
Abstract
Asthma is a common disease. The clinical diagnosis is usually confirmed on a pulmonary function test, which is not always readily accessible. We aimed to develop a computationally lightweight handcrafted machine learning model for asthma detection based on cough sounds recorded using mobile phones. Toward this aim, we proposed a novel feature extractor based on a one-dimensional version of the published attractive-and-repulsive center-symmetric local binary pattern (1D-ARCSLBP), which we tested on a new cough sound dataset. We prospectively recorded cough sounds from 511 asthmatics and 815 non-asthmatic subjects (comprising mostly healthy volunteers), which yielded 1875 one-second cough sound segments for analysis. Our model comprised four steps: (i) preprocessing, in which speech signals and stop times (silent zones between coughs) were removed, leaving behind analyzable cough sound segments; (ii) feature extraction, in which tunable q-factor wavelet transformation was used to perform multilevel signal decomposition into wavelet subbands, allowing 1D-ARCSLBP to extract local low- and high-level features; (iii) feature selection, in which neighborhood component analysis was used to select the most discriminative features; and (iv) classification, in which a standard shallow cubic support vector machine was deployed to calculate binary classification results (asthma versus non-asthma) using tenfold and leave-one-subject-out cross-validations. Our model attained 98.24% and 96.91% accuracy rates with tenfold and leave-one-subject-out cross-validation strategies, respectively, and obtained a low-time complexity. The excellent results confirmed the feature extraction capability of 1D-ARCSLBP and the feasibility of the model being developed into a real-world application for asthma screening.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Asthma is a chronic recurring disease caused by an increase in airway sensitivity [1] that can affect both large and small airways [2, 3]. It is characterized by bronchial inflammation, which induces increased airway secretions, bronchial wall swelling, and smooth muscle contraction [4]. In 2019, asthma afflicted 262 million people globally and caused the death of 455.000 [5, 6]. Its incidence is increasing [7], which is exacerbated by rising obesity, stress, mood disorders, medication use, environmental exposure to pollen, pets, smoke, air pollution, and indoor allergens such as house dust mites [8,9,10]. Although asthma can present at any age, 30% of cases occur in the first year of life. Indeed, asthma is the most common chronic disease in children. The risk of developing asthma is higher in those with a family history of asthma [11].
Asthmatic symptoms include recurrent coughing, wheezing, and shortness of breath, which can be triggered by dust, smoke, odor, and pollen. Asthma may be caused by allergies or it can develop independently of allergies [12]. In the presence of frequent cough episodes, day/night coughing, chest tightness, a family history of asthma, and allergic symptoms, asthma should be considered. Spirometry and peak expiratory flow rate (PEFR) measurement are diagnostic tests that can also quantify the severity of airflow limitation caused by bronchial narrowing, which is proportional to the level of airway inflammation [13]. Serial portable peak flow meter measurements can be used to track changes in airway narrowing, which is particularly useful for managing asthma in children [14]. Because allergens can cause asthma, adjunctive allergy tests may be performed to identify culprit allergens [15]. Avoiding asthma triggers can help reduce the frequency of asthmatic attacks [16]. With contemporary medical care, asthma can generally be well controlled with inhaled medications, allowing patients to lead normal lives. However, underdiagnosis and under-treatment, which are more pervasive in low- and middle-income countries, are still responsible for residual risks, including mortality, among asthma patients.
While the clinical symptoms and signs of asthma are well-known, the physical examination may neither be sufficiently sensitive nor specific. Various machine learning models have been proposed to detect asthma automatically using recorded respiratory sounds. Haider and Behera [17] developed an automated method for detecting asthma and chronic obstructive pulmonary disease based on Hurst analysis, empirical mode decomposition, and spectral subtraction methods. Trained and tested on a dataset of lung sounds acquired from 80 normal, 80 asthmatic, and 80 chronic obstructive pulmonary disease subjects, the model attained 99.30% accuracy using a decision tree classifier. Kilic et al. [18] proposed a new machine learning model called global chaotic logistic pattern to discriminate asthma from other lung conditions and a healthy control group. TQWT-based signal decomposition was applied and four different feature selectors were used for this purpose. The support vector machine (SVM) algorithm was used as a classifier in the model, and a classification success of 98.53% was reported. Iqbal et al. [19] used machine learning methods for asthma detection on a four-class lung sound dataset comprising 100 normal, 321 wheezes (typical of asthma), 98 stridor, and 73 rattle sounds and attained 100% accuracy. Iqbal et al. [20] proposed a forecasting technique for real-time asthma disease detection on a cough sound dataset of 18 asthma patients and attained 99.91% accuracy. Sen et al. [21] recorded lung sounds with a 14-channel device to discriminate between chronic obstructive pulmonary disease (COPD) and asthma. Multivariate autoregressive model, Gaussian mixture model and SVM were used together. In this study, 98% classification accuracy was achieved using sound samples from 50 subjects. Khan et al. [22] developed a real-time system for real-time asthma detection on lung sounds based on signal normalization and empirical mode decomposition embedded on Raspberry Pi. The model attained 9.40% accuracy. On a lung sound dataset of 64 pneumonia, 48 asthma, and 100 healthy subjects, Yahyaoui and Yumusak [23] applied machine learning to detect pneumonia and asthma with 95.00% accuracy using the k-nearest neighbor classifier. Topaloglu et al. [24] proposed a ResNet18-based asthma detection model. For this purpose, a sound dataset was created using a digital stethoscope and these sound signals were converted into images using a Mel spectrogram. Next, features were extracted from these images using ResNet18 deep network architecture, and the most significant features were selected by iterative NCA algorithm. The selected features were classified using kNN and SVM algorithms. This model achieved a classification accuracy of 99.73%. Yue and Xu [25] developed an automated asthma and pneumonia detection model based on short-time energy and Mel-frequency cepstral coefficients. Their study of 850 cough sounds recorded from patients attained 93.34% accuracy using a SVM classifier. Tasar et al. [26] developed a piccolo pattern-based respiratory sound classification model. Three cases were created in the research. They classified 7 respiratory diseases including asthma. In the developed model, the kNN algorithm achieved the highest classification success and a classification performance of over 99% was obtained for each case. A small number of asthma detection studies were based on other signal inputs.
1.1 Motivation and our model
The main goal of our research is to design and implement an automated system dedicated to asthma screening. Based on a mobile-based machine learning model, our approach integrates a state-of-the-art feature extractor carefully tailored to the analysis of cough sounds. The ultimate goal is to achieve a higher level of accuracy in asthma detection, providing a solid foundation for the development of an efficient and reliable screening tool. We were motivated to develop an automated system to screen for asthma that is accessible and easy to implement, i.e., computationally lightweight. The reference standard for asthma diagnosis is formal pulmonary function tests, while PEFR measurement may be used for therapeutic monitoring in diagnosed patients. On clinical examination, lung auscultation may uncover wheezing sounds typical of acute asthma attacks, but stethoscopes are not readily available, and lung auscultation requires prior training. Many respiratory conditions, including asthma, present with cough, cough sounds, which can be readily recorded using mobile devices, may contain features that can be used to discriminate the underlying respiratory condition. To validate this hypothesis, a new cough sound-based machine learning model was proposed in this work and tested on a new dataset of cough sounds recorded from more than 1000 participants. We chose handcrafted machine learning over deep learning to economize on computational demands and running time. The proposed model comprised four steps: (i) preprocessing; (ii) feature extraction; (iii) feature selection; and (iv) classification. Asthma classification using cough sound recordings is technically challenging as they inadvertently contain ambient noise like speech and are of variable duration with inutile time pauses between the actual coughs. Hence, preprocessing was obligatory to remove unwanted speech and ambient noise from the sound signal and segment the signal into standardized segment lengths containing analyzable cough sounds to optimize the fidelity and data efficiency of the input cough sound signals. We used a one-dimensional (1D) version of the popular attractive repulsive center-symmetric local binary pattern (ARCSLBP) image descriptor [27] to extract features from the cough sound signals. However, 1D-ARCSLBP is a handcrafted feature extractor that, by itself, can only generate features at a low level. To overcome this constraint, we applied tunable q-factor wavelet transformation (TQWT) [28] to deconstruct the energy of the cough sound signal effectively into multiple low- and high-frequency wavelet bands. Applying 1D-ARCSLBP to the cough sound input signal and the wavelet subbands could extract features at both low and high levels. A simple neighborhood component function (NCA) [29] feature selector was applied to the extracted features to select the most discriminative features. These were fed to a downstream standard shallow SVM [30, 31] for classification.
1.2 Novelties and contributions
Novel contributions of this work include:
-
A new cough sound dataset was acquired from more than 1,000 subjects.
-
New preprocessing method for efficient removal of ambient noise, speech, and unwanted pauses in cough sound recordings.
-
Handcrafted 1D-ARCSLBP feature extraction enabled the model to inherit known advantages of ARCSLBP [27] for advanced signal processing without the need for parameter tuning.
-
Efficient and accurate computationally lightweight architecture built on shallow models that required linear running time to attain excellent performance commensurate with deep models (> 96% classification accuracy) on robust tenfold and LOSO CV.
2 Proposed model
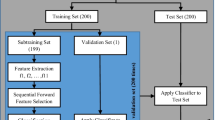
The handcrafted asthma classification model comprised four phases: (i) cough sound signal preprocessing; (ii) TQWT- and 1D-ARCSLBP-based feature extraction; (iii) NCA-based feature selection; and (iv) SVM-based classification using tenfold and LOSO CV (Fig. 1). Details of the steps are explained in the following subsections.

Block diagram of the proposed 1D-ARCSLBP-based model for asthma classification using recorded cough sounds. First, cough sound signal input samples of variable time lengths were preprocessed to remove ambient speech and segment the samples into one-second segments that each contained an analyzable “clean cough sound”. Next, TQWT was applied to each one-second clean cough sound segment to generate 12 wavelet subbands (t1, t2, t3,…t12). Next, 1D-ARCSLBP was applied to the clean cough sound segment and its 12 wavelet subbands to extract low- and high-level features. This yielded 13 feature vectors (f1, f2, f3,…f13) each of length 256, which were concatenated into a final feature vector of length 3,328 (= 13 × 256). From the latter, NCA selected the top 100 most discriminative features to feed to the SVM classifier for two-class classification of input cough sound samples into asthma versus non-asthma classes using tenfold and leave-one-subject-out cross-validation strategies
2.1 Preprocessing step
First, the recorded cough sound signal input samples were preprocessed to remove ambient speech using power spectrogram-based classification [32]. This model was used to detect cough sounds. Next, one-second segments containing analyzable “clean cough sound” were sifted from the input samples, which varied in duration, by applying a predetermined threshold (the threshold value is selected as 0.01 dB for these sounds) to remove inutile stop sounds (pauses) between the coughs and a standardized one-second segment length. A result summarizing the effect (before/after) of the Preprocessing step applied to cough sounds from asthma patients is given in Fig. 2. In addition, the steps of the preprocessing and the pseudocode (Algorithm 1) are given below:

Before and after the preprocessing step
As shown in Fig. 2, a preprocessing step was applied to remove the ambient and stop sounds from the raw signal. This step is effective in improving the accuracy of the proposed model. The steps of the preprocessing process are as follows:
Step 1 Obtain clean sounds from the collected sound samples by removing speech signals.
Step 2 Delete stop sounds (pauses) from the clean sound, retaining only usable cough sounds.
Step 3 Create one-second sound segments containing cough sounds to input into the model.

Pseudocode of cough sound preprocessing
2.2 Feature extraction step
TQWT was used to create wavelet subbands, from which low-and high-level features could be extracted. TQWT is a parametric signal transformation model that uses three parameters to assign the wavelet filters: Q (Q-factor) defines the oscillatory value; R is the redundancy value; and J is the number of levels. A multileveled (J + 1) wavelet transform is created using J parameters. In this work, we selected Q, R, and J parameter values of 1 (non-oscillatory decomposition), 3, and 11, respectively, to perform 12 levels of signal decomposition to generate 12 wavelet subbands. The signal sampling frequency determined the choice of J parameter value (48 kHz, i.e., each one-second segment contained 48,000 values) and the length of the overlapping block (9) employed in 1D-ARCSLBP-based local textural feature extraction, based on the following calculation: number of levels = 12 \(\left( { = \log_{2} \frac{48000}{9}} \right)\). The steps of the feature extraction are given below:
Step 4 Generate subbands from each sound segment using TQWT.
where \(w\) represents the wavelet subband structure with 12 wavelet subbands; and \(\phi (.)\), the TQWT function.
Step 5 Extract features from wavelet subbands and cough segments.
where \(\varphi (.)\) represents the 1D-ARCSLBP function, the pseudocode of which is given below.

Pseudocode of 1D-ARCSLBP feature extraction function
From algorithm 2, it can be seen that 1D-ARCSLBP generated seven attractive and seven repulsive bits per run. Two map signals were generated from each bit by deploying these attractive and repulsive bits. By extracting the histograms of these map values, 2 × 27 = 256 features were obtained. A block diagram summarizing Algorithm 2 is given in Fig. 3.

1D-ARCSLBP feature extraction method proposed in this work
As can be seen in Fig. 3, the median value of both the main signal and the overlapping block is calculated. In addition, the mean value of the overlapping block is determined. These values are then compared with the center value of the overlapping block. In this way, the first three bits of the attractive and repulsive bits are determined. The remaining four bits are obtained by sequential comparison. After this process, the attractive and repulsive bits are converted to decimals and added to the map signal. Finally, histograms are extracted using the map signal, and the two histograms are combined to obtain the feature vector.
Step 6 Concatenate all features generated from the cough sound segment and its 12 subbands into a final feature vector.
where \(X\) represents the final feature generated, and \(dim\) is the dimension of the dataset (number of signals). The length of \(X\) is 3328 (= 13 × 256).
2.3 Feature selection step
NCA, a simple but effective feature selector, was deployed to select the 100 most discriminative features from 3328 features in \(X\) based on the calculated individual feature weights, which represented the distinctive level of each feature. The main purpose of NCA is to bring together similar instances in the feature space and to remove instances belonging to different classes from each other. For this purpose, NCA optimizes an objective function. This function measures the similarity of a given pair of instances. In this research, the top 100 features were chosen on the qualified feature vector by sorting these features in descending order. Detailed steps of feature selection are given below:
Step 7 Apply NCA to the generated features to calculate 3,328 individual weights.
Step 8 Sort these weights and obtain sorted indexes.
Step 9 Choose the best 100 features.
2.4 Classification step
We used cubic SVM [33], a standard shallow classifier, for the two-class classification of input cough sound segments into asthma versus non-asthma classes. The main goal of SVM is to classify a dataset into two or more classes. In the case of binary classification, SVM tries to find a hyperplane that separates the classes as clearly as possible. In this paper, default hyperparameter settings were employed:
Kernel: polynomial;
Polynomial order: three;
Kernel scale: automatic;
Box constraint: one;
Validation: tenfold CV and LOSO CV.
Step 10 Classify the top 100 features by deploying SVM with tenfold and LOSO CVs.
3 Experiments
3.1 Experimental setup
The model was implemented in central processing unit mode on a personal computer with the following specifications: 16 GB memory, 512 GB solid-state disk, Intel i7 processor with a 4.3 GHz clock, and Windows 11 operating system. MATLAB programming environment was used in the model development process and the toolboxes, and libraries used in this process are listed in Table 1.
3.2 Dataset
The dataset comprised 994 and 881 cough sound recordings obtained from 511 asthmatics (103 male, 408 female; mean age 55.23 ± 14.97 years, range 10–2 years) and 815 non-asthmatic subjects (509 male, 306 female; most of the subjects in this group were healthy university students without a history of asthma), respectively. The cough sounds were recorded with varying durations in the hospital environment using a Samsung S6 Edge mobile phone. All recordings have a sampling frequency of 48 kHz. The duration of cough sound recordings obtained from 511 asthmatics ranges from a minimum of 0.5 s to a maximum of 6.59 s. Recordings from non-asthmatic subjects vary in length, ranging from 0.23 to 5.42 s. The cough sound recordings obtained from the subjects are in.wav file format. The hospital ethics committee had approved the retrospective collection of the cough sound dataset.
3.3 Performance evaluation metrics
For the evaluation of model performance for binary classification into asthma versus non-asthma classes, standard metrics were calculated: accuracy, sensitivity, specificity, precision, geometric mean (of sensitivity and specificity), and F1-score (harmonic mean of sensitivity and precision) [34, 35]. The mathematical equivalents of these performance metric values are given in Eqs. (5)-(10).
3.4 Results
Our model attained excellent results for binary classification of cough sounds into asthma versus non-asthma classes, with 98.24% and 96.91% accuracy rates on tenfold and LOSO CV (Table 2).
These metrics highlight the robust performance of our model, showcasing its accuracy, sensitivity, specificity, precision, geometric mean, and F1-score across different cross-validation techniques. As shown in Table 2, the proposed method achieves a very high classification success for both cross-validation techniques (98.24% and 96.91%). In addition, when the F1-score result is analyzed, a very high-performance value is achieved. This result demonstrates the ability of the proposed model to strike a harmonious balance between precision and sensitivity.
3.5 Time burden
The time complexity of our model, shown for every layer using big O notation, is shown in Table 3,
As can be seen in Table 3, the approximate computational complexity of the proposed method is \(O(n+k+d)\). Feature selection and classification steps are well-known methods in the literature, and their complexities are \(O(k)\) and \(O(d)\), respectively. The preprocessing and feature extraction steps consist of multiple phases. In this context, the time complexity of preprocessing (Algorithm 1) is analyzed in detail in Table 4.
When the analysis is performed using the cost and time information given in Table 4, the time complexity of the preprocessing step is given below:
Herein, \(c\) represents the cost and \(L\) represents the length of the signal. The values of \({\text{cost}}\), \({\text{cnt}}\) and \(f\) are neglected in the algorithmic analysis. In addition, since \(L\cong n\), the time complexity of the preprocessing step is \(O(n)\). The next phase of the proposed model is feature extraction. In this phase, the signal is decomposed into 12 levels using the TQWT algorithm. Then, features are extracted from both the raw signal and the subbands using the 1D-ARCSLBP method. The pseudo code for this process is given in Algorithm 3, and the time complexity calculated using this algorithm is shown in Table 5.
As shown in Table 5, the proposed methods consist of TQWT-based signal decomposition and 1D-ARCSLBP. Since TQWT is a signal decomposition process, the computational complexity of this step is \(O({\text{log}}n)\). In addition, an analysis of the computational complexity of the 1D-ARCSLBP method is given in Eqs. (14)-(19).
As shown in Eq. (19), the total computational complexity of the TQWT-based 1D-ARCSLBP method is \(O(n{\text{log}}n)\). In this context, considering all the steps performed, the preprocessing step is \(O(n)\), feature extraction step is \(O(n{\text{log}}n)\), feature selection step is \(O(k)\), and classification step is \(O(d)\). As a result of these calculated values, the time complexity of the model developed in this research is \(O(n{\text{log}}n+k+d)\).
4 Discussion
In this work, we have presented a new 1D-ARCSLBP-based cough sound classification architecture that was tested on a new two-class asthma cough sound dataset collected from more than 1000 patients. We were motivated by the success of ARCSLBP-based feature extraction in computer vision applications to develop a novel asthma cough sound classification model using a one-dimensional version of this feature extractor (1D-ARCSLBP). TQWT was incorporated to generate multilevel wavelet subbands from which both low- and high-level features could be extracted, effectively surmounting 1D-ARCSLBP’s ability to extract only low-level features. As a result of our conscious decision to employ only shallow functions, our model possessed a low-time burden (Table 3). Despite this, our handcrafted multileveled feature extraction-based architecture attained excellent performance with 98.24% and 96.91% accuracy rates on tenfold and LOSO CV, which is better than or commensurate with other state-of-art methods, including deep models (Table 6).
As shown in Table 6, the 1D-ARCSLBP and NCA-based model, which is a lightweight method proposed in this research, was validated by applying LOSO and tenfold CV strategies. In this context, a classification success of 96.91% for LOSO CV and 98.24% for tenfold CV was achieved. The dataset used in this research is larger than most of the state-of-the-art methods in the literature [21, 37, 39,40,41, 43]. In addition, two different validation strategies were used in this research. These strategies increase the reliability of the results obtained using the proposed method. The proposed method provides a lightweight solution according to the literature [24]. Tasar et al. [26] used 8 classes in their research. However, the computational complexity of the method used in this study is higher than our model. The LOSO strategy, which is used to ensure the generalizability of the results, has been used in only two studies [18, 43]. One of these studies, Singh et al. [43] achieved 94.52% classification success and the size of the dataset used in this study is quite small. Kilic et al. [18] achieved a higher classification success than our model. However, the computational complexity of the model developed in this research is higher than our model. In this context, when state-of-the-art methods are analyzed, the automatic asthma detection model presented in this research is more efficient in terms of both classification performance and computational complexity.
The model developed in this work uses the SVM algorithm as the classification method. In addition to this algorithm, some well-known classification algorithms in the literature were also tested. These are k-nearest neighbor (kNN), artificial neural network (ANN), decision tree (DT), and random forest (RF) algorithms. The SVM algorithm showed the best performance among these methods and the calculated classification accuracies (for tenfold CV) are comparatively given in Fig. 4.

Summary of classification results obtained with tenfold CV
As shown in Fig. 4, the best classification performance was obtained with the SVM algorithm. The DT algorithm showed the lowest classification performance with about 73%.
The advantages and limitations of our model are discussed below.
Advantages:
-
A learning architecture was built using novel 1D-ARCSLBP and other shallow methods. While computationally lightweight, it was demonstrated to be highly accurate when tested on a new asthma cough sound dataset comprising 1,875 samples recorded from 1,326 hospitalized subjects.
-
Over 96% accuracy rates for binary classification into asthma versus non-asthma classes were attained by deploying robust validation techniques. In particular, the LOSO CV results support the readiness of the model for implementation in real-world applications, e.g., in the clinic or hospital ward.
-
Our proposed architecture has linear time complexity (\(O(nlogn+k+d)\)), is very simple, and can be coded by researchers/developers efficiently.
Limitations:
-
The cough sounds were collected from a single center. The reliance on data from a solitary center may introduce potential biases and limit the generalizability of our findings. The specificity of the dataset to a particular demographic, environmental conditions, or healthcare setting raises concerns about the external validity of our model. The potential consequences of this constraint include the risk of model overfitting to the characteristics unique to the single-center dataset. Variabilities in cough sound patterns influenced by regional accents, environmental factors, or demographic differences may not be adequately captured. Consequently, the model may exhibit reduced performance when applied to diverse populations or alternative healthcare environments. However, in future works, multiple centers can contribute to a common larger dataset. Collaboration with multiple institutions or leveraging existing databases with diverse samples could be instrumental in addressing this limitation.
-
Cubic SVM was implemented with default settings. The use of default settings without hyperparameter optimization may result in suboptimal model performance. Cubic SVM has hyperparameters that, if left unoptimized, might not be well-suited for the specific characteristics of the dataset. This could lead to issues such as underfitting or overfitting, compromising the model's ability to generalize to new, unseen data. Hyperparameters can be further tuned using an optimizer to obtain better classification results. By optimizing hyperparameters, researchers can fine-tune the model to extract the best possible performance from the chosen algorithm, ensuring it aligns with the specific characteristics of the data.
Potential advantages and challenges in clinical applications:
-
The successful translation of our proposed model from a research context to practical, real-world scenarios, such as clinics or hospital wards, holds significant potential. The model's high accuracy in asthma screening can facilitate early detection of the condition. This, in turn, enables prompt intervention and treatment, potentially improving patient outcomes and reducing the burden on healthcare resources.
-
By automating the screening process, the proposed model has the potential to optimize healthcare resources. Clinics and hospital wards can allocate personnel more efficiently, directing attention to confirmed cases while streamlining the diagnostic workflow.
-
Seamless integration with existing healthcare systems can enhance the model's adoption. Compatibility with Electronic Health Records (EHR) or other clinical databases ensures a smooth incorporation into routine medical practices.
-
The challenges associated with diverse patient populations and varied cough sound characteristics across different clinical settings may affect the model's generalizability. Addressing this requires continuous validation and adaptation of the model to accommodate diverse datasets.
-
Ensuring regulatory compliance and adherence to healthcare standards are paramount. The proposed model must meet stringent regulatory requirements to guarantee patient safety and data security, adding an extra layer of complexity to implementation.
Clinician acceptance and training are crucial factors for successful integration. Clinicians may initially be skeptical of automated systems, and effective training programs must be implemented to familiarize healthcare professionals with the model’s capabilities and limitations.
5 Conclusions
Using a novel 1D-ARCSLBP feature extractor, a new hand-modeled architecture was proposed and studied on a new large cough sound dataset that comprised 1875 cough sound segments acquired from 1326 participants. Our model attained excellent 98.24% and 96.91% accuracy rates using tenfold and LOSO CV, respectively. Moreover, the model possessed a low-time complexity of O(nlogn + k + d). The excellent results confirmed the feature extraction capability of 1D-ARCSLBP on cough sound signals. In addition, the low-computational demands and ease of implementation position our model favorably against published state-of-the-art models, demonstrating that our model is ready to be developed into a real-world application.
Data availability
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to restrictions regarding Ethical Committee Institution.
References
Rubinfeld A, Pain M (1976) Perception of asthma. Lancet 307(7965):882–884
Eder W, Ege MJ, von Mutius E (2006) The asthma epidemic. N Engl J Med 355(21):2226–2235
Burgel P-R, Bergeron A, De Blic J, Bonniaud P, Bourdin A, Chanez P et al (2013) Small airways diseases, excluding asthma and COPD: an overview. Eur Respir Rev 22(128):131–147
Douwes J, Pearce N (2014) Epidemiology of respiratory allergies and asthma. Handb Epidemiol. https://doi.org/10.1007/978-0-387-09834-0_50
WHO (2022) Asthma. https://www.who.int/news-room/fact-sheets/detail/asthma
Vos T, Lim SS, Abbafati C, Abbas KM, Abbasi M, Abbasifard M et al (2020) Global burden of 369 diseases and injuries in 204 countries and territories, 1990–2019: a systematic analysis for the Global Burden of Disease Study 2019. Lancet 396(10258):1204–1222
Dodge RR, Burrows B (1980) The prevalence and incidence of asthma and asthma-like symptoms in a general population sample. Am Rev Respir Dis 122(4):567–575
Jones SC, Iverson D, Burns P, Evers U, Caputi P, Morgan S (2011) Asthma and ageing: an end user’s perspective-the perception and problems with the management of asthma in the elderly. Clin Exp Allergy 41(4):471–481
Gold D, Wright R (2005) Population disparities in asthma. Annu Rev Public Health 26:89–113
Bousquet J, Khaltaev N, Cruz AA, Denburg J, Fokkens W, Togias A et al (2008) Allergic rhinitis and its impact on asthma (ARIA) 2008. Allergy 63:8–160
Burke W, Fesinmeyer M, Reed K, Hampson L, Carlsten C (2003) Family history as a predictor of asthma risk. Am J Prev Med 24(2):160–169
Baldacci S, Maio S, Cerrai S, Sarno G, Baïz N, Simoni M et al (2015) Allergy and asthma: effects of the exposure to particulate matter and biological allergens. Respir Med 109(9):1089–1104
de Lange EE, Altes TA, Patrie JT, Gaare JD, Knake JJ, Mugler JP III et al (2006) Evaluation of asthma with hyperpolarized helium-3 MRI: correlation with clinical severity and spirometry. Chest 130(4):1055–1062
Sharek PJ, Mayer ML, Loewy L, Robinson TN, Shames RS, Umetsu DT et al (2002) Agreement among measures of asthma status: a prospective study of low-income children with moderate to severe asthma. Pediatrics 110(4):797–804
Cox L, Williams B, Sicherer S, Oppenheimer J, Sher L, Hamilton R et al (2008) Pearls and pitfalls of allergy diagnostic testing: report from the American college of allergy, asthma and immunology/American academy of allergy, asthma and immunology specific IgE test task force. Ann Allergy Asthma Immunol 101(6):580–592
Sennhauser FH, Braun-Fahrländer C, Wildhaber JH (2005) The burden of asthma in children: a European perspective. Paediatr Respir Rev 6(1):2–7
Haider NS, Behera A (2022) Computerized lung sound based classification of asthma and chronic obstructive pulmonary disease (COPD). Biocybern Biomed Eng 42(1):42–59
Kilic M, Barua PD, Keles T, Yildiz AM, Tuncer I, Dogan S et al (2024) GCLP: an automated asthma detection model based on global chaotic logistic pattern using cough sounds. Eng Appl Artif Intell 127:107184
Asim Iqbal M, Devarajan K, Ahmed SM (2022) An optimal asthma disease detection technique for voice signal using hybrid machine learning technique. Concur Comput Pract Exp 34(11):e6856
Iqbal MA, Devarajan K, Ahmed SM (2022) Real time detection and forecasting technique for asthma disease using speech signal and DENN classifier. Biomed Signal Process Control 76:103637
Sen I, Saraclar M, Kahya YP (2021) Differential diagnosis of asthma and COPD based on multivariate pulmonary sounds analysis. IEEE Trans Biomed Eng 68(5):1601–1610
Khan MU, Mobeen A, Samer S, Samer A (2021) Embedded system design for real-time detection of asthmatic diseases using lung sounds in cepstral domain. In: 6th International electrical engineering conference (IEEC 2021), pp 1–6
Yahyaoui A, Yumuşak N (2021) Deep and machine learning towards pneumonia and asthma detection. In: 2021 International conference on innovation and intelligence for informatics, computing, and technologies (3ICT). IEEE, pp 494–497
Topaloglu I, Barua PD, Yildiz AM, Keles T, Dogan S, Baygin M et al (2023) Explainable attention ResNet18-based model for asthma detection using stethoscope lung sounds. Eng Appl Artif Intell 126:106887
Yue L, Xu W (2021) Automatic classification of childhood asthma and pneumonia based on cough sound analysis. In: 2021 2nd international conference on artificial intelligence and computer engineering (ICAICE). IEEE, pp 779–783
Tasar B, Yaman O, Tuncer T (2022) Accurate respiratory sound classification model based on piccolo pattern. Appl Acoust 188:108589
Ruichek Y (2019) Attractive-and-repulsive center-symmetric local binary patterns for texture classification. Eng Appl Artif Intell 78:158–172
Selesnick IW (2011) Wavelet transform with tunable Q-factor. IEEE Trans Signal Process 59(8):3560–3575
Goldberger J, Hinton GE, Roweis S, Salakhutdinov RR (2004) Neighbourhood components analysis. Adv Neural Inf Process Syst 17:513–520
Vapnik V (1998) The support vector method of function estimation. In: Suykens JAK, Vandewalle J (eds) Nonlinear modeling. Springer, Boston, pp 55–85. https://doi.org/10.1007/978-1-4615-5703-6_3
Vapnik V (2013) The nature of statistical learning theory. Springer Science & Business Media, Berlin
Espi M, Fujimoto M, Kubo Y, Nakatani T (2014) Spectrogram patch based acoustic event detection and classification in speech overlapping conditions. In: 2014 4th joint workshop on hands-free speech communication and microphone arrays (HSCMA). IEEE, pp 117–121
Bagasta AR, Rustam Z, Pandelaki J, Nugroho WA (2019) Comparison of cubic SVM with Gaussian SVM: classification of infarction for detecting ischemic stroke. In: IOP conference series: materials science and engineering. IOP Publishing, p 052016
Powers DM (2020) Evaluation: from precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv preprint https://doi.org/10.48550/arXiv.2010.1606
Warrens MJ (2008) On the equivalence of Cohen’s kappa and the Hubert–Arabie adjusted Rand index. J Classif 25(2):177–183
Badnjević A, Gurbeta L, Cifrek M, Marjanovic D (2016) Classification of asthma using artificial neural network. In: 2016 39th international convention on information and communication technology, electronics and microelectronics (MIPRO). IEEE, pp 387–90
Islam MA, Bandyopadhyaya I, Bhattacharyya P, Saha G (2018) Multichannel lung sound analysis for asthma detection. Comput Methods Progr Biomed 159:111–123
Naqvi SZH, Arooj M, Aziz S, Khan MU, Choudhary MA (2020) Spectral analysis of lungs sounds for classification of asthma and pneumonia wheezing. In: 2020 International conference on electrical, communication, and computer engineering (ICECCE). IEEE, pp 1–6
Nabi FG, Sundaraj K, Lam CK (2019) Identification of asthma severity levels through wheeze sound characterization and classification using integrated power features. Biomed Signal Process Control 52:302–311
Badnjevic A, Cifrek M, Koruga D, Osmankovic D (2015) Neuro-fuzzy classification of asthma and chronic obstructive pulmonary disease. BMC Med Inform Decis Mak 15(3):1–9
Shaharum SM, Sundaraj K, Aniza S, Palaniappan R, Helmy K (2016) Classification of asthma severity levels by wheeze sound analysis. In: 2016 IEEE conference on systems, process and control (ICSPC). IEEE, pp 172–176
Khasha R, Sepehri MM, Taherkhani N (2021) Detecting asthma control level using feature-based time series classification. Appl Soft Comput 111:107694
Singh OP, Palaniappan R, Malarvili M (2018) Automatic quantitative analysis of human respired carbon dioxide waveform for asthma and non-asthma classification using support vector machine. IEEE Access 6:55245–55256
Acknowledgements
We gratefully acknowledge the Ethics Committee, Firat University, and the data transcription team.
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions. The authors state that this work has not received any funding.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors of this manuscript declare no conflicts of interest.
Ethical approval
This research has been approved on ethical grounds by the Non-Interventional Research Ethics Board Decisions, Firat University, on 7 June 2022 (2022/08–27).
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Barua, P.D., Keles, T., Kuluozturk, M. et al. Automated asthma detection in a 1326-subject cohort using a one-dimensional attractive-and-repulsive center-symmetric local binary pattern technique with cough sounds. Neural Comput & Applic (2024). https://doi.org/10.1007/s00521-024-09895-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00521-024-09895-5