
Abstract
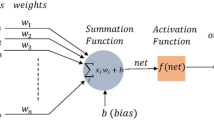
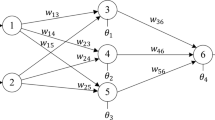
Multi-layer perceptron (MLP) in artificial neural networks (ANN) is one among the trained neural models which can hold several layers as a hidden layer for intensive training to obtain optimal results. On the other hand, the classification problem has a high level of attraction towards researchers to increase the accuracy in classification. In ANN, feedforward neural network (FNN) is one model that possesses the art of solving classification and regression problems. When input data is given to FNN, it will apply the sum of product rule and the activation function to map the input with its appropriate output. In the sum of product rule, a term called weights is to be chosen appropriately to map between the input and output. In standard FNN, the weights are chosen in a random way which may lead to slower convergence towards the optimal choice of weight values. In this paper, an effective optimization model is proposed to optimize the weights of MLP of FNN for effective classification problems. Four different datasets were chosen, and the results are interpreted with statistical performance measures.







Similar content being viewed by others

References
Mangasarian OL, Wolberg WH (1990) Cancer diagnosis via linear programming. University of Wisconsin-Madison, Computer Sciences Department
Rosenblatt F (1957) The perceptron, a perceiving and recognizing automaton project para. Cornell Aeronautical Laboratory
McCulloch WS, Pitts W (1943) A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biol. 5:115 133
Thirugnanasambandam K, Prakash S, Subramanian V et al (2019) Appl Intell 49:2059. https://doi.org/10.1007/s10489-018-1355-3
Werbos P (1974) Beyond regression: new tools for prediction and analysis in the behavioral sciences, Ph.D. thesis,. Harvard University
Patricia Melin P, Sanchez D, Castillo O (2012) Genetic optimization of modular neural networks with fuzzy response integration for human recognition. Inform Sci 197:1–19. https://doi.org/10.1016/j.ins.2012.02.027
Guo ZX, Wong WK, Li M (2012) Sparsely connected neural network-based time series forecasting. Inform. Sci 193:54–71. https://doi.org/10.1016/j.ins.2012.01.011(15.06.12)
Gardner MW, Dorling SR (1998) Artificial neural networks (the multilayer perceptron)—a review of applications in the atmospheric sciences. Atmos Environ 32:2627–2636
Barakat M, Lefebvre D, Khalil M, Druaux F, Mustapha O (2013) Parameter selection algorithm with self adaptive growing neural network classifier for diagnosis issues. Int J Mach Learn Cybern 4(3):217–233
Csáji BC (2001) Approximation with artificial neural networks. Etvs Lornd University, Hungary, Faculty of Sciences
Hornik K, Stinchcombe M, White H (1989) Multilayer feedforward networks are universal approximators. Neural Networks 2:359–366
Auer P, Burgsteiner H, Maass W (2008) A learning rule for very simple universal approximators consisting of a single layer of perceptrons. Neural Netw 21:786–795
Reed RD, Marks RJ (1998) Neural smithing: supervised learning in feedforward artificial neural networks. MIT Press
Werbos PJ (1992) Neurocontrol and supervised learning: an overview and evaluation. Handbook Intell Control 65:89
Oja E (2002) Unsupervised learning in neural computation. Theoret Comput Sci 287:187–207
Sejnowski TJ (1999) Unsupervised learning: foundations of neural computation. The MIT Press
Hush DR, Horne BG (1993) Progress in supervised neural networks. IEEE Signal Process Mag 10:8–39
Adeli H, Hung S (1994) An adaptive conjugate gradient learning algorithm for efficient training of neural networks. Appl Math Comput 62:81–102
Charalambous C (1992) Conjugate gradient algorithm for efficient training of artificial neural networks. IET, pp 301–310
Hagan MT, Menhaj MB (1994) Training feedforward networks with the Marquardt algorithm. IEEE Trans Neural Netw 5:989–993
Zhang N (2009) An online gradient method with momentum for two-layer feedforward neural networks. Appl. Math. Comput. 212:488–498
S.E. Fahlman, An empirical study of learning speed in back-propagation networks, Technical report, 1988, <http://repository.cmu.edu/cgi/viewcontent.cgi?article=2799&context=compsci>.
Vogl TP, Mangis J, Rigler A, Zink W, Alkon D (1988) Accelerating the convergence of the back-propagation method. Biol Cybern 59:257–263
Ng S, Cheung C, Leung S, Luk A (2003) Fast convergence for backpropagation network with magnified gradient function, vol 3. IEEE, pp 1903–1908
Gori M, Tesi A (1992) On the problem of local minima in backpropagation. IEEE Trans Pattern Anal Mach Intell 14:76 86
Lee Y, Oh SH, Kim MW (1993) An analysis of premature saturation in back propagation learning. Neural Netw 6:719 728
Magoulas G, Vrahatis M, Androulakis G (1997) On the alleviation of the problem of local minima in back-propagation. Nonlinear Anal 30:4545–4550
Jacobs RA (1988) Increased rates of convergence through learning rate adaptation. Neural Netw 1:295–307
van Ooyen A, Nienhuis B (1992) Improving the convergence of the back-propagation algorithm. Neural Netw 5:465–471
Weir MK (1991) A method for self-determination of adaptive learning rates in back propagation. Neural Netw 4:371 379
Gudise VG, Venayagamoorthy GK (2003) Comparison of particle swarm optimization and backpropagation as training algorithms for neural networks. IEEE, pp 110–117
Alweshah M, Alkhalaileh S, Albashish D, Mafarja M, Bsoul Q,Dorgham O (2020) A hybrid mine blast algorithm for feature selection problems. Soft Comput:1–18
Alweshah M (2020) Solving feature selection problems by combining mutation and crossover operations with the monarch butterfly optimization algorithm. Appl Intell:1–24
Agrawal P, Ganesh T, Mohamed AW (2020 Oct) A novel binary gaining–sharing knowledge-based optimization algorithm for feature selection. Neural Comput Appl. 26:1–20
Zhang J-R, Zhang J, Lok T-M, Lyu MR (2007) A hybrid particle swarm optimization–back-propagation algorithm for feedforward neural network training. Appl Math Comput 185(2):1026–1037
Blake C (1998) UCI repository of machine learning databases. http://www.ics.uci.edu/~mlearn/MLRepository.html
Wdaa A, Sttar I, Sttar A (2008) Differential evolution for neural networks learning enhancement. PhD diss., Universiti Teknologi Malaysia
Mirjalili S (2011) Hybrid particle swarm optimization and gravitational search algorithm for multilayer perceptron learning. Diss Universiti Teknologi Malaysia
Fine TL (1999) Feedforward neural network methodology. Springer Verlag
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Thirugnanasambandam, K., Prabu, U., Saravanan, D. et al. Fortified Cuckoo Search Algorithm on training multi-layer perceptron for solving classification problems. Pers Ubiquit Comput 27, 1039–1049 (2023). https://doi.org/10.1007/s00779-023-01716-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00779-023-01716-1