
Abstract
According to a survey on the cause of death among Japanese people, lifestyle-related diseases (such as malignant neoplasms, cardiovascular diseases, and pneumonia) account for 55.8% of all deaths. Three habits, namely, drinking, smoking, and sleeping, are considered the most important factors associated with lifestyle-related diseases, but it is difficult to measure these habits autonomously and regularly. Here, we propose a machine learning-based approach for detecting these lifestyle habits using voice data. We used classifiers and probabilistic linear discriminant analysis based on acoustic features, such as mel-frequency cepstrum coefficients (MFCCs) and jitter, extracted from a speech dataset we developed, and an X-vector from a pre-trained ECAPA-TDNN model. For training models, we used several classifiers implemented in MATLAB 2021b, such as support vector machines, K-nearest neighbors (KNN), and ensemble methods with some feature-projection options. Our results show that a cubic KNN method using acoustic features performs well on the sleep habit classification, while X-vector-based models perform well on smoking and drinking habit classifications. These results suggest that X-vectors may help estimate factors directly affecting the vocal cords and vocal tracts of the users (e.g., due to smoking and drinking), while acoustic features may help classify chronotypes, which might be informative with respect to the individuals’ vocal cord and vocal tract ultrastructure.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Lifestyle-related diseases are induced by physical and mental disorders related to various lifestyle disturbances. According to a survey conducted by the Ministry of Health, Labor, and Welfare of Japan, lifestyle-related diseases, such as malignant neoplasms, cardiovascular diseases, and pneumonia, account for 55.8% of all deaths in contemporary Japan (fig. 1 in [14]). The incidence of many of these diseases (e.g., lung cancer and cardiovascular diseases) has been continuously increasing. Smoking and alcohol consumption are cited as the main causes of these lifestyle-related diseases, but it is known that sleep habits can also contribute significantly, as poor sleep habits induce lifestyle-related diseases and mental disorders owing to impaired body rhythms and hormonal imbalance, as well as owing to accidents occurring as a result of lower alertness. In addition, because 20% of Japanese adults suffer from chronic insomnia, sleep habits have been of significant interest. In general, special equipment and appropriate medical care are required for measuring these lifestyle habits at medical institutions. Thus, it is difficult for many people to measure these parameters easily and routinely.
One approach toward conveniently measuring the individuals’ lifestyle factors is to use voice data and machine learning-based methods. Voice sounds are generated when glottal waves by vocal cords are articulated in the vocal tract. It is known that changes in a speaker’s voice occur because the vocal cords and vocal tract that generate the voice sounds are modulated by physical characteristics (such as sex and age) as well as lifestyle habits (such as smoking and drinking) [9, 13]. Therefore, since voice characteristics depend on lifestyle habits, it should be possible to detect these lifestyle habits by analyzing differences in the voice data. However, to the best of our knowledge, past studies have not attempted to detect the speakers’ level of intoxication, which is essential for measuring the degree of drinking and sleep habits, which in turn may indirectly affect lifestyle-related diseases.
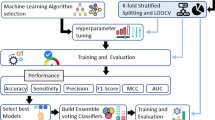
In this study, we propose a machine learning-based method for detecting the lifestyle habits of smoking, drinking, and sleeping (which might be among the major factors associated with lifestyle-related diseases) using voice data. Our approach may contribute to simplifying the prevention and diagnosis of lifestyle-related diseases. In addition, we utilize recently developed X-vectors [19], which are embeddings extracted from time delay neural networks (TDNNs), as acoustic features; this, in addition to some well-known voice features such as mel-frequency cepstrum coefficients (MFCCs), formant frequency (or resonance frequency), jitter, and i-vector. Note that past studies employing speaker recognition techniques often combined the above well-known features with machine learning-based models, such as support vector machines (SVMs), and probabilistic methods, such as probabilistic linear discriminant analysis (PLDA) [16, 22, 23]. For readers who are not familiar with this field, we provide a short description of the i-vector in Sect. 2.2, and define the other common features in Sect. 4.1.2. Although X-vectors are effective for speaker identification and are state-of-the-art features for representing speakers [19], they have never been used for estimating the speakers’ habit-related information, to the best of our knowledge (Fig. 1).

Causes of death in Japan (2020)
2 Related work
2.1 Effects of lifestyle on voice
Many studies have investigated the effects of lifestyle on voice. One of the earlier studies was performed as far back as 1994, by Niedzielsk et al. [16] That study revealed a relationship between the median and maximal values of jitter, an acoustic feature that represents the acceleration of a speaker’s voice, and correlates with the amount of alcohol consumed. The study also analyzed the effect of smoking on voice, from the perspective of some acoustic features, such as the formant frequency and jitter, and revealed the following: (i) for male speakers, the acoustic features representing voice perturbation (such as jitter) were affected by smoking; (ii) for female speakers, the formant frequency was affected by smoking.
Three types of sleep habits have been proposed, reflecting the characteristics of one’s internal clock, called the circadian rhythm type (chronotype); the sleep habits are roughly classified as “morning,” “middle,” and “night.” In 2018, Zacharia et al. [23] analyzed the effect of the chronotype on voice in terms of three acoustic features: (1) formant frequency, (2) jitter, and (3) shimmer, and reported that all three were significantly affected by the chronotype. These studies indicated that acoustic features extracted from human voice data reflect the speakers’ lifestyles. Therefore, by incorporating such features, it may be possible to estimate the speakers’ lifestyles.
2.2 Detecting lifestyle habits from voice data
Several studies have been conducted for detecting the speakers’ lifestyles from voice data. Most of these studies used statistical or machine learning-based approaches for training classifiers and/or probabilistic models using acoustic features extracted from the speakers’ voice data. For example, in 2020, Shenoi et al. [22] proposed a method for extracting multiple acoustic features from the speakers’ voice data, for detecting the speakers’ emotions and degree of intoxication. They extracted multiple acoustic features, such as the formant frequency, MFCCs, and zero-crossing rate (ZCRs), from German speakers’ voice datasets, and trained multiple classifiers, such as an SVM and a KNN method. As a result, they achieved an accuracy of 80% in binary classification with respect to intoxication, using the trained KNN and SVM.
In recent years, some studies have begun to employ not only the above-mentioned acoustic features, but also i-vectors, which can be obtained from MFCCs and have shown effectiveness in the field of speaker identification. In 2017, Amir et al. [17] proposed an automatic smoker-detection method for an NIST-SRE database consisting of English speakers. They used i-vectors and non-negative factor analysis (NFA) vectors extracted from MFCCs as features for training classifiers, such as logistic regression (LR), simple Bayesian classifier (NBC), Gaussian scoring (GS) and von Mises–Fisher scoring. Consequently, the log likelihood ratio cost (C\(_{llr}\)) was above 0.9, while the area under the receiver operating characteristic curve (AUROC) exceeded 0.7, demonstrating that i-vectors are effective for detecting smokers.
Our study also focused on sleep habits as a lifestyle habit affecting voice, but to date, there have been no studies that have used voice data for estimating sleep habits. A similar study was conducted by Faurholt et al. [5] in 2021. They estimated the information related to the speakers’ sleep rather than sleep habits. In particular, they classified diseases related to insomnia, a symptom of bipolar disorder, by analyzing patients’ voice data using machine learning-based methods. Specifically, they used a random forest (RF) classifier trained on acoustic features such as pitch, loudness, and energy, which were extracted from 121 voice data of bipolar patients in Denmark; the data were collected using smartphones for the purposes of insomnia classification. Their model achieved a recall of 0.39, a specificity of 0.73, and an AUROC of 0.59.
Besides smoking and drinking, the present study attempted to detect chronotypes with no precedent in the past. In addition to commonly used acoustic features, we used X-vector, a feature that has shown higher effectiveness than i-vectors in the context of speaker identification, and developed an approach for detecting such lifestyle habits by combining machine learning-based models and probabilistic methods.
3 Speech dataset
In this study, we developed a speech dataset comprising 2,000 recorded voice samples from 14 adult male (ages, 22–24) speakers of Japanese. An overview of the recording environment and the contents of the dataset are presented in Tables 1 and 2. The outline of the construction process of this dataset is as follows.
-
1.
We recorded the voices of the study subjects in the non-inebriated state. The subjects were asked to read aloud the provided texts (ATR phoneme balance, 503 sentences) into a microphone in front. Note that we restricted each voice record to only five sentences, for obtaining natural continuous speech data during recordings. Eventually, we split each record by sentence using audio processing, and obtained 2000 voice samples in total. Immediately after the above recording process, we also measured the exhaled carbon monoxide concentration of the recorded subject, to label the smoking status.
-
2.
We also recorded each subject’s voice in an intoxicated state. The subjects were asked to drink alcohol and measure their blood alcohol concentration (BAC). Then, we recorded the subjects’ voices using exactly the same procedure and texts as mentioned in the first step.
-
3.
The subjects were asked to write a morning-night type questionnaire, which will be described in detail later. We labeled the samples based on the exhaled carbon monoxide concentration for classifying the smoking habits, the level of intoxication for classifying the drinking habits, and the calculated morning-night type scores for classifying the sleeping habits. These lifestyle habits were defined as follows:
-
Smoking status We used a smokerlyzer, “pico-advanced smokerlyzer,” sold by Harada Sangyo Co., to measure the exhaled carbon monoxide concentration of the subjects. The subjects were classified as smokers if the concentration exceeded 10 ppm; otherwise, the subjects were classified as non-smokers.
-
Intoxication level We measured the BAC of the subjects using a breath alcohol concentration meter, and the level was determined by the criteria shown in Table 3 [1]. Note that we limited the range of intoxication to the light level, because we had to consider both the physical and mental health of our subjects. In our experiments, we used two levels of intoxication as labels: “0–1” and “2–3.”
-
Chronotype Ishibashi et al. [11] proposed a morning-night type questionnaire to quantitatively measure morning–night-type scores. Based on an experiment that involved 1,061 male subjects, they determined the threshold of the chronotype score as 46.1. We followed their definition of the chronotype categories. The study subjects were classified as “morning type” if their scores exceeded 46.1; otherwise, the subjects were classified as “night type.”
-
4 Proposed method
In this study, we developed a method for detecting the lifestyle habits of individuals using machine learning-based models with acoustic features, including X-vectors, extracted from the aforementioned speech dataset. Fig 2 shows an outline of the proposed method. We followed the conventional machine learning methodology, which amounts to preprocessing, model training, hyperparameter optimization, and performance evaluation.

Outline of the lifestyle classification approach
4.1 Preprocessing
First, we performed audio processing and acoustic feature extraction. In the following section, we describe these steps.
4.1.1 Audio processing
First, we excluded silence segments, and performed audio normalization and voice segmentation for each voice record of each subject. In particular, we deleted silence segments using the voice active detection (VAD) approach; this was applied to each record. We then normalized the volume of each record, to adjust for each individual’s voice level. Subsequently, voice segmentation was performed to extract the set of voice samples corresponding to each sentence. Through this process, we obtained five voice messages corresponding to the spoken text, which normalized the sound volumes of all voice records.
4.1.2 Acoustic feature extraction
We extracted acoustic features that represented the characteristics of a speaker’s speech from the obtained voice samples. We also standardized the extracted features to reduce the effect of differences in units on learning. The following features were extracted: MFCCs, perceptual linear prediction (PLP), formant frequency, harmonic-to-noise ratio (HNR), jitter, shimmer, cepstral peak prominence (CPP), vocal tract length estimates (VTLEs), speech rate, and spectral tilt. In the following section, we summarize the definitions of these acoustic features. Basically, we followed the definition of MFCCs and PLP in SIDEKIT [12], while for the other features, we used their definitions in VoiceLab [6]. SIDE KIT and VoiceLab are a Python library and software suite, respectively, that were used for extracting the above-mentioned features.
-
MFCC and PLP The MFCCs and PLP capture the acoustic characteristics of the vocal tract. They comprise filter banks based on perceptual scales called the mel and Burke scales. The MFCCs are calculated as follows:
-
1.
Pre-emphasizing: audio data are preprocessed in the time domain to emphasize higher frequencies.
-
2.
The spectrum amplitude is computed using the window function (Hamming window).
-
3.
The signal is filtered in the power spectral domain using a triangular filter bank, which is approximately linearly spaced on the mel scale and has equal bandwidth on the mel scale.
-
4.
The discrete cosine transformation of the log-spectrum is computed.
-
5.
Logarithmic energy is returned as the first coefficient of the feature vector.
-
1.
PLP is a noise-resistant acoustic feature [8], and we used it to minimize the effects of noise on our data set. The calculation process of the PLP was the same as that of the MFCCs, until the calculation of the power spectrum. We subjected the power spectrum to a Burke frequency filter bank, and calculated the autocorrelation coefficient by adjusting the loudness. Finally, we performed autoregressive and linear predictive coding (LPC) analyses to obtain the PLP cepstrum.
In addition to MFCCs and PLP with 13 cepstral coefficients, we also used a maximum of 20 MFCC cepstral coefficients based on the estimation method for speech analysis. However, by modeling speech signals using classifiers such as an SVM, we may obtain lower accuracy owing to the many features of the cepstral coefficients. Therefore, we selected 13 cepstral coefficients based on the results of our preliminary experiment. We also calculated the statistical features associated with these features, as follows:
-
Mean and standard deviation of the power spectrum.
-
Mean, standard deviation, max, min, and difference between them with respect to each dimension of the mel-band spectrum.
-
Max, min, and the difference between them with respect to each dimension of the critical band spectrum.
-
Mean with respect to each dimension of \(\Delta\)MFCC and \(\Delta\)PLP.
-
Formant Frequency Formant frequencies are multiple peaks that appear in a speaker’s voice spectrum. They are called the fundamental frequency (F0), first formant (F1), and second formant (F2), in the order of decreasing frequency.
-
HNR The HNR is the ratio between the periodic and nonperiodic components of a speech sound.
-
jitter and Shimmer Jitter is the period difference between adjacent cycles in an audio waveform, divided by the average of the entire period, indicating a period disturbance. Shimmer is the period in which the jitter is replaced by the amplitude, indicating an amplitude disturbance.
-
CPP CPP is the difference, in terms of the amplitude, between the highest peak of the cepstrum and the corresponding regression line, and is a numerical representation of the periodicity of a speech as a peak.
-
VTLE VTLE is the length of the vocal tract, which is estimated from the formant variance, calculated using the principal component analysis, and the geometric mean of the first four formant frequencies (F0-F4).
-
Speech Rate Speech rate indicates the state of speech calculated from the length of speech and the number of syllables in speech. In this study, we used the following three types: speech rate (number of syllables/length), articulation rate (number of syllables/speech duration), and average syllable duration (speech duration/number of syllables).
-
Spectral Tilt Spectral tilt is the slope of the regression between the frequency and amplitude of each sound.
For the above acoustic features, we also used dynamic features (delta parameters) and statistical features such as the mean and standard deviation.
4.1.3 X-vector
The X-vector is a fixed-length representation of a variable-length speech segment, proposed by Snyder et al. [19], which is an embedding extracted from a time delay neural network (TDNN) that uses MFCC vectors as input and is known to successfully capture speaker features, even if the TDNN does not recover the speaker’s features during training. In this study, we presented Japanese speech data to a pretrained ECAPA-TDNN model [3], which was proposed to validate speakers in the VoxCeleb [2, 15] datasets, and extracted 512-dimensional embedded features from the middle layer of the TDNN.
4.2 Model training
4.2.1 Classifiers
For machine learning-based methods, we used MATLAB 2021b, a numeric computing platform developed by MathWorks, with an extension called “statistics and machine learning toolbox.” We used the following classifiers, implemented in MATLAB, for our experiment:
-
Random forest
-
Linear discriminant
-
Quadratic discriminant
-
Naive Bayes (Gaussian)
-
SVM (linear, quadratic, cubic and Gaussian)
-
KNN (cosine, cubic, and weighted)
-
Ensemble (boosting tree, bagging tree, subspace discriminant, subspace KNN, and RUSBoost tree)
The dataset was divided into a training dataset for training the considered models and a testing dataset for the performance evaluation of the trained models. To prevent classification caused by features that strongly depended on stimuli, the testing dataset comprised only speaker data that were not contained in the training dataset. We used k-fold cross-validation during training to ensure unbiased training, where we set \(k=10\).
4.2.2 PLDA
PLDA is a linear discriminant analysis (LDA) method proposed by Sergey [10], based on a probabilistic approach. This method can be regarded as clustering based on the lifestyle labels presented during the training stage. In the testing stage, we calculated the PLDA scores for the training data belonging to each class, using Eq. 3, which will be described later in this section, and the given data were classified as the number of classes with the higher score. In the following, we provide some definitions of the calculation.
The probability density function (pdf) of a Gaussian mixture model was used to cluster the data.
where, \(\pi _{k}, \varvec{\mu }_{k}, \varvec{\Phi }_{k}\) are the weight, mean and covariance of the k-th Gaussian.
Let y be a potential class variable, representing the average of the classes/mixtures in the GMM. Given a class variable y, the probability of generating a data sample x is
where \(\varvec{u}\) and \(\varvec{v}\) are Gaussian random variables defined in the latent space, as follows:
Given data \(u_1\) and \(u_2\) of random classes, whether they belong to the same class is decided using the log likelihood ratio (PLDA score) derived from the following likelihood ratio R:
4.3 Hyperparameter optimization
Each classifier has its own set of hyperparameters, which are fixed during the training stage of the model; the given classifier’s accuracy may vary depending on the values of its hyperparameters. Thus, we optimized the hyperparameters for each classifier using Bayesian optimization.
4.4 Performance evaluation
In this study, we evaluated the performance of trained models with the highest accuracy using the confusion matrix and receiver operating characteristic (ROC) curve as performance evaluation metrics. The confusion matrix (Table 4) is a matrix whose elements are the values of four indices: (1) the number of true positives (TP), (2) the number of true negatives (TN), (3) the number of false positives (FP), and (4) the number of false negatives (FN).
Using these values, we can obtain the following seven performance evaluation indices: (1) the error rate (ERR), (2) the acceptance correct rate (ACC), (3) the true positive rate (TPR), (4) the false positive rate (FPR), (5) the percentage of response (PRE), (6) the reproduction rate (REC), and (7) the F-value (F1). These indices are defined as follows:
-
Accuracy Percentage of correctly classified data relative to the overall number of tested data.
$$\begin{aligned} A C C=\frac{T P+T N}{F P+F N+T P+T N}=1-E R R \end{aligned}$$(4) -
Precision Percentage of data that are truly positive relative to the overall number of data predicted to be positive.
$$\begin{aligned} P R E=\frac{T P}{T P+F P} \end{aligned}$$(5) -
Recall Percentage of data correctly classified as positive relative to the number of all positive data.
$$\begin{aligned} R E C=T P R=\frac{T P}{P}=\frac{T P}{F N+T P} \end{aligned}$$(6) -
F-value F-value is the harmonic mean of precision and recall.
$$\begin{aligned} F 1=2 \times \frac{P R E \times R E C}{P R E+R E C} \end{aligned}$$(7)As is well known, there is a trade-off between PRE and REC, and the F-value only becomes high when both of the component values are high. Thus, the F-value provides a better assessment of the performance of the trained model.
The ROC curve shows the TPR and FPR values for different classification thresholds. To compare the performances of the different models using ROCs, we calculated the AUROC metric. Intuitively, the higher the AUROC, the better is the performance of the trained model.
5 Experiment
5.1 Experimental environment
We conducted an experiment to classify the lifestyles of speakers by training machine learning-based models or PLDA with features (cf. Section 4.1.2) that were extracted from our speech dataset and evaluated the performance of each model to determine which models are more suitable for classifying different lifestyles. In Table 5, we detail the computational environment of our experiment. Using this environment, we conducted each trial of our experiment, including preprocessing, within a few hours.
5.2 Preprocessing
For audio preprocessing, we used the convolutional neural network (CNN)-based audio segmentation Python-based tool SpeechSegmenter [4] for the VAD, speech segmentation, and volume standardization. We also used the automated speech analysis Python-based software VoiceLab [7] to extract multiple acoustic features. To extract the X-vectors, we used the SpeechBrain speech analysis toolkit [18]. By preprocessing using the above software and/or libraries, we obtained 230-dimensional acoustic features and 512-dimensional X-vectors.
5.3 Model training and performance evaluation
For the training data, we applied the synthetic minority oversampling technique (SMOTE) to adjust the number of samples of the minority class to match those of the major class. We trained models to detect the lifestyle habits of individuals, that is, the smoking status, the intoxication level, and the chronotype (cf. Section 3). Using the extracted acoustic features, we trained machine learning-based models using 15 classifiers provided by MATLAB2021b cf. Section 4.2.1). To obtain the best results, we optimized the hyperparameters of the classifiers using Bayesian optimization. As for the extracted X-vectors, which were 512-dimensional embedded features (cf. Section 4.1.3), we used the PLDA toolkit [20] implemented in Python for training models.
Finally, using a testing dataset, we created confusion matrices, calculated the accuracy, precision, recall, and F-value metrics, built ROC curves, and compared the performances of the different models.

Visualized representation of our results
6 Results and discussion
We list the best results of our experiment in Table 6 and show the visualized representation of that in Fig. 3, where the AF-classifier (AF-PLDA) and Xvector-classifier (Xvector-PLDA) stand for a classifier (PLDA) with acoustic features (AF) and X-vector as inputs, respectively. Note that the minority classes of the smoking status, intoxication level, and chronotype were smokers, level 2–3, and morning type, respectively.
For AF-classifiers, the ensemble model on subspace KNN demonstrated the best performance with respect to the smoking status classification. Cubic SVM performed the best with respect to the intoxication classification, while cubic KNN performed the best with respect to the chronotype classification. As for the Xvector classifiers, cubic SVM exhibited the best performance with respect to the smoking status and intoxication level, while quadratic SVM demonstrated the best performance with respect to the chronotype. In the following section, we explain the results with respect to the classification performance of each label.
6.1 Smoking status and intoxication levels
Xvector-PLDA exhibited the best performance with respect to classifying both the smoking status and intoxication level, but the Xvector-classifier yielded a significantly higher ACC and lower REC, PRE, and F1 scores, indicating that the Xvector-based classifier suffered from overfitting. This indicates that the classification was biased toward nonsmokers and some intoxication levels. In other words, the classification of the smoking status and intoxication level using Xvectors was not optimal for classifiers but worked for PLDA. This might be owing to the probabilistic approach of PLDA, which differs from those of other classifiers in that“PLDA projects features onto the PCA subspace, which is optimal for classification by dimensionality reduction.” We also note that the SVM-based Xvector classifier exhibited the best performance with respect to the classification of both labels, and this might also be owing to the fact that “features were projected onto a high-dimensional feature space.”
The above suggests that the X-vector is a helpful feature for detecting smokers and intoxication levels, but not for learning approaches that do not project features onto the other space. It also suggests that X-vectors projected onto other spaces are more likely to capture the lifestyle effects such as smoking and drinking, which directly impact the vocal cords and vocal tract, which are the main components that generate voice.
6.2 Chronotype
For chronotype classification, the AF-classifier (cubic KNN) exhibited the best performance with respect to all the evaluation metrics. In addition, acoustic feature-based models tended to exhibit slightly better performance than X-vectors, suggesting that acoustic features may be able to represent voice differences among different chronotypes better than X-vectors. This might be owing to the fact that the X-vector is an embedded feature extracted from the TDNN pre-trained on large-scale speech data, and therefore, has the aspect of expressing “the difference from the general and average voice of the input speech.” In other words, since the indirect and long-term effects exerted on the voice-generating components by the chronotype are quite small, the difference in voice owing to these effects falls within the pre-trained category of general (or average) voices. Thus, acoustic features may include the effect of the chronotype on the formation of the vocal tract and vocal cords.
The KNN-based AF-classifiers exhibited the best performance with respect to classifying both the smoking status and the chronotype, suggesting that the classification approach in the same dimensional space may help classify voice by capturing the effects of the above speakers’ lifestyles included in the acoustic features. This is partly because the models based on PLDA and the Xvector-classifier (Quadratic SVM), which include an approach of the feature projection onto the other feature space, are inferior to those of the AF-classifier, which does not include this projection.
7 Conclusions
We proposed a machine learning-based method for classifying smoking, drinking, and sleeping habits based on the speakers’ speech information. We conducted experiments and performance evaluations of the classification using classifiers and PLDA with acoustic features and X-vector extracted from a speech dataset we developed as inputs. The results showed that acoustic feature-based cubic KNN achieved an F-value of 0.72 and an AUROC of 0.86 with respect to the chronotype classification. With respect to the smoking status and intoxication level classifications, X-vector based PLDA exhibited recalls of 0.73 and 0.84, respectively. However, the precision of these classifiers remains low and requires further improvement. These results indicate that the X-vector may be more helpful for classifying lifestyle habits that directly affect the vocal cords and vocal tract, such as smoking and drinking, while acoustic features may also be helpful for classifying the chronotype, which might be related to the formation of individuality of the vocal cords and vocal tract.
As a future direction, we may extend our approach to use deep learning models for feature selection and speaker identification that can handle the importance of acoustic features and SHAP (SHapley Additive exPlanation) values. To obtain more robust results, it may also be necessary to use X-vectors extracted from pretrained TDNNs using a large-scale corpus of Japanese speakers.
References
Alcohol Health and Medical Association: Alcohol blood levels and drunkenness. http://www.arukenkyo.or.jp/health/base/index.html Accessed 12 Nov 2021
Chung JS, Nagrani A, Zisserman A (2018) Voxceleb2: Deep speaker recognition. arXiv preprint arXiv:1806.05622
Desplanques B, Thienpondt J, Demuynck K (2020) ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in TDNN based speaker verification. arXiv preprint arXiv:2005.07143
Doukhan D, Carrive J, Vallet F, Larcher A, Meignier S (2018) An open-source speaker gender detection framework for monitoring gender equality. In: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5214–5218. 10.1109/ICASSP.2018.8461471
Faurholt-Jepsen M, Rohani DA, Busk J, Vinberg M, Bardram JE, Kessing LV (2021) Voice analyses using smartphone-based data in patients with bipolar disorder, unaffected relatives and healthy control individuals, and during different affective states. Int J Bipolar Disord 9(1):1–13
Feinberg D (2022) Voicelab: Software for fully reproducible automated voice analysis. Proc Interspeech 2022:351–355
Feinberg D, Cook O (2021) VoiceLab: Automated reproducible acoustical analysis. https://github.com/Voice-Lab/VoiceLab#voicelab
Hermansky H (1990) Perceptual linear predictive (plp) analysis of speech. J Acoust Soc Am 87(4):1738–1752
Hirabayashi H, Koshii K, Uno K, Ohgaki H, Nakasone Y, Fujisawa T, Shono N, Hinohara T, Hirabayashi K (1990) Laryngeal epithelial changes on effects of smoking and drinking. Auris Nasus Larynx 17(2):105–114
Ioffe S (2006) Probabilistic linear discriminant analysis. In: European Conference on Computer Vision. Springer, pp. 531–542
Ishihara K, Miyashita A, Inukami M, Fukuda K, Yamazaki K, Miyata H (1986) Results of a Japanese Morningness-Eveningness questionnaire survey. Psychol Res 57(2):87–91
Larcher A, Lee KA, Meignier S (2016) An extensible speaker identification sidekit in python. In: 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5095–5099. IEEE
Mayuko K, Ryuichi N, Toshio I, Hidenori K et al (2013) Voice tells your body information. Research Report Special Interest Group on MUSic and computer (MUS) 2013(47):1–6
Ministry of Health, Labour and Welfare: Overview of 2020 vital statistics monthly report (approximate). https://www.mhlw.go.jp/toukei/saikin/hw/jinkou/geppo/nengai20/. Accessed on 12 Nov 2021
Nagrani A, Chung JS, Xie W, Zisserman A (2020) VoxCeleb: Large-scale speaker verification in the wild. Comput Speech Lang 60:101027
Niedzielsk G, Pruszewicz A, Świdziński P (1994) Acoustic evaluation of voice in individuals with alcohol addiction. Folia Phoniatr Logop 46(3):115–122
Poorjam AH, Hesaraki S, Safavi S, van Hamme H, Bahari MH (2017) Automatic smoker detection from telephone speech signals. In: International Conference on Speech and Computer. Springer, pp 200–210
Ravanelli M, Parcollet T, Plantinga P, Rouhe A, Cornell S, Lugosch L, Subakan C, Dawalatabad N, Heba A, Zhong J, Chou JC, Yeh SL, Fu SW, Liao CF, Rastorgueva E, Grondin F, Aris W, Na H, Gao Y, Mori RD, Bengio Y (2021) SpeechBrain: A general-purpose speech toolkit. ArXiv:2106.04624
Snyder D, Garcia-Romero D, Sell G, Povey D, Khudanpur S (2018) X-vectors: Robust DNN embeddings for speaker recognition. In: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5329–5333. IEEE
Sojitra RB (2020) Probabilistic linear discriminant analysis. https://github.com/RaviSoji/plda
Speech Resources Consortium: Atr phoneme balance 503 sentence. http://research.nii.ac.jp/src/ATR503.html. Accessed 12 Nov 2021
Viswanath SV, Swarna K, Prasuna K (2020) An efficient state detection of a person by fusion of acoustic and alcoholic features using various classification algorithms. Int J Speech Technol 23(3):625–632
Zacharia T, Souza P, Mathew M, Souza G, James J, Baliga M (2018) Effect of circadian cycle on voice: a cross-sectional study with young adults of different chronotypes. J Laryngol Voice 8(1):19–23. https://doi.org/10.4103/jlv.JLV_15_18
Funding
Open access funding provided by Tokyo University of Science.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was presented in part at the joint symposium of the 27th International Symposium on Artificial Life and Robotics, the 7th International Symposium on BioComplexity, and the 5th International Symposium on Swarm Behavior and Bio-Inspired Robotics (Online, January 25–27, 2022).
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Yokoo, T., Hatano, R. & Nishiyama, H. Estimation of habit-related information from male voice data using machine learning-based methods. Artif Life Robotics 28, 520–529 (2023). https://doi.org/10.1007/s10015-023-00870-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10015-023-00870-2