
Abstract
Human action recognition using skeletons has become increasingly appealing to a growing number of researchers in recent years. It is particularly challenging to recognize actions when they are captured from different angles because there are so many variations in their representations. This paper proposes an automatic strategy for determining virtual observation viewpoints that are based on learning and data driven to solve the problem of view variation throughout an act. Our VA-CNN and VA-RNN networks, which use convolutional and recurrent neural networks with long short-term memory, offer an alternative to the conventional method of reorienting skeletons according to a human-defined earlier benchmark. Using the unique view adaption module, each network first identifies the best observation perspectives and then transforms the skeletons for end-to-end detection with the main classification network based on those viewpoints. The suggested view adaptive models can provide significantly more consistent virtual viewpoints using the skeletons of different perspectives. By removing views, the models allow networks to learn action-specific properties more efficiently. Furthermore, we developed a two-stream scheme (referred to as VA-fusion) that integrates the performance of two networks to obtain an improved prediction. Random rotation of skeletal sequences is used to avoid overfitting during training and improve the reliability of view adaption models. An extensive experiment demonstrates that our proposed view adaptive networks outperform existing solutions on five challenging benchmarks.







Similar content being viewed by others
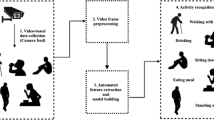

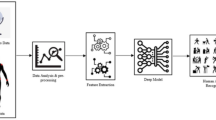
Data availability
The codes and data are available under request from the authors.
References
Aggarwal JK, Xia L (2014) Human activity recognition from 3d data: a review. Pattern Recogn Lett 48:70–80
Ba Jimmy Lei, Kiros Jamie Ryan, Hinton Geoffrey E (2016) Layer normalization. arXiv preprint arXiv:1607.06450
Bashir FI, Khokhar AA, Schonfeld D (2006) View-invariant motion trajectory-based activity classification and recognition. Multimedia Syst 12(1):45–54
Chi HG, Ha MH, Chi S, Lee SW, Huang Q, Ramani K (2022) InfoGCN: representation Learning for Human Skeleton-Based Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 20186–20196
Chi HG, Ha MH, Chi S, Lee SW, Huang Q, Ramani K (2022) InfoGCN: Representation Learning for Human Skeleton-Based Action Recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 20186–20196
Donahue J et al (2015) Long-term recurrent convolutional networks for visual recognition and description. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 2625–2634
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S, et al (2020) An image is worth 16x16 words: transformers for image recognition at scale. arXiv preprint arXiv:2010.11929
Du Y, Fu Y, Wang L (2016) Representation learning of temporal dynamics for skeleton- based action recognition. IEEE Trans Image Process 25(7):3010–3022
Du Y, Wang W, Wang L (2015) Hierarchical recurrent neural network for skeleton based action recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1110–1118
Evangelidis G, Singh G, Horaud R (2014) Skeletal quads: human action recognition using joint quadruples. In: 2014 22nd International Conference on Pattern Recognition, IEEE, pp 4513–4518
Farhadi A, Tabrizi MK (2008) “Learning to recognize activities from the wrong view point. In: European conference on computer vision, Springer, pp 154–166
Feng J-G, Xiao J (2015) View-invariant human action recognition via robust locally adaptive multi-view learning. Front Inf Technol Electron Eng 16(11):917–929
Gheflati B, Rivaz H (2021) Vision transformer for classification of breast ultrasound images. arXiv preprint arXiv:2110.14731
Han F, Reily B, Hoff W, Zhang H (2017) Space-time representation of people based on 3D skeletal data: a review. Comput Vis Image Underst 158:85–105
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 770–778
Hu J-F, Zheng W-S, Lai J, Zhang J (2015) Jointly learning heterogeneous features for RGB-D activity recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 5344–5352
Hu J-F, Zheng W-S, Ma L, Wang G, Lai J (2016) Real-time RGB-D activity prediction by soft regression. In: European Conference on Computer Vision, Springer, pp 280–296
Iosifidis A, Tefas A, Pitas I (2012) View-invariant action recognition based on artificial neural networks. IEEE Trans Neural Netw Learn Syst 23(3):412–424
I. R. (2014) Computer vision in robotics comes into focus. https://software.intel.com/en-us/realsense, in 2014
Ji X, Liu H (2010) Advances in view-invariant human motion analysis: a review. In IEEE Transcation on Systems, Man, Cybernetics 40(1)
Ji Y, Ye G, Cheng H (2014) Interactive body part contrast mining for human interaction recognition. In: 2014 IEEE International Conference on Multimedia and Expo Workshops (ICMEW), IEEE, pp 1–6
Junejo IN, Dexter E, Laptev I, Púrez P (2008) Cross-view action recognition from temporal self-similarities. In: European Conference on Computer Vision, Springer, pp 293–306
Ke Q, Bennamoun M, An S, Sohel F, Boussaid F (2017) A new representation of skeleton sequences for 3d action recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 3288–3297
Kingma DP, Ba J (2014) Adam: a method for stochastic optimization,” arXiv preprint arXiv:1412.6980
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. Adv Neural Inf Process Syst 25
Li R, Wang H (2022) Graph convolutional networks and LSTM for first-person multimodal hand action recognition. Mach Vis Appl 33(6):1–16
Li B, Dai Y, Cheng X, Chen H, Lin Y, He M (2017) Skeleton based action recognition using translation-scale invariant image mapping and multi-scale deep CNN. In: 2017 IEEE International Conference on Multimedia Expo Workshops (ICMEW), IEEE, pp 601–604
Liu M, Liu H, Chen C (2017) Enhanced skeleton visualization for view invariant human action recognition. Pattern Recogn 68:346–362
Liu J, Shah M, Kuipers B, Savarese S (2011) Cross-view action recognition via view knowledge transfer. In: CVPR 2011, IEEE, pp 3209–3216
Liu J, Wang G, Hu P, Duan L-Y, Kot AC (2017) Global context-aware attention lstm networks for 3d action recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1647–1656
Li R, Zickler T (2012) Discriminative virtual views for cross-view action recognition. In: 2012 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, pp 2855–2862
Ma Y, Yu C, Yan M, Sangaiah AK, Wu Y (2023) Dark-side avoidance of mobile applications with data biases elimination in socio-cyber world. IEEE Trans Comput Social Syst. https://doi.org/10.1109/TCSS.2023.3264696
Mahasseni B, Todorovic S (2013) Latent multitask learning for view-invariant action recognition. In: Proceedings of the IEEE International Conference on Computer Vision, pp 3128–3135
Mahmood F, Abbas K, Raza A, Khan MA, Khan PW (2019) Three dimensional agricultural land modeling using unmanned aerial system (UAS). Int J Adv Comput Sci Appl 10(1):443–449
Mehmood F, Chen E, Akbar MA, Alsanad AA (2021) Human action recognition of spatiotemporal parameters for skeleton sequences using MTLN feature learning framework. Electronics 10(21):2708
Poppe R (2010) A survey on vision-based human action recognition. Image Vis Comput 28(6):976–990
Presti LL, La Cascia M (2016) 3D skeleton-based human action classification: a survey. Pattern Recogn 53:130–147
Rahmani H, Bennamoun M (2017) Learning action recognition model from depth and skeleton videos. In: Proceedings of the IEEE International Conference on Computer Vision, pp 5832–5841
Rao C, Shah M (2001) View-invariance in action recognition. In: Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, 2: II–II
Razzaq A, Moughal T, Zia M, Qadri S, Muhammad S (2018) Robust kinematic skeleton of human 3D model in viewing straight limbs. Pak J Sci 70(4):342
Shahroudy A, Liu J, Ng T-T, Wang G (2016) Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1010–1019
Sangaiah AK, Javadpour A, Ja’fari F, Zhang W, Khaniabadi SM (2022) Hierarchical clustering based on dendrogram in sustainable transportation systems. IEEE Trans Intell Transp Syst. https://doi.org/10.1109/TITS.2022.3222789
Shotton J et al (2011) Real-time human pose recognition in parts from single depth images. In: CVPR 2011, IEEE, pp 1297–1304
Song YF, Zhang Z, Shan C, Wang L (2022) Constructing stronger and faster baselines for skeleton-based action recognition. IEEE Trans Pattern Anal Mach Intell
Song S, Lan C, Xing J, Zeng W, Liu J (2017) An end-to-end spatio-temporal attention model for human action recognition from skeleton data. In: Proceedings of the AAAI Conference on Artificial Intelligence 31(1)
Soomro K, Zamir AR, Shah M (2012) UCF101: a dataset of 101 human actions classes from videos in the wild,” arXiv preprint arXiv:1212.0402
Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R (2014) Dropout: a simple way to prevent neural networks from overfitting. J Mach Learn Res 15(1):1929–1958
Sutskever I, Vinyals O, Le QV (2014) Sequence to sequence learning with neural networks. Adv Neural Inf Process Syst 27
Tran D, Bourdev L, Fergus R, Torresani L, Paluri M (2015) Learning spatiotemporal features with 3d convolutional networks. In: Proceedings of the IEEE International Conference on Computer Vision, pp 4489–4497
Vemulapalli R, Arrate F, Chellappa R (2014) Human action recognition by representing 3d skeletons as points in a lie group. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 588–595
Wang L, et al (2016) Temporal segment networks: towards good practices for deep action recognition. In: European Conference on Computer Vision, Springer, pp 20–36
Wang X, Girshick R, Gupta A, He K (2018) Non-local neural networks, In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 7794–7803. https://doi.org/10.1109/CVPR.2018.00813
Wang J, Nie X, Xia Y, Wu Y, Zhu S-C (2014) Cross-view action modeling, learning and recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 2649–2656
Weinland D, Ronfard R, Boyer E (2011) A survey of vision-based methods for action representation, segmentation, and recognition. Comput Vis Image Underst 115(2):224–241
Weinland D, Özuysal M, Fua P (2010) Making action recognition robust to occlusions and viewpoint changes. In: European Conference on Computer Vision, Springer, pp 635–648
Wu X, Wang H, Liu C, Jia Y (2013) Cross-view action recognition over heterogeneous feature spaces. In: Proceedings of the IEEE International Conference on Computer Vision, pp 609–616
Xia L, Chen C-C, Aggarwal JK (2012) View invariant human action recognition using histograms of 3d joints. In: 2012 IEEE computer society conference on computer vision and pattern recognition workshops, IEEE, pp 20–27
Xu Q, Zheng W, Song Y, Zhang C, Yuan X, Li Y (2021) Scene image and human skeleton-based dual-stream human action recognition. Pattern Recogn Lett 148:136–145
Yan S, Xiong Y, Lin D (2018) Spatial temporal graph convolutional networks for skeleton- based action recognition. In: Thirty-Second AAAI Conference on Artificial Intelligence
Ye F, Pu S, Zhong Q, Li C, Xie D, Tang H (2020) Dynamic gcn: Context-enriched topology learning for skeleton-based action recognition. In: Proceedings of the 28th ACM International Conference on Multimedia, pp 55–63
Yun K, Honorio J, Chattopadhyay D, Berg TL, Samaras D (2012) Two-person interaction detection using body-pose features and multiple instance learning. In: 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, IEEE, pp 28–35
Zhang Z (2012) Microsoft kinect sensor and its effect. IEEE Multimedia 19(2):4–10
Zhang J, Li W, Ogunbona PO, Wang P, Tang C (2016) RGB-D-based action recognition datasets: a survey. Pattern Recogn 60:86–105
Zhang Z, Wang C, Xiao B, Zhou W, Liu S, Shi C (2013) Cross-view action recognition via a continuous virtual path. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 2690–2697
Zhu W et al (2016) Co-occurrence feature learning for skeleton based action recognition using regularized deep LSTM networks. In: Proceedings of the AAAI conference on artificial intelligence 30(1)
Zhang J, Feng W, Yuan T, Wang J, Sangaiah AK (2022) SCSTCF: spatial-channel selection and temporal regularized correlation filters for visual tracking. Appl Soft Comput 118:108485
Funding
This work was supported in part by the National Natural Science Foundation of China under Grants 62101503 and 62101505, and Henan Science and Technology Research Project under Grants 222102210102.
Author information
Authors and Affiliations
Contributions
Methodology and formal analysis are done by Faisal Mehmood, Enqing Chen, and Touqeer Abbas; project administration and data curation are done by Muhammad Azeem Akbar; and the final revision and English polishing are done by Arif Ali Khan. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Ethical approval
Not applicable as there are no human and or animal data involved.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Mehmood, F., Chen, E., Abbas, T. et al. Automatically human action recognition (HAR) with view variation from skeleton means of adaptive transformer network. Soft Comput (2023). https://doi.org/10.1007/s00500-023-08008-z
Accepted:
Published:
DOI: https://doi.org/10.1007/s00500-023-08008-z