
Abstract
Affective computing, a subcategory of artificial intelligence, detects, processes, interprets, and mimics human emotions. Thanks to the continued advancement of portable non-invasive human sensor technologies, like brain–computer interfaces (BCI), emotion recognition has piqued the interest of academics from a variety of domains. Facial expressions, speech, behavior (gesture/posture), and physiological signals can all be used to identify human emotions. However, the first three may be ineffectual because people may hide their true emotions consciously or unconsciously (so-called social masking). Physiological signals can provide more accurate and objective emotion recognition. Electroencephalogram (EEG) signals respond in real time and are more sensitive to changes in affective states than peripheral neurophysiological signals. Thus, EEG signals can reveal important features of emotional states. Recently, several EEG-based BCI emotion recognition techniques have been developed. In addition, rapid advances in machine and deep learning have enabled machines or computers to understand, recognize, and analyze emotions. This study reviews emotion recognition methods that rely on multi-channel EEG signal-based BCIs and provides an overview of what has been accomplished in this area. It also provides an overview of the datasets and methods used to elicit emotional states. According to the usual emotional recognition pathway, we review various EEG feature extraction, feature selection/reduction, machine learning methods (e.g., k-nearest neighbor), support vector machine, decision tree, artificial neural network, random forest, and naive Bayes) and deep learning methods (e.g., convolutional and recurrent neural networks with long short term memory). In addition, EEG rhythms that are strongly linked to emotions as well as the relationship between distinct brain areas and emotions are discussed. We also discuss several human emotion recognition studies, published between 2015 and 2021, that use EEG data and compare different machine and deep learning algorithms. Finally, this review suggests several challenges and future research directions in the recognition and classification of human emotional states using EEG.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
1.1 Brain–computer interface
A brain–computer interface (BCI) is a computer-based communication system that analyses signals produced by the central nervous system’s neural activity. It is a very effective communication technology that does not rely on neuromuscular or muscle pathways to accomplish communication, command, and hence action. While thinking with intention, the subject generates brain signals that are converted to commands for an output device. As a result, a new output channel is available to the brain [1, 2]. The basic goal of a BCI is to detect and assess the features of signals in the user’s brain that indicate the user’s intention. These features are then transmitted to an external device that executes to fulfill the user’s desired intention [1]. As depicted in Fig. 1, to achieve this goal, a BCI-based system has four sequential components: signal acquisition, preprocessing, translation, and feedback or device output.

BCI components
Signal acquisition, the first BCI component, is primarily responsible for receiving and recording the signals produced by neural activity, as well as sending these data to the preprocessing component for signal enhancement and noise reduction. Brain signal acquisition methods can be categorized as invasive and non-invasive. In invasive methods, electrodes are neuro-surgically placed either inside or on the surface of the user’s brain. Brain activity is recorded using external sensors in non-invasive technology [3]. After preprocessing, the important signal’s different characters (such as the signal’s characteristic connected to the user’s intention) are extracted from irrelevant data and presented in a way that allows them to be translated into output instructions. This component creates selective features for the improved signal, reduces the size of the data that can be sent to the translation algorithm, and then converts characters into the relevant instructions that the external device needs to complete the task (for example, instructions that complete the user’s intent). The output device is guided and controlled by the instructions acquired by the translation algorithm. It assists users in achieving their goals, such as selecting alphabets, controlling a mouse, operating a wheelchair, moving a robotic arm, and moving a paralyzed limb with a neuroprosthesis. Computers are currently the most often utilized output device for communication [4].
Electroencephalography (EEG) using externally inserted electrodes can measure neural activity useful for a BCI and is safe, inexpensive, non-invasive, easy to use, portable, and maintains high temporal resolution [5]. Because EEG may be employed in BCI systems in a variety of fields by a user without the assistance of a technician or operator, it has become popular among end users. BCIs have made contributions in a variety of fields, including education, medicine, psychology, and military affairs [6]. They are primarily used in the field of affective computing and as a form of assistance for paralyzed individuals. Spelling systems, medical neuroergonomics, wheelchair control, virtual reality, robot control, mental workload monitoring, gaming, driver fatigue monitoring, environment management, biometrics systems, and emotion detection are among the most significant successes in EEG-based BCIs [7].
1.2 Emotion recognition
In recent years, due to the increasing availability of various electronic devices, people have been spending more time on social media, playing online video games, shopping online, and using other electronic products. However, most modern human–computer interaction (HCI) systems are incapable of processing and comprehending emotional data and lack emotional intelligence. They are incapable of recognizing human emotions and using emotional data to make decisions and take action. In advanced intelligent HCI systems, resolving the absence of the relationship between humans and robots is crucial. Any HCI system that disregards human emotional states will be unable to respond appropriately to those emotions. To address this difficulty in HCI systems, machines must be able to understand and interpret human emotional states. A dependable, accurate, flexible, and powerful emotion recognition system is required to realize intelligent HCI systems HCI [8].
Because HCI is studied in various disciplines, including computer science, human-factors engineering, and cognitive science, the computer that powers an intelligent HCI system must be adaptable. To generate appropriate responses, human communication patterns must be comprehended accurately. The ability of a computer to comprehend human emotions and behavior is a critical component of its adaptability. Therefore, it is essential to recognize the user’s affective states to maximize and enhance the performance of HCI systems.
In an HCI system, the machine-to-operator interaction can be improved to make it more intelligent and user-friendly if the computer can precisely understand the human operator’s emotional state in real time. This new research area is called affective computing (AC). AC is an area of artificial intelligence that focuses on HCI through user affect detection. One of the key goals of the AC domain is to create ways for machines to interpret human emotion, which may improve their ability to communicate [9].
Behavior, speech, facial expressions, and physiological signals can all be used to identify human emotions [10,11,12]. The first three approaches are somewhat subjective. For example, the subjects under investigation may purposefully hide their genuine feelings, which could affect their performance. Emotion identification based on physiological signals is more reliable and objective [13].
BCIs are portable non-invasive sensor technologies that capture brain signals and use them as inputs for systems that understand the correlation between emotions and EEG changes to humanize HCIs [14]. The central nervous system generates EEG signals, which respond to emotional changes faster than other peripheral neural signals. Furthermore, it has been demonstrated that EEG signals provide essential features for emotional recognition [15].
1.3 Scientific perspective on emotion
In the following sections, we briefly discuss what emotion is, emotion representation models, and emotion elicited or evoked experiments.
1.3.1 What is emotion?
Emotion is a complicated condition that expresses human awareness and is described as a reaction to environmental stimuli [16]. Emotions are, in general, reactions to ideas, memories, or events that occur in our environment. It is essential for making decisions and human interpersonal communication. People make decisions depending on their emotional states; therefore, bad emotions can lead to not only psychological but also physical difficulties. Unfavorable emotions can contribute to poor health while positive emotions can lead to higher living standards [17].
1.3.2 Models of emotions
Historically, psychologists have used two techniques to characterize emotions: the discrete (basic) emotion model [18], and the dimensional model [19]. Dimensional models categorize emotions on dimensions or scales, and discrete emotion models comprise multiple major emotions and include two categories of emotions (positive and negative). Several theorists have conducted experiments to identify basic emotions and have offered a number of categorized models. Darwin [20] proposed an emotion theory that was later interpreted by Tomkins [21]. Tomkins claimed that discrete emotions comprise nine basic emotions: interest-excitement, surprise-startle, enjoyment-joy, distress-anguish, dissmell, fear-terror, anger-rage, contempt-disgust, and shame-humiliation. It is believed that these nine basic emotions play an important role in optimal mental health.
The Ekman model [22] is based on another well accepted theory. According to Ekman, basic emotions must include the following characteristics: (1) emotions are instinctive; (2) various people develop the same emotion in the same situation; (3) various people express basic emotions in comparable ways; (4) physiological patterns of diverse people are constant when basic emotions are produced. Ekman and his colleagues determined that there were six primary emotions that are universally recognizable by facial expression: sadness, surprise, happiness, disgust, fear, and anger. Other compound (non-basic) emotions, such as shyness, guilt, and contempt, can be generated from these six basic emotions. Many theorists and psychologists have included additional emotions in their sets of basic emotions that were not included in Ekman’s six. Some divided emotions into tiny groups [23,24,25,26,27,28], focusing on general feelings, such as fear or anger (as negative emotions) and happiness or love (as positive emotions). Others focused on finer nuances and divided emotions into larger groupings. Table 1 summarizes some of the most basic emotion models.
However, some theorists and researchers believe that discrete model has limits in terms of representing specific emotions over a wider range of affective states. In other words, everyday affective states are too complicated to be well represented by a small number of discrete categories. As a result, a new method known as dimensional emotion has been proposed. Emotion is organized in a multidimensional way in this model, with each dimension representing an emotional characteristic. Each emotion can be represented as a point in a multidimensional space. Rather than selecting discrete labels, one might express his or her feelings on a variety of continuous or discrete-valued scales, such as attention-rejection or pleasant-unpleasant. To date, numerous multidimensional techniques to model emotions have been offered by researchers. Here are a few examples: (a) Russell’s circumplex 2D model, which can include up to 150 affective labels using arousal and valence dimensions [19]; (b) Whissell’s continuous 2D space, with evaluation and activation as dimensions [34]; and (c) Schloberg’s three-dimensional emotion model, which adds an attention-rejection dimension to the two-dimensional model [35].
Russell’s 2D emotion model is used most frequently. As shown in Fig. 2, the vertical axis represents the arousal dimension (expressing the emotional intensity of the experience, ranging from low to excitement), and the horizontal axis represents the valence dimension (showing the degree of cheerfulness or joy, ranging from negative to positive). There are four categories of emotions in the arousal-valence coordinate system. The negative emotions are represented on the left side of the coordinate and the positive emotions are shown on the right. The valence axis represents both positive and negative emotions, and the arousal axis varies from inactive to active emotions. Figure 2 shows the first area, which comprises high arousal positive valence (HAPV) emotions which range from pleased to excited. Area 2 comprises high arousal negative valence (HANV) emotions that vary from nervous to annoying. Area 3 comprises low arousal negative valence (LANV) emotions. The last area encompasses low arousal positive valence (LAPV) emotions (calm to relax). As shown in Fig. 2, the first two zones reflect high arousal (active) emotions, whereas the last two zones indicate low arousal (inactive) emotions.

The 2D emotion model
1.3.3 Emotions elicitation models
The ability to induce/elicit the experimental subject’s emotional state in certain appropriate ways, i.e., emotional arousal, is a crucial step in emotion detection on the basis of physiological signals. There are three major methods for eliciting emotions. First, evoking emotions by creating simulated scenarios. People have a habit of generating some unforgettable emotions in the past. It is also feasible to elicit emotions by having the subjects recall fragments from their past experiences that have distinct emotional colors. The problem of this approach is that it cannot ensure that the subject will generate the matching emotion, and the time of the associated emotion is immeasurable. Second, eliciting emotions by displaying videos, music, photographs, and other stimulating materials. This is a frequent approach for eliciting emotions, getting the participants to generate emotional states and label them objectively. Finally, the subject must play a computer or video game. Computer games are not only physically beneficial but also they are psychologically beneficial. Subjects just listen and watch the sounds of the environment while using short films or clips. Subjects in computer games, on the other hand, do not just observe or watch the stimuli; they actually experiment with the scene firsthand. They adopt the role model of the game characters, and this has a similar effect on the individuals’ emotions.
The most common resources for emotion elicitation are the International Affective Digitized Sound System (IADS) [36] and the International Affective Picture System (IAPS) [37]. These datasets contain standardized emotional stimuli. As a result, it is valuable in experimental studies. IAPS is made up of 1200 photographs divided into 20 groups of 60 images. Each photograph is assigned a valence and arousal value. The newest edition of IADS includes 167 digitally recorded natural sounds that are common in everyday life and are categorized for valence, dominance, and arousal. Using the Self-Assessment Manikin system [38], participants labeled the dataset. The authors of [39] state that emotions evoked by visual or aural stimuli are comparable. The results of affective labeling of multimedia, on the other hand, may not be generalizable to everyday situations or more interactive situations. As a result, more investigations involving interactive emotional stimuli in order to guarantee generalizability of BCI results are welcome. Only a few studies, to our knowledge, have employed more interactive situations to produce emotions, such as individuals playing games or using flight simulators.
1.4 Motivations and main contributions
The motivations for this review is to enable researchers to use machine learning methods to increase the rate of accurate and quick recognition of human emotional states from EEG-based BCI. The objective of this review is to identify different studies in the literature that use machine and deep learning approaches to classify human emotional states using EEG. Thus, the primary contributions of this study are to seek answers to the following questions:
-
What are emotion, emotion models and emotion elicitation experiments?
-
What is the role of brain–computer interface in emotion recognition?
-
What is the relation between EEG data and emotional states in humans?
-
What are the different feature extraction methods?
-
What are the different feature selection and reduction methods?
-
Which machine and deep learning techniques are currently being used to classify human emotional states using EEG-based BCI?
-
What evaluation measures are utilized to assess the efficacy of the classification models?
-
What is the recent work in the field of human emotion recognition using EEG data?
-
What are the problems that need to be solved and the research directions that should be pursued in the future in the recognition of human emotional states using EEG data?
1.5 Paper organization
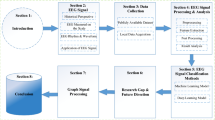
The structure of this paper is as follows: Sect. 1 describes background about brain–computer interface, emotion recognition and application areas of its techniques, different emotional elicitation models. Section 2 introduces the role of each brain area in the formation of emotions, describes EEG frequency bands and EEG characteristics, and investigates the relationship between emotions and EEG data. Section 3 describes the structure of EEG-based human emotion recognition BCI models and provides an overview of EEG signal acquisition, preprocessing, feature extraction, feature reduction and selection, classification, and performance evaluation for emotion recognition problem. Section 4 describes public databases of EEG data for emotional information and presents background information on deep and machine learning approaches. Section 5 introduces related studies that analyze machine and deep learning techniques to recognize human emotional states using EEG-based BCI. Challenges and future research directions will be covered in Sect. 6. Finally, Sect. 7 concludes the research review.
2 Emotion and EEG signals overview
This section gives an overview of EEG and emotion. The brain’s structure and functions are described in Sect. 2.1. The cerebral cortex is typically separated into four areas, each one performs a distinct function. The prefrontal cortex (PFC) has been proven to be the most closely connected with emotion in studies. Section 2.2 describes in detail the electroencephalogram, its origin, its frequency bands and its characteristics. Section 2.3 provides background information on the association between emotional changes and EEG signals, and the brain areas most associated with emotions, with the goal of using fewer electrodes to achieve good emotion classification performance.
2.1 Brain’s structure and functions
The cerebellum, cerebrum, and brainstem are the three major components of the human brain. The cerebral cortex, brain nucleus, and limbic system make up the cerebrum. Cognitive and higher-level emotional functions are principally controlled by the cerebral cortex. It is found on the human brain’s outermost layer, with a thickness of around 1-4 mm, and is primarily made up of grey matter, with white matter below [40]. The brain is divided into left and right hemispheres by a central sulcus in the middle. As shown in Fig. 3 [6], the Frontal Lobe, Occipital Lobe, Parietal Lobe, and Temporal Lobe are the four areas of the cerebral cortex. The functions of these four areas are distinct. The frontal lobe is placed before the brain’s central sulcus. It is in charge of higher cognitive activities. Prefrontal lobe, frontal motion area, and primary motion area are all part of it. They are mainly in charge of planning, thinking, and physiological functions associated with a person’s emotions and needs. Behind the central sulcus and just ahead of the occipital fissure is the parietal lobe. It is a sensory centre of the highest level. It is primarily responsible for the integration of somatosensory information as well as the reaction to spatial information such as pain, pressure, temperature, taste, and touch. This area is also linked to logical and mathematical thinking. Under the lateral fissure is the temporal lobe, with the frontal lobe in front, the occipital lobe in the back, and the parietal lobe above. It is primarily in charge of processing auditory and smell information, and is associated with emotion and memory (mental activities). Finally, the occipital lobe is situated behind the occipital sulcus, in the back of the hemisphere, and is mostly in charge of processing vision-related information. It also has to do with a person’s memory, behavioral perception, and abstract conceptions

Physiological structure of the cerebral cortex
2.2 EEG signals
2.2.1 History of EEG
The brain works by transferring electrical signals between neurons. One method to study the brain’s electrical activity is to record the potential of the scalp caused by brain activity. The signal that is recorded, i.e., the potential variations between two placements, is called an electroencephalogram (EEG). EEG is one of the most efficient methods to monitor brain activity, often known as brain wave. Hans Berger recorded the first human EEG in 1929 and published the first human EEG paper [41]. As a major in the field, it was he who devised the term “ectroencephalogram”. Richard Caton’s early research on animal brain activity in the nineteenth century were the foundation for his work. Electrophysiologists and neurophysiologists gradually verified his results, allowing EEG research in clinical medicine and brain science to advance quickly. The changes in emotion can be understood by studying the EEG signals. The central nervous system’s (CNS) functional and physiological changes can be reflected in neuronal potentials. The EEG does not just represent the electrical activity of a single neuron, but rather the electrical activity of a group of neurons in the brain area where the EEG measuring electrode is positioned. As a result, the EEG signal includes a wealth of useful and meaningful psychophysiological information. In medicine, EEG signal classification, processing, and analysis can give an objective basis for detecting some diseases. In neuro-engineering, disabled people can use EEG signals produced by motion imagery or mind to control wheelchairs or robotic limbs. This is a popular topic right now that is known as Brain-Computer Interface (BCI). Analysis and processing of EEG signals is always problematic in brain research because of the non-stationarity of EEG data and the numerous environmental influences.
2.2.2 Basics of EEG
EEG signals are classified into five categories based on the variation in frequency bands: delta (0.5–4 Hz), theta (4–8 Hz), alpha (8–13 Hz), beta (13–30 Hz), and gamma (> 30 Hz), as depicted in Fig. 4 [6].
Delta waves usually occur in the frontal cortex with amplitude 20–200 \(\upmu\)V. They are usually detected in an unconscious state of lack of oxygen, deep, dreamless sleep, or being anaesthetized. The wave would vanish in an adult who is awake and alert. Theta waves usually appear in the parietal and temporal lobes with amplitude 100–150 \(\upmu\)V. They are associated with relaxation state and working memory load. Theta waves on the frontal midline will rise when positive emotions are evoked. Alpha waves mainly occur in the occipital lobe and parietal lobe with amplitude 20–100 \(\upmu\)V. They can be detected in resting state with eyes closed. External stimuli like visual or auditory stimuli, or when individuals are engaged in mental activity, can cause alpha waves to disappear. They have more oscillatory energy than beta and gamma waves in both positive and negative emotions.
Beta waves are typically only observed in the frontal lobe; however, when one is contemplating, the beta wave emerges in a variety of locations. The amplitude is 5–20 \(\upmu\)V. They happen when a person’s mind is very active and focused. The cerebral cortex is dominated by alpha waves while the human body is relaxed, and beta rhythm gradually fades as emotional activity increases. When the CNS is under tension/stress/strain, the Alpha wave’s amplitude decreases while the Beta frequency increases, and the Alpha wave progressively turns into a Beta wave. When the cerebral cortex appears to be in a beta state, it usually means that it is excited. Gamma waves are found with different sensory and non-sensory cortical networks. The amplitude is commonly lower than 2 \(\upmu\)V. They are associated with brain cognitive tasks and functions at a high level like information reception, processing, integration, transmission, and feedback in the brainstem as well as activities that demand a lot of attention (concentration). They are frequently observed during multi-modal sensory processing [5, 6, 8, 13].

The waveforms of five EEG bands
2.2.3 EEG signal characteristics
EEG signal is a direct representation of brain activity and is useful in the study of human brain physiological phenomena. The following are its primary characteristics [6, 8]
-
1.
Recordings of EEG are typically noisy and sensitive to interference from the environment. They are generally mingled with other signals (including EOG, ECG, and EMG ), interferences, artifacts, and noises.
-
2.
EEG signals can be classified as spontaneous or evoked. During the signal acquisition process, various peripheral physiological signals will inevitably affect spontaneous EEG or evoked potentials. EEG signals are very nonlinear due to adaptation of human tissues or physiological regulation.
-
3.
EEG signal change is unstable, susceptible to external environmental variables, and has a strong non-stationarity property. To discover and recognize features of EEG signals, several studies employ statistical analytic approaches.
-
4.
Although EEG signals have a frequency range of 0.5–100 Hz, the low-frequency range of 0.5–30 Hz is the most relevant to cognition. Researchers usually decompose it into five sub-bands of frequency, each of which corresponds to a distinct cognitive function.
The two forms of EEG waves are commonly classed as spontaneous and evoked. The nervous system produces a rhythmic potential fluctuation without any external stimuli, which is known as spontaneous EEG. Evoked potentials are measurable potential changes in the cerebral cortex as a result of external excitation/stimulation of the human sensory organs.
2.3 EEG signals in emotion recognition
We need to understand the sources of emotions in our bodies in order to teach the computer to understand and recognize them. Emotions can be expressed verbally, such as through well-known words, or nonverbally, such as through voice tone, facial expression, and our nervous system’s physiological changes. Because facial expressions and voice can be faked or cannot be considered as a result of a certain emotion, they are not trustworthy predictors of emotion. Because the user has no control over the physiological signals, they are more precise. The fundamental sources of emotion in our bodies are physiological changes. Physiological changes can be divided into two categories: those that affect the Central Nervous System (CNS) and those that affect the Peripheral Nervous System (PNS). The spinal cord and brain make up the CNS. The brain is the control center for everything in our bodies, and changes in electrical activity are translated into various actions and emotions. The electroencephalogram (EEG) is a test that measures electrical changes in the brain. EEG is described as alternating-type electrical activity recorded from the surface of the scalp using metal electrodes and conductive medium [42].
EEG contains a wealth of useful information on the brain’s many physiological states. It responds more quickly and sensitively to changes in affective states, and thus it is a particularly valuable tool for understanding human emotional states. The low-frequency region evokes emotional EEG more fully than the high-frequency band, and negative emotions are more widespread and intense than positive emotions [6]. In the presence of joyful, sad, and frightening emotions, the average power of Beta, Alpha, and Theta waves on the brain’s midline will be dramatically different, indicating that the EEG’s midline power spectrum is one of the most useful features of the classification of emotions [43].
According to physiological research, humans’ higher emotional cognitive functions are primarily controlled by the cerebral cortex. Through EEG-based emotion detection, it would be beneficial to find the brain regions that are closely related to emotion [44]. The electrodes are first classified according to where they are placed in the cerebral cortex. Each group of electrodes’ EEG features are extracted, and then emotion classification is conducted. The feature selection algorithm sorts/ranks all of the electrodes according to their degree of importance, and then the significance of the electrodes is illustrated using a brain topographic map, allowing for easier recognition of the brain regions where the electrodes with a higher rank are distributed.
According to certain researchers who study functional brain connectivity based on EEG, there is a correlation between emotional states and specific areas of the brain. According to Ekman and Davidson [45], the left frontal portions of the brain are activated by enjoyment. The functional connection network was integrated with local activation by the authors in [46] to depict the activity of local parts of the brain that reacts to emotions and reflects the interactions between critical brain areas. Another study discovered that when individuals adopted fear emotions, their left frontal activity decreased [47]. Pleasurable emotions are associated with increased theta band power in the frontal midline while unpleasant emotions are associated with the opposite [48]. These studies reveal a correlation between changes in emotion and the characteristics of the corresponding EEG signals, which is more useful for researching EEG signal emotion classification. This also gives a neurophysiological foundation for detecting emotions from EEG data.
3 EEG-based BCI emotion recognition methodology
The architecture of an EEG-based BCI system for emotion recognition is shown in Fig. 5. EEG signal acquisition, preprocessing, feature extraction, feature selection, emotion classification, and performance evaluation are distinct processes that will be discussed in the following sections.

Architecture of an EEG-based BCI system for emotion recognition
3.1 EEG signal acquisition
EEG is now universally accepted as a standard method to measure electrical activity of the brain. Modern EEG equipment includes a set of electrodes, a data storage unit, an amplifier, and a display unit. Invasive and non-invasive EEG signal acquisition methods are available. In the invasive method, the ratio of signal to noise and signal intensity are both high. Electrodes must be surgically implanted into the skull cavity, and the electrodes penetrate the brain’s cortex, making it difficult to operate. In the non-invasive acquisition approach, the electrodes are attached to the subject’s scalp. This approach is straightforward to use and is the most common acquisition method in contemporary BCI research. EEG signals can be efficiently acquired using low-cost wearable EEG headsets and helmets that place non-invasive electrodes throughout the scalp. Various low-cost EEG-based BCI devices are currently available on the market [49].
Research objectives differ; therefore, in EEG experiments that focus on emotion recognition, the gathered EEG signals differ as do the number and location of electrodes. The International 10–20 electrode placement system is used in most EEG emotion experiments. The electrode count varies from six to 62. Based on Fig. 6 [8], it was found that EEG electrodes that are linked to emotions were mostly distributed in the frontal lobe (red), the parietal lobe (green), the occipital lobe (blue), the temporal lobe (yellow), and in the central area (squares). The front polar, anterior frontal, frontal, front central, temporal, parietal, and occipital regions of the brain are abbreviated FP, AF, F, FC, T, P, and O, respectively. The left hemisphere is indicated by an odd number suffix, and the right hemisphere is indicated by an even number suffix. These areas match the physiological basis of emotion creation precisely. The extracted feature dimension can be lowered significantly by adjusting the electrode distribution. Calculation complexity can be reduced, making the experiment simpler and easier to carry out.

Electrodes for EEG recording in different lobes
3.2 EEG signal preprocessing
Preprocessing EEG signals is concerned with signal cleaning and enhancement. EEG signals are inherently weak and can be easily infected by noise from both internal and external sources. The noise could be generated by electrodes or by the human body itself. The term “artifacts” refers to these noises. EEG electrodes can pick up undesired electrical physiological signals, such as the electromyogram (EMG) from eye blinks and neck muscles, while recording an EEG signal. When the subject moves, there are also worries regarding motion artifacts caused by cable movement and electrode displacement. As a result, the preprocessing phase is crucial to reduce these artifacts in the raw EEG data, which could influence posterior classification. Whether these artifacts should be deleted must be evaluated carefully as they may contain essential information about emotional states and may enhance the performance of emotion detection systems.
To reduce the artifacts in the collected EEG signals, frequency domain filters can be used to narrow the bandwidth of the EEG to be studied. High-frequency filters, low-frequency filters (also called high-pass and low-pass filters by electrical engineers), Butterworth filters, and notch filters are some of the most frequently used filters. Frequencies between 1 and 50–60 Hz are filtered using high- and low-frequency filters. A Butterworth filter has a wide transition zone and a flat reaction in the stopband and passband. Notch filters are employed to prevent a specific frequency rather than a range of frequencies from being transmitted. A notch filter is used to remove the frequency of electrical networks, which normally varies between 50 and 60 Hz based on the frequency of the standard electrical signal in the particular country [13]. When filters are utilized, they must be used carefully to avoid signal distortions.
Common methods for preprocessing EEG data that have been employed in various studies include independent component analysis (ICA) [50], principal component analysis (PCA) [51], common average reference (CAR) [52] and common spatial patterns (CSP) [53]. When employing multi-channel recordings, PCA and ICA tools use blind source analysis to remove noise from the source signals, allowing them to be utilized to remove artifacts and reduce noise. The CSP method identifies spatial filters that can be used to identify signals that correlate with muscular motions. For noise reduction, the CAR is ideal.
EEG data from emotional and baseline (non-emotional) states are included in the preprocessed EEG data for emotion detection. Furthermore, the physiological signals reveal significant heterogeneity between individuals (i.e., variation from one person to the next). At various points in time and/or in various environments, different emotions may be evoked, even when the subject and stimulus material are the same. As a result, among the preprocessing methods, to reduce the impact of the prior stimulus material on the emotional state that follows, as well as the impact of individual variances in physiological signals, the features of the baseline EEG (before any type of emotional stimulation) were removed from the features of EEG after the emotional stimulation. Then, the remaining features are scaled to an interval of [0, 1] [8]. Individual variances in subjective emotional responses for a similar stimulus are a major difficulty in emotion recognition research. Consequently, most studies have a limited number of emotion classes. Many studies of DEAP emotion recognition [54] focus on binary (high vs. low arousal or positive vs. negative) classification problems [55,56,57,58,59], and the target emotional labels are typically determined by utilizing a simple hard threshold of the subjects’ subjective rating data.
3.2.1 Independent component analysis
Independent component analysis (ICA) is a statistical method for finding linear projections of observable data that maximize mutual independence [60]. When used for blind source separation (BSS), ICA seeks to recover independent sources from mixes of those sources using multi-channel observations. In EEG signal processing, ICA separates signals into neural independent source activities originating from various brain areas and non-neural independent source activities (artifactual components) related to eye movements, blinks, heart, muscle, and line noise, which can be easily comprehended based on their spatio-temporal characteristics [50].
The following is a description of the ICA problem. Assume a linear mixing model, m channel EEG signals, \(X=[x_1,x_2,...x_m]\) of n independent sources \(s=[s_1,s_2\ldots s_n]\). The observed signals vector X can be expressed as:
where A is a mixing matrix with the size of \(m\times n\). Activities of independent components (recovered source signals), V, were obtained by applying an unmixing matrix W (i.e., an inverse of the matrix A) to X [60]:
where each column of \(W^{-1}\) comprises electrode weights (i.e., a spatial projection) of an independent component and each row of W is a spatial filter for estimating an independent component.
Three steps are involved in ICA-based artifact removal: (a) apply ICA to EEG data, (b) identify and delete artifact-related independent components, and (c) project EEG-related independent components back to electrodes to rebuild artifact-corrected EEG data. In general, prior knowledge of the spatio-temporal characteristics of EEG artifacts can be used to identify artifact independent components.
Many studies have demonstrated the superiority of ICA in removing EEG artifacts. ICA was used by Wang et al. [50] to correct EEG signals recorded during a movement-planning task that involves a lot of muscle and aye movements. After removing artifact components coming from muscle and eye activities, EEG signals encoding movement directions can be used to anticipate the direction of an intended movement. In a sleepiness monitoring study [61], the ICA-based artifact removal was employed as a routine way to correct the EEG data recorded in a driving process, which comprised multiple body/head movements. After reducing EMG/EOG artifacts from motor imagery-based BCIs, performance of the system (e.g., classification accuracy) was improved [62].
3.3 EEG feature extraction
After preprocessing and noise reduction , the following stage is to extract features. After the signals have been cleaned of noise, the BCI must extract critical features that will be sent to the classifier. The major goal of feature extraction in the emotion recognition process using EEG data is to obtain information that can effectively reflect an individual’s emotional state. Subsequently, such information may be used in emotion classification algorithms. The accuracy of emotion identification is mostly determined by the extracted features. Therefore, extracting essential EEG features of emotional states is critical.
Conventional EEG feature analyses are often conducted in the time, frequency, and time-frequency domains. Because of the nonlinear properties of EEG data, nonlinear dynamics analysis of EEG signals can be employed for more in-depth study. This section will cover four EEG feature analysis methods used to recognize emotions: time, frequency, and time-frequency domains, as well as nonlinear feature analyses.
Table 2 shows the feature extraction methods used in the studies covered in this review. Figure 7 presents the usage percentage of the domains of features that have been employed in many of the research papers in this review. The most commonly utilized features are those in the time-frequency domain (35%). Frequency domain features are second (27%), and time domain features are third (20%). Furthermore, raw data (without features) are also utilized (11%). Raw data are utilized as input for deep learning algorithms. Using raw data produces acceptable results, presumably because information is retained and the risk of omitting important signal features associated with emotion is eliminated. Nonlinear features were also utilized (7%).

Pie chart of the domains of the features used in the studies discussed in this review
3.3.1 Time domain analyses
For a long time, time domain analyses have been applied in the research of brain activity. The majority of EEG acquisition equipment on the market today gathers EEG data in the time domain. There are many techniques in the time domain for the analysis of the EEG such as event-related potential (ERP), histogram analysis method, Hjorth features/parameters: activity, mobility and complexity [87], higher-order crossing (HOC) [88, 89], principal component analysis (PCA) [90], independent component analysis (ICA), and Higuchi’s fractal dimensions (FD) as a measurement of self-similarity and complexity of the signals in this domain [91]. These techniques rely on extracting time-based features. In addition, there are statistical features like mean, power, maximum, minimum, median, standard deviation, skewness, variance, relative band energy, kurtosis, and so on [55, 92]. The geometric features of EEG signals are the starting point for time domain analysis, and these features can be statistically analyzed by the EEG analyzer with precision and intuition. The features in this domain comprise EEG data with minimal loss of information. However, because of the complicated waveform of EEG data, there is no common method for analyzing EEG signals’ time-domain features. Therefore EEG analysts must have extensive expertise and knowledge.
3.3.2 Frequency domain analyses
Features in the frequency domain have been demonstrated to be more successful for automatic emotion identification using EEG than features in the time-domain. Frequency domain analysis methods convert time-domain EEG signals to frequency domain signals in order to evaluate and extract frequency domain features. The EEG signal is usually divided into various sub-bands, and features like power spectral density (PSD), logarithm energy spectrum, higher-order spectrum (HOS), and differential entropy (DE) retrieved for analysis. The most common method to perform frequency analysis is to apply the fast Fourier transform (FFT) directly to a short EEG segment [93, 94].
3.3.2.1 Differential entropy
Differential entropy (DE) is the logarithm energy spectrum in a particular frequency band for a fixed-length EEG sequence [95]. Like the entropy for assessing the complexity of continuous random variables, DE can be represented as:
f(y) is the probability density function of y, where y is a random variable. Experiments reveal that after band-pass filtering, a series of sub-frequency bands of EEG signals roughly obey Gauss distribution \(N(\mu , \sigma ^2)\), and its differential entropy can be calculated as:
3.3.3 Time-frequency domain analyses
The above methods use the time or frequency-domain characteristics of EEG, respectively, as the detection criteria. These methods are based on the assumptions that the EEG signals are linear and quasi-stationary, i.e., the frequency content of the EEG signals is assumed to be constant during the analysis window. Recent research, however, has revealed that EEG signals have non-stationary characteristics. The time domain analysis of a signal, using techniques based on features such as amplitude, duration, variance, and autocorrelation are not suitable for analyzing a non-stationary signal like the adult EEG signal. Analysis of a non-stationary signal requires information about the distribution of energy over different frequencies and the frequency variations over time. This information is not provided neither by the time domain analysis techniques nor the frequency domain analysis. The frequency domain representation has the disadvantage that all temporal information is lost when forming the spectrum. Due to these limitations, alternative tools have been developed to represent the signals known as time-frequency domain.
The time-frequency domain analysis technique combines information from the time and frequency domains and allowing for time-frequency domain localized analysis. As a result, time-frequency-domain features are well suited to capture time-varying and non-stationary signals, which can be used to characterize various emotional states. The most widely used approach in time-frequency analysis is the Wavelet transform [96]. Short-time Fourier transform (STFT) [6], Hilbert Huang transform (HHT) [97] and wavelet packet transform (WPT) [98] are also essential time-frequency domain analysis approaches.
3.3.3.1 Wavelet transform
The wavelet transform (WT) is a method of signal processing for dealing with nonlinear and non-stationary signals. An important feature of WT is that at high frequencies it gives perfect time information and at lower frequencies it gives perfect frequency information. Because the signals in emotion detection applications typically comprise low-frequency data with a lengthy time duration and high-frequency data with a short time duration, this characteristic is significant. Another benefit of the wavelet transform is that it allows for a more flexible time-frequency representation of a signal by using analysis windows of varied sizes, which allows a selective analysis during the extraction of features to recognize different emotions and increases the performance classification system. EEG signal multi-scale analysis using WT enables EEG signal to provide details as well as approximations at various wavelet scales. EEG signal wavelet decomposition yields a set of wavelet coefficients at various scales. These coefficients can be utilized as a signal’s feature set for classification because they can fully characterize the signal’s characteristics. The wavelet function \(\psi (t)\) is defined as follows:
where a and b are represented as scale factor and time-shift, respectively. There are two types of wavelet transform: continuous wavelet transform (CWT) and discrete wavelet transform (DWT) [99]. The following is how the CWT is defined:
where x(t) is a signal that needs to be processed. The wavelet analysis will be much more efficient if the scales and shifts parameters are converted into powers of two, known as dyadic scales and positions. The DWT, which is depicted as follows, provides such analysis:
where \(2^j\) and \(2^j{k}\) are substituted for a and b, respectively.
3.3.4 Nonlinear feature analyses
EEG signals are highly complex and have nonlinear and non-periodic proprieties that can be studied by nonlinear dynamic analysis. In recent years, there are many nonlinear analysis methods that have become popular in the analysis of EEG data [100,101,102]. Among the nonlinear dynamic methods are permutation entropy [103], approximate entropy [104], singular value decomposition entropy, power spectrum entropy [105] and sample entropy [106].
3.4 EEG feature selection and reduction
In EEG-based emotion recognition, the feature selection and reduction process is crucial. In a BCI system, the feature vectors are often of high dimensionality [107]. As a result, feature selection and/or feature reduction techniques are frequently used to minimize the number of features. Such techniques simplify the problem’s complexity; only features that carry significant information are passed to a classifier. Selecting an appropriate feature selection and reduction technique can increase both model training efficiency and prediction accuracy.
Feature selection is a technique for efficiently removing a huge number of unnecessary (or redundant) features based on particular usefulness criteria in order to obtain the best results with the least amount of data processing. Feature selection approaches also lower the chance of overfitting if the dataset includes many features but there are not enough observations. By extracting crucial information from a dataset, feature/dimensionality reduction seeks to transform high-dimensional data into a comprehensible representation of lower dimensions [108]. Ideally, the reduced representations should contain the fewest number of parameters necessary to account for the data’s observed properties [109]. The importance of feature reduction stems from its capacity to alleviate the dimensionality curse that plagues high-dimensional datasets. In general, feature selection and reduction are required to aid in data visualization and comprehension, minimize model training time and avoid the curse of dimensionality, all of which improve model prediction performance (or generalizability).
The common methods for EEG feature/dimensionality reduction are Principal Component Analysis (PCA) [110, 111], linear discriminant analysis (LDA) [112] and Independent Component Analysis (ICA) [112]. PCA attempts to represent d-dimensional data in a less-dimensional space. This will limit the range of possibilities as well as the complexities of time and space. Here, the goal is to represent data in a space that accurately reflects variance in terms of the sum squared error. Additional information can be found in the literature [112]. ICA converts a signal that is multivariate and random to a signal with mutually independent components. From mixed signals, this approach can be utilized to extract independent components. Here, independence means that the information provided by one component cannot be derived from the others. Details are given in [112, 113]. The goal of LDA is to produce a new variable that incorporates the original predictors. This is performed by maximizing the differences in the new variable between the predefined groups. The idea is to integrate the prediction scores into a single new composite variable known as the discriminant score. Details are given in [112].
A search strategy and evaluation criterion can be used to categorize feature selection methods [114]. Two distinct techniques, filter and wrapper, could be used to assess a subset of features that have been selected. Filter methods [115, 116] pick features before delivering them to the classification algorithm. In other words, filter techniques choose a subset of features based on prior understanding of the problem of classification or statistics acquired from the data, and they do so independently of the classifier design. Generally, filter methods are fast due to the fact that they select the most relevant features from the training data and then discard certain features based on a specific threshold. Because they are less computationally expensive, these approaches are ideal for extremely large datasets. Wrapper algorithms [117, 118] execute feature selection in the context of (and in conjunction with) the classification algorithm. The classifier is used in the feature selection process as a subroutine in these approaches to assess the feature set that has been selected. These techniques represent a type of optimization algorithm that employs the classification results as the target function. Wrapper methods are computationally intensive, which restricts their application to huge datasets, where their aim is to improve accuracy. In addition to these two methods, the built-in method is used internally in classifier algorithms like deep learning. Wrapper methods require more computation than the built-in method.
Table 3 shows the feature selection and reduction methods used in the studies discussed in this review. Figure 8 presents the usage percentage of the feature selection and reduction methods that have been used in the various studies reviewed in this paper. 56% of these studies do not use a feature selection or reduction method. Built-in methods, which operate internally in classification algorithms like deep learning are frequently used (37%), followed by reduction methods (e.g., PCA and ICA), filter methods (e.g., mRMR) (25% of each), and wrapper methods (e.g., PSO) (13%). More details about the filter and wrapper feature selection methods are provided in the following sections.

Pie chart of common EEG feature selection and reduction methods used in the studies discussed in this review
3.4.1 Filter methods
Filter methods use different ranking techniques, selected due to their simplicity and success in different applications, to order the features. Ranking methods score each feature based on its relevance and use a threshold to remove features below the threshold. Because they are used before classification to filter out the less important variables, ranking methods are filter methods. Various measurements and definitions for a variable’s relevance have been presented in several publications [119, 120]. One of these definitions is that “If a feature is conditionally independent of the labels of the classes, it is considered irrelevant”. The relevance of features will be measured by different techniques such as the Pearson correlation coefficient of the mutual information (MI) technique [121]. Some researchers have applied filtering methods to find the most relevant features to discriminate different emotions [105]. The majority of filtering algorithms are univariate, meaning they consider each input feature individually, so that each feature can be self-evaluated and independent of the others. This can lead to two issues: features discarded because they are not individually relevant may become relevant when combined with others and features that are considered individually as relevant may result in unneeded redundancies. The most widely used filter method is the wavelet transform
3.4.1.1 Minimal redundancy maximal relevance
Minimal redundancy maximal relevance (mRMR) is a filter-based feature selection algorithm that has been proved to be computationally fast [122]. The main goal of mRMR is to find a subset of features in the feature space of the given samples that have minimal redundancy with other features but maximum relevance to the target class. The MRMR algorithm measures the relevance of features to target classes or other features in the feature space using mutual information. It is based on two principles: maximum relevance and minimum redundancy. Maximum relevance is defined as follows:
where S stands for feature set and \(I(x_i, c)\) for mutual information between feature i and target class c. The minimum redundancy between features is computed as follows:
where \(I(x_i, x_j)\) stands for mutual information between feature i and j.
We can get the feature selection criterion for the mRMR method by combining Eqs. 8 and 9:
3.4.2 Wrapper methods
Sequential selection algorithms and heuristic search algorithms are two types of wrapper methods. The sequential selection [123, 124] algorithm starts with a blank set and adds features till the maximum performance of the objective function/classification is achieved. In order to expedite the selection process, a criterion is chosen that gradually improves the objective function till the maximum performance is achieved with the fewest features possible. The heuristic search algorithms assess various subsets to enhance the objective function. In feature selection, searching an optimal subset is critical. Despite the fact that a heuristic search approach does not assure that the optimal subset will be found, it generally discovers a satisfactory answer in a reasonable amount of time [125]. Specific heuristics produced to address a specific problem, while general-purposed metaheuristics developed to handle a variety of problems are the two types of heuristic methods [125]. Metaheuristics have demonstrated its efficiency and efficacy in handling difficult and large-scale challenges in engineering design, data mining scheduling, and machine learning over the last two decades.
The majority of nature-inspired algorithms are metaheuristics [126]. Evolutionary-based (e.g., artificial immune systems and evolutionary algorithms), swarm-based (e.g., particle swarm optimization, ant colony and bee colony), and physics-based(e.g., simulated annealing)) are the three main sources of inspiration [125]. Exploration of the search space and exploitation of the optimal solutions discovered are two paradoxical criteria that all of these techniques have in common [125]. Swarm intelligence-inspired optimization techniques have increased in popularity over the previous decade. Swarms of flocks of birds, social insects and schools of fish are all models for them. The advantage of these approaches compared to traditional techniques is their flexibility and robustness. Because of these qualities, swarm intelligence is a successful design model for algorithms that tackle more complicated problems.
New evolutionary algorithms have recently been presented and demonstrated good performance in many applications when it comes to the challenge of selecting features. In [127], the Ant Lion Optimizer (ALO) was used as a feature selection wrapper model to address this problem. Grey wolf optimizer (GWO) was effectively used to solve feature selection problems in [128]. In [129], the authors used particle swarm optimization (PSO) in facial expression-based emotion recognition for feature selection. Moreover in [130], authors used differential evolution (DE) algorithm as a wrapper-based feature selection algorithm for classification of motor imagery EEG signals.
3.5 EEG emotion classification
EEG data collection, preprocessing, feature extraction, feature selection or reduction, and emotion classification are all steps in the process of building an emotion recognition model. One of the most crucial aspects of developing a successful emotion classification system is finding the best classifier that is able to accurately classify various emotions. The developed classifier has an important influence on emotion recognition accuracy [131]. A classifier relies on a mathematical function that predicts the true class of an unknown observation in a validation dataset. A variety of classification methods have been employed in the affective computing domain to classify affective EEG data. These classifiers range from conventional classifiers (traditional machine learning algorithms) like support vector machines and decision trees, and linear discriminant analysis to advanced classifiers (deep learning algorithms), such as recurrent neural networks and long short term memory.
3.6 Performance evaluation
The findings for emotion recognition must be presented in a consistent manner in order for various study groups to comprehend and compare them. As a result, it is critical to select and specify evaluation techniques carefully [132]. A confusion matrix and accuracy are the most recommended performance evaluation measures for evaluating the emotion classifier’s performance. Based on the confusion matrix, five classification performance measures, i.e., specificity, recall (sensitivity), precision, F-measure, and area under the curve (AUC) are usually calculated. In general, these measures are calculated based on four major metrics of a binary classification outcome (positive/negative), true positive (TP) and true negative (TN) which indicate correctly identified emotional states, and false positive (FP) and false negative (FN), which indicate false identification of emotional states. These performance measures are defined as follows.
Accuracy (Acc): This metric measures how many cases are correctly classified. If the classes are balanced, that is, if each class has an equal amount of samples, it works well. It is calculated by Eq. 11
Sensitivity (Sens): It is also called true positive rate or recall. It evaluates how often a classifier properly classifies a good outcome. It is defined by Eq. 12
Specificity (Spec): It is also known as true negative rate. It calculates the percentage of times a classifier correctly categorises a negative outcome. As a result, the False Positive Rate (FPR) equals 1-specificity. Spec can be calculated by Eq. 13
Precision (Prec): This metric represents the percentage of correct classifications. It can be denoted by Eq. 14
F-Measure (F): It represents the harmonic mean of Precision and Sensitivity. It is important because the higher the precision, the lower the sensitivity, and vice versa. It is measurable by Eq. 15
AUC: The receiver operator characteristic (ROC) curve is a probability curve that graphs the Sens against FPR at various threshold values. The ROC curve depicts a classifier’s performance at different degrees of significance. The area under the ROC curve (AUC) summarizes the ROC curve that indicates how well a classifier can discriminate between true positive and true negative.
4 Basics and background
4.1 EEG emotion recognition datasets
This section provides a summary of the public EEG datasets for emotional recognition that were used in the various researches in this review. Table 4 shows that seven public EEG datasets were used for emotional recognition, including DEAP, MAHNOB-HCI tagging, DREAMER, SEED, AMIGOS, SAFE and GAMOMA datasets. These datasets are useful for study, and they have been used in a number of emotion recognition studies. Figure 9 shows the percentage of EEG datasets utilized in emotion recognition according to the studies in this review. DEEP and SEED are the most commonly employed (51% and 19% of participation, respectively). Other studies (17 %) employed their own datasets, which are often not openly accessible. DREAMER is a publicly available dataset appeared with a participation of 7% in this review. The MAHNOB-HCI, GAMOMA and AMIGOS appeared in our research sample, each with a 2% participation rate.

Pie chart of the EEG datasets for emotion recognition utilized in the studies discussed in this review
4.2 Overview of machine learning
The problem of emotion recognition can be represented as a classification or regression problem. The distinction is based primarily on the emotional model used to represent emotions, which was discussed in Sect. 1.3.2. Emotions are represented as distinct entities with labels in categorical representations. Dimensional models, in contrast to discrete representations, try to describe emotions using continuous values of their defining features, which are commonly represented on axes.
The majority of previous techniques, as shown in Sect. 5.1, treat emotion recognition as a classification problem, attempting to distinguish between categories emotions, or between different areas of Russell’s 2D emotion model. In general, the literature contributes far more to emotion classification than it does to emotional dimension regression. As a result, in this section, we’ll be concentrating on machine learning classification techniques.
In the systems that recognize emotions, machine learning algorithms were used to classify different emotional states from EEG-based BCI. Using the scopus database as a source of information, Figure 10a shows statistics for machine learning and EEG emotion recognition and classification research from 2012 to 2021. Figure 10b displays the machine learning distribution in the EEG emotion recognition research area.

The machine learning methods for EEG emotion recognition studies conducted in the recent decade [2012–2021] based on the scopus database
As an artificial intelligence product, machine learning has played a significant role in distinguishing between distinct brain activity patterns; thus, it has become an important part of BCI’s data analysis. Machine learning can learn important knowledge and rules from the source task and then apply them to the target task. Furthermore, machine learning data mining technology can store data in a data management system and analyze it using machine learning algorithms, resulting in the extraction of potentially important information. The machine learning algorithm chosen can have a big impact on the final classification or prediction outcomes [138].
There are two categories of machine learning models: supervised and unsupervised learning. Supervised machine learning is a technique for determining the classifier’s parameters using training data. After seeing the output value, the learning task is to set the value of its parameters for any valid input value. A test dataset containing data that has not been contributed to the model while learning is fed into the classifier to validate the performance of a learnt algorithm. Unsupervised learning, on the other hand, is a machine learning technique that determines parameters based on input data and a cost function that must be reduced. In recent years, several ML models have been implemented for the management of the classification of EEG signals for human emotion recognition. Among these methods are Support Vector Machines (SVM), Naïve Bayes (NB), k-nearest neighbor (K-NN), Decision Trees (DT), Random forest (RF) and Artificial Neural Networks (ANN), which are widely used as classification methods; we will briefly describe them in the following sections.
4.2.1 Support vector machine
Support vector machine (SVM) is a supervised ML technique able to solve linear and nonlinear regression and classification problems. Vladimir Vapnik was the one who introduced it [139]. SVM has been employed in a variety of applications, including Face detection and recognition [140,141,142], Disease diagnosis [143,144,145], and Text Recognition [146,147,148]. In general, the SVMs are intuitive, theoretically well founded and have proven to be virtually successful.
SVM’s main goal is to locate hyperplanes that precisely separate various groups (two or more classes) of n-dimensional data. SVM is based on training cases put on the edge of the class descriptor, known as support vectors; every other case is eliminated. Based on the labels or classes you’ve defined, SVM tries to maximize the separation boundaries between your data points. As a result, the optimum hyperplane with the longest distance to the closest training point of any class is obtained to accomplish good feature separation. When SVM is unable to separate data linearly, it uses kernel functions to map/transform input data into high-dimensional feature spaces. In a high-dimensional space, it is feasible to design a hyperplane that enables linear separation (which in the lower-dimensional input space corresponds to a curved surface). As a result, in SVM, the kernel function is crucial. Kernel functions such as polynomial, linear and Gaussian can be employed in practice.
Optimization algorithms can be used to find a particular global optimum for SVM parameters such as the kernel function parameter \(\sigma\) and the misclassification trade-off factor c, which controls the trade-off between the maximum margin and the smallest training error. As a result, the performance of SVM-based classification is determined by parameter optimization and the selection of a suitable kernel function. SVM parameter settings that are incorrect result in poor classification results such as overfitting or underfitting. [149]. SVM provides the benefit that the problem of overfitting can be simply managed by selecting a proper data separation margin (i.e., support vectors) [150].
4.2.2 Artificial neural network
Artificial neural networks (ANNs) are a form of machine learning technique that was developed to simulate the human brain [151]. That is, much as neurons in human nervous system can learn from previous data, the ANN may learn from data and respond in the form of classifications or predictions. It is made up of simple processing units, known as artificial neurons or nodes, and their connections. The weight of any connection between two units is used to assess what is the impact of one unit on the other. Some units serve as input nodes, some serve as hidden nodes, and the rest serve as output nodes, doing summation and thresholding [150].
In a neural network, there are three essential layers: input layers, hidden layers and output layer [152], as shown in Fig. 11. The input layer of an ANN is the initial layer that receives data in the form of numbers, texts, image pixels, audio files and so on. The hidden layers are in the midst of the ANN model. It is possible to have a single hidden layer, such as in a perceptron, or numerous hidden layers. These hidden layers use the input data to execute various types of mathematical computations and recognize patterns. The result gained by the middle layer’s rigorous computations is in the output layer.
A neural network’s performance is affected by a number of parameters and hyper-parameters. The output of ANNs is mostly influenced by these parameters. Weights, biases, batch size, learning rate and other parameters are among them. The artificial neuron is a component of the artificial neural network (ANN) that is designed to mimic the function of a biological neuron. Each artificial neuron (node) in the network is with a set of weights attached to it as shown in Fig. 12. The weighted sum of the inputs and the bias are calculated using a transfer function. The activation function receives the result after the transfer function has computed the sum. The activation functions fire the appropriate result from the node based on the output received. The activation function checks if the output meets a specified threshold and outputs zero or one. Sigmoid, ReLU, Softmax, Tanh and other common activation functions are utilized in Artificial Neural Networks [153]. We get the final output based on the value fired by the node. Then, with the help of the error functions, we calculate the differences between the predicted and actual outputs and, using backpropagation, modify the weights of the neural network.
There are many various types and architectures of neural networks, each with a basic difference in how they learn; they are well described in the literature [151, 152]. Among these architectures are multilayer perceptron neural network (MLPNN) and Extreme Learning Machine (ELM).

Basic architecture of ANN

Model of an artificial neuron
4.2.3 Decision tree
Decision tree (DT) is a common machine learning method used for both regression and classification problems. It is based on the division of the data set into several subset according to a criterion that maximizes the separation of the data, repeating this process recursively to produce a tree [154, 155]. The most commonly used criterion is information gain, which means that the reduction of entropy due to each split is maximized.
Each leaf node in a decision tree is assigned a class label; nonterminal nodes, such as the root node and other internal nodes, carry attribute testing conditions that help distinguish records with distinctive characteristics [156]. Each decision tree node can be defined as a rule. The upper nodes in the decision tree have a greater impact on the overall sample accuracy [157].
J. Ross Quinlan created ID3 (Iterative Dichotomizer 3), a decision tree-generating algorithm, in the late 1970s and early 1980s. He presented the C4.5 method as an improved version of ID3 a few years later. According to [158], C4.5 provides the foundation for new supervised classification algorithms. The J48 algorithm is a Java-based version of the C4.5 classification method, which emerged as a result of the necessity of recoding the algorithm after it was first built in C [156]. The algorithm always chooses the best locally evaluated step, regardless of whether or not it will generate the optimal solution, and it breaks down a problem into sub-problems by generating subtrees between the root and the leaves. Salvatore Ruggieri created EC4.5, a classification technique that calculates the identical decision trees as C4.5 but at up to five times the performance gain, in 2002. [159].
Decision trees have the benefit over other machine learning methods in that they are not black-box models and can be easily expressed as rules. This advantage has a greater impact in many application domains, so that these models are widely used.
4.2.4 Random forest
Random forest (RF) [160] is a sophisticated ensemble approach that uses a forest of decision trees to do classification and regression during training. It is based on the bagging algorithm concept. It can handle large amounts of data because it only employs a subset of features while creating decision trees. It takes a fraction of the time to train compared to other classifiers [161]. Random Forest is a popular classification technique due to all of these qualities. The voting of all decision trees determines the ultimate output of RF [162]. Step-by-step RF working model is explained below:
-
The training sets are chosen at random and are the same size as the sample set.
-
Each training set is utilized to build a decision tree.
-
Extract a group of attributes at random from all attributes with the same likelihood, and after that choose the best attribute to split the nodes from this subset.
-
Prediction is obtained from each decision tree.
-
Vote is obtained for each predicted result.
-
Final decision is made by selecting the maximum voted results
4.2.5 k-nearest neighbor
k-nearest neighbor (K-NN) is one of supervised and statistics-based machine learning algorithms used for regression and classification problems [163]. The K-NN algorithm has been greatly refined over time and is now widely utilized in a variety of fields: text recognition [164], emotion recognition [165] and face recognition [166]. The idea of K-NN based on a measure of similarity (e.g., distance function) between the training and test set. Find the training example that is most similar to object x when asked to identify its class. After that, label x with the class of this example. The accuracy of the algorithm may improve as the number of nearest neighbors (k) increases.
The K-NN approach starts by choosing a training sample set. Select the number of neighbors (k). K-NN uses the Euclidean distance between the test sample and the training samples to discover the nearest K-samples in the training set for each new test instance as shown in Eq.16. Count how many training samples each class has among the K neighbors you have chosen. The target class of the test instance is determined by the most common class value of K-training samples [163]. The expense of K-NN is excessive calculation complexity. The volume of data in the dataset determines the computational complexity. As a result, K-NN is best suited to data sets with a modest number of samples.
4.2.6 Naive Bayes
A naive Bayes (NB) classifier is a probabilistic classification algorithm which is based on Bayes’ theorem with high independence assumptions [167, 168]. The NB classifier assumes that the presence (or absence) of one feature in a class has no bearing on the presence (or absence) of other features. The NB classifier makes the assumption that the presence (or lack) of one feature in a class has no influence on the presence (or lack) of other features. The maximum likelihood technique is utilized in order to calculate parameters in naïve Bayes models [169]. The NB classifier can be taught very effectively in a supervised learning setting, on the basis of the accurate nature of the probability model, and requires minimal training data for classification. The resulting class in this classifier is the one with the highest post-probability.
4.3 Overview of deep learning
Deep learning (DL) is a subset of machine learning and artificial intelligence that can learn from the given data [170]. In several classification and regression tasks and datasets, DL can yield significant results. It has become a popular topic in the computing world, with applications in healthcare, visual recognition, text analytics, cybersecurity, and a variety of other fields [171].
DL employs several hidden layers in neural networks to perform numerous levels of nonlinear operations. Functions that are complex can be trained to identify output classes in a classification task using various transformations and several hidden layers. Several studies on the use of deep learning (DL) techniques for automated emotion recognition have recently been published, despite the fact that they are fairly new when compared to the lengthy history of emotion study in psychophysiology. Based on data from the scopus database, Figure 13a shows statistics for DL and EEG emotion recognition and classification research from 2014 to 2021. Figure 13b displays the DL distribution in the EEG emotion recognition research area.

The deep learning methods for EEG emotion recognition studies conducted in the recent decade [2014–2021] based on the scopus database
To improve classification performance and save computing time, feature extraction and feature selection find a smaller feature set. Deep and shallow feature extraction are two types of feature extraction. Features that have been handcrafted in diverse analytic domains, like time domain, frequency domain, and time-frequency domain, are referred to as shallow features. As described in section 3.4, numerous feature selection or reduction approaches are used to minimize the higher-dimensional features. Shallow features, unfortunately, rely largely on heuristics and necessitate a huge amount of labeled data, which can be difficult to obtain in the context of real-world applications. Manual features extraction and selection is usually time-consuming and tedious, but it has a significant influence on machine learning models’ performance. Shallow features made by hand are frequently domain-specific, making them difficult to reuse in other problems.
Classical feature engineering and machine learning techniques may struggle to extract complicated and nonlinear patterns from time series data with several variables. Also, picking the most important features from a big feature set is crucial and will necessitate the use of dimensionality reduction approaches. Additionally, feature extraction and selection take a long time to compute. The cost of computing feature selection, for example, may grow exponentially as feature dimensionality grows. Search algorithms, in general, may fail to find the best feature set for a particular ML model.
Many researchers have focused on DL techniques in order to solve the challenges of extracting useful and stable features from time series data. DL makes it easier to extract handmade features for ML algorithms. Rather, it has the capability of learning the hierarchical representation of the feature autonomously. In a traditional machine learning pipeline, this removes the requirement for feature space reconstruction and data preprocessing. Artificial neural networks (ANN) are at the heart of deep learning, with the “deep” in the name indicating the number of layers in a neural network. A neural network having more than three layers, encompassing inputs and outputs, is known as a deep learning algorithm. DL’s career began in the 1980s. Perhaps the first artificial neural network was the neocognitron [172] to have the “deep” property and take neurophysiological insights into consideration. Hinton and Salakhutdinov [173] made a significant contribution to feature extraction in 2006, which has been followed up on in subsequent years [174,175,176,177]. According to various research [178,179,180], multilayer NNs can be used to represent and learn features utilizing iterative or non-iterative methodologies.
Deep neural networks are utilized in DL techniques to extract relevant features by applying high-level data representation. The ability to deal directly with raw data and automate the extraction and selection of features is an appealing aspect of DL approaches. The network is fed with time series samples and a hidden representation of the preceding layer’s inputs is created after each nonlinear transformation, resulting in a hierarchical data representation structure. To put it another way, in a deep network paradigm, each layer takes the outputs from the preceding layer and uses a nonlinear mapping to turn them into a new feature set.
Recently, deep learning algorithms like autoencoder, deep belief network (DBN), convolutional neural network and recurrent neural network have generated a great impact in different applications such as speech recognition, computer vision, object recognition, natural language processing and machine translation. Different deep architecture models are proposed and applied to EEG signals and achieved comparable results compared to other conventional methods [181,182,183,184]. In recent years, DL has been utilized to construct emotion recognition architectures that can be reconfigured due to its ability to provide high-level data abstraction.
In recent years, several DL models have been implemented to manage the classification of EEG signals for human emotion recognition. Among these methods, recurrent neural network (RNN) with long short-term memory networks (LSTMs) as special type of it and convolutional neural network (CNN), which are widely employed as classification methods; we will briefly describe them in the following sections.
4.3.1 Recurrent neural network
The recurrent neural network (RNN) is a deep learning method for processing variable-length sequential data like time series data (sensors), sound or written natural language. It is made up of cyclically connected feedforward neural networks. It leverages the temporal correlations between the data at different points in time to map the full history of input into the network and anticipate each output.
In a standard neural network, all inputs (and outputs) are considered to be independent of one another. RNN is a kind of neural network that has cyclic connections and can learn temporal sequential data. RNN networks can catch temporal patterns that are dynamic and save information thanks to that each hidden layer has internal feedback loops. Multiple nodes make up an RNN’s hidden layer, which generates outputs on the basis of the inputs currently available and prior hidden states.
The backpropagation through time (BPTT) algorithm [185] can be utilized to train RNNs. However, RNNs are difficult to train because of exploding gradient and vanishing issues, which can make it difficult for the network to back propagate gradients over extended time intervals [186, 187]. This restricts the amount of context they have access to, which is crucial for sequence data. As a result, the long short-term memory (LSTM) and gate recurrent unit (GRU) [187] have grown in popularity as alternatives.
4.3.1.1 Long short-term memory network
Long short-term memory networks (LSTMs) are a kind of recurrent neural network (RNN) with a unique architecture. Hochreiter and Schmidhuber introduced it in 1997 [188] to address the issue of long-term dependency in RNNs. Because a conventional RNN is taught by backpropagation through time (BPTT) [185], learning long sequences can be challenging, which leads to the vanishing/exploding gradient problem [186]. The RNN cell is substituted with a gated cell, such as an LSTM cell, to overcome this problem.
The LSTM cells have a memory block and gates that allow information to pass via the LSTM connection. There are a number of connections to go in and out of these gates. In the memory blocks, the temporal state of the network is stored in memory cells with self-connections and the flow of information is controlled by specific multiplicative units called gates [188]. In the original construction, each memory block had three gates: an input gate, a forget gate and an output gate. The first gate is a forget gate, which uses a sigmoid layer to choose which information from the cell state should be discarded. The input gate is the second gate that includes a sigmoid layer for determining what values have been set to update and a tanh layer for creating a vector of newly updated values. Finally, the current state’s output will be computed using the sigmoid layer and the updated cell state. The sigmoid layer determines which aspects of the cell state are final.
4.3.2 Convolutional neural network
Convolutional neural network (CNN) is a kind of deep, feedforward artificial neural networks based on the structure of the visual cortex of animals and is most commonly used for analyzing images. The assumption that the inputs are images is obvious in CNN architectures, allowing us to encode specific attributes into the architecture. As a result, constructing the forward function is more efficient, and the network’s parameters count is drastically decreased. Unlike a conventional fully connected network, in which a neuron is connected to all of the neurons in the layer preceding it, a neuron in a CNN is only connected to a special portion of the layer known as the local receptive field. CNN has three different types of layers in its design: (1) convolution, (2) pooling, and (3) fully connected layers [189]. Convolution and pooling layers are for feature extraction, while a fully connected layer transfers those features into ultimate output, like classification.
The convolution layer is a critical part of the CNN design since it extracts features, which often involves a mix of linear and nonlinear processes, such as the convolution process and activation functions. Convolution is a form of linear process that is utilized to extract features and it consists of several feature maps. Local characteristics of distinct points in the former are extracted using each neuron of the same feature map. A nonlinear activation function is applied to the outputs of a linear operation like convolution. The rectified linear unit (ReLU) is the most widely used nonlinear activation function nowadays, which is used to convert linear operation to nonlinear. The pooling layer is utilized to minimize the feature maps’ dimension and improve feature extraction robustness. The convolved layer output values are also selected using a sliding filter in the pooling layer. The mean and max-pooling layers are the two forms of pooling layer. The fully connected layer receives all of the features that have been created. This layer’s output is a probability distribution for all classes. The fully connected layer is the classification’s final result. It combines all of the neurons from the prior layer into a single layer.
5 Human emotion recognition techniques using EEG-based BCI
Several research papers on emotion recognition employing BCI devices for EEG data collection have been published in recent years. These papers use several techniques of machine and deep learning. According to the scopus database, Fig. 14 shows the number of articles from 2015 to 2021 that employed the most widely used classifiers: ANN, SVM, RF, K-NN, NB, and deep learning. In this section, we will discuss and review some of widespread machine and deep learning techniques for EEG emotion recognition as shown in the following sections.

The number of publications from 2015 to 2021 of the most commonly used machine and deep learning methods for EEG emotion recognition based on scopus database
5.1 Machine learning methods for EEG emotion recognition
Different methods of machine learning are used to classify different emotional states from EEG data like support vector machine (SVM), random forest (RF), k-nearest neighbor (K-NN), extreme learning machine (ELM), artificial neural network (ANN) and naive Bayes (NB). These shallow classification techniques all classify EEG signals based on their features alone, without taking into account the signals’ internal temporal dynamic information [190]. Table 5 summarizes the research in emotion recognition from EEG from 2015 to 2021 using machine learning techniques. Figure 15 illustrates a chart of the usage percentage of several methods of machine learning used for EEG emotion recognition addressed in this review.

Various machine learning methods used in EEG emotion recognition addressed in this review
According to Table 5, traditional machine learning methods’ classification accuracy ranges from 61.17 to 93%. As shown in Fig. 15, SVM and its derivatives are the most commonly used, contributing for 41%, and the related kernel functions are Gaussian, linear, radial basis functions (RBF) and so on. Artificial Neural Networks (ANN) and its architecture MLPNN are the second most popular, with 18% usage. RF is chosen by 14% of the researchers. The usage of the K-NN is similar to that of the DT, each accounting for 9%. Only 5% of the researchers choose NB. ELM is the least commonly used, with approximately 4%. SVM, as a representation of classical machine learning techniques, has the advantage of being able to separate classes in a higher-dimensional space using different kernel functions, and it has long been chosen by most researchers. As a result, it ranks first in this review in terms of algorithm usage frequency.
5.2 Deep learning methods for EEG emotion recognition
In the last few years, deep learning techniques have been adopted by a large number of researchers. Because of their advantages of recurrent neural network (RNN), convolutional neural network (CNN), deep neural network (DNN), deep belief network (DBN) and long- and short-term memory (LSTM) in representational learning and high classification accuracy, they can be used to classify more complicated situations. As a result, a growing number of researchers consider deep learning to be an important study method for EEG emotion detection. Table 6 summarizes the research in this field using deep learning methods from 2015 to 2021. Figure 16 illustrates a chart of the usage percentage of different deep learning techniques used for EEG emotion recognition addressed in this review.

Different deep learning methods used in EEG emotion recognition addressed in this review
According to Table 6, the deep learning algorithms’ classification accuracy varies between 61.25% and 97.56%. It can be seen that traditional machine learning methods do not have a classification effect as good as deep learning methods. To determine the characteristics of EEG signals, classical machine learning techniques necessitate a lot of previous knowledge. However, various people have significant differences in the complicated cognitive process, making it difficult to find effective features. All of this makes improving the EEG signal classification accuracy extremely difficult. Deep learning, unlike traditional machine learning algorithms, does not necessitate extensive previous knowledge or manual extraction of features. It is capable of extracting features from complicated data on a level-by-level basis. As shown in Fig. 16, LSTM and its derivatives are the most commonly utilized, accounting for 50% of the total. CNN and its derivatives are the second most popular, accounting for 36% of the studies. DBN and DNN are the least popular, each with a proportion of 7%.
6 Challenges and future research directions
As this review study has shown, we can employ BCI devices to record EEG signals and analyze them using modern ML and DL algorithms for real-world applications of emotion detection technology. However, there are unresolved issues there that need to be addressed. On average, existing approaches to emotion detection utilizing EEG signals produced classification accuracies greater than 80%, which appears to be appropriate for practical applications; however, recognition accuracy is unique to each application and highly reliant on the datasets used in the study. The following are some of the open issues and directions for future research in the field of emotion recognition that were discovered during this review.
-
1.
The existing research primarily focuses on the subjective dependent emotion recognition problem, which requires a personalized classifier for each participant. A model of emotion recognition that is subject-independent (or generic) and suitable for a collection of individuals would be extremely useful in real-world circumstances. However, to achieve emotion detection accuracy that is consistent across individuals, the subject-independent classifier model must be integrated with the transfer learning technique.
-
2.
The majority of known EEG datasets were collected using visual elicitation tools in laboratory settings. In earlier studies, the emotional condition of the subjects before the experiments were conducted was not considered. Such individual differences can cause datasets to be inconsistent.
-
3.
Many studies only considered a binary classification of each emotion dimension.
-
4.
In many emotion recognition studies, researchers examined EEG data under different emotional states and neglected the baseline (spontaneous) EEG data.
-
5.
EEG-based emotion detection of mixed emotions, such as bittersweet feelings, that integrate positive and negative influences perceived at the same time, was not found in the literature. The research to improve creative performance is linked to these mixed emotions, which is why they are interesting [198].
In addition to the above points, the following will be considered in future work.
-
1.
Traditionally, actual emotion classes have been labeled based on a predetermined subjective rating data threshold. Unfortunately, determining the appropriate threshold is difficult. A novel approach is to consider the valence as well as the arousal dimensions at the same time and then utilize data clustering methods to find the emotion actual classes.
-
2.
EEG-based BCI system components, such as feature extraction and selection, are continually evolving. They ought to be established on a thorough comprehension of the physiology and biology of the brain. The creation of distinctive features has the potential to dramatically improve the results of emotion detection systems. As an example, time-domain characteristics are mixed with frequency, time-frequency features, and channel location.
-
3.
Emotional models with more dimensions must be developed. Currently, the two-dimensional emotion model is widely employed. Multi-class emotion recognition necessitates the development of higher-dimensional emotion models. For example, accumulated analysis of the context information of the subject can predict the ’stance’ dimension in a three-dimensional emotion model (i.e., arousal, stance, and valence).
-
4.
Advanced machine learning approaches, such as deep and transferable ML techniques, must be developed. Emotions are a reflection of cognitive processes linked to biological comprehension and psychophysiological occurrences, and their creation is a subjective and difficult procedure. As a result, proposing a recognition method solely based on classic ML methods is problematic.
-
5.
To monitor temporal emotional fluctuations in real time, traditional time series analysis approaches must be integrated with machine learning techniques [55, 199,200,201,202,203].
-
6.
The majority of engineering techniques for emotion recognition show that arousal categorization is usually more accurate than valence distinction. The rationale for this could be that arousal level changes are directly related to autonomic nervous system activities (e.g., skin conductivity and blood pressure) that are simple to measure, while the distinction of valence level necessitates a factor analysis of ANS reactions that are cross-associated. As a result, we will need to create an emotion-specific categorization framework and extract a variety of valence-relevant characteristics from EEG data in a variety of analysis domains (e.g., time-frequency, frequency, time, entropy, and multi-scale entropy).
-
7.
We need to create more datasets that employ active elicitation techniques such as video games because they better imitate “real-life” experiences and are more effective at inducing emotion.
7 Conclusion
Emotion recognition has grown in importance in the HCI field as technologies for human–machine systems and automation improve. In recent years, EEG-based BCI emotion recognition has received increasing attention in the affective computing field. Numerous research studies have been undertaken due to significant advances in the creation of affordance and easy to use BCI devices. We examined over 195 publications for this review. We covered state-of-the-art EEG emotion identification approaches developed in recent years (2015 to 2021). We also considered existing datasets and described the main components of the emotion detection pipeline utilizing EEG-based BCI. EEG signals are dependable data that cannot be faked or simulated. EEG reacts to emotional changes in real time. The following computational processes comprise the general methodology for EEG-based BCI emotion recognition: data collecting, preprocessing, feature extraction, feature selection or dimensionality reduction, classification, and performance evaluation. In our review, we focused on several techniques for preprocessing, feature extraction, and feature selection/dimensionality reduction. In addition, we reviewed various machine and deep learning classification techniques and commonly used performance metrics. Investigating the relationship between brain signals and emotions is a difficult task, as shown in this review, and new methodologies and implementations are constantly being developed. Many of the current challenges are expected to be resolved soon, paving the way for a wide range of potential applications based on EEG-based emotion identification. It is intended that this review will provide researchers, particularly those just starting out in the field, insight into the current state of research into the recognition and categorization of emotional-oriented EEG features.
References
Mudgal SK, Sharma SK, Chaturvedi J, Sharma A (2020) Brain computer interface advancement in neurosciences: applications and issues. Interdiscip Neurosurg 20:100694
Wolpaw JR, Birbaumer N, McFarland DJ, Pfurtscheller G, Vaughan TM (2002) Brain-computer interfaces for communication and control. Clin Neurophysiol 113(6):767–791
Abdulkader SN, Atia A, Mostafa M-SM (2015) Brain computer interfacing: applications and challenges. Egypt Inf J 16(2):213–230
Jerry JS, Dean JK, Jonathan RW (2012) Brain–computer interfaces in medicine. In Mayo Clinic Proceedings, volume 87. Elsevier, pp 268–279
Khosla A, Khandnor P, Chand T (2020) A comparative analysis of signal processing and classification methods for different applications based on eeg signals. Biocybern Biomed Eng 40(2):649–690
Jiang W, Mei W (2021) Review of the emotional feature extraction and classification using eeg signals. Cognitive Robotics
Mamunur R, Norizam S, Anwar PPAM, Rabiu MM, Bifta SB, Sabira K et al (2020) Current status, challenges, and possible solutions of eeg-based brain-computer interface: a comprehensive review. Front Neurorob 14:25
Zhang J, Yin Z, Chen P, Nichele S (2020) Emotion recognition using multi-modal data and machine learning techniques: A tutorial and review. Inform Fusion 59:103–126
Calvo RA, D’Mello S (2010) Affect detection: an interdisciplinary review of models, methods, and their applications. IEEE Trans Affect Comput 1(1):18–37
Valery P (1999) Emotion in speech: Recognition and application to call centers. In: Proceedings of artificial neural networks in engineering, volume 710, p 22
Keith A, McOwan PW (2006) A real-time automated system for the recognition of human facial expressions. IEEE Trans Syst Man Cybernet B (Cybernetics) 36(1):96–105
Yin Z, Zhao M, Wang Y, Yang J, Zhang J (2017) Recognition of emotions using multimodal physiological signals and an ensemble deep learning model. Comput Methods Programs Biomed 140:93–110
Torres EP, Torres EA, Hernández-Álvarez M, Yoo SG (2020) Eeg-based bci emotion recognition: a survey. Sensors 20(18):5083
He Z, Li Z, Yang F, Wang L, Li J, Zhou C, Pan J (2020) Advances in multimodal emotion recognition based on brain-computer interfaces. Brain Sci 10(10):687
Xiaowei L, Bin H, Tingshao Z, Jingzhi Y, Fang Z (2009) Towards affective learning with an eeg feedback approach. In: Proceedings of the first ACM international workshop on Multimedia technologies for distance learning, pp 33–38
Mauss IB, Robinson MD (2009) Measures of emotion: a review. Cogn Emot 23(2):209–237
Naji M, Firoozabadi M, Azadfallah P (2015) Emotion classification during music listening from forehead biosignals. SIViP 9(6):1365–1375
Paul E (1992) Are there basic emotions? Psychol Rev
Russell JA (1980) A circumplex model of affect. J Pers Soc Psychol 39(6):1161
Charles D (2015) The expression of the emotions in man and animals. University of Chicago Press, Chicago
Silvan T (1962) Affect imagery consciousness: Volume I: The positive affects. Springer publishing company
Ekman P, Oster H (1979) Facial expressions of emotion. Annu Rev Psychol 30(1):527–554
Gray JA (1985) A whole and its parts: behaviour, the brain, cognition and emotion. Bull British Psychol Soc
Mowrer O (1960) Learning theory and behavior. American Psychological Association, Washington
Watson JB, Kimble GA (2017) Behaviorism. Routledge, London
Gurney E (1884) What is an emotion? Mind 9(35):421–426
Panksepp J (1982) Toward a general psychobiological theory of emotions. Behav Brain Sci 5(3):407–422
Weiner B, Sarah G (1984) An attributional approach to emotional development. Emot Cognit Behav 167–191
Arnold MB (1960) Emotion and personality. American Psychological Association, Washington
Johnson-Laird PN, Oatley K (1989) The language of emotions: An analysis of a semantic field. Cogn Emot 3(2):81–123
Frijda NH et al (1986) The emotions. Cambridge University Press, Cambridge
Izard Carroll E (2013) Human emotions. Springer, New York
McDougall William (2015) An introduction to social psychology. Psychology Press, London
Whissell CM (1989) The dictionary of affect in language. In: The measurement of emotions. Elsevier, pp 113–131
Schlosberg H (1954) Three dimensions of emotion. Psychol Rev 61(2):81
Yang W, Makita K, Nakao T, Kanayama N, Machizawa MG, Sasaoka T, Sugata A, Kobayashi R, Hiramoto R, Yamawaki S et al (2018) Affective auditory stimulus database: An expanded version of the international affective digitized sounds (iads-e). Behav Res Methods 50(4):1415–1429
Lang PJ, Bradley MM, Cuthbert BN et al (1997) International affective picture system (iaps): technical manual and affective ratings. NIMH Center Study Emot Attent 1(39–58):3
Bradley MM, Lang PJ (1994) Measuring emotion: the self-assessment manikin and the semantic differential. J Behav Ther Exp Psychiatry 25(1):49–59
Zhou F, Xingda Q, Jiao J, Helander MG (2014) Emotion prediction from physiological signals: a comparison study between visual and auditory elicitors. Interact Comput 26(3):285–302
Yin Z, Zhang J (2018) Task-generic mental fatigue recognition based on neurophysiological signals and dynamical deep extreme learning machine. Neurocomputing 283:266–281
Berger H (1929) Über das elektroenkephalogramm des menschen. Arch Psychiatr Nervenkr 87(1):527–570
Teplan M et al (2002) Fundamentals of eeg measurement. Measure Sci Rev 2(2):1–11
Zhao G, Zhang Y, Ge Y (2018) Frontal eeg asymmetry and middle line power difference in discrete emotions. Front Behav Neurosci 12:225
Zheng W-L, Bao-Liang L (2015) Investigating critical frequency bands and channels for eeg-based emotion recognition with deep neural networks. IEEE Trans Auton Ment Dev 7(3):162–175
Ekman P, Davidson RJ (1993) Voluntary smiling changes regional brain activity. Psychol Sci 4(5):342–345
Li P, Liu H, Si Y, Li C, Li F, Zhu X, Huang X, Zeng Y, Yao D, Zhang Y et al (2019) Eeg based emotion recognition by combining functional connectivity network and local activations. IEEE Trans Biomed Eng 66(10):2869–2881
Bhatti AM, Majid M, Anwar SM, Khan B (2016) Human emotion recognition and analysis in response to audio music using brain signals. Comput Hum Behav 65:267–275
Lee Y-Y, Hsieh S (2014) Classifying different emotional states by means of eeg-based functional connectivity patterns. PLoS ONE 9(4):e95415
Peterson V, Galván C, Hernández H, Spies R (2020) A feasibility study of a complete low-cost consumer-grade brain-computer interface system. Heliyon 6(3):e03425
Wang Y, Jung T-P (2012) Improving brain–computer interfaces using independent component analysis. In: Towards practical brain–computer interfaces. Springer, pp 67–83
Ofner P, Müller-Putz GR (2015) Movement target decoding from eeg and the corresponding discriminative sources: A preliminary study. In: 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE, pp 1468–1471
Alhaddad MJ, Kamel M, Malibary H, Thabit K, Dahlwi F, Hadi A (2012) P300 speller efficiency with common average reference. In: International conference on autonomous and intelligent systems. Springer, pp 234–241
Li X, Fan H, Wang H, Wang L (2019) Common spatial patterns combined with phase synchronization information for classification of eeg signals. Biomed Signal Process Control 52:248–256
Koelstra S, Muhl C, Soleymani M, Lee J-S, Yazdani A, Ebrahimi T, Pun T, Nijholt A, Patras I (2011) Deap: A database for emotion analysis; using physiological signals. IEEE Trans Affect Comput 3(1):18–31
Atkinson J, Campos D (2016) Improving bci-based emotion recognition by combining eeg feature selection and kernel classifiers. Expert Syst Appl 47:35–41
Chen J, Bin H, Moore P, Zhang X, Ma X (2015) Electroencephalogram-based emotion assessment system using ontology and data mining techniques. Appl Soft Comput 30:663–674
Özerdem MS, Polat H (2017) Emotion recognition based on eeg features in movie clips with channel selection. Brain informatics 4(4):241–252
Mert A, Akan A (2018) Emotion recognition based on time-frequency distribution of eeg signals using multivariate synchrosqueezing transform. Digit Signal Process 81:106–115
Kumar N, Khaund K, Hazarika SM (2016) Bispectral analysis of eeg for emotion recognition. Procedia Comput Sci 84:31–35
Hyvärinen A, Oja E (2000) Independent component analysis: algorithms and applications. Neural Netw 13(4–5):411–430
Papadelis C, Chen Z, Kourtidou-Papadeli C, Bamidis PD, Chouvarda I, Bekiaris E, Maglaveras N (2007) Monitoring sleepiness with on-board electrophysiological recordings for preventing sleep-deprived traffic accidents. Clin Neurophysiol 118(9):1906–1922
Asadi Ghanbari A, Nazari Kousarrizi MR, Teshnehlab M, Aliyari M (2009) An evolutionary artifact rejection method for brain computer interface using ica. Int J Electr Comput Sci 9(9):48–53
Iacoviello D, Petracca A, Spezialetti M, Placidi G (2015) A real-time classification algorithm for eeg-based bci driven by self-induced emotions. Comput Methods Programs Biomed 122(3):293–303
Alakus TB, Gonen M, Turkoglu I (2020) Database for an emotion recognition system based on eeg signals and various computer games-gameemo. Biomed Signal Process Control 60:101951
Li M, Hongpei X, Liu X, Shengfu L (2018) Emotion recognition from multichannel eeg signals using k-nearest neighbor classification. Technol Health Care 26(S1):509–519
Garg A, Kapoor A, Bedi AK, Sunkaria RK (2019) Merged lstm model for emotion classification using eeg signals. In: 2019 International conference on Data Science and Engineering (ICDSE). IEEE, pp 139–143
Zheng W-L, Zhu J-Y, Bao-Liang L (2017) Identifying stable patterns over time for emotion recognition from eeg. IEEE Trans Affect Comput 10(3):417–429
Qing C, Qiao R, Xiangmin X, Cheng Y (2019) Interpretable emotion recognition using eeg signals. Ieee Access 7:94160–94170
Gupta R, Falk TH et al (2016) Relevance vector classifier decision fusion and eeg graph-theoretic features for automatic affective state characterization. Neurocomputing 174:875–884
Arnau-González P, Arevalillo-Herráez M, Ramzan N (2017) Fusing highly dimensional energy and connectivity features to identify affective states from eeg signals. Neurocomputing 244:81–89
Chen T, Sihang J, Ren F, Fan M, Yu G (2020) Eeg emotion recognition model based on the libsvm classifier. Measurement 164:108047
Yin Z, Liu L, Chen J, Zhao B, Wang Y (2020) Locally robust eeg feature selection for individual-independent emotion recognition. Expert Syst Appl 162:113768
Chakladar DD, Chakraborty S (2018) Eeg based emotion classification using correlation based subset selection. Biol Inspired Cognit Architec 24:98–106
Salankar N, Mishra P, Garg L (2021) Emotion recognition from eeg signals using empirical mode decomposition and second-order difference plot. Biomed Signal Process Control 65:102389
Huang C (2021) Recognition of psychological emotion by eeg features. Network Model Analysis Health Inform Bioinform 10(1):1–11
Subasi A, Tuncer T, Dogan S, Tanko D, Sakoglu U (2021) Eeg-based emotion recognition using tunable q wavelet transform and rotation forest ensemble classifier. Biomed Signal Process Control 68:102648
Pane ES, Wibawa AD, Purnomo MH (2019) Improving the accuracy of eeg emotion recognition by combining valence lateralization and ensemble learning with tuning parameters. Cogn Process 20(4):405–417
Joshi VM, Ghongade RB (2020) Idea: Intellect database for emotion analysis using eeg signal. J King Saud Univ-Comput Inform Sci
Yang J, Huang X, Hongkai W, Yang X (2020) Eeg-based emotion classification based on bidirectional long short-term memory network. Procedia Comput Sci 174:491–504
Pandey P, Seeja KR (2019) Subject independent emotion recognition from eeg using vmd and deep learning. J King Saud Univ-Comput Inform Sci
Sharma R, Pachori RB, Sircar P (2020) Automated emotion recognition based on higher order statistics and deep learning algorithm. Biomed Signal Process Control 58:101867
Wei C, Chen L, Song Z, Lou X, Li D (2020) Eeg-based emotion recognition using simple recurrent units network and ensemble learning. Biomed Signal Process Control 58:101756
Topic A, Russo M (2021) Emotion recognition based on eeg feature maps through deep learning network. Int J Eng Sci Technol
Sakalle A, Tomar P, Bhardwaj H, Acharya D, Bhardwaj A (2021) A lstm based deep learning network for recognizing emotions using wireless brainwave driven system. Expert Syst Appl 173:114516
Song T, Zheng W, Song P, Cui Z (2018) Eeg emotion recognition using dynamical graph convolutional neural networks. IEEE Trans Affect Comput 11(3):532–541
Liu S, Wang X, Zhao L, Zhao J, Xin Q, Wang S (2020) Subject-independent emotion recognition of eeg signals based on dynamic empirical convolutional neural network. IEEE/ACM Trans Comput Biol Bioinform
Hjorth B (1970) Eeg analysis based on time domain properties. Electroencephalogr Clin Neurophysiol 29(3):306–310
Petrantonakis PC, Hadjileontiadis LJ (2009) Emotion recognition from eeg using higher order crossings. IEEE Trans Inf Technol Biomed 14(2):186–197
Petrantonakis PC, Hadjileontiadis LJ (2010) Emotion recognition from brain signals using hybrid adaptive filtering and higher order crossings analysis. IEEE Trans Affect Comput 1(2):81–97
Shaw L, Routray A (2016) Statistical features extraction for multivariate pattern analysis in meditation eeg using pca. In: 2016 IEEE EMBS International Student Conference (ISC). IEEE, pp 1–4
Liu Y, Sourina O (2014) Eeg-based subject-dependent emotion recognition algorithm using fractal dimension. In: 2014 IEEE international conference on systems, man, and cybernetics (SMC). IEEE, pp 3166–3171
Yuen CT, San San W, Seong TC, Rizon M (2009) Classification of human emotions from eeg signals using statistical features and neural network. Int J Integrat Eng 1(3)
Murugappan M, Subbulakshmi M (2013) Human emotion recognition through short time electroencephalogram (eeg) signals using fast fourier transform (fft). In: 2013 IEEE 9th international colloquium on signal processing and its applications. IEEE, pp 289–294
Yoon HJ, Chung SY (2013) Eeg-based emotion estimation using Bayesian weighted-log-posterior function and perceptron convergence algorithm. Comput Biol Med 43(12):2230–2237
Shi L-C, Jiao Y-Y, Lu B-L (2013) Differential entropy feature for eeg-based vigilance estimation. In: 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE, pp 6627–6630
Subasi A (2007) Eeg signal classification using wavelet feature extraction and a mixture of expert model. Expert Syst Appl 32(4):1084–1093
Li Y, Yingle F, Gu L, Qinye T (2009) Sleep stage classification based on eeg Hilbert–Huang transform. In: 2009 4th IEEE conference on industrial electronics and applications. IEEE, pp 3676–3681
Ting W, Guo-Zheng Y, Bang-Hua Y, Hong S (2008) Eeg feature extraction based on wavelet packet decomposition for brain computer interface. Measurement 41(6):618–625
Houssein EH, Hamad A, Hassanien AE, Fahmy AA (2019) Epileptic detection based on whale optimization enhanced support vector machine. J Inf Optim Sci 40(3):699–723
Guido RC (2018) A tutorial review on entropy-based handcrafted feature extraction for information fusion. Inform Fusion 41:161–175
Vijith VS, Elsa Jacob J, Iype T, K Gopakumar, George Yohannan D (2016) Epileptic seizure detection using non linear analysis of eeg. In: 2016 International conference on inventive computation technologies (ICICT), vol 3. IEEE, pp 1–6
Zhang C, Wang H, Rongrong F (2013) Automated detection of driver fatigue based on entropy and complexity measures. IEEE Trans Intell Transp Syst 15(1):168–177
Nicolaou N, Georgiou J (2012) Detection of epileptic electroencephalogram based on permutation entropy and support vector machines. Expert Syst Appl 39(1):202–209
Pincus SM (1991) Approximate entropy as a measure of system complexity. Proc Natl Acad Sci 88(6):2297–2301
Zhang A, Yang B, Huang L (2008) Feature extraction of eeg signals using power spectral entropy. In: 2008 international conference on BioMedical engineering and informatics, vol 2. IEEE, pp 435–439
Richman JS, Randall Moorman J (2000) Physiological time-series analysis using approximate entropy and sample entropy. Am J Physiol-Heart Circulat Physiol 278(6):H2039–H2049
Lotte F, Congedo M, Lécuyer A, Lamarche F, Arnaldi B (2007) A review of classification algorithms for eeg-based brain-computer interfaces. J Neural Eng 4(2):R1
Ayyagari SSDP, Jones RD, Weddell SJ (2021) Detection of microsleep states from the eeg: a comparison of feature reduction methods. Med Biol Eng Comput 1–15
Fukunaga K (2013) Introduction to statistical pattern recognition. Elsevier, Amsterdam
Liu J, Meng H, Li M, Zhang F, Qin R, Nandi AK (2018) Emotion detection from eeg recordings based on supervised and unsupervised dimension reduction. Concurrency Comput: Pract Exp 30(23):e4446
Doma V, Pirouz M (2020) A comparative analysis of machine learning methods for emotion recognition using eeg and peripheral physiological signals. J Big Data 7(1):1–21
Abdulhamit Subasi M, Gursoy I (2010) Eeg signal classification using pca, ica, lda and support vector machines. Expert Syst Appl 37(12):8659–8666
Widodo A, Yang B-S (2007) Application of nonlinear feature extraction and support vector machines for fault diagnosis of induction motors. Expert Syst Appl 33(1):241–250
Mafarja M, Mirjalili S (2018) Whale optimization approaches for wrapper feature selection. Appl Soft Comput 62:441–453
Cabrera AF, Farina D, Dremstrup K (2010) Comparison of feature selection and classification methods for a brain–computer interface driven by non-motor imagery. Med Biol Eng Comput 48(2):123–132
Koprinska I (2009) Feature selection for brain-computer interfaces. In: Pacific-Asia conference on knowledge discovery and data mining. Springer, pp 106–117
Kohavi R, John GH (1997) Wrappers for feature subset selection. Artif Intell 97(1–2):273–324
Sabeti M, Boostani R, Katebi SD, Price GW (2007) Selection of relevant features for eeg signal classification of schizophrenic patients. Biomed Signal Process Control 2(2):122–134
John GH, Kohavi R, Pfleger K (1994) Irrelevant features and the subset selection problem. In: Machine learning proceedings. Elsevier, pp 121–129
Langley P et al (1994) Selection of relevant features in machine learning. In: Proceedings of the AAAI Fall symposium on relevance 184:245–271
Battiti R (1994) Using mutual information for selecting features in supervised neural net learning. IEEE Trans Neural Networks 5(4):537–550
Peng H, Long F, Ding C (2005) Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans Pattern Anal Mach Intell 27(8):1226–1238
Reunanen J (2003) Overfitting in making comparisons between variable selection methods. J Mach Learn Res 3:1371–1382
Pudil P, Novovičová J, Kittler J (1994) Floating search methods in feature selection. Pattern Recogn Lett 15(11):1119–1125
Talbi E-G (2009) Metaheuristics: from design to implementation, vol 74. Wiley, Hoboken
Fister Jr I, Yang X-S, Fister I, Brest J, Fister D (2013) A brief review of nature-inspired algorithms for optimization. arXiv preprint arXiv:1307.4186
Zawbaa HM, Emary E, Parv B (2015) Feature selection based on antlion optimization algorithm. In 2015 Third world conference on complex systems (WCCS). IEEE, pp 1–7
Emary E, Zawbaa HM, Hassanien AE (2016) Binary grey wolf optimization approaches for feature selection. Neurocomputing 172:371–381
Mistry K, Zhang L, Neoh SC, Lim CP, Fielding B (2016) A micro-ga embedded pso feature selection approach to intelligent facial emotion recognition. IEEE Trans Cybern 47(6):1496–1509
Baig MZ, Aslam N, Shum HPH, Zhang L (2017) Differential evolution algorithm as a tool for optimal feature subset selection in motor imagery eeg. Expert Syst Appl 90:184–195
Kim KH, Bang SW, Kim SR (2004) Emotion recognition system using short-term monitoring of physiological signals. Med Biol Eng Compu 42(3):419–427
Ilyas MZ, Saad P, Ahmad MI (2015) A survey of analysis and classification of eeg signals for brain-computer interfaces. In 2015 2nd International Conference on Biomedical Engineering (ICoBE). IEEE, pp 1–6
Soleymani M, Lichtenauer J, Pun T, Pantic M (2011) A multimodal database for affect recognition and implicit tagging. IEEE Trans Affect Comput 3(1):42–55
Ruo-Nan Duan, Jia-Yi Zhu, Bao-Liang Lu (2013) Differential entropy feature for eeg-based emotion classification. In 2013 6th International IEEE/EMBS Conference on Neural Engineering (NER). IEEE, pp 81–84
Katsigiannis S, Ramzan N (2017) Dreamer: A database for emotion recognition through eeg and ecg signals from wireless low-cost off-the-shelf devices. IEEE J Biomed Health Inform 22(1):98–107
Miranda Correa JA, Khomami Abadi M, Sebe N, Patras I (2018) Amigos: a dataset for affect, personality and mood research on individuals and groups. IEEE Trans Affect Comput
Lan Z, Liu Y, Sourina O, Wang L, Scherer R, Müller-Putz G (2020) Safe: An eeg dataset for stable affective feature selection. Adv Eng Inform 44:101047
Lv Z, Qiao L, Wang Q, Piccialli F (2020) Advanced machine-learning methods for brain-computer interfacing. IEEE/ACM Trans Comput Biol Bioinform
Drucker H, Donghui W, Vapnik VN (1999) Support vector machines for spam categorization. IEEE Trans Neural Networks 10(5):1048–1054
Kumar S, Singh S, Kumar J (2018) Automatic live facial expression detection using genetic algorithm with haar wavelet features and svm. Wireless Pers Commun 103(3):2435–2453
Kumar S, Singh S, Kumar J (2019) Multiple face detection using hybrid features with svm classifier. In: Data and communication networks. Springer, pp 253–265
Shi L, Wang X, Shen Y (2020) Research on 3d face recognition method based on lbp and svm. Optik 220:165157
Asuntha A, Brindha A, Indirani S, Srinivasan A (2016) Lung cancer detection using svm algorithm and optimization techniques. J Chem Pharm Sci 9(4):3198–3203
Dolatabadi AD, Khadem SEZ, Asl BM (2017) Automated diagnosis of coronary artery disease (cad) patients using optimized svm. Comput Methods Programs Biomed 138:117–126
Nilashi M, Ahmadi N, Samad S, Shahmoradi L, Ahmadi H, Ibrahim O, Asadi S, Abdullah R, Abumalloh RA, Yadegaridehkordi E (2020) Disease diagnosis using machine learning techniques: A review and classification. Journal of Soft Computing and Decision Support Systems 7(1):19–30
Francis LM, Sreenath N (2020) Tedless-text detection using least-square svm from natural scene. Journal of King Saud University-Computer and Information Sciences 32(3):287–299
Lin W, Ji D, Yanan L (2017) Disorder recognition in clinical texts using multi-label structured svm. BMC Bioinformatics 18(1):1–11
Hassan AKA, Mahdi BS, Mohammed AA (2019) Arabic handwriting word recognition based on scale invariant feature transform and support vector machine. Iraqi Jf Sci 381–387
Shalev-Shwartz S, Ben-David S (2014) Understanding machine learning: from theory to algorithms. Cambridge University Press, Cambridge
Chen W-H, Hsu S-H, Shen H-P (2005) Application of svm and ann for intrusion detection. Computers & Operations Research 32(10):2617–2634
Basheer IA, Hajmeer M (2000) Artificial neural networks: fundamentals, computing, design, and application. J Microbiol Methods 43(1):3–31
Fausett LV (2006) Fundamentals of neural networks: architectures, algorithms and applications. Pearson Education India
Sharma S, Sharma S (2017) Activation functions in neural networks. Towards Data Science 6(12):310–316
Quinlan JR (2014) C4. 5: programs for machine learning. Elsevier
Loh W-Y (2011) Classification and regression trees. Wiley Interdiscip Rev: Data Min Knowl Discov 1(1):14–23
Bastos NS, Marques BP, Adamatti DF, Billa CZ (2020) Analyzing eeg signals using decision trees: a study of modulation of amplitude. Comput Intell Neurosci
Rasoul Safavian S, Landgrebe D (1991) A survey of decision tree classifier methodology. IEEE Trans Syst Man Cybern 21(3):660–674
Rafik Khairul Amin, Yuliant Sibaroni, et al (2015) Implementation of decision tree using c4. 5 algorithm in decision making of loan application by debtor (case study: Bank pasar of yogyakarta special region). In 2015 3rd International Conference on Information and Communication Technology (ICoICT), pp 75–80. IEE
Ruggieri S (2002) Efficient c4. 5 [classification algorithm]. IEEE Trans Knowl Data Eng 14(2):438–444
Tin Kam Ho (1995) Random decision forests. In Proceedings of 3rd international conference on document analysis and recognition, volume 1. IEEE, pp 278–282
Değer Ayata, Yusuf Yaslan, Mustafa Kamaşak (2016) Emotion recognition via random forest and galvanic skin response: Comparison of time based feature sets, window sizes and wavelet approaches. In 2016 Medical Technologies National Congress (TIPTEKNO). IEEE, pp 1–4
Breiman L (2001) Random forests. Mach Learn 45(1):5–32
Peterson LE (2009) K-nearest neighbor. Scholarpedia 4(2):1883
Pascal Soucy, Guy W Mineau (2001) A simple knn algorithm for text categorization. In: Proceedings 2001 IEEE international conference on data mining. IEEE, pp 647–648
Fatemeh Bahari, Amin Janghorbani (2013) Eeg-based emotion recognition using recurrence plot analysis and k nearest neighbor classifier. In 2013 20th Iranian Conference on Biomedical Engineering (ICBME). IEEE, pp 228–233
Sasirekha K, Thangavel K (2019) Optimization of k-nearest neighbor using particle swarm optimization for face recognition. Neural Comput Appl 31(11):7935–7944
Wang H, Zhang Y et al (2016) Detection of motor imagery eeg signals employing naïve bayes based learning process. Measurement 86:148–158
M Wiggins, Ashraf Saad, Brian Litt, and George Vachtsevanos. Evolving a bayesian classifier for ecg-based age classification in medical applications. Applied soft computing, 8(1):599–608, 2008
Sharmila A, Geethanjali P (2016) Dwt based detection of epileptic seizure from eeg signals using naive bayes and k-nn classifiers. Ieee Access 4:7716–7727
Dong S, Wang P, Abbas K (2021) A survey on deep learning and its applications. Computer Science Review 40:100379
Iqbal H Sarker. Deep learning: a comprehensive overview on techniques, taxonomy, applications and research directions. SN Computer Science, 2(6):1–20, 2021
Fukushima K (1980) A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol Cybern 36:193–202
Hinton GE, Salakhutdinov RR (2006) Reducing the dimensionality of data with neural networks. science 313(5786):504–507
Yoshua Bengio, Pascal Lamblin, Dan Popovici, Hugo Larochelle (2007) Greedy layer-wise training of deep networks. In Advances in neural information processing systems, pp 153–160
Pascal Vincent, Hugo Larochelle, Isabelle Lajoie, Yoshua Bengio, Pierre-Antoine Manzagol, Léon Bottou (2010) Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. Journal of machine learning research, 11(12)
Chamara L, Zhou H, Huang GB, Vong CM (2013) Representational learning with extreme learning machine for big data. IEEE Intell Syst 28(6):31–34
Chen M, Weinberger KQ, Zhixiang X, Sha F (2015) Marginalizing stacked linear denoising autoencoders. The Journal of Machine Learning Research 16(1):3849–3875
Cao J, Zhao Y, Lai X, Ong MEH, Yin C, Koh ZX, Liu N (2015) Landmark recognition with sparse representation classification and extreme learning machine. J Franklin Inst 352(10):4528–4545
Cao J, Zhang K, Luo M, Yin C, Lai X (2016) Extreme learning machine and adaptive sparse representation for image classification. Neural Netw 81:91–102
Yang Y, Wu QMJ (2015) Multilayer extreme learning machine with subnetwork nodes for representation learning. IEEE transactions on cybernetics 46(11):2570–2583
Zhang J, Wu Y (2018) Automatic sleep stage classification of single-channel eeg by using complex-valued convolutional neural network. Biomedical Engineering/Biomedizinische Technik 63(2):177–190
Jiao Y, Deng Y, Luo Y, Bao-Liang L (2020) Driver sleepiness detection from eeg and eog signals using gan and lstm networks. Neurocomputing 408:100–111
Soumalya Sarkar, Kishore Reddy, Alex Dorgan, Cali Fidopiastis, Michael Giering (2016) Wearable eeg-based activity recognition in phm-related service environment via deep learning. international Journal of Prognostics and Health Management, 7(4)
Maiorana E (2020) Deep learning for eeg-based biometric recognition. Neurocomputing 410:374–386
Guo J (2013) Backpropagation through time. Unpubl. ms. Harbin Institute of Technology 40:1–6
Sepp Hochreiter, Yoshua Bengio, Paolo Frasconi, Jürgen Schmidhuber, et al (2001) Gradient flow in recurrent nets: the difficulty of learning long-term dependencies
Reddy BK, Delen D (2018) Predicting hospital readmission for lupus patients: An rnn-lstm-based deeplearning methodology. Comput Biol Med 101:199–209
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780
Yamashita R, Nishio M, Do RKG, Togashi K (2018) Convolutional neural networks: an overview and application in radiology. Insights Imaging 9(4):611–629
Alarcao SM, Fonseca MJ (2017) Emotions recognition using eeg signals: A survey. IEEE Trans Affect Comput 10(3):374–393
Harsh Dabas, Chaitanya Sethi, Chirag Dua, Mohit Dalawat, Divyashikha Sethia (2018) Emotion classification using eeg signals. In Proceedings of the 2018 2nd International Conference on Computer Science and Artificial Intelligence, pp 380–384,
Gao Y, Jong Lee H, Mehmood RM (2015) Deep learninig of eeg signals for emotion recognition. In: 2015 IEEE international conference on multimedia & expo workshops (ICMEW). IEEE, pp 1–5
Aya Hassouneh AM, Mutawa MM (2020) Development of a real-time emotion recognition system using facial expressions and eeg based on machine learning and deep neural network methods. Informatics in Medicine Unlocked 20:100372
Cui H, Aiping Liu X, Zhang XC, Wang K, Chen X (2020) Eeg-based emotion recognition using an end-to-end regional-asymmetric convolutional neural network. Knowl-Based Syst 205:106243
Huang D, Chen S, Liu C, Zheng L, Tian Z, Jiang D (2021) Differences first in asymmetric brain: A bi-hemisphere discrepancy convolutional neural network for eeg emotion recognition. Neurocomputing 448:140–151
Alhagry S, Fahmy AA, El-Khoribi RA (2017) Emotion recognition based on eeg using lstm recurrent neural network. Emotion 8(10):355–358
Salama ES, El-Khoribi RA, Shoman ME, Wahby Shalaby MA (2018) Eeg-based emotion recognition using 3d convolutional neural networks. Int J Adv Comput Sci Appl 9(8):329–337
Kung FYH, Chao MM (2019) The impact of mixed emotions on creativity in negotiation: An interpersonal perspective. Front Psychol 9:2660
Zheng W (2016) Multichannel eeg-based emotion recognition via group sparse canonical correlation analysis. IEEE Transactions on Cognitive and Developmental Systems 9(3):281–290
Hadjidimitriou SK, Hadjileontiadis LJ (2012) Toward an eeg-based recognition of music liking using time-frequency analysis. IEEE Trans Biomed Eng 59(12):3498–3510
Jenke R, Peer A, Buss M (2014) Feature extraction and selection for emotion recognition from eeg. IEEE Trans Affect Comput 5(3):327–339
Chatterjee R, Tanmoy Maitra SK, Islam H, Hassan MM, Alamri A, Fortino G (2019) A novel machine learning based feature selection for motor imagery eeg signal classification in internet of medical things environment. Futur Gener Comput Syst 98:419–434
Moreira MWL, Rodrigues JJPC, Kumar N, Saleem K, Illin IV (2019) Postpartum depression prediction through pregnancy data analysis for emotion-aware smart systems. Information Fusion 47:23–31
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
The authors have declared that there is no conflicts of interest. Non-financial competing interests.
Human or animals participants
This article does not contain any studies with human participants or animals performed by any of the authors.
CRediT author statement
Essam H. Houssein was involved in supervision, methodology, conceptualization, formal analysis, visualization, and writing–review & editing. Asmaa Hammad was involved in formal analysis, visualization, resources, data curation, and writing—original draft. Abdelmgeid A. Ali was involved in supervision, methodology, and writing—review & editing. All authors read and approved the final paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Houssein, E.H., Hammad, A. & Ali, A.A. Human emotion recognition from EEG-based brain–computer interface using machine learning: a comprehensive review. Neural Comput & Applic 34, 12527–12557 (2022). https://doi.org/10.1007/s00521-022-07292-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-022-07292-4