
Abstract
Let \((\sigma _N^{(i)})_{i \in I}\) be a family of symmetric permutations of the entries of a Wigner matrix \({\mathbf {W}}_N\). We characterize the limiting traffic distribution of the corresponding family of dependent Wigner matrices \(({\mathbf {W}}_N^{\sigma _N^{(i)}})_{i \in I}\) in terms of the geometry of the permutations. We also consider the analogous problem for the limiting joint distribution of \(({\mathbf {W}}_N^{\sigma _N^{(i)}})_{i \in I}\). In particular, we obtain a description in terms of semicircular families with general covariance structures. As a special case, we derive necessary and sufficient conditions for traffic independence as well as sufficient conditions for free independence.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Free probability is a noncommutative (NC) probability theory built on Voiculescu’s free independence. In the landmark work [21], Voiculescu showed that free independence describes the large dimension limit behavior of independent random matrices in many generic situations. In recent years, the necessity of independence in this paradigm has been challenged. Mingo and Popa showed that freeness from the transpose occurs in unitarily invariant ensembles [11]. Cébron, Dahlqvist, and Male extended these results to a larger class of dependent matrices using the traffic probability framework [5]. We now know freeness to be a generic phenomenon for random matrices of cactus-type [1].
In a different direction, one can simply view the transpose as a particular permutation \(\sigma _N\) of the entries of a matrix \({\mathbf {A}}_N\). Naturally, one can then ask when such a permutation produces asymptotic freeness for the pair \(({\mathbf {A}}_N, {\mathbf {A}}_N^{\sigma _N})\). This question was first considered by Popa, who found a sufficient condition for asymptotic freeness in the case of the GUE using the Wick calculus [19]. Similar results exist for other ensembles [7, 10, 12,13,14, 18]. In this article, we extend the analysis to general Wigner matrices and general NC covariance structures.
1.1 Statement of results
First, we specify the matrix model under consideration.
Definition 1.1
(Wigner matrix). For each \(N \in {\mathbb {N}}\), let \(\big ({\mathbf {X}}_N(j, k)\big )_{1 \le j \le k \le N}\) be a family of independent random variables such that:
-
(i)
the off-diagonal entries \(\big ({\mathbf {X}}_N(j, k)\big )_{1 \le j < k \le N}\) are complex-valued, centered, and of unit variance and pseudovariance \({\mathbb {E}}\big [{\mathbf {X}}_N(j, k)^2\big ] = \beta \in [-1, 1]\);
-
(ii)
the diagonal entries \(\big ({\mathbf {X}}_N(j, j)\big )_{1 \le j \le N}\) are real-valued and of finite variance;
-
(iii)
we have a strong uniform control on the moments
$$\begin{aligned} \sup _{N \in {\mathbb {N}}} \sup _{1 \le j \le k \le N} {\mathbb {E}}\big [|{\mathbf {X}}_N(j, k)|^\ell \big ] \le m_\ell < \infty . \end{aligned}$$(1)
We call the random self-adjoint matrix defined by
a Wigner matrix.
For a tuple \((j, k) \in [N]^2\), we define the transpose permutation
We say that a permutation \(\sigma _N: [N]^2 \rightarrow [N]^2\) is symmetric if it commutes with the transpose \(\sigma _N \circ \intercal = \intercal \circ \sigma _N\), in which case the permuted matrix
is again a Wigner matrix. Note that a symmetric permutation necessarily maps the diagonal to the diagonal. Moreover, if \(\sigma _N, \rho _N \in \mathfrak {S}([N]^2)\), then
Hereafter, when we refer to a matrix \({\mathbf {A}}_N\) (resp., permutation \(\sigma _N\)), we implicitly refer to a sequence of matrices \(({\mathbf {A}}_N)_{N \in {\mathbb {N}}}\) (resp., permutations \((\sigma _N)_{N \in {\mathbb {N}}}\)).
Consider a family of symmetric permutations \((\sigma _N^{(i)})_{i \in I}\) and the corresponding family of (dependent) Wigner matrices \(({\mathbf {M}}_N^{(i)})_{i \in I} = ({\mathbf {W}}_N^{\sigma _N^{(i)}})_{i \in I}\). Popa showed that if \({\mathbf {W}}_N {\mathop {=}\limits ^{d}}{\text {GUE}}(N, \frac{1}{N})\), then
is a sufficient condition for the asymptotic freeness of the family \(({\mathbf {M}}_N^{(i)})_{i \in I}\) [19, Theorem 3.2]. In other words, \(({\mathbf {M}}_N^{(i)})_{i \in I}\) converges to a semicircular system \((s_i)_{i \in I}\). We extend this result in the following ways. First, we consider Wigner matrices in the generality of Definition 1.1. Notably, condition (2) is not sufficient for general \(\beta \). Second, we consider general covariance structures for the limiting family \((s_i)_{i \in I}\). Finally, we determine necessary and sufficient conditions for asymptotic traffic independence (resp., sufficient conditions for asymptotic freeness).
To motivate the results, we consider the informative case of a pair of matrices \(({\mathbf {W}}_N, {\mathbf {W}}_N^{\sigma _N})\). Heuristically, the independence of the entries of \({\mathbf {W}}_N\) suggests that if we can typically avoid repeating a permuted entry (i.e., avoid the situation of \({\mathbf {W}}_N^{\sigma _N}(j, k) = {\mathbf {W}}_N(j, k)\)) when expanding the trace, then the calculation should follow the usual case of independent Wigner matrices. As a first guess, one might then expect that a vanishing proportion of fixed points
would suffice; however, the location of the permuted entry plays a crucial role. For example, in the case of the transpose \(\sigma _N = \intercal \), the pair \(({\mathbf {W}}_N, {\mathbf {W}}_N^{\intercal })\) converges to a semicircular family of covariance \(\begin{pmatrix} 1 &{} \beta \\ \beta &{} 1 \end{pmatrix}\) [1, Corollary 3.9]. This leads us to consider the set of transposed entries
The case of \(\beta = 1\) suggests that a nontrivial proportion of fixed points should contribute to the covariance accordingly. As a second guess, one might then expect that the limits
would produce a semicircular family of covariance \(\begin{pmatrix} 1 &{} a+b\beta \\ a+b\beta &{} 1 \end{pmatrix}\); however, the multiplicative structure of a semicircular family requires a certain homogeneity in the proportion of fixed points (resp., transposed points) in any given row that the limits (3) alone do not impose. For example, consider the permutation
See Fig. 1 for an illustration. A straightforward calculation shows that
whereas
unless \(\beta = 1\). This leads us to consider the refinement

The action of \(\rho _N\): black entries are fixed and gray entries are sent to their transpose (color figure online)
But even this is not enough: as we will see, certain locations contribute to the trace expansion at a higher rate, leading to nonstandard joint distributions. For example, consider the operator-valued matrices
where \(s_1, s_2, s_3, c_1, c_2, c_3 \in (\mathcal {A}, \varphi )\) are \(*\)-free with \(s_1, s_2, s_3\) standard semicircular and \(c_1, c_2, c_3\) standard circular. Then \(A_1, A_2 \in ({\text {Mat}}_{3 \times 3}({\mathbb {C}}) \otimes \mathcal {A}, {{\,\mathrm{tr}\,}}\otimes \varphi )\) are standard semicircular with
The additional contributions to the mixed fourth moment come from the terms
One can easily construct a sequence of permutations \((\sigma _N)_{N \in {\mathbb {N}}}\) with \({\text {FP}}(\sigma _N) = {\text {TP}}(\sigma _N) = \emptyset \) such that the pair \(({\mathbf {W}}_N, {\mathbf {W}}_N^{\sigma _N})\) converges to \((A_1, A_2)\) in distribution.
To ensure that our limit is distributed as a semicircular family in the traffic sense, we must avoid the possibility of the permuted entries meeting up in a way that overcontributes as in (4). As it turns out, this only happens if the entries are moved within a grid.
Definition 1.2
For an entry \((j, k) \in [N]^2\), we define the subset
For a permutation \(\sigma _N \in \mathfrak {S}([N]^2)\), we define
We say that \(\sigma _N\) stays off the grid if \(\#({\text {Grid}}(\sigma _N)) = o(N^2)\). See Fig. 2 for an illustration.

An example of an entry (in red) and its grid (in gray) (color figure online)
By definition, the identity permutation \({{\,\mathrm{id}\,}}_{[N]^2} \in \mathfrak {S}([N]^2)\) stays off the grid. Furthermore, the grid condition is stable with respect to inversion: if \(\sigma _N\) stays off the grid, then \(\sigma _N^{-1}\) stays off the grid. For notational convenience, we write \(({\mathbf {M}}_N^{(i)})_{i \in I} = ({\mathbf {W}}_N^{\sigma _N^{(i)}})_{i \in I}\). We can now state our main results.
Theorem 1.3
Let \((\sigma _N^{(i)})_{i \in I}\) be a family of symmetric permutations. First, suppose that \(\beta \in (-1, 1)\). If
-
(i)
\(\displaystyle \lim _{N \rightarrow \infty } \max _{j \in [N]} \frac{\#\Big ({{\text {FP} }}\big ((\sigma _N^{(i')})^{-1} \circ \sigma _N^{(i)}, j\big )\Big )}{N} \!=\! \lim _{N \rightarrow \infty } \min _{j \in [N]} \frac{\#\Big ({{\text {FP} }}\big ((\sigma _N^{(i')})^{-1} \circ \sigma _N^{(i)}, j\big )\Big )}{N} = a_{i, i'}\);
-
(ii)
\(\displaystyle \lim _{N \rightarrow \infty } \max _{j \in [N]} \frac{\#\Big ({{\text {TP} }}\big ((\sigma _N^{(i')})^{-1} \circ \sigma _N^{(i)}, j\big )\Big )}{N} \!=\! \lim _{N \rightarrow \infty } \min _{j \in [N]} \frac{\#\Big ({{\text {TP} }}\big ((\sigma _N^{(i')})^{-1} \circ \sigma _N^{(i)}, j\big )\Big )}{N} = b_{i, i'}\);
-
(iii)
\((\sigma _N^{(i')})^{-1} \circ \sigma _N^{(i)}\) stays off the grid for every \(i, i' \in I\),
then \(({\mathbf {M}}_N^{(i)})_{i \in I}\) converges in traffic distribution to a semicircular traffic family \((t_i)_{i \in I}\) of covariance

and pseudocovariance

Conversely, if \(({\mathbf {M}}_N^{(i)})_{i \in I}\) converges in traffic distribution to \((t_i)_{i \in I}\) as above, then
-
(I)
\(\displaystyle \lim _{N \rightarrow \infty } \frac{\#\Big ({{\text {FP} }}\big ((\sigma _N^{(i')})^{-1} \circ \sigma _N^{(i)}\big )\Big )}{N^2} = a_{i, i'}\);
-
(II)
\(\displaystyle \lim _{N \rightarrow \infty } \frac{\#\Big ({{\text {TP} }}\big ((\sigma _N^{(i')})^{-1} \circ \sigma _N^{(i)}\big )\Big )}{N^2} = b_{i, i'}\);
-
(III)
\((\sigma _N^{(i')})^{-1} \circ \sigma _N^{(i)}\) stays off the grid for every \(i, i' \in I\).
If \(\beta \in \{-1, 1\}\), then the result holds with conditions (i) and (ii) replaced by the weaker condition
conditions (I) and (II) replaced by the weaker condition
-
(IV)
\(\displaystyle \lim _{N \rightarrow \infty } \frac{\#\Big ({{\text {FP} }}\big ((\sigma _N^{(i')})^{-1} \circ \sigma _N^{(i)}\big )\Big ) + \#\Big ({{\text {TP} }}\big ((\sigma _N^{(i')})^{-1} \circ \sigma _N^{(i)}\big )\Big ) \beta }{N^2} = a_{i, i'} + b_{i, i'}\beta ;\)
and, if \(\beta = -1\), (III) replaced by the weaker condition
In particular, if \(\beta \in (-1, 1)\) (resp., \(\beta = 1\)), then conditions (I) and (II) (resp., condition (IV)) with \(a_{i, i'} = b_{i, i'} = 0\) for \(i \ne i'\) and condition (III) are necessary and sufficient for the asymptotic traffic independence of the \(({\mathbf {M}}_N^{(i)})_{i \in I}\).
Remark 1.4
The reader may wonder why \(\beta = -1\) is an exceptional case. Roughly speaking, the issue arises from precise cancellations between the variance and the pseudovariance. See Remarks 2.5 and 2.9 for more details.
We would like to use the cactus-cumulant correspondence in [1, §3.1] to translate Theorem 1.3 to a more familiar free probabilistic statement; however, not all of the observables in the traffic framework appear in the usual NC framework. Restricting our analysis to this smaller class of observables, we obtain the following corollary.
Corollary 1.5
Let \((\sigma _N^{(i)})_{i \in I}\) be a family of symmetric permutations. Suppose that \(\beta \in [-1, 1]\). If
-
(a)
$$\begin{aligned}&\lim _{N \rightarrow \infty } \max _{j \in [N]} \frac{\#\Big ({{\text {FP} }}\big ((\sigma _N^{(i')})^{-1} \circ \sigma _N^{(i)}, j\big )\Big ) + \#\Big ({{\text {TP} }}\big ((\sigma _N^{(i')})^{-1} \circ \sigma _N^{(i)}, j\big )\Big )\beta }{N} \\&\quad = \lim _{N \rightarrow \infty } \min _{j \in [N]} \frac{\#\Big ({{\text {FP} }}\big ((\sigma _N^{(i')})^{-1} \circ \sigma _N^{(i)}, j\big )\Big ) + \#\Big ({{\text {TP} }}\big ((\sigma _N^{(i')})^{-1} \circ \sigma _N^{(i)}, j\big )\Big )\beta }{N} = c_{i, i'}; \end{aligned}$$
-
(b)
\((\sigma _N^{(i')})^{-1} \circ \sigma _N^{(i)}\) stays off the grid for every \(i, i' \in I\),
then \(({\mathbf {M}}_N^{(i)})_{i \in I}\) converges in distribution to a semicircular family \((s_i)_{i \in I}\) of covariance \({\mathbf {K}}(i, i') = c_{i, i'}\). If \(\beta = 0\), then we can relax the grid condition (b) to Popa’s condition for the GUE (2). If one is only interested in freeness  , then the homogeneity condition (a) can be replaced by the averaged quantity
, then the homogeneity condition (a) can be replaced by the averaged quantity
-
(A)
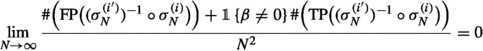 .
.
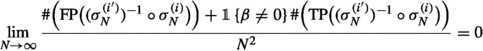 .
.Remark 1.6
Popa’s sufficient condition for the GUE amounts to an asymmetric version of staying off the grid: in Fig. 2, one simply needs to avoid the entries in the same row or the same column as the red entry. Indeed, the entries in the remainder of the grid do not factor into the calculations for the GUE since the pseudovariance \(\beta = 0\) in this case. For general \(\beta \), one needs to rule out the contributions from such arrangements. For example, consider the symmetric permutation defined by
See Fig. 3 for an illustration. Then
however, \(\#({\text {Grid}}(\eta _N)) \sim N^2\). A straightforward calculation shows that
which implies that \(({\mathbf {W}}_N, {\mathbf {W}}_N^{\eta _N})\) does not converge to a semicircular family for \(\beta \ne 0\) (and so condition (2) is no longer sufficient). This discrepancy is brought to the fore in the traffic framework, where the additional linear algebraic structure of the graph operations necessitates the grid condition.

The action of \(\eta _N\) on off-diagonal entries: on the left, \(k \equiv 1 \bmod 2\); on the right, \(k \equiv 0 \bmod 2\). In both cases, entries with the same number swap positions
Remark 1.7
If \(b_{i, i'} \ne 0\), then the restriction to \(\beta \in [-1, 1]\) is necessary to ensure convergence to a semicircular family in certain cases. For example, if \(\beta \in {\mathbb {D}}\), then a straightforward calculation shows that
If \(({\mathbf {W}}_N, {\mathbf {W}}_N^\intercal )\) converges to a semicircular family, then the calculations above would imply that
which reduces to
and so \(\beta \in {\mathbb {D}}\cap {\mathbb {R}}= [-1, 1]\).
The obstruction from the transposed entries in the case of strictly complex \(\beta \) becomes apparent in the traffic framework. Even in the usual case of independent Wigner matrices, the limiting traffic distribution for such \(\beta \) is unwieldy [2, Equation (3.16)]. One can obtain a similarly unwieldy formula for the limiting traffic distribution of \(({\mathbf {M}}_N^{(i)})_{i \in I}\). On the other hand, the transposed entries are the sole obstruction to convergence to a semicircular family. In particular, Corollary 1.5 still holds for general \(\beta \in {\mathbb {D}}\) after replacing the \(\beta \) terms in condition (a) with  under the additional assumption
under the additional assumption
-
(c)
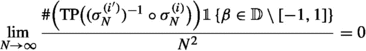 .
.
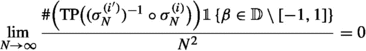 .
.1.2 Examples and simulations
Let \(({\mathbf {A}}_N, {\mathbf {B}}_N)\) be a pair of Wigner matrices. If \({\mathbf {A}}_N\) and \({\mathbf {B}}_N\) were independent, then they would be asymptotically free and the empirical spectral distribution of the anticommutator \([{\mathbf {A}}_N, {\mathbf {B}}_N] = {\mathbf {A}}_N{\mathbf {B}}_N + {\mathbf {B}}_N{\mathbf {A}}_N\) would converge to the symmetric Poisson distribution \(\nu _{\mathcal {SP}}\) as \(N \rightarrow \infty \) [16], where

For our simulations, we will instead consider dependent Wigner matrices \(({\mathbf {A}}_N, {\mathbf {B}}_N) = ({\mathbf {W}}_N, {\mathbf {W}}_N^{\sigma _N})\). The values of \(\beta \) and the permutations \(\sigma _N\) will be chosen to satisfy Corollary 1.5 and produce asymptotic freeness. To demonstrate this, we plot the eigenvalues of the anticommutator \([{\mathbf {A}}_N, {\mathbf {B}}_N]\) against the limiting density \(\nu _{\mathcal {SP}}(dx)\).
Example 1.8
For \(n \in {\mathbb {N}}\), let
Of course, if \(n = 1\), then \(\zeta _{N, n} = {{\,\mathrm{id}\,}}_{[N]^2}\). In general, \(\zeta _{N, n}\) fixes approximately \(\frac{1}{n}\) of the entries and sends \(\frac{n-1}{n}\) of the entries to their transpose in a way that satisfies the homogeneity condition (a). Note that negative values of \(\beta \) allow one to in some sense eliminate dependence: we illustrate this by choosing n and \(\beta \) such that \(\frac{1}{n} + \frac{n-1}{n}\beta = 0\). See Fig. 4.
Example 1.9
Let \(\sigma _N\) be the transpose with respect to the anti-diagonal. In other words,
One easily sees that
Corollary 1.5 and Remark 1.7 then guarantee asymptotic freeness for the pair \(({\mathbf {W}}_N, {\mathbf {W}}_N^{\sigma _N})\) for any \(\beta \in {\mathbb {D}}\). We choose non-Gaussian distributions for the entries of \({\mathbf {W}}_N\) to further emphasize this universality. See Fig. 5.

Histograms of the empirical spectral distribution of the anticommutator \([{\mathbf {W}}_N, {\mathbf {W}}_N^{\zeta _{N, n}}]\) overlaid for two values of \((\beta , n)\) and plotted against the limiting density \(\nu _{\mathcal {SP}}(dx)\). The overlapping region takes on the color blue + red = purple. The Wigner matrix \({\mathbf {W}}_N\) is chosen to be Gaussian with \(N = 10000\) (color figure online)

Histograms of the empirical spectral distribution of the anticommutator \([{\mathbf {W}}_N, {\mathbf {W}}_N^{\sigma _N}]\) overlaid for two values of \(\beta \) and plotted against the limiting density \(\nu _{\mathcal {SP}}(dx)\). The overlapping region takes on the color blue + red = purple. The blue corresponds to a real symmetric Rademacher Wigner matrix (\(\beta = 1\)); the red corresponds to a complex Hermitian analogue of the Rademacher where the real and imaginary parts of the upper triangular entries are identically equal \(X+iX\) (\(\beta = \sqrt{-1}\)); in both cases, \(N = 10000\) (color figure online)
1.3 Background
We briefly review the relevant aspects of the NC framework. We refer the reader to [15, 17, 20] for detailed treatments.
Definition 1.10
(Free probability). A NC probability space (ncps) is a pair \((\mathcal {A}, \varphi )\) with \(\mathcal {A}\) a unital algebra over \({\mathbb {C}}\) and \(\varphi : \mathcal {A} \rightarrow {\mathbb {C}}\) a unital linear functional. The distribution of a family of random variables \({\mathbf {a}} = (a_i)_{i \in I} \subset \mathcal {A}\) is the linear functional
where \({\mathbb {C}}\langle {\mathbf {x}}\rangle \) is the free algebra over the indeterminates \({\mathbf {x}} = (x_i)_{i \in I}\) and \(P({\mathbf {a}}) \in \mathcal {A}\) is the usual evaluation. A sequence of families \({\mathbf {a}}_N = (a_N^{(i)})_{i \in I} \subset (\mathcal {A}_N, \varphi _N)\) converges in distribution if the corresponding sequence of distributions \((\mu _{{\mathbf {a}}_N})_{N \in {\mathbb {N}}}\) converges pointwise. Note that the limit defines a new ncps \(({\mathbb {C}}\langle {\mathbf {x}}\rangle , \lim _{N \rightarrow \infty } \mu _{{\mathbf {a}}_N})\).
Let \((\mathcal {NC}(n), \le )\) denote the poset of noncrossing partitions of [n] with the reversed refinement order. We write \(0_n\) for the minimal element consisting of singletons; \(1_n\) for the maximal element consisting of a single block; and \(\text {M}{\ddot{\text {o}}}\text {b}_{\mathcal {NC}}\) for the corresponding Möbius function. For a noncrossing partition \(\pi \in \mathcal {NC}(n)\), we define the multilinear functional
where a block \(B = (i_1< \cdots < i_m) \in \pi \) defines a partial product
The free cumulant \(\kappa _\pi \) is the multilinear functional \(\kappa _\pi : \mathcal {A}^n \rightarrow {\mathbb {C}}\) obtained from the Möbius convolution
By the Möbius inversion formula, this is equivalent to
We use the notation \(\kappa _n = \kappa _{1_n}\), which allows us to formulate the multiplicative property of the free cumulants:
where \(B = (i_1< \cdots < i_m)\) is a block as before and
Subsets \((\mathcal {S}_i)_{i \in I}\) of a ncps \((\mathcal {A}, \varphi )\) are freely independent if for any \(n \ge 2\) and \(a_1, \ldots , a_n\) such that \(a_j \in \mathcal {S}_{i(j)}\),
A sequence of families \(({\mathbf {a}}_N)_{N \in {\mathbb {N}}}\) is asymptotically free if it converges in distribution to a limit \({\mathbf {x}}\) that is free in \(({\mathbb {C}}\langle {\mathbf {x}}\rangle , \lim _{N \rightarrow \infty } \mu _{{\mathbf {a}}_N})\).
We focus on one specific distribution in the NC framework. In particular, we recall the NC analogue of the multivariate normal distribution.
Example 1.11
(Semicircular family). Let \(({\mathbf {K}}(i, i'))_{i, i' \in I}\) be a real positive semidefinite matrix. A family of random variables \({\mathbf {s}} = (s_i)_{i \in I}\) in a ncps \((\mathcal {A}, \varphi )\) is a (centered) semicircular family of covariance \({\mathbf {K}}\) if
and all other cumulants on \({\mathbf {s}}\) vanish. Equivalently, for any \(n \in {\mathbb {N}}\),
where \(\mathcal {NC}_2(n) \subset \mathcal {NC}(n)\) is the subset of noncrossing pair partitions of [n]. In particular, the \((s_i)_{i \in I}\) are free iff \(({\mathbf {K}}(i, i'))_{i, i' \in I}\) is diagonal, in which case we call \((s_i)_{i \in I}\) a semicircular system.
A well-known result of Dykema proves that independent Wigner matrices \(({\mathbf {W}}_N^{(i)})_{i \in I} \subset (L^{\infty -}(\Omega , \mathcal {F}, {\mathbb {P}}) \otimes {\text {Mat}}_N({\mathbb {C}}), {\mathbb {E}}[{{\,\mathrm{tr}\,}}(\cdot )])\) converge in distribution to a semicircular system [6, Theorem 2.1].
We will also need some basics from the traffic framework. We refer the reader to [1, 5, 9] for detailed treatments.
Definition 1.12
(Traffic probability). A multidigraph \(G = (V, E, {{\,\mathrm{src}\,}}, {{\,\mathrm{tar}\,}})\) consists of a nonempty set of vertices V, a set of edges E, and a pair of maps \({{\,\mathrm{src}\,}}, {{\,\mathrm{tar}\,}}: E \rightarrow V\) indicating the source and target of each edge. When the context is clear, we omit the maps \({{\,\mathrm{src}\,}}, {{\,\mathrm{tar}\,}}\) from the notation and simply write \(G = (V, E)\).
Let I be an index set. A test graph in I is a pair \(T = (G, \gamma )\) consisting of a finite connected multidigraph G with edge labels \(\gamma : E \rightarrow I\). For a partition \(\pi \in \mathcal {P}(V)\), we define \(T^\pi \) as the quotient test graph obtained from T by identifying vertices in the same block in \(\pi \). Formally, \(T^\pi = (V^\pi , E^\pi , {{\,\mathrm{src}\,}}^\pi , {{\,\mathrm{tar}\,}}^\pi , \gamma ^\pi )\), where
-
(i)
\(V^\pi = V/\sim _\pi = \{B : B \in \pi \}\);
-
(ii)
\(E^\pi = E\);
-
(iii)
\({{\,\mathrm{src}\,}}^\pi = [\cdot ]_\pi \circ {{\,\mathrm{src}\,}}\) and \({{\,\mathrm{tar}\,}}^\pi = [\cdot ]_\pi \circ {{\,\mathrm{tar}\,}}\);
-
(iv)
\(\gamma ^\pi = \gamma \).
We write \(\mathcal {T}\langle I \rangle \) for the set of all test graphs in I and \({\mathbb {C}}\mathcal {T}\langle I \rangle \) for the complex vector space spanned by \(\mathcal {T}\langle I \rangle \).
For the purposes of this article, a traffic space is a pair \((\mathcal {A}, \tau )\) with \(\mathcal {A}\) a unital algebra over \({\mathbb {C}}\) and \(\tau : {\mathbb {C}}\mathcal {T}\langle \mathcal {A} \rangle \rightarrow {\mathbb {C}}\) a unital linear functional called the traffic state. Unital in this context simply means that \(\tau [T_0] = 1\) for the trivial test graph \(T_0\) consisting of a single isolated vertex. We also work with a transform of the traffic state called the injective traffic state:
where \(\text {M}{\ddot{\text {o}}}\text {b}_{\mathcal {P}}\) is the Möbius function on the the poset of partitions \((\mathcal {P}(V), \le )\) with the reversed refinement order and \(0_V\) is the singleton partition. By the Möbius inversion formula, this is equivalent to
Every traffic space \((\mathcal {A}, \tau )\) defines a ncps \((\mathcal {A}, \varphi _\tau )\), where

The traffic distribution of a family of random variables \({\mathbf {a}} = (a_i)_{i \in I} \subset \mathcal {A}\) is the linear functional
where \(T({\mathbf {a}}) \in \mathcal {T}\langle \mathcal {A}\rangle \) is the test graph obtained by replacing the edge labels \(\gamma : E \rightarrow I\) with edge labels
In particular, the traffic distribution \(\nu _{{\mathbf {a}}}\) contains the information of the distribution \(\mu _{{\mathbf {a}}}\) via (8). A sequence of families \({\mathbf {a}}_N = (a_N^{(i)})_{i \in I}\) converges in traffic distribution if the corresponding sequence of traffic distributions \((\nu _{{\mathbf {a}}_N})_{N \in {\mathbb {N}}}\) converges pointwise. Note that the limit defines a new traffic space \(({\mathbb {C}}\langle {\mathbf {x}}\rangle , \lim _{N \rightarrow \infty } \nu _{{\mathbf {a}}_N})\). The injective traffic distribution and convergence in injective traffic distribution are defined in the obvious way. Naturally, the Möbius relation implies that convergence in traffic distribution is equivalent to convergence in injective traffic distribution.
Let \(T = (V, E, \gamma ) \in \mathcal {T}\langle J \rangle \) be a test graph in the disjoint union \(J = \sqcup _{i \in I} J_i\). We think of each of the subsets \(J_i\) as a different color for the edges via the labeling \(\gamma : E \rightarrow J\). A colored component in T is a connected component in the subgraph obtained from T by only keeping the edges coming from a single color \(\gamma ^{-1}(J_i) \subset E\). We write \(\mathcal {CC}_i(T)\) for the set of i-colored components in T and \(\mathcal {CC}(T) = \sqcup _{i \in I} \mathcal {CC}_i(T)\) for the set of all colored components. The graph of colored components \(\mathcal {GCC}(T)\) is the simple bipartite graph \((V \sqcup \mathcal {CC}(T), E_{\mathcal {GCC}(T)})\) where adjacency is determined by inclusion in T: if \(v \in V\) and \(C \in \mathcal {CC}(T)\), then
Random variables \({\mathbf {a}} = \sqcup _{i \in I} {\mathbf {a}}_i\) with \({\mathbf {a}}_{i} = (a_{i, j})_{j \in J_i}\) are traffic independent if

A sequence of families \(({\mathbf {a}}_N)_{N \in {\mathbb {N}}}\) is asymptotically traffic independent if it converges in traffic distribution to a limit \({\mathbf {x}}\) that is traffic independent in \(({\mathbb {C}}\langle {\mathbf {x}}\rangle , \lim _{N \rightarrow \infty } \nu _{{\mathbf {a}}_N})\).
Similarly, we focus on one specific distribution in the traffic framework. It will be helpful to introduce some notation beforehand.
Notation 1.13
Let \(G = (V, E, {{\,\mathrm{src}\,}}, {{\,\mathrm{tar}\,}})\) be a multidigraph. We distinguish between loops \(\mathcal {L} \subset E\) and non-loop edges \(\mathcal {N} = \mathcal {L}^c\). We define \(\widetilde{G} = (V, \widetilde{E})\) as the undirected graph obtained from G by omitting the direction and multiplicity of the edges. Formally, \(\widetilde{E} = \{[e] : e \in E\}\), where \([e] = \{e' \in E : e \sim e'\}\) and
The partition \(E = \mathcal {L} \sqcup \mathcal {N}\) then drops to a partition of the quotient \(\widetilde{E}= \widetilde{\mathcal {L}} \sqcup \widetilde{\mathcal {N}}\). In particular, we can write the underlying simple graph in G as \({\underline{G}} = (V, \widetilde{\mathcal {N}})\). If our graph comes with edge labels \(\gamma : E \rightarrow I\), then we record the undirected multiplicity of a label i in a class of edges [e] with
We use the notation \(m_{[e]} = \#([e]) = \sum _{i \in I} m_{[e], i}\) for the total multiplicity of the edge [e]. See Fig. 6 for an illustration.

An example of a multidigraph \(G = (V, E)\), the undirected and multiplicity free graph \(\widetilde{G} = (V, \widetilde{E})\), and the underlying simple graph \({\underline{G}} = (V, \widetilde{\mathcal {N}})\)
Example 1.14
(Semicircular traffic family). A double tree is a multidigraph \(G = (V, E, {{\,\mathrm{src}\,}}, {{\,\mathrm{tar}\,}})\) with no loops \(\mathcal {L} = \emptyset \) such that the underlying simple graph \({\underline{G}} = (V, \widetilde{\mathcal {N}})\) is a tree with edge multiplicity \(m_{[e]} = 2\) for every \([e] \in \widetilde{\mathcal {N}}\). We call the edges \([e] = \{e, e'\} \in \widetilde{\mathcal {N}}\) in a double tree twin edges. Twin edges \(\{e, e'\}\) are congruent (resp., opposing) if \({{\,\mathrm{src}\,}}(e) = {{\,\mathrm{src}\,}}(e')\) and \({{\,\mathrm{tar}\,}}(e) = {{\,\mathrm{tar}\,}}(e')\) (resp., \({{\,\mathrm{src}\,}}(e) = {{\,\mathrm{tar}\,}}(e')\) and \({{\,\mathrm{tar}\,}}(e) = {{\,\mathrm{src}\,}}(e')\)).
Let \(({\mathbf {K}}(i, i'))_{i, i' \in I}\) be a real positive semidefinite matrix and \(({\mathbf {J}}(i, i'))_{i, i' \in I}\) a real symmetric matrix. A family of random variables \({\mathbf {s}} = (s_i)_{i \in I}\) in a traffic space \((\mathcal {A}, \tau )\) is a semicircular traffic family of covariance \({\mathbf {K}}\) and pseudocovariance \({\mathbf {J}}\) if

In particular, the \((s_i)_{i \in I}\) are traffic independent iff \(({\mathbf {K}}(i, i'))_{i, i' \in I}\) and \(({\mathbf {J}}(i, i'))_{i, i' \in I}\) are diagonal.
A semicircular traffic family can be realized as follows. We define a traffic state on the algebra of random matrices \(\mathcal {A} = L^{\infty -}(\Omega , \mathcal {F}, {\mathbb {P}}) \otimes {\text {Mat}}_N({\mathbb {C}})\) by
In particular, note that \(\varphi _{\tau _N}(\cdot ) = {\mathbb {E}}[{{\,\mathrm{tr}\,}}(\cdot )]\). For notational convenience, we abbreviate
The injective traffic state admits a particularly simple form in this case:
where \(\phi : V \hookrightarrow [N]\) denotes an injective map. A result of Male proves that independent Wigner matrices \(({\mathbf {W}}_N^{(i)})_{i \in I}\) converge in traffic distribution to a semicircular traffic family of covariance  [9, Proposition 3.1]. See [2, 3] for additional work on Wigner matrices and their generalizations in the traffic framework.
[9, Proposition 3.1]. See [2, 3] for additional work on Wigner matrices and their generalizations in the traffic framework.
As the name suggests, a semicircular traffic family \({\mathbf {a}} = (a_i)_{i \in I} \subset (\mathcal {A}, \tau )\) of covariance \({\mathbf {K}}\) and pseudocovariance \({\mathbf {J}}\) defines a semicircular family of covariance \({\mathbf {K}}\) in \((\mathcal {A}, \varphi _\tau )\). This follows from the cactus-cumulant correspondence [1, §3.1]; however, the converse does not hold. For example, Dykema’s result for independent Wigner matrices \(({\mathbf {W}}_N^{(i)})_{i \in I}\) holds for arbitrary pseudovariances \((\beta _i)_{i \in I} \subset {\mathbb {D}}\), whereas the case of strictly complex \(\beta _i\) does not have the multiplicative structure of (9) if there are any congruent twin edges [2, Equation (3.16)]. In particular, note that the distribution \(\mu _{{\mathbf {a}}}\) does not require the full knowledge of the traffic distribution \(\nu _{{\mathbf {a}}}\). Indeed, the definition (8) only requires the information of \(\nu _{{\mathbf {a}}}\) on simple directed cycles, which we can compute with the information of \(\nu _{{\mathbf {a}}}^0\) on any test graph that can be obtained as a quotient of a simple directed cycle. One can easily verify that a double tree obtained as a quotient of a simple directed cycle can only have opposing twin edges [2, Figure 5]. Since the pseudovariances \((\beta _i)_{i \in I}\) only appear in (9) alongside congruent twin edges, the limiting traffic distribution of \(({\mathbf {W}}_N^{(i)})_{i \in I}\) for general \((\beta _i)_{i \in I} \subset {\mathbb {D}}\) still defines a semicircular family of covariance  in \((\mathcal {A}, \varphi _\tau )\).
in \((\mathcal {A}, \varphi _\tau )\).
The preceding paragraph outlines the strategy we adopt in the proof of Corollary 1.5. After proving Theorem 1.3, we will analyze the relevant contributions from the traffic distribution to the usual distribution. This restriction to test graphs arising as quotients of simple directed cycles explains the difference between the conditions in Theorem 1.3 and Corollary 1.5.
2 Proofs of the main results
2.1 Asymptotics for the injective traffic distribution of \(({\mathbf {M}}_N^{(i)})_{i \in I}\)
We prove Theorem 1.3 in steps. First, we show that staying off the grid allows us to restrict our attention to double trees.
Lemma 2.1
Let \(\mathcal {M}_N = ({\mathbf {M}}_N^{(i)})_{i \in I}\). Suppose that \((\sigma _N^{(i')})^{-1} \circ \sigma _N^{(i)}\) stays off the grid for every \(i, i' \in I\). If \(T \in \mathcal {T}\langle I \rangle \) is not a double tree, then \(\nu _{\mathcal {M}_N}^0[T] = o_T(1)\).
Proof
For a test graph \(T = (V, E, \gamma ) \in \mathcal {T}\langle I \rangle \), the injective traffic distribution can be written as
Our strong moment assumption (1) implies that
uniformly in N and \(\phi \). We immediately obtain the elementary bound
which is quite far from what we need. To this end, we define the sets
where we recall that \(E = \mathcal {L} \sqcup \mathcal {N}\). Note that
Now, suppose that there exists an edge \(e_0 \in \mathcal {N}_1\). Since the elements \(({\mathbf {X}}_N(j, k))_{1 \le j < k \le N}\) are independent and centered, the injectivity of the map \(\phi \) implies that
unless there exists another edge \(e_1 \in E\) such that
Since \(m_{[e_0]} = 1\), we know that \([e_1] \ne [e_0]\). Furthermore, since the permutations \((\sigma _N^{(i)})_{i \in I}\) are symmetric, it must be that \(e_1 \in \mathcal {N}\). Applying the inverse, (13) is equivalent to
In particular, \(\{\phi ({{\,\mathrm{tar}\,}}(e_1)), \phi ({{\,\mathrm{src}\,}}(e_1))\}\) is completely determined by \(\{\phi ({{\,\mathrm{tar}\,}}(e_0)), \phi ({{\,\mathrm{src}\,}}(e_0))\}\) and \(\{\gamma (e_0), \gamma (e_1)\}\). This means we no longer have the freedom to choose the value of \(\phi \) on \(\{{{\,\mathrm{tar}\,}}(e_1), {{\,\mathrm{src}\,}}(e_1)\}\). Since \([e_1] \ne [e_0]\), we know that
The singleton edge \([e_0]\) then reduces the number of degrees of freedom in choosing our map \(\phi \) by
This is true of every singleton edge in \({\underline{G}} = (V, \widetilde{\mathcal {N}})\); however, it could be that the matching edge \([e_1]\) is also a singleton \(m_{[e_1]} = 1\).
Let
We refine the obvious bound \(\#(A_N) = O(N^{\#(V)})\) by exploring the underlying simple graph \({\underline{G}} = (V, \widetilde{\mathcal {N}})\) with the restriction from the previous paragraph in mind. We keep track of the vertices (resp., edges) we have encountered so far in our exploration with the set \(V_{{\text {enc}}}\) (resp., \(\widetilde{\mathcal {N}}_{{\text {enc}}}\)), updating it as we go. We think of \(V_{{\text {enc}}}\) as the set of vertices for which we have already assigned the values \(\phi |_{V_{{\text {enc}}}}\). Of course, since T is connected, we know that \({\underline{G}}\) is still connected. We start with \((V_{{\text {enc}}}, \widetilde{\mathcal {N}}_{{\text {enc}}}) = (\emptyset , \emptyset )\) and choose an arbitrary initial vertex \(v_0 \in V\), for which there are at most N choices of \(\phi (v_0) \in [N]\). Having made this choice, we update \(V_{{\text {enc}}} = V_{{\text {enc}}} \cup \{v_0\}\).
At any given stage, we have a list of encountered vertices \(V_{{\text {enc}}}\) and encountered edges \(\widetilde{\mathcal {N}}_{{\text {enc}}}\). If there are no remaining edges \(\widetilde{\mathcal {N}} \setminus \widetilde{\mathcal {N}}_{{\text {enc}}} = \emptyset \), then we stop. Otherwise, there is an edge \([e] \in \widetilde{\mathcal {N}}\setminus \widetilde{\mathcal {N}}_{{\text {enc}}}\) incident to a vertex \(v \in V_{{\text {enc}}}\). Let \(w \in \{{{\,\mathrm{src}\,}}(e), {{\,\mathrm{tar}\,}}(e)\}\setminus \{v\}\) be the other vertex incident to this edge. Again, we have at most N choices for \(\phi (w)\); however, it could be that we already encountered w earlier (for example, \({\underline{G}}\) is not necessarily a tree). In the latter case, the choice of \(\phi (w)\) has already been made and we do not get to choose again. In any event, we update \(V_{{\text {enc}}} = V_{{\text {enc}}} \cup \{w\}\) and \(\widetilde{\mathcal {N}}_{{\text {enc}}} = \widetilde{\mathcal {N}}_{{\text {enc}}} \cup \{[e]\}\). If [e] is further a singleton edge, then we know that \(\phi \) matches [e] to another edge \([e']\) as in (14) and we lose the freedom to choose the value(s) \(\phi |_{\{{{\,\mathrm{tar}\,}}(e'),{{\,\mathrm{src}\,}}(e')\}\setminus \{{{\,\mathrm{tar}\,}}(e),{{\,\mathrm{src}\,}}(e)\}}\). Of course, it could be that \((\{{{\,\mathrm{tar}\,}}(e'),{{\,\mathrm{src}\,}}(e')\}\setminus \{{{\,\mathrm{tar}\,}}(e),{{\,\mathrm{src}\,}}(e)\}) \cap V_{{\text {enc}}} \ne \emptyset \). In any event, for any edge \(e'\) matched to e by \(\phi \) (possibly more than one), we update \(V_{{\text {enc}}} = V_{{\text {enc}}} \cup \{{{\,\mathrm{tar}\,}}(e'),{{\,\mathrm{src}\,}}(e')\}\) and \(\widetilde{\mathcal {N}}_{{\text {enc}}} = \widetilde{\mathcal {N}}_{{\text {enc}}} \cup \{[e']\}\) and start the procedure again.
The procedure stops once we have explored all of the edges \(\widetilde{\mathcal {N}}_{{\text {enc}}} = \widetilde{\mathcal {N}}\). Since \({\underline{G}}\) is connected, this means that we will have explored all of the vertices \(V_{{\text {enc}}} = V\). In other words, we will have constructed a function \(\phi : V \hookrightarrow [N]\). To bound the number of possible functions constructed in this manner, note that every exploration of an edge contributes a factor of at most N; however, if the edge happens to be a singleton edge, it automatically explores at least one other edge at no cost (i.e., we do not count this induced exploration toward the runtime). In the worst case scenario (i.e., longest total exploration time), a singleton edge explores exactly one other edge, which itself is also a singleton edge, using up an edge that would have given us a free exploration. Counting the runtime of the procedure then gives the bound
Of course, this is only a refinement of our earlier bound if \(1 + \#(\widetilde{\mathcal {N}}_{\ge 2}) + \frac{\#(\widetilde{\mathcal {N}}_1)}{2} < \#(V)\), which is not true in general. Nevertheless, putting the runtime bound (15) back into the injective traffic distribution (11), we have the asymptotic
We can rewrite the exponent as
So, in view of (12), we can already assume that \(\mathcal {L} = \emptyset \) and \(\#(\mathcal {N}_{\ge 2}) = 2\#(\widetilde{\mathcal {N}}_{\ge 2})\), the last equality implying that \(m_{[e]} \in \{1, 2\}\) for every \([e] \in \widetilde{\mathcal {N}}\).
Even so, we see that the injective traffic distribution is only just surviving the normalization: anything strictly less than runtime bound would result in \(\nu _{\mathcal {M}_N}^0[T] = o_T(1)\). In fact, the runtime bound already implicitly assumes some optimality in the matching between singleton edges, which we explain now. Suppose that there are singleton edges [e] and \([e']\) matched by \(\phi \) in the exploration procedure. For concreteness, assume that [e] is the edge that we explore and \([e']\) is the edge that gets matched to [e] as a result of the free exploration induced by [e]. Let \(A_{N, \phi } \subset A_N\) be the subset of vertex labelings with the same matching of the edges as \(\phi \). Note that it is possible for \(A_{N, \phi } = A_{N, \phi '}\) with \(\phi \ne \phi '\). In particular, there are only finitely many different matchings of the edges: this number only depends on the finite graph T and is independent of N.
Since \({\underline{G}}\) is connected, we know that there exists a path \(([e_1], \ldots , [e_k])\) in \({\underline{G}}\) with \([e_1] = [e]\) and \([e_k] = [e']\): by a path, we mean a walk with no repetition of vertices. We claim that for any such path, there must exist singleton edges \([e_j]\) and \([e_{j+1}]\) along this path that are matched by \(\phi \) unless \(\#(A_{N, \phi }) = o_T(N^{\#(\widetilde{\mathcal {N}}_{\ge 2}) + \frac{\#(\widetilde{\mathcal {N}}_1)}{2} - \frac{\#(E)}{2}})\). In other words, there must exist adjacent singleton edges along this path that get matched if the injective traffic distribution is to survive the normalization. We prove this by induction on the length k of the path. The base case \(k = 2\) is trivial since \([e_1]\) and \([e_2]\) will be adjacent by definition. Suppose that \(k > 2\) and we know the result for all shorter lengths. In that case, \([e_1]\) and \([e_k]\) are not adjacent, meaning
But then the choice of \(\phi |_{\{{{\,\mathrm{tar}\,}}(e_1), {{\,\mathrm{src}\,}}(e_1)\}}\) determines the value of \(\phi \) on two other vertices \(\phi |_{\{{{\,\mathrm{tar}\,}}(e_k)), {{\,\mathrm{src}\,}}(e_k)\}}\). We choose to bound \(\#(A_{N, \phi })\) by starting the exploration procedure at a vertex incident to \([e_1]\) and immediately getting matched to \([e_k]\). We can then explore the intermediate path \(([e_2], \ldots , [e_{k-1}])\); however, by the time we explore \([e_{k-1}]\), we do not get to choose the value of the vertex we encounter at this stage since it was already encountered earlier by the free exploration coming from \([e_k]\). This would drop a factor of N from our runtime bound unless the exploration of \([e_{k-1}]\) was a free exploration coming from another singleton edge \([e'']\). Furthermore, the optimality of the runtime bound says that a singleton edge should only get matched to exactly one other (singleton) edge, so \([e_{k-1}]\) itself must be a singleton edge. Since we have only explored the edges along the path \(([e_1], \ldots , [e_k])\), it must be that \([e''] = [e_{k''}]\) for some \(1< k'' < k-1\). In that case, \(([e_{k''}], \ldots , [e_{k-1}])\) is a shorter path with singleton edges \([e_{k''}]\) and \([e_{k-1}]\) matched by \(\phi \) and we can apply the induction hypothesis.
We modify our test graph to keep track of the constraints on the vertex labelings \(\phi \) induced by the matchings. If [e] and \([e']\) are adjacent singleton edges that are matched by \(\phi \), then we can record the reduction in the degrees of freedom in choosing \(\phi \) by identifying the vertices \(\{{{\,\mathrm{tar}\,}}(e'),{{\,\mathrm{src}\,}}(e')\}\setminus \{{{\,\mathrm{tar}\,}}(e),{{\,\mathrm{src}\,}}(e)\}\) and \(\{{{\,\mathrm{tar}\,}}(e),{{\,\mathrm{src}\,}}(e)\}\setminus \{{{\,\mathrm{tar}\,}}(e'),{{\,\mathrm{src}\,}}(e')\}\) (we can think of pinching the edges [e] and \([e']\) together). From the point of view of our refined runtime bound above, this removes a pair of adjacent singleton edges along the path from \([e_1]\) to \([e_k]\). We can apply the same reasoning to this new test graph to continue pinching possibly newly adjacent singleton edges matched by \(\phi \) until there are no more singleton edges. See Fig. 7 for an illustration.

An example of the successive pinching of adjacent singleton edges starting with T and resulting in \(T^\phi \). The dashed lines above the edges indicate the edge matchings induced by \(\phi \). The dashed lines below the edges indicate the corresponding vertices that are identified as a result of the pinching. For simplicity, the test graphs are drawn with undirected edges
We explain the intuition behind this result. A matching between singleton edges that are not adjacent is costly because it explores an additional two vertices. If we incur such a matching, we need to proceed optimally to meet the upper bound of the runtime procedure. This can only be achieved if we use free explorations to bridge between the non-adjacent singleton edges. If we think of building a bridge by laying down edges from both sides, then the adjacent singleton edges that get matched are where the two sides meet.
Now, assume that \(\phi \) is such an optimal matching. Let \(T^\phi = (V^\phi , E^\phi , \gamma ^\phi )\) be the test graph obtained from T by pinching all the adjacent singleton edges matched by \(\phi \) iteratively. Formally, we obtain \(T^\phi \) from T as follows. First, we pinch the adjacent singleton edges matched by \(\phi \). Note that this might create newly adjacent singleton edges that are matched by \(\phi \), in which case we repeat the pinching process. Our analysis above shows that we will eventually stop, at which point we no longer have any singleton edges. Of course, \(\#(E^\phi ) = \#(E)\), and we can rephrase our refined runtime bound as \(\#(A_{N, \phi }) = O_T(N^{\#(V^\phi )})\).
We claim that \(\nu _{\mathcal {M}_N}^0[T] = o_T(1)\) unless there exists a matching induced by a vertex labeling \(\phi \) such that \(T^\phi \) is a double tree. Indeed, by our earlier work, we already know that \(\nu _{\mathcal {M}_N}^0[T] = o_T(1)\) unless \(\mathcal {L}^\phi = \emptyset \) and \(\#(\mathcal {N}_{\ge 2}^\phi ) = 2\#(\widetilde{\mathcal {N}}_{\ge 2}^\phi )\), where the superscript corresponds to the constructions from before, but now for the test graph \(T^\phi \). The pinching implies that we no longer have any singleton edges, so \(\widetilde{\mathcal {N}}_1^\phi = \emptyset \). Under these conditions, \(T^\phi \) is a double tree iff \(\#(V^\phi ) = \#(\widetilde{\mathcal {N}}^\phi ) + 1\). To finish, assume that \(\#(V^\phi ) < \#(\widetilde{\mathcal {N}}^\phi ) + 1\). In that case,
and the contributions to \(\nu _{\mathcal {M}_N}^0[T]\) from this class of vertex labelings is
Since there are only a finite class of matchings of T, the claim follows.
We summarize our progress so far:
unless \(\mathcal {L} = \emptyset \), \(\#(\mathcal {N}_{\ge 2}) = \#(\mathcal {N}_2)\), and there exists a matching of singleton edges such that the resulting pinched test graph is a double tree. In particular, if there are no singleton edges to pinch, then the test graph is already a double tree. Moreover, the pinching involves a sequence of successively adjacent singleton edges. We finish by using the grid condition to rule out the possibility of pinching.
If [e] and \([e']\) are adjacent singleton edges matched by \(\phi \), then we can write the condition in (14) for this pair as
By assumption, \((\sigma _N^{(i')})^{-1} \circ \sigma _N^{(i)}\) stays off the grid for every \(i, i' \in I\), which implies that
Indeed, we can start our procedure at a vertex incident to [e] and immediately get matched to \([e']\): staying off the grid implies that the total cost at this point is \(o(N^2)\) as opposed to our earlier \(O(N^2)\). We conclude that
unless there are no singleton edges to match, as was to be shown. \(\square \)
We see that staying off the grid restricts the possible support of our limiting injective traffic distribution to double trees. The actual calculation on double trees requires our other assumption about the homogeneity of the fixed points (resp., transposed points).
Lemma 2.2
Suppose that we have the limits
If \(T \in \mathcal {T}\langle I \rangle \) is a double tree, then

Proof
Assume that \(T = (V, E, \gamma ) \in \mathcal {T}\langle I \rangle \) is a double tree. We rewrite the injective traffic state accordingly:
We would like to use the independence of the \(({\mathbf {X}}_N(j, k))_{1 \le j < k \le N}\) and the injectivity of \(\phi \) to factor the expectation; however, the map \(\phi \) could possibly match different edges as in (14). Fortunately, our earlier work shows that this is typically not the case. In particular, matching edges reduces the number of degrees of freedom, and we only have just enough to survive the normalization as it is since \(\#(V) = \#(\mathcal {N}) + 1\). Using our strong moment assumption (1), we see that the contribution from any given summand is bounded, which allows us to pass to the desired factorization at negligible cost:
Similarly, since most maps from V to [N] are injective (\(\lim _{N \rightarrow \infty } \frac{N^{\underline{\#(V)}}}{N^{\#(V)}} = 1\)), we can further write
for any enumeration \(v_1, \ldots , v_{\#(V)}\) of the vertices.
We calculate the possible contributions from a pair of twin edges:
Of course, we need to know the value of \(\phi (e) = (\phi ({{\,\mathrm{tar}\,}}(e)), \phi ({{\,\mathrm{src}\,}}(e))\) to make this determination, but the limits in (17) imply that the average contribution over all possible values of \(\phi ({{\,\mathrm{src}\,}}(e))\) is asymptotically independent of the choice of \(\phi ({{\,\mathrm{tar}\,}}(e))\) (and vice versa). We can then hope to evaluate the large N limit of our injective traffic distribution by interpreting the normalized iterated sum as a successive chain of conditional expectations.
To achieve this, we consider the following enumeration of the vertices. First, we enumerate the leaves of our double tree \(v_1, \ldots , v_{n_1}\). We then remove these vertices and all incident edges, resulting in a new double tree with strictly fewer vertices. We repeat the procedure until all vertices have been accounted for \(v_1, \ldots , v_{n_1}, v_{n_1 + 1}, \ldots , v_{n_2}, \ldots , v_{\#(V)}\). Using this iterative stripping process and the limits in (17), we see that

as was to be shown. \(\square \)
Remark 2.3
If \(\beta \in (-1, 1)\), the limits in (17) are equivalent to
and
In the case of \(\beta \in \{-1, 1\}\), either of the two sets of limits above already implies the other, which is all we need to justify the convergence in (18). This explains the weaker condition replacing conditions (i) and (ii) in Theorem 1.3.
This proves the first half of Theorem 1.3. For the second half, we start with the converse of Lemma 2.1.
Lemma 2.4
Suppose that \(\beta \in (-1, 1]\) and \(\nu _{\mathcal {M}_N}^0[T] = o_T(1)\) whenever \(T \in \mathcal {T}\langle I \rangle \) is not a double tree. Then \((\sigma _N^{(i')})^{-1} \circ \sigma _N^{(i)}\) stays off the grid for every \(i, i' \in I\).
Proof
By assumption,

where
Similarly,

where
In other words, the sets
satisfy the asymptotics
Since \(\beta \in (-1, 1]\), this implies
The symmetry of the permutations then implies that
as was to be shown. \(\square \)
Remark 2.5
In the case of \(\beta = -1\), the asymptotics in (19) only allow us to conclude that
which is the weaker condition replacing condition (III) in Theorem 1.3. Applying the Cauchy-Schwarz inequality to the asymptotic from the the non-double tree

one can upgrade this to
This seems like the most natural candidate to replace the grid condition in the case of \(\beta = -1\).
It remains to prove the necessity of conditions (I) and (II) in Theorem 1.3, which can be seen from the simplest nontrivial double tree.
Lemma 2.6
Suppose that \(\beta \in (-1, 1)\) and \(\mathcal {M}_N\) converges in traffic distribution to a semicircular traffic family of covariance \({\mathbf {K}}\) and pseudocovariance \({\mathbf {J}}\). Then
Proof
By assumption,

As before,
Thus,
A similar expansion of the limit

shows that
Since \(\beta \in (-1, 1)\), the limits (21) and (22) are equivalent to the desired limits (20). \(\square \)
Remark 2.7
If \(\beta \in \{-1, 1\}\), then either of the limits (21) or (22) is enough to determine the other, which explains the weaker condition (IV) replacing conditions (I) and (II) in Theorem 1.3.
Finally, if \(\beta \in (-1, 1)\) (resp., \(\beta = 1\)), we prove that conditions (I) and (II) (resp. condition (IV)) with \(a_{i, i'} = b_{i, i'} = 0\) for \(i \ne i'\) and condition (III) are necessary and sufficient for the asymptotic traffic independence of the \(({\mathbf {M}}_N^{(i)})_{i \in I}\). The necessity already follows from our work above and the definition of a semicircular traffic family (recall Example 1.14). To prove sufficiency, we need only to show that conditions (I) and (II) (resp. condition (IV)) with \(a_{i, i'} = b_{i, i'} = 0\) are enough to repeat the calculation in Lemma 2.2. In other words, we do not need the finer control within each row given by (17) if we know the overall proportion is vanishing.
Lemma 2.8
Suppose that
for any \(i \ne i'\) and \(T \in \mathcal {T}\langle I \rangle \) is a double tree. Then

Proof
Suppose that T has a mixed twin edge \([e_0] = \{e_0, e_0'\}\), i.e., \(\gamma (e_0) \ne \gamma (e_0')\). We need to show that \(\nu _{\mathcal {M}_N}^0[T] = o_T(1)\). As in Lemma 2.2, we can pass to a factorization at a negligible cost:
We rewrite the product to extract the mixed twin edge:
where
thanks to our strong moment assumption (1). This implies
however, the limit in (23) implies that “most” maps \(\phi : V \hookrightarrow [N]\) yield a zero summand
In particular,
as was to be shown.
On the other hand, if T does not have any mixed twin edges, then the limit follows from the factorization and the fact that

if \(\gamma (e) = \gamma (e')\). \(\square \)
Remark 2.9
In the case of \(\beta = -1\), the vanishing on mixed double trees would imply that

if \(i \ne i'\). The same reasoning as in Remark 2.5 allows us to conclude that
This seems like the most natural candidate to replace (23) in the case of \(\beta = -1\).
2.2 Asymptotics for the distribution of \(({\mathbf {M}}_N^{(i)})_{i \in I}\)
We now restrict our attention to the distribution of \(({\mathbf {M}}_N^{(i)})_{i \in I}\). Equation (8) allows us to translate this problem to understanding the injective traffic distribution of \(({\mathbf {M}}_N^{(i)})_{i \in I}\) on test graphs that can be obtained as a quotient of a simple directed cycle. Note that Lemma 2.1 still applies, allowing us to restrict our attention to quotients that are double trees. Since a double tree obtained as a quotient of a simple directed cycle can only have opposing twin edges [2, Figure 5], condition (a) of Corollary 1.5 is already enough to calculate the limit in Equation (18) of Lemma 2.2. This proves the first part of Corollary 1.5.
If \(\beta = 0\), then we do not need to worry about the full grid in Equation (16). Indeed, if [e] and \([e']\) are adjacent singleton edges matched by \(\phi \), then either

or

since the subsequent pinching must produce an opposing twin edge. We can assume that we are in the first case without loss of generality. Then either
or
The first case produces a zero term
while the second case is covered by Popa’s condition (2).
If one is only interested in freeness, then we can settle for the averaged condition in Equation (A), which can be used to replace the condition in Equation (23) of Lemma 2.8 (recall that we only care about double trees with opposing twin edges). A similar argument proves the sufficiency of condition (c) for general \(\beta \in {\mathbb {D}}\). This completes the proof of Corollary 1.5.
References
Au, B., Male, C.: Rigid structures in the universal enveloping traffic space, Preprint. arXiv:2011.05472v1
Au, B.: Traffic distributions of random band matrices. Electron. J. Probab. 23, paper no. 77, 48 pp (2018)
Au, B.: Finite-rank perturbations of random band matrices via infinitesimal free probability. Comm. Pure Appl. Math. 74(9), 1855–1895 (2021)
Bezanson, J., Edelman, A., Karpinski, S., Shah, V.B.: Julia: a fresh approach to numerical computing. SIAM Rev. 59(1), 65–98 (2017)
Cébron, G., Dahlqvist, A., Male, C.: Traffic distributions and independence II: universal constructions for traffic spaces, Preprint. arXiv:1601.00168v2
Dykema, K.: On certain free product factors via an extended matrix model. J. Funct. Anal. 112(1), 31–60 (1993)
Hao, Z., Popa, M.: A combinatorial result on asymptotic independence relations for random matrices with non-commutative entries. J. Operator Theory 80(1), 47–76 (2018)
Jones, D.C., Arthur, B., Nagy, T., Mattriks, Gowda, S., Godisemo, Holy, T., Noack, A., Sengupta, A., Darakananda, D., Adam B, Dunning, I., Leblanc, S., Huijzer, R., Fischer, K., Chudzicki, D., Piibeleht, M., Mellnik, A., Kleinschmidt, D., Breloff, T., Yu, Y., Huchette, J., Innes, M.J., inkyu, john verzani, Pelenitsyn, A., Coalson, C., O’Mara, C., Saba, E.: Giovineitalia/gadfly.jl: v1.3.3, (May 2021)
Male, C.: Traffic distributions and independence: permutation invariant random matrices and the three notions of independence. Mem. Amer. Math. Soc. 267(1300), v+88 (2020)
Mingo, J.A., Popa, M.: The partial transpose and asymptotic free independence for Wishart random matrices: Part II, Preprint. arXiv:2005.04348v1
Mingo, J.A., Popa, M.: Freeness and the transposes of unitarily invariant random matrices. J. Funct. Anal. 271(4), 883–921 (2016)
Mingo, J.A., Popa, M.: Freeness and the partial transposes of Wishart random matrices. Canad. J. Math. 71(3), 659–681 (2019)
Mingo, J.A., Popa, M., Szpojankowski, K.: Asymptotic \(\ast \)-distribution of permuted Haar unitary matrices, Preprint. arXiv:2006.05408v3
Mingo, J.A., Popa, M., Szpojankowski, K.: On the partial transpose of a Haar unitary matrix, Preprint. arXiv:2105.04076v1
Mingo, J.A., Speicher, R.: Free probability and random matrices, Fields Institute Monographs, vol. 35, Springer, New York; Fields Institute for Research in Mathematical Sciences, Toronto, ON (2017)
Nica, A., Speicher, R.: Commutators of free random variables. Duke Math. J. 92(3), 553–592 (1998)
Nica, A., Speicher, R.: Lectures on the combinatorics of free probability, London Mathematical Society Lecture Note Series, vol. 335, Cambridge University Press, Cambridge (2006)
Popa, M., Hao, Z.: An asymptotic property of large matrices with identically distributed Boolean independent entries, Infin. Dimens. Anal. Quantum Probab. Relat. Top. 22(4), 1950024, 22 (2019)
Popa, M.: Asymptotic free independence and entry permutations for Gaussian random matrices, Preprint. arXiv:1812.01692v2
Voiculescu, D.V., Dykema, K.J., Nica, A.: Free random variables, CRM Monograph Series, vol. 1, American Mathematical Society, Providence, RI, 1992, A noncommutative probability approach to free products with applications to random matrices, operator algebras and harmonic analysis on free groups
Voiculescu, D.: Limit laws for random matrices and free products. Invent. Math. 104(1), 201–220 (1991)
Acknowledgements
The author thanks Jonathan Novak for suggesting an investigation into the joint distribution of Wigner matrices with permuted entries. The author also thanks the anonymous referees for their constructive feedback. The simulations in this article were performed in Julia [4] and the data plotted using Gadfly [8]. The figures in this article were produced in Inkscape.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Au, B. Semicircular families of general covariance from Wigner matrices with permuted entries. Probab. Theory Relat. Fields 184, 1167–1196 (2022). https://doi.org/10.1007/s00440-022-01143-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00440-022-01143-y