
Abstract
We consider a lognormal diffusion process having a multisigmoidal logistic mean, useful to model the evolution of a population which reaches the maximum level of the growth after many stages. Referring to the problem of statistical inference, two procedures to find the maximum likelihood estimates of the unknown parameters are described. One is based on the resolution of the system of the critical points of the likelihood function, and the other is on the maximization of the likelihood function with the simulated annealing algorithm. A simulation study to validate the described strategies for finding the estimates is also presented, with a real application to epidemiological data. Special attention is also devoted to the first-passage-time problem of the considered diffusion process through a fixed boundary.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Growth curves with sigmoidal behavior are widely used in several applied fields including biology (see, for instance, Brauer and Castillo-Chavez (2012)), software reliability (cf. Erto et al. (2020), Inoue and Yamada (2013)) and economics (see, for example, Smirnov and Wang (2020)). During the times different kinds of sigmoidal curves have been introduced such as logistic, Gompertz, Korf, Bertalanffy, etc. Many efforts have been made essentially for two main purposes: (i) unification of classical models (see Chakraborty et al. (2019)), and (ii) generalizations of growth curves (see, for example, Asadi et al. (2020), Di Crescenzo and Spina (2016) and Romero et al. (2016)).
The differential equations which drive the growth of the aforementioned deterministic models are very useful to describe population dynamics. However, in order to make them more realistic, it is necessary to introduce a noise term in the equation. In this way, the differential equations are replaced by stochastic ones. Most of the times, the analysis of the resulting stochastic equation is quite complex, and the transition probability density of the resulting diffusion process cannot be determined (for example, see Campillo et al. (2018), in which the authors propose, for this reason, a new approach to find the maximum likelihood estimates). Models based on diffusion processes are commonly used in various fields of applications, for example plant dynamics (cf. Rupšys et al. (2020), where a hybrid growth is based on Gompertz and Vasicek models), resources consumption (for instance, Nafidi et al. (2019) use the Brennan-Schwartz process to model electricity consumption in Morocco) or particular fish species growth (cf. a stochastic version of the open-ended logistic model considered in Yoshioka et al. (2019)).
In a recent paper, Di Crescenzo et al. (2021) focus on the generalization of the classical logistic growth model introducing more than one inflection point. To this end, firstly, two different birth-death processes, one with linear birth and death rates and the other with quadratic rates, were considered. Then, a diffusive approximation was performed leading to a non-homogeneous lognormal diffusion process with mean of multi-sigmoidal logistic type. Attention was also given to the description of its main features of interest in applied contexts. For instance, the mean of the process is a generalized version of the classical logistic function (see, for instance, Di Crescenzo and Paraggio (2019)) with more than one inflection point. The transition probability density of the process has been obtained explicitly and has been applied to plant dynamics.
Starting from the theoretical results of the previous works, in the present paper we approach the problem of the inference of the stochastic model. This is done by means of the maximum likelihood method, thanks to the availability in closed form of the likelihood function. We also address the treatment of some collateral problems that emerge in the development carried out, such as: (i) obtaining initial solutions to solve the system of likelihood equations, and (ii) bounding the parametric space for addressing the estimation by metaheuristic procedures. All development is supported by simulation examples. Subsequently, in order to provide an example of application to real phenomena, we adopt the proposed model to describe the behavior of the data on the evolution of COVID-19 in different European countries during the two first waves of infection. Indeed, some of the main features of the diffusion process, such as the mean, the mode and the quantiles, may be used for prediction purposes and they are expressed as a function of the parameters of the process.
The problem of parameters estimation has been considered in several papers, for instance in Shimizu and Iwase (1987) and in Tanaka (1987). See also the more recent works of Garcia (2019), in which the author converts the maximization of the likelihood function into an equivalent problem regarding the minimization of a square error, and of Ramos-Ábalos et al. (2020) where maximum likelihood estimates of the parameters of the powers of the homogeneous Gompertz diffusion process are obtained.
Two different strategies to obtain the maximum likelihood estimates of the parameters are introduced. The first is based on the solution of the system of the critical points of the likelihood function, and the other stems from a meta-heuristic optimization method (simulated annealing) to maximize the likelihood function.
This is the outline of the content of the paper. In Sect. 2, the most relevant characteristics of the deterministic and the corresponding stochastic model are recalled. Then, the problem of finding the maximum likelihood estimates of the involved parameters is described in Sect. 3. In several contexts of population dynamics, it may be relevant to know how long the population spends below a certain control threshold. For this reason the first-passage-time (FPT) problem is also addressed. More precisely, in Sect. 4, the R-package fptdApprox (see Román-Román et al. (2020)) is used to determine the approximated FPT density of the lognormal diffusion process through a constant boundary. With the purpose of validating the described procedures for finding the maximum likelihood estimates, a simulation study is presented in Sect. 5. Finally, in Sect. 6 we propose an application of the model to real data concerning the COVID-19 infections in France, Italy, Spain and United Kingdom.
2 The multisigmoidal logistic model and the corresponding diffusion process
Consider the classical logistic equation
with \(r, \eta , C>0\). If the intrinsic growth rate r is replaced by a polynomial P(t), then the solution of this equation, with the initial condition \(l(t_0)=l_0\), is given by
where \(Q(t)-Q(t_0)=\int _{t_0}^tP(\tau )d\tau \). With the hypotesis that \(Q(t)\rightarrow +\infty \) when \(t\rightarrow \infty \), the carrying capacity of this generalized model is given by \(\frac{C}{\eta }\), and thus it is independent from the initial condition \(l_0\). In order to obtain a generalized logistic function in which the carrying capacity is dependent on the initial condition, we consider the following equation (cf. in Di Crescenzo et al. (2021))
with
for \(\eta >0\), \(\theta =(\eta ,\beta ^T)^T\) with \(\beta ^T=(\beta _1,\dots , \beta _p)\in {\mathbb {R}}^p\), where
and \(P_\beta (t)=\displaystyle \frac{d}{dt}Q_\beta (t)\). Under these assumptions, the solution of the ordinary differential equation (1), with initial condition \(l_m(t_0)=l_0\), is the so-called multisigmoidal logistic function given by
We point out that the function \(l_m\) may exhibit more than one inflection point, and its carrying capacity is
where \(C=C(l_0,\eta ,\beta , t_0)=l_0\left( \eta +e^{-Q_\beta (t_0)}\right) \) and \(Q_\beta \) is defined in Eq. (3). It is easy to note that the function (4) is not monotonous in general, since the monotonicity intervals depend on the coefficients \(\beta _1,\dots ,\beta _p\) of the polynomial \(Q_\beta \), and the carrying capacity is the maximum value attainable by the function \(l_m\). See Fig. 1 for some plots of the multisigmoidal logistic function.

The multisigmoidal logistic function for some choices of the parameters: \(t_0=0\), \(l_0=\frac{10}{1+\eta }\), \(\eta =e^{-1}\), \(\beta _1=0.1\), a \(\beta _2=-0.009\) and, from bottom to top, \(\beta _3=0.0002, 0.0003, 0.0004\); b \(\beta _2=-0.007\) and, from bottom to top, \(\beta _3=0.0002, 0.0003, 0.0004\)
The investigation of the inflection points in the case of multisigmoidal growth curves are of great interest. Unfortunately, since the expression of function (4) is quite complex, these points cannot be obtained explicitly, but it is possible to provide an equation in the unknown t solved by the inflection points, that is
In Fig. 2, the multisigmoidal logistic function and the corresponding inflection points are shown for some choices of the parameters.

The multisigmoidal logistic function and the corresponding inflection points for \(t_0=0\), \(l_0=5\), \(\eta =e^{-1}\), \(\beta _1=0.1\), a \(\beta _2=-0.009\) and \(\beta _3=0.0002\); b \(\beta _2=-0.007\) and \(\beta _3=0.0001\)
2.1 The corresponding diffusion process
In Di Crescenzo et al. (2021), a special time-dependent lognormal diffusion process \(\left\{ X(t);t\in I\right\} \) has been considered, with \(I=[t_0,+\infty )\) and infinitesimal moments
where \(h_\theta \) is defined in (2), \(\theta = (\eta ,\beta ^T )^T\) and \(\sigma >0\). The aforementioned process is determined by the following stochastic differential equation, obtained from Eq. (1) by adding a multiplicative noise term,
where \({\mathop {=}\limits ^{d}}\) means equality in distribution, and where W(t) denotes a Wiener process independent from the (possibly random) initial state \(X_0\), for \(t\ge t_0\). We point out that this is not the only way to randomize the growth deterministic equation. Indeed, in the case of random catastrophes, it may be more appropriate to consider as a noise term a Poisson process (see for example Schlomann (2018)). The solution of Eq. (8) is
with
The existence and uniqueness of solution of the linear stochastic differential equation (8) is ensured by virtue of the continuity of function \(h_{\theta }(t)\) (see, for example, Arnold (1974)). Moreover, if either \(X_0\) is degenerated at \(x_0\), in the sense that \({\mathbb {P}}\left[ X(t_0)=x_0\right] =1\), or \(X_0\) follows a lognormal distribution \(\varLambda _1\left( \mu _0,\sigma _0^2\right) \), then the finite dimensional distributions of the process are lognormal. Namely, for any \(n\in {\mathbb {N}}\) and \(t_0\le t_1<\ldots <t_n\), the vector \(\left( X(t_1),\dots , X(t_n)\right) ^T\) follows an n-dimensional lognormal distribution \(\varLambda _n\left( \epsilon , \Sigma \right) \), where the entries of the vector \(\epsilon \) are given by
and the components of the matrix \(\Sigma =(\sigma _{i,j})\) are given by
Further, the conditional distribution of the process follows a lognormal distribution, i.e. for \(s<t\)
From the above mentioned distributions, some characteristics associated to the process can be obtained (cf. Di Crescenzo et al. (2021)). For example, the mean of X(t) conditional on \(X(t_0)=x_0\) is given by
Moreover, if \(X(t_0){\mathop {=}\limits ^{d}}X_0\) then the mean of X(t) is
and the \(\alpha \)-percentiles for \(t\ge t_0\) are
for \(0<\alpha <1\), where \(z_\alpha \) is the \(\alpha \)-percentile of the standard normal random variable. Note that the conditional mean (11) and the mean (12) are multisigmoidal logistic functions of t, in the sense that they solve the multisigmoidal logistic equation (1).
3 Maximum likelihood estimations
The stochastic model introduced in Sect. 2.1 can be employed in several applications, especially for describing real populations that exhibit a growth pattern with more than one inflection point. Clearly, in order to apply this model to real data, the unknown parameters need to be estimated. In Sect. 2.1 we obtained the distribution of the diffusion process X(t) defined in (9). Now we propose to estimate the parameters by means of the classical maximum likelihood method. The adoption of this strategy is particularly suggested by the availability in closed form of the transition distribution of the process X(t). Hence, we follow the same lines introduced in Román-Román et al. (2018) for general lognormal diffusion processes. We consider a discrete sampling of X(t) based on d independent sample paths, with \(n_i\) different observation instants for the i-th sample path, i.e. \(t_{ij}\), \(j=1,\dots , n_i\), for \(i=1,\dots ,d\). For simplicity, assume that the first observation time is identical for any trajectory, i.e. \(t_{i1}=t_0\), \(i=1,\dots ,d\). Moreover, let the vector \({\mathbb {X}}_i=\left( X(t_{i1}),\dots , X(t_{in_i})\right) ^T\) contain the variables of the i-th sample path, for \(i=1,\dots , d\), and let \({\mathbb {X}}=\left( {\mathbb {X}}_1^T|\dots | \mathbb X_d^T\right) ^T\). By supposing that \(X(t_0)\) follows a one-dimensional lognormal distribution \(\varLambda _1\left( \mu _1,\sigma _1^2\right) \) and by considering the transitions of the process X(t), the probability density function of \({\mathbb {X}}\) has the following expression
where \(x^T=\left( x_{1,1},\dots ,x_{1,n_1}|\dots |x_{d,1},\dots ,x_{d,n_d}\right) \in {\mathbb {R}}_+^{n+d}\) is a vector of dimension \(n+d\), with
Recalling (10), the parameters in (14) are given by
and
with
In order to obtain a more manageable expression of the density (14), the following change of variables may be considered:
Hence, the probability density function of the vector \(\mathbb V=\left[ {\mathbb {V}}_0^T|{\mathbb {V}}_1^T|\dots |\mathbb V_d^T\right] ^T=\left[ {\mathbb {V}}_0^T|{\mathbb {V}}_{(1)}^T\right] ^T\), with \({\mathbb {V}}_{(1)}^T=\left( {\mathbb {V}}_1^T|\dots |{\mathbb {V}}_d^T\right) \), and \({\mathbb {V}}_i^T=(V_{i1}, V_{i2}, \ldots , V_{i n_i})\), is
for \(v=(v_{01},\dots , v_{0d}, v_{11},\dots , v_{{1},{n_1-1}},\ldots , v_{d1},\dots , v_{d,{n_d-1}})^T\in {\mathbb {R}}^{n+d}\), with n defined in (15), where \(lv_0=\left( \log v_{01},\dots ,\log v_{0d}\right) ^T\), and \(\mu _1\in {\mathbb {R}}\), \(\sigma _1^2\in \mathbb R_+\), \({\mathbb {I}}_d=(1,\dots ,1)^T_{d\times 1}\), with \(\gamma ^\xi =(\gamma ^\xi _{11},\ldots , \gamma ^\xi _{1,n_1-1},\ldots , \gamma ^\xi _{d1},\ldots , \gamma ^\xi _{d,n_d-1})^T \in \mathbb R^{n\times 1}\) and \(\gamma ^\xi _{ij}=\left( \varDelta _i^{j+1,j}\right) ^{-1/2}m_\xi ^{i,j+1,j}\), for \(j=1,\dots ,n_i-1\) and \(i=1,\dots ,d\).
By setting \(\alpha =\left( \mu _1,\sigma _1^2\right) ^T\) and supposing that \(\alpha \) and \(\xi \) are functionally independent, the log-likelihood function is given by
with
and
The maximum likelihood estimations (MLEs) of \(\alpha =\left( \mu _1,\sigma _1^2\right) ^T\) can be computed easily. Indeed, by differentiating \(L_{{\mathbb {V}}}\), from (17) we obtain
Further on, in order to find the maximum likelihood estimates of \(\xi \), two different approaches are available:
-
(i)
solving the nonlinear system \(\frac{\partial }{\partial \xi }{{\tilde{L}}}_{{\mathbb {V}}}=0,\)
-
(ii)
maximizing the objective function \({{\tilde{L}}}_{{\mathbb {V}}}\).
Hereafter, in the Sects. 3.1 and 3.2 we provide a description of the two strategies, whereas in Sect. 5 we present an application to a simulation study that involves the given strategies.
The availability of the probability density function of \({\mathbb {X}}\) in (14) allows to obtain explicitly the log-likelihood function given in (17). Consequently, following the maximum likelihood estimation procedure, in Sect. 3.1 we obtain the associated system of equations, the final form being reported in Eq. (23) below. However, since such system does not have an explicit solution, its resolution must be obtained by adopting numerical methods.
3.1 Solving the nonlinear system
Recalling that \(\theta ^T=(\theta _0,\theta _1,\dots ,\theta _p)=(\eta ,\beta _1,\dots ,\beta _p)\), the partial derivatives of \({{\tilde{L}}}_{{\mathbb {V}}}\) are given by
where
with
Hence, the MLEs are the solutions of the following system of \(p+2\) nonlinear equations
By defining the following quantities
with \(l=0,1,\dots ,p\), the last \(p+1\) equations of the system (19) can be written as follows
Substituting the expression (16) of \(m_\xi \) in the previous equations, one has
where, for any \(l=0,1,\dots ,p\), one has
Hence, until now, the expression of the system solved by the MLEs is
The first equation of system (21) can be further simplified. Indeed, by setting
one has
Consequently, the system (21) finally becomes
Note that (23) is a system of \(p+2\) equations in the unknowns contained in \(\xi =(\eta ,\beta _1,\dots ,\beta _p,\sigma ^2)^T\).
Remark 1
For the first equation of the system (23) in the unknown \(\sigma ^2\), since \(Z_3>0\), \(n>0\) and
the only acceptable solution is
Clearly, since in general system (23) cannot be solved analytically, then a numerical approach is needed. Specifically, we adopt the well-known Newton-Raphson method to solve (23) (for instance, see Dennis and Schnabel (1996)). For such an iterative method, an initial approximation for the solution of the system is needed. It can be obtained by a procedure similar to that used by Román-Román et al. (2019). For the initial solution of the vector \(\theta = \left( \eta , \beta _1,\dots ,\beta _p\right) ^T\), by considering the multisigmoidal logistic function, i.e.
it can be supposed, without loss of generality, that \(t_0=0\) (see Remark 2.1 of Di Crescenzo et al. (2021)), so that
Then, considering the sampling \({\mathbb {X}}=\left( {\mathbb {X}}_1^T| \dots | {\mathbb {X}}_d^T \right) ^T\) defined in Sect. 3, consisting of d independent sample paths of the process X(t), for simplicity we suppose that any sample path of the process has the same number of observations, i.e. \(n_i=N\) for any \(i=1,\dots , d\). However, the following remarks hold even in more general cases. Moreover, let \(m_j\) be the values of the mean of the sample paths at the time \(t_j\), for \(j=1,\dots , N\), that is
where \(x_{ij}\) is the value of the i-th sample path at the time \(t_j\).
In general, the carrying capacity \(C/\eta \) is unknown. We suppose that the observations are available over a large time interval, such that the evolution of the population is terminated over such an interval. Hence, the carrying capacity \(C/\eta \) can be approximated with the last value of the sample mean \(m_N\). This approximation can be adopted also in the other cases, since it is used just to construct an initial solution for the parameters of the Newton-Raphson method for the estimate of \(\theta \). Thus, we can consider a polynomial regression for the pairs
The coefficients \(({{\hat{\beta }}}_1,\dots ,{{\hat{\beta }}}_p,\log {{\hat{\eta }}})\) of the approximating polynomial will be the initial values for the parameters \((\beta ^T,\log \eta )\). Thus, the initial solution for \(\eta \) is given by \({{\hat{\eta }}}\).
Finally, in order to construct the initial solution of \(\sigma ^2\), let us now recall that for a lognormal distribution \(Y\sim \varLambda _1(\alpha ,\delta )\), one has \(\log Y\sim \mathcal N(\alpha ,\delta )\), so that the quantity \(2\log \frac{m}{m^g}\) gives an approximation for \(\delta \), where m and \(m^g\) are respectively the arithmetic sample mean and the geometric sample mean of a random sample \((y_1,\ldots , y_n)\) from Y. Hence, one has
Since \({\mathbb {E}}[Y]=e^{\alpha +\delta /2}\) is estimated by the sample mean m, we have
As a consequence, in our setting an estimate for \(\sigma _0^2+\sigma ^2t_j\) is given by
where \(m_j\) and \(m_j^g\) denote respectively the arithmetic and the geometric sample mean of the observations performed at the time \(t_j\). Hence, an initial approximation for \(\sigma ^2\) can be obtained by performing a simple linear regression of \(\sigma _j^2-\sigma _0^2\) against \(t_j\).
In conclusion, in order to obtain the maximum likelihood estimates of the parameters contained in \(\xi =(\eta ,\beta _1,\dots ,\beta _p,\sigma ^2)^T\), the steps of the proposed strategy to solve the system (23) are:
-
(i)
finding an initial solution for the parameters \(\eta \) and \(\beta \) with a polynomial regression of \(-\log \left( \frac{m_N}{m_j}-1\right) \) against \(t_j\), for any \(j=1,\dots , N-1\);
-
(ii)
finding an initial solution for \(\sigma ^2\) with a simple linear regression of \(\sigma _j^2-\sigma _0^2\) against \(t_j\), with \(\sigma ^2_j=2\log \frac{m_j}{m_j^g}\), for any \(j=1,\dots ,N\) and where \(\sigma _0^2\) can be obtained by means of the second of Eqs. (18);
-
(iii)
using the Newton-Raphson method to solve the system (23), with the initial solutions determined at steps (i) and (ii).
The adoption of the above strategy requires to start from good initial solutions for the unknown parameters. Unfortunately, even in this case it is not always possible to guarantee the convergence of this method. For this reason, recently various procedures have been proposed aimed at addressing the maximization of the likelihood function, by viewing this as a direct optimization problem. Indeed, there is a wide range of stochastic metaheuristic methods, which can be classified into two large families: those based on trajectories and those based on swarms. Hereafter, in Sect. 3.2 we employ one of the most widely used, the Simulated Annealing. This method requires necessarily to bound the parametric space, and this matter is the object of Sect. 3.2.2.
3.2 Maximizing the log-likelihood function
Let us now illustrate a strategy based on Simulated Annealing (S.A.) and finalized to obtain the MLEs for the parameters of the process (9). We first provide a brief description of this method in Sect. 3.2.1. Then, in Sect. 3.2.2 we describe a suitable criterion to restrict the parametric space, this being essential to apply the S.A. method in the remainder of the paper.
3.2.1 Brief notes on Simulated Annealing
The aim of this section is to determine the MLEs by using the S.A. algorithm. The aforementioned method, introduced in Kirkpatrick et al. (1983), is a meta-heuristic optimization algorithm used for problems like finding \(\displaystyle \arg \min _{\theta \in \Theta } f(\theta )\). It is considered more suitable with respect to other numerical algorithms since it needs less restrictive conditions regarding the regularity of the domain \(\Theta \) and the analytical properties of the objective function f. The algorithm works such that in every step a random point is chosen in the solution space. If the new solution is better than the previous one, then the latter is replaced. Otherwise, if the new solution is worse than the previous, then the latter may be replaced with a probability rate \(\rho =\min \{\exp (-\varDelta f/T),1\}\) which depends on the increase of the objective function \(\varDelta f=f(\xi )-f(\theta _0)\) and on a suitable scale factor T, that is named ‘temperature’ in agreement with the metallurgical process of annealing that inspired this algorithm. We recall that the S.A. is successful because it avoids local minima. In recent years it has been widely used in the context of estimation in diffusion processes (see, for example Luz Sant’Ana et al. (2018) and Román-Román and Torres-Ruiz (2015)).
In this context, the algorithm works in the following way. It begins with an initial choice \(\theta _0\) for the parameters of interest, then \(\xi \) is generated from an uniform distribution in a neighborhood \(\nu (\theta _0)\) of \(\theta _0\). Then, a new value \(\theta _1\) of \(\theta \) is obtained in such a way
Consequently, if \(f(\xi )\le f(\theta _0)\), then \(\rho =1\) and therefore \(\theta _0\) is replaced by \(\xi \). Otherwise, if \(f(\xi )>f(\theta _0)\), then \(\xi \) may be accepted anyway with probability \(\rho \in (0,1)\). The temperature T is defined in such a way that at the beginning the probability of accepting \(\xi \) is high, and during the execution of the algorithm the function T decreases. The initial temperature \(T_0\) must be sufficiently large so that the algorithm accept the solutions which let the objective function increases with a large probability \(p_0\). In literature, the choices of the initial parameters are usually \(p_0=0.9\) and \(T_0=-\varDelta f^+/\log p_0\), where \(\varDelta f^+\) denotes the average increase of the objective function in an application test where all the solutions which cause an increase are accepted. The cooling process which defines the temperature T is usually chosen of geometric type, i.e. \(T_i=\gamma T_{i-1}\) for \(i=1,2,\dots \). Usually the constant \(\gamma \) is chosen among 0.8 and 0.99 in order to have a slow cooling procedure. In our case, we set \(\gamma =0.95\). In any iteration of the algorithm, a chain of L new solutions is obtained, for \(L=50\). As required, the algorithm stops when at least one of the following rules is satisfied: (i) the last L obtained values are equal, (ii) the maximum number of iterations (1000, in our case) is attained, (iii) the final temperature \(T_F=10^{-7}\) is reached.
3.2.2 Bounding the parametric space
S.A. needs a restriction of the solution space \(\Theta \), namely the set which contains the parameters \(\xi =(\eta ,\beta ^T,\sigma ^2)^T\). Until now, this space is continuous and unbounded, since
We consider \(0<\sigma <0.1\) so that the simulated sample paths are less variable around the sample mean, and thus the multisigmoidal logistic profile is advisable. For the parameters \(\beta =\left( \beta _1,\dots ,\beta _p\right) ^T\), we find the confidence intervals by using the data of the polynomial regression performed previously to find the initial solutions. More in detail, it is known that the carrying capacity of the multisigmoidal logistic model with \(t_0=0\) is \(l_0 \left( 1+\frac{1}{\eta }\right) \) (see Eq. (5)). The carrying capacity can be approximated with the last value of the sample mean, whereas the initial value \(l_0\) with the first value of the sample mean (24), so that one has
From Eq. (25), it easily follows \(\eta \approx \left( \frac{m_N}{m_1}-1\right) ^{-1}\) and thus an approximation of \(\eta \) is
Considering Eqs. (4) and (5), for \(t_0=0\) one has
so that
Hence, by replacing \(\eta \) with its estimate \({{\hat{\eta }}}\), we can use the resulting confidence intervals of the parameters of the polynomial regression as intervals of variation for the parameter \(\beta \) of the diffusion process. We adopt a confidence level equal to 0.999, to attain a high probability that the true parameter \(\beta \) belong to the computed intervals.
In order to approximate the range of variation of \(\eta \), from Eq. (25) we have that the last value of the i-th sample path satisfies
where \(x_{i,j}\) with \(i=1,2,\dots ,d\) and \(j=1,2,\dots ,n_i\) are the sample data. Hence, for the range of variation of \(\eta \) one has \(\eta \in (a,b)\), where
In conclusion, the following bounded intervals are employed:
-
for \(\beta _1,\dots ,\beta _p\) we consider the confidence intervals of the coefficients of the polynomial regression of \(-\log \left[ \left( \frac{m_N}{m_j}-1\right) {{\hat{\eta }}}\right] \) against \(t_j\), for \(j=1,\dots ,N\), where \({{\hat{\eta }}}=\displaystyle \left( \frac{m_N}{m_1}-1\right) ^{-1}\),
-
for \(\eta \) we consider the interval \(I_\eta =\left( a,b\right) \), with a and b defined in (26),
-
for \(\sigma ^2\) we consider the interval \(I_{\sigma ^2}=\left( 0,0.01\right) \).
3.3 Asymptotic distribution of the MLEs
On the ground of the results given in Sect. 5 of Román-Román et al. (2018), in this section we aim to determine the asymptotic distribution of the MLEs (i) of the parameters \(\mu _1,\sigma _1^2\) of the initial distribution, and (ii) of the parameters \(\xi =(\eta ,\beta ^T,\sigma ^2)^T\) of the process.
-
(i)
The exact distribution of \({{\widehat{\mu }}}_1\) is normal \({\mathcal {N}}\left( \mu _1,\frac{\sigma _1^2}{d}\right) \), whereas the exact distribution of \(d\,\frac{{{\widehat{\sigma }}}_1^2}{\sigma _1^2}\) is chi-square \(\chi _{d-1}^2\), cf. Román-Román et al. (2018).
-
(ii)
The asymptotic distribution of \({{\widehat{\xi }}}\) is a \((p+2)\)-dimensional normal distribution with mean \(\xi \) and covariance matrix \(I(\xi )^{-1}\), i.e. \({\mathcal {N}}_{p+2}\left( \xi , I(\xi )^{-1}\right) \), where \(I(\xi )\) denotes Fisher’s information matrix of \(\xi \). For the diffusion process X(t) with a multisigmoidal logistic mean,
\(I(\xi )\in {\mathbb {R}}^{(p+2)\times (p+2)}\) can be expressed as
where \(\Xi _\xi \in {\mathbb {R}}^{(p+1)\times (p+1)}\) is given by
with
and \({_lD_\theta }^{i,j+1,j}\) is defined in the third of Eqs. (20). Moreover, \(\frac{\partial }{\partial \theta }\gamma _{\xi }\in {\mathbb {R}}^{(p+1)\times 1}\) is defined as
Finally, \(Z_3\) is given in the second of Eqs. (22). We point out that the matrix (27) will be used in Sect. 5 to determine the asymptotic variances for the estimates of the parameters and an approximation of the confidence intervals. Indeed, by applying the delta method (cf. Oehlert (1992)), any q-parametric function \(g({{\hat{\xi }}})\) with \(q\le p+2\) asymptotically has a q-dimensional normal distribution, i.e. (cf. Román-Román et al. (2018))
where \(\nabla g(\xi )\) is the vector of partial derivatives of \(g(\xi )\) with respect to \(\xi \).
In the following section we address a relevant problem for the applications, namely the FPT problem of the diffusion process X(t) through a continuous boundary. Subsequently, in Sect. 5 we adopt a simulation-based approach as the basis of both computational methods described so far, namely the Newton-Raphson method and the S.A. method. The estimates of the parameters obtained through these methods are then used to perform inference on the FPT density.
4 First-passage-time problem
The FPT problem of a stochastic process X(t) through a boundary S(t) is a problem of great interest in many fields of application, such as medicine, biology or mathematical finance, since the threshold S(t) may represent a critical value of the modeled population size. Considering a stochastic process \(\left\{ X(t);t_0\le t\le T\right\} \), the FPT of the process X(t) through the continuous boundary S(t), given \(X(t_0)=x_0\), is defined as the following random variable
Finding the expression of the distribution of the variable T is hard in general. However, in literature there are several studies for particular types of processes, for example diffusion processes. It has been shown that if S(t) is a continuous and differentiable function, then the density of T, denoted by \(g\left( S(t),t|x_0,t_0\right) \), solves a II-kind Volterra equation (cf. Eq. (2.4) of Buonocore et al. (1987)). The aforementioned Volterra equation has an explicit solution only for certain special boundaries (see for example Sects. 2.3 and 4.3 of Giorno and Nobile (2019) in which the FPT density through special boudaries has been obtained for the restricted Gompertz-type diffusion processes). In certain instances, it is appropriate to adopt numerical procedures in order to approximate its solution. To this aim Buonocore et al. (1987) proposed a simple but efficient algorithm, based on the composite trapezoidal formula. More in detail, Theorem 4 of Buonocore et al. (1987) proves the convergence of the approximated FPT density to the theoretical one. However, the application of the proposed numerical procedure requires (i) the choice of a suitable step h of integration which ensures a good approximation of the real solution, (ii) the choice of an initial time instant \(t_0\) and (iii) the choice of the final time instant \(T=t_0+Nh\). Román-Román et al. (2008) studied the problems related to the practical application of the numerical procedure. The first problem is linked with a suitable choice of h. Indeed, taking into account the result of Theorem 4 of Buonocore et al. (1987), it is easy to note that the convergence is ensured when \(h\rightarrow 0^+\). Consequently, the value of h should be small enough, but sufficiently far from 0. Indeed, if h is excessively small, then the computational cost may increase in vain because, with a larger integration step, a similar approximation may be obtained with a smaller number of iterations. On the other hand, if h is excessively large, the approximation may be unsatisfactory. These problems depend on the localization of the FPT T, and may be solved if the range of variation of T is known. For this reason, Román-Román et al. (2008) introduced a function, called ‘FPT location’ (FPTL), finalized to obtain, from a heuristic point of view, the range of variation of T. Specifically, the FPTL function is defined as follows
where \(F(x,t|x_0,t_0)\) is the transition distribution of the process X(t). Referring to the diffusion process with infinitesimal moments given by Eq. (7), and by considering a fixed and constant boundary \(S>x_0\), given \(X(t_0)=x_0\), the FPTL function for the process X(t) is given by
where \(\varPhi \) is the standard normal distribution and
The information provided by the FPTL function is relevant for an efficient application of the algorithm proposed by Buonocore et al. (1987). Indeed, thanks to the FPTL function, an adaptive step of integration can be obtained. In this way, the execution time of the algorithm is reduced.
Example 1
Let X(t) be a diffusion process with infinitesimal moments (7), with \(p=3\), \(Q_\beta (t)=0.1t-0.009t^2+0.0002t^3\), \(\eta =e^{-1}\), \(\sigma =0.01\), \(t_0=0\), and \(X_0=5\) a.s. See Fig. 3 for the plot of 100 simulated sample paths of the process. Let us study the FPT density through the fixed boundary \(S=3\, x_0=15\), by using the information provided by the FPTL function and the R package fptdApprox (for references, see Román-Román et al. (2012), Román-Román et al. (2014) and Román-Román et al. (2020)).

100 simulated sample paths of the process X(t) with \(p=3\), \(Q_\beta (t)=0.1t-0.009t^2+0.0002t^3\), \(\eta =e^{-1}\), \(\sigma =0.01\), \(t_0=0\) and \(x_0=5\). The black line represents the sample mean of the process, while the red line represents the boundary \(S=15\)

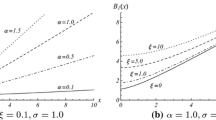
a The FPTL function and b the approximated FPT density of the process X(t) through the constant boundary \(S=15\), for the same assumptions of Fig. 3
Figure 4a shows the FPTL function (obtained by means the function FPTL of the package fptdApprox), whereas the approximated FPT density (obtained using the package fptdApprox) is plotted in Fig. 4b. Other useful quantities related to the FPT density are given in Table 1.
5 Simulation
In Sect. 3, two procedures have been introduced to obtain the MLEs of the parameters involved in the diffusion process (9). The former procedure is based on the numerical resolution of a system of nonlinear equations, whereas the latter is based on the application of S.A. algorithm. In this section, a simulation study is developed to verify the validity of the two aforementioned procedures. We consider the diffusion process X(t) with infinitesimal moments (7), for \(p=3\), and \(\beta _1\in \left\{ 0.1,0.5\right\} \), \(\beta _2\in \left\{ -0.009,-0.007\right\} \), \(\beta _3\in \left\{ 0.0002, 0.0004\right\} \), \(\eta \in \left\{ e^{-1},e^{-3}\right\} \) and \(\sigma \in \left\{ 0.01,0.05\right\} \). These choices of the parameters are performed arbitrarily, to obtain different patterns of the growth curve. For example, the choice \(\beta _1=0.1\), \(\beta _2=-0.009\), \(\beta _3=0.0002\), \(\eta =e^{-1}\) refers to the case of a non monotonous multisigmoidal logistic function, whereas the choice \(\beta _1=0.1\), \(\beta _2=-0.007\), \(\beta _3=0.0003\) and \(\eta =e^{-1}\) to the case of an increasing multisigmoidal logistic curve (see Fig. 5). To estimate the parameters in \(\xi \), we consider the 32 combinations of the values of the parameters listed in Table 2, with \(x_0=5\) in every case. For each case, we simulate 200 sample paths of X(t), by generating 501 simulated points at equidistant times for \(0\le t\le 50\).

100 simulated sample paths of the diffusion process for \(\sigma =0.01\), \(\eta =e^{-1}\) and a \(\beta _1=0.1\), \(\beta _2=-0.009\), \(\beta _3=0.0002\) and b \(\beta _1=0.1\), \(\beta _2=-0.007\), \(\beta _3=0.0003\) (simulation study)
The remainder of this section is organized as follows: (a) since the degree of the polynomial \(Q_\beta \) is unknown a priori, we propose the use of the strategy described in Román-Román et al. (2019), by increasing the degree until the goodness of fit is optimal; (b) considering the degree obtained at the step (a), we use the two procedures described in Sects. 3.1 and 3.2 to find the MLEs of the parameters.
The choice of the best degree of the polynomial \(Q_\beta \) is performed under the goodness of fit criteria based on the four following measures:
-
(i)
the absolute relative error (RAE) between the sample mean and the estimated mean, i.e.
$$\begin{aligned} RAE_p=\frac{1}{N}\sum _{i=1}^N\frac{\left| m_i-\hat{\mathbb E}(X^{(p)}(t_i))\right| }{m_i},\qquad p=2,3,\dots , \end{aligned}$$where \(\hat{{\mathbb {E}}}(X^{(p)}(t_i))\) denotes the mean of the estimated process considering a polynomial \(Q_\beta \) of degree p;
-
(ii)
the Akaike information criterion (AIC), which is defined as
$$\begin{aligned} AIC_p=2(p+2)-2L_{{\mathbb {V}}}({{\hat{\alpha }}}, {{\hat{\xi }}}), \qquad p=2,3\dots , \end{aligned}$$ -
(iii)
the Bayesian information criterion (BIC), which is given by
$$\begin{aligned} BIC_p=(p+2)\log (n)-2L_{{\mathbb {V}}}({{\hat{\alpha }}}, {{\hat{\xi }}}), \qquad p=2,3\dots , \end{aligned}$$where n represents the number of observations,
-
(iv)
the resistor-average distance (\(D_{RA}\)) between the sample distribution \(f_C\) and the p-th estimated distribution \(f_{S_p}\), for \(p=2,\dots ,6\), which is defined as the following harmonic mean (cf. Johnson and Sinanovic (2001)):
$$\begin{aligned} D_{RA}(f_C||f_{S_p})(t)=\frac{D_{KL}(f_C||f_{S_p}) (t)\cdot D_{KL}(f_{S_p}||f_{C}) (t)}{D_{KL}(f_C||f_{S_p}) (t) + D_{KL}(f_{S_p}||f_{C}) (t)}, \qquad t\ge t_0, \end{aligned}$$where \(D_{KL}\) denotes the Kullback-Leibler divergence. Assuming that the sample distribution is lognormal with parameters
$$\begin{aligned} \mu _C(t)\approx {\widehat{\mu }}_t= \log (m_g(t)), \qquad \sigma _C^2(t)\approx {\widehat{\sigma }}_t^2=2\log \frac{m(t)}{m_g(t)}, \end{aligned}$$and that the estimated distribution is lognormal with parameters
$$\begin{aligned} \mu (t)\approx {\widehat{\mu }}_0+H_{{{\widehat{\xi }}}}(t_0,t), \qquad \sigma (t)\approx {\widehat{\sigma }}_0^2+{\widehat{\sigma }}^2(t-t_0), \end{aligned}$$the Kullback-Leibler divergence between the sample distribution \(f_C\) and the p-th estimated distribution \(f_{S_p}\) for \(p=2,\dots ,6\) is given by, for any \(t\ge t_0\)
$$\begin{aligned}&D_{KL}(f_C||f_{S_p})(t)\\&\qquad =\frac{1}{2}\left[ \log \left( \frac{{\widehat{\sigma }}_0^2+{{\widehat{\sigma }}}^2(t-t_0)}{{\widehat{\sigma }}_t^2}\right) +\frac{{\widehat{\sigma }}_t^2+\left( {{\widehat{\mu }}}_t-{\widehat{\mu }}_0-H_{{{\widehat{\xi }}}}(t_0,t)\right) ^2}{{\widehat{\sigma }}_0^2+{{\widehat{\sigma }}}^2(t-t_0)}-1\right] , \end{aligned}$$with \(H_{{{\widehat{\xi }}}}(t_0,t)\) defined in (10). Clearly, if the theoretical distribution of the process is known, one can alternatively compute the resistor-average distance between the theoretical and the estimated distribution. We consider the expected distance and the median of the distance as reference values for the resistor-average distance.

The resistor average distance between a–b the sample and the estimated distribution, and c–d the theoretical and estimated distribution for the case 1 of Table 2, for different degrees of the polynomial (simulation study)
In cases (ii) and (iii), the stochastic model is characterized by \(p+2\) parameters. Moreover, \(L_{\mathbb {V}}(\alpha ,\xi )\) is defined in (17), and \({{\hat{\alpha }}}\) and \({{\hat{\xi }}}\) are the MLEs of the parameters \(\alpha \) and \(\xi \). The best fit is attained for the smallest value of the considered goodness measures. Table 3 shows the estimated parameters for the case no. 1 of Table 2, which is obtained by solving the system (23) for different degrees of the polynomial \(Q_\beta \). Furthermore, the results about the goodness of measures are given in Table 4 and in Fig. 6. It can be noticed that the estimated parameters for \(p=3\) and \(p=4\) are almost identical, and that \(\beta _4\) is very close to zero in the case \(p=4\). Hence, the results concerning the measures of goodness obtained in these two cases are quite similar. This conclusion is also confirmed by the analysis of the RAE measures (in Table 4), that are often used to measure the fit error of the model in terms of the fit of the mean function. The analysis is performed in terms of the scale of judgment of the model accuracy based on the Mean Absolute Percentage Error (MAPE), cf. Klimberg et al. (2010) and Lewis (1982). Indeed, the judgment suggested by the MAPE shows that \(p=3\) and \(p=4\) are referred as highly accurate, whereas \(p=2\) is evaluated as good forecast, with both \(p=5\) and \(p=6\) considered as reasonable forecast. Consequently, the choice \(p=3\) is taken as the best, since it involves the lowest number of parameters.

The RAE for a \(\eta =e^{-1}\) and \(\sigma \in [0.01,0.05]\), b \(\sigma =0.05\) and \(\eta \in \left[ e^{-3},e^{-1}\right] \) and c \(\sigma =0.01\), \(\eta =e^{-1}\) and with respect of the number of replications. In all the cases \(Q_\beta (t)=0.1t-0.009t^2+0.0002t^3\) (simulation study)

The theoretical, sample and estimated means of the process X(t) for the parameters of the cases number 1 and 2 of Table 2 (from left to right). The results are obtained via Newton-Raphson method in (a) and (b) and via S.A. in (c) and (d). (Simulation study)
The same result can be obtained for the other parameters choices, but it is omitted for brevity. Here, we limit to mention that the AIC and its Bayesian version, the BIC, provide a global measure of the adjustment to the model in terms of the likelihood that the model itself gives to the observed sample, so that these measures also allow for model selection criteria. The AIC and the BIC are seen often as complementary measures to the use of the Resistor Average Distance between the sample and the theoretical distributions of the model. However, there is no criterion that indicates that one measure is better than another, and thus in general the use of several alternative measures is recommended, as usual in practical applications. In our analysis, the coincidence of the conclusions suggested by these measures supports the final decision. Hence, from now on, a polynomial of degree \(p=3\) will be considered.
Table 5 shows the estimated values of the parameters obtained by solving the nonlinear system (23) by means of the Newton-Raphson method. These values provide good parameters estimates, especially when \(\sigma \) is small. The last column of the Table 5 contains the RAE. In this case, it is defined as
where \(m_i\) are the values of the sample mean and \(\hat{\mathbb E}(X^{(3)}(t_i))\) are the values of the estimated mean at the time \(t_i\) considering a polynomial of degree \(p=3\). For a comparison between \(\sigma \) or \(\eta \) and the RAE, see Fig. 7a–b: it can be noticed that the value of the RAE shows an increasing trend with respect to the parameter \(\sigma \), whereas it shows a constant trend with respect to \(\eta \). In Fig. 8a–b the theoretical, sample and estimated sample means for the parameters choices number 1 and 2 of the Table 2 are shown. Clearly, the best estimation is obtained when \(\sigma \) is small.
Further on, the estimated values obtained via S.A. are given in Table 6, whose last column contains the value of the RAE defined in Eq. (28). Since S.A. is a heuristic algorithm, the MLEs have been computed as the average of the results obtained by 10 uses of the procedure. Figure 8c–d provide the theoretical, the sample and the estimated (via S.A.) means for the cases no. 1 and no. 2 of the Table 2. In addition, in Fig. 7c, the trend of the RAE is plotted as a function of the number of replications: clearly, the goodness of the results improves as the number of replications increases.
Moreover, Table 7 contains the estimated values of the parameters (obtained by solving the system (23)), as well as their real values and the asymptotic estimation error. Finally, Table 7 provides various confidence intervals obtained by applying the delta method and using the distribution given in Sect. 3.3 for the case no. 1 of Table 2.
5.1 Approximation of FPT density
In this section, the FPT problem is analyzed. With reference to a diffusion process X(t) with a multisigmoidal logistic mean and \(Q_\beta (t)= 0.1t-0.009t^2+0.0002t^3\), \(\eta =e^{-1}\) and \(\sigma =0.01\), we construct 50 simulated sample paths (see Fig. 9a), each one being formed by 361 data simulating \(X(t_i)\) for \(t_i=(i-1)\, 0.1\), \(i=1,\dots , 361\). As in Sect. 5, we first chose the optimal polynomial degree (which corresponds to the best fit), and then we found the MLEs of the parameters by solving the system (23). Further on, the R package fptdApprox is used to approximate the FPT density of the process through a constant threshold \(S=15\). Table 8 provides the estimated parameters, whereas Fig. 9b shows the theoretical, the sample and the estimated means, for \(p=2,3,4,5,6\).

a 50 simulated sample paths of the diffusion process X(t) for \(\sigma =0.01\) , \(\eta =e^{-1}\) and \(Q_\beta (t)=0.1t-0.009t^2+0.0002t^3\). b Theoretical, sample and estimated means of the process X(t) for the FPT density approximation (simulation study—FPT problem)
Table 9 provides the four goodness measures for the considered degrees p of the polynomial \(Q_\beta \). Figure 10 shows the resistor-average distances between the theoretical and the estimated distributions, and also between the sample and the estimated distributions. From the given results it follows that the best degree is \(p=3\).

Resistor-average distance between a the theoretical and the estimated distributions and b between the sample and the estimated distributions for the FPT density approximation (simulation study - FPT problem)
Using the estimated model obtained so far, we now focus on the approximation of the FPT density through the boundary \(S=15\). Figure 11 shows the approximated FPT density and the FPTL function realized with the package fptdApprox. Finally, in Table 10 other useful quantities related to the FPT density are provided. It is worth noting that the results obtained in this section are in agreement with those given in Example 4.1.

The approximated FPT density and the FPTL function of the process X(t) through the boundary \(S=15\) (simulation study—FPT problem)
6 Application to real data
Multisigmoidal functions are suitable to model several special growth phenomena in which the carrying capacity is reached after various stages. In any of these stages a linear growth trend is followed by an explosion of exponential type which finally flattens to a specific value. A growth of this kind is typical of some fruit species, such as peaches or coffee berries (see, for instance the application given in Sect. 3 of Di Crescenzo et al. (2021)). But also some population diseases follow an expansion with a multisigmoidal trend. In this section we apply the considered stochastic model to data concerning the COVID-19 infections in four different European countries, taken from Worldometers (2020). This is just an example finalized to show an application of the multisigmoidal logistic model, without taking into account specific more sophisticated models that describe epidemiological phenomena with greater precision. First of all, we note that the trend of infections in France, Italy, Spain and United Kingdom is similar (see Fig. 12a).

a Number of infections in France, Italy, Spain and United Kingdom, the black line represents the sample mean. b Sample and the estimated means obtained by solving the system (23) (real application)
This suggests to view these data as different trajectories of the diffusion process X(t) defined on \(I=[t_0,t_f]\), having a multisigmoidal logistic mean (cf. Sect. 2.1). Hence, in order to find the MLEs of the parameters, we apply the procedure described in Sect. 3.1. For each country, the initial time \(t_0=0\) corresponds to the 30-th day after the one in which the number of infections exceeded 100 (March 30th for France, March 24th for Italy, March 21st for Spain, April 5th for UK), and the final time is chosen as \(t_f=250\). For any path, the data are scaled as divided by their maximum value, so to be interpreted as a percentage of the last and therefore the maximum value of the growth curve. The estimated means obtained for different degrees are plotted in Fig. 12b. Table 11 provides the initial and the estimated values of the parameters, whereas Table 12 shows the four measures of goodness, for different degrees of the polynomial. Regarding the RAE, every time the degree increases, the approximation improves, whereas the AIC, the BIC and resistor-average distance show that the best choice is \(p=3\).
Regarding the last measure of goodness, see also Fig. 13a, in which the resistor-average distances between the sample and the estimated distributions are provided. Hence, in view of the results obtained for the measures of goodness, the degree \(p=3\) is considered.
Table 13 shows the estimated values of the parameters, the estimation of their standard error and the \(95\%\), \(90\%\) and \(75\%\) percentiles.
Moreover, the \(\alpha \)-percentiles (13) of the estimated diffusion process with \(p=3\) are provided in Fig. 13b with \(\alpha =95,90,75\). Let us now consider a restricted time range from \(t_0=0\) to \(t_f=246\), in order to predict the trend of the growth curve in a short-term prediction analysis. Indeed, forecasting the number of infections during a disease in progress is interesting also in the case of short terms, especially for the goodness of estimation (better in this case than in the long term analysis) and for the timeliness of the results. The considered procedure is the same of the one used above, so (i) the best degree p for the polynomial \(Q_\beta \) is chosen by considering various measures of goodness, and (ii) the estimated values of the parameters are used to construct a diffusion process X(t) defined on \(I=[0,250]\). The estimated values of the parameters are given in Table 14, the values of the four measures of goodness are given in Table 15, and finally in Fig. 14a we provide the resistor-average distances between the restricted sample and the estimated distributions. See also Fig. 14b for the plots of the estimated means for different degrees of the polynomial.

a The resistor-average distances between the sample and the estimated distributions considering different degrees of the polynomial. b The \(\alpha \)-percentiles of the estimated diffusion process X(t) obtained for a degree \(p=3\) and for \(\alpha =95,90,75\) (real application)
Also in this case, the RAE does not provide a good measure of goodness, since every time the degree increases, the approximation improves. From the remaining results, the best choice is \(p=3\), which corresponds to the lowest value of the BIC and of the AIC, and to the lowest resistor-average distance. Hence, considering \(p=3\) and the corresponding estimated values of the parameters, Fig. 15a provides the sample and the estimated means in the complete time range, i.e. in \(I_C=[0,250]\). The relative errors between the values of the sample and the estimated means are given in Table 16; note that in all cases they are less than \(3\%\).
6.1 Approximation of FPT density
This section is devoted to the FPT problem. Considering an initial portion of the available data and setting a constant boundary, an estimate of the FPT density is constructed using the numerical procedures recalled in Sect. 4. The resulting FPT density is then compared to the approximated FPT density obtained by using the whole data set.
More in detail, we consider only the first 220 data of COVID-19 infections in the restricted time range \(I_R=[0, 219]\) and we investigate the best model to fit them. The choice of the optimal degree p of the polynomial \(Q_\beta \) is based on the measures of goodness (i)–(iv) described in Sect. 5. The estimated parameters (given in Table 17) are obtained by solving the system (23).
By comparing the results given in Table 18 and in Fig. 15b, we choose \(p=3\) as the optimal degree.
Then, we fix a constant threshold \(S=0.7\) which corresponds to the \(70\%\) of the last and maximum data in the complete time range \(I_C=[0,250]\) and we use the R package fptdApprox to obtain an estimation of the FPT density. The choice of the constant boundary \(S=0.7\) is not random. Indeed, it is worth observing that the descendent inflection points correspond to the peaks of the function representing the daily increments of the infections. More in detail, by means of Eq. (6), the function representing the sample mean of the infections shows two descendent inflection points, one at the time \(t_{F1}=21.65\) and the other at the time \(t_{F2}=220.66\). The population sizes corresponding to the inflection time instants are \(S_{F1}=0.08\) and \(S_{F2}=0.7\). In the time interval \([0,t_{F1}]\), the mean function has a logistic trend, hence the FPT problem through the boundary \({S_{F1}}\) is beyond the scope of the present work. Instead, since the mean in the time interval \([0, t_{F2}]\) has a multisigmoidal logistic profile, we focus our attention to the FPT problem through the threshold \(S=S_{F2}=0.7\).

a Resistor-average distances between the sample and the estimated distributions in the restricted time range. b Sample and the estimated means obtained by solving the system (23) in the restricted time range (real application with \(t_f=246\))

a The sample and the forecasted means in the complete time range \(I_C=[0,250]\) considering a degree \(p=3\). b Resistor-average distances between the sample and the estimated distributions in the restricted time range \(I_R\). c Approximated FPT density and d FPTL function in the restricted time range \(I_R\) through the boundary \(S=0.7\) (real application—FPT problem)
The approximated FPT density and the FPTL function of the estimated process X(t) through the boundary \(S=0.7\) are plotted in Fig. 15c–d. In order to validate the predicted results concerning the FPT, we consider also the same problem in the complete time range \(I_C\). The forecasted results for the restricted time range \(I_R\) and the approximated results for the complete time range \(I_C\) are given in Table 19. We note that the most meaningful index is the mode, since it corresponds to the peak of the FPT density and the two modes (namely, the mode in the restricted and in the complete time ranges) are quite close to each other (the relative error between the two values is about \(1\%\)).
7 Conclusions
During the recent years, many sigmoidal stochastic models have been introduced to study phenomena of interest in various different scientific areas. In order to model more complex population dynamics in which the maximum level of the growth is reached after many stages, we referred to the multisigmoidal logistic stochastic growth model. More in detail, the present work has been devoted to the analysis of the corresponding statistical inference and of the FPT problem. Two procedures useful to find the MLEs of the parameters have been described, one based on the resolution of the system of the critical points of the likelihood function, and the other one based on the maximization of the likelihood function by means of the S.A. algorithm. Then, the described strategies have been validated with a simulation study. The last section of the paper has been devoted to a real application concerning COVID-19 infections in four different European countries (France, Italy, Spain and United Kingdom). The data have been fitted using a suitable multisigmoidal logistic stochastic model. Finally, a study regarding the FPT through a fixed boundary has been also performed.
Future developments can be oriented to find the MLEs of the parameters with other meta-heuristic optimization procedures (such as Variable Neighborhood Search or other swarm-based algorithms) in order to obtain nice estimates in a short computational time. We aim also to introduce a more sophisticated model suitable to describe better epidemiological dynamics with multiple waves, starting from the multisigmoidal logistic equation. Moreover, aiming at a thorough analysis of the convergence speed for parameter estimation in stochastic differential equations, these approaches will be compared with applications of the recent method called ‘covariance matrix adaptation evolution strategy’. Indeed, the latter is used often in the presence of several parameters (cf., for instance, Ghosh et al. (2012) and Willjuice and Baskar (2010)).
References
Arnold L (1974) Stochastic differential equations: theory and applications. Wiley, New York
Asadi M, Di Crescenzo A, Sajadi FA, Spina S (2020) A generalized Gompertz growth model with applications and related birth-death processes. Ric Mat. https://doi.org/10.1007/s11587-020-00548-y
Brauer F, Castillo-Chavez C (2012) Mathematical models in population biology and epidemiology, 2nd edn. Springer, New York
Buonocore A, Nobile AG, Ricciardi LM (1987) A new integral equation for the evaluation of first-passage-time probability densities. Adv Appl Prob 19:784–800. https://doi.org/10.2307/1427102
Campillo F, Joannides M, Larramendy-Valverde I (2018) Parameter identification for a stochastic logistic growth model with extinction. Commun Stat Simul Comput 47(3):721–737. https://doi.org/10.1080/03610918.2017.1291960
Chakraborty B, Bhowmick AR, Chattopadhyay J, Bhattacharya S (2019) A novel unification method to characterize a broad class of growth curve models using relative growth rate. Bull Math Biol 81:2529–2552. https://doi.org/10.1007/s11538-019-00617-w
Dennis JE, Schnabel RB (1996) Numerical methods for unconstrained optimization and nonlinear equations. Class Appl Math SIAM 5:86–110. https://doi.org/10.1137/1.9781611971200
Di Crescenzo A, Paraggio P (2019) Logistic growth described by birth-death and diffusion processes. Mathematics 7(489):1–28. https://doi.org/10.3390/math7060489
Di Crescenzo A, Spina S (2016) Analysis of a growth model inspired by Gompertz and Korf laws, and an analogous birth-death process. Math Biosci 282:121–134. https://doi.org/10.1016/j.mbs.2016.10.005
Di Crescenzo A, Paraggio P, Román-Román P, Torres-Ruiz F (2021) Applications of the multi-sigmoidal deterministic and stochastic logistic models for plant dynamics. Appl Math Model 92:884–904. https://doi.org/10.1016/j.apm.2020.11.046
Erto P, Giorgio M, Lepore A (2020) The generalized inflection S-shaped software reliability growth model. IEEE Trans Reliab 69(1):228–244. https://doi.org/10.1109/TR.2018.2869466
Garcia O (2019) Estimating reducible stochastic differential equations by conversion to a least-squares problem. Comput Stat 34:23–46. https://doi.org/10.1007/s00180-018-0837-4
Ghosh S, Das S, Roy S, Minhazul Islam SK, Suganthan PN (2012) A differential covariance matrix adaptation evolutionary algorithm for real parameter optimization. Inf Sci 182:199–219. https://doi.org/10.1016/j.ins.2011.08.014
Giorno V, Nobile AG (2019) Restricted Gompertz-type diffusion processes with periodic regulation functions. Mathematics 7(555):1–19. https://doi.org/10.3390/math7060555
Inoue S, Yamada S (2013) Lognormal process software-reliability modeling with testing-effort. JSEA 6(4A):8–14. https://doi.org/10.4236/jsea.2013.64A002
Johnson DH, Sinanovic S (2001) Symmetrizing the Kullback-Leibler distance. IEEE Transactions on Information Theory
Kirkpatrick S, Gelatt CD, Vecchi MP (1983) Optimization by simulated annealing. Sci New Ser 220(4598):671–680. https://doi.org/10.1126/science.220.4598.671
Klimberg RK, Sillup GP, Boyle KJ, Tavva V (2010) Forecasting performance measures—what are their practical meaning? In: Lawrence KD, Klimberg RK (eds) Advances in business and management forecasting. Emerald Group Publishing Limited, Bingley, vol 7, pp 137–147
Lewis CD (1982) Industrial and business forecasting methods: a practical guide to exponential smoothing and curve fitting. Butterworth Scientific, London
Luz Sant’Ana I, Román-Román P, Torres-Ruiz F (2018) The Hubbert diffusion process: estimation via simulated annealing and variable neighborhood search procedures–application to forecasting peak oil production. Appl Stoch Models Bus Ind 34:376–394. https://doi.org/10.1002/asmb.2306
Nafidi A, Moutabir G, Gutiérrez-Sánchez R (2019) Stochastic Brennan-Schwartz diffusion process: statistical computation and application. Mathematics 7(11):1062. https://doi.org/10.3390/math7111062
Oehlert GW (1992) A note on the delta method. Am Stat 46(1):27–29. https://doi.org/10.2307/2684406
Ramos-Ábalos EM, Gutiérrez-Sánchez R, Nafidi A (2020) Powers of the stochastic Gompertz and lognormal diffusion processes, statistical inference and simulation. Mathematics 8(588):1–13. https://doi.org/10.3390/math8040588
Román-Román P, Torres-Ruiz F (2015) A stochastic model related to the Richards-type growth curve. Estimation by means of simulated annealing and variable neighborhood search. Appl Math Comput 266:579–598. https://doi.org/10.1016/j.amc.2015.05.096
Román-Román P, Serrano-Pérez JJ, Torres-Ruiz F (2008) First-passage-time location function: application to determine first-passage. Time densities in diffusion processes. Comput Stat Data Anal 52:4132–4146. https://doi.org/10.1016/j.csda.2008.01.017
Román-Román P, Serrano-Pérez JJ, Torres-Ruiz F (2012) An R package for an efficient approximation of first-passage-time densities for diffusion processes based on the FPTL function. Appl Math Comput 218:8408–8428. https://doi.org/10.1016/j.amc.2012.01.066
Román-Román P, Serrano-Pérez JJ, Torres-Ruiz F (2014) More general problems on first-passage times for diffusion processes: a new version of the fptdApprox R package. Appl Math Comput 244:432–446. https://doi.org/10.1016/j.amc.2014.06.111
Román-Román P, Serrano-Pérez JJ, Torres-Ruiz F (2018) Some notes about inference for the lognormal diffusion process with exogenous factors. Mathematics 6:85. https://doi.org/10.3390/math6050085
Román-Román P, Serrano-Pérez JJ, Torres-Ruiz F (2019) A note on estimation of multi-sigmoidal Gompertz functions with random noise. Mathematics 7:541. https://doi.org/10.3390/math7060541
Román-Román P, Serrano-Pérez JJ, Torres-Ruiz F (2020) fptdApprox: approximation of first-passage-time densities for diffusion processes, version 2.2, February 28. https://cran.r-project.org/web/packages/fptdApprox/
Romero D, Rico N, Garcia-Arenas MI (2016) Modellation and forecast of traffic series by a stochastic process. In: Rojas I, Pomares H (eds) Time series analysis and forecasting, contributions to statistics. Springer, Cham, pp 279–292. https://doi.org/10.1007/978-3-319-28725-6
Rupšys P, Narmontas M, Petrauskas E (2020) A multivariate hybrid stochastic differential equation model for whole-stand dynamics. Mathematics 8(12):2230. https://doi.org/10.3390/math8122230
Schlomann B (2018) Stationary moments, diffusion limits, and extinction times for logistic growth with random catastrophes. J Theor Biol 454:154–163. https://doi.org/10.1016/j.jtbi.2018.06.007
Shimizu K, Iwase K (1987) Unbiased estimation of the autocovariance function in a stationary generalized lognormal process. Commun Stat Theory Methods 16(7):2145–2154. https://doi.org/10.1080/03610928708829496
Smirnov R, Wang K (2020) In search of a new economic model determined by logistic growth. Eur J Appl Math 31(2):339–368. https://doi.org/10.1017/S0956792519000081
Tanaka M (1987) Estimation of the autocorrelation coefficients in a stationary lognormal process. J Jpn Stat Soc 17(2): 137–148. https://doi.org/10.11329/jjss1970.17.137
Willjuice IM, Baskar S (2010) Covariance matrix adaptation evolution strategy based design of centralized PID controller. Exp Syst Appl 37:5775–5781. https://doi.org/10.1016/j.eswa.2010.02.031
Worldometers, Covid-19 data. https://www.worldometers.info/coronavirus/. Accessed Dec 2020
Yoshioka H, Yaegashi Y, Yoshioka Y, Tsugihashi K (2019) A short note on analysis and application of a stochastic open-ended logistic growth model. Lett Biomath 6(1):67–77. https://doi.org/10.1080/23737867.2019.1691946
Acknowledgements
Antonio Di Crescenzo and Paola Paraggio are members of the research group GNCS of INdAM (Istituto Nazionale di Alta Matematica).This work was supported in part by the Ministerio de Ciencia e Innovación, Spain, under Grant PID2020-1187879GB-100 by FEDER/Junta de Andalucía-Consejería de Economía y Conocimiento, under Grant A-FQM-456-UGR18, by the “María de Maeztu” Excellence Unit IMAG, reference CEX2020-001105-M, funded by MCIN/AEI/10.13039/501100011033/, and by Italian MIUR-PRIN 2017, project “Stochastic Models for Complex Systems”, No. 2017JFFHSH. Paola Paraggio thanks the Department of Statistics and Operations Research, Faculty of Sciences of the University of Granada and the Institute of Mathematics of the University of Granada (IMAG) for the hospitality during the one-month visit carried out in 2019.
Funding
Open access funding provided by Università degli Studi di Salerno within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Di Crescenzo, A., Paraggio, P., Román-Román, P. et al. Statistical analysis and first-passage-time applications of a lognormal diffusion process with multi-sigmoidal logistic mean. Stat Papers 64, 1391–1438 (2023). https://doi.org/10.1007/s00362-022-01349-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00362-022-01349-1
Keywords
- Lognormal diffusion process
- Multi-sigmoidal growth
- Maximum likelihood estimation
- Asymptotic distribution
- First-passage-time
- First-passage-time location function