
Abstract
Ground motion scenarios exists for most of the seismically active areas around the globe. They essentially correspond to shaking level maps at given earthquake return times which are used as reference for the likely areas under threat from future ground displacements. Being landslides in seismically actively regions closely controlled by the ground motion, one would expect that landslide susceptibility maps should change as the ground motion patterns change in space and time. However, so far, statistically-based landslide susceptibility assessments have primarily been used as time-invariant.In other words, the vast majority of the statistical models does not include the temporal effect of the main trigger in future landslide scenarios. In this work, we present an approach aimed at filling this gap, bridging current practices in the seismological community to those in the geomorphological and statistical ones. More specifically, we select an earthquake-induced landslide inventory corresponding to the 1994 Northridge earthquake and build a Bayesian Generalized Additive Model of the binomial family, featuring common morphometric and thematic covariates as well as the Peak Ground Acceleration generated by the Northridge earthquake. Once each model component has been estimated, we have run 1000 simulations for each of the 217 possible ground motion scenarios for the study area. From each batch of 1000 simulations, we have estimated the mean and 95% Credible Interval to represent the mean susceptibility pattern under a specific earthquake scenario, together with its uncertainty level. Because each earthquake scenario has a specific return time, our simulations allow to incorporate the temporal dimension into any susceptibility model, therefore driving the results toward the definition of landslide hazard. Ultimately, we also share our results in vector format – a .mif file that can be easily converted into a common shapefile –. There, we report the mean (and uncertainty) susceptibility of each 1000 simulation batch for each of the 217 scenarios.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The definition of landslide hazard originally proposed by Varnes and the IAEG Commission on Landslides and Other Mass-Movements (1984) and later updated by Guzzetti et al. (1999) features a spatial component aimed at defining “where” slope failures can be expected, a temporal component, aimed at defining “when” or how frequently the slope instability process is expected and an additional component aimed at defining “how large or destructive” a single landslide or a landslide population may be.
The susceptibility is by far the most studied element among the three (Reichenbach et al. 2018), whereas the “size or destructiveness” is the least common although it has been highlighted to be crucial even in international guidelines (Fell et al. 2008).
The temporal component is usually investigated separately from the susceptibility, this being the case of rainfall-threshold studies (e.g., Aleotti 2004; Guzzetti et al. 2004; Wu et al. 2015) or Early Warning Systems (e.g., Graziella et al. 2015; Greco et al. 2013; Guzzetti et al. 2019). Because of this, few examples exist where the spatial and temporal components of the landslide hazard are combined together (e.g., Ghosh et al. 2012; Fan et al. 2021). The typical statistically-based example corresponds to Cama et al. (2015) where the authors tried to calibrate a susceptibility model over past landslides and validate it over a subsequent landslide inventory. However, this approach assumes the susceptibility to be stable across time and neglects any dependence between past and future slope failures. A step forward in this direction has been proposed by Samia et al. (2017) where the authors accounted for landslide interactions across time by simplistically building multi-temporal susceptibility models where the next model features as covariate the presence-absence signal of the previous event. However, this approach retrieves a single parameter for the whole study area to describe the temporal dependence, which is also determined in a discrete series of temporal values. The same concept has been recently brought even further by Lombardo et al. (2020) where the authors assessed the space-time landslide intensity (number of landslide per mapping unit) by featuring a temporal dependence at the Slope Unit level via a Autoregressive model. However, even in these cases, the residual space-time dependence due to the trigger is not directly incorporated in the analyses.
Only few examples directly include the trigger effect in the susceptibility/hazard models. For instance, Nowicki et al. (2014); Nowicki Jessee et al. (2018) demonstrate how the US Geological Survey provides a statistically-based near real-time prediction by using a model that has initially estimated the effect of ground motion over the available set of global earthquake-induced landslides (EQIL) (Schmitt et al. 2017; Tanyaş et al. 2017). Then by assuming that the effect is constant for other earthquakes, they plug-in the ground motion of near real-time earthquakes to produce case-specific prediction maps.
Apart from statistical approaches, there is a large literature aiming at assessing landslide hazard via probabilistic assessments (e.g., Jibson et al. 2000; Romeo 2000; Del Gaudio et al. 2003; Del Gaudio and Wasowski 2004; Rathje and Saygili 2008; Saygili and Rathje 2009). Jibson et al. (2000) developed one of a pioneer probabilistic seismic landslide hazard assessment method to conduct a regional-scale seismic slope stability analysis. In fact, the 1994 Northridge earthquake made this progress possible as this is the first earthquake for which extensive data on engineering properties of geologic units, ground shaking, and triggered landslides were available (Jibson et al. 1998, 2000). Jibson et al. (2000) used these data sets and combined shear-strength data for each geologic unit in the area with slope derived from a 10-m digital elevation model (DEM) to predict the threshold ground-shaking acceleration required for the initiation of the sliding (referred to as the critical or yield acceleration). They then predicted the resulting displacement using an empirical displacement model based on Newmark’s sliding-block method (Newmark 1965) that used shaking levels recorded during the earthquake. Finally, they compared the predicted displacements to the EQIL inventory and showed that increasing predicted Newmark displacement does, in fact, correlate with increasing landslide frequency. The study provides a simple mathematical relation between predicted Newmark displacement and the probability of landsliding. This study thus provides a basic quantitative framework for using a physical modeling approach to estimate seismic landslide hazards at regional scale. In fact, this approach was also improved by adopting some of the inputs of these physical-based models from scenario-based earthquakes (e.g., Rathje and Saygili 2008; Saygili and Rathje 2009)). As with most physically based methods, this simplified mechanistic approach has the advantage of more accurately reflecting the underlying processes, despite the uncertainties caused by those simplifications (Allstadt et al. 2017). But the geotechnical and seismic data required to apply this model are not available everywhere and can be difficult to estimate.
A similar framework is also adopted in the context of rainfall-induced landslide. Kirschbaum and Stanley (2018) demonstrate how the NASA provides near real-time prediction by using a model that has initially estimated the precipitation effect over the available set of global rainfall-induced landslides (Kirschbaum et al. 2010, 2015). Then the near real-time landslide prediction is obtained by plugging in meteorological estimates of the incoming storms.
These methods are extremely useful if not fundamental to support the initial stages of any disaster, helping authorities to prioritize certain regions or actions as a function of the expected hazard. However, they cannot support long term planning because of their near real-time nature.
A comprehensive landslide susceptibility or hazard assessment, helpful to plan strategies for the expected disasters in the future, should integrate both morphological information as well as the expected scenarios of the given trigger. Some examples that fit in this description can be found in Ko and Lo (2018); Melchiorre and Frattini (2012) where the authors integrate to a baseline prediction model possible rainfall scenarios or, in Lari et al. (2014) where the authors simulate rockfalls of different sizes. However, despite some specific cases mostly dealing with rainfall induced landslides (Kirschbaum et al. 2009), scenario-based landslide hazard realizations are not as common as in other geoscience branches. For instance, in engineering or seismology it is common practice to produce scenario-based seismic hazard maps where the scenario at hand corresponds to the exceedance probability of an extreme ground motion occurring within a certain return time (e.g., Abrahamson and Bommer 2005; Hanks et al. 2005; Lee et al. 2000; Montilla et al. 2003).
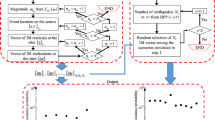
In this work, we took inspiration from the scenario-based studies mentioned above in relation to rainfall-induced landslides and from the scenario-based context in seismology. More specifically, we include scenario-based realizations of ground motion patterns into Slope-Unit-based landslide susceptibility models, via statistical simulation. We do this by building a Generalized Additive Model (GAM, Goetz et al. 2015; Lombardo et al. 2018) of a binomial family using as target variable the presence/absence distribution of EQIL associated with the 1994 Northridge earthquake (Harp and Jibson 1995, 1996). We correlate this inventory to geomorphological parameters together with the Peak Ground Acceleration (PGA) of the Northridge seismic trigger (Worden and Wald 2016). From this reference model, we then simulate 1000 statistical realizations of the estimated susceptibility for each of the 217 ground motion scenarios in the Northridge area available at (USGS 2017). As a result, we are able to draw information already developed from the seismological community, and feature it into susceptibility models that can therefore reflect the estimated susceptibility at given return times of the seismic trigger. Our susceptibility then both features a native spatial characteristic together with the coexisting temporal dimension carried by the scenario-based PGAs.
Overall, we present our study by introducing the 1994 Northridge earthquake, the associated landslide inventory Sect. 2.1 and the available earthquake scenarios for the study area Sect. 2.2. Subsequently, we describe the modeling strategy and the simulation steps Sect. 3 whereas the results are shown in Sect. 4. Section 5 provides our interpretation of the framework we propose and Sect. 6 lists our concluding remarks and future perspectives. Supplementary materials are located at this link: https://doi.org/10.17026/dans-xjk-5676. A description of the supplements can be found in Sect. 7.
2 Study area
2.1 Northridge earthquake and co-seismic landslides
To carry out our analyses, we focus on the 1994 Northridge earthquake, which is considered a milestone (Fan et al. 2019) because this earthquake led the scientific community to make digital seismic networks widespread across the globe (Wald et al. 2003). Also, the U.S. Geological Survey (USGS) ShakeMap system was developed (Wald et al. 1999) following the Northridge earthquake. This system provides worldwide estimates of ground-motion parameters and thus provides a fundamental information for many EQIL modeling studies, which is still commonly used across the whole geoscientific community (Allstadt et al. 2017).

a Normalized co-seismic landslide density generated by the Northridge earthquake; b Ground motion due to the Northridge earthquake expressed in terms of PGA
The landslides triggered by the Northridge earthquake (see Fig. 1a) were mapped by Harp and Jibson (1995, 1996). They indicated that they mapped at least 90 percent of the landslide affected area using high-altitude analog aerial photography. They also reported that they most likely missed not more than about 20 percent of landslides greater than 5m and not more than 50 percent of those smaller than 5m in the maximum planar dimension. As a result, they mapped 11,111 landslides over an area of about \(10,000 km^2\). The majority of the landslides were reported as shallow (\(1-5 m\)), highly disrupted falls and slides in weakly cemented clastic sediment (Harp and Jibson 1995). This inventory is still considered nowadays one of the most detailed EQIL datasets in landslide science because of its high quality and completeness (Harp et al. 2011; Malamud et al. 2004; Tanyaş et al. 2018; Tanyaş and Lombardo 2020).
2.2 Scenario-based ground motion data
The Shakemap System of the USGS not only provides actual estimates of ground motion parameters associated to earthquakes occurring all over the globe, but it also provides ShakeMaps for US based on deterministic ruptures from U.S. National Seismic Hazard Map event catalog produced by Petersen et al. (2008). More specifically, the available scenarios correspond to time-independent PGA maps for 2% and 10% probability of exceedance in 50 years for peak horizontal ground acceleration (Petersen et al. 2008). These scenarios originate from a subset of the possible rupture planes which are characteristic of all known active faults in a given region. Furthermore, a single scenario represents one single realization of a potential earthquake nucleation, assuming an underlying magnitude, hypocenter and rupture plane, although directivity is not accounted for. As a results, the USGS Shakemap System provides a comprehensive seismic hazard assessment for specific seismically active landscapes within the United States (USGS 2017).

a Distribution of scenario-based earthquakes (both epicenters and rupture planes), the cyan polygon shows the study area for which we extracted the corresponding 217 scenarios; b Probability Density Distribution of the selected and rescaled scenario-based PGAs
For the area affected by the Northridge earthquake, not only the specific ground motion is available (see Fig. 1b) but also a wide number of possible scenarios. Among the available scenarios, here we extract 217 cases which fall within the landslide affected area due to the Northridge earthquake. This information is geographically shown in Fig. 2a and the corresponding 218 PGA distributions are summarized in Fig. 2b where the PGA values have been all rescaled to emphasise similarities and differences among the possible ground motion realizations.
3 Modeling strategy
3.1 Mapping unit choice and presence/absence assignment criterion
Any landslide susceptibility model cannot be defined without a reference mapping unit. A mapping unit correspond to the geographical object upon which any study area is partitioned. Apart from the common grid-cell choice (Reichenbach et al. 2018), Slope Units (SUs) subdivide the terrain between streamlines and ridges under the constrain of Slope and Aspect within-unit homogeneity (Alvioli et al. 2016). On the one hand, the strength of using SUs resides in the representation of the morphodynamic response of a landslide, which is entirely neglected when using grid-cells. On the other hand, SUs require an additional aggregation step of the finely described predisposing factors, compared to the grid-cell counterpart.
In this work, we adopt SUs as the mapping unit of our choice, the reason being their ability to reliably mimic the geomorphological response to slope instability.
We compute SUs via the software r.slopeunits made available by Alvioli et al. (2016) by adopting:
-
Shuttle Radar Topography Mission (SRTM) Digital Elevation Model (DEM, of approximately 30-m resolution Jarvis et al. 2008).
-
a large flow accumulation threshold (\(500,000m^2\)) to ensure that all the possible scale-dependent SU can be examined during the calculations.
-
a relatively small minimum SU area (\(50,000m^2\)) to reliably partition the space at a small to medium scale
-
a circular variance of 0.5.
From the resulting polygonal partition of the study area, we then assigned the landslide presence condition for SU which intersect the mapped landslide polygon of the co-seismic Northridge inventory. The absence case, is of course the complementary situation.
3.2 Covariates
Our covariate set features both morphometric and thematic properties in addition to the Northridge ground motion expressed in term of PGA. The initial set has been chosen in accordance to the literature, extracting the most common covariate in landslide susceptibility studies (Budimir et al. 2015; Lombardo and Tanyas 2020; Reichenbach et al. 2018).
The morphometric properties correspond to DEM derivatives from the SRTM DEM. Specifically, we computed: (1) Slope (Zevenbergen and Thorne 1987), (2) Planar (3) and Profile Curvatures (Heerdegen and Beran 1982), (4) Vector Ruggedness Measure (VRM, Sappington et al. 2007), (5) Local Relief (LR, Jasiewicz and Stepinski 2013).
In addition to those, we also compute the Euclidean distance from each centroid, of a squared lattice coinciding with the DEM resolution, to the nearest river channel. And, complete our covariate set with the Soil Depth map locally estimated, digitized and made available by (NRCS 2010) together with the actual SU extent measured in \(m^2\).
Notably, mapping unit of our choice does not coincide with the covariates mentioned above. For this reason, whether the resolution was higher than the SU dimension, we computed the mean and standard deviation values of each covariate distribution within the SUs. And, for Soil Depth and Northridge PGA, we opted to solely estimate the mean value because the soil map is originated from studies at scales ranging from 1:12,000 to 1:63,360 and the resolution provided by the Shakemap System is approximately 1km.
Prior to any modeling routine, we rescaled each covariate by mean zero unit variance (substracting the mean and dividing by the standard deviation) to ensure that the covariates would share the same unitless scale, hence to ensure their comparison once we fit out model.
3.3 LASSO-penalized Generalized Linear Model
The most common approach to build landslide susceptibility models is a Logistic Regression (Reichenbach et al. 2018) formulated in a Generalized Linear Model (GLM) which assumed that landslide presences/absences are distributed over space according to the Bernoulli probability distribution (Akgün and Türk 2011; Brenning 2005; Das et al. 2010).
The definition of a GLM for a binomial case can be summarised as follows:
where \(\pi \) is the probability that Y takes the value 1 (or a landslide is present at a given mapping unit), \(\eta \) is the logit link and \(\beta \)s are the estimated regression coefficients for a covariate which is assumed to behave linearly with respect to slope instability conditions. And, by making the logit function explicit, the probability of landslide occurrence can be obtained as follows:
where the numerator is the linear combination of each model component, the latter being a single or multiple regression constants or the product between the regression coefficient and the corresponding vector of a given covariate values.
The choice of covariates can span over several morphometric and thematic properties in the literature (Budimir et al. 2015), although some of them may not contribute to explain the landslide distribution. In such cases, maintaining a covariate set with non-informative covariates may not only increase the dimension of the model space but also bring collinearity issues and reduce the overall predictive capacity (Castro Camilo et al. 2017). As a result, variable selection procedures are often implemented to reduce high predictor dimensionality issues. The most common variable selection found in the geoscientific literature corresponds to the Stepwise case (e.g., Mathew et al. 2009; Cama et al. 2017), although, irrespective of being foward or backward, it has been proven to be flawed in the statistical literature (see, Harrell Jr 2015). However, much more robust alternative variable selection procedures exist and among them, the Least Absolute Shrinkage (LASSO) and Selection Operator has been proven to provide not only better performance in landslide susceptibility models but also to be able to more strictly reduce the number of covariates while simultaneously addressing collinearity issues (see Amato et al. 2019, and explanation therein).
The LASSO selection is controlled by a penalization or shrinkage parameter, usually reported as \(\lambda \). More specifically, as \(\lambda \) increases the model is forced to remove redundant information from the covariate set (see Lombardo and Mai 2018, and explanation therein).
In this work, we adopt a LASSO-penalized GLM purely to screen out non-informative covariates and subsequently test a more complex version of a GLM. We do this by using the glmnet package (Friedman et al. 2009) in R where by default, for 100 \(\lambda \) values the functions implements a purely random 10-fold cross-validation scheme (see Hastie and Qian 2014, and explanation therein) to explore the hold-out performance variability as the penalization increases.
3.4 Generalized additive model
A Generalized Additive Model or GAM (Brenning 2008; Lombardo et al. 2018) is an extension to the linear framework available in the simpler GLM case. A GAM, in addition to being able to feature linear relations (fixed effects) between covariates and landslide instances, it provides a framework to account for all sorts of nonlinear relations (random effects). The latter can correspond to categorical cases where discrete covariate classes are modeled independently from each other or, to ordinal cases where discrete covariate classes are modeled with inter-class dependence or, to latent effects over space (Lombardo et al. 2019) and time (Lombardo et al. 2020).
A generic formulation for a binomial case can be summarized as follows:
where f here stands for a nonlinear function of a covariate X with n discrete classes. In this work, we chose f to be a random walk of the first order, or a Spline (Bakka et al. 2018; Conoscenti et al. 2016), which is meant to ensure that the ordinal structure between adjacent classes of a reclassified continuous covariates is not lost. In this work we adopt a Bayesian version of a GAM by using the R (R Core Team 2013) package R-INLA (see Rue et al. 2009, 2017, and explanation therein). We chose a Bayesian version because any model (and each of its components) falling in this category is natively characterized by a distribution of values rather than the frequentist counterpart. This will be particularly relevant in the formulation of the simulation steps described in Sect. 3.5.
3.4.1 10-fold cross-validation
The landslide literature reports several cross validation schemes. Among these, very poor examples can be found in articles where a given model is merely validated once (e.g., Arabameri et al. 2020) and much more scientifically sound cases where k-fold cross-validation (CV) schemes are implemented (e.g., Steger et al. 2020) to express the variability of model performance as the training and test subsets are iteratively sampled at random. The idea behind a k-fold CV is to statistically represent a large portion of the datatest at hand (both in terms of presence-absence cases and associated covariates) hence providing a description of mean predictive skill of a given model together with the associated uncertainty.
In this work, we opt for a special case of a k-fold CV. Specifically, we choose to randomly select from our dataset ten random partitions each corresponding to 10% of the total, but imposing that a given SU can be sampled only once. As a result, we do not only explore a large portion of the dataset but its entirety, by calibrating over 90% and validating onto the complementary 10%. Notably, by rearranging the ten 10% subsets, a fully predicted susceptibility map can be obtained, therefore reducing the effect that same SUs, and associated characteristic may yield in the calibration stage.
3.5 Statistical simulations
Statistical simulations are feasible in any statistical context, being frequentist or Bayesian. However, the latter case is particularly suitable to support such operations. Once a model is fitted, each component, from the intercept to fixed and random effects, is characterized by a whole parameter distribution. Therefore, it is possible to randomly generate any number of possible realization of each parameter. And, by solving for Eq. 3 it is possible to retrieve the full spectrum of possible susceptibility estimates (Ferkingstad et al. 2015).
In this work, we use a specific type of simulations. We initially fit a model where the presence/absence distribution corresponds to the co-seismic landslides triggered by the Northridge earthquake, and where the covariate set features come covariates together with the Northridge PGA. On the basis of the distribution of each model component, we then simulate according to the scheme mentioned above. However, we use a plug-in structure (Stanton and Diggle 2013), where the Northridge PGA values are removed and substituted by each of the 217 possible PGA scenarios for the study area. For each of the 217 PGA scenarios, we produce 1000 simulations and store the mean resulting suscptibility together with the 95% credible interval expressed as the difference between the 97.5 and the 2.5 percentiles of the 1000 simulations.
Ultimately, we call each mean simulated susceptibility together with the posterior susceptibility estimated for the Northridge earthquake. And we use this combined information to assess which SU exhibits a landslide-prone probability across the entirety of susceptibility realizations, together with its uncertainty.
4 Results
4.1 LASSO covariate selection
Figure 3 summarizes the LASSO variable selection, where the AUC is shown to sligthly decrease as \(\lambda \) increases up to a minimum number of 6 covariates (vertical dashed line to the right). Any further combination of covariates with number less than 6 is shown to rapidly weaken the model to an extent where the performance significantly drop, hence depriving the model of fundamental information to explain the presence/absence landslide distribution.

LASSO variable selection. The x-axis to the bottom reports the shrinkage parameter \(\lambda \) in logarithmic scale (for conciseness) whereas the second axis to the top clarifies the consequent number of covariates. The y-axis shows the associated performance variability (expressed in AUC) tested in a purely random 10-fold CV. Red circles correspond to the mean AUC at specific \(\lambda \) whereas the uncertainty around it is expressed as two times the standard deviation across each CV. The vertical dashed line to the left corresponds to the most conservative model. The vertical dashed line to the right corresponds to a model where the AUC has not significantly decreased compared to smaller values of \(\lambda \) but larger \(\lambda \) values would yield a significant drop in AUC
The six selected covariates correspond to the SU Area, VRM\(_\mu \), VRM\(_\sigma \), PGA, Slope\(_\sigma \) and Soil Depth.
4.2 Covariate effects
Here we report the covariate effects from the Bayesian GAM framework we followed after selecting our parameter space via LASSO. More specifically, out of the six covariates mentioned above, we opted to model the Slope\(_\sigma \) and Soil Depth as ordinal properties with a Random Walk of the first order used to impose adjacent class dependency.

Summary of fixed and random effects of our reference susceptibility model for the Northridge earthquake. Fixed effects are shown in panel a, whereas the random effect for the Slope\(_\sigma \) is shown in panel b and the same for Soil Depth is shown in panel c
Figure 4a summarizes the posterior distribution of each covariate used linearly in our model. Specifically, they are all shown to be significant (each distribution is above the zero line) but with various levels of associated uncertainty. The SU Area is clearly the parameter with the narrowest posterior distribution, followed by the PGA. The two components of the VRM signal have comparable uncertainty levels. Taking this aside, the PGA shows the greatest influence with respect to the final susceptibility, for the regression coefficients are all expressed in the same unitless scale due to the mean zero unit variance step we mentioned in Sect. 3.2. As for the two random effects, both clearly behave in a nonlinear fashion, supporting our choice. For the Slope\(_\sigma \), small variations of slope steepness within a SU negatively contribute to the susceptibility. From slope steepness variations (measured in \(1\sigma \)) greater than 5 degrees, the effect becomes positive, indicating landslide-prone conditions. As for the Soil Depth, a peculiar pattern is shown. Two separate portions of the soil depth distribution contribute to decrease the estimated susceptibility whereas from approximately 0.4m to 1.0m the effect is opposite. This result well aligns to the description of the landslides provided by Harp and Jibson (1995, 1996). The authors report that the vast majority of co-seismic landslides were shallow-seated.
4.3 Cross-validation performance
Figure 5 summarizes the overall predictive performance for the 10-fold CV scheme we implement for the co-Northridge susceptibility. As the validation subset changes, a limited variability in the resulted performance metrics can be seen. This is graphically depicted with a limited spread of the ROC curves and consequently in their AUC estimates. More specifically, The median AUC is approximately 0.82, which corresponds to an excellent performance according to the AUC classification proposed by Hosmer and Lemeshow (2000).

Summary the 10-fold CV performance. Panel (a) shows the Receiver Operating Characteristic curves, one for each of the ten CV. Panel (b) summarises the distribution of associated AUC values
4.4 Benchmark Northridge susceptibility
A number of studies have already focused on the co-seismic landslide susceptibility induced by the 1994 Northridge earthquake (e.g., Godt et al. 2008; Nowicki et al. 2014; Nowicki Jessee et al. 2018; Tanyas et al. 2019). For this reason, and in light to the different aim of this work, we choose to report the posterior mean susceptibility in its numerical form, together with its uncertainty measured in a 95% CI. For conciseness, we do not report the same information in map form.

Error plot showing the relation between the posterior mean of the co-Northridge susceptibility and its associated uncertainty
Figure 6 shows the error plot. This graph is crucial in most landslide susceptibility studies (Rossi et al. 2010). In fact, an ideal model should produce very low and very high susceptibility estimates associated with low uncertainty. If such condition is met, because the potential users typically operate in this range of probabilities, they can trust the results and plan accordingly. Conversely, the only portion of the error plot which is accepted to report the highest uncertainty corresponds to the central portion of the susceptibility distribution, where the determination of likely landslide-prone SUs is intrinsically more difficult (Lombardo et al. 2016; Reichenbach et al. 2018) In this sense, the posterior estimates show a clear bell shape, suggesting that the model behaves as intended.
4.5 Scenario-based susceptibility
In this section we report the result of our simulation scheme. We remind here that we have run 1000 simulations for each of the 217 ground-motions scenarios extracted for the study area. This information is shared in the supplementary material, at the following link: https://doi.org/10.17026/dans-xjk-5676. At this address we deposited both the SU vector file (.mif) and scenario-based susceptibility maps reported as the mean and 95%CI for each of the 1000 simulation batches. Also, we listed all the links to download the PGA scenarios from the USGS ShakeMap system. In Figure 7 we show the Probability Density Functions of each mean scenario-based susceptibility computed from the (\(1000\times 217\)) simulations.

PDFs of the mean susceptibility estimated computed from the 1000 simulation batch for each of the 217 ground motion scenarios
A similar information is summarized in map form in Figure 8, where out of all the simulations we extract the global mean and associated uncertainty. Additionally we report the worst-case scenario where we computed for each SU in the study area the maximum probability out of all the mean scenario-based susceptibilities.

Descriptive statistics of the 217 ground motion scenarios (and 1000 simulations for each case) together with the 1994 Northridge susceptibility. Panel (a) shows the mean susceptibility of all the possible ground motions scenarios combined. Panel (b) reports the uncertainty in the susceptibility estimates for all scenarios. Panel (c) depicts the susceptibility corresponding to the maximum probability values for each SU and for all scenarios together
To provide a more intuitive understanding of our simulation scheme we propose, we select five among the largest scenario-based ground motions available at the USGS Shakemap service, falling within the study area. Their epicenters, rupture planes and metadata are shown in Fig. 9a. In the same figure we plot the mean susceptibility map computed from the 1000 simulations, for each of the five scenarios (Fig. 9b-f).

Panel (a) shows a geographical summary of a selected number of scenario bases epicenters and associated rupture planes. The white polygon corresponds to our study area. For each case shown in the previous panel, we report the corresponding mean susceptibility map out of the 1000 simulation runs (panels b to f)
5 Discussions
In this work, we take advantage of a plug-in simulation procedure. We initially calibrate a GAM-susceptibility model for the 1994 Northridge earthquake. And, on the basis of the estimated fixed and random effects (and associated distributions) we substitute the PGA pattern from the Northridge with each of the available 217 PGA scenarios within the study area. For each PGA scenario, we then run 1000 simulations to capture the variability of the susceptibility pattern as the ground motion changes from one predicted scenario to another. The distribution of the mean susceptibility for each simulation batch appears quite different from case to case. This is shown in Fig. 7 with large oscillations. This information is further clarified in Fig. 8 where the mean susceptibility of all the \(1000 \times 217\) simulations is plotted in map form together with the 95% CI and maximum level. The global mean (Fig. 8a) shows few extremely susceptible slopes scattered over the landscape. Notably, by computing the mean for all simulations, the susceptibility may be smoothed and end up showing a low variability or a limited number of expected unstable SUs. Conversely, by looking at the maximum susceptibility across all the simulations (worst-case global scenario in Fig. 8c), three regions within the study area appear more prone to fail than the rest. The steep SUs located along the coastline are part of the worst case scenario as well as a sequence of SU approximately aligned from East to West. These are SUs exposed to the main bulk of scenario-based ground motion patterns. Ultimately, the third cluster of highly susceptible SUs is located to the Northern sector of the study area where the topography is significantly rough and scenario-based ground motion quite common among the selected cases.
To provide further examples of our simulation procedure, Fig. 9 moves away from the global summary provided above, and depicts five cases for which the PGA was reported to the be among the largest of the 217 scenarios we examined. Here the ground motion effect is particularly evident for each of the five mean simulated susceptibilities reflects different susceptible SUs. However, despite we managed to capture the seismic effect over the co-Nortridge landslides and project it over the scenario-based ShakeMaps, the model may still lacks part of the information required to fully describe the physics of earthquake-induced ground deformation. In fact, on the one hand the directivity is not included in the ground motion scenarios (Allstadt et al. 2018). Therefore, some specific portion of the landscape aligned to the main direction of the earthquake radiation pattern may still not appear as susceptible as they may be. On the other hand, even the topographic amplification is not accounted for in the earthquake scenarios (Allstadt et al. 2018). As a result, the spatial dependence that narrow mountaintops should exhibit between susceptibility and the wavefield amplification is also neglected.
However, despite minor spatial dependency issues, our model is able to efficiently include any PGA effect into any potential susceptibility realization within the study area under the assumption that the PGA effect we estimated for the Northridge model (see Sect. 4.4) is robust. We believe so because the governing mechanical laws that link the slope instability to the ground shaking should not change with time. As a result, the only limiting factor for similar procedures should depend on the statistical inference. In this sense, we believe the fixed effect for the PGA to be well-estimated (see Fig. 4a) both in its amplitude (posterior mean) and significance (posterior 95% credible interval above the zero line).
Throughout the manuscript we have referred to our simulation results in terms of susceptibility. However, we would like to point out that the scenario-based PGA estimates provided by the USGS ShakeMap system have a temporal connotation. As mentioned before, USGS (2017) reports each scenario to be associated with a return time of 50 years. Therefore, our results, either if we examine specific scenarios like in Fig. 9 or if we consider the combined effects of all scenarios together like in Fig. 8, both express probabilities of landslide occurrence (susceptibility) within an expected timespan of 50 years. This definition satisfies most the notion of landslide hazard (Fell et al. 2008; Guzzetti et al. 1999). As a result, we argue that the method we propose allows one to develop predictive maps which contain similar if not the same information to scenario-based landslide-hazard maps.
6 Concluding remarks
We conclude this section by stressing that this application could actually be replicated in any other landslide hazard assessment. The only requirement is the availability of the co-seismic landslide inventory and ground motion (to build the reference model) as well as the predicted PGA scenarios (to simulate). Furthermore, in regions with a similar morpho-tectonic setting, there is no strict requirement other than the sole availability of PGA scenarios. In fact, under the assumption that landslides may respond in a similar manner to the ground motion as they did for the Northridge earthquake, we could use the very same statistical model we generated here to simulate in other geographic contexts. The only difference would be that the plug-in procedure, should be extended not only to the PGA scenarios but to the morphometric properties of the target area.
We also stress here that the use of the scenario-based ground motion is only one possible application in simulating landslide prone conditions. In fact, one could follow the same strategy and simulate over precipitations, land use changes and or, much closer to the framework we propose here, over past ground motion scenarios. The latter could unravel potential landslide prone-conditions in the past and help explore historical data for which data is usually poor or non-existing. An example that goes in this research direction can be found in the companion paper to the present one (Luo et al. 2021).
Data availability
Supplementary materials are located at this link: https://doi.org/10.17026/dans-xjk-5676. They contain the results of our analyses including a vector file – the extension is .mif and can be easily converted into a more common shapefile –. There, we report the mean (and uncertainty) susceptibility of each 1000 simulation batch for each of the 217 scenarios. And, we also list the corresponding ground motion scenarios, with associated links to download the actual PGA maps.
References
Abrahamson NA, Bommer JJ (2005) Probability and uncertainty in seismic hazard analysis. Earthq spectra 21(2):603–607
Akgün A, Türk N (2011) Mapping erosion susceptibility by a multivariate statistical method: a case study from the Ayvalık region. NW Turkey. Comput Geosci 37(9):1515–1524
Aleotti P (2004) A warning system for rainfall-induced shallow failures. Eng geol 73(3–4):247–265
Allstadt KE, Jibson RW, Thompson EM et al (2018) Improving near-real-time coseismic landslide models: lessons learned from the 2016 Kaikōura, New Zealand, earthquake. Bull Seismol Soc Am 108:1649–1664. https://doi.org/10.1785/0120170297
Allstadt KE, Thompson EM, Hearne M, Jessee MN, Zhu J, Wald DJ, Tanyas H (2017) Integrating landslide and liquefaction hazard and loss estimates with existing USGS real-time earthquake information products. In 16th World Conference on Earthquake Engineering
Alvioli M, Marchesini I, Reichenbach P, Rossi M, Ardizzone F, Fiorucci F, Guzzetti F (2016) Automatic delineation of geomorphological slope units with r.slopeunits v1.0 and their optimization for landslide susceptibility modeling. Geoscientific Model Dev 9(11):3975–3991
Amato G, Eisank C, Castro-Camilo D, Lombardo L (2019) Accounting for covariate distributions in slope-unit-based landslide susceptibility models a case study in the alpine environment. Eng Geol 260:105237
Arabameri A, Saha S, Roy J, Chen W, Blaschke T, Tien Bui D (2020) Landslide susceptibility evaluation and management using different machine learning methods in the Gallicash river Watershed Iran. Remote Sensing 12(3):475
Bakka H, Rue H, Fuglstad G-A, Riebler A, Bolin D, Illian J, Krainski E, Simpson D, Lindgren F (2018) Spatial modeling with R-INLA: a review. Wiley Interdisciplinary Rev: Computational Statistics 10(6):e1443
Brenning A (2005) Spatial prediction models for landslide hazards: review, comparison and evaluation. Nat Hazards Earth Syst Sci 5(6):853–862
Brenning A (2008) Statistical geocomputing combining R and SAGA: the example of landslide susceptibility analysis with generalized additive models. Hamburger Beiträge zur Physischen Geographie und Landschaftsökologie 19(23–32):410
Budimir MEA, Atkinson PM, Lewis HG (2015) A systematic review of landslide probability mapping using logistic regression. Landslides pp. 1–18
Cama M, Lombardo L, Conoscenti C, Agnesi V, Rotigliano E (2015) Predicting storm-triggered debris flow events: application to the 2009 Ionian Peloritan disaster (Sicily, Italy). Nat Hazards Earth Syst Sci 15(8):1785–1806
Cama M, Lombardo L, Conoscenti C, Rotigliano E (2017) Improving transferability strategies for debris flow susceptibility assessment: application to the Saponara and Itala catchments (Messina, Italy). Geomorphology 288:52–65
Castro Camilo D, Lombardo L, Mai P, Dou J, Huser R (2017) Handling high predictor dimensionality in slope-unit-based landslide susceptibility models through LASSO-penalized generalized linear model. Environ Model Softw 97:145–156
Conoscenti C, Rotigliano E, Cama M, Caraballo-Arias NA, Lombardo L, Agnesi V (2016) Exploring the effect of absence selection on landslide susceptibility models: a case study in Sicily, Italy. Geomorphology 261:222–235
Das I, Sahoo S, van Westen C, Stein A, Hack R (2010) Landslide susceptibility assessment using logistic regression and its comparison with a rock mass classification system, along a road section in the northern Himalayas (India). Geomorphology 114(4):627–637
Del Gaudio V, Pierri P, Wasowski J (2003) An approach to time-probabilistic evaluation of seismically induced landslide hazard. Bulletin Seismol Soc Am 93(2):557–569
Del Gaudio V, Wasowski J (2004) Time probabilistic evaluation of seismically induced landslide hazard in Irpinia (Southern Italy). Soil Dyn Earthq Eng 24(12):915–928
Fan X, Scaringi G, Korup O, West AJ, van Westen CJ, Tanyas H, Hovius N, Hales TC, Jibson RW, Allstadt KE et al (2019) Earthquake-induced chains of geologic hazards: patterns, mechanisms, and impacts. Rev Geophys 57(2):421–503
Fan X, Yunus AP, Scaringi G, Catani F, Siva Subramanian S, Xu Q, Huang R (2021) Rapidly evolving controls of landslides after a strong earthquake and implications for hazard assessments. Geophys Res Lett 48(1):e2020GL090509
Fell R, Corominas J, Bonnard C, Cascini L, Leroi E, Savage WZ et al (2008) Guidelines for landslide susceptibility, hazard and risk zoning for land-use planning. Eng Geol 102(3–4):99–111
Ferkingstad E, Rue H et al (2015) Improving the INLA approach for approximate Bayesian inference for latent Gaussian models. Electron J Statistics 9(2):2706–2731
Friedman J, Hastie T, Tibshirani R (2009) glmnet: Lasso and elastic-net regularized generalized linear models. R package version 1(4)
Ghosh S, van Westen CJ, Carranza EJM, Jetten VG, Cardinali M, Rossi M, Guzzetti F (2012) Generating event-based landslide maps in a data-scarce Himalayan environment for estimating temporal and magnitude probabilities. Eng Geol 128:49–62
Godt J, Sener B, Verdin K, Wald D, Earle P, Harp E, Jibson R (2008) Rapid assessment of earthquake-induced landsliding. Proc First World Landslide Forum, United Nations Univ, Tokyo 4:219–222
Goetz J, Brenning A, Petschko H, Leopold P (2015) Evaluating machine learning and statistical prediction techniques for landslide susceptibility modeling. Comput Geosci 81:1–11
Graziella D, Ingeborg K, Monica S, Nils-Kristian O, Ragnar E, Erik J, Hervé C (2015) Landslide early warning system and web tools for real-time scenarios and for distribution of warning messages in Norway. Engineering Geology for Society and Territory-Volume 2. Springer, New york, pp 625–629
Greco R, Giorgio M, Capparelli G, Versace P (2013) Early warning of rainfall-induced landslides based on empirical mobility function predictor. Eng Geol 153:68–79
Guzzetti F, Cardinali M, Reichenbach P, Cipolla F, Sebastiani C, Galli M, Salvati P (2004) Landslides triggered by the 23 November 2000 rainfall event in the Imperia Province, Western Liguria Italy. Eng Geol 73(3–4):229–245
Guzzetti F, Carrara A, Cardinali M, Reichenbach P (1999) Landslide hazard evaluation: a review of current techniques and their application in a multi-scale study Central Italy. Geomorphology 31(1):181–216
Guzzetti F, Gariano SL, Peruccacci S et al (2020) Geographical landslide early warning systems. Earth-Science Rev 200:102973. https://doi.org/10.1016/j.earscirev.2019.102973
Hanks TC, Abrahamson N, Board M, Boore DM, Brune J, Cornell C (2005) Observed ground motions, extreme ground motions, and physical limits to ground motions. Directions in strong motion instrumentation. Springer, New York, pp 55–59
Harp EL, Jibson RW (1995) Inventory of landslides triggered by the 1994 Northridge, California earthquake. Technical report, US Geological Survey
Harp EL, Jibson RW (1996) Landslides triggered by the 1994 Northridge, California, earthquake. Bulletin Seismol Soc Am 86(1B):S319–S332
Harp EL, Keefer DK, Sato HP, Yagi H (2011) Landslide inventories: the essential part of seismic landslide hazard analyses. Eng Geol 122(1–2):9–21
Harrell FE Jr (2015) Regression modeling strategies: with applications to linear models, logistic and ordinal regression, and survival analysis. Springer, New York
Hastie T, Qian J (2014) Glmnet vignette. Retrieve from http://www. web.stanford.edu/~hastie/Papers/Glmnet_Vignette.pdf. Accessed September 20, 2016
Heerdegen RG, Beran MA (1982) Quantifying source areas through land surface curvature and shape. J Hydrol 57(3–4):359–373
Hosmer DW, Lemeshow S (2000) Appl Logist Regres, 2nd edn. Wiley, New York
Jarvis A, Reuter HI, Nelson A, Guevara E (2008) Hole-filled SRTM for the globe Version 4
Jasiewicz J, Stepinski TF (2013) Geomorphons–a pattern recognition approach to classification and mapping of landforms. Geomorphology 182:147–156
Jibson RW, Harp EL, Michael JA (1998) A method for producing digital probabilistic seismic landslide hazard maps: an example from the Los Angeles, California, area. US Department of the Interior, US Geological Survey
Jibson RW, Harp EL, Michael JA (2000) A method for producing digital probabilistic seismic landslide hazard maps. Eng Geol 58(3–4):271–289
Kirschbaum D, Adler R, Hong Y, Lerner-Lam A (2009) Evaluation of a preliminary satellite-based landslide hazard algorithm using global landslide inventories. Nat Hazards Earth Syst Sci 9(3):673–686
Kirschbaum D, Stanley T (2018) Satellite-based assessment of rainfall-triggered landslide hazard for situational awareness. Earth’s Future 6(3):505–523
Kirschbaum D, Stanley T, Zhou Y (2015) Spatial and temporal analysis of a global landslide catalog. Geomorphology 249:4–15
Kirschbaum DB, Adler R, Hong Y, Hill S, Lerner-Lam A (2010) A global landslide catalog for hazard applications: method, results, and limitations. Nat Hazards 52(3):561–575
Ko FW, Lo FL (2018) From landslide susceptibility to landslide frequency: a territory-wide study in Hong Kong. Eng Geol 242:12–22
Lari S, Frattini P, Crosta G (2014) A probabilistic approach for landslide hazard analysis. Eng Geol 182:3–14
Lee LH, Lee HH, Han SW (2000) Method of selecting design earthquake ground motions for tall buildings. Struct Des Tall Build 9(3):201–213
Lombardo L, Fubelli G, Amato G, Bonasera M (2016) Presence-only approach to assess landslide triggering-thickness susceptibility: a test for the Mili catchment (north-eastern Sicily, Italy). Nat Hazards 84(1):565–588
Lombardo L, Mai PM (2018) Presenting logistic regression-based landslide susceptibility results. Eng Geol 244:14–24
Lombardo L, Opitz T, Ardizzone F, Guzzetti F, Huser R (2020) Space-time landslide predictive modelling. Earth-Sci Rev 209:03318103318
Lombardo L, Opitz T, Huser R (2018) Point process-based modeling of multiple debris flow landslides using INLA: an application to the 2009 Messina disaster. Stoch Environ Res Risk Assess 32(7):2179–2198
Lombardo L, Opitz T, Huser R (2019) 3 - Numerical recipes for landslide spatial prediction using R-INLA: a step-by-step tutorial. In: Pourghasemi HR, Gokceoglu C (eds) Spatial Modeling in GIS and R for Earth and environmental sciences. Elsevier, Netherlands, pp 55–83
Lombardo L, Tanyas H (2020) Chrono-validation of near-real-time landslide susceptibility models via plug-in statistical simulations. Eng Geol 278:105818
Luo L, Lombardo L, van Westen C, Pei X, Huang R (2021) From scenario-based seismic hazard to scenario-based landslide hazard: rewinding to the past via statistical simulations. Stochastic environmental research and risk assessment pp 1–22
Malamud BD, Turcotte DL, Guzzetti F, Reichenbach P (2004) Landslide inventories and their statistical properties. Earth Surf Processes Landf 29(6):687–711
Mathew J, Jha V, Rawat G (2009) Landslide susceptibility zonation mapping and its validation in part of Garhwal Lesser Himalaya, India, using binary logistic regression analysis and receiver operating characteristic curve method. Landslides 6(1):17–26
Melchiorre C, Frattini P (2012) Modelling probability of rainfall-induced shallow landslides in a changing climate, Otta Central Norway. Climatic change 113(2):413–436
Montilla JAP, Hamdache M, Casado CL (2003) Seismic hazard in Northern Algeria using spatially smoothed seismicity. Results for peak ground acceleration. Tectonophysics 372(1–2):105–119
Newmark NM (1965) Effects of earthquakes on dams and embankments. Geotechnique 15(2):139–160
Nowicki MA, Wald DJ, Hamburger MW, Hearne M, Thompson EM (2014) Development of a globally applicable model for near real-time prediction of seismically induced landslides. Eng Geol 173:54–65
Nowicki Jessee M, Hamburger M, Allstadt K, Wald D, Robeson S, Tanyas H, Hearne M, Thompson E (2018) A global empirical model for near-real-time assessment of seismically induced landslides. J Geophys Res: Earth Surf 123(8):1835–1859
NRCS (2010) Soil survey staff, natural resources conservation service, United States department of agriculture. Soil Survey Geographic (SSURGO) - Database for northeast Tennessee
Petersen MD, Frankel AD, Harmsen SC, Mueller CS, Haller KM, Wheeler RL, Wesson RL, Zeng Y, Boyd OS, Perkins DM et al. (2008) Documentation for the 2008 update of the United States national seismic hazard maps. Technical report, Geological Survey (US)
Rathje EM, Saygili G (2008) Probabilistic seismic hazard analysis for the sliding displacement of slopes: scalar and vector approaches. J Geotech Geoenviron Eng 134(6):804–814
Reichenbach P, Rossi M, Malamud BD, Mihir M, Guzzetti F (2018) A review of statistically-based landslide susceptibility models. Earth-Sci Rev 180:60–91
Romeo R (2000) Seismically induced landslide displacements: a predictive model. Eng Geol 58(3–4):337–351
Rossi M, Witt A, Guzzetti F, Malamud BD, Peruccacci S (2010) Analysis of historical landslide time series in the Emilia-Romagna region, northern Italy. Earth Surf Processes Landf 35(10):1123–1137
Rue H, Martino S, Chopin N (2009) Approximate Bayesian inference for latent Gaussian models by using integrated nested Laplace approximations. J R Statistical Soc: Series B 71(2):319–392
Rue H, Riebler A, Sørbye SH, Illian JB, Simpson DP, Lindgren FK (2017) Bayesian computing with INLA: a review. Annu Rev Statistics Appl 4:395–421
Samia J, Temme AJ, Bregt A, Wallinga J, Guzzetti F, Ardizzone F, Rossi M (2017) Do landslides follow landslides? insights in path dependency from a multi-temporal landslide inventory. Landslides 14:547–558
Sappington JM, Longshore KM, Thompson DB (2007) Quantifying landscape ruggedness for animal habitat analysis: a case study using bighorn sheep in the Mojave Desert. J Wildl Manag 71(5):1419–1426
Saygili G, Rathje EM (2009) Probabilistically based seismic landslide hazard maps: an application in Southern California. Eng Geol 109(3–4):183–194
Schmitt RG, Tanyas H, Jessee MAN, Zhu J, Biegel KM, Allstadt KE, Jibson RW, Thompson EM, van Westen CJ, Sato HP, Wald DJ, Godt JW, Gorum T, Xu C, Rathje EM, Knudsen KL (2017) An open repository of earthquake-triggered ground-failure inventories. U.S. Geological Survey Data Series 1064
Stanton MC, Diggle PJ (2013) Geostatistical analysis of binomial data: generalised linear or transformed Gaussian modelling? Environmetrics 24(3):158–171
Steger S, Schmaltz E, Glade T (2020) The (f) utility to account for pre-failure topography in data-driven landslide susceptibility modelling. Geomorphology 354:107041
Tanyaş H, van Westen C, Allstadt K, Nowicki AJM, Görüm T, Jibson R, Godt J, Sato H, Schmitt R, Marc O, Hovius N (2017) Presentation and analysis of a worldwide database of earthquake-induced landslide inventories. J Geophys Res: Earth Surf 122(10):1991–2015
Tanyaş H, Allstadt KE, van Westen CJ (2018) An updated method for estimating landslide-event magnitude. Earth surf processes landf 43(9):1836–1847
Tanyaş H, Lombardo L (2020) Completeness Index for Earthquake-Induced Landslide Inventories. Engineering Geology 264:105331
Tanyas H, Rossi M, Alvioli M, van Westen CJ, Marchesini I (2019) A global slope unit-based method for the near real-time prediction of earthquake-induced landslides. Geomorphology 327:126–146
R Core Team (2013) R: a language and environment for statistical computing, p 201
USGS (2017) U.S. Geological Survey, 2017, USGS Earthquake Scenario Map (BSSC 2014). accessed on March 15, 2020
Varnes and the IAEG commission on landslides and other mass-movements (1984) Landslide hazard zonation: a review of principles and practice. Natural Hazards, Series. Paris: United Nations Economic, Scientific and cultural organization. UNESCO 3, 63
Wald D, Wald L, Worden B, Goltz J (2003) ShakeMap, a tool for earthquake response. Technical report
Kanamori TH, Scrivner H (1999) TriNet “ShakeMaps”: rapid generation of peak ground motion and intensity maps for earthquakes in southern California. Earthq Spectra 15(3):537–555
Worden C, Wald D (2016) ShakeMap manual online: Technical manual, user’s guide, and software guide. US Geol. Surv.
Wu Y-M, Lan H-X, Gao X, Li L-P, Yang Z-H (2015) A simplified physically based coupled rainfall threshold model for triggering landslides. Eng Geol 195:63–69
Zevenbergen LW, Thorne CR (1987) Quantitative analysis of land surface topography. Earth surface processes and landforms 12(1):47–56
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lombardo, L., Tanyas, H. From scenario-based seismic hazard to scenario-based landslide hazard: fast-forwarding to the future via statistical simulations. Stoch Environ Res Risk Assess 36, 2229–2242 (2022). https://doi.org/10.1007/s00477-021-02020-1
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-021-02020-1