
Abstract
Domain adaptation (DA) is a new learning framework dealing with learning problems where the target test data are drawn from a distribution different from the one that has generated the learning source data. In this article, we introduce self-labeling domain adaptation boosting (SLDAB), a new DA algorithm that falls both within the theory of DA and the theory of Boosting, allowing us to derive strong theoretical properties. SLDAB stands in the unsupervised DA setting where labeled data are only available in the source domain. To deal with this more complex situation, the strategy of SLDAB consists in jointly minimizing the empirical error on the source domain while limiting the violations of a natural notion of pseudo-margin over the target domain instances. Another contribution of this paper is the definition of a new divergence measure aiming at penalizing models that induce a large discrepancy between the two domains, reducing the production of degenerate models. We provide several theoretical results that justify this strategy. The practical efficiency of our model is assessed on two widely used datasets.











Similar content being viewed by others



Notes
The \(\mathcal {H}\)-divergence is defined with respect to the hypothesis class \(\mathcal {H}\) by: \(\sup _{h,h'\in \mathcal {H}}\left| \mathbb {E}_{x\sim \mathcal {T}}[h(x)\ne h'(x)]-\mathbb {E}_{x'\sim \mathcal {S}}[h(x')\ne h'(x')]\right| \), it can be empirically estimated by learning a classifier able to discriminate source and target instances [5].
True labels are assumed well balanced, if not \(p_n\) has to be reweighted accordingly.
http://archive.ics.uci.edu/ml/datasets/Spambase.
Fig. 7 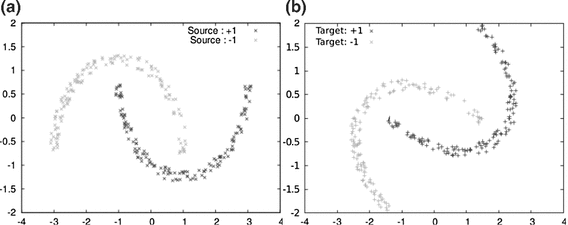
Examples from the Moons database. a Describes examples from the source domain, while b contains data from the target domain, obtained after a \(30^{\circ }\) rotation

References
Balcan M-F, Blum A (2006) On a theory of learning with similarity functions. In: Proceedings of ICML’06, pp 73–80
Balcan M-F, Blum A, Srebro N (2008) Improved guarantees for learning via similarity functions. In: Proceedings of COLT’08, pp 287–298
Bartlett PL, Mendelson S (2002) Rademacher and gaussian complexities: Risk bounds and structural results. J Mach Learn Res 3:463–482
Becker C, Christoudias C, Fua P (2013) Non-linear domain adaptation with boosting. In: Proceedings of NIPS’13, pp 485–493
Ben-David S, Blitzer J, Crammer K, Kulesza A, Pereira F, Vaughan J (2010) A theory of learning from different domains. Mach Learn 79(1–2):151–175
Bennett K, Demiriz A, Maclin R (2002) Exploiting unlabeled data in ensemble methods. In: Proceedings of KDD’02, pp 289–296
Bickel S, Brückner M, Scheffer T (2007) Discriminative learning for differing training and test distributions. In: Proceedings of ICML’07, ACM, New York, NY, USA, pp 81–88
Blitzer J, Dredze M, Pereira F (2007) Biographies, bollywood, boom-boxes and blenders: domain adaptation for sentiment classification. In: Proceedings of ACL’07
Blitzer J, McDonald R, Pereira F (2006) Domain adaptation with structural correspondence learning. In: Proceedings of EMNLP’06, pp 120–128
Blum A, Mitchell T (1998) Combining labeled and unlabeled data with co-training. In: Proceedings of the eleventh annual conference on Computational learning theory, Proceedings of COLT’98, ACM, pp 92–100
Bruzzone L, Marconcini M (2010) Domain adaptation problems: a dasvm classification technique and a circular validation strategy. IEEE Trans Pattern Anal Mach Intell 32:770–787
Chelba C, Acero A (2006) Adaptation of maximum entropy capitalizer: Little data can help a lot. Comput Speech Lang 20(4):382–399
Dai W, Yang Q, Xue G, Yu Y (2007) Boosting for transfer learning. In: Proceedings of ICML’07, pp 193–200
Daumé H III (2007) Frustratingly easy domain adaptation. In: Proceedings of ACL’07, pp 256–263
Dudík M, Schapire RE, Phillips SJ (2005) Correcting sample selection bias in maximum entropy density estimation. In: Proceedings of NIPS’05
Florian R, Hassan H, Ittycheriah A, Jing H, Kambhatla N, Luo X, Nicolov N, Roukos S (2004) A statistical model for multilingual entity detection and tracking. In: Proceedings of HLT-NAACL’04, pp 1–8
Freund Y, Schapire R (1996) Experiments with a new boosting algorithm. In: Proceedings of ICML’96, pp 148–156
Habrard A, Peyrache J-P, Sebban M (2013) Iterative self-labeling domain adaptation for linear structured image classification. Int J Artific Intell Tools 22(5). doi:10.1142/S0218213013600051
Harel M, Mannor S (2012) The perturbed variation. In: Proceedings of NIPS’12, pp 1943–1951
Huang J, Smola A, Gretton A, Borgwardt K, Schölkopf B (2006) Correcting sample selection bias by unlabeled data. In: Proceedings of NIPS’06, pp 601–608
Ji Y, Chen J, Niu G, Shang L, Dai X (2011) Transfer learning via multi-view principal component analysis. J Comput Sci Technol 26(1):81–98
Jiang J (2008) A literature survey on domain adaptation of statistical classifiers. Technical report, Computer Science Department at University of Illinois, Urbana-Champaign
Joachims T (1999) Transductive inference for text classification using support vector machines. In: Proceedings of ICML’1999, ICML ’99, pp 200–209
Kolmogorov A, Tikhomirov V (1961) \(\epsilon \)-entropy and \(\epsilon \)-capacity of sets in functional spaces. Am Math Soc Transl 2(17):277–364
Koltchinskii V (2001) Rademacher penalties and structural risk minimization. IEEE Trans Inf Theory 47(5):1902–1914
Leggetter C, Woodland P (1995) ‘Maximum likelihood linear regression for speaker adaptation of continuous density hidden markov models’. Comput Speech Lang 2:171–185
Mallapragada P, Jin R, Jain A, Liu Y (2009) Semiboost: Boosting for semi-supervised learning. IEEE T. PAMI 31(11):2000–2014
Mansour Y, Mohri M, Rostamizadeh A (2008) Domain adaptation with multiple sources. In: Proceedings of NIPS’08, pp 1041–1048
Mansour Y, Mohri M, Rostamizadeh A (2009) Domain adaptation: learning bounds and algorithms. In: Proceedings of COLT’09
Mansour Y, Schain M (2012) Robust domain adaptation. In: Proceedings of ISAIM’12
Margolis A (2011) A literature review of domain adaptation with unlabeled data, Tec. Report, pp 1–42
Martínez A (2002) Recognizing imprecisely localized, partially occluded, and expression variant faces from a single sample per class. IEEE T. PAMI 24(6):748–763
Morvant E, Habrard A, Ayache S (2011) Sparse domain adaptation in projection spaces based on good similarity functions. In: Proceedings of ICDM’11, pp 457–466
Morvant E, Habrard A, Ayache S (2012) Parsimonious unsupervised and semi-supervised domain adaptation with good similarity functions. Knowl Inform Syst (KAIS) 33(2):309–349
Pan SJ, Yang Q (2010) A survey on transfer learning. IEEE Trans Knowl Data Eng 22:1345–1359
Pérez Ó, Sánchez-Montañés MA (2007) A new learning strategy for classification problems with different training and test distributions. In: Proceedings of IWANN’07, pp 178–185
Quionero-Candela J, Sugiyama M, Schwaighofer A, Lawrence N (2009) Dataset shift in machine learning. MIT Press, Cambridge
Roark B, Bacchiani M (2003) Supervised and unsupervised pcfg adaptation to novel domains. In: Proceedings of HLT-NAACL’03
Satpal S, Sarawagi S (2007) Domain adaptation of conditional probability models via feature subsetting. In: Proceedings of PKDD’07, pp 224–235
Schapire RE, Singer Y (1999) Improved boosting algorithms using confidence-rated predictions. Mach Learn 37(3):297–336
Schapire R, Freund Y, Barlett P, Lee W (1997) Boosting the margin: A new explanation for the effectiveness of voting methods. In: Proceedings of ICML’97, pp 322–330
Sugiyama M, Nakajima S, Kashima H, von Bünau P, Kawanabe M (2008) Direct importance estimation with model selection and its application to covariate shift adaptation. In: Proceedings of NIPS’07
Tsuboi Y, Kashima H, Hido S, Bickel S, Sugiyama M (2009) Direct density ratio estimation for large-scale covariate shift adaptation, Proceedings of JIP’09 17, pp 138–155
Valiant L (1984) A theory of the learnable. Commun ACM 27(11):1134–1142
van der Vaart A, Wellner J (1996) Weak convergence and empirical processes. Springer series in statistics. Springer, Berlin
Xu H, Mannor S (2010a) Robustness and generalization. In: Proceedings of COLT’10, pp 503–515
Xu H, Mannor S (2010b) Robustness and generalization. In: Proceedings of COLT’10, pp 503–515
Xu H, Mannor S (2012a) Robustness and generalization. Mach Learn 86(3):391–423
Xu H, Mannor S (2012b) Robustness and generalization. Mach Learn 86(3):391–423
Yao Y, Doretto G (2010) Boosting for transfer learning with multiple sources. In Proceedings of CVPR’10, pp 1855–1862
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Habrard, A., Peyrache, JP. & Sebban, M. A new boosting algorithm for provably accurate unsupervised domain adaptation. Knowl Inf Syst 47, 45–73 (2016). https://doi.org/10.1007/s10115-015-0839-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10115-015-0839-2