
Abstract
Modeling wind speed data is the prime requirement for harnessing the wind energy potential at a given site. While the Weibull distribution is the most commonly employed distribution in the literature and in practice, numerous scientific articles have proposed various alternative continuous probability distributions to model the wind speed at their convenient sites. Fitting the best distribution model to the data enables the practitioners to estimate the wind power density more accurately, which is required for wind power generation. In this paper we comprehensively review fourteen continuous probability distributions, and investigate their fitting capacities at seventeen locations of India covering the east and west offshore corner as well as the mainland, which represents a large variety of climatological scenarios. A first main finding is that wind speed varies a lot inside India and that one should treat each site individually for optimizing wind power generation. A second finding is that the wide acceptance of the Weibull distribution should at least be questioned, as it struggles to represent wind regimes with heterogeneous data sets exhibiting multimodality, high levels of skewness and/or kurtosis. Our study reveals that mixture distributions are very good alternative candidates that can model difficult shapes and yet do not require too many parameters.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
1.1 Historical development of wind speed modeling with probability distributions
Mid 20th Century was an epoch when the world started exploring the wind energy potential. With its emerging demand for power and vulnerability to oil crises, India started its wind energy program in 1983–84. The success of the wind energy program lies in the accuracy of the assessment of wind flow patterns at a potential site. Wind energy is a site-specific and intermittent source of power. Therefore, an extensive wind resources assessment is an essential prerequisite for harnessing the wind power potential at a given site. Wind resource assessment estimates wind flow patterns based on several factors: available wind data, topographical conditions, meteorological conditions, etc. This necessitates the involvement of statistics in evaluating wind flow patterns, which is critical in designing mega-structures and optimizing energy generation from the wind. In statistical terms, the wind flow pattern is not stable in the short term. Nonetheless, it exhibits a consistent and stable pattern over the long term (except for radical and lasting changes due to climate change, which can be spotted by statistical approaches such as change-point detection Aminikhanghahi and Cook (2017)). According to Zhang (2015), wind statistics is a scientific field that examines the wind patterns over a significant duration. Wind data is viewed as a continuous random variable, leading to the use of continuous probability distributions to model the predictable wind pattern. Since the 1940s till today, several papers have been published that used different continuous probability distributions to describe the wind speed, including (Akpinar and Akpinar 2004a, 2009; Jaramillo and Borja 2004; Carta and Ramirez 2007a, b; Carta and Mentado 2007; Gokcek et al. 2007; Vicente 2008; Akdağ et al. 2010; Fyrippis et al. 2010; Safari and Gasore 2010; Chang 2011b; Morgan et al. 2011; Safari 2011; Soukissian 2013; Zhang et al. 2013; Alavi et al. 2016; Hu et al. 2016; Jung et al. 2017; Kantar et al. 2018) and Mohammadi et al. (2017). Distributions with up to 2 parameters were used to model unimodal data, while data exhibiting bimodality have been modeled using multi-parameter distributions, in particular as mixtures of 2-parameter distributions.
Sherlock (1951) recommended utilizing the Pearson type III distribution which is essentially the Gamma distribution, due to its successful and widespread use. The distribution employs two parameters, a scale parameter and a shape parameter and performs well in modeling natural phenomena specificity velocity data.
Luna and Church (1974) used the 2-parameter log-normal distribution for studying air pollution level. The same distribution was implemented by Kaminsky (1977) and Justus (1978) for wind speed analyses, but since then it has only very rarely been considered for fitting this type of data (Tar 2008; Garcia et al. 1998; Bogardi and Matyasovzky 1996).
In the 1970s, the Rayleigh (R) and Weibull (W) distributions entered the scene to model the wind speed (Hennessey Jr 1978). Until the late 1990s, the Weibull distribution proves to be superior to earlier distributions with a low (\(<=2\)) number of parameters (Morgan 1995; Akpinar and Akpinar 2004b, 2005; Pishgar-Komleh et al. 2015; Pishgar-Komleh and Akram 2017). Therefore, it has been a part of widely used computer modeling softwares such as HOMER (Rehman et al. 2007; Van Alphen et al. 2007) and WASP (Hunter and Elliot 1994; Sahin et al. 2005). For instance, the Weibull distribution showed better fitting than Rayleigh (Bidaoui et al. 2019), exponential, square root normal, log-normal and Gamma distributions (Chang 2011b). However, it is well known that the Weibull distribution is not suitable for fitting bimodal data or data with high volume (\(>15\) % of total wind data set) of low wind speed (meaning 0 m/s) (Carta and Ramírez 2007a, b). Therefore a lot of research efforts have been oriented to find alternatives for and modifications to the Weibull distribution (e.g., Chadee and Sharma (2001); Carta and Mentado (2007); Bali and Theodossiou (2008); Akpinar and Akpinar (2009); Akdağ et al. (2010); Chang (2011b); Chellali et al. (2012); Akgül et al. (2016); Bracale et al. (2017); Aries et al. (2018)). A 3-parameter Weibull distribution with an added location parameter is another suitable alternative to fit wind data of low wind speed (Chalamcharla and Doraiswamy 2016). However, Chadee and Sharma (2001) noted that including the extra location parameter in the estimation process creates challenges, and a positive value for this parameter results in an unrealistic condition of zero probability of wind speeds less than the parameter value. To address high probabilities of zero wind speeds, Carta et al. (2008) proposed using a singly truncated normal (TN) distribution. In cases where wind speed data has infrequent low speeds, Bardsley (1980) recommended the use of the inverse Gaussian distribution as a viable alternative to the 3-parameter Weibull distribution with a positive location parameter. Bivona et al. (2003) fitted all non-zero wind speeds with the Weibull distribution and treated zero wind speeds separately. Table 1 shows comparative studies of the most classical 2-parameter distributions for wind speed modeling.
As there was no universal acceptance of the Weibull distribution (Carta et al. 2009), the search for other distributions intensified, leading to numerous studies, and new distributions were developed. Ouarda et al. (2016) revealed the importance of skewness and kurtosis while modeling the data sets. Some new distributions which were earlier used in other applications were also tested for goodness-of-fit of wind speed data. Soukissian (2013) has introduced the 4-parameter Johnson \(S_B\) distribution for wind speed data modeling and compared it with the Weibull distribution. He revealed that indiscriminate use of the Weibull distribution is unjustified and found that the Johnson \(S_B\) distribution is a much more suitable model for 11 and 8 buoys of Eastern and Western Mediterranean Sea, respectively.
Various authors have proposed using two-component mixture distributions with different weight proportions to model bimodal wind speed data. Most proposed mixture distributions comprise a Weibull component (Jaramillo and Borja 2004; Carta and Ramírez 2007a;b; Akpinar and Akpinar 2009; Akdağ et al. 2010; Shin et al. 2016) and are typically of the type Weibull–Weibull, truncated normal-Weibull, and Gamma-Weibull. Table 2 provides a summary of articles in which mixture models have been applied for wind speed modeling.
1.2 Review of methods used for parameter estimation in continuous probability distributions
There exist numerous different methods to estimate the parameters of continuous probability distributions, such as for instance the method of moments (MoM), the least square method (LSM), the L-moment method and the maximum likelihood method (ML). Various articles have compared distinct methods in the context of wind data modeling, including (Akdağ and Dinler 2009; Carta et al. 2009; Bagiorgas et al. 2011; Chang 2011a; Morgan et al. 2011; Saleh et al. 2012; Arslan et al. 2014; Azad et al. 2014; De Andrade et al. 2014; Akdağ and Güler 2015; Mohammadi et al. 2016). In the next paragraph we shall briefly point out the pros and cons of these methods, and refer the reader to Gugliani et al. (2018) for a more detailed analysis.
For the LSM, the best estimator is the one that minimizes the sum of squared errors between the observed and the corresponding theoretical values from the distribution. The LSM thus is based on the cumulative distribution function (cdf) of a continuous random variable, function which describes the probability for this random variable to be smaller than a given value. This can lead to complex calculations, in which case it is recommended to solve the equation using a nonlinear technique such as Levenberg–Marquardt (Akdağ et al. 2010).
The MoM is the simplest computational method as it estimates the distribution’s parameters using the sample moments. In this way, the parameters are estimated by equating the theoretical moments with the sample moments. However, the method has certain drawbacks (e.g., it can lack robustness), as pointed out in Akdağ and Dinler (2009).
Hosking (1990) proposed the L-moment as another important parameter estimation method. The L-moments are more robust than conventional moments to outliers in the data and enable more secure inferences to be made from small samples about an underlying probability distribution. They are less susceptible to sampling variability, which makes it more suitable for modeling extreme data. Several authors (Gubareva 2011; Murshed et al. 2011; Strupczewski et al. 2011; Papalexiou and Koutsoyiannis 2013; Rutkowska et al. 2017; Ul Hassan et al. 2019; Nerantzaki and Papalexiou 2022) have utilized this method to fit generalized extreme value distributions to rainfall, flood, streamflow data across various parts of the world. Comparative studies of this method with other two methods, viz., MLE and MoM reveals that it is equivalently good as compared to MLE (Rowinski et al. 2002; Gubareva and Gartsman 2010; Hu et al. 2020) and outperforms MoM in parameter estimation (Murshed et al. 2011; Vivekanandan 2015).
The ML method selects those values of parameters that maximize the probability under that distribution of obtaining the randomly observed sample. Suppose \((v_1, v_2, \ldots , v_n)\) is the vector of the observations and \(\varvec{\theta }\) is the vector of the parameters. The likelihood function is defined as the product of probability density functions (pdfs), which we denote here as f, evaluated at each individual observation
Subsequently, the log-likelihood function is obtained as
By setting the partial derivatives of the log-likelihood function with respect to \(\varvec{\theta }\) to zero
the maximum likelihood estimates (MLEs) of the parameters are obtained by solving the system of equations, however solving the likelihood equations can be tricky and require numerical methods (Chang 2011a).
1.3 Model selection criteria
In the statistical literature, there exist various criteria to identify the best-fitting distribution for a given data set. In studies about wind speed data, the most commonly used are the coefficient of determination (\(R^2\)), the root mean square error (RMSE) (Akdağ et al. 2010; Aries et al. 2018), the chi-square (\(\chi ^2\)) (Akpinar and Akpinar 2009) and the Kolmogorov–Smirnov (K–S) goodness-of-fit tests (Ayyub and McCuen 2016; Chang 2011a).
In this paper, the K–S goodness-of-fit test has been used to measure the closeness of the fitted cdf with the cumulative relative frequency of the sample wind speed data and to indicate whether or not a distribution is suitable to fit a given data set. The K–S test is defined as the max-error between two cumulative distribution functions
where F(v) is a fitted cdf and G(v) is the cumulative relative frequency of a sample.
However, among all acceptable distributions, they do not tell which one fits best (p-values only serve to reject a distribution for fit or not, but one should not compare p-values among themselves to rank distributions). Such a ranking is provided by information criteria such as the Akaike Information Criterion (AIC) which is based on a compromise between the goodness-of-fit of a distribution in terms of the likelihood function and the number of parameters to estimate, and this compromise is obtained via a penalization on that number. The mathematical expression for AIC is given as
where L is the likelihood and N is the number of parameters of the model. The smallest AIC value indicates the most suitable distribution. This distribution, however, is not guaranteed to give a reasonable fit (the AIC would also choose the best among bad-fitting distributions). Therefore the best strategy is to first compare distributions via the AIC and then test the best-fitting distribution through the K–S goodness-of-fit test.
1.4 Contribution of the present paper
Given the plethora of different proposals of distributions for modeling wind speed, it is not obvious to know which one to use. As indicated in Tables 1 and 2, comparisons have already been made, but so far no paper has done a really exhaustive comparison taking also mixture components into account. Moreover, the comparison of distributions in the literature is mostly along the coastal line of countries, and often a single distribution performs better than others for all the locations under consideration. However, this factor is not valid for a vast country like India. The main land of India is full of various hills across its geography. These hilly regions also have the capability to harness the wind energy potential. The additional advantage of these hilly regions is that they are not prone to cyclones thanks to their higher topography compared to surrounding land. Once wind turbines have been installed, they can operate at their full capacity producing uninterrupted power supply, without the fear of damage to the power plant. Therefore, in this study, we have taken as many as seventeen locations covering the main land, western coastal region, and eastern coastal region of India, so that the manufacturers can identify the most suitable distributions for their probable site before installing the power plant.
The wind speed data utilized in this study were recorded at a height of \(10 \mathrm {~m}\) by the Indian Meteorological Department (IMD), Pune, assuming no density variation occurs vertically with height for long slender structures. The vertical change in wind speed with altitude typically follows the power law. Upon estimating the mean wind speed at a height of \(10 \mathrm {~m}\) using parameters from the most appropriate distribution, the mean wind speed at higher altitudes will be computed using the power law. This computation will enable a judicious selection of the type of wind turbine required for installation at a specific height. Consequently, a comparative evaluation of various distributions is necessary to assess the most suitable distribution for site-specific wind speed data. This evaluation is crucial in determining the appropriate wind turbine for optimal performance at different altitudes.
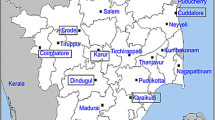
Following these motivations, in this paper we review and compare various probability distributions that have been suggested over the years by different researchers for wind resources assessment. Moreover, we shall also include some novel distributions that have primarily been used in other domains such as economics and reliability analysis or financial assessment. Many more (too many) probability distributions exist for describing positive data, see Sinner et al. (2022) for an overview. We restrict to those fourteen that we judge most important for modeling wind speed (see Sect. 2), and we estimate their parameters by the ML method, yielding precise estimates with minimal variance. The ML method allows us to use the AIC as criterion to compare the distributions. According to Ley et al. (2021), a good probability distribution should both be versatile, i.e. fit various distinct shapes, and parameter parsimonious, hence ideally not have too many parameters as this complicates interpretation and can lead to overfitting. Therefore, we choose the AIC as a goodness-of-fit criterion and the Kolmogorov–Smirnov test as a goodness-of-fit test. As case study we consider long-term wind speed data of seventeen onshore locations in India, which are described in Sect. 3. Nine sites lie in the seven windy states of India, and eight sites are from the state with zero wind power generation (as per physical report published by the Ministry of New & Renewable Energy). See Fig. 1. The results are presented and discussed in Sect. 4, while Sect. 5 provides a conclusion.

The locations of the seventeen considered stations in India (https://www.surveyofindia.gov.in/pages/outline-maps-of-india)
2 Overview of the considered continuous distributions
The distributions relevant for this study are briefly described in what follows. We start from 1- and 2-parameter distributions and end with 4- and 5-parameter distributions.
2.1 Weibull distribution
The 2-parameter Weibull distribution (W) is a classical distribution for wind speed data analysis, in particular unimodal frequency distributions. Originally the Weibull-distribution has 3 parameters, the third being known as the location parameter used for defining the lowest value in a data set. Since for wind speed this corresponds to 0, the location parameter can be dropped (or, say, implicitly equated to 0) and the 3-parameter Weibull distribution simplifies to the 2-parameter Weibull distribution. This 2-parameter Weibull distribution has been extensively employed to estimate the wind power potential or, to be more specific, in the estimation of wind characteristics, see e.g. Bivona et al. (2003); Akpinar and Akpinar (2004a, 2005); Gokcek et al. (2007); Fyrippis et al. (2010); Safari and Gasore (2010); Dursun et al. (2011); Baseer et al. (2017). The pdf and cdf of the 2-parameter Weibull distribution are respectively given by
and
where k is the non-dimensional shape parameter and s the scale parameter whose dimension is the same as that of the variable v. For clarification purposes we mention that the variable v stands for the wind speed that we wish to model. Besides a reasonably good fit to wind speed data, there are two further reasons for the popularity of the Weibull distribution: (a) there exist formulas that allow a vertical extrapolation of the wind characteristics (Tar 2008; Safari and Gasore 2010), and (b) it is very practical for calculating the capacity factor, power coefficient, and output power of wind turbines (Jangamshetti and Rau 1999; Dursun et al. 2011; Gugliani et al. 2021).
2.2 Rayleigh distribution
The Rayleigh (R) distribution is a 1-parameter distribution that arises as a special case of the Weibull distribution whose shape parameter is fixed to 2. Consequently, the expression of pdf and cdf of the Rayleigh distribution are given as
and
2.3 Birnbaum–Saunders distribution
The 2-parameter Birnbaum–Saunders (BS) distribution is known as fatigue life distribution and was promoted in the two papers Birnbaum and Saunders (1969a, b). It has been developed by making a monotonic transformation of the standard normal random variable. The pdf and cdf of the BS distribution are given as
and
where \(\beta\) is a scale parameter, \(\alpha\) is a shape parameter and \(\Phi\) (.) is the standard normal cdf.
2.4 Gamma distribution
The Gamma (G) distribution is a 2-parameter distribution whose curve drops off much more gradually than that of the exponential distribution for shape parameters \(\zeta\) > 1 and more quickly for \(\zeta\)< 1. The pdf and cdf are
and
where \(\zeta\) and \(\beta\) are the shape and scale parameters, respectively, and \(\Gamma (.)\) is the gamma function. The chi-squared distribution is a special case of the Gamma corresponding to \(\beta =2\) and \(\zeta =k/2\) for some positive integer k.
2.5 Nakagami distribution
The 2-parameter Nakagami (Na) distribution is strongly related to the G distribution (Nakagami 1960) and it is extensively used in communication engineering (Pajala et al. 2006; Beaulieu and Cheng 2005). Suppose V has the G distribution in (2), then \(\sqrt{V/\zeta }\) follows the Na distribution. The pdf and cdf of the Nakagami distribution are given as
and
where P and \(\Gamma\) are the upper incomplete gamma and gamma functions, respectively.
2.6 Log-normal distribution
If a random variable V follows the log-normal (LN) distribution, then \(Y = \ln V\) has the normal distribution. The expressions for the pdf and cdf of the log-normal distribution are
and
2.7 Truncated normal distribution
If the support of the density of a normal random variable Y is truncated on the left at zero, the resulting truncated random variable \(V > 0\) follows the truncated normal (TN) distribution with pdf and cdf
and
2.8 Inverse Gaussian distribution (Wald distribution)
The inverse Gaussian (IG) is a skewed, 2-parameter distribution which is similar to the Gamma distribution with greater skewness and a sharper peak. The name is misleading in the sense that an IG random variable is not obtained as inverse of a normal random variable, but it is related to two distinct quantities of Brownian motions that the IG and normal describe. This distribution is suitable to fit unimodal and positively skewed data sets. The pdf of the IG is given as
where \(\mu\) 0 is the mean and \(\lambda\) 0 is the shape parameter. The cdf can be expressed in terms of the standard normal distribution function \(\Phi (.)\) by
The IG has the property that if a random variable V follows the inverse Gaussian distribution with parameters \(\mu\) and \(\lambda\), then a scalar multiple cV with \(c>0\) follows the same distribution with parameters \(c\mu\) and \(c\lambda\), respectively.
2.9 Johnson S\({}_{B}\) distribution
The Johnson S\({}_{B}\) (JSB) distribution is one of the Johnson distributions (Johnson 1949) and remarkably flexible. This flexibility is owed to the presence of 4 parameters; as of now, we move indeed from 2-parameter distributions to distributions with 4 or more parameters. The pdf and cdf of the JSB distribution are given by
and
where \(\xi \le v\le \xi +\lambda\), \(\xi\) is the location parameter, \(\lambda\)> 0 is the scale parameter and \(\gamma\) and \(\delta\) > 0 are shape parameters. The JSB distribution actually also has been derived from a normal distribution. Indeed, if a random variable V follows the JSB distribution, then \(Z=\gamma +\delta \ln \left( \frac{Y}{1-Y}\right)\) with \(Y=(V-\xi )/\lambda\) follows the standard normal distribution.
2.10 Generalized beta distribution of the second kind
The generalized beta distribution of the second kind (GB2) introduced by McDonald and Xu (1995) is a 4-parameter flexible distribution which is mostly applied as a size distribution of income in economics. The pdf of the GB2 is given by
where \(a,p,q>0\) are shape parameters, \(b>0\) is a scale parameter and \(B(p,q)=\frac{\Gamma (p)\Gamma (q)}{\Gamma (p+q)}\) is the beta function. The cdf of the GB2 is
where \(I_{x}(p,q)=\frac{B_x(p,q)}{B(p,q)}\) is the incomplete beta function.
2.11 Generalized hyperbolic distribution
The generalized hyperbolic (GH) distribution is a 5-parameter distribution introduced by Barndorff-Nielsen (1978) and contains numerous well-known special cases such as variance-gamma, Laplace, hyperbolic, Student’s t, Cauchy, normal inverse Gaussian and normal distributions. It can model skew as well as light- and heavy-tailed data. Through a location-scale transformation, the pdf of the GH distribution is given as
with
and
where m and \(\delta\) are the mean and variance of the distribution, respectively, where \(K{}_{\lambda }\)(.) denotes the modified Bessel function of the third kind with order \(\lambda\) \(\in {\mathbb {R}}\) , \(\lambda\) and \(\alpha\) > 0 are shape parameters, |\(\beta\)|< 1 is a skewness parameter, \(\sigma\) > 0 a scale parameter and \(\mu\) \(\in {\mathbb {R}}\) a location parameter.
2.12 Mixture distributions
Consider a finite set of pdfs \(f_1(v),..., f_k(v)\) and weights \(w_1,..., w_k\) such that \(w_i \ge 0\) and \(\sum _{i=1}^{k} w_i = 1\). A mixture distribution f(v) is then represented by
Mixture distributions are useful for modeling heterogeneous wind data, see, e.g., Jaramillo and Borja (2004); Carta and Ramírez (2007a, b); Akpinar and Akpinar (2009); Akdağ et al. (2010); Qin et al. (2009, 2012) or Alonzo et al. (2017). The following mixture distributions are investigated in this paper as two-component mixture models (\(k=2\) in (4)).
2.12.1 Weibull–Weibull distribution
The Weibull–Weibull distribution (WW) consists of two Weibull components with different weight proportions. Jaramillo and Borja (2004) used this distribution for the first time for wind speed data analysis of La Ventosa, Mexico, while Akdağ et al. (2010) analyzed the wind speed data of nine buoys located in the Ionian and Aegean Sea (Eastern Mediterranean) with the WW distribution and compared it with the conventional Weibull distribution.
2.12.2 Truncated normal-Weibull distribution
The truncated normal-Weibull distribution (TNW) is based on the truncated normal (3) and the Weibull (1) distributions. Carta and Ramírez (2007a, b) analyzed the wind speed data of 16 locations of the Canarian Archipelago that comprised both unimodal and bimodal distributions with the TNW, WW and W distributions.
2.12.3 Truncated normal-Gamma distribution
The truncated normal-Gamma distribution (TNG) is a mixture of the truncated normal (3) and the Gamma (2) distributions. Gugliani et al. (2017) found this distribution to model best the wind speed data at the Trivandrum site in India.
3 Data description
We have considered long-term wind speed data from the Indian Meteorology Department Pune, IMD, that has a significant number of weather stations across India. Dyne pressure tube anemometer is the instrument employed by IMDs to record wind speed data. It is located at the height of 10 m above the mean ground level at a position utterly free from obstructions to the airflow. Typically, these observatories are established near airports to take advantage of open terrain. In this paper, wind speed data of seventeen stations, namely Bangalore, Dolphin Nose, Amritsa, Palam, New Delhi, Jaipur, Lucknow, Allahabad, Gaya, New Kandla, Ahmedabad, Bhopal, Indore, Jamshedpur, Calcutta, Hyderabad and Tuticorin, have been considered for the case study (see Fig. 1). Table 3 provides some information about the geographical coordinates of stations and the wind speed observations for each station. In this study, the impact of null wind speed has been checked and found to be occurring in less than 15\(\%\) of the cases. This is considered to be marginally low (Takle and Brown 1978; Razika and Marouane 2014), therefore any null values have been removed from the hourly data series.
Table 4 shows the statistical description of wind speed data for the seventeen considered locations in India. From Table 4 it has been revealed that New Kandla and Calcutta have maximum wind speed. The two stations are located in India’s western and eastern offshore and near the Arabian Sea and Bay of Bengal, respectively. The New Kandla and Indore are two stations showing mean and median wind speed well above the cut-in (2–3 m/s) wind speed of wind turbines at 10 m height, followed by Tuticorin. These sites are therefore the most probable sites for installing a wind farm. Tuticorin has the smallest skewness (in absolute value), whereas Bangalore has the highest among all stations. The Dolphin Nose exhibits negative skewness, however this might be associated with the fact that we have less than 10,000 observations at that station. The kurtosis of all stations is higher than 3 except for Indore which is a land lock fastest growing city. The high kurtosis value reveals that all the stations’ wind speed histogram is leptokurtic except for Indore. Furthermore, the CV is maximum for Allahabad, followed by Calcutta and Amritsar, and least for Indore. A high CV value means a wide variation in wind speed from the mean wind speed.
4 Result and discussions
The ML method was used to estimate the parameters of the fourteen distributions analyzed in the seventeen locations in India. To compare the performance of different models, we used the AIC as a goodness-of-fit criterion and the Kolmogorov–Smirnov (K–S) test as a goodness-of-fit test. Tables 6 and 7 in the Appendix contain the estimated values of the parameters for the fourteen distributions in the seventeen locations, while Table 8 in the Appendix shows the AIC values. The distribution with minimum AIC is the most suitable distribution for the given data set. Among 5-parameter distributions, the truncated normal-Gamma distribution outperforms all other distributions at four locations, followed by the Weibull–Weibull distribution at three stations, the generalized hyperbolic distribution at two locations and the truncated normal-Weibull at one location. At four locations the 4-parameter generalized beta distribution of second kind has the best performance as a wind speed model. At three locations have 2-parameter distributions come out as most suitable, twice the Birnbaum–Saunders distribution and once the Gamma distribution. If we compare only 2-parameter distributions among themselves, then the Gamma is judged the most suitable six times, the Birnbaum–Saunders four times, the Weibull distribution three times, and the Nakagami and the truncated normal distributions respectively two times. Note however that the Weibull is sometimes only beaten by a very small margin, in particular by the Nakagami distribution. Nevertheless, these findings reveal the interesting fact that one should not blindly use the Weibull distribution out of convenience, as better choices are definitely available, even among 2-parameter distributions. For each station, the best fitted model along with the corresponding AIC, the p-value of the K–S test, the coefficient of determination \(R^2\) and RMSE are summarized in Table 5. We see that, at \(5\%\) level, only 4 best-fitting distributions would be rejected, while none would be rejected at \(3\%\) level, showing, especially at such a high number of observations, that the selected distributions are very suitable models for the data under investigation.
For visual inspection, we provide the wind speed histograms and empirical cdfs along with pdfs and cdfs of the best fitted models for four locations in India, namely Bangalore, Hyderabad, Jaipur and New Kandla, see Figs. 2 and 3. The plots for other distributions and stations are of course available upon request, as we did not want to render the paper unnecessarily long. Note that we chose as class width for the bins 2 km/h following the recent suggestions by Deep et al. (2020), who illustrated the appropriateness of a 2 km/h class width for removing the sampling error. As general conclusion, we find that, for highly skewed and leptokurtic histograms, distributions with more than 2 parameters are more suitable, which explains why multiparameter or mixture models are such good choices. The reader is referred to Gugliani et al. (2018) to calculate the wind power density by knowing the pdf of different distributions.

Wind speed histograms and empirical cdfs at a Banglore and b Jaipur stations along with the pdfs and cdfs of the best fitted distributions

Wind speed histograms and empirical cdfs at c Hyderabad and d New Kandla stations along with the pdfs and cdfs of the best fitted distributions
5 Conclusions
Fourteen continuous probability distributions have been reviewed and compared for modeling wind speed data at seventeen locations in India covering the east and west offshore corner and the mainland of India, hence a large variety of distinct climatological situations. Our aim was to identify the site-specific best distribution that can model the wind speed data with minimum amount of parameters and maximum agreement with the given wind data set. The Maximum Likelihood method has been used to estimate the parameters of the distributions. We determined the most suitable distribution by means of the AIC and checked the suitability with the Kolmogorov–Smirnov test. We found that out of the seventeen locations, four wind speed sites have been best modeled by the truncated normal-Gamma distribution, four by the generalized beta distribution of second kind, three by the Weibull–Weibull distribution, two respectively by the generalized hyperbolic and the Birnbaum–Saunders distributions, and one respectively by the truncated normal-Weibull distribution and Gamma distribution.
Our study reveals two main important messages, namely (i) that wind speed varies quite a lot within India from one location to another and that one should treat each geographic situation individually for best wind power generation, and (ii) that the wide acceptance of the Weibull distribution should at least be questioned, as it cannot perfectly represent all the wind regimes for wind speed modeling, especially wind regimes with heterogeneous data sets exhibiting multimodality, high levels of skewness and/or kurtosis. Instead, more suitable probability distributions such as those presented in this paper should be selected for each wind regime to minimize errors in the estimation of the wind energy potential at a given site. Our study shows that mixture distributions are very good candidates.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request. The data are not publicly available due to the private policy by the Indian Meteorological Department.
Code availability
The code is available from the corresponding author upon reasonable request.
References
Akdağ SA, Dinler A (2009) A new method to estimate Weibull parameters for wind energy applications. Energy Convers Manag 50(7):1761–1766
Akdağ SA, Güler Ö (2015) A novel energy pattern factor method for wind speed distribution parameter estimation. Energy Convers Manag 106:1124–1133
Akdağ S, Bagiorgas H, Mihalakakou G (2010) Use of two-component Weibull mixtures in the analysis of wind speed in the Eastern Mediterranean. Appl Energy 87(8):2566–2573
Akgül FG, Şenoğlu B, Arslan T (2016) An alternative distribution to Weibull for modeling the wind speed data: inverse Weibull distribution. Energy Convers Manag 114:234–240
Akpinar E, Akpinar S (2004a) Determination of the wind energy potential for Maden, Turkey. Energy Convers Manag 45(18–19):2901–14
Akpinar E, Akpinar S (2004b) Statistical analysis of wind energy potential on the basis of the Weibull and Rayleigh distributions for Agin-Elazig, Turkey. Proc Inst Mech Eng Part A J Power Energy 218(8):557–565
Akpinar EK, Akpinar S (2005) An assessment on seasonal analysis of wind energy characteristics and wind turbine characteristics. Energy Convers Manag 46(11–12):1848–1867
Akpinar S, Akpinar EK (2009) Estimation of wind energy potential using finite mixture distribution models. Energy Convers Manag 50(4):877–884
Alavi O, Mohammadi K, Mostafaeipour A (2016) Evaluating the suitability of wind speed probability distribution models: a case of study of east and southeast parts of Iran. Energy Convers Manag 119:101–108
Alonzo B, Ringkjob HK, Jourdier B et al (2017) Modelling the variability of the wind energy resource on monthly and seasonal timescales. Renew Energy 113:1434–1446
Amaya-Martínez PA, Saavedra-Montes AJ, Arango-Zuluaga EI (2014) A statistical analysis of wind speed distribution models in the Aburrá Valley, Colombia. CT &F-Ciencia, Tecnología y Futuro 5(5):121–136
Aminikhanghahi S, Cook DJ (2017) A survey of methods for time series change point detection. Knowl Inf Syst 51(2):339–367
Aries N, Boudia SM, Ounis H (2018) Deep assessment of wind speed distribution models: a case study of four sites in Algeria. Energy Convers Manag 155:78–90
Arslan T, Bulut YM, Yavuz AA (2014) Comparative study of numerical methods for determining Weibull parameters for wind energy potential. Renew Sustain Energy Rev 40:820–825
Ayyub BM, McCuen RH (2016) Probability, statistics, and reliability for engineers and scientists. CRC Press
Azad AK, Rasul MG, Yusaf T (2014) Statistical diagnosis of the best Weibull methods for wind power assessment for agricultural applications. Energies 7(5):3056–3085
Bagiorgas HS, Giouli M, Rehman S et al (2011) Weibull parameters estimation using four different methods and most energy-carrying wind speed analysis. Int J Green Energy 8(5):529–554
Bali TG, Theodossiou P (2008) Risk measurement performance of alternative distribution functions. J Risk Insur 75(2):411–437
Bardsley W (1980) Note on the use of the inverse Gaussian distribution for wind energy applications. J Appl Meteorol Climatol 19(9):1126–1130
Barndorff-Nielsen O (1978) Hyperbolic distributions and distributions on hyperbolae. Scand J Stat 5(3):151–157
Baseer MA, Meyer JP, Rehman S et al (2017) Wind power characteristics of seven data collection sites in Jubail, Saudi Arabia using Weibull parameters. Renew Energy 102:35–49
Beaulieu NC, Cheng C (2005) Efficient Nakagami-m fading channel simulation. IEEE Trans Veh Technol 54(2):413–424
Bidaoui H, El Abbassi I, El Bouardi A et al (2019) Wind speed data analysis using Weibull and Rayleigh distribution functions, case study: five cities northern Morocco. Procedia Manuf 32:786–793
Birnbaum ZW, Saunders SC (1969a) Estimation for a family of life distributions with applications to fatigue. J Appl Probab 6(2):328–347
Birnbaum ZW, Saunders SC (1969b) A new family of life distributions. J Appl Probab 6(2):319–327
Bivona S, Burlon R, Leone C (2003) Hourly wind velocity analysis in Sicily. Renew Energy 28(9):1371–1385
Bogardi I, Matyasovzky I (1996) Estimating daily wind speed under climate change. Sol Energy 57(3):239–248
Bracale A, Carpinelli G, De Falco P (2017) A new finite mixture distribution and its expectation-maximization procedure for extreme wind speed characterization. Renew Energy 113:1366–1377
Brano VL, Orioli A, Ciulla G et al (2011) Quality of wind speed fitting distributions for the urban area of Palermo, Italy. Renew Energy 36(3):1026–1039
Carta JA, Mentado D (2007) A continuous bivariate model for wind power density and wind turbine energy output estimations. Energy Convers Manag 48(2):420–432
Carta J, Ramirez P (2007a) Analysis of two-component mixture Weibull statistics for estimation of wind speed distributions. Renew Energy 32(3):518–531
Carta JA, Ramírez P (2007b) Use of finite mixture distribution models in the analysis of wind energy in the Canarian Archipelago. Energy Convers Manag 48(1):281–291
Carta JA, Ramírez P, Velázquez S (2008) Influence of the level of fit of a density probability function to wind-speed data on the WECS mean power output estimation. Energy Convers Manag 49(10):2647–2655
Carta JA, Ramirez P, Velazquez S (2009) A review of wind speed probability distributions used in wind energy analysis: case studies in the Canary Islands. Renew Sustain Energy Rev 13(5):933–955
Chadee JC, Sharma C (2001) Wind speed distributions: a new catalogue of defined models. Wind Eng 25(6):319–337
Chalamcharla SC, Doraiswamy ID (2016) Mathematical modeling of wind power estimation using multiple parameter Weibull distribution. Wind Struct 23(4):351–366
Chang TP (2011a) Estimation of wind energy potential using different probability density functions. Appl Energy 88(5):1848–1856
Chang TP (2011b) Performance comparison of six numerical methods in estimating Weibull parameters for wind energy application. Appl Energy 88(1):272–282
Chellali F, Khellaf A, Belouchrani A et al (2012) A comparison between wind speed distributions derived from the maximum entropy principle and Weibull distribution. Case of study; six regions of Algeria. Renew Sustain Energy Rev 16(1):379–385
De Andrade CF, Neto HFM, Rocha PAC et al (2014) An efficiency comparison of numerical methods for determining Weibull parameters for wind energy applications: a new approach applied to the northeast region of Brazil. Energy Convers Manag 86:801–808
de Lima Leite M, das Virgens Filho JS (2011) Adjustment of models of probability distribution to hourly wind speed series for Ponta Grossa, Paraná State. Acta Sci Technol 33(4):447
Deep S, Sarkar A, Ghawat M et al (2020) Estimation of the wind energy potential for coastal locations in India using the Weibull model. Renew Energy 161:319–339
Dursun B, Alboyaci B, Gokcol C (2011) Optimal wind-hydro solution for the Marmara region of Turkey to meet electricity demand. Energy 36(2):864–872
Fyrippis I, Axaopoulos PJ, Panayiotou G (2010) Wind energy potential assessment in Naxos Island, Greece. Appl Energy 87(2):577–586
Garcia A, Torres J, Prieto E et al (1998) Fitting wind speed distributions: a case study. Solor Energy 62(2):139–144
Gokcek M, Bayulken A, Bekdemir K (2007) Investigation of wind characteristics and wind energy potential in Kirklareli, Turkey. Renew Energy 32(10):1739–1752
Gubareva TS (2011) Types of probability distributions in the evaluation of extreme floods. Water Resour 38:962–971
Gubareva TS, Gartsman BI (2010) Estimating distribution parameters of extreme hydrometeorological characteristics by L-moments method. Water Resour 37:437–445
Gugliani G, Sarkar A, Mandal S et al (2017) Location wise comparison of mixture distributions for assessment of wind power potential: a parametric study. Int J Green Energy 14(9):737–753
Gugliani G, Sarkar A, Ley C et al (2018) New methods to assess wind resources in terms of wind speed, load, power and direction. Renew Energy 129:168–182
Gugliani GK, Sarkar A, Ley C et al (2021) Identification of optimum wind turbine parameters for varying wind climates using a novel month-based turbine performance index. Renew Energy 171:902–914
Hennessey JP Jr (1978) A comparison of the Weibull and Rayleigh distributions for estimating wind power potential. Wind Eng 2:156–164
Hosking JR (1990) L-moments: analysis and estimation of distributions using linear combinations of order statistics. J R Stat Soc Ser B Stat Methodol 52(1):105–124
Hu Q, Wang Y, Xie Z et al (2016) On estimating uncertainty of wind energy with mixture of distributions. Energy 112:935–962
Hu L, Nikolopoulos EI, Marra F, Anagnostou EN (2020) Sensitivity of flood frequency analysis to data record, statistical model, and parameter estimation methods: an evaluation over the contiguous United States. J Flood Risk Manag 13(1):e12580
Hunter R, Elliot G (1994) Wind-diesel systems: a guide to the technology and its implementation. Cambridge University Press
Jangamshetti SH, Rau VG (1999) Site matching of wind turbine generators: a case study. IEEE Trans Energy Convers 14(4):1537–1543
Jaramillo O, Borja M (2004) Wind speed analysis in La Ventosa, Mexico: a bimodal probability distribution case. Renew Energy 29(10):1613–1630
Johnson NL (1949) Systems of frequency curves generated by methods of translation. Biometrika 36(1/2):149–176
Jung C, Schindler D, Laible J et al (2017) Introducing a system of wind speed distributions for modeling properties of wind speed regimes around the world. Energy Convers Manag 144:181–192
Justus CG (1978) Winds and wind system performance. Research supported by the National Science Foundation and Energy Research and Development Administration Philadelphia
Kaminsky F (1977) Four probability densities/log-normal, gamma, Weibull, and Rayleigh/and their application to modelling average hourly wind speed. In: international solar energy society, annual meeting, 19_6–19_10
Kantar YM, Usta I, Arik I et al (2018) Wind speed analysis using the extended generalized Lindley distribution. Renew Energy 118:1024–1030
Kiss P, Jánosi IM (2008) Comprehensive empirical analysis of ERA-40 surface wind speed distribution over Europe. Energy Convers Manag 49(8):2142–2151
Ley C, Babić S, Craens D (2021) Flexible models for complex data with applications. Annu Rev Stat Appl 8:369–391
Luna R, Church H (1974) Estimation of long-term concentrations using a “universal’’ wind speed distribution. J Appl Meteorol Climatol 13(8):910–916
McDonald JB, Xu YJ (1995) A generalization of the beta distribution with applications. J Econom 66:133–152
Mohammadi K, Alavi O, Mostafaeipour A et al (2016) Assessing different parameters estimation methods of Weibull distribution to compute wind power density. Energy Convers Manag 108:322–335
Mohammadi K, Alavi O, McGowan JG (2017) Use of Birnbaum–Saunders distribution for estimating wind speed and wind power probability distributions: a review. Energy Convers Manag 143:109–122
Morgan VT (1995) Statistical distributions of wind parameters at Sydney, Australia. Renew Energy 6(1):39–47
Morgan EC, Lackner M, Vogel RM et al (2011) Probability distributions for offshore wind speeds. Energy Convers Manag 52(1):15–26
Murshed MS, Kim S, Park JS (2011) Beta-K distribution and its application to hydrologic events. Stoch Environ Res Risk Assess 25:897–911
Nakagami M (1960) The m-distribution–a general formula of intensity distribution of rapid fading. Statistical methods in radio wave propagation. Elsevier, pp 3–36
Nerantzaki SD, Papalexiou SM (2022) Assessing extremes in hydroclimatology: a review on probabilistic methods. J Hydrol 605:127302
Ouarda TB, Charron C, Chebana F (2016) Review of criteria for the selection of probability distributions for wind speed data and introduction of the moment and l-moment ratio diagram methods, with a case study. Energy Convers Manag 124:247–265
Pajala E, Isotalo T, Lakhzouri A et al. (2006) An improved simulation model for Nakagami-m fading channels for satellite positioning applications. In: 3rd workshop on position. Navigation and communication, Hannover, Germany, pp 81–89
Papalexiou SM, Koutsoyiannis D (2013) Battle of extreme value distributions: a global survey on extreme daily rainfall. Water Resour Res 49(1):187–201
Philippopoulos K, Deligiorgi D, Karvounis G (2012) Wind speed distribution modeling in the greater area of Chania, Greece. Int J Green Energy 9(2):174–193
Pishgar-Komleh S, Akram A (2017) Evaluation of wind energy potential for different turbine models based on the wind speed data of Zabol region, Iran. Sustain Energy Technol Assess 22:34–40
Pishgar-Komleh S, Keyhani A, Sefeedpari P (2015) Wind speed and power density analysis based on Weibull and Rayleigh distributions (a case study: Firouzkooh county of Iran). Renew Sustain Energy Rev 42:313–322
Qin X, Zhang J, Yan X (2009) A finite mixture three-parameter Weibull model for the analysis of wind speed data. In: 2009 international conference on computational intelligence and software engineering, pp 1–3
Qin X, Zhang JS, Yan Xd (2012) Two improved mixture Weibull models for the analysis of wind speed data. J Appl Meteorol Climatol 51(7):1321–1332
Rajapaksha K, Perera K (2016) Wind speed analysis and energy calculation based on mixture distributions in Narakkalliya, Sri Lanka. J Natl Sci Found Sri Lanka 44(4):409
Razika NII, Marouane M (2014) Comparison between hybrid Weibull and MEP methods for calculating wind speed distribution. In: IEEE (ed) 2014 5th international renewable energy congress (IREC), pp 1–6
Rehman S, El-Amin I, Ahmad F et al (2007) Feasibility study of hybrid retrofits to an isolated off-grid diesel power plant. Renew Sustain Energy Rev 11(4):635–653
Rowinski PM, Strupczewski WG, Singh VP (2002) A note on the applicability of log-Gumbel and log-logistic probability distributions in hydrological analyses. Hydrol Sci J 47(1):107–122
Rutkowska A, Żelazny M, Kohnová S, Łyp M, Banasik K (2017) Regional L-moment-based flood frequency analysis in the Upper Vistula River Basin, Poland. Pure Appl Geophys 174:701–721
Safari B (2011) Modeling wind speed and wind power distributions in Rwanda. Renew Sustain Energy Rev 15(2):925–935
Safari B, Gasore J (2010) A statistical investigation of wind characteristics and wind energy potential based on the Weibull and Rayleigh models in Rwanda. Renew Energy 35(12):2874–2880
Sahin B, Bilgili M, Akilli H (2005) The wind power potential of the eastern Mediterranean region of Turkey. J Wind Eng Ind Aerodyn 93(2):171–183
Saleh H, Abou El-Azm Aly A, Abdel-Hady S (2012) Assessment of different methods used to estimate Weibull distribution parameters for wind speed in Zafarana wind farm, Suez Gulf, Egypt. Energy 44(1):710–719
Sherlock R (1951) Analyzing winds for frequency and duration. On atmospheric pollution. Springer, pp 42–49
Shin JY, Ouarda TB, Lee T (2016) Heterogeneous mixture distributions for modeling wind speed, application to the UAE. Renew Energy 91:40–52
Sinner C, Dominicy Y, Trufin J, Waterschoot W, Weber P, Ley C (2023) From Pareto to Weibull–a constructive review of distributions on \(\mathbb{R}+\). Int Stat Rev 91(1):35-54
Sohoni V, Gupta S, Nema R (2016) A comparative analysis of wind speed probability distributions for wind power assessment of four sites. Turk J Electr Eng Comput Sci 24(6):4724–4735
Soukissian T (2013) Use of multi-parameter distributions for offshore wind speed modeling: the Johnson SB distribution. Appl Energy 111:982–1000
Strupczewski WG, Kochanek K, Markiewicz I, Bogdanowicz E, Weglarczyk S, Singh VP (2011) On the tails of distributions of annual peak flow. Hydrol Res 42(2–3):171–192
Takle ES, Brown JM (1978) Note on the use of Weibull statistics to characterize wind-speed data. J Appl Meteorol 1962–1982(17):556–559
Tar K (2008) Some statistical characteristics of monthly average wind speed at various heights. Renew Sustain Energy Rev 12(6):1712–1724
Ul Hassan M, Hayat O, Noreen Z (2019) Selecting the best probability distribution for at-site flood frequency analysis; a study of Torne River. SN Appl Sci 1:1–10
Van Alphen K, van Sark WG, Hekkert MP (2007) Renewable energy technologies in the Maldives–determining the potential. Renew Sustain Energy Rev 11(8):1650–1674
Vicente RT (2008) Influence of the fitted probability distribution type on the annual mean power generated by wind turbines: a case study at the Canary Islands. Energy Convers Manag 49(8):2047–2054
Vivekanandan N (2015) Flood frequency analysis using method of moments and L-moments of probability distributions. Cogent Eng 2(1):1018704
Yin J (1997) A comparative study of the statistical distributions of wave heights. China Ocean Eng 3:285–304
Zamani A, Badri M (2015) Wave energy estimation by using a statistical analysis and wave buoy data near the southern Caspian Sea. China Ocean Eng 29(2):275–286
Zhang MH (2015) Wind resource assessment and micro-siting: science and engineering. Wiley
Zhang J, Chowdhury S, Messac A et al (2013) A multivariate and multimodal wind distribution model. Renew Energy 51:436–447
Zhou J, Erdem E, Li G et al (2010) Comprehensive evaluation of wind speed distribution models: a case study for North Dakota sites. Energy Convers Manag 51(7):1449–1458
Acknowledgements
The first author is thankful to Prof. Arnab Sarkar from IIT BHU for motivating him to conduct research in climatology. We would like to thank the Indian Institute of Technology for providing the facilities, the Indian Meteorological Department (IMD), Pune, for supplying the data used in this research, and the Bhabha Atomic Research Center (BARC), Mumbai, for providing the necessary funds to carry out the reported research work. However, the opinions expressed in this manuscript are those of the authors and not of these agencies. The research of the third and fourth authors is supported in part by the RDP grant at university of Pretoria, the National Research Foundation (NRF) of South Africa, Ref.: RA210106581084, grant No. 150170; ref. SRUG2204203865, RA171022270376 ( Grant No: 119109), the South African DST-NRF-MRC SARChI Research Chair in Biostatistics (Grant No. 114613) and DSI-NRF Centre of Excellence in Mathematical and Statistical Sciences (CoE-MaSS), South Africa. The opinions expressed and conclusions arrived at are those of the authors and are not necessarily to be attributed to the CoE-MaSS or the NRF.
Funding
Open access funding provided by University of Pretoria. Board of Research in Nuclear Sciences (Project Code: M-21-114) The authors are grateful to the Indian Meteorological Department, Pune, for the supply of wind data to carry out this research work and BRNS for providing funding to get these data. We are also thankful to our respective organizations, for motivating us, to carry out research in the field of climatology.
Author information
Authors and Affiliations
Contributions
The authors have contributed equally to this work.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Ethical approval
The authors have declared that the research work carried out in this manuscript is the original work of the authors and no data have been collected without the consent of the competent authority.
Consent to participate
All the authors have willingly participated in this research work.
Consent for publication
All the authors have given their consent for submission and subsequent publication of the manuscript in Nature Energy.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gugliani, G.K., Ley, C., Nakhaei Rad, N. et al. Comparison of probability distributions used for harnessing the wind energy potential: a case study from India. Stoch Environ Res Risk Assess 38, 2213–2230 (2024). https://doi.org/10.1007/s00477-024-02676-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-024-02676-5