
Abstract
Retinal diseases that are not treated in time can cause irreversible, permanent damage, including blindness. Although a patient may suffer from more than one retinal disease at the same time, most of the studies focus on the diagnosis of a single disease only. Therefore, to detect multi-label retinal diseases from color fundus images, we developed an end-to-end deep learning architecture that combines the EfficientNet backbone with the ML-Decoder classification head in this study. While EfficientNet provides powerful feature extraction with fewer parameters via compound scaling, ML-Decoder further improves efficiency and flexibility by reducing quadratic dependency to a linear one and using a group decoding scheme. Also, with the use of sharpness-aware minimization (SAM) optimizer, which minimizes loss value and loss sharpness simultaneously, higher accuracy rates have been reached. In addition, a significant increase in EfficientNet performance is achieved by using image transformations and concatenation together. During the training phase, the random application of the image transformations allows for increasing the image diversity and makes the model more robust. Besides, fusing fundus images of left and right eyes at the pixel level extracts useful information about their relationship. The performance of the final model was evaluated on the publicly available Ocular Disease Intelligent Recognition (ODIR) dataset consisting of 10,000 fundus images, and superior results were obtained in all test set scenarios and performance metrics than state-of-the-art methods. The best results we obtained in the threefold cross-validation scenario for the kappa, F1, and AUC scores are 68.96%, 92.48%, and 94.80%, respectively. Moreover, it can be considered attractive in terms of floating point operations per second (FLOP) and a number of parameters.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
The retina is a layered tissue that is sensitive to light and covers the inner back of the eye. It absorbs incoming light and converts the light energy into neural signals processed by the brain’s visual cortex for visual recognition [1]. Deformation of this tissue can cause some partial vision problems, vision loss, and even blindness [2]. Retinal diseases can be revealed by examining abnormalities in retinal regions such as the optic nerve, vessels, macula, and optic plate. The most common retinal diseases are diabetic retinopathy (DR), age-related macular degeneration (AMD), cataract, and glaucoma. The importance of these diseases is increasing with each passing day. According to a study, it is estimated that 288 million people will have AMD by 2040, and the number of people with DR will be tripled by 2050 [3]. In addition, according to the World Health Organization’s report in 2021, it is said that 2.2 billion people are visually impaired, and about half of them can be cured [4]. For this reason, early diagnosis and timely treatment are important and can significantly prevent blindness. Different imaging techniques have been developed to detect retinal diseases. The most commonly used of them are optical coherence tomography (OCT) and color fundus photography (CFP). Because it is cost-effective and noninvasive, CFP is used by specialists as a primary retinal imaging technique for early diagnosis [5]. However, diagnosing retinal diseases by ophthalmologists is time-consuming and laborious. Moreover, the number of ophthalmologists for manual retinal screening is far from sufficient in most rural and underdeveloped areas. For these reasons, the development of automatic retinal scanning systems is essential.
Recently, with the increase in the computing power of computers, deep learning models—especially convolutional neural networks (CNN)—have gained importance and have made significant contributions to the field of medical image analysis [6]. Regarding retinal disease diagnosis, CNN-based deep networks such as EfficientNet, ResNet, and Inception have shown promising performance in various applications, from segmentation to classification. Despite the promising performance obtained, automatic retinal scanning systems can have some difficulties and weaknesses: The retina images can involve anomalies belonging to multiple diseases, and we can have data for only one eye. Most studies on the recognition of retinal diseases consist of studies on detecting a single disease or using single-labeled datasets. However, a patient may simultaneously suffer from more than one retinal disease in real life. In addition, the presence of one disease can significantly affect the performance of diagnosing another disease [7].
In this study, firstly, the performance of the EfficientNet-B4 [8] model was measured as a baseline architecture, and then, its performance was improved by image transformations and pixel-level fusion. Then, the updated baseline model was further improved by replacing the global average pooling (GAP) and fully connected layer (FCL) with the ML-Decoder [9] classification head and EfficientNet-B4 with EfficientNet-B5 backbone. Finally, the SAM (sharpness-aware minimization) optimizer [10], which provides better generalization ability, is adapted to the framework instead of the Adam optimizer. The performance of the proposed model was evaluated on the ODIR-5K [11] dataset, which involves binocular fundus images and multi-label/multi-class outputs for each individual. Interpretation of left and right eye images together with patient-level diagnosis, as clinical ophthalmologists do, allows useful correlation information to be discovered between them. Besides the significant decrease in the number of parameters compared to other studies, the best result in the literature has been achieved.
In summary, our contributions to this study are:
-
A deep learning model that uses EfficientNet-B5 as a backbone and ML-Decoder [9] as a classification head is proposed for the classification of multi-label retinal fundus images. Especially with the first use of ML-Decoder in this field, the advantage of transformer structures has been obtained without extra computational overhead.
-
It is for the first time that a sharpness-aware minimization (SAM) optimization procedure that improves the general performance is utilized for the multi-label retinal diseases classification.
-
Applying binocular fundus image concatenation and random image diversification via some transformations in the training phase together is proposed for multi-label retinal disease classification. In this way, the performance of the EfficientNet model is optimized.
-
The proposed model reduces computational costs using fewer model parameters when compared with state-of-the-art models.
-
Compared with the most successful methods available in the literature, the best performance was achieved on the public widely used ODIR-5K [11] dataset with the proposed model.
The remainder of this paper is organized as follows. Related works for the classification of multi-label fundus images are discussed in Sect. 2. Section 3 presents the proposed multi-label retinal disease classification model. In Sect. 4, we introduce the dataset and evaluation criteria and discuss the results in different aspects. Finally, we conclude the work in Sect. 5.
2 Related works
There are many studies in the literature on the classification of retinal diseases through fundus imaging. In most of these studies, the authors focused on the recognition of a single disease with popular machine/deep learning methods through images containing only one disease, such as glaucoma [12], diabetic retinopathy [13], or cataract [14]. However, in real life, a patient’s retinal image may contain more than one disease. Therefore, this study considers the classification of multi-label retinal diseases. When the studies in this field are examined, it can be seen that two multi-label retinal image datasets are publicly available. These datasets are Ocular Disease Intelligent Recognition (ODIR) [11] and Retinal Fundus Multi-disease Image Dataset (RFMiD) [15]. Since their characteristics and properties are different, experiments were carried out by selecting only one of these datasets in the literature. Hence, studies on both datasets will be discussed separately in this section.
Overview of the studies that use ODIR dataset: In [16], histogram equalization was applied to the images at gray and color levels. The images obtained from histogram equalization were given parallel as input to two separate EfficientNet models, and the extracted features were combined before the classification step. In [17], two models of the same type were used for the left and right eye images, as in [16]. On the other hand, the VGG-16 model was preferred instead of EfficientNet in [16]. Li et al. [18] gave the images of the left and right eyes to their dedicated backbone VGG-16 models, and the features obtained from the models’ output were fused with summation. It was observed that this fusion scheme gave better results than concatenation and multiplication. He et al. [19] proposed an attention mechanism called Spatial Correlation Module (SCM), which captures the relationship between the left and right eyes on a pixel basis. With the addition of SCM to the ResNet-101 backbone, the final score ((AUC + F1 + kappa)/3) was increased from 81.2 to 82.7%. Although the performance has increased with this module, the number of parameters has also increased significantly. In [20], the effects of various image enhancement methods were analyzed. Also, it is the first study that proposes a transformer-based model on the OIA-ODIR dataset. In [21], a knowledge distillation-based model was developed to improve performance. Clinical features were combined with features extracted by the ResNet-101 model, and 93.80% AUC was obtained. Ou et al. [22] built a four-stage model: two for feature extraction and feature enrichment, one for attention mechanism, and one for classification. Although there is a significant increase in performance, it has a notable disadvantage in terms of the number of parameters. In [23], subsequent to the EfficientNet-B4 backbone, interdependencies between the labels were obtained with the hybrid graph convolution network (GCN)-based feature extraction. All the extracted features were given as input to the LightGBM classifier. This so-called MCGL-Net architecture increased the classification performance of the multi-label model. In [24], the DKCNet model, which discovers the region-based distinctive features, was proposed, and undersampling/oversampling operations were performed to overcome the class imbalance problem. In addition, unlike other studies, the label information of both eyes was separated, and an image-level diagnosis was applied instead of a patient-level one. In [25], the features obtained from the backbone networks were combined with a structure called multi-scale dilated convolution. Then, with the DenseNet model, a final score of 79.3% and 77.7% was obtained for the off-site and on-site test datasets of OIA-ODIR, respectively.
Overview of the studies that use RFMiD dataset: Müller et al. [26] used DenseNet201, EfficientNet-B4, ResNet-101, and Inception-V3 models and increased the performance by applying hybrid ensemble learning strategy to the results obtained from these four models. In [27], the highest classification result on the RFMiD validation data was obtained by means of using the EfficientNet-B5 and EfficientNet-B6 models, keeping the size of the input images high, and taking the average test score of the models. Oh et al. [28] designed a two-branched architecture: One branch includes all labels, and the other one does not include only disease risk label. For each branch, two classifiers were formed for minority and majority classes, and the results were combined. In [29], experiments were carried out on eight classes with more than 100 samples only. In the study, the performance was enhanced with the EfficientNet-B4 model and a spatial attention mechanism that strengthens the feature extraction capacity of the network. Rodriguez et al. [30] constituted a new dataset named MuReD by the combination of three datasets: ARIA, STARE, and RFMiD. Various deep learning models were tested, and the best performance was obtained with the DenseNet161 model.
Since the RFMiD dataset contains fewer samples (especially for some disease groups), the class imbalance problem becomes more apparent, and it contains only one eye image per individual; the experiments were conducted on the ODIR-5K dataset in our study.
3 Methods
3.1 Baseline model
In this study, firstly, a baseline architecture has been constituted in which the EfficientNet model is preferred as a backbone. EfficientNet-B4 from the EfficientNet model family is chosen because it provides an acceptable solution in terms of recognition performance and number of parameters. The baseline model primarily takes the left and right eye fundus images as separate inputs to the EfficientNet-B4 network. Then, the features obtained from this network are combined by concatenating them in the depth dimension. With the GAP process, the spatial dimension is reduced to one, and the relationship of the feature maps to the class labels is emphasized. Also, this process is popular as it contains no parameters to optimize and avoids overfitting. At the end of the network architecture, the classification process is completed with the fully connected layer and sigmoid activation function. Although the focal loss was developed for imbalanced datasets and focused on hard examples, BCE loss was tested in the study and gave better results than focal loss. This is likely due to the low imbalance rate in the dataset. The general structure of the baseline model is visualized in Fig. 1.
3.2 Proposed model
The model proposed in this study includes three main differences that contribute positively to the classification performance compared to the baseline model described above. These are (from input to output): (i) Preprocessing step: In the training stage of the model, for each epoch, the fundus images of the left and right eye are randomly processed with some transformations. These transformations are translation, scaling, rotation, brightness and contrast change, hue, saturation, and value change. All of them can be interpreted as a kind of data augmentation process that provides some invariance to the affine transformations and color illumination changes. Thus, it is ensured that the deep learning model is more robust against diversity that may occur in the images taken with different cameras from different people in different postures at different times. Furthermore, the generalization ability of the model can be increased, and overfitting can be avoided. In addition to the image transformations, image concatenation at the pixel level is used in the proposed model. The left and right eye fundus images are given to the same backbone model separately, and then, features are fused before the classification head in the baseline model. Alternatively, these two images are fused at the pixel level in the proposed model by adding one under the other as a single image. Thus, both images of an individual are given to the backbone network as a whole, and the relations between them are successfully revealed at the feature extraction stage. (ii) ML-Decoder: One of the most important contributions of the study is the adaptation of the ML-Decoder structure to the place of GAP and FCL in the classification part of the model. This attention-based classification head strengthens classification accuracy via better utilization of spatial data. Details of the ML-Decoder structure are given in Sect. 3.2.2. (iii) SAM optimizer [10]: In the proposed model, Adam optimizer is replaced with the SAM optimizer to train the model. It can be seen as an enhancement to a base optimizer such as stochastic gradient descent (SGD). SAM optimizer searches parameters with low loss and curvature in all neighborhoods instead of only searching parameters with low training loss. In this way, the generalization ability of the model is improved. Also, it is empirically proved that the SAM optimizer gives superior performance on pre-trained models, and it is robust enough to label noise.
The general scheme of the proposed model is shown in Fig. 2. In the figure, FC and GAP denote fully connected and global average pooling, respectively. The parts that differ from the baseline model are colored in red.
In the proposed model, after the concatenation process, the input image I (\(I \in\) \(\mathbb {R}^{2H\times W\times 3}\), H and W refer to the height and width of the image, and 3 refers to the three color channels) is given to the backbone, and F (\(F \in\) \(\mathbb {R}^{2h\times w\times c}\), h, w, and c are the height, width, and number of feature maps) is obtained as the output. In the next step, the obtained feature maps F are given as input to the ML-Decoder classification head. Finally, multi-label class predictions are generated from the output of the sigmoid activation functions.

Baseline model

Proposed model with ML-Decoder
3.2.1 EfficientNet backbone
In order to obtain optimal features with deep learning, it is important to choose a model that provides high performance with few parameters. Generally, the number of parameters and FLOPS are related to the model’s width, depth, and resolution. In the EfficientNet deep learning models family [8], all these variables are scaled to yield eight models (EfficientNet-B0–EfficientNet-B7) with different levels of complexity and input image sizes. Additionally, it is less prone to overfitting, less costly, and faster to train with the use of depth-wise separable convolution layers and inverted residual blocks, which are also used in MobileNet models. Furthermore, it has squeeze-and-excitation (SE) blocks [31] that give each channel the ability to learn its own weight by itself. Thereby, it has become one of the most advanced CNN models today. In this study, EfficientNet-B4 and EfficientNet-B5 models are chosen as the backbone network for feature extraction, taking into account the performance and cost trade-offs.
3.2.2 ML-Decoder
In this study, the ML-Decoder [9], a recently developed attention-based classification head module, was adapted to the end of the EfficientNet backbone. It improves the performance of the model by focusing more on features in proportion to its contribution to classification ability. ML-Decoder predicts the class labels based on queries and utilizes spatial data more efficiently than GAP. The overall architecture of the ML-Decoder is shown in Fig. 3.

Overall structure of ML-Decoder
ML-Decoder is a lightweight updated version of the transformer decoder structure. It is accomplished by removing the self-attention block from the transformer decoder [32] and using a group decoding scheme. Considering that N is the number of classes and K is the number of group queries, the cost is reduced from \(O(N^2)\) to O(N) with the removal of self-attention and from O(N) to O(K) with Group Decoding. The full diagram of ML-Decoder with group decoding is depicted in Eq. 1, where \(G_q\) and E are the input group queries and spatial embedding tensor, respectively:
ML-Decoder relies on the multi-head attention module. Multi-head attention has three inputs: Query (Q), Key (K), and Value (V). It is depicted in Eq. 2, where \(W_i^Q\), \(W_i^K\), \(W_i^V\), and \(W^O\) are learnable parameters. In group fully connected pooling, which is the last part of ML-Decoder, there are two options: full decoding and group decoding. The main difference between them is that each query checks for the existence of a single or several classes. In full decoding scheme, each query checks the existence of a single class, while in group decoding, each query checks the existence of several classes. Since the number of classes is limited (\(N = 8\)), the full decoding scheme was preferred in this study.
3.2.3 Sharpness-aware minimization
In deep learning applications, selecting an optimizer to update model parameters that minimize the loss value has an essential role. In this study, SAM optimizer [10] is adapted instead of the Adam optimizer to enhance generalization capability by simultaneously minimizing loss value and loss sharpness (characterized by neighboring points with uniformly low training loss values). Moreover, SAM tackles the problem of label noise.
Let \(S \overset{\Delta }{=}\cup _{i=1}^n\{(x_i,y_i)\}\), and \(w \in W \subseteq \mathbb {R}^d\) denote a training set and model parameters, respectively. The objective function of the SAM optimizer can be defined as in Eq. 3.
where \(\lambda\) is a hyperparameter for regularization and \(\rho\) is a hyperparameter for loss sharpness. In Eq. 3, \(L_S^\textrm{SAM}(w)\) and \(L_{s}(w)\) denote the SAM loss function and training set loss function, and \(\lambda \Vert w \Vert _2^2\) is the standard L2 regularization term.
By carrying out Taylor expansion, differentiation, and some drop operations, an efficient approximation for the gradient of the SAM loss function \(\nabla _{w}L_{S}^\textrm{SAM}(w)\) is obtained in Eq. 4.
where approximation of the epsilon neighborhood \(\hat{\epsilon }\) is given by Eq. 5.
where \(1/p + 1/q = 1\).
The algorithm of SAM optimizer involves two successive training steps repeated until convergence: parameter estimation and weight update. In the first step, the equation \(\hat{\epsilon }(w)\) is evaluated via batch’s training loss, while in the subsequent step, the gradient approximation \(\nabla _{w}L_{S}^\textrm{SAM}(w)\) of the objective function is evaluated and added to the model parameters w by multiplying with a constant.
4 Experiments and results
4.1 Experimental preparation
4.1.1 Dataset
The performance evaluations are performed on a multi-label, publicly available ODIR-5K dataset [11] consisting of 10,000 fundus images. The images in the dataset were collected from different hospitals and medical centers in China and took ten months to be labeled by specialist doctors. If the specialist doctors disagreed, the labeling was done by majority vote. The dataset includes left and right eye images of 5,000 people, and the images were obtained via three cameras with three different resolutions. It has eight categories: seven for diseases and one for normal. These tags are normal image (N), diabetic retinopathy (D), glaucoma (G), cataract (C), age-related macular degenerate (A), hypertension (H), myopia (M), and other abnormalities (O). Other abnormalities were gathered under a single label because of the samples’ rareness. The split form of the ODIR-5K dataset into training, off-site, and on-site is called OIA-ODIR. The training, off-site, and on-site datasets contain information on 3,500, 500, and 1,000 patients, respectively. The distribution of class-based image numbers in the dataset is shown in Table 1. When the table is examined, it can be seen that the dataset is imbalanced in terms of sample numbers per class. For example, there are 1,130 samples for disease D and 103 for disease H. The representation percentages of each class in the training set are mainly consistent with those in the off-site and on-site test sets. The dataset is a powerful tool for measuring the performance of developed models as it simulates real-life challenges. For instance, the cup-to-disk ratio is the most critical indicator for glaucoma screening, or the macular region is atrophying geographically in AMD disease.
4.1.2 Evaluation metrics
In this study, area under curve (AUC in Eq. 6), F1-score (F1 in Eq. 7), kappa score (K in Eq. 8), and accuracy (Acc in Eq. 9) are selected as performance evaluation metrics. The AUC value close to 1 indicates that the model is more successful and stable. Similarly, the F1-score is higher only when both recall and precision are high. Another criterion, the kappa coefficient, is used to measure the consistency, and the range is from \(-1\) to 1. The formulas for AUC, F1, kappa score, and Acc are shown below.
where TP, TN, FP, and FN refer to the number of true positive, true negative, false positive, and false negative predictions, respectively. TPR and FPR are true positive and false positive rates, respectively.
4.1.3 Training environment and configuration
The publicly available framework Pytorch (version 1.10.1) was used to implement the proposed models. All the experiments ran on 4 x NVIDIA V100 GPUs (16 GB GPU Memory per GPU). In this study, all training model parameters are evaluated comprehensively. We trained the proposed model for different epochs and obtained the best results on the validation dataset for 40. Also, we scheduled the learning rate by using a 1-cycle policy, with a maximal learning rate of 4e−4 and 1e−4 for the backbone and ML-Decoder, respectively. The batch size was configured to be 8. The parameters of the transformations applied in the image transformation stage are as follows: upper and lower scale factors: 0.81 and 1.21; shift factor range for both height and width: 0.10; rotation range: (\(-180\), 180); factor range for changing brightness and contrast: (\(-0.1\), 0.1); range for changing hue, saturation, and value: (\(-5\), 5); and probability of applying the transform: 0.5.
4.2 Results
In the experiments, two different scenarios used in the literature for the training/test set separation of the ODIR-5K dataset were taken into account, and the results were given separately. In the first scenario, the dataset is randomly divided into three folds, and cross-validation is applied by training on each combination of two folds and testing on the remaining fold. Then, the average results of these folds are reported as threefold CV results. In the other scenario, the dataset is divided into training, off-site, and on-site test sets, as in [22]. Performance is evaluated separately over off-site and on-site test sets.
Primarily, the effect of the preprocessing phase applied in the development of the proposed model from the baseline model on the overall performance is revealed in Table 2. The first row in the table indicates that 60.82% kappa, 90.68% F1, and 91.31% AUC values are obtained with the baseline model. In the second row, the results achieved by applying the image transformation step during the training phase of the baseline model are given. It is observed that there is a great improvement in the results for each metric. In particular, the 3.86% increase in kappa score reveals the importance of this process. The positive contribution to the classification ability should have arisen from the increased generalization performance of the model. This is an outcome of simulating the natural diversity in the images that may occur from device and posture differences during the training phase. The results obtained from giving the images to the input of the backbone network by combining them spatially are shown in the third row. If these results are compared with the previous results, it is seen that the pixel-level fusion approach produced better results than fusion at feature level. The possible reason is that the backbone network learns the relationship using the left and right eye information together while extracting features. As a result, Table 2 indicates that by adding the image transformation step and image concatenation together, the performance of the baseline model increased by 6.75%, 1.35%, and 2.20% for kappa, F1, and AUC scores, respectively.
After getting improvements by applying image transformations and pixel-level fusion, we tried additional deep learning models to provide a more comprehensive evaluation in Table 3. We preferred to use the most popular deep learning models such as InceptionResNet-V2, ResNet-50, Inception-V3, and DenseNet-121 in addition to EfficientNet-B4 as in [33, 34]. For all models, image transformations and pixel-level fusion were adapted. Although the EfficientNet-B4 model has fewer FLOPs than other models, it gives the best performance for all metrics.
4.3 The effect of ML-Decoder module and SAM optimizer
In this subsection, the quantitative results of using EfficientNet-B5 as a backbone, ML-Decoder as a classification head, and SAM optimizer as an optimization procedure are analyzed in Table 4 for all training/test scenarios. Although the EfficientNet-B5 model includes more parameters, it outperformed the EfficientNet-B4 model in almost all metrics (except threefold CV without ML-Decoder) due to its ability to learn features at higher abstraction levels. The most important contribution of our study, ML-Decoder, yields extra improvement in the results when used instead of GAP and FCL block (only the AUC score decreases slightly for the on-site test set). The use of SAM optimizer instead of Adam also contributed positively to the result for all metrics. Thus, compared to the improved model (with the preprocessing step), the proposed final model (using ML-Decoder, EfficientNet-B5, and SAM optimizer) draws attention by achieving a total increase of 2.48% for kappa, 0.50% for F1, and 1.25% for AUC scores on off-site test set. Similarly, in other scenarios (threefold CV and on-site), there are improvements for all metrics.
If we compare the test scenarios in Table 4, it can be seen that threefold CV experiments give higher results in kappa and F1-score metrics than off-site experiments but generally slightly lower for AUC values. On the other hand, on-site experiments produced lower results for all metrics than the other two test scenarios.
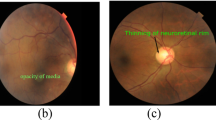
The performance of the proposed model is also visually analyzed with Gradient Weighted Class Activation Mapping (Grad-CAM) [35], as shown in Fig. 4. Grad-CAM is a popular generalization of CAM that gives information about the most relevant regions of an image for a particular class. In the figure, the first and third columns show input fundus images that have ocular diseases. The second and fourth columns correspond to Grad-CAMs generated by the proposed model. Regions with a stronger influence on the prediction findings are highlighted in red, whereas regions with a lower influence are highlighted in blue. It can be seen that the proposed method detects the lesion parts quite successfully. For example, since the optic disk for glaucoma and the macula for AMD are the most important regions in the retina, the proposed model largely covers the relevant regions.

Grad-CAMs obtained with the proposed model: a normal image b normal image Grad-CAM, c glaucoma, d glaucoma Grad-CAM, e myopia, f Myopia Grad-CAM, g AMD, and h AMD Grad-CAM
The class-wise accuracy rates of the proposed model are evaluated and listed in Table 5 for further analysis. The following conclusions can be drawn from the results in the table: (i) the off-site and on-site accuracy results are close to each other, as in the average results. (ii) Generally, the accuracy is higher for the minority classes. The accuracy values of these classes are mainly evaluated on negative samples due to the large number of negative samples in minority classes. For example, the highest class-wise accuracy values were obtained for hypertension, myopia, and AMD diseases, which have the fewest samples. (iii) Normal and other abnormality classes showed the weakest performance as they involve high sample diversity.
4.4 Comparisons
The classification performance of the proposed model is compared with the state-of-the-art models in the literature in Table 6 for kappa, F1, and AUC scores. The experimental results of [22, 25] are given for off-site/on-site test sets. Similarly, the performance evaluation of the methods proposed in [17, 19] on off-site/on-site test sets was obtained from [22]. In [19, 21], threefold CV average results are given only. Wang et al. [16] applied a tenfold CV to 7,000 images and measured the performance on 1,000 images. On the other hand, Sun et al. [23] allocated 70% of the dataset to the training set and 30% to the test set. The results of the studies [16, 23, 24] are given in the threefold CV section since performance is not measured on off-site/on-site datasets. The results, which do not use oversampling, of [24] are given to make a fair comparison. Comprehensive analysis for revealing the effect of oversampling is also given in Table 7. When the results are analyzed, it can be seen that the proposed model performs superiorly in the literature for all metrics and test scenarios. Also, in parallel with the results in the literature, the highest performance was obtained from threefold CV, off-site, and on-site experiments, respectively. The proposed model yielded 4.66%, 11.57%, and 9.82% higher values for the kappa score metric than the highest values in the literature for threefold CV, off-site, and on-site experiments, respectively. Similarly, for F1: 0.88%, 2.07%, and 1.92%; and for AUC: 1.30%, 2.72%, and 2.74% performance increment has been achieved.
Bhati et al. [24] balanced all classes in the dataset using an oversampling method for the final results of their study. We also applied the same approach to the dataset and obtained better results than [24] as given in Table 7. With the proposed model, 7.41%, 2.58%, and 2.89% higher values for kappa, F1, and AUC metrics are achieved, respectively.
To compare the classification performance comprehensively, we list the computational parameters of different models in Table 8. The ML-Decoder and EfficientNet-B5 parts used in the proposed model contributed positively to the classification performance. However, it caused an increase in the number of parameters. Despite this increase, it seems that it requires fewer parameters and FLOPs than other state-of-the-art methods, except for [17], which has low performance. It should also be noted that the ML-Decoder imposes very little overhead in terms of FLOP.
5 Conclusion
In this study, we have developed a framework for detecting multi-label retinal diseases and achieved challenging results on the public ODIR dataset. At first, we optimized the EfficientNet backbone with a few touches: some image transformation operations for training data and pixel-level fusion. Then, we proposed using an ML-Decoder classification head with an EfficientNet backbone for retinal disease classification from fundus images. Finally, the parameters of the model are optimized using SAM optimizer instead of Adam optimizer. Our model outperforms state-of-the-art deep learning models for all metrics and test set scenarios. Also, better results were obtained with fewer model parameters and FLOPs. Furthermore, visual Grad-CAMs and class-wise analysis are presented in the paper. In future work, we intend to generate GAN-based synthetic images for the imbalanced data problem. Thus, performance can be improved by augmenting the multi-label data to construct more precise interrelationships between labels. The proposed model has pretty good scalability and can be easily extended beyond classifying ophthalmic diseases, such as colon gastrointestinal disease classification.
Data availability
The dataset analyzed during the current study is available in the ODIR 2019 repository: https://odir2019.grand-challenge.org
References
Abràmoff MD, Garvin MK, Sonka M (2010) Retinal imaging and image analysis. IEEE Rev Biomed Eng 3:169–208
Bourne RR, Stevens GA, White RA, Smith JL, Flaxman SR, Price H, Jonas JB, Keeffe J, Leasher J, Naidoo K et al (2013) Causes of vision loss worldwide, 1990–2010: a systematic analysis. Lancet Glob Health 1(6):339–349
Schmidt-Erfurth U, Sadeghipour A, Gerendas BS, Waldstein SM, Bogunović H (2018) Artificial intelligence in retina. Prog Retin Eye Res 67:1–29
Blindness and vision impairment. https://www.who.int/news-room/fact-sheets/detail/blindness-and-visual-impairment
Ahmad M, Kasukurthi N, Pande H (2019) Deep learning for weak supervision of diabetic retinopathy abnormalities. In: 2019 IEEE 16th international symposium on biomedical imaging (ISBI 2019). IEEE, pp 573–577
Litjens G, Kooi T, Bejnordi BE, Setio AAA, Ciompi F, Ghafoorian M, Van Der Laak JA, Van Ginneken B, Sánchez CI (2017) A survey on deep learning in medical image analysis. Med Image Anal 42:60–88
Li Z, He Y, Keel S, Meng W, Chang RT, He M (2018) Efficacy of a deep learning system for detecting glaucomatous optic neuropathy based on color fundus photographs. Ophthalmology 125(8):1199–1206
Tan M, Le Q (2019) Efficientnet: rethinking model scaling for convolutional neural networks. In: International conference on machine learning. PMLR, pp 6105–6114
Ridnik T, Sharir G, Ben-Cohen A, Ben-Baruch E, Noy A (2021) Ml-decoder: scalable and versatile classification head. arXiv preprint arXiv:2111.12933
Foret P, Kleiner A, Mobahi H, Neyshabur B (2020) Sharpness-aware minimization for efficiently improving generalization. arXiv preprint arXiv:2010.01412
Peking University International Competition on Ocular Disease Intelligent Recognition (ODIR-2019). https://odir2019.grand-challenge.org
Fu H, Cheng J, Xu Y, Zhang C, Wong DWK, Liu J, Cao X (2018) Disc-aware ensemble network for glaucoma screening from fundus image. IEEE Trans Med Imaging 37(11):2493–2501
Gulshan V, Peng L, Coram M, Stumpe MC, Wu D, Narayanaswamy A, Venugopalan S, Widner K, Madams T, Cuadros J et al (2016) Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 316(22):2402–2410
Zhang H, Niu K, Xiong Y, Yang W, He Z, Song H (2019) Automatic cataract grading methods based on deep learning. Comput Methods Programs Biomed 182:104978
Pachade S, Porwal P, Thulkar D, Kokare M, Deshmukh G, Sahasrabuddhe V, Giancardo L, Quellec G, Mériaudeau F (2021) Retinal fundus multi-disease image dataset (RFMID): a dataset for multi-disease detection research. Data 6(2):14
Wang J, Yang L, Huo Z, He W, Luo J (2020) Multi-label classification of fundus images with efficientnet. IEEE Access 8:212499–212508
Gour N, Khanna P (2021) Multi-class multi-label ophthalmological disease detection using transfer learning based convolutional neural network. Biomed Signal Process Control 66:102329
Li N, Li T, Hu C, Wang K, Kang H (2020) A benchmark of ocular disease intelligent recognition: one shot for multi-disease detection. In: International symposium on benchmarking, measuring and optimization. Springer, pp 177–193
He J, Li C, Ye J, Qiao Y, Gu L (2021) Multi-label ocular disease classification with a dense correlation deep neural network. Biomed Signal Process Control 63:102167
Yang H, Chen J, Xu M (2021) Fundus disease image classification based on improved transformer. In: 2021 International conference on neuromorphic computing (ICNC). IEEE, pp 207–214
He J, Li C, Ye J, Qiao Y, Gu L (2021) Self-speculation of clinical features based on knowledge distillation for accurate ocular disease classification. Biomed Signal Process Control 67:102491
Ou X, Gao L, Quan X, Zhang H, Yang J, Li W (2022) Bfenet: a two-stream interaction CNN method for multi-label ophthalmic diseases classification with bilateral fundus images. Comput Methods Programs Biomed 219:106739
Sun K, He M, Xu Y, Wu Q, He Z, Li W, Liu H, Pi X (2022) Multi-label classification of fundus images with graph convolutional network and lightgbm. Comput Biol Med 149:105909
Bhati A, Gour N, Khanna P, Ojha A (2023) Discriminative kernel convolution network for multi-label ophthalmic disease detection on imbalanced fundus image dataset. Comput Biol Med 106519
Zhu D, Ge A, Chen X, Liu S, Wang Q, Wu J (2022) A deep learning analysis framework for ophthalmic diseases and physical health from binocular fundus image pairs. Authorea Preprints
Müller D, Soto-Rey I, Kramer F (2021) Multi-disease detection in retinal imaging based on ensembling heterogeneous deep learning models. IOS Press, Amsterdam
Hanson0910/Pytorch-RIADD: 1st solution for retinal image analysis for multi-disease detection challenge(riadd (ISBI-2021)). https://github.com/Hanson0910/Pytorch-RIADD
Oh Y-t, Park H (2022) End-to-end two-branch classifier for retinal imaging analysis. In: 2022 international conference on electronics, information, and communication (ICEIC). IEEE, pp 1–3
Sun K, He M, He Z, Liu H, Pi X (2022) Efficientnet embedded with spatial attention for recognition of multi-label fundus disease from color fundus photographs. Biomed Signal Process Control 77:103768
Rodriguez M, AlMarzouqi H, Liatsis P (2022) Multi-label retinal disease classification using transformers. IEEE J Biomed Health Inform
Hu J, Shen L, Sun G (2018) Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 7132–7141
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I (2017) Attention is all you need. In: Advances in neural information processing systems, vol 30
Mozaffari J, Amirkhani A, Shokouhi SB (2024) Colongen: an efficient polyp segmentation system for generalization improvement using a new comprehensive dataset. Phys Eng Sci Med 1–17
Mozaffari J, Amirkhani A, Shokouhi SB (2023) A survey on deep learning models for detection of Covid-19. Neural Comput Appl 1–29
Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, Batra D (2017) Grad-cam: visual explanations from deep networks via gradient-based localization. In: IEEE international conference on computer vision, ICCV 2017, Venice, Italy, 22–29 Oct 2017, pp 618–626. https://doi.org/10.1109/ICCV.2017.74
Acknowledgements
The numerical calculations reported in this paper were fully performed at TUBITAK ULAKBIM, High Performance and Grid Computing Center (TRUBA resources)
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sivaz, O., Aykut, M. Combining EfficientNet with ML-Decoder classification head for multi-label retinal disease classification. Neural Comput & Applic (2024). https://doi.org/10.1007/s00521-024-09820-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00521-024-09820-w