
Abstract
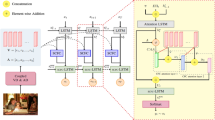
Image caption can automatically generate a descriptive sentence according to the image. Transformer-based architectures show significant performance in image captioning, in which object-level visual features are encoded to generate vector representations, and they are fed into the decoder to generate descriptions. However, the existing methods mainly focus on the object-level regions and ignore the no-target area of the image, which will affect the context of visual information. In addition, the decoder fails to efficiently exploit the visual information transmitted by the encoder in the language generation steps. In this paper, we propose Gated Adaptive Controller Attention (GACA), which separately explores the complementarity of text features with the region and grid features in attentional operations, and then uses a gating mechanism to adaptively fuse the two visual features to obtain comprehensive image representation. During decoding, we design a Layer-wise Enhanced Cross-Attention (LECA) module, the enhanced visual features are obtained by cross-attention calculation between the generated word embedded vectors and multi-level visual information in the encoder. Through an extensive set of experiments, we demonstrate that our proposed model achieves new state-of-the-art performance on the MS COCO dataset.







Similar content being viewed by others


Data availability
All the data mentioned in the manuscript is freely available online.
References
Anderson, P., Fernando, B., Johnson, M., Gould, S.: (2016) SPICE: semantic propositional image caption evaluation. In: Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part V
Anderson, P., He, X., Buehler, C., Teney, D., Johnson, M., Gould, S., Zhang, L.: Bottom-up and top-down attention for image captioning and VQA. CoRR:abs/1707.07998 (2017)
Ba, L.J., Kiros, J.R., Hinton, G.E.: Layer normalization. CoRR:abs/1607.06450 (2016)
Biten, AF., Litman, R., Xie, Y., Appalaraju, S., Manmatha, R.: Latr: layout-aware transformer for scene-text VQA. CoRR abs/2112.12494, 2112.12494 (2021)
Chung, J., Gülçehre, Ç., Cho, K., Bengio, Y.: Empirical evaluation of gated recurrent neural networks on sequence modeling. CoRR abs/1412.3555 (2014)
Cornia, M., Stefanini, M., Baraldi, L., Cucchiara, R.: Meshed-memory transformer for image captioning. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13–19, 2020, Computer Vision Foundation/IEEE, pp. 10575–10584 (2020)
Devlin, J., Chang, M., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. Association for Computational Linguistics, pp. 4171–4186 (2019)
Fang, H., Gupta, S., Iandola, F.N., Srivastava, R.K., Deng, L., Dollár, P., Gao, J., He, X., Mitchell, M., Platt, J.C., Zitnick, C.L., Zweig, G.: From captions to visual concepts and back. IEEE Computer Society, pp. 1473–1482 (2015)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. CoRR abs/1512.03385 (2015)
Herdade, S., Kappeler, A., Boakye, K., Soares, J.: (2019) Image captioning: transforming objects into words. pp. 11135–11145
Hermann, K.M., Kociský, T., Grefenstette, E., Espeholt, L., Kay, W., Suleyman, M., Blunsom, P.: Teaching machines to read and comprehend. Adv. Neural Inf. Process. Syst. 28, 1693–1701 (2015)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. (1997)
Huang, L., Wang, W., Chen, J., Wei, X.: Attention on attention for image captioning. IEEE, pp. 4633–4642 (2019)
Ji, J., Luo, Y., Sun, X., Chen, F., Luo, G., Wu, Y., Gao, Y., Ji, R.: Improving image captioning by leveraging intra- and inter-layer global representation in transformer network. In: National Conference on Artificial Intelligence (2021)
Jiang, H., Misra, I., Rohrbach, M., Learned-Miller, E.G., Chen, X.: In defense of grid features for visual question answering. CoRR abs/2001.03615 (2020)
Jiang, W., Ma, L., Jiang, Y., Liu, W., Zhang, T.: Recurrent Fusion Network for Image Captioning, pp. 510–526. Springer, Berlin (2018)
Kadlec, R., Schmid, M., Bajgar, O., Kleindienst, J.: Text understanding with the attention sum reader network. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Vol. 1: Long Papers (2016)
Karpathy, A., Fei-Fei, L.: Deep visual-semantic alignments for generating image descriptions. IEEE Trans. Pattern Anal. Mach. Intell. 39(4), 664–676 (2017)
Lavie, A., Agarwal, A.: Meteor: an automatic metric for MT evaluation with high levels of correlation with human judgments. In: Workshop on Statistical Machine Translation (2007)
Li, G., Zhu, L., Liu, P., Yang, Y.: Entangled transformer for image captioning. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV) (2019)
Li, J., Yao, P., Guo, L., Zhang, W.: Boosted transformer for image captioning. Appl. Sci. 9, 3260 (2019). https://doi.org/10.3390/app9163260
Lin, C.Y.: Rouge: a package for automatic evaluation of summaries (2004)
Liu, F., Liu, Y., Ren, X., He, X., Sun, X.: Aligning visual regions and textual concepts for semantic-grounded image representations. In: 33rd Conference on Neural Information Processing Systems (NeurIPS 2019) (2019)
Liu, W., Chen, S., Guo, L., Zhu, X., Liu, J.: CPTR: full transformer network for image captioning. CoRR abs/2101.10804, 2101.10804 (2021)
Lu, J., Xiong, C., Parikh, D., Socher, R.: Knowing when to look: adaptive attention via a visual sentinel for image captioning. IEEE Computer Society, pp. 3242–3250 (2017)
Luo, Y., Ji, J., Sun, X., Cao, L., Wu, Y., Huang, F., Lin, C., Ji, R.: Dual-Level Collaborative Transformer for Image Captioning, pp. 2286–2293. AAAI Press, Palo Alto (2021)
Messina, N., Falchi, F., Esuli, A., Amato, G.: Transformer reasoning network for image- text matching and retrieval. IEEE, pp. 5222–5229 (2020)
Papineni, K., Roukos, S., Ward, T., Zhu, W.: (2002) Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, July 6–12, 2002, Philadelphia, PA, USA
Ren, S., He, K., Girshick, R.B., Sun, J.: Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39(6), 1137–1149 (2017)
Rennie, S.J., Marcheret, E., Mroueh, Y., Ross, J., Goel, V.: Self-critical sequence training for image captioning. CoRR abs/1612.00563, 1612.00563 (2016)
Sammani, F., Melas-Kyriazi, L.: Show, edit and tell: a framework for editing image captions. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020)
Simonyan, K,, Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: Bengio, Y., LeCun, Y. (eds) 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7–9, 2015, Conference Track Proceedings (2015)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I.: Attention is all you need. pp. 5998–6008 (2017)
Vedantam, R., Zitnick, CL., Parikh, D.: CIDEr: consensus-based image description evaluation. CoRR abs/1411.5726 (2014)
Veit, A., Matera, T., Neumann, L., Matas, J., Belongie, S.J .: COCO-Text: dataset and benchmark for text detection and recognition in natural images. CoRR abs/1601.07140 (2016)
Wang, W., Chen, Z., Hu, H.: Hierarchical Attention Network for Image Captioning, pp. 8957–8964. AAAI Press, Palo Alto (2019)
Wei, Y., Wu, C., Li, G., Shi, H.: Sequential transformer via an outside-in attention for image captioning. Eng. Appl. Artif. Intell. 108, 104574 (2022)
Xian, T., Li, Z., Zhang, C., Ma, H.: Dual global enhanced transformer for image captioning. Neural Netw. 148, 129–141 (2022)
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A.C., Salakhutdinov, R., Zemel, R.S., Bengio, Y.: (2015) Show, attend and tell: neural image caption generation with visual attention. CoRR abs/1502.03044
Yang, X., Tang, K., Zhang, H., Cai, J.: Auto-encoding scene graphs for image captioning. Computer Vision Foundation/IEEE, pp. 10685–10694 (2019)
Yao, T., Pan, Y., Li, Y., Mei, T.: Exploring Visual Relationship for Image Captioning. Lecture Notes in Computer Science, vol. 11218, pp. 711–727. Springer, Berlin (2018)
You, Q., Jin, H., Wang, Z., Fang, C., Luo, J.: Image captioning with semantic attention. IEEE Computer Society, pp. 4651–4659 (2016)
Yu, J., Li, J., Yu, Z., Huang, Q.: Multimodal transformer with multi-view visual representation for image captioning. IEEE Trans. Circuits Syst. Video Technol. 30(12), 4467–4480 (2020)
Zhang, X., Sun, X., Luo, Y., Ji, J., Zhou, Y., Wu, Y., Huang, F., Ji, R.: RSTNET: captioning with adaptive attention on visual and non-visual words. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19–25, 2021, Computer Vision Foundation/IEEE, pp. 15465–15474 (2021)
Zhu, X., Li, L., Liu, J., Peng, H., Niu, X.: Captioning transformer with stacked attention modules. Appl. Sci. 8 (2018)
Author information
Authors and Affiliations
Contributions
Lijingdan performed the data analyses, wrote the manuscript and contributed to the conception of the study; Wangyi contributed significantly to analysis and manuscript preparation; Zhaodexin helped perform the analysis with constructive discussions. All authors reviewed the manuscript
Corresponding author
Ethics declarations
Conflict of interest
The authors certify that there is no conflict of interest with any individual/organization for the present work.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Li, J., Wang, Y. & Zhao, D. Layer-wise enhanced transformer with multi-modal fusion for image caption. Multimedia Systems 29, 1043–1056 (2023). https://doi.org/10.1007/s00530-022-01036-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00530-022-01036-z