
Abstract
In this paper, we consider the problem of how to alleviate the conditional independence assumption of naive Bayes. We try to find an equivalent set of variables for the attributes of the class such that these variables are nearly conditionally independent. For the case that all attributes are continuous variables, we put forward the theory of class-weighting supervised principal component analysis (CWSPCA) to improve naive Bayes. For the categorical case, we construct the equivalent variables by rearranging the values of the attributes, and propose the decremental association rearrangement (DAR) algorithm and its multiple version (MDAR). Finally, we make a benchmarking study to show the performance of our methods. The experimental results reveal that naive Bayes can be greatly improved by means of properly transforming the original attributes.








Similar content being viewed by others
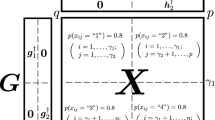


Notes
Combined with Table 2 and the computational complexity of the exhaustive algorithm, one running needs about
$$\begin{aligned} \frac{(4\times 5-1)!}{3\times 3-1}\times {2.50541}\div (3600\times 24 \times 365)\approx 2.3969\times 10^5 \end{aligned}$$years on average! This is why we should use heuristic algorithms to search the optimal rearrangement.
Abbreviations
- ANOVA :
-
Analysis of variance
- ARNB:
-
Naive Bayes by attribute-recombining
- BN:
-
Bayesian network
- CAWNB :
-
Class-specific attribute weighted NB
- CIA:
-
Conditional independence assumption
- DAG:
-
Directed acyclic graph
- DAR :
-
Decremental association rearrangement
- DFS :
-
Depth-first search
- MCC:
-
Matthews correlation coefficients
- MDAR :
-
Multiple decremental association rearrangement
- NB:
-
Naive Bayes
- CWSPCA :
-
Class-weighting supervised PCA
- PCA:
-
Principal component analysis
- RT:
-
Running time
- UCI:
-
University of California at Irvinerepository
References
Bair E, Hastie T, Paul D, Tibshirani R (2006) Prediction by supervised principal components. J Am Stat Assoc 101:119–137
Barshan E, Ghodsi A, Azimifar Z, Jahromi MZ (2011) Supervised principal component analysis: visualization, classification and regression on subspaces and submanifolds. Pattern Recognit 44:1357–1371
Bromberg F, Margaritis D (2009) Improving the reliability of causal discovery from small data sets using argumentation. J Mach Learn Res 10:301–340
Chao GQ, Luo Y, Ding WP (2019) Recent advances in supervised dimension reduction: a survey. Mach Learn Knowl Extr 1:341–358
Chicco D, Jurman G (2020) The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genomics 21:6
Comon P (1994) Independent component analysis: a new concept? Signal Process 36(3):287–314
Cover TM, Thomas JA (2006) Elements of information theory, 2nd edn. Wiley, Hoboken
De Campos L (2006) A scoring function for learning Bayesian networks based on mutual information and conditional independence tests. J Mach Learn Res 7:2149–2187
Gorodkin J (2004) Comparing two K-category assignments by a K-category correlation coefficient. Comput Biol Chem 28(5):367–374
Hall M (2007) A decision tree-based attribute weighting filter for naive Bayes. Knowl Based Syst 20(2):120–126
Hotelling H (1936) Relations between two sets of variates. Biometrika 28(3–4):321–377
Ji Y, Yu S, Zhang Y (2011) A novel naive Bayes model: packaged hidden naive Bayes. In: 6th IEEE joint international information technology and artificial intelligence conference, China, Chongqing, pp 484–487
Jiang L, Zhang H, Cai Z (2009) A novel Bayes model: hidden naive Bayes. IEEE Trans Knowl Data Eng 21(10):1361–1371
Jiang L, Zhang L, Yu L, Wang D (2019) Class-specific attribute weighted naive Bayes. Pattern Recognit 88:321–330
Kononenko I (1991) semi-naive Bayesian classifier. In: Proceedings of the 6th European working session on learning, Porto, Portugal, pp 206–219
Kumar N, Khatri S (2017) Implementing WEKA for medical data classification and early disease prediction. In: 3rd international conference on computational intelligence & communication technology, Ghaziabad, pp 1–6
Lemeire J (2007) Learning causal models of multivariate systems and the value of it for the performance modeling of computer programs. PhD thesis, ASP/VUBPRESS/UPA
Li QY, Tian P (2019) The application of naive Bayes algorithm based on principal component analysis in spam user identification. Math Pract Theor 49(1):134–138
Li HJ, Wang ZX, Wang LM, Yuan SM (2004) Improving performance of naive Bayes by principal component analysis. Chin J Sci Instrum 25(S2):384–386
Liu XQ, Liu XS (2016) Swamping and masking in Markov boundary discovery. Mach Learn 104:25–54
Liu XQ, Liu XS (2018) Markov blanket and Markov boundary of multiple variables. J Mach Learn Res 19:1–50
Lu M, Lee HS, Hadley D, Huang JZ, Qian X (2014) Supervised categorical principal component analysis for genome-wide association analyses. BMC Genomics 15:1–10
Matthews B (1975) Comparison of the predicted and observed secondary structure of T4 phage lysozyme. Biochim Biophys Acta (BBA) Protein Struct 405(2):442–451
Mihaljevic B, Larrañaga P, Bielza C (2013) Augmented semi-naive Bayes classifier. In: Bielza C et al (eds) Advances in Artificial Intelligence. CAEPIA 2013, vol 8109. Lecture notes in computer science. Springer, Berlin
Neapolitan RE (2004) Learning Bayesian networks. Prentice Hall, Upper Saddle River
Pazzani MJ (1996) Constructive induction of Cartesian product attributes. In: Proceedings of the information, statistics and induction in science conference, pp 66–77
Pearl J (1988) Probabilistic reasoning in intelligent systems: networks of plausible inference. Morgan Kaufmann, San Francisco
Pearson K (1901) On lines and planes of closest fit to systems of points in space. Philos Magn 2(11):559–572
Rammal A, Perrin E, Vrabie V, Assaf R, Fenniri H (2017) Selection of discriminant mid-infrared wavenumbers by combining a naive Bayesian classifier and a genetic algorithm: Application to the evaluation of lignocellulosic biomass biodegradation. Math Biosci 289:153–161
Rao CR, Toutenburg H (1995) Linear models: least squares and alternatives. Springer, NewYork
Ruan C, Feng T, Guo KX, Lu YL, Yu M (2018) WiFi indoor localization algorithm based on PCA-WBayes. Transdomain Microsyst Technol 37(8):124–126
Santiago-Mozos R, Leiva-Murillo J, Pérez-Cruz F, Artés-Rodríguez A (2003) Supervised-PCA and SVM classifiers for object detection in infrared images. In: Proceedings of the IEEE conference on advanced video and signal based surveillance, pp 122–127
Statnikov A, Lytkin NI, Lemeire J, Aliferis CF (2013) Algorithms for discovery of multiple Markov boundaries. J Mach Learn Res 14(1):499–566
Stephens CR, Huerta HF, Linares AR (2018) When is the naive Bayes approximation not so naive? Mach Learn 107:397–441
Tang B, He H, Baggenstoss PM, Kay S (2016) A Bayesian classification approach using class-specific features for text categorization. IEEE Trans Knowl Data Eng 28(6):1602–1606
Varando G, Bielza C, Larrañaga P (2015) Decision boundary for discrete Bayesian network classifiers. J Mach Learn Res 16:2725–2749
Verma P, Sood SK, Kaur H (2020) A Fog-Cloud based cyber physical system for Ulcerative Colitis diagnosis and stage classification and management. Microprocess Microsyst 72:102929
Wang S (1987) Theory of linear models and its applications. Anhui Education Press, China
Warner HR, Toronto AF, Veasey LG, Stephenson R (1961) A mathematical approach to medical diagnosis: application to congenital heart disease. J Am Med Assoc 177:177–183
Youn E, Jeong MK (2009) Class dependent feature scaling method using naive Bayes classifier for text datamining. Pattern Recognit Lett 30(5):477–485
Yu J, Ping P, Wang L, Kuang L, Li X, Wu Z (2018) A novel probability model for LncRNAC disease association prediction based on the naive Bayesian classifier. Genes 9(7):345
Yu L, Jiang L, Wang D, Zhang L (2019) Toward naive Bayes with attribute value weighting. Neural Comput Appl 31:5699–5713
Zaidi NA, Cerquides J, Carman MJ, Webb GI (2013) Alleviating naive Bayes attribute independence assumption by attribute weighting. J Mach Learn Res 14:1947–1988
Zhang L, Guo H (2006) Introduction to Bayesian networks. Science Press, Beijing
Zhang H, Jiang L, Yu L (2020) Class-specific attribute value weighting for Naive Bayes. Inform Sci 508:260–274
Zheng F, Webb GI (2017) Semi-naive Bayesian Learning. In: Sammut C, Webb GI (eds) Encyclopedia of machine learning and data mining. Springer, Boston
Acknowledgements
Thanks to the following scholars for their valuable comments and constructive suggestions in preparing the draft of this paper: Yu-Ting Liu, Yu Huang, Hai-Wen Chen, Wen-Wen Liu, Jun-Liang Li, Xiao-Hu Luo, Li-Li Xiao, Cheng-Yao Ji.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was supported by NSF of China (51535005, 51675212), the Fundamental Research Funds for the Central Universities (NP2017101, NC2018001), and the Challenge Cup Innovation Project of HYIT.
Appendices
Appendix A: Proofs
1.1 A.1 Proof of Result 1
Result 3
\(\varvec{\alpha }_2^*\triangleq \varvec{\alpha }_{\max }(\varvec{Q}_{\varvec{A}_1}\varvec{\varSigma }\varvec{Q}_{\varvec{A}_1})\) solves the following problem:
with \(\lambda _2^*\triangleq \lambda _{\max }(\varvec{Q}_{\varvec{A}_1}\varvec{\varSigma }\varvec{Q}_{\varvec{A}_1})\) as the maximum.
Proof
By the restrictions of (2.6), \(\varvec{A}_1^T\varvec{\alpha }_2={\varvec{0}}_{r\times 1}\). Then, the vector \(\varvec{\alpha }_2\) can be expressed as \(\varvec{\alpha }_2 = \varvec{Q}_{\varvec{A}_1}\varvec{\alpha }\) for any \(\varvec{\alpha }\in {\mathbb {R}}^k\). Consequently, the problem (2.6) reduces to
due to the fact that \(\varvec{Q}_{\varvec{A}_1}\) is symmetric and idempotent. Writing the Lagrange multiplier function as
it follows that
Denote \(\varvec{\alpha }^*\triangleq \varvec{\alpha }_{\max }(\varvec{Q}_{\varvec{A}_1}\varvec{\varSigma }\varvec{Q}_{\varvec{A}_1})\). This means \(\varvec{\alpha }_2^*=\varvec{Q}_{\varvec{A}_1}\varvec{\alpha }^*=\varvec{\alpha }^*\) solves (2.6), with
since \(\varvec{Q}_{\varvec{A}_1}\varvec{\varSigma }\varvec{Q}_{\varvec{A}_1} \varvec{\alpha }^* = \lambda _2^*\varvec{\alpha }^* \) implies \(\varvec{\alpha }^*\in {\mathscr {C}}(\varvec{Q}_{\varvec{A}_1})\) and thus \(\varvec{Q}_{\varvec{A}_1}\varvec{\alpha }^*=\varvec{\alpha }^*\). The proof is completed. \(\square \)
1.2 A.2 Proof of Result 2
Result 4
\(\varvec{\alpha }_{(2)}\) solves (2.8), getting \(\lambda _{(2)}\) as the maximum of the objective function.
Proof
Noting \(\big (\varvec{\alpha }_{(1)}^T\varvec{\varSigma }_{\ell }\varvec{\alpha }_2\big )^2=\varvec{\alpha }_2^T\big (\varvec{\varSigma }_{\ell }\varvec{\alpha }_{(1)}\varvec{\alpha }_{(1)}^T\varvec{\varSigma }_{\ell }\big )\varvec{\alpha }_2\) is actually a quadratic form of \(\varvec{\alpha }_2\), the conclusion holds clearly. The proof is completed. \(\square \)
1.3 A.3 Proof of Theorem 2
Theorem 2
(Correctness of MDAR) Let the rearranged variables outputted by MDAR be \(Y_1,\ldots ,Y_k\). Assume the joint probability distribution of \(Y_1,\ldots ,Y_k,C\) are strictly positive. If  holds for any i and j (\(i\ne j\)), then \(\textrm{P}(C = c \mid Y_1 = y_1, \ldots , Y_k = y_k) \propto \textrm{P}(C = c)\textstyle \prod \nolimits _{i=1}^k \textrm{P}(Y_i = y_i \mid C = c)\).
holds for any i and j (\(i\ne j\)), then \(\textrm{P}(C = c \mid Y_1 = y_1, \ldots , Y_k = y_k) \propto \textrm{P}(C = c)\textstyle \prod \nolimits _{i=1}^k \textrm{P}(Y_i = y_i \mid C = c)\).
Proof
It suffices to show  holds for \(i = 2,\ldots ,k\), in view of
holds for \(i = 2,\ldots ,k\), in view of
In fact, by the positive-distribution condition, the composition (or local composition) property (Pearl 1988; Statnikov et al. 2013; Liu and Liu 2018) holds for \(Y_1,\ldots ,Y_k\) given C. This combined with  and
and  implies
implies  . By the principle of mathematical induction, it can be easily shown that
. By the principle of mathematical induction, it can be easily shown that  holds for \(i = 3,\ldots ,k\). The proof is completed. \(\square \)
holds for \(i = 3,\ldots ,k\). The proof is completed. \(\square \)
1.4 A.4 Several Theoretical Derivations for Sect. 2.1.3
This appendix gives some necessary theoretical derivations for Sect. 2.1.3. All notations are defined in Sect. 2.1.3. The derivations are itemized as follows:
-
For (2.9):
$$\begin{aligned} f(\varvec{\alpha }_2)\triangleq & {} \varvec{\alpha }_2^T\varvec{\varSigma }\varvec{\alpha }_2-\textstyle \sum \limits _{\ell =1}^rp_{\ell }\,\! \tfrac{\big (\varvec{\alpha }_{(1)}^T\varvec{\varSigma }_{\ell }\varvec{\alpha }_2\big )^2}{\varvec{\alpha }_{(1)}^T\varvec{\varSigma }_{\ell }\varvec{\alpha }_{(1)}} ~\geqslant ~ \varvec{\alpha }_2^T\varvec{\varSigma }\varvec{\alpha }_2-\textstyle \sum \limits _{\ell =1}^rp_{\ell }\,\! \tfrac{\big (\varvec{\alpha }_{(1)}^T\varvec{\varSigma }_{\ell }\varvec{\alpha }_{(1)}\big )\! \big (\varvec{\alpha }_2^T\varvec{\varSigma }_{\ell }\varvec{\alpha }_2\big )}{\varvec{\alpha }_{(1)}^T\varvec{\varSigma }_{\ell }\varvec{\alpha }_{(1)}}\\= & {} \varvec{\alpha }_2^T\varvec{\varSigma }\varvec{\alpha }_2-\textstyle \sum \limits _{\ell =1}^rp_{\ell }\,\!\varvec{\alpha }_2^T\varvec{\varSigma }_{\ell }\varvec{\alpha }_2 ~=~\varvec{\alpha }_2^T\!\left( \varvec{\varSigma }-\textstyle \sum \limits _{\ell =1}^rp_{\ell }\,\!\varvec{\varSigma }_{\ell }\right) \varvec{\alpha }_2~=~0. \end{aligned}$$ -
For (2.10):
$$\begin{aligned} f(\varvec{\alpha }_2)= & {} \varvec{\alpha }_2^T\varvec{\varSigma }\varvec{\alpha }_2-\textstyle \sum \limits _{\ell =1}^rp_{\ell }\,\! \tfrac{\big (\varvec{\alpha }_2^T\varvec{\varSigma }_{\ell }\varvec{\alpha }_{(1)}\big )\! \big (\varvec{\alpha }_{(1)}^T\varvec{\varSigma }_{\ell }\varvec{\alpha }_2\big )}{\varvec{\alpha }_{(1)}^T\varvec{\varSigma }_{\ell }\varvec{\alpha }_{(1)}}\\= & {} \varvec{\alpha }_2^T\!\left( \varvec{\varSigma }-\textstyle \sum \limits _{\ell =1}^rp_{\ell }\,\! \tfrac{\varvec{\varSigma }_{\ell }\varvec{\alpha }_{(1)}\varvec{\alpha }_{(1)}^T\varvec{\varSigma }_{\ell }}{\varvec{\alpha }_{(1)}^T\varvec{\varSigma }_{\ell }\varvec{\alpha }_{(1)}}\right) \varvec{\alpha }_2\\= & {} \varvec{\alpha }_2^T\!\left( \textstyle \sum \limits _{\ell =1}^rp_{\ell }\,\!\varvec{\varSigma }_\ell -\textstyle \sum \limits _{\ell =1}^rp_{\ell }\,\! \tfrac{\varvec{\varSigma }_{\ell }\varvec{\alpha }_{(1)}\varvec{\alpha }_{(1)}^T\varvec{\varSigma }_{\ell }}{\varvec{\alpha }_{(1)}^T\varvec{\varSigma }_{\ell }\varvec{\alpha }_{(1)}}\right) \varvec{\alpha }_2\\= & {} \varvec{\alpha }_2^T\!\left[ \textstyle \sum \limits _{\ell =1}^rp_{\ell }\,\!\!\left( \varvec{\varSigma }_\ell - \tfrac{\varvec{\varSigma }_{\ell }\varvec{\alpha }_{(1)}\varvec{\alpha }_{(1)}^T\varvec{\varSigma }_{\ell }}{\varvec{\alpha }_{(1)}^T\varvec{\varSigma }_{\ell }\varvec{\alpha }_{(1)}}\right) \right] \varvec{\alpha }_2\\= & {} \varvec{\alpha }_2^T\!\left[ \textstyle \sum \limits _{\ell =1}^rp_{\ell }\,\!\varvec{\varSigma }_{\ell }^{\frac{1}{2}}\!\left( \varvec{I}_k- \varvec{P}_{\varvec{\varSigma }_{\ell }^{\frac{1}{2}}\varvec{\alpha }_{(1)}}\right) \varvec{\varSigma }_{\ell }^{\frac{1}{2}}\right] \varvec{\alpha }_2\\= & {} \varvec{\alpha }_2^T\!\left( \textstyle \sum \limits _{\ell =1}^rp_{\ell }\,\!\varvec{\varSigma }_{\ell }^{\frac{1}{2}} \varvec{Q}_{\varvec{\varSigma }_{\ell }^{\frac{1}{2}}\varvec{\alpha }_{(1)}}\varvec{\varSigma }_{\ell }^{\frac{1}{2}}\right) \varvec{\alpha }_2, \end{aligned}$$ -
For (2.13):
$$\begin{aligned}~~~ \varvec{\alpha }_j^T\varvec{\varSigma }_{(j)}\varvec{\alpha }_j= & {} \bigg (\textstyle \sum \limits _{a=1}^{k}b_a\varvec{q}_a\Bigg )^T\!\varvec{\varSigma }_{(j)}\bigg (\textstyle \sum \limits _{a=1}^{k}b_a\varvec{q}_a\bigg )\\= & {} \bigg (\textstyle \sum \limits _{a=j}^{k}b_a\varvec{q}_a\Bigg )^T\!\varvec{\varSigma }_{(j)}\bigg (\textstyle \sum \limits _{a=j}^{k}b_a\varvec{q}_a\bigg )\\\leqslant & {} \bigg (\textstyle \sum \limits _{a=j}^{k}b_a\varvec{q}_a\Bigg )^T\!\varvec{\varSigma }\bigg (\textstyle \sum \limits _{a=j}^{k}b_a\varvec{q}_a\bigg )\\= & {} \bigg (\textstyle \sum \limits _{a=j}^{k}b_a\varvec{q}_a\Bigg )^T\! \bigg (\textstyle \sum \limits _{a=1}^{k}\nu _a\varvec{q}_a\varvec{q}_a^T\bigg ) \bigg (\textstyle \sum \limits _{a=j}^{k}b_a\varvec{q}_a\bigg )\\= & {} \textstyle \sum \limits _{a=j}^{k}\nu _ab_a^2\leqslant \nu _j\textstyle \sum \limits _{a=j}^{k}b_a^2\leqslant \nu _j\textstyle \sum \limits _{a=1}^{k}b_a^2 ~=~\nu _j, \end{aligned}$$in view of \(\varvec{\alpha }_j^T\varvec{\alpha }_j=\textstyle \sum \nolimits _{a=1}^{k}b_a^2=1\), with equalities holding if and only if \(\varvec{\alpha }_j=\varvec{q}_j\).
Appendix B: A Note on the Hybrid Case
Consider now a three-attribute model, containing the class C taking the values \(\{1,\ldots ,r\}\), two normally distributed continuous attribute \(X_1\) and \(X_2\), and a categorical attribute \(Y_1\) taking \(\{1,\ldots ,r_1\}\).
1.1 B.1 Independence between \(X_i\) and \(Y_1\)
Clearly, the dependence between the continuous attribute \(X_i\) (\(i=1\) or 2) and the categorical attribute \(Y_1\) can be tested statistically by virtue of the one-way analysis of variance (analysis of variance (ANOVA) in what follows. For any \(j\in \{1,\ldots ,r_1\}\), pick out the observations of \(X_i\) with \(Y_1\) taking j, denoted as \(x_{ij1},\ldots ,x_{ijn_j}\). Put the within-group average and the total average as
respectively, in which \(n=\sum _{j=1}^{r_1}n_j\). Further, write the sum of total squares, the sum of within-group squares, and the sum of between-group squares as
Then, \(\mathrm {SS_T}\) can be decomposed as the sum of \(\mathrm {SS_W}\) and \(\mathrm {SS_B}\). For convenience, hereinafter we assume the normality and variance homogeneity always hold in any case. Otherwise, testing  will be very complex. Under this assumption, we have the one-way ANOVA table shown in Table 8.
will be very complex. Under this assumption, we have the one-way ANOVA table shown in Table 8.

1.2 B.2 Independence between \(X_i\) and \(Y_1\) Conditioned on \(C=\ell \)
To check if \(X_i\) and \(Y_1\) are independent given \(C=\ell \in \{1,\ldots ,r\}\), we only use the observations associated with \(C=\ell \) to perform the corresponding ANOVA. An “\((\ell )\)” will be added to the superscript if necessary. Specifically, pick out the observations of \(X_i\) associated with \(Y_1=j\) and \(C=\ell \), denoted as \(x_{ij1}^{(\ell )},\ldots ,x_{ijn_j^{(\ell )}}^{(\ell )}\). Put the within-group average and the total average as
respectively, in which \(n^{(\ell )}=\sum _{j=1}^{r_1}n_j^{(\ell )}\). Further, write
Under the assumption that the normality and variance homogeneity hold, the one-way ANOVA table shown in Table 9 can be used to test  .
.

1.3 B.3 Weakening the Dependence between \(X_i\) and \(Y_1\) Conditioned on C
As seen, the p value is descending with respect to (w.r.t.) the value of F (equivalently, descending w.r.t. \(\mathrm {SS_B^{(\ell )}}\big /\mathrm {SS_T^{(\ell )}}\)). Hence, to weaken the dependence between \(X_i\) and \(Y_1\) given C, we need to find an optimal transformation for \(X_i\), in the sense that F or \(\mathrm {SS_B^{(\ell )}}\big /\mathrm {SS_T^{(\ell )}}\) can be as small as possible. Note that a transformation should not depend on the values of C, since we not only train an NB but also use the NB to classify new observations, for which the classes are unknown. Put
where \(\delta _{\{Y_1=j\}}=1\) if \(Y_1=j\) and \(\delta _{\{Y_1=j\}}=0\) otherwise. This coincides with multiplying the observed value of \(X_i\) w.r.t. \(Y_1=j\), namely \(x_{ijk}\), by \(a_{ij}\) for any \(k=1,\ldots ,n_j\). That is, \(z_{ijk}=a_{ij}x_{ijk}\). It can be as an artificial observation of \(Z_i\). Denote these artificial observations associated with \(C=\ell \) by \(z_{ijk}^{(\ell )}\) for \(k=1,\ldots ,n_j^{(\ell )}\) and put the within-group average and the total average as
respectively. Further, write the transformed sum of total squares, the transformed sum of within-group squares, and the transformed sum of between-group squares as
Then, the desirable transformations should be such that the sum (or maximum) of \(\textrm{TSS}_{\mathrm B; \, i}^{(\ell )}\big /\textrm{TSS}_{\mathrm T; \, i}^{(\ell )}\) is minimized for each i. In other words, we should solve the following optimization problem
in which \(\ell \ge 2\). For this problem, we have not obtained an analytical solution, so it can be as an open problem currently.
1.4 B.4 Weakening the Dependence between \((X_1, X_2)\) and \(Y_1\) Conditioned on C
In Appendix B.3, we weaken the dependence between \(X_i\) and \(Y_1\) conditioned on C by the method similar to the univariate ANOVA. To weaken the dependence between total \((X_1, X_2)\) and \(Y_1\) conditioned on C, a naive idea is then to borrow the bivariate ANOVA.
If the model contains continuous attributes \((X_1,\ldots ,X_p)\) and two (or more) categorical attributes \((Y_1, \ldots , Y_q)\), we can first joint \(Y_1, \ldots , Y_q\) as one (categorical variable) and then use the idea similar to the multivariate ANOVA.
Finally, impose CWSPCA on \(Z_i\)’s and MDAR on \(Y_j\)’s to further alleviate CIA.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Liu, XQ., Wang, XC., Tao, L. et al. Alleviating conditional independence assumption of naive Bayes. Stat Papers (2023). https://doi.org/10.1007/s00362-023-01474-5
Received:
Revised:
Published:
DOI: https://doi.org/10.1007/s00362-023-01474-5