
Abstract
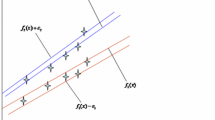
This paper improves the recently proposed twin support vector regression (TSVR) by formulating it as a pair of linear programming problems instead of quadratic programming problems. The use of 1-norm distance in the linear programming TSVR as opposed to the square of the 2-norm in the quadratic programming TSVR leads to the better generalization performance and less computational time. The effectiveness of the enhanced method is demonstrated by experimental results on artificial and benchmark datasets.

Similar content being viewed by others

Notes
Available from http://lib.stat.cmu.edu/datasets/.
Available from http://www.itl.nist.gov/div898/strd/nls/nls-main.shtml.
References
Bi J, Bennett KP (2003) A geometric approach to support vector regression. Neurocomputing 55:79–108
Blake CI, Merz CJ (1998) UCI repository for machine learning databases. [http://www.ics.uci.edu/~mlearn/MLRepository.html]
Chang C-C, Lin C-J (2001) LIBSVM: a library for support vector machines. [http://www.csie.ntu.edu.tw/~cjlin]
Cherkassky V, Ma YQ (2004) Practical selection of SVM parameters and noise estimation for SVM regression. Neural Netw 17:113–126
Christianini V, Shawe-Taylor J (2002) An introduction to support vector machines and other kernel-based learning methods. Cambridge University Press, Cambridge
De Boor C, Rice JR (1968) Least-squares cubic spline approximation. II: variable knots, CSD Technical Report 21, Purdue University, IN
Demšar J (2006) Statistical comparisons of classifiers over multiple data sets. J Mach Learn Res 7:1–30
Ghorai S, Mukherjee A, Dutta PK (2009) Nonparallel plane proximal classifier. Signal Proc 89:510–522
Ghorai S, Hossain SJ, Mukherjee A, Dutta PK (2010) Newton’s method for nonparallel plane proximal classifier with unity norm hyperplanes. Signal Proc 90:93–104
Jayadeva, Khemchandani R, Chandra S (2007) Twin support vector machines for pattern classification. IEEE Trans Pattern Anal Mach Intell 29(5):905–910
Joachims T (1999) Making large-scale SVM learning practical. In: Schölkopf B, Burges CJC, Smola AJ (eds) Advances in Kernel methods–support vector learning. MIT Press, Cambridge, pp 169–184
Jiao L, Bo L, Wang L (2007) Fast sparse approximation for least squares support vector machine. IEEE Trans Neural Netw 18(3):685–697
Keerthi SS, Shevade SK, Bhattacharyya C, Murthy K (2001) Improvements to Platt’s SMO algorithm for SVM classifier design. Neural Comput 13(3):637–649
Keerthi SS, Shevade SK (2003) SMO algorithm for least squares SVM formulations. Neural Comput 15(2):487–507
Kumar MA, Gopal M (2008) Application of smoothing technique on twin support vector machines. Pattern Recogn Lett 29:1842–1848
Kumar MA, Gopal M (2009) Least squares twin support vector machines for pattern classification. Expert Syst Appl 36:7535–7543
Kruif BJ, Vries A (2004) Pruning error minimization in least squares support vector machines. IEEE Trans Neural Netw 14(3):696–702
Lee Y-J, Hsieh W-F, Huang C-M (2005) ɛ-SSVR: a smooth support vector machine forɛ -insensitive regression. IEEE Trans Knowl Data Eng 17(5):678–685
Mangasarian OL, Wild EW (2006) Multisurface proximal support vector classification via generalized eigenvalues. IEEE Trans Pattern Anal Mach Intell 28(1):69–74
Mangasarian OL (2006) Exact 1-norm support vector machine via unconstrained convex differentiable minimization. J Mach Learn Res 7:1517–1530
Osuna E, Freund R, Girosi F (1997) An improved training algorithm for support vector machines. In: Principe J, Gile L, Morgan N, Wilson E (eds) Neural networks for signal processing VII–proceedings of the 1997 IEEE workshop. IEEE. pp 276–285
Peng X (2009) TSVR: an efficient twin support vector machine for regression. Neural Netw. doi:10.1016/j.neunet.2009.07.002
Platt JC (1999) Fast training of support vector machines using sequential minimal optimization. In: Schölkopf B, Burges CJC, Smola AJ (eds) Advances in kernel methods–support vector learning. MIT Press, Cambridge, pp 185–208
Shevade SK, Keerthi SS, Bhattacharyya C, Murthy KRK (2000) Improvements to the SMO algorithm for SVM regression. IEEE Trans Neural Netw 11(5):1188–1193
Suykens JAK, Vandewalle J (1999) Least squares support vector machine classifiers. Neural Proc Lett 9(3):293–300
Suykens JAK, Gestel T, Brabanter J, Moor B, Vandewalle J (2002) Least squares support vector machines. World Scientific, Singapore
Vapnik VN (1995) The natural of statistical learning theory. Springer, New York
Vapnik VN (1998) Statistical learning theory. Wiley, New York
Wang W, Xu Z (2004) A heuristic training for support vector regression. Neurocomputing 61:259–275
Zeng XY, Chen XW (2005) SMO-based pruning methods for sparse least squares support vector machines. IEEE Trans Neural Netw 16(6):1541–1546
Zhao Y, Sun J (2009) Recursive reduced least squares support vector regression. Pattern Recogn 42:837–842
Acknowledgments
The authors gratefully acknowledge the helpful comments and suggestions of the reviewers, which have improved the presentation. The work is supported by the National Science Foundation of China (Grant No. 70601033) and Innovation Fund for Graduate Student of China Agricultural University (Grant No. KYCX2010105).
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
We show the computational process of the average rank of the three algorithms on RMSE values in Table 6.
Rights and permissions
About this article
Cite this article
Zhong, P., Xu, Y. & Zhao, Y. Training twin support vector regression via linear programming. Neural Comput & Applic 21, 399–407 (2012). https://doi.org/10.1007/s00521-011-0525-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-011-0525-6