
Abstract
Nonlinear phenomena (NLP) in animal vocalizations arise from irregularities in the oscillation of the vocal folds. Various non-mutually exclusive hypotheses have been put forward to explain the occurrence of NLP, from adaptive to physiological ones. Non-human primates often display NLP in their vocalizations, yet the communicative role of these features, if any, is still unclear. We here investigate the occurrence of NLP in the song of a singing primate, the indri (Indri indri), testing for the effect of sex, age, season, and duration of the vocal display on their emission. Our results show that NLP occurrence in indri depends on phonation, i.e., the cumulative duration of all the units emitted by an individual, and that NLP have higher probability to be emitted in the later stages of the song, probably due to the fatigue indris may experience while singing. Furthermore, NLP happen earlier in the vocal display of adult females than in that of the adult males, and this is probably due to the fact that fatigue occurs earlier in the former because of a greater contribution within the song. Our findings suggest, therefore, that indris may be subjected to physiological constraints during the singing process which may impair the production of harmonic sounds. However, indris may still benefit from emitting NLP by strengthening the loudness of their signals for better advertising their presence to the neighboring conspecific groups.
Similar content being viewed by others


Introduction
Nonlinear phenomena (NLP) are produced by irregular vibrations of the vocal folds (Herzel et al. 1995). They represent any abruption in the synchronization of the vocal folds leading to unstable oscillations (Tyson et al. 2007) and resulting in a variety of perceptually harsh and rough vocalizations (Fitch et al. 2002). NLP generally occurring in mammalian emissions belong to the following four major groups: (1) chaotic phenomena arising from aperiodic oscillations (Fitch et al. 2002), (2) splitting of harmonic cycles due to differential vibration of the vocal folds (Wilden et al. 1998; Riede et al. 2004), (3) simultaneous emission of sounds produced by different phonatory sources within the vocal tract (Reby et al. 2016), and (4) sudden changes in the fundamental frequency (Riede et al. 2004).
Previous research provided various explanations for the occurrence of NLP in animal vocalizations. A broad of evidence shows that the emergence of nonlinearities in mammalian vocalizations may reflect the emotional state of the emitter, e.g., stress or arousal (Blumstein and Récapet 2009; Blesdoe and Blumstein 2014; Fuchs et al. 2021; Marx et al. 2021; Massenet et al. 2022). Such sounds are indeed often associated with aversive states, such as rage, pain, and fear in animals, including humans (Anikin 2020; Marx et al. 2021). Alternative hypotheses highlighted that NLP may serve the function of grabbing the attention of conspecifics in the context of alarm calls in the presence of predators (Townsend and Manser 2011; Karp et al. 2014; Volodin et al. 2018), or triggering the listener’s attention by adding unpredictability within calling and thus make these signals hard to ignore (Fitch et al. 2002; Townsend and Manser 2011; Karp et al. 2014). Previous studies also suggested that NLP can facilitate the transmission of indexical cues to conspecifics, including individual identity, and that they can be exploited thanks to natural selection (Fitch et al. 2002). Besides adaptive explanations, other evidence indicates that nonlinear vocal dynamics may be a mere by-product of physiological constraints involving a certain degree of vocal fatigue (Riede et al. 2004; Boucher 2008; Krajewski et al. 2010; Weissmann et al. 2020; Sportelli et al. 2022). As such, fatigue may reflect a short-term effort necessary for dealing with challenging vocal performances (Weissmann et al. 2020) or a long-term one due to constant intense activity over time, for example during a season (Vannoni and McElligott 2009). In this framework, it has been argued that NLP may be associated with individual characteristics of the emitter such as body size, health, reproductive state, age, or sex (Riede 2007; Vannoni and McElligott 2009; Cazau et al. 2016; Weissmann et al. 2020; Anikin et al. 2021; Marx et al. 2021). NLP may therefore play also a role in sexual selection by conveying information on male quality to females, as previously reported in baboons, deer, and whales (Fischer et al. 2004; Reby and Charlton 2012; Cazau et al. 2016). However, in organized communicative systems, nonlinear vocal signals may be critical in providing information about individuality and urgency without complex neural control (Fitch et al. 2002).
Non-human primates have been indicated as animals that frequently exhibit NLP in their vocalizations (Fitch et al. 2002). Recent findings show that it is the peculiar morphology of their larynx that makes them susceptible to nonlinearities and that the prevention of such features in humans seems to be favored by a loss of complexity in the vocal anatomy. This, in turn, may have contributed to the development of speech under cognitive control (Nishimura et al. 2022). Additionally, the avoidance of nonlinearities in humans seems to elicit an attraction for clearly harmonic sounds and a preference for consonance rather than dissonance perception (Wagner et al. 2020). However, beyond humans, there are other primate species capable of emitting harmonic signals, such as singing primates (De Gregorio et al. 2022a). It is, therefore, of particular interest to investigate the occurrence of NLP in these species to unravel the significance of such unique features.
Among singing primates, there is only one lemur species, the indri (Indri indri). Indris inhabit the mountain rainforests of Madagascar, live in small family groups including a reproductive pair and its offspring (Torti et al. 2017), and they occupy territories that are defended through the emission of songs (Torti et al. 2013), which spread through the forest for kilometers (Spezie et al. 2022). Indri songs represent long calls that require a high energy demand (Zanoli et al. 2020) similar to what happens in the songs of other singing primates (De Gregorio et al. 2022a). We refer to songs to indicate a series of different types of frequency-modulated notes, i.e., units, uttered according to a hierarchical structure (De Gregorio et al. 2022a). Indris emit sexually dimorphic songs showing major differences in both frequency and temporal features (Giacoma et al. 2010; Gamba et al. 2016; Zanoli et al. 2020) starting with harsh roars given by all group members, followed by harmonic frequency-modulated units organized in phrases (Zanoli et al. 2020). Youngsters and subadults may sing with parents, in duets or choruses (Giacoma et al. 2010), and undergo changes during growth according to their age and sex (De Gregorio et al. 2021). Furthermore, parent–offspring turn-taking dynamics affect the vocal behavior of the adults (De Gregorio et al. 2022b). Female songs are less stereotyped than male songs (Zanoli et al. 2020), and both probably play a role in communicating group size and composition to conspecifics, and in finding partners to form new groups (Pollock 1986; Giacoma et al. 2010). Indri songs are essentially of three types (Pollock 1986). Cohesion songs are emitted when the group members are not in visual contact. Territorial songs are performed when two groups meet at the border of their territory and engage in singing battles. However, the most common song that indris daily emit is known as advertisement song whose main purpose is to signal their presence to conspecific groups nearby (Torti et al. 2013). Furthermore, indri songs adhere to the laws of compression as follows: they show a trade-off between the length of the signal and that of its components and a balance between signal duration and occurrence (Valente et al. 2021), suggesting the need for compensating the cost of sustained vocal emission.
This study aims at understanding whether vocal fatigue may represent a proxy for the occurrence of NLP within the song of the indris. To answer this question, we investigated whether the total occurrence of NLP may be explained by the duration of the vocal display and increase as singing proceeds. We also investigated whether NLP varies between seasons and occur evenly between the two sexes and across different age classes.
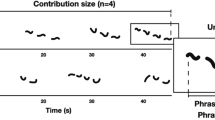
Since the presence of nonlinearities in animal vocalizations has been considered a potential indicator of vocal fatigue (Riede et al. 2004; Boucher 2008), we hypothesized an effect of the duration of the vocal display on the occurrence of NLP due to a trade-off between the need for conveying important information to conspecifics and the effort required to perform long, complex, and potentially exhausting vocal performances. To test this hypothesis, we considered the vocal display in terms of three temporal variables, namely the song duration, i.e., the length of the song, the duration of the individual contribution, i.e., the duration of the individual singing including silences between one uttered unit and another, and the duration of the individual phonation, i.e., the cumulative duration of all the uttered units (Fig. 1). We then tested which of these variables could better explain the total occurrence of NLP within a song. Considering that the individual phonation corresponds to the actual individual engagement and may, therefore, better reflect a short-term physical effort, we predicted that (1) this may be the best variable to explain the total occurrence of NLP within a song among the three temporal variables we considered. Furthermore, we tested whether NLP have a higher probability to be emitted at the beginning or at the end of the individual’s phonation. We predicted that (2) NLP distribution may change depending on the timing of the signal, i.e., the initial or the final portion of the song, and increase in number over time as the vocal display proceeds. We also hypothesized an effect of the season on the total NLP occurrence. We therefore predicted (3) a higher occurrence of nonlinearities during the reproductive season when indris sing more often (Ravaglia et al. 2023) and may be more prone to long-term vocal fatigue. Last, we hypothesized that NLP occurrence may be influenced by the sex and the age of the singer due to the different vocal behavior and engagement of adults and juveniles of both sexes to the song. Given that females emit a higher number of units and phrases than males (Giacoma et al. 2010; Zanoli et al. 2020), show longer contributions, and exhibit shorter intervals between the onsets of two consecutive units compared to males (De Gregorio et al. 2019), we predicted (4) that female singing may be more difficult to sustain and that, therefore, female contributions may show a higher NLP occurrence than male ones. We also predicted (5) that NLP may occur earlier in females who may suffer vocal fatigue before than males. Furthermore, since previous research showed that NLP may play a role in making signals unpredictable and preventing the habituation of listeners and that this may be particularly effective for those individuals who are potentially more exposed to dangers or need more attention (Fitch et al. 2002; Blumstein and Récapet 2009; Karp et al. 2014), we predicted that 6) juveniles exhibit a higher occurrence of NLP than adults.

a Spectrogram of an advertisement song of an adult male and an adult female indri singing in the Maromizaha forest (Madagascar). The fundamental frequency is highlighted in ochre (female) and green (male). Red dotted lines highlight NLP. b Blue bar shows song duration, i.e., the duration between the beginning of the first roar to the end of the last unit of the duet or chorus. c An ochre and green bar show the female and male individual contributions, i.e., the duration between the beginning of the first unit of an individual and the end of the last unit of the same individual. d An ochre (female) and green (male) sections of the bars display the phonation of both sexes, i.e., the sum of the duration of all the units of a specific individual contribution. Among phonation intervals, red denotes the NLP, which are numbered consecutively
Methods
Subjects and recordings
Between 2010 and 2020, we recorded the songs of seven habituated groups of wild indris living in the Maromizaha New Protected Area (18°56′49′′S, 48°27′53′′E, Madagascar). We selected 15 advertisement songs (Torti et al. 2013; Fig. 1a) for each group (duets and choruses). Out of the 105 songs, 64 were recorded during the reproductive season (September–February, Ravaglia et al. 2023), and 41 during the non-reproductive season (March-August, Ravaglia et al. 2023). We recorded the songs at a 2–10 m distance using solid-state recorders (sampling rate: 44.1 kHz; 16-bit resolution) connected to shotgun microphones oriented toward the emitters. All the songs were spontaneously emitted by the individuals, without the use of playback stimuli. By using focal animal sampling (Altmann 1974), we were able to discriminate between the singing individuals and attribute each vocalization to its emitter. See S1 Supplementary Information for details on the identity, group, sex, age, season, and number of contributions per individual who engaged in the songs we used in this study.
Acoustic analysis
We used Praat 6.2.07 (Boersma and Weenink 2022) to visually inspect each song spectrogram. A first operator (WC) manually labeled all the vocal units of the singer and identified NLP (.Textgrid format; labels: linear or nonlinear). Examples of NLP are shown in S2 – Supplementay Information. We then randomly selected 10% of the contributions from our sample, and a second operator (TR) separately labeled the units following the same methodology. We reached an inter-rater agreement equal to 89.98% and a proportion of observed agreement of 0.88 out of all the labeled units. We then calculated the Cohen’s Kappa, taking into account the inter-observers chance agreement, obtaining a K = 0.72 (values between 0.40 and 0.75 are considered to represent a good agreement, values above 0.75 represent excellent agreement – Fleiss et al. 2003). We did not consider roars for our NLP count as their structure prevents the recognition of their actual emitter (Valente et al. 2021), although we included them when measuring the duration of each song. We measured three temporal variables (Fig. 1 b-d and S3 – Supplementary Information): song duration, from the beginning of the first roar to the ending of the last modulated unit; the duration of the individual contributions (contribution), from the beginning of the first modlated unit to the ending of the last modulated unit (long notes and descending phrases, see Giacoma et al. 2010) emitted by a singer; the individual phonation (phonation), i.e., the cumulative duration of all the units emitted within a contribution (De Gregorio et al. 2019). We calculated such temporal variables to be able to test our first two hypotheses. Since the songs were recorded at different distances and in different weather conditions, we were not able to reliably assess a measure of the loudness. However, previous data revealed that indri songs can reach 110 dB at 0.50 m (Zanoli et al. 2020), and there is no evidence that the loudness of the song varies according to the duration. We, therefore, were not able to test whether and how much loudness played a role in the NLP occurrence.
Statistical analysis
We built three Generalized Linear Mixed Models (GLMM; glmmTMB package, R Core Team 2021, version 4.1.2), each testing for the effect of one temporal variable (song duration, contribution, or phonation; predictors) on the occurrence of NLP. The response variable followed a Poisson distribution, as specified in each model. W e also tested the effect of sex (female or male) and age (i.e., adults, from 6 years old and juveniles, i.e., non-reproductive individuals, from 2 years old, Rolle et al. 2021) in interaction, and season (reproductive or non-reproductive). Each model included a song code and an individual code, i.e., unique acronyms indicating a particular song and a particular individual as random factors. With the aim of understanding which of the three temporal variables better explained the occurrence of NLP in songs, we selected the model showing the best goodness of fit first through a likelihood ratio test (Anova with argument test “Chisq”; Dobson 2002) to compare each model with one another, then by using Efron’s pseudo R-squared test (performance package).
We then split the temporal variable contained in the best-fitting model into duration quartiles. We counted the number of NLP occurring in each quartile to understand if the NLP distribution changed as vocal display proceeded. To test this hypothesis, we ran a GLMM using NLP occurrence within each quartile as the response variable (one count of NLP occurrence per every quartile), which followed a Poisson distribution. The explanatory variables were the temporal variable, its quartiles (as an integer variable), the interaction between sex and age, and season. The model included the song and individual identity codes as random factors.
For all the models we ran, we verified the significance of the full model (including explanatory variables and random factors) versus the null model (including random factors only) through a likelihood ratio test (Anova with argument test “Chisq”, Dobson 2002). We also verified the assumptions that the residuals were normally distributed and homogenous by looking at a qqplot and the distribution of the residuals plotted against the fitted values (a function provided by R. Mundry). We excluded the presence of collinearity among predictors by verifying the Variance Inflation Factors (VIFs, performance package). We also performed pairwise comparisons for each level of the factors in the model using a post-hoc test (emmeans package). Finally, potential overdispersion was evaluated for each model using performance package in R. None of the models was flawed by overdispersion.
To test whether NLP occur earlier in females than males, we also tested whether the timing of the onset of NLP differed among sex and age classes by looking at how quickly the first nonlinear phenomenon occurs, i.e., latency to first nonlinear phenomenon. To do so, we calculated the time the first nonlinear phenomenon occurred in an individual contribution and performed a survival analysis in R (ggsurvFit and survival packages). We first generated Kaplan–Meier plots to show the survival curves, i.e., time-to-event endpoints by using the time at which the first nonlinear phenomenon occurred as the response variable and the interaction between sex and age as the predictor variable, and we calculated the average survival time, i.e., the average latency to first nonlinear phenomenon for each predictor level, i.e., females, males, adults, and juveniles. We then compared the survival times between groups by using a log-rank test. Finally, we performed pairwise comparisons for each factor level in the model by using a post-hoc (survminer package).
Results
In 245 contributions emitted by 28 individuals (8 adult females, 11 adult males, 3 juvenile females, 5 juvenile males, and 1 female whose age was unknown), we identified 1418 NLP (618 emitted by adult females, 642 by adult males, 25 by juvenile females, and 133 by juvenile males). 952 out of 1418 NLP were emitted during the reproductive season. Contributions per sex and age were distributed as follows: 99 for adult females, 110 for adult males, 11 for juvenile females, 23 for juvenile males, and 2 for a female whose age was unknown and was, therefore, not included in the analyses. The percentage of NLP on the total number of emitted units per sex, age, and season is shown in Fig. 2. For each of the three models testing the effect of temporal variables on total NLP occurrence, the three full models were significantly different from the null ones (song duration: Chisq = 35.549, df = 8, p < 0.001; contribution: Chisq = 85.556, df = 8, p < 0.001; phonation: Chisq = 118.421, df = 8, p < 0.001). Furthermore, for all models, the temporal variables had a significant effect on the number of NLP (Figs. 3, 4, 5; song duration: estimate = 0.005, z = 5.343, p < 0.001; contribution: estimate = 0.008, z = 9.480, p < 0.001; phonation: estimate = 0.030, z = 11.680, p < 0.001; Tables 1, 2 ,3).

Percentage (%) of NLP in the song units given by the 28 sampled individuals of indris (total n of emitted units = 4995; total n of NLP = 1418). The percentage is calculated by dividing the number of units showing NLP for a particular individual by the total number of emitted notes. We show the results by sex (female, male), age (adult and juvenile) and season (non-reproductive, reproductive)

Effect plots of the GLMM, considering sex and age and their interaction, testing for the effect of the temporal variable song duration (in seconds) on the occurrence of NLP (shaded areas indicate 95% confidence intervals; observations n = 227). Song duration positively and significantly affects the occurrence of NLP. Age (A = adult, J = juvenile) and season (NR = non-reproductive, R = reproductive) have a significant effect on the occurrence of NLP, and are displayed on the right with effect plots (boxplots). Sex alone (F = female, M = male) and the interaction between sex and age were not significant and therefore not shown

Effect plots of the GLMM, considering sex and age and their interaction, testing for the effect of the temporal variable contribution (in seconds) on the occurrence of NLP (shaded areas indicate 95% confidence intervals; observations n = 227). Contribution positively and significantly affects the occurrence of NLP. Age (A = adult, J = juvenile) and the interaction between age and sex (F = female, M = male) have a significant effect on the occurrence of NLP and are displayed on the right with effect plots (boxplots). Season does not have an effect on NLP occurrence and therefore not shown

Effect plots of the GLMM, considering sex and age and their interaction, testing for the effect of the temporal variable phonation (in seconds) on the occurrence of NLP (shaded areas indicate 95% confidence intervals; observations n = 227). Phonation positively and significantly affects the occurrence of NLP. No factors among age (A = adult, J = juvenile), sex (F = female, M = male), their interaction or season (R = reproductive, NR = non-reproductive) have a significant effect on the occurrence of NLP and therefore not shown
Considering the effect of season, sex, and age, the model with song duration as a predictor showed a significant effect of age and season on NLP occurrence (age: estimate = – 0.877, z = – 2.670, p = 0.008; season: estimate = 0.167, z = – 1.976, p = 0.048; Table 1). Specifically, the number of NLP was significantly higher in adult than in juvenile females and in the reproductive than in the non-reproductive season (Table 1).
The model with contribution as a predictor showed a significant effect of both age and its interaction with sex overall (age: estimate = – 0.665, z = – 2.090, p = 0.037; sex*age: estimate = 0.911, z = 2.312, p = 0.021; Table 2), but no significant post-hoc comparisons (Table 2). The number of NLP was significantly higher in adults than juveniles. Moreover, age had a significant effect on NLP occurrence also in interaction with sex, although no contrasts significantly differed from one another (Table 2).
The model including phonation as a predictor did not show any significant effect other than phonation and no significant post-hoc contrasts, i.e., age, sex, interaction, and season did not predict the occurrence of NLP (Table 3).
When comparing the three models, we found that the model including phonation as a predictor for NLP occurrence was the best-fitting one (pseudo R2 song duration: 0.632; pseudo R2 contribution: 0.645; pseudo R2 phonation: 0.652; song duration vs contribution: Chisq = 50.007, df = 8, p < 0.001; contribution vs phonation: Chisq = 35.865, df = 8, p < 0.001; song duration vs phonation: Chisq = 82.872, df = 8, p < 0.001).
Considering that, we split phonation into duration quartiles and found that the occurrence of NLP increased with quartiles Fig. 6; phonation: estimate = 0.028, z = 12.200, p < 0.001; quartiles: estimate = 0.259, z = 10.598, p < 0.001; Table 4). We did not detect a significant effect of sex, age, their interaction, and season on NLP occurrence (Table 4).

Effect plot of the GLMM testing for the effect of the quartile of phonation, phonation, sex, age, and their interaction on the occurrence of NLP in the specific quartile. The model showed that the occurrence of NLP increased with phonation and quartile. Shaded areas indicate 95% confidence intervals
Kaplan–Meier plots show the survival curves for all the four categories we considered in the survival analysis, i.e., adult females, adult males, juvenile females, and juvenile males (Fig. 7). We found that there was a significant difference in the survival curves and, therefore, in the latency to the first nonlinear phenomenon between sex and age classes as resulted from the log-rank test (Chisq = 17.700, df = 3, p < 0.001; S4 – Supplementary Information). Specifically, half of the time adult females emitted their first nonlinear phenomenon within 10.848 s (average survival time = 10.848 s), whereas half of the time the first nonlinear phenomenon for adult males occurred within 18.784 s (average survival time = 18.784 s). The post-hoc revealed that this difference was significant, showing that, on average, the first nonlinear phenomenon occurs earlier in adult females than adult males (p < 0.001, S4—Supplementary Information).

Kaplan–Meier curves plotting the time at which the first nonlinear phenomenon occurred within an individual contribution (x-axis) and the probability of emitting the first nonlinear phenomenon after a certain period of time (y-axis). Factor levels sex = ‘male’ (M) and ‘female’ (F); factor levels age = ‘juvenile’ (J) and ‘adult’ (A)
Discussion
Our study aimed to investigate whether vocal fatigue may play a role in the emission of NLP and whether season, sex, and age may influence such phenomena accordingly. We demonstrated that NLP occurrence is best predicted by the phonation, although also song duration and contribution showed a positive effect on the response variable. Furthermore, NLP progressively increase with phonation. We also searched for an effect of the seasonality, and we found that for the same duration of the song, the number of NLP was smaller during the non-reproductive season. Moreover, we tested whether sex affects the occurrence of NLP, and although we did not identify sex differences in terms of total occurrence, we found that adult females emit their first nonlinear phenomenon earlier than adult males. Finally, we found that being an adult is associated with increased NLP within song duration and contribution, and that adult females produce significantly more NLP than juvenile females within the song.
We provided evidence for a positive relationship between the duration of the vocal display and NLP occurrence, and we showed that phonation is the best predictor among the three temporal variables we considered. We also found a positive effect of the phonation quartiles, indicating that NLP increase over time and are likely to occur more often during the final stages of the phonation. Our results confirm our first two predictions and suggest that effective engagement in singing determines how many NLP an individual emits. Like in chimpanzees’ vocalizations (Riede et al. 2004, 2007) and hyrax songs (Weissmann et al. 2020), intense vocal activity may favor the emergence of vocal nonlinearities. Indeed, the production of harmonic sounds may be limited by physiological constraints while singing long and demanding calls; as such, indris may experience vocal fatigue leading to an increase in NLP production. In agreement with previous studies on humans (Boucher 2008) and chimpanzees (Riede et al. 2004), vocal fatigue may thus foster the deterioration of vocal emission.
Although we predicted that NLP occurrence may be significantly higher during the reproductive season, when indris sing more often, we only found a weak positive effect of the season in the first model we built. NLP occurrence shows a low seasonal pattern related to the song duration, but we did not detect any effect concerning either the contribution or phonation. This finding may suggest that a certain degree of fatigue might be experienced by indris every time they emit songs, regardless of the season. According to our results, whether there is an accumulation of fatigue in indris during particular periods of the year is unclear, in contrast with previous findings that reported a change in NLP rates in the male calls of fallow bucks (Dama dama) according to a seasonal pattern (Vannoni and McElligott 2009) or demonstrated how the prolonged effort needed to sustain long calls leads to vocal fatigue (Castellano and Gamba 2011).
Considering sex and age in interaction, we found an overall effect of these two terms in the model including contribution as a predictor. However, we found no support for our prediction that NLP occurrence is higher in females than males, in disagreement with previous findings on baboons’ loud calls (Fischer et al. 2004), humpback whales’ songs (Cazau et al. 2016), and rock hyraxes’ songs (Demartsev et al. 2016). We found sex differences only in terms of latency to the first nonlinear phenomenon. Indeed, based on our findings, adult females are likely to emit their first nonlinear phenomenon earlier than adult males, i.e., there is a significant difference in the latency to the first nonlinear phenomenon between adult females and males, in agreement with what we predicted. Therefore, our results show that despite both sexes experiencing similar levels of fatigue, adult females could be affected by the vocal effort quicker than adult males, given that females emit more units and more phrases (Giacoma et al. 2010; Zanoli et al. 2020) and take shorter intervals in between units compared to males (De Gregorio et al. 2019). Hence, adult males may be able to rest and maintain vocal control more easily yet we cannot exclude that any difference in the way indris emit the first nonlinear phenomenon might be also related to sex-specific factors, such as female hormone levels during oestrus, which might affect the vocal behavior and sound production, as previously underlined in humans (Raj et al. 2010) and giant pandas (Charlton et al. 2018).
We finally rejected our prediction that juveniles emit NLP more frequently than adults. Instead, we found evidence that NLP occurrence is predicted by age but that adults are likely to emit more NLP than juveniles. This tendency is particularly strong between adult and juvenile females. Specifically, with an equal duration of the song, adult females tend to produce more NLP than juvenile ones. However, the small sample size of the juvenile females might partially affect this result. Our findings disagree with the hypothesis that NLP may be produced more by younger individuals to make their signals harder to ignore (Fitch et al. 2002; Massenet et al. 2022). However, a higher NLP occurrence in adults may suggest a loss in larynx control in older individuals, representing an aging indicator similar to what has been reported in dogs (Marx et al. 2021).
Whether physiological constraints hamper the emission of harmonic units, NLP may result as a mere byproduct of energetically expensive vocalizations (Zanoli et al. 2020) or a specific phonatory system (Gamba et al. 2011). This might be due to a compensatory mechanism balancing the cost of sustaining long calls. It has been observed that NLP may be typical of species that exhibit peculiar communication systems basend on exhausting and loud calls, such as anurans (Feng et al. 2009) and whales (Cazau et al. 2016). Although essentially depending on physiological constraints emerging when performing long calls, NLP emission might be still improving unpredictability in the indris’ songs, thus facilitating other groups’ reception of their signals at long distances in the dense rainforest they inhabit. In this sense, NLP could have cognitive implications for a receiver. Indeed, where advertisement songs take the shape of long modulated sequences, neurally cheap unpredictability may serve the adaptive functions of making nonlinear vocalizations challenging to ignore, similar to rhesus macaque calls (Fitch et al. 2002). Even if those songs are critical to understanding the position in the home range of particular groups and space animals in the different forest patches (Torti et al. 2013, 2017), they can ignore those howling sounds while, for instance, continuing feeding on a particular tree. In this framework, cognitive processes may guide perceptual dynamics by classifying calls based on experience, potentially attributing the presence of NLP to a greater or lesser degree of urgency of the received signal.
In conclusion, despite NLP being common in the vocal repertoire of non-human primates (Fitch et al. 2002; Nishimura et al. 2022), the study of these features is still in its infancy. Our work investigated and quantified the occurrence of NLP in the songs of a lemur species. Addressing this topic in other primate species will be extremely important in framing the occurrence of NLP among the Strepsirrhini sub-order and among singing primates. Further studies will deepen our understanding of the occurrence of NLP across these taxa and provide new insights into the ecological role of these signals. For example, a more complete comprehension of the NLP occurrence will include differentiating and quantifying nonlinearities based on their spectral features.
Availability of data and materials
Data used in this study are available on request to the corresponding author and will be loaded on github once the manuscript will be accepted for publication.
References
Anikin A (2020) The perceptual effects of manipulating nonlinear phenomena in synthetic nonverbal vocalizations. Bioacoustics 29(2):226–247. https://doi.org/10.1080/09524622.2019.1581839
Anikin A, Pisanski K, Massenet M, Reby D (2021) Harsh is large: nonlinear vocal phenomena lower voice pitch and exaggerate body size. Proc R Soc B 288:20210872. https://doi.org/10.1098/rspb.2021.0872
Blesdoe EK, Blumstein DT (2014) What is the sound of fear? Behavioral responses of white-crowned sparrows Zonotrichialeucophrys to synthesized nonlinear acoustic phenomena. Cu Zool 60(4):534–541. https://doi.org/10.1093/czoolo/60.4.534
Blumstein DT, Récapet C (2009) The sound of arousal: the addition of novel non-linearities increases responsiveness in marmot alarm calls. Ethology 115(11):1074–1081. https://doi.org/10.1111/j.1439-0310.2009.01691.x
Boersma P, Weenink D (2022). Praat: doing phonetics by computer [Computer program]. Version 6.2.07, retrieved 28 January 2022 from http://www.praat.org/.
Boucher VJ (2008) Acoustic correlates of fatigue in laryngeal muscles: findings for a criterion-based prevention of acquired voice pathologies. J Speech Lang Hear Res 51(5):1161–1170. https://doi.org/10.1044/1092-4388(2008/07-0005)
Castellano S, Gamba M (2011) Marathon callers: acoustic variation during sustained calling in treefrogs. Ethol Ecol Evol 23:329–342. https://doi.org/10.1080/03949370.2011.575801
Cazau D, Adam O, Aubin T, Laitman JT, Reidenberg JS (2016) A study of vocal nonlinearities in humpback whale songs: from production mechanisms to acoustic analysis. Sci Rep 6:31660. https://doi.org/10.1038/srep31660
Charlton BD, Martin-Wintle OMA, Zhang H, Swaisgood RR (2018) Vocal behaviour predicts mating success in giant pandas. R Soc Open Sci. https://doi.org/10.1098/rsos.181323
De Gregorio C, Zanoli A, Valente D, Torti V, Bonadonna G, Randrianarison RM, Giacoma C, Gamba M (2019) Female indris determine the rhythmic structure of the song and sustain a higher cost when the chorus size increases. Curr Zool 65(1):89–97. https://doi.org/10.1093/cz/zoy058
De Gregorio C, Carugati F, Estienne V, Valente D, Raimondi T, Torti V, Miaretsoa L, Ratsimbazafy J, Gamba M, Giacoma C (2021) Born to sing! Song development in a singing primate. Cu Zool 67(6):597–608. https://doi.org/10.1093/cz/zoab018
De Gregorio C, Carugati F, Valente D, Raimondi T, Torti V, Miaretsoa L, Gamba M, Giacoma C (2022a) Notes on a tree: reframing the relevance of primate choruses, duets, and solo songs. Ethol Ecol Evol 34(3):205–219. https://doi.org/10.1080/03949370.2021.2015451
De Gregorio C, Zanoli A, Carugati F, Raimondi T, Valente D, Torti V, Miaretsoa L, Rajaonson A, Gamba M, Giacoma C (2022b) Parent-offspring turn-taking dynamics influence parents' song structure and elaboration in a singing primate. Front Ecol Evol 10:906322. https://doi.org/10.3389/fevo.2022.906322
Demartsev V, Bar Ziv E, Shani U, Goll Y, Koren L, Geffen E (2016) Harsh vocal elements affect counter-singing dynamics in male rock hyrax. Behav Ecol 27(5):1397–1404. https://doi.org/10.1093/beheco/arw063
Dobson AJ (2002) An introduction to generalized linear models, 2nd edn. Chapman and Hall/CRC Press, Boca Raton, FL
Feng AS, Riede T, Arch VS, Yu Z, Xu Z, Yu Y, Shen J (2009) Diversity of the vocal signals of concave-eared torrent frogs (Odorranatormota): evidence for individual signatures. Ethology 115(11):1015–1028. https://doi.org/10.1111/j.1439-0310.2009.01692.x
Fischer J, Kitchen DM, Seyfarth RM, Cheney DL (2004) Baboon loud calls advertise male quality: acoustic features and their relation to rank, age, and exhaustion. Behav Ecol Sociobiol 56:140–148. https://doi.org/10.1007/s00265-003-0739-4
Fitch WT, Neubauer J, Herzel H (2002) Calls out of chaos: the adaptive significance of nonlinear phenomena in mammalian vocal production. Anim Behav 63(3):407–418. https://doi.org/10.1006/anbe.2001.1912
Fleiss JL, Levin B, Paik MC (2003) The measurement of interrater agreement. In: Shewart WA, Wilks SS (Eds) Statistical methods for rates and proportions, Third Edition, Chapter 18. https://doi.org/10.1002/0471445428.ch18
Fuchs E, Beeck VC, Baotic A, Stoeger AS (2021) Acoustic structure and information content of trumpets in female Asian elephants (Elephas maximus). PLoS ONE 16(11):e0260284. https://doi.org/10.1371/journal.pone.0260284
Gamba M, Favaro L, Torti V, Sorrentino V, Giacoma C (2011) Vocal tract flexibilty and variation in the vocal output in wild indris. Bioacoustics 20(3):251–265. https://doi.org/10.1080/09524622.2011.9753649
Gamba M, Torti V, Estienne V, Randrianarison RM, Valente D, Rovara P, Bonadonna G, Friard O, Giacoma C (2016) The indris have got rhythm! Timing and pitch variation of a primate song examined between sexes and age classes. Front Neurosci. https://doi.org/10.3389/fnins.2016.00249
Giacoma C, Sorrentino V, Rabarivola C, Gamba M (2010) Sex differences in the song of Indri indri. Int J Primatol 31:539–551. https://doi.org/10.1007/s10764-010-9412-8
Herzel H, Berry D, Titze I, Steinecke I (1995) Nonlinear dynamics of the voice: signal analysis and biomechanical modeling. Chaos 5(30):30–34. https://doi.org/10.1063/1.166078
Karp D, Manser MB, Wiley EM, Townsend SW (2014) Nonlinearities in meerkat alarm calls prevent receivers from habituating. Ethology 120(2):189–196. https://doi.org/10.1111/eth.12195
Krajewski J, Sommer D, Schnupp T, Laufenberg T, Heinze C, Golz M (2010) Applying nonlinear dynamics features for speech-based fatigue detection. Proceedings of the 7th international conference on methods and techniques in behavioral research 23:1–5. https://doi.org/10.1145/1931344.1931367.
Marx A, Lenkei R, Fraga PP, Bakos E, Faragó T (2021) Occurrences of non-linear phenomena and vocal harshness in dog whines as indicators of stress and ageing. Sci Rep 11:4468. https://doi.org/10.1038/s41598-021-83614-1
Massenet M, Anikin A, Pisanski K, Reynaud K, Mathevon N, Reby D (2022) Nonlinear vocal phenomena affect human perceptions of distress, size and dominance in puppy whines. Proc R Soc B 28(1973):1–9. https://doi.org/10.1098/rspb.2022.0429
Nishimura T, Tokuda IT, Miyachi S, Dunn JC, Herbst CT, Ishimura K, Kaneko A, Kinoshita T, Koda H, Saers JPP, Imai H, Matsuda T, Larsen ON, Jürgens U, Hirabayashi H, Kojima S, Fitch WT (2022) Evolutionary loss of complexity in human vocal anatomy as an adaptation for speech. Sci 377(6607):760–763. https://doi.org/10.1126/science.abm1574
Pollock JI (1986) The song of the indris (Indri indri); Primates; Lemuroidea: natural history form and function. Int J Primatol 7:225–264. https://doi.org/10.1007/BF02736391
Raj A, Gupta B, Chowdhury A, Chadha S (2010) A study of voice changes in various phases of menstrual cycle and in postmenopausal women. J Voice 24(3):363–368. https://doi.org/10.1016/j.jvoice.2008.10.005
Ravaglia D, Ferrario V, De Gregorio C, Carugati F, Raimondi T, Cristiano W, Torti V, Von Hardenberg A, Ratsimbazafy J, Valente D, Giacoma C, Gamba M (2023) There you are! Automated detection of indris’ songs on features extracted from passive acoustic recordings. Animals 13(2):241. https://doi.org/10.3390/ani13020241
Reby D, Charlton BD (2012) Attention grabbing in red deer sexual calls. Anim Cognit 15:265–270. https://doi.org/10.1007/s10071-011-0451-0
Reby D, Wyman MT, Frey R, Passilongo D, Gilbert J, Locatelli Y, Charlton BD (2016) Evidence of biphonation and source-filter interactions in the bugles of male North American wapiti (Cervuscanadensis). J Exp Biol 219(Pt 8):1224–1236. https://doi.org/10.1242/jeb.131219
Riede T (2007) Nonlinear acoustic in the pant hoots of common chimpanzees (Pan troglodytes): vocalizing at the edge. J Acoust Soc Am 121(3):1758. https://doi.org/10.1121/1.2427115
Riede T, Owren MJ, Arcadi AC (2004) Nonlinear acoustics in pant hoots of common chimpanzees (Pan troglodytes): frequency jumps, subharmonics, biphonation, and deterministic chaos. Am J Primatol 64(3):277–291. https://doi.org/10.1002/ajp.20078
Rolle F, Torti V, Valente D, De Gregorio C, Giacoma C, Von Hardenberg A (2021) Sex and age-specific survival and life expectancy in a free ranging population of Indri indri. Eur Zool j 88(1):796–806. https://doi.org/10.1080/24750263.2021.1947398
Spezie G, Torti V, Bonadonna G, De Gregorio C, Valente D, Giacoma C, Gamba M (2022) Evidence for acoustic discrimination in lemurs: a playback experiment in wild indris (Indri indri). Cu Zool. https://doi.org/10.1093/cz/zoac009
Sportelli JJ, Jones BJ, Ridgway SH (2022) Non-linear phenomena: a common acoustic feature of bottlenose dolphin (Tursiopstruncatus) signature whistles. Bioacoustics. https://doi.org/10.1080/09524622.2022.2106306
Torti V, Gamba M, Rabemananjara ZH, Giacoma C (2013) The songs of the indris (Mammalia: Primates: Indridae): contextual variation in the long-distance calls of a lemur. It J Zool 80(4):596–607. https://doi.org/10.1080/11250003.2013.845261
Torti V, Bonadonna G, De Gregorio C, Valente D, Randrianarison RM, Friard O, Pozzi L, Gamba M, Giaxoma C (2017) An intra-population analysis of the indris’ song dissimilarity in the light of genetic distance. Sci Rep. https://doi.org/10.1038/s41598-017-10656-9
Townsend SW, Manser MB (2011) The function of nonlinear phenomena in meerkat alarm calls. Biol Lett 7(1):47–49. https://doi.org/10.1098/rsbl.2010.0537
Tyson RB, Nowacek DP, Miller PJO (2007) Nonlinear phenomena in the vocalizations of North Atlantic right whales (Eubalaenaglacialis) and killer whales (Orcinus orca). J Acoust Soc Am 122:1365–1373. https://doi.org/10.1121/1.2756263
Valente D, De Gregorio C, Favaro L, Friard O, Miaretsoa L, Raimondi T, Ratsimbazafy J, Torti V, Zanoli A, Giacoma C, Gamba M (2021) Linguistic laws of brevity: conformity in Indri indri. Anim Cognit 24:897–906. https://doi.org/10.1007/s10071-021-01495-3
Vannoni E, McElligott AG (2009) Fallow bucks get hoarse: vocal fatigue as a possible signal to conspecifics. Anim Behav 78(1):3–10. https://doi.org/10.1016/j.anbehav.2009.03.015
Volodin IA, Matrosova VA, Frey R, Kozhevnikova JD, Isaeva IL, Volodina EV (2018) Altai pika (Ochotona alpina) alarm calls: individual acoustic variation and the phenomenon of call-synchronous ear folding behavior. Sci Nat. https://doi.org/10.1007/s00114-018-1567-8
Wagner B, Bowling DL, Hoeschele M (2020) Is consonance attractive to budgerigars? No evidence from a place preference study. Anim Cogn 23:973–987. https://doi.org/10.1007/s10071-020-01404-0
Weissmann YA, Demartsev V, Ilany A, Barocas A, Bar-Zv E, Koren L, Geffen E (2020) A crescendo in the inner structure of snorts: a reflection of increasing arousal in rock hyrax songs? Anim Behav 166:163–170. https://doi.org/10.1016/j.anbehav.2020.06.010
Wilden I, Herzel H, Peters G, Tembrock G (1998) Subharmonics, biphonation, and deterministic chaos in mammalian vocalization. Bioacoustics 9(3):171–196. https://doi.org/10.1080/09524622.1998.9753394
Zanoli A, De Gregorio C, Valente D, Torti V, Bonadonna G, Randrianarison RM, Giacoma C, Gamba M (2020) Sexually dimorphic phrase organization in the song of the indris (Indri indri). Am J Primatol 82(6):e23132. https://doi.org/10.1002/ajp.23132
Acknowledgements
We thank the local research guides working at the Maromizaha Multipurpose Center and all the assistants helping during data collection. We are grateful to the Groupe d'Étude et des Recherche sur les Primates de Madagascar (GERP) for the support during the field activities. We also wish to thank Chester Zoo, Dr Cesare Avesani Zaborra, and Dr Caterina Spiezio for the support and financial assistance, and Prof Sergio Castellano for fruitful discussion of our results. Finally, we thank Dr Guillaume Dezecache and the anonymous reviewer for their insightful comments on earlier versions of the manuscript.
Funding
Open access funding provided by Università degli Studi di Torino within the CRUI-CARE Agreement. Not applicable.
Author information
Authors and Affiliations
Contributions
Conceptualization: WC, MG, TR; Data curation: WC. Methodology: MG, WC, TR, DV. Formal analysis and investigation: WC, TR. Visualisation: TR, WC. Writing—original draft preparation: WC, TR. Supervision: MG, CG. All authors reviewed and approved the last version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The Authors declare that they have no competing interests.
Ethical approval
The authors collected the data under the research permits issued each year by the Ministère de l’Environnement et du Développement Durable (MEDD) and Madagascar National Parks (formerly ANGAP): No. 118/ 10/ MEF/ SG/ DGF/ DCB.SAP/ SCBSE; No. 293/ 10/ MEF/ SG/ DGF/ DCB.SAP/ SCB, N°274/11/MEF/SG/DGF/DCB.SAP/SCB, N°245/12/MEF/SG/DGF/DCB.SAP/SCB, N°066/14/MEF/SG/DGF/DCB.SAP/SCB, N°180/15/MEEMF/SG/DGF/DAPT/SCBT, N°98/16/MEEMF/SG/DGF/DAPT/SCB.Re and N°217/16/MEEMF/SG/DGF/DSAP/SCB.Re, 73/17/MEEF/SG/DGF/DSAP/SCB.RE, 91/18/MEEF/SG/DGF/DSAP/SCB.Re, 118/19/MEDD/SG/DGEF/DSAP/DGRNE and 284/19/MEDD/SG/DGEF/DSAP/DGRNE, 338/19/MEDD/SG/DGEF/DSAP/DGRNE.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cristiano, W., Raimondi, T., Valente, D. et al. Singing more, singing harsher: occurrence of nonlinear phenomena in a primate’ song. Anim Cogn 26, 1661–1673 (2023). https://doi.org/10.1007/s10071-023-01809-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10071-023-01809-7