
Abstract
Congenital hypogonadotropic hypogonadism (CHH) is a clinically and genetically heterogeneous congenital disease. Symptoms cover a wide spectrum from mild forms to complex phenotypes due to gonadotropin-releasing hormone (GnRH) deficiency. To date, more than 40 genes have been identified as pathogenic cause of CHH. These genes could be grouped into two major categories: genes controlling development and GnRH neuron migration and genes being responsible for neuroendocrine regulation and GnRH neuron function. High-throughput, next-generation sequencing (NGS) allows to analyze numerous gene sequences at the same time. Nowadays, whole exome or whole genome datasets could be investigated in clinical genetic diagnostics due to their favorable cost–benefit. The increasing genetic data generated by NGS reveal novel candidate genes and gene variants with unknown significance (VUSs). To provide clinically valuable genetic results, complex clinical and bioinformatics work are needed. The multifaceted genetics of CHH, the variable mode of inheritance, the incomplete penetrance, variable expressivity and oligogenic characteristics further complicate the interpretation of the genetic variants detected. The objective of this work, apart from reviewing the currently known genes associated with CHH, was to summarize the advantages and disadvantages of the NGS-based platforms and through the authors’ own practice to guide through the whole workflow starting from gene panel design, performance analysis and result interpretation. Based on our results, a genetic diagnosis was clearly identified in 21% of cases tested (8/38).
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Congenital hypogonadotropic hypogonadism (CHH)
Congenital hypogonadotropic hypogonadism (CHH) as a clinically heterogeneous entity
Congenital hypogonadotropic hypogonadism (CHH) is a genetic condition characterized by incomplete or absent puberty and infertility due to central (tertiary or hypothalamic) hypogonadism caused by gonadotropic hormone-releasing hormone (GnRH) deficiency. Three clinical forms are distinguished by the European consensus: (1) GnRH deficiency with defective sense of smell (Kallmann syndrome, KS), (2) isolated GnRH deficiency (normosmic CHH) and the third form when KS/CHH is part of a complex genetic syndrome (Boehm et al. 2015). CHH has an incidence of 1:125,000 in female and 1:30,000 in males indicating the male predominance (Stamou and Georgopoulos 2018). CHH has a heterogeneous clinical appearance, and lately the constitutional delay of growth and puberty (CDGP), the adult-onset hypogonadotropic hypogonadism and the hypothalamic amenorrhea are also considered as a milder end of the spectrum (Stamou and Georgopoulos 2018). Most patients are diagnosed in adolescence due to delayed puberty. In male, neonate cryptorchidism and micropenis can be considered as signs of CHH, but there are no specific signs of CHH in female neonates (Young et al. 2019). Prepubertal testes and undervirilized secondary sexual features are the most common symptoms in males, while absence of breast development and primary amenorrhea occur in females as a consequence of CHH (Young et al. 2019). The disease can be diagnosed in adulthood as well by low libido, infertility, bone loss and fractures when it is untreated (Young et al. 2019). Interestingly, in 10–20% of the cases, CHH is reported reversible, however, the pathophysiology behind this is not clearly revealed (Stamou and Georgopoulos 2018; Young et al. 2019). To establish the biochemical diagnosis in infants is challenging as GnRH neurons are active only during mini-puberty (4–8 weeks after birth) and after that, their activity becomes quiescent until puberty. In adolescence, results of biochemical tests (basal and stimulated blood levels of sex hormones and gonadotropins), brain imaging for examination of olfactory bulbs, assessment of smell and evaluation of family history are parts of the routine medical investigations. (Naturally, additional work-ups, i.e. evaluation of bones, kidneys and sexual organs, are also required for diagnosis and for differential diagnostic purposes (Young et al. 2019). Constitutional delayed of growth and puberty (CDGP) is defined as the lack of the start of sexual maturation at an age > 2 SDs above the mean for a given population (Stamou and Georgopoulos 2018). There is no identifiable cause behind and finally puberty occurs. 50–80% of CDGP individuals have positive family history of the phenomenon, and approximately 10% of CHH patients have relatives with CDGP (Stamou and Georgopoulos 2018). Differentiating CDGP and CHH in adolescence is challenging as to date no gold-standard diagnostic test is known for this purpose (Young et al. 2019).
There are non-reproductive features as well that are commonly recognized in patients with CHH. Midline facial defects (cleft lip or palate), dental agenesis, unilateral renal agenesis, short metacarpals, hearing loss, synkinesia, cerebellar ataxia can appear additionally to CHH (Young et al. 2019). Furthermore, the disease can occur as part of complex genetic syndromes summarized in Table 1.
Diagnostics and genetic counseling is important in CHH as effective therapies are available for the development of secondary sexual features and fertility (Maione et al. 2018; Young et al. 2019).
Adult onset of hypogonadotropic hypogonadism is a rare form of CHH. It is a non-reversible, long-lasting condition but the etiology and pathogenesis have to be investigated and demonstrated. The diagnosis can be made when all other acquired causes of hypogonadotropic hypogonadism (e.g. structural anomalies, infiltrative/inflammatory origin, pituitary/CNS tumors etc.) have been excluded (Stamou and Georgopoulos 2018).
Genetic background of CHH
CHH is heterogeneous not only clinically but also genetically. To date, more than 40 genes have been identified as pathogenic cause in the background of the disease (Boehm et al. 2015; Maione et al. 2018; Stamou and Georgopoulos 2018). Analysis the individual CHH genes (Table 1) one by one exceeds the goal of our study, but these are excellently reviewed in recent papers (Topaloglu and Kotan 2016; Topaloğlu 2018; Maione et al. 2018). Genes implicated in the pathogenesis of CHH are usually divided into two major categories (Boehm et al. 2015; Topaloğlu 2018; Maione et al. 2018; Stamou and Georgopoulos 2018). The first group consists of genes that control development and GnRH neuron migration. Therefore, the pathogenic variants of these genes are frequently associated with anosmia and midline developmental anomalies (Table 1). The second group of genes is responsible for neuroendocrine physiology and GnRH neuron function (either by afferent modulators or by regulating GnRH secretion), these can be detected in normosmic CHH forms. Although there are genes with multiple roles that participate in both mechanisms, their mutations can be often identified in both anosmic and normosmic forms (Boehm et al. 2015; Maione et al. 2018; Stamou and Georgopoulos 2018) (Table 1).
Autosomal dominant, autosomal recessive and X-linked inheritance have been identified, however, with the availability of high-throughput next-generation sequencing at least 20% of CHH cases have thought to be di- or oligogenic. In these cases, two or more gene variants can be identified in the same patient (Boehm et al. 2015) (Table 1). Still, in more than half of the CHH cases, there is no pathogenic mutation identified. Among the main genetic forms of CHH, the most common autosomal recessively inherited types are caused by GNRHR, KISS1R and TACR3 variants (Maione et al. 2018). Kallmann syndrome caused by ANOS1 gene mutations is inherited by X-linked recessive trait as it is located on chromosome X. FGFR1 and PROK2/PROKR2 lead to autosomal dominantly inherited type of CHH (Boehm et al. 2015; Maione et al. 2018). Regarding FGFR1, nearly half, regarding PROK2/PROKR2, nearly two-third of the cases exhibit incomplete penetrance and variable expressivity that complicate the determination of inheritance (Maione et al. 2018). Recently, a normosmic CHH patient was reported who inherited a pathogenic variant in GNRHR gene in a homozygous form due to the occurrence of uniparental isodisomy (Cioppi et al. 2019). (Uniparental disomy-UPD is a non-Mendelian inheritance pattern when an individual has inherited two copies of a specific chromosome (or part of it) from a single parent. When a chromosomal pair inherited from the same parent, it is called uniparental heterodisomy, when two identical chromosomes are inherited it is called uniparental isodisomy (iUPD). This discovery further complicates the inheritance pattern of CHH and raises the possibility of the same phenomenon in case of other genes as well.
Individual relevance of genes in oligogenic CHH cases are needed to be interpreted with cautions. For instance, another candidate CHH gene NSMF (earlier NELF), listed in the expert consensus statement, has now a controversial role (Spilker et al. 2016). Several publications reported NSMF variants in CHH patients alone or in combination with a mutation in another gene (Miura et al. 2004; Pitteloud et al. 2007; Xu et al. 2011) underlining again its questionable role (Spilker et al. 2016).
Interestingly, rare variants of TAC3, TACR3 and other genes are suggested to be linked with CHH reversal that further raises the possibility of therapy discontinuation from time to time to test the reversibility of CHH in these carriers (Gianetti et al. 2010; Boehm et al. 2015).
Variants of known CHH genes have been investigated and identified in CDGP and in cases with hypothalamic amenorrhea too. This suggests that the time of menarche and menopause are genetically determined which is strongly supported by family histories (Stamou and Georgopoulos 2018).
In CDGP, Zhu et al. identified that variants in CHH genes were enriched in CDGP family members compared to unaffected family members suggesting the genetic link between CHH and CDGP (Zhu et al. 2015). This is further supported by variants identified in CDGP patients in TAC3, TACR3, IL17RD, GNRHR, PROKR2, HS6ST1, FGFR1, FEZF1, AXL genes (Gianetti et al. 2012; Tusset et al. 2012; Zhu et al. 2015; Hietamäki et al. 2017; Cassatella et al. 2018). However, results of Cassatella et al. demonstrated that CDGP and CHH have distinct genetic profiles that may facilitate the differential diagnosis in patients presenting with delayed puberty (Cassatella et al. 2018).
Hypothalamic amenorrhea is also a reversible dysfunctional feature that can be triggered by nutritional deficit, extensive exercise or psychological stress. Genetic variants have been identified in FGFR1, PROKR2, GNRHR and ANOS1 genes suggesting that these mutations may contribute to the variable functional changes in GnRH secretion (Caronia et al. 2011).
CHH can be also part of complex genetic syndromes which are summarized by Boehm et al. and genetic background are summarized in Table 1 (Boehm et al. 2015).
Genetic testing and genetic counseling in CHH
Testing strategies
Although high-throughput screening can be recommended, targeted panel testing, prioritization and gene selection based on clinical data are also possible (Boehm et al. 2015; Topaloğlu 2018; Stamou and Georgopoulos 2018). The first step is to exclude the presence of genetic syndromes based on clinical findings. When a clinical geneticist based on the whole clinical presentation indicates a specific syndrome (e.g. CHARGE sy., Bardet-Biedl sy., Gordon-Holmes sy., see details in Table 1) targeted gene testing is recommended. When complex syndromes can be excluded additional associated signs and symptoms can increase the probability of finding casual mutations (Boehm et al. 2015). For instance, besides anosmia/hyposmia, bimanual synkinesia or renal agenesis can associate with ANOS1 mutation (Fig. 1). Cleft palate/lip, dental agenesis and digital bone anomalies were frequently associated with CHH caused by mutations in genes of FGF8 signaling (FGFR1, FGF8, HS6ST1) (Costa-Barbosa et al. 2013; Boehm et al. 2015). Hearing impairment commonly appeared with CHH in CHD7, SOX10 or IL17RD mutation carriers (Costa-Barbosa et al. 2013; Boehm et al. 2015). Additionally, early onset of morbid obesity with CHH could suggest variants in LEP, LEPR or PCSK1 genes (Jackson et al. 1997; Farooqi and O’Rahilly 2008). If CHH is associated with severe adrenal insufficiency congenital adrenal hypoplasia caused by NR0B1 (DAX1) is likely.

Combined pituitary hormone deficiency (CHPD) should also be clinically investigated/excluded as CHH and CHPD have overlapping genetic etiologies. If isolated CHPD is diagnosed, genetic testing of genes encoding the pituitary transcription factors (PROP1, POU1F1, LHX4, LHX3 and HESX1) should be recommended (Fang et al. 2016). However, lately, variants of certain CHH genes including CHD7, PROKR2, WDR11, FGFR1 and FGF8 have also been implicated in CPHD (Raivio et al. 2012; Fang et al. 2016). Similar to CHH, CPHD is suggested to be a multifactorial disease as symptoms frequently present incomplete penetrance even harboring the very same mutations (Raivio et al. 2012).
Genetic testing starts with evaluation of the inheritance pattern using pedigree analysis. However, Mendelian inheritance have been described for the majority of genes associated with CHH, some genes show different inheritance patterns (e.g. FGFR1: AD/AR/oligogenic/de novo; PROK2/PROKR2: AD/AR/oligogenic), see Table 1 (Boehm et al. 2015; Maione et al. 2018).
Parallel with revolution of molecular genetic technologies for patients with CHH multi-gene panel testing can be recommended, because there is a wide overlap between both symptoms and genetic background (Boehm et al. 2015; Maione et al. 2018). Since expert consensus have been published in 2015 (Boehm et al. 2015) several high-throughput multi-gene panel studies were carried out. However, there is no consented gene list that should be offered for patients providing an accurate diagnosis for the majority of cases. After publication of the expert consensus 7 CHH gene panel testing studies were reported (Table 2) (Quaynor et al. 2016; Aoyama et al. 2017; Wang et al. 2017; Cassatella et al. 2018; Zhou et al. 2018; Amato et al. 2019; Kim et al. 2019). In these studies, 25–261 genes were included as susceptibility genes of CHH. The positive detection rate varied between 33 and 56% (Table 2). Mutations in the FGFR1 gene were found the most commonly (in all eight studies), ANOS1 (in seven studies) and CHD7, PROKR2, TACR3 and IL17RD variants were also frequently detected (in six studies) among different groups (Table 2). Analyzing the detection rate by patient number FGFR1 variants were detected most commonly, in an average of 11.4% of all investigated patients, CHD7, PROKR2 and ANOS1 in 8.4, 6.4 and 5.7% of patients, respectively, across all studies. All other gene variants were found less than an average of 3% in these patients (see details in Table 2). Di- and oligogenic cases occurred approximately between 10 and 20% of all cases.
Genetic counseling
Genetic screening is essential in CHH as it can be treated and patients could have a good reproductive prognosis upon treatment (see details in (Boehm et al. 2015; Maione et al. 2018). Genetic counseling should give information on heritability for other family members too, and also required before family planning (Maione et al. 2018).
In certain cases, heritability can be determined relatively easily. For instance, in case of GNRH1/GNRHR, TAC3/TACR3, KISS1/KISS1R, autosomal recessive inheritance pattern is characteristic, while ANOS1 is inherited as an X-linked trait (Maione et al. 2018). However, for genes of which variants inherited by an autosomal dominant way, the penetrance and expressivity can be variable. In case of FGFR1 nearly half, regarding PROK2/PROKR2 nearly two-third of the cases exhibit incomplete penetrance and variable expressivity complicating the determination of the inheritance pattern (Maione et al. 2018). Regarding certain genes (e.g. FGFR1), de novo mutations are also relatively common that has to be taken into consideration when analyzing pedigrees.
Additionally, together with the availability of NGS, the main challenge is to distinguish true oligogenicity from rare variants which appear as incidental findings and are not related to the phenotype. In determination of oligogenicity, genotype–phenotype co-segregation should be assessed by investigating both the affected and healthy family members. In addition, in diagnosis of oligogenicity, Maione et al. (2018) suggested that oligogenic load has to be correlated with phenotype severity. There are several complicating factors (small families, not available or not compliant family members, incomplete penetrance and variable expressivity) in segregation analysis, still, it is one of the most important way to identify the closest evidence of pathogenicity clinically besides in vitro and in vivo studies (Oliver et al. 2015; Maione et al. 2018). Additionally, in clinical interpretation of variants of unknown significance (VUSs), clinical data (genotype–phenotype segregation) are of utmost important.
Once heritability is assessed, risk of disease transmission can be discussed according to the Mendelian rules.
Prognosis has also to be discussed as approximately 20% of the cases appear to be spontaneously reversible. From genetic point of view, to date TAC3 and TACR3 loss of function variants were described to be associated with CHH reversal (Gianetti et al. 2010), but with the increasing data provided by high-throughput NGS platforms, the number of genes connected to this phenomenon will probably increase as well.
Next-generation sequencing allows evaluation of sequence variants of several genes at the same time in a cost-effective way
Formerly, genetic testing was confined to rare genetic disorders due to their complexity, labour intensity and cost. Now, NGS-based methods are widely available allowing to test even hundreds of genes at the same time. Therefore, NGS has been rapidly integrated into laboratory diagnostics workflows for identification of germline mutations in inherited diseases. Due to its time and cost effectiveness, it is especially useful in cases when several genes have been identified in the background of a certain genetic condition such as CHH.
NGS-based platform options for clinical genetic diagnostics
Although the technology allows to investigate the sequence of the whole genome (WGS, whole genome sequencing) or exome (WES, whole exome sequencing) currently, the most prevalent applications of NGS in clinical practice are the evaluation of certain genes using targeted gene panels (Di Resta et al. 2018).
As WGS covers the whole genome (coding and noncoding regions) it may seem the most preferable choice in identification of pathogenic gene mutations in inherited diseases. The advantage of WGS is that library preparation is straightforward as it does not require target enrichment. Additionally, data obtained from WGS can easily be used for detection of CNVs. However, among NGS approaches it gives the least average depth of coverage and it is still a costly technology (Di Resta et al. 2018). Also, from clinical point of view, the interpretation of noncoding variants and variants of unknown significance (VUSs) make its utility limited.
WES aims to cover all coding regions in the genome. Exome contains all of the protein-coding regions of genes and it comprises ~ 1–2% of the genome, yet contains ~ 85% of known disease causing mutations. Its cost is also more preferable and it is a more feasible option comparing to WGS (Di Resta et al. 2018). Usually, the average exome coverage of a WES test is 90–95% due to sequence complexity. WES is sometimes used by clinical laboratories by interpreting only genes which have been already associated with any disease. When mutation has not been identified data analysis can be extended to the remaining exome regions. It has been shown that WES provides diagnosis in approximately of 11–40% of cases where the clinical diagnosis were uncertain (Sawyer et al. 2016). Furthermore, because the depth of coverage for WES is not uniform the sensitivity is usually lower compared to those observed in case of targeted disease panels.
Customized targeted gene panels offer the ability to perform fast and low-cost screening option, therefore, currently, it is the most widely used NGS approach in clinical practice (Di Resta et al. 2018; Wang et al. 2018; Graziola et al. 2019). By focusing on a limited set of genes selected for certain clinical condition, it is able to provide high coverage that increases analytical sensitivity even in detection of mosaicism. Furthermore, because the role of genes included in these panels are known to be associated with the particular condition the detection rate (positive finding) is also higher compared to WES (Di Resta et al. 2018; Wang et al. 2018; Graziola et al. 2019). Targeted panels give the advantage to avoid incidental, secondary findings and to decrease the number of VUSs detected.
Therefore, when the genetic background is well-defined, targeted testing of a gene panel could offer at a relatively low-cost sensitive detection of genetic variants responsible for a disease. However, when no suspect genes stand behind the clinical phenotype, exome sequencing may provide a wider screening option, but in these cases, trio sequencing would allow a more comprehensive result compared to the “only” individual sequencing.
Workflow of an NGS-based genetic analysis
NGS-based sequencing analysis comprises of three steps: (1) library preparation, (2) parallel sequencing and (3) data analysis and variant interpretation (Oliver et al. 2015).
Molecular genetic analysis is routinely performed using DNA extracted from peripheral blood or buccal mucosa. In our example, we used DNA samples of 38 consecutive patients and 2 family members with hypogonadotropic hypogonadism referred to our diagnostics laboratory. Fourteen patients developed the disease ≤ 18 years [2 girls and 12 boys with an average age of 16.2 year (± 2.1 years)]. Twenty-four patients developed disease in adult age (3 females, 21 males with an average age of 31.8 years (± 12.7 years). Patient characteristics, clinical findings, laboratory results and imaging studies are included in Supplementary Table 1. Our study was approved by the Scientific and Research Committee of the Medical Research Council of Ministry of Health, Hungary (67/PI/2012). All samples were obtained after acquiring written informed consent from all adult patients and permissions were given by parents of all minors. For NGS-based technologies, the amount and quality of input DNA is an essential factor. Degradation or low concentration of DNA may jeopardize the analysis.
For any NGS-based strategy, library preparation is a key step in the laboratory workflow. The instrumentation determines the library preparations, because high-throughput instruments allow larger analysis. Barcodes (unique, short sequences) are used to label different samples enabling pooling patients’ samples into one reaction and decreasing the per-sample cost. Library preparation methods can be grouped into two main categories by principle used for gene amplifications: (1) PCR-based and (2) hybridization-based methods (Butz and Patócs 2019). Although processes using hybridization-based capture are more time consuming and labour intensive, those have the advantage of having greater tolerance against sequence variations (sequence variants and copy-number alteration).
The sequencing characteristics (read length, output read number, cost and run time) of each platform can be different that are needed to be taken into consideration.
For an in-house panel design (gene selection), the recommendation of the European Society of Human Genetics should be followed. Only genes with known relationship between genotype and phenotype should be included in the analysis for diagnostic purposes (Matthijs et al. 2016). Also, the guideline states that “to avoid irresponsible testing, for the benefit of the patients, ‘core disease gene list’ should be established by the clinical and laboratory experts” (Matthijs et al. 2016). Therefore, consensus statements and guidelines, OMIM (Online Mendelian Inheritance in Man) database and literature search should be assessed to assemble genes in a diagnostic panel. For CHH, there is an available European Consensus Statement (Boehm et al. 2015) which was used as a primary guide during our panel design too.
Accordingly, our panel was designed during the first half of 2017. Some CHH-related genes were left out, mostly those which have been already introduced earlier into clinical practice in our laboratory (e.g. genes responsible for combined pituitary deficiency or adrenal diseases) (Halász et al. 2006; Bertalan et al. 2019) or due to the capacity of the applied method. Genes associated with complex syndromes were not present either in our selection owing to our patient profile. Finally, 41 genes were analyzed (see in Supplementary Table 2 and in Table 3).
We selected NimbleGene approach to create the appropriate hybridization capture probe set for our gene list using NimbleDesign Software (https://sequencing.roche.com/en/products-solutions/by-category/target-enrichment/software/nimble-design-software.html) targeting the region of interests (exons + /– 30 bp/exon). Capture probe synthesis was done by the supplier. Library was prepared following double capture; the library quantification was performed following the manufacturer’s instructions (NimbleGen SeqCap EZ Library protocol). Sequencing runs were done on Illumina MiSeq instrument using MiSeq Reagent Micro Kit v2.
Sequencing data processing, performance analysis
During NGS, huge amount of data is produced which require special bioinformatics handling and analysis (Biesecker and Green 2014), therefore, appropriate hardware, software and expert personnel are required for data analysis (Oliver et al. 2015). Currently, there is no gold standard, freely available tool or filtering settings for bioinformatics analysis related to clinical applications of NGS. Each laboratory has to develop and validate its own pipeline (Oliver et al. 2015).
First step of sequencing data analysis is base calling that is integrated into the instrument’s software. During the next step, raw sequence reads are aligned to the reference human genome (Sayitoğlu 2016). Quality filtering of read alignment defines sensitivity and specificity of the test. Using very strong filtering could lead to loss of variants, while inclusive filters can minimize false negative results but it will increase the burden of confirmatory analysis. Both coverage depth and uniformity are important regarding detection accuracy. In germline testing, a minimum of 20 reads/alleles are required for diagnostic purposes. On the other hand, as read/error ratio increases with the increase of coverage practically 300–500 reads/target has been suggested to be enough for diagnostics (Strom 2016; Deans et al. 2017; Butz and Patócs 2019). Even if the coverage is adequate, it is important to evaluate coverage uniformity in order not to miss certain regions falling below the detection cut-off, because variants not detected will not be further analyzed (Rizzo and Buck 2012). In certain cases, due to sequence complexity, 1–2% of the targeted region may not be covered (Rizzo and Buck 2012).
Variant calling is performed to identify alterations compared to the reference sequence (Oliver et al. 2015). In this step, false sequence variants are omitted by investigating variant allele frequency (VAF) (Lee et al. 2014; Deans et al. 2017). (VAF is the percentage of sequence reads divided by the overall coverage of the particular locus. In germline testing, VAF represents diploid zygosity (near 0 and 100% for homozygosity and near 50% for heterozygosity). Unfortunately, results of different variant calling algorithms do not correlate well, therefore, to maintain technical validity, confirmatory tests are recommended (Trubetskoy et al. 2015; Matthijs et al. 2016; Muller et al. 2016). In germline NGS applications, Sanger sequencing is generally accepted for validation.
As In Vitro Diagnosis (IVD) proved NGS-based assays are not widely available, each laboratory has to develop and validate their own protocols including from sample and library preparation, bioinformatics analysis and quality assurance (Rehm et al. 2013). In our analysis, we followed the Genome Analysis Tool Kit (GATK) Best Practices guideline using the germline short variant discovery (SNPs + Indels) algorithm (DePristo et al. 2011). A minimum coverage of 20 reads was applied as detection filter. In our gene panel, all regions were covered by 71 ± 14 reads/base (see details regarding each gene in Table 3).
The accuracy depends on the depth of sequence coverage therefore NGS gene panels show the highest diagnostic accuracy (Oliver et al. 2015). Indeed, in a recent study, comparing different exome sequencing platforms found that 93.2% of the investigated regions were covered > 10 reads (Kong et al. 2018) (of the covered regions the sensitivity was reported 97.5–99.99%). Comparably, in our panel, 97.2% of the investigated regions (86,329 bp) was covered > 20 read/base. Of the investigated region, 14,532 bp was assessed by Sanger sequencing as well, and all detected variants were identified by both approach, therefore the specificity of our panel was 100%.
Variant interpretation
Variant interpretation are guided by expert recommendations for clinical diagnostics [American College of Medical Genetics and Genomics (ACMG), European Society of Human Genetics (ESHG)] which should be followed for all laboratories offering NGS-based diagnostics (Rehm et al. 2013; Richards et al. 2015; Matthijs et al. 2016).
WGS usually identifies 3–4 million, while WES detects usually 15,000–20,000 variants. Therefore, variant prioritization and interpretation are needed to determine the one or the few pathogenic variants responsible for disease (Fig. 2). First step is to assess the prevalence of certain variants in general population-based databases to filter out frequent variants assuming that pathogenic variants are not common in the broad population. However, in oligogenic diseases, relatively frequent variants can have additional or genetic modifier effect on the phenotype (Maione et al. 2018).

Process of molecular genetic testing by NGS from NGS data analysis to variant interpretation. See details in the text
Analyzing the functional consequence of a certain variant may help the interpretation. Using various algorithms (Fig. 2), variants can be classified to have low, moderate or high impact on protein function. It has to be kept in mind that even synonymous variants could sometimes influence splicing and, therefore, amino acid composition of the mature protein resulting in a pathogenic variant (Gianetti et al. 2010; Courage et al. 2019). After classification, further gene, variant and disease specific databases together with peer-reviewed literature data (Fig. 2) can help the accurate interpretation (Richards et al. 2015).
To estimate the pathogenicity of variants of uncertain significance (VUS) is more challenging. Multiple sources of information (variant frequency, in silico predictions of variant effect on protein function and subsidiary functional studies) are needed to be taken into account in order to follow recommendations of guidelines in categorization of a particular variant (Richards et al. 2015; Matthijs et al. 2016). In this framework, in vitro and in vivo functional assays are not always available. These experiments are labour intensive, need longer time, and typically performed as the part of research.
The molecular genetic laboratory report should focus on containing the clinically relevant information for clinicians together with a brief description of all NGS quality metrics (technical characteristics, bioinformatics pipelines, validation), variant annotations and classification (Richards et al. 2015; Matthijs et al. 2016). Disease-specific statements and/or recommendation can greatly guide the interpreter in variant evaluation. The raw data and the full report should also be available upon request.
In our case, for variant filtering, the following parameters were used: minor allele frequency (MAF) cut-off 1%, coding properties (synonymous variants were omitted), and variants’ effects were evaluated by prediction softwares (SNPeffect—Cingolani et al. 2012 and DANN). Variant interpretation was done following the ACMG recommendation (Richards et al. 2015). Additionally, the European Consensus Statement on congenital hypogonadotropic hypogonadism, Human Gene Mutation Database (HGMD) and peer-viewed articles were searched to categorize the detected variants.
All identified Class V, IV and III variants (pathogenic, likely pathogenic and variant of unknown significance, VUS) were validated using conventional bidirectional Sanger sequencing on an Applied Biosystems 3130 Genetic Analyzer System. Following Sanger validation of all pathogenic, likely pathogenic and VUS variants we found 100% of concordance between NGS and Sanger results.
Pathogenicity of the identified variants, genotype–phenotype correlation
After publication of the CHH expert consensus recommendation 7 NGS panel studies have been published about the molecular genetic analysis of CHH. Including our current study, a total of 588 patients with CHH and 72 patients with CDGP were evaluated. Using various NGS approaches of these patients 262 (44%) with CHH and 5 (5.5%) with CDGP diagnosis carried a pathogenic variant (Table 2).
Regarding phenotype–genotype correlation some authors reported inconclusive results and little co-segregation by analyzing pedigrees in their cohorts (Aoyama et al. 2017; Zhou et al. 2018), probably due to the complex genetic background of CHH. However, differences in genetic profile among populations are indicated in Chinese and Japanese cohorts (Aoyama et al. 2017; Zhou et al. 2018). Zhou et al. reported that in Chinese population, cryptorchidism was the most common accompanying feature in addition to CHH, but no single gene in their panel showed association with this abnormality (Zhou et al. 2018). Wang et al. reported that the frequency of PROKR2 mutations was higher in dual CHH patients (showing hypothalamic and/or pituitary defects with testicular hypoplasia) when compared to other CHH cases. The authors suggested that testicular development are affected in early life reflecting the results of animal experiments where the loss of Prokr2 compromised the integrity of the testicular vasculature (Wang et al. 2017).
In Kallmann syndrome, anosmia/hyposmia is part of the clinical picture, and ANOS1, CHD7, FGFR1, PROK2, PROKR2, and SEMA3A variants were reported to be involved in isolated congenital anosmia (Alkelai et al. 2017). The genetic background of CHH reversal is still unclear, however, the recently identified IGSF10 and GNRHR variants in addition to previously reported TAC3 and TACR3 variants need further studies for clarification of their pathogenic role (Amato et al. 2019).
The genetic background of CDGP and CHH share common aspects, they also have distinct profiles. In CHH patients, both mutations and oligogenicity of CHH genes have been more commonly identified compared to CDGP (Cassatella et al. 2018). In turn, the genetic profile of CDGP resembled more closely to those founded in control cohort. No pathogenic alterations, but frequent (MAF 1.0–2.5%) genetic variants have been more commonly detected in CDGP compared to controls suggesting their genetic modifier’s role (Cassatella et al. 2018).
In CHH, oligogenicity was reported between 0 and 19% (Table 2). Interestingly, in Japanese populations Aoyama et al. did not find any patients with CHH caused by di-/oligogenic mutations (Aoyama et al. 2017) while Quaynor et al. described that the majority of the suggested di- and oligogenic background could be supported by pedigree analysis (9/11 pedigrees) in their cohort (Quaynor et al. 2016). Nevertheless, others suggested that with the increase of the numbers of genes investigated the detection rate of oligogenicity will increase (Amato et al. 2019) making difficult to prove the true role of di/oligogenic findings (Maione et al. 2018).
Our panel identified a total of 31 variants in 22 probands (1)13 patients with only 1 variant per individual; (2) 1 patient with compound heterozygous variants in the GNRHR gene; (3) 8 patients with 2 heterozygous variants in two different genes (digenic case). The digenic rate was 21% (8/38). The eight pathogenic/likely pathogenic variants, detected in eight patients, hence the genetic cause was clearly identified in 21% of cases tested. (8/38 = 21%). In three patients the pathogenic mutations were detected together with variants of unknown significance (VUSs) (Patient IDs: 10, 29 and 31). In addition, in 14 patients, only VUSs were identified (in 6 patients, 2 and in 8 patients, 1 VUS) which need further studies (Table 4). Grouping our patients into adult and pediatric groups, our data show that clearly pathogenic variants in adult patients were identified in 7 (29%; 7/24), while in 1 pediatric cases (7%; 1/14).
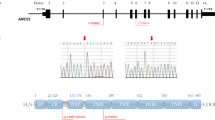
In pediatric cases where healthy parents were available for genetic test, we performed family screening. Healthy parents of patients with IDs “26”, “33” and “37” were available for assessment of variant pathogenicity. By sequencing the particular variants in unaffected parents, we concluded that combination of SPRY4 p.Cys209Tyr and AMH p.Arg254Pro variants were probably not disease causing as the healthy father also carried the same genotype. Our family screening suggests that the originally predicted as likely pathogenic variant (AMHR2 p.Arg495Gln) is benign for CHH and might be VUS for delayed puberty because the unaffected father carried the same variant in heterozygous form. The co-existence of TAC3 p.His83Pro with MASTL p.His707Leu (Patient “26”) could be potentially pathogenic as they were inherited from different parents. Naturally, in CDGP cases, follow-up time (onset of puberty could spontaneously occur) and further studies will possibly clarify the pathogenicity of these variants.
During the family screening of our case, Patient ID “9” the same pathogenic mutation was identified in his clinically affected brother (Patient ID “10”). There are phenotypes are similar, however, in Patient ID “10” anosmia was present.
It is noteworthy that some alterations (such as repetitive sequences, copy-number variations, long insertion–deletions, structural variants, aneuploidy or epigenetic alterations) are not well detectable by NGS methods Therefore, when these types of alterations are expected the appropriate method (such as multiplex ligation probe amplification (MLPA) or microarray-based comparative genomic hybridization (aCGH)) should be used.
Summary and conclusion
Congenital hypogonadotropic hypogonadism has a heterogeneous clinical phenotype and genetic background. Especially in pediatric cases, even clinical diagnosis can be challenging (ie. pubertal delay vs. hypogonadism). Genetics data regarding hypogonadotropic hypogonadism with the wider availability of next-generation sequencing are increasing but appropriate tool and expertise are needed for correct interpretation of these results in clinical practice. Based on recent data, in more 50% of cases, the disease causing genetic alterations could be found. In house developed gene panels together with appropriate validation steps have at least the same diagnostic accuracy as the WES. The main challenge in NGS-based methods is the interpretation of variants with unknown significance. For clinical point of view, a great majority of data generated by exome and panel sequencing have still been waiting for clinical validation. The potentially new candidate genes and variants have to be further analyzed functionally (in vitro and in vivo animal experiments) together with thorough clinical genotype–phenotype investigations to prove their disease causing effects. The latter is especially challenging in CHH as the clinical phenotype cover a broad spectrum even in cases harboring the same mutation. In CHH, another great challenge is to distinguish true oligogenic inheritance from incidental, rare findings that are not in relation with CHH. The difficulty in determining inheritance due to non-complete penetrance and variable expressivity together with oligogenicity could mean a difficult situation for genetic counselors. However, over time with the increasing genetic data linked to clinical information will reveal the complex genetic landscape of CHH and eventually it will help variant interpretation.
References
Abreu AP, Kaiser UB, Latronico AC (2010) The role of prokineticins in the pathogenesis of hypogonadotropic hypogonadism. Neuroendocrinology 91:283–290. https://doi.org/10.1159/000308880
Alkelai A, Olender T, Dode C et al (2017) Next-generation sequencing of patients with congenital anosmia. Eur J Hum Genet 25:1377–1387. https://doi.org/10.1038/s41431-017-0014-1
Alsters SI, Goldstone AP, Buxton JL et al (2015) Truncating Homozygous Mutation of Carboxypeptidase E (CPE) in a Morbidly Obese Female with Type 2 Diabetes Mellitus, Intellectual Disability and Hypogonadotrophic Hypogonadism. PLoS One 10:e0131417. https://doi.org/10.1371/journal.pone.0131417
Amato LGL, Montenegro LR, Lerario AM et al (2019) New genetic findings in a large cohort of congenital hypogonadotropic hypogonadism. Eur J Endocrinol 181:103–119. https://doi.org/10.1530/EJE-18-0764
Aoyama K, Mizuno H, Tanaka T et al (2017) Molecular genetic and clinical delineation of 22 patients with congenital hypogonadotropic hypogonadism. J Pediatr Endocrinol Metab 30:1111–1118. https://doi.org/10.1515/jpem-2017-0035
Beneduzzi D, Trarbach EB, Min L et al (2014) Role of gonadotropin-releasing hormone receptor mutations in patients with a wide spectrum of pubertal delay. Fertil Steril 102:838–846.e2. https://doi.org/10.1016/j.fertnstert.2014.05.044
Bertalan R, Bencsik Z, Mezei P et al (2019) Novel frameshift mutation of the NR0B1(DAX1) in two tall adult brothers. Mol Biol Rep 46:4599–4604. https://doi.org/10.1007/s11033-019-04688-9
Biesecker LG, Green RC (2014) Diagnostic clinical genome and exome sequencing. N Engl J Med 370:2418–2425. https://doi.org/10.1056/NEJMra1312543
Boehm U, Bouloux P-M, Dattani MT et al (2015) European consensus statement on congenital hypogonadotropic hypogonadism—pathogenesis, diagnosis and treatment. Nat Rev Endocrinol 11:547–564. https://doi.org/10.1038/nrendo.2015.112
Butz H, Patócs A (2019) Brief summary of the most important molecular genetic methods (PCR, qPCR, microarray, next-generation sequencing, etc.). In: Igaz P, Patócs A (eds) Genetics of Endocrine diseases and syndromes. Springer International Publishing, Cham, pp 33–52
Cariboni A, André V, Chauvet S et al (2015) Dysfunctional SEMA3E signaling underlies gonadotropin-releasing hormone neuron deficiency in Kallmann syndrome. J Clin Invest 125:2413–2428. https://doi.org/10.1172/JCI78448
Caronia LM, Martin C, Welt CK et al (2011) A genetic basis for functional hypothalamic amenorrhea. N Engl J Med 364:215–225. https://doi.org/10.1056/NEJMoa0911064
Cassatella D, Howard SR, Acierno JS et al (2018) Congenital hypogonadotropic hypogonadism and constitutional delay of growth and puberty have distinct genetic architectures. Eur J Endocrinol 178:377–388. https://doi.org/10.1530/EJE-17-0568
Chew S, Balasubramanian R, Chan WM et al (2013) A novel syndrome caused by the E410K amino acid substitution in the neuronal β-tubulin isotype 3. Brain 136:522–535. https://doi.org/10.1093/brain/aws345
Cingolani P, Platts A, Wang LL et al (2012) A program for annotating and predicting the effects of single nucleotide polymorphisms, SnpEff: SNPs in the genome of Drosophila melanogaster strain w1118; iso-2; iso-3. Fly (Austin) 6:80–92. https://doi.org/10.4161/fly.19695
Cioppi F, Riera-Escamilla A, Manilall A et al (2019) Genetics of ncHH: from a peculiar inheritance of a novel GNRHR mutation to a comprehensive review of the literature. Andrology 7:88–101. https://doi.org/10.1111/andr.12563
Cole LW, Sidis Y, Zhang C et al (2008) Mutations in prokineticin 2 and prokineticin receptor 2 genes in human gonadotrophin-releasing hormone deficiency: molecular genetics and clinical spectrum. J Clin Endocrinol Metab 93:3551–3559. https://doi.org/10.1210/jc.2007-2654
Costa EM, Bedecarrats GY, Mendonca BB, Arnhold IJ, Kaiser UB, Latronico AC (2001) Two novel mutations in the gonadotropin-releasing hormone receptor gene in Brazilian patients with hypogonadotropic hypogonadism and normal olfaction. J Clin Endocrinol Metab 86:2680–2686. https://doi.org/10.1210/jcem.86.6.7551
Costa-Barbosa FA, Balasubramanian R, Keefe KW et al (2013) Prioritizing genetic testing in patients with kallmann syndrome using clinical phenotypes. J ClinEndocrinol Metabol 98:E943–E953. https://doi.org/10.1210/jc.2012-4116
Courage C, Jackson CB, Owczarek-Lipska M et al (2019) Novel synonymous and missense variants in FGFR1 causing Hartsfield syndrome. Am J Med Genet 179:2447–2453. https://doi.org/10.1002/ajmg.a.61354
Deans ZC, Costa JL, Cree I et al (2017) Integration of next-generation sequencing in clinical diagnostic molecular pathology laboratories for analysis of solid tumours; an expert opinion on behalf of IQN Path ASBL. Virchows Arch 470:5–20. https://doi.org/10.1007/s00428-016-2025-7
DePristo MA, Banks E, Poplin R et al (2011) A framework for variation discovery and genotyping using next-generation DNA sequencing data. Nat Genet 43:491–498. https://doi.org/10.1038/ng.806
Di Resta C, Galbiati S, Carrera P, Ferrari M (2018) Next-generation sequencing approach for the diagnosis of human diseases: open challenges and new opportunities. EJIFCC 29:4–14
Digilio MC, Magliozzi M, Di Pede A et al (2019) Familial aggregation of "apple peel" intestinal atresia and cardiac left-sided obstructive lesions: a possible causal relationship with NOTCH1 gene mutations. Am J Med Genet A 179:1570–1574. https://doi.org/10.1002/ajmg.a.61195
Dodé C, Teixeira L, Levilliers J et al (2006) Kallmann syndrome: mutations in the genes encoding prokineticin-2 and prokineticin receptor-2. PLoS Genet 2:e175. https://doi.org/10.1371/journal.pgen.0020175
Fang Q, George AS, Brinkmeier ML et al (2016) Genetics of combined pituitary hormone deficiency: roadmap into the genome era. Endocr Rev 37:636–675. https://doi.org/10.1210/er.2016-1101
Farooqi IS, O’Rahilly S (2008) Mutations in ligands and receptors of the leptin–melanocortin pathway that lead to obesity. Nat Rev Endocrinol 4:569–577. https://doi.org/10.1038/ncpendmet0966
Gianetti E, Tusset C, Noel SD et al (2010) TAC3/TACR3 mutations reveal preferential activation of gonadotropin-releasing hormone release by neurokinin b in neonatal life followed by reversal in adulthood. J Clin Endocrinol Metabol 95:2857–2867. https://doi.org/10.1210/jc.2009-2320
Gianetti E, Hall JE, Au MG et al (2012) When genetic load does not correlate with phenotypic spectrum: lessons from the gnrh receptor (GNRHR). J Clin Endocrinol Metabol 97:E1798–E1807. https://doi.org/10.1210/jc.2012-1264
Graziola F, Garone G, Stregapede F et al (2019) Diagnostic yield of a targeted next-generation sequencing gene panel for pediatric-onset movement disorders: a 3-year cohort study. Front Genet 10:1026. https://doi.org/10.3389/fgene.2019.01026
Gürbüz F, Kotan LD, Mengen E et al (2012) Distribution of gene mutations associated with familial normosmic idiopathic hypogonadotropic hypogonadism. J Clin Res Pediatr Endocrinol 4:121–126. https://doi.org/10.4274/jcrpe.725
Halász Z, Tőke J, Patócs A et al (2006) High prevalence of PROP1 gene mutations in hungarian patients with childhood-onset combined anterior pituitary hormone deficiency. Endocr 30:255–260. https://doi.org/10.1007/s12020-006-0002-7
Hannema SE, Wit JM, Houdijk ME et al (2016) Novel leptin receptor mutations identified in two girls with severe obesity are associated with increased bone mineral density. Horm Res Paediatr 85:412–420. https://doi.org/10.1159/000444055
Hietamäki J, Hero M, Holopainen E et al (2017) GnRH receptor gene mutations in adolescents and young adults presenting with signs of partial gonadotropin deficiency. PLoS ONE 12:e0188750. https://doi.org/10.1371/journal.pone.0188750
Hughes LA, McKay-Bounford K, Webb EA et al (2019) Next generation sequencing (NGS) to improve the diagnosis and management of patients with disorders of sex development (DSD). Endocr Connect 8:100–110. https://doi.org/10.1530/EC-18-0376
Izumi Y, Suzuki E, Kanzaki S et al (2014) Genome-wide copy number analysis and systematic mutation screening in 58 patients with hypogonadotropic hypogonadism. Fertil Steril 102:1130–1136.e3. https://doi.org/10.1016/j.fertnstert.2014.06.017
Jackson RS, Creemers JWM, Ohagi S et al (1997) Obesity and impaired prohormone processing associated with mutations in the human prohormone convertase 1 gene. Nat Genet 16:303–306. https://doi.org/10.1038/ng0797-303
Känsäkoski J, Fagerholm R, Laitinen EM et al (2014) Mutation screening of SEMA3A and SEMA7A in patients with congenital hypogonadotropic hypogonadism. Pediatr Res 75:641–644. https://doi.org/10.1038/pr.2014.23
Kim JH, Seo GH, Kim G-H et al (2019) Targeted gene panel sequencing for molecular diagnosis of Kallmann syndrome and normosmic idiopathic hypogonadotropic hypogonadism. Exp Clin Endocrinol Diabetes 127:538–544. https://doi.org/10.1055/a-0681-6608
Kong SW, Lee IH, Liu X et al (2018) Measuring coverage and accuracy of whole-exome sequencing in clinical context. Genet Med 20:1617–1626. https://doi.org/10.1038/gim.2018.51
Kotan LD, Cooper C, Darcan Ş et al (2016) Idiopathic hypogonadotropic hypogonadism caused by inactivating mutations in SRA1. J Clin Res Pediatr Endocrinol 8:125–134. https://doi.org/10.4274/jcrpe.3248
Lee H, Deignan JL, Dorrani N et al (2014) Clinical exome sequencing for genetic identification of rare Mendelian disorders. JAMA 312:1880–1887. https://doi.org/10.1001/jama.2014.14604
Maione L, Dwyer AA, Francou B et al (2018) Genetics in endocrinology: genetic counseling for congenital hypogonadotropic hypogonadism and Kallmann syndrome: new challenges in the era of oligogenism and next-generation sequencing. Eur J Endocrinol 198:R55–R80. https://doi.org/10.1530/EJE-17-0749
Malone SA, Papadakis GE, Messina A et al (2019) Defective AMH signaling disrupts GnRH neuron development and function and contributes to hypogonadotropic hypogonadism. Elife 8:e47198. https://doi.org/10.7554/eLife.47198
Mancini A, Howard SR, Cabrera CP et al (2019) EAP1 regulation of GnRH promoter activity is important for human pubertal timing. Hum Mol Genet 28:1357–1368. https://doi.org/10.1093/hmg/ddy451
Matthijs G, Souche E, Alders M et al (2016) Guidelines for diagnostic next-generation sequencing. Eur J Hum Genet 24:2–5. https://doi.org/10.1038/ejhg.2015.226
Miraoui H, Dwyer AA, Sykiotis GP et al (2013) Mutations in FGF17, IL17RD, DUSP6, SPRY4, and FLRT3 are identified in individuals with congenital hypogonadotropic hypogonadism. Am J Hum Genet 92:725–743. https://doi.org/10.1016/j.ajhg.2013.04.008
Miura K, Acierno JS, Seminara SB (2004) Characterization of the human nasal embryonic LHRH factor gene, NELF, and a mutation screening among 65 patients with idiopathic hypogonadotropic hypogonadism (IHH). J Hum Genet 49:265–268. https://doi.org/10.1007/s10038-004-0137-4
Monnier C, Dodé C, Fabre L et al (2009) PROKR2 missense mutations associated with Kallmann syndrome impair receptor signalling activity. Hum Mol Genet 18:75–81. https://doi.org/10.1093/hmg/ddn318
Muller E, Goardon N, Brault B et al (2016) OutLyzer: software for extracting low-allele-frequency tumor mutations from sequencing background noise in clinical practice. Oncotarget 7:79485–79493. https://doi.org/10.18632/oncotarget.13103
Oliver GR, Hart SN, Klee EW (2015) Bioinformatics for clinical next generation sequencing. Clin Chem 61:124–135. https://doi.org/10.1373/clinchem.2014.224360
Patel RM, Liu D, Gonzaga-Jauregui C et al (2017) An exome sequencing study of Moebius syndrome including atypical cases reveals an individual with CFEOM3A and a TUBB3 mutation. Cold Spring Harb Mol Case Stud 3:a000984. https://doi.org/10.1101/mcs.a000984
Pitteloud N, Quinton R, Pearce S et al (2007) Digenic mutations account for variable phenotypes in idiopathic hypogonadotropic hypogonadism. J Clin Invest 117:457–463. https://doi.org/10.1172/JCI29884
Quaynor SD, Bosley ME, Duckworth CG et al (2016) Targeted next generation sequencing approach identifies eighteen new candidate genes in normosmic hypogonadotropic hypogonadism and Kallmann syndrome. Mol Cell Endocrinol 437:86–96. https://doi.org/10.1016/j.mce.2016.08.007
Radhakrishna U, Bornholdt D, Scott HS et al (1999) The phenotypic spectrum of GLI3 morphopathies includes autosomal dominant preaxial polydactyly type-IV and postaxial polydactyly type-A/B; No phenotype prediction from the position of GLI3 mutations. Am J Hum Genet 65:645–655. https://doi.org/10.1086/302557
Raivio T, Avbelj M, McCabe MJ et al (2012) Genetic overlap in Kallmann syndrome, combined pituitary hormone deficiency, and septo-optic dysplasia. J Clin Endocrinol Metabol 97:E694–E699. https://doi.org/10.1210/jc.2011-2938
Rehm HL, Bale SJ, Bayrak-Toydemir P et al (2013) ACMG clinical laboratory standards for next-generation sequencing. Genet Med 15:733–747. https://doi.org/10.1038/gim.2013.92
Reynaud R, Jayakody SA, Monnier C et al (2012) PROKR2 variants in multiple hypopituitarism with pituitary stalk interruption. J Clin Endocrinol Metab 97:E1068–E1073. https://doi.org/10.1210/jc.2011-3056
Richards S, Aziz N, Bale S et al (2015) Standards and guidelines for the interpretation of sequence variants: a joint consensus recommendation of the American College of Medical Genetics and Genomics and the Association for Molecular Pathology. Genet Med 17:405–424. https://doi.org/10.1038/gim.2015.30
Rizzo JM, Buck MJ (2012) Key principles and clinical applications of “next-generation” DNA sequencing. Cancer Prev Res 5:887–900. https://doi.org/10.1158/1940-6207.CAPR-11-0432
Salian-Mehta S, Xu M, Knox AJ et al (2014) Functional consequences of AXL sequence variants in hypogonadotropic hypogonadism. J Clin Endocrinol Metab 99:1452–1460. https://doi.org/10.1210/jc.2013-3426
Sawyer SL, Hartley T, Dyment DA et al (2016) Utility of whole-exome sequencing for those near the end of the diagnostic odyssey: time to address gaps in care: Whole-exome sequencing for rare disease diagnosis. Clin Genet 89:275–284. https://doi.org/10.1111/cge.12654
Sayitoğlu M (2016) Clinical interpretation of genomic variations. Turk J Haematol 33:172–179. https://doi.org/10.4274/tjh.2016.0149
Spilker C, Grochowska KM, Kreutz MR (2016) What do we learn from the murine Jacob/Nsmf gene knockout for human disease? Rare Dis 4:e1241361. https://doi.org/10.1080/21675511.2016.1241361
Stamou MI, Georgopoulos NA (2018) Kallmann syndrome: phenotype and genotype of hypogonadotropic hypogonadism. Metabolism 86:124–134. https://doi.org/10.1016/j.metabol.2017.10.012
Strobel A, Issad T, Camoin L, Ozata M, Strosberg AD (1998) A leptin missense mutation associated with hypogonadism and morbid obesity. Nat Genet 18:213–215. https://doi.org/10.1038/ng0398-213
Strom SP (2016) Current practices and guidelines for clinical next-generation sequencing oncology testing. Cancer Biol Med 13:3–11. https://doi.org/10.28092/j.issn.2095-3941.2016.0004
Tommiska J, Toppari J, Vaaralahti K et al (2012) PROKR2 mutations in autosomal recessive Kallmann syndrome. Fertil Steril. 99:815–818. https://doi.org/10.1016/j.fertnstert.2012.11.003
Topaloglu AK, Lu ZL, Farooqi IS et al (2006) Molecular genetic analysis of normosmic hypogonadotropic hypogonadism in a Turkish population: identification and detailed functional characterization of a novel mutation in the gonadotropin-releasing hormone receptor gene. Neuroendocrinology 84:301–308. https://doi.org/10.1159/000098147
Topaloglu AK, Kotan LD (2016) Genetics of hypogonadotropic hypogonadism. Endocr Dev 29:36–49. https://doi.org/10.1159/000438841
Topaloğlu AK (2018) Update on the genetics of idiopathic hypogonadotropic hypogonadism. J Clin Res Pediatr Endocrinol 30:113–122. https://doi.org/10.4274/jcrpe.2017.S010
Trubetskoy V, Rodriguez A, Dave U et al (2015) Consensus Genotyper for Exome Sequencing (CGES): improving the quality of exome variant genotypes. Bioinformatics 31:187–193. https://doi.org/10.1093/bioinformatics/btu591
Tusset C, Noel SD, Trarbach EB et al (2012) Mutational analysis of TAC3 and TACR3 genes in patients with idiopathic central pubertal disorders. Arq Bras Endocrinol Metab 56:646–652. https://doi.org/10.1590/S0004-27302012000900008
Wang Y, Gong C, Qin M et al (2017) Clinical and genetic features of 64 young male paediatric patients with congenital hypogonadotropic hypogonadism. Clin Endocrinol 87:757–766. https://doi.org/10.1111/cen.13451
Wang L, Zhang J, Chen N et al (2018) Application of whole exome and targeted panel sequencing in the clinical molecular diagnosis of 319 Chinese families with inherited retinal dystrophy and comparison study. Genes 9:e360. https://doi.org/10.3390/genes9070360
Xu N, Kim H-G, Bhagavath B et al (2011) Nasal Embryonic LHRH Factor (NELF) mutations in patients with normosmic hypogonadotropic hypogonadism and Kallmann syndrome. Fertil Steril 95(1613–20):e1–7. https://doi.org/10.1016/j.fertnstert.2011.01.010
Young J, Xu C, Papadakis GE et al (2019) Clinical management of congenital hypogonadotropic hypogonadism. Endocrine Rev 40:669–710. https://doi.org/10.1210/er.2018-00116
Zhou C, Niu Y, Xu H et al (2018) Mutation profiles and clinical characteristics of Chinese males with isolated hypogonadotropic hypogonadism. Fertil Steril 110:486–495.e5. https://doi.org/10.1016/j.fertnstert.2018.04.010
Zhu J, Choa RE-Y, Guo MH et al (2015) A shared genetic basis for self-limited delayed puberty and idiopathic hypogonadotropic hypogonadism. J Clin Endocrinol Metabol 100:E646–E654. https://doi.org/10.1210/jc.2015-1080
Acknowledgements
Open access funding provided by Semmelweis University (SE). The authors would like to thank pediatric and adult endocrinologists for referring patients for genetic testing: Dr Zita Halász, Dr. Ágnes Sallai, Dr. Miklós Góth, Dr. Éva Csajbók, Dr. Zsuzsanna Valkusz, Dr. Ágota Muzsnai, Dr. Marianna Hartwig, Dr. Orsolya Benn, Dr. Katalin Horváth, Dr. Violetta Csákváry, Dr. Zoltán Görömbey, Dr. Zsolt Nagy and prof. Dr. Miklós Tóth. The authors acknowledge the financial support of the National Program of Bionics (Program Medical Bionics lead by Attila Patócs).
Funding
Financial support was provided by the National Program of Bionics (Program Medical Bionics lead by Attila Patócs).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Butz, H., Nyírő, G., Kurucz, P.A. et al. Molecular genetic diagnostics of hypogonadotropic hypogonadism: from panel design towards result interpretation in clinical practice. Hum Genet 140, 113–134 (2021). https://doi.org/10.1007/s00439-020-02148-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00439-020-02148-0