
Abstract
In traditional two-stage mixed-integer recourse models, the expected value of the total costs is minimized. In order to address risk-averse attitudes of decision makers, we consider a weighted mean-risk objective instead. Conditional value-at-risk is used as our risk measure. Integrality conditions on decision variables make the model non-convex and hence, hard to solve. To tackle this problem, we derive convex approximation models and corresponding error bounds, that depend on the total variations of the density functions of the random right-hand side variables in the model. We show that the error bounds converge to zero if these total variations go to zero. In addition, for the special cases of totally unimodular and simple integer recourse models we derive sharper error bounds.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Stochastic programming is a methodology for modeling optimization problems under uncertainty. Traditionally, this uncertainty is accounted for by minimizing the expected total costs, and thus implicitly, a neutral stance toward risk is assumed. For recurring problems that have to be solved many times, this approach is justified by the law of large numbers. However, in many other applications we face a single-shot problem in which avoiding risk is desired.
In this paper, we focus on a class of models from stochastic programming that explicitly incorporate this aversion toward risk: mean-risk models. In these models, a weighted average of the expected total costs and a measure of risk is minimized. Thus, a balance is struck between minimizing the cost on average and avoiding high levels of risk. In particular, we will consider mean-risk models with two time stages, integer decision variables, and conditional value-at-risk (CVaR) as the risk measure. The random parameters in our model are the second-stage right-hand side and cost vector, and the technology matrix. Moreover, a key assumption is that the random right-hand side vector is continuously distributed. We refer to these models as two-stage mixed-integer mean-CVaR recourse models.
Integer decision variables are often required for realistic modeling of, e.g., indivisibilities or on/off decisions. However, including them in mean-CVaR recourse models makes these models significantly harder to solve than their continuous counterparts. Indeed, for continuous mean-CVaR recourse models, efficient solution methods are available from the literature. These methods exploit the convexity of the objective function. See, e.g., Ahmed [2], Miller and Ruszczyński [31], and Noyan [32] for decomposition algorithms based on the L-shaped algorithm by Van Slyke and Wets [52] and Rockafellar [37] for a progressive hedging algorithm.
Mixed-integer mean-CVaR recourse models, however, are generally not convex so that the aforementioned convex optimization-based methods cannot be applied. Thus, alternative solution methods are required for these models. Schultz and Tiedemann [44] show that the problem can be reformulated as a large-scale mixed-integer linear program (MILP) if the probability distributions of the random variables in the model are discrete and finite. Based on this reformulation they propose a decomposition algorithm using Lagrangean relaxation of the nonanticipativity constraints. Other authors solve the large-scale MILP reformulation using standard MILP solvers (e.g., [47]) or develop heuristics for specific problem settings [5]. However, these solution methods can only solve problems of limited size.
We will take a fundamentally different approach to deal with integer decision variables in mean-CVaR recourse models. Instead of aiming for an exact optimal solution, we will construct approximation models with a convex objective function. The rationale of doing so is that these convex approximation models can be solved efficiently using techniques from convex optimization, similar as continuous mean-CVaR recourse models. To guarantee the performance of the resulting approximating solutions we derive error bounds on the convex approximations. Such convex approximations and corresponding error bounds have been derived for risk-neutral mixed-integer stochastic programming problems; see Sect. 2.3 for a review of them. However, to our knowledge, this is the first paper that considers convex approximations for mixed-integer stochastic programs in a risk-averse setting.
The main contribution of this paper is that we construct convex approximations and derive corresponding error bounds for two-stage mixed-integer mean-CVaR recourse models. These error bounds converge to zero if the total variations of the probability density functions of the random right-hand side variables in the model converge to zero. Intuitively, this means that any mixed-integer mean-CVaR recourse model can be approximated arbitrarily well by a convex approximation if the variability of the random right-hand side variables in the model is sufficiently large. For the special cases of totally unimodular (TU) and simple integer mean-CVaR recourse models we perform a specialized analysis to derive tighter bounds. For the latter type of models, it turns out that the bound is particularly small if the random right-hand side variable in the model has a decreasing hazard rate.
The remainder of the paper is organized as follows. In Sect. 2 we formulate the mathematical model and review the relevant literature. Next, in Sect. 3 we consider the general setting of two-stage mixed-integer mean-CVaR recourse models and derive convex approximations with asymptotically converging error bounds. Section 4 deals with the special cases of TU and simple integer mean-CVaR recourse models. Section 5 provides a discussion of the results and directions for further research. Finally, Appendix A contains a generalization of existing risk-neutral results that we use in this paper and Appendix B contains proofs of several lemmas, propositions, and theorems.
2 Problem formulation and literature review
2.1 Problem formulation
We consider the two-stage mixed-integer mean-CVaR recourse model
where \(X = \{ x \in \mathbb {R}^{n_1} \ | \ Ax = b \}\) represents the set of feasible first-stage decisions that have to be made before some random parameters \(\xi \) are known, and \(\mathscr {Q}^{\beta }_\rho \) is the mean-CVaR recourse function
with weight parameter \(\rho \in [0,1]\). Here, the mean recourse function Q and the CVaR recourse function \(R^{\beta }\) are defined by
where \({{\,\mathrm{CVaR}\,}}_\beta \) is the \(\beta \)-conditional value-at-risk (\(\beta \in (0,1)\)) defined in Definition 1, and v is the second-stage value function, defined by
The second-stage decision variables y represent the recourse actions that can be taken after the realization of \(\xi := (q, T, h)\) is known, in order to compensate for infeasibilities in the goal constraint \(Tx = h\). For ease of exposition, we assume that the first-stage decision variables x are continuous. However, all results in this paper still hold when some or all of these variables are restricted to be integer.
As an example of an application of our model, we discuss a stylized version of the disaster relief planning problem of Alem et al. [5] in Example 1 below.
Example 1
Consider the problem of distributing relief goods (water, food, medicine, etc.) after a natural disaster. A priori, the location and size of the disaster are naturally uncertain. However, where to store the relief goods needs to be determined before the disaster takes place. The goal is both to minimize the financial cost and to avoid shortages of relief goods at locations of need. We can model this problem using a two-stage mixed-integer mean-CVaR model.
In the first stage (before the disaster) we have to decide how many relief goods to store at each available storage location. The first-stage costs are the cost of acquiring these goods. When the disaster strikes, the required amount of relief goods in every area becomes known. In the second-stage, we need to allocate vehicles to transport goods from the different storage locations to the affected areas. The second-stage costs consist of the cost of using these vehicles plus a penalty on any unsatisfied demand (shortages) of relief goods. Since high shortages should be avoided, this problem is naturally modeled using a risk-averse approach. Furthermore, note that integer variables are needed to model the number of allocated vehicles in the second stage. \(\triangle \)
Our goal is to construct convex approximations \(\tilde{\mathscr {Q}}^{\beta }_\rho \) of the form \(\tilde{\mathscr {Q}}^{\beta }_\rho = (1-\rho )\tilde{Q} + \rho \tilde{R}^{\beta }\) for the mean-CVaR recourse function \(\mathscr {Q}^{\beta }_\rho \). Since convex approximations \(\tilde{Q}\) of Q are available in the literature (see Sect. 2.3), we focus on constructing convex approximations \(\tilde{R}^{\beta }\) of \(R^{\beta }\). As a performance guarantee, we will derive an upper bound on
Since
we will focus on deriving an upper bound on \(\Vert R^{\beta } -\tilde{R}^{\beta }\Vert _\infty \). Bounds on \(\Vert Q - \tilde{Q}\Vert _\infty \) are known from the literature. However, since these existing bounds only apply to recourse models with randomness in the right-hand side vector h only, we generalize them to our setting in Appendix A, where we allow q and T to be random as well.
Throughout this paper, we make the following assumptions.
Assumption 1
We assume that
- (a)
the recourse is complete and sufficiently expensive, i.e., \( -\infty< v(\xi , x) < \infty \), for all \(\xi \in \varXi \) and \(x \in \mathbb {R}^{n_1}\), where \(\varXi \) denotes the support of \(\xi \).
- (b)
the expectation of the \(\ell _1\) norm of \(\xi \) is finite, i.e., \(\mathbb {E}_\xi \Vert \xi \Vert _1 < \infty \), where \(\Vert \xi \Vert _1 :=\sum _{j=1}^n |q_j| + \sum _{i=1}^{m}\sum _{j=1}^{n_1} |T_{ij}| +\sum _{i=1}^{m} |h_i| \),
- (c)
the recourse matrix W is integer,
- (d)
the support \(\varXi \) of \(\xi \) can be written as \(\varXi = \varXi ^q \times \varXi ^T \times \varXi ^h\), where \(\varXi ^q\) is finite. Moreover, h is continuously distributed on \(\varXi ^h\) with joint pdf f,
- (e)
(q, T) and h are pairwise independent.
Assumption 1(a)–(b) ensure that Q(x) and \(R^{\beta }(x)\) are finite for every \(x \in \mathbb {R}^{n_1}\). Next, Assumption 1(c) is required for the proof of Theorem 1. However, this assumption is not very restrictive, since any rational matrix can be transformed into an integer one by appropriate scaling. Assumption 1(d)–(e) restrict the random right-hand side vector h to be continuously distributed. This is the key assumption on the random parameters \(\xi \) in our paper. The remaining assumptions in Assumption 1(d)–(e) are for ease of presentation; similar results as in this paper can be obtained for relaxed versions of these assumptions. Finally, we note that we assume that the probability distribution of \(\xi \) is known or can be accurately estimated, based on, e.g., historical data or expert opinions.
2.2 Conditional value-at-risk
In our risk-averse stochastic programming approach, we use conditional value-at-risk (CVaR) as the measure of risk. For probability parameter \(\beta \in (0,1)\), the \(\beta \)-CVaR of a random variable \(\theta \), written as \({{\,\mathrm{CVaR}\,}}_\beta [\theta ]\), has the interpretation of the conditional expectation of \(\theta \), given that \(\theta \) is at least as large as its \(\beta \)-quantile. Thus, intuitively, \({{\,\mathrm{CVaR}\,}}_\beta [\theta ]\) represents the average of the \(100(1-\beta )\%\) worst values of \(\theta \). We use the minimization representation of CVaR by Rockafellar and Uryasev [38] as our definition.
Definition 1
Let \(\theta \) be a random variable and let \(\beta \in (0,1)\) be given. Then, the \(\beta \)-CVaR of \(\theta \) is defined as
Our choice for CVaR is motivated by the fact that this risk measure satisfies several desirable theoretical properties. First of all, CVaR is a coherent risk measure [38], and thus satisfies the axiomatic properties proposed by Artzner et al. [7]. In contrast, several popular risk measures such as value-at-risk violate some of these properties [1]. Second, Ogryczak and Ruszczyński [34] show that mean-CVaR recourse models are consistent with second-order stochastic dominance, a tool that establishes a preorder of random variables. This is relevant, since consistency with second-order stochastic dominance is desirable for accurately modeling risk aversion [26]. Third, Schultz and Tiedemann [44] show that mixed-integer mean-CVaR recourse models exhibit desirable properties such as continuity and stability. Furthermore, they show that under mild technical conditions an optimal solution to these models exist.
Due to its desirable properties, CVaR is one of the most popular risk measures in the literature on risk-averse optimization under uncertainty. For instance, it is the most popular choice for applications in supply chain network design under uncertainty [19]. See, e.g., [18, 36, 43, 46,47,48, 54] for applications of mean-CVaR recourse models in this field. Other areas of application include disaster relief planning [5, 32, 33], (energy) production planning [4, 9, 21, 27], transportation network protection [29], and water allocation [56]. The popularity of CVaR, and of mean-CVaR recourse models in particular, underlines the relevance of the models studied in this paper.
2.3 Solution methods for risk-neutral mixed-integer recourse models
Traditional solution methods for risk-neutral mixed-integer recourse models combine solution methods from deterministic mixed-integer and stochastic continuous optimization. See, e.g., Laporte and Louveaux [25] for the integer L-shaped method, Carøe and Schultz [12] for dual decomposition, Ahmed et al. [3] for branch-and-bound, Sen and Higle [45] for disjunctive decomposition, and [6, 8, 11, 16, 22, 35, 55] for recent work on cutting plane techniques. In general, however, these solution methods have difficulties solving large problem instances because they aim at finding an exact optimal solution. In contrast, we merely aim at finding good or near-optimal solutions to our mixed-integer mean-CVaR recourse model by means of convex approximations. For this reason, the remainder of this subsection is devoted to the literature on convex approximations for the corresponding risk-neutral case.
Convexity properties of risk-neutral mixed-integer stochastic programming problems were first analyzed by Klein Haneveld et al. [23] for the special case of simple integer recourse models. In fact, they exactly identified the probability distributions for which the mean recourse function Q in such models is convex. For all other cases, they derive so-called \(\alpha \)-approximations \(\tilde{Q}_\alpha \) of Q and corresponding error bounds. These convex approximations are extended by van der Vlerk to TU integer recourse models [50] and mixed-integer recourse models with a single recourse constraint [51]. However, only for the latter type of model does he derive an error bound for these convex approximations.
Recently, substantial progress has been made in deriving error bounds for convex approximations of mixed-integer recourse models with multiple non-separable recourse constraints. For example, for TU integer recourse models, Romeijnders et al. [39] derive an error bound for the \(\alpha \)-approximations from [50]. This error bound depends on the total variations of the density functions of the random right-hand side variables in the model. In particular, if these total variations are small, then the error bound is small and hence, the convex approximation is good. This is confirmed by numerical experiments in [42]. A tighter error bound is derived for an alternative convex approximation, called the shifted LP-relaxation approximation; see [41]. In fact, it is shown that the error bound is the best possible in a worst-case sense. The main building blocks in the derivation of this error bound are total variation bounds for the expectation of periodic functions.
The latest developments in this area are the extension of these convex approximations to the general case of two-stage mixed-integer recourse models. In particular, Romeijnders et al. [40] extend the shifted LP-relaxation approximation to this case, while van der Laan and Romeijnders [49] generalize the \(\alpha \)-approximations. For both approximations, a corresponding asymptotic error bound is derived, which converges to zero as the total variations of the density functions in the model go to zero. These bounds are derived by exploiting asymptotic periodicity of the second-stage value functions in combination with the total variation bounds from [41].
In this paper we generalize several results from this convex approximation literature to the risk-averse case. In particular, in Sect. 3 we use the asymptotic periodicity of mixed-integer value functions to derive convex approximations for general mixed-integer mean-CVaR recourse models. Moreover, we derive error bounds for these convex approximations using the total variation error bounds on the expectation of periodic functions from [41]. We also use these total variation bounds in Sect. 4 in a specialized analysis of TU integer and simple integer mean-CVaR recourse models.
2.3.1 Total variation
Similar to the error bounds for risk-neutral models from the literature, the error bounds in this paper will depend on the total variation of the one-dimensional conditional density functions of the random right-hand side variables in the model. Therefore, we conclude this section by defining the notion of total variation and some related concepts.
Definition 2
Let \(f: \mathbb {R} \rightarrow \mathbb {R}\) be a real-valued function and let \(I \subset \mathbb {R}\) be an interval. Let \(\varPi (I)\) denote the set of all finite ordered sets \(P = \{z_1, \ldots , z_{N+1} \}\) with \(z_1< \cdots < z_{N+1}\) in I. Then, the total variation of f on I, denoted by \(|\varDelta |f(I)\), is defined by
where \(V_f(P) := \sum _{i = 1}^{N} | f(z_{i+1}) - f(z_i) |\). We write \(|\varDelta |f := |\varDelta |f(\mathbb {R})\). We say that f is of bounded variation if \(|\varDelta |f < +\infty \).
Since the error bounds that we derive in this paper depend on the total variations of the one-dimensional conditional density functions of the random right-hand side variables in the model, we assume that these conditional density functions are of bounded variation.
Definition 3
For every \(i = 1,\ldots ,m\) and \(t_{-i} \in \mathbb {R}^{m-1}\), define the ith conditional density function\(f_i(\cdot |t_{-i})\) of the m-dimensional joint pdf f as
where \(f_{-i}\) represents the (marginal) joint density function of \(h_{-i}\), the random vector obtained by removing the ith element of h.
Definition 4
We denote by \(\mathscr {H}^m\) the set of all m-dimensional joint pdfs f whose conditional density functions \(f_i(\cdot |t_{-i})\) are of bounded variation for all \(t_{-i} \in \mathbb {R}^{m-1}\), \(i=1,\ldots ,m\).
3 General two-stage mixed-integer mean-CVaR recourse models
In this section we will derive convex approximations with corresponding error bounds for general mixed-integer mean-CVaR recourse models. The approach is based on the analysis by Romeijnders et al. [40] for the risk-neutral case. Although our mean-CVaR recourse model can be reformulated as a risk-neutral recourse model, the resulting model differs in structure from the model considered in [40]. We first lay out this structural difference.
To reformulate our model as a risk-neutral model, note that by Definition 1,
Based on this expression we introduce a new recourse function
where \(v^{\zeta }\) is the corresponding second-stage value function, defined as
Using these two functions the mixed-integer mean-CVaR recourse model (1) can be reformulated as
Interpreting \(\zeta \) as a first-stage variable, as suggested by [38], we observe that (10) reduces to a risk-neutral mixed-integer recourse problem. Here, for any \(\xi \in \varXi \) and \(x \in \mathbb {R}^{n_1}\) the second-stage value function \(v^{\zeta }\) can be written as
Observe that the right-hand side of the constraint \(\eta - qy - z =-\,\zeta \) does not depend on h, but only on the first-stage variable \(\zeta \). This means that, in contrast with Romeijnders et al. [40], the problem in (10) corresponds to a risk-neutral mixed-integer recourse model in which not all right-hand side variables are random. Since the results in [40] heavily rely on the pdfs of these (continuously distributed) random right-hand side variables, they are not applicable to the risk-neutral reformulation above and hence, an additional analysis is necessary. Moreover, this subtle difference in the right-hand side has surprising consequences for the type of convex approximation that we will derive.
3.1 Asymptotic semi-periodicity of \(v^{\zeta }\)
The first step in our analysis is proving that the value function \(v^{\zeta }\) is asymptotically semi-periodic in h; see Proposition 1. By asymptotic semi-periodicity we mean that on particular unbounded subsets of its domain, \(v^{\zeta }\) is the sum of a linear and periodic function. Gomory [17] identified this for the pure integer case and Romeijnders et al. [40] generalized it to the mixed-integer case. In this section we use the notation of the latter reference. We also repeat some of the definitions they introduced for the sake of completeness.
To understand why \(v^{\zeta }\) exhibits semi-periodicity, consider the LP-relaxation \(v_\text {LP}\) of the mixed-integer value function v and let \(q \in \varXi ^q\) be fixed. By the basis decomposition theorem by Walkup and Wets [53], we can identify basis matrices \(B^k\) and corresponding polyhedral cones \(\varLambda ^k \subseteq \mathbb {R}^m\), \(k \in K^q\), such that for all \(h - Tx \in \varLambda ^k\), the function \(v_\text {LP}(\xi , x)\) attains its value through the basis matrix \(B^k\), i.e., \(v_\text {LP}(\xi , x) =q_{B^k}(B^k)^{-1}(h - Tx)\). We will see that a similar result holds for the mixed-integer value function v, but only on shifted versions \(\varLambda ^k(d^k)\) of the cones \(\varLambda ^k, \ k \in K^q\).
Remark 1
Throughout this paper we omit the dependence of, e.g., \(\varLambda ^k\) and \(d^k\) on q. Instead, we assume without loss of generality that the index sets \(K^q\), \(q \in \varXi ^q\), are disjoint, i.e., \(K^{q_1} \cap K^{q_2} = \emptyset \) for all \(q_1, q_2 \in \varXi ^q\) with \(q_1 \ne q_2\). Note, however, that it is still possible that, e.g., \(B^{k_1} = B^{k_2}\) for some \(k_1 \in K^{q_1}\), \(k_2 \in K^{q_2}\), with \(q_1 \ne q_2\).
Definition 5
Let \(\varLambda \subset \mathbb {R}^m\) be a closed convex cone and let \(d \in \mathbb {R}_+\) be given. Then, we define \(\varLambda (d)\) as the set of points in \(\varLambda \) with at least Euclidean distance d to the boundary of \(\varLambda \).
Romeijnders et al. [40] show that there exist constants \(d^k>0\), \(k \in K^q\), such that for all \(h - Tx \in \varLambda ^k(d^k)\), the mixed-integer value function \(v(\xi , x)\) attains its value through the basis matrix \(B^k\). That is, \(v(\xi , x) = q_{B^k}(B^k)^{-1}(h - Tx) + \psi ^k(h - Tx)\), where the function \(\psi ^k\) represents the “penalty” incurred from having integer decision variables. These functions \(\psi ^k\) are \(B^k\)-periodic on \(\varLambda ^k(d^k)\). It turns out that \(v^{\zeta }\) exhibits the same type of periodicity.
Definition 6
Let the function \(g : \mathbb {R}^m \rightarrow \mathbb {R}^n\) be given and let B be an \(m \times m \) matrix. Then, g is called B-periodic if \(g(x) =g(x+Bl)\) for every \(x \in \mathbb {R}^m\) and \(l \in \mathbb {Z}^m\).
Proposition 1
Consider the second-stage value function \(v^{\zeta }\) from (9) for a fixed \(q \in \varXi ^q\). Then, there exist dual feasible basis matrices \(B^k\) of \(v_\text {LP}\), closed convex polyhedral cones \(\varLambda ^k := \{ t \in \mathbb {R}^m \ | \ (B^k)^{-1}t \ge 0 \}\), positive constants \(d^k\) and \(r^k\), and \(B^k\)-periodic functions \(\psi ^k\), \(k \in K^q\), such that
- (i)
\(\cup _{k = 1}^K \varLambda ^k = \mathbb {R}^m\),
- (ii)
\(({{\,\mathrm{int}\,}}\varLambda ^k) \cap ({{\,\mathrm{int}\,}}\varLambda ^l) =\emptyset \) for every \(k, l \in K^q\) with \(k\ne l\),
- (iii)
for every \(k \in K^q\),
$$\begin{aligned} v^{\zeta }(\xi , x)&= \big ( q_{B^k} (B^k)^{-1} (h - Tx) + \psi ^k (h - Tx) - \zeta \big )^+, \quad h - Tx \in \varLambda ^k(d^k), \end{aligned}$$where \(\psi ^k \equiv \psi ^l\) if \(q_{B^k}(B^k)^{-1} =q_{B^l}(B^l)^{-1}\),
- (iv)
for every \(k \in K^q\)
$$\begin{aligned} 0 \le \psi ^k(s) \le r^k, \quad s \in \mathbb {R}^m. \end{aligned}$$
Proof
Since W is an integer matrix by Assumption 1(c), the result follows directly from Theorem 2.9 in [40] and the definition of \(v^{\zeta }\). \(\square \)
Proposition 1 shows that on shifted convex cones \(\varLambda ^k(d^k)\), the approximating value function \(v^{\zeta }\) is the positive part of the sum of a linear and a periodic function in h. Hence, \(v^{\zeta }\) is indeed asymptotically semi-periodic in h.
3.2 Convex approximations of \(v^{\zeta }\) and \(R^{\beta }\)
In this subsection we construct two convex approximations \(\hat{v}^{\zeta }\) and \(\tilde{v}^{\zeta }_\alpha \) of the second-stage value function \(v^{\zeta }\), yielding two corresponding convex approximations \(\hat{R}^{\beta }\) and \(\tilde{R}^{\beta }_\alpha \) of the CVaR recourse function \(R^{\beta }\). Moreover, we derive a characterization of the differences \(v^{\zeta } - \hat{v}^{\zeta }\) and \(v^{\zeta } - \tilde{v}^{\zeta }_\alpha \). These characterizations are used in Sect. 3.3 to derive upper bounds on the approximation errors \(| R^{\beta } - \hat{R}^{\beta } |\) and \(| R^{\beta } -\tilde{R}^{\beta }_\alpha |\).
3.2.1 Construction of the convex approximations
We will use the asymptotic periodicity of v from Proposition 1 in order to construct two types of convex approximations of \(v^{\zeta }\). For \(q \in \varXi ^q\), \(k \in K^q\), and \(\zeta \in \mathbb {R}\) given, we know from Proposition 1 that
Observe that the first-stage decision vector x appears as an argument of the \(B^k\)-periodic function \(\psi ^k\). This means that for \(h -Tx \in \varLambda ^k(d^k)\), the function \(v^{\zeta }(\xi , x)\) is periodic in x. This periodicity is the cause of the non-convexity of \(v^{\zeta }(\xi , x)\) in x. In order to construct convex approximations of \(v^{\zeta }\), we propose two “convexifying” adjustments to this periodic term \(\psi ^k(h - Tx)\).
A first convex approximation of \(v^{\zeta }\) is obtained by replacing \(\psi ^k\) by its mean value \(\varGamma ^k\). This results in a shifted version of the LP-relaxation with shifting constant \(\varGamma ^k\). Hence, we refer to this kind of approximation as the shifted LP-relaxation approximation. Since every \(B^k\)-periodic function is also \(p_kI_m\)-periodic with \(p_k := |\det (B^k)|\) (see [40]), we can characterize the mean value of \(\psi ^k\) as
Surprisingly, however, in our mean-CVaR recourse model we need to make an adjustment in order to be able to derive an asymptotically converging error bound. In particular, for \(k \in K^q\) with \(q_{B^k}=0\), we should use the mean value of \((\psi ^k - \zeta )^+ +\zeta \) instead of \(\varGamma ^k\). In Example 2 we illustrate in more detail why this adjustment is needed.
To construct a second convex approximation of \(v^{\zeta }\), we replace the term Tx in the argument of \(\psi ^k\) by a constant vector \(\alpha \in \mathbb {R}^m\), yielding \(\psi ^k(h - \alpha )\). We call the resulting approximation a generalized\(\alpha \)-approximation; cf. [49]. This approximation is still semi-periodic in h, and thus not convex in h. However, it is convex in x, which is what we desire for optimization purposes.
Both approaches above yield an approximation of \(v^{\zeta }(\xi ,x)\) for \(h - Tx \in \varLambda ^k(d^k)\) for each \(k \in K^q\). We combine these approximations by taking the pointwise maximum over all \(k \in K^q\).
Definition 7
Consider the mixed-integer value function \(v^{\zeta }\) from (9) and let \(B^k\), \(q_{B^k}\), and \(\psi ^k\), \(k \in K^q\), \(q \in \varXi ^q\), be the basis matrices, corresponding cost vectors, and \(B^k\)-periodic functions from Proposition 1, respectively. Then, we define the shifted LP-relaxation approximation\(\hat{v}^{\zeta }\) of \(v^{\zeta }\) by
where for every \(k \in K^q\),
with \(p_k := |\det (B^k)|\). Moreover, for every \(\xi \in \varXi \), \(x \in \mathbb {R}^{n_1}\), and \(\zeta \in \mathbb {R}\), we define the generalized\(\alpha \)-approximation\(\tilde{v}^{\zeta }_\alpha \) of \(v^{\zeta }\) with parameter \(\alpha \in \mathbb {R}^m\) by
As mentioned before, we make an adjustment to the shifted LP-relaxation approximation in the case \(q_{B^k} = 0\). Instead of using the mean value \(\varGamma ^k\) of \(\psi ^k\), we use the mean value of \((\psi ^k - \zeta )^+ + \zeta \). In the example below we show that this adjustment is necessary in order to derive error bounds that are asymptotically converging, in the sense that they converge to zero as the total variations of the conditional density functions of the random right-hand side variables \(h_i\), \(i=1,\ldots ,m\), go to zero.
Example 2
Consider a mixed-integer value function v given by
where \(\varXi ^q = \{1\}\), \(\varXi ^T = \{[1]\}\), and \(\varXi ^h = \mathbb {R}\). The LP-relaxation \(v_{LP}\) of v equals \(v_{LP} \equiv 0\), since for every \(\hat{h} := h - x \in \mathbb {R}\) with \(\hat{h} \ge 0\) we can select \(y^+ = \hat{h}, \ y^ - = u = 0\) and for \(\hat{h} < 0\) we can select \(y^- = -\hat{h}, \ y^+ = u = 0\). Indeed, if \(\hat{h} > 0\), then \(y^+\) is the basic variable corresponding to basis matrix \(B^1 =[1]\) with costs \(q_{B^1} = 0\) and if \(\hat{h} < 0\), then \(y^-\) is the basic variable corresponding to \(B^2 = [-1]\) with \(q_{B^2} = 0\). Since the mixed-integer value function v equals \(v(\xi , x) =\psi (\hat{h}) := \hat{h}-\lfloor \hat{h}\rfloor \) for all \(\hat{h} \in \mathbb {R}\), we have \(\psi ^1 = \psi ^2 = \psi \) and thus \(\varGamma ^1 = \varGamma ^2 =\int _0^1\psi (s)ds = \frac{1}{2}\).
Now suppose that we simply use \(\varGamma ^k\) (rather than \(\varGamma ^k_\zeta \)) to construct the convex approximation
of \(v^{\zeta }\) and the corresponding convex approximation \(\bar{R}^{\beta }(x) := \min _{\zeta \in \mathbb {R}}\big \{ \zeta +\tfrac{1}{1-\beta } \bar{R}^*(x,\zeta ) \big \}\) of \(R^{\beta }\), where \(\bar{R}^*(x, \zeta ) := \mathbb {E}_\xi \big [ \bar{v}^{\zeta }(\xi , x) \big ]\). We will show that the resulting approximation error \(\Vert R^{\beta } - \bar{R}^{\beta } \Vert _\infty \) is not asymptotically converging in general.
First note that for every \(x \in \mathbb {R}\) we have \(\bar{R}^\beta (x) = \min _{\zeta \in \mathbb {R}} \big \{ \zeta + \tfrac{1}{1-\beta } (\tfrac{1}{2} - \zeta )^+ \big \} = \text {CVaR}_\beta \big [\tfrac{1}{2}\big ] = \tfrac{1}{2}\) by definition of CVaR. Now, suppose that h is uniformly distributed on the interval [0, N], where N is a positive integer, and consider the value \(x=0\) for the first-stage decision variable. Then, since h is continuously distributed we know from [38] that \(R^{\beta }(x) = {{\,\mathrm{CVaR}\,}}_\beta [v(\xi , x)] = \mathbb {E}_h[v(\xi , x) \ | \ v(\xi , x) \ge q_\beta (x)]\), where \(q_\beta (x)\) is the \(\beta \)-quantile of \(v(\xi , x) = \psi (\hat{h}) = h - \lfloor h\rfloor \). It follows by straightforward computation that \(R^{\beta }(x) = 1 - \beta /2\). Hence, \(|R^{\beta }(x) -\bar{R}^{\beta }(x)| = |\tfrac{1}{2} - \beta /2|\), which is positive if \(\beta \ne \tfrac{1}{2}\). Note that this expression does not depend on N. Hence, as N goes to infinity (i.e., the total variation of the density function of h goes to zero), the approximation error remains constant, i.e., it does not converge to zero asymptotically. \(\triangle \)
Using the approximating value functions from Definition 7, we define corresponding convex approximations of the CVaR recoure function \(R^{\beta }\). These can be seen as extensions of the convex approximations in [40, 49] to our mean-CVaR setting.
Definition 8
Consider the CVaR recourse function \(R^{\beta }\) from (4). We define the shifted LP-relaxation approximation\(\hat{R}^{\beta }\) of \(R^{\beta }\) by
where \(\hat{R}^*(x, \zeta ) := \mathbb {E}_\xi \big [ \hat{v}^{\zeta }(\xi , x) \big ]\), with \(\hat{v}^{\zeta }\) defined in Definition 7. Moreover, we define the generalized\(\alpha \)-approximation\(\tilde{R}^{\beta }_\alpha \) of \(R^{\beta }\) with parameter \(\alpha \in \mathbb {R}^m\) by
where \(\tilde{R}^*_\alpha (x, \zeta ) := \mathbb {E}_\xi \big [ \tilde{v}^{\zeta }_\alpha (\xi , x) \big ]\), with \(\tilde{v}^{\zeta }_\alpha \) defined in Definition 7.
Since the approximations from Definition 8 are convex, the resulting convex approximation models can be solved using techniques from convex optimization. As a result, they can be solved much more efficiently than the original (non-convex) model in (1). This is indeed true for the generalized \(\alpha \)-approximations, whereas for the shifted LP-relaxation approximation some computational challenges remain.
The first computational challenge is that the shifted LP-relaxation approximation \(\hat{R}^{\beta }\) requires computing the means \(\varGamma _\zeta ^k\) for all \(k \in K^q\). For special cases, such as pure integer recourse models with a totally unimodular recourse matrix W (cf. Sect. 4), it is possible to derive analytic expressions for these means. However, in general they need to be approximated in practical computations. In contrast, the generalized \(\alpha \)-approximations only need computation of the function values \(\psi ^k(h - \alpha )\), which are obtained by solving a single mixed-integer linear program, or in fact a Gomory relaxation of this mixed-integer linear program.
The second computational challenge is that the convex approximations are defined as the maximum over all dual feasible basis matrices \(B^k\), \(k \in K^q\), of which there are exponentially many in general. This challenge can be overcome for both approximations by taking the optimal basis matrix of the LP-relaxation instead of the maximum, see also [49]. This is again an approximation, but van der Laan and Romeijnders [49] show both theoretically and using numerical experiments that it yields good results.
Finally, we remark that for computational purposes the continuously distributed random vectors in the model need to be discretized. For instance, using Jensen [20] and Edmundson–Madansky [14, 30] lower and upper bounds or using a sample average approximation (SAA), see [24]. However, if the discretization is fine enough, this does not affect the quality of the convex approximations.
3.2.2 Properties of \(\hat{v}^{\zeta }\) and \(\tilde{v}^{\zeta }_\alpha \)
We now present several properties of the approximating value functions \(\hat{v}^{\zeta }\) and \(\tilde{v}^{\zeta }_\alpha \). In particular, we focus on the differences \(v^{\zeta } - \hat{v}^{\zeta }\) and \(v^{\zeta } - \tilde{v}^{\zeta }_\alpha \), which can be interpreted as the underlying difference functions in the approximation errors \(|R^{\beta } - \hat{R}^{\beta }|\) and \(|R^{\beta } -\tilde{R}^{\beta }_\alpha |\). Since several proofs of the results in this subsection are similar to the proofs of corresponding results in [40] for the risk-neutral case, we postpone them to the Appendix. Moreover, since the derivations for \(\hat{v}^{\zeta }\) and \(\tilde{v}^{\zeta }_\alpha \) are analogous, we will avoid repetition and focus on \(\hat{v}^{\zeta }\) in our discussions.
First we show that the difference between \(v^{\zeta }\) and its shifted LP-relaxation approximation \(\hat{v}^{\zeta }\) is uniformly bounded.
Lemma 1
Consider the value function \(v^{\zeta }\) from (9) and its shifted LP-relaxation approximation \(\hat{v}^{\zeta }\) and generalized \(\alpha \)-approximation \(\tilde{v}^{\zeta }_\alpha \) from Definition 7. Then, there exists a constant \(\gamma > 0\) such that for every \(\zeta \in \mathbb {R}\),
Proof
See Appendix. \(\square \)
Next, we work towards a characterization of the difference \(v^{\zeta } - \hat{v}^{\zeta }\) in terms of periodic functions. Recall from Proposition 1 that for any given \(q \in \varXi ^q\), \(k \in K^q\), and \(h - Tx \in \varLambda ^k(d_k)\), the value of \(v^{\zeta }(\xi , x)\) is generated by the dual feasible basis matrix \(B^k\), i.e., \(v^{\zeta }(\xi , x) = \big (q_{B^k}(B^k)^{-1}(h-Tx) +\psi ^k(h - Tx) - \zeta \big )^+\). The following lemma shows that on a subset \(\sigma ^k + \varLambda ^k\) of \(\varLambda ^k(d_k)\), the convex approximation \(\hat{v}^{\zeta }(\xi , x)\) is generated by the same basis matrix \(B^k\).
Lemma 2
Consider the value function \(v^{\zeta }\) from (9) and its shifted LP-relaxation approximation \(\hat{v}^{\zeta }\) from Definition 8. Moreover, let \(B^k\), \(\varLambda ^k\), and \(d^k\) be the basis matrices, cones, and scalars from Proposition 1. Then, for every \(q \in \varXi ^q\) and \(k \in K^q\), there exists a vector \(\sigma ^k \in \varLambda ^k(d_k)\) such that
and
Proof
See Appendix. \(\square \)
Since \(\sigma ^k + \varLambda ^k \subseteq \varLambda ^k(d^k)\), it now follows that for all \(h - Tx \in \sigma ^k + \varLambda ^k\), both \(v^{\zeta }\) and \(\hat{v}^{\zeta }\) are generated by the same basis matrix \(B^k\). Using this fact, we can derive subsets of \(\sigma ^k + \varLambda ^k\), \(k \in K^q\), on which the difference \(v^{\zeta } - \hat{v}^{\zeta }\) is \(B^k\)-periodic with a mean value of zero. In particular, if \(q_{B^k} \ne 0\), then (using \(0 \le \psi ^k \le r^k\)),
whereas if \(q_{B^k} = 0\) we have (using the definition of \(\varGamma ^k_\zeta \))
where \(\mu ^k_\zeta := p_k^{-m} \int _0^{p_k} \cdots \int _{0}^{p_k} (\psi ^k(s) - \zeta )^+ ds_1 \ldots ds_m\). Indeed the right-hand sides above are \(B^k\)-periodic functions of h. Moreover, it can be shown that the complement of these subsets on which \(v^{\zeta } - \hat{v}^{\zeta }\) is \(B^k\)-periodic, \(k \in K^q\), is “relatively small”, in the sense that it can be covered by finitely many hyperslices. We summarize these results below.
Definition 9
A hyperslice in \(\mathbb {R}^m\) is a set H of the form
where \(a \in \mathbb {R}^m {\setminus } \{0\}\), \(b \in \mathbb {R}\), and \(\delta \in \mathbb {R}\) with \(\delta > 0\).
Proposition 2
Consider the value function \(v^{\zeta }\) from (9) and its convex approximations \(\hat{v}^{\zeta }\) and \(\tilde{v}^{\zeta }_\alpha \) from Definition 7. Then, for every \(q \in \varXi ^q\) and \(\zeta \in \mathbb {R}\), there exists a finite number of closed convex polyhedral sets \(\mathscr {A}_j \subseteq \mathbb {R}^m\), \(j \in J^q_\zeta \), whose interiors are mutually disjoint, such that
- (i)
for all \(h - Tx \in \mathscr {A}_j\), \(j \in J^q_\zeta \), we can write
$$\begin{aligned} v^{\zeta }(\xi , x) - \hat{v}^{\zeta }(\xi , x) = \phi ^{\zeta }_j(h - Tx), \ \ \text {and} \ \ \ v^{\zeta }(\xi , x) - \tilde{v}^{\zeta }_\alpha (\xi , x) =\bar{\phi }^{\zeta }_j(h - Tx), \end{aligned}$$where \(\phi ^{\zeta }_j\) and \(\bar{\phi }^{\zeta }_j\) are bounded \(B^k\)-periodic functions for some \(k \in K^q\) with mean value equal to zero.
- (ii)
the set \(\mathscr {N}^q_\zeta := \mathbb {R}^m {\setminus } \bigcup _{j \in J^q_\zeta } \mathscr {A}_j\) can be covered by finitely many hyperslices.
Proof
See Appendix. \(\square \)
3.3 Total variation error bounds
We now derive upper bounds on the approximation errors \(|R^{\beta }(x) -\hat{R}^{\beta }(x)|\) and \(|R^{\beta }(x) -\tilde{R}^{\beta }_\alpha (x)|\) using the results from Sect. 3.2.2. We outline our approach for \(\hat{R}^{\beta }\); the analysis for \(\tilde{R}^{\beta }_\alpha \) is analogous.
We first derive an upper bound on \(|R^*(x, \zeta ) - \hat{R}^*(x, \zeta )|\). For every \(x \in \mathbb {R}^{n_1}\) and \(\zeta \in \mathbb {R}\), we have by definition of \(R^*\) and \(\hat{R}^*\) that
where we use that the right-hand side vector h is independent from (q, T) by Assumption 1(e). Consider the integral over \(\mathbb {R}^m\) in (12) for a fixed \(q \in \varXi ^q\) and \(T \in \varXi ^T\). The main idea is to use Proposition 2 to split up this integral into integrals over two types of subsets of \(\mathbb {R}^m\): subsets \(\mathscr {A}_j\), \(j \in J^q_\zeta \), on which the expression \(v^{\zeta } - \hat{v}^{\zeta }\) in the integrand is a \(B^k\)-periodic function for some \(k \in K^q\), and the complement \(\mathscr {N}^q_\zeta \) of these subsets. Then, the integrals over \(\mathscr {A}_j\), \(j \in J^q_\zeta \), can be bounded using a result from [40] that exploits periodicity in the integrand. Furthermore, the integral over the complement set \(\mathscr {N}^q_\zeta \) can be bounded using Lemma 1 and another result in [40] that provides an upper bound on the probability \(\mathbb {P}\{ h - Tx \in \mathscr {N}^q_\zeta \ | \ q, T \}\). Together, this yields a uniform upper bound on \(|R^*(x, \zeta ) -\hat{R}^*(x, \zeta )|\). Finally, is not hard to prove that this also constitutes an upper bound on \(\Vert R^{\beta } - \hat{R}^{\beta } \Vert _\infty \).
Theorem 1
Consider the CVaR recourse function \(R^{\beta }\) from (4). Moreover, consider its shifted LP-relaxation approximation \(\hat{R}^{\beta }\) and generalized \(\alpha \)-approximation \(\tilde{R}^{\beta }_\alpha \) with parameter \(\alpha \in \mathbb {R}^m\) from Definition 8. Then, there exist finite, positive constants \(C_1\) and \(C_2\) such that for all \(f \in \mathscr {H}^m\) we have
and
Proof
We will prove (13); the proof of (14) is completely analogous. First, we show that \(\Vert R^{\beta } -\hat{R}^{\beta } \Vert _\infty \le \tfrac{1}{1-\beta } \Vert R^* - \hat{R}^* \Vert _\infty \). Fix \(x \in \mathbb {R}^{n_1}\) and let \(\zeta ^*\) be the minimizer in the minimization representation of \(R_\beta (x)\) in (7). Since \(\zeta ^*\) is not necessarily optimal for the minimization problem defining \(\hat{R}_\beta (x)\) in Definition 8, we have \(\hat{R}_\beta (x) -R_\beta (x) \le \tfrac{1}{1-\beta }\big (\hat{R}^*_\beta (x,\zeta ^*) -R^*_\beta (x,\zeta ^*)\big ) \le \tfrac{1}{1-\beta } \Vert \hat{R}^*_\beta - R^*_\beta \Vert _\infty \). Using an analogous argument for the reverse difference, we obtain \(\Vert R_\beta - \hat{R}_\beta \Vert _\infty \le \tfrac{1}{1-\beta } \Vert \hat{R}^*_\beta - R^*_\beta \Vert _\infty \).
Next, we derive a constant \(C_1\) such that \(\Vert R^* -\hat{R}^*\Vert _\infty \le C_1 \sum _{i=1}^{m} \mathbb {E}_{{h}_{-i}} \left[ |\varDelta |f_i(\cdot |h_{-i}) \right] \). Let \(x \in \mathbb {R}^{n_1}\) and \(\zeta \in \mathbb {R}\) be given and take (12) as a starting point. Splitting up the integral in the right-hand side of (12) according to Proposition 2 yields
where we write \(\xi _s := (q, T, s)\), \(s \in \mathbb {R}^m\). Consider the first term in the right-hand side of (15). Since \(Tx + \mathscr {A}_j\) is a convex set and \(\phi ^j_\zeta \) is a bounded zero-mean \(B^{k_j}\)-periodic function for some \(k_j \in K^q\), we can apply Theorem 4.13 from [40] to obtain
Next, consider the second term in the right-hand side of (15). Applying Lemma 1 to this integral, we obtain
By Proposition 2(ii), the set \(\mathscr {N}^q_\zeta \) in the right-hand side above can be covered by finitely many hyperslices. By Theorem 4.6 from [40], this implies that there exists a constant \(D^q > 0\) such that \(\mathbb {P}\{ h - Tx \in \mathscr {N}^q_\zeta \ | \ q, T \} \le D^q \sum _{i=1}^{m} \mathbb {E}_{h_{-i}} \big [ |\varDelta |f_i(\cdot | h_{-i}) \big ]\). Substituting this into (17) yields
for some constant \(D^q>0\). Now, defining \(C^q := \gamma D^q +\sum _{j \in J^q_\zeta }\frac{1}{4}r^{k_j} |\det (B^{k_j})|\), and substituting (16) and (18) into (15), we obtain
Finally, defining \(C_1 := \max _{q \in \varXi ^q} C^q\) and substituting (19) into (12) yields
Now, (13) follows from the inequality \(\Vert R_\beta - \hat{R}_\beta \Vert _\infty \le \tfrac{1}{1-\beta } \Vert \hat{R}^*_\beta - R^*_\beta \Vert _\infty \) and the observation that the right-hand side above does not depend on the value of x or \(\zeta \). \(\square \)
The error bounds from Theorem 1 are asymptotically converging, i.e., they converge to zero as the total variations of the density functions of the random right-hand side variables in the model converge to zero. For instance, for independently distributed normal random variables this is the case if all standard deviations \(\sigma _i\) go to \(\infty \). In fact, Theorem 1 implies that any mixed-integer CVaR recourse function \(R_\beta \) can be approximated reasonably well by a convex approximation \(\hat{R}_\beta \) or \(\tilde{R}^{\beta }_\alpha \) if the aforementioned total variations are small.
Interestingly, the error bounds from Theorem 1 differ from their risk-neutral counterparts in Proposition 3 only by an additional factor \(\tfrac{1}{1-\beta }\). Hence, combining these error bounds with corresponding risk-neutral error bounds as suggested in (6) results in an expression for the joint error bound with a similar asymptotic behavior.
4 Two-stage TU integer mean-CVaR recourse models
In this section we derive tighter error bounds for the special case of two-stage TU integer mean-CVaR recourse models. That is, we consider the model from Sect. 2.1 and we make the additional assumption that the second-stage value function can be written as
where \(\bar{W}\) is a totally unimodular matrix. This is indeed a special case of the value function (5) from Sect. 2.1, with \(n_3 = m\), \(q = (\bar{q}, 0)\), \(y = (\bar{y}, z)\), and \(W = [\bar{W} \,{-}\,I_m]\), where \(I_m\) is the \(m \times m\) identity matrix. We exploit the special structure of this model to derive sharper error bounds for the shifted LP-relaxation and generalized \(\alpha \)-approximation than those in Theorem 1.
4.1 Convex approximations
The TU integer structure of the value function v from (20) allows for simplified representations of the convex approximations \(\hat{R}^{\beta }\) and \(\tilde{R}^{\beta }_\alpha \) from Definition 7. These will be used in the proofs of the tighter error bounds in Theorem 2 and 3. We first derive a simplified representation of v itself.
Since \(\bar{W}\) is a TU (and thus, integer) matrix, it follows that
where the round-up operator \(\lceil \cdot \rceil \) is defined element-wise for vectors. By Assumption 1(a) and strong LP-duality, we obtain the dual maximization problem
Here, the dual feasible region \(\{ \lambda \in \mathbb {R}_+^m \ | \ \lambda \bar{W} \le \bar{q} \}\) is a non-empty, bounded polyhedron for every \(q \in \varXi ^q\), and hence it has a positive, finite number of extreme points. These extreme points can be characterized as \(\lambda ^k := q_{B^k}(B^k)^{-1}, \ k \in K^q\). Note that at least one of these points is optimal in the dual problem. Hence, we can write
Based on (21) we can derive simplified representations of the convex approximations \(\hat{R}^{\beta }\) and \(\tilde{R}^{\beta }_\alpha \) from Definition 7.
Lemma 3
Let \(R^{\beta }(x) = {{\,\mathrm{CVaR}\,}}_\beta [v(\xi , x)]\) be the CVaR recourse function from (4), where v is the TU integer value function from (20). Then, the convex approximations \(\hat{R}^{\beta }\) and \(\tilde{R}^{\beta }_\alpha \) from Definition 8 can be represented as
for all \(x \in \mathbb {R}^{n_1}\), where \(\hat{v}\) and \(\tilde{v}_\alpha \) are defined by
for all \(\xi \in \varXi \), \(x \in \mathbb {R}^{n_1}\), where \(\iota _m = (1, \ldots , 1) \in \mathbb {R}^m\).
Proof
Let \(\xi \in \varXi \), \(\zeta \in \mathbb {R}\), and \(x \in \mathbb {R}^{n_1}\) be given and consider the function \(\hat{v}^{\zeta }(\xi , x)\) from Definition 7. By Example 3.4 in [40] it follows from straightforward analysis that \(\hat{v}^{\zeta }(\xi ,x) = (\hat{v}(\xi , x) - \zeta )^+\). Then, from the definition of \(\hat{R}^{\beta }\) and the definition of CVaR, it follows that \(\hat{R}^{\beta }(x) = {{\,\mathrm{CVaR}\,}}[\hat{v}(\xi , x)]\). The proof for \(\tilde{R}^{\beta }_\alpha \) is analogous. \(\square \)
Note that the convex approximations \(\hat{R}^{\beta }\) and \(\tilde{R}^{\beta }_\alpha \) in Lemma 3 are structurally similar to the original CVaR recourse function \(\hat{R}^{\beta }\), while the approximating value functions \(\hat{v}\) and \(\tilde{v}_\alpha \) are structurally similar to the mixed-integer value function v in (21).
4.2 Error bounds
In this subsection we derive tight error bounds for the shifted LP-relaxation approximation \(\hat{R}^{\beta }\) and the generalized \(\alpha \)-approximation \(\tilde{R}^{\beta }_\alpha \) by exploiting the TU integer structure of the value function v. Since the derivations for \(\hat{R}^{\beta }\) and \(\tilde{R}^{\beta }_\alpha \) are analogous, we only discuss the derivation for the former.
Our approach to derive sharp error bounds consists of three main steps. First, in Lemma 4 we find an upper bound on the approximation error \(\hat{R}^{\beta }(x) -R^{\beta }(x)\) in terms of the approximation error for a risk-neutral recourse function, under a conditional probability distribution. Second, we apply existing results from the risk-neutral literature to this approximation error to obtain an error bound, in terms of this conditional probability distribution. Finally, we rewrite this error bound in terms of the original probability distribution; the resulting error bounds are presented in Theorems 2 and 3.
By definition of CVaR we have
where an optimal argument \(\zeta \) is given by the \(\beta \)-value-at-risk (VaR) of \(v(\xi , x)\), defined by \(\zeta ^{\beta }(x) := \min \big \{ \zeta \in \mathbb {R}\ | \ \mathbb {P}\{ v(\xi , x) \le \zeta \} \ge \beta \big \}\) ; see [38]. By Lemma 3, the approximation \(\hat{R}^{\beta }(x)\) has a similar representation, with the \(\beta \)-VaR of \(\hat{v}(\xi , x)\) as an optimal argument: \(\hat{\zeta }^{\beta }(x) := \min \big \{ \zeta \in \mathbb {R}\ | \ \mathbb {P}\{\hat{v}(\xi , x) \le \zeta \} \ge \beta \big \}\). Note that \(\zeta ^{\beta }(x) \ne \hat{\zeta }^{\beta }(x)\) in general. However, since \(\zeta ^{\beta }(x)\) is optimal for \(R^{\beta }(x)\) and feasible for \(\hat{R}^{\beta }(x)\), we obtain the inequality
Using this inequality as a starting point, we will derive an upper bound on the approximation error \(\hat{R}^{\beta }(x) - R^{\beta }(x)\). An analogous derivation will yield an upper bound on the reverse difference \(R^{\beta }(x) - \hat{R}^{\beta }(x)\).
We start by deriving an upper bound on the expression
in the right-hand side of (22). For the sake of argument, suppose that we could remove the positive part operators in (23). Then, we would obtain \(\varDelta ^{\beta }(x;q,T) = \mathbb {E}_{h} \big [ \hat{v}(\xi , x) - v(\xi , x) \big ]\). Note that this is the approximation error for a risk-neutral recourse function. Hence, we could directly apply existing results from the risk-neutral literature [41] to obtain an upper bound. Using this idea, we take the approach of conditioning on two complementary cases. In the first case, the positive part operators indeed drop out, while the second case reduces to zero.
Lemma 4
Let \(q \in \varXi ^q\), \(T \in \varXi ^T\), and \(x \in \mathbb {R}^{n_1}\) be given and consider \(\varDelta ^{\beta }(x;q,T)\) from (23). Then,
Proof
We take (23) as a starting point and consider the complementary cases \(\hat{v}(\xi , x) > \zeta ^{\beta }(x)\) and \(\hat{v}(\xi , x) \le \zeta ^{\beta }(x)\). First, suppose that \(\hat{v}(\xi , x) > \zeta ^{\beta }(x)\). Then, \((\hat{v}(\xi , x) - \zeta ^{\beta }(x))^+ = \hat{v}(\xi , x) - \zeta ^{\beta }(x)\). Using this fact and \((v(\xi , x) - \zeta ^{\beta }(x))^+ \ge v(\xi , x) - \zeta ^{\beta }(x)\), we obtain
Second, suppose that \(\hat{v}(\xi , x) \le \zeta ^{\beta }(x)\). Then, \((\hat{v}(\xi , x) - \zeta ^{\beta }(x))^+ = 0\). Using \((v(\xi , x) -\zeta ^{\beta }(x))^+ \ge 0\), we get
Using (24) and (25) and defining \(p^{\beta }_x := \mathbb {P}\{ \hat{v}(\xi , x) > \zeta ^{\beta }(x) \ | \ q, T \} = 0\), we find by conditioning on \(\hat{v}(\xi , x) > \zeta ^{\beta }(x)\) and \(\hat{v}(\xi , x) \le \zeta ^{\beta }(x)\) that
The result follows from the observation that the second term above equals zero. \(\square \)
Remark 2
In Lemma 4 it could be that \(\mathbb {P}\{\hat{v}(\xi , x) > \zeta ^{\beta }(x) \ | \ q, T \} = 0\), in which case the conditional expectation \(\mathbb {E}_{h}[\hat{v}(\xi , x) -v(\xi , x) \ | \ \hat{v}(\xi , x) > \zeta ^{\beta }(x) ]\) is ill-defined. In that case, we define this conditional expectation as zero. Then, we clearly have that \(\varDelta ^{\beta }(x; q, T) \le 0\), so Lemma 4 remains valid. \(\triangle \)
Lemma 4 provides an upper bound on \(\varDelta ^{\beta }(x;q,T)\) in terms of the approximation error of a risk-neutral model under a conditional probability distribution. This means that we can directly apply existing error bounds for risk-neutral recourse functions to obtain an upper bound on \(\varDelta ^{\beta }(x; q, T)\) and thus, on \(\hat{R}^{\beta }(x) - R^{\beta }(x)\). Note, however, that this upper bound will be in terms of the conditional pdf of h, given \(\hat{v}(\xi , x) > \zeta ^{\beta }(x)\). By rewriting this upper bound in terms of the original pdf f of h, we obtain the error bounds in Theorem 2. These uniform error bounds can be interpreted as the risk-averse generalizations of Proposition 4 in the Appendix.
Theorem 2
Consider the CVaR recourse function \(R^{\beta }\) from (4), where v is the TU integer value function from (20), and consider its shifted LP-relaxation approximation \(\hat{R}^{\beta }\) and generalized \(\alpha \)-approximation \(\tilde{R}^{\beta }_\alpha \) from Definition 8. Then, if \(f \in \mathscr {H}^m\), we have
where for every \(i=1,\ldots ,m\), we have \(\bar{\lambda }^*_i := \mathbb {E}_q[\lambda ^*_{q,i} ]\), with \(\lambda ^*_{q,i} := \max _{k \in K^q} \{\lambda ^k_i \}\), \(q \in \varXi ^q\), and the function \(g:\mathbb {R}_+ \rightarrow \mathbb {R}\) is defined by
Proof
See Appendix. \(\square \)
In comparison with Theorem 1, Theorem 2 provides tractable analytic expressions (in terms of \(\bar{\lambda }^*_i\)) for the constants \(C_1\) and \(C_2\). Using these expressions, the error bounds from Theorem 2 are generally much tighter than those from Theorem 1. Moreover, observe that the error bounds from Theorem 2 differ from their risk-neutral counterparts in Proposition 4 only in the additional factor \(\tfrac{1}{1-\beta }\), similar as for the error bounds from Theorem 1 in Sect. 3. Finally, it should be noted that the error bounds for the shifted LP-relaxation approximation \(\hat{R}^{\beta }\) are a factor 2 smaller than those for the \(\alpha \)-approximation \(\tilde{R}^{\beta }_\alpha \).
It turns out that we can derive even tighter bounds by exploiting the fact that the expectation in Lemma 4 is conditional on \(\hat{v}(\xi , x) > \zeta ^{\beta }(x)\). Intuitively, this means that the (upper bound on the) approximation error \(\hat{R}^{\beta }(x) - R^{\beta }(x)\) is only determined by values of \(\xi \) for which \(\hat{v}(\xi , x)\) is large. Since the TU integer approximating value function \(\hat{v}\) is monotone in \(h_i\), it follows that for a given x, q, T, and \(h_{-i}\), this is equivalent to \(h_i \ge \tau _i\) for some \(\tau _i \in \mathbb {R}\). Hence, we only need to account for the total variation over the interval \([\tau _i, +\infty )\), for some appropriately defined scalar \(\tau _i\).
Definition 10
Let v be the second-stage value function from (20) and let \(\hat{v}\) and \(\tilde{v}_\alpha \) be as in Lemma 3. Furthermore, let \(\zeta ^{\beta }(x) := \min \big \{ \zeta \in \mathbb {R}\ | \ \mathbb {P}\{ v(\xi , x) \le \zeta \} \ge \beta \big \}\) denote the \(\beta \)-VaR of \(v(\xi , x)\) and similarly, let \(\hat{\zeta }^{\beta }(x)\) and \(\tilde{\zeta }^{\beta }_\alpha (x)\) denote the \(\beta \)-VaR of \(\hat{v}(\xi , x)\) and \(\tilde{v}_\alpha (\xi , x)\), respectively. Finally, let \(i=1,\ldots ,m\), be given and define \(\xi _{-i} := (q, T, h_{-i})\). Then, for every \(\xi _{-i} \in \varXi ^q \times \varXi ^T \times \mathbb {R}^{m-1}\), we define
Theorem 3
Consider the setting of Theorem 2 If \(f \in \mathscr {H}^m\), then for every \(x \in \mathbb {R}^{n_1}\) we have
where g is the function from Theorem 2 and for every \(i=1,\ldots ,m\), the constants \(\lambda ^*_{q,i} := \max _{k \in K^q} \{ \lambda ^k_i \}\), \(q \in \varXi ^q\), are as in Theorem 2, and \(\hat{\tau }^{\beta }_{x,i}\) and \(\tilde{\tau }^{\beta ,\alpha }_{x,i}\) are defined in Definition 10.
Proof
See Appendix. \(\square \)
Theorem 3 exploits the fact that CVaR represents the expected value of the \((1-\beta )\times 100\%\) worst-case values only. As a result, the error bounds in Theorem 3 only depend on the total variation of the conditional pdfs of h over that part of its support that corresponds to these worst-case values. Since this support decreases if \(\beta \) increases, this total variation is non-increasing in \(\beta \). This effect explains why, contrary to what Theorem 1 suggests, the approximation errors \(|R^{\beta }(x) - \hat{R}^{\beta }(x)|\) and \(|R^{\beta }(x) - \tilde{R}^{\beta }_\alpha (x)|\) may actually be decreasing in \(\beta \). We illustrate this for the special case of simple integer recourse models in the next subsection.
4.3 Simple integer recourse
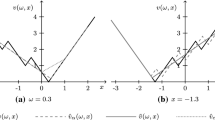
In this subsection we study the behavior of the error bounds from Theorem 3 in the special case of so-called one-dimensional simple integer recourse (SIR). Similar as in the risk-neutral case [23, 28, 41], we can exploit the special structure of this problem to construct a convex approximation with a sharp error bound. Surprisingly, for random variables h with a non-increasing positive tail, the error bound depends on the hazard rate of the distribution of h. Contrary to the bound in Theorem 1 from Sect. 3, this error bound is not necessarily large if \(\beta {\uparrow } 1\). This is a desirable property, since we are generally interested in large values for the CVaR parameter \(\beta \in (0,1)\). In fact, we prove that for heavy-tailed distributions with a decreasing hazard rate the error bound converges to zero if \(\beta {\uparrow } 1\).
The one-dimensional simple integer recourse model is defined as a special case of the TU integer recourse model defined by (20), with \(n_2 = 1\), \(\bar{W} = [1]\), \(\bar{q}=1\) and \(T=[1]\). Note that q and T are assumed to be deterministic; only the right-hand side vector \(h \in \mathbb {R}\) is random, with pdf f and cdf F. The second-stage value function can then be written as
while its convex approximations \(\hat{v}\) and \(\tilde{v}_\alpha \) reduce to
for all \(h, x \in \mathbb {R}\). Below we analyze the error bounds from Theorem 3 for these convex approximations. However, since the bounds for \(\hat{R}^{\beta }\) and \(\tilde{R}^{\beta }_\alpha \) differ only by a factor 2, we present the results for the shifted LP-relaxation \(\hat{R}^{\beta }\) only. We start by presenting a simplified version of the error bound in (29) from Theorem 3.
Corollary 1
Let \(R^{\beta }\) be the CVaR recourse function from (4), where v is the SIR value function from (31). Moreover, let \(\hat{R}^{\beta }\) be the shifted LP-relaxation approximation from Definition 8. Then,
where \(\tau ^{\beta } := F^{-1}(\beta ) - 1\) and g is defined in (28).
Proof
See Appendix. \(\square \)
It is not immediately clear whether the error bound in Corollary 1 is increasing or decreasing in \(\beta \). On the one hand, the fraction \(\tfrac{1}{1-\beta }\) increases in \(\beta \) and goes to \(+\infty \) as \(\beta {\uparrow } 1\). On the other hand, \(g\big (|\varDelta |f\big ( [\tau ^{\beta }, +\infty ) \big )\big )\) decreases in \(\beta \) and goes to zero as \(\beta {\uparrow } 1\), since the left end-point \(\tau ^{\beta }\) of the interval over which we take the total variation of f goes to \(+\infty \). Below, we identify conditions on the tail of the pdf f under which the error bound goes to zero as \(\beta {\uparrow } 1\). We do so for random variables h for which the pdf f has a positive, non-increasing right tail; see Assumption 2. This includes many commonly-used probability distributions such as the normal, gamma, Weibull, and lognormal distribution.
Assumption 2
The pdf f of the random variable h has a positive, non-increasing right tail. That is, there exists a scalar \(z \in \mathbb {R}\) such that f is positive and non-increasing on \([z, +\infty )\).
Corollary 2
Consider the setting of Corollary 1 and suppose that Assumption 2 holds. Then, for \(\beta \ge F(z+1)\), we have
Proof
Since \(\beta \ge F(z + 1)\), it follows that \(\tau ^{\beta } \ge z\). Since f has a non-increasing right tail, this implies that \(|\varDelta |f \big ( [\tau ^{\beta }, +\infty ) \big ) = f(\tau _\beta )\). The result now follows from the observation that \(g(t) \le 1/8\) for all \(t \ge 0\). \(\square \)
The error bound from Corollary 2 is closely related to the hazard rate of h. It turns out that the error bound (and hence, also the error itself) converges to zero if this hazard rate goes to zero.
Definition 11
Let h be a continuous random variable with pdf f and cdf F. Then, the hazard rate\(\lambda \) of h is defined as
We say h has a decreasing hazard rate if \(\lim \nolimits _{t \rightarrow \infty } \lambda (t) = 0\).
Theorem 4
Let \(R^{\beta }\) be the CVaR recourse function from (4), where v is the SIR value function from (31). Moreover, let \(\hat{R}^{\beta }\) be the shifted LP-relaxation approximation from Definition 8. Suppose that Assumption 2 holds and that h has a decreasing hazard rate. Then,
Proof
For \(\beta \) sufficiently close to 1, the condition \(\beta \ge F(z+1)\) of Corollary 2 holds. Hence, by Corollary 2 it follows that
Consider the limit in the right-hand side above. Performing a change of variable \(t = F^{-1}(\beta )\), and using that \(\lim \nolimits _{\beta {\uparrow } 1} F^{-1}(\beta ) = +\infty \), we get
where the last equality follows by Lemma 5 in Appendix B. Substituting this into (33) completes the proof. \(\square \)
Theorem 4 shows that the convex approximation \(\hat{R}^{\beta }\) is good for large values of \(\beta \) if h has a decreasing hazard rate. Since every distribution with a decreasing hazard rate has a heavy tail [15], the convex approximation is good in cases where extreme events are relatively likely to occur. Interestingly, this is precisely the situation in which explicit modeling of risk is desired. More generally, contrary to what the error bounds from Theorem 1 suggest, Theorem 4 provides evidence that the approximation errors of our convex approximations need not explode as \(\beta {\uparrow } 1\). In fact, they may even converge to zero.
5 Summary and conclusions
We considered two-stage mean-CVaR recourse models, where the second-stage problem is a mixed-integer linear program. These models are non-convex due to the presence of integer variables and hence, they are extremely hard to solve. Inspired by results from the literature on corresponding risk-neutral models we construct convex approximation models, which can be solved efficiently using techniques from convex optimization. In particular, we define two types of convex approximations of the CVaR recourse function \(R_\beta \).
In order to guarantee the performance of the resulting approximate solutions, we derive error bounds: upper bounds on the approximation errors. These error bounds depend on the total variations of the one-dimensional conditional density functions of the random right-hand side variables in the model. In particular, the error bounds converge to zero if all these total varations go to zero. This implies that all CVaR recourse functions \(R_\beta \) can be approximated arbitrarily well by a convex function if these total variations are small enough.
For the special case of two-stage TU integer mean-CVaR recourse models, we derive sharper error bounds by exploiting the special structure of these problems. In particular, for simple integer recourse models we show that the error bound is small if the random right-hand side variable in the model has a decreasing hazard rate, implying that its distribution is heavy-tailed. In such a situation, explicit modeling of risk aversion is desired to accurately model the underlying practical decision problem. Hence, our convex approximation approach works well in precisely those cases in which risk-averse optimization is relevant.
Future research efforts may be aimed at finding sharper error bounds for other special cases of two-stage mixed-integer mean-CVaR recourse models. Other directions for future research include assessing the actual performance of the approximations (compared to their error bounds) in a numerical study and constructing convex approximations for mixed-integer mean-risk recourse models with other risk measures than CVaR.
References
Acerbi, C., Tasche, D.: On the coherence of expected shortfall. J. Bank. Finance 26(7), 1487–1503 (2002)
Ahmed, S.: Convexity and decomposition of mean-risk stochastic programs. Math. Program. 106(3), 433–446 (2006)
Ahmed, S., Tawarmalani, M., Sahinidis, N.V.: A finite branch-and-bound algorithm for two-stage stochastic integer programs. Math. Program. 100, 355–377 (2004)
Alem, D., Morabito, R.: Risk-averse two-stage stochastic programs in furniture plants. OR Spectr. 35, 773–806 (2013)
Alem, D., Clark, A., Moreno, A.: Stochastic network models for logistics planning in disaster relief. Eur. J. Oper. Res. 255(1), 187–206 (2016)
Angulo, G., Ahmed, S., Dey, S.S.: Improving the integer L-shaped method. INFORMS J. Comput. 28(3), 483–499 (2016)
Artzner, P., Delbaen, F., Eber, J.M., Heath, D.: Coherent measures of risk. Math. Finance 9(3), 203–228 (1999)
Bansal, M., Huang, K.L., Mehrotra, S.: Tight second stage formulations in two-stage stochastic mixed integer programs. SIAM J. Optim. 28(1), 788–819 (2018)
Beraldi, P., Violi, A., Carrozzino, G., Bruni, M.E.: A stochastic programming approach for the optimal management of aggregated distributed energy resources. Comput. Oper. Res. 96, 199–211 (2018)
Blair, C.E., Jeroslow, R.G.: The value function of a mixed integer program: II. Discrete Math. 25(1), 7–19 (1979)
Bodur, M., Dash, S., Günlük, O., Luedtke, J.: Strengthened benders cuts for stochastic integer programs with continuous recourse. INFORMS J. Comput. 29(1), 77–91 (2017)
Carøe, C.C., Schultz, R.: Dual decomposition in stochastic integer programming. Oper. Res. Lett. 24, 37–45 (1999)
Cook, W., Gerards, A.M.H., Schrijver, A., Tardos, É.: Sensitivity theorems in integer linear programming. Math. Program. 34(3), 251–264 (1986)
Edmundson, H.: Bounds on the Expectation of a Convex Function of a Random Variable. Technical report, The RAND Corporation (1956)
Foss, S., Korshunov, D., Zachary, S.: An Introduction to Heavy-Tailed and Subexponential Distributions. Springer, New York (2011)
Gade, D., Küçükyavuz, S., Sen, S.: Decomposition algorithms with parametric Gomory cuts for two-stage stochastic integer programs. Math. Program. 144, 39–64 (2014)
Gomory, R.E.: Some polyhedra related to combinatorial problems. Linear Algebra Appl. 2(4), 451–558 (1969)
Govindan, K., Fattahi, M.: Investigating risk and robustness measures for supply chain network design under demand uncertainty: a case study of glass supply chain. Int. J. Prod. Econ. 183, 680–699 (2017)
Govindan, K., Fattahi, M., Keyvanshokooh, E.: Supply chain network design under uncertainty: a comprehensive review and future research directions. Eur. J. Oper. Res. 263(1), 108–141 (2017)
Jensen, J.L.W.V.: Sur les fonctions convexes et les inégalités entre les valeurs moyennes. Acta mathematica 30, 175–193 (1906)
Jovanović, N., García-González, J., Barquín, J., Cerisola, S.: Electricity market short-term risk management via risk-adjusted probability measures. IET Gener. Transm. Distrib. 11(10), 2599–2607 (2017)
Kim, K., Mehrotra, S.: A two-stage stochastic integer programming approach to integrated staffing and scheduling with application to nurse management. Oper. Res. 63(6), 1431–1451 (2015)
Klein Haneveld, W.K., Stougie, L., van der Vlerk, M.H.: Simple integer recourse models: convexity and convex approximations. Math. Program. 108(2–3), 435–473 (2006)
Kleywegt, A.J., Shapiro, A., Homem-de mello, T.: The sample average approximation method for stochastic discrete optimization. SIAM J. Optim. 12(2), 479–502 (2002)
Laporte, G., Louveaux, F.V.: The integer L-shaped method for stochastic integer programs with complete recourse. Oper. Res. Lett. 13, 133–142 (1993)
Levy, H.: Stochastic dominance and expected utility: survey and analysis. Manag. Sci. 38(4), 555–593 (1992)
Lima, R.M., Conejo, A.J., Langodan, S., Hoteit, I., Knio, O.M.: Risk-averse formulations and methods for a virtual power plant. Comput. Oper. Res. 96, 349–372 (2018)
Louveaux, F.V., van der Vlerk, M.H.: Stochastic programming with simple integer recourse. Math. Program. 61(1–3), 301–325 (1993)
Lu, J., Gupte, A., Huang, Y.: A mean-risk mixed integer nonlinear program for transportation network protection. Eur. J. Oper. Res. 265(1), 277–289 (2018)
Madansky, A.: Bounds on the expectation of a convex function of a multivariate random variable. Ann. Math. Stat. 30(3), 743–746 (1959)
Miller, N., Ruszczyński, A.: Risk-averse two-stage stochastic linear programming: modeling and decomposition. Oper. Res. 59(1), 125–132 (2011)
Noyan, N.: Risk-averse two-stage stochastic programming with an application to disaster management. Comput. Oper. Res. 39(3), 541–559 (2012)
Noyan, N., Balcik, B., Atakan, S.: A stochastic optimization model for designing last mile relief networks. Transp. Sci. 50(3), 1092–1113 (2016)
Ogryczak, W., Ruszczyński, A.: Dual stochastic dominance and related mean-risk models. SIAM J. Optim. 13(1), 60–78 (2002)
Qi, Y., Sen, S.: The Ancestral Benders’ cutting plane algorithm with multi-term disjunctions for mixed-integer recourse decisions in stochastic programming. Math. Program. 161, 193–235 (2017)
Rahimi, M., Ghezavati, V.: Sustainable multi-period reverse logistics network design and planning under uncertainty utilizing conditional value at risk (CVaR) for recycling construction and demolition waste. J. Clean. Prod. 172, 1567–1581 (2018)
Rockafellar, R.T.: Solving stochastic programming problems with risk measures by progressive hedging. Set Valued Var. Anal. 26, 759–768 (2018)
Rockafellar, R.T., Uryasev, S.: Conditional value-at-risk for general loss distributions. J. Bank. Finance 26(7), 1443–1471 (2002)
Romeijnders, W., van der Vlerk, M.H., Klein Haneveld, W.K.: Convex approximations for totally unimodular integer recourse models: a uniform error bound. SIAM J. Optim. 25(1), 130–158 (2015)
Romeijnders, W., Schultz, R., van der Vlerk, M.H., Klein Haneveld, W.K.: A convex approximation for two-stage mixed-integer recourse models with a uniform error bound. SIAM J. Optim. 26(1), 426–447 (2016)
Romeijnders, W., van der Vlerk, M.H., Klein Haneveld, W.K.: Total variation bounds on the expectation of periodic functions with applications to recourse approximations. Math. Program. 157(1), 3–46 (2016)
Romeijnders, W., Morton, D.P., van der Vlerk, M.H.: Assessing the quality of convex approximations for two-stage totally unimodular integer recourse models. INFORMS J. Comput. 29(2), 211–231 (2017)
Sawik, T.: Selection of resilient supply portfolio under disruption risks. Omega 41(2), 259–269 (2013)
Schultz, R., Tiedemann, S.: Conditional value-at-risk in stochastic programs with mixed-integer recourse. Math. Program. 105(2–3), 365–386 (2006)
Sen, S., Higle, J.L.: The C3 theorem and a D2 algorithm for large scale stochastic mixed-integer programming: set convexification. Math. Program. 104, 1–20 (2005)
Soleimani, H., Govindan, K.: Reverse logistics network design and planning utilizing conditional value at risk. Eur. J. Oper. Res. 237(2), 487–497 (2014)
Soleimani, H., Seyyed-Esfahani, M., Kannan, G.: Incorporating risk measures in closed-loop supply chain network design. Int. J. Prod. Res. 52(6), 1843–1867 (2014)
Toso, E.A.V., Alem, D.: Effective location models for sorting recyclables in public management. Eur. J. Oper. Res. 234(3), 839–860 (2014)
van der Laan, N., Romeijnders, W.: Generalized alpha-approximations for two-stage mixed-integer recourse models. Technical report, University of Groningen (2018)
van der Vlerk, M.H.: Convex approximations for complete integer recourse models. Math. Program. 99(2), 297–310 (2004)
van der Vlerk, M.H.: Convex approximations for a class of mixed-integer recourse models. Ann. Oper. Res. 177(1), 139–150 (2010)
Van Slyke, R.M., Wets, R.: L-shaped linear programs with applications to optimal control and stochastic programming. SIAM J. Appl. Math. 17(4), 638–663 (1969)
Walkup, D.W., Wets, R.J.B.: Lifting projections of convex polyhedra. Pac. J. Math. 28(2), 465–475 (1969)
Zeballos, L.J., Méndez, C.A., Barbosa-Povoa, A.P.: Design and planning of closed-loop supply chains: a risk-averse multistage stochastic approach. Ind. Eng. Chem. Res. 55, 6236–6249 (2016)
Zhang, M., Küçükyavuz, S.: Finitely convergent decomposition algorithms for two-stage stochastic pure integer programs. SIAM J. Optim. 24(4), 1933–1951 (2014)
Zhang, W., Rahimian, H., Bayraksan, G.: Decomposition algorithms for risk-averse multistage stochastic programs with application to water allocation under uncertainty. INFORMS J. Comput. 28(3), 385–404 (2016)
Acknowledgements
We thank two anonymous reviewers for their comments on an earlier version of this manuscript.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Maarten H. van der Vlerk was actively involved in an early stage of this research, but passed away during the writing of this paper.
The research of Ward Romeijnders has been supported by Grant 451-17-034 4043 from The Netherlands Organisation for Scientific Research (NWO).
Appendices
Appendix A: Random q and T in risk-neutral models
In this appendix, we generalize error bounds for convex approximations of risk-neutral mixed-integer recourse models to the case where also q and T are random. In the risk-neutral literature [40, 41, 49], convex approximations of the mean recourse function Q with corresponding error bounds exist, but for a setting where only the right-hand side vector h is random. We extend these results to the case where also q and T are random. We state these results here since we use them to prove our results in the risk-averse setting. Hence, we make the same assumptions as in Sect. 2, i.e., h and (q, T) are pairwise independent, where h has a joint pdf f and q has a finite support \(\varXi ^q\).
Similar as in the main body of this paper, we consider two settings: general two-stage mixed-integer recourse models (cf. Sect. 3) and the special case of TU integer recourse models (cf. Sect. 4). For both classes of recourse models, we consider two types of convex approximations of the mean recourse function Q: the shifted LP-relaxation approximation \(\hat{Q}\) and the (generalized) \(\alpha \)-approximation \(\tilde{Q}_\alpha \).
1.1 A.1 General mixed-integer recourse
We first consider the general case of two-stage mixed-integer recourse models. Consider the mean recourse function Q from (3), i.e.
We define two convex approximations of Q, based on the approximations in [49] and [40].
Definition 12
Consider the general mixed-integer mean recourse function Q from (3). We define its shifted LP-relaxation approximation\(\hat{Q}\) and its generalized\(\alpha \)-approximation\(\tilde{Q}_\alpha \) with parameter \(\alpha \in \mathbb {R}^m\) by
respectively, where \(\hat{v}\) and \(\tilde{v}_\alpha \) are defined by
where \(\varGamma ^k := p_k^{-m} \int _{0}^{p_k} \cdots \int _{0}^{p_k} \psi ^k(s) ds_1 \cdots ds_m\), \(p_k := |\det B^k|\), and \(B^k\) and \(\psi ^k\), \(k \in K^q\), are as in Proposition 1.
We provide a uniform error bound for each of the two convex approximations defined above. These bounds are generalizations of Theorem 5.1 in [40] and Theorem 4 in [49] to the case where also q and T are random.
Proposition 3
Consider the mean recourse function Q from (3) and its convex approximations \(\hat{Q}\) and \(\tilde{Q}_\alpha \) from Definition 12. Then, if \(f \in \mathscr {H}^m\), there exist finite, positive constants \(\bar{C}_1\) and \(\bar{C}_2\) such that
Proof
From Theorem 5.1 in [40] we know that if q and T are deterministic, then there exists a constant \(C^q > 0\), such that
It can indeed be shown (by going through the proofs in [40]) that this bound depends on q but not on T, hence the notation \(B^q\) and \(C^q\). Now let \(x \in \mathbb {R}^{n_1}\) be given. Then, using Jensen’s inequality, independence between (q, T) and h, and the error bound above, we have
Now, defining \(\bar{C}_1 := \max _{q \in \varXi ^q} \{ C^q \}\), (34) follows from the observation that this upper bound on \(|Q(x) - \hat{Q}(x)|\) does not depend on x. The proof of (35) is analogous, except for the fact that we use Theorem 4 from [49] instead of Theorem 5.1 from [40]. \(\square \)
From the construction of the constants \(\bar{C}_1\) and \(\bar{C}_2\) in the proof, it is not hard to see that the error bounds from Proposition 3 reduce to the existing bounds from Theorem 5.1 in [40] and Theorem 4 in [49] if q and T are deterministic.
1.2 A.2 TU integer recourse
Next, we consider the special case of two-stage TU integer recourse models. That is, we make the additional assumption that the second-stage value function is defined as in (20). It is not hard to show that in this case the approximating value functions \(\hat{v}\) and \(\tilde{v}_\alpha \) reduce to the functions from Lemma 3 (see Example 3.4 in [40] and Example 3 in [49]).
Again, we provide an error bound for both convex approximations: \(\hat{Q}\) and \(\tilde{Q}_\alpha \). This result is a generalization of Theorems 5 and 6 from [41] to the case where also q and T are random.
Proposition 4
Consider the mean recourse function \(Q(x) = \mathbb {E}_{\xi }[v(\xi , x)]\) from (3), and assume that v has a TU integer structure, i.e., v is as in (20). Furthermore, let \(\hat{Q}\) and \(\tilde{Q}_\alpha \) be the convex approximations of Q from Definition 12. Then, if \(f \in \mathscr {H}^m\), we have
where \(\bar{\lambda }^*_i := \mathbb {E}_q\big [ \max _{k \in K^q} \{q_{B^k}(B^k)^{-1} e_i \} \big ]\), \(i=1,\ldots ,m\), with \(e_i\) the ith unit vector in \(\mathbb {R}^m\), and g is the function from Theorem 2
Proof
From Theorem 6 in [41], we know that for any \(q \in \varXi ^q\) and \(T \in \varXi ^T\), we have
where \(\lambda ^*_{q,i} := \max _{k \in K^q}\{ q_{B^k}(B^k)^{-1} e_i \}\) depends on q but not on T. Now, (36) follows by same line of reasoning as in the proof of Proposition 3. The proof of (37) is similar, but we use Theorem 5 instead of Theorem 6 from [41], resulting in an error bound that is a factor 2 larger. \(\square \)
Appendix B: Proofs of several lemmas, propositions, and theorems
Proof of Lemma 1
Let \(v^{\zeta }_{\text {LP}}\) be the LP-relaxation of \(v^{\zeta }\) and fix \(q \in \varXi ^q\). Then, by e.g., [10, 13], there exists a constant \(\gamma _q>0\) such that \(|v^{\zeta }(\xi , x) -v^{\zeta }_\text {LP}(\xi , x)| \le \gamma _q\) for all \(T \in \varXi ^T\), \(h \in \varXi ^h\), \(x \in \mathbb {R}^{n_1}\), and \(\zeta \in \mathbb {R}\). Next, we show that \(|v^{\zeta }_\text {LP}(\xi , x) - \hat{v}^{\zeta }(\xi , x)| \le \bar{r}_q\) for all \(T \in \varXi ^T\), \(h \in \varXi ^h\), \(x \in \mathbb {R}^{n_1}\), and \(\zeta \in \mathbb {R}\), where \(\bar{r}_q := \max _{k \in K^q} r^k\). By definition of \(v^{\zeta }_\text {LP}\) and \(\hat{v}^{\zeta }\), we have
where the last inequality follows from \(\varGamma ^k_\zeta \ge 0\), \(k \in K^q\), \(\zeta \in \mathbb {R}\). We consider two cases. First, suppose \(\zeta \le \bar{r}_q\). Then, \(0 \le \varGamma ^k_\zeta \le \bar{r}_q\) for every \(k \in K^q\) and using the above it follows that \(|v^{\zeta }_\text {LP}(\xi , x) - \hat{v}^{\zeta }(\xi , x)| \le \bar{r}_q\). Second, suppose \(\zeta > \bar{r}_q\). Let \(k^*\) be the maximizing index for \(\hat{v}^{\zeta }(\xi , x)\). We consider two subcases. Firstly, suppose that \(q_{B^{k^*}} = 0\). Then, \(\varGamma ^{k^*}_\zeta = \zeta \) and it follows that \(\max _{k \in K^q} \{ q_{B^k} (B^k)^{-1} (h - Tx) \} \le \zeta \). Hence, \(|v^{\zeta }_\text {LP}(\xi , x) - \hat{v}^{\zeta }(\xi , x)| = | 0 - ( \zeta - \zeta )^+ | = 0\). Secondly, suppose that \(q_{B^{k^*}} \ne 0\). Since \(\varGamma ^k_\zeta \ge \varGamma ^k\) for all \(\zeta \in \mathbb {R}\) and \(\varGamma ^k_\zeta = \varGamma ^k\) if \(q_{B^k} \ne 0\), we have \(\hat{v}^{\zeta }(\xi , x) = \big ( \max _{k \in K^q} \{ q_{B^k} (B^k)^{-1} (h - Tx) + \varGamma ^k \} - \zeta \big )^+\). Hence, similar to the inequalities above, we have \(|v^{\zeta }_\text {LP}(\xi , x) -\hat{v}^{\zeta }(\xi , x)| \le \max _{k \in K^q} \{ | \varGamma ^k | \} \le \bar{r}_q\).
Now, define \(\gamma := \max _{q \in \varXi ^q}\{ \gamma _q + \bar{r}_q \}\). Then, using the above we have \(\Vert v^{\zeta } - \hat{v}^{\zeta } \Vert _\infty \le \Vert v^{\zeta } - v^{\zeta }_\text {LP} \Vert _\infty + \Vert v^{\zeta }_\text {LP} - \hat{v}^{\zeta } \Vert _\infty \le \gamma \). The proof of \(\Vert v^{\zeta } - \tilde{v}^{\zeta }_\alpha \Vert _\infty \le \gamma \) is analogous. \(\square \)
Proof of Lemma 2
Let \(q \in \varXi ^q\), \(k \in K^q\), and \(\zeta \in \mathbb {R}\) be given. We will show that there exists \(\sigma ^{kl} \in \varLambda ^k(d^k)\) such that for every \(l \ne k\) and \(\hat{h} := h - Tx \in \sigma ^{kl} + \varLambda ^k\),
By LP-duality, we know that for the LP-relaxation \(v_\text {LP}\) of v we have \({v}_\text {LP}(\xi , x) = \max _{k \in K^q} \{q_{B^k}(B^k)^{-1}\hat{h}\}\), where the index \(k \in K^q\) is optimal if \(\hat{h} \in \varLambda ^k\). Fix \(k,l \in K^q\) with \(l \ne k\). Then, the above implies that \(q_{B^k}(B^k)^{-1}\hat{h} \ge q_{B^l}(B^l)^{-1}\hat{h}, \ \hat{h} \in \varLambda ^k\). Suppose that \(q_{B^k}(B^k)^{-1} = q_{B^l}(B^l)^{-1}\). Then by Proposition 1(iii), \(\psi ^k = \psi ^l\). Hence, \(\varGamma _\zeta ^k = \varGamma _\zeta ^l\) and (38) holds for \(\sigma ^{kl} = 0\).
Next, suppose that \(q_{B^k}(B^k)^{-1} \ne q_{B^l}(B^l)^{-1}\). Then, there exists some \(s^*\in \varLambda ^k(d^k)\) such that \(q_{B^k}(B^k)^{-1}s^* > q_{B^l}(B^l)^{-1}s^*\). Fix such an \(s^*\). We distinguish two cases. First, suppose that \(q_{B^l}\ne 0\). Then, \(\varGamma _\zeta ^l = \varGamma ^l \le r^l\). For a large enough scalar \(\gamma \ge 1\), we find \(q_{B^k}(B^k)^{-1}(\gamma s^*) > q_{B^l}(B^l)^{-1}(\gamma s^*) + r^l\). Observing that \(\varGamma _\zeta ^k \ge 0\), this implies that
Second, suppose that \(q_{B^l} = 0\). If \(\zeta < r^l\), then by definition, \(\varGamma _\zeta ^l \le r^l\) and hence, (39) holds true. Conversely, if \(\zeta \ge r^l\), then \(\varGamma _\zeta ^l = \zeta \) and hence, \((q_{B^l}(B^l)^{-1}(\gamma s^*) + \varGamma _\zeta ^l - \zeta )^+ = 0\). It follows that (39) holds.
Combining all cases above, we conclude that (38) holds for \(\sigma ^{kl} := \gamma s^*\). Moreover, since \(s^* \in \varLambda ^k(d^k)\) and \(\gamma \ge 1\), we have \(\sigma ^{kl} \in \varLambda ^k(d^k)\). Now, similar as in the proof of Proposition 3.7 in [40], taking the intersection of the shifted cones \(\sigma ^{kl} + \varLambda ^k\), \(k,l \in K^q\), \(k\ne l\), yields a set \(\sigma ^k + \varLambda ^k\), where \(\sigma ^k \in \varLambda ^k(d_k)\). From the construction of this set and (38) we conclude that \(\hat{v}^{\zeta }\) attains its value through the basis matrix \(B^k\) for all \(h - Tx \in \sigma ^k + \varLambda ^k\). The proof for \(\tilde{v}^{\zeta }_\alpha \) is analogous. \(\square \)
Proof of Proposition 2
We prove the result for \(\hat{v}^{\zeta }\); the proof for \(\tilde{v}^{\zeta }_\alpha \) is analogous. Let \(q \in \varXi ^q\) be fixed and note that for every \(k \in K^q\), we have by Proposition 1, Lemma 2, and \(\sigma ^k + \varLambda ^k \subseteq \varLambda ^k(d_k)\) that both \(v^{\zeta }(\xi , x)\) and \(\hat{v}^{\zeta }(\xi , x)\) are generated by the same basis matrix \(B^k\) if \(h - Tx \in \sigma ^k + \varLambda ^k\). Using this observation we will construct sets \(\mathscr {A}_j\), \(j \in J^q_\zeta \), such that (i) holds.
For every \(k \in K^q\) we do the following. Firstly, if \(q_{B^k} =0\), then we define \(\mathscr {A}_k := \sigma ^k + \varLambda ^k\). Then, for \(h - Tx \in \mathscr {A}_k\) we have \(v^{\zeta }(\xi , x) -\hat{v}^{\zeta }(\xi , x) = (\psi ^k(h - Tx) - \zeta )^+ -p_k^{-m}\int _{0}^{p_k} \cdots \int _{0}^{p_k}(\psi ^k(s) - \zeta )^+ ds_1 \cdots ds_m\). Clearly, this is a zero-mean \(B^k\)-periodic function of \(h - Tx\). Secondly, if \(q_{B^k} \ne 0\), then we define the sets \(\mathscr {A}_{k^+} := \{ s \in \sigma ^k + \varLambda ^k \ | \ q_{B^k}(B^k)^{-1}s \ge \zeta \}\) and \(\mathscr {A}_{k^-} := \{ s \in \sigma ^k + \varLambda ^k \ | \ q_{B^k}(B^k)^{-1}s \le \zeta - r^k \}\). Then, for \(h - Tx \in \mathscr {A}_{k^+}\), we have \(v^{\zeta }(\xi , x) - \hat{v}^{\zeta }(\xi , x) = \psi ^k(h - Tx) - \varGamma ^k\), and for \(h - Tx \in \mathscr {A}_{k^-}\), we have \(v^{\zeta }(\xi , x) - \hat{v}^{\zeta }(\xi , x) = 0\). In both cases, we obtain a zero-mean \(B^k\)-periodic function of \(h - Tx\). Now, defining the sets \(\mathscr {A}_j\), \(j \in J^q_\zeta \), as the sets \(\mathscr {A}_k\), \(\mathscr {A}_{k^+}\), and \(\mathscr {A}_{k^-}\), \(k \in K^q\), described above, (i) clearly holds.
Finally, we show that for these sets \(\mathscr {A}_j\), \(j \in J^q_\zeta \), (ii) holds. Observe that \(\mathscr {N}^q_\zeta = \mathbb {R}^m {\setminus } \bigcup _{j \in J^q_\zeta } \mathscr {A}_j = \big ( \mathbb {R}^m {\setminus } \bigcup _{k \in K^q} (\sigma ^k + \varLambda ^k) \big ) \cup \big (\bigcup _{k \in \bar{K}^q} \{ s \in \sigma ^k + \varLambda ^k \ | \ \zeta - r^k< q_{B^k}(B^k)^{-1}s < \zeta \} \big )\), where \(\bar{K}^q := \{k \in K^q \ | \ q_{B^k} \ne 0 \}\). Then, by Lemma 3.9 in [40], there exist hyperslices \(H^q_{ik}\), \(i=1,\ldots ,m\), \(k \in K^q\), such that \(\mathbb {R}^m {\setminus } \bigcup _{k \in K^q} (\sigma ^k + \varLambda ^k) \subseteq \bigcup _{k \in K^q} \bigcup _{i=1}^m H^q_{ik}\). Moreover, defining the hyperslices \(\bar{H}^q_{\zeta , k} := \{ s \in \mathbb {R}^m \ | \ \zeta - r^k \le q_{B^k}(B^k)^{-1}s \le \zeta \}\), \(k \in \bar{K}^q\), we have \(\bigcup _{k \in \bar{K}^q} \{ s \in \sigma ^k + \varLambda ^k \ | \ \zeta - r^k< q_{B^k}(B^k)^{-1}s < \zeta \} \subseteq \bigcup _{k \in K^q} \bar{H}^q_{\zeta , k}\). Hence, \(\mathscr {N}^q_\zeta \subseteq \big (\bigcup _{k \in K^q} \bigcup _{i=1}^m H_{ik} \big ) \cup \big ( \bigcup _{k \in \bar{K}^q} \bar{H}^q_{\zeta , k} \big )\), i.e., \(\mathscr {N}^q_\zeta \) can be covered by finitely many hyperslices. \(\square \)
Proof of Theorems 2 and 3
We take Lemma 4 as a starting point and we temporarily fix \(q \in \varXi ^q\), \(T \in \varXi ^T\), and \(x \in \mathbb {R}^{n_1}\). Note that the conditional expectation in Lemma 4 can be written as \(\mathbb {E}_{h^{\beta }_x}[\hat{v}(q, T, h^{\beta }_x, x) - v(q, T, h^{\beta }_x, x)]\), where \(h^{\beta }_{x}\) is the random vector defined by its joint pdf \(f^{\beta }_x := f(\cdot | \hat{v}(\xi , x) > \zeta ^{\beta }(x))\). Now, applying Theorem 6 from [41] to the conditional expectation in Lemma 4, we obtain
where \(h^{\beta }_{x, -i}\) denotes the random vector \(h^{\beta }_x\) without its ith element. Note that substituting (40) into (22) already provides us with an upper bound on the approximation error \(\hat{R}^{\beta }(x) - R^{\beta }(x)\). However, this bound is in terms of the conditional pdf \(f^{\beta }_x\). The rest of this proof is concerned with manipulating the right-hand side of (40) such that we end up with error bounds in terms of the original pdf f.
Consider the expected value in (40). Since \(g(\cdot )\) is concave, it follows by Jensen’s inequality that
We will derive two upper bounds on the expected value in the right-hand side of (41).
Using the definition of \(f^{\beta }_{x,i}(\cdot | \cdot )\), we have
where \(\varTheta ^{\beta }_{x,-i} := \big \{ t_{-i} \in \mathbb {R}^{m-1} \ | \ f^{\beta }_{x,-i}(t_{-i}) > 0 \big \}\) and \(f^{\beta }_x(\cdot ; t_{-i})\) denotes \(f^{\beta }_x(t)\) as a function of \(t_i\). We derive two upper bounds on \(|\varDelta |f^{\beta }_x(\cdot ; t_{-i})\). Define the set \(\mathscr {T}^{\beta }_{x,i}(t_{-i}) := \big \{ t_i \in \mathbb {R}\ | \ \hat{v}(q,T,t,x) > \zeta ^{\beta }(x) \big \}\). Since \(\lambda ^k \ge 0\), \(k \in K^q\), it follows by definition of \(\hat{v}(\xi , x)\) that \(\hat{v}(\xi , x)\) is monotonely non-decreasing and lower semi-continuous in \(h_i\) for every \(i=1,\ldots ,m\). Hence, the set \(\mathscr {T}^{\beta }_{x,i}(t_{-i})\) is of the form \(\mathscr {T}^{\beta }_{x,i}(t_{-i}) = (\tau ^{\beta }_{x,i}(t_{-i}), +\infty )\), where \(\tau ^{\beta }_{x,i}(t_{-i}) := \inf \{ h_i \in \mathbb {R}\ | \ \hat{v}(\xi , x) > \zeta ^{\beta }(x)\}\). Now, by definition of \(f^{\beta }_x\), we have \(f^{\beta }_x(t) = \tfrac{1}{p^{\beta }_x} \mathbb {1}_{\big [t_i > \tau ^{\beta }_{x,i}(t_{-i})\big ]} f(t)\), where \(p^{\beta }_x := \mathbb {P}\{ \hat{v}(\xi , x) > \zeta ^{\beta }(x) \ | \ q, T \}\). From this expression it is immediately clear that
Alternatively, using \(\hat{\tau }^{\beta }_{x,i}(t_{-i}) \le \tau ^{\beta }_{x,i}(t_{-i})\) (by definition of \(\hat{\tau }^{\beta }_{x,i}\) and \(\tau ^{\beta }_{x,i}(t_{-i})\)), we have
Hence, we have found two alternative upper bounds on \(|\varDelta |f^{\beta }_x (\cdot ; t_{-i})\).
Returning to (42), define \(\varTheta _{-i} :=\big \{ t_{-i} \in \mathbb {R}^{m-1} \ | \ f_{-i}(t_{-i}) > 0 \big \}\) and observe that \(\varTheta ^{\beta }_{x,-i} \subseteq \varTheta _{-i}\). Using this fact and (43), we obtain
Similarly, using (44) instead of (43) we obtain
Now, combining (22), (40), (41) and (45), we obtain
Since \(\tfrac{1}{p^{\beta }_x} \ge 1\) and g is non-decreasing and concave with \(g(0) = 0\), we can move the factor \(\tfrac{1}{p^{\beta }_x}\) in front of the function g to obtain an upper bound, i.e.,
where we use the definition of \(\bar{\lambda }^*_i\) and the fact that \(\lambda ^*_{q,i} g\Big ( \mathbb {E}_{h_{-i}} \big [ |\varDelta |f_i(\cdot | h_{-i})\Big )\) does not depend on T. An analogous proof shows that the right-hand side above is also an upper bound on the reverse approximation error \(R^{\beta }(x) - \hat{R}^{\beta }(x)\). Observing that this upper bound does not depend on x completes the proof of (26) in Theorem 2. The proof of (29) in Theorem 3 is analogous, but instead of (45) we use (46).
Finally, the proofs of the error bounds (27) in Theorem 2 and (30) in Theorem 3 for the \(\alpha \)-approximation \(\tilde{R}^{\beta }_\alpha \) are analogous to the proofs of (26) and (29), respectively. The only difference is that instead of using Theorem 6 from [41], we use Theorem 5 from that reference to obtain an analogue of (40). \(\square \)
Proof of Corollary 1
Direct application of (29) from Theorem 3 yields
where \(\hat{\tau }^{\beta }_x := \inf \big \{ h \in \mathbb {R}\ | \ \hat{v}(h, x)> \zeta ^{\beta }(x) \ \vee \ v(h, x) > \hat{\zeta }^{\beta }(x) \big \}\). Here we used that \(\lambda ^*_{q,i} = 1\), which follows directly from the dual representation of \(v(\xi , x)\) in (21) for the simple integer case. Now, consider the definition of \(\hat{\tau }^{\beta }_x\) above. It is not hard to verify that \(\zeta ^{\beta }(x) = v(F^{-1}(\beta ), x)\) and \(\hat{\zeta }^{\beta }(x) = \hat{v}(F^{-1}(\beta ), x)\). Using the definition of v(h, x) and \(\hat{v}(h, x)\) it follows that \(\inf \{h \in \mathbb {R}\ | \ \hat{v}(h, x) > \zeta ^{\beta }(x) \} \ge F^{-1}(\beta ) - 1\) and \(\inf \{ h \in \mathbb {R}\ | \ v(h, x) >\hat{\zeta }^{\beta }(x) \} \ge F^{-1}(\beta ) - 1\). Substituting this into \(\hat{\tau }^{\beta }_x\) and observing that the result does not depend on x proves (32). \(\square \)
Lemma 5
Let h be a random variable such that Assumption 2 holds. If h has a decreasing hazard rate, then
Proof
Define \(\bar{F}(t) := 1 - F(t)\), \(A_t := \bar{F}(t - 1) -\bar{F}(t)\), and \(B_t := \bar{F}(t)\), \(t \in \mathbb {R}\). We first show that \(\lim \nolimits _{t \rightarrow \infty } \tfrac{\bar{F}(t-1)}{\bar{F}(t)} = \lim \nolimits _{t \rightarrow \infty } \tfrac{A_t + B_t}{B_t} = 1\). For the sake of contradiction, suppose \(\lim \nolimits _{t \rightarrow \infty } \tfrac{A_t + B_t}{B_t} \ne 1\). Since \(\tfrac{A_t + B_t}{B_t} \ge 1\) for all \(t \in \mathbb {R}\), this means that there exists \(\varepsilon > 0\) such that for all \(t_0 \in \mathbb {R}\), there exists \(t \ge t_0\) such that \(\tfrac{A_t + B_t}{B_t} \ge 1 +\varepsilon \), i.e., \(\tfrac{A_t}{B_t} \ge \varepsilon \), i.e., \(\tfrac{B_t}{A_t} \le 1/\varepsilon \). Let such an \(\varepsilon >0\), \(t_0 \in \mathbb {R}\), and \(t \ge \max \{ t_0, z + 1 \}\) be given. Consider \(\lambda (t-1) = \tfrac{f(t-1)}{\bar{F}(t - 1)}\). Since f is non-increasing on \([z,+\infty )\) by Assumption 2, we have \(A_t = \int _{t-1}^{t} f(s) ds \le f(t-1)\). Hence,
Define \(\bar{\varepsilon } := \tfrac{\varepsilon }{1 + \varepsilon }\). We have shown that for every \(t_0 \in \mathbb {R}\) there exists some \(t \ge t_0\) such that \(\lambda (t - 1) \ge \bar{\varepsilon }\). This contradicts our assumption that \(\lim \nolimits _{t \rightarrow \infty } \lambda (t) = 0\). Hence, by contradiction it follows that \(\lim \nolimits _{t \rightarrow \infty } \tfrac{\bar{F}(t-1)}{\bar{F}(t)} = 1\).
Now, using the algebraic limit theorem it follows that
where we used the fact that h has a decreasing hazard rate. \(\square \)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/),which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
van Beesten, E.R., Romeijnders, W. Convex approximations for two-stage mixed-integer mean-risk recourse models with conditional value-at-risk. Math. Program. 181, 473–507 (2020). https://doi.org/10.1007/s10107-019-01428-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10107-019-01428-6
Keywords
- Stochastic programming
- Mean-risk models
- Conditional value-at-risk
- Mixed-integer recourse
- Convex approximations