
Abstract
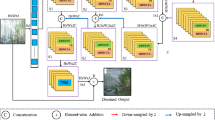
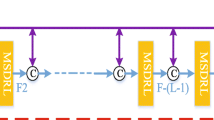
Recently, convolutional neural networks (CNNs) have achieved remarkable success on single-image rain removal task. However, due to the intrinsic locality of convolution operations, CNN-based models generally demonstrate limitations in explicitly modeling long-range dependency. Transformer has achieved milestones in many artificial intelligence fields by mitigating the shortcomings of CNNs but can result in limited localization abilities and high computational cost. To this end, we propose a novel global–local transformer, termed GLFormer to model long-range dependencies for rain removal while remaining efficient. Specifically, we use a window-based local transformer block to build the shallow layers of GLFormer for processing high-resolution feature maps, which greatly reduces the computational complexity. And a global transformer block is designed to construct deep layers which can model long-range dependencies with global self-attention. Powered by these designs, GLFormer avoids the limitation of computing self-attention within a local window that lacks global feature inference and reduces the computational effort to a large extent. Considering that local details are crucial for the recovery of degraded images, we further employ convolution operation in both global and local transformer blocks to improve its potential for capturing local context. In addition, a self-supervised pre-training strategy is further introduced to mining sufficient image priors by utilizing ultra-large unlabeled image datasets. Our proposed method is extensively evaluated on several benchmark datasets, and the results show GLFormer to be superior than the state-of-the-art approaches built upon convolution.







Similar content being viewed by others

References
Garg K, Nayar SK (2005) When does a camera see rain? Tenth IEEE Int Conf Comput Vis (ICCV’05) 1(2):1067–1074 (IEEE)
Barnum PC, Narasimhan S, Kanade T (2010) Analysis of rain and snow in frequency space. Int J Comput Vision 86(2):256–274
Bossu J, Hautiere N, Tarel J-P (2011) Rain or snow detection in image sequences through use of a histogram of orientation of streaks. Int J Comput Vision 93(3):348–367
Chen Y-L, Hsu C-T (2013) A generalized low-rank appearance model for spatio-temporally correlated rain streaks. In: Proceedings of the IEEE international conference on computer vision, pp 1968–1975
Zheng X, Liao Y, Guo W, Fu X, Ding X (2013) Single-image-based rain and snow removal using multi-guided filter. In: International conference on neural information processing, pp 258–265. Springer
Ding X, Chen L, Zheng X, Huang Y, Zeng D (2016) Single image rain and snow removal via guided l0 smoothing filter. Multimedia Tools Appl 75(5):2697–2712
Gu S, Meng D, Zuo W, Zhang L (2017) Joint convolutional analysis and synthesis sparse representation for single image layer separation. In: Proceedings of the IEEE international conference on computer vision, pp 1708–1716
Deng S, Wei M, Wang J, Feng Y, Liang L, Xie H, Wang FL, Wang M (2020) Detail-recovery image deraining via context aggregation networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 14560–14569
Wang H, Xie Q, Zhao Q, Meng D (2020) A model-driven deep neural network for single image rain removal. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 3103–3112
Luo Y, Xu Y, Ji H (2015) Removing rain from a single image via discriminative sparse coding. In: Proceedings of the IEEE international conference on computer vision, pp 3397–3405
Li Y, Tan RT, Guo X, Lu J, Brown MS (2016) Rain streak removal using layer priors. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2736–2744
Miao Y, Jia H, Tang K (2021) Chinese font migration combining local and global features learning. Pattern Anal Appl 24:1533–1547
Wan Y, Cheng Y, Shao M (2022) Mslanet: multi-scale long attention network for skin lesion classification. Appl Intell, 1–19
Zhou J, Meng M, Xing J, Xiong Y, Xu X, Zhang Y (2021) Iterative feature refinement with network-driven prior for image restoration. Pattern Anal Appl 24:1623–1634
Chen S, Zhang Y, Yin B, Wang B (2021) Trfh: towards real-time face detection and head pose estimation. Pattern Anal Appl 24:1745–1755
Fu X, Huang J, Ding X, Liao Y, Paisley J (2017) Clearing the skies: a deep network architecture for single-image rain removal. IEEE Trans Image Process 26(6):2944–2956
Fu X, Huang J, Zeng D, Huang Y, Ding X, Paisley J (2017) Removing rain from single images via a deep detail network. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3855–3863
Jiang K, Wang Z, Yi P, Chen C, Huang B, Luo Y, Ma J, Jiang J (2020) Multi-scale progressive fusion network for single image deraining. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 8346–8355
Yang Y, Lu H (2019) Single image deraining via recurrent hierarchy enhancement network. In: Proceedings of the 27th ACM international conference on multimedia, pp 1814–1822
Hu X, Fu C-W, Zhu L, Heng P-A (2019) Depth-attentional features for single-image rain removal. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 8022–8031
Yi Q, Li J, Dai Q, Fang F, Zhang G, Zeng T (2021) Structure-preserving deraining with residue channel prior guidance. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 4238–4247
Zamir SW, Arora A, Khan S, Hayat M, Khan FS, Yang M-H, Shao L (2021) Multi-stage progressive image restoration. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 14821–14831
Yasarla R, Sindagi VA, Patel VM (2020) Syn2real transfer learning for image deraining using gaussian processes. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 2726–2736
Wan Y, Cheng Y, Shao M, Gonzàlez J (2022) Image rain removal and illumination enhancement done in one go. Knowl-Based Syst 252:109244
Wang T, Yang X, Xu K, Chen S, Zhang Q, Lau RW (2019) Spatial attentive single-image deraining with a high quality real rain dataset. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 12270–12279
Li X, Wu J, Lin Z, Liu H, Zha H (2018) Recurrent squeeze-and-excitation context aggregation net for single image deraining. In: Proceedings of the European conference on computer vision (ECCV), pp 254–269
Ren D, Zuo W, Hu Q, Zhu P, Meng D (2019) Progressive image deraining networks: A better and simpler baseline. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 3937–3946
Chen M, Radford A, Child R, Wu J, Jun H, Luan D, Sutskever I (2020) Generative pretraining from pixels. In: International conference on machine learning, pp 1691–1703. PMLR
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S et al (2020) An image is worth 16x16 words: transformers for image recognition at scale. arXiv preprint arXiv:2010.11929
Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S (2020) End-to-end object detection with transformers. In: European conference on computer vision, pp 213–229. Springer
Zhu X, Su W, Lu L, Li B, Wang X, Dai J (2020) Deformable detr: deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159
Dai Z, Cai B, Lin Y, Chen J (2021) Up-detr: Unsupervised pre-training for object detection with transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 1601–1610
Chen H, Wang Y, Guo T, Xu C, Deng Y, Liu Z, Ma S, Xu C, Xu C, Gao W (2021) Pre-trained image processing transformer. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 12299–12310
Cao J, Li Y, Zhang K, Van Gool L (2021) Video super-resolution transformer. arXiv preprint arXiv:2106.06847
Wang C, Xing X, Wu Y, Su Z, Chen J (2020) Dcsfn: Deep cross-scale fusion network for single image rain removal. In: Proceedings of the 28th ACM international conference on multimedia, pp 1643–1651
Wang Y, Xu Z, Wang X, Shen C, Cheng B, Shen H, Xia H (2021) End-to-end video instance segmentation with transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 8741–8750
Esser P, Rombach R, Ommer B (2021) Taming transformers for high-resolution image synthesis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 12873–12883
Jiang Y, Chang S, Wang Z (2021) Transgan: Two pure transformers can make one strong gan, and that can scale up. Adv Neural Inf Process Syst 34
Liang J, Cao J, Sun G, Zhang K, Van Gool L, Timofte R (2021) Swinir: image restoration using swin transformer. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 1833–1844
Ba JL, Kiros JR, Hinton GE (2016) Layer normalization. arXiv preprint arXiv:1607.06450
Wu H, Xiao B, Codella N, Liu M, Dai X, Yuan L, Zhang L (2021) Cvt: Introducing convolutions to vision transformers. arXiv preprint arXiv:2103.15808
Hendrycks D, Gimpel K (2016) Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415
Deng J, Dong W, Socher R, Li L-J, Li K, Fei-Fei L (2009) Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition, pp 248–255. IEEE
Garg K, Nayar SK (2006) Photorealistic rendering of rain streaks. ACM Trans Graph (TOG) 25(3):996–1002
Yang W, Tan RT, Feng J, Liu J, Guo Z, Yan S (2017) Deep joint rain detection and removal from a single image. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1357–1366
Zhang H, Sindagi V, Patel VM (2019) Image de-raining using a conditional generative adversarial network. IEEE Trans Circuits Syst Video Technol 30(11):3943–3956
Zhang H, Patel VM (2018) Density-aware single image de-raining using a multi-stream dense network. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 695–704
Huynh-Thu Q, Ghanbari M (2008) Scope of validity of PSNR in image/video quality assessment. Electron Lett 44(13):800–801
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP (2004) Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process 13(4):600–612
Loshchilov I, Hutter F (2016) Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983
Zamir SW, Arora A, Khan S, Hayat M, Khan FS, Yang M-H, Shao L (2021) Multi-stage progressive image restoration. In: CVPR
Ronneberger O, Fischer P, Brox T (2015) U-net: convolutional networks for biomedical image segmentation. Springer International Publishing, Berlin
Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, Lin S, Guo B (2021) Swin transformer: hierarchical vision transformer using shifted windows. arXiv preprint arXiv:2103.14030
Everingham M, Zisserman A, Williams CK, Van Gool L, Allan M, Bishop CM, Chapelle O, Dalal N, Deselaers T, Dorkó G et al. (2008) The pascal visual object classes challenge 2007 (voc2007) results
Redmon J, Farhadi A (2018) Yolov3: an incremental improvement. arXiv preprint arXiv:1804.02767
Acknowledgments
The authors are very indebted to the anonymous referees for their critical comments and suggestions for the improvement of this paper. This work was supported by National Key Research and Development Program of China (2021YFA1000102), and in part by the grants from the National Natural Science Foundation of China (Nos. 61673396, 61976245), Natural Science Foundation of Shandong Province, China (No. ZR2022MF260). All authors read and approved the final manuscript.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose. The authors have no competing interests to declare that are relevant to the content of this article. All authors certify that they have no affiliations with or involvement in any organization or entity with any financial interest or non-financial interest in the subject matter or materials discussed in this manuscript. The authors have no financial or proprietary interests in any material discussed in this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Wan, Y., Shao, M., Bao, Z. et al. Global–local transformer for single-image rain removal. Pattern Anal Applic 26, 1527–1538 (2023). https://doi.org/10.1007/s10044-023-01184-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10044-023-01184-6