2016, CEUR Workshop Proceedings, vol. 1694, pp. 22–31. CEUR-WS.org (2016). http://ceur-ws.org/Vol-1694/FlexMDE2016_paper_3.pdf
Kolovos, D.S., Paige, R.F.: Towards a modular and flexible human-usable textual syntax for EMF models. In: R. Hebig, T. Berger (eds.) Proceedings of MODELS 2018 Workshops: ModComp, MRT, OCL, FlexMDE, EXE, COMMitMDE, MDETools, GEMOC, MORSE, MDE4IoT, MDEbug, MoDeVVa, ME, MULTI, HuFaMo, AMMoRe, PAINS co-located with ACM/IEEE 21st International Conference on Model Driven Engineering Languages and Systems (MODELS 2018), Copenhagen, Denmark, October, 14, 2018, CEUR Workshop Proceedings, vol. 2245, pp. 223–232. CEUR-WS.org (2018). http://ceur-ws.org/Vol-2245/flexmde_paper_3.pdf
Kolovos, D.S., Paige, R.F., Polack, F.: The epsilon object language (EOL). In: A. Rensink, J. Warmer (eds.) Model Driven Architecture—Foundations and Applications, 2nd European Conference, ECMDA-FA 2006, Bilbao, Spain, July 10–13, 2006, Proceedings, Lecture Notes in Computer Science, vol. 4066, pp. 128–142. Springer (2006). https://doi.org/10.1007/11787044_11
Kleppe, A.: Software Language Engineering: Creating Domain-Specific Languages Using Metamodels. Addison-Wesley Professional (2008)
Bettini, L.: Implementing Domain-Specific Languages with Xtext and Xtend. Packt Publishing Ltd. (2016)
Efftinge, S., Eysholdt, M., Köhnlein, J., Zarnekow, S., von Massow, R., Hasselbring, W., Hanus, M.: Xbase: implementing domain-specific languages for Java. ACM SIGPLAN Not. 48(3), 112–121 (2012)
Bettini, L.: Implementing type systems for the ide with xsemantics. J. Log. Algebr. Methods Progr. 85(5, Part 1), 655–680 (2016). https://doi.org/10.1016/j.jlamp.2015.11.005. (Special Issue on Automated Verification of Programs and Web Systems)
Wachsmuth, G.H., Konat, G.D., Visser, E.: Language design with the spoofax language workbench. IEEE Softw. 31(5), 35–43 (2014)
Kuhn, H.W.: The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 2(1–2), 83–97 (1955). https://doi.org/10.1002/nav.3800020109
YAML: YAML Ain’t Markup Language. https://yaml.org/
JSON: JavaScript Object Notation. https://www.json.org/
Levenshtein, V.I.: Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 10, 707–710 (1966)
Rose, L.M., Paige, R.F., Kolovos, D.S., Polack, F.: The epsilon generation language. In: I. Schieferdecker, A. Hartman (eds.) Model Driven Architecture—Foundations and Applications, 4th European Conference, ECMDA-FA 2008, Berlin, Germany, June 9–13, 2008. Proceedings, Lecture Notes in Computer Science, vol. 5095, pp. 1–16. Springer (2008). https://doi.org/10.1007/978-3-540-69100-6_1
Foundation, E.: Xcore. https://wiki.eclipse.org/Xcore
Foundation, E.: OCLInEcore. https://wiki.eclipse.org/OCL/OCLinEcore
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Zhenjiang Hu.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The work presented in this paper has been funded through the HICLASS InnovateUK project (Contract No. 113213).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kolovos, D., de la Vega, A. Flexmi: a generic and modular textual syntax for domain-specific modelling. Softw Syst Model 22, 1197–1215 (2023). https://doi.org/10.1007/s10270-022-01064-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10270-022-01064-3