
Abstract
Purpose
Appendicitis is among the most common acute conditions treated by general surgery. While uncomplicated appendicitis (UA) can be treated delayed or even non-operatively, complicated appendicitis (CA) is a serious condition with possible long-term morbidity that should be managed with urgent appendectomy. Distinguishing both conditions is usually done with computed tomography. The goal of this study was to develop a model to reliably predict CA with widespread available clinical and laboratory parameters and without the use of sectional imaging.
Methods
Data from 1132 consecutive patients treated for appendicitis between 2014 and 2021 at a tertiary care hospital were used for analyses. Based on year of treatment, the data was divided into training (n = 696) and validation (n = 436) samples. Using the development sample, candidate predictors for CA—patient age, gender, body mass index (BMI), American Society of Anesthesiologist (ASA) score, duration of symptoms, white blood count (WBC), total bilirubin and C-reactive protein (CRP) on admission and free fluid on ultrasound—were first investigated using univariate logistic regression models and then included in a multivariate model. The final development model was tested on the validation sample.
Results
In the univariate analysis age, BMI, ASA score, symptom duration, WBC, bilirubin, CRP, and free fluid each were statistically significant predictors of CA (each p < 0.001) while gender was not (p = 0.199). In the multivariate analysis BMI and bilirubin were not predictive and therefore not included in the final development model which was built from 696 patients. The final development model was significant (x2 = 304.075, p < 0.001) with a sensitivity of 61.7% and a specificity of 92.1%. The positive predictive value (PPV) was 80.4% with a negative predictive value (NPV) of 82.0%. The receiver operator characteristic of the final model had an area under the curve of 0.861 (95% confidence interval 0.830–0.891, p < 0.001. We simplified this model to create the NoCtApp score. Patients with a point value of ≤ 2 had a NPV 95.8% for correctly ruling out CA.
Conclusions
Correctly identifying CA is helpful for optimizing patient treatment when they are diagnosed with appendicitis. Our logistic regression model can aid in correctly distinguishing UA and CA even without utilizing computed tomography.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Acute appendicitis is among the most common diagnoses in emergency rooms and general surgery departments with an annual incidence of nearly 100 cases per 100,000 adults [1]. While it is considered a disease of the younger population, it is also frequently encountered in the elderly [2]. Prediction models for appendicitis have been reported by several groups. The most well known and most commonly used risks scores are the Alvarado score and the Appendicitis Inflammatory Response (AIR) score [3, 4] which use clinical and laboratory data to predict appendicitis. The seminal APPAC I and APPAC II trial have shown favorable outcomes after non-operative management in the absence of complicated appendicitis (CA) [5, 6], which has become an alternative to surgery in current clinical practice for uncomplicated appendicitis (UA) [5, 7, 8]. Before inclusion into the trial, CA (perforation, gangrene, or abscess) had to be ruled out via computed tomography (CT) [5, 6], which harbors an inherent risk of cancerogenicity due to ionizing radiation, especially in the young [9]. In countries that are prone to medical litigation suits, nearly all patients undergo CT scans during the diagnostic process. The MUSTANG Trial reported that 90% of patients in the USA that are diagnosed with appendicitis had preoperative CT scans, and a CT scan is considered the appropriate tool to diagnose appendicitis by the American College of Radiology [10, 11]. In Europe, the imaging of choice is a focused ultrasound [12,13,14]. However, there is limited data on the discrimination of UA and CA without the use of a CT or magnetic resonance imaging (MRI) [15].
The primary goal of this study was to develop a prediction model for complicated appendicitis in a patient cohort that underwent appendectomy at a tertiary teaching facility without the use of sectional imaging and to compare its predictive potential to the Atema score and C-reactive protein (CRP) alone. The secondary goal was to develop a predictive risk score for easy clinical application.
Materials and methods
Study cohort
We retrospectively analyzed a convenient cohort of 1880 consecutive adult patients (age ≥ 16 years) that underwent appendectomy at our tertiary teaching facility between 2014 and 2021. Patients were identified with the procedure codes for appendectomy, partial cecectomy or ileocecal resection. After exclusion of duplicates, the operation reports were screened by a clinician to exclude patients with incorrect procedure codes or indications other than acute appendicitis. Patients that had elective appendectomy or appendectomy during other procedures were excluded from the analysis, as were all patients who were taken to the operating room for the suspicion of appendicitis but were ultimately diagnosed to have different diseases (mainly gynecological infections or inflammatory bowel diseases). Ultimately 1218 patients fulfilled the criteria of having been treated surgically for acute appendicitis. For details, see Fig. 1. None of these patients was treated antibiotically. All patients underwent surgical resection.

Study cohort flow diagram
Given the size of the dataset (with more than 400 cases of complicated appendicitis), no formal sample-size calculation was performed. However, according to a previous simulation study sample sizes of > 500 with 50 events per predictor are considered adequate and reasonably close to population level patterns [16].
Clinical definitions
CA was defined as the presence of gangrenous or necrotizing appendicitis, local abscess, perforation of the appendix or the presence of peritonitis. All other patients were classified as having UA. All diagnoses were clinically made by the surgeon and histopathology did not alter this classification since the purpose was to determine postoperative care, which should not be based on pathological results available 48 h after the procedure.
Model building
Only patients with complete data were included in analyses: n = 1132. The majority of missing data were due to lacking preoperative ultrasound (in favor of primary computed tomography). For the univariate analysis, we assessed the following parameters: age, gender, body mass index (BMI), American Society of Anesthesiologists (ASA) score, duration of symptoms in full days (rounded appropriately) at the time of presentation to the emergency department, free fluid on ultrasound, white blood count (WBC), CRP, and total bilirubin.
The following parameters were not assessed: body temperature at presentation, diameter of appendix on ultrasound, presence of appendicoliths on ultrasound (all three due to inconsistent documentation in the admission charts or ultrasound reports), procalcitonin, delta neutrophil index, neutrophil-to-lymphocyte ratio (all three not routinely ordered during preoperative labs).
To allow for validation the patients were split up into two groups. The development cohort included 696 patients (61.5%) that were treated before 2019. The validation cohort was made up of the 436 patients (35.5%) treated from 2019.
Simplification for clinical use
In order to facilitate clinical use of our prediction model, we simplified the outcome parameters. In order to identify appropriate cutoff values, we classed the linear parameters into ordinal categories that then were collapsed if they had similar odds when compared to the reference. This process was repeated until there were no more than three outcomes for age, WBC, and CRP. The threshold values were defined to be comparable to the Atema score.
Age was grouped as Age0, ≤ 40 years; Age1, 40.01 to 60 years; Age2, > 60 years.
ASA was grouped as ASA0 ≤ ASA II; ASA1 was ASA III.
Gender was grouped as Gender0 = female; Gender1 = male.
Symptom duration was grouped as Symptoms0, ≤ 2 days; Symptoms1, > 2 days.
WBC was grouped as WBC0 ≤ 14,000 white cells; WBC1 = 14,001 to 18,000 white cells; WBC 2 > 18,000 WBC.
CRP was grouped as CRP0 ≤ 5 mg/dl; CRP1 = 5.01 mg/dl to 10 mg/dl, CRP2 > 10 mg/dl.
Free fluid on ultrasound was grouped as FF0 = no free fluid on US; FF1 free fluid on US.
Reference standard test
There is no reference standard test to diagnose complicated appendicitis. It is usually diagnosed clinically during surgery. Likely to most commonly accepted reference standard test pre-op would be a CT scan. Given the nature of our clinical pathways and the low number of CT scans performed, a comparison with CT results was not possible for the lack of available data. The lack of data availability was also the reason the Atema score was not used as the reference standard. Therefore, we decided to define CRP in mg/dl as our reference standard, for its completeness of data and widespread clinical use. Both the outcomes of our model and the prediction of CA with CRP had dichotomous outcomes, for which there were no indeterminate test results.
Transparent reporting
Our aim was to report our results according to the Standards for Reporting Diagnostic Accuracy (STARD 2015) guidelines [17].
Statistical analyses
Comparison between the patients with complicated and uncomplicated appendicitis was carried out using chi-square (Χ2) test or Fisher’s exact test for nominal variables and Mann-Whitney U-test (MWU) for continuous variables, as appropriate. Comparisons with p values less than 0.05 were considered to be statistically significant. All p values in this manuscript are results of two-sided testing. Bonferroni-correction was applied where necessary. Binary logistic regression was used to build prediction models: odds ratio (OR) with 95% confidence intervals (95% CI) are presented in this paper. First, all individual predictors were assessed in univariate models. These parameters were then combined in a multivariate model. For the model building, Harrell’s rule of ten was applied [18]. We calculated the sensitivity, specificity as well as positive and negative predictive values for the model predictions. To calculate diagnostic accuracy of our model, area under the receiver operator characteristics curve (AUROC) was assessed for candidate models).
All statistical analyses were carried out using IBM SPSS Statistics for Windows, Version 28.0 (IBM Corp., Armonk, NY, USA).
Results
Patient characteristics
The final patient cohort of 1132 patients with no missing data is summarized in Table 1. The table also shows the patient characteristics of included patients across appendicitis subgroups. Of the 1132 patients, 729 were diagnosed with UA and 403 with CA. The gender distribution was similar for both groups. Patients in the CA group were significantly older (48.2 vs. 32.1 years, MWU < 0.001) and reported a longer duration of symptoms (median of 2 vs. 1 days, MWU < 0.001). The ASA score was generally higher in the complicated group (Χ2 p < 0.001) and free fluid on preoperative ultrasound was more common in the complicated group (Χ2 p < 0.001).
Model building
In order to identify predictors, univariate binominal logistic regression was performed for candidate predictor measures. The odds ratio and 95% CI for each predictor variable are displayed in Table 2. With regard to previously published studies, the following parameters were evaluated: age, gender, BMI, ASA score, free fluid on ultrasound, WBC, CRP, and bilirubin. WBC was rounded to the next 1000 and CRP to a single digit without decimals. Except for gender all parameters appeared to be potential predictors of CA.
Correlation of linear parameters
In order to rule out collinearity of the parameters of the final model cohort, we performed Pearson’s correlation for age, duration of symptoms WBC, and CRP both for the overall cohort, the uncomplicated and the complicated subgroups. In the overall cohort except for the age and CRP none of the correlations was more than weakly correlated (age and CRP ρ = 0.345, p < 0.001). For details, see Table 3.
Multivariate analysis of a development model and validation
To allow for validation the sample was split into a development dataset (patients treated before 2019, n = 696, 61.5%) and a validation dataset (patients treated 2019 or after, n = 436, 38.5%). The predictors were then combined into the development model. Both BMI and total bilirubin, while being univariate predictors of CA, were removed from the model since they were not statistically significant predictors and did not substantively improve overall model fit. The development model was significant (x2 = 304.075, p < 0.001) which indicates the capability of the model to distinguish uncomplicated from complicated appendicitis. The model accounted for approximately 35.4% (Cox and Snell R2) to 48.9% (Nagelkerke’s R2) which indicates a moderate to strong model and was able to correctly identify 81.6% of disease severity. The Hosmer-Lemeshow goodness of fit test was not significant (p = 0.636) indicating that the model has a sufficient fit. The sensitivity of this model was 61.7% with a specificity of 92.1%. The positive predictive value (PPV) was 80.4% with a negative predictive value (NPV) of 82.0%. The receiver operator characteristic (ROC) analysis of the development model (Fig. 2) had an area under the curve (AUC) of 0.861 (95% CI 0.830–0.891, p < 0.001).

Receiver operator characteristic (ROC) analysis of the development model (red). Area under the curve 0.861 (95% CI 0.830–0.891) compared to the validation model (pink) 0.823 (95% CI 0.781–0.865) and CRP (blue) 0.804 (95% CI 0.768–0.840)
Using the scoring wizard function of SPSS, the developed model was then applied to the remaining data in the validation dataset. Of the patients in the validation cohort, 96 were correctly identified as complicated appendicitis out of 119, whereas 250 were correctly identified as uncomplicated out of 317. The sensitivity was 56,9% with a specificity of 91.6%. The NPV was 78.9% with a PPV of 80.7% and an accuracy of 79.4%. The AUROC was 0.823 (95% CI 0.781–0.865, p < 0.001).
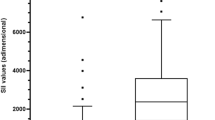
The Beta regression coefficients were multiplied by three and rounded to the next whole number to create a scoring system from which the NoCtApp score was calculated by addition of the seven individual point values each patient was awarded. The distribution is shown in Fig. 3. The minimum number of points was 0 whereas the maximum NoCtApp score was 25. The distribution of scores between the CA and UA patients is depicted in Fig. 3. In order to avoid underdiagnosing complicated appendicitis the goal was to define an acceptable false-negative rate of around 5%. Twenty-two patients with CA had a NoCtApp score ≤ 2 accounting for 5.5% of CA. A NoCtApp score ≤ 2 has a sensitivity of 94.5% with a specificity of 68.2%. The NPV was 95.8% with a PPV of 62.2% and an accuracy of 77.8%.

Distribution of total risk scores in the uncomplicated and complicated group
Comparison of the model to the reference standard CRP
Our development model predicted 148/184 (PPV = 80.4%) cases of CA as well as 420/512 (NPV = 82.0%) of UA correctly. It had diagnostic accuracy of 81.6% with a sensitivity of 61.7%, a specificity of 92.1%. The AUROC for the model was 0.861 (0.830–0.891) compared to CRP (blue) 0.804 (0.768–0.840). CRP by itself predicted 126/163 (PPV = 77.3%) cases of CA and 419/533 (NPV 78.6%) of UA correctly. It had an accuracy of 78.3% with a sensitivity of 52.5% and a specificity of 91.9%. For details, see Fig. 4.

Flow diagram according to STARD 2015
Discussion
As a result of this study, we propose the NoCtApp score to be used as a clinical risk score for the differentiation of uncomplicated and complicated appendicitis based on easily reproducible parameters (age, gender, ASA score, symptom duration, free fluid on US, WBC, and CRP) that can be calculated within seconds. While treatment for UA was both shown to be safely delayed or even non-surgical, misdiagnosing CA can have severe consequences for the patient. While our score ranges from 0 to 25 points we set the cutoff at ≤ 2 vs > 2 points, since this has a NPV of 95,8%. While around 95% of patients with CA had a NoCtApp of > 2, so did more than half of UA patients. In order to avoid falls negatives. Patients with a NoCtApp score of > 2 points should be offered early laparoscopy or sectional imaging.
Over the last 40 years, many studies have focused on the value of clinical, laboratory and imaging parameters in the diagnosis of appendicitis. Individual parameters were combined to several risk scores of which the most widely accepted ones are the Alvarado and the AIR score [3, 4]. In 2021, Andersson et al. published prospective follow-up data on 3878 patients assessed with their AIR score. They proposed outpatient follow-up for low risk scores, surgical exploration for high risk scores and either sectional imaging or short-term clinical reassessment or extended imaging for medium risk scores.
CT scans for the diagnosis of appendicitis are the diagnostic standard in the US and most studies rely heavily on sectional imaging [19,20,21,22]. Sectional imaging is less frequently utilized in Europe due to its cost, harm from radiation and the widespread availability of focused ultrasound [13, 23]. Additionally, CTs have been reported to underdiagnose CA. In up to 22% of patients were found to have complicated disease during surgery [24]. Bolmers et al. recently reported a diagnostic accuracy of CTs for the distinction of CA from UA with a sensitivity of 45%, a specificity of 88% and a NPV of 58% [14]. A recent multicentric British study by Javanmard-Emamghissi et al. demonstrated favorable outcome for antibiotically managed appendicitis. They reported a 70% rate of CT scans in some 3400 patients. While this is comparably low to other randomized trials, they do not report on the outcomes of the patients that did not undergo a CT or how they concluded that the remaining 30% could be managed without a CT-scan [25]. It goes without saying, that while we generally strive to avoid iodizing radiation, CTs can detect unexpected differentials and cases of appendicitis secondary to (obstructing) tumors [26, 27].
There is no formal gold standard test that could serve as a reference standard for our model/ index test. Given our low rate of CT scans we are unable to compare our test results to CT results. Arguably the most similar reference would be the 2015 Atema score. Atema et al. published a scoring system to distinguish UA from CA in 2015 in 395 patients that were taken to the OR for an appendectomy. They proposed two models on the base of clinical, laboratory and imaging findings (comparing computed tomography to ultrasound). Their ultrasound model was created from 312 patients and had an AUC of 0.82 for correctly predicting CA [28]. The most obvious reference standard for our study would be the Atema score from 2015, unfortunately not all the predictors presented in their study were available in our dataset (or clinical database) [28]. In our literature research, it was the most widely accepted risk score that did not make use of sectional imaging. Similar to the Atema score for ultrasound-driven decision-making, we explored our data and developed a model from 696 patients operated before 2019 that we then validated with the 436 patients that were treated from 2019 onwards. Their final model included age ≥ 45 years, white cell count > 13,000/ml, CRP in mg/dl ≤ 5, 5.1–10 or >10, duration of symptoms ≥ 2 days and free fluid on ultrasound in their model. Additionally, that model contained core body temperature in °C ≤ 37.0, 37.1 – 37.9 or ≥ 38.0 and ultrasound finding of an appendicolith. The same group performed a retrospective follow-up study to evaluate their model’s negative predictive value to rule out CA to serve as a selection tool for studies. That model correctly identified 93.8% of the patients that presented with UA [29]. Our model included different cut-offs for age and white cell counts, as well as gender and ASA score but not body temperature and appendicolith and is therefore likely easier to reproduce and less likely biased from errors in temperature measurement or ultrasound interobserver disparities. Our model had an AUROC of 0.861 in the score development sample and performed well in the validation cohort with an AUROC of 0.823. The model was then modified into the NoCtApp risk score that can be easily adapted to the clinical setting in the for selecting patients to consider for sectional imaging or prioritize in the operating room schedule.
Several individual laboratory parameters have been discussed as independent predictors of CA. The most commonly accepted one is elevated C-reactive protein (Xu et al. > 3.8 mg/dl, Moon et al. > 7.05 mg/dl, Akai et al. > 0.5 mg/dl OR 10.15), which was reported to have an AUC of 0.796 – 0.853 to detect CA [21, 30,31,32]. This matched our results in that we found CRP to be the strongest individual predictor of CA. Therefore, we decided to define CRP as the reference standard for our model. CRP alone was able to correctly predict 78.3% of the cases correctly and had with an AUC of 0.804 similar discriminatory power as described in the aforementioned studies.
Other parameters are discussed more controversially, such as bilirubin. While some found hyperbilirubinemia to be predictive of appendicitis or more specifically perforation, others were less keen about the predictive benefits [33,34,35,36]. While we did find hyperbilirubinemia to be more common among patients with CA in univariate analysis, it did not add predictive accuracy to the multivariate model and was not retained. Less widely accepted parameters include hyponatremia [37] and hyperfibrinogenemia [38, 39], which we did not routinely study and therefore could not include in our model.
When in doubt surgical exploration or a CT scan can and should be discussed with the patient for patient- “assisted” decision-making process. Our general practice is to avoid CT scans in patients under 40 years and to rather take them to OR for laparoscopy since they are at an increased risk of developing radiation-induced malignancy in the future [9]. Our risk score aids in identifying CA correctly and prioritize these patients on the theater schedule.
Strength and limitations
With all diagnostic regression modelling studies, there are limitations to be discussed. All data included in this study were collected at the same institution. We used a convenient dataset for our analysis for which we did not perform case sample size calculation or did prospective data collection. While this is a sizeable cohort with 696 patients for the model development and 436 patients to validate the model in, not being able to control which parameters to collect made comparison to a reference standard nearly impossible. This is further complicated by the fact that no gold standard has been defined/accepted for the diagnosis of CA. This poses a methodical challenge to the researcher, given that there is no obvious reference standard to compare one’s model to. Just by the nature of our clinical care we were unable to use CT results or Atema score as the reference. Given the retrospective analysis, the diagnosis of CA was made based on information taken from the operation reports. There was a risk for bias given that there were no routine intraoperative images available for secondary assessment by the study team. Lastly, this model was created with a dataset of proven cases of acute appendicitis. A universal clinical application of such a model is limited by the complex differential diagnoses to appendicitis which need to be considered.
Conclusion
Predicting acute complicated appendicitis without sectional imaging with the aid of our regression model appears to be possible. Its’ predictive value was higher than that of CRP and similar to the Atema score but potentially easier to reproduce. While the NoCtApp score predicts complicated appendicitis fairly well, the model should be tested in a prospective cohort potentially with external validation before clinical implementation.
Availability of data and material
Anonymized data can be provided on further request.
Code availability
Not applicable.
References
Ferris M, Quan S, Kaplan BS et al (2017) The global incidence of appendicitis: a systematic review of population-based studies. Ann Surg 266:237–241. https://doi.org/10.1097/sla.0000000000002188
Fugazzola P, Ceresoli M, Agnoletti V et al (2020) The SIFIPAC/WSES/SICG/SIMEU guidelines for diagnosis and treatment of acute appendicitis in the elderly (2019 edition). World J Emerg Surg 15:19. https://doi.org/10.1186/s13017-020-00298-0
Alvarado A (1986) A practical score for the early diagnosis of acute appendicitis. Ann Emerg Med 15:557–564. https://doi.org/10.1016/s0196-0644(86)80993-3
Andersson M, Kolodziej B, Andersson RE (2021) Validation of the appendicitis inflammatory response (AIR) score. World J Surg 45:2081–2091. https://doi.org/10.1007/s00268-021-06042-2
Salminen P, Paajanen H, Rautio T et al (2015) Antibiotic therapy vs appendectomy for treatment of uncomplicated acute appendicitis: the APPAC randomized clinical trial. JAMA 313:2340–2348. https://doi.org/10.1001/jama.2015.6154
Sippola S, Haijanen J, Grönroos J et al (2021) Effect of oral moxifloxacin vs intravenous ertapenem plus oral levofloxacin for treatment of uncomplicated acute appendicitis: the APPAC II randomized clinical trial. JAMA 325:353–362. https://doi.org/10.1001/jama.2020.23525
Hansson J, Körner U, Khorram-Manesh A et al (2009) Randomized clinical trial of antibiotic therapy versus appendicectomy as primary treatment of acute appendicitis in unselected patients. Br J Surg 96:473–481. https://doi.org/10.1002/bjs.6482
Flum DR, Davidson GH, Monsell SE et al (2020) A randomized trial comparing antibiotics with appendectomy for appendicitis. N Engl J Med 383:1907–1919. https://doi.org/10.1056/NEJMoa2014320
Lee KH, Lee S, Park JH et al (2021) Risk of hematologic malignant neoplasms from abdominopelvic computed tomographic radiation in patients who underwent appendectomy. JAMA Surg 156:343–351. https://doi.org/10.1001/jamasurg.2020.6357
Yeh DD, Eid AI, Young KA et al (2021) Multicenter Study of the Treatment of Appendicitis in America: Acute, Perforated, and Gangrenous (MUSTANG), an EAST multicenter study. Ann Surg 273:548–556. https://doi.org/10.1097/sla.0000000000003661
Garcia EM, Camacho MA, Karolyi DR et al (2018) ACR Appropriateness Criteria® right lower quadrant pain-suspected appendicitis. J Am Coll Radiol 15:S373-s387. https://doi.org/10.1016/j.jacr.2018.09.033
Teoule P, Laffolie J, Rolle U et al (2020) Acute appendicitis in childhood and adulthood. Dtsch Arztebl Int 117:764–774. https://doi.org/10.3238/arztebl.2020.0764
van Rossem CC, Bolmers MD, Schreinemacher MH et al (2016) Diagnosing acute appendicitis: surgery or imaging? Colorectal Dis 18:1129–1132. https://doi.org/10.1111/codi.13470
Bolmers MDM, Bom WJ, Scheijmans JCG et al (2022) Accuracy of imaging in discriminating complicated from uncomplicated appendicitis in daily clinical practice. Int J Colorectal Dis 37:1385–1391. https://doi.org/10.1007/s00384-022-04173-z
Bom WJ, Scheijmans JCG, Salminen P et al (2021) Diagnosis of uncomplicated and complicated appendicitis in adults. Scand J Surg 110:170–179. https://doi.org/10.1177/14574969211008330
Bujang MA, Sa’at N, Sidik T et al (2018) Sample size guidelines for logistic regression from observational studies with large population: emphasis on the accuracy between statistics and parameters based on real life clinical data. Malays J Med 25:122–130. https://doi.org/10.21315/mjms2018.25.4.12
Bossuyt PM, Reitsma JB, Bruns DE et al (2015) STARD 2015: an updated list of essential items for reporting diagnostic accuracy studies. BMJ 351:h5527. https://doi.org/10.1136/bmj.h5527
Harrell FE Jr, Lee KL, Mark DB (1996) Multivariable prognostic models: issues in developing models, evaluating assumptions and adequacy, and measuring and reducing errors. Stat Med 15:361–387. https://doi.org/10.1002/(SICI)1097-0258(19960229)15:4%3C361::AID-SIM168%3E3.0.CO;2-4
Avanesov M, Wiese NJ, Karul M et al (2018) Diagnostic prediction of complicated appendicitis by combined clinical and radiological appendicitis severity index (APSI). Eur Radiol 28:3601–3610. https://doi.org/10.1007/s00330-018-5339-9
Imaoka Y, Itamoto T, Takakura Y et al (2016) Validity of predictive factors of acute complicated appendicitis. World J Emerg Surg 11:48. https://doi.org/10.1186/s13017-016-0107-0
Xu T, Zhang Q, Zhao H et al (2021) A risk score system for predicting complicated appendicitis and aid decision-making for antibiotic therapy in acute appendicitis. Ann Palliat Med 10:6133–6144
Kim TH, Cho BS, Jung JH et al (2015) Predictive factors to distinguish between patients with noncomplicated appendicitis and those with complicated appendicitis. Ann Coloproctol 31:192–197. https://doi.org/10.3393/ac.2015.31.5.192
Gorter RR, Eker HH, Gorter-Stam MA et al (2016) Diagnosis and management of acute appendicitis. EAES consensus development conference 2015. Surg Endosc 30:4668–4690. https://doi.org/10.1007/s00464-016-5245-7
Lastunen K, Leppäniemi A, Mentula P (2021) Perforation rate after a diagnosis of uncomplicated appendicitis on CT. BJS Open 5. https://doi.org/10.1093/bjsopen/zraa034
Javanmard-Emamghissi H, Hollyman M, Boyd-Carson H et al (2021) Antibiotics as first-line alternative to appendicectomy in adult appendicitis: 90-day follow-up from a prospective, multicentre cohort study. Br J Surg 108:1351–1359. https://doi.org/10.1093/bjs/znab287
Gardner CS, Jaffe TA, Nelson RC (2015) Impact of CT in elderly patients presenting to the emergency department with acute abdominal pain. Abdom Imaging 40:2877–2882. https://doi.org/10.1007/s00261-015-0419-7
Hustey FM, Meldon SW, Banet GA et al (2005) The use of abdominal computed tomography in older ED patients with acute abdominal pain. Am J Emerg Med 23:259–265. https://doi.org/10.1016/j.ajem.2005.02.021
Atema JJ, van Rossem CC, Leeuwenburgh MM et al (2015) Scoring system to distinguish uncomplicated from complicated acute appendicitis. Br J Surg 102:979–990. https://doi.org/10.1002/bjs.9835
Geerdink TH, Augustinus S, Atema JJ et al (2021) Validation of a scoring system to distinguish uncomplicated from complicated appendicitis. J Surg Res 258:231–238. https://doi.org/10.1016/j.jss.2020.08.050
Kim M, Kim SJ, Cho HJ (2016) International normalized ratio and serum C-reactive protein are feasible markers to predict complicated appendicitis. World J Emerg Surg 11:31. https://doi.org/10.1186/s13017-016-0081-6
Sasaki Y, Komatsu F, Kashima N et al (2020) Clinical prediction of complicated appendicitis: A case-control study utilizing logistic regression. World J Clin Cases 8:2127–2136. https://doi.org/10.12998/wjcc.v8.i11.2127
Moon HM, Park BS, Moon DJ (2011) Diagnostic value of C-reactive protein in complicated appendicitis. J Korean Soc Coloproctol 27:122–126. https://doi.org/10.3393/jksc.2011.27.3.122
Akai M, Iwakawa K, Yasui Y et al (2019) Hyperbilirubinemia as a predictor of severity of acute appendicitis. J Int Med Res 47:3663–3669. https://doi.org/10.1177/0300060519856155
Burcharth J, Pommergaard HC, Rosenberg J et al (2013) Hyperbilirubinemia as a predictor for appendiceal perforation: a systematic review. Scand J Surg 102:55–60. https://doi.org/10.1177/1457496913482248
Adams HL, Jaunoo SS (2016) Hyperbilirubinaemia in appendicitis: the diagnostic value for prediction of appendicitis and appendiceal perforation. Eur J Trauma Emerg Surg 42:249–252. https://doi.org/10.1007/s00068-015-0540-x
Muller S, Falch C, Axt S et al (2015) Diagnostic accuracy of hyperbilirubinaemia in anticipating appendicitis and its severity. Emerg Med J 32:698–702. https://doi.org/10.1136/emermed-2013-203349
Giannis D, Matenoglou E, Moris D (2020) Hyponatremia as a marker of complicated appendicitis: a systematic review. Surgeon 18:295–304. https://doi.org/10.1016/j.surge.2020.01.002
Zhao L, Feng S, Huang S et al (2017) Diagnostic value of hyperfibrinogenemia as a predictive factor for appendiceal perforation in acute appendicitis. ANZ J Surg 87:372–375. https://doi.org/10.1111/ans.13316
Alvarez-Alvarez FA, Maciel-Gutierrez VM, Rocha-Muñoz AD et al (2016) Diagnostic value of serum fibrinogen as a predictive factor for complicated appendicitis (perforated). A cross-sectional study. Int J Surg 25:109–113. https://doi.org/10.1016/j.ijsu.2015.11.046
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
Jens Strohäker: study conception and design, analysis of data and interpretation, drafting of manuscript. Martin Brüschke: acquisition of data, critical revision of manuscript. You-Shan Feng: analysis of data and interpretation, critical revision of manuscript. Christian Beltzer: analysis of data and interpretation, critical revision of manuscript. Alfred Königsrainer: critical revision of manuscript. Ruth Ladurner: critical revision of manuscript, supervision.
Corresponding author
Ethics declarations
Ethics approval
All research was performed to ethical standards of the declaration of Helsinki and all amendments. The study was approved by the ethics committee of the Tuebingen University Hospital under the reference number 771/2019BO2, approved: 22 October 2019. Due to the retrospective character of this study individual written consent was waved by the local ethics committee.
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Strohäker, J., Brüschke, M., Feng, YS. et al. Predicting complicated appendicitis is possible without the use of sectional imaging—presenting the NoCtApp score. Int J Colorectal Dis 38, 218 (2023). https://doi.org/10.1007/s00384-023-04501-x
Accepted:
Published:
DOI: https://doi.org/10.1007/s00384-023-04501-x